Golang for and range
Vòng lặp là một cấu trúc điều khiển mà tất cả các ngôn ngữ lập trình đều có, ngoài việc sử dụng vòng lặp ba phần truyền thống, Go còn giới thiệu từ khóa range để giúp chúng ta duyệt nhanh qua các loại tập hợp như mảng, slice, bảng băm và kênh. Phần này sẽ phân tích sâu hơn về hai loại vòng lặp trong Go, đó là vòng lặp for và vòng lặp for-range, chúng ta sẽ phân tích cấu trúc thời gian chạy của hai vòng lặp này và nguyên lý thực hiện của chúng.
Vòng lặp for cho phép chúng ta tách biệt dữ liệu và logic trong mã code, cho phép mã code cùng một đoạn xử lý có thể được sử dụng nhiều lần. Chúng ta sẽ bắt đầu bằng việc phân tích mã assembly tương ứng với vòng lặp for trong Go, dưới đây là một đoạn mã vòng lặp ba phần truyền thống, chúng ta sẽ biên dịch nó thành các mã hợp ngữ:
package main
func main() {
for i := 0; i < 10; i++ {
println(i)
}
}
"".main STEXT size=98 args=0x0 locals=0x18
00000 (main.go:3) TEXT "".main(SB), $24-0
...
00029 (main.go:3) XORL AX, AX ;; i := 0
00031 (main.go:4) JMP 75
00033 (main.go:4) MOVQ AX, "".i+8(SP)
00038 (main.go:5) CALL runtime.printlock(SB)
00043 (main.go:5) MOVQ "".i+8(SP), AX
00048 (main.go:5) MOVQ AX, (SP)
00052 (main.go:5) CALL runtime.printint(SB)
00057 (main.go:5) CALL runtime.printnl(SB)
00062 (main.go:5) CALL runtime.printunlock(SB)
00067 (main.go:4) MOVQ "".i+8(SP), AX
00072 (main.go:4) INCQ AX ;; i++
00075 (main.go:4) CMPQ AX, $10 ;; So sánh biến i và 10
00079 (main.go:4) JLT 33 ;; Chuyển tới dòng 33 nếu i < 10
...Ở đây, chúng ta phân tích quá trình thực thi các mã hợp ngữ thành ba phần:
- 0029 ~ 0031: Khởi tạo vòng lặp;
- Khởi tạo biến
itrong thanh ghiAXvà thực hiện lệnhJMP 75để nhảy đến dòng 0075;
- Khởi tạo biến
- 0075 ~ 0079: Kiểm tra điều kiện kết thúc vòng lặp, so sánh
itrong thanh ghi với 10;- Lệnh
JLT 33sẽ nhảy đến dòng 0033 để thực hiện phần thân vòng lặp nếu giá trị của biến nhỏ hơn 10; - Lệnh
JLT 33sẽ thoát khỏi phần thân vòng lặp và thực hiện các mã code phía dưới nếu giá trị của biến lớn hơn 10;
- Lệnh
- 0033 ~ 0072: Các câu lệnh bên trong vòng lặp;
- In nội dung biến bằng nhiều mã hợp ngữ;
- Lệnh
INCQ AXsẽ tăng biến lên một đơn vị, sau đó so sánh với 10 và quay lại bước thứ hai;
Vòng lặp for-range cũng có cấu trúc tương tự sau khi được tối ưu. Dù là khởi tạo biến, thực thi phần thân vòng lặp hay kiểm tra điều kiện cuối cùng, đều hoàn toàn giống nhau, vì vậy không cần phân tích các mã hợp ngữ tương ứng ở đây.
package main
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
println(i)
}
}Trong ngôn ngữ assembly, cả vòng lặp for truyền thống và vòng lặp for-range đều sử dụng các lệnh nhảy như JMP để quay lại vị trí bắt đầu của vòng lặp và tái sử dụng mã code. Từ việc các vòng lặp khác nhau có cùng mã assembly có thể đoán được rằng, cấu trúc điều khiển sử dụng for-range cuối cùng cũng sẽ được biên dịch thành vòng lặp for thông thường, phân tích phía sau cũng sẽ chứng minh điều này.
