Java Collection - Map
Giới thiệu về Map
Kiến trúc của Map
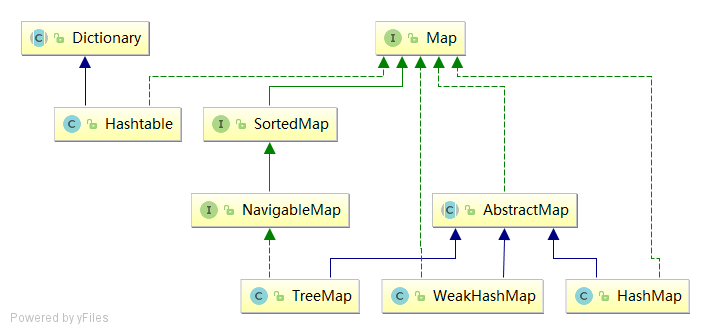
Dòng họ Map bao gồm các thành viên chính sau:
Maplà gốc của dòng họ Map, là một giao diện dùng để lưu trữ các cặp khóa-giá trị (key-value). Map không thể chứa các khóa trùng lặp; mỗi khóa chỉ có thể ánh xạ tới một giá trị duy nhất.AbstractMapkế thừa từ lớp trừu tượngMap, nó triển khai các API cốt lõi củaMap. Các lớp triển khaiMapkhác có thể kế thừa từAbstractMapđể tránh việc lặp lại mã.SortedMapkế thừa từ giao diệnMap. Nội dung củaSortedMapđược sắp xếp theo cặp khóa-giá trị, việc sắp xếp được thực hiện thông qua việc triển khai một bộ so sánh (Comparator).NavigableMapkế thừa từSortedMap. So vớiSortedMap,NavigableMapcung cấp một loạt các phương thức “điều hướng”; ví dụ như “lấy các cặp khóa-giá trị lớn hơn hoặc bằng một đối tượng nào đó”, “lấy các cặp khóa-giá trị nhỏ hơn hoặc bằng một đối tượng nào đó”, v.v.HashMapkế thừa từAbstractMap, nhưng không triển khai giao diệnNavigableMap.HashMapchủ yếu được sử dụng để lưu trữ các cặp khóa-giá trị không có thứ tự, và việc tìm kiếm trongHashMaprất hiệu quả.HashMaplà một trong nhữngMapđược sử dụng rộng rãi nhất.Hashtablemặc dù không kế thừa từAbstractMap, nhưng nó kế thừa từDictionary(cũng là giao diện khóa-giá trị), và triển khai giao diệnMap. Do đó,Hashtablechủ yếu được sử dụng để lưu trữ các cặp khóa-giá trị không có thứ tự. So vớiHashMap,Hashtablesử dụng từ khóasynchronizedtrong các phương thức chính để đảm bảo đồng bộ hóa luồng. Tuy nhiên, do độ chi tiết của khóa quá lớn, nó ảnh hưởng đến tốc độ đọc và ghi, vì vậy trong các ứng dụng Java hiện đại, hầu như không sử dụngHashtable. Thay vào đó, nếu cần đảm bảo đồng bộ hóa, thường sử dụngConcurrentHashMap.TreeMapkế thừa từAbstractMapvà triển khai giao diệnNavigableMap.TreeMapchủ yếu được sử dụng để lưu trữ các cặp khóa-giá trị có thứ tự, sắp xếp dựa trên một bộ so sánh của kiểu phần tử.WeakHashMapkế thừa từAbstractMap. Khóa củaWeakHashMaplà các tham chiếu yếu (WeakReference), chức năng chính của nó là khi bộ nhớ GC không đủ,WeakHashMapsẽ tự động thu hồi các khóa trong nó, tránh việc lãng phí không gian bộ nhớ. Rõ ràng,WeakHashMapthích hợp để sử dụng như một bộ nhớ cache.
Giao diện Map
Định nghĩa của Map như sau:
public interface Map<K,V> { }Map là một giao diện dùng để lưu trữ các cặp khóa-giá trị (key-value).
Giao diện Map cung cấp ba loại xem Collection, cho phép truy cập dữ liệu dưới dạng tập hợp khóa, tập hợp giá trị hoặc tập hợp cặp khóa-giá trị.
