Đồng bộ hóa và các Collection trong Java
Collection đồng bộ hóa
Giới thiệu về Collection đồng bộ hóa
Trong Java, Collection đồng bộ hóa chủ yếu bao gồm 2 loại:
Vector,Stack,HashtableVector-Vectorthực hiện giao diệnList.Vectorthực tế là một mảng, tương tự nhưArrayList. Tuy nhiên, các phương thức trongVectorđều được đồng bộ hóa, tức là đã thực hiện các biện pháp đồng bộ hóa.Stack-Stackcũng là một Collection đồng bộ hóa, các phương thức của nó cũng được đồng bộ hóa, thực tế nó kế thừa từ lớpVector.Hashtable-Hashtablethực hiện giao diệnMap, nó tương tự nhưHashMap, nhưngHashtableđã được xử lý đồng bộ hóa, trong khiHashMapkhông có.
- Các lớp được tạo bằng các phương thức tĩnh trong lớp
Collections(nhưCollections.synchronizedXXX)
Vấn đề với Synchronized Collection
Nguyên tắc đồng bộ hóa của Collection đồng bộ hóa là sử dụng từ khóa synchronized trên các phương thức chính như get, set, size,… synchronized đảm bảo chỉ có một luồng có thể thực thi một phương thức hoặc một khối mã trong cùng một thời điểm.
Nếu bạn muốn biết thêm về
synchronizedcách sử dụng và nguyên tắc, vui lòng tham khảo: Java Concurrency Core Mechanism
Vấn đề về hiệu suất
Đồng bộ hóa độc quyền của synchronized tạo ra chi phí cho việc chặn và đánh thức các luồng. Rõ ràng, phương pháp này có hiệu suất kém hơn so với việc sử dụng các Collection không đồng bộ.
Lưu ý: Đặc biệt là trước khi Java 1.6 tối ưu hóa
synchronized, chi phí chặn luồng rất cao.
Vấn đề về an toàn
Collection đồng bộ hóa thực sự an toàn không?
Thực tế không phải lúc nào cũng đúng. Khi thực hiện các hoạt động phức tạp (không phải hoạt động nguyên tử), vẫn cần phải sử dụng khóa để bảo vệ. Các hoạt động phức tạp phổ biến bao gồm:
- Lặp lại: Truy cập các phần tử lặp đi lặp lại cho đến khi duyệt qua tất cả các phần tử;
- Bỏ qua: Tìm phần tử tiếp theo (n phần tử tiếp theo) dựa trên thứ tự đã chỉ định của phần tử hiện tại;
- Phép tính điều kiện: Ví dụ: thêm nếu không tồn tại;
❌ Ví dụ không an toàn
public class VectorDemo {
static Vector<Integer> vector = new Vector<>();
public static void main(String[] args) {
while (true) {
vector.clear();
for (int i = 0; i < 10; i++) {
vector.add(i);
}
Thread thread1 = new Thread() {
@Override
public void run() {
for (int i = 0; i < vector.size(); i++) {
vector.remove(i);
}
}
};
Thread thread2 = new Thread() {
@Override
public void run() {
for (int i = 0; i < vector.size(); i++) {
vector.get(i);
}
}
};
thread1.start();
thread2.start();
while (Thread.activeCount() > 10) {
System.out.println("Có đồng thời tồn tại 10 luồng trở lên, thoát");
return;
}
}
}
}Chương trình trên có thể gây ra lỗi vượt quá chỉ số mảng.
Vector là an toàn đối với luồng, vậy tại sao vẫn có lỗi này?
Điều này xảy ra vì, đối với Vector, mặc dù chỉ có một luồng có thể truy cập nó vào một thời điểm, nhưng không loại trừ khả năng sau:
Khi một luồng tại một thời điểm thực hiện câu lệnh này:
for(int i=0;i<vector.size();i++)
vector.get(i);Giả sử lúc này phương thức size của vector trả về là 10 và giá trị của i là 9
Sau đó một luồng khác thực hiện câu lệnh này:
for(int i=0;i<vector.size();i++)
vector.remove(i);Xóa phần tử có chỉ số 9.
Vì vậy, việc truy cập phần tử có chỉ số 9 bằng phương thức get sẽ gây ra vấn đề.
✔ Ví dụ an toàn
Do đó, để đảm bảo an toàn luồng, phải thực hiện đồng bộ bổ sung tại điểm gọi phương thức, như dưới đây:
public class VectorDemo2 {
static Vector<Integer> vector = new Vector<Integer>();
public static void main(String[] args) {
while (true) {
for (int i = 0; i < 10; i++) {
vector.add(i);
}
Thread thread1 = new Thread() {
@Override
public void run() {
synchronized (VectorDemo2.class) { // Thực hiện đồng bộ bổ sung
for (int i = 0; i < vector.size(); i++) {
vector.remove(i);
}
}
}
};
Thread thread2 = new Thread() {
@Override
public void run() {
synchronized (VectorDemo2.class) {
for (int i = 0; i < vector.size(); i++) {
vector.get(i);
}
}
}
};
thread1.start();
thread2.start();
while (Thread.activeCount() > 10) {
System.out.println("Có đồng thời tồn tại 10 luồng trở lên, thoát");
return;
}
}
}
}ngoại lệ ConcurrentModificationException:
Khi truy cập và sửa đổi đồng thời các Collection như Vector, sẽ gây ra ngoại lệ ConcurrentModificationException. Về vấn đề này sẽ được trình bày trong các bài viết sau.
Tuy nhiên, vấn đề này không xảy ra với các Collection đồng thời.
Concurrent Collection
Giới thiệu về Concurrent Collection
Concurrent Collection là các Collection an toàn luồng, nghĩa là chúng được thiết kế để xử lý đồng thời mà không cần sử dụng các khóa đồng bộ hóa bên ngoài.
