Go: Map Principal
Map là gì?
Wikipedia định nghĩa map như thế này:
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type composed of a collection of (key, value) pairs, such that each possible key appears at most once in the collection.
Có hai điểm chính: map được hình thành từ các cặp khóa-giá trị (key-value) và mỗi khóa chỉ xuất hiện một lần.
Các hoạt động liên quan đến map chủ yếu bao gồm:
- Thêm một cặp key-value - Add hoặc insert;
- Xóa một cặp key-value - Remove hoặc delete;
- Sửa đổi giá trị tương ứng với một khóa - Reassign;
- Tra cứu giá trị tương ứng với một khóa - Lookup.
Nói một cách đơn giản, đó là các hoạt động cơ bản thêm, xóa, tra cứu, sửa đổi.
Thiết kế map cũng được gọi là vấn đề từ điển, nhiệm vụ của nó là thiết kế một cấu trúc dữ liệu để duy trì một tập hợp dữ liệu và đồng thời thực hiện các hoạt động thêm, xóa, tra cứu và sửa đổi trên tập hợp đó. Có hai cấu trúc dữ liệu chính: bảng tìm kiếm bằng băm (Hash table) và cây tìm kiếm (Search tree).
Bảng tìm kiếm bằng băm sử dụng một hàm băm để phân phối khóa vào các thùng (bucket, cũng chính là các chỉ số của mảng) khác nhau. Điều này giúp giảm thiểu chi phí tính toán hàm băm và thời gian truy cập hằng số vào mảng. Trong nhiều tình huống, bảng tìm kiếm bằng băm có hiệu suất cao.
Tuy nhiên, bảng tìm kiếm bằng băm thường gặp vấn đề va chạm (colison), tức là các khóa khác nhau được hàm băm đến cùng một thùng. Thông thường có hai phương pháp để xử lý: phương pháp liên kết (chaining) và phương pháp địa chỉ mở (open addressing). Phương pháp liên kết sẽ biểu diễn một thùng dưới dạng một danh sách liên kết, tất cả các khóa rơi vào cùng một thùng sẽ được chèn vào danh sách này. Phương pháp địa chỉ mở sẽ tìm một vị trí trống sau mảng để đặt khóa mới khi xảy ra va chạm.
Cây tìm kiếm thường sử dụng cây tìm kiếm tự cân bằng, bao gồm cây AVL, cây đỏ-đen (Red-Black Tree). Trong phỏng vấn, thường được hỏi về cây đỏ-đen và yêu cầu viết mã cây đỏ-đen, thậm chí có thể ngay cả người phỏng vấn cũng không thể viết mã cây đỏ-đen, rất vô lý.
Hiệu suất tìm kiếm xấu nhất của cây tìm kiếm tự cân bằng là O(logN), trong khi bảng tìm kiếm bằng băm xấu nhất là O(N). Tuy nhiên, hiệu suất tìm kiếm trung bình của bảng tìm kiếm bằng băm là O(1), nếu hàm băm được thiết kế tốt, trường hợp xấu nhất gần như không xảy ra. Một điểm khác, khi duyệt cây tìm kiếm tự cân bằng, chuỗi khóa trả về thường được sắp xếp theo thứ tự tăng dần; trong khi bảng tìm kiếm bằng băm thì không có thứ tự.
Cách triển khai map trong Go
Đầu tiên, tôi xin nêu rõ phiên bản Go mà tôi sử dụng:
go version go1.9.2 darwin/amd64Như đã đề cập trước đó, Go sử dụng bảng tìm kiếm bằng băm và giải quyết xung đột bằng cách sử dụng danh sách liên kết.
Tiếp theo, chúng ta sẽ khám phá cơ chế cốt lõi của map và xem xét cấu trúc nội bộ của nó.