Các lớp triển khai của Map có thể lưu trữ các phần tử theo thứ tự hoặc không theo thứ tự. Ví dụ, lớp TreeMap sẽ lưu trữ các phần tử theo thứ tự, trong khi HashMap không đảm bảo thứ tự.
Các lớp triển khai của Map nên cung cấp hai phương thức xây dựng “tiêu chuẩn”:
- Phương thức xây dựng không tham số, dùng để tạo một Map trống.
- Phương thức xây dựng với một tham số kiểu Map, dùng để tạo một Map mới có cùng cặp khóa-giá trị với tham số đầu vào.
Thực tế, phương thức xây dựng thứ hai cho phép người dùng sao chép bất kỳ Map nào để tạo ra một Map tương tự. Mặc dù không thể bắt buộc thực hiện đề xuất này (vì giao diện không thể chứa phương thức xây dựng), nhưng tất cả các triển khai Map thông thường trong JDK đều tuân thủ nó.
Giao diện Map.Entry
Map.Entry thường được sử dụng để truy cập Map thông qua Iterator.
Map.Entry là một giao diện nội bộ của Map, Map.Entry đại diện cho một cặp khóa-giá trị, Map sử dụng phương thức entrySet() để lấy một tập hợp các Map.Entry, từ đó thực hiện các thao tác trên cặp khóa-giá trị.
Lớp trừu tượng AbstractMap
Định nghĩa của AbstractMap như sau:
public abstract class AbstractMap<K,V> implements Map<K,V> {}Lớp trừu tượng AbstractMap cung cấp triển khai cốt lõi của giao diện Map, giúp giảm thiểu công việc cần thiết để triển khai giao diện Map.
Để triển khai một Map không thể sửa đổi, người lập trình chỉ cần mở rộng lớp này và cung cấp triển khai của phương thức entrySet(), phương thức này sẽ trả về một tập hợp các cặp khóa-giá trị của Map. Thông thường, tập hợp trả về sẽ được triển khai trên AbstractSet. Tập hợp này không hỗ trợ các phương thức add() hoặc remove(), và trình lặp của nó cũng không hỗ trợ phương thức remove().
Để triển khai một Map có thể sửa đổi, người lập trình phải ghi đè phương thức put() của lớp này (nếu không sẽ ném ra UnsupportedOperationException), và cũng phải triển khai phương thức remove() của trình lặp trả về từ entrySet().iterator().
Giao diện SortedMap
Định nghĩa của SortedMap như sau:
public interface SortedMap<K,V> extends Map<K,V> { }SortedMap kế thừa từ Map, đây là một Map có thứ tự.
SortedMap có hai cách sắp xếp: sắp xếp tự nhiên hoặc sắp xếp theo bộ so sánh được chỉ định bởi người dùng. Tất cả các phần tử được chèn vào SortedMap phải triển khai giao diện Comparable (hoặc được chấp nhận bởi bộ so sánh được chỉ định).
Ngoài ra, tất cả các lớp triển khai của SortedMap nên cung cấp 4 phương thức xây dựng “tiêu chuẩn”:
- Phương thức xây dựng
voidkhông tham số, tạo mộtSortedMaptrống và sắp xếp theo thứ tự tự nhiên của khóa. - Phương thức xây dựng với một tham số kiểu
Comparator, tạo mộtSortedMaptrống và sắp xếp theo bộ so sánh được chỉ định. - Phương thức xây dựng với một tham số kiểu
Map, tạo mộtSortedMapmới với các cặp khóa-giá trị tương tự như tham số đầu vào và sắp xếp theo thứ tự tự nhiên của khóa. - Phương thức xây dựng với một tham số kiểu
SortedMap, tạo một SortedMap mới với các cặp khóa-giá trị và phương thức sắp xếp tương tự nhưSortedMapđầu vào. Mặc dù không thể bắt buộc thực hiện đề xuất này (vì giao diện không thể chứa phương thức khởi tạo), nhưng tất cả các triển khaiSortedMapthông thường trong JDK đều tuân thủ nó.
