1. Lexical Analysis
Mã nguồn trong mắt máy tính “thực sự là một mớ hỗn độn, một chuỗi bao gồm các ký tự, không thể hiểu được, tất cả các ký tự trong máy tính không có sự khác biệt, để hiểu những ký tự này, điều đầu tiên chúng ta cần làm là phân nhóm các kí tự, điều này có thể làm giảm chi phí hiểu chuỗi, đơn giản hóa quá trình phân tích mã nguồn.
make(chan int)Ngay cả những người không biết lập trình khi nhìn thấy phản ứng đầu tiên của đoạn mã trên cũng nên chia chuỗi trên thành nhiều phần - make, chan, int và dấu ngoặc đơn, quá trình phân rã văn bản bằng là Phân tích từ - Lexical Analysis. Phân tích từ là quá trình chuyển đổi chuỗi thành các token.
lex
lex là một công cụ để phân tích từ, mã được tạo ra bởi lex có thể phân rã các ký tự trong một tập tin thành một chuỗi Token, mà nhiều ngôn ngữ sử dụng trong giai đoạn đầu của thiết kế để nhanh chóng thiết kế nguyên mẫu. Phân tích từ là một nhiệm vụ với một mô hình cố định, sự xuất hiện của công cụ trừu tượng hơn là không thể tránh khỏi. Là một trình tạo mã, lex sử dụng cú pháp tương tự như ngôn ngữ C. Chúng tôi hiểu lex là một regular matching generator, nó sẽ sử dụng biểu thức chính quy phù hợp để quét dòng chảy ký tự đầu vào, dưới đây là một ví dụ về một tập tin lex:
%{
#include <stdio.h>
%}
Các tệp được xác định tốt này có thể phân tích cú pháp các từ khóa package và import, các ký tự đặc biệt phổ biến, số và mã định danh. Mặc dù các quy tắc ở đây có thể có thể thô sơ và không hoàn hảo, nhưng nó dễ dàng hơn để phân tích đoạn mã sau:
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello")
}Mã lex đuôi .l không thể chạy trực tiếp, trước tiên chúng ta cần mở rộng simplego.l ở trên thành mã ngôn ngữ C thông qua lệnh lex, nơi bạn có thể biên dịch và in nội dung của tệp bằng cách thực hiện các lệnh như sau:
$ lex simplego.l
$ cat lex.yy.c
...
int yylex (void) {
...
while ( 1 ) {
...
yy_match:
do {
register YY_CHAR yy_c = yy_ec[YY_SC_TO_UI(*yy_cp)];
if ( yy_accept[yy_current_state] ) {
(yy_last_accepting_state) = yy_current_state;
(yy_last_accepting_cpos) = yy_cp;
}
while ( yy_chk[yy_base[yy_current_state] + yy_c] != yy_current_state ) {
yy_current_state = (int) yy_def[yy_current_state];
if ( yy_current_state >= 30 )
yy_c = yy_meta[(unsigned int) yy_c];
}
yy_current_state = yy_nxt[yy_base[yy_current_state] + (unsigned int) yy_c];
++yy_cp;
} while ( yy_base[yy_current_state] != 37 );
...
do_action:
switch ( yy_act )
case 0:
...
case 1:
YY_RULE_SETUP
printf("PACKAGE ");
YY_BREAK
...
}lex.yy.c có 600 hàng đầu tiên về cơ bản là khai báo và định nghĩa của macro và hàm, và mã được tạo ra sau này chủ yếu phục vụ hàm yylex, sử dụng [Deterministic Finite Automaton](Deterministic Finite Automaton, DFA](https://en.wikipedia.org/wiki/Deterministic_finite_automaton)). Cấu trúc chương trình để phân tích dòng ký tự đầu vào, vòng lặp while trong mã trên là cơ thể chính của máy tự động hữu hạn này, nếu bạn nhìn kỹ vào mã được tạo ra bởi tập tin này sẽ thấy rằng không có hàm main trong tập tin hiện tại, chức năng main được xác định trong thư viện liblex, vì vậy khi biên dịch thực sự cần phải thêm tùy chọn -ll bổ sung:
$ cc lex.yy.c -o simplego -ll
$ cat main.go | ./simplegoKhi chúng tôi biên dịch mã ngôn ngữ C thông qua gcc thành mã nhị phân, chúng ta có thể sử dụng đường ống để vượt qua mã ngôn ngữ Go được đề cập ở trên dưới dạng đầu vào vào trình phân tích từ được tạo ra, và trình phân tích từ này in ra những điều sau đây:
PACKAGE IDENT
IMPORT LPAREN
QUOTE IDENT QUOTE
RPAREN
IDENT IDENT LPAREN RPAREN LBRACE
IDENT DOT IDENT LPAREN QUOTE IDENT QUOTE RPAREN
RBRACETừ đầu ra ở trên, chúng ta có thể thấy bóng tối của mã nguồn Go, lex tạo ra các nhà phân tích từ vạch lexer phá vỡ các chuỗi vốn khó hiểu của máy thành nhiều Token theo cách phù hợp chính quy, tạo điều kiện xử lý sau.

