Hadoop MapReduce
Giới thiệu MapReduce
Hadoop MapReduce là một framework tính toán phân tán, được sử dụng để viết các ứng dụng xử lý hàng loạt. Chương trình đã viết có thể được gửi đến cụm Hadoop để xử lý song song trên tập dữ liệu lớn.
MapReduce được thiết kế dựa trên các nguyên tắc sau:
- Phân chia và chinh phục, tính toán song song
- Điện toán di động, không phải dữ liệu di động
Công việc MapReduce chia tập dữ liệu đầu vào thành các khối độc lập, các khối này được xử lý bằng map theo cách song song, framework sắp xếp đầu ra của map, sau đó đưa vào reduce. Framework MapReduce được thiết kế đặc biệt để xử lý các cặp <key,value>, nó coi đầu vào của công việc là một tập hợp các cặp <key,value> và tạo ra một tập hợp các cặp <key,value> làm đầu ra. Cả đầu vào và đầu ra của key và value phải thực hiện interface Writable.
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
Đặc điểm
- Tính toán theo dữ liệu
- Khả năng mở rộng tốt: khả năng tính toán tăng gần tuyến tính khi số lượng nút tăng
- Khả năng chịu lỗi cao
- Giám sát trạng thái
- Thích hợp cho xử lý hàng loạt dữ liệu ngoại tuyến lớn
- Giảm ngưỡng lập trình phân tán
Các tình huống ứng dụng
Tình huống phù hợp:
- Thống kê dữ liệu, ví dụ: thống kê PV, UV của trang web
- Xây dựng chỉ mục cho công cụ tìm kiếm
- Truy vấn dữ liệu lớn
Tình huống không phù hợp:
- OLAP
- Yêu cầu trả về kết quả trong mili giây hoặc giây
- Tính toán dòng
- Tập dữ liệu đầu vào của tính toán dòng là động, trong khi MapReduce là tĩnh
- Tính toán DAG
- Có sự phụ thuộc giữa nhiều công việc, đầu vào của công việc sau là đầu ra của công việc trước, tạo thành đồ thị có hướng không chu trình DAG
- Kết quả đầu ra của mỗi công việc MapReduce sẽ được ghi xuống đĩa, tạo ra một lượng lớn IO đĩa, dẫn đến hiệu suất rất thấp
Mô hình lập trình MapReduce
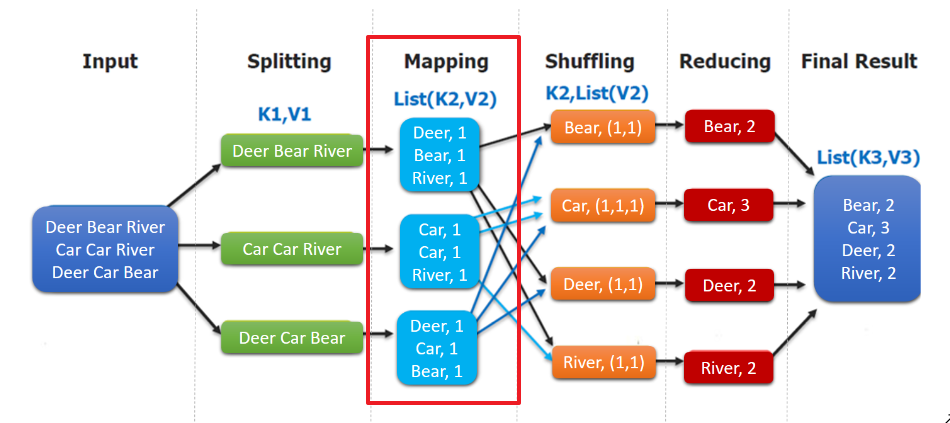
Mô hình lập trình MapReduce: Chương trình MapReduce được chia thành hai giai đoạn, giai đoạn Map (ánh xạ) và giai đoạn Reduce (giảm).
