Hiểu sâu về Serialization trong Java
Keyword:
Serializable,serialVersionUID,transient,Externalizable,writeObject,readObject
Giới thiệu về Serialization
Trong quá trình truyền thông qua mạng, dữ liệu phải được chuyển đổi thành dạng nhị phân. Tuy nhiên, các tham số đầu vào và đầu ra của các yêu cầu từ phía gọi là các đối tượng. Đối tượng không thể truyền trực tiếp qua mạng, vì vậy cần chuyển đổi nó thành dạng nhị phân có thể truyền được và thuật toán chuyển đổi phải là đảo ngược được.
- Serialization: Serialization là quá trình chuyển đổi đối tượng thành dạng nhị phân.
- Deserialization: Deserialization là quá trình chuyển đổi dạng nhị phân thành đối tượng.
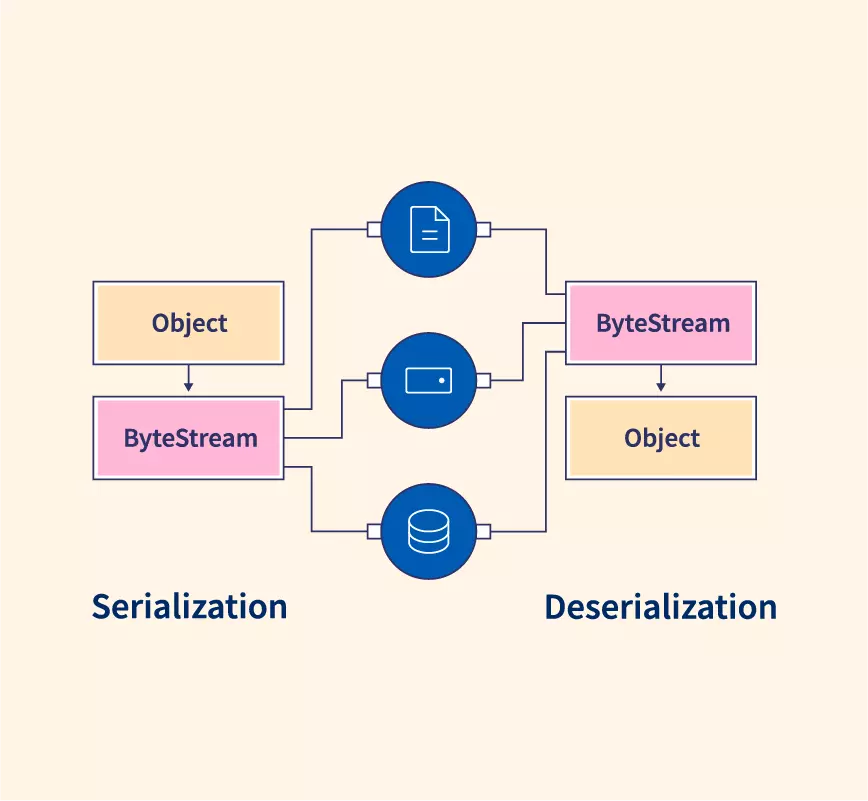
Mục đích của Serialization
- Serialization cho phép lưu trữ dãy byte của đối tượng - lưu trữ trong bộ nhớ, tệp tin, cơ sở dữ liệu.
- Truyền dữ liệu dạng byte của đối tượng qua mạng.
- RMI (Remote Method Invocation) - Gọi phương thức từ xa.
JDK Serialization
Trong JDK, có một cách tích hợp sẵn để thực hiện việc serialization.
ObjectInputStream và ObjectOutputStream
Java sử dụng luồng đầu vào và đầu ra đối tượng để thực hiện serialization và deserialization:
- Phương thức
writeObject()của lớpjava.io.ObjectOutputStreamđược sử dụng để thực hiện serialization. - Phương thức
readObject()của lớpjava.io.ObjectInputStreamđược sử dụng để thực hiện deserialization.
