Go: Map Extend
Mục đích của việc sử dụng bảng băm (map) là để tìm kiếm nhanh các key mục tiêu. Tuy nhiên, khi thêm key vào map, khả năng xảy ra va chạm key cũng ngày càng cao. 8 ô (cell) trong mỗi bucket sẽ dần trở nên đầy, hiệu suất tìm kiếm, chèn và xóa key cũng sẽ giảm đi. Trường hợp lý tưởng là mỗi bucket chỉ chứa một key, điều này sẽ đạt được hiệu suất O(1), nhưng đồng thời cũng tiêu tốn quá nhiều không gian.
Go sử dụng 8 key trong mỗi bucket, sau đó lại phải xác định key cụ thể trong bucket đó, điều này lại tốn thời gian để tiết kiệm không gian.
Tuy nhiên, cần có một chỉ số để đánh giá tình trạng đã mô tả ở trên, đó là “tỷ lệ tải” (load factor). Trong mã nguồn Go, “tỷ lệ tải” được định nghĩa như sau:
loadFactor := count / (2^B)Ở đây, count là số lượng phần tử trong map, 2^B đại diện cho số lượng bucket.
Tiếp theo là điều kiện để kích hoạt việc mở rộng map: Khi thêm key vào map, điều kiện sau sẽ được kiểm tra, nếu thỏa mãn cả hai điều kiện, việc mở rộng sẽ được kích hoạt:
- Tỷ lệ tải vượt qua ngưỡng, ngưỡng được định nghĩa trong mã nguồn là 6.5.
- Số lượng bucket overflow quá nhiều: Khi B nhỏ hơn 15, tức là số lượng bucket tổng cộng 2^B nhỏ hơn 2^15, nếu số lượng bucket overflow vượt quá 2^B; Khi B >= 15, tức là số lượng bucket tổng cộng 2^B lớn hơn hoặc bằng 2^15, nếu số lượng bucket overflow vượt quá 2^15.
Trong mã nguồn Go, các hàm kiểm tra điều kiện này được viết như sau:
// src/runtime/hashmap.go/mapassign
// Kích hoạt việc mở rộng map
if !h.growing() && (overLoadFactor(int64(h.count), h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
}
// Tỷ lệ tải vượt quá 6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// Số lượng bucket overflow quá nhiều
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}Giải thích:
- Điều kiện 1: Chúng ta biết rằng mỗi bucket có 8 ô trống. Trong trường hợp không có overflow và tất cả các bucket đều đầy, tỷ lệ tải tính toán ra là 8. Do đó, khi tỷ lệ tải vượt quá 6.5, điều này cho thấy nhiều bucket sắp đầy, hiệu suất tìm kiếm và chèn giảm đi. Khi điều kiện này xảy ra, việc mở rộng là cần thiết.
- Điều kiện 2: Đây là bổ sung cho điều kiện 1. Điều này ám chỉ rằng trong trường hợp tỷ lệ tải khá nhỏ, điều này có nghĩa là tổng số phần tử trong map ít, nhưng số lượng bucket lại nhiều (thực tế được phân bổ nhiều bucket, bao gồm nhiều bucket overflow). Hiện tượng này xảy ra khi chúng ta liên tục thêm và xóa các phần tử. Đầu tiên, chúng ta thêm nhiều phần tử, dẫn đến việc tạo ra nhiều bucket, nhưng tỷ lệ tải không đạt ngưỡng của điều kiện 1, không kích hoạt việc mở rộng để giải quyết tình huống này. Sau đó, chúng ta xóa các phần tử để giảm tổng số phần tử, sau đó thêm nhiều phần tử khác, dẫn đến việc tạo ra nhiều bucket overflow, nhưng không vi phạm điều kiện 1. Điều này dẫn đến việc áp dụng điều kiện 2. Đây giống như một thành phố trống, có nhiều nhà nhưng ít người, tất cả đều phân tán, việc tìm kiếm trở nên khó khăn.
Cả hai điều kiện trên đều sẽ kích hoạt việc mở rộng. Tuy nhiên, chiến lược mở rộng sẽ khác nhau, vì hai điều kiện này đối phó với các tình huống khác nhau.
Đối với điều kiện 1, khi có quá nhiều phần tử và quá ít bucket, quá trình mở rộng đơn giản: tăng B lên 1, số lượng bucket tối đa (2^B) tăng gấp đôi số lượng bucket ban đầu (2^B * 2). Lưu ý rằng lúc này, các phần tử vẫn nằm trong bucket cũ và chưa được chuyển sang bucket mới. Bucket mới chỉ có số lượng tối đa là số lượng bucket ban đầu (2^B).
