Cài đặt môi trường Hadoop Cluster
Kịch bản Cluster
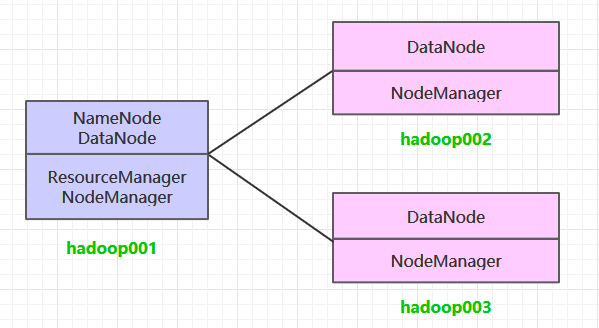
Ở đây, chúng tôi sẽ cài đặt một cụm Hadoop 3 nút, trong đó ba máy chủ đều triển khai dịch vụ DataNode và NodeManager, nhưng chỉ có hadoop001 triển khai dịch vụ NameNode và ResourceManager.
Điều kiện tiên quyết
Hadoop hoạt động phụ thuộc vào JDK, cần được cài đặt trước. Các bước cài đặt được tổng hợp riêng tại:
Cấu hình đăng nhập không cần mật khẩu
Tạo khóa
Trên mỗi máy chủ, sử dụng lệnh ssh-keygen để tạo cặp public key và private key:
ssh-keygenĐăng nhập không cần mật khẩu
Đưa public key của hadoop001 vào tệp ~/ .ssh/authorized_key của máy cục bộ và máy từ xa:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop003Xác nhận đăng nhập không cần mật khẩu
ssh hadoop002
ssh hadoop003Cài đặt Cluster
Tải và giải nén
Tải về gói cài đặt Hadoop từ trang chủ, địa chỉ tải về là: Index of /hadoop/common/hadoop-2.10.2
# Giải nén
tar -zvxf hadoop-2.10.2.tar.gzCấu hình biến môi trường
Chỉnh sửa tệp profile:
# vim /etc/profileThêm cấu hình sau:
export HADOOP_HOME=/usr/app/hadoop-2.10.2
export PATH=${HADOOP_HOME}/bin:$PATH
Thực hiện lệnh source, để cấu hình có hiệu lực ngay lập tức:
source /etc/profileChỉnh sửa cấu hình
Truy cập thư mục ${HADOOP_HOME}/etc/hadoop, chỉnh sửa các tệp cấu hình. Nội dung của từng tệp cấu hình như sau:
1. hadoop-env.sh
# Chỉ định vị trí cài đặt JDK
export JAVA_HOME=/usr/java/jdk1.8.0_201/2. core-site.xml
<configuration>
<property>
<!--Chỉ định địa chỉ giao tiếp hệ thống tệp giao thức hdfs của namenode-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--Chỉ định thư mục lưu trữ tệp tạm thời của cụm hadoop-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>3. hdfs-site.xml
<property>
<!--Vị trí lưu trữ dữ liệu (tức là dữ liệu siêu dữ liệu) của nút namenode, có thể chỉ định nhiều thư mục để thực hiện chống lỗi, các thư mục được phân tách bằng dấu phẩy-->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!--Vị trí lưu trữ dữ liệu (tức là khối dữ liệu) của nút datanode-->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>4. yarn-site.xml
<configuration>
<property>
<!--Cấu hình dịch vụ phụ trợ chạy trên NodeManager. Cần cấu hình thành mapreduce_shuffle sau khi có thể chạy chương trình MapReduce trên Yarn.-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--Tên máy chủ của resourcemanager-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
</configuration>
5. mapred-site.xml
<configuration>
<property>
<!--Chỉ định công việc mapreduce chạy trên yarn-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5. slaves
Cấu hình tên máy chủ hoặc địa chỉ IP của tất cả các nút phụ thuộc, mỗi dòng một. Tất cả các dịch vụ DataNode và NodeManager trên tất cả các nút phụ thuộc sẽ được khởi động.
hadoop001
hadoop002
hadoop003Phân phối chương trình
Phân phối gói cài đặt Hadoop đến hai máy chủ khác, sau khi phân phối, đề xuất cũng cấu hình biến môi trường Hadoop trên hai máy chủ này.