Ở đây chúng tôi đã cho độc giả thấy toàn bộ quá trình từ định nghĩa các tập tin .l, sử dụng lex để biên dịch các tập tin .l thành mã ngôn ngữ C và nhị phân, và cuối cùng các trình phân tích từ được tạo ra cũng có thể chuyển đổi mã ngôn ngữ Go đơn giản thành chuỗi Token. Việc sử dụng lex là tương đối đơn giản, chúng ta có thể sử dụng nó để nhanh chóng thực hiện các nhà phân tích từ, tôi tin rằng độc giả cũng có một sự hiểu biết nhất định về nó.
Go
Phân tích từ của ngôn ngữ Go giải quyết là thông qua struct src/cmd/compile/internal/syntax/scanner.go, có thể giữ tệp nguồn dữ liệu hiện đang được quét, chế độ được kích hoạt và Token hiện đang được quét:
type scanner struct {
source
mode uint
nlsemi bool
// current token, valid after calling next()
line, col uint
blank bool // line is blank up to col
tok token
lit string // valid if tok is _Name, _Literal, or _Semi ("semicolon", "newline", or "EOF"); may be malformed if bad is true
bad bool // valid if tok is _Literal, true if a syntax error occurred, lit may be malformed
kind LitKind // valid if tok is _Literal
op Operator // valid if tok is _Operator, _AssignOp, or _IncOp
prec int // valid if tok is _Operator, _AssignOp, or _IncOp
}Tất cả các loại Token được hỗ trợ trong ngôn ngữ Go được xác định trong tệp src/cmd/compile/internal/syntax/tokens.go, tất cả các loại token đều là số nguyên dương và bạn có thể tìm thấy một số định nghĩa token phổ biến trong tệp này, chẳng hạn như operator, delimiter và keyword:
const (
_ token = iota
_EOF // EOF
// operators and operations
_Operator // op
...
// delimiters
_Lparen // (
_Lbrack // [
...
// keywords
_Break // break
...
_Type // type
_Var // var
tokenCount //
)Loại Token được xác định từ ngôn ngữ Go, chúng ta có thể chia các yếu tố trong ngôn ngữ thành nhiều danh mục khác nhau, cụ thể là tên và số lượng theo nghĩa đen, dấu hiệu hành động, dấu tách và từ khóa. Phân tích từ chủ yếu được xử lý trong cmd/compile/internal/syntax.scanner, và cụ thể hơn là hàm cmd/compile/internal/syntax.scanner.next. Thân của hàm 250 dòng này là một cấu trúc switch/case:
func (s *scanner) next() {
...
s.stop()
startLine, startCol := s.pos()
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
s.line, s.col = s.pos()
s.blank = s.line > startLine || startCol == colbase
s.start()
if isLetter(s.ch) || s.ch >= utf8.RuneSelf && s.atIdentChar(true) {
s.nextch()
s.ident()
return
}
switch s.ch {
case -1:
s.tok = _EOF
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(false)
...
}
}Mỗi lần thông qua ký tự gần nhất chưa được phân tích sẽ được lấy qua hàm cmd/compile/internal/syntax.source.nextch, sau đó kiểm tra các trường hợp khác nhau tùy thuộc vào ký tự hiện tại. Nếu bạn gặp phải dấu cách và ngắt dòng, các ký tự trống này sẽ bỏ qua trực tiếp. Nếu ký tự hiện tại là 0, hàm cmd/compile/internal/syntax.scanner.number cố gắng khớp với một số.