Đối với điều kiện 2, thực tế là không có quá nhiều phần tử, nhưng có quá nhiều bucket overflow, cho thấy nhiều bucket chưa đầy. Giải pháp là tạo ra một bucket mới và di chuyển các phần tử từ bucket cũ sang bucket mới, làm cho các key trong cùng một bucket được sắp xếp gần nhau hơn. Kết quả là tiết kiệm không gian, tăng hiệu suất sử dụng bucket và cải thiện hiệu suất tìm kiếm và chèn của map.
Về cách thực hiện mở rộng, vì việc mở rộng map yêu cầu di chuyển lại các key/value từ địa chỉ bộ nhớ cũ sang địa chỉ bộ nhớ mới, nếu có nhiều key/value cần di chuyển, nó sẽ ảnh hưởng đến hiệu suất. Do đó, quá trình mở rộng của map trong Go được thực hiện theo cách gọi là “mở rộng dần”, nghĩa là các key hiện có không được di chuyển một lần, mà chỉ di chuyển tối đa 2 bucket mỗi lần.
Trước tiên, chúng ta hãy xem công việc được thực hiện trong hàm hashGrow(), sau đó xem cách di chuyển bucket được thực hiện trong growWork().
func hashGrow(t *maptype, h *hmap) {
// B+1 tương đương với gấp đôi không gian ban đầu
bigger := uint8(1)
// Đối với điều kiện 2
if !overLoadFactor(int64(h.count), h.B) {
// Thực hiện mở rộng bằng cùng kích thước, vì vậy B không thay đổi
bigger = 0
h.flags |= sameSizeGrow
}
// Gắn oldbuckets vào buckets
oldbuckets := h.buckets
// Cấp phát không gian mới cho buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// Thực hiện mở rộng
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// Tiến trình di chuyển được đặt về 0
h.nevacuate = 0
// Số lượng overflow buckets được đặt về 0
h.noverflow = 0
// ……
}Chức năng chính là cấp phát không gian mới cho các bucket, xử lý các cờ liên quan: ví dụ, cờ nevacuate được đặt thành 0, đại diện cho tiến trình di chuyển hiện tại là 0.
Cần đề cập đến xử lý của h.flags:
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}Đây là toán tử &^, còn được gọi là toán tử “and not”. Ví dụ:
x = 01010011
y = 01010100
z = x &^ y = 00000011Nếu bit tương ứng của y là 1, thì bit tương ứng của z sẽ là 0, ngược lại bit tương ứng của z sẽ giống với giá trị bit tương ứng của x.
Vì vậy, đoạn mã trên xử lý flags như sau: trước tiên, xóa các bit tương ứng của iterator và oldIterator trong h.flags, sau đó, nếu bit iterator là 1, thì chuyển nó sang bit oldIterator, làm cho oldIterator trở thành 1. Ý nghĩa ẩn đằng sau là: buckets hiện tại đã được gắn vào oldbuckets, các bit tương ứng cũng được chuyển sang oldIterator.
Một số cờ tương ứng như sau:
// Có thể có iterator sử dụng buckets
iterator = 1
// Có thể có iterator sử dụng oldbuckets
oldIterator = 2
// Có goroutine đang ghi key vào map
hashWriting = 4
// Mở rộng cùng kích thước (điều kiện 2)
sameSizeGrow = 8Tiếp theo, chúng ta sẽ xem hàm growWork() thực hiện công việc di chuyển thực sự.
func growWork(t *maptype, h *hmap, bucket uintptr) {
// Xác định bucket cũ tương ứng với bucket đang sử dụng
evacuate(t, h, bucket&h.oldbucketmask())
// Di chuyển thêm một bucket để tăng tốc quá trình di chuyển
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}Hàm h.growing() rất đơn giản:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}Nếu oldbuckets không nil, điều này cho thấy việc di chuyển vẫn chưa hoàn thành và cần tiếp tục di chuyển.
Dòng code bucket&h.oldbucketmask() như được giải thích trong chú thích mã nguồn, được sử dụng để xác định bucket cần di chuyển là bucket đang sử dụng. Hàm oldbucketmask() trả về giá trị mask của map trước khi mở rộng.
Khái niệm bucketmask có tác dụng làm cho giá trị hash của key và bucketmask AND với nhau, kết quả thu được là bucket mà key nên nằm trong. Ví dụ, nếu B = 5, thì bucketmask có 5 bit thấp là 11111, các bit khác là 0. Việc AND giữa giá trị hash và bucketmask có nghĩa là chỉ có 5 bit thấp của giá trị hash quyết định key nằm trong bucket nào.
Tiếp theo, chúng ta tập trung vào hàm evacuate, là hàm quan trọng trong quá trình di chuyển. Mã nguồn được đính kèm dưới đây, đừng lo lắng, tôi sẽ thêm chú thích rộng lớn, chú thích này chắc chắn sẽ giúp bạn hiểu được. Sau đó, tôi sẽ giải thích quá trình di chuyển chi tiết.
