Bắt đầu với Data Structure & Algorithm
Độ phức tạp thời gian
Đối với cơ sở dữ liệu, điều quan trọng không phải là khối lượng dữ liệu, mà là làm thế nào các hoạt động tăng lên khi khối lượng dữ liệu tăng lên.
Độ phức tạp thuật toán kéo theo độ phức tạp thời gian (time complexity) và độ phức tạp không gian (space complexity). Vui lòng đọc Complexity Analysis
Merge Sort
Đối với cơ sở dữ liệu, bạn cần phải hiểu cách thức hoạt động của hàm sort() này.
Merge Sort chia bài toán lớn thành các bài toán nhỏ, giải quyết bài toán ban đầu bằng cách giải quyết các bài toán nhỏ. Thuật toán này theo tư tưởng chia để trị (deidve and conquer)
Tại sao lại là Merge Sort?
- Bạn có thể thay đổi thuật toán để tiết kiệm không gian bộ nhớ bằng cách không tạo chuỗi mới mà thay đổi trực tiếp chuỗi đầu vào. Lưu ý: Thuật toán này được gọi là in-place algorithm
- Bạn có thể thay đổi thuật toán để bạn có thể tránh Disk I/O khổng lồ bằng cách sử dụng cả dung lượng đĩa và một lượng nhỏ bộ nhớ. Phương pháp là chỉ tải các phần hiện đang được xử lý vào bộ nhớ. Đây là một kỹ thuật quan trọng khi sắp xếp một vài GB bảng trong bộ đệm bộ nhớ chỉ 100MB. Lưu ý: Thuật toán này được gọi là external sorting.
- Bạn có thể thay đổi thuật toán để dễ dàng chạy trên đa nhân / đa luồng / đa máy chủ. Ví dụ, sắp xếp hợp nhất phân tán là một trong những thành phần quan trọng của Hadoop, một big data framework nổi tiếng.
Binary Search Tree
Độ phức tạp thời gian của truy vấn trong cơ sở dữ liệu là không thể sử dụng ma trận, thay vào đó sử dụng Binary Search Tree (BST), vui lòng xem Binary Search Tree
- Binary Search Tree chỉ yêu cầu truy cấn O(log(n)), trong khi nếu bạn sử dụng mảng trực tiếp, bạn sẽ cần truy vấn O(n)
B Tree
Tree làm việc tốt với việc tìm một giá trị cụ thể, nhưng khi bạn cần phải tìm nhiều yếu tố giữa hai giá trị, bạn có thể gặp rắc rối lớn. Chi phí của bạn sẽ là O(N) vì bạn phải tìm mỗi nút của cây để xác định xem nó có nằm giữa 2 giá trị đó hay không (ví dụ: sử dụng inorder traversal trên cây). Và thao tác này không phải là thuận lợi cho Disk I/O, bởi vì bạn phải đọc toàn bộ cây. Chúng ta cần phải tìm một phương pháp truy vấn phạm vi hiệu quả.
Nếu bạn thêm hoặc xóa một hàng trong cơ sở dữ liệu (do đó trong chỉ mục cây B + có liên quan):
- Bạn phải duy trì thứ tự giữa các nút trong B+ Tree, nếu không các nút sẽ trở nên lộn xộn và bạn không thể tìm thấy nút bạn muốn.
- Bạn phải giảm thiểu số lớp của B+ Tree, nếu không độ phức tạp của O (log(N) sẽ trở thành O (N
Nói cách khác, B Tree cần phải tự sắp xếp và tự cân bằng. Rất may, chúng có xóa và chèn thông minh. Nhưng điều này cũng mang lại chi phí: trong B+ Tree, chèn và xóa là độ phức tạp O(log(N). Vì vậy, một số người đã nghe nói rằng sử dụng quá nhiều Index không phải là một ý tưởng tốt như vậy. Đúng vậy, bạn đã làm chậm hoạt động của một hàng trong bảng chèn/cập nhật/xóa nhanh chóng vì cơ sở dữ liệu cần phải cập nhật chỉ mục của bảng với chi phí cao cho mỗi hoạt động O(log(N). Hơn nữa, tăng chỉ mục có nghĩa là mang lại nhiều khối lượng công việc hơn cho Transaction Manager (sẽ được đề cập phía dưới).
Hash Table
Hash Table rất hữu ích khi bạn muốn tìm các giá trị một cách nhanh chóng. Hơn nữa, sự hiểu biết về Hash Table sẽ giúp chúng ta hiểu các hoạt động kết nối phổ biến tiếp theo của một cơ sở dữ liệu được gọi là “hash connection”. Cấu trúc dữ liệu này cũng được sử dụng bởi cơ sở dữ liệu để lưu một cái gì đó bên trong (chẳng hạn như bảng khóa hoặc vùng đệm, mà sẽ nghiên cứu dưới đây)
Tại sao không sử dụng mảng?
- Nếu có một hash function tốt, độ phức tạp thời gian tìm kiếm trong Hash Table là O(1).
- Một Hash Table có thể được nạp chỉ một nửa vào bộ nhớ, và hash bucket còn lại có thể được giữ lại trên đĩa cứng.
- Với mảng, bạn cần một không gian bộ nhớ liên tục. Nếu bạn tải một bảng lớn, thật khó để phân bổ đủ không gian bộ nhớ liên tục.
Tổng quan SQL DB
Cơ sở dữ liệu (database) thường có thể được hiểu bằng cách sử dụng đồ họa sau:
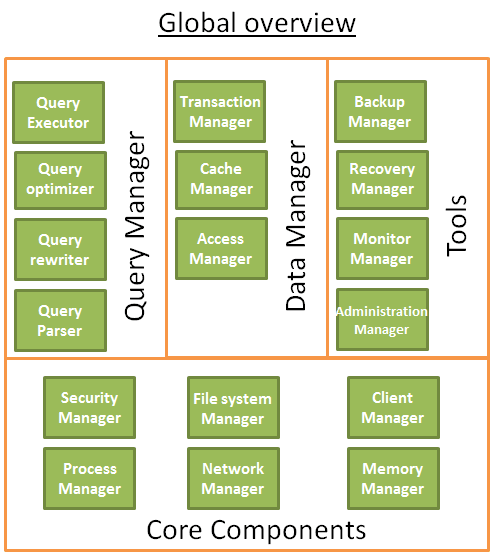
Các thành phần cốt lõi (Core Components)
-
Trình quản lý quy trình (process manager): Nhiều cơ sở dữ liệu có process/thread pool cần được quản lý đúng cách. Hơn nữa, để đạt được hoạt động trong nanosecond, một số cơ sở dữ liệu hiện đại sử dụng thread riêng của họ thay vì OS thread.
-
Network manager: Internet I/O là một vấn đề lớn, đặc biệt là đối với cơ sở dữ liệu phân tán. Vì vậy, một số cơ sở dữ liệu có trình quản lý mạng riêng.
-
**Trình quản lý hệ thống tệp (File system manager):**Disk I/O là nút thắt cổ chai chính của cơ sở dữ liệu. Nó là rất quan trọng để có một trình quản lý hệ thống tập tin để xử lý hoàn hảo hệ thống tập tin OS hoặc thậm chí thay thế hệ thống tập tin OS.
-
Memory manager: Để tránh giảm hiệu suất do disk I/O gây ra, cần rất nhiều bộ nhớ. Nhưng nếu bạn muốn xử lý bộ nhớ dung lượng lớn, bạn cần trình quản lý bộ nhớ hiệu quả, đặc biệt là khi bạn có rất nhiều truy vấn để sử dụng bộ nhớ cùng một lúc.
-
Security Manager: Được sử dụng để xác thực và phân quyền người dùng.
-
Trình quản lý khách hàng (Client manager): Được sử dụng để quản lý kết nối khách hàng.
-
……
Công cụ (Tools)
-
Trình quản lý sao lưu (Backup manager): Được sử dụng để lưu và khôi phục dữ liệu.
-
Trình quản lý phục hồi (Recovery manager): Được sử dụng để khởi động lại cơ sở dữ liệu đến trạng thái nhất quán sau khi sự cố.
-
Monitor manager: Công cụ để ghi lại hoạt động cơ sở dữ liệu và cung cấp cơ sở dữ liệu giám sát.
-
Administration manager: Được sử dụng để lưu siêu dữ liệu như tên và cấu trúc của bảng, cung cấp các công cụ để quản lý cơ sở dữ liệu, mẫu, không gian bảng.
-
……
Trình quản lý truy vấn (Query Manager)
-
Trình phân tích cú pháp truy vấn (Query parser): Được sử dụng để kiểm tra xem truy vấn có hợp pháp hay không
-
Trình viết lại truy vấn (Query Rewriter): Để tối ưu hóa trước truy vấn
-
Trình tối ưu hóa truy vấn (Query Optimizer): Để tối ưu hóa truy vấn
-
Trình thực thi truy vấn (Query Executor): Được sử dụng để biên dịch và thực thi truy vấn
Trình quản lý dữ liệu (Data Manager)
-
Trình quản lý giao dịch (Transaction Manager): Được sử dụng để xử lý các giao dịch
-
Trình quản lý bộ nhớ cache (Cache Manager): Dữ liệu được đặt trong bộ nhớ trước khi nó được sử dụng, hoặc trước khi dữ liệu được ghi vào đĩa
-
Trình quản lý truy cập dữ liệu (Data Access Manager): Truy cập dữ liệu trong đĩa
Quá trình truy vấn dữ liệu
Chương này tập trung vào cách cơ sở dữ liệu có thể quản lý truy vấn SQL thông qua các quy trình sau:
- Trình quản lý khách hàng
- Trình quản lý truy vấn
- Trình quản lý dữ liệu (bao gồm trình quản lý phục hồi)
- Trình quản lý khách hàng
Trình quản lý khách hàng (Client Manager)
Trình quản lý khách hàng xử lý giao tiếp khách hàng. Khách hàng có thể là một máy chủ (trang web) hoặc một người dùng cuối hoặc ứng dụng cuối cùng. Trình quản lý khách hàng thông qua một loạt các API nổi tiếng (JDBC, ODBC, OLE-DB … ) cung cấp những cách khác nhau để truy cập vào cơ sở dữ liệu. Trình quản lý khách hàng cũng cung cấp API truy cập cơ sở dữ liệu độc quyền.
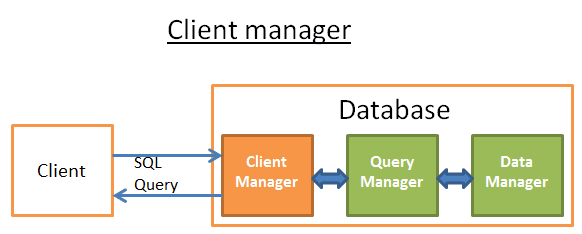
Khi bạn kết nối với cơ sở dữ liệu:
- Trình quản lý bắt đầu bằng cách kiểm tra thông tin xác minh (tên người dùng và mật khẩu) của bạn và sau đó kiểm tra xem bạn có quyền truy cập vào cơ sở dữ liệu hay không. Các quyền này được gán bởi DBA.
- Trình quản lý sau đó kiểm tra xem có một tiến trình nhàn rỗi (hoặc luồng) để xử lý truy vấn của bạn không?
- Trình quản lý cũng kiểm tra xem cơ sở dữ liệu có tải nặng hay không?
- Trình quản lý có thể chờ một lúc để có được tài nguyên cần thiết. Nếu thời gian chờ đạt đến thời gian chờ, nó sẽ đóng kết nối và đưa ra thông báo lỗi có thể đọc được.
- Trình quản lý sau đó sẽ gửi truy vấn của bạn cho trình quản lý truy vấn để xử lý.
- Bởi vì quá trình xử lý truy vấn không phải là ‘không đầy đủ thì không có’, một khi nó nhận được dữ liệu từ trình quản lý truy vấn, nó sẽ lưu một phần kết quả vào bộ đệm và bắt đầu gửi cho bạn.
- Nếu bạn gặp sự cố, Trình quản lý đóng kết nối, gửi cho bạn thông tin giải thích có thể đọc được và sau đó giải phóng tài nguyên.
Trình quản lý truy vấn
Phần này là sức mạnh của cơ sở dữ liệu, trong đó một truy vấn được viết xấu có thể được chuyển đổi thành mã thực thi nhanh chóng, và kết quả thực thi mã được gửi đến trình quản lý khách hàng.
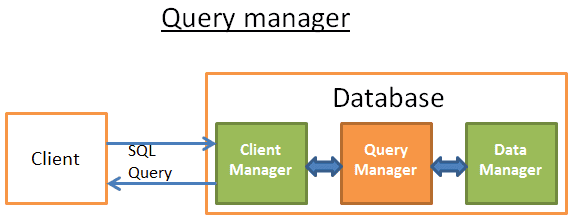
Quá trình hoạt động nhiều bước này như sau:
-
Truy vấn đầu tiên được phân tích cú pháp (parser) và xác định xem nó có hợp pháp hay không
-
Sau đó được viết lại (rewrite), loại bỏ các hoạt động vô dụng và tham gia phần tối ưu hóa trước (pre-optimized)
-
Sau đó được tối ưu hóa (optimized) để cải thiện hiệu suất và được chuyển đổi thành mã thực thi (translated into executable code) và kế hoạch truy cập dữ liệu (data access plans).
