Tóm tắt phỏng vấn Elasticsearch
Triển khai cụm
Cấu hình triển khai ES:
5 nút (cấu hình: 8 nhân 64 G 1T), tổng cộng 320 G, 5 T.
Khoảng 10+ chỉ mục, 5 phân đoạn, lượng dữ liệu mới hàng ngày là khoảng 2G, 40 triệu bản ghi. Bản ghi được lưu trữ trong 30 ngày.
Tối ưu hóa hiệu suất
filesystem cache
Dữ liệu bạn ghi vào es, thực tế đã được ghi vào tệp trên đĩa, khi truy vấn, hệ điều hành sẽ tự động lưu trữ dữ liệu từ tệp trên đĩa vào filesystem cache.
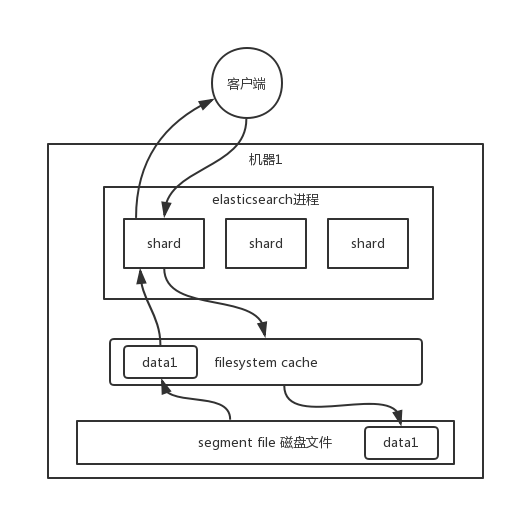
Cơ chế tìm kiếm của es phụ thuộc nặng nề vào filesystem cache cơ sở. Nếu bạn cung cấp thêm bộ nhớ cho filesystem cache, cố gắng để bộ nhớ có thể chứa tất cả các tệp dữ liệu chỉ mục idx segment file, thì khi bạn tìm kiếm, hầu như tất cả các hoạt động đều đi qua bộ nhớ, hiệu suất sẽ rất cao.
Hiệu suất có thể chênh lệch đến mức độ nào? Trong nhiều thử nghiệm và kiểm tra áp lực của chúng tôi trước đây, nếu đi qua đĩa, thì thời gian tìm kiếm chắc chắn là ở mức giây, từ 1 giây, 5 giây đến 10 giây. Nhưng nếu đi qua filesystem cache, nghĩa là đi qua bộ nhớ thuần túy, thì hiệu suất thường cao hơn một bậc so với việc đi qua đĩa, cơ bản là ở mức mili giây, từ vài mili giây đến vài trăm mili giây.
Ở đây có một ví dụ thực tế. Một công ty có 3 máy chủ es, mỗi máy chủ có vẻ như có nhiều bộ nhớ, 64G, tổng bộ nhớ là 64 * 3 = 192G. Mỗi máy chủ cung cấp cho es jvm heap là 32G, vì vậy phần còn lại cho filesystem cache chỉ là 32G mỗi máy, tổng cộng trong cụm, cho filesystem cache chỉ là 32 * 3 = 96G bộ nhớ. Tuy nhiên, vào thời điểm đó, tất cả các tệp dữ liệu chỉ mục trên đĩa, trên 3 máy, tổng cộng chiếm 1T dung lượng đĩa, lượng dữ liệu es là 1T, vì vậy lượng dữ liệu mỗi máy là 300G. Hiệu suất tốt không? Bộ nhớ filesystem cache chỉ có 100G, chỉ một phần mười dữ liệu có thể được đặt trong bộ nhớ, phần còn lại đều ở trên đĩa, sau đó bạn thực hiện hoạt động tìm kiếm, hầu hết các hoạt động đều đi qua đĩa, hiệu suất chắc chắn sẽ kém.
Về cơ bản, nếu bạn muốn es hoạt động tốt, trường hợp tốt nhất là bộ nhớ máy của bạn có thể chứa ít nhất một nửa tổng lượng dữ liệu của bạn.
Dựa trên kinh nghiệm thực tế trong môi trường product của chúng tôi, trường hợp tốt nhất là chỉ lưu trữ một lượng dữ liệu nhỏ trong es, chỉ là những chỉ mục mà bạn cần tìm kiếm, nếu bộ nhớ dành cho filesystem cache là 100G, thì bạn nên kiểm soát lượng dữ liệu chỉ mục dưới 100G. Trong trường hợp này, hầu hết dữ liệu của bạn đều đi qua bộ nhớ để tìm kiếm, hiệu suất rất cao, thường có thể trong vòng 1 giây.
Ví dụ, bạn hiện có một hàng dữ liệu. id, name, age …. 30 trường. Nhưng bây giờ, bạn chỉ cần tìm kiếm dựa trên ba trường id, name, age. Nếu bạn ngây thơ ghi tất cả các trường của một hàng dữ liệu vào es, điều này sẽ dẫn đến việc 90% dữ liệu không được sử dụng để tìm kiếm, nhưng vẫn chiếm không gian filesystem cache trên máy chủ es, dữ liệu mỗi hàng càng lớn, filesystem cache có thể lưu trữ càng ít dữ liệu. Thực tế, chỉ cần ghi vào es một số trường ít cần tìm kiếm, ví dụ, chỉ cần ghi vào es id, name, age ba trường, sau đó bạn có thể lưu trữ dữ liệu trường khác trong mysql/hbase, chúng tôi thường khuyến nghị sử dụng cấu trúc es + hbase.
Đặc điểm của hbase là phù hợp cho việc lưu trữ dữ liệu trực tuyến lớn, tức là hbase có thể ghi vào dữ liệu lớn, nhưng không nên thực hiện tìm kiếm phức tạp, chỉ cần thực hiện một số hoạt động đơn giản dựa trên id hoặc phạm vi. Tìm kiếm từ es dựa trên tên và tuổi, kết quả có thể chỉ là 20 doc id, sau đó tìm kiếm dữ liệu đầy đủ tương ứng với mỗi doc id từ hbase, đưa ra, sau đó trả về cho phía trước.