1. Hiện tượng
Trước khi tìm hiểu cách thức thực hiện của hai loại vòng lặp khác nhau, chúng ta có thể xem xét một số vấn đề mà chúng ta có thể gặp phải khi sử dụng for và range, chúng ta có thể tìm câu trả lời trong mã nguồn để hiểu rõ hơn về cách thức thực hiện của chúng.
Vòng lặp vô hạn
Nếu chúng ta thay đổi các phần tử của mảng trong quá trình lặp, liệu chúng ta có thể tạo ra một vòng lặp vô hạn không? Bạn có thể thử chạy đoạn mã sau:
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}$ go run main.go
1 2 3 1 2 3Kết quả đầu ra của đoạn mã trên cho thấy vòng lặp chỉ duyệt qua ba phần tử ban đầu của slice, việc thêm phần tử mới vào mảng không làm tăng số lần thực hiện vòng lặp, vì vậy vòng lặp cuối cùng vẫn dừng lại.
Con trỏ ma thuật
Ví dụ thứ hai liên quan đến một lỗi thường gặp khi sử dụng Go. Khi chúng ta duyệt qua một mảng, nếu chúng ta lấy địa chỉ của biến trả về từ range và lưu trữ vào một mảng hoặc bảng băm khác, chúng ta sẽ gặp hiện tượng khó hiểu, đoạn mã dưới đây sẽ in ra “3 3 3”:
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}$ go run main.go
3 3 3Ngay cả những lập trình viên có kinh nghiệm cũng có thể mắc phải lỗi này, cách làm đúng là sử dụng &arr[i] thay vì &v, chúng ta sẽ tìm hiểu nguyên nhân đằng sau hiện tượng này ở phần sau.
Xóa slice
Khi chúng ta muốn xóa một slice hoặc bảng băm trong Go, chúng ta thường sử dụng phương pháp sau để đặt tất cả các phần tử của mảng về giá trị 0:
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}Việc duyệt qua từng phần tử của slice và bảng băm có vẻ rất tốn kém, vì mảng, slice và bảng băm chiếm không gian bộ nhớ liên tục, vì vậy phương pháp nhanh nhất là xóa nội dung của không gian bộ nhớ này trực tiếp. Khi biên dịch đoạn mã trên, chúng ta sẽ nhận được các mã hợp ngữ sau:
"".main STEXT size=93 args=0x0 locals=0x30
0x0000 00000 (main.go:3) TEXT "".main(SB), $48-0
...
0x001d 00029 (main.go:4) MOVQ "".statictmp_0(SB), AX
0x0024 00036 (main.go:4) MOVQ AX, ""..autotmp_3+16(SP)
0x0029 00041 (main.go:4) MOVUPS "".statictmp_0+8(SB), X0
0x0030 00048 (main.go:4) MOVUPS X0, ""..autotmp_3+24(SP)
0x0035 00053 (main.go:5) PCDATA $2, $1
0x0035 00053 (main.go:5) LEAQ ""..autotmp_3+16(SP), AX
0x003a 00058 (main.go:5) PCDATA $2, $0
0x003a 00058 (main.go:5) MOVQ AX, (SP)
0x003e 00062 (main.go:5) MOVQ $24, 8(SP)
0x0047 00071 (main.go:5) CALL runtime.memclrNoHeapPointers(SB)
...Từ mã hợp ngữ được tạo ra, chúng ta có thể thấy trình biên dịch sẽ trực tiếp sử dụng runtime.memclrNoHeapPointers để xóa dữ liệu trong slice, đó là những gì chúng tôi sẽ giới thiệu ở phần sau.
