Hiểu sâu về Java SPI cấp độ mã nguồn
Giới thiệu về SPI
SPI viết tắt của Service Provider Interface, là một cơ chế trong Java được thiết kế để cho phép các bên thứ ba triển khai hoặc mở rộng các API. Nó là một cơ chế để tải động dịch vụ. SPI trong Java có bốn yếu tố chính:
- SPI Interface: Đây là Interface hoặc lớp trừu tượng mà các lớp triển khai dịch vụ phải tuân thủ.
- Lớp triển khai SPI: Đây là các lớp cụ thể cung cấp dịch vụ.
- Cấu hình SPI: Đây là tệp cấu hình theo quy ước của SPI, cung cấp logic để tìm kiếm các lớp triển khai dịch vụ. Tệp cấu hình phải được đặt trong thư mục
META-INF/servicesvà tên tệp phải trùng với tên đầy đủ của Interface dịch vụ. Mỗi dòng trong tệp chứa thông tin chi tiết về lớp triển khai dịch vụ, cũng là tên đầy đủ của lớp triển khai dịch vụ. - ServiceLoader: Đây là lớp cốt lõi của SPI Java, được sử dụng để tải các lớp triển khai SPI. Lớp
ServiceLoadercung cấp các phương thức hữu ích để lấy các triển khai cụ thể, lặp qua chúng hoặc tải lại dịch vụ.
Ví dụ về SPI
Để hiểu rõ hơn, chúng ta có thể xem xét một ví dụ cụ thể về cách sử dụng Java SPI.
Interface SPI
Đầu tiên, chúng ta cần định nghĩa một Interface SPI, không có gì khác biệt so với việc định nghĩa một Interface thông thường.
package com.hnv99.javacore.spi;
public interface DataStorage {
String search(String key);
}Lớp triển khai SPI
Giả sử, chúng ta cần sử dụng hai loại lưu trữ dữ liệu khác nhau trong chương trình - Mysql và Redis. Do đó, chúng ta cần hai lớp triển khai khác nhau để hoàn thành công việc tương ứng.
Lớp triển khai Mysql
package com.hnv99.javacore.spi;
public class MysqlStorage implements DataStorage {
@Override
public String search(String key) {
return "【Mysql】Tìm kiếm " + key + " - Kết quả: No";
}
}Lớp triển khai Redis
package com.hnv99.javacore.spi;
public class RedisStorage implements DataStorage {
@Override
public String search(String key) {
return "【Redis】Tìm kiếm " + key + " - Kết quả: Yes";
}
}Đến đây, việc định nghĩa Interface và triển khai Interface không có gì khác biệt so với việc định nghĩa và triển khai một Interface Java thông thường.
Cấu hình SPI
Nếu muốn tìm hiểu về dịch vụ bằng cơ chế SPI Java, chúng ta cần định nghĩa logic tìm kiếm dịch vụ trong cấu hình SPI. Tệp cấu hình SPI phải được đặt trong thư mục META-INF/services và tên tệp phải trùng với tên đầy đủ của Interface dịch vụ. Ví dụ mã nguồn này, tên tệp cấu hình phải là com.hnv99.javacore.spi.DataStorage và nội dung tệp như sau:
com.hnv99.javacore.spi.MysqlStorage
com.hnv99.javacore.spi.RedisStorage
ServiceLoader
Sau khi hoàn thành các bước trên, chúng ta có thể sử dụng ServiceLoader để tải dịch vụ. Ví dụ dưới đây mô tả cách sử dụng ServiceLoader:
import java.util.ServiceLoader;
public class SpiDemo {
public static void main(String[] args) {
ServiceLoader<DataStorage> serviceLoader = ServiceLoader.load(DataStorage.class);
System.out.println("============ Kiểm tra SPI Java ============");
serviceLoader.forEach(loader -> System.out.println(loader.search("Yes Or No")));
}
}Kết quả:
============ Kiểm tra SPI Java ============
【Mysql】Tìm kiếm Yes Or No - Kết quả: No
【Redis】Tìm kiếm Yes Or No - Kết quả: Yes
Nguyên lý của SPI
Trong phần trước, chúng ta đã tìm hiểu về các yếu tố và cách sử dụng Java SPI. Bạn có bao giờ tự hỏi Java SPI khác biệt như thế nào so với Interface Java thông thường và làm thế nào Java SPI hoạt động không? Thực tế, cơ chế Java SPI phụ thuộc vào lớp ServiceLoader để phân tích và tải dịch vụ. Do đó, nắm vững quy trình làm việc của ServiceLoader có nghĩa là bạn đã hiểu nguyên lý của SPI. Mã nguồn của ServiceLoader rất ngắn gọn, tiếp theo, chúng ta hãy đọc mã nguồn để từng bước hiểu quy trình làm việc của ServiceLoader.
Biến thành viên của ServiceLoader
Trước tiên, hãy xem biến thành viên của lớp ServiceLoader, để có một cái nhìn tổng quan, mã nguồn sau sẽ sử dụng chúng.
public final class ServiceLoader<S> implements Iterable<S> {
// Đường dẫn thư mục tệp cấu hình SPI
private static final String PREFIX = "META-INF/services/";
// Dịch vụ SPI sẽ được tải
private final Class<S> service;
// ClassLoader được sử dụng để tải dịch vụ SPI
private final ClassLoader loader;
// Ngữ cảnh kiểm soát truy cập khi tạo ServiceLoader
private final AccessControlContext acc;
// Bộ nhớ đệm dịch vụ SPI, được sắp xếp theo thứ tự khởi tạo
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// Trình lặp lười biếng
private LazyIterator lookupIterator;
// ...
}Quy trình làm việc của ServiceLoader
(1) Phương thức tĩnh ServiceLoader.load
Ứng dụng tải dịch vụ Java SPI bằng cách gọi phương thức tĩnh ServiceLoader.load. Phương thức tĩnh ServiceLoader.load có tác dụng:
- Xác định ClassLoader và ngữ cảnh kiểm soát truy cập;
- Sau đó, tải lại dịch vụ SPI
- Xóa tất cả các dịch vụ SPI đã được khởi tạo khỏi bộ nhớ đệm
- Dựa trên ClassLoader và loại SPI, tạo trình lặp lười biếng
Ở đây, trích dẫn mã nguồn liên quan đến ServiceLoader.load như sau:
// service là loại Interface SPI được mong muốn tải
// loader là ClassLoader được sử dụng để tải dịch vụ SPI
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
// Phương thức xây dựng riêng tư
// Tải lại dịch vụ SPI
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}(2) Ứng dụng duyệt qua các phiên bản SPI bằng phương thức iterator của ServiceLoader
Lớp ServiceLoader được định nghĩa là triển khai của Interface Iterable<T>, vì vậy nó có thể được lặp lại. Thực tế, lớp ServiceLoader duy trì một bộ nhớ đệm providers (LinkedHashMap), bộ nhớ đệm providers này chứa các phiên bản SPI đã tải thành công, trong đó khóa của Map là tên đầy đủ của lớp triển khai SPI và giá trị là một đối tượng thể hiện của lớp triển khai đó.