Java 1.5 đã cung cấp nhiều Collection đồng thời thông qua gói J.U.C (Java Util Concurrent). Sử dụng Collection thay thế Synchronized Collection có thể cải thiện đáng kể khả năng mở rộng và giảm rủi ro.
Gói J.U.C cung cấp một số Collection đồng thời rất hữu ích như sau:
| Collection đồng thời | Collection tương ứng | Mô tả |
|---|---|---|
ConcurrentHashMap | HashMap | Trước Java 1.8 sử dụng cơ chế khóa phân đoạn để tinh chỉnh độ tinh vi của khóa, giảm độ chặn, từ đó tăng khả năng đồng thời; Sau Java 1.8 dựa trên CAS. |
ConcurrentSkipListMap | SortedMap | Dựa trên cấu trúc dữ liệu Skip List |
CopyOnWriteArrayList | ArrayList | |
CopyOnWriteArraySet | Set | Dựa trên CopyOnWriteArrayList |
ConcurrentSkipListSet | SortedSet | Dựa trên ConcurrentSkipListMap |
ConcurrentLinkedQueue | Queue | Hàng đợi không giới hạn an toàn luồng. Sử dụng danh sách liên kết đơn. Hỗ trợ FIFO. |
ConcurrentLinkedDeque | Deque | Hàng đợi hai chiều không giới hạn an toàn luồng. Sử dụng danh sách liên kết hai chiều. Hỗ trợ FIFO và FILO. |
ArrayBlockingQueue | Queue | Hàng đợi chặn dựa trên mảng. |
LinkedBlockingQueue | Queue | Hàng đợi chặn dựa trên danh sách liên kết. |
LinkedBlockingDeque | Deque | Hàng đợi hai chiều chặn dựa trên danh sách liên kết. |
Collection đồng thời được đặt tên theo ba nhóm chính:
Concurrent- Loại này có mức độ cạnh tranh khá cao so với
CopyOnWrite, nhưng chi phí ghi thấp hơn. - Ngoài ra,
Concurrentthường cung cấp mức độ nhất quán duyệt thấp hơn, có nghĩa là khi duyệt bằng trình lặp, nếu có sự thay đổi trong Collection, trình lặp vẫn có thể tiếp tục duyệt. Điều này không chính xác hoàn toàn, nhưng đó là sự cân nhắc để đạt được hiệu suất đồng thời, có thể hiểu. So với việc sử dụng Collection đồng bộ, điều này sẽ gây ra vấn đềfail-fast, nghĩa là nếu phát hiện sự thay đổi trong quá trình duyệt, ngoại lệConcurrentModificationExceptionsẽ được ném và không tiếp tục duyệt.
- Loại này có mức độ cạnh tranh khá cao so với
CopyOnWrite- Một luồng ghi, nhiều luồng đọc. Không cần khóa khi đọc, khóa được sử dụng để đảm bảo an toàn khi ghi, tuy nhiên, tiêu thụ không gian lớn hơn.Blocking- Thường sử dụng khóa bên trong để triển khai khả năng chặn.
:x: Ví dụ sai, gây ra ngoại lệ ConcurrentModificationException:
public void removeKeys(Map<String, Object> map, final String... keys) {
map.keySet().removeIf(key -> ArrayUtil.contains(keys, key));
}:x: Ví dụ sai, gây ra ngoại lệ ConcurrentModificationException:
public static <K, V> Map<K, V> removeKeys(Map<String, Object> map, final String... keys) {
for (K key : keys) {
map.remove(key);
}
return map;
}Map trong môi trường đồng thời
Nếu yêu cầu dữ liệu phải được đồng nhất mạnh mẽ, thì cần sử dụng Hashtable. Trong hầu hết các tình huống, dữ liệu thường chỉ cần đồng nhất yếu, vì vậy có thể sử dụng ConcurrentHashMap. Nếu lượng dữ liệu trong khoảng hàng triệu và có nhiều hoạt động thêm, xóa, sửa, thì có thể xem xét sử dụng ConcurrentSkipListMap.
List trong môi trường đồng thời
Nếu có nhiều hoạt động đọc và ít hoạt động ghi, hãy sử dụng CopyOnWriteArrayList.
Nếu có nhiều hoạt động ghi và ít hoạt động đọc, hãy sử dụng ConcurrentLinkedQueue. Tuy nhiên, vì nó không giới hạn kích thước, nên cần có giới hạn dung lượng để tránh mở rộng vô tận và gây ra lỗi tràn bộ nhớ.
Map
Trong Java, có hai lớp triển khai của giao diện Map là ConcurrentHashMap và ConcurrentSkipListMap. Sự khác biệt chính giữa chúng từ quan điểm ứng dụng là ConcurrentHashMap có key không có thứ tự, trong khi ConcurrentSkipListMap có key được sắp xếp. Do đó, nếu bạn cần đảm bảo thứ tự của key, bạn chỉ có thể sử dụng ConcurrentSkipListMap.
Khi sử dụng ConcurrentHashMap và ConcurrentSkipListMap, cần lưu ý rằng cả key và value không được null, nếu không sẽ gây ra ngoại lệ NullPointerException.
ConcurrentHashMap
ConcurrentHashMap là một phiên bản thread-safe của HashMap, được sử dụng để thay thế Hashtable.
Tính năng của ConcurrentHashMap
ConcurrentHashMap triển khai giao diện ConcurrentMap, và ConcurrentMap mở rộng từ giao diện Map.
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
// ...
}ConcurrentHashMap triển khai bao gồm tất cả các tính năng cơ bản của HashMap, bao gồm cấu trúc dữ liệu, chiến lược đọc và ghi, v.v.
