Tổng hợp các câu hỏi phỏng vấn mạng máy tính thường gặp (Phần 1)
Cơ bản về mạng máy tính
Mô hình mạng phân lớp
Mô hình bảy lớp OSI là gì? Chức năng của mỗi lớp là gì?
Mô hình bảy lớp OSI là một mô hình mạng phân lớp được tổ chức tiêu chuẩn hóa quốc tế (ISO) đề xuất, cấu trúc tổng quan và chức năng của mỗi lớp như sau:
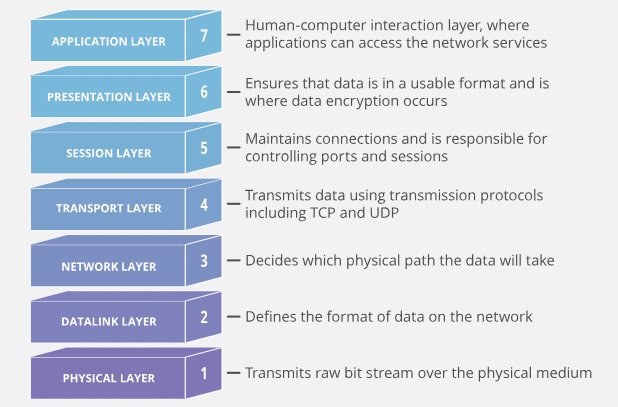
Mỗi lớp tập trung vào một nhiệm vụ cụ thể và mỗi lớp đều cần sử dụng các chức năng được cung cấp bởi lớp dưới, ví dụ như lớp vận chuyển cần sử dụng chức năng định tuyến và địa chỉ của lớp mạng để biết nơi gửi dữ liệu đến.
Mô hình OSI bảy lớp có cấu trúc rõ ràng và lý thuyết hoàn chỉnh, nhưng nó phức tạp và không thực tế, và một số chức năng được lặp lại trong nhiều lớp.
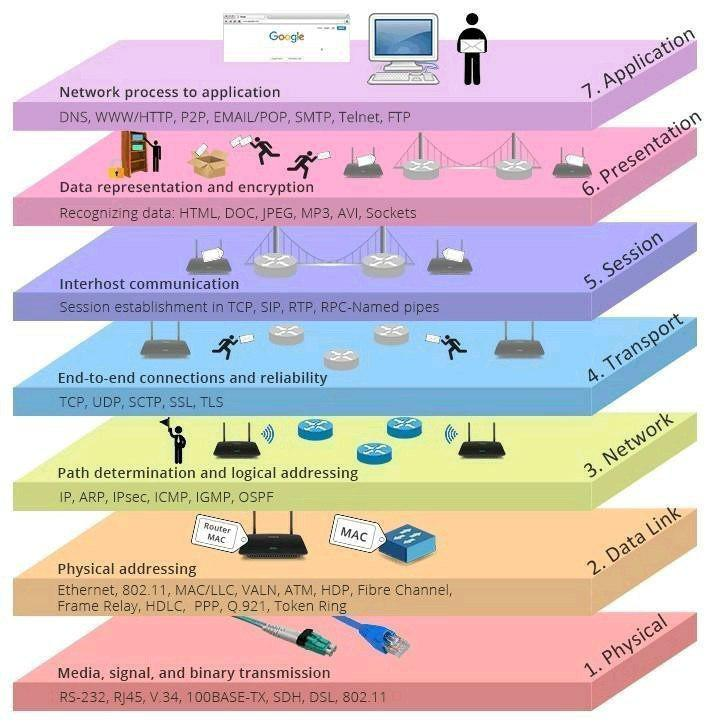
Hình ảnh trên có thể trừu tượng, dưới đây là một hình ảnh trực quan hơn mà tôi đã tìm thấy trên Google, rất tuyệt vời!
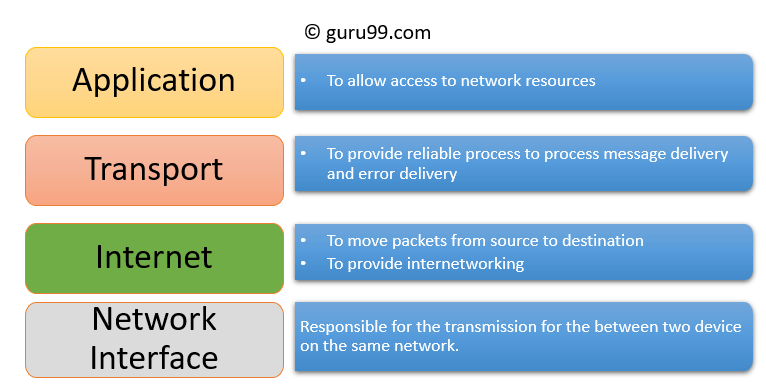
Mô hình bốn tầng TCP/IP là gì? Chức năng của mỗi tầng là gì?
Mô hình bốn lớp TCP/IP là một mô hình hiện đang được sử dụng rộng rãi, chúng ta có thể coi mô hình TCP/IP là phiên bản tinh gọn của mô hình bảy lớp OSI, gồm 4 lớp sau:
- Tầng ứng dụng
- Tầng vận chuyển
- Tầng mạng
- Tầng giao diện mạng
Cần lưu ý rằng, chúng ta không thể khớp hoàn toàn mô hình bốn lớp TCP/IP và mô hình bảy lớp OSI, nhưng có thể tương ứng một cách đơn giản như hình dưới đây:
Tại sao mạng cần phân lớp?
Khi nói về phân lớp, chúng ta có thể bắt đầu bằng việc xem xét việc phát triển một ứng dụng back-end bằng cách sử dụng một framework. Thông thường, chúng ta sẽ chia hệ thống thành ba lớp (hệ thống phức tạp có thể có nhiều lớp hơn):
- Repository (truy vấn cơ sở dữ liệu)
- Service (xử lý logic kinh doanh)
- Controller (giao tiếp dữ liệu giữa front-end và back-end)
Hệ thống phức tạp cần được phân lớp vì mỗi lớp cần tập trung vào một loại công việc cụ thể. Lý do mạng cũng phân lớp cũng tương tự, mỗi lớp chỉ tập trung vào một loại công việc.