Ví dụ về serialization và deserialization:
public class SerializeDemo01 {
enum Sex {
MALE,
FEMALE
}
static class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name = null;
private Integer age = null;
private Sex sex;
public Person() { }
public Person(String name, Integer age, Sex sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString() {
return "Person{" + "name='" + name + '\'' + ", age=" + age + ", sex=" + sex + '}';
}
}
/**
* Serialization
*/
private static void serialize(String filename) throws IOException {
File f = new File(filename); // Define the save path
OutputStream out = new FileOutputStream(f); // File output stream
ObjectOutputStream oos = new ObjectOutputStream(out); // Object output stream
oos.writeObject(new Person("Jack", 30, Sex.MALE)); // Save the object
oos.close();
out.close();
}
/**
* Deserialization
*/
private static void deserialize(String filename) throws IOException, ClassNotFoundException {
File f = new File(filename); // Define the save path
InputStream in = new FileInputStream(f); // File input stream
ObjectInputStream ois = new ObjectInputStream(in); // Object input stream
Object obj = ois.readObject(); // Read the object
ois.close();
in.close();
System.out.println(obj);
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
final String filename = "d:/text.dat";
serialize(filename);
deserialize(filename);
}
}
// Output:
// Person{name='Jack', age=30, sex=MALE}Quá trình serialization của JDK được thực hiện như thế nào?
Quá trình serialization là quá trình đọc dữ liệu đối tượng và liên tục chèn các ký tự phân cách đặc biệt vào, các ký tự này được sử dụng để cắt ngang trong quá trình deserialization, giống như dấu câu trong văn bản được sử dụng để tách câu.
- Dữ liệu tiêu đề được sử dụng để khai báo giao thức serialization, phiên bản serialization, để hỗ trợ việc tương thích ngược với các phiên bản cao hơn.
- Dữ liệu đối tượng chủ yếu bao gồm tên lớp, chữ ký, tên thuộc tính, kiểu thuộc tính và giá trị thuộc tính. Tất nhiên còn có các dữ liệu khác như mục đầu mục cuối cùng và chỉ có giá trị thuộc tính là giá trị thực sự của đối tượng. Các thông tin khác là siêu dữ liệu cho quá trình deserialization.
- Trong trường hợp có sự xuất hiện của việc áp dụng tham chiếu đối tượng và kế thừa, quá trình này sẽ tiếp tục lặp lại “ghi đối tượng”.
🔔 Lưu ý: Khi sử dụng serialization đối tượng Java, khi lưu trữ một đối tượng, nó sẽ được lưu trữ thành một nhóm byte và sau này các byte này sẽ được hợp thành một đối tượng. Điều cần chú ý là serialization của đối tượng chỉ lưu trạng thái của nó, tức là các biến thành viên của nó. Do đó, serialization không quan tâm đến biến static trong class.
Giao diện Serializable
Lớp được serialize phải thuộc một trong các loại Enum, Array và Serializable, nếu không sẽ gây ra ngoại lệ NotSerializableException. Điều này xảy ra vì: trong quá trình thực hiện serialize, kiểu dữ liệu sẽ được kiểm tra và nếu không đáp ứng yêu cầu của kiểu dữ liệu serialize, một ngoại lệ sẽ được gây ra.
【Ví dụ】Lỗi NotSerializableException
public class UnSerializeDemo {
static class Person { // Nội dung khác bỏ qua }
// Nội dung khác bỏ qua
}Kết quả: Kết quả là xuất hiện thông tin ngoại lệ như sau.
Exception in thread "main" java.io.NotSerializableException:
...
serialVersionUID
Hãy chú ý đến trường serialVersionUID, bạn có thể thấy trường này trong vô số lớp Java.
serialVersionUID có tác dụng gì và làm cách nào để sử dụng serialVersionUID?
serialVersionUID là một phiên bản định danh được tạo ra cho mỗi lớp có khả năng tuần tự hóa trong Java. Nó được sử dụng để đảm bảo rằng khi giải tuần tự hóa, các đối tượng gửi đi và nhận được là tương thích. Nếu serialVersionUID của lớp nhận được không khớp với serialVersionUID của người gửi, sẽ xảy ra ngoại lệ InvalidClassException.
Nếu lớp có khả năng tuần tự hóa không khai báo rõ ràng serialVersionUID, thì quá trình tuần tự hóa runtime sẽ tính toán giá trị mặc định của serialVersionUID dựa trên các khía cạnh của lớp. Tuy vậy, vẫn nên chỉ định giá trị của serialVersionUID một cách rõ ràng trong từng lớp có khả năng tuần tự hóa. Bởi vì các phiên bản JDK biên dịch khác nhau có thể sinh ra các giá trị mặc đinh cho serialVersionID khác nhau, dẫn đến ngoại lệ InvalidClassExceptions khi giải tuần tự hóa.
Trường serialVersionUID phải có kiểu static final long.