Duyệt một cách ngẫu nhiên
Khi chúng ta sử dụng range để duyệt qua một bảng băm trong Go, thì thường chúng ta sẽ sử dụng cấu trúc mã sau, nhưng đoạn mã này sẽ in ra kết quả khác nhau mỗi lần chạy:
func main() {
hash := map[string]int{
"1": 1,
"2": 2,
"3": 3,
}
for k, v := range hash {
println(k, v)
}
}Hai lần chạy mã trên có thể cho kết quả khác nhau, lần chạy đầu tiên sẽ in ra 2 3 1, lần chạy thứ hai sẽ in ra 1 2 3, nếu chúng ta chạy đủ nhiều lần, cuối cùng sẽ có một số cách khác nhau để duyệt qua bảng băm.
$ go run main.go
2 2
3 3
1 1
$ go run main.go
1 1
2 2
3 3Go, trong quá trình chạy đã đưa ra tính không xác định cho việc duyệt qua bảng băm, cũng là cách Go thông báo cho tất cả người dùng Go rằng chương trình không nên phụ thuộc vào việc duyệt qua bảng băm một cách ổn định, chúng ta sẽ giới thiệu cách Go đưa ra tính không xác định trong quá trình duyệt qua ở phần tiếp theo.
2. Vòng lặp cổ điển
Trong Go, vòng lặp cổ điển được xem như một nút kiểu OFOR trong trình biên dịch. Nút này bao gồm bốn phần:
Ninit: Khởi tạo vòng lặp.Left: Điều kiện tiếp tục vòng lặp.Right: Mã được thực hiện sau mỗi lần lặp.NBody: Thân vòng lặp.
for Ninit; Left; Right {
NBody
}Trong giai đoạn tạo mã trung gian SSA, phương thức cmd/compile/internal/gc.state.stmt sẽ thực hiện mã sau khi phát hiện nút đầu vào có kiểu OFOR. Mã này sẽ chia các đoạn mã trong vòng lặp thành các khối khác nhau:
func (s *state) stmt(n *Node) {
switch n.Op {
case OFOR, OFORUNTIL:
bCond, bBody, bIncr, bEnd := ...
b := s.endBlock()
b.AddEdgeTo(bCond)
s.startBlock(bCond)
s.condBranch(n.Left, bBody, bEnd, 1)
s.startBlock(bBody)
s.stmtList(n.Nbody)
b.AddEdgeTo(bIncr)
s.startBlock(bIncr)
s.stmt(n.Right)
b.AddEdgeTo(bCond)
s.startBlock(bEnd)
}
}Một đoạn mã vòng lặp thông thường sẽ được chuyển thành cấu trúc điều khiển dưới đây, trong đó bao gồm 4 khối khác nhau. Các khối mã này được kết nối với nhau để tạo ra các mối quan hệ nhảy trong ngôn ngữ máy, tương tự như cấu trúc điều khiển vòng lặp thông thường mà chúng ta hiểu.
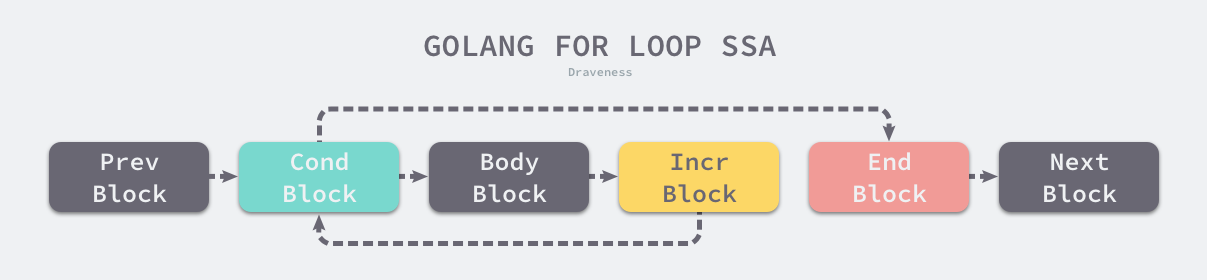
Trong giai đoạn tạo mã máy, các khối mã này sẽ được chuyển thành mã máy và ngôn ngữ máy chạy trên kiến trúc CPU cụ thể, đó chính là các hướng dẫn hợp ngữ chúng ta đã biên dịch trước đó.