ConcurrentHashMap không thực hiện việc khóa toàn bộ Map để cung cấp truy cập độc quyền. Do đó, không thể tạo ra các hoạt động nguyên tử mới bằng cách khóa từ phía khách hàng. Tuy nhiên, một số hoạt động phức tạp phổ biến như “thêm nếu không có”, “xóa nếu bằng” và “thay thế nếu bằng” đã được triển khai như các hoạt động nguyên tử và được triển khai xung quanh các giao diện mở rộng của ConcurrentMap.
public interface ConcurrentMap<K, V> extends Map<K, V> {
// Thêm một cặp key-value chỉ khi key chưa tồn tại
V putIfAbsent(K key, V value);
// Xóa một cặp key-value chỉ khi key đã được ánh xạ đến value
boolean remove(Object key, Object value);
// Thay thế một cặp key-value chỉ khi key đã được ánh xạ đến oldValue
boolean replace(K key, V oldValue, V newValue);
// Thay thế một cặp key-value chỉ khi key đã được ánh xạ đến một giá trị
V replace(K key, V value);
}Khác với Hashtable, các trình lặp được cung cấp bởi ConcurrentHashMap không ném ngoại lệ ConcurrentModificationException, do đó không cần khóa bảo vệ trong quá trình lặp.
Lưu ý: Một số phương thức tính toán trên toàn bộ Map như
sizevàisEmptykhông trả về giá trị chính xác và thời gian thực, vì kết quả trả về có thể đã quá hạn trong quá trình tính toán. Đây là một sự cân nhắc thiết kế, trong môi trường đồng thời, các phương thức này thường không cần chính xác thời gian thực và không có ý nghĩa lớn.ConcurrentHashMapgiảm tính năng của các phương thức này để tăng hiệu suất cho các hoạt động quan trọng hơn nhưget,put,containsKey,remove, v.v.
Cách sử dụng ConcurrentHashMap
Ví dụ: Không gây ra ngoại lệ ConcurrentModificationException
Cách sử dụng cơ bản của ConcurrentHashMap tương tự như HashMap. Khác với HashMap và Hashtable, các trình lặp được cung cấp bởi ConcurrentHashMap không ném ngoại lệ ConcurrentModificationException, do đó không cần khóa bảo vệ trong quá trình lặp.
public class ConcurrentHashMapDemo {
public static void main(String[] args) throws InterruptedException {
// HashMap sẽ gây ra ngoại lệ ConcurrentModificationException khi truy cập đồng thời
// Map<Integer, Character> map = new HashMap<>();
Map<Integer, Character> map = new ConcurrentHashMap<>();
Thread wthread = new Thread(() -> {
System.out.println("Thread ghi đang chạy");
for (int i = 0; i < 26; i++) {
map.put(i, (char) ('a' + i));
}
});
Thread rthread = new Thread(() -> {
System.out.println("Thread đọc đang chạy");
for (Integer key : map.keySet()) {
System.out.println(key + " - " + map.get(key));
}
});
wthread.start();
rthread.start();
Thread.sleep(1000);
}
}Nguyên lý hoạt động của ConcurrentHashMap
ConcurrentHashMapđã trải qua nhiều sự phát triển, đặc biệt là trong Java 1.7 và Java 1.8, có sự khác biệt lớn về cấu trúc dữ liệu và cơ chế đồng thời.
- Java 1.7
- Cấu trúc dữ liệu: Mảng + Danh sách liên kết đơn
- Cơ chế đồng thời: Sử dụng cơ chế khóa phân đoạn để tinh chỉnh độ tinh vi của khóa, giảm độ chặn và tăng khả năng đồng thời.
- Java 1.8
- Cấu trúc dữ liệu: Mảng + Danh sách liên kết đơn + Cây đỏ-đen
- Cơ chế đồng thời: Hủy bỏ cơ chế khóa phân đoạn, thay vào đó sử dụng CAS + synchronized để triển khai.
Triển khai trong Java 1.7
Trong Java 1.7, ConcurrentHashMap sử dụng cơ chế khóa phân đoạn, trong đó mỗi phân đoạn (Segment) là một khóa. Mỗi phân đoạn chứa một mảng HashEntry, tương tự như HashMap, các mục có cùng giá trị băm được lưu trữ dưới dạng danh sách liên kết.
HashEntry sử dụng trường volatile value để đảm bảo tính nhìn thấy dữ liệu và tận dụng cơ chế của các đối tượng không thay đổi để cải thiện hiệu suất bằng cách sử dụng các hoạt động nguy hiểm (Unsafe) do JVM đã tối ưu hóa, ví dụ như volatile access.
Khi thực hiện các hoạt động ghi đồng thời, ConcurrentHashMap sẽ lấy khóa tái nhập (ReentrantLock) để bảo vệ tính nhất quán của dữ liệu. Do vậy, trong quá trình chỉnh sửa song song, Segment tương ứng sẽ bị khóa lại.
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
final Segment<K,V>[] segments;
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}Triển khai trong Java 1.8
- Cải tiến cấu trúc dữ liệu: Tương tự như HashMap, cấu trúc dữ liệu ban đầu là mảng + danh sách liên kết đơn, đã được thay đổi thành cấu trúc mảng + danh sách liên kết đơn + cây đỏ-đen. Khi xảy ra xung đột băm, dữ liệu sẽ được lưu vào danh sách liên kết của ngăn chỉ định trong mảng. Khi chiều dài của danh sách vượt quá 8 phần tử, nó sẽ được chuyển thành cây đỏ-đen để giảm thời gian tìm kiếm xuống và nâng cao hiệu suất.