Vậy, tại sao mạng cần phân lớp? Tôi nghĩ có ba lý do chính:
- Các lớp độc lập với nhau: Các lớp trong mạng độc lập với nhau, không cần quan tâm đến cách thức thực hiện của các lớp khác, chỉ cần biết cách gọi các chức năng đã được cung cấp bởi lớp dưới (có thể hiểu đơn giản là gọi các phương thức). Điều này tương tự như việc phân lớp trong việc phát triển hệ thống.
- Tăng tính linh hoạt và khả năng thay thế: Mỗi lớp có thể sử dụng công nghệ phù hợp nhất để triển khai, chỉ cần đảm bảo các chức năng cung cấp và giao diện đã được định nghĩa không thay đổi. Hơn nữa, mỗi lớp có thể được sửa đổi hoặc thay thế theo nhu cầu mà không ảnh hưởng đến cấu trúc của toàn bộ mạng. Điều này tương tự như nguyên tắc của chúng ta trong việc phát triển hệ thống, đó là sự tập trung cao và sự phụ thuộc thấp.
- Chia vấn đề lớn thành các vấn đề nhỏ hơn: Phân lớp có thể chia nhỏ các vấn đề phức tạp của mạng thành nhiều vấn đề nhỏ hơn, rõ ràng và đơn giản hơn để xử lý và giải quyết. Điều này làm cho việc thiết kế, triển khai và chuẩn hóa hệ thống mạng phức tạp trở nên dễ dàng hơn. Điều này tương tự như việc chúng ta phân tách chức năng của hệ thống và chia nhỏ các vấn đề phức tạp thành các vấn đề nhỏ hơn, có định nghĩa ranh giới (mục tiêu và giao diện) rõ ràng hơn.
Tôi nghĩ đến một câu nói rất nổi tiếng trong thế giới máy tính, tôi muốn chia sẻ nó với bạn:
Bất kỳ vấn đề nào trong lĩnh vực khoa học máy tính đều có thể được giải quyết bằng cách thêm một lớp trung gian gián tiếp, toàn bộ hệ thống máy tính được thiết kế theo cấu trúc phân lớp từ trên xuống dưới.
Các giao thức phổ biến trong mạng
Các giao thức phổ biến trong tầng ứng dụng?
- HTTP (Hypertext Transfer Protocol, Giao thức truyền tải siêu văn bản): Dựa trên giao thức TCP, là một giao thức được sử dụng để truyền tải siêu văn bản và nội dung đa phương tiện, chủ yếu được thiết kế để giao tiếp giữa trình duyệt web và máy chủ web. Khi chúng ta duyệt web bằng trình duyệt, trang web được tải qua các yêu cầu HTTP.
- SMTP (Simple Mail Transfer Protocol, Giao thức truyền tải thư đơn giản): Dựa trên giao thức TCP, là một giao thức được sử dụng để gửi thư điện tử. Lưu ý: SMTP chỉ chịu trách nhiệm cho việc gửi thư, không phải là giao thức nhận thư. Để nhận thư từ máy chủ thư, cần sử dụng giao thức POP3 hoặc IMAP.
- POP3/IMAP (Giao thức nhận thư): Dựa trên giao thức TCP, cả hai đều là các giao thức dùng để nhận thư. Giao thức IMAP là một giao thức mới hơn so với POP3, nó mạnh mẽ hơn về tính năng và hiệu suất. IMAP hỗ trợ tìm kiếm, đánh dấu, phân loại, lưu trữ thư và đồng bộ hóa trạng thái thư giữa nhiều thiết bị. Hầu hết các ứng dụng thư điện tử và máy chủ hiện đại đều hỗ trợ IMAP.
- FTP (File Transfer Protocol, Giao thức truyền tải tệp): Dựa trên giao thức TCP, là một giao thức được sử dụng để truyền tải tệp tin giữa các máy tính, nó ẩn đi sự khác biệt về hệ điều hành và cách lưu trữ tệp tin. Lưu ý: FTP là một giao thức không an toàn vì dữ liệu không được mã hóa trong quá trình truyền tải. Đề nghị sử dụng các giao thức an toàn hơn như SFTP khi truyền tải dữ liệu nhạy cảm.
- Telnet (Giao thức đăng nhập từ xa): Dựa trên giao thức TCP, được sử dụng để đăng nhập vào máy chủ từ xa thông qua một terminal. Một trong những nhược điểm lớn nhất của Telnet là tất cả dữ liệu (bao gồm tên người dùng và mật khẩu) được gửi dưới dạng văn bản không mã hóa, điều này có nguy cơ an ninh tiềm ẩn. Đây là lý do tại sao hiện nay Telnet ít được sử dụng và thay thế bằng giao thức truyền tải mạng an toàn hơn được gọi là SSH.
- SSH (Secure Shell Protocol, Giao thức truyền tải mạng an toàn): Dựa trên giao thức TCP, cung cấp truy cập an toàn và truyền tải tệp tin qua mạng thông qua việc mã hóa và xác thực.
- RTP (Real-time Transport Protocol, Giao thức truyền tải thời gian thực): Thường dựa trên giao thức UDP, nhưng cũng hỗ trợ giao thức TCP. Nó cung cấp khả năng truyền tải dữ liệu thời gian thực từ điểm này đến điểm khác, nhưng không đảm bảo chất lượng truyền tải thời gian thực và không có tính năng dự trữ tài nguyên, những tính năng này được thực hiện bởi WebRTC.
- DNS (Domain Name System, Hệ thống tên miền): Dựa trên giao thức UDP, được sử dụng để giải quyết vấn đề ánh xạ giữa tên miền và địa chỉ IP.
Để biết thêm thông tin chi tiết về các giao thức này, vui lòng xem bài viết Tổng quan về các giao thức tầng ứng dụng.
Các giao thức phổ biến trong tầng vận chuyển?
- TCP (Transmission Control Protocol, Giao thức điều khiển truyền tải): Cung cấp dịch vụ truyền tải dữ liệu đáng tin cậy và dựa trên kết nối.