-
Kế hoạch sau đó được biên dịch (compiled)
-
Cuối cùng, được thực thi (excuted)
Tôi sẽ không khám phá quá nhiều hai bước cuối cùng ở đây, bởi vì họ không quá quan trọng.
Trình phân tích cú pháp truy vấn (Query Parser)
Mỗi câu lệnh SQL được gửi đến trình phân tích cú pháp để kiểm tra cú pháp và nếu truy vấn của bạn sai, trình phân tích cú pháp sẽ từ chối truy vấn đó. Ví dụ, nếu bạn viết “SLECT …” Thay vì “SELECT…”, thì không có gì dưới đây.
Nhưng điều này không hoàn tất, trình phân tích cú pháp cũng sẽ kiểm tra xem từ khóa có sử dụng đúng thứ tự hay không, chẳng hạn như WHERE sẽ bị từ chối trước khi SELECT.
Trình phân tích cú pháp sau đó muốn phân tích các bảng và trường trong truy vấn, sử dụng siêu dữ liệu cơ sở dữ liệu để kiểm tra:
- Bảng có tồn tại hay không
- Trường của bảng có tồn tại hay không
- Tính toán cho một loại trường có thể không (ví dụ: bạn không thể so sánh số nguyên với chuỗi, bạn không thể sử dụng hàm substring() cho một số nguyên)
Tiếp theo, trình phân tích cú pháp kiểm tra xem bạn có quyền đọc (hoặc viết) bảng trong truy vấn hay không. Nhấn mạnh một lần nữa: các quyền này được cấp phát bởi DBA.
Trong quá trình phân tích cú pháp, truy vấn SQL được chuyển đổi thành đại diện nội bộ (internal representation) (thường là một cây).
Nếu mọi thứ đều ổn, đại diện nội bộ được gửi đến trình viết lại truy vấn.
Trình viết lại truy vấn bộ (Query Rewriter)
Ở bước này, tôi đã có một đại diện nội bộ của truy vấn, mục tiêu của trình viết lại là:
- Truy vấn được tối ưu hóa trước
- Tránh các tính toán không cần thiết
- Giúp trình tối ưu hóa tìm ra giải pháp tốt nhất hợp lý
Trình viết lại thực hiện kiểm tra truy vấn theo một tập hợp các quy tắc đã biết. Nếu truy vấn phù hợp với một quy tắc của một mẫu, truy vấn sẽ được viết lại theo quy tắc này. Dưới đây là danh sách không đầy đủ các quy tắc (tùy chọn):
- Hợp nhất view: Nếu bạn sử dụng view trong truy vấn của mình, view sẽ được chuyển đổi thành mã SQL của nó.
- Làm phẳng truy vấn con: Truy vấn con rất khó tối ưu hóa, vì vậy trình viết lại sẽ cố gắng loại bỏ truy vấn con
- Ví dụ:
SELECT PERSON.*
FROM PERSON
WHERE PERSON.person_key IN
(SELECT MAILS.person_key
FROM MAILS
WHERE MAILS.mail LIKE 'christophe%');sẽ được chuyển đổi thành:
SELECT PERSON.*
FROM PERSON, MAILS
WHERE PERSON.person_key = MAILS.person_key
and MAILS.mail LIKE 'christophe%';- Loại bỏ các toán tử không cần thiết: Ví dụ: nếu bạn sử dụng DISTINCT và bạn thực sự có các ràng buộc UNIQUE (điều này ngăn chặn sự trùng lặp dữ liệu), từ khóa DISTINCT sẽ bị xóa.
- Loại trừ các JOIN dư thừa: Nếu cùng một điều kiện JOIN xảy ra hai lần, chẳng hạn như điều kiện JOIN ẩn trong view hoặc JOIN vô dụng phát sinh từ khả năng truyền, chúng sẽ bị loại bỏ.
- Hằng số tính toán gán: Nếu truy vấn của bạn cần tính toán, tính toán được thực hiện một lần trong quá trình viết lại. Ví dụ: WHERE AGE > 10+2 được chuyển đổi sang WHERE AGE > 12 và TODATE (“date string”) được chuyển đổi sang giá trị ngày ở định dạng datetime.
- (Nâng cao) Cắt phân vùng (Partition Pruning): Nếu bạn sử dụng bảng phân vùng, trình viết lại có thể tìm thấy phân vùng bạn cần sử dụng.
- (Nâng cao) view vật lý (Materialized view rewrite): Nếu bạn có view vật lý phù hợp với một tập hợp con của vị ngữ truy vấn, trình viết lại sẽ kiểm tra xem view có được cập nhật và sửa đổi truy vấn hay không, cho phép truy vấn sử dụng view vật lý thay vì bảng gốc.
- (Nâng cao) Quy tắc tùy chỉnh: Nếu bạn có các quy tắc tùy chỉnh để sửa đổi truy vấn (giống như Oracle policy), trình viết lại sẽ thực hiện các quy tắc này.
- (Nâng cao) Chuyển đổi OLAP: chức năng phân tích / cửa sổ, star join, chức năng ROLLUP … Chuyển đổi xảy ra (nhưng tôi không chắc chắn điều này được thực hiện bởi trình viết lại hoặc trình tối ưu hóa, vì cả hai quá trình được liên kết chặt chẽ và phải xem cơ sở dữ liệu là gì).
Truy vấn sau khi viết lại tiếp tục được gửi đến trình tối ưu hóa, tại thời điểm này niềm vui bắt đầu.
Thống kê
Trước khi nghiên cứu cách cơ sở dữ liệu tối ưu hóa truy vấn. chúng ta cần nói về thống kê, vì cơ sở dữ liệu không có số liệu thống kê là ngu ngốc. Cơ sở dữ liệu không phân tích dữ liệu của riêng bạn trừ khi bạn nói ra rõ ràng. Không có phân tích nào có thể khiến cơ sở dữ liệu đưa ra các giả định (rất) kém.
Tuy nhiên, cơ sở dữ liệu cần loại thông tin nào?
Tôi phải nói (ngắn gọn) về cách cơ sở dữ liệu và hệ điều hành lưu dữ liệu. Đơn vị nhỏ nhất được sử dụng cho cả hai được gọi là trang hoặc khối (mặc định 4 hoặc 8 KB). Điều này có nghĩa là nếu bạn chỉ cần 1KB, bạn cũng sẽ chiếm một trang. Nếu kích thước của trang là 8KB, bạn lãng phí 7KB.
Quay lại và tiếp tục nói về thống kê! Khi bạn yêu cầu cơ sở dữ liệu thu thập số liệu thống kê, cơ sở dữ liệu tính toán các giá trị sau:
- Số lượng hàng và trang trong bảng
- Trong mỗi cột trong bảng:
- Giá trị duy nhất
- Độ dài dữ liệu (tối thiểu, tối đa, trung bình)
- Phạm vi dữ liệu (tối thiểu, tối đa, trung bình)
- Thông tin chỉ mục của bảng
Các số liệu thống kê này giúp trình tối ưu hóa ước tính Disk I/O, CPU và sử dụng bộ nhớ cần thiết cho truy vấn
Thống kê cho mỗi cột là rất quan trọng. Ví dụ: nếu một bảng PERSON cần phải được JOIN với 2 cột: LAST_NAME, FIRST_NAME. Theo thống kê, cơ sở dữ liệu biết rằng FIRST_NAME chỉ có 1.000 giá trị khác nhau và LAST_NAME có 1.000.000 giá trị khác nhau. Vì vậy, cơ sở dữ liệu được JOIN theo LAST_NAME, FIRST_NAME. Bởi vì LAST_NAME không có khả năng lặp lại, so sánh 2, 3 ký tự đầu tiên của LAST_NAME là đủ trong hầu hết các trường hợp, điều này sẽ làm giảm đáng kể số lần so sánh.
Tuy nhiên, đây chỉ là những số liệu thống kê cơ bản. Bạn có thể yêu cầu cơ sở dữ liệu làm một số liệu thống kê nâng cao được gọi là histogram. Histogram là số liệu thống kê về phân phối giá trị cột. Ví dụ:
- Các giá trị xuất hiện thường xuyên nhất
- Phân vị (quantiles)
- …
Các số liệu thống kê bổ sung này giúp cơ sở dữ liệu tìm thấy kế hoạch truy vấn tốt hơn, đặc biệt là đối với các vị ngữ phương trình (ví dụ: WHERE AGE = 18) hoặc vị ngữ phạm vi (ví dụ: WHERE AGE > 10 và AGE < 40) vì cơ sở dữ liệu có thể hiểu rõ hơn về các dòng dữ liệu loại số liên quan đến các vị ngữ này (Lưu ý: Tên kỹ thuật của khái niệm này được gọi là tỷ lệ chọn).
Số liệu thống kê được lưu trữ trong siêu dữ liệu cơ sở dữ liệu, chẳng hạn như vị trí thống kê của bảng (không phân vùng):
- Oracle: USER / ALL / DBA_TABLES và USER / ALL / DBA_TAB_COLUMNS
- DB2: SYSCAT. TABLES và SYSCAT. COLUMNS
Số liệu thống kê phải được cập nhật kịp thời. Nếu một bảng có 1.000.000 hàng và cơ sở dữ liệu nghĩ rằng nó chỉ có 500 hàng, không có gì tồi tệ hơn thế. Nhược điểm duy nhất của thống kê là cần có thời gian để tính toán, đó là lý do tại sao hầu hết các cơ sở dữ liệu không tự động tính toán số liệu thống kê theo mặc định. Khi dữ liệu đạt đến một triệu cấp độ thống kê trở nên khó khăn, tại thời điểm này, bạn có thể chọn chỉ làm số liệu thống kê cơ bản hoặc thực hiện thống kê trên một mẫu cơ sở dữ liệu.
Ví dụ, một dự án mà cần phải xử lý hàng trăm triệu dữ liệu trên mỗi bảng và tôi đã chọn chỉ thống kê 10%, dẫn đến tiêu thụ thời gian rất lớn. Ví dụ này chứng minh rằng đây là một quyết định tồi vì đôi khi 10% oracle 10G được chọn từ một cột cụ thể của một bảng cụ thể rất khác so với tất cả 100% (điều này hiếm khi xảy ra đối với các bảng có 100 triệu hàng dữ liệu). Số liệu thống kê sai này đã dẫn đến một truy vấn được cho là 30 giây để hoàn thành cuối cùng được thực hiện trong tám giờ, quá trình tìm kiếm nguyên nhân gốc rễ của hiện tượng này là một cơn ác mộng. Ví dụ này cho thấy tầm quan trọng của thống kê.
Lưu ý: Tất nhiên, mỗi cơ sở dữ liệu có số liệu thống kê cụ thể và cao hơn. Nếu bạn muốn biết thêm thông tin, hãy đọc tài liệu về cơ sở dữ liệu. Mặc dù vậy, tôi đã cố gắng hết sức để hiểu làm thế nào số liệu thống kê được sử dụng, và tài liệu chính thức tốt nhất tôi tìm thấy đến từ PostgreSQL.
Trình tối ưu hóa truy vấn (Query optimizer)
Tất cả các cơ sở dữ liệu hiện đại đang tối ưu hóa truy vấn với tối ưu hóa dựa trên chi phí, tức là cost-based optimization - CBO. Sự thật là thiết lập một chi phí cho mỗi tính toán, bằng cách áp dụng một loạt các tính toán chi phí thấp nhất, để tìm cách tốt nhất để giảm chi phí truy vấn.
Để hiểu các nguyên tắc của trình tối ưu hóa chi phí, tôi nghĩ rằng nó là tốt hơn để sử dụng một ví dụ để “cảm nhận” sự phức tạp đằng sau nhiệm vụ này. Ở đây tôi sẽ đưa ra 3 cách để kết nối 2 bảng và chúng ta sẽ sớm thấy rằng ngay cả một truy vấn nối đơn giản là một cơn ác mộng đối với trình tối ưu hóa. Sau đó, chúng ta sẽ tìm hiểu cách trình tối ưu hóa thực sự hoạt động.
Đối với các hoạt động JOIN, tôi sẽ tập trung vào độ phức tạp thời gian của chúng, tuy nhiên, trình tối ưu hóa cơ sở dữ liệu tính toán chi phí CPU, chi phí Disk I/O và yêu cầu bộ nhớ của chúng. Sự khác biệt giữa độ phức tạp thời gian và chi phí CPU là chi phí thời gian là một xấp xỉ (được chuẩn bị cho một kẻ lười biếng như tôi). Và chi phí CPU, tôi bao gồm tất cả các tính toán ở đây, chẳng hạn như: cộng, phán đoán điều kiện, nhân, lặp lại … Ngoài ra, những gì khác:
Mỗi hoạt động high-level code yêu cầu một số lượng cụ thể của các hoạt động CPU low-level.