Dữ liệu ghi vào es nên nhỏ hơn hoặc bằng, hoặc hơi lớn hơn dung lượng bộ nhớ của filesystem cache của es. Sau đó, bạn có thể mất 20ms để tìm kiếm từ es, sau đó tìm kiếm từ hbase dựa trên id được trả về từ es, tìm kiếm 20 bản ghi, có thể mất thêm 30ms, có thể bạn đã chơi như vậy trước đây, 1T dữ liệu đều đặt trong es, mỗi truy vấn đều mất 5~10s, bây giờ có thể hiệu suất sẽ cao hơn, mỗi truy vấn chỉ mất 50ms.
Dữ liệu khởi động
Giả sử, ngay cả khi bạn làm theo phương án đã nêu ở trên, lượng dữ liệu được ghi vào mỗi máy trong cụm es vẫn vượt quá gấp đôi filesystem cache, ví dụ, bạn ghi 60G dữ liệu vào một máy, nhưng filesystem cache chỉ có 30G, vẫn còn 30G dữ liệu ở trên đĩa.
Thực tế, bạn có thể thực hiện khởi động dữ liệu.
Ví dụ, nếu bạn nói về Weibo, bạn có thể lấy một số dữ liệu từ các người dùng VIP, những người thường xuyên được xem nhiều, bạn tự tạo một hệ thống phía sau, sau mỗi một thời gian, hệ thống phía sau của bạn sẽ tìm kiếm dữ liệu nóng, và đẩy vào filesystem cache, sau đó, khi người dùng thực sự đến xem dữ liệu nóng này, họ sẽ trực tiếp tìm kiếm từ bộ nhớ, rất nhanh.
Hoặc là thương mại điện tử, bạn có thể lấy một số sản phẩm được xem nhiều nhất thường xuyên, chẳng hạn như iPhone 15, dữ liệu nóng được tạo trước bằng một chương trình phía sau, sau mỗi phút, bạn tự động truy cập một lần, và đẩy vào filesystem cache.
Đối với những dữ liệu mà bạn cho là nóng, và thường xuyên có người truy cập, nên tạo một hệ thống khởi động bộ đệm chuyên dụng, tức là, sau mỗi một khoảng thời gian, truy cập trước vào dữ liệu nóng, để dữ liệu vào filesystem cache. Như vậy, khi người khác truy cập lần sau, hiệu suất chắc chắn sẽ tốt hơn nhiều.
Phân tách nóng và lạnh
es có thể thực hiện việc phân tách ngang tương tự như mysql, tức là, đặt một lượng lớn dữ liệu ít được truy cập, tần suất thấp vào một chỉ mục riêng biệt, sau đó đặt dữ liệu nóng được truy cập thường xuyên vào một chỉ mục riêng biệt. Tốt nhất là đặt dữ liệu lạnh vào một chỉ mục, sau đó đặt dữ liệu nóng vào một chỉ mục khác, điều này có thể đảm bảo rằng sau khi dữ liệu nóng được khởi động, hãy để chúng ở trong filesystem os cache càng nhiều càng tốt, đừng để dữ liệu lạnh xóa bỏ chúng.
Bạn xem, giả sử bạn có 6 máy, 2 chỉ mục, một cho dữ liệu lạnh, một cho dữ liệu nóng, mỗi chỉ mục có 3 shard. 3 máy đặt chỉ mục dữ liệu nóng, 3 máy khác đặt chỉ mục dữ liệu lạnh. Sau đó, bạn sẽ dành nhiều thời gian truy cập vào chỉ mục dữ liệu nóng, dữ liệu nóng có thể chiếm 10% tổng lượng dữ liệu, lúc này lượng dữ liệu rất nhỏ, gần như tất cả đều được giữ trong filesystem cache, điều này có thể đảm bảo rằng hiệu suất truy cập dữ liệu nóng rất cao. Nhưng đối với dữ liệu lạnh, nó nằm trong một chỉ mục khác, không ở cùng máy với chỉ mục dữ liệu nóng, không có liên hệ gì với nhau. Nếu có người truy cập dữ liệu lạnh, có thể nhiều dữ liệu đang ở trên đĩa, lúc này hiệu suất sẽ kém một chút, chỉ có 10% người truy cập dữ liệu lạnh, 90% người đang truy cập dữ liệu nóng, không sao cả.
Thiết kế mô hình document
Đối với MySQL, chúng ta thường xuyên có một số truy vấn liên kết phức tạp. Trong es, chúng ta nên xử lý như thế nào, truy vấn liên kết phức tạp trong es nên tránh sử dụng càng nhiều càng tốt, một khi sử dụng, hiệu suất thường không tốt.
Tốt nhất là hoàn thành liên kết trước trong hệ thống Java, và ghi dữ liệu đã liên kết trực tiếp vào es. Khi tìm kiếm, không cần sử dụng cú pháp tìm kiếm của es để hoàn thành truy vấn liên kết như join.
Thiết kế mô hình document rất quan trọng, nhiều hoạt động, không nên chờ đến khi tìm kiếm mới thực hiện các hoạt động phức tạp khác nhau. es hỗ trợ rất nhiều hoạt động, không nên cố gắng sử dụng es để thực hiện một số thao tác mà nó không làm tốt. Nếu thực sự có thao tác như vậy, hãy cố gắng hoàn thành nó khi thiết kế mô hình document, khi ghi dữ liệu. Ngoài ra, đối với một số hoạt động quá phức tạp, như join/nested/parent-child tìm kiếm nên tránh càng nhiều càng tốt, hiệu suất đều rất kém.
Tối ưu hóa hiệu suất phân trang
Phân trang của es khá khó khăn, tại sao? Ví dụ, giả sử bạn có 10 bản ghi trên mỗi trang, và bạn muốn truy vấn trang thứ 100, thực tế, nó sẽ lấy 1000 bản ghi đầu tiên được lưu trữ trên mỗi shard và đưa chúng vào một nút điều phối, nếu bạn có 5 shard, thì sẽ có 5000 bản ghi, sau đó nút điều phối sẽ xử lý và hợp nhất 5000 bản ghi này, sau đó lấy 10 bản ghi cuối cùng trên trang thứ 100.