Giao diện NavigableMap
NavigableMap được định nghĩa như sau:
public interface NavigableMap<K,V> extends SortedMap<K,V> { }NavigableMap kế thừa từ SortedMap, nó cung cấp các phương thức tìm kiếm phong phú.
NavigableMap cung cấp các chức năng sau:
- Lấy cặp khóa-giá trị
- Các phương thức
lowerEntry,floorEntry,ceilingEntryvàhigherEntrylần lượt trả về các đối tượngMap.Entryliên quan đến khóa nhỏ hơn, nhỏ hơn hoặc bằng, lớn hơn hoặc bằng, lớn hơn khóa đã cho. - Các phương thức
firstEntry,pollFirstEntry,lastEntryvàpollLastEntrylần lượt trả về và/hoặc xóa các cặp khóa-giá trị nhỏ nhất và lớn nhất (nếu tồn tại), nếu không tồn tại trả về null.
- Các phương thức
- Lấy khóa. Tương tự như chức năng thứ nhất.
- Các phương thức
lowerKey,floorKey,ceilingKeyvàhigherKeylần lượt trả về các khóa nhỏ hơn, nhỏ hơn hoặc bằng, lớn hơn hoặc bằng, lớn hơn khóa đã cho.
- Các phương thức
- Lấy tập hợp khóa
- Các phương thức
navigableKeySetvàdescendingKeySetlần lượt trả về tập hợp khóa theo thứ tự tăng dần/giảm dần.
- Các phương thức
- Lấy tập hợp cặp khóa-giá trị con
Lớp trừu tượng Dictionary
Định nghĩa của lớp trừu tượng Dictionary như sau:
public abstract class Dictionary<K,V> {}Dictionary là một lớp trừu tượng được định nghĩa từ JDK 1.0, nó chứa các phương thức cơ bản để thao tác với các cặp khóa-giá trị.
Lớp HashMap
Lớp HashMap là một trong những lớp Map được sử dụng phổ biến nhất.
Điểm chính của HashMap
Từ tên của lớp HashMap, chúng ta có thể thấy rằng HashMap lưu trữ các cặp khóa-giá trị theo cách phân tán.
HashMap cho phép sử dụng giá trị null và khóa null. (HashMap tương đương với Hashtable, ngoại trừ việc nó không đồng bộ và cho phép giá trị null). Lớp này không đảm bảo thứ tự; đặc biệt là thứ tự các phần tử có thể thay đổi theo thời gian.
HashMap có hai tham số ảnh hưởng đến hiệu suất của nó: dung lượng ban đầu và hệ số tải.
- Dung lượng là số lượng ngăn trong bảng băm, dung lượng ban đầu là dung lượng khi bảng băm được tạo.
- Hệ số tải là mức tối đa cho phép của bảng băm trước khi nó được tự động mở rộng. Khi số lượng entry trong bảng băm vượt quá tích của hệ số tải và dung lượng hiện tại, bảng băm sẽ được tái cấu trúc (tức là tái xây dựng cấu trúc dữ liệu nội bộ), thông thường bảng băm có khoảng gần bằng gấp đôi dung lượng hiện tại.
Thường thì, hệ số tải mặc định (0.75) cung cấp một sự cân bằng tốt giữa thời gian và không gian. Giá trị cao hơn sẽ giảm thiểu không gian nhưng tăng thời gian tìm kiếm (phản ánh trong hầu hết các hoạt động của lớp HashMap, bao gồm get và put). Khi đặt dung lượng ban đầu, nên xem xét số lượng entry trong bản đồ và hệ số tải để giảm thiểu số lần thực hiện lại. Nếu dung lượng ban đầu lớn hơn số lượng entry tối đa chia cho hệ số tải, không có sự thay đổi lại sẽ xảy ra.
Nếu có nhiều bản đồ cần lưu trữ trong một HashMap instance, việc tạo một dung lượng đủ lớn cho bản đồ sẽ cho phép hiệu suất lưu trữ của bản đồ cao hơn so với việc thực hiện lại tự động khi tăng kích thước bảng. Lưu ý rằng việc sử dụng nhiều khóa có cùng hashCode() là một cách đáng tin cậy để làm giảm hiệu suất của bất kỳ bảng băm nào. Để cải thiện vấn đề này, khi khóa là Comparable, lớp này có thể sử dụng thứ tự so sánh giữa các khóa để giúp phân tách chúng.