Đối với Intel Core i7, Intel Pentium 4, AMD Opteron… Vv, (xét chu kỳ CPU), chi phí hoạt động của CPU là khác nhau, có nghĩa là nó phụ thuộc vào kiến trúc của CPU.
Sử dụng độ phức tạp thời gian dễ dàng hơn nhiều (ít nhất là đối với tôi), và sử dụng nó tôi cũng có thể tìm hiểu về khái niệm CBO. Vì Disk I/O là một khái niệm quan trọng, thỉnh thoảng tôi cũng đề cập đến nó. Hãy nhớ rằng hầu hết thời gian thắt cổ chai là Disk I/O thay vì sử dụng CPU.
Chỉ mục (Index)
Khi nghiên cứu B Tree, tôi đã nói về Index, hãy nhớ rằng các chỉ số đã được sắp xếp.
Chỉ để tham khảo: Ngoài ra còn có các loại chỉ mục khác, chẳng hạn như bitmap index, không giống như chi phí của chỉ mục B+ Tree về CPU, Disk I/O và bộ nhớ.
Ngoài ra, nhiều cơ sở dữ liệu hiện đại để cải thiện chi phí thực thi truy vấn, chỉ có thể tự động tạo chỉ mục tạm thời cho các truy vấn hiện tại.
Đường dẫn truy cập (access path)
Trước khi áp dụng toán tử liên kết (join), trước tiên bạn cần lấy dữ liệu. Dưới đây là cách để có được dữ liệu.
Lưu ý: Vì vấn đề thực sự với tất cả các đường dẫn truy cập là Disk I/O, tôi sẽ không nói quá nhiều về độ phức tạp thời gian.
- Quét đầy đủ (full scan)
Nếu bạn đã đọc kế hoạch thực thi, bạn chắc chắn đã thấy từ “quét đầy đủ” (hoặc chỉ quét’). Nói một cách đơn giản, quét đầy đủ là cơ sở dữ liệu đọc đầy đủ một bảng hoặc chỉ mục. Đối với Disk I/O, rõ ràng là quét bảng đầy đủ có chi phí cao hơn so với quét đầy đủ chỉ mục.
- Quét phạm vi
Các loại quét khác được quét theo chỉ mục, chẳng hạn như khi bạn sử dụng vị ngữ WHERE AGE > 20 AND AGE < 40
Tất nhiên, bạn cần phải có chỉ mục trên trường AGE để quét phạm vi chỉ mục.
Trong phần đầu tiên, chúng ta đã biết rằng chi phí thời gian của truy vấn phạm vi là khoảng log(N) + M, ở đây N là khối lượng dữ liệu được chỉ mục và M là số dòng được ước tính trong phạm vi. Nhờ thống kê, chúng ta mới có thể biết giá trị của N và M (Lưu ý: M là vị ngữ AGE > 20 AND AGE < 40). Ngoài ra, bạn không cần phải đọc toàn bộ chỉ mục khi quét phạm vi, vì vậy nó không tốn kém như quét đầy đủ trên Disk I/O.
- Quét duy nhất
Nếu bạn chỉ cần lấy một giá trị từ chỉ mục, bạn có thể quét duy nhất.
- Truy cập theo ROW ID
Trong hầu hết các trường hợp, nếu cơ sở dữ liệu sử dụng chỉ mục, nó phải tìm các hàng liên quan đến chỉ mục, điều này sẽ được sử dụng theo cách truy cập dựa trên ROW ID.
Ví dụ: nếu bạn chạy:
SELECT LASTNAME, FIRSTNAME from PERSON WHERE AGE = 28Nếu cột age của bảng person có chỉ mục, trình tối ưu hóa sẽ sử dụng chỉ mục để tìm mọi người ở tất cả các lứa tuổi 28, sau đó nó sẽ đi vào bảng để đọc các hàng có liên quan, đó là bởi vì chỉ có thông tin age trong chỉ mục và bạn muốn họ và tên.
Tuy nhiên, nếu bạn thực hiện một cách tiếp cận khác:
SELECT TYPE_PERSON.CATEGORY from PERSON, TYPE_PERSON
WHERE PERSON.AGE = TYPE_PERSON.AGEChỉ mục của bảng PERSON được sử dụng để kết nối bảng TYPE_PERSON, nhưng bảng PERSON không được truy cập dựa trên ROW ID vì bạn không yêu cầu thông tin trong bảng đó.
Mặc dù phương pháp này hoạt động tốt ở một lượng nhỏ truy cập, vấn đề thực sự với hoạt động này thực sự là Disk I/O. Nếu cần rất nhiều truy cập dựa trên ROW ID, cơ sở dữ liệu có thể chọn quét đầy đủ.
- Đường dẫn khác
Tôi không liệt kê tất cả các đường dẫn truy cập và bạn có thể đọc tài liệu Oracle nếu bạn quan tâm. Các cơ sở dữ liệu khác có thể được gọi khác nhau nhưng các khái niệm đằng sau nó là như nhau.
Phép kết nối (join)
Bây giờ chúng ta đã biết làm thế nào để có được dữ liệu, sau đó kết nối chúng ngay !
Những gì tôi muốn trình bày là ba phép kết nối phổ biến: Merge Join, Hash Join và Nested Loop Join. Nhưng trước đó, tôi cần phải giới thiệu một từ mới: quan hệ bên trong và bên ngoài (inner relation and outer relation) có thể là:
- Một bảng
- Một chỉ mục
- Kết quả trung gian của phép tính trước đó (ví dụ: kết quả của các phép kết nối trước đó)
Khi bạn kết nối hai quan hệ, thuật toán kết nối xử lý hai quan hệ là khác nhau. Trong phần còn lại của bài viết này, tôi sẽ giả định:
- Quan hệ bên ngoài là tập dữ liệu bên trái
- Quan hệ bên trong là tập dữ liệu bên phải
Ví dụ: A JOIN B là kết nối giữa A và B, Ở đây A là quan hệ bên ngoài và B là quan hệ bên trong.
Trong hầu hết các trường hợp, chi phí của A JOIN B khác với chi phí của B JOIN A.
Trong phần này, tôi cũng sẽ giả định rằng quan hệ bên ngoài có một yếu tố N và quan hệ bên trong có yếu tố M. Hãy nhớ rằng trình tối ưu hóa thực sự biết giá trị của N và M thông qua thống kê.
Lưu ý: N và M là lực lượng của quan hệ.
Nested Loop Join
Nested Loop Join là đơn giản nhất.
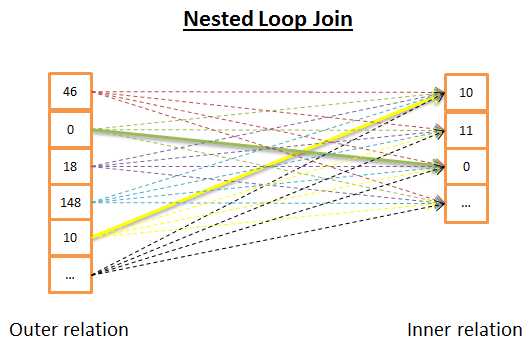
Dưới đây là một số lý do:
- Đối với mỗi dòng của quan hệ bên ngoài, xem tất cả các hàng trong quan hệ bên trong để tìm các hàng phù hợp
Dưới đây là mã giả:
nested_loop_join(array outer, array inner)
for each row a in outer
for each row b in inner
if (match_join_condition(a,b))
write_result_in_output(a,b)
end if
end for
end forVì đây là một lần lặp kép, độ phức tạp thời gian là O(N*M).
Về phía Disk I/O, vòng lặp bên trong yêu cầu đọc M hàng từ quan hệ bên trong với mỗi hàng trong N hàng của quan hệ bên ngoài. Thuật toán này yêu cầu đọc N + N * M hàng từ disk. Tuy nhiên, nếu quan hệ bên trong đủ nhỏ để bạn có thể đọc nó vào bộ nhớ, chỉ có M + N lần đọc. Sau khi sửa đổi như vậy, quan hệ bên trong phải là tối thiểu vì nó có nhiều cơ hội hơn để nạp vào bộ nhớ.
Không có sự khác biệt về chi phí CPU, nhưng về Disk I/O thì tốt nhất là mỗi quan hệ chỉ đọc một lần.
Tất nhiên, quan hệ bên trong có thể được thay thế bằng chỉ mục và thuận lợi hơn cho Disk I/O.
Vì thuật toán này rất đơn giản, phiên bản sau đây có lợi hơn cho Disk I/O khi quan hệ bên trong quá lớn để nạp vào bộ nhớ. Dưới đây là một số lý do:
- Để tránh đọc hai quan hệ từng dòng
- Bạn có thể đọc chúng, lưu hai dòng dữ liệu (được đọc trong hai quan hệ) vào bộ nhớ,
- So sánh hai cụm dữ liệu, giữ lại các cặp thoả mãn
- Sau đó tải các cụm dữ liệu mới từ đĩa để tiếp tục so sánh
- Cho đến khi tất cả dữ liệu được nạp.
Thuật toán có thể như sau:
// improved version to reduce the disk I/O.
nested_loop_join_v2(file outer, file inner)
for each bunch ba in outer
// ba is now in memory
for each bunch bb in inner
// bb is now in memory
for each row a in ba
for each row b in bb
if (match_join_condition(a,b))
write_result_in_output(a,b)
end if
end for
end for
end for
end forVới phiên bản này, độ phức tạp thời gian không thay đổi, nhưng truy cập disk giảm:
- Với phiên bản trước, thuật toán yêu cầu truy cập
N + N * Mlần (một dòng cho mỗi truy cập). - Với phiên bản mới, truy cập đĩa trở thành số lượng cụm dữ liệu quan hệ bên ngoài + số lượng cụm dữ liệu quan hệ bên ngoài * Số lượng cụm dữ liệu cho quan hệ bên trong.
- Tăng kích thước của các cụm dữ liệu có thể làm giảm truy cập disk.
Hash Join
Hash Join phức tạp hơn, nhưng trong nhiều trường hợp, chi phí thấp hơn so với Nested Loop Join.
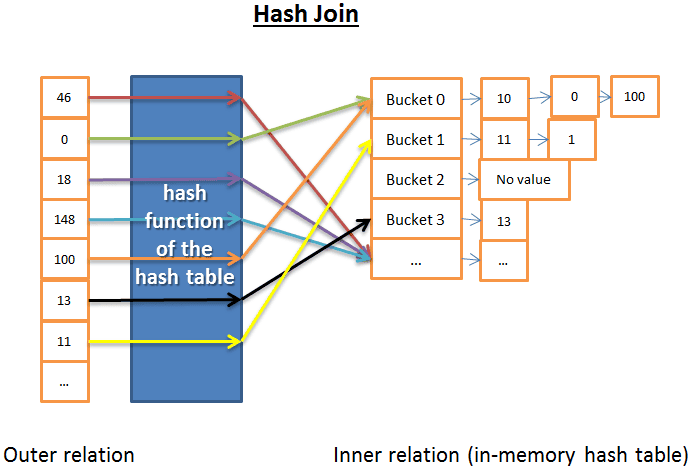
Nguyên tắc của Hash Join là:
- Đọc tất cả các hàng của quan hệ bên trong
- Xây dựng một bảng băm (hash table) trong bộ nhớ
- Đọc từng hàng của quan hệ bên ngoài + (sử dụng hàm băm (hash function) của bảng băm (hash table)) để tính toán giá trị băm (hash value) của mỗi hàng để tìm bên trong thùng băm (hash bucket) có liên quan trong quan hệ bên trong
- Xác định có khớp với các hàng của quan hệ bên ngoài hay không?
Về độ phức tạp của thời gian, tôi cần phải đưa ra một số giả định để đơn giản hóa vấn đề:
- quan hệ bên trong được chia thành X thùng băm
- Hàm băm phân phối gần như đồng đều giá trị băm của dữ liệu trong mỗi quan hệ, có nghĩa là kích thước thùng băm là như nhau.
- Các yếu tố của quan hệ bên ngoài phù hợp với tất cả các yếu tố trong thùng băm, với chi phí là số lượng các hàng trong thùng băm.
Độ phức tạp thời gian là (M/X) * N + chi phí tạo bảng băm (M) + chi phí hàm băm * N. Nếu hàm băm tạo ra thùng băm đủ nhỏ, độ phức tạp là O(M+N).
Ngoài ra còn có một phiên bản Hash Join, có lợi cho bộ nhớ nhưng không đủ tốt cho disk I/O. Lần này nó trông như thế này:
- Tính toán bảng băm của cả hai quan hệ bên trong và bên ngoài
- Lưu bảng băm vào disk
- Sau đó so sánh từng thùng băm (một trong số đó được đọc vào bộ nhớ và đọc từng dòng khác).
Merge Join
Merge Join là thuật toán liên kết duy nhất tạo ra sắp xếp.
Lưu ý: Merge Join đơn giản này không phân biệt giữa bảng bên trong hoặc bề ngoài. Hai bảng đóng cùng một vai trò. Nhưng thực sự thực hiện theo những cách khác nhau, chẳng hạn như khi xử lý các giá trị trùng lặp.