# Phân phối gói cài đặt đến hadoop002
scp -r /usr/app/hadoop-2.10.2/ hadoop002:/usr/app/
# Phân phối gói cài đặt đến hadoop003
scp -r /usr/app/hadoop-2.10.2/ hadoop003:/usr/app/Khởi tạo
Thực hiện lệnh khởi tạo namenode trên Hadoop001:
hdfs namenode -format
Khởi động cụm
Truy cập vào thư mục ${HADOOP_HOME}/sbin của Hadoop001, khởi động Hadoop. Lúc này, các dịch vụ liên quan trên hadoop002 và hadoop003 cũng sẽ được khởi động:
# Khởi động dịch vụ dfs
start-dfs.sh
# Khởi động dịch vụ yarn
start-yarn.shKiểm tra cụm
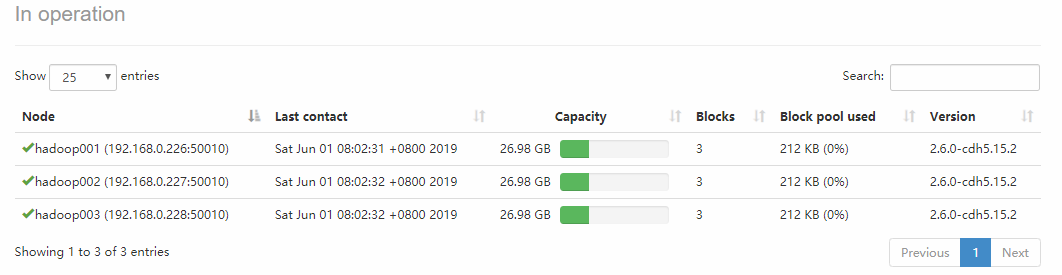
Sử dụng lệnh jps để kiểm tra quy trình dịch vụ trên mỗi máy chủ, hoặc truy cập trực tiếp vào giao diện Web-UI để kiểm tra, cổng là 50070. Bạn có thể thấy có ba Datanode có sẵn:

Nhấp vào Live Nodes để vào, bạn có thể xem chi tiết về mỗi DataNode:
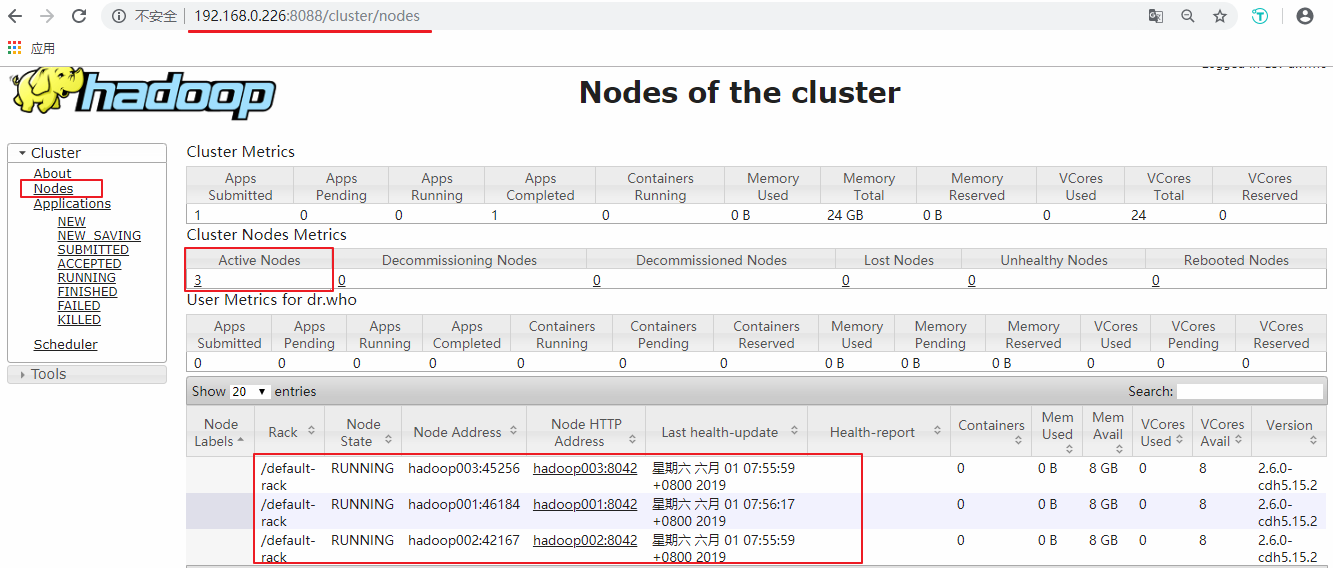
Tiếp theo, bạn có thể kiểm tra tình hình của Yarn, số cổng là 8088:
Gửi dịch vụ đến cụm
Cách gửi công việc đến cụm hoàn toàn giống với môi trường đơn máy, ở đây, chúng tôi sẽ sử dụng chương trình mẫu tính toán Pi được tích hợp sẵn trong Hadoop làm ví dụ, bạn có thể thực thi trên bất kỳ nút nào, lệnh như sau:
hadoop jar /usr/app/hadoop-2.10.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.2.jar pi 3 3