Mô hình bộ nhớ của map
Trong mã nguồn, cấu trúc dữ liệu đại diện cho map là hmap, nó là viết tắt của hashmap:
// A header for a Go map.
type hmap struct {
// Số lượng phần tử, khi gọi len(map), giá trị này được trả về trực tiếp
count int
flags uint8
// log_2 của độ dài của mảng buckets
B uint8
// Số lượng bucket overflow xấp xỉ
noverflow uint16
// Giá trị hash0 được sử dụng để tính toán hash của key
hash0 uint32
// Con trỏ trỏ đến mảng buckets, kích thước là 2^B
// Nếu số lượng phần tử là 0, thì giá trị này là nil
buckets unsafe.Pointer
// Khi mở rộng với cùng dung lượng, độ dài của buckets và oldbuckets sẽ bằng nhau
// Khi mở rộng, độ dài của buckets sẽ là gấp đôi so với oldbuckets
oldbuckets unsafe.Pointer
// Chỉ số này cho biết tiến trình mở rộng, buckets dưới địa chỉ này đã được di chuyển
nevacuate uintptr
extra *mapextra // các trường tùy chọn
}Lưu ý, B là log_2 của độ dài của mảng buckets, có nghĩa là độ dài của mảng buckets là 2^B. Mảng buckets chứa các bucket, mỗi bucket chứa key và value, chúng ta sẽ nói về nó sau.
buckets là một con trỏ, cuối cùng nó trỏ đến một cấu trúc:
type bmap struct {
tophash [bucketCnt]uint8
}Nhưng đây chỉ là cấu trúc bề ngoài của bucket (src/runtime/hashmap.go), trong quá trình biên dịch, nó sẽ được mở rộng động để tạo ra một cấu trúc mới:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}bmap được gọi là bucket trong ngôn ngữ thông thường, mỗi bucket có thể chứa tối đa 8 cặp key. Các key này rơi vào cùng một bucket vì sau khi được tính toán bằng hàm băm, kết quả hàm băm của chúng thuộc cùng một thùng. Trong mỗi bucket, vị trí mà key sẽ nằm trong bucket được xác định bằng 8 bit cao của giá trị hash được tính từ key (mỗi bucket có tối đa 8 vị trí).
Dưới đây là một hình ảnh tổng quan:
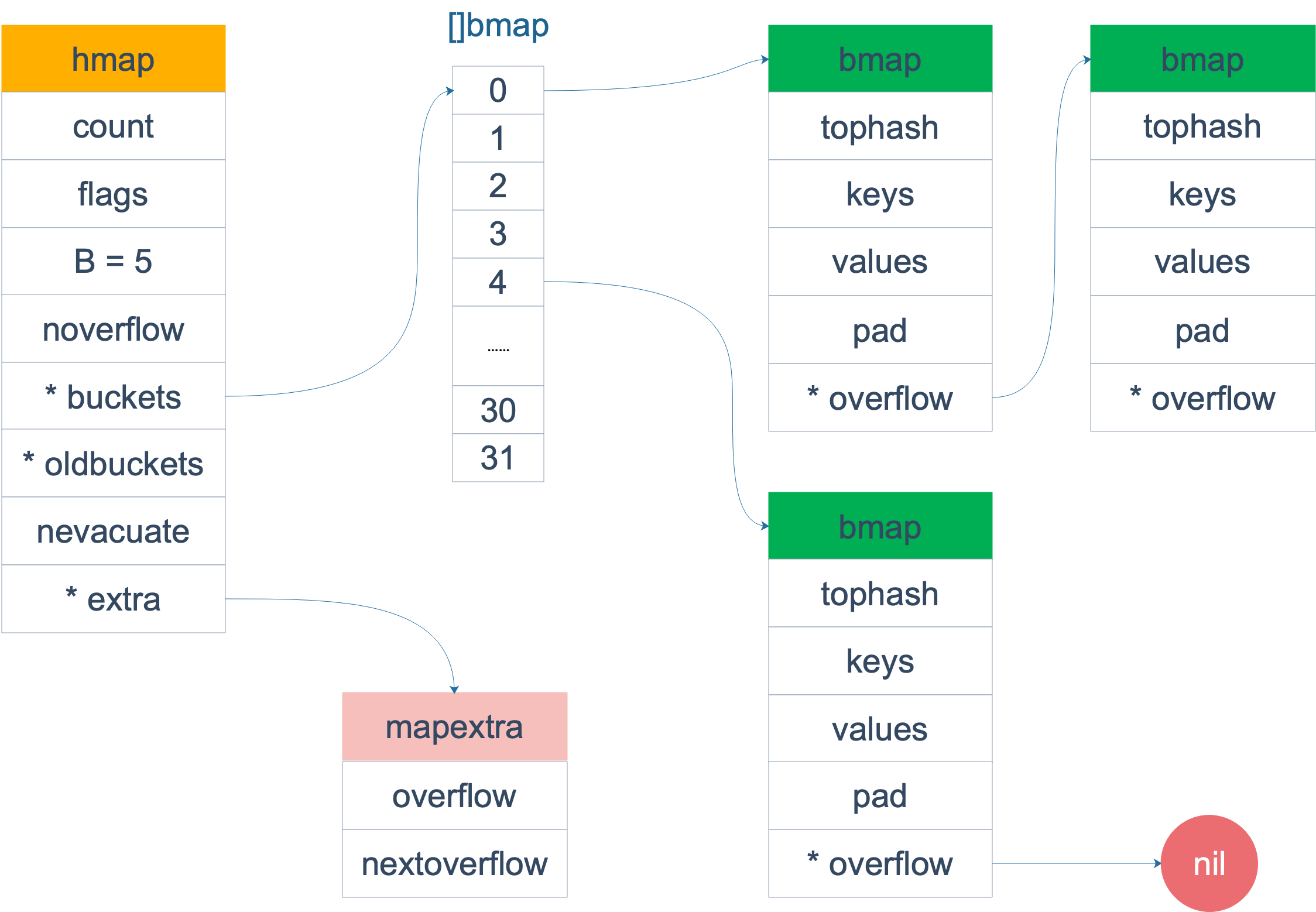