-
- (Tùy chọn) Hoạt động sắp xếp các kết hợp (join): cả hai nguồn đầu vào được sắp xếp theo từ khóa được liên kết.
-
- Hoạt động hợp nhất các kết hợp : các nguồn đầu vào đã được sắp xếp được hợp nhất với nhau.
- Sort
Tôi đã nói về Merge Sort, là một thuật toán sắp xếp tốt (nhưng không phải là tốt nhất, hoặc hash Join tốt hơn nếu bộ nhớ là đủ).
Tuy nhiên, đôi khi tập dữ liệu đã được sắp xếp, chẳng hạn như:
-
Nếu bên trong bảng có thứ tự, chẳng hạn như một bảng có chỉ mục trong điều kiện nối (index-organized table)
-
Nếu quan hệ là một chỉ mục trong điều kiện kết nối
-
Nếu phép kết nối áp dụng với kết quả trung gian mà đã được sắp xếp trong một truy vấn
-
Merge Join
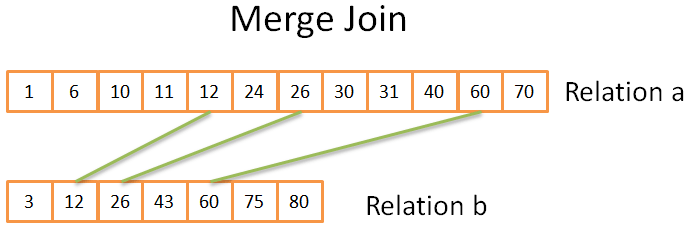
Phần này rất giống với các hoạt động hợp nhất trong merge sort. Nhưng lần này, tôi không chọn tất cả các yếu tố từ hai quan hệ, nhưng chỉ chọn cùng một yếu tố. Sự thật là như sau:
- Trong hai quan hệ, so sánh các yếu tố hiện tại (hiện tại = lần đầu tiên xuất hiện)
- Nếu giống nhau, đưa cả hai yếu tố vào kết quả và so sánh yếu tố tiếp theo trong cả hai quan hệ
- Nếu khác nhau, hãy tìm yếu tố tiếp theo trong quan hệ với các yếu tố nhỏ nhất (vì yếu tố tiếp theo có thể phù hợp)
- Lặp lại các bước 1, 2, 3 cho đến khi yếu tố cuối cùng của một trong các quan hệ.
Bởi vì cả hai quan hệ đã được sắp xếp, bạn không cần phải “nhìn lại”, vì vậy phương pháp này có hiệu quả.
Đây đơn giản là kĩ thuật two pointer, duyệt trên hai mảng đã sắp xếp.
Thuật toán là một phiên bản đơn giản vì nó không xử lý các tình huống xảy dữ liệu trùng (tức là nhiều kết hợp) trên cùng mảng trong cả hai mảng. Phiên bản thực tế phức tạp hơn, vì vậy tôi đã chọn phiên bản đơn giản hóa.
Nếu cả hai quan hệ đã được sắp xếp, độ phức tạp của thời gian là O(N+M)
Nếu hai quan hệ cần được sắp xếp, độ phức tạp thời gian là chi phí sắp xếp hai quan hệ: O(N*Log(N) + M*Log(M))
Thuật toán nào là tốt nhất?
Nếu có tốt nhất, không cần phải làm cho nhiều loại như vậy. Câu hỏi này là khó, bởi vì nhiều yếu tố cần xem xét, chẳng hạn như:
- Bộ nhớ nhàn rỗi: Nếu bạn không có đủ bộ nhớ, hãy chọn Hash Join (ít nhất là hoàn toàn trong bộ nhớ).
- Kích thước của cả hai tập dữ liệu. Ví dụ, nếu một bảng lớn nối một bảng nhỏ, thì Nested Loop Join nhanh hơn so với Hash Join, vì sau này có chi phí cao để tạo ra bảng băm; Nếu cả hai bảng đều rất lớn, Nested Loop Join có chi phí cpu rất cao.
- Nếu có chỉ mục: Nếu có hai chỉ mục B+ Tree, lựa chọn thông minh dường như là Merge Join.
- Kết quả có cần phải được sắp xếp hay không?: Ngay cả khi bạn đang sử dụng một tập dữ liệu chưa được sắp xếp, mặc dù có chi phí cao hơn (vì phải sắp xếp) nhưng bạn có thể vẫn muốn sử dụng Merge Join nếu sau khi có được kết quả được sắp xếp, bạn có thể liên kết nó với một Merge Join khác (hoặc có thể vì truy vấn yêu cầu kết quả sắp xếp ngầm hoặc rõ ràng với các thao tác như ORDER BY/GROUP BY/DISTINCT).
- Quan hệ đã được sắp xếp: Tại thời điểm này, Merge Join là lựa chọn tốt nhất.
- Loại kết nối: Là kết nối tương đương (ví dụ: tableA.col1 = tableB.col2)? Hoặc Inner Join? Outer Join? Cartesian Join? Hoặc Self Join? Một số kết nối không hoạt động trong một môi trường cụ thể.
- Phân phối dữ liệu: Nếu dữ liệu về điều kiện kết nối là lệch (ví dụ: để kết nối người với họ (lastname), nhưng nhiều người có cùng họ), Hash Join sẽ là một thảm họa vì hàm băm sẽ tạo ra thùng băm phân bố rất không đồng đều.
- Nếu bạn muốn các hoạt động kết nối sử dụng đa luồng hoặc đa tiến trình.
Để biết thêm thông tin, bạn có thể đọc tài liệu cho DB2, ORACLE hoặc SQL Server.
Ví dụ đơn giản
Chúng tôi đã nghiên cứu 3 loại phép kết nối. Bây giờ, ví dụ, chúng ta sẽ kết nối 5 bảng để có được tất cả thông tin của một người. Một người có thể có:
- Nhiều số điện thoại di động (MOBILES)
- Nhiều hộp thư (MAILS)
- Nhiều địa chỉ (ADRESSES)
- Nhiều tài khoản ngân hàng (BANK_ACCOUNTS)
Nói cách khác, chúng ta cần phải nhanh chóng nhận được câu trả lời với truy vấn sau:
SELECT * from PERSON, MOBILES, MAILS, ADRESSES, BANK_ACCOUNTS
WHERE
PERSON.PERSON_ID = MOBILES.PERSON_ID
AND PERSON.PERSON_ID = MAILS.PERSON_ID
AND PERSON.PERSON_ID = ADRESSES.PERSON_ID
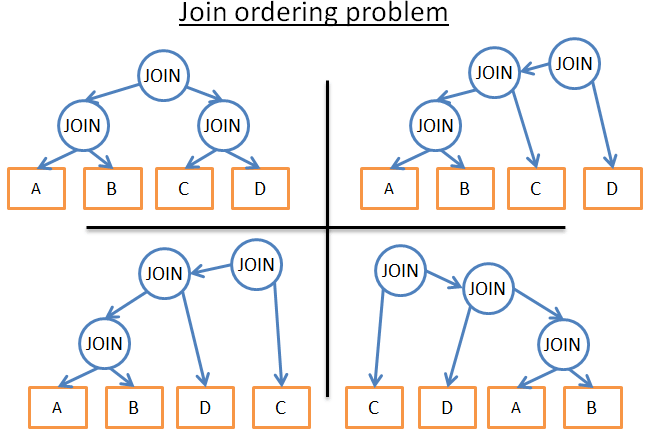
AND PERSON.PERSON_ID = BANK_ACCOUNTS.PERSON_IDLà một trình tối ưu hóa truy vấn, tôi phải tìm cách tốt nhất để xử lý dữ liệu. Nhưng có 2 câu hỏi:
- Loại nào được sử dụng cho mỗi kết nối?
- Tôi có 3 lựa chọn (hash, merge, nested loop) và có thể sử dụng 0, 1 hoặc 2 chỉ mục cùng lúc (không cần phải nói rằng có nhiều loại chỉ mục).
- Kết nối được thực hiện theo thứ tự nào?
Ví dụ: hình ảnh sau đây cho thấy kế hoạch thực thi có thể được sử dụng cho 4 bảng chỉ 3 lần join:
Các truy vấn trong thực tế cũng có các toán tử quan hệ khác, chẳng hạn như OUTER JOIN, CROSS JOIN, GROUP BY, ORDER BY, PROJECTION, UNION, INTERSECT, DISTINCT … Điều này có nghĩa là nhiều khả năng hơn.
Vì vậy, làm thế nào để cơ sở dữ liệu xử lý?
Dynamic Programing, Greedy Heuristic
Dynamic Programming, Greedy, and Heuristic Algorithm
Cơ sở dữ liệu quan hệ sẽ thử một số phương pháp mà tôi vừa đề cập, và công việc thực sự của trình tối ưu hóa là tìm một giải pháp tốt trong một khoảng thời gian giới hạn.
Hầu hết thời gian, trình tối ưu hóa không tìm thấy giải pháp tốt nhất, nhưng giải pháp có thể xem là “tốt” (đương nhiên là cũng có những lúc tốt trong ngoặc kép thật)
- Quy hoạch động (Dynamic Programming)
Đối với các truy vấn quy mô nhỏ, có thể áp dụng một cách tiếp cận trâu (brute-force). Nhưng để các truy vấn quy mô trung bình cũng có thể được thực hiện một cách tiếp cận trâu, chúng tôi có một cách để tránh các tính toán không cần thiết, đó là quy hoạch động.
Ý tưởng đằng sau những từ này là nhiều kế hoạch thực hiện rất giống nhau. Hãy xem các kế hoạch dưới đây:
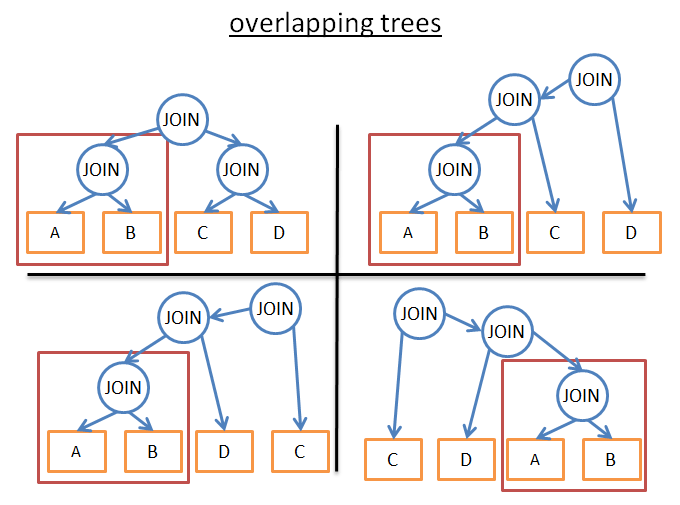
Tất cả chúng đều có cùng một cây con (A JOIN B), vì vậy bạn không cần phải tính toán chi phí của cây con này trong mỗi kế hoạch, tính toán một lần, lưu kết quả và tái sử dụng khi gặp lại cây con này. Theo cách nói chính thức hơn, chúng ta đang phải đối mặt với một vấn đề chồng chéo. Để tránh tính toán trùng lặp một số kết quả, chúng tôi sử dụng phương pháp ghi nhớ.
Áp dụng kĩ thuật này, chúng tôi không còn độ phức tạp (2*N)!/(N+1)!, nhưng “chỉ” 3^N. Trong ví dụ 4 JOIN trên, điều này có nghĩa là giảm số lần sắp xếp từ 336 xuống còn 81 lần. Nếu đó là một truy vấn lớn hơn, chẳng hạn như 8 JOIN (thực sự không phải là rất lớn), giảm 57.657.600 xuống còn 6.551.
Đối với các truy vấn quy mô lớn, bạn cũng có thể sử dụng các phương pháp quy hoạch động, nhưng kèm với các quy tắc bổ sung(hoặc thuật toán heuristics) để giảm khả năng.
- Nếu chúng ta chỉ phân tích một loại kế hoạch cụ thể (ví dụ: cây sâu bên trái left-deep tree), chúng ta sẽ nhận được
n*2^nthay vì3^n.
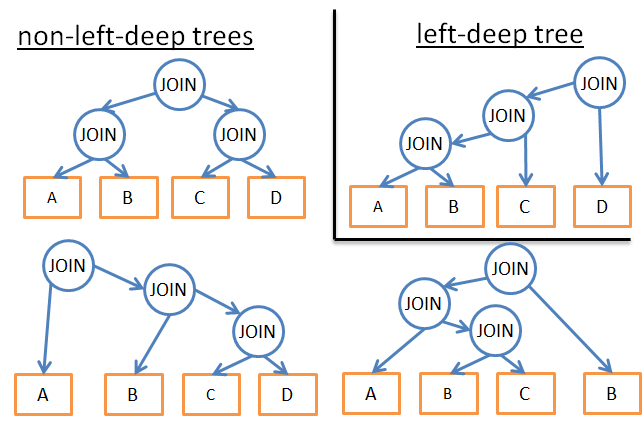
-
Nếu chúng ta thêm các quy tắc hợp lý để tránh kế hoạch cho một số mô hình (ví dụ: ‘nếu một bảng có chỉ mục cho các vị ngữ được chỉ định, không cố gắng merge join với bảng, nhưng với chỉ mục), chúng ta sẽ giảm số lượng khả năng mà không gây ra thiệt hại quá mức cho kịch bản tốt nhất.