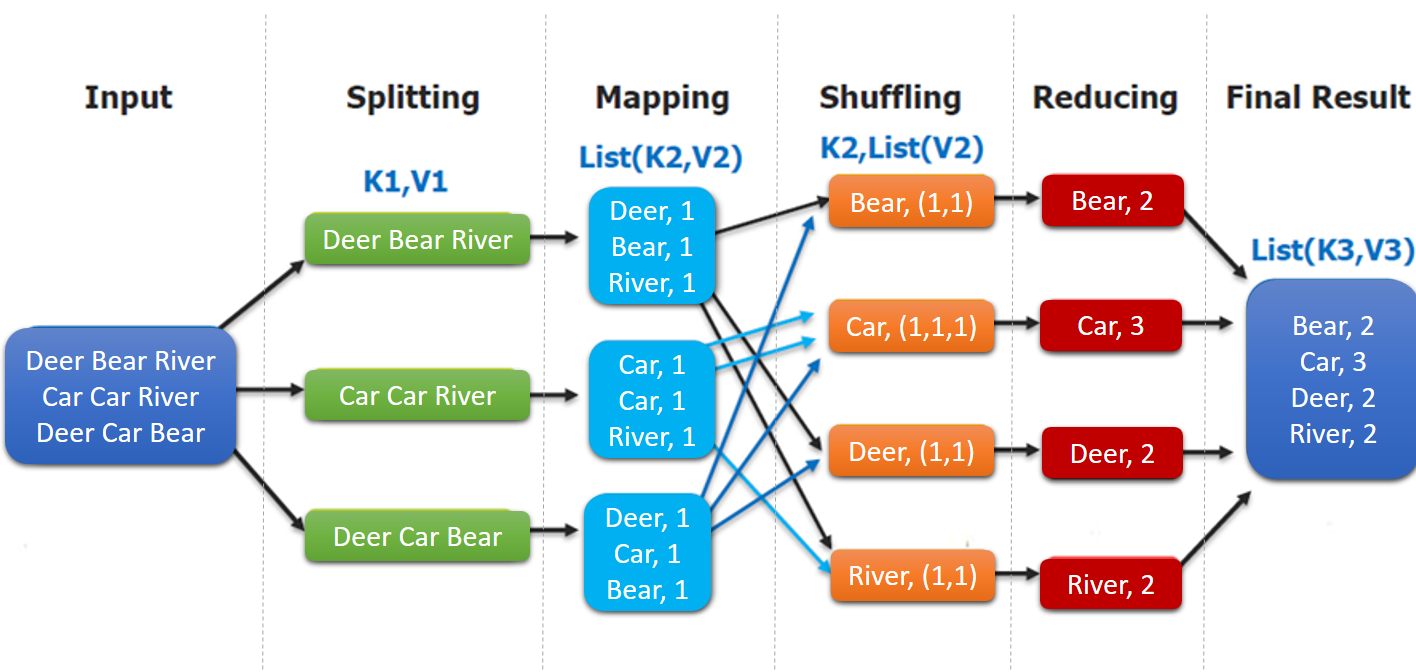
- Input : Đọc tệp văn bản;
- Splitting : Chia tệp theo dòng, lúc này
K1là số dòng,V1là nội dung văn bản tương ứng; - Mapping : Xử lý song song mỗi dòng theo cách chia theo khoảng trắng, chia thành
List(K2,V2), trong đóK2là mỗi từ, do đang thống kê tần suất từ, nên giá trịV2là 1, đại diện cho xuất hiện 1 lần; - Shuffling:Do hoạt động
Mappingcó thể được xử lý song song trên các máy khác nhau, nên cần thông quashufflingđể phân phối dữ liệu có cùng giá trịkeyvào cùng một nút để hợp nhất, như vậy mới có thể thống kê kết quả cuối cùng, lúc này nhận đượcK2là mỗi từ,List(V2)là một tập hợp có thể lặp lại,V2là V2 trong Mapping; - Reducing : Trong ví dụ này, chúng tôi đang thống kê tổng số lần xuất hiện của từ, vì vậy
Reducingthực hiện hoạt động giảm tổng trênList(V2), và cuối cùng đưa ra kết quả.