HashMap không phải là an toàn luồng.
Nguyên lý hoạt động của HashMap
Cấu trúc dữ liệu của HashMap
Các trường chính của HashMap:
table-HashMapsử dụng một mảngNode<K,V>[]kiểu dữ liệutableđể lưu trữ các phần tử.size- Dung lượng ban đầu. Ban đầu là 16 và tự động mở rộng khi không đủ dung lượng.loadFactor- Hệ số tải. Mức tối đa cho phép của bảng băm trước khi nó được tự động mở rộng, mặc định là 0.75.
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
// Mảng này được khởi tạo khi sử dụng lần đầu tiên và được điều chỉnh theo nhu cầu. Khi phân bổ, độ dài luôn là lũy thừa của 2.
transient Node<K,V>[] table;
// Lưu trữ bộ entrySet() được cache. Lưu ý rằng trường AbstractMap được sử dụng cho keySet() và values().
transient Set<Map.Entry<K,V>> entrySet;
// Số cặp khóa-giá trị trong bản đồ
transient int size;
// Số lần cấu trúc của HashMap đã được thay đổi. Cấu trúc thay đổi là những thay đổi sửa đổi số lượng ánh xạ trong HashMap hoặc sửa đổi cấu trúc nội bộ của nó (ví dụ: tái cấu trúc).
transient int modCount;
// Giá trị ngưỡng tiếp theo (dung lượng * hệ số tải).
int threshold;
// Hệ số tải của bảng băm
final float loadFactor;
}Các phương thức khởi tạo của HashMap
public HashMap(); // Hệ số tải mặc định là 0.75
public HashMap(int initialCapacity); // Hệ số tải mặc định là 0.75; Khởi tạo với dung lượng ban đầu
public HashMap(int initialCapacity, float loadFactor); // Khởi tạo với dung lượng ban đầu và hệ số tải
public HashMap(Map<? extends K, ? extends V> m) // Hệ số tải mặc định là 0.75Phương thức put
Phương thức put có cách thức triển khai như sau:
- Tính toán hash code của key bằng cách gọi phương thức
hash(key), sau đó tính toán vị trí lưu trữ của Node dựa trên giá trị hash. - Nếu không có va chạm hash, Node mới được đặt trực tiếp vào bucket. Nếu có va chạm hash, Node mới sẽ được thêm vào cuối danh sách liên kết.
- Nếu danh sách liên kết trở nên quá dài (lớn hơn hoặc bằng
TREEIFY_THRESHOLD, giá trị là 8), danh sách liên kết sẽ được chuyển đổi thành cây đỏ-đen (Red-Black Tree). - Nếu Node đã tồn tại, giá trị cũ sẽ được thay thế bằng giá trị mới.
- Nếu số lượng bucket vượt quá dung lượng * hệ số tải (
threshold),HashMapsẽ tự động mở rộng gấp đôi dung lượng.
Đoạn mã cụ thể như sau:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// Tính toán hash code của key
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// Nếu bảng chưa được tạo, tạo mới
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// Tính toán index và xử lý trường hợp null
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// Node đã tồn tại
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// Danh sách liên kết đã chuyển thành cây
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// Danh sách liên kết
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// Ghi giá trị mới
if (e != null) { // Node đã tồn tại
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}Tại sao tính toán hash sử dụng phép dịch bit không dấu 16 bit của hashcode.
Giả sử chúng ta muốn thêm hai đối tượng a và b vào HashMap, nếu độ dài mảng là 16, lúc này đối tượng a và b sẽ được tính toán thông qua công thức (n - 1) & hash, tức là (16-1) & a.hashCode và (16-1) & b.hashCode, 15 ở dạng nhị phân là 0000000000000000000000000001111, giả sử hashCode của đối tượng A là 1000010001110001000001111000000, hashCode của đối tượng B là 0111011100111000101000010100000, bạn sẽ nhận thấy kết quả của phép AND trên đều là 0. Điều này khiến kết quả băm rất thất vọng, rõ ràng không phải là một thuật toán băm tốt.