func (s *scanner) number(seenPoint bool) {
kind := IntLit
base := 10 // number base
digsep := 0
invalid := -1 // index of invalid digit in literal, or < 0
s.kind = IntLit
if !seenPoint {
digsep |= s.digits(base, &invalid)
}
s.setLit(kind, ok)
}
func (s *scanner) digits(base int, invalid *int) (digsep int) {
max := rune('0' + base)
for isDecimal(s.ch) || s.ch == '_' {
ds := 1
if s.ch == '_' {
ds = 2
} else if s.ch >= max && *invalid < 0 {
_, col := s.pos()
*invalid = int(col - s.col) // record invalid rune index
}
digsep |= ds
s.nextch()
}
return
}Hàm cmd/compile/internal/syntax.scanner.number ở trên bỏ qua rất nhiều mã, bao gồm cách khớp với số dấu chấm động, số mũ và số phức, chúng tôi chỉ đơn giản là nhìn vào logic của phân tích từ phù hợp với số nguyên: liên tục nhận được các ký tự mới nhất trong vòng lặp for, lấy các ký tự thông qua cmd/compile/internal/syntax.source.nextch và thêm vào vùng đệm của hàm cmd/compile/internal/syntax.scanner;
Trình phân tích từ trong gói cmd/compile/internal/syntax.scanner cũng chỉ cung cấp cho hàm tầng trên cmd/compile/internal/syntax.scanner.next, quá trình phân tích từ đều là thô, cmd/compile/internal/syntax.scanner.next để có được Token mới nhất nếu cần thiết.
Các yếu tố từ ngữ của ngôn ngữ Go tương đối đơn giản, sử dụng switch / case khổng lồ này để phân tích từ cũng thuận tiện và thuận tiện hơn, ngôn ngữ Go ban đầu mặc dù sử dụng công cụ lex này để tạo ra phân tích cú pháp từ, nhưng cuối cùng vẫn sử dụng Go để tạo ra trình phân tích từ riêng, sử dụng trình phân tích từ viết của riêng mình để phân tích chính nó.
2. Syntax Analysis
Phân tích cú pháp Syntax Analysis là quá trình phân tích văn bản đầu vào được tạo thành từ Token Sequence dựa trên một hình thức cụ thể của phương pháp ngữ pháp (Grammar) và xác định cấu trúc ngữ pháp của nó. Từ định nghĩa ở trên, kết quả đầu ra của trình phân tích từ - Token Sequence là đầu vào của trình phân tích cú pháp.
Quá trình phân tích cú pháp sử dụng phương pháp suy luận từ trên xuống hoặc từ dưới lên, trước khi giới thiệu phân tích ngữ pháp ngôn ngữ Go, chúng tôi sẽ giới thiệu phương pháp phân tích và phân tích trong phân tích ngữ pháp.
Grammer
Context-free grammar là một công cụ được sử dụng để định hình hóa, mô tả chính xác một ngôn ngữ lập trình, chúng tôi có thể xác định cú pháp của một ngôn ngữ thông qua ngữ pháp, chủ yếu bao gồm một loạt các quy tắc sản xuất để chuyển đổi chuỗi (Production rule). Mỗi quy tắc sản xuất trong ngữ cảnh không liên quan sẽ chuyển đổi dấu không kết thúc ở phía bên trái của quy tắc thành chuỗi ở bên phải, bao gồm bốn phần sau:
Dấu chấm dứt là một biểu tượng không còn có thể được mở rộng trong văn bản, không phải là dấu chấm chấm dứt, nhưng cũng có thể được mở rộng thông qua các quy tắc sản xuất, chẳng hạn như “id”, “123” và các biểu tượng khác hoặc số lượng theo nghĩa đen11。
- 𝑁 Một tập hợp hạn chế các dấu không kết thúc;
- Σ Một tập hợp các dấu chấm dứt hạn chế;
- 𝑃 Quy tắc sản xuất hạn chế một tập hợp các;
- 𝑆 Biểu tượng bắt đầu duy nhất trong bộ sưu tập không kết thúc;
Ngữ pháp được định nghĩa là một nhóm bốn phần (𝑁,Σ,𝑃,𝑆). Một số phần của nhóm meta này là bốn biểu tượng được đề cập ở trên, quan trọng nhất trong số đó là quy tắc sản xuất, mỗi quy tắc sản xuất sẽ chứa dấu không kết thúc, dấu chấm chấm dứt hoặc biểu tượng bắt đầu, chúng ta có thể đưa ra một ví dụ đơn giản ở đây:
- 𝑆→𝑎𝑆𝑏
- 𝑆→𝑎𝑏
- 𝑆→𝜖
Các quy tắc trên tạo thành một văn bản có thể đại diện cho ab, aabb và aaa. Các chuỗi như bbb, ngôn ngữ lập trình được thể hiện bằng loạt quy tắc sản xuất này, nơi chúng ta có thể đi từ src/cmd/compile/internal/syntax/parser.go13 Trích xuất một số quy tắc sản xuất của ngôn ngữ Go trong tài liệu:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
PackageClause = "package" PackageName .
PackageName = identifier .
ImportDecl = "import" ( ImportSpec | "(" { ImportSpec ";" } ")" ) .
