Golang Compile: Link Process
Chúng ta bắt đầu với một ví dụ “Hello World”:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}Khi chúng ta gõ mã “hello world” trên bàn phím, tệp hello.go được lưu trữ trên đĩa cứng dưới dạng một chuỗi byte, mỗi byte đại diện cho một ký tự.
Sử dụng vim để mở tệp hello.go, trong chế độ lệnh, nhập lệnh:
:%!xxdđể xem nội dung tệp trong vim dưới dạng thập lục phân:

Cột bên trái đại diện cho giá trị địa chỉ, cột giữa đại diện cho ký tự ASCII tương ứng với văn bản, cột bên phải là mã nguồn của chúng ta. Sau đó, chạy lệnh man ascii trong terminal:
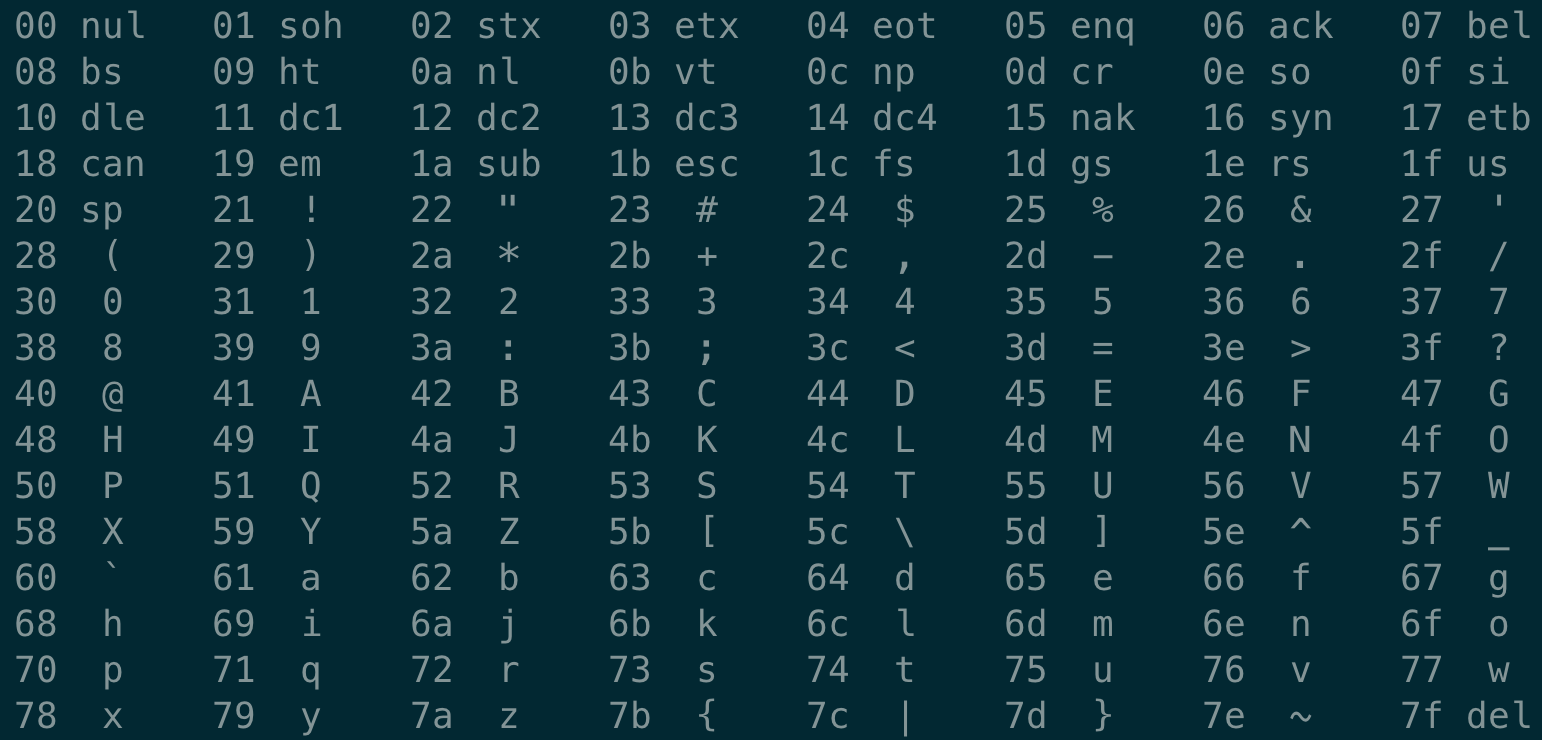
So sánh với bảng ký tự ASCII, chúng ta có thể nhận thấy cột giữa và cột bên phải tương ứng một cách một-một. Nghĩa là tệp hello.go vừa được viết là các ký tự ASCII, nó được gọi là “tệp văn bản”, trong khi các tệp khác được gọi là “tệp nhị phân”.
