Tóm tắt phỏng vấn Redis
Các kiểu dữ liệu trong Redis
【Câu hỏi】
- Redis có những kiểu dữ liệu nào?
- Các kiểu dữ liệu trong Redis phù hợp với những tình huống nào?
【Trả lời】
Các kiểu dữ liệu trong Redis và ứng dụng của chúng
Các kiểu dữ liệu có đặc điểm và ứng dụng chi tiết, bạn có thể tham khảo: Redis Data Types and Applications
(1) Redis hỗ trợ năm kiểu dữ liệu cơ bản:
- String: Thường được sử dụng cho bộ nhớ đệm KV (key-value).
- Hash: Lưu trữ dữ liệu có cấu trúc, ví dụ: thông tin sản phẩm, thông tin người dùng, v.v.
- List: Lưu trữ danh sách, ví dụ: danh sách người theo dõi, danh sách bình luận bài viết, v.v. Có thể sử dụng lệnh lrange để truy vấn theo trang.
- Set: Lưu trữ danh sách không trùng lặp, ví dụ: danh sách người theo dõi, v.v. Có thể thực hiện các phép giao, hợp, hiệu trên set. Ví dụ: lấy danh sách bạn chung của hai người.
- Sorted Set: Lưu trữ danh sách không trùng lặp có điểm số, ví dụ: các bảng xếp hạng.
(2) Ngoài ra, còn có các kiểu dữ liệu nâng cao như Bitmaps, HyperLogLogs, GEO, Streams.
Xóa dữ liệu trong Redis
【Câu hỏi】
- Redis có những chiến lược xóa dữ liệu nào?
- Những chiến lược xóa này phù hợp với những tình huống nào?
- Redis có những phương pháp nào để xóa các key không còn hiệu lực?
- Làm thế nào để đặt thời gian hết hạn cho các key trong Redis?
- Nếu được yêu cầu triển khai thuật toán LRU, bạn sẽ làm như thế nào?
【Trả lời】
(1) Chiến lược xóa dữ liệu trong Redis là: xóa định kỳ + xóa lười.
- Phương pháp tiêu cực (passive way): Khi truy cập vào một key và phát hiện rằng key đã hết hạn, Redis sẽ xóa key đó.
- Phương pháp tích cực (active way): Định kỳ chọn một số key đã đặt thời gian hết hạn và xóa chúng.
(2) Các chiến lược xóa dữ liệu trong Redis:
noeviction: Khi sử dụng hết bộ nhớ, tất cả các lệnh yêu cầu bộ nhớ sẽ bị lỗi. Đây là chiến lược mặc định của Redis.allkeys-lru: Trong không gian key chính, ưu tiên xóa các key không được sử dụng gần đây nhất.allkeys-random: Trong không gian key chính, xóa ngẫu nhiên một key.volatile-lru: Trong không gian key có đặt thời gian hết hạn, ưu tiên xóa các key không được sử dụng gần đây nhất.volatile-random: Trong không gian key có đặt thời gian hết hạn, xóa ngẫu nhiên một key.volatile-ttl: Trong không gian key có đặt thời gian hết hạn, ưu tiên xóa các key có thời gian hết hạn sớm hơn.
(3) Cách chọn chiến lược xóa dữ liệu:
- Nếu dữ liệu phân bố không đồng đều, tức là một số dữ liệu có tần suất truy cập cao, một số dữ liệu có tần suất truy cập thấp, hãy sử dụng
allkeys-lru. - Nếu dữ liệu phân bố đồng đều, tức là tất cả dữ liệu có cùng tần suất truy cập, hãy sử dụng
allkeys-random. - Chiến lược
volatile-lruvàvolatile-randomphù hợp khi ta muốn sử dụng một Redis instance cho cả việc caching và lưu trữ, tuy nhiên ta cũng có thể sử dụng hai Redis instance để đạt được cùng hiệu quả. - Đặt thời gian hết hạn cho key thực tế sẽ tiêu tốn nhiều bộ nhớ hơn, do đó, chúng tôi đề xuất sử dụng chiến lược
allkeys-lruđể tận dụng bộ nhớ hiệu quả hơn.