-
Nếu chúng ta thêm các quy tắc vào quá trình (chẳng hạn như các hoạt động kết nối trước tất cả các tính toán quan hệ khác), chúng ta cũng có thể giảm đáng kể khả năng.
-
……
-
Thuật toán tham lam (Greed Alogrithm)
Tuy nhiên, trình tối ưu hóa phải đối mặt với một truy vấn rất lớn, hoặc để tìm câu trả lời càng sớm càng tốt (tuy nhiên tốc độ truy vấn không nhanh), một thuật toán khác, được gọi là thuật toán tham lam.
Nguyên tắc là lập kế hoạch truy vấn theo một quy tắc (hoặc heuristic) một cách dần dần. Theo quy tắc này, các thuật toán tham lam dần dần tìm kiếm các thuật toán tốt nhất, xử lý một JOIN đầu tiên, sau đó thêm một JOIN mới theo cùng một quy tắc cho mỗi bước.
Hãy xem xét một ví dụ đơn giản. Ví dụ, một truy vấn JOIN cho 5 bảng (A, B, C, D, E) 4 lần, để đơn giản hóa việc chúng tôi sử dụng JOIN lồng nhau như một phương pháp kết nối có thể, chúng tôi làm theo quy tắc “sử dụng kết nối chi phí thấp nhất”.
- Chọn một bắt đầu trực tiếp từ 5 bảng (ví dụ: A)
- Tính toán mỗi kết nối với A (A là một quan hệ bên trong hoặc bên ngoài)
- Khám phá “A JOIN B” có chi phí thấp nhất
- Tính toán chi phí của mỗi kết quả được kết nối với
A JOIN B(A JOIN Blà quan hệ bên trong hoặc bên ngoài) - Khám phá
(A JOIN B) JOIN Ccó chi phí thấp nhất - Tính toán chi phí của mỗi kết quả được kết hợp với
(A JOIN B) JOIN C. - ……
- Hoàn thiện kế hoạch thực hiện
((A JOIN B) JOIN C) JOIN D ) JOIN E)
Bởi vì chúng tôi bắt đầu một cách tùy tiện với bảng A, chúng ta có thể sử dụng cùng một thuật toán trong B, sau đó C, sau đó D, sau đó E. Cuối cùng giữ lại kế hoạch thực hiện với chi phí thấp nhất.
Nhân tiện, thuật toán này có một cái tên, được gọi là “Nearest Neighbor Algorithm”.
Bỏ qua các chi tiết, chỉ cần một mô hình tốt và sắp xếp độ phức tạp Nlog(N), vấn đề có thể dễ dàng được giải quyết. Độ phức tạp của thuật toán này là O(Nlog(N), so sánh với O(3^N) của dynamic programming. Nếu bạn có một truy vấn lớn 20 JOIN, điều này có nghĩa là 26 vs 3,486,784,401, một sự khác biệt lớn!
Vấn đề với thuật toán này là giả định chúng tôi thực hiện là tìm cách tốt nhất để kết nối 2 bảng, giữ lại kết quả kết nối này và kết nối bảng tiếp theo để có được chi phí thấp nhất. Tuy nhiên:
- Ngay cả giữa A, B, C,
A JOIN Bcó giá thấp nhất (A JOIN C) JOIN Bcó thể tốt hơn so với(A JOIN B) JOIN C.
Để cải thiện tình trạng này, bạn có thể sử dụng các thuật toán tham lam dựa trên các quy tắc khác nhau nhiều lần và giữ lại kế hoạch thực hiện tốt nhất.
Bộ nhớ cache kế hoạch truy vấn (Query Plan Cache)
Vì việc tạo kế hoạch truy vấn tốn thời gian, hầu hết các cơ sở dữ liệu lưu kế hoạch trong bộ nhớ query plan cache để tránh tính toán trùng lặp. Chủ đề này là lớn hơn bởi vì cơ sở dữ liệu cần phải biết khi nào để cập nhật các kế hoạch lỗi thời. Cách tiếp cận là đặt giới hạn trên và nếu một bảng thay đổi thống kê vượt quá giới hạn trên, kế hoạch truy vấn về bảng sẽ bị xóa khỏi bộ nhớ cache.
Trình thực thi truy vấn (Query Excuter)
Ở giai đoạn này, chúng tôi có một kế hoạch thực hiện được tối ưu hóa và biên dịch thành mã thực thi. Sau đó, nếu có đủ tài nguyên (bộ nhớ, CPU), trình thực thi truy vấn sẽ thực thi nó. Các toán tử (JOIN, SORT BY …) trong kế hoạch có thể được thực hiện theo thứ tự hoặc song song, tùy thuộc vào trình thực thi. Để lấy và ghi dữ liệu, trình thực thi truy vấn tương tác với trình quản lý dữ liệu, phần tiếp theo của bài viết này thảo luận về trình quản lý dữ liệu.
Trình quản lý dữ liệu
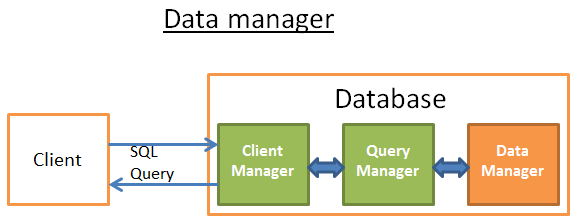
Ở bước này, trình quản lý truy vấn thực hiện truy vấn và yêu cầu dữ liệu từ bảng và chỉ mục. Nhưng có 2 câu hỏi:
- Cơ sở dữ liệu quan hệ sử dụng mô hình giao dịch, vì vậy bạn không thể có được phần dữ liệu này khi người khác sử dụng hoặc sửa đổi dữ liệu cùng một lúc.
- Trích xuất dữ liệu là hoạt động chậm nhất trong cơ sở dữ liệu, vì vậy trình quản lý dữ liệu cần phải đủ thông minh để có được dữ liệu và lưu nó trong bộ đệm bộ nhớ.
Trong phần này, chúng ta hãy xem làm thế nào cơ sở dữ liệu quan hệ xử lý cả hai vấn đề.
Trình quản lý bộ nhớ cache (Cache Manager)
Như đã đề cập trước đó, nút thắt chai chính của cơ sở dữ liệu là Disk I/O. Để cải thiện hiệu suất, cơ sở dữ liệu hiện đại sử dụng trình quản lý bộ nhớ cache.
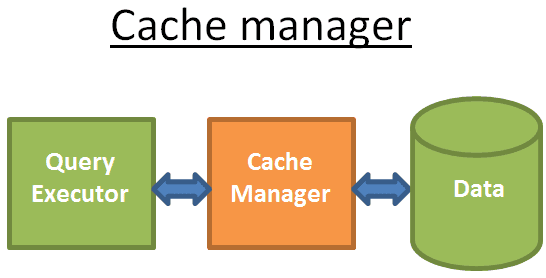
Trình thực thi truy vấn không lấy dữ liệu trực tiếp từ hệ thống tệp, nhưng từ trình quản lý bộ nhớ cache. Trình quản lý bộ nhớ cache có một khu vực bộ nhớ cache được gọi là vùng đệm (buffer pool), đọc dữ liệu từ bộ nhớ có thể cải thiện đáng kể hiệu suất cơ sở dữ liệu. Thật khó để đưa ra một mức độ định lượng cho điều này, bởi vì nó phụ thuộc vào những gì bạn cần:
- Truy cập tuần tự (ví dụ: quét đầy đủ) vs truy cập ngẫu nhiên (ví dụ: truy cập theo row id)
- Đọc hay ghi
Và loại disk được sử dụng bởi cơ sở dữ liệu:
- 7.2k/10k/15k rpm hard drive
- SSD
- RAID 1/5/…
Để tôi nói, bộ nhớ nhanh hơn 100 đến 100.000 lần so với disk. Tuy nhiên, điều này dẫn đến một vấn đề khác (cơ sở dữ liệu luôn luôn như vậy …), trình quản lý bộ nhớ cache cần phải có được dữ liệu trước khi Trình thực thi truy vấn sử dụng dữ liệu, nếu không trình quản lý truy vấn sẽ phải chờ đợi vì đọc dữ liệu từ disk chậm.
Đọc trước (Pre-Reading)
Vấn đề này được gọi đọc trước (pre-reading). Trình thực thi truy vấn biết dữ liệu nào nó sẽ cần vì nó hiểu toàn bộ luồng truy vấn và dữ liệu trên disk thông qua thống kê. Quá trình này trông như thế này:
- Khi Trình thực thi truy vấn xử lý lô dữ liệu đầu tiên của nó, trình quản lý bộ nhớ cache được yêu cầu tải trước lô dữ liệu thứ hai
- Khi bạn bắt đầu xử lý lô dữ liệu thứ hai, hãy nói với trình quản lý bộ nhớ cache để tải trước lô dữ liệu thứ ba và nói với trình quản lý bộ nhớ cache rằng lô đầu tiên có thể được xóa khỏi bộ nhớ cache.
- ……
Trình quản lý bộ nhớ cache lưu tất cả dữ liệu này trong vùng đệm. Để xác định xem một dữ liệu có hữu ích hay không, trình quản lý bộ nhớ cache đã thêm thông tin bổ sung (được gọi là chốt (latch)) vào dữ liệu được lưu trong bộ nhớ cache.
Đôi khi Trình thực thi truy vấn không biết những gì về dữ liệu nó cần và một số cơ sở dữ liệu không cung cấp chức năng này. Thay vào đó, họ sử dụng một phương pháp đọc trước suy đoán (ví dụ: nếu Trình thực thi truy vấn muốn dữ liệu 1, 3, 5, nó có thể sẽ đọc trước 7, 9, 11) hoặc đọc trước tuần tự (tại thời điểm này trình quản lý bộ nhớ cache chỉ đơn giản là tải dữ liệu liên tục tiếp theo từ đĩa sau khi đọc một loạt dữ liệu).
Để theo dõi tình trạng hoạt động đọc trước, cơ sở dữ liệu hiện đại giới thiệu một thước đo được gọi là (bộ đệm / bộ nhớ cache) hay (buffer / cache) để hiển thị tần suất dữ liệu được yêu cầu được tìm thấy trong bộ nhớ cache thay vì đọc từ disk.
Lưu ý: Tỷ lệ trúng bộ nhớ cache (cache hit ratio) kém không phải lúc nào cũng có nghĩa là bộ nhớ cache hoạt động kém.
Bộ đệm chỉ là dung lượng hạn chế của bộ nhớ, vì vậy để tải dữ liệu mới khi đã đầy, nó cần phải loại bỏ một số dữ liệu. Tải và xóa bộ nhớ cache đòi hỏi một số chi phí disk và network I/O. Nếu bạn có một truy vấn được thực hiện thường xuyên, sau đó tải kết quả truy vấn mỗi lần và xóa nó, hiệu quả là quá thấp. Cơ sở dữ liệu hiện đại giải quyết vấn đề này với chính sách thay thế bộ đệm.
Chính sách thay thế bộ đệm
Hầu hết các cơ sở dữ liệu hiện đại (ít nhất là SQL Server, MySQL, Oracle và DB2) sử dụng thuật toán LRU.
LRU
LRU (Least Recently Used) : bỏ đi phần tử ít được sử dụng gần đây nhất. Nguyên tắc đằng sau nó: dữ liệu được giữ lại trong bộ nhớ cache được sử dụng gần đây nhất, có nhiều khả năng sẽ được tái sử dụng.
Hình minh họa:
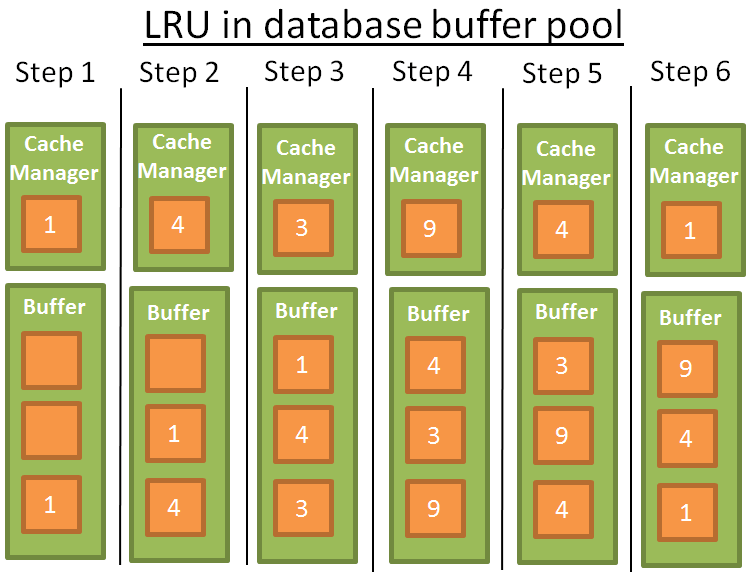
Để hiểu rõ hơn, tôi giả định rằng dữ liệu trong bộ đệm không bị khóa bởi chốt (có nghĩa là nó có nghĩa là nó có thể được gỡ bỏ). Trong ví dụ đơn giản này, bộ đệm có thể lưu 3 thành viên:
- 1: Trình quản lý bộ nhớ cache (CM) sử dụng dữ liệu 1 và đặt nó vào bộ đệm trống
- 2: CM sử dụng dữ liệu 4 và đặt nó vào bộ đệm
- 3: CM sử dụng dữ liệu 3 và đặt nó vào bộ đệm
- 4: CM sử dụng dữ liệu 9, bộ đệm đã đầy, vì vậy dữ liệu 1 đã bị xóa vì là lần cuối cùng nó được sử dụng gần đây là xa nhất và dữ liệu 9 được thêm vào bộ đệm
- 5: CM sử dụng dữ liệu 4, dữ liệu 4 đã ở trong bộ đệm, vì vậy nó một lần nữa trở thành phần tử được sử dụng gần đây.