Tất nhiên, nếu nhìn sâu hơn, tất cả dữ liệu trong máy tính như tệp trên đĩa, dữ liệu trong mạng thực chất là một chuỗi các bit, và cách chúng ta hiểu nó phụ thuộc vào ngữ cảnh. Trong các ngữ cảnh khác nhau, một chuỗi byte giống nhau có thể được hiểu là một số nguyên, số thực, chuỗi ký tự hoặc chỉ thị máy.
Và như tệp hello.go này, 8 bit, tức là một byte được coi là một đơn vị (giả sử các ký tự trong chương trình nguồn là mã ASCII), cuối cùng được giải thích dưới dạng mã nguồn Go có thể đọc được.
Chương trình Go không thể chạy trực tiếp, mỗi câu lệnh Go phải được chuyển đổi thành một loạt các chỉ thị ngôn ngữ máy cấp thấp, sau đó đóng gói các chỉ thị này lại thành một tệp nhị phân trên đĩa, được gọi là tệp mục tiêu thực thi.
Quá trình chuyển đổi từ tệp nguồn thành tệp mục tiêu thực thi:
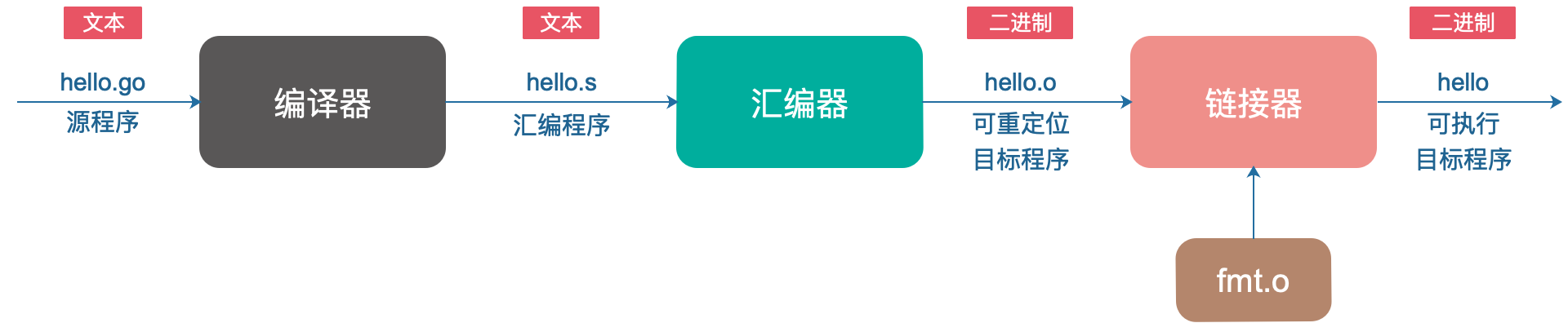
Hệ thống biên dịch Go hoàn thành các giai đoạn trên. Bạn chắc chắn đã biết về GCC (GNU Compile Collection), còn được gọi là bộ biên dịch GNU, nó hỗ trợ nhiều ngôn ngữ như C, C++, Java, Python, Objective-C, Ada, Fortran, Pascal và có thể tạo mã máy cho nhiều máy khác nhau.
Tệp mục tiêu thực thi có thể được thực thi trực tiếp trên máy tính. Thông thường, nó sẽ thực hiện một số công việc khởi tạo; tìm điểm vào của hàm main, thực thi mã người dùng đã viết; sau khi thực thi xong, hàm main thoát ra; sau đó thực hiện một số công việc kết thúc, quá trình hoàn tất.
Trong các phần tiếp theo của bài viết này, chúng ta sẽ khám phá quá trình “biên dịch” và “chạy” của Go.
Mã nguồn của trình biên dịch Go nằm trong đường dẫn src/cmd/compile, và mã nguồn của trình liên kết nằm trong đường dẫn src/cmd/link.
Quá trình biên dịch
Tôi thích sử dụng IDE để viết mã nguồn, và trong trường hợp mã nguồn Go, tôi sử dụng Goland. Đôi khi, chỉ cần nhấp vào nút Run trên thanh menu của IDE, chương trình sẽ chạy. Thực tế, điều này ẩn chứa quá trình biên dịch và liên kết, và chúng ta thường gộp quá trình biên dịch và liên kết thành một quá trình gọi là Build.
Quá trình biên dịch là quá trình phân tích từ vựng, phân tích cú pháp, phân tích ngữ nghĩa, tối ưu hóa và cuối cùng tạo ra tệp mã hợp ngữ với phần mở rộng .s.
Sau đó, trình dịch mã hợp ngữ sẽ chuyển đổi mã hợp ngữ thành các chỉ thị máy tính có thể thực thi. Vì mỗi câu lệnh hợp ngữ gần như tương ứng với một chỉ thị máy, nên quá trình này đơn giản chỉ là một một tương ứng đơn giản, không có phân tích cú pháp, ngữ nghĩa hoặc tối ưu hóa.