- Cải tiến cơ chế đồng thời:
- Loại bỏ trường segments và sử dụng
transient volatile HashEntry<K,V>[] tableđể lưu trữ dữ liệu, sử dụng các phần tử trong mảng table như khóa để khóa từng hàng dữ liệu, từ đó giảm thiểu khả năng xung đột đồng thời. - Sử dụng thao tác CAS +
synchronizedcho các tình huống cụ thể có thể không có khóa. Sử dụng các biện pháp cơ bản như Unsafe hay LongAdder để tối ưu hóa trong các tình huống cực đoan. Trong JDK hiện đại, synchronized đã được tối ưu hóa liên tục và không cần quá lo lắng về sự khác biệt về hiệu suất. Ngoài ra, so với ReentrantLock, nó giúp giảm tiêu thụ bộ nhớ, điều này là một lợi thế rất lớn.
- Loại bỏ trường segments và sử dụng
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}Thực hành với ConcurrentHashMap
Ví dụ sai của ConcurrentHashMap
public class WrongConcurrentHashMapDemo {
// Số lượng luồng
private static int THREAD_COUNT = 10;
// Tổng số lượng phần tử
private static int ITEM_COUNT = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
// Số lượng ban đầu là 900 phần tử
System.out.println("Kích thước ban đầu:" + concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
// Sử dụng thread pool để xử lý đồng thời
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
// Kiểm tra còn bao nhiêu phần tử cần bổ sung
int gap = ITEM_COUNT - concurrentHashMap.size();
System.out.println("Kích thước còn thiếu:" + gap);
// Bổ sung phần tử
concurrentHashMap.putAll(getData(gap));
}));
// Đợi tất cả các nhiệm vụ hoàn thành
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
// Số lượng phần tử cuối cùng sẽ là 1000 chứ?
System.out.println("Kích thước cuối cùng:" + concurrentHashMap.size());
}
private static ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(
Collectors.toConcurrentMap(
i -> UUID.randomUUID().toString(),
i -> i,
(o1, o2) -> o1,
ConcurrentHashMap::new));
}
}
// Expect: finish size:1000
// Output: finish size:(> 1000)Kích thước ban đầu là 900, đúng như dự đoán, cần bổ sung thêm 100 phần tử.
Kết quả dự đoán là 1000 phần tử, nhưng thực tế lại lớn hơn 1000 phần tử.
【Phân tích】
ConcurrentHashMap có những hạn chế về phương thức và khả năng mà nó cung cấp:
- Sử dụng ConcurrentHashMap không đảm bảo tính nhất quán giữa các hoạt động trên nó, không có đảm bảo rằng không có luồng khác đang thao tác trên nó. Nếu cần đảm bảo tính nhất quán, cần thêm khóa bằng cách sử dụng synchronized.
- Các phương thức tổng hợp như size, isEmpty và containsValue có thể phản ánh trạng thái trung gian của ConcurrentHashMap trong trường hợp đa luồng. Do đó, trong trường hợp đa luồng, giá trị trả về của các phương thức này chỉ có thể được sử dụng tham khảo, không thể sử dụng để điều khiển tiến trình. Rõ ràng, việc sử dụng phương thức size để tính giá trị khác biệt là một biện pháp điều khiển.
- Các phương thức tổng hợp như putAll cũng không đảm bảo tính nguyên tử, trong quá trình putAll, việc truy xuất dữ liệu có thể truy xuất được một phần dữ liệu.
Sửa lỗi ví dụ sai của ConcurrentHashMap phiên bản 1.0
Bằng cách sử dụng synchronized để khóa, tất nhiên có thể đảm bảo tính nhất quán của dữ liệu, nhưng đánh đổi hiệu suất của ConcurrentHashMap, không thể tận dụng các tính năng đặc biệt của ConcurrentHashMap.
public class WrongConcurrentHashMapDemo {
// Số lượng luồng
private static int THREAD_COUNT = 10;
// Tổng số lượng phần tử
private static int ITEM_COUNT = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
// Số lượng ban đầu là 900 phần tử
System.out.println("Kích thước ban đầu:" + concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
// Sử dụng thread pool để xử lý đồng thời
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
// Kiểm tra còn bao nhiêu phần tử cần bổ sung
synchronized (concurrentHashMap) {
int gap = ITEM_COUNT - concurrentHashMap.size();
System.out.println("Kích thước còn thiếu:" + gap);
// Bổ sung phần tử
concurrentHashMap.putAll(getData(gap));
}
}));
// Đợi tất cả các nhiệm vụ hoàn thành
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
// Số lượng phần tử cuối cùng sẽ là 1000 chứ?
System.out.println("Kích thước cuối cùng:" + concurrentHashMap.size());
}
private static ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(
Collectors.toConcurrentMap(
i -> UUID.randomUUID().toString(),
i -> i,
(o1, o2) -> o1,
ConcurrentHashMap::new));
}
}Sửa lỗi ví dụ sai của ConcurrentHashMap phiên bản 2.0
public class WrongConcurrentHashMapDemo {
// Số lần lặp
private static int LOOP_COUNT = 10000000;
// Số lượng luồng
private static int THREAD_COUNT = 10;
// Tổng số lượng phần tử
private static int ITEM_COUNT = 1000;
public static void main(String[] args) throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start("normaluse");
Map<String, Long> normaluse = normaluse();
stopWatch.stop();
Assert.isTrue(normaluse.size() == ITEM_COUNT, "Lỗi kích thước normaluse");
Assert.isTrue(normaluse.values().stream()
.mapToLong(aLong -> aLong).reduce(0, Long::sum) == LOOP_COUNT
, "Lỗi đếm normaluse");
stopWatch.start("gooduse");
Map<String, Long> gooduse = gooduse();
stopWatch.stop();
Assert.isTrue(gooduse.size() == ITEM_COUNT, "Lỗi kích thước gooduse");
Assert.isTrue(gooduse.values().stream()
.mapToLong(l -> l)
.reduce(0, Long::sum) == LOOP_COUNT
, "Lỗi đếm gooduse");
System.out.println(stopWatch.prettyPrint());
}
private static Map<String, Long> normaluse() throws InterruptedException {
ConcurrentHashMap<String, Long> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
synchronized (freqs) {
if (freqs.containsKey(key)) {
freqs.put(key, freqs.get(key) + 1);
} else {
freqs.put(key, 1L);
}
}
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
return freqs;
}
private static Map<String, Long> gooduse() throws InterruptedException {
ConcurrentHashMap<String, LongAdder> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
freqs.computeIfAbsent(key, k -> new LongAdder()).increment();
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
return freqs.entrySet().stream()
.collect(Collectors.toMap(
e -> e.getKey(),
e -> e.getValue().longValue())
);
}
}List
CopyOnWriteArrayList
CopyOnWriteArrayList là một lớp ArrayList an toàn cho luồng. CopyOnWrite có nghĩa là khi ghi, biến chia sẻ sẽ được sao chép thành một bản mới. Việc sao chép này giúp các hoạt động đọc không cần khóa (tức là không bị chặn).