Tuy nhiên, nếu chúng ta dịch bit phải hashCode 16 bit (h >>> 16) (h >>> 16 đại diện cho dịch bit phải không dấu 16 bit), tức là lấy một nửa giá trị của kiểu int, chúng ta có thể chia đôi chuỗi nhị phân này và sử dụng phép XOR bit (nếu hai số tại vị trí tương ứng là khác nhau, kết quả sẽ là 1, ngược lại sẽ là 0), điều này sẽ tránh tình huống trên xảy ra. Đó chính là cách thức cụ thể của phương thức hash(). Tóm lại, mục đích là cố gắng làm lộn xộn giá trị hashCode tham gia tính toán của 16 bit thấp nhất.
Phương thức get
Sau khi hiểu về phương thức put, phương thức get trở nên đơn giản hơn. Ý tưởng chính như sau:
-
Tính toán hash code của key bằng cách gọi phương thức
hash(key), sau đó tính toán vị trí của Node trong bucket. -
Nếu Node đầu tiên trong bucket trùng khớp với key, trả về giá trị tương ứng.
-
Nếu có xung đột hash, tìm kiếm entry tương ứng trong danh sách liên kết.
-
Nếu là cây, tìm kiếm trong cây đỏ-đen bằng cách sử dụng
key.equals(k), độ phức tạp O(logn). -
Nếu là danh sách liên kết, tìm kiếm trong danh sách liên kết bằng cách sử dụng
key.equals(k), độ phức tạp O(n).
-
Cụ thể, mã nguồn triển khai như sau:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// Trường hợp trùng khớp
if (first.hash == hash && // luôn kiểm tra node đầu tiên
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// Trường hợp không trùng khớp
if ((e = first.next) != null) {
// Trường hợp cây
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// Trường hợp danh sách liên kết
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}Phương thức hash
Công thức tính chỉ số của bucket trong HashMap là key.hashCode() ^ (h >>> 16).
Dưới đây là một giải thích chi tiết về công thức này.
Trong quá trình get và put, khi tính toán chỉ số, trước tiên ta thực hiện phép hash trên hashCode, sau đó tính toán chỉ số dựa trên giá trị hash, như hình dưới đây:
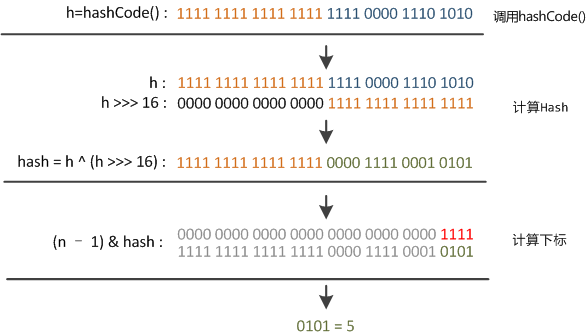
Phương thức hash được thực hiện như sau:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}Có thể thấy rằng phương thức này thực hiện việc giữ nguyên 16 bit cao nhất và thực hiện phép XOR giữa 16 bit thấp và 16 bit cao.
Khi thiết kế phương thức hash này, vì độ dài của bảng table hiện tại là một lũy thừa của 2, và trong quá trình tính toán chỉ số, ta sử dụng phép AND (&) thay vì phép chia lấy dư (%):
(n - 1) & hashNhà thiết kế cho rằng phương pháp này dễ gây va chạm. Tại sao lại như vậy? Hãy suy nghĩ xem, khi n - 1 là 15 (0x1111), thực tế chỉ có 4 bit thấp là có hiệu lực, dễ gây ra va chạm.
Do đó, nhà thiết kế đã nghĩ ra một phương pháp tổng thể (kết hợp tốc độ, hiệu quả và chất lượng) là thực hiện phép XOR giữa 16 bit cao và 16 bit thấp. Nhà thiết kế cũng giải thích rằng vì phân bố hashCode hiện tại đã khá tốt, ngay cả khi có va chạm, ta vẫn sử dụng cây có độ phức tạp O(logn) để xử lý. Chỉ cần thực hiện phép XOR đơn giản, giảm thiểu chi phí hệ thống và không gây ra va chạm do việc không có sự tham gia của bit cao trong tính toán chỉ số (khi độ dài của bảng nhỏ), dẫn đến va chạm.