Khi ứng dụng gọi phương thức iterator của ServiceLoader, ServiceLoader sẽ kiểm tra xem bộ nhớ đệm providers có dữ liệu không: nếu có, nó sẽ trả về trình lặp của bộ nhớ đệm providers; nếu không, nó sẽ trả về trình lặp lười biếng của nó.
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}(3) Quy trình làm việc của trình lặp lười biếng
Trong mã nguồn trên, đã đề cập đến lookupIterator là một trình lặp lười biếng, và LazyIterator được sử dụng để tải lười biếng các phiên bản SPI. Vậy, LazyIterator hoạt động như thế nào?
Ở đây, trích dẫn mã nguồn quan trọng của LazyIterator:
-
Phương thức
hasNextService:- Ghép
META-INF/services/+ tên đầy đủ của Interface SPI - Thử tải tệp cấu hình bằng ClassLoader
- Phân tích nội dung tệp cấu hình để lấy tên đầy đủ của lớp triển khai SPI
nextName
- Ghép
-
Phương thức
nextService:- Phương thức
hasNextService()đã phân tích được tên đầy đủ của lớp triển khai SPInextName, sử dụng reflection để lấy định nghĩa lớp triển khai SPIClass<?>. - Sau đó, thử tạo một đối tượng dịch vụ SPI bằng cách sử dụng phương thức
newInstancecủaClass<?>. Nếu thành công, nó sẽ thêm đối tượng này vào bộ nhớ đệm providers và trả về đối tượng đó.
- Phương thức
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a s");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}SPI và ClassLoader
Sau khi đọc mã nguồn ServiceLoader, chúng ta đã hiểu cơ chế làm việc của Java SPI, tức là tải tệp cấu hình SPI bằng ClassLoader, phân tích dịch vụ SPI và sau đó tạo một phiên bản dịch vụ SPI bằng reflection. Bây giờ, hãy suy nghĩ về việc tại sao khi tải dịch vụ SPI, cần chỉ định ClassLoader?
Đối với những người đã học về JVM, chắc chắn đã biết về mô hình ủy quyền của ClassLoader (Parents Delegation Model). Mô hình ủy quyền yêu cầu tất cả các ClassLoader, ngoại trừ ClassLoader đầu tiên (BootstrapClassLoader), đều phải có một ClassLoader cha riêng của mình. Mối quan hệ cha con giữa các ClassLoader thường được thực hiện thông qua mối quan hệ hợp thành (Composition), chứ không phải thông qua mối quan hệ kế thừa (Inheritance). Sơ đồ thể hiện mô hình ủy quyền của ClassLoader như sau:
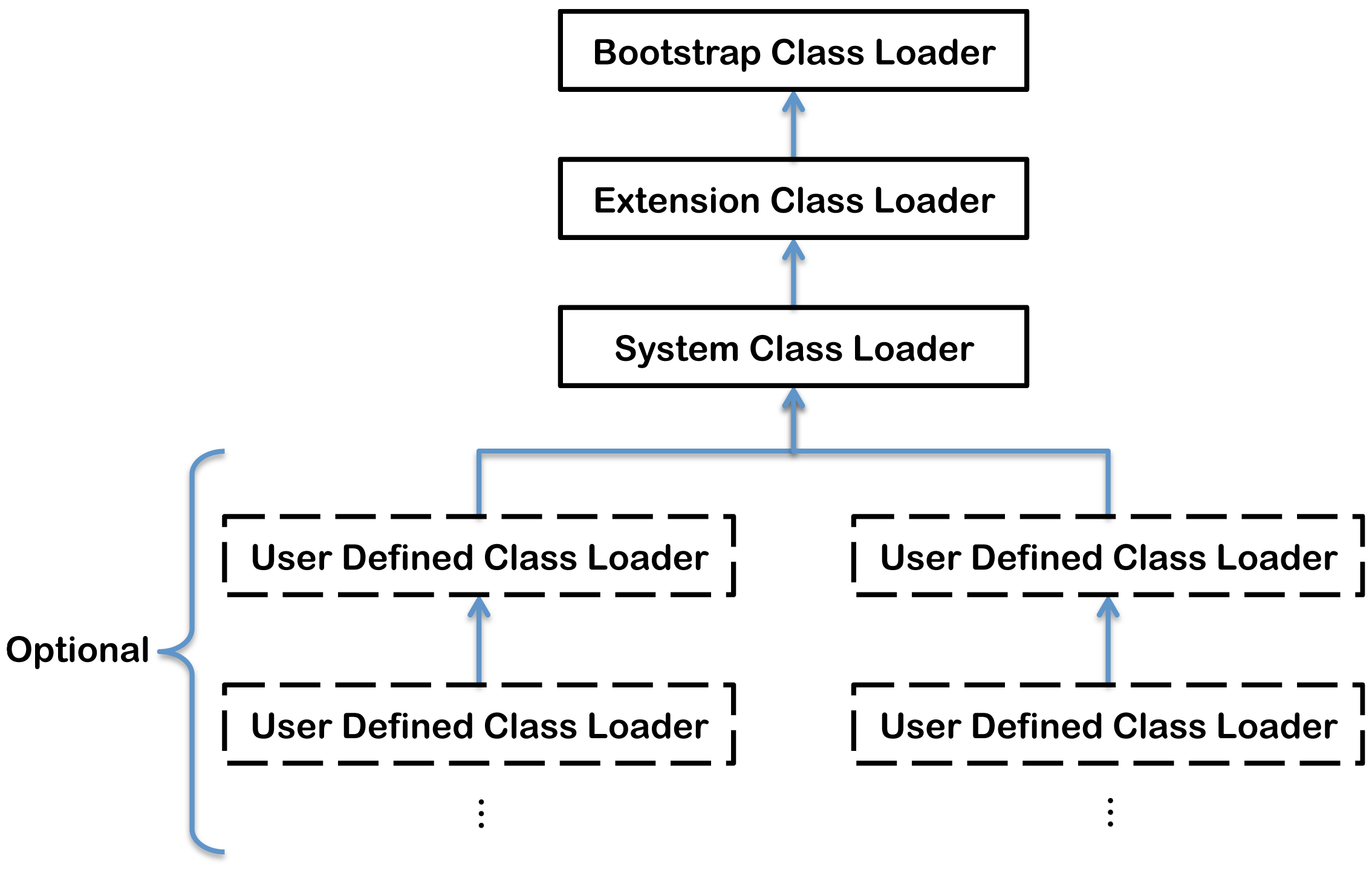
Cơ chế ủy quyền kép đặt quy định rằng: một ClassLoader trước tiên chuyển yêu cầu tải lớp cho ClassLoader cha, chỉ khi ClassLoader cha không thể hoàn thành yêu cầu tải lớp mới thử tải.