Dưới đây là mã nguồn:
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// Địa chỉ của bucket cũ
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// Kết quả là 2^B, ví dụ B = 5, kết quả là 32
newbit := h.noldbuckets()
// Hàm băm cho khóa
alg := t.key.alg
// Nếu bucket chưa được di chuyển
if !evacuated(b) {
var (
// Địa chỉ bucket đích cho việc di chuyển
x, y *bmap
// Con trỏ trỏ đến key/val trong x,y
xi, yi int
// Con trỏ trỏ đến key trong x,y
xk, yk unsafe.Pointer
// Con trỏ trỏ đến value trong x,y
xv, yv unsafe.Pointer
)
// Mặc định là mở rộng cùng kích thước, không thay đổi số thứ tự bucket trước và sau
// Sử dụng x để di chuyển
x = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
xi = 0
xk = add(unsafe.Pointer(x), dataOffset)
xv = add(xk, bucketCnt*uintptr(t.keysize))、
// Nếu không phải mở rộng cùng kích thước, số thứ tự bucket trước và sau thay đổi
// Sử dụng y để di chuyển
if !h.sameSizeGrow() {
// y đại diện cho số thứ tự bucket tăng thêm 2^B
y = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
yi = 0
yk = add(unsafe.Pointer(y), dataOffset)
yv = add(yk, bucketCnt*uintptr(t.keysize))
}
// Duyệt qua tất cả các bucket, bao gồm cả overflow buckets
// b là địa chỉ của bucket cũ
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
// Duyệt qua tất cả các cell trong bucket
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
// Giá trị top hash của cell hiện tại
top := b.tophash[i]
// Nếu cell trống, tức không có key
if top == empty {
// Đánh dấu nó đã được "di chuyển"
b.tophash[i] = evacuatedEmpty
// Tiếp tục cell tiếp theo
continue
}
// Thông thường không xảy ra trường hợp này
// Cell chưa được di chuyển chỉ có thể là trống hoặc
// top hash bình thường (lớn hơn minTopHash)
if top < minTopHash {
throw("bad map state")
}
k2 := k
// Nếu key là con trỏ, giải tham chiếu
if t.indirectkey {
k2 = *((*unsafe.Pointer)(k2))
}
// Mặc định sử dụng X, mở rộng cùng kích thước
useX := true
// Nếu không phải mở rộng cùng kích thước
if !h.sameSizeGrow() {
// Tính toán giá trị băm, giống như khi ghi key lần đầu
hash := alg.hash(k2, uintptr(h.hash0))
// Nếu có một goroutine đang duyệt qua map
if h.flags&iterator != 0 {
// Nếu có cùng giá trị key nhưng giá trị băm tính toán khác nhau
if !t.reflexivekey && !alg.equal(k2, k2) {
// Chỉ có thể xảy ra khi giá trị float là NaN()
if top&1 != 0 {
// Đặt bit B thành 1
hash |= newbit
} else {
// Đặt bit B thành 0
hash &^= newbit
}
// Lấy 8 bit cao nhất làm giá trị top hash
top = uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
}
}
// Tùy thuộc vào giá trị băm mới, bit oldB+1 có giá trị 0 hoặc 1
// Chi tiết xem trong bài viết sau
useX = hash&newbit == 0
}
// Nếu key được di chuyển vào phần X
if useX {
// Đánh dấu giá trị top hash của cell cũ, cho biết nó đã được di chuyển vào phần X
b.tophash[i] = evacuatedX
// Nếu xi bằng 8, tức là sẽ tràn
if xi == bucketCnt {
// Tạo một bucket mới
newx := h.newoverflow(t, x)
x = newx
// Xi bắt đầu từ 0
xi = 0
// Xk là vị trí di chuyển key đến
xk = add(unsafe.Pointer(x), dataOffset)
// Xv là vị trí di chuyển value đến
xv = add(xk, bucketCnt*uintptr(t.keysize))
}
// Đặt giá trị top hash
x.tophash[xi] = top
// Key là con trỏ
if t.indirectkey {
// Sao chép key cũ (là con trỏ) vào vị trí mới
*(*unsafe.Pointer)(xk) = k2 // copy pointer
} else {
// Sao chép key cũ (là giá trị) vào vị trí mới
typedmemmove(t.key, xk, k) // copy value
}
// Value là con trỏ, thao tác tương tự với key
if t.indirectvalue {
*(*unsafe.Pointer)(xv) = *(*unsafe.Pointer)(v)
} else {
typedmemmove(t.elem, xv, v)
}
// Di chuyển đến cell tiếp theo
xi++
xk = add(xk, uintptr(t.keysize))
xv = add(xv, uintptr(t.valuesize))
} else { // Key được di chuyển vào phần Y, thao tác tương tự với phần X
// ……
// Bỏ qua phần này, thao tác giống với phần X
}
}
}
// Nếu không có goroutine nào đang sử dụng bucket cũ, xóa bucket cũ để giúp gc
if h.flags&oldIterator == 0 {
b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// Chỉ xóa phần key,value của bucket, giữ lại phần top hash để chỉ định trạng thái di chuyển
if t.bucket.kind&kindNoPointers == 0 {
memclrHasPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
} else {
memclrNoHeapPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
}
}
}
// Cập nhật tiến trình di chuyển
// Nếu bucket di chuyển trong lần di chuyển này bằng với tiến trình hiện tại
if oldbucket == h.nevacuate {
// Tăng tiến trình lên 1
h.nevacuate = oldbucket + 1
// Các thử nghiệm cho thấy 1024 là quá nhiều ít nhất một đơn vị.