Nếu vẫn có va chạm thường xuyên, điều gì sẽ xảy ra? Nhà thiết kế đã giải thích rằng họ sử dụng cây để xử lý va chạm thường xuyên (we use trees to handle large sets of collisions in bins). Trong JEP-180, mô tả vấn đề này như sau:
Cải thiện hiệu suất của
java.util.HashMaptrong điều kiện va chạm hash cao bằng cách sử dụng cây cân bằng thay vì danh sách liên kết để lưu trữ các mục của bản đồ. Thực hiện cải tiến tương tự trong lớpLinkedHashMap.
Trước đây, trong việc lấy phần tử của HashMap, ta thực hiện hai bước cơ bản:
- Đầu tiên, thực hiện hash dựa trên hashCode(), sau đó xác định chỉ số của bucket.
- Nếu khóa của nút trong bucket không phải là khóa ta cần, ta tìm kiếm trong chuỗi bằng cách sử dụng keys.equals().
Trong việc triển khai trước JDK8, va chạm được giải quyết bằng cách sử dụng danh sách liên kết. Trong trường hợp va chạm nghiêm trọng, khi thực hiện lấy phần tử, độ phức tạp của hai bước là O(1) + O(n). Do đó, khi va chạm nghiêm trọng và n rất lớn, tốc độ O(n) sẽ ảnh hưởng đến hiệu suất.
Vì vậy, trong JDK8, ta sử dụng cây đỏ-đen thay thế danh sách liên kết. Điều này làm cho độ phức tạp trở thành O(1) + O(logn), giải quyết vấn đề này một cách tương đối tốt. Kết quả của các bài kiểm tra hiệu suất có trong bài viết Tăng hiệu suất của HashMap trong JDK8 đã được thể hiện.
Triển khai resize
Khi thực hiện put, nếu tỷ lệ sử dụng bucket hiện tại vượt quá giới hạn Load Factor mong muốn, ta sẽ thực hiện resize. Trong quá trình resize, đơn giản là mở rộng số bucket lên gấp đôi, sau đó tính toán lại chỉ số và đặt lại nút vào bucket mới.
Khi vượt quá giới hạn, ta thực hiện resize. Tuy nhiên, vì ta sử dụng mở rộng lũy thừa của 2 (tức là độ dài mở rộng gấp đôi), vị trí của các phần tử sẽ nằm ở vị trí ban đầu hoặc vị trí ban đầu cộng với 2 lũy thừa.
Làm thế nào để hiểu điều này? Ví dụ, khi ta mở rộng từ 16 lên 32, các thay đổi cụ thể như sau:
Do đó, sau khi tính toán lại hash, vì n tăng gấp đôi, phần mở rộng mới có thể được coi là bit mới được thêm vào có giá trị 1 hoặc 0, với xác suất là ngẫu nhiên. Nếu là 0, chỉ số không thay đổi, nếu là 1, chỉ số sẽ trở thành “chỉ số ban đầu + oldCap”. Hãy xem ví dụ dưới đây về việc mở rộng từ 16 lên 32:
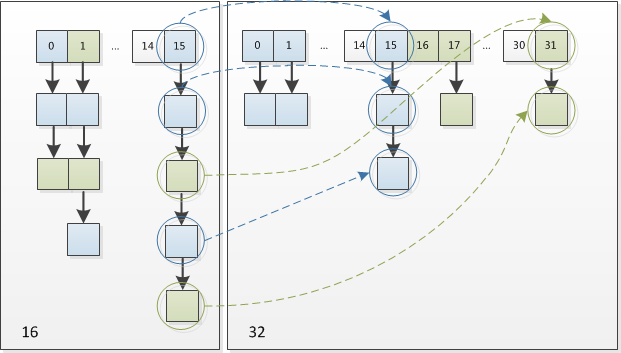
Thiết kế này thực sự rất tinh vi, không chỉ tiết kiệm thời gian tính toán lại hash mà còn đồng thời, vì bit mới được thêm vào có thể coi là ngẫu nhiên (có giá trị 0 hoặc 1), do đó quá trình resize đã phân tán đồng đều các nút va chạm vào bucket mới.