Lợi ích của ủy quyền kép: làm cho các lớp Java cùng với ClassLoader của chúng có một mối quan hệ phân cấp ưu tiên tự nhiên, từ đó đảm bảo việc tải lớp được thống nhất, không gặp vấn đề tải lặp lại:
- Ngăn chặn việc có nhiều bản sao của bytecode trong bộ nhớ cho cùng một lớp
- Đảm bảo ứng dụng Java chạy một cách an toàn và ổn định
Ví dụ: java.lang.Object được lưu trữ trong rt.jar. Nếu chúng ta viết một lớp khác có tên java.lang.Object và đặt nó trong classpath, chương trình vẫn có thể biên dịch thành công. Bởi vì mô hình ủy quyền kép tồn tại, lớp Object trong rt.jar có mức ưu tiên cao hơn lớp Object trong classpath, bởi vì lớp Object trong rt.jar được tải bởi ClassLoader khởi động, trong khi lớp Object trong classpath được tải bởi ClassLoader ứng dụng. Chính vì lớp Object trong rt.jar có mức ưu tiên cao hơn, nên tất cả các lớp Object trong chương trình đều là lớp này.
Hạn chế của ủy quyền kép: ClassLoader con có thể sử dụng các lớp đã được tải bởi ClassLoader cha, trong khi ClassLoader cha không thể sử dụng các lớp đã được tải bởi ClassLoader con. Điều này dẫn đến việc mô hình ủy quyền kép không thể giải quyết tất cả các vấn đề về ClassLoader. Java SPI đối mặt với vấn đề này:
- Interface SPI là một phần của thư viện lõi Java, được tải bởi
BootstrapClassLoader; - Trong khi các lớp Java triển khai SPI thường được tải bởi
AppClassLoader.BootstrapClassLoaderkhông thể tìm thấy các lớp triển khai SPI, vì nó chỉ tải thư viện lõi Java. Nó cũng không thể ủy quyền choAppClassLoader, vì nó là ClassLoader cấp cao nhất. Điều này giải thích tại sao khi tải dịch vụ SPI, chúng ta cần chỉ định ClassLoader. Vì nếu không chỉ định ClassLoader, chúng ta sẽ không thể lấy được dịch vụ SPI.
Nếu không có cài đặt nào, ClassLoader ngữ cảnh của luồng ứng dụng Java mặc định là AppClassLoader. Khi sử dụng Interface SPI trong thư viện lõi, ClassLoader được truyền vào sử dụng ClassLoader ngữ cảnh của luồng, từ đó có thể tải được lớp triển khai SPI. ClassLoader ngữ cảnh của luồng thường được sử dụng trong nhiều cài đặt SPI.
Thường có thể sử dụng Thread.currentThread().getClassLoader() và Thread.currentThread().getContextClassLoader() để lấy ClassLoader ngữ cảnh của luồng.
Nhược điểm của Java SPI
Java SPI có một số hạn chế:
- Không thể tải theo yêu cầu, cần duyệt qua tất cả các triển khai và khởi tạo, sau đó mới có thể tìm thấy triển khai mà chúng ta cần. Nếu không muốn sử dụng một số lớp triển khai hoặc việc khởi tạo một số lớp tốn thời gian, chúng vẫn được tải và khởi tạo, điều này gây lãng phí.
- Cách lấy một lớp triển khai không linh hoạt đủ, chỉ có thể lấy thông qua Iterator, không thể lấy lớp triển khai tương ứng với một tham số nào đó.
- Việc sử dụng đồng thời nhiều luồng của một thể hiện của lớp ServiceLoader không an toàn.
Ứng dụng của SPI
SPI được sử dụng rộng rãi trong phát triển Java. Đầu tiên, trong gói java.util.spi của Java đã định nghĩa nhiều Interface SPI. Dưới đây là một số Interface SPI:
- TimeZoneNameProvider: Cung cấp tên múi giờ được địa phương hóa cho lớp TimeZone.
- DateFormatProvider: Cung cấp định dạng ngày tháng và thời gian cho một ngôn ngữ cụ thể.
- NumberFormatProvider: Cung cấp định dạng tiền tệ, số nguyên và phần trăm cho lớp NumberFormat.
- Driver: Từ phiên bản 4.0 trở đi, JDBC API hỗ trợ chế độ SPI. Phiên bản cũ sử dụng phương thức Class.forName() để tải trình điều khiển.
- PersistenceProvider: Cung cấp triển khai của API JPA.
- Và nhiều hơn nữa.
Ngoài ra, SPI còn được sử dụng trong nhiều ứng dụng khác. Dưới đây là một số ví dụ điển hình.
Ứng dụng SPI trong JDBC DriverManager
Là một lập trình viên Java, đặc biệt là lập trình viên CRUD, chắc chắn bạn đã quen thuộc với JDBC. Chúng ta đều biết rằng có nhiều loại cơ sở dữ liệu quan hệ như Mysql, Oracle, PostgreSQL, v.v. Làm thế nào JDBC nhận diện các trình điều khiển cơ sở dữ liệu khác nhau?
Tạo kết nối cơ sở dữ liệu
Trước hết, hãy xem lại cách JDBC tạo kết nối cơ sở dữ liệu.
Trước JDBC 4.0, khi tạo kết nối cơ sở dữ liệu, chúng ta thường sử dụng phương thức Class.forName(XXX) để tải trình điều khiển cơ sở dữ liệu tương ứng, sau đó lấy kết nối cơ sở dữ liệu và thực hiện các hoạt động CRUD khác.
Class.forName("com.mysql.jdbc.Driver")Tuy nhiên, kể từ JDBC 4.0, không cần sử dụng phương thức Class.forName(XXX) để tải trình điều khiển cơ sở dữ liệu nữa, chỉ cần lấy kết nối trực tiếp. Điều này rõ ràng rất tiện lợi, nhưng làm thế nào để thực hiện điều này?