Phân tán, bạn muốn xem 10 bản ghi trên trang thứ 100, không thể nói rằng từ 5 shard, mỗi shard chỉ xem 2 bản ghi, cuối cùng hợp nhất thành 10 bản ghi tại nút điều phối, phải không? Bạn phải lấy 1000 bản ghi từ mỗi shard, sau đó sắp xếp, lọc, v.v., dựa trên yêu cầu của bạn, sau đó phân trang một lần nữa, lấy dữ liệu trên trang thứ 100. Khi bạn lật trang, càng sâu, mỗi shard trả về càng nhiều dữ liệu, và thời gian xử lý của nút điều phối càng lâu, rất khó chịu. Vì vậy, khi sử dụng es để phân trang, bạn sẽ thấy rằng càng lật đến sau, càng chậm.
Chúng tôi cũng đã gặp vấn đề này trước đây, sử dụng es để phân trang, một số trang đầu tiên chỉ mất vài chục mili giây, khi lật đến trang thứ 10 hoặc vài chục trang, cơ bản mất 5~10 giây mới có thể lấy một trang dữ liệu.
Có giải pháp nào không?
Không cho phép phân trang sâu (mặc định hiệu suất phân trang sâu rất kém)
Nói với quản lý sản phẩm rằng, hệ thống của bạn không cho phép lật trang quá sâu, mặc định là càng lật sâu, hiệu suất càng kém.
Tương tự như việc kéo xuống để hiển thị thêm sản phẩm được đề xuất trong ứng dụng
Tương tự như trong Weibo, kéo xuống để làm mới Weibo, hiển thị từng trang, bạn có thể sử dụng scroll api. Đối với cách sử dụng, hãy tự tìm kiếm trên internet.
Scroll sẽ tạo ra một bản chụp toàn bộ dữ liệu cho bạn một lần, sau đó mỗi lần kéo xuống để lật trang tiếp theo sẽ thông qua việc di chuyển con trỏ scroll_id, nhận trang tiếp theo như vậy, hiệu suất sẽ cao hơn rất nhiều so với hiệu suất phân trang đã nói ở trên, cơ bản là ở mức mili giây.
Tuy nhiên, điểm duy nhất là, điều này phù hợp với việc lật trang khi kéo xuống giống như Weibo, không thể tùy ý nhảy đến bất kỳ trang nào. Nghĩa là, bạn không thể truy cập trang thứ 10 trước, sau đó đi đến trang thứ 120, sau đó lại quay lại trang thứ 58, không thể nhảy trang tùy ý. Vì vậy, nhiều sản phẩm hiện nay không cho phép bạn tùy ý lật trang, ứng dụng, cũng như một số trang web, chỉ cho phép bạn kéo xuống, lật từng trang một.
Khi khởi tạo, bạn phải chỉ định tham số scroll, thông báo cho es cần lưu trữ ngữ cảnh tìm kiếm này trong bao lâu. Bạn cần đảm bảo rằng người dùng sẽ không tiếp tục lật trang trong vài giờ, nếu không có thể sẽ thất bại do quá thời gian.
Ngoài việc sử dụng scroll api, bạn cũng có thể sử dụng search_after. Ý tưởng của search_after là sử dụng kết quả của trang trước để giúp tìm kiếm dữ liệu trên trang tiếp theo, rõ ràng, cách này cũng không cho phép bạn tùy ý lật trang, bạn chỉ có thể lật từng trang một. Khi khởi tạo, bạn cần sử dụng một trường giá trị duy nhất làm trường sắp xếp.
1.1. Tối ưu hóa giai đoạn thiết kế
(1) Dựa trên yêu cầu tăng trưởng kinh doanh, tạo chỉ mục dựa trên mẫu ngày, cuộn chỉ mục qua API roll over;
(2) Sử dụng bí danh để quản lý chỉ mục;
(3) Mỗi ngày vào lúc nửa đêm, thực hiện thao tác force_merge trên chỉ mục để giải phóng không gian;
(4) Sử dụng cơ chế phân tách nóng và lạnh, lưu trữ dữ liệu nóng vào SSD để cải thiện hiệu suất tìm kiếm; dữ liệu lạnh được thu nhỏ định kỳ để giảm bớt lưu trữ;
(5) Sử dụng curator để quản lý vòng đời chỉ mục;
(6) Chỉ đặt tokenizer một cách hợp lý cho các trường cần phân mảnh;
(7) Giai đoạn Mapping kết hợp đầy đủ các thuộc tính của từng trường, liệu có cần tìm kiếm, liệu có cần lưu trữ, v.v…….
1.2. Tối ưu hóa viết
(1) Thiết lập số lượng bản sao là 0 trước khi ghi;
(2) Tắt refresh_interval trước khi ghi, đặt là -1, vô hiệu hóa cơ chế làm mới;
(3) Trong quá trình ghi: sử dụng bulk để ghi hàng loạt;
(4) Phục hồi số lượng bản sao và khoảng thời gian làm mới sau khi ghi;
(5) Cố gắng sử dụng id tự động sinh.
1.3. Tối ưu hóa truy vấn
(1) Vô hiệu hóa wildcard;
(2) Vô hiệu hóa terms hàng loạt (trường hợp hàng trăm hàng nghìn);
(3) Tận dụng tối đa cơ chế chỉ mục đảo ngược, nếu có thể dùng loại keyword thì hãy dùng keyword;
(4) Khi lượng dữ liệu lớn, bạn có thể định chỉ mục dựa trên thời gian trước khi tìm kiếm;
(5) Thiết lập cơ chế định tuyến hợp lý.
1.4. Tối ưu hóa khác
Tối ưu hóa triển khai, tối ưu hóa kinh doanh, v.v.
Phần nêu trên chỉ đề cập đến một phần, người phỏng vấn sẽ cơ bản đánh giá kinh nghiệm thực hành hoặc vận hành trước đây của bạn.
Nguyên lý hoạt động
Quá trình ghi dữ liệu es
- Máy khách chọn một node để gửi yêu cầu đi, node này là
coordinating node(nút điều phối). Coordinating nodethực hiện định tuyến cho document, chuyển yêu cầu đến node tương ứng (có primary shard).Primary shardtrên node thực tế xử lý yêu cầu, sau đó đồng bộ hóa dữ liệu vớireplica node.Coordinating nodenếu phát hiệnprimary nodevà tất cảreplica nodeđều đã hoàn thành, thì trả kết quả phản hồi cho máy khách.
Quá trình đọc dữ liệu es
Có thể truy vấn thông qua doc id, sẽ dựa vào doc id để thực hiện hash, xác định lúc đó đã phân doc id vào shard nào, từ shard đó truy vấn.