3. Vòng lặp theo phạm vi
So với vòng lặp cổ điển đơn giản, vòng lặp theo phạm vi (range loop) trong Go phổ biến hơn và cũng phức tạp hơn trong việc triển khai. Loại vòng lặp này kết hợp cả từ khóa for và range, và trình biên dịch sẽ chuyển đổi tất cả các vòng lặp for-range thành vòng lặp cổ điển trong quá trình biên dịch. Từ góc nhìn của trình biên dịch, điều này có nghĩa là nút kiểu ORANGE sẽ được chuyển đổi thành nút kiểu OFOR:

Quá trình chuyển đổi kiểu nút xảy ra trong giai đoạn tạo mã trung gian, tất cả các vòng lặp for-range sẽ được chuyển đổi thành các câu lệnh cơ bản chỉ chứa biểu thức cơ bản trong hàm cmd/compile/internal/gc.walkrange. Tiếp theo, chúng ta sẽ phân tích quá trình xử lý khi duyệt qua mảng và slice, bảng băm, chuỗi và kênh.
Array và Slice
Đối với mảng và slice, Go có ba cách khác nhau để duyệt qua chúng. Ba cách lặp này tương ứng với các điều kiện khác nhau trong mã, và chúng sẽ được chuyển đổi thành các logic điều khiển khác nhau trong hàm cmd/compile/internal/gc.walkrange. Chúng ta sẽ phân tích các logic này theo từng trường hợp:
- Phân tích duyệt qua mảng và slice để xóa tất cả các phần tử.
- Phân tích duyệt qua mảng và slice chỉ quan tâm đến chỉ số và dữ liệu.
- Phân tích duyệt qua mảng và slice chỉ quan tâm đến chỉ số.
- Phân tích duyệt qua mảng và slice quan tâm đến cả chỉ số và dữ liệu.
func walkrange(n *Node) *Node {
switch t.Etype {
case TARRAY, TSLICE:
if arrayClear(n, v1, v2, a) {
return n
}Hàm cmd/compile/internal/gc.arrayClear là một tối ưu rất thú vị, nó sẽ tối ưu hóa việc duyệt qua mảng hoặc slice và xóa tất cả các phần tử:
// Mã gốc
for i := range a {
a[i] = zero
}
// Mã tối ưu
if len(a) != 0 {
hp = &a[0]
hn = len(a)*sizeof(elem(a))
memclrNoHeapPointers(hp, hn)
i = len(a) - 1
}So với việc duyệt qua từng phần tử của mảng hoặc slice và xóa nó, Go sẽ sử dụng trực tiếp hàm runtime.memclrNoHeapPointers hoặc runtime.memclrHasPointers để xóa toàn bộ dữ liệu trong không gian bộ nhớ của mảng và sau đó cập nhật chỉ số duyệt qua mảng. Điều này cũng giải thích tại sao chúng ta đã quan sát được hiện tượng trong phần vòng lặp vô hạn.