-
Interface JDBC: Đầu tiên, Java đã tích hợp Interface
java.sql.Drivercho JDBC. -
Triển khai Interface JDBC: Các trình điều khiển cơ sở dữ liệu riêng biệt tự triển khai Interface
java.sql.Driverđể quản lý kết nối cơ sở dữ liệu.-
Mysql: Trong gói trình điều khiển Java của Mysql
mysql-connector-java-XXX.jar, bạn có thể tìm thấy thư mụcMETA-INF/services. Thư mục này chứa một tệp có tênjava.sql.Driver, nội dung của tệp làcom.mysql.cj.jdbc.Driver.com.mysql.cj.jdbc.Driverchính là triển khai củajava.sql.Drivercho Mysql. Như hình dưới đây: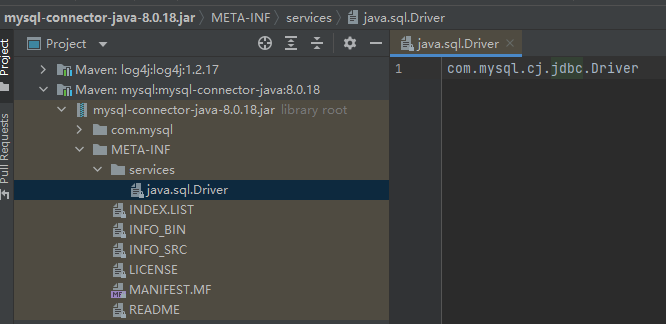
-
PostgreSQL: Trong gói trình điều khiển Java của PostgreSQL
postgresql-42.0.0.jar, bạn cũng có thể tìm thấy cấu hình tương tự, nội dung của tệp làorg.postgresql.Driver,org.postgresql.Driverchính là triển khai củajava.sql.Drivercho PostgreSQL.
-
-
Tạo kết nối cơ sở dữ liệu
Ví dụ với Mysql, mã tạo kết nối cơ sở dữ liệu như sau:
final String DB_URL = String.format("jdbc:mysql://%s:%s/%s", DB_HOST, DB_PORT, DB_SCHEMA); connection = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);
DriverManager
Từ bài viết trước, chúng ta đã biết DriverManager là yếu tố quan trọng để tạo kết nối đến cơ sở dữ liệu. Vậy nó hoạt động như thế nào?
Chúng ta có thể thấy rằng nó tải và khởi tạo các đối tượng driver. Hãy xem phương thức loadInitialDrivers:
private static void loadInitialDrivers() {
String drivers;
try {
drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
} catch (Exception ex) {
drivers = null;
}
// Sử dụng classloader để lấy tất cả các lớp driver hiện thực java.sql.Driver
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
// Sử dụng SPI, tải tất cả các dịch vụ Driver
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
// Lấy iterator
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
// Lặp qua iterator
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Không làm gì cả
}
return null;
}
});
// In thông tin về driver cơ sở dữ liệu
println("DriverManager.initialize: jdbc.drivers = " + drivers);
if (drivers == null || drivers.equals("")) {
return;
}
String[] driversList = drivers.split(":");
println("number of Drivers:" + driversList.length);
for (String aDriver : driversList) {
try {
println("DriverManager.Initialize: loading " + aDriver);
// Thử khởi tạo driver
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
} catch (Exception ex) {
println("DriverManager.Initialize: load failed: " + ex);
}
}
}Các bước chính trong đoạn mã trên là:
- Lấy danh sách các lớp driver từ biến hệ thống.
- Sử dụng SPI để lấy danh sách các lớp driver triển khai.
- Lặp qua danh sách các driver, thử khởi tạo từng lớp driver cụ thể.
- Sử dụng danh sách driver lấy được ở bước 1 để khởi tạo các lớp driver cụ thể.
Cần chú ý đến đoạn mã sau:
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);Ở đây, chúng ta thực tế đang lấy một trình lặp java.util.ServiceLoader.LazyIterator. Khi gọi phương thức hasNext, nó sẽ tìm kiếm thư mục META-INF/services trong classpath và các file java.sql.Driver trong các file jar, sau đó tìm thấy tên đầy đủ của lớp driver hiện thực trong file đó. Khi gọi phương thức next, nó sẽ thử khởi tạo một đối tượng của lớp driver dựa trên tên đầy đủ của lớp driver.
Ứng dụng SPI - Common-Logging
common-logging (còn được gọi là Jakarta Commons Logging, viết tắt là JCL) là một công cụ Interface log phổ biến.
Lớp cốt lõi của common-logging là LogFactory, LogFactory là một lớp trừu tượng, nó có trách nhiệm tải cài đặt log cụ thể.
Phương thức nhập khẩu của nó là phương thức getLog, mã nguồn như sau:
public static Log getLog(Class clazz) throws LogConfigurationException {
return getFactory().getInstance(clazz);
}
public static Log getLog(String name) throws LogConfigurationException {
return getFactory().getInstance(name);
}Từ mã nguồn trên, chúng ta có thể thấy rằng getLog sử dụng mô hình Factory, nó trước tiên gọi phương thức getFactory để lấy lớp Factory cụ thể của thư viện log, sau đó tạo một thể hiện log dựa trên tên lớp hoặc kiểu dữ liệu.
Phương thức LogFactory.getFactory có trách nhiệm chọn ra Factory log phù hợp, mã nguồn như sau:
public static LogFactory getFactory() throws LogConfigurationException {
// Bỏ qua...
// Tải tệp cấu hình commons-logging.properties
Properties props = getConfigurationFile(contextClassLoader, FACTORY_PROPERTIES);
// Bỏ qua...
// Xác định xem LogFactory cụ thể nào sẽ được tạo
// (1) Thử đọc thuộc tính toàn cục org.apache.commons.logging.LogFactory
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] Looking for system property [" + FACTORY_PROPERTY +
"] to define the LogFactory subclass to use...");
}
try {
// Nếu chỉ định thuộc tính org.apache.commons.logging.LogFactory, thử tạo một thể hiện của lớp cụ thể
String factoryClass = getSystemProperty(FACTORY_PROPERTY, null);
if (factoryClass != null) {
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] Creating an instance of LogFactory class '" + factoryClass +
"' as specified by system property " + FACTORY_PROPERTY);
}
factory = newFactory(factoryClass, baseClassLoader, contextClassLoader);
} else {
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] No system property [" + FACTORY_PROPERTY + "] defined.");
}
}
} catch (SecurityException e) {
// Xử lý ngoại lệ
} catch (RuntimeException e) {
// Xử lý ngoại lệ
}
// (2) Sử dụng cơ chế Java SPI, thử tìm kiếm lớp cài đặt org.apache.commons.logging.LogFactory trong thư mục META-INF/services của classpath
if (factory == null) {
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] Looking for a resource file of name [" + SERVICE_ID +
"] to define the LogFactory subclass to use...");
}
try {
final InputStream is = getResourceAsStream(contextClassLoader, SERVICE_ID);
if( is != null ) {
// This code is needed by EBCDIC and other strange systems.