Trong mô hình lập trình MapReduce, các hoạt động splitting và shuffing đều được thực hiện bởi framework, chúng ta chỉ cần tự thực hiện mapping và reducing, đây cũng là nguồn gốc của tên gọi MapReduce.
combiner & partitioner
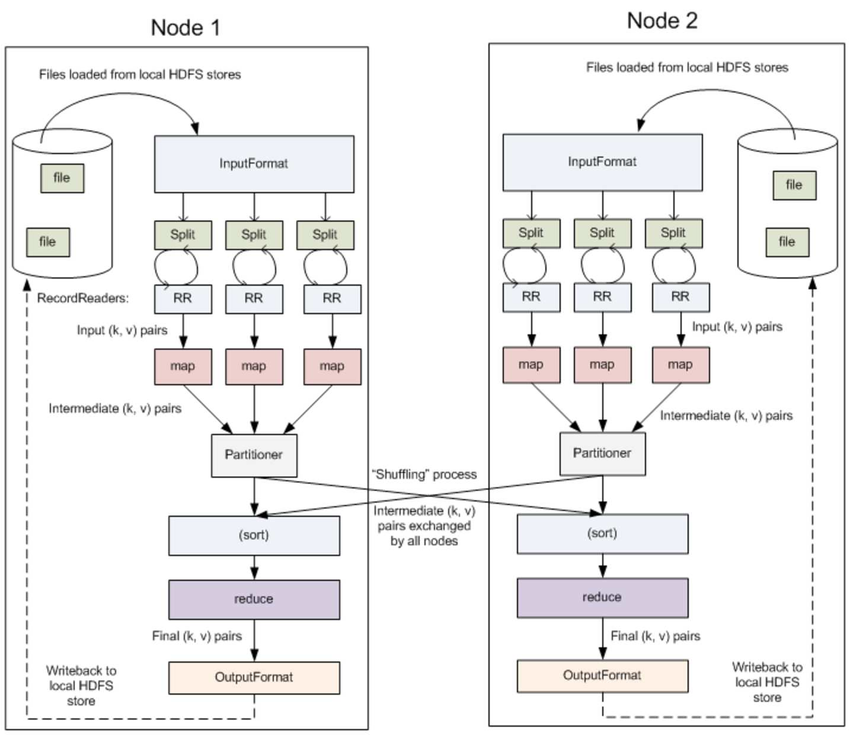
InputFormat & RecordReaders
InputFormat chia tệp đầu ra thành nhiều InputSplit, và RecordReaders chuyển đổi InputSplit thành cặp <key, value> chuẩn, làm đầu ra cho map. Ý nghĩa của bước này là chỉ khi chia cắt logic và chuyển đổi thành định dạng cặp key-value chuẩn, mới có thể cung cấp đầu vào cho nhiều map để xử lý song song.
Combiner
combiner là một hoạt động tùy chọn sau khi map hoạt động, thực tế đó là một hoạt động reduce cục bộ, chủ yếu là sau khi map tính toán ra tệp trung gian, nó thực hiện một hoạt động hợp nhất đơn giản trên các key trùng lặp. Ở đây, chúng tôi sử dụng thống kê tần suất từ làm ví dụ:
map ghi lại mỗi từ hadoop là 1 khi gặp phải nó, nhưng trong bài viết này, hadoop có thể xuất hiện nhiều lần, do đó tệp đầu ra map sẽ có rất nhiều dư thừa, do đó, trước khi tính toán reduce, nó thực hiện một hoạt động hợp nhất trên các key giống nhau, do đó, lượng dữ liệu cần truyền sẽ giảm, hiệu suất truyền sẽ được cải thiện.
Tuy nhiên, không phải tất cả các tình huống đều phù hợp với combiner, nguyên tắc sử dụng nó là đầu ra của combiner sẽ không ảnh hưởng đến đầu vào cuối cùng của reduce, ví dụ: khi tính tổng, giá trị lớn nhất, giá trị nhỏ nhất, combiner có thể được sử dụng, nhưng khi tính toán giá trị trung bình, combiner không thể được sử dụng.