Trình biên dịch là một công cụ dùng để dịch ngôn ngữ cao cấp thành ngôn ngữ máy, quá trình biên dịch thường được chia thành 6 bước: quét (scan), phân tích cú pháp (syntax analysis), phân tích ngữ nghĩa (semantic analysis), tối ưu hóa mã nguồn (source code optimization), tạo mã (code generation) và tối ưu hóa mã đích (target code optimization). Hình ảnh dưới đây được trích từ cuốn sách “The Self-Taught Programmer”:
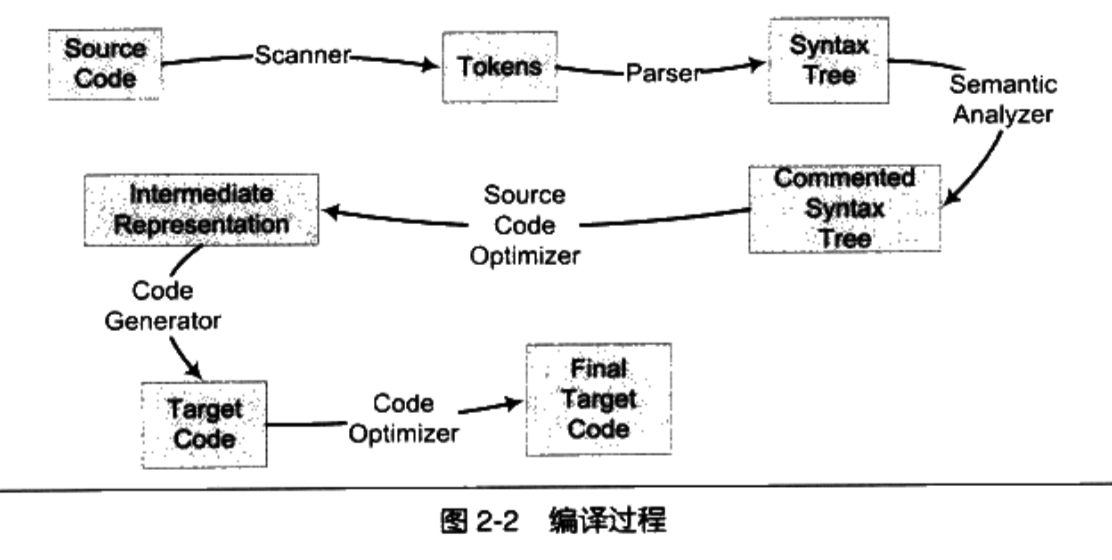
Phân tích từ vựng (Lexical Analysis)
Dựa trên các ví dụ trước đó, chúng ta biết rằng tệp chương trình Go, từ máy tính nhìn vào, chỉ là một chuỗi các bit nhị phân. Chúng ta có thể đọc được nó là do Goland đã mã hóa chuỗi bit nhị phân này theo mã ASCII (thực tế là UTF-8). Ví dụ, chúng ta chia nhóm 8 bit thành một nhóm, tương ứng với một ký tự, và sau đó so sánh với bảng mã ASCII để tìm ra ký tự tương ứng.
Khi tất cả các bit nhị phân được chuyển đổi thành ký tự ASCII, chúng ta có thể thấy một chuỗi có ý nghĩa. Nó có thể là từ khóa như “package”; có thể là chuỗi ký tự như “Hello World”.
Phân tích từ vựng thực hiện công việc này. Đầu vào là tệp chương trình Go gốc, nhưng đối với trình phân tích từ vựng, nó chỉ là một chuỗi các bit nhị phân, không biết nó là gì. Sau khi được phân tích bởi trình phân tích từ vựng, nó trở thành một chuỗi các token có ý nghĩa. Đơn giản mà nói, phân tích từ vựng là quá trình chuyển đổi một chuỗi ký tự thành một chuỗi các token có ý nghĩa.
Chúng ta hãy xem định nghĩa trên Wikipedia:
Phân tích từ vựng (lexical analysis) là quá trình chuyển đổi một chuỗi ký tự thành một chuỗi các token. Chương trình hoặc hàm thực hiện phân tích từ vựng được gọi là trình phân tích từ vựng (lexical analyzer), còn được gọi là trình quét (scanner). Trình phân tích từ vựng thường tồn tại dưới dạng một hàm, được gọi bởi trình phân tích cú pháp.
Tệp .go được đưa vào trình quét (Scanner), nó sử dụng một thuật toán tương tự với máy trạng thái hữu hạn để chia chuỗi ký tự của mã nguồn thành một chuỗi các token.
Các token thường được phân loại thành các loại sau: từ khóa, từ định danh, từ nguyên thủy (bao gồm số và chuỗi), và các ký tự đặc biệt (như dấu cộng, dấu bằng).