- 6: CM sử dụng dữ liệu 1, bộ đệm đầy đủ, vì vậy dữ liệu 9 đã bị xóa vì là lần gần đây nhất nó được sử dụng là xa nhất và dữ liệu 1 được thêm vào bộ đệm
- ……
Thuật toán này hoạt động tốt, nhưng có một số hạn chế. Điều gì sẽ xảy ra nếu bạn thực hiện quét toàn bộ trên một bảng lớn? Nói cách khác, điều gì sẽ xảy ra khi kích thước của bảng/chỉ mục vượt quá bộ đệm? Sử dụng thuật toán này sẽ xóa tất cả dữ liệu trong bộ nhớ cache trước đó và dữ liệu được quét đầy đủ có khả năng chỉ được sử dụng một lần.
Cải thiện
Để ngăn chặn hiện tượng này, một số cơ sở dữ liệu đã thêm các quy tắc đặc biệt, chẳng hạn như mô tả trong tài liệu Oracle:
『 Đối với các bảng rất lớn, cơ sở dữ liệu thường sử dụng đường dẫn trực tiếp để đọc, tức là tải trực tiếp các khối […] để tránh lấp đầy bộ đệm. Đối với các bảng có kích thước trung bình, cơ sở dữ liệu có thể được đọc trực tiếp hoặc cache dữ liệu đã đọc. Nếu bạn chọn đọc bộ nhớ cache, cơ sở dữ liệu đặt khối ở đuôi LRU để ngăn chặn bộ đệm hiện tại bị xóa.』
Ngoài ra còn có một số khả năng, chẳng hạn như sử dụng phiên bản cao cấp của LRU, được gọi là LRU-K. Ví dụ, SQL Server sử dụng LRU-2。
Nguyên tắc của thuật toán này là xem xét nhiều lịch sử hơn. LRU đơn giản (tức là LRU-1) chỉ xem xét dữ liệu được sử dụng lần cuối. Còn LRU-K:
- Hãy xem xét dữ liệu được sử dụng K lần cuối cùng
- Số lần dữ liệu được sử dụng được thêm vào trọng lượng
- Một loạt dữ liệu mới được tải vào bộ nhớ cache và dữ liệu cũ nhưng thường được sử dụng sẽ không bị xóa (vì trọng lượng cao hơn)
- Tuy nhiên, thuật toán này không giữ lại dữ liệu không còn được sử dụng trong bộ nhớ cache
- Vì vậy, nếu dữ liệu không còn được sử dụng, giá trị trọng lượng giảm theo thời gian
Tính toán trọng lượng là tốn kém, vì vậy SQL Server chỉ sử dụng K = 2, hiệu suất giá trị tốt và chi phí bổ sung được chấp nhận.
Các thuật toán khác
Tất nhiên có các thuật toán khác để quản lý bộ nhớ cache, chẳng hạn như:
- 2Q (giống thuật toán LRU-K)
- CLOCK (giống thuật toán LRU-K)
- MRU (thuật toán mới nhất được sử dụng, cùng một logic nhưng các quy tắc khác nhau với LRU)
- LRFU(Least Recently and Frequently Used)
- ……
Bộ đệm ghi (Write Buffer)
Tôi chỉ tìm hiểu bộ nhớ cache đọc - tải trước dữ liệu trước khi sử dụng. Bộ đệm ghi được sử dụng để lưu dữ liệu, ghi hàng loạt vào disk, thay vì ghi dữ liệu từng cái một, dẫn đến nhiều truy cập disk duy nhất.
Hãy nhớ rằng bộ đệm lưu các trang (đơn vị dữ liệu nhỏ nhất) chứ không phải là hàng (row) (đơn vị logic mà người nhìn vào dữ liệu). Nếu các trang trong vùng đệm được sửa đổi nhưng chưa được ghi vào disk, đó là một trang bẩn. Có rất nhiều thuật toán để quyết định thời điểm tốt nhất để ghi các trang bẩn, nhưng vấn đề này có liên quan cao đến khái niệm giao dịch (transaction), và bây giờ chúng ta sẽ nói về các giao dịch (transaction).
Trình quản lý giao dịch (Transaction Manager)
Cuối cùng nhưng không kém phần quan trọng, là trình quản lý giao dịch, và chúng ta sẽ thấy quá trình này đảm bảo rằng mỗi truy vấn được thực hiện trong giao dịch của riêng nó. Nhưng trước khi chúng ta bắt đầu, chúng ta cần phải hiểu khái niệm về các giao dịch ACID.
“I’m on acid”
Một giao dịch ACID là một đơn vị làm việc đảm bảo bốn tính chất:
- Nguyên tử (Atomicity): Giao dịch được thực hiện đầy đủ hoặc hủy bỏ hoàn toàn, ngay cả khi nó chạy liên tục trong 10 giờ. Nếu giao dịch sụp đổ, trạng thái trở lại trước khi giao dịch (transaction rollback).
- Tính nhất quán (Consistency): Chỉ dữ liệu hợp pháp (tùy thuộc vào các ràng buộc quan hệ và chức năng) mới có thể được ghi vào cơ sở dữ liệu và tính nhất quán có liên quan đến nguyên tử và cách ly.
- Độc lập (Isolation): Nếu 2 giao dịch A và B chạy cùng một lúc, kết quả cuối cùng của giao dịch A và B là như nhau, cho dù A kết thúc trước/sau/trong khi B chạy.
- Bền vững (Durability): Một khi giao dịch được cam kết (có nghĩa là thực hiện thành công), bất cứ điều gì xảy ra (sự cố hoặc lỗi), dữ liệu được lưu trữ trong cơ sở dữ liệu.
Trong cùng một giao dịch, bạn có thể chạy nhiều truy vấn SQL để đọc, tạo, cập nhật và xóa dữ liệu. Khi hai giao dịch sử dụng cùng một dữ liệu, rắc rối đến. Ví dụ điển hình là chuyển tiền từ tài khoản A đến tài khoản B. Giả sử có 2 giao dịch:
- Giao dịch 1 (T1) rút $100 từ tài khoản A vào tài khoản B
- Giao dịch 2 (T2) rút $ 50 từ tài khoản A cho tài khoản B
Hãy trở lại để xem các thuộc tính ACID:
- Atomicity đảm bảo rằng bất cứ điều gì xảy ra trong T1 (sự cố máy chủ, gián đoạn mạng … ), không thể xuất hiện hiện tượng tài khoản A đã bị rút 100$ nhưng không gửi cho tài khoản B (đây là trạng thái không nhất quán của dữ liệu).
- Isolation đảm bảo rằng nếu T1 và T2 xảy ra cùng một lúc, cuối cùng A sẽ giảm 150 thay vì các kết quả khác, chẳng hạn như vì phần T2 xóa hành vi của T1, A giảm 50 (đây cũng là trạng thái không nhất quán).
- Durability đảm bảo rằng nếu T1 vừa được cam kết, cơ sở dữ liệu sụp đổ và T1 sẽ không biến mất mà không có dấu vết.
- Consistency đảm bảo rằng tiền không được tạo ra hoặc mất mát trong hệ thống.
Kiểm soát đồng thời (Concurrency Control)
Vấn đề thực sự với việc đảm bảo isolation, consistency, and atomicity là write operation (add, update, delete) đối với cùng một dữ liệu:
- Nếu tất cả các giao dịch chỉ đọc dữ liệu, chúng có thể hoạt động cùng một lúc và không thay đổi hành vi của một giao dịch khác.
- Nếu (ít nhất) có một giao dịch sửa đổi dữ liệu được đọc bởi các giao dịch khác, cơ sở dữ liệu cần phải tìm một cách để ẩn những thay đổi như vậy cho các giao dịch khác. Ngoài ra, nó cũng cần phải đảm bảo rằng sửa đổi này sẽ không bị xóa bởi một giao dịch khác mà bạn không thấy dữ liệu này sửa đổi.
Vấn đề này được gọi là kiểm soát đồng thời (concurency control).
Giải pháp đơn giản nhất là thực hiện lần lượt từng giao dịch (tức là thực hiện theo thứ tự), nhưng điều này hoàn toàn không có khả năng mở rộng, chỉ có một nhân hoạt động trên một máy chủ đa nhân / đa luồng và không hiệu quả.
- Lý tưởng nhất là mỗi khi một giao dịch được tạo hoặc hủy bỏ:
- Giám sát tất cả các hoạt động của tất cả các giao dịch
- Kiểm tra xem các phần của 2 (hoặc nhiều) giao dịch xung đột do đọc/sửa cùng một dữ liệu hay không?
- Sắp xếp lại các hoạt động trong các giao dịch xung đột để giảm các phần xung đột
- Thực hiện các phần xung đột theo một thứ tự nhất định (trong khi các giao dịch không xung đột vẫn đang chạy đồng thời)
- Xem xét rằng giao dịch có thể bị hủy bỏ
Theo cách nói chính thức hơn, đây là một vấn đề lập lịch cho xung đột. Cụ thể hơn, đây là một vấn đề tối ưu hóa rất khó khăn và chi phí CPU rất lớn. Cơ sở dữ liệu cấp doanh nghiệp không thể chịu đựng được việc chờ đợi hàng giờ để tìm lịch trình tốt nhất cho mỗi hoạt động giao dịch mới, vì vậy hãy sử dụng một cách ít lý tưởng hơn để tránh lãng phí nhiều thời gian hơn để giải quyết xung đột.
Trình quản lý khóa (Lock Manager)
Để giải quyết vấn đề này, hầu hết các cơ sở dữ liệu sử dụng khóa và / hoặc kiểm soát phiên bản dữ liệu. Đây là một chủ đề lớn, tôi sẽ tập trung vào khóa, và một chút kiểm soát phiên bản dữ liệu.
Khóa bi quan (pessimistic lock)
Nguyên tắc là:
- Nếu một giao dịch yêu cầu một dữ liệu, nó khóa dữ liệu
- Nếu một giao dịch khác cũng cần dữ liệu này, nó phải chờ giao dịch đầu tiên từ bỏ dữ liệu đó
Ổ khóa này gọi là khóa độc quyền.
Nhưng việc sử dụng khóa độc quyền cho một giao dịch chỉ đọc dữ liệu là tốn kém, bởi vì nó sẽ buộc các giao dịch khác chỉ cần đọc cùng một dữ liệu chờ đợi. Vì vậy, có một loại khóa khác, khóa chia sẻ (shared lock).
Khóa chia sẻ trông như thế này:
- Nếu một giao dịch chỉ cần đọc dữ liệu A, nó sẽ thêm “khóa chia sẻ” vào dữ liệu A và đọc
- Nếu giao dịch thứ hai cũng cần chỉ đọc dữ liệu A, nó sẽ thêm “khóa chia sẻ” dữ liệu A và đọc
- Nếu giao dịch thứ ba cần phải sửa đổi dữ liệu A, nó sẽ thêm “khóa độc quyền” vào dữ liệu A, nhưng phải chờ đợi cho hai giao dịch khác từ bỏ khóa chia sẻ của họ.
Tương tự như vậy, nếu khóa độc quyền được thêm một khối dữ liệu, một giao dịch mà chỉ cần đọc dữ liệu đó thì phải chờ khóa độc quyền từ bỏ trước khi thêm khóa chia sẻ cho dữ liệu đó.
