OS Interview Q&A
Sự khác biệt và sự liên hệ giữa tiến trình (process), luồng (thread) và Corountine
| Tiến trình | Luồng | Corountine | |
|---|---|---|---|
| Định nghĩa | Đơn vị cơ bản của cấp phát và sở hữu tài nguyên | Đơn vị cơ bản của việc thực thi chương trình | Luồng nhẹ của người dùng, đơn vị cơ bản của lập lịch nội bộ luồng |
| Chuyển đổi | Lưu trữ môi trường CPU của tiến trình (ngăn xếp, thanh ghi, bảng trang và xử lý tập tin v.v.) và thiết lập môi trường CPU của tiến trình mới | Lưu trữ và thiết lập nội dung bộ đếm chương trình (PC - Program Counter), một số thanh ghi và ngăn xếp | Lưu trữ ngữ cảnh thực thi và ngăn xếp trước đó, sau đó khôi phục khi chuyển đổi trởlại |
| Bộ chuyển đổi | Hệ điều hành | Hệ điều hành | Người dùng |
| Quá trình chuyển đổi | Chế độ người dùng → Chế độ kernel → Chế độ người dùng | Chế độ người dùng → Chế độ kernel → Chế độ người dùng | Chế độ người dùng (không vào kernel) |
| Ngăn xếp cuộc gọi | Ngăn xếp kernel | Ngăn xếp kernel | Ngăn xếp người dùng |
| Sở hữu tài nguyên | Tài nguyên CPU, tài nguyên bộ nhớ, tài nguyên tệp và bộ điều khiển v.v. | Bộ đếm chương trình, thanh ghi, ngăn xếp và từ điển trạng thái | Có ngữ cảnh và ngăn xếp riêng |
| Đồng thời | Chuyển đổi giữa các tiến trình để thực hiện đồng thời, mỗi tiến trình chiếm CPU để thực hiện song song | Nhiều luồng trong cùng một tiến trình thực hiện đồng thời | Chỉ có thể chạy một coroutine vào cùng một thời điểm, trong khi các coroutine khác ở trạng thái ngủ, phù hợp cho xử lý tách biệt nhiệm vụ theo khoảng thời gian |
| Chi phí hệ thống | Chuyển đổi không gian địa chỉ ảo, chuyển đổi ngăn xếp nhân và bối cảnh phần cứng, mất hiệu suất bộ nhớ cache CPU, chuyển đổi bảng trang, chi phí lớn | Khi chuyển đổi chỉ cần lưu và thiết lập một số ít nội dung thanh ghi, do đó chi phí rất nhỏ | Trực tiếp hoạt động trên ngăn xếp thì gần như không có chi phí chuyển đổi kernel, có thể truy cập biến toàn cục mà không cần khóa nên việc chuyển ngữ cảnh rất nhanh |
| Giao tiếp | Giao tiếp giữa các tiến trình cần có sự trợ giúp từ hệ điều hành | Các luồng có thể truy cập trực tiếp vào đoạn dữ liệu của tiến trình (như biến toàn cục) để giao tiếp | Chia sẻ bộ nhớ, hàng đợi tin nhắn |
- Tiến trình là đơn vị cơ bản để cấp phát và sở hữu tài nguyên. Khi chạy một chương trình thực thi, sẽ tạo ra một hoặc nhiều tiến trình, tiến trình là chương trình đã chạy.
- Luồng là đơn vị cơ bản để lập lịch thực thi chương trình, mỗi tiến trình có thể có nhiều luồng, luồng chính là tiến trình nhẹ. Mỗi tiến trình có một luồng chính duy nhất. Khi luồng chính kết thúc, tiến trình cũng kết thúc. Một số điểm cần lưu ý: coroutine là một luồng nhẹ của người dùng, đơn vị cơ bản của lập lịch nội bộ luồng.
So sánh giữa luồng và tiến trình
- Luồng khởi động nhanh, nhẹ nhàng
- Chi phí hệ thống của luồng nhỏ.
- Sử dụng luồng có một số khó khăn, cần xử lý vấn đề tính nhất quán dữ liệu
- Cùng một luồng chia sẻ heap, biến toàn cục, biến tĩnh, con trỏ, tham chiếu, tệp v.v., trong khi sở hữu ngăn xếp riêng
Bổ sung cách khác để hỏi
Sự khác biệt giữa luồng và tiến trình?
- Lập lịch: Luồng là đơn vị cơ bản để lập lịch (PC, mã trạng thái, thanh ghi thông thường, ngăn xếp). Tiến trình là đơn vị cơ bản để cấp phát tài nguyên của hệ điều hành (mở tệp, heap, vùng tĩnh, đoạn mã, v.v.).
- Đồng thời: Nhiều luồng trong cùng một tiến trình có thể chạy đồng thời (tốt nhất là bằng số lõi CPU); Nhiều tiến trình có thể chạy đồng thời.
- Sở hữu tài nguyên: Luồng không sở hữu tài nguyên hệ thống, nhưng nhiều luồng trong cùng một tiến trình có thể chia sẻ tài nguyên của tiến trình mẹ. Tiến trình là đơn vị độc lập sở hữu tài nguyên.
- Chi phí hệ thống: Tạo và hủy luồng chỉ cần xử lý giá trị PC, mã trạng thái, thanh ghi và ngăn xếp. Tạo và hủy tiến trình đòi hỏi phải cấp phát và hủy cấu trúc task_struct.
Một tiến trình có thể tạo ra bao nhiêu luồng và phụ thuộc vào điều gì?
Điều này phụ thuộc vào hệ điều hành cụ thể:
- Nếu là hệ điều hành 32 bit, không gian ảo của người dùng chỉ có 3GB, nếu cấp phát 10MB không gian ngăn xếp khi tạo luồng, một tiến trình tối đa chỉ có thể tạo khoảng 300 luồng.
- Nếu là hệ điều hành 64 bit, không gian ảo của người dùng lớn đến 128TB, lý thuyết không bị giới hạn bởi kích thước bộ nhớ ảo, mà bị giới hạn bởi các tham số hoặc hiệu suất của hệ thống.
Ngoài ra, quá nhiều luồng sẽ dẫn đến lãng phí thời gian trong việc chuyển đổi luồng, ảnh hưởng tiêu cực đến hiệu suất chạy chương trình, luồng không cần thiết phải được hủy ngay lập tức.
Sự khác biệt giữa ngắt ngoại và ngoại lệ?
Ngắt ngoại (External Interrupt) là sự kiện xảy ra do các sự kiện ngoại vi khác như ngắt hoàn thành I/O, đại diện cho việc xử lý đầu vào/đầu ra của thiết bị đã hoàn thành và bộ xử lý có thể gửi yêu cầu I/O tiếp theo. Ngoài ra, còn có các ngắt như ngắt đồng hồ, ngắt bảng điều khiển và các ngắt khác.
Trong khi đó, ngoại lệ (Exception) là sự kiện xảy ra do các sự kiện nội bộ của bộ xử lý khi thực hiện các chỉ thị, ví dụ như mã lệnh không hợp lệ, vượt quá giới hạn địa chỉ, tràn số học, v.v.
Mô hình tiến trình và luồng bạn biết bao nhiêu?
Việc hiểu và nắm vững về tiến trình và luồng là cơ bản để hiểu và kiểm soát hệ thống. Ý nghĩa cốt lõi của chúng không chỉ đơn giản là “luồng là đơn vị lập lịch, tiến trình là đơn vị cấp phát tài nguyên”.
Đa luồng (Multi-Threading)
Ở đây, chúng ta sẽ thảo luận về mô hình đa luồng trong không gian người dùng, trong đó một tiến trình có nhiều luồng. Tất cả các luồng trong cùng một tiến trình chia sẻ cùng một không gian bộ nhớ của tiến trình, các biến toàn cục được định nghĩa trong tiến trình sẽ được tất cả các luồng chia sẻ và có thể đọc và sửa đổi giá trị của chúng. Ví dụ, nếu có biến toàn cục int i = 10 trong tiến trình, tất cả các luồng đang chạy trong tiến trình đó có thể đọc và thay đổi giá trị của i. Tuy nhiên, thứ tự thực hiện của các luồng khác nhau không thể kiểm soát và có thể dẫn đến những kết quả không mong muốn khi truy cập vào tài nguyên chung.
Chúng ta phải nhớ rằng “i = i + 1” không phải là một hoạt động nguyên tử trên máy tính. Nó bao gồm việc truy xuất bộ nhớ, tính toán và ghi vào bộ nhớ, và việc chuyển đổi giữa các luồng có thể xảy ra bất kỳ lúc nào trong quá trình này. Do đó, các thứ tự thực hiện khác nhau có thể dẫn đến kết quả không mong muốn.
Tuy nhiên, mặc dù việc sử dụng luồng đem lại nhiều thách thức về an toàn, nhưng cũng mang lại nhiều lợi ích. Đầu tiên, chương trình ban đầu được thực hiện theo trình tự có thể được chia thành nhiều luồng độc lập, mỗi luồng hoàn thành một số công việc riêng biệt (tốt nhất là các công việc không liên quan). Ví dụ, Zalo có thể có một luồng xử lý trò chuyện và một luồng xử lý tải lên tệp, hai luồng này không tác động lẫn nhau. Đối với người dùng, nó sẽ trông giống như hai nhiệm vụ đồng thời đang được thực hiện, hãy tưởng tượng nếu thực hiện nhiệm vụ này theo trình tự, việc chờ đợi trò chuyện bị chặn liên tục cho đến khi tải lên dữ liệu hoàn thành sẽ là một tình huống khó xử.
Đối với luồng, tôi nghĩ rằng việc hiểu rõ hai điểm sau là rất quan trọng:
- Có hoặc không có thứ tự truy cập giữa các luồng (phụ thuộc luồng)
- Các luồng chia sẻ truy cập vào cùng một biến (vấn đề đồng bộ hóa)
Ngoài ra, chúng ta thường chỉ nói về việc chia sẻ tài nguyên của một tiến trình bởi nhiều luồng, nhưng ít khi đề cập đến phần riêng tư của từng luồng. Ngoài việc định danh luồng bằng tid, mỗi luồng cũng có không gian ngăn xếp riêng của nó, các luồng không thể truy cập vào nội dung ngăn xếp của các luồng khác.
Là đơn vị nhỏ nhất của lập lịch, việc lập lịch luồng chỉ cần lưu trữ ngăn xếp luồng, dữ liệu thanh ghi và PC, so với việc chuyển đổi tiến trình, việc chuyển đổi luồng có thể tiết kiệm nhiều hơn.
Có nhiều giao diện liên quan đến luồng, quan trọng là hiểu ý nghĩa của các tham số và giá trị trả về.
-
Tạo và kết thúc luồng
-
Kiến thức cơ bản:
Trong một tệp, các hàm thường được thực hiện theo thứ tự xuất hiện trong hàm main, nhưng trong hệ thống chia thời gian, chúng ta có thể cho mỗi hàm hoạt động như một luồng riêng biệt và chạy song song, cách đơn giản nhất là sử dụng mô hình đa luồng. Trong hàm main, gọi giao diện đa luồng để tạo luồng, mỗi luồng tương ứng với một hàm cụ thể (hoạt động), điều này cho phép chúng ta không cần tuân theo thứ tự xuất hiện của các hàm trong main, tránh tình trạng bận rộn. Các giao diện cơ bản của luồng như sau.
-
Giao diện liên quan:
-
Tạo luồng:
int pthread_create(pthread_t *tidp, const pthread_attr_t *attr, void *(*start_rtn)(void*), void *arg);Tạo một luồng mới,
pthreadvàstart_routinekhông thể thiếu, lần lượt được sử dụng để định danh luồng và điểm vào của hàm thực thi, các tham số khác có thể được điền bằng NULL.pthread: Dùng để trả về tid của luồng,*pthreadlà giá trịtid, kiểu dữ liệupthread_t == unsigned long int.attr: Con trỏ đến cấu trúc thuộc tính luồng, được sử dụng để thay đổi thuộc tính của luồng được tạo, điền NULL để sử dụng giá trị mặc định.start_routine: Địa chỉ đầu tiên của hàm thực thi của luồng, truyền con trỏ hàm.arg: Sử dụng con trỏ kiểu không dấu để truyền tham số hàm, ở trong hàm được truyền vào, trước tiên ép kiểu thành kiểu cần thiết.
-
Lấy ID luồng:
pthread_t pthread_self();Gọi khi cần in ra ID luồng.
-
Chờ luồng kết thúc:
int pthread_join(pthread_t tid, void** retval);Gọi từ luồng chính, chờ luồng con kết thúc và thu hồi tài nguyên của nó, tương tự như wait/waitpid trong tiến trình, luồng gọi pthread_join sẽ bị chặn.
tid: Được nhận từ con trỏ khi tạo luồng.retval: Con trỏ đến giá trị trả về.
-
Kết thúc luồng:
pthread_exit(void *retval);Được gọi từ luồng con, được sử dụng để kết thúc luồng hiện tại và truyền giá trị trả về qua retval, giá trị trả về này có thể được truy cập thông qua pthread_join.
-
Tách luồng:
int pthread_detach(pthread_t tid);Cả luồng chính và luồng con đều có thể gọi. Trong luồng chính, gọi
pthread_detach(tid), trong luồng con, gọipthread_detach(pthread_self()), sau khi gọi, luồng sẽ tách rời luồng chính và tự động thu hồi tài nguyên khi luồng con kết thúc.tid: Giống như trên.
-
-
-
Thay đổi giá trị thuộc tính luồng
-
Kiến thức cơ bản:
Đối tượng thuộc tính luồng có kiểu
pthread_attr_t, cấu trúc được định nghĩa như sau:typedef struct{ int detachstate; // Trạng thái tách luồng int schedpolicy; // Chính sách lập lịch luồng struct sched_param schedparam; // Tham số lập lịch luồng int inheritsched; // Tính kế thừa lập lịch luồng int scope; // Phạm vi hoạt động của luồng // Dưới đây là cài đặt ngăn đệm cuối ngăn xếp luồng size_t guardsize; // Kích thước bộ đệm cảnh báo cuối ngăn xếp luồng int stackaddr_set; // Cài đặt ngăn xếp luồng void * stackaddr; // Vị trí ngăn xếp luồng size_t stacksize; // Kích thước ngăn xếp luồng }pthread_attr_t;
-
-
Các giao diện liên quan:
Đối với hầu hết các tham số trong cấu trúc trên, chúng ta có thể sử dụng các hàm hệ thống
pthread_attr_get()vàpthread_attr_set()để thiết lập và lấy giá trị. Ở đây, tôi không liệt kê từng cái một.
Đa tiến trình (Multi-Processing)
Mỗi tiến trình là đơn vị cơ bản của việc cấp phát tài nguyên.
Cấu trúc của một tiến trình bao gồm các phần sau: Code, Data, Stack, Heap. Code là mã nhị phân tĩnh, nhiều chương trình có thể chia sẻ.
Thực tế, sau khi tiến trình con được tạo bởi tiến trình cha, ngoài pid, hầu hết các phần của tiến trình cha và con đều giống nhau.
Tiến trình cha và con chia sẻ toàn bộ dữ liệu, nhưng điều này không có nghĩa là chúng đang làm việc trên cùng một khối dữ liệu. Khi tiến trình con đọc hoặc ghi dữ liệu, nó sẽ sao chép lại một bản sao của dữ liệu chung, sau đó thực hiện các hoạt động trên bản sao dữ liệu đó.
Nếu tiến trình con muốn chạy đoạn mã riêng của mình, nó có thể tải lại đoạn mã mới bằng cách gọi hàm execv(). Sau đó, tiến trình con sẽ hoạt động độc lập với tiến trình cha.
Khi chúng ta thực thi một chương trình trong shell, quá trình tạo ra các tiến trình con từ tiến trình shell và sau đó tải lại đoạn mã mới bằng cách gọi execv() là quá trình diễn ra.
-
Tạo và kết thúc tiến trình
-
Kiến thức cơ bản:
Có hai cách để tạo tiến trình, một là do hệ điều hành tạo ra và một là do tiến trình cha tạo ra. Quá trình từ khởi động máy tính đến thực thi chương trình trong terminal như sau: tiến trình 0 → tiến trình 1 của kernel → tiến trình 1 của người dùng (tiến trình init) → tiến trình getty → tiến trình shell → tiến trình thực thi lệnh. Do đó, khi chúng ta thực thi một tệp tin thực thi bằng cách gõ
./programtrong terminal, tất cả các tiến trình được tạo ra đều là con của tiến trình shell, đó cũng là lý do tại sao khi shell đóng, các tiến trình được thực thi trong shell cũng tự động đóng. Để tạo ra các tiến trình con khác từ tiến trình shell, chúng ta cần sử dụng các giao diện sau. -
Các giao diện liên quan:
-
Tạo tiến trình:
pid_t fork(void);Giá trị trả về: -1 nếu có lỗi; trong tiến trình cha, trả về pid > 0; trong tiến trình con, trả về pid = 0.
-
Kết thúc tiến trình:
void exit(int status);- status là trạng thái thoát, được lưu trong biến toàn cục S?; thường thì 0 đại diện cho thoát bình thường.
-
Lấy PID:
pid_t getpid(void);Trả về pid của tiến trình gọi.
-
Lấy PID của tiến trình cha:
pid_t getppid(void);Trả về
pidcủa tiến trình cha.
-
-
Thêm thông tin bổ sung:
-
Cách thoát bình thường:
exit(),_exit(),return(trong hàm main).Sự khác biệt giữa
exit()và_exit():exit()là sự đóng gói của__exit(), cả hai đều kết thúc tiến trình và thực hiện các công việc liên quan đến kết thúc, khác biệt chính là hàm_exit()không làm mới luồng dữ liệu sau khi đóng tất cả các mô tả, trong khiexit()sẽ làm mới dữ liệu trước khi gọi hàm_exit().Sự khác biệt giữa
returnvàexit():exit()là một hàm, nhưng có tham số, sau khi thực hiện xong, quyền điều khiển được chuyển cho hệ thống. return nếuđượcsử dụng trong một hàm gọi, sau khi thực hiện xong, quyền điều khiển được chuyển cho tiến trình gọi, nếu nó được sử dụng trong hàm main, quyền điều khiển được chuyển cho hệ thống. -
Cách thoát bất thường:
abort(), tín hiệu kết thúc.
-
-
-
Điều khiển tiến trình Linux
-
Không gian địa chỉ của tiến trình (không gian địa chỉ)
Bộ nhớ ảo cung cấp một không gian địa chỉ hệ thống duy nhất cho mỗi tiến trình.
Mặc dù nội dung không gian địa chỉ của mỗi tiến trình không giống nhau, nhưng chúng có cấu trúc tương tự. Đáy không gian địa chỉ của tiến trình X86 Linux là dành cho chương trình người dùng, bao gồm vùng mã, vùng dữ liệu, vùng heap, vùng ngăn xếp và nhiều hơn nữa. Các vùng mã và dữ liệu được ánh xạ từ các đoạn tương ứng của tệp thực thi trong không gian địa chỉ ảo.
Có một số địa chỉ “nhạy cảm” cần lưu ý, đoạn mã bắt đầu từ 0x08048000 cho tiến trình 32 bit. Từ 0xC0000000 đến 0xFFFFFFFF là không gian địa chỉ của kernel, thông thường, mã chạy ở chế độ người dùng (sử dụng không gian địa chỉ người dùng từ 0x00000000 đến 0xC0000000), khi có một cuộc gọi hệ thống, chuyển đổi chế độ CPU bằng cách đặt bit chế độ trong thanh ghi điều khiển, chuyển sang chế độ kernel, trong chế độ này (chế độ siêu người dùng), tiến trình có thể truy cập vào tất cả các vị trí bộ nhớ và thực hiện tất cả các lệnh.
-
Bảng điều khiển tiến trình (bộ điều khiển)
Lịch trình tiến trình thực chất là việc chọn bộ điều khiển tiến trình tương ứng, bộ điều khiển tiến trình chứa thông tin cơ bản về tiến trình.
-
Chuyển đổi ngữ cảnh
Hệ điều hành quản lý tất cả các bộ điều khiển tiến trình và bộ điều khiển tiến trình chứa tất cả thông tin trạng thái của tiến trình. Mỗi lần chọn một tiến trình, chúng ta gọi đó là một chuyển đổi ngữ cảnh, thực chất là chuyển đổi trạng thái hiện tại, bao gồm thanh ghi thông thường, thanh ghi số học, thanh ghi trạng thái, bộ đếm chương trình, ngăn xếp người dùng và cấu trúc dữ liệu hạt nhân (bảng trang, bảng tiến trình, bảng tệp) và nhiều hơn nữa.
Khi tiến trình đang chạy, kernel có thể quyết định giành quyền từ tiến trình hiện tại và bắt đầu tiến trình mới, quá trình này được thực hiện thông qua việc chuyển đổi ngữ cảnh để thay đổi trạng thái hiện tại.
Một lần chuyển đổi ngữ cảnh hoàn chỉnh thường là từ tiến trình chạy ở chế độ người dùng, sau đó chuyển sang chế độ kernel để thực hiện các lệnh kernel, sau đó quay trở lại chế độ người dùng, lúc này đã chuyển sang tiến trình B.
Bạn hiểu về các thuật toán lập lịch tiến trình không?
1. First-Come First-Served (FCFS) - Đến trước, phục vụ trước
Thuật toán lập lịch không tranh chấp, lập lịch theo thứ tự yêu cầu.
Thuận lợi cho công việc dài, nhưng không thuận lợi cho công việc ngắn, vì công việc ngắn phải chờ đến khi công việc dài trước đó hoàn thành trước khi thực hiện, trong khi công việc dài lại mất nhiều thời gian để thực hiện, dẫn đến thời gian chờ đợi của công việc ngắn quá lâu.
2. Shortest Job First (SJF) - Tiến trình ngắn nhất trước
Thuật toán lập lịch không tranh chấp, lập lịch theo thứ tự công việc có thời gian chạy ước tính ngắn nhất.
Công việc dài có thể bị đói, trong trạng thái chờ mãi mãi cho đến khi công việc ngắn hoàn thành. Vì nếu có liên tục công việc ngắn đến, công việc dài sẽ không bao giờ được lập lịch.
3. Shortest Remaining Time Next (SRTN) - Tiến trình còn lại ngắn nhất tiếp theo
Phiên bản tranh chấp của thuật toán ưu tiên công việc ngắn nhất, lập lịch theo thứ tự thời gian còn lại ngắn nhất. Khi một công việc mới đến, thời gian chạy toàn bộ của nó được so sánh với thời gian còn lại của quá trình hiện tại.
Nếu công việc mới cần ít thời gian hơn, quá trình hiện tại sẽ bị treo, công việc mới được chạy. Nếu không, công việc mới sẽ đợi.
4. Round Robin (RR) - Vòng quay
Sắp xếp tất cả các quá trình sẵn sàng theo nguyên tắc FCFS thành một hàng đợi, mỗi lần lập lịch, CPU được cấp cho quá trình đầu tiên trong hàng đợi, quá trình này có thể thực hiện một đơn vị thời gian.
Khi hết thời gian, bộ đếm thời gian sẽ phát ra ngắt đồng hồ, chương trình lập lịch sẽ dừng việc thực hiện của quá trình hiện tại và đưa nó vào cuối hàng đợi, đồng thời tiếp tục cấp CPU cho quá trình đầu tiên trong hàng đợi.
Hiệu suất của thuật toán vòng quay thời gian phụ thuộc rất nhiều vào kích thước đơn vị thời gian:
- Vì việc chuyển đổi quá trình phải lưu trữ thông tin quá trình và tải thông tin quá trình mới, nếu đơn vị thời gian quá nhỏ, việc chuyển đổi quá trình sẽ diễn ra quá thường xuyên, dẫn đến việc mất quá nhiều thời gian cho việc chuyển đổi quá trình.
- Nếu đơn vị thời gian quá lớn, thì tính thời gian thực hiện không được đảm bảo.
5. Priority Scheduling - Lập lịch ưu tiên
Mỗi quá trình được gán một mức ưu tiên, lập lịch theo mức ưu tiên.
Để tránh quá trình ưu tiên thấp không bao giờ được lập lịch, có thể tăng mức ưu tiên của quá trình chờ theo thời gian.
6. Multilevel Queue - Hàng đợi đa cấp
Một quá trình cần thực hiện 100 đơn vị thời gian, nếu sử dụng thuật toán vòng quay thời gian, sẽ cần thay đổi 100 lần.
Hàng đợi đa cấp được thiết lập cho các quá trình cần thực hiện liên tiếp nhiều đơn vị thời gian, nó có nhiều hàng đợi, mỗi hàng đợi có kích thước đơn vị thời gian khác nhau, ví dụ 1, 2, 4, 8, … Quá trình trong hàng đợi đầu tiên chưa hoàn thành sẽ được chuyển đến hàng đợi tiếp theo.
Cách tiếp cận này, quá trình trước đó chỉ cần thay đổi 7 lần. Mỗi hàng đợi có mức ưu tiên khác nhau, mức ưu tiên cao nhất ở trên cùng. Vì vậy, chỉ khi không có quá trình trong hàng đợi trước đó mới có thể lập lịch cho quá trình trong hàng đợi hiện tại.
Bạn có thể coi thuật toán lập lịch này là sự kết hợp giữa thuật toán vòng quay thời gian và thuật toán ưu tiên.
7. Phương pháp giao tiếp giữa các tiến trình trong Linux?
- Pipe (Đường ống):
- Pipe vô danh (tệp bộ nhớ): Pipe là một cách giao tiếp bán song công, dữ liệu chỉ có thể chảy một chiều và chỉ có thể sử dụng giữa các tiến trình có mối quan hệ họ hàng. Mối quan hệ họ hàng của tiến trình thường đề cập đến mối quan hệ cha-con.
- Pipe có tên (tệp FIFO, sử dụng hệ thống tệp): Pipe có tên cũng là một cách giao tiếp bán song công, nhưng cho phép sử dụng giữa các tiến trình không có mối quan hệ họ hàng. Pipe có tên hoạt động theo nguyên tắc FIFO (First-In-First-Out).
- Bộ nhớ chia sẻ: Bộ nhớ chia sẻ là việc ánh xạ một phần bộ nhớ có thể được truy cập bởi các tiến trình khác, bộ nhớ chia sẻ được tạo bởi một tiến trình nhưng nhiều tiến trình khác cũng có thể truy cập. Bộ nhớ chia sẻ là cách giao tiếp IPC (Inter-Process Communication) nhanh nhất, nó được thiết kế đặc biệt để khắc phục hiệu suất thấp của các cách giao tiếp khác giữa các tiến trình.
- Hàng đợi tin nhắn (Message Queue): Hàng đợi tin nhắn là một danh sách liên kết chứa các tin nhắn, được lưu trữ trong kernel và được xác định bởi một định danh hàng đợi tin nhắn. Hàng đợi tin nhắn khắc phục nhược điểm của việc truyền thông tin ít, pipe chỉ có thể chứa dữ liệu không có định dạng và kích thước bộ đệm bị giới hạn.
- Socket: Sử dụng cho việc giao tiếp giữa các tiến trình trên các máy khác nhau, cũng có thể được sử dụng làm cách giao tiếp giữa hai tiến trình trên cùng một máy.
- Tín hiệu (Signal): Được sử dụng để thông báo cho tiến trình nhận biết rằng một sự kiện đã xảy ra, ví dụ như nhấn tổ hợp phím
Ctrl + Clà một tín hiệu. - Semaphore (Đèn tín hiệu): Semaphore là một bộ đếm, được sử dụng để kiểm soát quyền truy cập của nhiều tiến trình vào tài nguyên chia sẻ. Nó thường được sử dụng như một cơ chế khóa, để đồng bộ hóa và kiểm soát truy cập vào vùng khu vực quan trọng và tránh xung đột truy cập.
Cơ chế đồng bộ trong Linux?
- Semaphore POSIX: Có thể sử dụng để đồng bộ tiến trình và cũng có thể sử dụng để đồng bộ luồng.
- Mutex POSIX + Biến điều kiện: Chỉ có thể sử dụng để đồng bộ luồng.
Nếu hệ thống có bảng nhanh, quá trình chuyển đổi địa chỉ sẽ thay đổi như thế nào?
① CPU cung cấp địa chỉ logic, được tính toán bởi một phần cứng nào đó để lấy số trang và độ lệch trong trang, sau đó so sánh số trang với tất cả các số trang trong bảng nhanh.
② Nếu tìm thấy số trang khớp, điều đó có nghĩa là mục bảng trang mà muốn truy cập có bản sao trong bảng nhanh, sau đó lấy số khối bộ nhớ tương ứng với trang đó từ bảng nhanh, sau đó kết hợp số khối bộ nhớ với độ lệch trong trang để tạo thành địa chỉ vật lý cuối cùng, cuối cùng, truy cập đơn vị bộ nhớ tương ứng với địa chỉ vật lý đó. Do đó, nếu bảng nhanh trúng, chỉ cần truy cập một lần để truy cập một địa chỉ logic.
③ Nếu không tìm thấy số trang khớp, sau đó cần truy cập bảng trang trong bộ nhớ để tìm mục bảng trang tương ứng, lấy số khối bộ nhớ nơi trang được lưu trữ từ bảng trang, sau đó kết hợp số khối bộ nhớ với độ lệch trong trang để tạo thành địa chỉ vật lý cuối cùng, cuối cùng, truy cập đơn vị bộ nhớ tương ứng với địa chỉ vật lý đó. Do đó, nếu bảng nhanh không trúng, cần hai lần truy cập (lưu ý: sau khi tìm thấy mục bảng trang, cần lưu nó vào bảng nhanh đồng thời để sử dụng lại trong tương lai. Nhưng nếu bảng nhanh đã đầy, cần thay thế mục bảng trang cũ theo thuật toán đã định sẵn).
Do tốc độ truy vấn bảng nhanh nhanh hơn rất nhiều so với truy vấn bảng trang, do đó chỉ cần trúng bảng nhanh, có thể tiết kiệm rất nhiều thời gian.
Vì nguyên tắc vùng lân cận, tỷ lệ trúng bảng nhanh thường có thể đạt trên 90%.
Ví dụ: Hệ thống nào đó sử dụng quản lý bộ nhớ phân trang cơ bản và sử dụng cơ chế bảng nhanh để chuyển đổi địa chỉ. Thời gian truy cập vào bảng nhanh là 1us, thời gian truy cập vào bộ nhớ là 100us. Nếu tỷ lệ trúng bảng nhanh là 90%, thì thời gian trung bình để truy cập một địa chỉ logic là bao nhiêu?
(1+100) * 0.9 + (1+100+100) * 0.1 = 111 us
Một số hệ thống hỗ trợ việc tìm kiếm cùng lúc trong bảng nhanh và bảng chậm, trong trường hợp này, thời gian trung bình sẽ là (1+100) * 0.9+ (100+100) *0.1=110.9 us
Nếu không sử dụng cơ chế bảng nhanh, thời gian truy cập một địa chỉ logic sẽ là 100+100 = 200us
Rõ ràng, sau khi giới thiệu cơ chế bảng nhanh, tốc độ truy cập một địa chỉ logic nhanh hơn rất nhiều.
Sự khác biệt giữa trao đổi bộ nhớ và ghi đè là gì?
Công nghệ trao đổi chủ yếu được thực hiện giữa các tiến trình (hoặc công việc) khác nhau, trong khi ghi đè được sử dụng trong cùng một chương trình hoặc tiến trình.
Có những thuật toán cấp phát phân vùng động nào và bạn có thể nói về từng thuật toán được không?
1. Thuật toán phù hợp đầu tiên (First Fit Algorithm)
Ý tưởng thuật toán: Mỗi lần cấp phát, tìm kiếm tuần tự các phân vùng trống từ đầu đến cuối và chọn phân vùng đầu tiên có đủ kích thước để phù hợp với quy mô yêu cầu.
Cách thực hiện: Các phân vùng trống được liên kết theo thứ tự tăng dần của địa chỉ. Mỗi lần cấp phát, tìm kiếm tuần tự trong danh sách phân vùng trống (hoặc bảng phân vùng trống) và chọn phân vùng trống đầu tiên có kích thước đủ để đáp ứng yêu cầu.
2. Thuật toán phù hợp tốt nhất (Best Fit Algorithm)
Ý tưởng thuật toán: Vì cấp phát động là một phương pháp cấp phát liên tục, không gian được cấp phát cho các tiến trình phải là một vùng liên tục. Do đó, để đảm bảo khi có “tiến trình lớn” đến, có một vùng liên tục lớn đủ để sử dụng, có thể ưu tiên sử dụng các phân vùng nhỏ hơn.
Cách thực hiện: Các phân vùng trống được liên kết theo thứ tự tăng dần của kích thước. Mỗi lần cấp phát, tìm kiếm tuần tự trong danh sách phân vùng trống (hoặc bảng phân vùng trống) và chọn phân vùng trống nhỏ nhất có kích thước đủ để đáp ứng yêu cầu.
3. Thuật toán phù hợp tồi nhất (Worst Fit Algorithm)
Còn được gọi là thuật toán phù hợp lớn nhất (Largest Fit).
Ý tưởng thuật toán: Để giải quyết vấn đề của thuật toán phù hợp tốt nhất - tức là để lại quá nhiều mảnh nhỏ khó sử dụng, có thể ưu tiên sử dụng phân vùng trống lớn nhất mỗi lần cấp phát, điều này sẽ giúp giữ lại các phân vùng trống không quá nhỏ và dễ sử dụng hơn.
Cách thực hiện: Các phân vùng trống được liên kết theo thứ tự giảm dần của kích thước. Mỗi lần cấp phát, tìm kiếm tuần tự trong danh sách phân vùng trống (hoặc bảng phân vùng trống) và chọn phân vùng trống lớn nhất có kích thước đủ để đáp ứng yêu cầu.
4. Thuật toán kề cận (Next Fit Algorithm)
Ý tưởng thuật toán: Thuật toán phù hợp đầu tiên luôn bắt đầu tìm kiếm từ đầu danh sách phân vùng trống, điều này có thể làm tăng thời gian tìm kiếm. Nếu chúng ta bắt đầu tìm kiếm từ vị trí kết thúc của lần cấp phát trước đó, chúng ta có thể giảm thiểu thời gian tìm kiếm.
Cách thực hiện: Các phân vùng trống được liên kết theo thứ tự tăng dần của địa chỉ (có thể được sắp xếp thành danh sách vòng). Mỗi lần cấp phát, bắt đầu tìm kiếm từ vị trí kết thúc của lần cấp phát trước đó và chọn phân vùng trống đầu tiên có kích thước đủ để đáp ứng yêu cầu.
5. Tổng kết
Thuật toán phù hợp đầu tiên không chỉ đơn giản mà thường là tốt nhất và nhanh nhất, nhưng thuật toán phù hợp đầu tiên có thể dẫn đến việc có nhiều phân vùng nhỏ khó sử dụng và tăng thời gian tìm kiếm. Thuật toán kề cận cố gắng giải quyết vấn đề này, nhưng thực tế, nó thường dẫn đến việc phân vùng cuối cùng trong bộ nhớ bị chia nhỏ thành các mảnh nhỏ, nó thường kém hơn kết quả của thuật toán phù hợp đầu tiên.
Thuật toán phù hợp tốt nhất dẫn đến nhiều mảnh nhỏ, thuật toán phù hợp tồi nhất dẫn đến không có phân vùng lớn. Sau các thử nghiệm, thuật toán phù hợp đầu tiên tốt hơn thuật toán phù hợp tốt nhất và thuật toán phù hợp tồi nhất.
| Thuật toán | Ý tưởng thuật toán | Sắp xếp phân vùng | Ưu điểm | Nhược điểm |
|---|---|---|---|---|
| Phù hợp đầu tiên | Tìm kiếm tuần tự các phân vùng trống từ đầu đến cuối | Phân vùng trống được liên kết theo thứ tự tăng dần của địa chỉ | Tốt nhất và nhanh nhất. Thuật toán có chi phí thấp, sau khi thu hồi phân vùng, thường không cần sắp xếp lại danh sách phân vùng trống | |
| Phù hợp tốt nhất | Ưu tiên sử dụng các phân vùng nhỏ hơn để giữ lại các phân vùng lớn hơn | Phân vùng trống được liên kết theo thứ tự tăng dần của kích thước | Sẽ có nhiều phân vùng lớn hơn được giữ lại, đáp ứng tốt hơn yêu cầu của các quy trình lớn | Sẽ tạo ra nhiều mảnh nhỏ khó sử dụng; Thuật toán có chi phí cao, sau khi thu hồi phân vùng, có thể cần sắp xếp lại danh sách phân vùng trống |
| Phù hợp tồi nhất | Ưu tiên sử dụng phân vùng trống lớn nhất để tránh tạo ra các mảnh nhỏ không sử dụng được | Phân vùng trống được liên kết theo thứ tự giảm dần của kích thước | Có thể giảm thiểu số lượng mảnh nhỏ khó sử dụng | Phân vùng lớn dễ bị sử dụng hết, không tốt cho các quy trình lớn; Thuật toán có chi phí cao(lý do giống như thuật toán phù hợp tốt nhất) |
| Kề cận | Bắt đầu tìm kiếm từ vị trí kết thúc của lần cấp phát trước đó | Phân vùng trống được liên kết theo thứ tự tăng dần của địa chỉ (có thể được sắp xếp thành danh sách vòng) | Không cần tìm kiếm từ phân vùng nhỏ ở đầu danh sách, Thuật toán có chi phí thấp(lý do giống như thuật toán phù hợp đầu tiên) | Có thể làm cho phân vùng cuối cùng trong bộ nhớ bị chia nhỏ thành các mảnh nhỏ; Thuật toán có chi phí cao(lý do giống như thuật toán phù hợp đầu tiên) |
Bạn có hiểu về công nghệ ảo hóa không?
Công nghệ ảo hóa chuyển đổi một thực thể vật lý thành nhiều thực thể logic.
Có hai loại công nghệ ảo hóa chính: công nghệ ghép kênh phân chia thời gian và công nghệ ghép kênh phân chia không gian.
Đa tiến trình và đa luồng: Nhiều tiến trình có thể được thực thi đồng thời trên cùng một bộ xử lý bằng công nghệ ghép kênh phân chia theo thời gian, cho phép lần lượt từng tiến trình đảm nhận bộ xử lý, mỗi lần chỉ thực hiện một lát cắt thời gian nhỏ và chuyển đổi nhanh chóng.
Bộ nhớ ảo sử dụng công nghệ ghép kênh phân chia không gian, giúp trừu tượng hóa bộ nhớ vật lý thành một không gian địa chỉ và mỗi tiến trình có không gian địa chỉ riêng. Các trang của không gian địa chỉ được ánh xạ tới bộ nhớ vật lý. Tất cả các trang của không gian địa chỉ không cần phải nằm trong bộ nhớ vật lý. Khi một trang không có trong bộ nhớ vật lý được sử dụng, thuật toán thay thế trang được thực thi để thay thế trang vào bộ nhớ.
Bạn biết bao nhiêu về việc chuyển đổi trạng thái của quá trình?
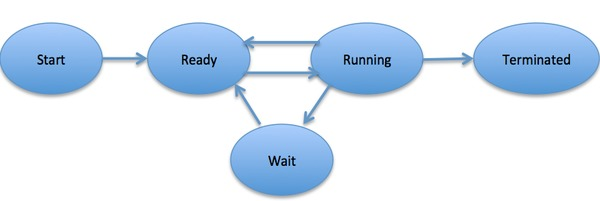
- Trạng thái sẵn sàng (ready): đang chờ được lập lịch
- Trạng thái đang chạy (running)
- Trạng thái bị chặn (waiting): đang chờ tài nguyên
Cần lưu ý các điểm sau:
- Chỉ có thể chuyển đổi giữa trạng thái sẵn sàng và trạng thái đang chạy, các trạng thái khác đều là chuyển đổi một chiều. Quá trình ở trạng thái sẵn sàng sẽ nhận được thời gian CPU thông qua thuật toán lập lịch và chuyển sang trạng thái đang chạy; sau khi hết thời gian CPU được cấp cho nó, quá trình sẽ chuyển sang trạng thái sẵn sàng, chờ đợi lịch trình tiếp theo.
- Trạng thái bị chặn là do thiếu tài nguyên cần thiết và chuyển từ trạng thái đang chạy sang. Tuy nhiên, tài nguyên thiếu không bao gồm thời gian CPU, thiếu thời gian CPU sẽ chuyển từ trạng thái đang chạy sang trạng thái sẵn sàng.
Bạn có thể giải thích quá trình chuyển đổi địa chỉ logic thành địa chỉ vật lý thông qua một ví dụ không?
Chúng ta có thể sử dụng bảng trang (page table) của quá trình để chuyển đổi địa chỉ logic thành địa chỉ vật lý.
Ví dụ: Giả sử chúng ta có một tiến trình với kích thước trang (page size) là 4KB và kích thước bộ nhớ vật lý là 16KB. Địa chỉ logic là 12-bit và địa chỉ vật lý cũng là 12-bit.
Bước 1: Phân trang
Chúng ta chia bộ nhớ ảo thành các trang có kích thước 4KB. Mỗi trang được đánh số từ 0 đến 15.
Bước 2: Tạo bảng trang
Tạo một bảng trang với 16 mục, mỗi mục chứa một địa chỉ vật lý tương ứng với trang tương ứng. Ví dụ, trang 0 được ánh xạ vào địa chỉ vật lý 0x000, trang 1 được ánh xạ vào địa chỉ vật lý 0x100, và cứ tiếp tục như vậy.
Bước 3: Chuyển đổi địa chỉ logic thành địa chỉ vật lý
Giả sử chúng ta có địa chỉ logic là 0xABC. Ta có thể xác định rằng phần cao nhất của địa chỉ này (0xA) là chỉ số của trang và phần thấp nhất (0xBC) là độ lệch (offset) trong trang.
Sử dụng bảng trang, ta có thể tìm được địa chỉ vật lý tương ứng với trang 0xABC là 0x100 + 0xBC = 0x1BC.
Bước 4: Truy cập địa chỉ vật lý
Sau khi xác định được địa chỉ vật lý tương ứng, chúng ta có thể truy cập vào địa chỉ vật lý này để đọc hoặc ghi dữ liệu.
Quá trình chuyển đổi địa chỉ logic thành địa chỉ vật lý này giúp hệ thống máy tính quản lý bộ nhớ một cách hiệu quả và cho phép sử dụng bộ nhớ ảo lớn hơn kích thước bộ nhớ vật lý thực tế.
Bạn có thể giải thích bốn phương pháp đồng bộ hóa quá trình không?
1. Vùng quan trọng (Critical Section)
Mã lệnh truy cập tài nguyên quan trọng được gọi là vùng quan trọng (critical section).
Để đảm bảo quá trình truy cập tài nguyên quan trọng một cách đồng bộ, mỗi quá trình phải kiểm tra trước khi vào vùng quan trọng.
// entry section
// critical section;
// exit section2. Đồng bộ hoá và Loại trừ lẫn nhau
- Đồng bộ hoá (Synchronize): Mối quan hệ trực tiếp giữa nhiều tiến trình do hợp tác tạo ra, tạo ra một quá trình thực hiện trước sau.
- Loại trừ lẫn nhau (Mutual Exclusion): Chỉ một quá trình có thể vào vùng quan trọng tại một thời điểm.
3. Semaphore
Semaphore (Đếm) là một biến nguyên, có thể thực hiện các hoạt động down và up, còn được gọi là hoạt động P và V.
- down: Nếu giá trị của Semaphore lớn hơn 0, thực hiện phép trừ 1; nếu giá trị của Semaphore bằng 0, tiến trình sẽ ngủ và chờ đến khi Semaphore lớn hơn 0.
- up: Thực hiện phép cộng 1 cho Semaphore, đánh thức các tiến trình đang ngủ để hoàn thành phép down.
Các hoạt động down và up cần được thiết kế như là các nguyên tố không thể chia, thường được thực hiện bằng cách tắt ngắt khi thực hiện các hoạt động này.
Nếu giá trị của Semaphore chỉ có thể là 0 hoặc 1, thì được gọi là Mutex (Khóa tương hỗ), trong đó 0 đại diện cho việc khóa vùng gian lận và 1 đại diện cho việc mở khóa vùng gian lận.
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// Vùng gian lận
up(&mutex);
}
void P2() {
down(&mutex);
// Vùng gian lận
up(&mutex);
}Sử dụng Semaphore để giải quyết bài toán Producer-Consumer
Mô tả bài toán: Sử dụng một vùng đệm để lưu trữ các sản phẩm, chỉ khi vùng đệm chưa đầy, Producer mới có thể đặt sản phẩm vào; chỉ khi vùng đệm không trống, Consumer mới có thể lấy sản phẩm ra.
Vì vùng đệm là tài nguyên chung, nên cần sử dụng một Mutex (khóa tương hỗ) để kiểm soát việc truy cập đồng thời vào vùng đệm.
Để đồng bộ hóa hành vi của Producer và Consumer, cần ghi nhận số lượng sản phẩm trong vùng đệm. Số lượng này có thể được đếm bằng Semaphore, trong đó cần sử dụng hai Semaphore: empty (đếm số vùng đệm trống) và full (đếm số vùng đệm đầy).
Lưu ý, không thể khóa vùng đệm trước khi kiểm tra Semaphore. Điều này có nghĩa là không thể thực hiện down(mutex) trước down(empty). Nếu làm như vậy, có thể xảy ra tình huống sau: Producer khóa vùng đệm và thực hiện down(empty), nhận thấy empty = 0, sau đó Producer ngủ.
Consumer không thể vào vùng quan trọng, vì Producer đã khóa vùng đệm, Consumer không thể thực hiện phép up(empty), empty luôn bằng 0, dẫn đến Producer chờ mãi mà không giải phóng khóa, Consumer cũng sẽ chờ mãi.
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}4. Monitor (Quản trị)
Việc sử dụng cơ chế Semaphore để giải quyết bài toán Producer-Consumer đòi hỏi mã điều khiển từ phía khách hàng, trong khi Monitor (Quản trị) tách riêng mã điều khiển ra khỏi mã khách hàng, không chỉ dễ dàng hơn trong việc gọi mã khách hàng mà còn giảm thiểu khả năng xảy ra lỗi.
Ngôn ngữ C không hỗ trợ Monitor, ví dụ mã dưới đây sử dụng ngôn ngữ tương tự Pascal để mô tả Monitor. Mã Monitor cung cấp hai phương thức insert() và remove(), mã khách hàng gọi hai phương thức này để giải quyết bài toán Producer-Consumer.
monitor ProducerConsumer
integer i;
condition c;
procedure insert();
begin
// ...
end;
procedure remove();
begin
// ...
end;
end monitor;Monitor có một tính năng quan trọng: chỉ có một tiến trình có thể sử dụng Monitor tại một thời điểm. Khi một tiến trình không thể tiếp tục thực thi, nó không thể chiếm giữ Monitor mãi mãi, nếu không, các tiến trình khác sẽ không bao giờ có thể sử dụng Monitor.
Monitor giới thiệu biến điều kiện và các hoạt động liên quan: wait() và signal() để thực hiện các hoạt động đồng bộ. Thực hiện wait() trên biến điều kiện sẽ dẫn đến tiến trình gọi bị chặn, nhường Monitor cho một tiến trình khác. Hoạt động signal() được sử dụng để đánh thức các tiến trình bị chặn.
Sử dụng Monitor để giải quyết bài toán Producer-Consumer
// Monitor
monitor ProducerConsumer
condition full, empty;
integer count := 0;
condition c;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count + 1;
if count = 1 then signal(empty);
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count - 1;
if count = N -1 then signal(full);
end;
end monitor;
// Khách hàng Producer
procedure producer
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item);
end
end;
// Khách hàng Consumer
procedure consumer
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item);
end
end;17. Quản lý bộ nhớ trong hệ điều hành
Trong quá trình quản lý bộ nhớ, hệ điều hành thực hiện các công việc sau:
- Phân bổ và thu hồi không gian bộ nhớ: Hệ điều hành phân bổ không gian bộ nhớ cho các tiến trình và thu hồi không gian bộ nhớ khi tiến trình kết thúc hoặc không cần sử dụng nữa.
- Mở rộng logic của không gian bộ nhớ: Hệ điều hành cung cấp các kỹ thuật để mở rộng không gian bộ nhớ logic, cho phép tiến trình sử dụng không gian bộ nhớ lớn hơn dung lượng thực tế của bộ nhớ vật lý.
- Chuyển đổi địa chỉ: Hệ điều hành cung cấp chức năng chuyển đổi địa chỉ, chịu trách nhiệm chuyển đổi địa chỉ logic của tiến trình thành địa chỉ vật lý tương ứng để truy cập vào bộ nhớ.
- Bảo vệ bộ nhớ: Hệ điều hành đảm bảo rằng các tiến trình chỉ có thể truy cập vào không gian bộ nhớ của chính mình và không gian bộ nhớ được bảo vệ của các tiến trình khác.
18. Phương pháp truyền thông giữa các tiến trình (trên Linux và Windows) và giữa các luồng (trên Linux và Windows)
Phương pháp truyền thông giữa các tiến trình:
| Tên và phương pháp |
|---|
| Pipe (Ống): Cho phép một tiến trình và một tiến trình khác có cùng tổ tiên truyền thông tin |
| Named Pipe (Ống có tên): Tương tự như pipe, nhưng có thể được sử dụng cho bất kỳ cặp tiến trình nào, được tạo ra bằng lệnh mkfifo hoặc cuộc gọi hệ thống mkfifo |
| Message Queue (Hàng đợi tin nhắn): Là một bảng kết nối các tin nhắn, bao gồm cặp tin nhắn POSIX và hàng đợi tin nhắn System V. Tiến trình có quyền thích hợp có thể thêm tin nhắn vào hàng đợi và tiến trình có quyền đọc có thể đọc tin nhắn từ hàng đợi |
| Semaphore (Đồng bộ): Semaphore chủ yếu được sử dụng làm phương tiện đồng bộ hóa giữa các tiến trình và giữa các luồng cùng tiến trình |
| Shared Memory (Bộ nhớ chia sẻ): Cho phép nhiều tiến trình truy cập vào cùng một không gian bộ nhớ, là hình thức IPC nhanh nhất |
| Signal (Tín hiệu): Là một phương pháp truyền thông phức tạp, được sử dụng để thông báo cho tiến trình nhận biết về một sự kiện nào đó, không chỉ được sử dụng cho truyền thông giữa các tiến trình mà còn cho tiến trình gửi tín hiệu cho chính nó |
| Memory Mapping (Ánh xạ bộ nhớ): Cho phép truyền thông giữa bất kỳ hai tiến trình nào, mỗi tiến trình sẽ ánh xạ một tệp chia sẻ vào không gian địa chỉ của nó |
| Socket: Là phương pháp truyền thông chung hơn giữa các tiến trình, có thể được sử dụng cho truyền thông giữa các máy khác nhau |
Phương pháp truyền thông giữa các luồng:
| Tên và phương pháp |
|---|
| Linux: |
| Signal (Tín hiệu): Tương tự như truyền thông giữa các tiến trình |
| Locking Mechanism (Cơ chế khóa): Bao gồm khóa độc quyền, khóa đọc/ghi và khóa quay |
| Conditional Variable (Biến điều kiện): Sử dụng để thông báo và mở khóa, kết hợp với khóa độc quyền |
| Semaphore (Đồng bộ): Bao gồm semaphore không tên và semaphore có tên |
| Windows: |
| Global Variable (Biến toàn cục): Sử dụng khi nhiều luồng truy cập vào một biến toàn cục, thường được khai báo với từ khóa volatile để tránh việc tối ưu hóa từ trình biên dịch |
| Message Mechanism (Cơ chế tin nhắn): Gồm hai giao diện truyền thông: PostMessage và PostThreadMessage, PostMessage dùng để gửi tin nhắn từ luồng con đến cửa sổ chính, PostThreadMessage dùng để gửi tin nhắn giữa hai luồng bất kỳ |
| CEvent Object (Đối tượng CEvent): Là một đối tượng trong MFC, được sử dụng để truyền thông và đồng bộ hóa giữa các luồng, là một phương pháp để đồng bộ trực tiếp giữa các luồng |
Mục đích của bộ nhớ ảo là gì?
Mục đích của bộ nhớ ảo là mở rộng bộ nhớ vật lý thành bộ nhớ logic lớn hơn, từ đó cung cấp cho chương trình một lượng bộ nhớ có sẵn nhiều hơn.
Để quản lý bộ nhớ hiệu quả hơn, hệ điều hành trừu tượng hóa bộ nhớ thành không gian địa chỉ. Mỗi chương trình có không gian địa chỉ riêng, được chia thành nhiều trang (page).
Các trang này được ánh xạ vào bộ nhớ vật lý, nhưng không cần phải ánh xạ vào vùng nhớ vật lý liên tiếp và không cần phải có tất cả các trang trong bộ nhớ vật lý. Khi chương trình tham chiếu đến một trang không có trong bộ nhớ vật lý, phần cứng sẽ thực hiện ánh xạ cần thiết, đưa phần bị thiếu vào bộ nhớ vật lý và thực hiện lại lệnh không thành công.
Từ mô tả trên, có thể thấy rằng bộ nhớ ảo cho phép chương trình không cần phải ánh xạ tất cả các trang trong không gian địa chỉ vào bộ nhớ vật lý, nghĩa là một chương trình không cần phải được tải toàn bộ vào bộ nhớ để chạy, điều này làm cho việc chạy các chương trình lớn trên bộ nhớ hạn chế trở nên khả thi.
Ví dụ, một máy tính có thể tạo ra địa chỉ 16 bit, vì vậy không gian địa chỉ của một chương trình là từ 0 đến 64K. Máy tính này chỉ có 32KB bộ nhớ vật lý, công nghệ bộ nhớ ảo cho phép máy tính này chạy một chương trình có kích thước 64K.
Giới thiệu về một số loại khóa đồng bộ
Khóa đọc/ghi (Read/Write Lock)
- Nhiều người đọc có thể đọc cùng một lúc.
- Người viết phải độc quyền (chỉ cho phép một người viết viết và không cho phép đọc hoặc viết đồng thời).
- Người viết được ưu tiên hơn người đọc (nếu có người viết, các người đọc sau phải chờ đợi cho đến khi người viết hoàn thành).
Khóa tương hỗ (Mutex Lock)
Chỉ có một tiến trình hoặc luồng có thể sở hữu khóa tương hỗ tại một thời điểm, các tiến trình hoặc luồng khác phải chờ đợi.
Khóa tương hỗ là một dạng khóa đồng bộ, trong đó tiến trình hoặc luồng phải chờ đợi để có thể sở hữu khóa trước khi thực hiện các thao tác cần đồng bộ hóa. Khi một tiến trình hoặc luồng sở hữu khóa, các tiến trình hoặc luồng khác không thể sở hữu khóa cho đến khi khóa được giải phóng.
Biến điều kiện (Condition Variable)
Biến điều kiện được sử dụng để thông báo và mở khóa khi một điều kiện nào đó xảy ra, thường được sử dụng kết hợp với khóa tương hỗ.
Biến điều kiện cho phép tiến trình hoặc luồng chờ đợi cho đến khi một điều kiện nhất định được đáp ứng. Khi điều kiện không được đáp ứng, tiến trình hoặc luồng sẽ giải phóng khóa và chờ đợi cho đến khi được thông báo rằng điều kiện đã thay đổi. Sau khi được thông báo, tiến trình hoặc luồng sẽ thực hiện lại việc kiểm tra điều kiện và tiếp tục thực hiện các thao tác cần thiết.
Khóa quay (Spin Lock)
Khóa quay là một loại khóa đồng bộ trong đó nếu tiến trình không thể lấy được khóa, nó sẽ tiếp tục lặp lại việc thử lấy khóa thay vì chờ đợi.
Khóa quay thuộc loại khóa bận rộn (busy-waiting), nghĩa là nếu một tiến trình không thể lấy được khóa, nó sẽ tiếp tục lặp lại việc thử lấy khóa cho đến khi khóa được giải phóng. Khóa quay thường được sử dụng trong các tình huống mà thời gian chờ đợi là ngắn và khóa sẽ được giải phóng nhanh chóng.
Các loại khóa luồng (POSIX) mà bạn biết là gì?
Khóa tương hỗ (Mutex Lock)
Khóa tương hỗ thuộc loại khóa “sleep-waiting”. Ví dụ, trên một máy tính hai nhân, có hai luồng A và B chạy trên core 0 và core 1 tương ứng. Giả sử luồng A muốn lấy khóa của một khu vực quan trọng thông qua hoạt động pthread_mutex_lock, nhưng khóa này đang được luồng B nắm giữ. Khi đó, luồng A sẽ bị chặn và được chuyển vào hàng đợi chờ thông qua việc chuyển ngữ cảnh, trong khi core 0 có thể chạy các tác vụ khác (ví dụ: luồng C).
Biến điều kiện (Condition Variable)
Biến điều kiện được sử dụng để thông báo và mở khóa khi một điều kiện nhất định xảy ra, thường được sử dụng kết hợp với khóa tương hỗ.
Biến điều kiện cho phép luồng chờ đợi cho đến khi một điều kiện cụ thể được đáp ứng. Khi điều kiện không được đáp ứng, luồng sẽ giải phóng khóa và chờ đợi cho đến khi có thông báo rằng điều kiện đã thay đổi. Sau khi được thông báo, luồng sẽ kiểm tra lại điều kiện và tiếp tục thực hiện các thao tác cần thiết.
Khóa quay (Spin Lock)
Khóa quay thuộc loại khóa “busy-waiting”, có nghĩa là nếu một luồng không thể lấy được khóa, nó sẽ tiếp tục lặp lại việc thử lấy khóa thay vì chờ đợi.
Khóa quay được sử dụng trong các tình huống mà thời gian chờ đợi ngắn và khóa sẽ được giải phóng nhanh chóng. Khóa quay không gây ngủ cho người gọi, do đó hiệu suất của khóa quay cao hơn so với khóa tương hỗ.
Tuy nhiên, khóa quay cũng có một số hạn chế:
- Khóa quay liên tục sử dụng CPU trong khi chưa lấy được khóa, do đó tiêu tốn tài nguyên CPU. Nếu không thể lấy khóa trong thời gian ngắn, nó có thể làm giảm hiệu suất CPU.
- Trong việc sử dụng khóa quay, có thể xảy ra tình trạng chết khóa (deadlock) khi có sự gọi đệ quy.
- Khóa quay chỉ cần thiết khi hệ điều hành có thể bị gián đoạn hoặc hỗ trợ SMP (Symmetric Multi-Processing), trong môi trường đơn nhân không thể gián đoạn, hoạt động của khóa quay sẽ là không có tác dụng. Khóa quay thích hợp cho các tình huống mà người sử dụng khóa giữ khóa trong thời gian ngắn.
Ghi đè bộ nhớ là gì? Có những đặc điểm gì?
Trong quá trình chạy chương trình, không phải lúc nào cũng cần truy cập vào tất cả các phần của chương trình và dữ liệu (đặc biệt là đối với các chương trình lớn). Do đó, không gian người dùng có thể được chia thành một khu vực cố định và một số khu vực ghi đè. Các phần thường xuyên hoạt động được đặt trong khu vực cố định, các phần khác được chia thành các đoạn dựa trên mối quan hệ gọi, đầu tiên các đoạn sẽ được đặt trong khu vực ghi đè, các đoạn khác được đặt trong bộ nhớ ngoài, và trước khi gọi, hệ thống sẽ chuyển chúng vào khu vực ghi đè và thay thế các đoạn đã có trong khu vực ghi đè.
Các đặc điểm của kỹ thuật ghi đè bao gồm: phá vỡ giới hạn phải tải toàn bộ thông tin của một tiến trình vào bộ nhớ trước khi chạy; khi số lượng mã chạy đồng thời vượt quá bộ nhớ chính, tiến trình vẫn không thể chạy; và lưu ý rằng chỉ có các đoạn trong khu vực ghi đè mới có thể được cập nhật trong bộ nhớ, các đoạn không nằm trong khu vực ghi đè sẽ luôn nằm trong bộ nhớ.
Trao đổi bộ nhớ là gì? Có những đặc điểm gì?
Ý tưởng thiết kế của kỹ thuật trao đổi: Khi không gian bộ nhớ khan hiếm, hệ thống tạm thời chuyển một số tiến trình từ bộ nhớ vào bộ nhớ ngoài, và chuyển một số tiến trình đã đủ điều kiện chạy từ bộ nhớ ngoài vào bộ nhớ (tiến trình được lập lịch động giữa bộ nhớ và đĩa).
- Trao đổi vào: Di chuyển các chương trình đã sẵn sàng để cạnh tranh chạy trên CPU từ bộ nhớ ngoài vào bộ nhớ.
- Trao đổi ra: Di chuyển các chương trình đang chờ (hoặc bị tước quyền chạy theo nguyên tắc lập lịch CPU) từ bộ nhớ vào bộ nhớ ngoài để giải phóng không gian bộ nhớ.
Khi nào sẽ thực hiện trao đổi bộ nhớ?
Thường thì trao đổi bộ nhớ được thực hiện khi có nhiều tiến trình đang chạy và không gian bộ nhớ khan hiếm, và tạm dừng khi tải trọng hệ thống giảm. Ví dụ: Nếu phát hiện rằng có nhiều tiến trình đang chạy và thường xuyên xảy ra trang trống, điều này cho thấy bộ nhớ đang khan hiếm, lúc này có thể chuyển một số tiến trình ra khỏi bộ nhớ; nếu tỷ lệ trang trống giảm đáng kể, có thể tạm dừng trao đổi.
Khi thoát khỏi terminal, tiến trình đang chạy trên terminal sẽ như thế nào?
Khi thoát khỏi terminal, terminal sẽ gửi tín hiệu SIGHUP cho tiến trình bash tương ứng. Sau khi nhận được tín hiệu này, tiến trình bash sẽ truyền nó cho các tiến trình trong session. Nếu tiến trình không xử lý tín hiệu SIGHUP đặc biệt, tiến trình sẽ thoát khi terminal đóng lại.
33. Sự khác biệt giữa bảng trang có bộ nhớ cache (fast table) và không có bộ nhớ cache
| Quá trình chuyển đổi địa chỉ | Số lần truy cập bộ nhớ để truy cập một địa chỉ logic | |
|---|---|---|
| Cơ chế chuyển đổi địa chỉ cơ bản | ① Tính số trang và độ lệch trang ② Kiểm tra tính hợp lệ của số trang ③ Tra cứu bảng trang để tìm số khối bộ nhớ chứa trang ④ Dựa trên số khối bộ nhớ và độ lệch trang để tìm địa chỉ vật lý ⑤ Truy cập vào đơn vị bộ nhớ mục tiêu | Hai lần truy cập |
| Cơ chế chuyển đổi địa chỉ có bộ nhớ cache | ① Tính số trang và độ lệch trang ② Kiểm tra tính hợp lệ của số trang ③ Tra cứu bộ nhớ cache. Nếu trúng, ta có thể biết số khối bộ nhớ chứa trang và có thể thực hiện bước ⑤ trực tiếp; nếu không trúng, thực hiện bước ④ ④ Tra cứu bảng trang để tìm số khối bộ nhớ chứa trang và sao chép mục bảng trang vào bộ nhớ cache ⑤ Dựa trên số khối bộ nhớ và độ lệch trang để tìm địa chỉ vật lý ⑥ Truy cập vào đơn vị bộ nhớ mục tiêu | Trúng bộ nhớ cache, chỉ cần một lần truy cập Trượt bộ nhớ cache, cần hai lần truy cập |
Trong quá trình thực hiện malloc để yêu cầu bộ nhớ, hệ điều hành thực hiện như thế nào?
Từ góc độ của hệ điều hành, malloc được thực hiện thông qua hai cuộc gọi hệ thống: brk và mmap.
- brk làm cho con trỏ địa chỉ cao nhất của phân đoạn dữ liệu của quá trình (.data) di chuyển lên, điều này mở rộng kích thước của heap trong quá trình chạy.
- mmap tìm một vùng nhớ ảo trống trong không gian địa chỉ ảo của quá trình, điều này cho phép quá trình có một vùng nhớ heap có thể hoạt động.
Thường thì, khi cấp phát bộ nhớ nhỏ hơn 128k, sử dụng cuộc gọi brk để có được không gian địa chỉ ảo, và khi cấp phát bộ nhớ lớn hơn 128k, sử dụng cuộc gọi mmap để có được không gian địa chỉ ảo.
Quá trình đầu tiên sử dụng hai cuộc gọi hệ thống này để có được hoặc mở rộng không gian địa chỉ ảo của quá trình, nhận địa chỉ ảo tương ứng. Khi truy cập vào các địa chỉ ảo này, thông qua ngắt trang trống, hạt nhân cấp phát bộ nhớ vật lý tương ứng, điều này hoàn thành quá trình cấp phát bộ nhớ.
Bạn có biết về nguyên lý cục bộ không? Có hai nguyên lý cục bộ chính là gì? Mỗi nguyên lý đó là gì?
Nguyên lý cục bộ chính là nguyên lý thời gian cục bộ và nguyên lý không gian cục bộ.
Nguyên lý thời gian cục bộ (Temporal Locality): Nếu một lệnh trong chương trình được thực thi, thì trong thời gian ngắn sau đó, lệnh đó có thể được thực thi lại. Nếu một dữ liệu được truy cập, thì trong thời gian ngắn sau đó, dữ liệu đó có thể được truy cập lại. Điều này xảy ra vì chương trình thường có nhiều vòng lặp, và dữ liệu thường được truy cập nhiều lần.
Nguyên lý không gian cục bộ (Spatial Locality): Một khi một chương trình truy cập vào một đơn vị lưu trữ, thì trong thời gian ngắn sau đó, các đơn vị lưu trữ gần kề cũng có thể được truy cập. Điều này xảy ra vì nhiều dữ liệu được lưu trữ liên tiếp trong bộ nhớ và các lệnh trong chương trình thường được lưu trữ liên tiếp trong bộ nhớ.
Nguyên lý cục bộ cho thấy rằng việc tận dụng hiệu quả thời gian và không gian truy cập dữ liệu là rất quan trọng để tăng hiệu suất của chương trình và hệ thống.
Tiến trình cha, tiến trình con, nhóm tiến trình, công việc và phiên làm việc
Tiến trình cha
Tiến trình cha là tiến trình đã tạo ra một hoặc nhiều tiến trình con.
Tiến trình con
Tiến trình con là một tiến trình mới được tạo ra bằng cách sử dụng lệnh fork. Lệnh fork được gọi một lần nhưng trả về hai lần. Sự khác biệt giữa hai lần trả về là giá trị trả về của tiến trình con là 0, trong khi giá trị trả về của tiến trình cha là ID của tiến trình mới (tiến trình con). Lý do trả về ID của tiến trình con cho tiến trình cha là vì một tiến trình có thể có nhiều hơn một tiến trình con và không có hàm nào cho phép một tiến trình có thể lấy tất cả ID của tất cả các tiến trình con của nó. Đối với tiến trình con, lý do mà fork trả về 0 cho nó là vì nó có thể gọi getpid() để lấy ID của chính nó và có thể gọi getppid() để lấy ID của tiến trình cha. (ID tiến trình 0 luôn được sử dụng bởi tiến trình trao đổi, vì vậy ID của một tiến trình con không thể là 0).
Sau khi fork, hệ điều hành sẽ tạo một bản sao của tiến trình cha hoàn toàn giống với tiến trình con, mặc dù được gọi là cha con, nhưng trong hệ điều hành, chúng giống như anh em, 2 tiến trình này chia sẻ không gian mã nhưng không gian dữ liệu là độc lập, nội dung của không gian dữ liệu trong tiến trình con là bản sao đầy đủ của tiến trình cha, con trỏ chỉ thị cũng hoàn toàn giống nhau, tiến trình con có vị trí hiện tại của tiến trình cha (bộ đếm chương trình của hai tiến trình là giống nhau, nghĩa là tiến trình con bắt đầu chạy từ điểm trả về của fork), nhưng có một điểm khác biệt, nếu fork thành công, giá trị trả về của tiến trình con là 0, giá trị trả về của tiến trình cha là số ID của tiến trình con, nếu fork không thành công, tiến trình cha sẽ trả về lỗi.
Tiến trình con kế thừa từ tiến trình cha:
- Các số hiệu người dùng (UIDs) và nhóm (GIDs) của quyền hạn của tiến trình (real/effect/saved).
- Môi trường.
- Ngăn xếp.
- Bộ nhớ.
- Số hiệu nhóm của tiến trình.
Các thuộc tính duy nhất của tiến trình con:
- ID tiến trình;
- Số ID tiến trình cha khác nhau (lưu ý: số ID tiến trình con và số ID tiến trình cha của tiến trình cha là khác nhau, số ID tiến trình cha có thể được lấy bằng hàm getppid);
- Tài nguyên sử dụng được đặt thành 0.
Nhóm tiến trình
Nhóm tiến trình là một tập hợp các tiến trình, trong đó có một tiến trình nhóm trưởng, ID tiến trình của nó bằng với ID của nhóm tiến trình (PGID). Miễn là một tiến trình nào đó trong nhóm tiến trình vẫn tồn tại, nhóm tiến trình đó vẫn tồn tại, không liên quan đến việc tiến trình nhóm trưởng có kết thúc hay không.
Công việc
Shell điều khiển công việc (job) hoặc nhóm tiến trình (Process Group), không phải là tiến trình.
Một công việc tiền trình có thể bao gồm nhiều tiến trình, một công việc nền cũng có thể bao gồm nhiều tiến trình. Shell có thể chạy một công việc tiền trình và bất kỳ số lượng công việc nền nào, đây được gọi là điều khiển công việc.
Phiên làm việc
Phiên làm việc (session) là một tập hợp các nhóm tiến trình. Một phiên làm việc có thể có một terminal điều khiển. Mở một cửa sổ trong xshell hoặc WinSCP là tạo một phiên làm việc mới.
Sự khác biệt giữa ngoại lệ và ngắt trong Linux
Ngắt (Interrupt)
Chúng ta đều biết rằng khi chúng ta gõ phím, nó sẽ tạo ra một ngắt. Khi đọc/ghi dữ liệu từ ổ cứng, cũng sẽ tạo ra một ngắt. Vì vậy, chúng ta cần biết rằng hầu hết các ngắt được tạo ra bởi các thiết bị phần cứng và về mặt vật lý, chúng là các tín hiệu điện, sau đó chúng được gửi từ bộ điều khiển ngắt đến CPU. Sau đó, CPU xác định ngắt được gửi từ thiết bị phần cứng nào (được xác định trong kernel), cuối cùng, CPU gửi nó đến kernel để xử lý.
Ngắt phần mềm và ngắt mềm (Software Interrupt)
Ngoài các ngắt phần cứng, còn có một số ngắt được tạo ra bởi phần mềm, được gọi là ngắt phần mềm (Software Interrupt), phổ biến nhất là Int 0x80 để gọi hệ thống. Đồng thời, ngắt phần mềm cũng khác với ngắt mềm (SoftIRQ), ngắt mềm được sử dụng chủ yếu cho phần dưới của xử lý ngắt (Bottom Halves), các phần không quan trọng của xử lý ngắt, nhằm cải thiện hiệu suất và thời gian thực của xử lý ngắt, thường được sử dụng trong xử lý ngắt liên quan đến I/O.
Có hai phương pháp để xử lý phần dưới của xử lý ngắt, ngoài ngắt mềm, còn có tasklet, hai phương pháp này có một số khác biệt và liên quan đến nhau:
- Cả hai đều có thể đăng ký để làm nhiệm vụ trì hoãn xử lý ngắt;
- Cùng một loại tasklet chỉ có thể thực thi tuần tự, trong khi các ngắt mềm cùng loại có thể thực thi đồng thời trên nhiều CPU, các ngắt mềm và tasklet của các loại khác nhau đều có thể thực thi đồng thời;
- Tasklet được xây dựng dựa trên hai ngắt mềm, lần lượt là HI_SOFTIRQ và TASKLET_SOFTIRQ.
Ngoại lệ (Exception)
Khi chúng ta học “Nguyên lý tổ chức máy tính”, chúng ta biết hai khái niệm, khi CPU xử lý chương trình mà không có trong bộ nhớ, nó sẽ tạo ra một ngoại lệ không có trang (Page Fault); khi chạy chương trình chia cho 0, nó sẽ tạo ra một ngoại lệ chia cho 0. Vì vậy, chúng ta cũng cần nhớ rằng ngoại lệ được tạo ra bởi CPU và sau đó gửi cho kernel để yêu cầu xử lý các ngoại lệ này.
Điểm tương đồng
-
Cả hai đều được gửi từ CPU đến kernel để xử lý.
-
Luồng xử lý của chương trình được thiết kế tương tự.
Sự khác biệt
-
Nguồn gốc khác nhau, ngoại lệ được tạo ra bởi CPU, trong khi ngắt chủ yếu được tạo ra bởi các thiết bị phần cứng.
-
Kernel cần gọi các chương trình xử lý khác nhau tùy thuộc vào xem có phải là ngoại lệ hay ngắt.
-
Ngắt không đồng bộ với đồng hồ, điều này có nghĩa là ngắt có thể xảy ra bất kỳ lúc nào; ngoại lệ được tạo ra bởi CPU, vì vậy nó đồng bộ với đồng hồ.
-
Khi xử lý ngắt, nó đang ở ngữ cảnh ngắt; khi xử lý ngoại lệ, nó đang ở ngữ cảnh tiến trình.
Bố cục bộ nhớ trong môi trường Windows và Linux
Không gian người dùng của bộ nhớ được chia thành 6 phân đoạn khác nhau:
- Đoạn tệp chương trình, bao gồm mã thực thi nhị phân;
- Đoạn dữ liệu đã khởi tạo, bao gồm hằng số tĩnh;
- Đoạn dữ liệu chưa khởi tạo, bao gồm biến tĩnh chưa khởi tạo;
- Đoạn heap, bao gồm bộ nhớ được cấp phát động, tăng từ địa chỉ thấp lên trên;
- Đoạn ánh xạ tệp, bao gồm thư viện động, bộ nhớ chia sẻ, v.v., tăng từ địa chỉ thấp lên trên (phụ thuộc vào phần cứng và phiên bản kernel);
- Đoạn ngăn xếp, bao gồm biến cục bộ và ngữ cảnh gọi hàm. Kích thước ngăn xếp là cố định, thường là
8 MB. Tuy nhiên, hệ thống cũng cung cấp các tham số để tùy chỉnh kích thước;
Bố cục bộ nhớ của một chương trình được biên dịch từ C/C++
-
Vùng ngăn xếp (stack) - Tăng địa chỉ xuống dưới, được tự động cấp phát và giải phóng bởi trình biên dịch, lưu trữ giá trị tham số của hàm, giá trị biến cục bộ, v.v. Cách hoạt động tương tự như ngăn xếp trong cấu trúc dữ liệu, ngăn xếp LIFO (Last-In-First-Out).
-
Vùng heap - Tăng địa chỉ lên trên, thường được cấp phát và giải phóng bởi người lập trình viên. Nếu người lập trình không giải phóng, hệ điều hành có thể thu hồi khi chương trình kết thúc. Lưu ý rằng nó khác với heap trong cấu trúc dữ liệu, cách cấp phát tương tự như danh sách liên kết.
-
Vùng toàn cục (static) - Lưu trữ biến toàn cục và biến tĩnh trong cùng một vùng, biến toàn cục và biến tĩnh được khởi tạo trong một vùng, biến toàn cục và biến tĩnh chưa khởi tạo trong một vùng khác. - Hệ thống giải phóng sau khi chương trình kết thúc.
-
Vùng hằng số văn bản - Chuỗi hằng số được lưu trữ ở đây. Hệ điều hành giải phóng sau khi chương trình kết thúc.
-
Vùng mã chương trình (text) - Lưu trữ mã nhị phân của các hàm.
Khi chương trình cấp phát bộ nhớ động từ heap, thì hoạt động của bộ nhớ ảo như thế nào?
Bảng trang (Page Table): Đây là một cấu trúc dữ liệu được lưu trữ trong bộ nhớ vật lý, nó ghi lại quan hệ ánh xạ giữa các trang ảo và các trang vật lý.
Khi tiến hành cấp phát bộ nhớ động, ví dụ qua hàm malloc() hoặc từ khóa new trong ngôn ngữ lập trình cao cấp khác, hệ điều hành sẽ tạo ra hoặc yêu cầu một không gian bộ nhớ ảo trong ổ cứng và cập nhật vào bảng trang (thêm một mục nhập của bảng PTE để chỉ định rằng PTE này liên kết với một trang ảo mới được tạo ra trong ổ cứng), thông qua PTE để thiết lập quan hệ ánh xạ giữa các trang ảo và các trang vật lý.
Các thuật toán lập lịch đĩa phổ biến
Thời gian đọc/ghi một khối đĩa bị ảnh hưởng bởi các yếu tố sau:
- Thời gian quay (thời gian để trục chính quay đến vị trí phù hợp cho đầu đọc/ghi)
- Thời gian tìm kiếm (thời gian di chuyển của cần ghi/đọc để đến vị trí phù hợp trên đường kính)
- Thời gian truyền dữ liệu thực tế
Trong đó, thời gian tìm kiếm là lâu nhất, do đó mục tiêu chính của lập lịch đĩa là làm cho thời gian tìm kiếm trung bình của đĩa là ngắn nhất.
1. First-Come, First-Served (FCFS)
Lập lịch theo thứ tự các yêu cầu đĩa đến.
Ưu điểm là công bằng và đơn giản. Nhược điểm là không tối ưu hóa thời gian tìm kiếm trung bình vì không có tối ưu hóa cho thời gian tìm kiếm.
2. Shortest Seek Time First (SSTF)
Ưu tiên lập lịch cho các yêu cầu đĩa gần nhất với vị trí hiện tại của đầu đọc/ghi.
Mặc dù thời gian tìm kiếm trung bình thấp, nhưng không công bằng. Nếu yêu cầu đĩa mới đến luôn gần hơn yêu cầu đang chờ đợi, yêu cầu đang chờ đợi sẽ bị bỏ qua, gây ra tình trạng đói đến.
3. Elevator (SCAN) Algorithm
Cơ chế của thuật toán Elevator (SCAN) tương tự như hoạt động của thang máy, luôn di chuyển theo một hướng cho đến khi không còn yêu cầu chưa hoàn thành trong cùng một hướng, sau đó thay đổi hướng.
Thuật toán Elevator (SCAN) và quá trình hoạt động của thang máy tương tự nhau, luôn hoạt động theo một hướng cho đến khi không còn yêu cầu chưa hoàn thành trong cùng một hướng, sau đó thay đổi hướng.
Vì đã xem xét hướng di chuyển, nên tất cả các yêu cầu đĩa sẽ được đáp ứng, giải quyết vấn đề đói đến của SSTF.
Mối quan hệ giữa không gian trao đổi và bộ nhớ ảo
Không gian trao đổi (Swap Space)
Không gian trao đổi (Swap space) trong Linux được sử dụng khi bộ nhớ vật lý (RAM) đã đầy. Khi hệ thống cần thêm tài nguyên bộ nhớ, nhưng bộ nhớ vật lý đã đầy, các trang không hoạt động trong bộ nhớ sẽ được di chuyển vào không gian trao đổi. Mặc dù không gian trao đổi có thể giúp máy tính có ít bộ nhớ vật lý, nhưng không nên coi đây là một thay thế cho bộ nhớ. Không gian trao đổi nằm trên ổ đĩa và tốc độ truy cập nhanh hơn so với việc truy cập vào bộ nhớ vật lý.
Không gian trao đổi có thể là một phân vùng trao đổi đặc biệt (phương pháp được khuyến nghị), tệp trao đổi hoặc sự kết hợp của cả hai. Tổng kích thước của không gian trao đổi nên tương đương với hai lần kích thước bộ nhớ của máy tính và không vượt quá 2048MB (2GB).
Bộ nhớ ảo (Virtual Memory)
Bộ nhớ ảo là tập hợp các tệp dữ liệu được gắn kết với hoạt động của tệp. Nó là một tệp “WIN386.SWP” trong thư mục WINDOWS, tệp này sẽ tự động mở rộng và thu hẹp. Tốc độ của bộ nhớ ảo là chậm nhất vì nó sử dụng không gian trên ổ đĩa. Tất cả các chương trình chạy trên máy tính đều phải thông qua bộ nhớ để thực thi. Nếu chương trình thực thi lớn hoặc có nhiều chương trình chạy, bộ nhớ vật lý của chúng ta sẽ bị tiêu thụ nhanh chóng. Vì không gian trên ổ đĩa có sức chứa hàng chục đến hàng trăm GB, Windows sử dụng kỹ thuật bộ nhớ ảo để sử dụng một phần không gian trên ổ đĩa làm bộ nhớ.
Cái nào nhanh hơn để tạo một đối tượng từ heap hoặc stack? (Điều tra so sánh hiệu quả cấp phát của heap và stack)
Hãy xem xét nó từ hai khía cạnh:
-
Cấp phát và giải phóng thì khi cấp phát và giải phóng thì heap phải gọi các hàm (malloc, free) Ví dụ khi cấp phát thì nó sẽ vào không gian heap để tìm một không gian có kích thước vừa đủ (vì nhiều lần cấp phát và giải phóng sẽ gây phân mảnh bộ nhớ), sẽ tốn một khoảng thời gian nhất định. Để biết chi tiết, bạn có thể xem mã nguồn của malloc và miễn phí. Hàm này thực hiện rất nhiều công việc bổ sung, nhưng ngăn xếp không cần những thứ này.
-
Thời gian truy cập, truy cập một đơn vị cụ thể của heap cần hai lần truy cập vào bộ nhớ, lần đầu tiên bạn phải lấy con trỏ, lần thứ hai là dữ liệu thực và ngăn xếp chỉ cần được truy cập một lần. Ngoài ra, xác suất nội dung của heap bị hệ điều hành tráo đổi sang bộ nhớ ngoài lớn hơn xác suất của ngăn xếp và ngăn xếp nói chung không bị tráo đổi.
Các phương pháp cấp phát bộ nhớ phổ biến là gì?
phương pháp cấp phát bộ nhớ
(1) Được phân bổ từ vùng lưu trữ tĩnh. Bộ nhớ được cấp phát khi chương trình được biên dịch và bộ nhớ này tồn tại trong suốt quá trình chạy chương trình. Chẳng hạn như biến toàn cục, biến tĩnh.
(2) Được tạo trên ngăn xếp. Khi một hàm được thực thi, các đơn vị lưu trữ của các biến cục bộ trong hàm có thể được tạo trên ngăn xếp và các đơn vị lưu trữ này sẽ tự động được giải phóng khi quá trình thực thi hàm kết thúc. Hoạt động cấp phát bộ nhớ ngăn xếp được tích hợp trong tập lệnh của bộ xử lý, hoạt động này rất hiệu quả nhưng dung lượng bộ nhớ được cấp phát bị hạn chế.
(3) Cấp phát từ heap hay còn gọi là cấp phát bộ nhớ động. Khi chương trình đang chạy, sử dụng malloc hoặc new để áp dụng cho bất kỳ dung lượng bộ nhớ nào và lập trình viên chịu trách nhiệm về thời điểm sử dụng free hoặc delete để giải phóng bộ nhớ. Tuổi thọ của bộ nhớ động do chúng tôi xác định và nó rất linh hoạt để sử dụng, nhưng nó cũng có nhiều vấn đề nhất.
Trong quá trình trao đổi bộ nhớ, tiến trình bị đẩy ra được lưu trữ ở đâu?
Tiến trình bị đẩy ra được lưu trữ trên đĩa cứng, còn được gọi là bộ nhớ ngoài. Trong hệ điều hành có chức năng trao đổi bộ nhớ, không gian đĩa cứng được chia thành hai phần: khu vực tệp và khu vực trao đổi. Khu vực tệp được sử dụng chủ yếu để lưu trữ các tệp tin, với mục tiêu tối đa hóa sử dụng không gian lưu trữ, do đó quản lý không gian tệp tin được thực hiện bằng cách phân bổ rời rạc. Khu vực trao đổi chỉ chiếm một phần nhỏ không gian đĩa cứng, và dữ liệu của các tiến trình bị đẩy ra sẽ được lưu trữ trong khu vực này. Vì tốc độ trao đổi bộ nhớ trực tiếp ảnh hưởng đến tốc độ tổng thể của hệ thống, do đó quản lý không gian trao đổi thường tập trung vào tốc độ trao đổi, thường sử dụng phương pháp phân bổ liên tục (sau khi đã học về quản lý tệp tin, bạn có thể hiểu thêm về điều này). Tóm lại, tốc độ I/O của khu vực trao đổi nhanh hơn khu vực tệp tin.
Trong quá trình trao đổi bộ nhớ, có một số tiến trình được ưu tiên xem xét trước. Bạn có thể giải thích được không?
Có một số tiến trình được ưu tiên xem xét trong quá trình trao đổi bộ nhớ. Dưới đây là một số tiến trình được ưu tiên:
- Tiến trình bị chặn (blocked) có thể được ưu tiên để được đẩy ra khỏi bộ nhớ. Điều này xảy ra khi tiến trình đang chờ đợi một tài nguyên nào đó, ví dụ như đọc dữ liệu từ đĩa cứng. Bằng cách đẩy ra tiến trình bị chặn, hệ điều hành có thể giải phóng bộ nhớ cho các tiến trình khác có thể tiếp tục thực thi.
- Tiến trình có mức ưu tiên thấp có thể được đẩy ra khỏi bộ nhớ. Điều này xảy ra khi hệ điều hành cần giải phóng bộ nhớ cho các tiến trình có mức ưu tiên cao hơn, như các tiến trình quan trọng hơn hoặc đang chạy trong chế độ ưu tiên cao.
- Để tránh việc tiến trình có mức ưu tiên thấp bị đẩy vào bộ nhớ và sau đó bị đẩy ra ngay lập tức, một số hệ điều hành cũng xem xét thời gian tiến trình đã ở trong bộ nhớ. Nếu một tiến trình đã ở trong bộ nhớ trong một khoảng thời gian đủ lâu, nó có thể được ưu tiên để tiếp tục thực thi.
Lưu ý rằng PCB (Process Control Block) luôn luôn nằm trong bộ nhớ và không bao giờ bị đẩy ra khỏi bộ nhớ. PCB chứa thông tin quan trọng về tiến trình và được sử dụng để quản lý và điều khiển tiến trình.
ASCII, Unicode và UTF-8 là gì và khác nhau như thế nào?
ASCII
ASCII (American Standard Code for Information Interchange) chỉ có 127 ký tự, đại diện cho chữ cái tiếng Anh in hoa, chữ cái tiếng Anh thường, số và một số ký hiệu. Tuy nhiên ASCII không đủ để biểu diễn các ký tự trong các ngôn ngữ khác.
Unicode
Vì mỗi quốc gia có ngôn ngữ riêng của mình, trong việc biên tập văn bản đa ngôn ngữ, có thể gặp phải vấn đề mã hóa không đúng, do đó, Unicode ra đời để thống nhất các ngôn ngữ này vào một định dạng mã hóa. Thông thường, mỗi ký tự Unicode được biểu diễn bằng hai byte, trong khi ASCII chỉ sử dụng một byte cho mỗi ký tự. Điều này có nghĩa là nếu bạn biên tập văn bản chỉ bằng tiếng Anh, sử dụng mã hóa Unicode sẽ tốn gấp đôi không gian lưu trữ so với mã hóa ASCII, điều này không hiệu quả trong việc lưu trữ và truyền tải dữ liệu.
UTF-8
Để giải quyết vấn đề trên, UTF-8 (Unicode Transformation Format - 8-bit) được phát triển để chuyển đổi mã hóa Unicode thành “mã hóa biến đổi” có thể thay đổi độ dài. UTF-8 mã hóa các ký tự Unicode thành 1-6 byte dựa trên giá trị số, trong đó các chữ cái tiếng Anh được mã hóa thành một byte. Nếu bạn chỉ biên tập văn bản bằng tiếng Anh, việc sử dụng UTF-8 sẽ tiết kiệm không gian lưu trữ rất nhiều, và mã ASCII cũng là một phần của UTF-8.
Mối quan hệ giữa ba mã hóa này
Sau khi hiểu về ASCII, Unicode và UTF-8, chúng ta có thể tóm tắt cách làm việc của hệ thống mã hóa ký tự thông dụng trong hệ thống máy tính hiện nay:
-
Trong bộ nhớ máy tính, sử dụng mã hóa Unicode để thống nhất. Khi cần lưu trữ vào đĩa cứng hoặc truyền tải, chuyển đổi sang mã hóa UTF-8.
-
Khi sử dụng trình soạn thảo văn bản, các ký tự UTF-8 được đọc từ tệp tin và chuyển đổi thành ký tự Unicode trong bộ nhớ, sau đó, khi hoàn thành chỉnh sửa, lưu lại bằng cách chuyển đổi từ Unicode sang UTF-8 và lưu vào tệp tin.
-
Khi duyệt web, máy chủ sẽ chuyển đổi nội dung Unicode động thành UTF-8 trước khi truyền đến trình duyệt
Cách thực hiện các hoạt động nguyên tử (atomic operations) là gì?
Bộ xử lý sử dụng cơ chế khóa bộ nhớ hoặc khóa bus để thực hiện các hoạt động nguyên tử giữa các bộ xử lý đa nhân. Đầu tiên, bộ xử lý tự động đảm bảo tính nguyên tử của các hoạt động cơ bản trên bộ nhớ. Bộ xử lý đảm bảo rằng việc đọc hoặc ghi một byte từ bộ nhớ hệ thống là nguyên tử, có nghĩa là khi một bộ xử lý đọc một byte, các bộ xử lý khác không thể truy cập vào địa chỉ bộ nhớ của byte đó. Pentium 6 và các bộ xử lý mới nhất tự động đảm bảo tính nguyên tử của các hoạt động 16/32/64 bit trên cùng một dòng bộ nhớ, nhưng các hoạt động phức tạp hơn trên bộ nhớ không thể tự động đảm bảo tính nguyên tử, ví dụ như truy cập qua độ rộng bus, qua nhiều dòng bộ nhớ và qua bảng trang.
Tuy nhiên, bộ xử lý cung cấp hai cơ chế khóa để đảm bảo tính nguyên tử của các hoạt động phức tạp trên bộ nhớ.
(1) Sử dụng khóa bus để đảm bảo tính nguyên tử: Cơ chế đầu tiên là sử dụng khóa bus để đảm bảo tính nguyên tử. Nếu nhiều bộ xử lý cùng thời điểm thực hiện các hoạt động đọc/sửa đổi/ghi trên biến chia sẻ (ví dụ: i++ là một hoạt động đọc/sửa đổi), biến chia sẻ sẽ được các bộ xử lý thực hiện cùng một lúc, điều này không đảm bảo tính nguyên tử của hoạt động đọc/sửa đổi. Ví dụ, nếu i=1 và chúng ta thực hiện hai hoạt động i++, kết quả dự kiến là 3, nhưng có thể kết quả là 2, như hình dưới đây.
CPU1 CPU2
i=1 i=1
i+1 i+1
i=2 i=2Nguyên nhân có thể là nhiều bộ xử lý cùng đọc biến i từ bộ nhớ cache của mình, thực hiện các hoạt động tăng giá trị và ghi lại vào bộ nhớ hệ thống. Vì vậy, để đảm bảo tính nguyên tử của hoạt động đọc/sửa đổi biến chia sẻ, cần đảm bảo rằng khi CPU1 đọc/sửa đổi biến chia sẻ, CPU2 không thể truy cập vào bộ nhớ cache chứa địa chỉ bộ nhớ của biến đó.
Bộ xử lý sử dụng khóa bus để giải quyết vấn đề này. Khóa bus là việc sử dụng tín hiệu LOCK# do bộ xử lý cung cấp. Khi một bộ xử lý đầu ra tín hiệu này trên bus, các yêu cầu từ các bộ xử lý khác sẽ bị chặn lại, bộ xử lý đó có thể chiếm quyền sử dụng bộ nhớ chia sẻ.
(2) Sử dụng khóa cache để đảm bảo tính nguyên tử: Cơ chế thứ hai là sử dụng khóa cache để đảm bảo tính nguyên tử. Trong cùng một thời điểm, chúng ta chỉ cần đảm bảo tính nguyên tử của các hoạt động trên một địa chỉ bộ nhớ cụ thể, không cần đảm bảo tính nguyên tử của toàn bộ bộ nhớ. Tuy nhiên, việc khóa bus sẽ làm chặn giao tiếp giữa CPU và bộ nhớ, điều này là không hiệu quả, vì vậy các bộ xử lý hiện đại sử dụng khóa cache để tối ưu hóa.
Khóa cache được sử dụng khi vùng nhớ được cache trong bộ nhớ cache của bộ xử lý và được khóa trong quá trình LOCK. Khi thực hiện hoạt động LOCK trên vùng nhớ đã được khóa, bộ xử lý không phát LOCK# trên bus, mà thay vào đó, nó sửa đổi địa chỉ bộ nhớ nội bộ và cho phép cơ chế đồng bộ hóa cache đảm bảo tính nguyên tử của hoạt động. Vì cơ chế đồng bộ hóa cache sẽ ngăn chặn việc sửa đổi dữ liệu trong cùng một vùng nhớ bị cache bởi hai bộ xử lý trở lên cùng một lúc.
Tuy nhiên, có hai trường hợp mà bộ xử lý không sử dụng khóa cache. Trường hợp thứ nhất là khi dữ liệu không thể được cache trong bộ xử lý hoặc dữ liệu trải dài qua nhiều dòng cache (cache line), bộ xử lý sẽ sử dụng khóa bus. Trường hợp thứ hai là một số bộ xử lý không hỗ trợ khóa cache. Đối với Intel 486 và bộ xử lý Pentium, ngay cả khi vùng nhớ được cache trong dòng cache của bộ xử lý, khóa bus vẫn được sử dụng.
Bạn có biết những điểm quan trọng cần chú ý về việc trao đổi bộ nhớ không?
- Cần sao lưu bộ nhớ trao đổi, thường là trên đĩa nhanh, nó phải đủ lớn và cung cấp truy cập trực tiếp đến các hình ảnh bộ nhớ này.
- Để sử dụng hiệu quả CPU, thời gian thực hiện của mỗi tiến trình cần phải dài hơn thời gian trao đổi, và thời gian trao đổi chủ yếu bị ảnh hưởng bởi thời gian chuyển đổi, thời gian chuyển đổi tăng theo tỷ lệ thuận với không gian bộ nhớ được trao đổi.
- Nếu tiến trình được trao đổi, đảm bảo không gian bộ nhớ của tiến trình đó tăng theo tỷ lệ thuận.
- Không gian trao đổi thường được sử dụng như một phần của đĩa, độc lập với hệ thống tệp, do đó việc sử dụng có thể nhanh chóng.
- Trình trao đổi thường bắt đầu hoạt động khi có nhiều tiến trình đang chạy và không gian bộ nhớ khan hiếm, và tạm dừng khi tải trọng hệ thống giảm.
- Trong nhiều hệ thống, các biến thể của chiến lược trao đổi vẫn được sử dụng, mặc dù trao đổi thông thường không được sử dụng nhiều.
Có thể phân biệt được sự khác nhau giữa hệ thống đồng thời và song song không?
Đồng thời đề cập đến việc nhiều chương trình có thể chạy cùng một lúc trong một khoảng thời gian, trong khi song song đề cập đến việc có thể thực hiện nhiều chỉ thị cùng một thời điểm.
Song song yêu cầu hỗ trợ phần cứng, chẳng hạn như đa luồng, bộ xử lý đa nhân hoặc hệ thống tính toán phân tán.
Hệ điều hành sử dụng quy trình và luồng để cho phép các chương trình chạy đồng thời.
Tổng kết các thuật toán thay trang trang
1. Thuật toán thay thế tốt nhất (OPT)
Thuật toán thay thế tốt nhất (OPT, Optimal): Mỗi lần chọn trang để loại bỏ sẽ là trang không bao giờ được sử dụng sau này hoặc không được truy cập trong thời gian dài nhất, điều này đảm bảo tỷ lệ thiếu trang thấp nhất.
Thuật toán thay thế tốt nhất có thể đảm bảo tỷ lệ thiếu trang thấp nhất, nhưng thực tế, chỉ có thể biết được trang nào sẽ được truy cập tiếp theo trong quá trình thực hiện quá trình. Hệ điều hành không thể dự đoán trước được chuỗi truy cập trang. Do đó, thuật toán thay thế tốt nhất không thể thực hiện được.
2. Thuật toán thay trang theo thứ tự vào trước ra trước (FIFO)
Thuật toán thay thế theo nguyên tắc “First In First Out” (FIFO): Mỗi lần chọn trang để loại bỏ là trang đã vào bộ nhớ lâu nhất.
Cách thực hiện: Sắp xếp các trang được đưa vào bộ nhớ theo thứ tự đến của chúng, khi cần loại bỏ trang, chọn trang ở đầu hàng đợi. Độ dài tối đa của hàng đợi phụ thuộc vào số khối bộ nhớ được cấp cho quá trình.
Hiện tượng Belady - Khi số khối bộ nhớ được cấp cho quá trình tăng lên, số lần thiếu trang không giảm mà tăng lên.
Chỉ có thuật toán FIFO mới gây ra hiện tượng Belady, trong khi thuật toán LRU và OPT không bao giờ gặp hiện tượng Belady. Ngoài ra, mặc dù thuật toán FIFO dễ hiện thực, nhưng thuật toán này không phù hợp với quy luật hoạt động thực tế của quá trình, vì các trang vào trước cũng có thể được truy cập nhiều nhất. Do đó, hiệu suất của thuật toán kém.
Thuật toán FIFO có hiệu suất kém vì các trang vào sớm thường được truy cập thường xuyên. Các trang này được đưa vào và loại bỏ liên tục trong thuật toán FIFO và có hiện tượng Belady. Hiện tượng Belady là hiện tượng khi sử dụng thuật toán FIFO, nếu không cấp đủ trang cho quá trình, đôi khi số trang được cấp tăng lên nhưng tỷ lệ thiếu trang lại tăng lên.
3. Thuật toán thay thế LRU (Least Recently Used)
Thuật toán thay thế LRU (Least Recently Used): Mỗi lần chọn trang để loại bỏ sẽ là trang không được sử dụng gần đây nhất.
Cách thực hiện: Gán một trường “thời gian truy cập” trong mục bảng trang tương ứng với mỗi trang, ghi lại thời gian từ lần truy cập trước đến hiện tại (thực hiện thuật toán này cần hỗ trợ phần cứng đặc biệt, mặc dù hiệu suất của thuật toán tốt, nhưng thực hiện khó khăn và tốn kém). Khi cần loại bỏ một trang, chọn trang có giá trị thời gian lớn nhất trong các trang hiện có, tức là trang không được sử dụng gần đây nhất.
Thuật toán LRU có hiệu suất tốt, nhưng yêu cầu hỗ trợ phần cứng đặc biệt như thanh ghi và ngăn xếp. LRU là thuật toán loại hàng đợi, lý thuyết có thể chứng minh, thuật toán loại hàng đợi không thể gặp hiện tượng Belady.
Khi làm bài tập thủ công, nếu cần loại bỏ trang, bạn có thể kiểm tra ngược lại các số trang đang có trong bộ nhớ. Trong quá trình quét ngược, số trang xuất hiện cuối cùng sẽ là trang cần loại bỏ.
4. Thuật toán thay thế Clock
Thuật toán thay thế tốt nhất OPT có hiệu suất tốt nhất nhưng không thể thực hiện; Thuật toán FIFO dễ hiện thực nhưng hiệu suất kém; Thuật toán LRU có hiệu suất tốt và gần với OPT nhất, nhưng thực hiện yêu cầu phần cứng đặc biệt và tốn kém.
Vì vậy, nhà thiết kế hệ điều hành đã thử nghiệm nhiều thuật toán, cố gắng tiếp cận hiệu suất LRU với mức độ tốn kém nhỏ hơn, những thuật toán này là biến thể của thuật toán Clock, vì thuật toán phải quét vòng lặp bộ đệm giống như đồng hồ. Do đó, gọi là thuật toán Clock.
Thuật toán thay thế Clock là một thuật toán cân bằng giữa hiệu suất và tốn kém, còn được gọi là thuật toán CLOCK hoặc thuật toán Not Recently Used (NRU).
Cách thực hiện đơn giản của thuật toán Clock: Gán một bit truy cập cho mỗi trang, sau đó liên kết các trang trong bộ nhớ thành một hàng đợi vòng. Khi cần loại bỏ một trang, chỉ cần kiểm tra bit truy cập của trang. Nếu là 0, chọn trang đó để loại bỏ; nếu là 1, đặt nó thành 0 tạm thời không loại bỏ, tiếp tục kiểm tra trang tiếp theo. Nếu trong vòng quét lần này tất cả các trang đều là 1, sau đó đặt tất cả các bit truy cập của các trang này thành 0 và tiếp tục quét lần thứ hai (trong lần quét thứ hai này, chắc chắn sẽ có ít nhất một trang có bit truy cập là 0, do đó thuật toán Clock đơn giản chọn một trang để loại bỏ sẽ đi qua hai lần quét).
5. Thuật toán thay thế Clock cải tiến
Thuật toán thay thế Clock đơn giản chỉ xem xét xem một trang đã được truy cập gần đây chưa. Tuy nhiên, trong thực tế, nếu trang bị loại bỏ không được sửa đổi, không cần thực hiện hoạt động I/O để ghi lại bộ nhớ ngoại vi. Chỉ khi trang bị loại bỏ đã được sửa đổi, mới cần ghi lại bộ nhớ ngoại vi.
Do đó, ngoài việc xem xét xem một trang đã được truy cập gần đây hay chưa, hệ điều hành cũng nên xem xét xem trang đã được sửa đổi hay chưa. Trong các điều kiện khác nhau như nhau, nên ưu tiên loại bỏ trang chưa được sửa đổi để tránh hoạt động I/O. Đây là ý tưởng của thuật toán thay thế Clock cải tiến. Bit sửa đổi = 0, cho biết trang chưa được sửa đổi; bit sửa đổi = 1, cho biết trang đã được sửa đổi.
Để thuận tiện cho việc thảo luận, trạng thái của mỗi trang trong bộ nhớ có thể được biểu thị dưới dạng (bit truy cập, bit sửa đổi). Ví dụ (1, 1) biểu thị một trang đã được truy cập gần đây và đã được sửa đổi.
Thuật toán Clock cải tiến yêu cầu xem xét cả bit truy cập và bit sửa đổi của một trang cụ thể để quyết định xem có thay thế trang đó hay không. Trong quá trình viết thuật toán thực tế, cũng có thể sử dụng một mảng số nguyên có độ dài tương tự để chỉ định trạng thái sửa đổi của mỗi khối bộ nhớ. Bit truy cập A và bit sửa đổi M có thể tạo thành bốn loại trang sau:
Quy tắc thuật toán:
- Vòng lặp đầu tiên: Bắt đầu từ vị trí hiện tại, quét đến trang đầu tiên (A = 0, M = 0) để thay thế. Đây là trang không được truy cập gần đây nhất và không được sửa đổi, là trang tốt nhất để loại bỏ.
- Vòng lặp thứ hai: Nếu quét đầu tiên không thành công, quét lại từ đầu để tìm trang đầu tiên (A = 1, M = 0) để thay thế. Trong vòng lặp này, tất cả các trang đã được quét đều được đặt bit truy cập thành 0.
- Vòng lặp thứ ba: Nếu quét thứ hai không thành công, quét lại từ đầu để tìm trang đầu tiên (A = 0, M = 1) để thay thế. Trong vòng lặp này, không thay đổi bất kỳ bit nào.
- Vòng lặp thứ tư: Nếu quét thứ ba không thành công, quét lại từ đầu để tìm trang đầu tiên (A = 1, M = 1) để thay thế.
Vì vòng lặp thứ hai đã đặt tất cả các bit truy cập của các trang thành 0, do đó sau vòng lặp thứ ba và thứ tư, chắc chắn sẽ có một trang được chọn, vì vậy thuật toán thay thế Clock cải tiến chọn một trang để loại bỏ sẽ đi qua tối đa bốn vòng lặp.
Quy tắc thuật toán: Đặt tất cả các trang có thể bị thay thế vào một hàng đợi vòng.
- Vòng lặp đầu tiên: Bắt đầu từ vị trí hiện tại, quét đến trang đầu tiên (0, 0) để thay thế. Trong vòng lặp này, không thay đổi bất kỳ bit nào. (Ưu tiên 1: Trang không được truy cập gần đây nhất và không được sửa đổi)
- Vòng lặp thứ hai: Nếu quét đầu tiên không thành công, quét lại từ đầu để tìm trang đầu tiên (0, 1) để thay thế. Trong vòng lặp này, đặt tất cả các trang đã được quét thành bit truy cập = 0.
(Ưu tiên 2: Trang không được truy cập gần đây nhất nhưng đã được sửa đổi) - Vòng lặp thứ ba: Nếu quét thứ hai không thành công, quét lại từ đầu để tìm trang đầu tiên (0, 0) để thay thế. Trong vòng lặp này, không thay đổi bất kỳ bit nào.
(Ưu tiên 3: Trang đã được truy cập gần đây nhưng chưa được sửa đổi) - Vòng lặp thứ tư: Nếu quét thứ ba không thành công, quét lại từ đầu để tìm trang đầu tiên (0, 1) để thay thế.
(Ưu tiên 4: Trang đã được truy cập gần đây và đã được sửa đổi)
Vì vòng lặp thứ hai đã đặt tất cả các bit truy cập của các trang thành 0, do đó sau vòng lặp thứ ba và thứ tư, chắc chắn sẽ có một trang được chọn, vì vậy thuật toán thay thế Clock cải tiến chọn một trang để loại bỏ sẽ đi qua tối đa bốn vòng lặp.
6. Tổng kết
| Thuật toán | Quy tắc thực hiện | Ưu điểm và nhược điểm |
|---|---|---|
| OPT | Ưu tiên loại bỏ trang không được truy cập trong thời gian dài nhất | Tỷ lệ thiếu trang thấp nhất, hiệu suất tốt nhất; nhưng không thể thực hiện được |
| FIFO | Ưu tiên loại bỏ trang vào trước | Dễ hiện thực, nhưng hiệu suất kém, có thể gây ra hiện tượng Belady |
| LRU | Ưu tiên loại bỏ trang không được sử dụng gần đây nhất | Hiệu suất tốt, nhưng yêu cầu hỗ trợ phần cứng đặc biệt |
| CLOCK (NRU) | Quét vòng các trang và loại bỏ trang có bit truy cập là 0 | Dễ hiện thực, hiệu suất tương đối tốt, chi phí thấp |
| CLOCK cải tiến | Xem xét cả bit truy cập và bit sửa đổi của mỗi trang để quyết định loại bỏ trang | Cân bằng giữa hiệu suất và chi phí |
Chia sẻ là gì?
Chia sẻ là quá trình cho phép nhiều tiến trình đồng thời sử dụng các tài nguyên trong hệ thống.
Có hai phương pháp chia sẻ: chia sẻ đồng thời và chia sẻ tuần tự.
Các tài nguyên chia sẻ tuần tự được gọi là tài nguyên quan trọng, ví dụ như máy in, chỉ cho phép một tiến trình truy cập vào cùng một thời điểm và cần sử dụng cơ chế đồng bộ để đảm bảo truy cập tuần tự.
Tổng kết về vấn đề liên quan đến Deadlock, đầy đủ nhất!
Deadlock là quá trình hai (hoặc nhiều) luồng đang chờ đợi lẫn nhau để truy cập vào dữ liệu của nhau, sự phát sinh của deadlock sẽ làm cho chương trình bị treo, và nếu không giải phóng khóa, chương trình sẽ không bao giờ tiếp tục được.
1. Nguyên nhân gây ra deadlock
Ví dụ: Hai luồng A và B, hai dữ liệu 1 và 2. Trong quá trình thực thi, luồng A trước tiên khóa tài nguyên 1, sau đó cố gắng khóa tài nguyên 2, nhưng do sự chuyển đổi luồng, luồng A không thể khóa tài nguyên 2. Khi chuyển đổi sang luồng B, luồng B trước tiên khóa tài nguyên 2, sau đó cố gắng khóa tài nguyên 1, nhưng do tài nguyên 1 đã được luồng A khóa, luồng B không thể khóa thành công. Khi chuyển đổi sang luồng A, luồng A cũng không thể khóa tài nguyên 2 thành công. Do đó, hai luồng A và B đang chờ đợi lẫn nhau để truy cập vào một tài nguyên đã được khóa, gây ra deadlock.
Lý thuyết cho rằng deadlock xảy ra khi có bốn điều kiện cần thiết, không thể thiếu bất kỳ điều kiện nào:
- Điều kiện độc quyền: Tiến trình yêu cầu tài nguyên cần thiết có tính độc quyền, nếu có tiến trình khác yêu cầu tài nguyên đó, tiến trình yêu cầu phải chờ đợi.
- Điều kiện không thể tước đoạt: Tiến trình không thể bị tước đoạt tài nguyên đã nhận cho đến khi tiến trình tự giải phóng.
- Điều kiện yêu cầu và giữ: Tiến trình đang giữ các tài nguyên hiện có và yêu cầu tài nguyên mới, tiến trình vẫn giữ các tài nguyên hiện có trong khi yêu cầu tài nguyên mới.
- Điều kiện chờ đợi vòng tròn: Tồn tại một chuỗi chờ đợi vòng tròn tài nguyên tiến trình, trong đó mỗi tiến trình đã nhận các tài nguyên mà tiến trình tiếp theo trong chuỗi yêu cầu.
2. Mô phỏng deadlock
Mô phỏng deadlock thông qua mã nguồn, yêu cầu hai luồng và hai khóa tương hỗ.
#include <iostream>
#include <vector>
#include <list>
#include <thread>
#include <mutex> //Thêm thư viện khóa tương hỗ
using namespace std;
class A {
public:
//Thêm tin nhắn, mô phỏng việc tạo ra tin nhắn liên tục
void insertMsg() {
for (int i = 0; i < 100; i++) {
cout << "Thêm một tin nhắn:" << i << endl;
my_mutex1.lock(); //Dòng 1
my_mutex2.lock(); //Dòng 2
Msg.push_back(i);
my_mutex2.unlock();
my_mutex1.unlock();
}
}
//Đọc tin nhắn
void readMsg() {
int MsgCom;
for (int i = 0; i < 100; i++) {
MsgCom = MsgLULProc(i);
if (MsgLULProc(MsgCom)) {
//Đã đọc tin nhắn
cout << "Tin nhắn đã được đọc" << MsgCom << endl;
}
else {
//Tin nhắn tạm thời trống
cout << "Tin nhắn trống" << endl;
}
}
}
//Mã khóa và mở khóa
bool MsgLULProc(int &command) {
int curMsg;
my_mutex2.lock(); //Dòng 3
my_mutex1.lock(); //Dòng 4
if (!Msg.empty()) {
//Đọc tin nhắn, đọc xong xóa
command = Msg.front();
Msg.pop_front();
my_mutex1.unlock();
my_mutex2.unlock();
return true;
}
my_mutex1.unlock();
my_mutex2.unlock();
return false;
}
private:
std::list<int> Msg; //Biến tin nhắn
std::mutex my_mutex1; //Đối tượng khóa tương hỗ 1
std::mutex my_mutex2; //Đối tượng khóa tương hỗ 2
};
int main() {
A a;
//Tạo một luồng chèn tin nhắn
std::thread insertTd(&A::insertMsg, &a); //Phải truyền tham chiếu để đảm bảo cùng một đối tượng
//Tạo một luồng đọc tin nhắn
std::thread readTd(&A::readMsg, &a); //Phải truyền tham chiếu để đảm bảo cùng một đối tượng
insertTd.join();
readTd.join();
return 0;
}Dòng 1 và dòng 2 biểu thị luồng A trước tiên khóa tài nguyên 1, sau đó khóa tài nguyên 2, dòng 3 và dòng 4 biểu thị luồng B trước tiên khóa tài nguyên 2, sau đó khóa tài nguyên 1, đáp ứng các điều kiện để xảy ra deadlock.
3. Giải pháp cho Deadlock
Đảm bảo thứ tự khóa là nhất quán.
4. Các điều kiện cần thiết cho Deadlock
- Điều kiện độc quyền: Tiến trình yêu cầu tài nguyên có tính độc quyền, nếu có tiến trình khác yêu cầu tài nguyên đó, tiến trình yêu cầu phải chờ đợi.
- Điều kiện không thể tước: Tiến trình không thể bị tước tài nguyên đã nhận cho đến khi tự giải phóng.
