Hive Quick Start
Giới thiệu
Hive là một kho dữ liệu được xây dựng trên nền tảng của Hadoop, nó có thể ánh xạ các tệp dữ liệu có cấu trúc thành bảng và cung cấp chức năng truy vấn tương tự SQL. Câu truy vấn SQL được sử dụng để truy vấn sẽ được chuyển đổi thành các công việc MapReduce và sau đó được gửi đến Hadoop để chạy.
Đặc điểm:
- Dễ sử dụng, dễ tiếp cận (cung cấp ngôn ngữ truy vấn giống SQL được gọi là HQL), cho phép người có kinh nghiệm với SQL nhưng không biết lập trình Java cũng có thể thực hiện phân tích dữ liệu lớn một cách tốt;
- Linh hoạt, có thể tùy chỉnh hàm người dùng (UDF) và định dạng lưu trữ;
- Thiết kế cho khả năng tính toán và lưu trữ cho các tập dữ liệu cực lớn, mở rộng cụm dễ dàng;
- Quản lý siêu dữ liệu thống nhất, có thể chia sẻ dữ liệu với presto/impala/sparksql và các công cụ khác;
- Độ trễ thực thi cao, không phù hợp cho xử lý dữ liệu thời gian thực, nhưng phù hợp cho xử lý dữ liệu lớn ngoại tuyến.
Kiến trúc của Hive
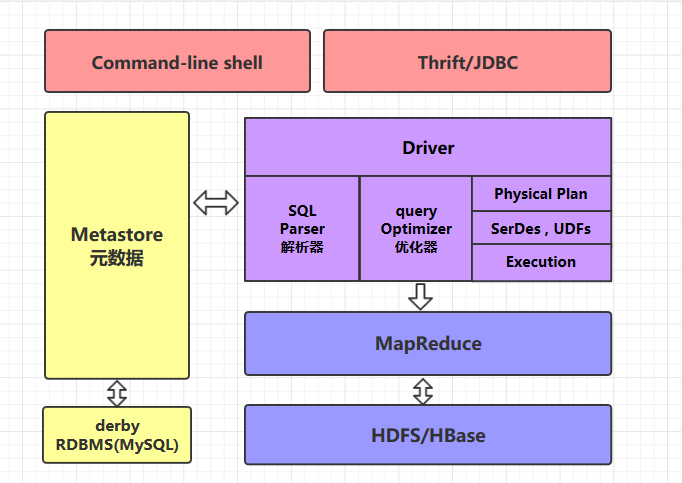
command-line shell & thrift/jdbc
Có thể sử dụng hai cách để thao tác dữ liệu: command line và thrift/jdbc:
- Command-line: Thao tác dữ liệu thông qua giao diện dòng lệnh hive;
- Thrift/jdbc: Thao tác dữ liệu theo cách tiêu chuẩn của JDBC thông qua giao thức thrift.
Metastore
Trong Hive, các thông tin như tên bảng, cấu trúc bảng, tên trường, kiểu dữ liệu trường, ký tự phân cách của bảng được gọi chung là metadata. Tất cả metadata mặc định được lưu trữ trong cơ sở dữ liệu derby tích hợp trong Hive. Tuy nhiên, vì derby chỉ có thể có một phiên bản, tức là không thể có nhiều khách hàng dòng lệnh truy cập cùng một lúc, nên trong môi trường sản xuất thực tế, thường sử dụng MySQL để thay thế derby.
Hive thực hiện quản lý metadata thống nhất, điều này có nghĩa là nếu bạn tạo một bảng trên Hive, sau đó bạn cũng có thể trực tiếp sử dụng nó trên presto/impala/sparksql. Chúng sẽ lấy thông tin metadata thống nhất từ Metastore. Tương tự, nếu bạn tạo một bảng trên presto/impala/sparksql, bạn cũng có thể sử dụng nó trên Hive.
Luồng thực thi HQL
Khi thực thi một câu lệnh HQL, Hive sẽ đi qua các bước sau:
- Phân tích cú pháp: Sử dụng Antlr để xác định quy tắc cú pháp của SQL, hoàn thành phân tích từ vựng SQL, cú pháp và chuyển đổi SQL thành cây cú pháp trừu tượng (AST Tree);
- Phân tích ngữ nghĩa: Duyệt qua cây AST, trừu tượng hóa các thành phần cơ bản của truy vấn thành khối truy vấn (QueryBlock);
- Tạo kế hoạch thực thi logic: Duyệt qua QueryBlock, dịch thành cây thực hiện logic (OperatorTree);
- Tối ưu hóa kế hoạch thực thi logic: Trình tối ưu hóa logic thực hiện các biến đổi trên OperatorTree, hợp nhất các ReduceSinkOperator không cần thiết, giảm lượng dữ liệu shuffle;
- Tạo kế hoạch thực thi vật lý: Duyệt qua OperatorTree, dịch thành nhiệm vụ MapReduce;
- Tối ưu hóa kế hoạch thực thi vật lý: Trình tối ưu hóa vật lý thực hiện các biến đổi nhiệm vụ MapReduce, tạo ra kế hoạch thực hiện cuối cùng.