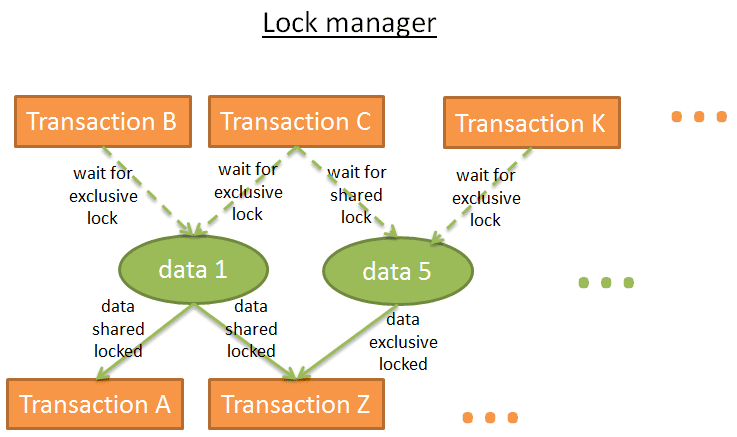
Trình quản lý khóa là quá trình thêm và giải phóng khóa, lưu thông tin khóa trong nội bộ với một bảng băm (với key là dữ liệu bị khóa) và hiểu rằng mỗi khối dữ liệu là:
- Bị khóa bởi giao dịch nào
- Giao dịch nào đang chờ dữ liệu được mở khóa
Bế tắc (Deadlock)
Nhưng sử dụng khóa có thể dẫn đến một tình huống mà 2 giao dịch luôn chờ đợi một mảnh dữ liệu:
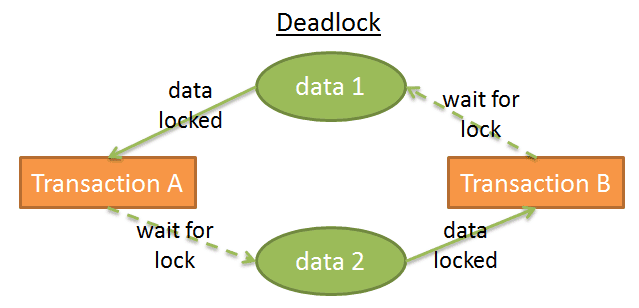
Trong hình này:
- Giao dịch A thêm khóa độc quyền vào dữ liệu 1 và chờ đợi để có được dữ liệu 2
- Giao dịch B thêm khóa độc quyền cho dữ liệu 2 và chờ đợi để có được dữ liệu 1
Nó được gọi là bế tắc (deadlock).
Khi bế tắc xảy ra, trình quản lý khóa sẽ chọn hủy bỏ (rollback) một giao dịch để loại bỏ bế tắc. Đây là một quyết định khó khăn:
- Huỷ các giao dịch có ít sửa đổi dữ liệu nhất (điều này làm giảm chi phí rollback)?
- Huỷ các giao dịch có thời gian ngắn nhất vì người dùng của các giao dịch khác chờ đợi lâu hơn?
- Huỷ các giao dịch tốn ít thời gian để kết thúc hơn(tránh đói tài nguyên)?
- Một khi rollback xảy ra, có bao nhiêu giao dịch sẽ bị ảnh hưởng bởi rollback?
Trước khi thực hiện lựa chọn, trình quản lý khóa cần kiểm tra xem có bế tắc hay không.
Bảng băm có thể được coi là một đồ thị (xem đồ thị ở trên), trong đó nếu chu trình xuất hiện cho thấy bế tắc. Vì vòng lặp kiểm tra là tốn kém (đồ thị bao gồm tất cả các ổ khóa là rất lớn), nó thường được giải quyết theo những cách đơn giản: sử dụng thời gian chờ (timeout). Nếu một khóa không được thêm vào trong thời gian chờ, sau đó giao dịch sẽ đi vào trạng thái bế tắc.
Trình quản lý khóa cũng có thể kiểm tra xem khóa có trở thành bế tắc hay không trước khi thêm khóa đó, nhưng nó vẫn tốn kém để làm điều đó một cách hoàn hảo. Do đó, các tiền kiểm thử (preflight) này thường thiết lập một số quy tắc cơ bản.
Two-Phase Locking Protocol
Cách dễ nhất để đạt được sự độc lập thuần túy là để có được một khóa khi bắt đầu giao dịch và giải phóng nó khi kết thúc. Điều đó có nghĩa là, trước khi giao dịch bắt đầu, bạn phải chờ đợi để đảm bảo rằng bạn có thể thêm tất cả các khóa và giải phóng khóa mà bạn giữ khi giao dịch kết thúc. Điều này là ok, nhưng rất nhiều thời gian đã bị lãng phí để chờ đợi cho tất cả các ổ khóa.
Cách nhanh hơn là giao thức khóa hai giai đoạn (Two-Phase Locking Protocol, được sử dụng bởi DB2 và SQL Server), nơi các giao dịch được chia thành hai giai đoạn:
- Giai đoạn tăng trưởng: Giao dịch có thể nhận được khóa, nhưng không thể giải phóng khóa.
- Giai đoạn thu hẹp: Giao dịch có thể giải phóng khóa (đối với dữ liệu đã được xử lý và không được xử lý lại), nhưng không thể có được khóa mới.
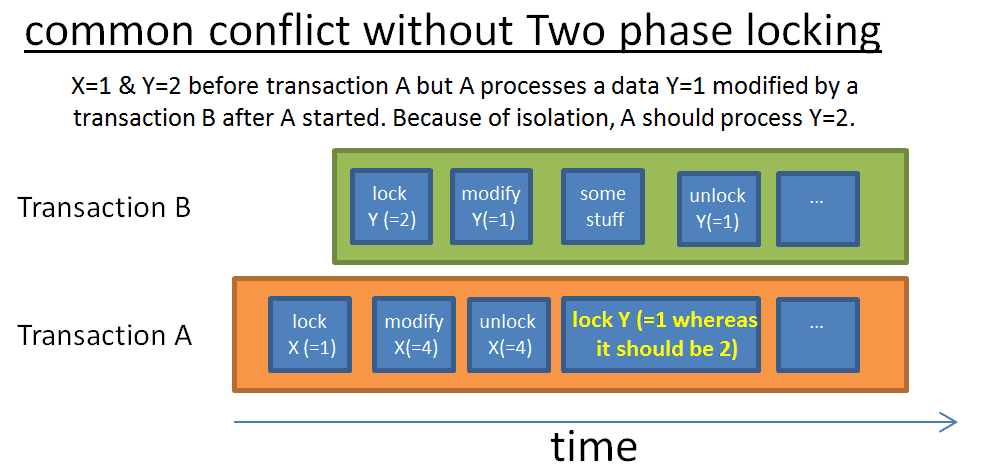
Quá trình đằng sau hai quy tắc đơn giản này là:
- Giải phóng khóa không còn được sử dụng để giảm thời gian chờ đợi cho các giao dịch khác
- Ngăn chặn tình huống sau xảy ra: dữ liệu thu được ban đầu từ giao dịch, được sửa đổi sau khi giao dịch bắt đầu, và sự không nhất quán xảy ra khi giao dịch đọc lại dữ liệu.
Quy tắc này hoạt động tốt, với một ngoại lệ: nếu một mảnh dữ liệu bị sửa đổi, các khóa liên quan bị giải phóng, giao dịch bị hủy bỏ (rollback), trong khi giao dịch khác đọc giá trị đã bị sửa đổi, nhưng giá trị cuối cùng này đã được rollback. Để tránh vấn đề này, tất cả các khóa độc quyền phải được giải phóng vào cuối giao dịch.
Nhiều hơn nữa
Tất nhiên, cơ sở dữ liệu thực tế sử dụng các hệ thống phức tạp hơn liên quan đến nhiều loại khóa hơn (ví dụ: khóa ý định, intention lock) và nhiều chi tiết hơn (krow-level lock, page-level lock, partition lock, table lock, table space lock), nhưng ý tưởng là như nhau.
Tôi chỉ tìm hiểu các phương pháp hoàn toàn dựa trên khóa và kiểm soát phiên bản dữ liệu là một cách khác để giải quyết vấn đề này.
Kiểm soát phiên bản (version control) trông như thế này:
- Mỗi giao dịch có thể sửa đổi cùng một dữ liệu tại cùng một thời điểm
- Mỗi giao dịch có bản sao riêng (hoặc phiên bản) của dữ liệu
- Nếu 2 giao dịch sửa đổi cùng một dữ liệu, chỉ chấp nhận một sửa đổi, còn lại sẽ bị từ chối và các giao dịch liên quan rollback (hoặc chạy lại)
Điều này sẽ cải thiện hiệu suất vì:
- Giao dịch đọc không chặn giao dịch viết
- Giao dịch viết không chặn đọc
- Không có chi phí bổ sung cho trình quản lý khóa “cồng kềnh và chậm”
Ngoại trừ khi hai giao dịch viết cùng một dữ liệu, kiểm soát phiên bản dữ liệu hoạt động tốt hơn so với khóa trong tất cả các khía cạnh. Chỉ có điều, bạn sẽ sớm phát hiện ra rằng sự tiêu thụ không gian disk là rất lớn.
Kiểm soát phiên bản dữ liệu và cơ chế khóa là hai hiểu biết khác nhau: khóa lạc quan và khóa bi quan. Cả hai đều có ưu và nhược điểm, hoàn toàn phụ thuộc vào việc kịch bản sử dụng (đọc nhiều hơn hoặc viết nhiều hơn).
Một số cơ sở dữ liệu, chẳng hạn như DB2 (cho đến phiên bản 9.7) và SQL Server (không có isolation snapshot), chỉ sử dụng cơ chế khóa. Những cơ sở dữ liệu khác như PostgreSQL, MySQL và Oracle sử dụng cơ chế kết hợp khóa và phiên bản chuột.
Trình quản lý nhật ký (Log Manager)
Như chúng ta đã biết, để cải thiện hiệu suất, cơ sở dữ liệu lưu dữ liệu trong bộ đệm bộ nhớ. Nhưng nếu máy chủ sụp đổ khi giao dịch được cam kết, dữ liệu vẫn còn trong bộ nhớ bị mất, làm suy yếu tính bền vững (durability) của giao dịch. Bạn có thể ghi tất cả dữ liệu trên disk, nhưng nếu máy chủ sụp đổ, dữ liệu cuối cùng có thể chỉ được ghi một phần vào disk, làm hỏng tính nguyên tử (atomicity) của giao dịch.
Bất kỳ sửa đổi nào được thực hiện bởi giao dịch phải bị hủy bỏ hoặc hoàn thành.
Có 2 cách để giải quyết vấn đề này:
-
Bản sao/Trang bóng (Shadow copies/pages): Mỗi giao dịch tạo ra một bản sao của cơ sở dữ liệu của riêng nó (hoặc một phần của cơ sở dữ liệu), và làm việc trên bản sao này. Khi xảy ra lỗi, bản sao này sẽ được loại bỏ; khi thành công, cơ sở dữ liệu ngay lập tức sử dụng một thủ thuật từ hệ thống tệp tin để thay thế bản sao vào trong dữ liệu, sau đó xóa đi các “dữ liệu cũ”.
-
Nhật ký giao dịch (Transaction log): Nhật ký giao dịch là một không gian lưu trữ, trước khi ghi vào đĩa mỗi lần, cơ sở dữ liệu sẽ viết thông tin vào nhật ký giao dịch. Điều này giúp cơ sở dữ liệu biết cách loại bỏ hoặc hoàn thành các giao dịch chưa hoàn thành khi xảy ra sự cố hoặc rollback của giao dịch.
WAL (Write-Ahead Logging)
Shadow copies/pages tạo ra rất nhiều chi phí disk khi chạy một cơ sở dữ liệu lớn với nhiều giao dịch hơn, vì vậy cơ sở dữ liệu hiện đại sử dụng transaction log. Nhật ký giao dịch phải được lưu trữ ổn định và tôi sẽ không đào sâu vào công nghệ lưu trữ, nhưng ít nhất Disk RAID là bắt buộc trong trường hợp disk lỗi.
Hầu hết các cơ sở dữ liệu (ít nhất là Oracle, SQL Server, DB2, PostgreSQL, MySQL và SQLite) xử lý nhật ký giao dịch bằng cách sử dụng giao thức nhật ký ghi trước (Write-Ahead Logging protocol, WAL). Giao thức WAL có 3 quy tắc:
- Mỗi sửa đổi cơ sở dữ liệu tạo ra một bản ghi nhật ký, và trước khi dữ liệu được ghi vào disk, bản ghi nhật ký phải được ghi vào nhật ký giao dịch.
- Ghi nhật ký phải được viết theo thứ tự; Bản ghi A xảy ra trước khi bản ghi B thì A phải được viết trước B.
- Khi một giao dịch được cam kết, trình tự cam kết phải được ghi vào nhật ký giao dịch trước khi giao dịch thành công.
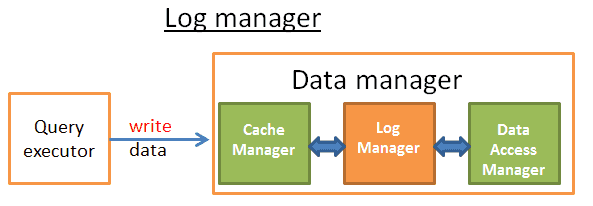
Công việc này được thực hiện bởi trình quản lý nhật ký. Sự hiểu biết đơn giản là trình quản lý nhật ký nằm giữa trình quản lý bộ nhớ cache (cache manager) và trình quản lý truy cập dữ liệu (data access manager, chịu trách nhiệm ghi dữ liệu vào disk), mỗi thao tác update / delete / create / commit / rollback ghi vào nhật ký giao dịch trước khi ghi vào disk. Quá trình này là đơn giản, lý do là làm thế nào để tìm một cách để viết nhật ký trong khi vẫn duy trì hiệu suất tốt, nếu nhật ký giao dịch được viết quá chậm, toàn bộ sẽ chậm lại.