Trường hợp không sử dụng combiner:
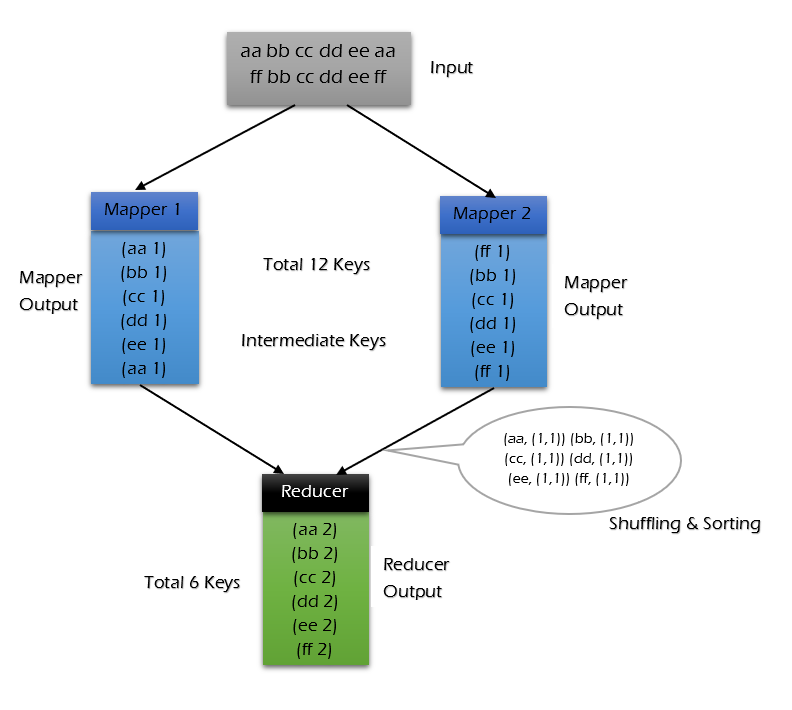
Trường hợp sử dụng combiner:
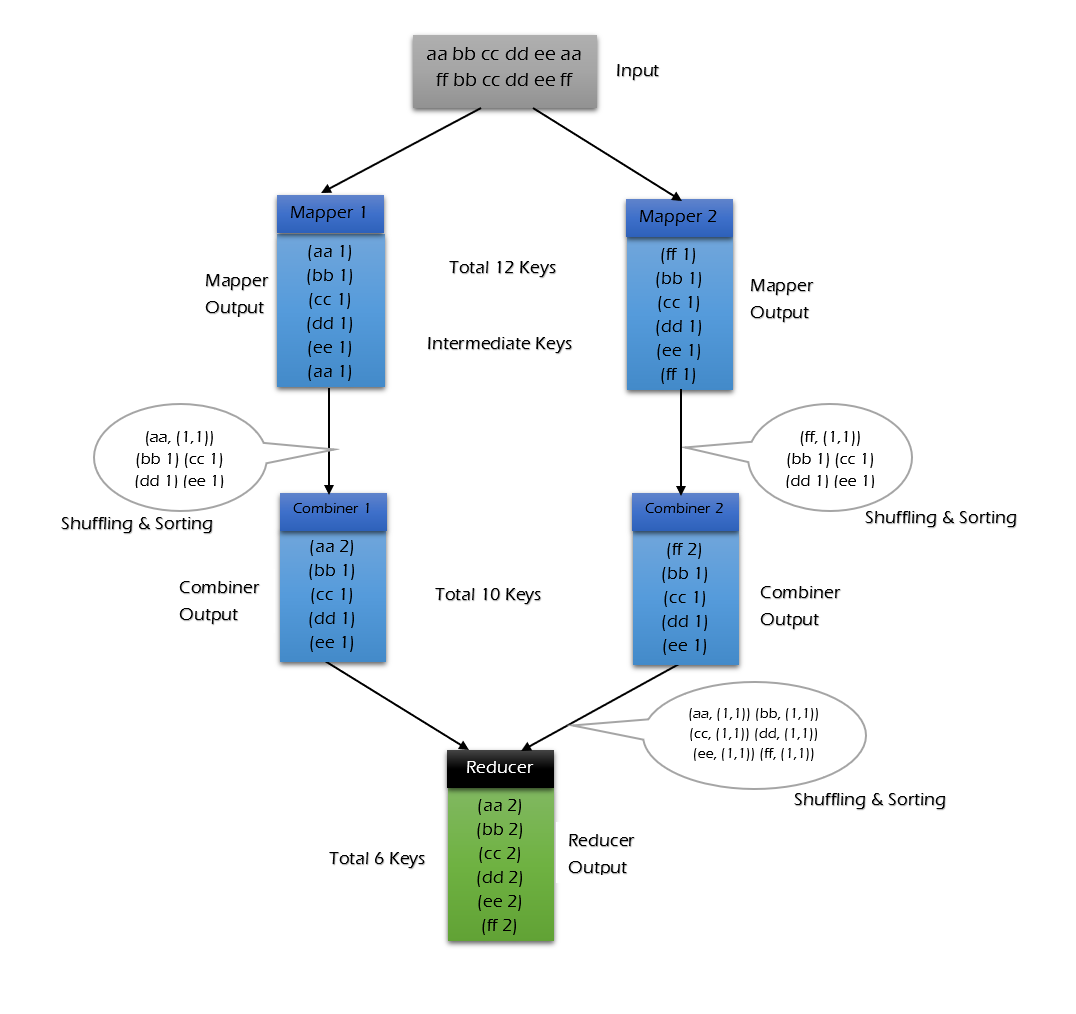
Có thể thấy khi sử dụng combiner, số lượng dữ liệu cần truyền đến reducer giảm từ 12keys xuống còn 10keys. Mức độ giảm phụ thuộc vào tỷ lệ lặp lại của keys, ví dụ sau về thống kê tần suất từ sẽ minh họa việc sử dụng combiner để giảm lượng truyền tải hàng trăm lần.
Partitioner
Partitioner có thể được hiểu như là một bộ phân loại, nó phân loại đầu ra của map dựa trên giá trị key khác nhau và gửi chúng đến reducer tương ứng. Nó hỗ trợ triển khai tùy chỉnh, và các ví dụ sau đây sẽ cung cấp một minh họa.
Ví dụ thống kê tần suất từ trong MapReduce
Giới thiệu dự án
Ở đây, chúng tôi cung cấp một ví dụ cổ điển về thống kê tần suất từ: thống kê số lần xuất hiện của mỗi từ trong dữ liệu mẫu sau.
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Để thuận tiện cho việc phát triển của mọi người, tôi đã đặt một lớp công cụ WordCountDataUtils trong mã nguồn của dự án, được sử dụng để mô phỏng việc tạo mẫu cho thống kê tần suất từ, và các tệp được tạo ra hỗ trợ xuất ra máy cục bộ hoặc viết trực tiếp vào HDFS.
Địa chỉ tải xuống mã nguồn đầy đủ của dự án: hadoop-word-count
Phụ thuộc dự án
Để lập trình MapReduce, bạn cần nhập phụ thuộc hadoop-client:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>WordCountMapper
Chia mỗi dòng dữ liệu theo dấu phân cách đã chỉ định. Điều cần lưu ý ở đây là trong MapReduce, bạn phải sử dụng các kiểu dữ liệu được Hadoop định nghĩa, bởi vì tất cả các kiểu dữ liệu được Hadoop định trước đều có thể được tuần tự hóa và so sánh, tất cả các kiểu dữ liệu đều đã thực hiện giao diện WritableComparable.
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}WordCountMapper tương ứng với hoạt động Mapping trong hình sau:
WordCountMapper kế thừa từ lớp Mapper, đây là một lớp dạng tổng quát, được định nghĩa như sau:
WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
......