Ví dụ, với đoạn mã sau:
slice[i] = i * (2 + 6)Tổng cộng có 16 ký tự không trống, sau khi được quét:
| Token | Loại |
|---|---|
slice | Từ định danh |
[ | Dấu ngoặc vuông trái |
i | Từ định danh |
] | Dấu ngoặc vuông phải |
= | Dấu gán |
i | Từ định danh |
* | Dấu nhân |
( | Dấu ngoặc trái |
2 | Số |
+ | Dấu cộng |
6 | Số |
) | Dấu ngoặc phải |
Ví dụ trên được trích từ cuốn sách “The Self-Taught Programmer” và giải thích về các nội dung liên quan đến biên dịch và liên kết, rất thú vị và đáng đọc.
Trình biên dịch Go (phiên bản Go 1.9.2) hỗ trợ các token được sử dụng trong trình quét, và mã nguồn của chúng nằm trong đường dẫn:
src/cmd/compile/internal/syntax/token.goHãy cảm nhận một chút:
var tokstrings = [...]string{
// source control
_EOF: "EOF",
// names and literals
_Name: "name",
_Literal: "literal",
// operators and operations
_Operator: "op",
_AssignOp: "op=",
_IncOp: "opop",
_Assign: "=",
_Define: ":=",
_Arrow: "<-",
_Star: "*",
// delimitors
_Lparen: "(",
_Lbrack: "[",
_Lbrace: "{",
_Rparen: ")",
_Rbrack: "]",
_Rbrace: "}",
_Comma: ",",
_Semi: ";",
_Colon: ":",
_Dot: ".",
_DotDotDot: "...",
// keywords
_Break: "break",
_Case: "case",
_Chan: "chan",
_Const: "const",
_Continue: "continue",
_Default: "default",
_Defer: "defer",
_Else: "else",
_Fallthrough: "fallthrough",
_For: "for",
_Func: "func",
_Go: "go",
_Goto: "goto",
_If: "if",
_Import: "import",
_Interface: "interface",
_Map: "map",
_Package: "package",
_Range: "range",
_Return: "return",
_Select: "select",
_Struct: "struct",
_Switch: "switch",
_Type: "type",
_Var: "var",
}Vẫn là những thứ quen thuộc, bao gồm tên và literal, toán tử, dấu phân cách và từ khóa.
Và đường dẫn đến trình quét (scanner) là:
Trong đó, hàm quan trọng nhất là hàm next(), nó liên tục đọc ký tự tiếp theo (không phải là byte tiếp theo, vì ngôn ngữ Go hỗ trợ mã Unicode, không giống ví dụ ASCII ở trước, một ký tự chỉ có một byte), cho đến khi những ký tự này có thể tạo thành một token.
func (s *scanner) next() {
// ……
redo:
// skip white space
c := s.getr()
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
// token start
s.line, s.col = s.source.line0, s.source.col0
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) {
s.ident()
return
}
switch c {
// ……
case '\n':
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(c)
// ……
default:
s.tok = 0
s.error(fmt.Sprintf("invalid character %#U", c))
goto redo
return
assignop:
if c == '=' {
s.tok = _AssignOp
return
}
s.ungetr()
s.tok = _Operator
}Logic chính của mã là thông qua c := s.getr() để lấy ký tự chưa được phân tích tiếp theo và bỏ qua các khoảng trắng, dòng mới, tab và ký tự xuống dòng. Sau đó, nó đi vào một câu lệnh switch-case lớn, khớp với các trường hợp khác nhau, cuối cùng có thể phân tích một token và ghi lại số dòng, số cột liên quan, hoàn thành quá trình phân tích một lần.
Trình phân tích từ vựng trong gói hiện tại cũng chỉ cung cấp phương thức
next, quá trình phân tích từ vựng là lười biếng, chỉ khi trình phân tích cú pháp ở tầng trên cần nó mới gọinextđể lấy token mới nhất.
Phân tích cú pháp (Syntax Analysis)
Chuỗi Token được tạo ra từ bước trước cần được xử lý tiếp để tạo ra một cây cú pháp trừu tượng (abstract syntax tree) với các nút là các “biểu thức” (expressions).