CopyOnWriteArrayList chỉ phù hợp cho các tình huống có ít hoạt động ghi và có thể chấp nhận sự không nhất quán ngắn hạn giữa đọc và ghi. Nếu tỷ lệ đọc và ghi cân bằng hoặc có nhiều hoạt động ghi, hiệu suất của CopyOnWriteArrayList sẽ rất kém.
Nguyên lý của CopyOnWriteArrayList
CopyOnWriteArrayList duy trì một mảng nội bộ và biến thành viên array trỏ đến mảng nội bộ này, tất cả các hoạt động đọc đều dựa trên mảng này, như hình dưới đây, Iterator duyệt qua mảng array.
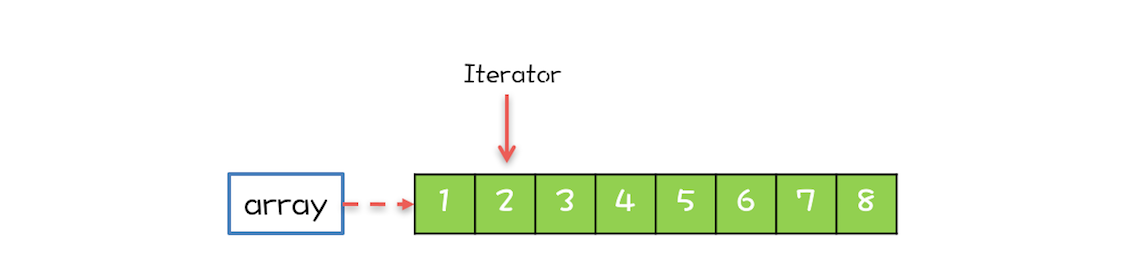
- lock - Sử dụng khóa tái nhập để thực hiện hoạt động sao chép khi ghi.
- array - Mảng đối tượng, dùng để lưu trữ các phần tử.
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;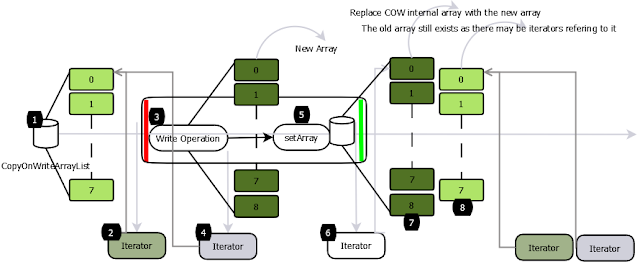
(1)Hoạt động đọc
Trong CopyOnWriteArrayList, các hoạt động đọc không đồng bộ vì chúng hoạt động trên bản sao của mảng nội bộ, do đó nhiều Iterator có thể duyệt qua mảng mà không bị chặn lẫn nhau (Thao tác 1,2,4).
Các hoạt động đọc của CopyOnWriteArrayList không cần khóa, nên hiệu suất cao.
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}(2)Hoạt động ghi
Tất cả các hoạt động ghi đều được đồng bộ hóa. Chúng hoạt động trên bản sao của mảng (Thao tác 3). Sau khi hoạt động ghi hoàn thành, mảng sao chép sẽ được thay thế bằng mảng đã sao chép và khóa sẽ được giải phóng. Việc thay thế mảng là một cuộc gọi nguyên tử (Thao tác 5).
Iterator tạo ra sau khi hoạt động ghi sẽ có thể nhìn thấy cấu trúc đã được sửa đổi (hình 6,7).
Thêm phần tử - Quá trình thêm đơn giản, sao chép bản sao của danh sách gốc, sau đó thực hiện hoạt động ghi trên bản sao mới và sau đó chuyển tham chiếu. Quá trình này cần khóa.
public boolean add(E e) {
// Khóa ReentrantLock để đảm bảo an toàn luồng
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// Sao chép danh sách gốc, độ dài tăng thêm 1
Object[] newElements = Arrays.copyOf(elements, len + 1);
// Thực hiện thêm phần tử trên bản sao mới
newElements[len] = e;
// Chuyển tham chiếu từ danh sách gốc sang bản sao mới
setArray(newElements);
return true;
} finally {
// Mở khóa
lock.unlock();
}
}Xóa phần tử - Quá trình xóa tương tự, sao chép các phần tử khác ngoại trừ phần tử cần xóa vào bản sao mới, sau đó chuyển tham chiếu để danh sách gốc trỏ đến bản sao mới. Cũng là hoạt động ghi, cần khóa.