- UDP (User Datagram Protocol, Giao thức gói người dùng): Cung cấp dịch vụ truyền tải dữ liệu không dựa trên kết nối và không đáng tin cậy (không đảm bảo tính tin cậy của dữ liệu), nhưng nhanh và đơn giản.
Các giao thức phổ biến trong tầng mạng?
- IP (Internet Protocol, Giao thức Internet): Một trong những giao thức quan trọng nhất trong giao thức TCP/IP, thuộc tầng mạng, chịu trách nhiệm định dạng gói tin, định tuyến và địa chỉ, để chúng có thể truyền qua mạng và đến đúng đích. Hiện nay, IP chủ yếu được chia thành hai phiên bản: IPv4 và IPv6, cả hai đều đang được sử dụng, nhưng IPv6 được đề xuất để thay thế IPv4.
- ARP (Address Resolution Protocol, Giao thức giải địa chỉ): Giao thức ARP giải quyết vấn đề chuyển đổi giữa địa chỉ mạng và địa chỉ liên kết. Vì trong quá trình truyền dữ liệu qua mạng, một gói dữ liệu IP cần biết địa chỉ tiếp theo (đích tiếp theo trên mạng vật lý) để đi đến đâu, nhưng địa chỉ IP là địa chỉ logic, trong khi địa chỉ MAC mới là địa chỉ vật lý, giao thức ARP giải quyết một số vấn đề liên quan đến chuyển đổi địa chỉ IP thành địa chỉ MAC.
- ICMP (Internet Control Message Protocol, Giao thức điều khiển thông điệp Internet): Một giao thức được sử dụng để truyền tải trạng thái mạng và thông báo lỗi, thường được sử dụng để chẩn đoán và khắc phục sự cố mạng. Ví dụ, công cụ Ping sử dụng giao thức ICMP để kiểm tra tính khả dụng của mạng.
- NAT (Network Address Translation, Chuyển đổi địa chỉ mạng): Giao thức NAT được sử dụng trong quá trình chuyển đổi địa chỉ từ mạng nội bộ sang mạng bên ngoài. Cụ thể, trong một mạng con nhỏ (LAN), các máy chủ sử dụng cùng một địa chỉ IP trong LAN đó, nhưng bên ngoài LAN, trên mạng rộng (WAN), cần có một địa chỉ IP duy nhất để xác định vị trí của LAN đó trên Internet.
- OSPF (Open Shortest Path First, Giao thức đường đi ngắn nhất mở): Một giao thức cổng nội bộ (IGP) phổ biến, cũng là một giao thức định tuyến động phổ biến, dựa trên thuật toán trạng thái liên kết, xem xét các yếu tố như băng thông và độ trễ của liên kết để chọn đường đi tốt nhất.
- RIP (Routing Information Protocol, Giao thức thông tin định tuyến): Một giao thức cổng nội bộ (IGP), cũng là một giao thức định tuyến động, dựa trên thuật toán vector khoảng cách, sử dụng số lượng bước nhảy cố định làm tiêu chí đo để chọn đường đi tốt nhất.
- BGP (Border Gateway Protocol, Giao thức cổng biên giới): Một giao thức định tuyến được sử dụng để trao đổi thông tin về khả năng tiếp cận mạng (Network Layer Reachability Information, NLRI) giữa các miền định tuyến trong lĩnh vực định tuyến, có tính linh hoạt và mở rộng cao.
Từ nhập URL đến hiển thị trang web, điều gì đã xảy ra? (Rất quan trọng)
Câu hỏi tương tự: Khi mở một trang web, quá trình này sử dụng những giao thức nào?
Trình duyệt từ nhập URL đến hiển thị trang web chủ yếu được chia thành các giai đoạn sau:
- Nhập URL
- Phân giải DNS
- Thiết lập kết nối TCP
- Gửi yêu cầu HTTP/HTTPS (thiết lập kết nối TLS nếu sử dụng HTTPS)
- Máy chủ phản hồi yêu cầu
- Trình duyệt phân tích cú pháp và hiển thị trang web
- Kết thúc yêu cầu HTTP và ngắt kết nối TCP
Bạn có thể tham khảo bài viết sau đây để biết thêm chi tiết: Web Flow
Có những mã trạng thái HTTP nào?
Mã trạng thái HTTP được sử dụng để mô tả kết quả của yêu cầu HTTP, ví dụ: 2xx đại diện cho yêu cầu được xử lý thành công.
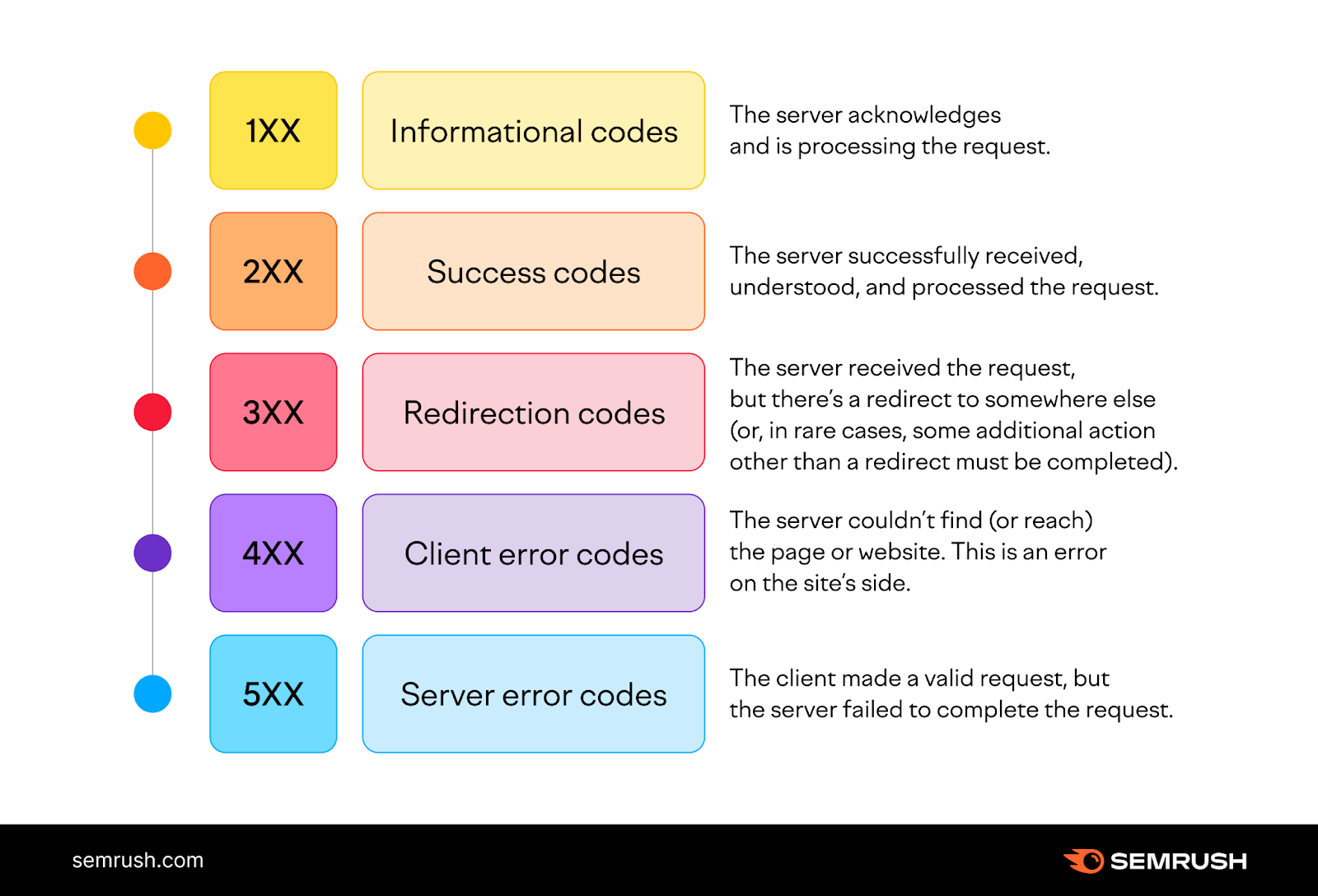
Để biết thêm thông tin chi tiết về mã trạng thái HTTP, bạn có thể tham khảo: HTTP response status codes - HTTP | MDN
Các trường phổ biến trong HTTP Header là gì?
| Tên trường | Mô tả | Ví dụ |
|---|---|---|
| Accept | Loại nội dung (Content-Types) mà yêu cầu có thể chấp nhận | Accept: text/plain |
| Accept-Charset | Bộ ký tự mà yêu cầu có thể chấp nhận | Accept-Charset: utf-8 |
| Accept-Datetime | Phiên bản dựa trên thời gian mà yêu cầu có thể chấp nhận | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
| Accept-Encoding | Danh sách các phương pháp mã hóa mà yêu cầu có thể chấp nhận. Xem thêm về nén HTTP | Accept-Encoding: gzip, deflate |