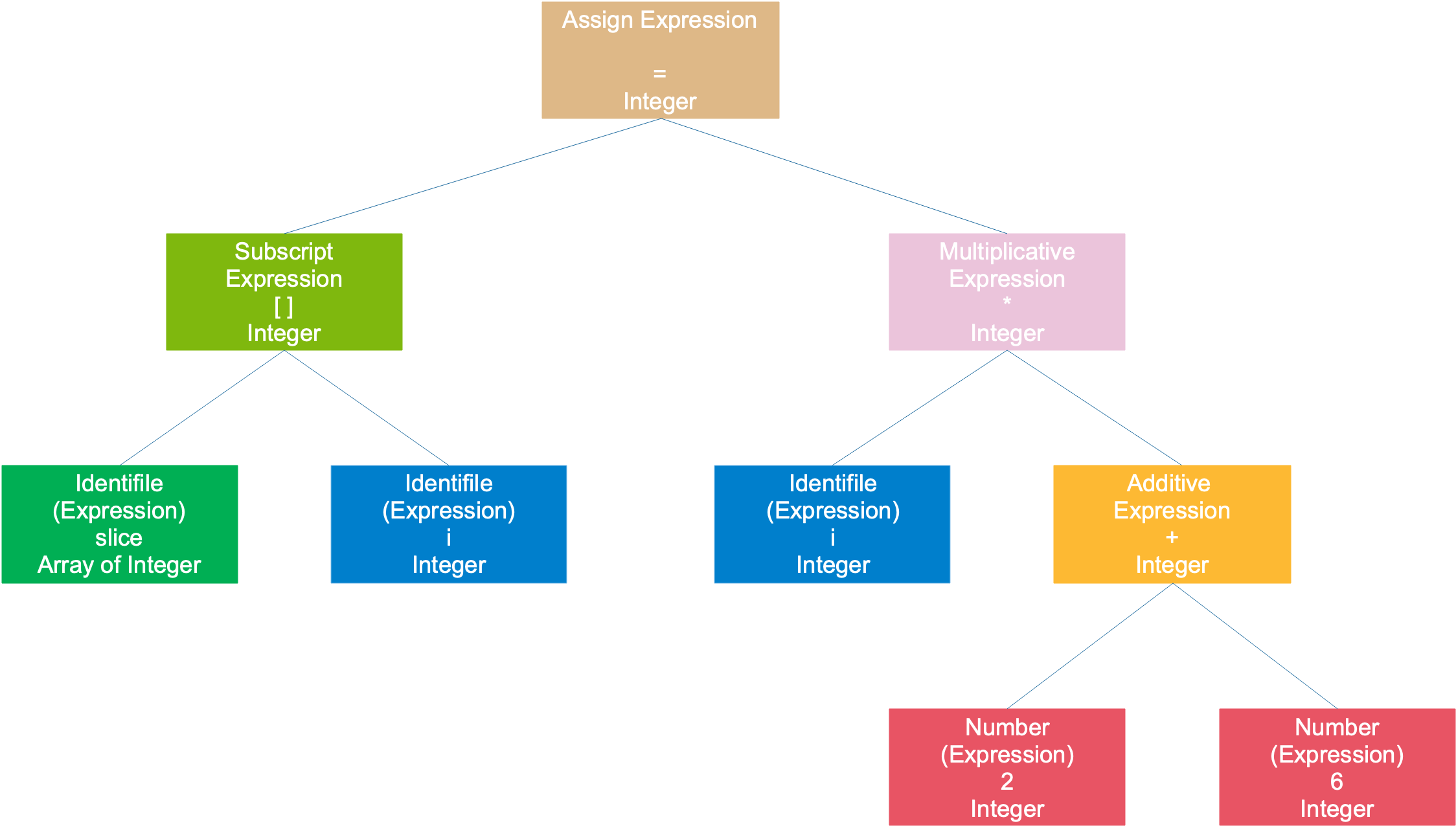
Ví dụ với câu lệnh ban đầu, slice[i] = i * (2 + 6) sẽ tạo ra một cây cú pháp như sau:
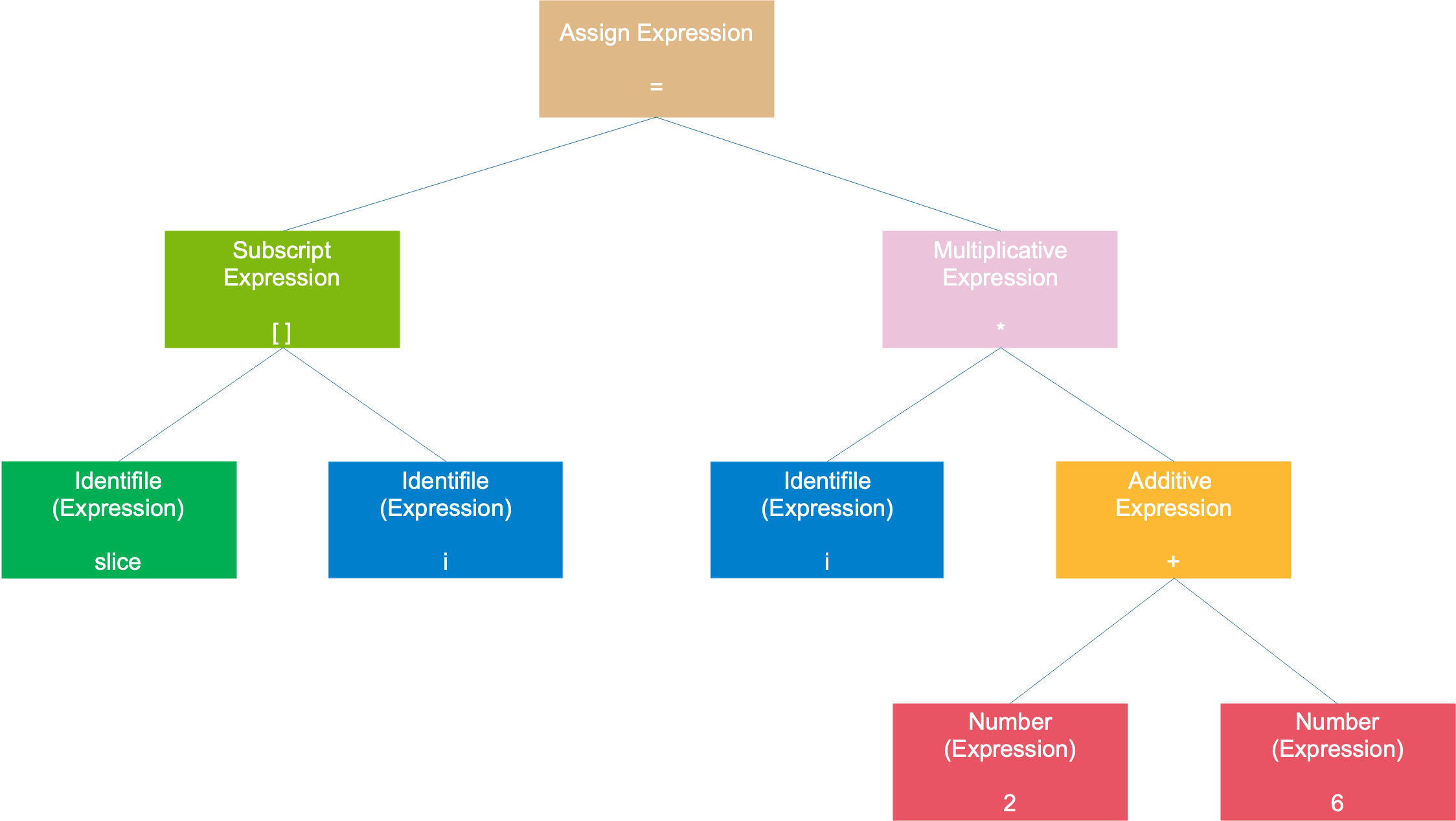
Toàn bộ câu lệnh được coi là một biểu thức gán, cây cú pháp có một cây con bên trái là biểu thức mảng, cây con bên phải là biểu thức nhân. Biểu thức mảng được tạo thành từ 2 biểu thức đơn. Biểu thức nhân được tạo thành từ một biểu thức đơn và một biểu thức cộng. Biểu thức cộng được tạo thành từ hai số. Các biểu thức và số là các lá của cây.
Quá trình phân tích cú pháp có thể phát hiện các lỗi cú pháp, ví dụ: thiếu dấu ngoặc, biểu thức cộng thiếu một toán hạng, v.v.
Phân tích cú pháp là quá trình phân tích và xác định cấu trúc ngữ pháp của một văn bản đầu vào dựa trên một ngữ pháp cú pháp cụ thể.
Phân tích ngữ nghĩa (Semantic Analysis)
Sau khi phân tích cú pháp, chúng ta không biết ý nghĩa cụ thể của câu. Ví dụ như hai cây con của dấu * ở trên nếu là hai con trỏ thì là không hợp lệ, nhưng phân tích cú pháp không thể phát hiện ra điều này, phân tích ngữ nghĩa làm nhiệm vụ này.