// Đặt nó vào đó như một biện pháp phòng chống, để đảm bảo hành vi O(1).
// Thử xem 1024 bucket tiếp theo
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
// Tìm bucket chưa được di chuyển
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// Bây giờ tất cả các bucket trước h.nevacuate đã được di chuyển
// Tất cả các bucket đã được di chuyển
if h.nevacuate == newbit {
// Xóa bucket cũ
h.oldbuckets = nil
// Xóa overflow bucket cũ
// Nhớ lại: [0] đại diện cho overflow bucket hiện tại
// [1] đại diện cho overflow bucket cũ
if h.extra != nil {
h.extra.overflow[1] = nil
}
// Xóa cờ đang mở rộng
h.flags &^= sameSizeGrow
}
}
}Hàm evacuate được sử dụng để di chuyển các bucket cũ sang các bucket mới trong quá trình mở rộng của map. Nhìn vào mã nguồn và các chú thích, ta có thể dễ dàng hiểu quá trình di chuyển tổng thể.
Mục đích của quá trình di chuyển là để chuyển các bucket cũ sang các bucket mới. Từ những giải thích trước đó, ta biết rằng để đáp ứng điều kiện 1, số lượng bucket mới sẽ là gấp đôi số lượng bucket cũ, và để đáp ứng điều kiện 2, số lượng bucket mới sẽ giống với số lượng bucket cũ.
Đối với điều kiện 2, việc di chuyển từ bucket cũ sang bucket mới có thể được thực hiện theo thứ tự số hiệu của bucket. Ví dụ, nếu trước đây nằm trong bucket số 0, sau khi di chuyển đến vị trí mới, nó vẫn sẽ nằm trong bucket số 0.
Đối với điều kiện 1, việc di chuyển từ bucket cũ sang bucket mới không đơn giản như vậy. Cần tính toán lại giá trị băm của key để xác định nó thuộc bucket nào. Ví dụ, trước đây B = 5, sau khi tính toán giá trị băm của key, chỉ cần xem 5 bit thấp nhất để xác định key thuộc bucket nào. Sau khi mở rộng, B trở thành 6, vì vậy cần xem thêm 1 bit, bit thứ 6 để xác định key thuộc bucket nào. Điều này được gọi là rehash.

Do đó, một key có thể có số hiệu bucket trước và sau khi di chuyển có thể giống nhau hoặc tăng lên 2^B (giá trị B ban đầu), phụ thuộc vào bit thứ 6 của giá trị băm.
Do đó, một key có thể có số hiệu bucket trước và sau khi di chuyển có thể giống nhau hoặc tăng lên 2^B (giá trị B ban đầu), phụ thuộc vào bit thứ 6 của giá trị băm.
Vào cuối, chúng ta cần làm rõ một điều: nếu sau khi mở rộng, B tăng lên 1, điều đó có nghĩa là tổng số bucket là gấp đôi số lượng ban đầu, bucket số 1 “phân kỳ” thành hai bucket.
Ví dụ, ban đầu B = 2, trong bucket số 1 có 2 key, giá trị băm thấp nhất của chúng là 010 và 110. Vì B ban đầu là 2, nên 2 bit thấp 10 quyết định chúng thuộc bucket số 2. Bây giờ B đã trở thành 3, vì vậy 010 và 110 lần lượt thuộc bucket số 2 và 6.