public E remove(int index) {
// Khóa
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
// Nếu phần tử cần xóa là phần tử cuối cùng, sao chép len-1 phần tử vào bản sao mới và chuyển tham chiếu
setArray(Arrays.copyOf(elements, len - 1));
else {
// Ngược lại, sao chép các phần tử khác ngoại trừ phần tử cần xóa vào bản sao mới và chuyển tham chiếu
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
// Mở khóa
lock.unlock();
}
}Ví dụ CopyOnWriteArrayList
public class CopyOnWriteArrayListDemo {
static class ReadTask implements Runnable {
List<String> list;
ReadTask(List<String> list) {
this.list = list;
}
public void run() {
for (String str : list) {
System.out.println(str);
}
}
}
static class WriteTask implements Runnable {
List<String> list;
int index;
WriteTask(List<String> list, int index) {
this.list = list;
this.index = index;
}
public void run() {
list.remove(index);
list.add(index, "write_" + index);
}
}
public void run() {
final int NUM = 10;
// ArrayList sẽ ném ra ngoại lệ ConcurrentModificationException khi truy cập đọc đồng thời
// List<String> list = new ArrayList<>();
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
for (int i = 0; i < NUM; i++) {
list.add("main_" + i);
}
ExecutorService executorService = Executors.newFixedThreadPool(NUM);
for (int i = 0; i < NUM; i++) {
executorService.execute(new ReadTask(list));
executorService.execute(new WriteTask(list, i));
}
executorService.shutdown();
}
public static void main(String[] args) {
new CopyOnWriteArrayListDemo().run();
}
}CopyOnWriteArrayList trong thực tế
@Slf4j
public class WrongCopyOnWriteList {
public static void main(String[] args) {
testRead();
testWrite();
}
public static Map testWrite() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
StopWatch stopWatch = new StopWatch();
int loopCount = 100000;
stopWatch.start("Write:copyOnWriteArrayList");
IntStream.rangeClosed(1, loopCount)
.parallel()
.forEach(__ -> copyOnWriteArrayList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
stopWatch.start("Write:synchronizedList");
IntStream.rangeClosed(1, loopCount)
.parallel()
.forEach(__ -> synchronizedList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map result = new HashMap();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}
private static void addAll(List<Integer> list) {
list.addAll(IntStream.rangeClosed(1, 1000000).boxed().collect(Collectors.toList()));
}
public static Map testRead() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
addAll(copyOnWriteArrayList);
addAll(synchronizedList);
StopWatch stopWatch = new StopWatch();
int loopCount = 1000000;
int count = copyOnWriteArrayList.size();
stopWatch.start("Read:copyOnWriteArrayList");
IntStream.rangeClosed(1, loopCount)
.parallel()
.forEach(__ -> copyOnWriteArrayList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
stopWatch.start("Read:synchronizedList");
IntStream.range(0, loopCount)
.parallel()
.forEach(__ -> synchronizedList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map result = new HashMap();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}
}Hiệu suất đọc cao hơn trăm lần so với hiệu suất ghi.
Set
Set là một giao diện trong Java, có hai cài đặt là CopyOnWriteArraySet và ConcurrentSkipListSet. Bạn có thể tham khảo các ví dụ sử dụng CopyOnWriteArrayList và ConcurrentSkipListMap đã được trình bày ở trên để biết các trường hợp sử dụng của chúng. Nguyên tắc hoạt động của chúng cũng tương tự.
Queue
Trong gói concurrent của Java, các cấu trúc dữ liệu hàng đợi (Queue) là phức tạp nhất và có thể được phân loại dựa trên hai khía cạnh. Một khía cạnh là được chặn hoặc không chặn, trong đó chặn có nghĩa là khi hàng đợi đầy, thao tác thêm vào sẽ bị chặn; khi hàng đợi trống, thao tác lấy ra sẽ bị chặn. Khía cạnh khác là đơn đầu hoặc đa đầu, đơn đầu có nghĩa là chỉ có thể thêm vào cuối hàng đợi và lấy ra từ đầu hàng đợi, trong khi đa đầu có nghĩa là có thể thêm vào và lấy ra từ cả đầu và cuối hàng đợi. Trong gói concurrent của Java, hàng đợi chặn đều được đánh dấu bằng từ khóa Blocking, hàng đợi đơn đầu sử dụng từ khóa Queue và hàng đợi đa đầu sử dụng từ khóa Deque.
BlockingQueue
BlockingQueue có nghĩa là một hàng đợi chặn. BlockingQueue thường được triển khai dựa trên cơ chế khóa. Trong BlockingQueue, khi hàng đợi đầy, thao tác thêm vào sẽ bị chặn; khi hàng đợi trống, thao tác lấy ra sẽ bị chặn.
Giao diện BlockingQueue được định nghĩa như sau:
public interface BlockingQueue<E> extends Queue<E> {}API chính:
// Lấy và loại bỏ phần tử đầu hàng đợi, nếu cần, nó sẽ chờ đến khi hàng đợi có phần tử
E take() throws InterruptedException;
// Thêm phần tử, nếu hàng đợi đã đầy, nó sẽ chờ đến khi có không gian trống trong hàng đợi
void put(E e) throws InterruptedException;BlockingQueue cung cấp bốn phương thức khác nhau để thực hiện các thao tác thêm, lấy và kiểm tra phần tử trong hàng đợi, cho phép sử dụng trong các tình huống khác nhau:
- Ném ra ngoại lệ;
- Trả về giá trị đặc biệt (null hoặc true/false, phụ thuộc vào thao tác cụ thể);
- Chờ đợi thao tác này cho đến khi thành công;
- Chờ đợi thao tác này cho đến khi thành công hoặc hết thời gian chờ.
Tóm lại:
| Ném ra ngoại lệ | Trả về giá trị đặc biệt | Chặn | Chặn với thời gian chờ | |
|---|---|---|---|---|
| Thêm | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| Lấy ra | remove() | poll() | take() | poll(time, unit) |
| Kiểm tra | element() | peek() | không áp dụng | không áp dụng |
BlockingQueue các lớp cài đặt đều tuân thủ các quy tắc này.