(4) Cách triển khai thuật toán LRU:
- Bạn có thể kế thừa lớp LinkedHashMap và ghi đè phương thức removeEldestEntry để triển khai một LRUCache đơn giản nhất.
Redis Lưu trữ
【Câu hỏi】
- Redis có bao nhiêu phương pháp lưu trữ?
- Đặc điểm và nguyên lý của các phương pháp lưu trữ khác nhau trong Redis là gì?
- RDB và AOF có ưu điểm và nhược điểm gì? Chúng phù hợp với những tình huống nào?
- Khi Redis thực hiện lưu trữ, liệu có thể xử lý các yêu cầu không?
- AOF có bao nhiêu tần suất đồng bộ?
【Trả lời】
Lưu trữ trong Redis
Chi tiết có thể tham khảo: Redis Persistence
(1) Redis hỗ trợ hai phương pháp lưu trữ: RDB và AOF.
(2) RDB là một bản sao dữ liệu nhị phân tại một thời điểm cụ thể.
Redis sẽ định kỳ tạo ra tệp RDB.
Quá trình tạo RDB: Redis fork một tiến trình con để tạo RDB; quá trình tạo RDB sử dụng chế độ Copy On Write, nghĩa là nếu nhận được yêu cầu ghi trong khi tạo RDB, Redis sẽ thực hiện thao tác trên bản sao gốc mà không ảnh hưởng đến công việc.
RDB chỉ khôi phục dữ liệu tại thời điểm tạo sao lưu, không thể khôi phục dữ liệu sau đó. Quá trình tạo RDB tốn nhiều tài nguyên. RDB thích hợp để làm sao lưu lạnh.
(3) AOF sẽ liên tục ghi các lệnh ghi vào cuối tệp nhật ký AOF.
AOF mất ít dữ liệu hơn RDB, nhưng tệp sẽ lớn hơn nhiều so với tệp RDB.
Thường thì, tần suất đồng bộ AOF được đặt là everysec.
(4) RDB hoặc AOF
Đề nghị sử dụng cả RDB và AOF. Sử dụng AOF để đảm bảo không mất dữ liệu và là lựa chọn đầu tiên để khôi phục dữ liệu; sử dụng RDB để sao lưu lạnh ở mức độ khác nhau, khi tệp AOF bị mất hoặc bị hỏng không thể sử dụng, vẫn có thể sử dụng RDB để khôi phục dữ liệu nhanh chóng.
Giao dịch Redis
【Câu hỏi】
- Vấn đề cạnh tranh đồng thời trong Redis là gì? Làm thế nào để giải quyết vấn đề này?
- Redis có hỗ trợ giao dịch không?
- Giao dịch Redis có phải là giao dịch theo nghĩa hẹp không? Tại sao Redis không hỗ trợ rollback.
- Làm thế nào để giao dịch Redis hoạt động?
- Bạn có hiểu về hành vi CAS trong giao dịch Redis không?
【Trả lời】
Tính năng và nguyên lý giao dịch trong Redis
Chi tiết có thể tham khảo: Redis Guide
Redis cung cấp không phải là giao dịch theo nghĩa hẹp, Redis chỉ đảm bảo thực hiện các lệnh tuần tự và đảm bảo thực hiện đầy đủ, nhưng khi một lệnh thất bại, Redis sẽ không rollback mà tiếp tục thực hiện.
Lý do Redis không hỗ trợ rollback:
- Lệnh Redis chỉ thất bại vì cú pháp sai hoặc lệnh được sử dụng trên khóa sai.
- Vì không cần hỗ trợ rollback, nên Redis có thể giữ cho bên trong đơn giản và nhanh chóng.