Hãy xem một ví dụ:
(1) Có một lớp có khả năng tuần tự hóa là Person
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
private String address;
// Các phương thức khởi tạo, getter, setter bị bỏ qua
}(2) Trong quá trình phát triển, chúng ta thêm một trường email vào lớp Person, như sau:
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
private String address;
private String email;
// Các phương thức khởi tạo, getter, setter bị bỏ qua
}Vì lớp này không tương thích với phiên bản cũ, chúng ta cần thay đổi số phiên bản:
private static final long serialVersionUID = 2L;Khi tiến hành giải tuần tự hóa lại sẽ gây ra ngoại lệ InvalidClassException.
Tóm lại, chúng ta có thể hiểu rõ: serialVersionUID được sử dụng để kiểm soát tính tương thích của phiên bản tuần tự hóa. Nếu chúng ta cho rằng các thay đổi trong lớp có khả năng tuần tự hóa là tương thích với phiên bản cũ, chúng ta không cần sửa serialVersionUID.
Cơ chế tuần tự hóa mặc định
Nếu chỉ đơn giản là làm cho một lớp triển khai giao diện Serializable mà không có bất kỳ xử lý nào khác, thì cơ chế tuần tự hóa mặc định sẽ được sử dụng.
Khi sử dụng cơ chế mặc định, khi tuần tự hóa một đối tượng, không chỉ đơn giản tuần tự hóa đối tượng hiện tại mà còn tuần tự hóa các trường của lớp cha và các đối tượng khác mà đối tượng hiện tại tham chiếu đến. Tương tự, các đối tượng khác được tham chiếu bởi các đối tượng này cũng sẽ được tuần tự hóa, và cứ tiếp tục như vậy. Do đó, nếu một đối tượng chứa các biến thành viên là đối tượng kiểu container và các phần tử của các container này cũng là đối tượng kiểu container, quá trình tuần tự hóa này sẽ phức tạp và tốn kém.
🔔 Lưu ý: Lớp cha và đối tượng tham chiếu ở đây cũng phải tuân thủ yêu cầu tuần tự hóa: Lớp được tuần tự hóa phải thuộc một trong các kiểu Enum, Array hoặc Serializable.
Điểm quan trọng của tuần tự hóa JDK
Tuần tự hóa của Java có thể đảm bảo việc lưu trữ trạng thái của đối tượng, nhưng khi gặp phải các cấu trúc đối tượng phức tạp, việc xử lý vẫn khá khó khăn. Dưới đây là một số điểm tổng hợp:
- Nếu lớp cha triển khai giao diện
Serializable, tất cả các lớp con cũng có thể được tuần tự hóa. - Nếu lớp con triển khai giao diện
Serializable, nhưng lớp cha không, thì lớp con có thể được tuần tự hóa chính xác, nhưng các thuộc tính của lớp cha sẽ không được tuần tự hóa (không báo lỗi, dữ liệu bị mất). - Nếu thuộc tính được tuần tự hóa là một đối tượng, thì đối tượng đó cũng phải triển khai giao diện
Serializable, nếu không sẽ bị báo lỗi. - Khi thực hiện tuần tự hóa ngược, nếu thuộc tính của đối tượng đã được thay đổi hoặc xóa bỏ, các thuộc tính đã được thay đổi sẽ bị mất, nhưng không báo lỗi.
- Khi thực hiện tuần tự hóa ngược, nếu
serialVersionUIDđã bị thay đổi, quá trình tuần tự hóa ngược sẽ thất bại.
transient
Trong các ứng dụng thực tế, đôi khi không thể sử dụng cơ chế tuần tự hóa mặc định. Ví dụ, muốn bỏ qua dữ liệu nhạy cảm trong quá trình tuần tự hóa, hoặc đơn giản hóa quá trình tuần tự hóa. Dưới đây là một số phương pháp ảnh hưởng đến quá trình tuần tự hóa.
Trong quá trình tuần tự hóa, cơ chế tuần tự hóa mặc định sẽ bỏ qua các trường được khai báo là transient, nghĩa là nội dung của trường này không thể truy cập sau khi tuần tự hóa.
Chúng ta hãy khai báo trường age của lớp Person trong ví dụ SerializeDemo01 là transient, như sau:
public class SerializeDemo02 {
static class Person implements Serializable {
transient private Integer age = null;
// Các nội dung khác bị bỏ qua
}
// Các nội dung khác bị bỏ qua
}
// Kết quả:
// name: Jack, age: null, sex: MALETừ kết quả đầu ra, có thể thấy rằng trường age không được tuần tự hóa.