BlockingQueue không chấp nhận phần tử null.
JDK cung cấp các hàng đợi chặn sau:
ArrayBlockingQueue- một hàng đợi chặn có giới hạn được tạo thành từ cấu trúc mảng.LinkedBlockingQueue- một hàng đợi chặn có giới hạn được tạo thành từ cấu trúc danh sách liên kết.PriorityBlockingQueue- một hàng đợi chặn vô hạn hỗ trợ sắp xếp theo ưu tiên.SynchronousQueue- một hàng đợi chặn không lưu trữ phần tử.DelayQueue- một hàng đợi chặn vô hạn được triển khai bằng cách sử dụng hàng đợi ưu tiên.LinkedTransferQueue- một hàng đợi chặn vô hạn được tạo thành từ cấu trúc danh sách liên kết.
BlockingQueue thường được triển khai dựa trên cơ chế khóa.
Lớp PriorityBlockingQueue
Lớp PriorityBlockingQueue được định nghĩa như sau:
public class PriorityBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {}Điểm chính của PriorityBlockingQueue
PriorityBlockingQueuecó thể được coi là phiên bản an toàn củaPriorityQueue.PriorityBlockingQueuetriển khaiBlockingQueue, cũng là một hàng đợi chặn.PriorityBlockingQueuetriển khaiSerializable, hỗ trợ việc tuần tự hóa.PriorityBlockingQueuekhông chấp nhận phần tử null.- Thao tác thêm vào
PriorityBlockingQueue(put) không bị chặn, vì nó là một hàng đợi vô hạn (thao tác lấy ra (take) sẽ bị chặn khi hàng đợi rỗng).
Nguyên tắc hoạt động của PriorityBlockingQueue
PriorityBlockingQueue có hai thành viên quan trọng:
private transient Object[] queue;
private final ReentrantLock lock;queuelà một mảngObjectdùng để lưu trữ các phần tử củaPriorityBlockingQueue.locklà một khóa có thể lặp lại, được sử dụng để đảm bảo rằng phương thức thêm vào và xóa phần tử chỉ được thực hiện bởi một luồng tại một thời điểm.
Mặc dù PriorityBlockingQueue có kích thước khởi tạo, nhưng nó không giới hạn kích thước. Nếu kích thước hiện tại đã đầy, việc thêm phần tử mới sẽ tự động mở rộng.
Lớp ArrayBlockingQueue
ArrayBlockingQueue là một hàng đợi chặn được tạo thành từ cấu trúc mảng.
Điểm chính của ArrayBlockingQueue
ArrayBlockingQueue được định nghĩa như sau:
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
// Kích thước mảng xác định giới hạn của hàng đợi, vì vậy phải chỉ định kích thước khi khởi tạo
public ArrayBlockingQueue(int capacity) { //... }
public ArrayBlockingQueue(int capacity, boolean fair) { //... }
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) { //... }
}Giải thích:
ArrayBlockingQueuetriển khaiBlockingQueue, cũng là một hàng đợi chặn.ArrayBlockingQueuetriển khaiSerializable, hỗ trợ việc tuần tự hóa.ArrayBlockingQueuelà một hàng đợi chặn có giới hạn được tạo thành từ cấu trúc mảng. Vì vậy, bạn phải chỉ định kích thước khi khởi tạo.
Nguyên tắc hoạt động của ArrayBlockingQueue
Các thành viên quan trọng trong ArrayBlockingQueue như sau:
// Mảng để lưu trữ các phần tử
final Object[] items;
// Vị trí lấy ra tiếp theo
int takeIndex;
// Vị trí thêm vào tiếp theo
int putIndex;
// Số lượng phần tử trong hàng đợi
int count;
// Các khóa sau đây được sử dụng để đồng bộ hóa các thao tác thêm, xóa và kiểm tra phần tử trong hàng đợi
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;ArrayBlockingQueue sử dụng một mảng final để lưu trữ dữ liệu, kích thước của mảng xác định giới hạn của hàng đợi.
ArrayBlockingQueue triển khai đồng bộ hóa hoạt động bằng cách yêu cầu lấy khóa độc quyền của AQS để thực hiện các thao tác thêm và xóa.
- Nếu hàng đợi trống, luồng đọc phải vào hàng đợi đọc và chờ đến khi luồng ghi thêm phần tử mới và kích hoạt luồng đọc đầu tiên trong hàng đợi đọc.
- Nếu hàng đợi đầy, luồng ghi phải vào hàng đợi ghi và chờ đến khi luồng đọc lấy ra phần tử và kích hoạt luồng ghi đầu tiên trong hàng đợi ghi.
Đối với ArrayBlockingQueue, chúng ta có thể chỉ định ba tham số sau khi tạo:
- Dung lượng hàng đợi, giới hạn số lượng phần tử tối đa được phép trong hàng đợi.
- Xác định khóa độc quyền là khóa công bằng hay không công bằng. Khóa không công bằng có hiệu suất cao hơn, trong khi khóa công bằng đảm bảo rằng luồng chờ lâu nhất luôn nhận được khóa trước.
- Có thể chỉ định một tập hợp để khởi tạo hàng đợi, các phần tử trong tập hợp này sẽ được thêm vào hàng đợi trong quá trình khởi tạo.
Lớp LinkedBlockingQueue
LinkedBlockingQueue là một hàng đợi chặn được tạo thành từ cấu trúc danh sách liên kết. Dễ bị hiểu nhầm là hàng đợi vô hạn, nhưng thực tế thì hành vi và mã trong nội bộ đều dựa trên logic có giới hạn, chỉ khác là nếu chúng ta không chỉ định dung lượng khi tạo hàng đợi, thì giới hạn dung lượng sẽ tự động được đặt thành Integer.MAX_VALUE, trở thành hàng đợi vô hạn.