Khi cả key và value trong map đều không phải là con trỏ và kích thước nhỏ hơn 128 byte, bmap sẽ được đánh dấu là không chứa con trỏ, điều này giúp tránh việc quét toàn bộ hmap trong quá trình thu gom rác (garbage collection). Tuy nhiên, chúng ta có thể thấy rằng bmap thực tế có một trường overflow là con trỏ, phá vỡ ý tưởng không chứa con trỏ của bmap. Trong trường hợp này, trường overflow sẽ được di chuyển vào trường mapextra.
type mapextra struct {
// overflow[0] chứa các bucket overflow cho hmap.buckets.
// overflow[1] chứa các bucket overflow cho hmap.oldbuckets.
overflow [2]*[]*bmap
// nextOverflow chứa các bucket overflow không sử dụng, đây là các bucket được cấp phát trước
nextOverflow *bmap
}bmap là nơi lưu trữ cặp khóa-giá trị (k-v), hãy xem xét cấu trúc nội bộ của bmap một cách cụ thể.

Hình trên là mô hình bộ nhớ của một bucket, HOB Hash đề cập đến top hash (sẽ giải thích ở dưới). Lưu ý rằng key và value được lưu trữ cùng nhau, không phải dạng key/value/key/value/…. Mã nguồn giải thích rằng điều này có lợi trong một số trường hợp, có thể loại bỏ trường padding, tiết kiệm không gian bộ nhớ.
Ví dụ, nếu có một loại map như sau:
map[int64]int8Nếu lưu trữ theo kiểu key/value/key/value/…, sau mỗi cặp key-value, phải có thêm padding 7 byte; trong khi nếu các key và value được gắn kết riêng biệt, theo dạng key/key/…/value/value/…, chỉ cần thêm padding ở cuối.
Mỗi bucket được thiết kế để chứa tối đa 8 cặp key-value, nếu có key-value thứ 9 rơi vào bucket hiện tại, thì cần tạo thêm một bucket và nối chúng với nhau thông qua con trỏ overflow.
Tạo map
Từ mặt cú pháp, việc tạo map rất đơn giản:
ageMp := make(map[string]int)
// Chỉ định độ dài của map
ageMp := make(map[string]int, 8)
// ageMp là nil, không thể thêm phần tử vào nó, sẽ gây ra panic ngay lập tức
var ageMp map[string]intThông qua hợp ngữ, chúng ta có thể thấy rằng thực tế là gọi hàm makemap, công việc chính là khởi tạo các trường của cấu trúc hmap, chẳng hạn như tính toán kích thước B, thiết lập giá trị băm hash0, vv.