Trong quá trình biên dịch, chúng ta chỉ có thể kiểm tra được ngữ nghĩa tĩnh, có thể coi đây là giai đoạn “mã” của quá trình, bao gồm việc phù hợp kiểu dữ liệu biến, chuyển đổi, v.v. Ví dụ, khi gán một giá trị số thực cho một biến con trỏ, kiểu không phù hợp rõ ràng, sẽ báo lỗi biên dịch. Nhưng đối với các lỗi có thể xảy ra trong quá trình chạy: vô tình chia cho 0, phân tích ngữ nghĩa không thể phát hiện được.
Sau khi hoàn thành giai đoạn phân tích ngữ nghĩa, loại của mỗi nút sẽ được gán nhãn:
Trình biên dịch Go sẽ kiểm tra kiểu dữ liệu của hằng số, kiểu, khai báo hàm và câu lệnh gán biến, sau đó kiểm tra kiểu của khóa trong bảng băm. Các hàm thực hiện kiểm tra kiểu thường có hàng nghìn dòng lệnh switch/case.
Kiểm tra kiểu là giai đoạn thứ hai của quá trình biên dịch Go, sau khi phân tích từ vựng và cú pháp, chúng ta có cây cú pháp trừu tượng tương ứng với mỗi tệp tin, sau đó kiểm tra kiểu sẽ duyệt qua các nút trong cây cú pháp trừu tượng và kiểm tra kiểu của mỗi nút, tìm ra các lỗi cú pháp có thể tồn tại.
Trong quá trình này, cây cú pháp trừu tượng có thể được sửa đổi, điều này không chỉ giúp tối ưu hóa biên dịch bằng cách loại bỏ các đoạn mã không được thực thi, mà còn thay đổi loại hoạt động của các từ khóa như make, new, v.v.