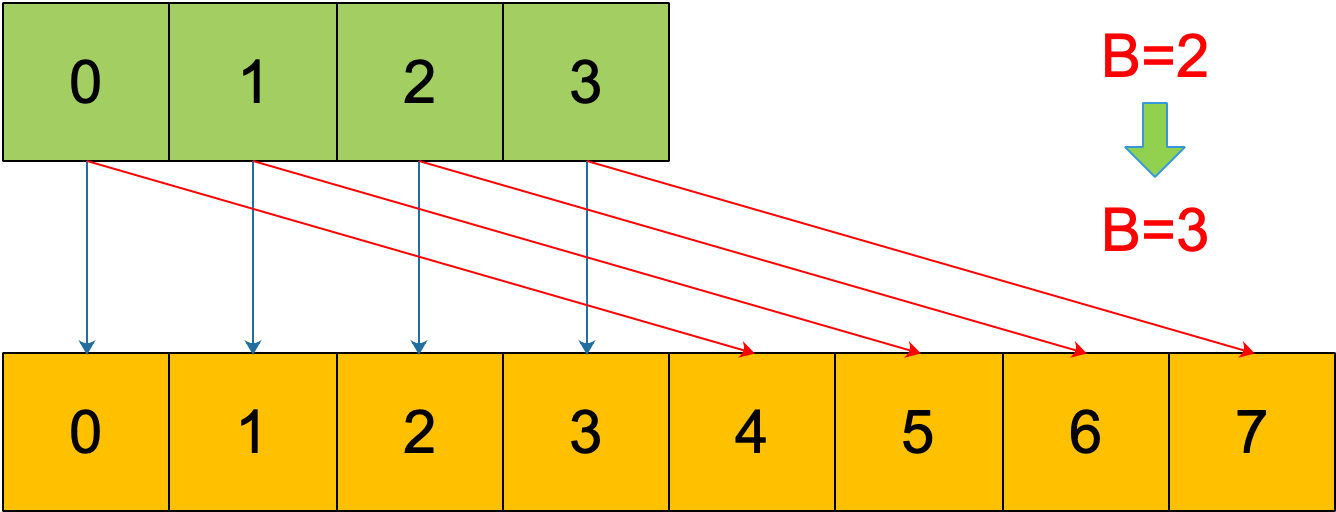
Hiểu được điều này, chúng ta sẽ sử dụng nó khi nói về việc lặp lại map.
Tiếp theo, hãy nói về một số điểm quan trọng trong hàm di chuyển:
Hàm evacuate chỉ hoàn thành việc di chuyển của một bucket trong mỗi lần gọi, do đó cần duyệt qua tất cả các cell trong bucket đó và sao chép các cell có giá trị sang vị trí mới. Bucket cũng có thể liên kết với các overflow bucket, chúng cũng cần được di chuyển. Do đó, có 2 vòng lặp, vòng lặp bên ngoài để duyệt qua các bucket và overflow bucket, vòng lặp bên trong để duyệt qua tất cả các cell trong bucket. Các vòng lặp như vậy xuất hiện khắp nơi trong mã nguồn của map, cần hiểu rõ.
Mã nguồn đề cập đến phần X, Y, thực tế là phần X là nửa đầu của bucket, phần Y là nửa sau của bucket. Một key trong một bucket có thể bị chia thành 2 bucket, một nằm trong phần X, một nằm trong phần Y. Vì vậy, trước khi di chuyển một cell, cần biết cell đó thuộc phần nào. Đơn giản, tính lại giá trị băm của key trong cell và xem thêm một bit để xác định nó thuộc phần nào, như đã được giải thích ở trên.
Có một trường hợp đặc biệt là: có một loại key, mỗi lần tính giá trị băm của nó, kết quả sẽ khác nhau. Key này chính là kết quả của math.NaN(), có ý nghĩa là not a number, kiểu dữ liệu là float64. Khi nó được sử dụng làm key trong map, trong quá trình di chuyển, sẽ gặp một vấn đề: tính toán lại giá trị băm của nó sẽ cho kết quả khác với giá trị băm ban đầu khi chèn key vào map!
Bạn có thể nghĩ rằng, điều này có nghĩa là key này sẽ không bao giờ được lấy ra bằng cách sử dụng câu lệnh m[math.NaN()]! Khi tôi sử dụng câu lệnh đó, tôi sẽ không nhận được kết quả. Key này chỉ có cơ hội xuất hiện khi duyệt qua toàn bộ map. Vì vậy, có thể chèn bất kỳ số lượng math.NaN() nào vào map làm key.
Khi di chuyển gặp key math.NaN(), chỉ cần sử dụng bit thấp nhất của tophash để xác định nó được phân vào phần X hay phần Y (nếu sau khi mở rộng, số lượng bucket là gấp đôi số lượng bucket ban đầu). Nếu bit thấp nhất của tophash là 0, nó được phân vào phần X; nếu là 1, nó được phân vào phần Y.