| Accept-Language | Danh sách các ngôn ngữ tự nhiên mà yêu cầu có thể chấp nhận | Accept-Language: en-US |
| Authorization | Thông tin xác thực được sử dụng cho xác thực giao thức truyền tải siêu văn bản (HTTP) | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | Chỉ thị mà tất cả các cơ chế bộ nhớ cache trong chuỗi yêu cầu/phản hồi phải tuân theo | Cache-Control: no-cache |
| Connection | Loại kết nối mà trình duyệt muốn ưu tiên sử dụng | Connection: keep-alive Connection: Upgrade |
| Content-Length | Độ dài của thân yêu cầu được biểu diễn bằng mảng byte tám bit (8 bit) | Content-Length: 348 |
| Content-MD5 | Giá trị băm MD5 nhị phân của nội dung yêu cầu, được mã hóa dưới dạng Base64 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Type | Loại phương tiện của yêu cầu (sử dụng cho các yêu cầu POST và PUT) | Content-Type: application/x-www-form-urlencoded |
| Cookie | Một hoặc nhiều cookie HTTP được gửi trước đó bởi máy chủ thông qua Set-Cookie | Cookie: $Version=1; Skin=new; |
| Date | Ngày và giờ gửi thông điệp (theo định dạng “Ngày HTTP” được xác định trong RFC 7231) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
| Expect | Cho biết khách hàng yêu cầu máy chủ thực hiện một hành động cụ thể | Expect: 100-continue |
| From | Địa chỉ email của người dùng khởi tạo yêu cầu | From: user@example.com |
| Host | Tên miền của máy chủ (sử dụng cho máy chủ ảo) và số cổng giao thức truyền tải mà máy chủ lắng nghe. Nếu cổng được yêu cầu là cổng tiêu chuẩn của dịch vụ tương ứng, cổng có thể bị bỏ qua. | Host: en.wikipedia.org:80 |
| If-Match | Chỉ thị rằng hoạt động chỉ được thực hiện nếu thực thể được cung cấp bởi khách hàng khớp với thực thể tương ứng trên máy chủ. | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | Cho phép trả về trạng thái 304 Not Modified chỉ khi nội dung tương ứng chưa được sửa đổi | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
| If-None-Match | Cho phép trả về trạng thái 304 Not Modified chỉ khi nội dung tương ứng chưa được sửa đổi | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | Nếu thực thể chưa được sửa đổi, chỉ gửi phần bị thiếu hoặc nhiều hơn của nó; nếu không, gửi toàn bộ thực thể mới | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | Chỉ thực hiện hành động chỉ khi thực thể chưa được sửa đổi từ thời điểm cụ thể | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
| Max-Forwards | Giới hạn số lần chuyển tiếp thông điệp có thể được thực hiện bởi proxy và cổng | Max-Forwards: 10 |
| Origin | Khởi tạo một yêu cầu chia sẻ tài nguyên gốc | Origin: http://www.example-social-network.com |
| Pragma | Các chỉ thị có liên quan đến cài đặt cụ thể, các trường này có thể tạo ra nhiều hiệu ứng trong chuỗi yêu cầu/phản hồi | Pragma: no-cache |
| Proxy-Authorization | Thông tin xác thực được sử dụng để xác thực với proxy | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | Chỉ yêu cầu một phần của một thực thể. Bắt đầu từ 0. Xem dịch vụ byte | Range: bytes=500-999 |
| Referer | Chỉ định trang web trước đó mà trình duyệt đã truy cập và dẫn đến trang web hiện tại | Referer: http://en.wikipedia.org/wiki/Main_Page |
| TE | Các phương pháp mã hóa truyền tải mà trình duyệt dự kiến chấp nhận: có thể sử dụng các giá trị trong trường Transfer-Encoding của phản hồi | TE: trailers, deflate |
| Upgrade | Yêu cầu máy chủ nâng cấp sang một giao thức khác | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | Chuỗi định danh trình duyệt của trình duyệt | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
| Via | Thông báo cho máy chủ rằng yêu cầu này đã được gửi bởi các proxy nào | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
| Warning | Cảnh báo chung, cho biết có thể có lỗi trong nội dung thân | Warning: 199 Miscellaneous warning |
HTTP và HTTPS khác nhau như thế nào? (Quan trọng)
- Cổng kết nối: HTTP mặc định sử dụng cổng 80, trong khi HTTPS mặc định sử dụng cổng 443.