}- KEYIN : Kiểu dữ liệu của key đầu vào trong
mapping, tức là offset của mỗi dòng (vị trí của ký tự đầu tiên trong mỗi dòng trong toàn bộ văn bản), kiểuLong, tương ứng với kiểuLongWritabletrong Hadoop; - VALUEIN : Kiểu dữ liệu của value đầu vào trong
mapping, tức là dữ liệu của mỗi dòng; kiểuString, tương ứng với kiểuTexttrong Hadoop; - KEYOUT :Kiểu dữ liệu của key đầu ra trong
mapping, tức là mỗi từ; kiểuString, tương ứng với kiểuTexttrong Hadoop; - VALUEOUT:Kiểu dữ liệu của value đầu ra trong
mapping, tức là số lần xuất hiện của mỗi từ; ở đây sử dụng kiểuint, tương ứng với kiểuIntWritable.
WordCountReducer
Trong Reduce, thực hiện việc đếm số lần xuất hiện của từ:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
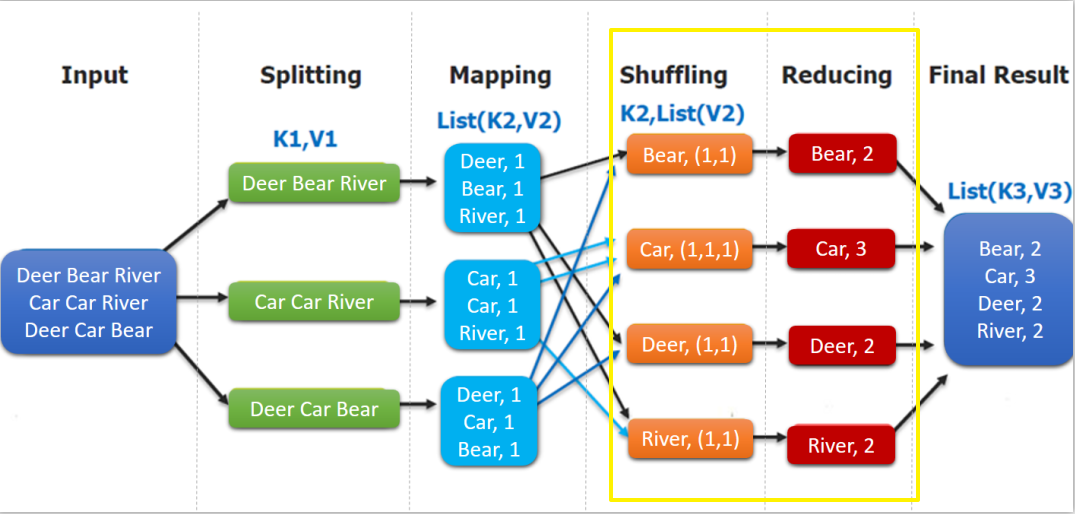
}Như hình dưới đây, đầu ra của shuffling là đầu vào của reduce. Ở đây, key là mỗi từ, values là một kiểu dữ liệu có thể lặp lại, tương tự như (1,1,1,…).