Sau khi xử lý trường hợp đặc biệt này, chúng ta có thể quay lại xử lý nút ORANGE. Ở đây, điều kiện kết thúc vòng lặp và mã được thực hiện sau mỗi lần lặp sẽ được thiết lập:
ha := a
hv1 := temp(types.Types[TINT])
hn := temp(types.Types[TINT])
init = append(init, nod(OAS, hv1, nil))
init = append(init, nod(OAS, hn, nod(OLEN, ha, nil)))
n.Left = nod(OLT, hv1, hn)
n.Right = nod(OAS, hv1, nod(OADD, hv1, nodintconst(1)))
if v1 == nil {
break
}Nếu vòng lặp là for range a {}, điều kiện này sẽ thỏa mãn điều kiện v1 == nil, có nghĩa là vòng lặp không quan tâm đến chỉ số và dữ liệu của mảng. Vòng lặp này sẽ được chuyển đổi thành mã sau:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
...
}Vòng lặp này là phiên bản đơn giản nhất của vòng lặp ORANGE. Vì mã gốc không cần truy cập vào chỉ số và dữ liệu của mảng, chỉ cần duyệt qua số lượng phần tử của mảng hoặc slice, nên nó sẽ tạo ra một vòng lặp đơn giản nhất.
Nếu chúng ta muốn truy cập vào chỉ số i khi duyệt qua mảng, chúng ta cũng có thể làm như sau for i := range a {}. Trình biên dịch sẽ tiếp tục xử lý mã sau:
if v2 == nil {
body = []*Node{nod(OAS, v1, hv1)}
break
}Nếu v2 == nil, điều này có nghĩa là chúng ta chỉ quan tâm đến chỉ số của mảng và không quan tâm đến dữ liệu. Nó sẽ chuyển đổi for i := range a {} thành mã sau, so với trường hợp đầu tiên, vòng lặp này sẽ chèn câu lệnh v1 := hv1 vào thân vòng lặp để truyền chỉ số duyệt qua mảng:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
for ; hv1 < hn; hv1++ {
v1 = hv1
...
}Hai trường hợp trên, mặc dù cũng là các trường hợp phổ biến khi sử dụng range, nhưng chúng ta cũng có thể muốn truy cập vào cả chỉ số và dữ liệu của mảng. Trường hợp này sẽ được xử lý bằng đoạn mã sau:
tmp := nod(OINDEX, ha, hv1)
tmp.SetBounded(true)
a := nod(OAS2, nil, nil)
a.List.Set2(v1, v2)
a.Rlist.Set2(hv1, tmp)
body = []*Node{a}
}
n.Ninit.Append(init...)
n.Nbody.Prepend(body...)
return n
}Đoạn mã này xử lý trường hợp người dùng muốn truy cập cả chỉ số và dữ liệu của mảng khi duyệt qua. Nó sẽ chèn câu lệnh gán để cho phép mã trong thân vòng lặp truy cập vào phần tử của mảng:
ha := a
hv1 := 0
hn := len(ha)
v1 := hv1
v2 := nil
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}Trong tất cả các vòng lặp range, Go sẽ tạo một biến mới ha để lưu trữ mảng hoặc slice gốc và sẽ sao chép giá trị của mảng trước khi duyệt qua. Vì quá trình gán này đã xảy ra, và chúng ta đã trước đó đã lấy độ dài của slice bằng từ khóa len, việc thêm phần tử mới vào slice sẽ không thay đổi số lần duyệt qua mảng, điều này cũng giải thích tại sao chúng ta đã quan sát được hiện tượng vòng lặp vô hạn.
Khi gặp loại vòng lặp range duyệt qua chỉ mục và phần tử cùng lúc, ngôn ngữ Go sẽ tạo thêm một biến v2 mới để lưu trữ các phần tử trong slice, biến v2 dùng trong vòng lặp sẽ được gán lại và ghi đè trong mỗi lần lặp. Khi gán Sao chép cũng sẽ được kích hoạt .
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for i, _ := range arr {
newArr = append(newArr, &arr[i])
}
for _, v := range newArr {
fmt.Println(*v)
}
}Vì địa chỉ của các biến trả về thu được trong vòng lặp hoàn toàn giống nhau nên hiện tượng ở phần con trỏ ma thuật sẽ xảy ra. Vì vậy khi duyệt qua mảng và muốn truy cập địa chỉ của các phần tử trong mảng, chúng ta không nên trực tiếp lấy địa chỉ của biến trả về từ range &v2, mà nên sử dụng hình thức &a[index].