Đúng, việc xác định bucket đích dựa trên giá trị tophash và giá trị băm mới được tính toán như sau:
if top&1 != 0 {
// Bit thấp nhất của tophash là 1
// Bit B của giá trị băm mới được đặt thành 1
hash |= newbit
} else {
// Bit B của giá trị băm mới được đặt thành 0
hash &^= newbit
}
// Nếu bit B của giá trị băm là 0, thì di chuyển vào phần x
// Khi B = 5, newbit = 32, 6 bit thấp nhất là 10 0000
useX = hash&newbit == 0Thực tế, key như vậy có thể di chuyển vào bất kỳ bucket nào, tuy nhiên, vẫn cần di chuyển vào hai bucket được chia sẻ như trong hình split bucket. Nhưng việc này có lợi ích, sẽ được giải thích chi tiết hơn khi nói về việc lặp lại map.
Sau khi xác định bucket đích, quá trình di chuyển trở nên dễ dàng hơn. Chỉ cần sao chép giá trị key/value từ vị trí nguồn sang vị trí đích tương ứng.
Đặt giá trị tophash của key trong bucket cũ thành evacuatedX hoặc evacuatedY, cho biết key đã được di chuyển vào phần X hoặc phần Y của map mới. Giá trị tophash của map mới được lấy từ 8 bit cao của giá trị băm của key.
Dưới đây là một cái nhìn tổng quan về sự thay đổi trước và sau khi mở rộng, được biểu diễn bằng các hình ảnh.
Trước khi mở rộng, B = 2, có tổng cộng 4 bucket, lowbits đại diện cho các bit thấp của giá trị băm. Giả sử chúng ta chỉ quan tâm đến bucket số 2. Và giả sử có quá nhiều overflow, gây ra mở rộng cùng kích thước (tương ứng với điều kiện 2 đã đề cập trước đó).
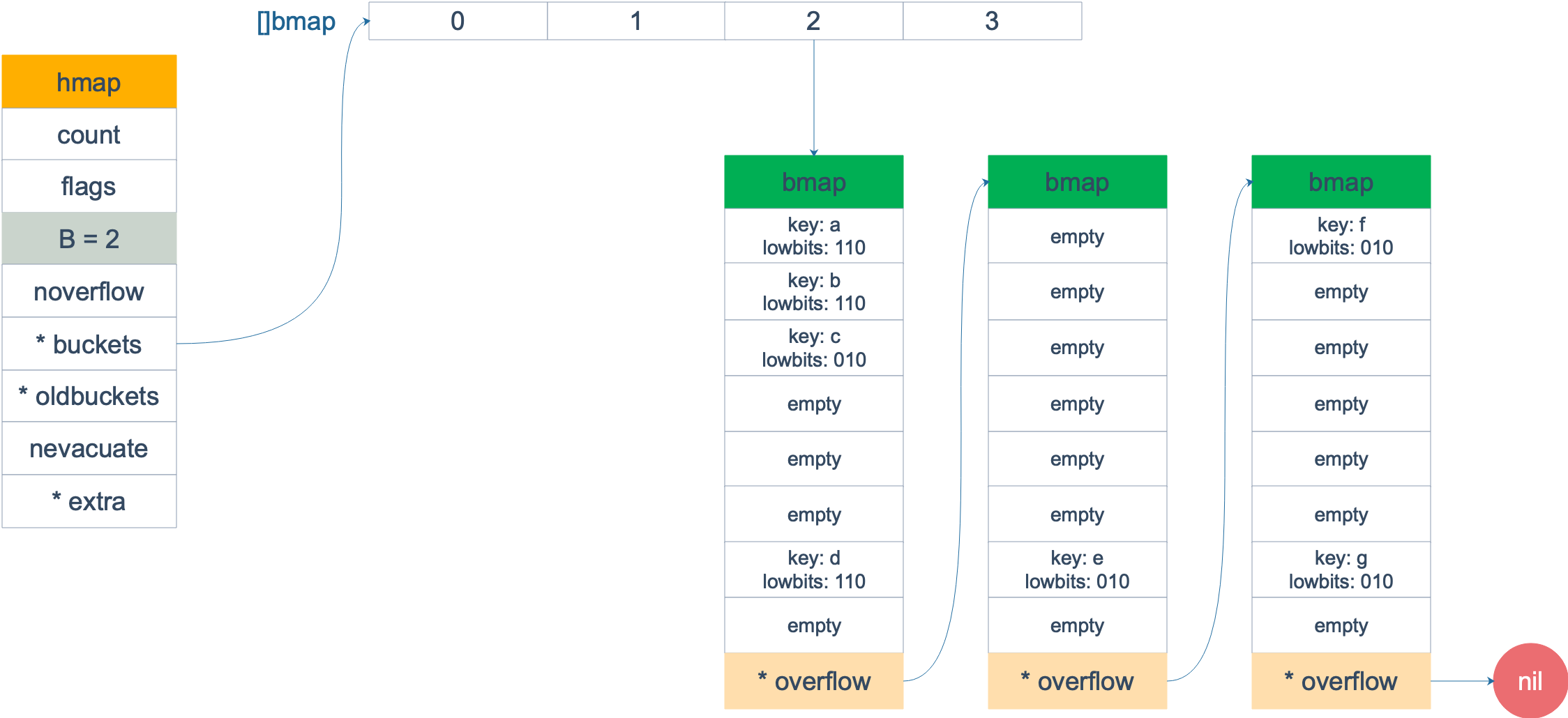
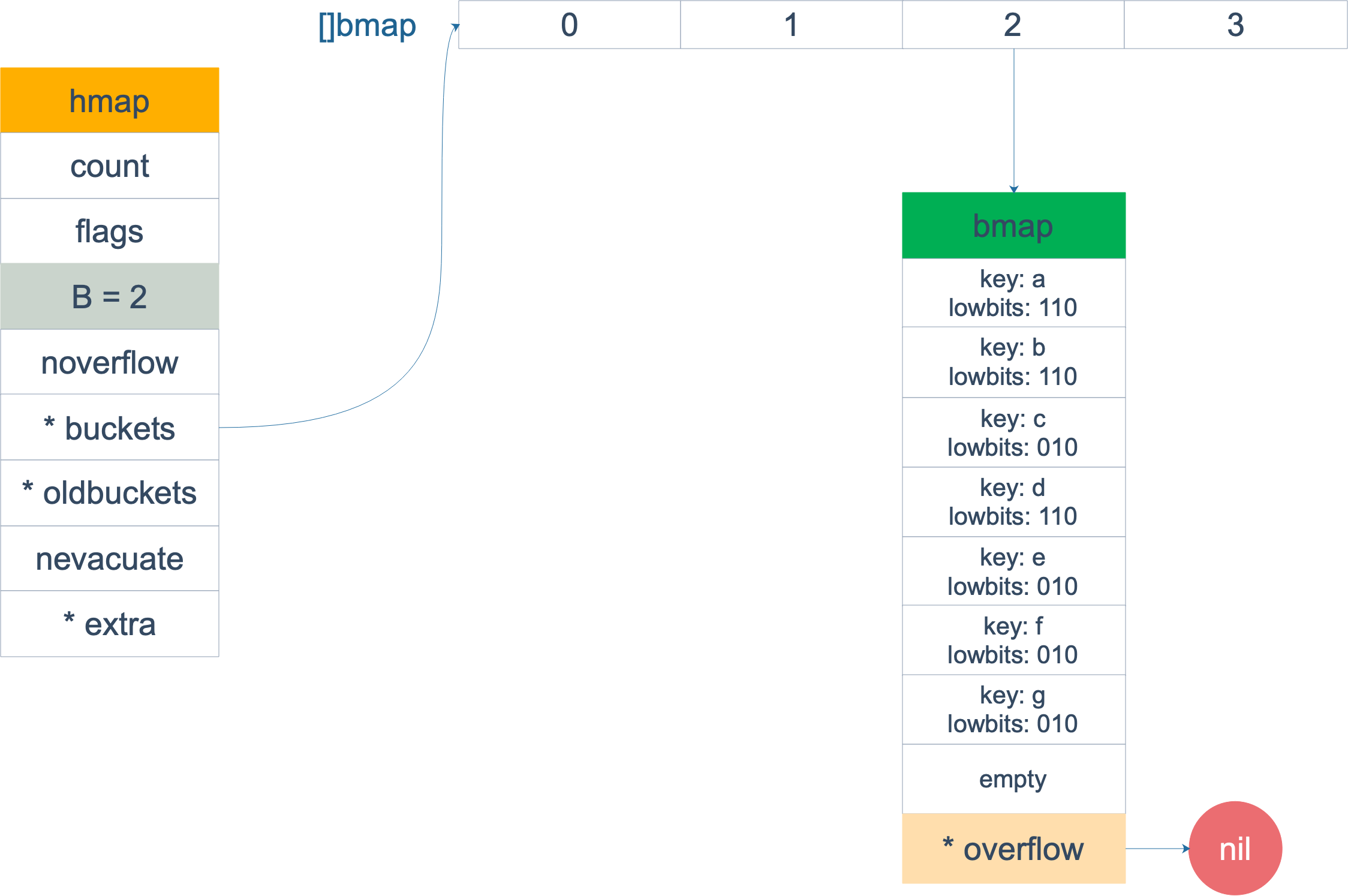
Sau khi mở rộng, các overflow bucket biến mất và các key tập trung vào một bucket, tăng tính hiệu quả của việc tìm kiếm.