- Máy khách gửi yêu cầu đến bất kỳ một node, trở thành
coordinate node. Coordinate nodethực hiện định tuyến hash chodoc id, chuyển yêu cầu đến node tương ứng, lúc này sẽ sử dụng thuật toán round-robin ngẫu nhiên, chọn ngẫu nhiên một trong sốprimary shardvà tất cả các bản sao của nó, để cân bằng tải yêu cầu đọc.- Node nhận yêu cầu trả document cho
coordinate node. Coordinate nodetrả document cho máy khách.
Quá trình tìm kiếm dữ liệu trong ES
Điểm mạnh nhất của ES là thực hiện tìm kiếm toàn văn, ví dụ, bạn có ba dữ liệu:
Java is interesting
Java is so difficult to learn
J2EE is great
Bạn tìm kiếm theo từ khóa java, nó sẽ tìm kiếm các document chứa java. ES sẽ trả về cho bạn: Java is interesting, Java is so difficult to learn
- Máy khách gửi yêu cầu đến một
coordinating node. - Nút điều phối chuyển yêu cầu tìm kiếm đến tất cả
primary shardhoặcreplica shardtương ứng. - Giai đoạn truy vấn (query phase): mỗi shard sẽ trả lại kết quả tìm kiếm của mình (thực tế chỉ là một số
doc id) cho nút điều phối, nút điều phối thực hiện các hoạt động như hợp nhất dữ liệu, sắp xếp, phân trang, etc., để tạo ra kết quả cuối cùng. - Giai đoạn lấy (fetch phase): sau đó, nút điều phối sẽ lấy dữ liệu
documentthực tế từ các node dựa trêndoc id, và cuối cùng trả lại cho máy khách.
Yêu cầu ghi được ghi vào primary shard, sau đó đồng bộ hóa với tất cả các replica shard; yêu cầu đọc có thể được đọc từ primary shard hoặc replica shard, sử dụng thuật toán round-robin.
Nguyên lý cơ bản khi ghi dữ liệu
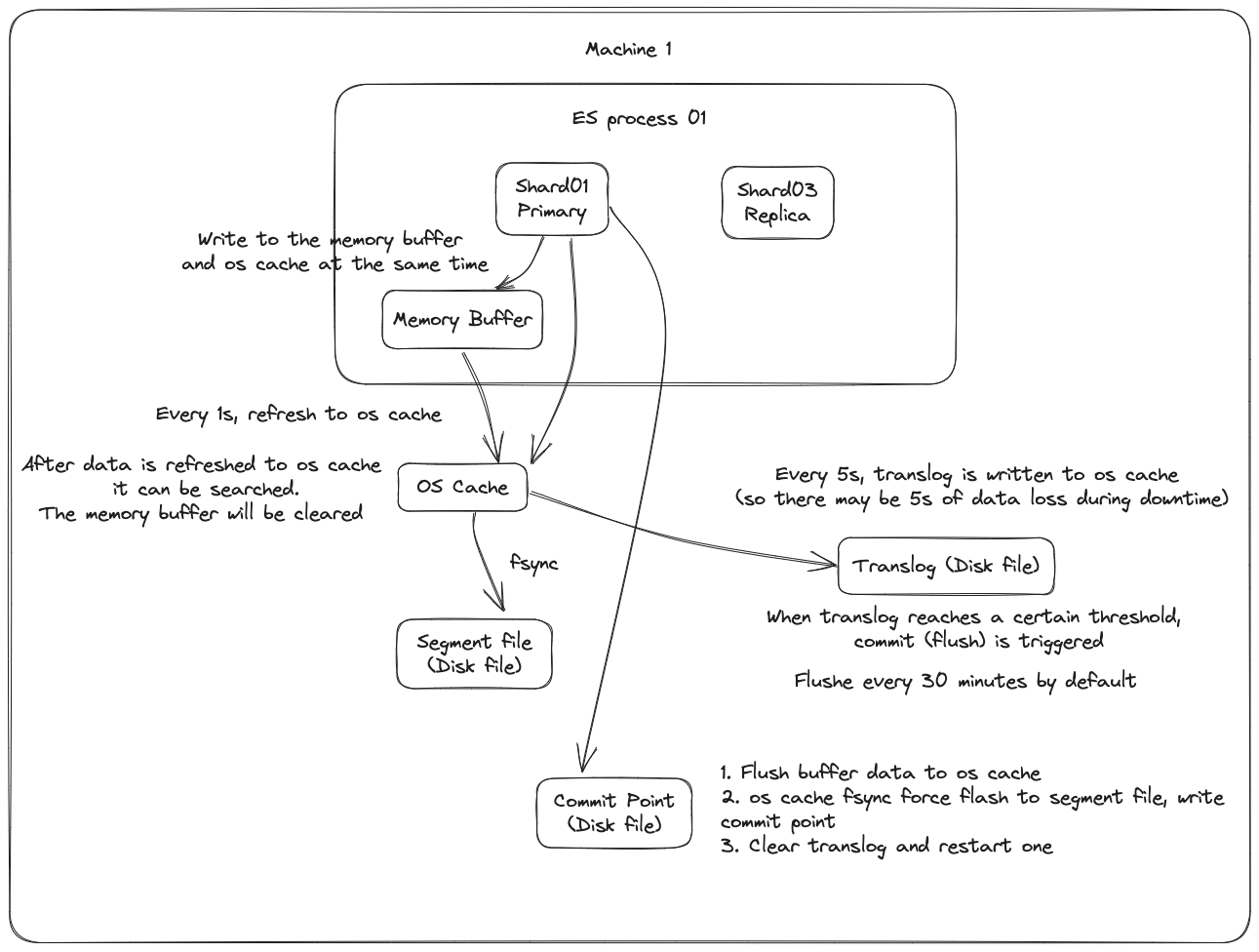
Đầu tiên, dữ liệu sẽ được ghi vào bộ đệm trong bộ nhớ (buffer), trong quá trình này dữ liệu không thể được tìm kiếm; đồng thời dữ liệu cũng được ghi vào tệp nhật ký translog.
Nếu bộ đệm gần như đầy, hoặc sau một khoảng thời gian nhất định, dữ liệu trong bộ đệm sẽ được refresh vào một segment file mới, nhưng lúc này dữ liệu không được ghi trực tiếp vào tệp segment file trên đĩa, mà phải đi vào os cache trước. Quá trình này được gọi là refresh.