- Tiền tố URL: Tiền tố URL của HTTP là
http://, trong khi tiền tố URL của HTTPS làhttps://. - Bảo mật và tài nguyên tiêu thụ: Giao thức HTTP hoạt động trên TCP và toàn bộ nội dung truyền tải đều là văn bản rõ, không thể xác minh danh tính của máy khách và máy chủ. HTTPS là giao thức HTTP hoạt động trên SSL/TLS, chạy trên TCP. Toàn bộ nội dung truyền tải được mã hóa, sử dụng mã hóa đối xứng, nhưng khóa mã hóa đối xứng được mã hóa bằng chứng chỉ của máy chủ. Vì vậy, HTTP không bảo mật bằng HTTPS, nhưng HTTPS tiêu tốn nhiều tài nguyên máy chủ hơn.
- SEO (Tối ưu hóa công cụ tìm kiếm): Các công cụ tìm kiếm thường ưu tiên hiển thị các trang web sử dụng giao thức HTTPS, vì HTTPS cung cấp tính bảo mật và bảo vệ quyền riêng tư cao hơn cho người dùng. Các trang web sử dụng giao thức HTTPS có thể được hiển thị ưu tiên trong kết quả tìm kiếm, ảnh hưởng đến SEO.
Để biết thêm thông tin chi tiết về sự khác nhau giữa HTTP và HTTPS, bạn có thể tham khảo bài viết: HTTPS and HTTP
HTTP/1.0 và HTTP/1.1 khác nhau như thế nào?
- Phương thức kết nối: HTTP/1.0 sử dụng kết nối ngắn, trong khi HTTP/1.1 hỗ trợ kết nối dài.
- Mã trạng thái phản hồi: HTTP/1.1 đã thêm vào nhiều mã trạng thái mới, chỉ có trong HTTP/1.1 có 24 mã trạng thái phản hồi lỗi. Ví dụ:
100 (Continue)- yêu cầu tiền nhiệm trước khi yêu cầu lớn,206 (Partial Content)- đánh dấu yêu cầu phạm vi,409 (Conflict)- yêu cầu xung đột với tài nguyên hiện tại,410 (Gone)- tài nguyên đã được chuyển đi và không có địa chỉ chuyển tiếp đã biết. - Cơ chế bộ nhớ cache: Trong HTTP/1.0, chủ yếu sử dụng các trường If-Modified-Since, Expires trong Header để xác định bộ nhớ cache. HTTP/1.1 đã giới thiệu nhiều chiến lược điều khiển bộ nhớ cache khác nhau như Entity tag, If-Unmodified-Since, If-Match, If-None-Match và nhiều trường cache khác để kiểm soát chiến lược bộ nhớ cache.
- Băng thông: Trong HTTP/1.0, có một số lãng phí băng thông, ví dụ: khi máy khách chỉ cần một phần của một đối tượng nhưng máy chủ lại gửi toàn bộ đối tượng và không hỗ trợ chức năng tiếp tục tải xuống. HTTP/1.1 đã giới thiệu trường Range trong tiêu đề yêu cầu, cho phép yêu cầu chỉ một phần của tài nguyên, trả về mã trạng thái 206 (Partial Content), điều này giúp phát triển viên có thể tự do chọn để tận dụng tối đa băng thông và kết nối.
- Xử lý tiêu đề Host: HTTP/1.1 đã giới thiệu tiêu đề Host, cho phép lưu trữ nhiều tên miền trên cùng một địa chỉ IP, từ đó hỗ trợ chức năng máy chủ ảo. Trong khi HTTP/1.0 không có tiêu đề Host, không thể thực hiện máy chủ ảo.
Để biết thêm thông tin chi tiết về sự khác nhau giữa HTTP/1.0 và HTTP/1.1, bạn có thể tham khảo bài viết: HTTP1.0 and HTTP1.1
Sự khác biệt giữa HTTP/1.1 và HTTP/2.0?
- Đa kênh (Multiplexing): HTTP/2.0 cho phép truyền cùng lúc nhiều yêu cầu và phản hồi trên cùng một kết nối (có thể coi là phiên bản nâng cấp của kết nối dài trong HTTP/1.1), mà không gây xung đột. HTTP/1.1 sử dụng cách kết nối tuần tự, mỗi yêu cầu và phản hồi đều cần kết nối riêng biệt, và trình duyệt thường giới hạn số lượng kết nối TCP là 6-8. Điều này làm cho HTTP/2.0 hiệu quả hơn trong xử lý nhiều yêu cầu, giảm độ trễ mạng và cải thiện hiệu suất.
- Khung nhị phân (Binary Frames): HTTP/2.0 sử dụng khung nhị phân để truyền dữ liệu, trong khi HTTP/1.1 sử dụng định dạng văn bản cho thông điệp. Khung nhị phân hiệu quả và tiết kiệm hơn về dữ liệu truyền tải, giảm lượng dữ liệu và tiêu thụ băng thông.