Bảng băm (Map)
Trong quá trình duyệt qua bảng băm, trình biên dịch Go sử dụng hai hàm runtime runtime.mapiterinit và runtime.mapiternext để thay thế vòng lặp for-range gốc:
ha := a
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit)
for ; hit.key != nil; mapiternext(&hit) {
key := *hit.key
val := *hit.val
}Trên đây là mã được mở rộng từ for key, val := range hash {}, trong quá trình xử lý nút TMAP trong cmd/compile/internal/gc.walkrange, trình biên dịch sẽ chèn các câu lệnh gán cần thiết vào trong vòng lặp:
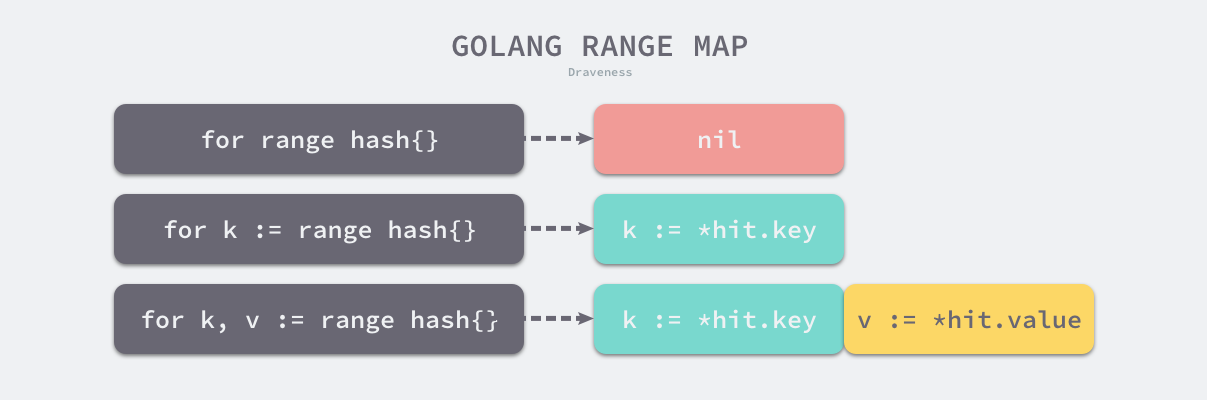
Ba trường hợp khác nhau trong hình trên chèn các câu lệnh gán khác nhau vào trong vòng lặp. Trong quá trình duyệt qua bảng băm, Go sẽ sử dụng hàm runtime.mapiterinit để khởi tạo phần tử bắt đầu của vòng lặp:
func mapiterinit(t *maptype, h *hmap, it *hiter) {
it.t = t
it.h = h
it.B = h.B
it.buckets = h.buckets
r := uintptr(fastrand())
it.startBucket = r & bucketMask(h.B)
it.offset = uint8(r >> h.B & (bucketCnt - 1))
it.bucket = it.startBucket
mapiternext(it)
}Trong đoạn mã trên, hàm này sẽ khởi tạo các trường trong cấu trúc runtime.hiter và sử dụng hàm runtime.fastrand để tạo ra một số ngẫu nhiên giúp chúng ta chọn một vị trí bắt đầu duyệt ngẫu nhiên trong bảng băm. Nhóm Go không muốn người dùng phụ thuộc vào thứ tự duyệt cố định, vì vậy họ đã sử dụng số ngẫu nhiên để đảm bảo tính ngẫu nhiên của việc duyệt.
Khi duyệt qua bảng băm, chúng ta sẽ sử dụng hàm runtime.mapiternext. Ở đây, chúng tôi đã đơn giản hóa rất nhiều logic, bỏ qua một số điều kiện biên và các hoạt động tương thích khi mở rộng bảng băm. Chúng tôi chỉ quan tâm đến mã lõi xử lý quá trình duyệt, chúng tôi sẽ chia hàm này thành hai phần: chọn thùng và duyệt các phần tử trong thùng. Đầu tiên là quá trình chọn thùng:
func mapiternext(it *hiter) {
h := it.h
t := it.t
bucket := it.bucket
b := it.bptr
i := it.i
alg := t.key.alg
next:
if b == nil {
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.value = nil
return
}
b = (*bmap)(add(it.buckets, bucket*uintptr(t.bucketsize)))
bucket++
if bucket == bucketShift(it.B) {
bucket = 0
it.wrapped = true
}
i = 0
}Mã này có hai chức năng chính:
- Khi thùng cần duyệt là trống, chọn một thùng mới để duyệt;
- Khi không có thùng nào cần duyệt, trả về cặp key-value
(nil, nil)và kết thúc quá trình duyệt;
Hàm runtime.mapiternext còn lại của mã này là tìm phần tử tiếp theo trong thùng, trong hầu hết các trường hợp, nó sẽ trực tiếp truy cập vào bộ nhớ để lấy địa chỉ bộ nhớ của cặp key-value mục tiêu. Tuy nhiên, nếu bảng băm đang mở rộng, nó sẽ gọi hàm runtime.mapaccessK để lấy cặp key-value:
for ; i < bucketCnt; i++ {
offi := (i + it.offset) & (bucketCnt - 1)
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.keysize))
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+uintptr(offi)*uintptr(t.valuesize))
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.reflexivekey() || alg.equal(k, k)) {
it.key = k
it.value = v
} else {
rk, rv := mapaccessK(t, h, k)
it.key = rk
it.value = rv
}
it.bucket = bucket
it.i = i + 1
return
}
b = b.overflow(t)
i = 0
goto next
}Khi chúng ta đã duyệt qua các phần tử bình thường của bảng băm, chúng ta sẽ sử dụng runtime.bmap.overflow để duyệt qua các phần tử tràn.
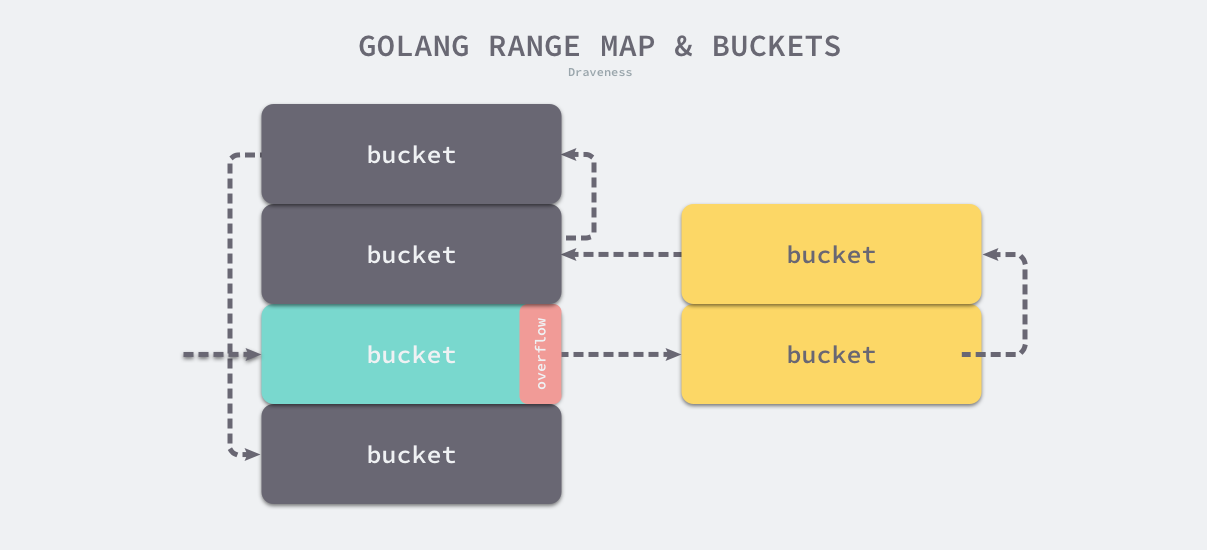
Tóm lại, thứ tự duyệt qua bảng băm sẽ bắt đầu bằng việc chọn một phần tử bình thường màu xanh lá cây để duyệt, sau đó duyệt qua tất cả các phần tử tràn màu vàng và cuối cùng duyệt qua các phần tử còn lại trong bảng băm theo thứ tự chỉ mục, cho đến khi tất cả các phần tử đều được duyệt qua.