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
// Bỏ qua các kiểm tra điều kiện...
// Tìm một giá trị B sao cho hệ số tải của map nằm trong phạm vi bình thường
B := uint8(0)
for ; overLoadFactor(hint, B); B++ {
}
// Khởi tạo bảng băm
// Nếu B bằng 0, thì buckets sẽ được phân bổ sau khi gán giá trị
// Nếu độ dài lớn, việc phân bổ bộ nhớ sẽ mất thời gian hơn
buckets := bucket
var extra *mapextra
if B != 0 {
var nextOverflow *bmap
buckets, nextOverflow = makeBucketArray(t, B)
if nextOverflow != nil {
extra = new(mapextra)
extra.nextOverflow = nextOverflow
}
}
// Khởi tạo hamp
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.count = 0
h.B = B
h.extra = extra
h.flags = 0
h.hash0 = fastrand()
h.buckets = buckets
h.oldbuckets = nil
h.nevacuate = 0
h.noverflow = 0
return h
}【Mở rộng 1】Có gì khác biệt khi slice và map được sử dụng như các tham số của hàm?
Lưu ý rằng kết quả trả về của hàm này là *hmap, đó là một con trỏ, trong khi hàm makeslice đã nói trước đó trả về Slice:
func makeslice(et *_type, len, cap int) sliceHãy xem lại định nghĩa cấu trúc của slice:
// runtime/slice.go
type slice struct {
array unsafe.Pointer // Con trỏ đến phần tử
len int // Độ dài
cap int // Sức chứa
}Cấu trúc này bao gồm con trỏ đến dữ liệu cơ sở.
Sự khác biệt giữa makemap và makeslice mang đến một điểm khác biệt: khi map và slice được sử dụng làm tham số của hàm, các hoạt động trên map bên trong hàm sẽ ảnh hưởng đến map gốc. Trong khi đó, các hoạt động trên slice sẽ không ảnh hưởng đến tham số gốc (đã được nói trong bài viết về slice trước đó).
Nguyên nhân chính: một cái là con trỏ (*hmap), một cái là cấu trúc (slice). Trong Go, tham số của hàm được truyền theo giá trị, trong hàm, tham số sẽ được sao chép vào bộ nhớ cục bộ. Con trỏ *hmap được sao chép xong, vẫn trỏ đến cùng một map, do đó, các hoạt động trên map bên trong hàm sẽ ảnh hưởng đến tham số thực. Trong khi đó, slice sau khi được sao chép, sẽ trở thành một slice mới, các hoạt động trên nó sẽ không ảnh hưởng đến tham số thực.
Hàm băm
Một điểm quan trọng của map là việc lựa chọn hàm băm. Khi chương trình khởi động, nó sẽ kiểm tra xem CPU có hỗ trợ AES hay không. Nếu có, nó sẽ sử dụng hàm băm AES, ngược lại sẽ sử dụng hàm băm memhash. Điều này được thực hiện trong hàm alginit(), nằm trong đường dẫn src/runtime/alg.go.
Hàm băm có hai loại: mã hóa và không mã hóa.
- Loại mã hóa thường được sử dụng cho việc mã hóa dữ liệu, tóm tắt số, ví dụ điển hình là md5, sha1, sha256, aes256.
-Loại không mã hóa thường được sử dụng cho việc tìm kiếm. Trong trường hợp ứng dụng của map, chúng ta sử dụng loại không mã hóa.Việc lựa chọn hàm băm chủ yếu xem xét hai điểm: hiệu suất và xác suất va chạm.
Trước đó, chúng ta đã nói về cấu trúc đại diện cho kiểu dữ liệu:
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
gcdata *byte
str nameOff
ptrToThis typeOff
}Trong đó, trường alg liên quan đến hàm băm, nó là một con trỏ đến cấu trúc sau:
// src/runtime/alg.go
type typeAlg struct {
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
}typeAlg bao gồm hai hàm, hàm hash tính toán giá trị băm của kiểu dữ liệu, trong khi hàm equal tính toán xem hai đối tượng liệu có băm bằng nhau hay không.