ImportSpec = [ "." | PackageName ] ImportPath .
ImportPath = string_lit .
TopLevelDecl = Declaration | FunctionDecl | MethodDecl .
Declaration = ConstDecl | TypeDecl | VarDecl .Go
Ngôn ngữ Go chi tiết hơn bằng văn pháp có thể được tìm thấy từ Language Specification14 Nó được tìm thấy ở đây không chỉ chứa văn pháp ngôn ngữ, mà còn chứa các yếu tố từ pháp, chức năng tích hợp và các thông tin khác.
Bởi vì mỗi tập tin mã nguồn Go cuối cùng được phân tích thành một cây ngữ pháp trừu tượng độc lập, cấu trúc hoặc biểu tượng bắt đầu của cây cú pháp là SourceFile:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .Go
Từ các quy tắc sản xuất liên quan đến SourceFile, chúng ta có thể thấy rằng mỗi tập tin chứa một định nghĩa package cũng như một tuyên bố import tùy chọn và các tuyên bố cấp cao nhất khác (TopLevelDecl), mỗi SourceFile tương ứng với một cmd/compile/internal/syntax.File, nơi bạn có thể dễ dàng tìm thấy kết nối từ định nghĩa của họ:
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}Tuyên bố cấp cao nhất có năm loại chính, cụ thể là hằng số, loại, biến, chức năng và phương pháp mà bạn có thể tìm thấy trong tệp src/cmd/compile/internal/syntax/parser.go.
ConstDecl = "const" ( ConstSpec | "(" { ConstSpec ";" } ")" ) .
ConstSpec = IdentifierList [ [ Type ] "=" ExpressionList ] .
TypeDecl = "type" ( TypeSpec | "(" { TypeSpec ";" } ")" ) .
TypeSpec = AliasDecl | TypeDef .
AliasDecl = identifier "=" Type .
TypeDef = identifier Type .
VarDecl = "var" ( VarSpec | "(" { VarSpec ";" } ")" ) .
VarSpec = IdentifierList ( Type [ "=" ExpressionList ] | "=" ExpressionList ) .Các phương pháp ngữ trên xác định ba cấu trúc phổ biến của hằng số, loại và biến trong ngôn ngữ Go, từ đó bạn có thể thấy nhiều từ khóa trong ngôn ngữ const, type và var, và chỉ cần nhớ lại mã ngôn ngữ Go mà chúng ta tiếp xúc hàng ngày có thể xác minh tính chính xác của văn bản ở đây.
Ngoài ba cấu trúc ngữ pháp đơn giản, định nghĩa của các hàm và phương pháp phức tạp hơn, và từ các phương pháp sau đây, chúng ta có thể thấy rằng Statement có thể được chuyển đổi thành tổng cộng 15 cấu trúc cú pháp khác nhau, bao gồm các câu lệnh như switch / case, if / else, vòng lặp for và select mà chúng ta thường sử dụng:
FunctionDecl = "func" FunctionName Signature [ FunctionBody ] .
FunctionName = identifier .
FunctionBody = Block .
MethodDecl = "func" Receiver MethodName Signature [ FunctionBody ] .
Receiver = Parameters .
Block = "{" StatementList "}" .
StatementList = { Statement ";" } .
Statement =
Declaration | LabeledStmt | SimpleStmt |
GoStmt | ReturnStmt | BreakStmt | ContinueStmt | GotoStmt |
FallthroughStmt | Block | IfStmt | SwitchStmt | SelectStmt | ForStmt |
DeferStmt .
SimpleStmt = EmptyStmt | ExpressionStmt | SendStmt | IncDecStmt | Assignment | ShortVarDecl .Các cấu trúc ngữ pháp khác nhau này cùng nhau xác định các cấu trúc ngữ pháp và biểu thức có thể được sử dụng trong ngôn ngữ Go, và bài viết này sẽ không được mô tả chi tiết hơn về nhiều hơn về Statement, và độc giả quan tâm có thể xem hướng dẫn sử dụng ngôn ngữ Go trực tiếp hoặc trực tiếp từ src/cmd/compile/internal/syntax/parser.go Tìm câu trả lời bạn muốn trong tệp.