Giả sử xảy ra mở rộng gấp đôi, sau khi mở rộng, key trong các bucket cũ được chia thành 2 bucket mới. Một bucket thuộc phần X, một bucket thuộc phần Y. Việc phân chia dựa trên lowbits của giá trị băm. Các bucket từ 0 đến 3 được gọi là phần X, các bucket từ 4 đến 7 được gọi là phần Y.
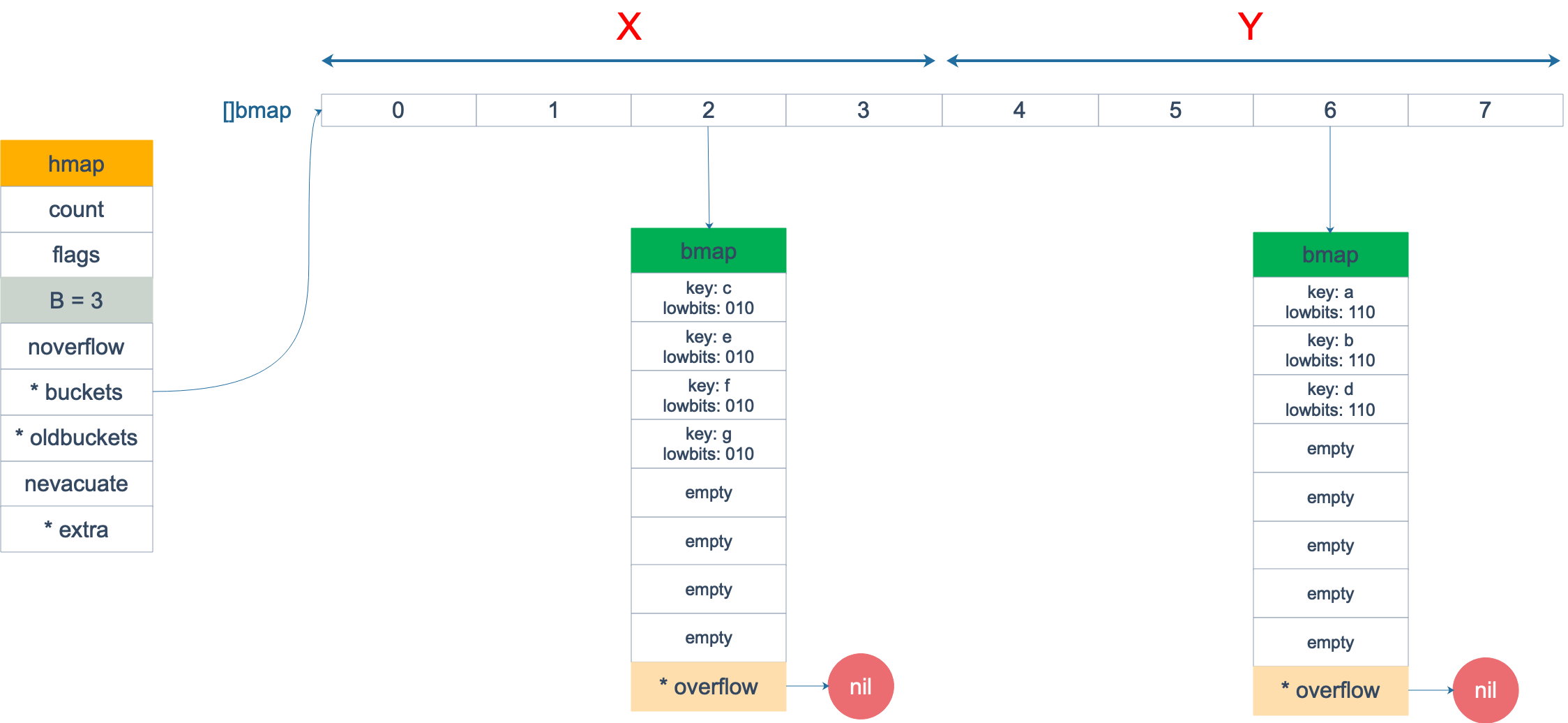
Lưu ý rằng hai hình ảnh trên đã bỏ qua tình trạng di chuyển của các bucket khác, chỉ đại diện cho tình trạng khi tất cả các bucket đã được di chuyển hoàn toàn. Trong thực tế, chúng ta biết rằng quá trình di chuyển là một quá trình “từ từ”, không thể di chuyển toàn bộ cùng một lúc. Vì vậy, con trỏ oldbuckets vẫn trỏ đến các []bmap cũ và giá trị tophash của key đã được di chuyển sẽ là giá trị trạng thái, cho biết key đã được di chuyển đến đâu.