Đối với kiểu dữ liệu string, hàm hash và equal của nó như sau:
func strhash(a unsafe.Pointer, h uintptr) uintptr {
x := (*stringStruct)(a)
return memhash(x.str, h, uintptr(x.len))
}
func strequal(p, q unsafe.Pointer) bool {
return *(*string)(p) == *(*string)(q)
}Dựa trên loại dữ liệu của khóa, trường alg của cấu trúc _type sẽ được thiết lập với hàm hash và equal tương ứng.
Quá trình xác định key
Key sau khi được tính toán bằng hàm băm sẽ cho ra giá trị băm, gồm 64 bit (trên máy 64 bit, không xét đến máy 32 bit vì hiện nay phổ biến là máy 64 bit). Trong quá trình xác định key thuộc vào bucket nào, chỉ có các bit cuối cùng B được sử dụng. B đã được đề cập trước đó. Ví dụ, nếu B = 5, số lượng bucket, tức là độ dài của mảng buckets, sẽ là 2^5 = 32.
Ví dụ, giờ có một key sau khi tính toán bằng hàm băm, cho ra giá trị băm:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010Sử dụng 5 bit cuối cùng (5 bit thấp), tức là 01010, có giá trị là 10, tức là bucket số 10. Thực tế, đây là phép toán lấy phần dư, nhưng vì phép toán lấy phần dư tốn kém, nên trong mã nguồn được thay thế bằng phép toán bit.
Tiếp theo, sử dụng 8 bit đầu tiên (8 bit cao) của giá trị băm, tìm vị trí của key trong bucket. Ban đầu, bucket không có key nào, key mới được thêm vào sẽ tìm vị trí trống đầu tiên và đặt vào đó.
Khi hai key khác nhau rơi vào cùng một bucket, tức là xảy ra xung đột băm. Phương pháp giải quyết xung đột là sử dụng phương pháp liên kết: trong bucket, tìm vị trí trống đầu tiên từ trước đến sau. Điều này có nghĩa là khi tìm kiếm một key nào đó, trước tiên tìm đến bucket tương ứng, sau đó duyệt qua các key trong bucket.
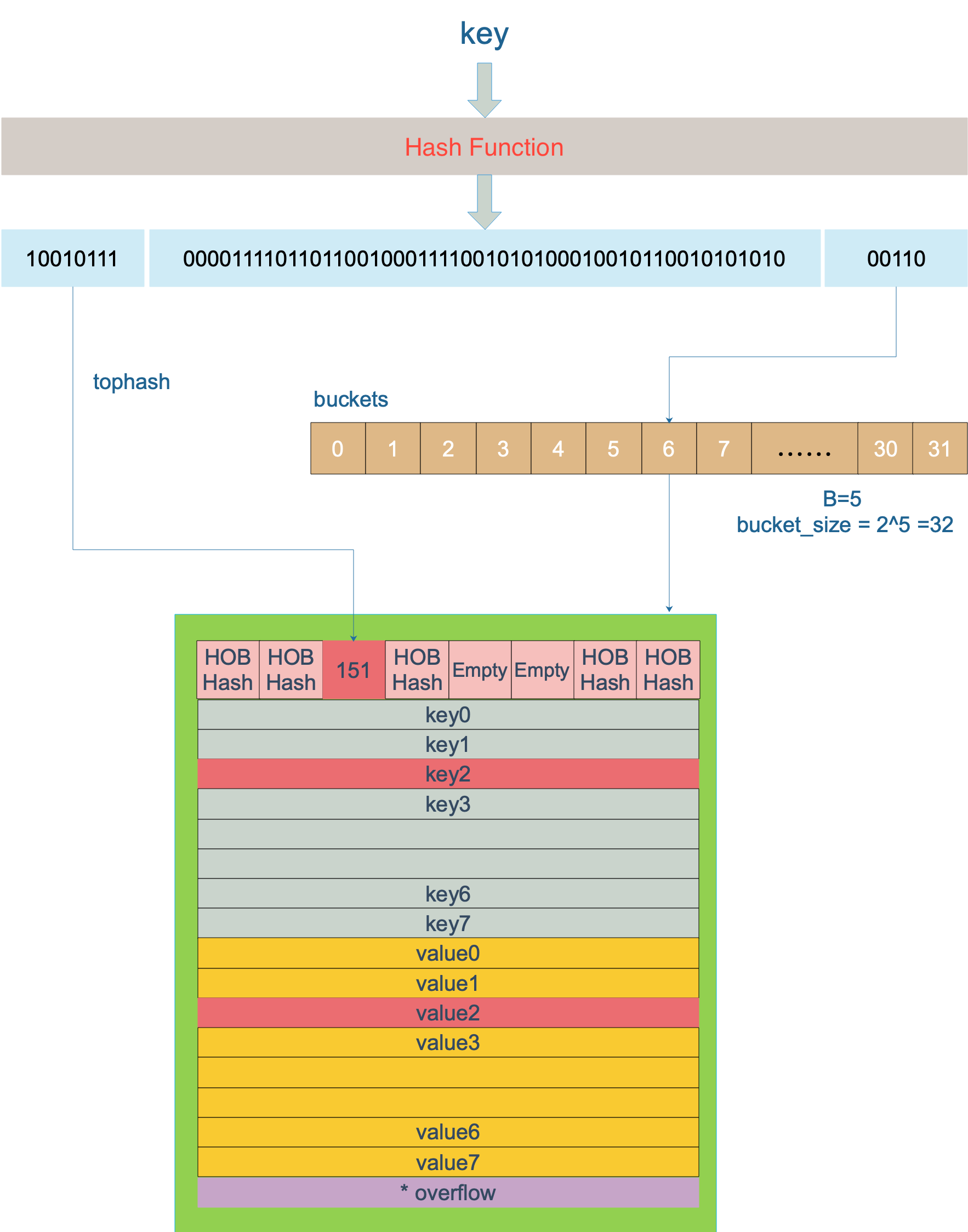
Trong hình ảnh trên, giả sử B = 5, vì vậy tổng số bucket là 2^5 = 32. Đầu tiên tính toán giá trị băm của key cần tìm, sử dụng 5 bit cuối cùng 00110, tìm đến bucket số 6 tương ứng, sau đó sử dụng 8 bit đầu tiên 10010111, tương ứng với số thập phân 151, tìm giá trị tophash (HOB Hash) là 151 trong bucket số 6, tìm thấy vị trí số 2, quá trình tìm kiếm key hoàn tất.