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// Nếu vượt quá giới hạn tối đa, ta không thể mở rộng nữa, chỉ còn cách để va chạm xảy ra
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// Nếu chưa vượt quá giới hạn tối đa, ta mở rộng lên gấp đôi
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// Tính toán giới hạn resize mới
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// Di chuyển từng bucket vào bucket mới
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// Chỉ số ban đầu
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// Chỉ số ban đầu + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Đặt vào bucket theo chỉ số ban đầu
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// Đặt vào bucket theo chỉ số ban đầu + oldCap
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}Lớp LinkedHashMap
Điểm chính của LinkedHashMap
LinkedHashMap duy trì một danh sách liên kết hai chiều để lưu trữ tất cả các mục (Entry) và đảm bảo thứ tự của các phần tử khi duyệt qua chúng (tức là thứ tự chèn).
| Điểm quan tâm | Kết luận |
|---|---|
| Cho phép cặp khóa-giá trị là null | Cả Khóa và Giá trị đều cho phép null |
| Cho phép dữ liệu trùng lặp | Khóa trùng sẽ ghi đè, Giá trị cho phép trùng lặp |
| Có thứ tự | Lưu trữ theo thứ tự chèn |
| An toàn đa luồng | Không an toàn đa luồng |
Điểm chính của LinkedHashMap
Cấu trúc dữ liệu của LinkedHashMap
LinkedHashMap duy trì một cặp con trỏ đầu cuối của kiểu LinkedHashMap.Entry<K,V>, lưu trữ tất cả dữ liệu dưới dạng danh sách liên kết hai chiều.
Nếu bạn đã học qua danh sách liên kết hai chiều trong cấu trúc dữ liệu, bạn sẽ hiểu rằng việc lưu trữ và truy cập các phần tử sẽ được thực hiện theo một thứ tự nhất định.
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
// Con trỏ đầu của danh sách liên kết hai chiều
transient LinkedHashMap.Entry<K,V> head;
// Con trỏ cuối của danh sách liên kết hai chiều
transient LinkedHashMap.Entry<K,V> tail;
// Phương thức sắp xếp duyệt: true cho thứ tự truy cập; false cho thứ tự chèn
final boolean accessOrder;
}LinkedHashMap kế thừa phương thức put của HashMap, nhưng không triển khai phương thức put riêng.
Lớp TreeMap
Điểm chính của TreeMap
TreeMap được triển khai dựa trên cây đỏ-đen.
TreeMap là một cấu trúc dữ liệu có thứ tự. Thứ tự được xác định bằng cách sử dụng thứ tự tự nhiên của khóa trong bản đồ hoặc thứ tự tùy chỉnh được cung cấp bởi bộ so sánh (Comparator).
TreeMap không an toàn đa luồng.
Nguyên lý của TreeMap
Phương thức put
public V put(K key, V value) {
Entry<K,V> t = root;
// Nếu cây rỗng, chèn nút đầu tiên
if (t == null) {
compare(key, key); // kiểm tra kiểu (và có thể là null)
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// Tách đường dẫn so sánh dựa trên bộ so sánh và so sánh tự nhiên
Comparator<? super K> cpr = comparator;
// Mỗi nút con bên trái nhỏ hơn nút cha; mỗi nút con bên phải lớn hơn nút cha
// Nếu có bộ so sánh, sử dụng bộ so sánh để so sánh
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// Nếu không có bộ so sánh, sử dụng thứ tự tự nhiên của khóa để so sánh
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// Nếu không tìm thấy khóa, chèn nút mới
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// Sau khi chèn, cần điều chỉnh để duy trì cân bằng của cây đỏ-đen
fixAfterInsertion(e);
size++;
modCount++;
return null;
}Phương thức get
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
// Sử dụng phiên bản dựa trên bộ so sánh để tối ưu hiệu suất
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
// Tìm kiếm theo cách tìm kiếm cây nhị phân, trả về nếu tìm thấy
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}Phương thức remove
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// Nếu nút hiện tại có cả nút con bên trái và bên phải, sử dụng nút kế tiếp để thay thế nút cần xóa
// Nếu nút cần xóa có 2 nút con
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p có 2 nút con
// Bắt đầu sửa chữa tại nút thay thế, nếu nó tồn tại.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) { // Nút cần xóa có một nút con
// Liên kết nút thay thế với nút cha
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Đặt các liên kết thành null để sử dụng trong fixAfterDeletion.