- Nén tiêu đề (Header Compression): HTTP/1.1 hỗ trợ nén nội dung (
Body) nhưng không hỗ trợ nén tiêu đề (Header). HTTP/2.0 hỗ trợ nén tiêu đề bằng cách sử dụng thuật toán HPACK được thiết kế đặc biệt cho nén tiêu đề, giảm tải mạng. - Đẩy từ máy chủ (Server Push): HTTP/2.0 hỗ trợ đẩy từ máy chủ, có thể đẩy các tài nguyên liên quan khi khách hàng yêu cầu một tài nguyên cụ thể, giảm số lượng yêu cầu và độ trễ của khách hàng. Trong khi đó, HTTP/1.1 yêu cầu khách hàng tự gửi yêu cầu để lấy các tài nguyên liên quan.
Hình ảnh minh họa về đa luồng trong HTTP/2.0 (Nguồn: HTTP/2 For Web Developers):
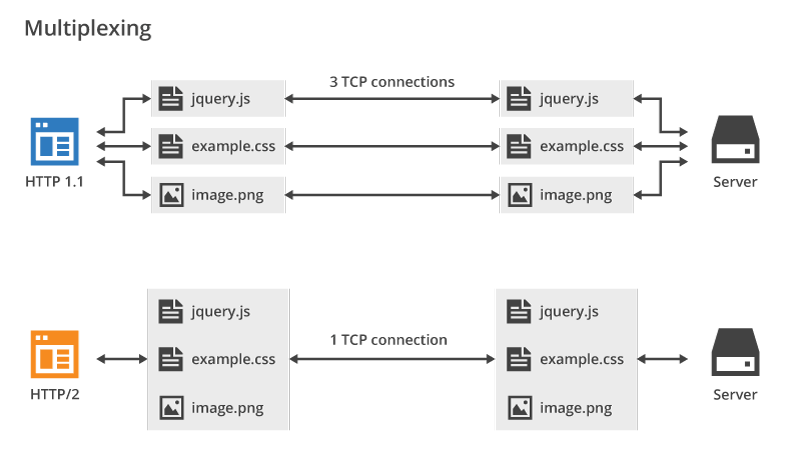
Có thể thấy, đa kênh trong HTTP/2.0 cho phép các yêu cầu khác nhau chia sẻ cùng một kết nối TCP, tránh việc tạo nhiều kết nối gây tốn kém không cần thiết, trong khi HTTP/1.1 mỗi yêu cầu đều tạo một kết nối riêng biệt.
Sự khác biệt giữa HTTP/2.0 và HTTP/3.0 là gì?
- Giao thức truyền tải: HTTP/2.0 được thực hiện dựa trên giao thức TCP, trong khi HTTP/3.0 thêm giao thức QUIC (Quick UDP Internet Connections) để thực hiện truyền tải đáng tin cậy, cung cấp độ an toàn tương đương với TLS/SSL và có độ trễ kết nối và truyền tải thấp hơn. QUIC có thể được coi là phiên bản nâng cấp của UDP, với nhiều tính năng mới như mã hóa, truyền lại dữ liệu, v.v. Trước đây, HTTP/3.0 được gọi là HTTP-over-QUIC, từ tên này chúng ta cũng có thể thấy rằng sự thay đổi lớn nhất của HTTP/3 là sử dụng QUIC.
- Thiết lập kết nối: HTTP/2.0 cần thông qua quá trình bắt tay ba bước cổ điển của TCP (vì việc thiết lập kết nối HTTPS an toàn cần thêm quá trình bắt tay TLS, tổng cộng cần khoảng 3 RTT). Nhờ vào tính năng của giao thức QUIC (TLS 1.3, ngoài việc hỗ trợ bắt tay 1 RTT, còn hỗ trợ bắt tay 0 RTT), việc thiết lập kết nối chỉ cần 0-RTT hoặc 1-RTT. Điều này có nghĩa là trong trường hợp tốt nhất, QUIC không cần thời gian phản hồi bổ sung nào để thiết lập kết nối mới.
- Chặn đầu hàng (Head-of-Line blocking): HTTP/2.0 sử dụng nhiều yêu cầu trên một kết nối TCP, một khi có gói tin bị mất, tất cả các yêu cầu HTTP đều bị chặn. Nhờ tính năng của giao thức QUIC, HTTP/3.0 giải quyết một phần vấn đề chặn đầu hàng (Head-of-Line blocking), một kết nối có thể thiết lập nhiều luồng dữ liệu khác nhau, các luồng dữ liệu này độc lập và không ảnh hưởng lẫn nhau, nếu một luồng dữ liệu bị mất, luồng dữ liệu khác không bị ảnh hưởng (tính chất này là kết hợp của đa kênh và kiểm tra tuần tự).
- Khôi phục lỗi: HTTP/3.0 có cơ chế khôi phục lỗi tốt hơn, khi gặp sự cố mất gói tin, độ trễ mạng, v.v., có thể khôi phục và truyền lại nhanh hơn. Trong khi đó, HTTP/2.0 phụ thuộc vào cơ chế khôi phục lỗi của TCP.
- Bảo mật: HTTP/2.0 và HTTP/3.0 đều có yêu cầu an ninh cao, hỗ trợ truyền thông mã hóa, nhưng cài đặt khác nhau. HTTP/2.0 sử dụng giao thức TLS để mã hóa, trong khi HTTP/3.0 dựa trên giao thức QUIC, bao gồm cơ chế mã hóa và xác thực tích hợp, cung cấp tính bảo mật mạnh hơn.
So sánh các bộ giao thức của HTTP/1.0, HTTP/2.0 và HTTP/3.0:
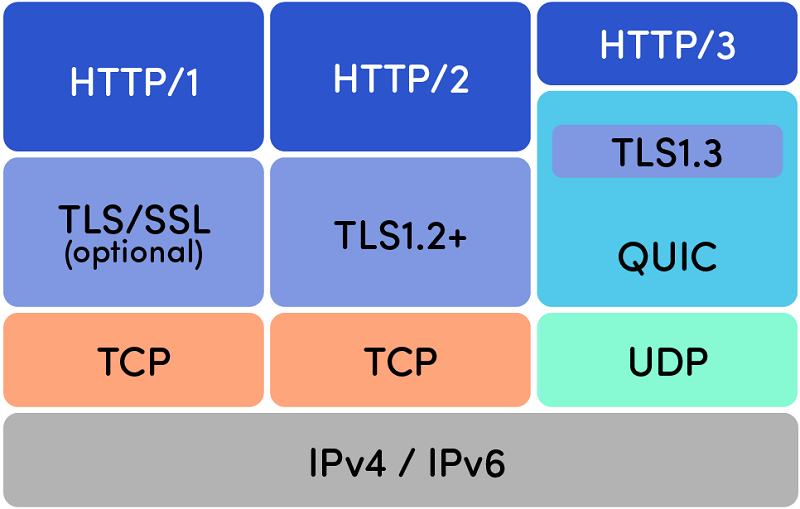
Để biết thêm chi tiết về sự tiến hóa từ HTTP/1.0 đến HTTP/3.0, bạn có thể đọc thêm bài viết HTTP1 đến HTTP3: Tối ưu hóa kỹ thuật.