Phương pháp phân tích
Phương pháp phân tích phân tích cú pháp thường được chia thành hai loại từ trên xuống và từ dưới lên, cả hai đều sử dụng các phương pháp khác nhau để suy luận chuỗi Token đầu vào:
- Phân tích từ trên xuống: Có thể được coi là quá trình tìm thấy dòng chảy đầu vào hiện tại, đối với bất kỳ luồng đầu vào nào, dựa trên biểu tượng đầu vào hiện tại, xác định một quy tắc sản xuất, sử dụng biểu tượng ở bên phải của quy tắc sản xuất để thay thế dấu không kết thúc tương ứng để suy luận xuống15;
- Phân tích từ dưới lên: Trình phân tích ngữ pháp bắt đầu với luồng đầu vào, mỗi lần cố gắng viết lại nhiều biểu tượng ở phía bên phải nhất, điều này thực sự nói rằng phân tích cú pháp sẽ được suy luận từ các biểu tượng đơn giản nhất, kết hợp vào cuối phân tích thành biểu tượng bắt đầu16;
Nếu người đọc không thể hiểu được định nghĩa ở trên, chúng tôi sẽ giới thiệu hai phương pháp phân tích khác nhau và quá trình phân tích cụ thể của chúng trong phần còn lại của phần này.
Từ trên xuống
LL VinFaLà một phương pháp ngữ pháp sử dụng phương pháp phân tích từ trên xuống từ trên xuống, dưới đây đưa ra một phương pháp LL phổ biến:
- 𝑆→𝑎𝑆1
- 𝑆1→𝑏𝑆1
- 𝑆1→𝜖
Giả sử chúng ta có các quy tắc sản xuất và luồng đầu vào ở trên, nếu phân tích cú pháp được thực hiện ở đây bằng cách sử dụng phương pháp từ trên xuống, chúng ta có thể hiểu được cách mỗi trình phân tích cú pháp sẽ được sử dụng thông qua các ký tự mới được thêm vào để mở luồng đầu vào hiện tại:
- 𝑆(start symbol)
- 𝑎𝑆1(Rule 1)
- 𝑎𝑏𝑆1(Rule 2)
- 𝑎𝑏𝑏𝑆1(Rule 2)
- 𝑎𝑏𝑏(Rule 3)
Phương pháp phân tích này chắc chắn sẽ bắt đầu phân tích biểu tượng, thông qua biểu tượng sắp tới của ngăn xếp để xác định cách không kết thúc ở phía bên phải của ngăn xếp hiện tại (𝑆 hoặc 𝑆1Mở rộng cho đến khi không có dấu chấm hết nào tồn tại trong toàn bộ chuỗi, toàn bộ quá trình phân tích cú pháp sẽ kết thúc.
Từ dưới lên
Nhưng nếu chúng ta sử dụng phương pháp từ dưới lên để phân tích luồng đầu vào, quá trình xử lý sẽ hoàn toàn khác nhau, với bốn phương pháp phổ biến là LR (0), SLR, LR (1) và LALR (1) sử dụng xử lý từ dưới lên. Chúng ta có thể viết ngắn gọn một phương pháp LR(0) hoạt động tương tự như trong phần trước:
- 𝑆→𝑆1
- 𝑆1→𝑆1𝑏
- 𝑆1→𝑎
Xử lý bằng văn bản tương đương ở trên cũng sử dụng các quy trình hoàn toàn khác nhau để mở rộng luồng đầu vào:
- 𝑎(into the stack)
- 𝑆1(Rule 3)
- 𝑆1𝑏(into the stack)
- 𝑆11(rule 2)
- 𝑆1𝑏(into the stack)
- 𝑆11(rule 2)
- 𝑆(rule 1)
Quá trình phân tích từ dưới lên duy trì một ngăn xếp để lưu trữ các biểu tượng không được quy định, thực hiện hai hành động khác nhau trong suốt quá trình, một được gọi là ngăn xếp nhập cảnh (Shift), có nghĩa là, biểu tượng tiếp theo vào ngăn xếp, và khác được gọi là quy ước (Reduce), có nghĩa là, các chuỗi ở phía bên phải được hợp nhất theo các quy tắc sản xuất.
Quá trình phân tích ở trên hoàn toàn khác với phương pháp phân tích từ trên xuống, và hai phương pháp phân tích khác nhau thực sự đại diện cho hai ý tưởng khác nhau trong khoa học máy tính - từ trừu tượng đến cụ thể và từ cụ thể đến trừu tượng.
Lookahead
Ngoài hai loại phương pháp phân tích cú pháp khác nhau là LL và LR, có một khái niệm rất quan trọng khác là nhìn về phía trước (Lookahead), trong trường hợp xung đột giữa các quy tắc sản xuất khác nhau, trình phân tích cú pháp hiện tại cần phải đọc trước một số Token để xác định quy tắc sản xuất nào nên được sử dụng để mở rộng hoặc quy định. Ví dụ, trong lalr(1), một token là cần thiết để đảm bảo rằng các quy tắc sản xuất xung đột có thể được xử lý đúng cách.