Giao diện Externalizable
Dù sử dụng từ khóa transient, hoặc sử dụng các phương thức writeObject() và readObject(), thực chất đều dựa trên giao diện Serializable để thực hiện việc tuần tự hóa.
JDK cung cấp một giao diện tuần tự hóa khác là Externalizable.
Khi một lớp có khả năng tuần tự hóa triển khai giao diện Externalizable, cơ chế tuần tự hóa mặc định dựa trên giao diện Serializable sẽ không còn hoạt động.
Chúng ta hãy thực hiện một số thay đổi dựa trên ví dụ SerializeDemo02, mã nguồn như sau:
public class ExternalizeDemo01 {
static class Person implements Externalizable {
transient private Integer age = null;
// Các nội dung khác bị bỏ qua
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException { }
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { }
}
// Các nội dung khác bị bỏ qua
}
// Kết quả:
// call Person()
// name: null, age: null, sex: nullTừ kết quả này, một mặt ta có thể thấy rằng không có trường nào của đối tượng Person được tuần tự hóa. Mặt khác, nếu chú ý, ta cũng có thể thấy rằng trong quá trình tuần tự hóa này, phương thức khởi tạo không tham số của lớp Person đã được gọi.
Externalizablekế thừa từSerializablevà thêm hai phương thức:writeExternal()vàreadExternal()để thực hiện một số thao tác đặc biệt trong quá trình tuần tự hóa và giải tuần tự hóa. Khi sử dụng giao diện này, chi tiết tuần tự hóa phải được thực hiện bởi người lập trình. Như mã nguồn trên, vìwriteExternal()vàreadExternal()không thực hiện bất kỳ xử lý nào, nên hành vi tuần tự hóa này sẽ không lưu/truy xuất bất kỳ trường nào. Đó là lý do tại sao tất cả các trường trong kết quả đầu ra đều rỗng.- Ngoài ra, khi sử dụng
Externalizableđể tuần tự hóa, khi đọc đối tượng, sẽ gọi phương thức khởi tạo không tham số của lớp được tuần tự hóa để tạo một đối tượng mới, sau đó điền giá trị của các trường của đối tượng đã được lưu vào đối tượng mới. Đây là lý do tại sao phương thức khởi tạo không tham số của lớp Person được gọi trong quá trình tuần tự hóa này. Do đó, lớp triển khai giao diệnExternalizablephải cung cấp một phương thức khởi tạo không tham số và quyền truy cập của nó phải làpublic.
Phương pháp thay thế cho giao diện Externalizable
Triển khai giao diện Externalizable cho phép kiểm soát các chi tiết của quá trình tuần tự hóa và giải tuần tự hóa. Tuy nhiên, còn một phương pháp thay thế khác: triển khai giao diện Serializable và thêm các phương thức writeObject(ObjectOutputStream out) và readObject(ObjectInputStream in). Các phương thức này sẽ được gọi tự động trong quá trình tuần tự hóa và giải tuần tự hóa.
Ví dụ như sau:
public class SerializeDemo03 {
static class Person implements Serializable {
transient private Integer age = null;
// Các nội dung khác bị bỏ qua
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
// Các nội dung khác bị bỏ qua
}
// Các nội dung khác bị bỏ qua
}
// Kết quả:
// name: Jack, age: 30, sex: MALETrong phương thức writeObject(), trước tiên sẽ gọi phương thức defaultWriteObject() trong ObjectOutputStream, phương thức này sẽ thực hiện cơ chế tuần tự hóa mặc định như đã mô tả ở phần trước, trong quá trình này trường age sẽ bị bỏ qua. Sau đó, gọi phương thức writeInt() để ghi trường age vào ObjectOutputStream. Phương thức readObject() cũng tương tự, nó được sử dụng để đọc đối tượng, nguyên tắc hoạt động giống như phương thức writeObject().
🔔 Lưu ý: Cả
writeObject()vàreadObject()đều là phương thứcprivate, vậy làm sao chúng được gọi? Đương nhiên, thông qua phản chiếu (reflection). Chi tiết có thể xem trong phương thứcwriteSerialDatacủaObjectOutputStreamvà phương thứcreadSerialDatacủaObjectInputStream.