Chuỗi (String)
Quá trình duyệt qua chuỗi tương tự như mảng, slice và bảng băm, chỉ khác là trong quá trình duyệt, chúng ta sẽ lấy byte tại chỉ mục tương ứng trong chuỗi và chuyển đổi byte đó thành rune. Cấu trúc for i, r := range s {} sẽ được chuyển đổi thành dạng như sau:
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf {
hv1++
} else {
hv2, hv1 = decoderune(ha, hv1)
}
v1, v2 = hv1t, hv2
}Trong phần trước về chuỗi, chúng tôi đã giới thiệu rằng chuỗi là một slice byte chỉ đọc, do đó khung được tạo bởi vòng lặp range trong quá trình biên dịch rất giống với slice, nhưng các chi tiết hơi khác một chút.
Khi truy cập vào phần tử trong chuỗi bằng chỉ mục, chúng ta nhận được byte và mã này sẽ được chuyển đổi thành kiểu rune. Nếu rune hiện tại là ASCII, thì chỉ chiếm 1 byte, và chỉ cần tăng chỉ mục lên 1 sau mỗi vòng lặp. Tuy nhiên, nếu rune hiện tại chiếm nhiều byte, hàm runtime.decoderune sẽ được sử dụng để giải mã. Chi tiết quá trình này sẽ không được giải thích ở đây.
Kênh (Channel)
Việc duyệt qua kênh bằng range cũng là một cách phổ biến, một câu lệnh như for v := range ch {} sẽ được chuyển đổi thành dạng như sau:
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
...
}Mã này có thể có một số khác biệt so với mã được biên dịch, nhưng cấu trúc và hiệu quả là hoàn toàn giống nhau. Vòng lặp này sẽ sử dụng <-ch để lấy giá trị đang chờ xử lý từ kênh, điều này sẽ gọi hàm runtime.chanrecv2 và chặn goroutine hiện tại. Khi runtime.chanrecv2 trả về, giá trị hb sẽ xác định xem giá trị hiện tại có tồn tại hay không:
- Nếu giá trị hiện tại không tồn tại, có nghĩa là kênh đã bị đóng.
- Nếu giá trị hiện tại tồn tại, giá trị
v1sẽ được gán và dữ liệu trong biếnhv1sẽ được xóa, sau đó chương trình sẽ tiếp tục chờ dữ liệu mới.
4. Tóm tắt
Trong phần này, chúng tôi đã giới thiệu hai từ khóa quan trọng for và range, những từ khóa không thể thiếu khi học và sử dụng ngôn ngữ Go. Bằng cách phân tích và nghiên cứu các nguyên tắc cơ bản của chúng, chúng tôi đã có cái nhìn rõ ràng hơn về các chi tiết triển khai, bao gồm việc sử dụng lại biến khi duyệt qua mảng và slice, nguyên tắc duyệt ngẫu nhiên của bảng băm và một số tối ưu hóa cơ bản. Tất cả những điều này giúp chúng ta hiểu và sử dụng ngôn ngữ Go một cách tốt hơn.