MULTI, EXEC, DISCARD và WATCH là các lệnh liên quan đến giao dịch Redis.
Redis có một giải pháp khóa lạc quan CAS tự nhiên để giải quyết vấn đề cạnh tranh đồng thời: trước khi ghi dữ liệu, ta kiểm tra xem timestamp của giá trị hiện tại có mới hơn timestamp của giá trị trong bộ nhớ cache hay không. Nếu là vậy, ta có thể ghi dữ liệu; ngược lại, ta không được ghi đè dữ liệu mới lên dữ liệu cũ.
Redis Pipeline
【Câu hỏi】
- Ngoài giao dịch, còn có cách nào khác để thực hiện lệnh Redis theo lô không?
【Trả lời】
Redis là một dịch vụ TCP dựa trên mô hình C/S và giao thức yêu cầu/đáp ứng. Redis hỗ trợ công nghệ Pipeline. Công nghệ Pipeline cho phép gửi yêu cầu một cách không đồng bộ, có nghĩa là cho phép gửi yêu cầu mới trong khi vẫn chưa nhận được phản hồi cho yêu cầu cũ. Điều này giúp tăng hiệu suất truyền tải. Khi sử dụng Pipeline để gửi các lệnh, Redis Server sẽ đặt một số yêu cầu vào hàng đợi bộ nhớ cache và gửi kết quả một lần duy nhất sau khi hoàn thành. Nếu cần gửi một số lượng lớn các lệnh, điều này sẽ chiếm nhiều bộ nhớ, do đó, nên xử lý theo số lượng hợp lý và chia thành các lô để xử lý.
Redis đồng thời cao
【Câu hỏi】
- Redis là mô hình đơn luồng, tại sao vẫn có khả năng xử lý thông lượng cao?
- Nguyên lý của I/O đa luồng trong Redis là gì?
- Redis Cluster được phân vùng và định vị như thế nào?
- Redis Cluster mở rộng như thế nào?
- Redis Cluster đảm bảo tính nhất quán dữ liệu như thế nào?
- Lập kế hoạch Redis Cluster như thế nào? Cách triển khai Redis Cluster trong môi trường sản xuất của công ty của bạn như thế nào?
【Trả lời】
Redis Cluster
Chi tiết có thể tham khảo: Redis Cluster
(1) Đơn luồng
Redis hoạt động trong chế độ một tiến trình đơn luồng, sử dụng hàng đợi để chuyển đổi truy cập đồng thời thành truy cập tuần tự. Redis vẫn có khả năng xử lý thông lượng cao vì:
- Cả đọc và ghi đều là hoạt động bộ nhớ.
- Redis sử dụng cơ chế IO đa luồng non-blocking IO multiplexing, đồng thời lắng nghe nhiều socket, đẩy các socket gây ra sự kiện vào hàng đợi bộ nhớ, và bộ phân phối sự kiện sẽ chọn trình xử lý sự kiện tương ứng để xử lý.
- Mô hình đơn luồng giúp tránh các chi phí của việc tạo, hủy và chuyển đổi ngữ cảnh luồng, và tránh xung đột tài nguyên.
(2) Mở rộng thông lượng và dung lượng lưu trữ
Redis đạt hiệu suất cao (mở rộng thông lượng và dung lượng lưu trữ) thông qua kiến trúc master-slave.
Redis Cluster sử dụng mô hình master-slave để cung cấp tính sẵn sàng cao. Chế độ master-slave bao gồm sao chép và chuyển đổi sự cố, đảm bảo tính sẵn sàng cao cho Redis Cluster. Thông thường, mô hình một chính nhiều phụ đã đáp ứng đủ yêu cầu của hầu hết các dự án. Tùy thuộc vào tải công việc thực tế, bạn có thể mở rộng khả năng xử lý đồng thời bằng cách tăng số nút.