WordCountApp
Tổ chức công việc MapReduce và gửi nó đến máy chủ để chạy, mã như sau:
/**
* Tổ chức công việc và gửi nó đến cụm để chạy
*/
public class WordCountApp {
// Ở đây để hiển thị tham số một cách trực quan, chúng tôi đã sử dụng mã cứng, trong thực tế có thể thông qua tham số bên ngoài
private static final String HDFS_URL = "hdfs://192.168.0.107:8020";
private static final String HADOOP_USER_NAME = "root";
public static void main(String[] args) throws Exception {
// Đường dẫn đầu vào và đầu ra của tệp được chỉ định bởi tham số bên ngoài
if (args.length < 2) {
System.out.println("Đường dẫn đầu vào và đầu ra là cần thiết!");
return;
}
// Cần chỉ rõ tên người dùng của hadoop, nếu không, khi tạo thư mục trên HDFS, có thể sẽ ném ra ngoại lệ không đủ quyền
System.setProperty("HADOOP_USER_NAME", HADOOP_USER_NAME);
Configuration configuration = new Configuration();
// Chỉ rõ địa chỉ của HDFS
configuration.set("fs.defaultFS", HDFS_URL);
// Tạo một công việc
Job job = Job.getInstance(configuration);
// Đặt lớp chính để chạy
job.setJarByClass(WordCountApp.class);
// Đặt Mapper và Reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// Đặt kiểu đầu ra của key và value trong Mapper
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// Đặt kiểu đầu ra của key và value trong Reducer
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// Nếu thư mục đầu ra đã tồn tại, bạn phải xóa nó trước, nếu không, khi chạy chương trình lặp lại, nó sẽ ném ra ngoại lệ
FileSystem fileSystem = FileSystem.get(new URI(HDFS_URL), configuration, HADOOP_USER_NAME);
Path outputPath = new Path(args[1]);
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
// Đặt đường dẫn đầu vào và đầu ra của tệp công việc
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, outputPath);
// Gửi công việc đến cụm và chờ cho đến khi nó hoàn thành, đặt tham số thành true đại diện cho việc in tiến trình tương ứng
boolean result = job.waitForCompletion(true);
// Đóng hệ thống tệp đã tạo trước đó
fileSystem.close();
// Dựa vào kết quả công việc, hủy máy ảo Java đang chạy, thoát chương trình
System.exit(result ? 0 : -1);
}
}Cần lưu ý: Nếu bạn không đặt kiểu đầu ra của hoạt động Mapper, chương trình mặc định rằng nó giống với kiểu đầu ra của hoạt động Reducer.
Gửi lên để chạy trên máy chủ
Trong phát triển thực tế, bạn có thể cấu hình môi trường phát triển hadoop trên máy cục bộ, và khởi động trực tiếp từ IDE để kiểm tra. Ở đây, chúng tôi chủ yếu giới thiệu việc đóng gói và gửi để chạy trên máy chủ. Do dự án này không sử dụng bất kỳ phụ thuộc bên thứ ba nào ngoài Hadoop, nên chỉ cần đóng gói trực tiếp:
mvn clean packageSử dụng lệnh sau để gửi công việc:
hadoop jar /usr/appjar/hadoop-word-count-1.0.jar \
com.heibaiying.WordCountApp \
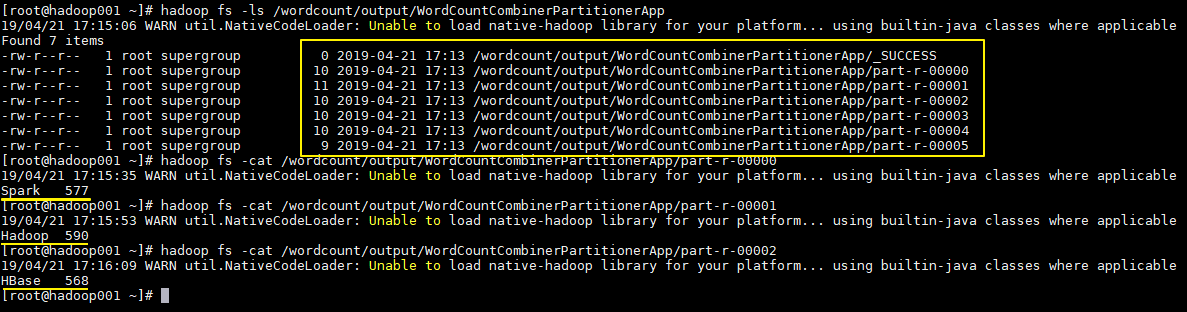
/wordcount/input.txt /wordcount/output/WordCountAppSau khi công việc hoàn thành, kiểm tra thư mục được tạo trên HDFS:
# Kiểm tra thư mục
hadoop fs -ls /wordcount/output/WordCountApp
# Kiểm tra kết quả thống kê
hadoop fs -cat /wordcount/output/WordCountApp/part-r-00000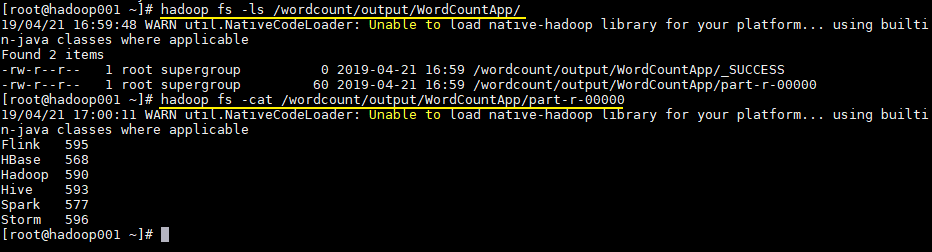
Tính năng nâng cao của ví dụ về thống kê tần suất từ: Combiner
Triển khai code
Để sử dụng tính năng combiner, bạn chỉ cần thêm dòng mã sau khi tổ chức công việc:
// Đặt Combiner
job.setCombinerClass(WordCountReducer.class);Kết quả thực thi
Sau khi thêm combiner, kết quả thống kê sẽ không thay đổi, nhưng bạn có thể thấy hiệu quả của combiner từ nhật ký đã in:
Nhật ký in khi không có combiner:
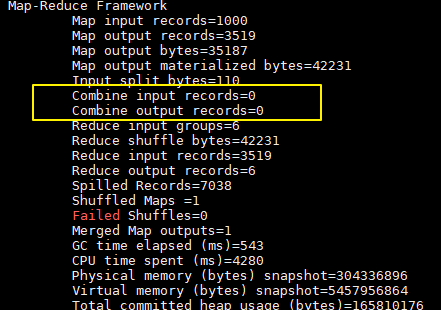
Nhật ký in sau khi thêm combiner:
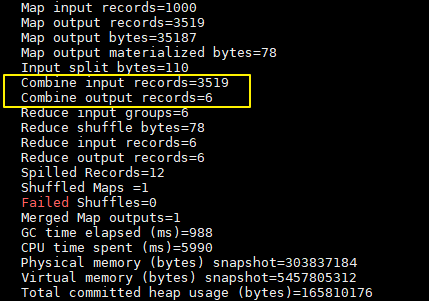
Ở đây chúng tôi chỉ có một tệp đầu vào và nó nhỏ hơn 128M, vì vậy chỉ có một Map xử lý. Bạn có thể thấy sau khi sử dụng combiner, số records giảm từ 3519 xuống còn 6 (trong mẫu chỉ có 6 loại từ), trong trường hợp này combiner có thể giảm đáng kể lượng dữ liệu cần truyền.
Tính năng nâng cao của ví dụ về thống kê tần suất từ: Partitioner
Partitioner mặc định
Giả sử chúng ta có một yêu cầu: xuất kết quả thống kê từ khác nhau vào các tệp khác nhau. Yêu cầu này thực ra khá phổ biến, ví dụ: khi thống kê doanh số sản phẩm, cần phân tách kết quả theo loại sản phẩm. Để thực hiện chức năng này, chúng tôi cần sử dụng Partitioner tùy chỉnh.
Đầu tiên, hãy giới thiệu quy tắc phân loại mặc định của MapReduce: khi tạo công việc, nếu không chỉ định, mặc định sẽ sử dụng HashPartitioner: thực hiện băm hash trên giá trị key và lấy phần dư của numReduceTasks. Triển khai như sau:
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}Tùy chỉnh Partitioner
Ở đây, chúng tôi thừa hưởng Partitioner để tùy chỉnh quy tắc phân loại, ở đây chúng tôi phân loại theo từ:
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
public int getPartition(Text text, IntWritable intWritable, int numPartitions) {
return WordCountDataUtils.WORD_LIST.indexOf(text.toString());
}
}Khi tạo job, chỉ định sử dụng quy tắc phân loại của chúng tôi và đặt số lượng reduce:
// Đặt quy tắc phân loại tùy chỉnh
job.setPartitionerClass(CustomPartitioner.class);
// Đặt số lượng reduce
job.setNumReduceTasks(WordCountDataUtils.WORD_LIST.size());Kết quả thực thi
Kết quả thực thi như sau, tạo ra 6 tệp riêng biệt, mỗi tệp chứa kết quả thống kê của từ tương ứng: