String là kiểu dữ liệu cơ bản trong ngôn ngữ Go. Mặc dù string thường được coi là một tổng thể nhưng thực chất nó là một không gian bộ nhớ liên tục, chúng ta cũng có thể hiểu nó là một mảng các ký tự. Phần này sẽ giới thiệu chi tiết về cách triển khai chuỗi, quá trình chuyển đổi và các thao tác phổ biến.
Chuỗi là một mảng các ký tự, trong ngôn ngữ C, chuỗi được biểu diễn bằng mảng ký tự char[]. Mảng này chiếm một không gian bộ nhớ liên tiếp, và các byte trong không gian bộ nhớ này cùng tạo nên chuỗi. Trong ngôn ngữ Go, chuỗi chỉ là một mảng byte chỉ đọc, dưới đây là hình ảnh minh họa cho cách chuỗi “hello” được lưu trữ trong bộ nhớ:

Nếu có một chuỗi tồn tại trong mã nguồn, trình biên dịch sẽ đánh dấu nó là dữ liệu chỉ đọc SRODATA. Giả sử chúng ta có đoạn mã sau, trong đó chứa một chuỗi, khi biên dịch đoạn mã này thành ngôn ngữ hợp ngữ, chúng ta có thể thấy chuỗi hello được đánh dấu là SRODATA
$ cat main.go
package main
func main() {
str := "hello"
println([]byte(str))
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
...Trong Go, chỉ đọc chỉ đồng nghĩa với việc chuỗi sẽ được cấp phát trong không gian bộ nhớ chỉ đọc, nhưng Go vẫn cho phép chúng ta thay đổi không gian bộ nhớ của biến kiểu string bằng cách chuyển đổi giữa string và slice []byte:
- Sao chép dữ liệu từ vùng nhớ này sang vùng nhớ heap hoặc stack.
- Chuyển đổi kiểu biến thành
[]bytevà sửa đổi dữ liệu byte. - Chuyển đổi lại slice
[]byteđã sửa đổi thànhstring.
Các ngôn ngữ khác như Java, Python và nhiều ngôn ngữ lập trình khác cũng có tính chất không thay đổi chuỗi. Đặc tính không thay đổi này đảm bảo rằng chúng ta không tham chiếu đến giá trị bị thay đổi một cách không mong muốn. Vì chuỗi trong Go có thể được sử dụng làm khóa băm, nếu khóa băm có thể thay đổi, không chỉ làm tăng độ phức tạp của việc triển khai băm mà còn có thể ảnh hưởng đến quá trình so sánh băm.
Cấu trúc dữ liệu
Trong Go, interface của string thực sự rất đơn giản, mỗi chuỗi sẽ được biểu diễn trong runtime bằng cấu trúc reflect.StringHeader như sau, bao gồm con trỏ trỏ tới mảng byte và kích thước của mảng:
type StringHeader struct {
Data uintptr
Len int
}So với cấu trúc của slice, chuỗi chỉ thiếu trường Cap để biểu diễn khả năng chứa của mảng. Vì cấu trúc của slice trong Go rất giống với chuỗi, nên chúng ta thường nói chuỗi là một loại slice chỉ đọc.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}Vì chuỗi là một kiểu chỉ đọc, chúng ta không thể thêm phần tử trực tiếp vào chuỗi để thay đổi không gian bộ nhớ của nó. Tất cả các thao tác ghi trên chuỗi đều được thực hiện thông qua việc sao chép dữ liệu.
Quá trình phân tích cú pháp
Trình phân tích từ sẽ phân tích và nhóm các chuỗi trong tệp nguồn trong giai đoạn phân tích từ. Nó sẽ chuyển đổi luồng ký tự vô nghĩa ban đầu thành chuỗi Token. Trong Go, chúng ta có thể khai báo chuỗi bằng hai cách, đó là dấu nháy kép và dấu nháy đơn:
str1 := "this is a string"
str2 := `this is another
string`Chuỗi được khai báo bằng dấu nháy kép không khác biệt nhiều so với chuỗi trong các ngôn ngữ khác. Nó chỉ được sử dụng để khởi tạo chuỗi trên một dòng duy nhất. Nếu chuỗi có chứa dấu nháy kép bên trong, chúng ta cần sử dụng ký tự \ để tránh lỗi phân tích từ vựng của trình biên dịch. Trong khi đó, chuỗi được khai báo bằng dấu nháy đơn không bị giới hạn bởi một dòng duy nhất. Khi sử dụng dấu nháy đơn, vì dấu nháy kép không còn đóng vai trò nhãn hiệu bắt đầu và kết thúc chuỗi, chúng ta có thể sử dụng dấu nháy kép trực tiếp trong chuỗi. Điều này rất tiện lợi khi viết JSON hoặc các định dạng dữ liệu phức tạp khác.
json := `{"author": "draven", "tags": ["golang"]}`Hai cách khai báo khác nhau thực sự có nghĩa là trình biên dịch Go phải có khả năng phân biệt và phân tích đúng hai định dạng chuỗi khác nhau. Trình quét cmd/compile/internal/syntax.scanner được sử dụng để phân tích chuỗi sẽ chuyển đổi chuỗi đầu vào thành luồng Token. Phương thức cmd/compile/internal/syntax.scanner.stdString là phương thức được sử dụng để phân tích chuỗi tiêu chuẩn sử dụng dấu nháy kép.
func (s *scanner) stdString() {
s.startLit()
for {
r := s.getr()
if r == '"' {
break
}
if r == '\\' {
s.escape('"')
continue
}
if r == '\n' {
s.ungetr()
s.error("newline in string")
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}Từ cách triển khai phương thức này, chúng ta có thể phân tích được cách Go xử lý chuỗi tiêu chuẩn:
- Chuỗi tiêu chuẩn được đánh dấu bằng dấu nháy kép ở đầu và cuối.
- Chuỗi tiêu chuẩn cần sử dụng ký tự backslash
\để thoát dấu nháy kép. - Chuỗi tiêu chuẩn không thể chứa ký tự xuống dòng ngầm định
\nnhư sau:
str := "start
end"Quy tắc phân tích chuỗi thô được khai báo bằng dấu nháy đơn rất đơn giản, cmd/compile/internal/syntax.scanner.rawString sẽ chia tất cả các ký tự không phải dấu nháy đơn vào phạm vi chuỗi hiện tại, cho phép chúng ta sử dụng chuỗi đa dòng phức tạp:
func (s *scanner) rawString() {
s.startLit()
for {
r := s.getr()
if r == '`' {
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}Cả chuỗi tiêu chuẩn và chuỗi thô đều được đánh dấu là StringLit và được chuyển đến giai đoạn phân tích cú pháp. Trong giai đoạn phân tích cú pháp, các biểu thức liên quan đến chuỗi sẽ được xử lý bởi phương thức cmd/compile/internal/gc.noder.basicLit:
func (p *noder) basicLit(lit *syntax.BasicLit) Val {
switch s := lit.Value; lit.Kind {
case syntax.StringLit:
if len(s) > 0 && s[0] == '`' {
s = strings.Replace(s, "\r", "", -1)
}
u, _ := strconv.Unquote(s)
return Val{U: u}
}
}Dù là đường dẫn gói trong câu lệnh import, nhãn trường trong cấu trúc hoặc chuỗi trong biểu thức, tất cả đều được xử lý bằng phương thức này để loại bỏ ký tự xuống dòng cuối cùng trong chuỗi thô và giải mã chuỗi Token bằng cách loại bỏ các ký tự không liên quan như dấu nháy kép từ cả hai phía của chuỗi.
strconv.Unquote xử lý nhiều trường hợp biên, dẫn đến việc cài đặt phức tạp. Nó không chỉ xử lý dấu nháy, mà còn xử lý mã hóa UTF-8 và nhiều logic xử lý khác, nhưng ở đây chúng ta không đi vào chi tiết.
Nối
Trong Go, để nối chuỗi, chúng ta sử dụng toán tử +. Trình biên dịch sẽ chuyển đổi nút OADD tương ứng với toán tử + thành nút OADDSTR, sau đó gọi hàm cmd/compile/internal/gc.addstr trong hàm cmd/compile/internal/gc.walkexpr để tạo mã để nối chuỗi:
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
...
case OADDSTR:
n = addstr(n, init)
}
}Hàm cmd/compile/internal/gc.addstr giúp chúng ta chọn hàm phù hợp để nối chuỗi trong quá trình biên dịch. Hàm này sẽ chọn logic khác nhau dựa trên số lượng chuỗi cần nối:
- Nếu số lượng chuỗi nhỏ hơn hoặc bằng 5, nó sẽ gọi các hàm
concatstring{2,3,4,5}tương ứng. - Nếu số lượng chuỗi lớn hơn 5, nó sẽ chọn hàm
runtime.concatstringsvà truyền vào một mảng slice.
func addstr(n *Node, init *Nodes) *Node {
c := n.List.Len()
buf := nodnil()
args := []*Node{buf}
for _, n2 := range n.List.Slice() {
args = append(args, conv(n2, types.Types[TSTRING]))
}
var fn string
if c <= 5 {
fn = fmt.Sprintf("concatstring%d", c)
} else {
fn = "concatstrings"
t := types.NewSlice(types.Types[TSTRING])
slice := nod(OCOMPLIT, nil, typenod(t))
slice.List.Set(args[1:])
args = []*Node{buf, slice}
}
cat := syslook(fn)
r := nod(OCALL, cat, nil)
r.List.Set(args)
...
return r
}Thực tế, bất kể sử dụng concatstring{2,3,4,5} nào, cuối cùng đều sẽ gọi hàm runtime.concatstrings. Hàm này sẽ duyệt qua các tham số slice và lọc bỏ các chuỗi rỗng, sau đó tính toán độ dài của chuỗi sau khi nối.
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}Nếu số lượng chuỗi không rỗng là 1 và chuỗi hiện tại không nằm trên stack, chúng ta có thể trả về chuỗi đó trực tiếp mà không cần thực hiện thêm bất kỳ thao tác nào.
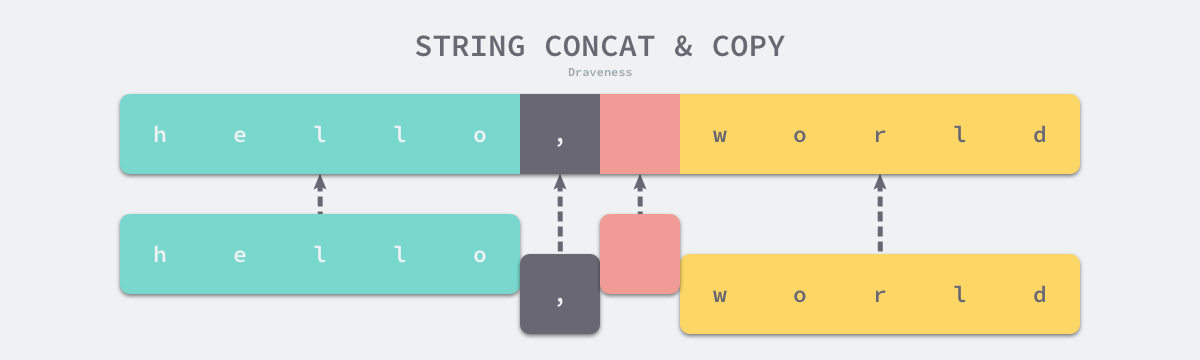
Tuy nhiên, trong trường hợp thông thường, runtime sẽ sử dụng hàm copy để sao chép nhiều chuỗi đầu vào vào không gian bộ nhớ của chuỗi đích. Chuỗi mới là một không gian bộ nhớ mới và không có liên kết với chuỗi ban đầu. Nếu chuỗi cần nối rất lớn, sự giảm hiệu năng do sao chép là không thể tránh khỏi.
Chuyển đổi kiểu
Khi chúng ta sử dụng Go để phân tích cú pháp và tuần tự hóa các định dạng dữ liệu như JSON, thường cần chuyển đổi dữ liệu giữa string và []byte. Tuy nhiên, chi phí của việc chuyển đổi kiểu không nhỏ như chúng ta tưởng. Chúng ta thường thấy các hàm như runtime.slicebytetostring xuất hiện trong Flame Graph và trở thành điểm nóng về hiệu năng của chương trình.