Mỗi giây, ES sẽ ghi dữ liệu trong bộ đệm vào một segment file mới, mỗi giây sẽ tạo ra một tệp đĩa segment file mới, tệp segment file này sẽ lưu trữ dữ liệu được ghi vào bộ đệm trong 1 giây gần đây.
Tuy nhiên, nếu không có dữ liệu trong bộ đệm, thì tất nhiên không có quá trình refresh nào được thực hiện, nếu có dữ liệu trong bộ đệm, mặc định sẽ thực hiện một lần refresh mỗi giây, đẩy dữ liệu vào một segment file mới.
Trên hệ điều hành, tệp đĩa thực tế đều có một thứ gọi là os cache, tức là trước khi dữ liệu được ghi vào tệp đĩa, nó sẽ được đưa vào os cache trước, đầu tiên vào bộ nhớ cache cấp hệ điều hành. Chỉ cần dữ liệu trong bộ đệm được chuyển vào os cache thông qua hoạt động refresh, dữ liệu này có thể được tìm kiếm.
Tại sao nói rằng ES là gần như thời gian thực? NRT, tên đầy đủ là near real-time. Mặc định là refresh mỗi giây một lần, vì vậy ES là gần như thời gian thực, vì dữ liệu được ghi vào sau 1 giây mới có thể được tìm thấy. Bạn có thể sử dụng restful api của es hoặc java api để thực hiện một hoạt động refresh thủ công, tức là thủ công đưa dữ liệu trong bộ đệm vào os cache, để dữ liệu có thể được tìm kiếm ngay lập tức. Miễn là dữ liệu được đưa vào os cache, bộ đệm sẽ được làm sạch, vì không cần giữ bộ đệm nữa, dữ liệu đã được lưu trữ trong tệp nhật ký translog một lần.
Lặp lại các bước trên, dữ liệu mới liên tục vào bộ đệm và translog, liên tục ghi dữ liệu buffer vào một segment file mới sau mỗi lần refresh, sau mỗi lần refresh bộ đệm sẽ được làm sạch, translog sẽ được giữ lại. Khi quá trình này tiếp diễn, translog sẽ ngày càng lớn. Khi translog đạt đến một độ dài nhất định, nó sẽ kích hoạt hoạt động commit.
Bước đầu tiên của hoạt động commit là ghi dữ liệu hiện có trong bộ đệm vào os cache, sau đó làm sạch bộ đệm. Sau đó, ghi một commit point vào tệp đĩa, trong đó đánh dấu tất cả các segment file tương ứng với commit point này, đồng thời buộc os cache chứa tất cả dữ liệu hiện tại để được fsync vào tệp đĩa. Cuối cùng, xóa tệp nhật ký translog hiện tại, khởi động lại một translog, lúc này hoạt động commit đã hoàn thành.
Hoạt động commit này được gọi là flush. Mặc định là mỗi 30 phút tự động thực hiện một lần flush, nhưng nếu translog quá lớn, cũng sẽ kích hoạt flush. Hoạt động flush tương ứng với toàn bộ quá trình commit, chúng ta có thể thông qua api của es, thực hiện thủ công hoạt động flush, thủ công fsync dữ liệu trong os cache vào đĩa.
Tệp nhật ký translog có vai trò gì? Trước khi bạn thực hiện hoạt động commit, dữ liệu có thể đang nằm trong bộ đệm hoặc nằm trong os cache. Dù là bộ đệm hay os cache đều là bộ nhớ, nếu máy này bị hỏng, dữ liệu trong bộ nhớ sẽ mất hết. Vì vậy, cần ghi các hoạt động tương ứng của dữ liệu vào một tệp nhật ký đặc biệt là translog, nếu máy bị hỏng lúc này, khi khởi động lại, es sẽ tự động đọc dữ liệu từ tệp nhật ký translog và phục hồi vào bộ nhớ buffer và os cache.
Thực tế, translog cũng được ghi vào os cache trước, mặc định là mỗi 5 giây sẽ đẩy vào đĩa một lần, vì vậy mặc định, có thể có 5 giây dữ liệu chỉ nằm trong bộ đệm hoặc os cache hoặc tệp translog, không nằm trên đĩa, nếu máy này bị hỏng lúc này, sẽ mất 5 giây dữ liệu. Nhưng hiệu suất như vậy tốt hơn, mất tối đa 5 giây dữ liệu. Bạn cũng có thể đặt translog để mỗi lần ghi phải fsync trực tiếp vào đĩa, nhưng hiệu suất sẽ kém hơn nhiều.
Thực tế, nếu bạn ở đây, nếu người phỏng vấn không hỏi bạn về vấn đề mất dữ liệu của es, bạn có thể tự hào với người phỏng vấn ở đây, bạn nói, thực tế es trước tiên là gần như thời gian thực, dữ liệu được ghi vào sau 1 giây mới có thể được tìm thấy; có thể mất dữ liệu. Có 5 giây dữ liệu, nằm trong bộ đệm, os cache của translog, os cache của segment file, không nằm trên đĩa, nếu máy này bị hỏng lúc này, sẽ dẫn đến mất 5 giây dữ liệu.
Tóm lại, dữ liệu được ghi vào bộ đệm trước, sau đó mỗi giây, dữ liệu sẽ được refresh vào os cache, khi dữ liệu đến os cache, dữ liệu có thể được tìm kiếm (đó là lý do tại sao chúng ta nói rằng từ khi dữ liệu được ghi vào cho đến khi có thể tìm kiếm, có độ trễ 1s). Mỗi 5 giây, dữ liệu sẽ được ghi vào tệp translog (do đó, nếu máy bị hỏng, tất cả dữ liệu trong bộ nhớ sẽ mất, tối đa sẽ mất 5s dữ liệu), khi translog lớn đến một mức độ nhất định, hoặc mặc định mỗi 30 phút, một hoạt động commit sẽ được kích hoạt, đẩy tất cả dữ liệu trong bộ đệm vào tệp segment filetrên đĩa.
Sau khi dữ liệu được ghi vào
segment file, chỉ mục đảo ngược cũng sẽ được tạo ngay lập tức.
Nguyên lý cơ bản khi xóa/cập nhật dữ liệu
Nếu là hoạt động xóa, khi commit sẽ tạo ra một tệp .del, trong đó đánh dấu một doc nhất định là trạng thái deleted, vì vậy khi tìm kiếm, dựa vào tệp .del, bạn sẽ biết liệu doc có bị xóa hay không.