Phương thức readResolve()
Khi sử dụng mẫu Singleton, chúng ta mong muốn một lớp chỉ có một phiên bản duy nhất. Tuy nhiên, nếu lớp đó có khả năng tuần tự hóa, thì tình huống có thể khác đi một chút. Trong trường hợp này, chúng ta sẽ thay đổi lớp Person trong phần 2 để triển khai mẫu Singleton, như sau:
public class SerializeDemo04 {
enum Sex {
MALE, FEMALE
}
static class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name = null;
transient private Integer age = null;
private Sex sex;
static final Person instance = new Person("Tom", 31, Sex.MALE);
private Person() {
System.out.println("call Person()");
}
private Person(String name, Integer age, Sex sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public static Person getInstance() {
return instance;
}
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
public String toString() {
return "name: " + this.name + ", age: " + this.age + ", sex: " + this.sex;
}
}
// Các phương thức tuần tự hóa và giải tuần tự hóa
public static void main(String[] args) throws IOException, ClassNotFoundException {
final String filename = "d:/text.dat";
serialize(filename);
deserialize(filename);
}
}
// Kết quả:
// name: Jack, age: null, sex: MALE
// falseLưu ý rằng đối tượng Person được lấy từ tệp không bằng với đối tượng singleton trong lớp Person. Để vẫn duy trì tính chất tuần tự hóa trong lớp Singleton, chúng ta có thể sử dụng phương thức readResolve(). Trong phương thức này, chúng ta trực tiếp trả về đối tượng singleton của lớp Person. Chúng ta thêm một phương thức readResolve() vào ví dụ SerializeDemo04 như sau:
public class SerializeDemo05 {
// Các phần khác bị bỏ qua
static class Person implements Serializable {
// private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
// in.defaultReadObject();
// age = in.readInt();
// }
// Thêm phương thức này
private Object readResolve() {
return instance;
}
// Các phần khác bị bỏ qua
}
// Các phần khác bị bỏ qua
}
// Kết quả:
// name: Tom, age: 31, sex: MALE
// trueVấn đề với JDK Serialization
- Không thể giao tiếp qua ngôn ngữ: JDK Serialization hiện chỉ áp dụng cho các framework được triển khai bằng Java, hầu hết các ngôn ngữ khác không sử dụng framework serialization của Java hoặc không triển khai giao thức serialization của JDK. Do đó, nếu hai ứng dụng được viết bằng các ngôn ngữ khác nhau cần giao tiếp với nhau, việc tuần tự hóa và giải tuần tự hóa đối tượng giữa hai dịch vụ sẽ không thể thực hiện được.
- Dễ bị tấn công: Đối tượng được giải tuần tự hóa thông qua việc gọi phương thức
readObject()trênObjectInputStream, điều này có thể tạo ra một phiên bản của hầu hết các đối tượng đã triển khai giao diệnSerializabletrên đường dẫn lớp. Điều này có nghĩa là trong quá trình giải tuần tự hóa dữ liệu byte, phương thức này có thể thực thi bất kỳ mã loại nào, điều này rất nguy hiểm. Với các đối tượng cần thời gian giải tuần tự hóa lâu, không cần thực thi bất kỳ mã nào, cũng có thể tạo ra một cuộc tấn công. Kẻ tấn công có thể tạo ra một chuỗi đối tượng lặp lại và sau đó chuyển đối tượng đã được tuần tự hóa vào chương trình để giải tuần tự hóa, điều này sẽ dẫn đến việc gọi phương thứchashCodenhiều lần, gây ra lỗi tràn ngăn xếp. Ví dụ dưới đây là một ví dụ tốt để minh họa điều này. - Dữ liệu tuần tự hóa quá lớn: JDK Serialization sử dụng
ObjectOutputStreamđể chuyển đổi đối tượng thành mã nhị phân, mảng byte được tạo ra rất lớn, ảnh hưởng đến hiệu suất lưu trữ và truyền dữ liệu. - Hiệu suất tuần tự hóa kém: Tuần tự hóa của Java tốn nhiều thời gian. Tốc độ tuần tự hóa cũng là một chỉ số quan trọng để đánh giá hiệu suất tuần tự hóa. Nếu tốc độ tuần tự hóa chậm, nó sẽ ảnh hưởng đến hiệu suất giao tiếp mạng và làm tăng thời gian phản hồi của hệ thống.
- Hạn chế lập trình tuần tự hóa:
- JDK Serialization yêu cầu triển khai giao diện
Serializable. - JDK Serialization yêu cầu chú ý đến
serialVersionUID.