p.left = p.right = p.parent = null;
// Sửa chữa nút thay thế
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // Trả về nếu chúng ta là nút duy nhất.
root = null;
} else { // Không có nút con. Sử dụng chính nó như là nút thay thế ảo và tách liên kết.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}Ví dụ TreeMap
public class TreeMapDemo {
private static final String[] chars = "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" ");
public static void main(String[] args) {
TreeMap<Integer, String> treeMap = new TreeMap<>();
for (int i = 0; i < chars.length; i++) {
treeMap.put(i, chars[i]);
}
System.out.println(treeMap);
Integer low = treeMap.firstKey();
Integer high = treeMap.lastKey();
System.out.println(low);
System.out.println(high);
Iterator<Integer> it = treeMap.keySet().iterator();
for (int i = 0; i <= 6; i++) {
if (i == 3) { low = it.next(); }
if (i == 6) { high = it.next(); } else { it.next(); }
}
System.out.println(low);
System.out.println(high);
System.out.println(treeMap.subMap(low, high));
System.out.println(treeMap.headMap(high));
System.out.println(treeMap.tailMap(low));
}
}WeakHashMap
Định nghĩa của WeakHashMap như sau:
public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V> {}WeakHashMap kế thừa từ AbstractMap và triển khai giao diện Map.
Giống như HashMap, WeakHashMap cũng là một bảng băm (hash table) và lưu trữ các cặp khóa-giá trị (key-value) trong đó cả khóa và giá trị đều có thể là null.
Tuy nhiên, khóa trong WeakHashMap là khóa yếu (weak key). Trong WeakHashMap, khi một khóa không còn được tham chiếu bởi đối tượng khác, nó sẽ tự động bị xóa khỏi WeakHashMap. Cụ thể hơn, đối với một khóa cụ thể, việc ánh xạ của nó không ngăn chặn việc thu gom rác bởi bộ thu gom rác, điều này làm cho khóa trở thành khóa có thể bị hủy, bị hủy và sau đó bị thu gom. Khi một khóa bị hủy, cặp khóa-giá trị tương ứng cũng sẽ được loại bỏ khỏi ánh xạ.
Nguyên lý của khóa yếu là gì? Đại khái là sử dụng WeakReference và ReferenceQueue để thực hiện.
Khóa trong WeakHashMap là khóa yếu (weak key), có nghĩa là nó là một WeakReference. ReferenceQueue là một hàng đợi, nó sẽ lưu trữ các khóa yếu (weak key) bị thu gom rác từ WeakHashMap. Các bước thực hiện như sau:
- Tạo một WeakHashMap và thêm các cặp khóa-giá trị vào WeakHashMap. Thực tế, WeakHashMap lưu trữ các Entry (cặp khóa-giá trị) thông qua một mảng table; Mỗi Entry thực tế là một danh sách liên kết đơn, tức là Entry là danh sách liên kết của các cặp khóa-giá trị.
- Khi một khóa yếu (weak key) không còn được tham chiếu bởi đối tượng khác và bị thu gom rác, nó sẽ được thêm vào hàng đợi ReferenceQueue.
- Khi chúng ta cần thao tác với WeakHashMap lần tiếp theo, chúng ta sẽ đồng bộ hóa table và queue. Table lưu trữ tất cả các cặp khóa-giá trị, trong khi queue lưu trữ các cặp khóa-giá trị bị thu gom rác; Đồng bộ hóa chúng có nghĩa là xóa các cặp khóa-giá trị bị thu gom rác khỏi table.
Đó là các bước để tự động xóa khóa yếu (weak key) khỏi WeakHashMap.
Giống như HashMap, WeakHashMap không đồng bộ. Chúng ta có thể sử dụng phương thức Collections.synchronizedMap để tạo ra một WeakHashMap đồng bộ.