- Điều kiện yêu cầu và giữ: Tiến trình giữ các tài nguyên hiện có và yêu cầu tài nguyên mới, tiến trình vẫn giữ các tài nguyên hiện có trong khi yêu cầu tài nguyên mới.
- Điều kiện chờ đợi vòng lặp: Tồn tại chuỗi chờ đợi vòng lặp tài nguyên giữa các tiến trình, trong đó mỗi tiến trình đã nhận các tài nguyên mà tiến trình tiếp theo trong chuỗi yêu cầu.
5. Giải pháp xử lý Deadlock
Có bốn phương pháp chính để xử lý Deadlock:
- Chiến lược “chim cánh cụt” (Ostrich algorithm)
- Phát hiện Deadlock và khôi phục
- Phòng ngừa Deadlock
- Tránh Deadlock
Chiến lược “chim cánh cụt” (Ostrich algorithm)
Đây là một phương pháp không thực hiện bất kỳ biện pháp nào để giải quyết Deadlock, mà chỉ đơn giản là giả vờ như không có vấn đề xảy ra. Vì giải quyết Deadlock có chi phí cao, nên phương pháp “chim cánh cụt” này sẽ đạt được hiệu suất cao hơn.
Khi Deadlock xảy ra và không ảnh hưởng đáng kể đến người dùng hoặc xác suất xảy ra Deadlock rất thấp, có thể áp dụng chiến lược “chim cánh cụt”.
Hầu hết các hệ điều hành, bao gồm Unix, Linux và Windows, đều xử lý Deadlock bằng cách đơn giản là bỏ qua nó.
Phát hiện Deadlock và khôi phục
Không cố gắng ngăn chặn Deadlock, mà chỉ khi phát hiện Deadlock xảy ra, thực hiện biện pháp để khôi phục.
-
Phát hiện Deadlock với một tài nguyên cho mỗi loại

Hình trên là biểu đồ phân phối tài nguyên, trong đó hình chữ nhật đại diện cho tài nguyên và hình tròn đại diện cho tiến trình. Mũi tên từ tài nguyên chỉ tiến trình đã nhận tài nguyên đó, mũi tên từ tiến trình chỉ tài nguyên mà tiến trình yêu cầu.
Hình a có thể tạo thành một vòng, như hình b, nó đáp ứng điều kiện vòng chờ đợi, do đó sẽ xảy ra Deadlock.
Thuật toán phát hiện Deadlock với một tài nguyên cho mỗi loại được thực hiện bằng cách kiểm tra xem đồ thị có hướng có chứa vòng hay không, bắt đầu từ một nút và thực hiện tìm kiếm theo chiều sâu, đánh dấu các nút đã được truy cập, nếu truy cập một nút đã được đánh dấu, có nghĩa là đồ thị có hướng chứa vòng, tức là phát hiện Deadlock.
-
Phát hiện Deadlock với nhiều tài nguyên cho mỗi loại
Trong hình trên, có ba tiến trình và bốn tài nguyên, mỗi số đại diện cho một loại tài nguyên, mỗi số trong mỗi tiến trình đại diện cho số lượng tài nguyên mà tiến trình đó sở hữu.
Tiến trình P1 và P2 đều không thể nhận được tài nguyên yêu cầu, chỉ có tiến trình P3 có thể, cho phép P3 thực hiện, sau đó giải phóng tài nguyên mà P3 sở hữu, lúc này A = (2 2 2 0). P2 cũng có thể thực hiện, sau đó giải phóng tài nguyên mà P2 sở hữu, A = (4 2 2 1). P1 cũng có thể thực hiện. Tất cả các tiến trình đều có thể thực hiện một cách suôn sẻ, không có Deadlock.
Thuật toán phát hiện Deadlock với nhiều tài nguyên cho mỗi loại được thực hiện bằng cách tìm một tiến trình chưa được đánh dấu, yêu cầu tài nguyên nhỏ hơn hoặc bằng A. Nếu tìm thấy một tiến trình như vậy, thêm vectơ hàng thứ i của ma trận C vào A, đánh dấu tiến trình đó và quay lại bước 1. Nếu không tìm thấy tiến trình như vậy, thuật toán kết thúc.
6. Khôi phục Deadlock
- Sử dụng khôi phục bằng cách cướp đoạt (Preemption)
- Sử dụng khôi phục bằng cách quay lại trạng thái trước (Rollback)
- Khôi phục bằng cách giết tiến trình (Killing process)
7. Phòng ngừa Deadlock
Phòng ngừa Deadlock trước khi chương trình chạy.
-
Phá vỡ điều kiện độc quyền
Ví dụ, kỹ thuật in ấn ngoại tuyến giả cho phép nhiều tiến trình cùng xuất, tiến trình duy nhất thực sự yêu cầu máy in là tiến trình bảo vệ máy in.
-
Phá vỡ điều kiện yêu cầu và giữ
Một cách thực hiện là quy định rằng tất cả các tiến trình phải yêu cầu tất cả các tài nguyên cần thiết trước khi bắt đầu thực thi.
-
Phá vỡ điều kiện không thể tước
Cho phép cướp tài nguyên
-
Phá vỡ điều kiện chờ đợi vòng lặp
Gán một số duy nhất cho tài nguyên, tiến trình chỉ có thể yêu cầu tài nguyên theo thứ tự số.
8. Tránh Deadlock
Tránh Deadlock trong quá trình chạy chương trình.
1. Trạng thái an toàn

Cột Has trong hình a biểu thị số lượng tài nguyên đã sở hữu, cột Max biểu thị tổng số lượng tài nguyên cần thiết, Free biểu thị số lượng tài nguyên có thể sử dụng. Bắt đầu từ hình a, cho phép B sở hữu tất cả tài nguyên cần thiết (hình b), sau khi hoàn thành, giải phóng B, lúc này Free trở thành 5 (hình c); tiếp theo, thực hiện tương tự với C và A, để tất cả các tiến trình đều chạy thành công, do đó trạng thái như hình a được coi là an toàn.
Định nghĩa: Nếu không có Deadlock xảy ra và ngay cả khi tất cả các tiến trình đột ngột yêu cầu tài nguyên tối đa của chúng, vẫn tồn tại một lịch trình lập trình có thể làm cho mỗi tiến trình hoàn thành, thì trạng thái đó được coi là an toàn.
Việc kiểm tra trạng thái an toàn tương tự như kiểm tra Deadlock, vì trạng thái an toàn yêu cầu không có Deadlock xảy ra. Thuật toán Banker’s Algorithm dưới đây rất giống với thuật toán kiểm tra Deadlock và có thể được tham khảo và so sánh.
2. Banker’s Algorithm cho một tài nguyên duy nhất
Banker’s Algorithm là một thuật toán được sử dụng bởi một ngân hàng nhỏ trong một thị trấn nhỏ, ngân hàng đã cam kết một số tiền vay cho một nhóm khách hàng, nhiệm vụ của thuật toán là kiểm tra xem việc đáp ứng yêu cầu có dẫn đến trạng thái không an toàn hay không, nếu có, thì từ chối yêu cầu; nếu không, cấp phát tài nguyên.
Trạng thái không an toàn như hình c, do đó thuật toán sẽ từ chối yêu cầu trước đó để tránh vào trạng thái như hình c.
3. Banker’s Algorithm cho nhiều tài nguyên
Trong hình trên, có năm tiến trình và bốn tài nguyên. Phần bên trái biểu thị tài nguyên đã được phân bổ, phần bên phải biểu thị tài nguyên cần phân bổ. Phần cuối cùng bên phải là E, P và A lần lượt biểu thị: tổng số tài nguyên, tài nguyên đã được phân bổ và tài nguyên có sẵn, lưu ý rằng ba vector này, không phải là giá trị cụ thể, ví dụ A = (1020) biểu thị 4 tài nguyên lần lượt còn lại 1/0/2/0.
4. Thuật toán kiểm tra trạng thái an toàn như sau:
- Tìm hàng trong ma trận bên phải mà nhỏ hơn hoặc bằng vector A. Nếu không có hàng như vậy, hệ thống sẽ gặp Deadlock và trạng thái không an toàn.
- Nếu tìm thấy hàng như vậy, đánh dấu quy trình tương ứng là kết thúc và thêm vector hàng thứ i của ma trận C vào vector A.
- Lặp lại hai bước trên cho đến khi tất cả các quy trình đều được đánh dấu là kết thúc, trạng thái là an toàn.
Nếu một trạng thái không an toàn, cần từ chối vào trạng thái đó.
Tại sao quản lý lưu trữ phân đoạn có phân mảnh bên ngoài nhưng không có phân mảnh bên trong? Tại sao phân bổ phân vùng cố định có phân mảnh bên trong mà không phải phân mảnh bên ngoài?
Phân bổ theo tỷ lệ là phân bổ theo yêu cầu, trong khi phân bổ cố định là phương pháp phân bổ cố định.
61. Phân mảnh nội và phân mảnh ngoại
Phân mảnh nội: Một phần của vùng nhớ được cấp phát cho một số quy trình không được sử dụng, thường xuất hiện trong cách phân bổ cố định.
Ví dụ: Tổng số bộ nhớ là 100M.
Phân bổ cố định, chia 100M thành 10 khối, mỗi khối 10M. Một chương trình cần 45M, vì vậy cần phân bổ 5 khối, khối thứ 5 chỉ sử dụng 5M, 5M còn lại là phân mảnh nội.
Phân bổ theo đoạn, phân bổ theo nhu cầu, một chương trình cần 45M, vì vậy cấp phát 45MB, 55M còn lại để các chương trình khác sử dụng, không có phân mảnh nội.
Phân mảnh ngoại: Một số khu vực trống trong bộ nhớ vì kích thước nhỏ và khó sử dụng, thường xuất hiện trong cách cấp phát động của bộ nhớ.
Phân bổ theo đoạn: Tổng số bộ nhớ là 100M, ví dụ, phân bổ bộ nhớ lần lượt là 5M, 15M, 50M, 25M. Sau một thời gian chạy, các chương trình 5M và 15M chạy xong và giải phóng bộ nhớ, các chương trình khác vẫn đang chạy, cấp phát thêm 10M bộ nhớ để các chương trình khác sử dụng, chỉ có thể phân bổ từ đầu, điều này dẫn đến phân mảnh ngoại là 10M + 5M.
Làm thế nào để loại bỏ phân mảnh ngoại
Đối với phân mảnh ngoại, nó có thể được loại bỏ thông qua kỹ thuật nén gọn, nghĩa là hệ điều hành thường xuyên di chuyển và sắp xếp các quy trình. Tuy nhiên, điều này yêu cầu hỗ trợ của thanh ghi địa chỉ tái định vị động và tương đối tốn thời gian. Quá trình nén gọn thực tế tương tự như chương trình chống phân mảnh đĩa trong hệ điều hành Windows, chỉ khác là nó nén gọn không gian lưu trữ ngoại vi.
Giải quyết vấn đề phân mảnh ngoại trong bộ nhớ là trao đổi bộ nhớ.
Chúng ta có thể ghi 256MB bộ nhớ mà chương trình âm nhạc đang sử dụng vào ổ cứng, sau đó đọc lại từ ổ cứng vào bộ nhớ. Tuy nhiên, khi đọc lại, chúng ta không thể tải lại vào vị trí ban đầu mà phải tiếp tục sau 512MB bộ nhớ đã được sử dụng. Điều này sẽ tạo ra một khoảng trống liên tục 256MB, cho phép chương trình mới có thể tải vào 200MB.
Khi thu hồi bộ nhớ, cần kết hợp các khoảng trống trống gần nhau càng nhiều càng tốt.
Cấu trúc von Neumann có bao nhiêu mô-đun? Tương ứng với các phần nào của máy tính hiện đại?
Cấu trúc von Neumann bao gồm các mô-đun sau:
- Bộ nhớ: Bộ nhớ trong
- Bộ điều khiển: Bộ điều khiển
- Bộ xử lý: CPU
- Thiết bị nhập: Bàn phím
- Thiết bị xuất: Màn hình, card mạng
Sự khác biệt giữa đa tiến trình và đa luồng là gì? Khi nào nên sử dụng đa luồng và khi nào nên sử dụng đa tiến trình?
- Đa tiến trình: Mỗi tiến trình có một không gian bộ nhớ riêng, và việc giao tiếp giữa các tiến trình được thực hiện thông qua cơ chế truyền thông như pipe hoặc socket. Đa tiến trình thích hợp khi nhiệm vụ cần xử lý có tính độc lập cao và không cần chia sẻ dữ liệu quá nhiều.
- Đa luồng: Tất cả các luồng trong một tiến trình chia sẻ cùng một không gian bộ nhớ và tài nguyên. Đa luồng thích hợp khi nhiệm vụ cần xử lý có tính tương tác cao và cần chia sẻ dữ liệu nhanh chóng và hiệu quả.
Có một số yếu tố cần xem xét khi quyết định sử dụng đa luồng hoặc đa tiến trình:
- Tần suất thay đổi: Nếu nhiệm vụ yêu cầu tạo và hủy các tiến trình hoặc luồng một cách thường xuyên, thì đa luồng có thể hiệu quả hơn vì nó không tốn kém như việc tạo và hủy tiến trình.
- Tính tương tác: Nếu các nhiệm vụ cần tương tác nhanh chóng và chia sẻ dữ liệu, thì đa luồng có thể là lựa chọn tốt hơn vì việc truyền thông giữa các luồng trong cùng một tiến trình nhanh chóng và đơn giản hơn so với truyền thông giữa các tiến trình.
- Phân tán: Nếu nhiệm vụ cần mở rộng sang nhiều máy tính hoặc nhiều lõi xử lý, thì đa tiến trình có thể là lựa chọn tốt hơn vì nó cho phép phân tán công việc trên nhiều máy tính hoặc nhiều lõi xử lý.
Tuy nhiên, thực tế thường sử dụng sự kết hợp của cả đa tiến trình và đa luồng để tận dụng lợi ích của cả hai.
Bạn biết bao nhiêu về giải pháp xử lý đồng thời cao của máy chủ?
- Tách dữ liệu ứng dụng và tài nguyên tĩnh: Tách riêng tài nguyên tĩnh (hình ảnh, video, js, css, vv.) vào máy chủ tài nguyên tĩnh riêng biệt, khi khách hàng truy cập, trả lại tài nguyên tĩnh từ máy chủ tài nguyên tĩnh, và trả lại dữ liệu ứng dụng từ máy chủ chính.
- Bộ nhớ cache trên máy khách: Sử dụng bộ nhớ cache trên máy khách để lưu trữ các phiên bản trước đó của trang web, giúp giảm tải cho máy chủ và tăng tốc độ truy cập.
- Cluster và phân tán: Sử dụng kiến trúc cluster và phân tán, phân tán công việc và tải trọng giữa nhiều máy chủ, giúp tăng tốc độ xử lý và khả năng chịu tải của hệ thống.
- Cân bằng tải: Sử dụng cân bằng tải để phân phối công việc đều đặn giữa các máy chủ, tránh quá tải và đảm bảo hiệu suất cao.
- Caching dữ liệu: Sử dụng bộ nhớ cache để lưu trữ dữ liệu phổ biến và truy cập nhanh hơn, giảm tải cho cơ sở dữ liệu và tăng tốc độ truy vấn.
- Tối ưu hóa cơ sở dữ liệu: Tối ưu hóa cấu trúc cơ sở dữ liệu, sử dụng chỉ mục, tối ưu hóa truy vấn và sử dụng các công nghệ như replication và sharding để tăng hiệu suất và khả năng chịu tải của cơ sở dữ liệu.
- Cân nhắc sử dụng CDN: Sử dụng mạng phân phối nội dung (CDN) để lưu trữ và phân phối tài nguyên tĩnh trên nhiều máy chủ trên toàn cầu, giúp tăng tốc độ truy cập và giảm tải cho máy chủ chính.
- Tối ưu hóa mã nguồn và cấu hình máy chủ: Tối ưu hóa mã nguồn ứng dụng và cấu hình máy chủ để tăng hiệu suất và khả năng chịu tải của hệ thống.
- Cân nhắc sử dụng các công nghệ mới: Xem xét sử dụng các công nghệ mới như serverless computing, containerization và microservices để tăng hiệu suất và khả năng mở rộng của hệ thống.