ARIES
Năm 1992, các nhà nghiên cứu IBM đã phát minh ra một phiên bản nâng cao của WAL, được gọi là ARIES. ARIES ít nhiều được sử dụng trong cơ sở dữ liệu hiện đại, logic không nhất thiết phải giống nhau, nhưng các khái niệm đằng sau AIRES có ở khắp mọi nơi. ARIES viết tắt của Algorithms for Recovery and Isolation Exploiting Semantics.
Công nghệ này để đạt được một mục tiêu kép:
- Ghi nhật ký trong khi vẫn duy trì hiệu suất tốt
- Phục hồi dữ liệu nhanh chóng và đáng tin cậy
Có một số lý do khiến cơ sở dữ liệu phải rollback giao dịch:
- Bởi vì người dùng hủy bỏ
- Bởi vì máy chủ hoặc mạng thất bại
- Bởi vì các giao dịch phá hủy tính toàn vẹn của cơ sở dữ liệu (chẳng hạn như một cột với các ràng buộc duy nhất và các giao dịch thêm các giá trị trùng lặp)
- Bởi vì bế tắc
Nhật ký (Log)
Đôi khi (chẳng hạn như lỗi mạng), cơ sở dữ liệu có thể khôi phục giao dịch. Làm thế nào điều này có thể được? Để trả lời câu hỏi này, chúng ta cần phải hiểu thông tin được lưu trong nhật ký.
Mỗi hành động (add/delete/modify) của giao dịch tạo ra một log bao gồm:
- LSN: Một số sê-ri nhật ký duy nhất (Log Sequence Number). LSN được phân bổ theo thứ tự thời gian, có nghĩa là nếu A hoạt động trước B, LSN của log A nhỏ hơn LSN của log B.
- TransID: ID giao dịch tạo ra hành động.
- PageID: Vị trí của dữ liệu sửa đổi trên disk. Đơn vị nhỏ nhất của dữ liệu disk là một trang, vì vậy vị trí của dữ liệu là nơi nó đang ở.
- PrevLSN: Liên kết cuối cùng được ghi lại nhật ký được tạo ra bởi cùng một giao dịch.
- UNDO: Phương pháp hủy bỏ thao tác này. Ví dụ: nếu hành động là cập nhật, UNDO sẽ hoặc lưu các giá trị/trạng thái phần tử trước khi cập nhật (physical UNDO), hoặc trở lại hoạt động đảo ngược của trạng thái ban đầu (logical UNDO, chỉ sử dụng UNDO logic vì xử lý physical UNDO quá lộn xộn).
- REDO: Phương pháp lặp lại hoạt động này. Tương tự như vậy, có 2 cách: hoặc lưu giá trị phần tử / trạng thái sau khi hoạt động hoặc lưu chính hành động để lặp lại.
- … :( để bạn tham khảo, một nhật ký ARIES cũng có 2 trường: UndoNxtLSN và Type).
Mỗi trang trên đĩa (lưu dữ liệu, không phải nhật ký được lưu) ghi lại LSN cuối cùng sửa đổi hoạt động dữ liệu đó.
Lưu ý: Theo như tôi biết, chỉ PostgreSQL không sử dụng UNDO mà thay vào đó sử dụng dịch vụ thu gom rác để xóa các phiên bản cũ hơn của dữ liệu. Điều này có liên quan đến việc thực hiện kiểm soát phiên bản dữ liệu của PostgreSQL.
Để minh họa tốt hơn điều này, điều này có một bản trình bày ghi nhật ký đơn giản được thực hiện bởi truy vấn “UPDATE FROM PERSON SET AGE = 18;” Kết quả:
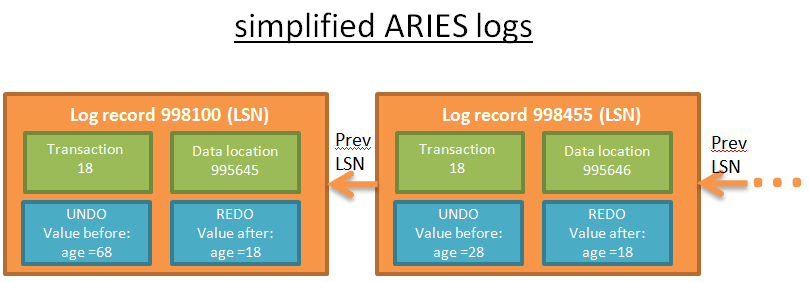
Mỗi nhật ký có một LSN duy nhất, và các bản ghi được liên kết với nhau thuộc về cùng một giao dịch. Nhật ký được liên kết theo thứ tự thời gian (nhật ký cuối cùng của danh sách liên kết được tạo ra bởi hành động cuối cùng).
Bộ đệm nhật ký (log buffer)
Để ngăn chặn ghi nhật ký trở thành nút thắt cổ chai chính, cơ sở dữ liệu sử dụng bộ đệm nhật ký.
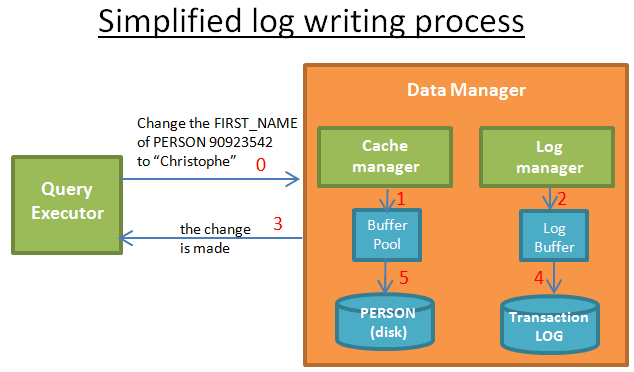
Khi trình thực thi truy vấn yêu cầu sửa đổi một lần:
- Trình quản lý bộ nhớ cache sẽ sửa đổi để lưu trữ bộ đệm của riêng mình
- Trình quản lý nhật ký lưu trữ các bản ghi có liên quan vào bộ đệm của riêng họ
- Đến bước này, trình thực thi truy vấn tin rằng thao tác đã hoàn tất (vì vậy bạn có thể yêu cầu sửa đổi khác);
- Sau đó (ngay sau đó) trình quản lý nhật ký ghi nhật ký vào nhật ký giao dịch, thời điểm ghinhật ký được xác định bởi một thuật toán.
- Sau đó (ngay sau đó) trình quản lý bộ nhớ cache ghi các sửa đổi vào disk và thời điểm ghi vào disk được được xác định bởi một thuật toán.
Khi giao dịch được cam kết, điều đó có nghĩa là 5 bước của mỗi hoạt động của giao dịch đã được hoàn thành. Viết nhật ký giao dịch rất nhanh vì nó chỉ đơn giản là “thêm một bản ghi ở đâu đó trong nhật ký giao dịch”; Và ghi dữ liệu vào disk phức tạp hơn, bởi vì nó cần phải “ghi dữ liệu bằng một cách để có thể đọc nhanh chóng”.
STEAL and FORCE strategies
Vì lý do hiệu suất, Bước 5 có thể được hoàn thành sau khi cam kết, bởi vì trong trường hợp xảy ra sự cố, cũng có thể khôi phục giao dịch với nhật ký REDO. Điều này được gọi là chính sách NO-FORCE.
Cơ sở dữ liệu có thể chọn chính sách FORCE, chẳng hạn như bước 5 phải được hoàn thành trước khi cam kết, để giảm tải khi phục hồi.
Một câu hỏi khác là để chọn xem dữ liệu là ghi từng bước (chính sách STEAL) hoặc người quản lý bộ đệm cần phải chờ đợi cho các lệnh cam kết để ghi tất cả cùng một lúc (chính sách NO-STEAL). Chọn STEAL hay NO-STEAL phụ thuộc vào những gì bạn muốn: viết nhanh nhưng phục hồi chậm từ nhật ký UNDO hoặc khôi phục nhanh chóng.
Dưới đây là tác động của các chính sách này đối với phục hồi:
- STEAL/NO-FORCE yêu cầu UNDO và REDO: hiệu suất cao, nhưng các quy trình nhật ký và phục hồi phức tạp hơn (ví dụ: ARIES). Hầu hết các cơ sở dữ liệu chọn chính sách này. Lưu ý: Đây là những gì tôi thấy từ nhiều bài báo học thuật và hướng dẫn, nhưng tôi không thấy điều này rõ ràng trong tài liệu chính thức.
- STEAL/ FORCE chỉ cần UNDO.
- NO-STEAL/NO-FORCE chỉ cần REDO.
- NO-STEAL/FORCE không cần bất cứ điều gì: hiệu suất tồi tệ nhất và yêu cầu bộ nhớ rất lớn.
Về phục hồi (recovery)
Ok, với nhật ký tốt, chúng ta hãy sử dụng chúng!
Giả sử thực tập sinh mới làm cho cơ sở dữ liệu sụp đổ, bạn khởi động lại cơ sở dữ liệu và quá trình phục hồi bắt đầu.
ARIES phục hồi từ sự cố có ba giai đoạn:
-
- Giai đoạn phân tích: Quá trình phục hồi đọc tất cả các bản ghi giao dịch để xây dựng lại dòng thời gian của những gì đã xảy ra trong quá trình sụp đổ, quyết định giao dịch nào sẽ rollback (tất cả các giao dịch chưa được gửi phải rollback), dữ liệu nào cần phải được viết khi tai nạn.
-
-
Giai đoạn Redo: Cấp độ này bắt đầu với một bản ghi nhật ký được chọn trong phân tích, sử dụng REDO để khôi phục cơ sở dữ liệu về trạng thái trước khi sụp đổ.
- Trong giai đoạn REDO, nhật ký REDO được xử lý theo thứ tự thời gian (sử dụng LSN).
- Đối với mỗi nhật ký, quá trình phục hồi đòi hỏi phải đọc LSN trang đĩa có chứa dữ liệu.
- Nếu LSN (trang đĩa) > = LSN (ghi nhật ký), dữ liệu đã được ghi vào đĩa trước khi sụp đổ (nhưng giá trị đã được ghi đè bởi một hành động sau nhật ký và trước khi sụp đổ), vì vậy không cần phải làm gì.
- Nếu LSN (trang đĩa) < LSN (ghi nhật ký), các trang trên đĩa sẽ được cập nhật.
- Ngay cả khi các giao dịch được rollback, REDO sẽ làm điều đó vì nó đơn giản hóa quá trình phục hồi (nhưng tôi tin rằng cơ sở dữ liệu hiện đại sẽ không làm điều đó).
-
-
- Giai đoạn Undo: Giai đoạn này rollback tất cả các giao dịch chưa hoàn thành khi tai nạn. rollback bắt đầu với nhật ký cuối cùng của mỗi giao dịch và xử lý nhật ký UNSO theo thứ tự đảo ngược thời gian (prevLSN được ghi lại bằng nhật ký).
Trong quá trình phục hồi, nhật ký giao dịch phải chú ý đến các hoạt động của quá trình phục hồi để dữ liệu ghi vào đĩa phù hợp với nhật ký giao dịch. Một giải pháp là loại bỏ các bản ghi nhật ký được tạo ra bởi các giao dịch bị hủy bỏ, nhưng điều này là quá khó khăn. Thay vào đó, ARIES ghi lại nhật ký bù trong nhật ký giao dịch để loại bỏ hợp lý các bản ghi nhật ký cho các giao dịch bị hủy bỏ.
Khi giao dịch bị hủy bỏ bằng tay hoặc bị hủy bỏ bởi người quản lý khóa (để loại bỏ bế tắc), hoặc chỉ vì lỗi mạng, giai đoạn phân tích không cần thiết. Đối với những gì cần REDO cần thông tin UNDO trong 2 bảng bộ nhớ:
- Bảng giao dịch (lưu trạng thái của tất cả các giao dịch hiện tại)
- Bảng trang bẩn (dữ liệu nào cần được ghi vào đĩa)
Khi một giao dịch mới được tạo ra, cả hai bảng được cập nhật bởi trình quản lý bộ nhớ cache và trình quản lý giao dịch. Bởi vì nó nằm trong bộ nhớ, chúng cũng bị phá hủy khi cơ sở dữ liệu sụp đổ.
Nhiệm vụ của giai đoạn phân tích là xây dựng lại hai bảng trên với thông tin trong nhật ký giao dịch sau khi sụp đổ. Để đẩy nhanh giai đoạn phân tích, ARIES đưa ra một khái niệm: check point, thỉnh thoảng ghi nội dung của bảng giao dịch và bảng trang bẩn và LSN cuối cùng vào đĩa. Vì vậy, trong giai đoạn phân tích, chỉ cần phân tích nhật ký sau LSN này.