HTTP là giao thức không lưu trạng thái, làm thế nào để lưu trạng thái người dùng?
HTTP là một giao thức không lưu trạng thái, tức là giao thức HTTP không tự lưu trạng thái giao tiếp giữa yêu cầu và phản hồi. Vậy làm thế nào để lưu trạng thái người dùng? Cơ chế Session được tạo ra để giải quyết vấn đề này, chức năng chính của Session là ghi lại trạng thái của người dùng bằng cách lưu trữ trên máy chủ. Một ví dụ điển hình là giỏ hàng, khi bạn thêm một sản phẩm vào giỏ hàng, hệ thống không biết đó là người dùng nào thực hiện hành động này, vì giao thức HTTP là không lưu trạng thái. Tuy nhiên, sau khi máy chủ tạo một Session đặc biệt cho người dùng, nó có thể xác định và theo dõi người dùng này (thông thường, máy chủ sẽ lưu trữ Session này trong một khoảng thời gian nhất định, sau đó sẽ xóa Session này).
Có nhiều phương pháp để lưu trữ Session trên máy chủ, phổ biến nhất là bằng bộ nhớ và cơ sở dữ liệu (ví dụ: sử dụng cơ sở dữ liệu bộ nhớ Redis để lưu trữ). Vì Session được lưu trữ trên máy chủ, vậy làm thế nào để thực hiện theo dõi Session? Trong hầu hết các trường hợp, chúng ta sử dụng việc gắn kết một ID Session vào Cookie để theo dõi.
Nếu Cookie bị vô hiệu hóa, chúng ta phải làm gì?
Phương pháp phổ biến nhất là sử dụng URL rewriting để trực tiếp gắn kết ID Session vào đường dẫn URL.
Sự khác nhau giữa URI và URL là gì?
- URI (Uniform Resource Identifier - Định danh tài nguyên thống nhất) là một định danh duy nhất cho một tài nguyên.
- URL (Uniform Resource Locator - Địa chỉ tài nguyên thống nhất) là một URI cụ thể, cung cấp đường dẫn đến tài nguyên đó. Nó là một URI cụ thể, có thể xác định một tài nguyên và chỉ ra cách locate (định vị) tài nguyên đó.
URI tương tự như số CMND, URL tương tự như địa chỉ nhà. URL là một loại URI cụ thể, nó không chỉ định duy nhất tài nguyên mà còn cung cấp thông tin về cách định vị tài nguyên đó.
Sự khác nhau giữa Cookie và Session là gì?
Tham khảo Cookie vs Session
Sự khác biệt giữa GET và POST
GET và POST là hai phương thức yêu cầu phổ biến trong giao thức HTTP, và chúng có các đặc điểm và cách sử dụng khác nhau trong các tình huống và mục đích khác nhau. Thông thường, chúng ta có thể phân biệt chúng dựa trên các khía cạnh sau đây (tập trung vào sự khác biệt về ý nghĩa):
- Ý nghĩa (khác biệt chính): GET thường được sử dụng để lấy hoặc truy vấn tài nguyên, trong khi POST thường được sử dụng để tạo hoặc chỉnh sửa tài nguyên.
- Idempotent: Yêu cầu GET là idempotent, có nghĩa là thực hiện nhiều lần không thay đổi trạng thái của tài nguyên, trong khi yêu cầu POST không idempotent, có nghĩa là mỗi lần thực hiện có thể tạo ra kết quả khác nhau hoặc ảnh hưởng đến trạng thái của tài nguyên.
- Định dạng: Tham số của yêu cầu GET thường được đặt trong URL, tạo thành chuỗi truy vấn (query string), trong khi tham số của yêu cầu POST thường được đặt trong phần thân yêu cầu (request body) và có thể sử dụng nhiều định dạng mã hóa, chẳng hạn như application/x-www-form-urlencoded, multipart/form-data, application/json, v.v. Độ dài URL của yêu cầu GET bị giới hạn bởi trình duyệt và máy chủ, trong khi kích thước phần thân yêu cầu POST không có giới hạn cụ thể. Tuy nhiên, thực tế là yêu cầu GET cũng có thể sử dụng phần thân yêu cầu để truyền dữ liệu, nhưng không khuyến khích làm như vậy vì có thể gây ra các vấn đề tương thích hoặc ý nghĩa.
- Bộ nhớ cache: Vì yêu cầu GET là idempotent, nó có thể được lưu trữ trong bộ nhớ cache của trình duyệt hoặc các nút trung gian khác (như proxy, gateway) để tăng hiệu suất và hiệu quả. Trong khi đó, yêu cầu POST không phù hợp để lưu trữ trong cache vì nó có thể có tác động phụ và cần phản hồi thời gian thực.
- Bảo mật: Cả yêu cầu GET và POST đều không an toàn nếu sử dụng giao thức HTTP vì giao thức HTTP truyền dữ liệu dưới dạng văn bản không mã hóa. Để bảo mật dữ liệu truyền, cần sử dụng giao thức HTTPS. Ngoài ra, yêu cầu GET so với yêu cầu POST dễ tiết lộ dữ liệu nhạy cảm hơn, vì tham số của yêu cầu GET thường nằm trong URL.