// It's a fix for bugs reported in xerces
BufferedReader rd;
try {
rd = new BufferedReader(new InputStreamReader(is, "UTF-8"));
} catch (java.io.UnsupportedEncodingException e) {
rd = new BufferedReader(new InputStreamReader(is));
}
String factoryClassName = rd.readLine();
rd.close();
if (factoryClassName != null && ! "".equals(factoryClassName)) {
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] Creating an instance of LogFactory class " +
factoryClassName +
" as specified by file '" + SERVICE_ID +
"' which was present in the path of the context classloader.");
}
factory = newFactory(factoryClassName, baseClassLoader, contextClassLoader );
}
} else {
// is == null
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] No resource file with name '" + SERVICE_ID + "' found.");
}
}
} catch (Exception ex) {
// Chú ý: Nếu lớp LogFactory cụ thể không tương thích với LogFactory vì một lý do nào đó, một ClassCastException sẽ được bắt ở đây và các nỗ lực sẽ tiếp tục để tìm một lớp tương thích.
if (isDiagnosticsEnabled()) {
logDiagnostic(
"[LOOKUP] A security exception occurred while trying to create an" +
" instance of the custom factory class" +
": [" + trim(ex.getMessage()) +
"]. Trying alternative implementations...");
}
// Bỏ qua
}
}
// (3) Thử tìm kiếm thuộc tính org.apache.commons.logging.LogFactory trong tệp commons-logging.properties trong thư mục classpath
if (factory == null) {
if (props != null) {
if (isDiagnosticsEnabled()) {
logDiagnostic(
"[LOOKUP] Looking in properties file for entry with key '" + FACTORY_PROPERTY +
"' to define the LogFactory subclass to use...");
}
String factoryClass = props.getProperty(FACTORY_PROPERTY);
if (factoryClass != null) {
if (isDiagnosticsEnabled()) {
logDiagnostic(
"[LOOKUP] Properties file specifies LogFactory subclass '" + factoryClass + "'");
}
factory = newFactory(factoryClass, baseClassLoader, contextClassLoader);
// TODO: Xem xét liệu chúng ta có cần xử lý ngoại lệ từ newFactory không
} else {
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] Properties file has no entry specifying LogFactory subclass.");
}
}
} else {
if (isDiagnosticsEnabled()) {
logDiagnostic("[LOOKUP] No properties file available to determine" + " LogFactory subclass from..");
}
}
}
// (4) Nếu không thỏa mãn các trường hợp trên, tạo một triển khai mặc định, tức là org.apache.commons.logging.impl.LogFactoryImpl
if (factory == null) {
if (isDiagnosticsEnabled()) {
logDiagnostic(
"[LOOKUP] Loading the default LogFactory implementation '" + FACTORY_DEFAULT +
"' via the same classloader that loaded this LogFactory" +
" class (ie not looking in the context classloader).");
}
factory = newFactory(FACTORY_DEFAULT, thisClassLoader, contextClassLoader);
}
if (factory != null) {
/**
* Luôn luôn lưu vào bộ nhớ cache sử dụng context class loader.
*/
cacheFactory(contextClassLoader, factory);
if (props != null) {
Enumeration names = props.propertyNames();
while (names.hasMoreElements()) {
String name = (String) names.nextElement();
String value = props.getProperty(name);
factory.setAttribute(name, value);
}
}
}
return factory;
}Từ mã nguồn của phương thức getFactory, chúng ta có thể thấy rằng, logic chính được chia thành 4 bước:
- Đầu tiên, thử tìm thuộc tính toàn cục
org.apache.commons.logging.LogFactory, nếu chỉ định lớp cụ thể, thử tạo một thể hiện. - Sử dụng cơ chế Java SPI, thử tìm lớp cài đặt
org.apache.commons.logging.LogFactorytrong thư mụcMETA-INF/servicescủa classpath. - Thử tìm thuộc tính
org.apache.commons.logging.LogFactorytrong tệpcommons-logging.propertiestrong thư mục classpath, nếu chỉ định lớp cụ thể, thử tạo một thể hiện. - Nếu không thỏa mãn các trường hợp trên, tạo một triển khai mặc định, tức là
org.apache.commons.logging.impl.LogFactoryImpl.
Ứng dụng SPI - Spring Boot
Spring Boot là một framework được xây dựng dựa trên Spring, với mục tiêu thiết kế là đơn giản hóa cấu hình và chạy ứng dụng Spring. Trong Spring Boot, có sử dụng rất nhiều tự động cấu hình để giảm thiểu việc cấu hình.
Dưới đây là một ví dụ về một ứng dụng Spring Boot, có thể thấy rằng mã nguồn rất ngắn gọn.
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
@RestController
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@GetMapping("/hello")
public String hello(@RequestParam(value = "name", defaultValue = "World") String name) {
return String.format("Hello %s!", name);
}
}Vậy Spring Boot làm thế nào để chỉ với vài dòng mã có thể chạy một ứng dụng Spring Boot? Chúng ta hãy đi từ mã nguồn và tìm hiểu từng bước để hiểu nguyên tắc hoạt động của nó.
Annotation @SpringBootApplication
Đầu tiên, lớp khởi chạy của ứng dụng Spring Boot sẽ được đánh dấu bằng chú thích @SpringBootApplication. Định nghĩa của chú thích @SpringBootApplication như sau:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(
excludeFilters = {@Filter(
type = FilterType.CUSTOM,
classes = {TypeExcludeFilter.class}
), @Filter(
type = FilterType.CUSTOM,
classes = {AutoConfigurationExcludeFilter.class}
)}
)
public @interface SpringBootApplication {
// ...
}Ngoài các chú thích @Target, @Retention, @Documented, @Inherited, chú thích @SpringBootApplication còn chứa các chú thích @SpringBootConfiguration, @EnableAutoConfiguration, @ComponentScan.
Annotation @SpringBootConfiguration
Từ định nghĩa của chú thích @SpringBootConfiguration, chú thích @SpringBootConfiguration thực chất là một chú thích @Configuration, điều này có nghĩa là lớp được chú thích bằng @SpringBootConfiguration sẽ được nhận dạng là một lớp cấu hình bởi Spring Boot.
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Configuration
public @interface SpringBootConfiguration {
@AliasFor(
annotation = Configuration.class
)
boolean proxyBeanMethods() default true;
}Annotation @EnableAutoConfiguration
Chú thích @EnableAutoConfiguration được định nghĩa như sau:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import({AutoConfigurationImportSelector.class})
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}Chú thích @EnableAutoConfiguration bao gồm hai chú thích @AutoConfigurationPackage và @Import({AutoConfigurationImportSelector.class}).
Annotation @AutoConfigurationPackage
@AutoConfigurationPackage sẽ đánh dấu lớp được chú thích là lớp cấu hình chính, package chứa lớp này sẽ được coi là package gốc, Spring Boot mặc định sẽ tự động quét tất cả các Spring Bean (các lớp được chú thích bằng @Component hoặc các chú thích con của @Component) trong package gốc này. Điều này giống với việc sử dụng context:component-scan trong cấu hình XML của Spring. Chú thích @AutoConfigurationPackage có chú thích @Import({Registrar.class}). Lớp Registrar được sử dụng để lưu trữ thông tin lớp khởi chạy của Spring Boot và package gốc.