Nếu không tìm thấy trong bucket và overflow không rỗng, tiếp tục tìm kiếm trong overflow bucket cho đến khi tìm thấy hoặc duyệt qua tất cả các key, bao gồm cả overflow bucket.
Bây giờ chúng ta hãy xem mã nguồn! Dựa vào hợp ngữ, chúng ta có thể thấy rằng hàm mapaccess1 là hàm cơ bản để tìm kiếm một key, các hàm tương tự, khác nhau ở phần tiếp theo sẽ được giải thích trong phần tiếp theo. Ở đây chúng ta chỉ xem hàm mapaccess1:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ……
// Nếu h không tồn tại hoặc h.count = 0, trả về giá trị zeroVal
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
// Xung đột giữa ghi và đọc
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// Hàm băm cho các loại key khác nhau được xác định tại thời điểm biên dịch
alg := t.key.alg
// Tính toán giá trị băm và thêm hash0 để tạo sự ngẫu nhiên
hash := alg.hash(key, uintptr(h.hash0))
// Ví dụ, nếu B = 5, thì m = 31, tức là 31 có dạng nhị phân là toàn 1
// Khi tính toán số thứ tự của bucket, ta sẽ sử dụng phép AND giữa hash và m
// Điều này có tác dụng là số thứ tự của bucket được xác định bởi 8 bit thấp nhất của hash
m := uintptr(1)<<h.B - 1
// b là địa chỉ của bucket
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// Nếu c != nil, có nghĩa là đã mở rộng
if c := h.oldbuckets; c != nil {
// Nếu không phải mở rộng cùng kích thước (xem phần mở rộng sau)
// Giải pháp cho điều kiện 1
if !h.sameSizeGrow() {
// Số lượng bucket mới là gấp đôi số lượng bucket cũ
m >>= 1
}
// Tính toán vị trí của key trong map cũ
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// Nếu oldb chưa được di chuyển vào bucket mới
// Tiếp tục tìm kiếm trong bucket cũ
if !evacuated(oldb) {
b = oldb
}
}
// Tính toán 8 bit cao của hash
// Tương đương với dịch phải 56 bit, chỉ lấy 8 bit cao