Nếu là hoạt động cập nhật, nó sẽ đánh dấu doc gốc là trạng thái deleted và sau đó ghi một dữ liệu mới.
Mỗi khi bộ đệm được refresh, một segment file sẽ được tạo ra, vì vậy mặc định là một segment file mỗi giây, vì vậy segment file sẽ ngày càng nhiều, lúc này sẽ thường xuyên thực hiện merge. Mỗi lần merge, nhiều segment file sẽ được hợp nhất thành một, đồng thời ở đây, doc được đánh dấu là deleted sẽ được xóa vật lý, sau đó ghi segment file mới vào đĩa, ở đây sẽ ghi một commit point, đánh dấu tất cả segment file mới, sau đó mở segment file để tìm kiếm, và sau đó xóa segment file cũ.
Lớp cơ bản Lucene
Đơn giản, Lucene chỉ là một thư viện jar, bên trong nó chứa các mã thuật toán đã được đóng gói để tạo chỉ mục đảo ngược. Khi chúng ta phát triển bằng Java, chúng ta chỉ cần import thư viện jar Lucene, sau đó phát triển dựa trên API của Lucene.
Thông qua Lucene, chúng ta có thể tạo chỉ mục cho dữ liệu hiện có, Lucene sẽ tổ chức cấu trúc dữ liệu chỉ mục trên ổ đĩa cục bộ cho chúng ta.
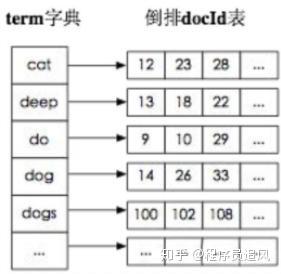
Chỉ mục đảo ngược
Trong công cụ tìm kiếm, mỗi tài liệu đều có một ID tài liệu tương ứng, nội dung tài liệu được biểu diễn dưới dạng một tập hợp các từ khóa. Ví dụ, sau khi phân loại, tài liệu 1 đã trích xuất 20 từ khóa, mỗi từ khóa đều ghi lại số lần xuất hiện và vị trí xuất hiện của nó trong tài liệu.
Vậy, chỉ mục đảo ngược là ánh xạ từ từ khóa đến ID tài liệu, mỗi từ khóa đều tương ứng với một loạt tài liệu, trong đó tất cả các tài liệu đều xuất hiện từ khóa.
Ví dụ.
Có các tài liệu sau:
| DocId | Doc |
|---|---|
| 1 | Cha của Google Maps chuyển sang Facebook |
| 2 | Cha của Google Maps gia nhập Facebook |
| 3 | Người sáng lập Google Maps, Lars rời Google để gia nhập Facebook |
| 4 | Cha của Google Maps chuyển sang Facebook có liên quan đến việc hủy dự án Wave |
| 5 | Cha của Google Maps, Lars gia nhập trang web xã hội Facebook |
Sau khi phân loại tài liệu, chúng ta nhận được chỉ mục đảo ngược sau.
| WordId | Word | DocIds |
|---|---|---|
| 1 | 1,2,3,4,5 | |
| 2 | Maps | 1,2,3,4,5 |
| 3 | Cha | 1,2,4,5 |
| 4 | Chuyển sang | 1,4 |
| 5 | 1,2,3,4,5 | |
| 6 | Gia nhập | 2,3,5 |
| 7 | Người sáng lập | 3 |
| 8 | Lars | 3,5 |
| 9 | Rời | 3 |
| 10 | Và | 4 |
| .. | .. | .. |
Ngoài ra, chỉ mục đảo ngược hữu ích còn có thể ghi lại nhiều thông tin hơn, chẳng hạn như thông tin tần suất tài liệu, cho biết có bao nhiêu tài liệu chứa một từ nhất định trong tập hợp tài liệu.
Vì vậy, với chỉ mục đảo ngược, công cụ tìm kiếm có thể dễ dàng phản hồi truy vấn của người dùng. Ví dụ, người dùng nhập truy vấn Facebook, hệ thống tìm kiếm tra cứu chỉ mục đảo ngược, đọc từ đó các tài liệu chứa từ này, các tài liệu này là kết quả tìm kiếm được cung cấp cho người dùng.
Cần chú ý đến hai chi tiết quan trọng của chỉ mục đảo ngược:
- Tất cả các mục từ trong chỉ mục đảo ngược tương ứng với một hoặc nhiều tài liệu;
- Các mục từ trong chỉ mục đảo ngược được sắp xếp theo thứ tự từ điển tăng dần.
Trên chỉ là một ví dụ đơn giản, không được sắp xếp theo thứ tự từ điển tăng dần một cách nghiêm ngặt.
Chỉ mục đảo ngược trong Elasticsearch là gì?
Người phỏng vấn: Tôi muốn hiểu rõ hơn về kiến thức cơ bản của bạn.
Trả lời: Hãy giải thích một cách dễ hiểu.
Thông thường, chúng ta tìm kiếm thông qua các bài viết, dò từng cái để tìm vị trí của từ khóa tương ứng.
Tuy nhiên, chỉ mục đảo ngược, thông qua chiến lược phân từ, tạo ra một bảng ánh xạ giữa từ và bài viết, bảng từ điển + ánh xạ này chính là chỉ mục đảo ngược. Với chỉ mục đảo ngược, chúng ta có thể thực hiện việc tìm kiếm bài viết với độ phức tạp thời gian là o(1), tăng đáng kể hiệu suất tìm kiếm.
Cách trả lời học thuật:
Chỉ mục đảo ngược, ngược lại với việc một bài viết chứa những từ nào, nó bắt đầu từ từ, ghi lại từ này đã xuất hiện trong những tài liệu nào, gồm hai phần - từ điển và bảng đảo ngược.
Điểm cộng: Cơ chế hoạt động cơ bản của chỉ mục đảo ngược dựa trên cấu trúc dữ liệu FST (Finite State Transducer).
Lucene từ phiên bản 4+ bắt đầu sử dụng cấu trúc dữ liệu FST một cách rộng rãi. FST có hai ưu điểm:
(1) Chiếm ít không gian. Bằng cách tái sử dụng tiền tố và hậu tố của các từ trong từ điển, nó đã nén không gian lưu trữ;
(2) Tốc độ truy vấn nhanh. Độ phức tạp thời gian truy vấn là O(len(str)).