Trong mô hình master-slave, nút chính làm việc với các hoạt động ghi (với hàng ngàn QPS trên máy đơn), trong khi các node phụ làm việc với các hoạt động truy vấn (với hàng trăm ngàn QPS trên máy đơn).
Hơn nữa, nếu bạn cần cache dữ liệu lớn, bạn sẽ cần phân vùng (sharding). Redis Cluster phân vùng bằng cách chia các hash slot ảo, mỗi nút chính đảm nhận một phạm vi hash slot nhất định. Khi cần mở rộng số lượng nút trong cluster, bạn chỉ cần phân lại các hash slot và redis-trib sẽ tự động di chuyển các khóa thuộc về các hash slot đã thay đổi.
(3) Đảm bảo tính nhất quán dữ liệu trong Redis Cluster
Redis Cluster sử dụng tính năng sao chép để đảm bảo tính nhất quán dữ liệu giữa các nút.
Khi một nút chủ thực hiện thay đổi dữ liệu, nó sẽ gửi thông điệp REPLICAOF cho các nút sao chép, yêu cầu sao chép dữ liệu. Các nút sao chép sẽ thực hiện sao chép dữ liệu từ nút chủ và đảm bảo tính nhất quán dữ liệu.
(4) Lập kế hoạch Redis Cluster
Lập kế hoạch Redis Cluster bao gồm phân vùng dữ liệu, định vị nút và cấu hình mạng.
Triển khai Redis Cluster trong môi trường sản xuất của công ty có thể bao gồm việc cài đặt các nút chủ và nút sao chép trên các máy chủ vật lý hoặc máy ảo, cấu hình mạng để cho phép giao tiếp giữa các nút, và đảm bảo tính nhất quán dữ liệu bằng cách đồng bộ dữ liệu giữa các nút chủ và nút sao chép.
Sao chép Redis
【Câu hỏi】
- Cơ chế hoạt động của sao chép Redis là gì? Sự khác biệt giữa sao chép Redis phiên bản cũ và phiên bản mới là gì?
- Làm thế nào để sao chép dữ liệu giữa các nút chính và nút phụ của Redis?
- Dữ liệu của Redis có tính nhất quán mạnh không?
【Trả lời】
Sao chép Redis
Chi tiết có thể tham khảo: Sao chép Redis
(1) Sao chép phiên bản cũ của Redis dựa trên lệnh SYNC. Nó bao gồm hai hoạt động: đồng bộ (sync) và truyền lệnh (command propagate). Phương pháp này có một số nhược điểm: không xử lý hiệu quả trường hợp sao chép sau khi mất kết nối.
(2) Sao chép phiên bản mới của Redis dựa trên lệnh PSYNC. Hoạt động đồng bộ được chia thành hai phần:
- Đồng bộ hoàn chỉnh (full resynchronization) được sử dụng cho lần sao chép đầu tiên.
- Đồng bộ một phần (partial resynchronization) được sử dụng cho sao chép sau khi mất kết nối.
- Bộ đếm sao chép (replication offset) giữa máy chủ chính và máy chủ phụ.
- Bộ đệm chờ sao chép (replication backlog) của máy chủ chính.
- ID chạy của máy chủ.
(3) Quá trình sao chép giữa các nút chính và nút phụ trong Redis:
- Bước 1. Thiết lập máy chủ chính và máy chủ phụ.
- Bước 2. Thiết lập kết nối TCP giữa máy chủ chính và máy chủ phụ.
- Bước 3. Gửi lệnh PING để kiểm tra trạng thái kết nối.
- Bước 4. Xác thực.
- Bước 5. Gửi thông tin cổng.
- Bước 6. Đồng bộ hoặc đồng bộ một phần.
- Bước 7. Truyền lệnh.