top := uint8(hash >> (sys.PtrSize*8 - 8))
// Tăng thêm minTopHash
if top < minTopHash {
top += minTopHash
}
for {
// Duyệt qua 8 vị trí trong bucket
for i := uintptr(0); i < bucketCnt; i++ {
// Nếu tophash không khớp, tiếp tục
if b.tophash[i] != top {
continue
}
// Nếu tophash khớp, xác định vị trí của key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// Nếu key là con trỏ
if t.indirectkey {
// Giải tham chiếu
k = *((*unsafe.Pointer)(k))
}
// Nếu key khớp
if alg.equal(key, k) {
// Xác định vị trí của value
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
// Giải tham chiếu value
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
// Đã duyệt qua tất cả các vị trí trong bucket (vẫn không tìm thấy), tiếp tục tìm kiếm trong overflow bucket
b = b.overflow(t)
// Đã duyệt qua tất cả overflow bucket, không tìm thấy key mục tiêu, trả về giá trị zeroVal
if b == nil {
return unsafe.Pointer(&zeroVal[0])
}
}
}Hàm trả về con trỏ của h[key], nếu không có key trong h, nó sẽ trả về giá trị zeroVal tương ứng với kiểu của key, không trả về nil.
Mã nguồn tổng thể khá đơn giản và không có gì khó hiểu. Hãy theo dõi các chú thích ở trên để hiểu từng bước.
Ở đây, tôi sẽ giải thích cách xác định key và value cũng như cách viết vòng lặp chính.
// Công thức xác định key
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// Công thức xác định value
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))b là địa chỉ của bmap, ở đây bmap vẫn là một cấu trúc được định nghĩa trong mã nguồn, chỉ chứa một mảng tophash. Sau khi được mở rộng bởi trình biên dịch, cấu trúc mới bao gồm các trường key, value, overflow. dataOffset là sự chênh lệch giữa key và địa chỉ bắt đầu của bmap:
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)Vì vậy, địa chỉ bắt đầu của key trong bucket là unsafe.Pointer(b) + dataOffset. Địa chỉ của key thứ i sẽ phải vượt qua i lần kích thước của key. Và chúng ta cũng biết rằng địa chỉ của value nằm sau tất cả các key, vì vậy địa chỉ của value thứ i sẽ phải được cộng thêm sự chênh lệch của tất cả các key. Sau khi hiểu được điều này, công thức xác định key và value ở trên sẽ dễ hiểu hơn.
Tiếp theo, vòng lặp lớn là một vòng lặp vô hạn, thông qua
b = b.overflow(t)Duyệt qua tất cả các bucket, đây tương đương với một danh sách liên kết các bucket.
Khi xác định một bucket cụ thể, vòng lặp bên trong sẽ duyệt qua tất cả các cell trong bucket đó, hoặc nói cách khác, tất cả các slot, tức là bucketCnt=8 slot. Quá trình lặp này:
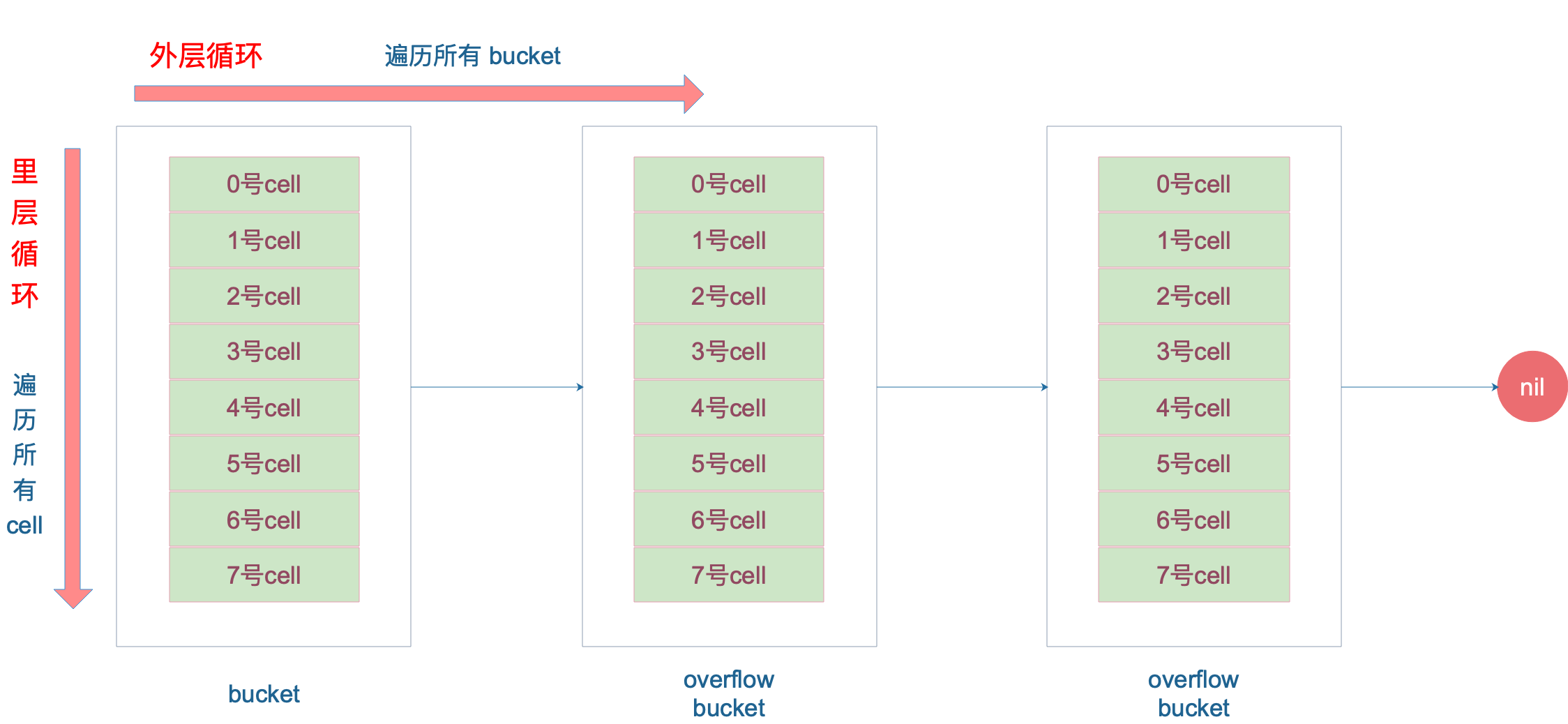
Tiếp theo, hãy nói về minTopHash. Khi giá trị tophash của một cell nhỏ hơn minTopHash, nó đánh dấu trạng thái di chuyển của cell đó. Vì giá trị trạng thái này được lưu trữ trong mảng tophash, để phân biệt với giá trị băm bình thường, sẽ có một giá trị tăng thêm: minTopHash. Điều này giúp phân biệt giữa giá trị tophash bình thường và giá trị tophash đại diện cho trạng thái.
Các trạng thái sau đây đại diện cho tình trạng của bucket:
// Ô trống, cũng là trạng thái ban đầu của bucket
empty = 0
// Ô trống, đại diện cho cell đã được di chuyển vào bucket mới
evacuatedEmpty = 1
// key, value đã được di chuyển hoàn toàn, nhưng key nằm trong nửa đầu của bucket mới,
// chúng ta sẽ nói về phần mở rộng sau này.
evacuatedX = 2
// Tương tự như trên, nhưng key nằm trong nửa sau
evacuatedY = 3
// Giá trị tophash tối thiểu bình thường
minTopHash = 4Trong mã nguồn, hàm sau được sử dụng để kiểm tra xem bucket đã được di chuyển hoàn toàn hay chưa:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}Chỉ lấy giá trị tophash đầu tiên trong mảng tophash và kiểm tra xem nó có nằm trong khoảng từ 0 đến 4 không. So sánh với các hằng số trên, khi giá trị tophash là evacuatedEmpty, evacuatedX, evacuatedY, có nghĩa là tất cả các key trong bucket này đã được di chuyển vào bucket mới.