- JDK Serialization yêu cầu triển khai giao diện
Serialization nhị phân
Phần trước đã chi tiết giới thiệu về cách thức serialization của JDK, tuy nhiên do hiệu suất không cao và tồn tại nhiều vấn đề khác, nên trong ngành công nghiệp đã có rất nhiều thư viện serialization nhị phân xuất sắc khác.
Protobuf
Protobuf là một chuẩn dữ liệu đa ngôn ngữ được Google sử dụng nội bộ trong công ty. Đây là một định dạng lưu trữ dữ liệu cấu trúc nhẹ, hiệu quả và hỗ trợ việc serialization cho các ngôn ngữ như Java, Python, C++, Go,… Khi sử dụng Protobuf, chúng ta cần xác định IDL (Interface description language), sau đó sử dụng trình biên dịch IDL của từng ngôn ngữ để tạo ra các lớp công cụ serialization.
Ưu điểm:
- Dung lượng sau khi serialize so với JSON hay Hessian nhỏ hơn rất nhiều
- Tốc độ serialize và deserialize rất nhanh mà không cần thông qua reflection để lấy kiểu
- Không phụ thuộc vào ngôn ngữ hoặc platform (dựa trên IDL), IDL có thể miêu tả ý nghĩa một cách rõ ràng, do đó có thể giúp đảm bảo không mất kiểu giữa các ứng dụng và không cần phải sử dụng trình phân tích XML tương tự
- Hỗ trợ việc nâng cấp và tương thích thông điệp, có thể đảm bảo tương thích ngược về sau
- Hỗ trợ đa ngôn ngữ: Java, C++, Python, Go, …
Nhược điểm:
- Protobuf khá khó sử dụng đối với các ngôn ngữ có khả năng reflection và linh hoạt.
Thrift
Thrift là một dự án mã nguồn mở của Apache, là một cách triển khai RPC (Remote Procedure Call) point-to-point.
Nó có các tính năng sau:
- Hỗ trợ nhiều ngôn ngữ (hiện tại hỗ trợ 28 ngôn ngữ như C++, Go, Java, Php, Python, Ruby, vv).
- Sử dụng công cụ trao đổi và lưu trữ dữ liệu lớn, có lợi thế về hiệu suất và kích thước so với JSON và XML trong việc truyền dữ liệu trong các hệ thống lớn.
- Hỗ trợ ba phương pháp mã hóa phổ biến (mã hóa nhị phân chung, mã hóa nhị phân nén, mã hóa nén trường tùy chọn).
Hessian
Hessian là một framework serialization đa ngôn ngữ, có kiểu dữ liệu động, nhị phân và gọn nhẹ. Giao thức Hessian nhỏ gọn hơn JDK và JSON, đồng thời hiệu suất của nó hiệu quả hơn nhiều so với tuần tự hóa JDK và JSON, đồng thời số lượng byte được tạo cũng nhỏ hơn.
Framework RPC Dubbo hỗ trợ Thrift và Hession.
Nó có các tính năng sau:
- Hỗ trợ nhiều ngôn ngữ khác nhau: Java, Python, C++, C#, PHP, Ruby,…
- Tương đối chậm so với các thư viện serialization nhị phân khác.
Hessian cũng tồn tại một số vấn đề. Phiên bản chính thức không hỗ trợ loại của một số đối tượng thông dụng trong Java:
- Các kiểu Linked như LinkedHashMap, LinkedHashSet, nhưng có thể được sửa chữa bằng cách mở rộng lớp CollectionDeserializer.
- Lớp Locale, có thể được sửa chữa bằng cách mở rộng lớp ContextSerializerFactory.
- Khi giải nén Byte/Short, chúng sẽ trở thành Integer.
Kryo
Kryo là một framework serialization nhanh chóng và hiệu quả cho Java. Kryo cũng có thể thực hiện sao chép sâu và sao chép nông tự động. Điều này là việc sao chép trực tiếp từ object sang object, không phải từ object sang byte.
Nó có các tính năng sau:
- Tốc độ cao, kích thước serialization nhỏ
- Chỉ hỗ trợ Java, không hỗ trợ ngôn ngữ khác
FST
FST là một thư viện serialization nhị phân được triển khai bằng Java.
Nó có các tính năng sau:
- Gần như tương thích 100% với JDK serialization và nhanh gấp 10 lần so với cách serialization ban đầu của JDK.
- Từ phiên bản 2.17 trở đi tương thích với Android.