Lưu ý rằng, tập trung vào sự khác biệt về ý nghĩa giữa GET và POST là quan trọng nhất. Trong quá trình sử dụng thực tế, cũng thông qua ý nghĩa để phân biệt việc sử dụng GET hoặc POST. Tuy nhiên, cũng có một số dự án sử dụng POST cho tất cả các yêu cầu, điều này không cố định, chỉ cần đạt được sự thống nhất trong nhóm dự án là được.
PING
PING làm việc như thế nào?
Lệnh PING là một công cụ chẩn đoán mạng phổ biến, thường được sử dụng để kiểm tra tính kết nối và độ trễ mạng giữa các máy chủ trong mạng.
Dưới đây là một ví dụ đơn giản, chúng ta sẽ PING đến trang web của Baidu.
# Gửi 4 gói tin PING đến google.com
❯ ping -c 4 google.com
PING google.com (142.251.130.14): 56 data bytes
64 bytes from 142.251.130.14: icmp_seq=0 ttl=54 time=30.836 ms
64 bytes from 142.251.130.14: icmp_seq=1 ttl=54 time=123.127 ms
64 bytes from 142.251.130.14: icmp_seq=2 ttl=54 time=30.311 ms
64 bytes from 142.251.130.14: icmp_seq=3 ttl=54 time=62.985 ms
--- google.com ping statistics ---
4 packets transmitted, 4 packets received, 0.0% packet loss
round-trip min/avg/maxKết quả PING thường bao gồm các thông tin sau:
- Thông tin ICMP Echo Request (yêu cầu ICMP Echo): số thứ tự, giá trị TTL (Time to Live).
- Tên miền hoặc địa chỉ IP của máy chủ đích: dòng đầu tiên trong kết quả.
- Thời gian đi lại (RTT, Round-Trip Time): tổng thời gian từ khi gửi yêu cầu ICMP Echo cho đến khi nhận được phản hồi ICMP Echo Reply, được sử dụng để đo độ trễ mạng.
- Thống kê (Statistics): bao gồm số lượng gói tin ICMP yêu cầu đã gửi, số lượng gói tin ICMP phản hồi đã nhận, tỷ lệ gói tin bị mất, giá trị RTT tối thiểu, trung bình, tối đa và độ lệch chuẩn.
Nếu máy chủ đích không phản hồi đúng, điều này cho thấy có vấn đề về kết nối giữa hai máy chủ (một số máy chủ hoặc quản trị mạng có thể vô hiệu hóa phản hồi yêu cầu ICMP, điều này cũng sẽ làm cho không nhận được phản hồi chính xác). Nếu thời gian đi lại (RTT) quá cao, điều này cho thấy có độ trễ mạng cao.
Nguyên lý hoạt động của lệnh PING là gì?
PING dựa trên ICMP (Internet Control Message Protocol, Giao thức Tin nhắn Điều khiển Internet) ở tầng mạng, và nguyên lý chính là gửi và nhận các gói tin ICMP trên mạng.
Gói tin ICMP chứa một trường loại, được sử dụng để xác định loại gói tin ICMP. Có nhiều loại gói tin ICMP, nhưng chúng có thể chia thành hai loại chính:
- Loại gói tin truy vấn: Gửi yêu cầu đến máy chủ đích và mong đợi nhận được phản hồi.
- Loại gói tin lỗi: Gửi thông báo lỗi đến máy chủ nguồn, để báo cáo về các vấn đề lỗi trong mạng.
Gói tin ICMP Echo Request (loại 8) và ICMP Echo Reply (loại 0) được sử dụng trong PING và thuộc loại gói tin truy vấn.
- Lệnh PING sẽ gửi yêu cầu ICMP Echo Request đến máy chủ đích.
- Nếu kết nối giữa hai máy chủ là bình thường, máy chủ đích sẽ trả lại một ICMP Echo Reply tương ứng.
DNS
DNS có tác dụng gì?
DNS (Domain Name System - Hệ thống tên miền) là một giao thức quan trọng được sử dụng khi người dùng truy cập vào một địa chỉ web. DNS giải quyết vấn đề tương ứng giữa tên miền và địa chỉ IP.
Trên một máy tính, có thể tồn tại bộ nhớ cache DNS của trình duyệt, bộ nhớ cache DNS của hệ điều hành và bộ nhớ cache DNS của bộ định tuyến. Nếu không tìm thấy trong bất kỳ bộ nhớ cache nào, DNS sẽ được sử dụng.
Hiện nay, DNS được thiết kế dựa trên mô hình cơ sở dữ liệu phân tán và phân cấp. DNS là một giao thức ứng dụng, nó có thể chạy trên giao thức UDP hoặc TCP, trên cổng 53.
Có những loại máy chủ DNS nào?
Các máy chủ DNS có thể được phân loại thành các cấp độ sau (tất cả các máy chủ DNS thuộc một trong bốn loại sau):
- Máy chủ DNS gốc: Máy chủ DNS gốc cung cấp địa chỉ IP của máy chủ TLD. Hiện nay chỉ có 13 nhóm máy chủ gốc trên thế giới, và hiện tại Việt Nam vẫn chưa có máy chủ gốc.
- Máy chủ DNS cấp cao nhất của miền cấp cao nhất (TLD): TLD là phần sau cùng của tên miền, ví dụ:
com,org,netvàedu. Mỗi quốc gia cũng có TLD riêng, ví dụ:uk,frvàca. Máy chủ TLD cung cấp địa chỉ IP của máy chủ DNS có thẩm quyền. - Máy chủ DNS có thẩm quyền: Mỗi tổ chức có các bản ghi DNS công khai phải cung cấp để ánh xạ tên miền của các máy chủ công khai này thành địa chỉ IP.
- Máy chủ DNS cục bộ: Mỗi nhà cung cấp dịch vụ Internet (ISP) đều có máy chủ DNS cục bộ của riêng họ. Khi một máy chủ gửi yêu cầu DNS, yêu cầu đó được gửi đến máy chủ DNS cục bộ, nó hoạt động như một proxy và chuyển tiếp yêu cầu đó vào cấu trúc DNS. Nghiêm ngặt mà nói, nó không thuộc cấu trúc DNS.
Quá trình phân giải DNS như thế nào?
Quá trình này có nhiều bước, tôi đã viết một bài viết riêng về nó: DNS