Go
Trình phân tích cú pháp của ngôn ngữ Go sử dụng phương pháp LALR(1) để phân tích chuỗi Token được xuất ra trong quá trình phân tích từ ngữ, suy luận bên phải cộng với xem xét về phía trước tạo thành nguyên tắc cơ bản nhất của trình phân tích cú pháp ngôn ngữ Go và là sự lựa chọn của hầu hết các ngôn ngữ lập trình.
Chúng tôi đã giới thiệu chức năng chính của trình biên dịch trong tổng quan, trong đó cmd/compile/internal/gc.parseFiles sử dụng nhiều Goroutine để phân tích cú pháp các tệp nguồn, quá trình phân tích cú pháp sẽ gọi cmd/compile/internal/syntax.Parse này khởi tạo một cmd/compile/internal/syntax.parser cấu trúc thể và thông qua cmd/compile/internal/syntax.parser.fileOrNil Phương pháp mở phân tích cú pháp từ và cú pháp của tệp hiện tại:
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
var p parser
p.init(base, src, errh, pragh, mode)
p.next()
return p.fileOrNil(), p.first
}Go
cmd/compile/internal/syntax.parser.fileOrNil thực sự là thực hiện ngôn ngữ Go được mô tả ở trên, đầu tiên sẽ giải quyết định nghĩa package ở đầu tệp:
// SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
func (p *parser) fileOrNil() *File {
f := new(File)
f.pos = p.pos()
if !p.got(_Package) {
p.syntaxError("package statement must be first")
return nil
}
f.PkgName = p.name()
p.want(_Semi)Từ phương pháp này ở trên, chúng ta có thể thấy rằng phương pháp hiện tại sẽ sử dụng cmd/compile/internal/syntax.parser.got để xác định xem Token tiếp theo có phải là từ khóa package hay không và nếu đó là từ khóa package, cmd/compile/internal/syntax.parser.name để khớp tên gói và lưu kết quả vào cấu trúc tệp trả về.
for p.got(_Import) {
f.DeclList = p.appendGroup(f.DeclList, p.importDecl)
p.want(_Semi)
}Sau khi bạn xác định tên gói của tệp hiện tại, hãy bắt đầu giải quyết tuyên bố import tùy chọn, mỗi import dường như là một tuyên bố khai báo trong trình phân tích cú pháp được thêm vào DeclList của tệp.
Sau đó, các chi nhánh khác nhau của switch được nhập dựa trên các từ khóa thu được bởi trình biên dịch, gọi cmd/compile/internal/syntax.parser.appendGroup và truyền cmd/compile/internal/syntax.parser.constDecl、cmd/compile/internal/syntax.parser.typeDecl hàm。
for p.tok != _EOF {
switch p.tok {
case _Const:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.constDecl)
case _Type:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.typeDecl)
case _Var:
p.next()
f.DeclList = p.appendGroup(f.DeclList, p.varDecl)
case _Func:
p.next()
if d := p.funcDeclOrNil(); d != nil {
f.DeclList = append(f.DeclList, d)
}
default:
...
}
}
f.Lines = p.source.line
return f
}cmd/compile/internal/syntax.parser.fileOrNil sử dụng rất nhiều phương pháp con để phân tích cú pháp các tệp đã nhập và cuối cùng sẽ trả về cmd/compile/internal/syntax.File cấu trúc.
Những người đọc ở đây có thể có một số nghi ngờ tại sao không nhìn thấy mã phân tích từ ngữ, đó là bởi vì máy phân tích từ cmd/compile/internal/syntax.scanner được nhúng trong cmd/compile/internal/syntax.parser như một cấu trúc, Vì vậy, p.next() trong phương pháp này thực sự gọi là cmd/compile/internal/syntax.scanner.next, nó sẽ trực tiếp lấy token tiếp theo trong tệp, vì vậy từ ngữ và phân tích cú pháp được thực hiện cùng nhau.
cmd/compile/internal/syntax.parser.fileOrNil cùng với các phương pháp con khác được thực hiện trong phương pháp này tạo thành một cây, nút gốc cây này là cmd/compile/internal/syntax.parser.fileOrNil, Nút con là cmd/compile/internal/syntax.parser.importDecl、cmd/compile/internal/syntax.parser.constDecl và các phương pháp khác, tương ứng với các quy tắc sản xuất trong ngôn ngữ Go.