- (Tùy chọn) Từ phiên bản 2.29 trở đi hỗ trợ mã hóa/giải mã bất kỳ biểu đồ đối tượng serializable thành JSON (bao gồm cả reference sharing).
JSON Serialization
Ngoài cách serialization nhị phân, bạn cũng có thể chọn cách serialization JSON. Hiệu suất của nó kém hơn so với serialization nhị phân, nhưng độ đọc được rất tốt và được sử dụng rộng rãi trong lĩnh vực Web.
JSON là gì?
JSON bắt nguồn từ một phần con của tiêu chuẩn ngôn ngữ JS ECMA262 năm 1999 (mục 15.12 mô tả định dạng và phân tích cú pháp), sau đó được xuất bản vào năm 2003 dưới dạng một định dạng dữ liệu ECMA404 (số thứ tự kỳ lạ có vài số không?). Năm 2006, nó được xuất bản dưới dạng rfc4627, tài liệu này có 18 trang, loại bỏ các phần không cần thiết và chỉ còn lại khoảng chừng 10 trang.
JSON được sử dụng rộng rãi và có hơn 100 thư viện JSON cho hơn 100 ngôn ngữ khác nhau: json.org.
Bạn có thể tìm hiểu thêm về JSON tại đây, Tất cả về JSON.
Tiêu chuẩn JSON
Đây có lẽ là một trong những tiêu chuẩn đơn giản nhất:
- Chỉ có hai cấu trúc: tập hợp các cặp khóa-giá trị trong đối tượng và mảng, đối tượng được đại diện bằng
{}, bên trong là"key":"value", mảng được đại diện bằng[], các giá trị khác nhau được phân tách bằng dấu phẩy. - Có 7 kiểu giá trị cơ bản:
false/null/true/object/array/number/string. - Ngoài ra, nó cho phép lồng ghép các cấu trúc để biểu thị dữ liệu phức tạp.
- Dưới đây là một ví dụ đơn giản:
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": "100"
},
"IDs": [116, 943, 234, 38793]
}
}Đọc thêm:
- http://www.json.org/json-vi.html - Giới thiệu về định dạng dữ liệu JSON.
- Tài liệu RFC về JSON
Ưu điểm và nhược điểm của JSON
Ưu điểm của JSON:
- Dựa trên văn bản thuần túy, nên rất dễ đọc cho con người.
- Quy chuẩn đơn giản, dễ xử lý, sẵn có để sử dụng. Đặc biệt là trong các ECMAScript đã được tích hợp sẵn và có thể sử dụng trực tiếp như một đối tượng.
- Không phụ thuộc vào nền tảng vì kiểu và cấu trúc không phụ thuộc vào nền tảng. Ngoài ra, việc xử lý cũng rất dễ dàng, có thể triển khai các thư viện xử lý khác nhau cho các ngôn ngữ khác nhau. Có thể được sử dụng làm giao thức định dạng truyền thông giữa nhiều hệ thống không tương tự nhau, đặc biệt là trong HTTP/REST.
Nhược điểm của JSON:
- Hiệu suất chỉ ở mức trung bình. Dữ liệu biểu diễn bằng văn bản thông thường thông generally so với số liệu hai chính phủ binary data , do đó ảnh hưởng hiệu suất khi truyền và xử lý.
- Thiếu schema (bảo mật), so với XML - một định dạng dữ liệu văn bản khác, JSON kém hơn rất nhiều về tính chính xác và phong phú của kiểu. XML có thể được xác định theo XSD hoặc DTD để xác định các định dạng phức tạp và kiểm tra xem tài liệu XML có tuân thủ yêu cầu định dạng hay không. Thậm chí, bạn còn có thể tạo mã hoạt động cho ngôn ngữ cụ thể dựa trên XSD, ví dụ như apache xmlbeans. Và những công cụ này khi kết hợp lại sẽ tạo thành một hệ sinh thái lớn, ví dụ: SOAP và WSDL được triển khai trên XML thông qua chuỗi quy ước ws-*. Tuy nhiên, ta cũng có thể nhận ra rằng JSON trong trường hợp thiếu quy ước đã linh hoạt hơn một chút, đặc biệt là gần đây REST đã phát triển nhanh chóng và đã xuất hiện một số tiến bộ liên quan schema (ví dụ: Hiểu JSON Schema, Sử dụng JSON Schema, Kiểm tra schema trực tuyến), cũng như WADL tương tự với WSDL (https://www.w3.org/Submission/wadl/) đã xuất hiện.