3. Elasticsearch có quá nhiều dữ liệu chỉ mục thì phải làm sao, cần tối ưu như thế nào, triển khai như thế nào?
Người phỏng vấn: Tôi muốn hiểu khả năng quản lý dữ liệu lớn của bạn.
Trả lời: Kế hoạch cho dữ liệu chỉ mục nên được lập trước, đúng như câu “Thiết kế trước, mã hóa sau”, như vậy mới có thể tránh hiệu quả sự tăng dữ liệu đột ngột dẫn đến khả năng xử lý không đủ của cụm, gây ảnh hưởng đến khách hàng trực tuyến tìm kiếm hoặc các hoạt động kinh doanh khác.
Cách tối ưu, như đã nói trong câu hỏi 1, tôi sẽ chi tiết hơn ở đây:
3.1 Về mặt chỉ mục động
Dựa trên mẫu + thời gian + rollover api để tạo chỉ mục, ví dụ: trong giai đoạn thiết kế, chúng ta xác định: định dạng mẫu của chỉ mục blog là: blog * index * timestamp, dữ liệu tăng mỗi ngày. Lợi ích của việc làm như vậy: không để cho sự tăng dữ liệu đột ngột dẫn đến một chỉ mục duy nhất có rất nhiều dữ liệu, gần như tiếp cận đường biên 2 lần lũy thừa 32 -1, lưu trữ chỉ mục đạt đến TB+ hoặc thậm chí lớn hơn.
Một khi một chỉ mục duy nhất rất lớn, các rủi ro như lưu trữ cũng theo sau, vì vậy cần cân nhắc trước và tránh ngay từ đầu.
3.2 Về mặt lưu trữ
Phân tách lưu trữ dữ liệu nóng và lạnh, dữ liệu nóng (ví dụ: dữ liệu trong 3 ngày hoặc một tuần gần đây), phần còn lại là dữ liệu lạnh.
Đối với dữ liệu lạnh không còn ghi thêm dữ liệu mới, có thể xem xét thực hiện thao tác force_merge và shrink định kỳ để tiết kiệm không gian lưu trữ và hiệu suất tìm kiếm.
3.3 Về mặt triển khai
Một khi không có kế hoạch trước, đây là chiến lược khẩn cấp.
Kết hợp với tính năng mở rộng động của ES, cách thêm máy động có thể giảm áp lực cụm, lưu ý: nếu trước đó kế hoạch cho nút chính là hợp lý, không cần khởi động lại cụm cũng có thể hoàn thành việc thêm động.
4. Elasticsearch thực hiện việc bầu chọn master như thế nào
Người phỏng vấn: Tôi muốn hiểu về nguyên lý cơ bản của cụm ES, không chỉ tập trung vào mặt kinh doanh nữa.
Trả lời:
Điều kiện tiên quyết:
(1) Chỉ có các nút ứng cử làm master (master: true) mới có thể trở thành master.
(2) Số lượng master tối thiểu (min_master_nodes) có mục đích ngăn chặn tình trạng “bộ não bị chia cắt” (split-brain).
Tôi đã kiểm tra lại mã nguồn, điểm vào chính là findMaster, nếu việc chọn master thành công thì trả về Master tương ứng, nếu không thì trả về null. Quy trình bầu chọn được mô tả như sau:
Bước đầu tiên: Xác nhận số lượng nút ứng cử làm master đã đạt chuẩn, giá trị được thiết lập trong elasticsearch.yml
discovery.zen.minimum_master_nodes;
Bước thứ hai: So sánh: đầu tiên xác định xem nút có đủ điều kiện để làm master hay không, nếu có thì ưu tiên trả về;
Nếu cả hai nút đều là nút ứng cử làm master, thì nút có id nhỏ hơn sẽ trở thành master. Lưu ý ở đây id là kiểu string.
Ghi chú: Phương pháp để lấy id của nút.
1GET /_cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
2ip port heapPercent heapMax id nameHãy mô tả chi tiết quá trình Elasticsearch lập chỉ mục cho một tài liệu
Người phỏng vấn: Tôi muốn hiểu về nguyên lý cơ bản của ES, không chỉ tập trung vào mặt kinh doanh nữa.
Trả lời:
Ở đây, việc lập chỉ mục tài liệu nên được hiểu là quá trình ghi tài liệu vào ES, tạo chỉ mục.
Việc ghi tài liệu bao gồm: ghi tài liệu đơn và ghi hàng loạt bulk, ở đây tôi chỉ giải thích: quá trình ghi tài liệu đơn.
Hãy nhớ hình này trong tài liệu chính thức.
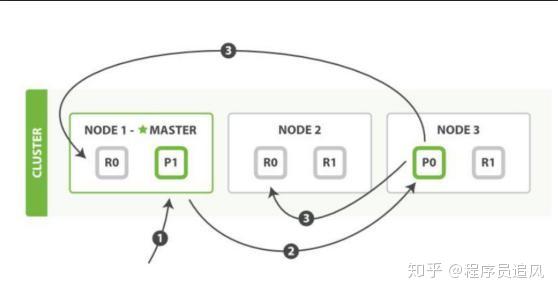
Bước đầu tiên: Khách hàng gửi yêu cầu ghi dữ liệu vào một nút nào đó trong cụm. (Nếu không chỉ định định tuyến/nút điều phối, nút nhận yêu cầu sẽ đóng vai trò là nút định tuyến.)
Bước thứ hai: Khi nút 1 nhận được yêu cầu, nó sử dụng _id của tài liệu để xác định tài liệu thuộc về shard 0. Yêu cầu sẽ được chuyển đến một nút khác, giả sử là nút 3. Do đó, shard chính của shard 0 được phân bổ trên nút 3.
Bước thứ ba: Nút 3 thực hiện thao tác ghi trên shard chính, nếu thành công, nó sẽ chuyển yêu cầu song song đến shard phụ trên nút 1 và nút 2, chờ kết quả trả về. Tất cả shard phụ đều báo cáo thành công, nút 3 sẽ báo cáo thành công cho nút điều phối (nút 1), nút 1 sẽ báo cáo thành công cho khách hàng yêu cầu.
Nếu người phỏng vấn hỏi thêm: Quá trình tài liệu lấy shard trong bước thứ hai là như thế nào?