Điểm chính của LinkedBlockingQueue
LinkedBlockingQueue được định nghĩa như sau:
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {}LinkedBlockingQueuetriển khaiBlockingQueue, cũng là một hàng đợi chặn.LinkedBlockingQueuetriển khaiSerializable, hỗ trợ việc tuần tự hóa.LinkedBlockingQueuelà một hàng đợi chặn được tạo thành từ cấu trúc danh sách liên kết, có thể được sử dụng như một hàng đợi vô hạn hoặc có giới hạn.- Trong
LinkedBlockingQueue, các phần tử được lưu trữ theo thứ tự chèn (FIFO).
Nguyên tắc hoạt động của LinkedBlockingQueue
Cấu trúc dữ liệu quan trọng trong LinkedBlockingQueue:
// Dung lượng hàng đợi
private final int capacity;
// Số lượng phần tử trong hàng đợi
private final AtomicInteger count = new AtomicInteger(0);
// Đầu hàng đợi
private transient Node<E> head;
// Cuối hàng đợi
private transient Node<E> last;
// Phương thức đọc (take, poll, peek) cần lấy khóa này
private final ReentrantLock takeLock = new ReentrantLock();
// Nếu hàng đợi trống khi thực hiện phương thức đọc, hãy chờ điều kiện notEmpty
private final Condition notEmpty = takeLock.newCondition();
// Phương thức ghi (put, offer) cần lấy khóa này
private final ReentrantLock putLock = new ReentrantLock();
// Nếu hàng đợi đầy khi thực hiện phương thức ghi, hãy chờ điều kiện notFull
private final Condition notFull = putLock.newCondition();Ở đây, chúng ta sử dụng hai cặp Lock và Condition:
takeLockvànotEmptyđược sử dụng cùng nhau: Nếu muốn lấy (take) một phần tử, cần lấy khóatakeLock, nhưng chỉ có khóa chưa đủ, nếu hàng đợi trống, cần điều kiệnnotEmpty(Condition) này.putLockvànotFullđược sử dụng cùng nhau: Nếu muốn thêm (put) một phần tử, cần lấy khóaputLock, nhưng chỉ có khóa chưa đủ, nếu hàng đợi đầy, cần điều kiệnnotFull(Condition) này.
Lớp SynchronousQueue
SynchronousQueue là một hàng đợi không lưu trữ phần tử. Mỗi thao tác xóa phải chờ thao tác thêm, và ngược lại, mỗi thao tác thêm cũng phải chờ thao tác xóa. Vậy dung lượng của hàng đợi này là bao nhiêu? Có phải là 1? Thực tế không phải vậy, dung lượng nội bộ của nó là 0.
SynchronousQueue được định nghĩa như sau:
public class SynchronousQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {}Lớp SynchronousQueue này được sử dụng trong lớp ScheduledThreadPoolExecutor của gói concurrent.
SynchronousQueue là một hàng đợi ảo, có nghĩa là dung lượng của nó là 0. Dữ liệu phải được chuyển từ một luồng ghi cho một luồng đọc, thay vì được ghi vào hàng đợi và chờ được tiêu thụ.
SynchronousQueue không thể sử dụng phương thức peek (trong đây phương thức này trả về null), vì phương thức này không phù hợp với đặc điểm của SynchronousQueue.
SynchronousQueue cũng không thể được lặp lại, vì không có phần tử nào để lặp lại.
Mặc dù SynchronousQueue gián tiếp triển khai giao diện Collection, nhưng nếu bạn sử dụng nó như một Collection, thì tập hợp này sẽ rỗng.
Tất nhiên SynchronousQueue không chấp nhận giá trị null (các lớp dữ liệu đóng gói trong gói concurrent không chấp nhận giá trị null, vì giá trị null thường được sử dụng cho mục đích khác, ví dụ như đại diện cho thất bại của một phương thức).
Lớp ConcurrentLinkedDeque
Deque tập trung vào việc hỗ trợ thêm và xóa từ cả đầu và cuối hàng đợi, do đó cung cấp các phương thức đặc biệt như:
addLast(e)vàofferLast(e)để thêm vào cuối hàng đợi.removeLast()vàpollLast()để xóa từ cuối hàng đợi.
Ứng dụng đồng thời của Queue
Queue được sử dụng rộng rãi trong các tình huống sản xuất - tiêu thụ. Trong tình huống đồng thời, sử dụng cơ chế chặn của BlockingQueue có thể giảm thiểu nhiều công việc phối hợp đồng thời.
Với nhiều cài đặt của Queue trong đó, làm sao để chọn?
- Xem xét yêu cầu về giới hạn của hàng đợi trong tình huống ứng dụng.
ArrayBlockingQueuecó giới hạn rõ ràng, trong khiLinkedBlockingQueuephụ thuộc vào việc chúng ta có chỉ định dung lượng khi tạo hàng đợi hay không,SynchronousQueuethậm chí không lưu trữ bất kỳ phần tử nào. - Về mặt sử dụng không gian,
ArrayBlockingQueuenén gọn hơnLinkedBlockingQueuevì nó không cần tạo nút, nhưng giai đoạn cấp phát ban đầu yêu cầu một không gian liên tục lớn hơn. - Trong tình huống chung,
LinkedBlockingQueuecó hiệu suất thường tốt hơnArrayBlockingQueuevì nó triển khai các hoạt động khóa tinh vi hơn. ArrayBlockingQueuetriển khai đơn giản hơn và dễ dự đoán hiệu suất hơn, là một “người chơi” ổn định.- Có thể bất ngờ rằng trong nhiều trường hợp, hiệu suất của
SynchronousQueuethường vượt xa các cài đặt khác, đặc biệt là trong các tình huống có số lượng phần tử nhỏ trong hàng đợi.