Ví dụ về từ khóa thường được sử dụng là make, nó có thể tạo ra nhiều loại như slice, map, channel, v.v. Ở bước này, đối với từ khóa make, tức là nút OMAKE, trước tiên sẽ kiểm tra kiểu tham số của nó, dựa trên kiểu khác nhau, sẽ đi vào các nhánh tương ứng. Nếu kiểu tham số là slice, sẽ đi vào nhánh TSLICE, kiểm tra xem len và cap có đáp ứng yêu cầu không, ví dụ len ⇐ cap. Cuối cùng, loại nút sẽ được thay đổi từ OMAKE thành OMAKESLICE.
Sinh mã trung gian (ntermediate Code Generation)
Chúng ta biết rằng quá trình biên dịch thường được chia thành phần trước và phần sau, phần trước tạo ra mã trung gian không phụ thuộc vào nền tảng, trong khi phần sau tạo ra mã máy khác nhau cho từng nền tảng.
Các giai đoạn như phân tích từ vựng, phân tích cú pháp, phân tích ngữ nghĩa và các giai đoạn trước đó đều thuộc về phần trước của trình biên dịch, trong khi các giai đoạn sau thuộc về phần sau của trình biên dịch.
Quá trình biên dịch có nhiều giai đoạn tối ưu, trong giai đoạn này, tối ưu hóa được thực hiện ở mức độ mã nguồn. Nó chuyển đổi cây cú pháp thành mã trung gian, đại diện cho cây cú pháp theo thứ tự.
Mã trung gian thường không phụ thuộc vào máy mục tiêu và môi trường chạy, nó có một số hình thức phổ biến: mã ba địa chỉ, mã P. Ví dụ, mã ba địa chỉ cơ bản như sau:
x = y op zđại diện cho việc thực hiện phép toán op giữa biến y và biến z, và gán kết quả cho biến x. op có thể là phép toán số học như cộng, trừ, nhân, chia.
Ví dụ mà chúng ta đã đưa ra có thể được viết dưới dạng:
t1 = 2 + 6
t2 = i * t1
slice[i] = t2Ở đây, 2 + 6 có thể tính toán trực tiếp, vì vậy biến t1 được “tối ưu” bỏ đi, và biến t1 có thể được tái sử dụng, do đó biến t2 cũng có thể được “tối ưu” bỏ đi. Sau khi tối ưu:
t1 = i * 8
slice[i] = t1Biểu diễn mã trung gian của ngôn ngữ Go là SSA (Static Single-Assignment, đơn gán tĩnh), được gọi là đơn gán vì mỗi tên chỉ được gán một lần trong SSA.
Trong giai đoạn này, các biến được sử dụng để tạo mã trung gian sẽ được thiết lập dựa trên kiến trúc CPU, ví dụ: kích thước con trỏ và thanh ghi được sử dụng bởi trình biên dịch, danh sách thanh ghi có sẵn, v.v. Phần tạo mã trung gian và tạo mã máy sẽ chia sẻ cùng cấu hình này.