Phương thức SpringFactoriesLoader.loadFactoryNames
@Import(AutoConfigurationImportSelector.class) có nghĩa là chú thích AutoConfigurationImportSelector sẽ được chú thích trực tiếp vào Spring Container. AutoConfigurationImportSelector có một phương thức chính là getCandidateConfigurations để lấy danh sách các cấu hình ứng cử viên. Phương thức này gọi phương thức SpringFactoriesLoader.loadFactoryNames, đây chính là cơ chế SPI của Spring Boot, nó có trách nhiệm tải tất cả các tệp META-INF/spring.factories, quá trình tải được thực hiện bởi SpringFactoriesLoader.
Tệp META-INF/spring.factories của Spring Boot thực chất là một tệp properties, nội dung dữ liệu là các cặp khóa-giá trị.
Phần mã nguồn quan trọng của phương thức SpringFactoriesLoader.loadFactoryNames:
// Định dạng của tệp spring.factories là: key=value1,value2,value3
// Lặp qua tất cả các tệp META-INF/spring.factories
// Phân tích tệp và lấy tên lớp factoryClass cho key
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
String factoryTypeName = factoryType.getName();
return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList());
}
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
// Thử lấy cache, nếu cache có dữ liệu, trả về trực tiếp
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
// Lấy đường dẫn tệp tài nguyên
Enumeration<URL> urls = (classLoader != null ?
classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
result = new LinkedMultiValueMap<>();
// Lặp qua tất cả các đường dẫn
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
// Phân tích tệp và lấy một tập hợp các Properties tương ứng
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
// Lặp qua các properties đã phân tích và tạo dữ liệu
for (Map.Entry<?, ?> entry : properties.entrySet()) {
String factoryTypeName = ((String) entry.getKey()).trim();
for (String factoryImplementationName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
result.add(factoryTypeName, factoryImplementationName.trim());
}
}
}
cache.put(classLoader, result);
return result;
}
catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}Tóm lại, phương thức trên thực hiện các công việc sau:
- Tải tất cả các tệp
META-INF/spring.factories, quá trình tải được thực hiện bởiSpringFactoriesLoader. - Lặp qua các tệp và phân tích tệp để lấy danh sách tên lớp factoryClass tương ứng với key.
Lớp AutoConfiguration của Spring Boot
Spring Boot có nhiều gói starter khác nhau, bạn có thể lựa chọn theo nhu cầu dự án thực tế. Trong quá trình phát triển dự án, chỉ cần thêm gói starter, chúng ta có thể sử dụng các tính năng liên quan với ít cấu hình, thậm chí không cần cấu hình gì. Qua quá trình SPI của Spring Boot đã hoàn thành nửa công việc tự động cấu hình, nhưng công việc còn lại sẽ được xử lý như thế nào?
Lấy ví dụ về gói jar spring-boot-starter-web, xem pom của nó, bạn có thể thấy nó phụ thuộc vào spring-boot-starter, tất cả các gói starter chính thức của Spring Boot đều phụ thuộc vào gói jar này. spring-boot-starter lại phụ thuộc vào spring-boot-autoconfigure, đây chính là bí mật của tự động cấu hình của Spring Boot.
Dựa trên cấu trúc của gói spring-boot-autoconfigure, nó có một META-INF/spring.factories, rõ ràng sử dụng SPI của Spring Boot để tự động cấu hình các lớp cấu hình trong đó.
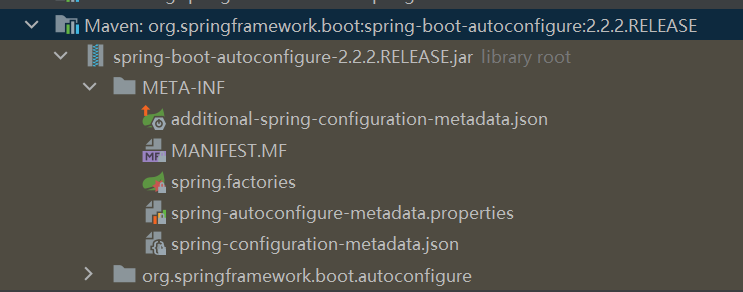
Hình ảnh sau đây là một phần nội dung của tệp META-INF/spring.factories trong spring-boot-autoconfigure, bạn có thể thấy nó đăng ký một danh sách dài các lớp AutoConfiguration sẽ được tự động tải.
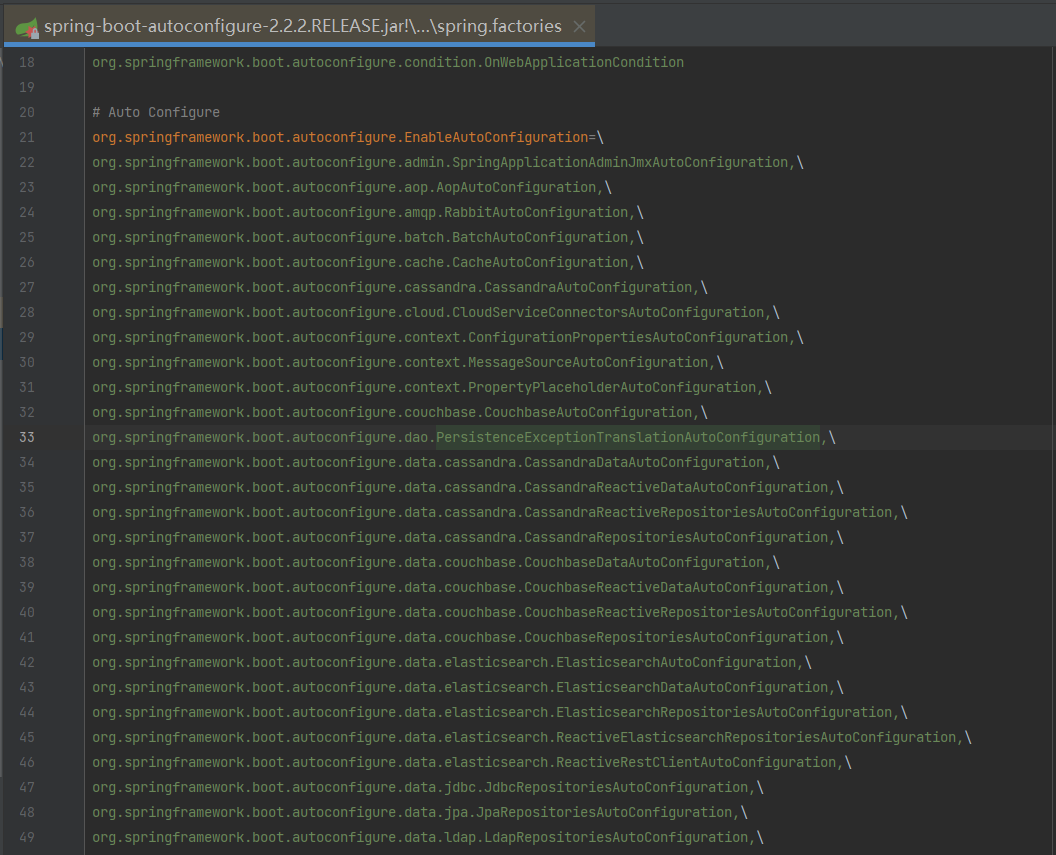
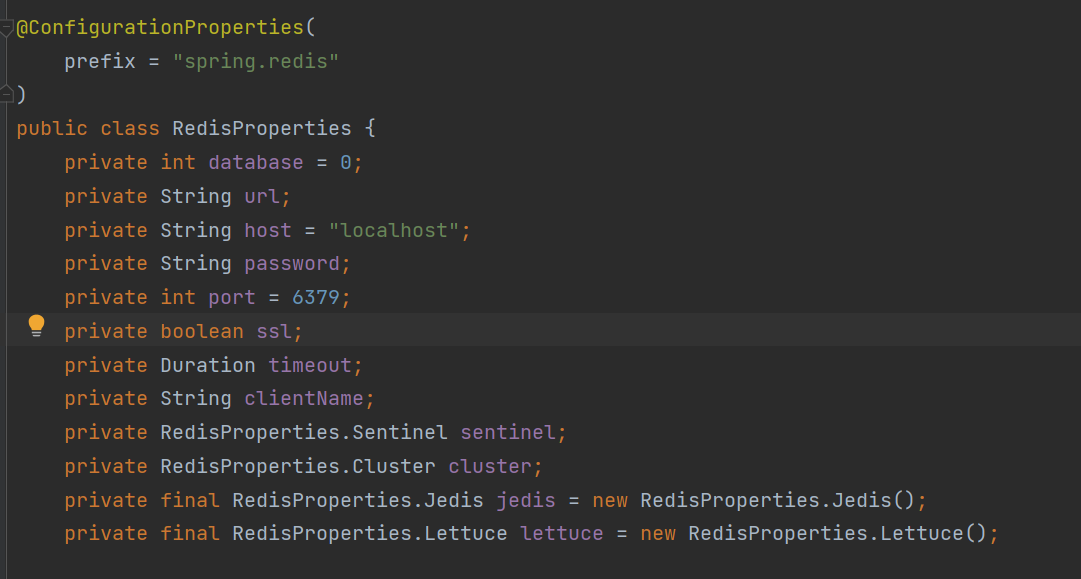