Thư viện JSON
Có nhiều thư viện JSON phổ biến trong Java:
- Fastjson - Thư viện JSON được phát triển bởi Alibaba, có hiệu suất rất tốt.
- Jackson - Cộng đồng rất tích cực và cập nhật nhanh. Thư viện JSON mặc định của Spring Framework.
- Gson - Thư viện JSON được phát triển bởi Google, là thư viện JSON chức năng đầy đủ nhất.
Về hiệu suất, trong hầu hết các trường hợp: Fastjson > Jackson > Gson.
Hướng dẫn mã hóa JSON
Tuân thủ thiết kế và phong cách mã hóa tốt có thể giải quyết trước 80% vấn đề, cá nhân khuyến nghị tuân thủ Google JSON Style Guide.
Dưới đây là một số điểm nổi bật:
- Tên thuộc tính và giá trị đều được bao bọc bằng dấu ngoặc kép, không đặt chú thích vào bên trong đối tượng, dữ liệu đối tượng phải đơn giản.
- Không nhóm các đối tượng thành các nhóm cấu trúc, khuyến nghị sử dụng cách tạo chuỗi nhị phân phẳng, không nên quá phức tạp.
- Đặt tên có ý nghĩa, ví dụ: số ít và số nhiều.
- Sử dụng kiểu ghi tắt camelCase, tuân theo quy tắc Bean.
- Sử dụng phiên bản để kiểm soát xung đột.
- Đối với các thuộc tính tùy chọn hoặc chứa giá trị rỗng hoặc null, xem xét loại bỏ thuộc tính đó khỏi JSON, trừ khi nó có ý nghĩa mạnh mẽ.
- Khi mã hóa kiểu enum, sử dụng tên thay vì giá trị.
- Xử lý ngày tháng theo định dạng chuẩn.
- Thiết kế tham số phân trang chung.
- Thiết kế xử lý ngoại lệ tốt.
JSON API và Google JSON Style Guide có nhiều điểm tương đồng.
JSON API là một tiêu chuẩn trao đổi dữ liệu, được sử dụng để xác định cách khách hàng có thể truy xuất và sửa đổi tài nguyên, cũng như cách máy chủ phản hồi các yêu cầu tương ứng.
JSON API được thiết kế để giảm số lượng yêu cầu và lượng dữ liệu được truyền qua mạng. Trong khi đảm bảo hiệu suất, nó không làm mất tính đọc được, tính linh hoạt và tính khám phá được.
Lựa chọn công nghệ serialization
Trên thị trường có rất nhiều công nghệ serialization khác nhau, vậy làm thế nào để chọn công nghệ phù hợp cho ứng dụng của chúng ta?
Khi lựa chọn công nghệ serialization, chúng ta cần xem xét các yếu tố sau theo thứ tự quan trọng từ cao đến thấp:
- Bảo mật: Công nghệ có tồn tại lỗ hổng nào không. Nếu có lỗ hổng, có khả năng bị tấn công.
- Tính tương thích: Công nghệ có tương thích tốt sau khi nâng cấp phiên bản không, có hỗ trợ nhiều loại đối tượng, có khả năng tương thích giữa các nền tảng và ngôn ngữ không. Độ ổn định và đáng tin cậy của việc gọi dịch vụ, quan trọng hơn hiệu suất của dịch vụ.
- Hiệu suất
- Thời gian: Thời gian để thực hiện serialization và deserialization càng ít càng tốt.
- Dung lượng: Dữ liệu sau khi serialization càng nhỏ càng tốt, giúp tăng hiệu suất truyền dữ liệu qua mạng.
- Dễ sử dụng: Thư viện có nhẹ nhàng, API có dễ hiểu và sử dụng.
Dựa trên các yếu tố trên, đề xuất lựa chọn công nghệ serialization như sau:
- JDK Serialization: Hiệu suất kém và có nhiều hạn chế sử dụng, không khuyến nghị sử dụng.
- Thrift, Protobuf: Phù hợp cho những ứng dụng cần hiệu suất cao và không yêu cầu trải nghiệm phát triển cao.
- Hessian: Phù hợp cho những ứng dụng yêu cầu trải nghiệm phát triển cao và hiệu suất tốt.
- Jackson, Gson, Fastjson: Phù hợp cho việc yêu cầu dữ liệu sau khi serialize có tính đọc tốt (chuyển thành json hoặc xml).