Trước khi tạo mã trung gian, một số thành phần của các nút trong cây cú pháp sẽ được thay thế. Ở đây, tôi trích dẫn một hình ảnh từ một bài viết liên quan về lý thuyết biên dịch trên trang blog “Programming by Faith”:
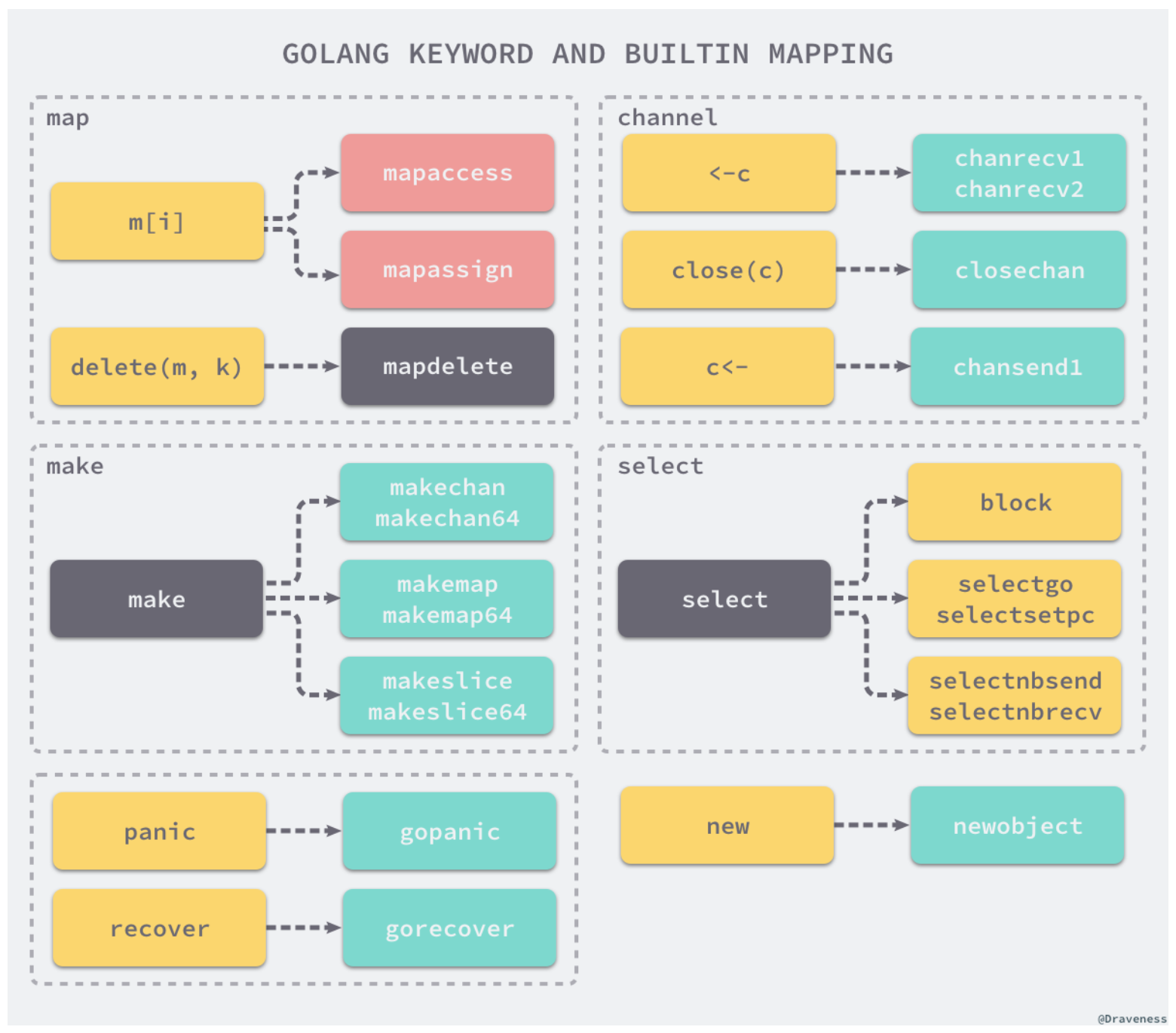
Ví dụ, phép toán trên map m[i], sẽ được chuyển đổi thành mapaccess hoặc mapassign.
Chương trình chính của ngôn ngữ Go khi thực thi sẽ gọi các hàm trong runtime, điều này có nghĩa là chức năng của từ khóa và hàm tích hợp thực tế được thực hiện bởi trình biên dịch và môi trường chạy của ngôn ngữ.
Quá trình tạo mã trung gian thực chất là quá trình chuyển đổi từ cây cú pháp trừu tượng (AST) sang mã trung gian SSA, trong quá trình này, các từ khóa trong cây cú pháp sẽ được cập nhật một lần nữa, cây cú pháp sau khi được cập nhật sẽ trải qua nhiều vòng xử lý để chuyển đổi thành mã trung gian SSA cuối cùng.
Tạo và tối ưu mã máy mục tiêu (Machine Code Generation and Optimization)
Máy tính khác nhau có độ dài từng byte, thanh ghi và các yếu tố khác khác nhau, điều này có nghĩa là mã máy chạy trên các máy tính khác nhau sẽ khác nhau. Bước cuối cùng là tạo ra mã máy có thể chạy trên các kiến trúc CPU khác nhau.
Để tận dụng tối đa hiệu suất của máy tính, trình tối ưu mã máy mục tiêu sẽ tối ưu hóa một số chỉ thị, ví dụ: sử dụng chỉ thị dịch chuyển thay vì chỉ thị nhân, v.v.
Tôi không có khả năng đi sâu vào lĩnh vực này, nhưng may mắn là cũng không cần phải đi sâu. Đối với các kỹ sư phát triển phần mềm ở tầng ứng dụng, chỉ cần hiểu một chút là đủ.
Quá trình liên kết (Link Process)
Quá trình biên dịch được thực hiện cho từng tệp riêng lẻ, và không thể tránh khỏi việc tham chiếu đến các biến toàn cục hoặc hàm được định nghĩa trong các module khác, chỉ có thể xác định địa chỉ của các biến hoặc hàm này trong giai đoạn này.
Quá trình liên kết là quá trình kết hợp các tệp đích được biên dịch thành một tệp thực thi. Tệp cuối cùng được chia thành các phân đoạn khác nhau, chẳng hạn như phân đoạn dữ liệu, phân đoạn mã, phân đoạn BSS, v.v., và sẽ được tải vào bộ nhớ khi chạy. Các phân đoạn khác nhau có các thuộc tính khác nhau về đọc, ghi, thực thi, bảo vệ sự chạy an toàn của chương trình.