Lấy ví dụ về RedisAutoConfiguration, trong lớp cấu hình này, các Bean sẽ được tạo ra dựa trên các điều kiện trong @ConditionalXXX, các tham số quan trọng cho việc tạo Bean được truyền vào thông qua RedisProperties.

RedisProperties chứa các thuộc tính quan trọng cho kết nối Redis, chỉ cần chỉ định các thuộc tính bắt đầu bằng spring.redis trong tệp cấu hình yml hoặc properties, chúng sẽ được tự động cấu hình vào RedisProperties.
Từ phân tích trên, chúng ta đã giải mã nguyên tắc hoạt động của tự động cấu hình của Spring Boot.
Ứng dụng Dubbo trong SPI
Dubbo không sử dụng Java SPI, mà thay vào đó, nó tự đóng gói một cơ chế SPI mới. Các tệp cấu hình cần thiết cho Dubbo SPI phải được đặt trong đường dẫn META-INF/dubbo, nội dung cấu hình có dạng như sau:
optimusPrime = org.apache.spi.OptimusPrime
bumblebee = org.apache.spi.Bumblebee
Khác với cấu hình lớp triển khai Java SPI, Dubbo SPI sử dụng cấu hình dưới dạng cặp khóa-giá trị, điều này cho phép tải lớp triển khai chỉ khi cần thiết. Ngoài việc hỗ trợ tải lớp triển khai theo yêu cầu, Dubbo SPI còn bổ sung các tính năng như IOC và AOP.
Điểm vào của ExtensionLoader
Các logic liên quan đến Dubbo SPI được đóng gói trong lớp ExtensionLoader, thông qua ExtensionLoader, có thể tải lớp triển khai cụ thể.
Phương thức getExtension của ExtensionLoader là phương thức vào của nó, mã nguồn của nó như sau:
public T getExtension(String name) {
if (name == null || name.length() == 0)
throw new IllegalArgumentException("Extension name == null");
if ("true".equals(name)) {
// Lấy lớp triển khai mặc định
return getDefaultExtension();
}
// Holder, như tên gọi, được sử dụng để giữ đối tượng mục tiêu
Holder<Object> holder = cachedInstances.get(name);
if (holder == null) {
cachedInstances.putIfAbsent(name, new Holder<Object>());
holder = cachedInstances.get(name);
}
Object instance = holder.get();
// Kiểm tra kép
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
// Tạo đối tượng thực hiện
instance = createExtension(name);
// Đặt đối tượng thực hiện vào holder
holder.set(instance);
}
}
}
return (T) instance;
}Có thể thấy, phương thức này có chức năng: trước tiên kiểm tra bộ nhớ cache, nếu không có trong cache, sau đó gọi phương thức createExtension để tạo đối tượng thực hiện. Vậy createExtension làm thế nào để tạo đối tượng thực hiện? Mã nguồn của nó như sau:
private T createExtension(String name) {
// Lấy tất cả các lớp triển khai từ tệp cấu hình, có thể nhận được bảng ánh xạ từ "tên mục cấu hình" đến "lớp cấu hình"
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
// Tạo đối tượng bằng phản chiếu
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
// Tiêm phụ thuộc vào đối tượng
injectExtension(instance);
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (wrapperClasses != null && !wrapperClasses.isEmpty()) {
// Tạo lần lượt đối tượng Wrapper
for (Class<?> wrapperClass : wrapperClasses) {
// Truyền instance hiện tại làm tham số cho phương thức tạo của Wrapper, sau đó tạo đối tượng Wrapper bằng phản chiếu.
// Sau đó, tiêm phụ thuộc vào đối tượng Wrapper, cuối cùng gán đối tượng Wrapper cho biến instance.
instance = injectExtension(
(T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("...");
}
}Có thể tóm tắt các bước làm của phương thức createExtension như sau:
- Lấy tất cả các lớp triển khai từ tệp cấu hình
- Tạo đối tượng thực hiện bằng phản chiếu
- Tiêm phụ thuộc vào đối tượng thực hiện
- Đóng gói đối tượng thực hiện trong đối tượng
Wrappertương ứng
Trong các bước trên, bước đầu tiên là quan trọng để tải lớp triển khai, bước thứ ba và bốn là cài đặt cụ thể của Dubbo IOC và AOP.