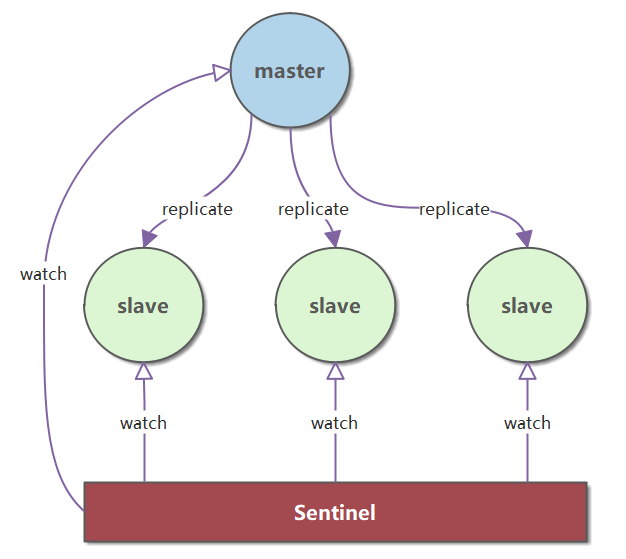
Redis Sentinel
【Câu hỏi】
- Redis làm thế nào để đảm bảo khả năng sẵn có cao?
- Chức năng của Redis Sentinel là gì?
- Nguyên lý hoạt động của Redis Sentinel là gì?
- Redis Sentinel làm thế nào để bầu ra người lãnh đạo (leader)?
- Redis làm thế nào để thực hiện chuyển giao khi xảy ra sự cố?
【Trả lời】
Redis Sentinel
Chi tiết có thể tham khảo: Redis Sentinel
(1) Khả năng sẵn có của Redis được đảm bảo thông qua Redis Sentinel (Redis triển khai giao thức Raft). Sentinel có thể theo dõi máy chủ chính và tự động bầu ra máy chủ chính mới khi máy chủ chính hiện tại bị ngừng hoạt động.
Hệ thống Sentinel gồm một hoặc nhiều phiên bản Sentinel có thể giám sát nhiều máy chủ chính và tất cả các máy chủ phụ của chúng. Khi máy chủ chính được giám sát bị ngừng hoạt động, Sentinel sẽ tự động nâng cấp một máy chủ phụ thành máy chủ chính mới và máy chủ chính mới sẽ tiếp tục xử lý các yêu cầu lệnh thay thế cho máy chủ chính bị ngừng hoạt động.
Redis vs. Memcached
【Câu hỏi】
Redis và Memcached có gì khác nhau?
Khi chọn công nghệ cache phân tán, nên chọn Redis hay Memcached và vì sao?
Mô hình luồng của Redis và Memcached là như thế nào?
Tại sao hiệu suất của Redis đơn luồng lại không kém cạnh so với Memcached đa luồng?
【Giải đáp】
Redis không chỉ hỗ trợ dữ liệu kiểu key/value đơn giản mà còn cung cấp lưu trữ cho các cấu trúc dữ liệu như list, set, zset, hash. Trong khi đó, memcache chỉ hỗ trợ kiểu dữ liệu đơn giản là String.
Redis hỗ trợ sao lưu dữ liệu theo mô hình master-slave.
Redis hỗ trợ bền vững dữ liệu bằng việc lưu giữ dữ liệu trong bộ nhớ vào ổ cứng để sử dụng lại sau khi khởi động lại. Trong khi đó, Memecache lưu toàn bộ dữ liệu trong bộ nhớ.
Tốc độ của Redis nhanh hơn rất nhiều so với Memcached.
Memcached sử dụng mô hình mạng multi-threading non-blocking IO; Redis sử dụng mô hình IO single-threading.
Nếu bạn muốn tìm hiểu chi tiết hơn, bạn có thể xem bài viết này: caching - Memcached vs. Redis? - Stack Overflow
Chiến lược cuối cùng: Các công việc sử dụng kiểu dữ liệu String của Redis có thể được thay thế bằng Memcached để nâng cao hiệu suất; Ngoài ra, ưu tiên sử dụng Redis.