Phương pháp của trình phân tích cú pháp ngôn ngữ Hình 2-8 Go
cmd/compile/internal/syntax.parser.fileOrNil、cmd/compile/internal/syntax.parser.constDecl và các phương pháp khác tương ứng với các quy tắc sản xuất trong Ngôn ngữ Go, ví dụcmd/compile/internal/syntax.parser.fileOrNil đạt được là:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .Dựa trên quy tắc này, chúng tôi hiểu rõ cách thực hiện máy phân tích ngữ pháp - ánh xạ tất cả các quy tắc sản xuất của ngôn ngữ lập trình đến phương pháp tương ứng, mà cấu trúc hình cây tạo thành cuối cùng trả về một cây ngữ pháp trừu tượng.
Bởi vì việc thực thi hầu hết các phương pháp rất giống nhau, chỉ có phương pháp cmd/compile/internal/syntax.parser.fileOrNil được thực hiện ở đây, để hiểu cách thực hiện các phương pháp khác, người đọc có thể tự xem src/cmd/compile/internal/syntax/parser.go, chứa tất cả các phương pháp cho giai đoạn phân tích cú pháp.
Hàm phụ trợ
Mặc dù việc thực thi các phương pháp tương tự khác sẽ không được mở ra ở đây, có một số phương pháp phụ trợ trong quá trình hoạt động của phân tích cú pháp, trước hết là cmd/compile/internal/syntax.parser.got và cmd/compile/internal/syntax.parser.want Hai phương pháp phổ biến:
func (p *parser) got(tok token) bool {
if p.tok == tok {
p.next()
return true
}
return false
}
func (p *parser) want(tok token) {
if !p.got(tok) {
p.syntaxError("expecting " + tokstring(tok))
p.advance()
}
}Go
cmd/compile/internal/syntax.parser.got chỉ được sử dụng để nhanh chóng đánh giá các từ khóa trong một số câu lệnh, nếu Token trong trình phân tích cú pháp hiện tại là Token đến sẽ bỏ qua Token trực tiếp và trả về true; Và cmd/compile/internal/syntax.parser.want là một gói đơn giản cho cmd/compile/internal/syntax.parser.got, nếu Token hiện tại không phải là những gì chúng tôi mong đợi, nó sẽ ngay lập tức trả về lỗi cú pháp và kết thúc biên dịch này.
Sự ra đời của hai phương pháp này có thể giúp các kỹ sư giảm số lượng lớn logic lặp đi lặp lại của các từ khóa phán đoán ở cấp trên và làm cho quá trình phân tích ngữ pháp cấp trên rõ ràng hơn.
Một phương pháp khác cmd/compile/internal/synctax.parser.appendGroup thực hiện phức tạp hơn một chút, vai trò chính của nó là tìm ra định nghĩa của hàng loạt, chúng ta có thể đưa ra một ví dụ ngắn gọn:
var (
a int
b int
)Go
Hai biến này thực sự thuộc về cùng một nhóm (Group), với các cấu trúc được xác định ở cấp cao nhất khác nhau cmd/compile/internal/syntax.parser.constDeclcmd/compile/internal/syntax.parser.varDecl Có một tham số bổ sung cmd/compile/internal/syntax.Group, tham số này được truyền qua cmd/compile/internal/syntax.parser.appendGroup:
func (p *parser) appendGroup(list []Decl, f func(*Group) Decl) []Decl {
if p.tok == _Lparen {
g := new(Group)