Để chuyển đổi từ mảng byte sang chuỗi, chúng ta sử dụng hàm runtime.slicebytetostring, ví dụ: string(bytes). Trong hàm này, trước hết nó xử lý hai trường hợp phổ biến, đó là mảng byte có độ dài bằng 0 hoặc 1, hai trường hợp này được xử lý rất đơn giản:
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}Sau khi xử lý, hàm này sẽ quyết định xem có cần cấp phát một không gian bộ nhớ mới cho chuỗi hay không dựa trên kích thước của bộ đệm đầu vào. runtime.stringStructOf sẽ chuyển đổi con trỏ chuỗi đầu vào thành con trỏ cấu trúc runtime.stringStruct, sau đó thiết lập con trỏ chuỗi str và độ dài len của cấu trúc. Cuối cùng, hàm runtime.memmove sẽ sao chép tất cả các byte từ mảng []byte gốc sang không gian bộ nhớ mới.
Khi chúng ta muốn chuyển đổi chuỗi thành kiểu []byte, chúng ta sử dụng hàm runtime.stringtoslicebyte, hàm này rất dễ hiểu:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}Hàm trên sẽ xử lý theo cách khác nhau dựa trên việc có cung cấp bộ đệm hay không:
- Khi có bộ đệm đầu vào, nó sẽ sử dụng bộ đệm đó để lưu trữ kiểu
[]byte. - Khi không có bộ đệm đầu vào, runtime sẽ gọi hàm
runtime.rawbytesliceđể tạo một mảng byte mới và sao chép nội dung của chuỗi vào đó.
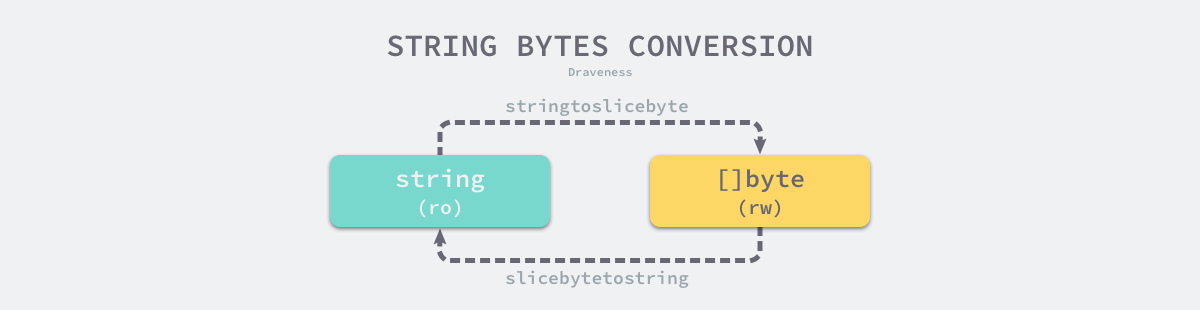
Mặc dù nội dung của chuỗi và []byte giống nhau, nhưng nội dung của chuỗi là chỉ đọc và không thể thay đổi bằng cách sử dụng chỉ số hoặc các phương thức khác. Trong khi đó, nội dung của []byte có thể đọc và ghi. Tuy nhiên, bất kể chuyển đổi từ kiểu này sang kiểu khác đều đòi hỏi sao chép dữ liệu và sự giảm hiệu năng của sao chép bộ nhớ sẽ tăng lên theo độ dài của chuỗi và []byte.
Tóm tắt
Chuỗi là một kiểu dữ liệu cơ bản trong Go. Trong phần này, chúng ta đã phân tích chi tiết về mối quan hệ giữa chuỗi và kiểu []byte, cũng như cách chuỗi được phân tích từ giai đoạn phân tích từ vựng. Với tính chất chỉ đọc, chúng ta không thể thay đổi cấu trúc của chuỗi, nhưng khi thực hiện các hoạt động như nối chuỗi và chuyển đổi kiểu, chúng ta cần chú ý đến hiệu năng. Trong các tình huống đòi hỏi hiệu năng tối đa, chúng ta nên giảm thiểu số lần chuyển đổi kiểu càng nhiều càng tốt.