Lấy tất cả các lớp triển khai
Trước khi lấy lớp triển khai theo tên, Dubbo cần phải phân tích tệp cấu hình để lấy bảng ánh xạ tên mục cấu hình đến lớp triển khai (Map<name, class>). Mã nguồn liên quan đến quá trình này như sau:
private Map<String, Class<?>> getExtensionClasses() {
// Lấy chú thích SPI, biến type ở đây được truyền vào khi gọi phương thức getExtensionLoader
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
if (defaultAnnotation != null) {
String value = defaultAnnotation.value();
if ((value = value.trim()).length() > 0) {
// Cắt chuỗi chú thích SPI
String[] names = NAME_SEPARATOR.split(value);
// Kiểm tra tính hợp lệ của chú thích SPI, nếu không hợp lệ, ném ra ngoại lệ
if (names.length > 1) {
throw new IllegalStateException("...");
}
// Đặt tên mặc định, xem getDefaultExtension
if (names.length == 1) {
cachedDefaultName = names[0];
}
}
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
// Tải tệp cấu hình trong thư mục chỉ định
loadDirectory(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
loadDirectory(extensionClasses, DUBBO_DIRECTORY);
loadDirectory(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}loadExtensionClasses thực hiện hai công việc chính, một là phân tích chú thích SPI, hai là gọi phương thức loadDirectory để tải tệp cấu hình trong thư mục chỉ định. Tiếp theo, chúng ta sẽ phân tích logic của loadDirectory.
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir) {
// fileName = đường dẫn thư mục + tên đầy đủ của type
String fileName = dir + type.getName();
try {
Enumeration<java.net.URL> urls;
ClassLoader classLoader = findClassLoader();
// Tải tất cả các liên kết tài nguyên dựa trên tên tệp
if (classLoader != null) {
urls = classLoader.getResources(fileName);
} else {
urls = ClassLoader.getSystemResources(fileName);
}
if (urls != null) {
while (urls.hasMoreElements()) {
java.net.URL resourceURL = urls.nextElement();
// Tải tài nguyên
loadResource(extensionClasses, classLoader, resourceURL);
}
}
} catch (Throwable t) {
logger.error("...");
}
}Phương thức loadDirectory trước tiên lấy tất cả các liên kết tài nguyên dựa trên tên tệp thông qua classLoader, sau đó gọi phương thức loadResource để tải tài nguyên. Chúng ta sẽ tiếp tục theo dõi phương thức loadResource.
private void loadResource(Map<String, Class<?>> extensionClasses,
ClassLoader classLoader, java.net.URL resourceURL) {
try {
BufferedReader reader = new BufferedReader(
new InputStreamReader(resourceURL.openStream(), "utf-8"));
try {
String line;
// Đọc nội dung cấu hình theo dòng
while ((line = reader.readLine()) != null) {
// Tìm vị trí ký tự #
final int ci = line.indexOf('#');
if (ci >= 0) {
// Cắt chuỗi trước ký tự #, nội dung sau # là chú thích, cần bỏ qua
line = line.substring(0, ci);
}
line = line.trim();
if (line.length() > 0) {
try {
String name = null;
int i = line.indexOf('=');
if (i > 0) {
// Cắt chuỗi theo dấu bằng =, lấy khóa và giá trị
name = line.substring(0, i).trim();
line = line.substring(i + 1).trim();
}
if (line.length() > 0) {
// Tải lớp và lưu lớp vào cache bằng phản chiếu
loadClass(extensionClasses, resourceURL,
Class.forName(line, true, classLoader), name);
}
} catch (Throwable t) {
IllegalStateException e = new IllegalStateException("...");
}
}
}
} finally {
reader.close();
}
} catch (Throwable t) {
logger.error("...");
}
}Phương thức loadResource được sử dụng để đọc và phân tích tệp cấu hình, sau đó tải lớp bằng phản chiếu và cuối cùng gọi phương thức loadClass để thực hiện các hoạt động khác. Phương thức loadClass chủ yếu được sử dụng để làm việc với cache, logic của nó như sau:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL,
Class<?> clazz, String name) throws NoSuchMethodException {
if (!type.isAssignableFrom(clazz)) {
throw new IllegalStateException("...");
}
// Kiểm tra xem lớp mục tiêu có chú thích Adaptive không
if (clazz.isAnnotationPresent(Adaptive.class)) {
if (cachedAdaptiveClass == null) {
// Đặt cachedAdaptiveClass vào bộ nhớ cache
cachedAdaptiveClass = clazz;
} else if (!cachedAdaptiveClass.equals(clazz)) {
throw new IllegalStateException("...");
}
// Kiểm tra xem clazz có phải là lớp Wrapper không
} else if (isWrapperClass(clazz)) {
Set<Class<?>> wrappers = cachedWrapperClasses;
if (wrappers == null) {
cachedWrapperClasses = new ConcurrentHashSet<Class<?>>();
wrappers = cachedWrapperClasses;
}
// Lưu clazz vào cachedWrapperClasses
wrappers.add(clazz);
// Chương trình vào nhánh này, cho thấy clazz là một lớp triển khai thông thường
} else {
// Kiểm tra xem clazz có constructor mặc định không, nếu không, ném ra ngoại lệ
clazz.getConstructor();
if (name == null || name.length() == 0) {
// Nếu name là null, thử lấy name từ chú thích Extension hoặc sử dụng tên lớp viết thường làm name
name = findAnnotationName(clazz);
if (name.length() == 0) {
throw new IllegalStateException("...");
}
}
// Cắt chuỗi name
String[] names = NAME_SEPARATOR.split(name);
if (names != null && names.length > 0) {
Activate activate = clazz.getAnnotation(Activate.class);
if (activate != null) {
// Nếu lớp có chú thích Activate, sử dụng phần tử đầu tiên của mảng names làm khóa,
// lưu ánh xạ giữa name và đối tượng chú thích Activate
cachedActivates.put(names[0], activate);
}
for (String n : names) {
if (!cachedNames.containsKey(clazz)) {
// Lưu ánh xạ giữa Class và name
cachedNames.put(clazz, n);
}
Class<?> c = extensionClasses.get(n);
if (c == null) {
// Lưu ánh xạ giữa name và Class
extensionClasses.put(n, clazz);
} else if (c != clazz) {
throw new IllegalStateException("...");
}
}
}
}
}Như trên, loadClass làm việc với các bộ nhớ cache khác nhau, như cachedAdaptiveClass, cachedWrapperClasses và cachedNames và còn lại không có gì đặc biệt.