p.list(_Lparen, _Semi, _Rparen, func() bool {
list = append(list, f(g))
return false
})
} else {
list = append(list, f(nil))
}
return list
}Go
cmd/compile/internal/syntax.parser.appendGroup sẽ gọi phương pháp f đến để khớp với luồng đầu vào và kết quả phù hợp được thêm vào một tham số khác cmd/compile/internal/syntax.File cấu trúc中的 DeclList mảng,import、const、var、type和 func khai báo tuyên bố tất cả các gọiimport cmd/compile/internal/syntax.parser.appendGroup 方法解析的。
Nút
Các nhà phân tích cú pháp cuối cùng sử dụng các cấu trúc khác nhau để xây dựng các nút trong cây ngữ pháp trừu tượng, trong đó nút gốc cmd/compile/internal/syntax.File chúng tôi đã giới thiệu ở trên, chứa tên gói của tệp hiện tại, danh sách tất cả các cấu trúc khai báo và số dòng tệp:
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
Lines uint
node
}Go
Các cấu trúc của các nút khác cũng được xác định trong tệp src/cmd/compile/internal/syntax/nodes.go, trong đó có tất cả các loại khai báo, như một cái nhìn tổng quan ngắn gọn về cấu trúc của tuyên bố chức năng:
type (
Decl interface {
Node
aDecl()
}
FuncDecl struct {
Attr map[string]bool
Recv *Field
Name *Name
Type *FuncType
Body *BlockStmt
Pragma Pragma
decl
}
}Go
Từ định nghĩa hàm, chúng ta có thể thấy rằng hàm chủ yếu bao gồm người nhận, tên hàm, loại chức năng và một số phần của cơ thể hàm trong cấu trúc cú pháp, cơ thể hàm cmd/compile/internal/syntax.BlockStmt bao gồm một loạt các biểu thức tạo thành cơ thể chính của hàm:
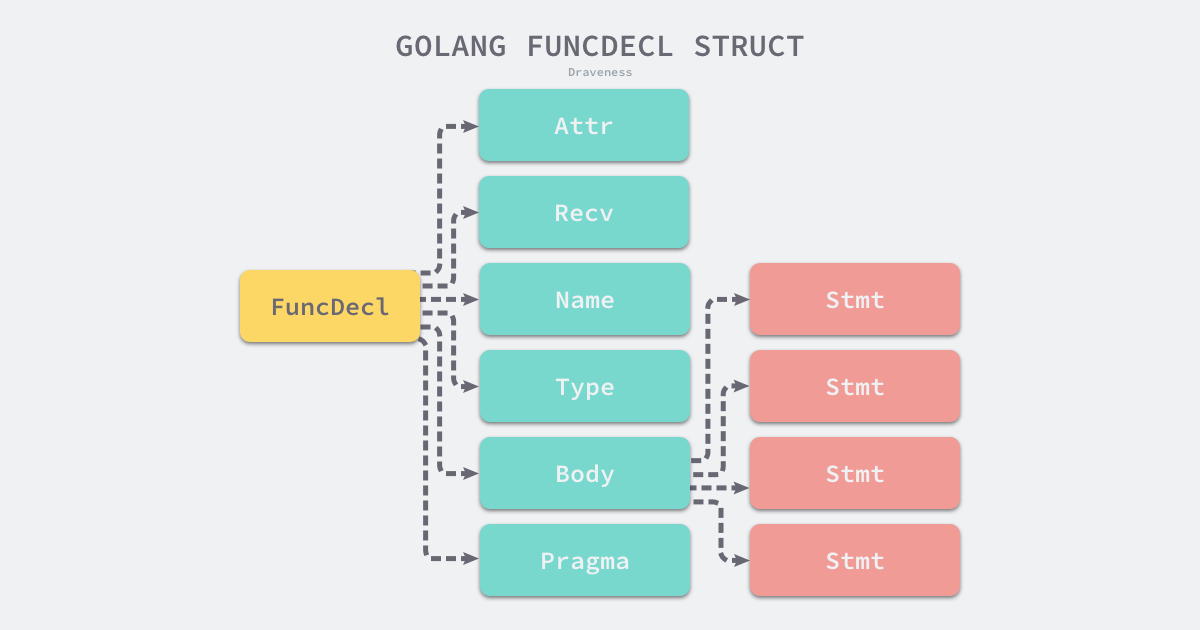
Cơ thể chính của hàm thực sự là một cmd/compile/internal/syntax.Stmt 数 cmd/compile/internal/syntax.Stmt là một giao diện thực hiện các loại thực hiện giao diện này thực sự rất nhiều, với tổng cộng 14 loại cmd/compile/internal/syntax.Stmt thực hiện:

Những loại cmd/compile/internal/syntax.Stmt tạo thành tất cả các mã ngôn ngữ Go theo lệnh, từ đó chúng ta có thể thấy nhiều cấu trúc điều khiển quen thuộc, chẳng hạn như if, for, switch và select, cũng phổ biến trong các ngôn ngữ lập trình khác.
3. Review
Phần này giới thiệu quá trình phân tích từ pháp và ngữ pháp của ngôn ngữ Go, chúng tôi không chỉ giới thiệu các nguyên tắc của từ pháp và phân tích ngữ pháp từ từ ở cấp độ lý thuyết, mà còn phân tích chi tiết cách trình biên dịch của ngôn ngữ Go thực hiện chức năng phân tích cú pháp và ngữ pháp ở cấp độ cơ bản.
Ngôn ngữ Go dùng phân tích từ cmd/compile/internal/syntax.scanner và phân tích cú pháp cmd/compile/internal/syntax.parser Hãy để chúng tôi có một sự hiểu biết rõ ràng hơn về quá trình xử lý mã nguồn của trình phân tích cú pháp, và chúng tôi cũng tìm thấy các từ khóa quen thuộc và cấu trúc ngữ pháp trong các phân tích ngữ pháp và ngữ pháp của ngôn ngữ Go, làm sâu sắc thêm sự hiểu biết của chúng tôi về ngôn ngữ Go.