Trả lời: Sử dụng thuật toán định tuyến để lấy, thuật toán định tuyến là quá trình tính toán id shard mục tiêu dựa trên định tuyến và id tài liệu.
1shard = hash(_routing) % (num_of_primary_shards)Hãy mô tả chi tiết quá trình tìm kiếm của Elasticsearch?
Người phỏng vấn: Tôi muốn hiểu về nguyên lý cơ bản của ES, không chỉ tập trung vào mặt kinh doanh nữa.
Trả lời:
Quá trình tìm kiếm được chia thành hai giai đoạn: “query” và “fetch”.
Mục đích của giai đoạn query: xác định vị trí, nhưng không lấy dữ liệu.
Các bước được tách ra như sau:
(1) Giả sử một chỉ mục dữ liệu có 5 shard chính + 1 shard phụ, tổng cộng 10 shard, mỗi yêu cầu sẽ trúng một trong các shard (chính hoặc phụ).
(2) Mỗi shard thực hiện truy vấn tại cục bộ, kết quả được trả về vào hàng đợi ưu tiên có thứ tự tại cục bộ.
(3) Kết quả từ bước (2) được gửi đến nút điều phối, nút điều phối tạo ra một danh sách sắp xếp toàn cầu.
Mục đích của giai đoạn fetch: lấy dữ liệu.
Nút định tuyến lấy tất cả các tài liệu và trả về cho khách hàng.
Khi triển khai Elasticsearch, có những phương pháp tối ưu hóa nào đối với Linux?
Người phỏng vấn: Tôi muốn hiểu về khả năng vận hành cụm ES.
Trả lời:
(1) Tắt bộ nhớ đệm swap;
(2) Đặt bộ nhớ heap thành: Min (bộ nhớ/nút, 32GB);
(3) Đặt số lượng tối đa của file handle;
(4) Kích thước của thread pool + hàng đợi cần được điều chỉnh theo nhu cầu kinh doanh;
(5) Phương pháp lưu trữ ổ đĩa RAID - nếu có điều kiện, sử dụng RAID10 để tăng hiệu suất của nút đơn và tránh sự cố lưu trữ ở nút đơn.
Cấu trúc bên trong của Lucene là gì?
Người phỏng vấn: Tôi muốn hiểu rộng và sâu về kiến thức của bạn.
Trả lời:
Lucene gồm hai quy trình chính: tạo chỉ mục và tìm kiếm. Có ba khía cạnh chính: tạo chỉ mục, chỉ mục và tìm kiếm. Chúng ta có thể mở rộng dựa trên khung này.
- Tạo chỉ mục (Index Creation): Đầu tiên, Lucene sẽ phân tích và xử lý dữ liệu thô, chẳng hạn như văn bản, để tạo ra một tập dữ liệu có cấu trúc có thể tìm kiếm được.
- Chỉ mục (Indexing): Sau đó, Lucene sẽ tạo ra một chỉ mục từ dữ liệu đã được xử lý. Chỉ mục này giống như một “mục lục” cho dữ liệu, giúp tăng tốc độ tìm kiếm.
- Tìm kiếm (Searching): Khi có yêu cầu tìm kiếm, Lucene sẽ sử dụng chỉ mục để nhanh chóng tìm ra kết quả phù hợp.
Đây là cấu trúc cơ bản của Lucene. Tuy nhiên, Lucene cũng hỗ trợ nhiều tính năng phức tạp hơn, chẳng hạn như tìm kiếm nâng cao, xếp hạng kết quả và nhiều hơn nữa.
Elasticsearch làm thế nào để thực hiện việc bầu chọn Master?
(1) Việc bầu chọn Master trong Elasticsearch do mô-đun ZenDiscovery chịu trách nhiệm, chủ yếu bao gồm hai phần: Ping (các nút sử dụng RPC này để phát hiện lẫn nhau) và Unicast (mô-đun đơn phát bao gồm một danh sách máy chủ để kiểm soát các nút nào cần ping).
(2) Đối với tất cả các nút có thể trở thành Master (node.master: true), sắp xếp theo nodeId theo thứ tự từ điển. Trong mỗi lần bầu cử, mỗi nút sẽ sắp xếp các nút mà nó biết theo thứ tự, sau đó chọn nút đầu tiên (vị trí thứ 0) và tạm thời coi nó là nút Master.
(3) Nếu số phiếu bầu cho một nút đạt đến một giá trị nhất định (số nút có thể trở thành Master là n/2 + 1) và nút đó cũng tự bầu chọn mình, thì nút đó sẽ trở thành Master. Ngược lại, quá trình bầu cử sẽ tiếp tục cho đến khi đạt được điều kiện trên.
(4) Bổ sung: Trách nhiệm chính của nút Master bao gồm việc quản lý cụm, nút và chỉ mục, không chịu trách nhiệm quản lý ở cấp độ tài liệu; nút data có thể tắt chức năng http*.
10. Trong Elasticsearch có các nút (ví dụ tổng cộng 20 nút), trong đó 10 nút đã chọn một Master, 10 nút còn lại đã chọn một Master khác, thì phải làm thế nào?
(1) Khi số lượng ứng cử viên Master của cụm không ít hơn 3, bạn có thể giải quyết vấn đề phân đôi bằng cách đặt số lượng phiếu tối thiểu để thông qua (discovery.zen.minimum_master_nodes) nhiều hơn một nửa số lượng ứng cử viên.
(3) Khi số lượng ứng cử viên là hai, bạn chỉ có thể chỉnh sửa để có một ứng cử viên Master duy nhất, các nút khác hoạt động như nút dữ liệu, để tránh vấn đề phân đôi.
Khi kết nối với cụm, khách hàng chọn nút cụ thể nào để thực hiện yêu cầu?
TransportClient sử dụng mô-đun transport để kết nối từ xa với một cụm Elasticsearch. Nó không tham gia vào cụm, chỉ đơn giản là nhận được một hoặc nhiều địa chỉ transport khởi tạo và giao tiếp với các địa chỉ này theo cách lập lịch.
Mô tả chi tiết quá trình Elasticsearch lập chỉ mục cho tài liệu.
Nút điều phối mặc định sử dụng ID tài liệu để tham gia vào tính toán (cũng hỗ trợ thông qua routing), để cung cấp một phân đoạn phù hợp cho định tuyến.
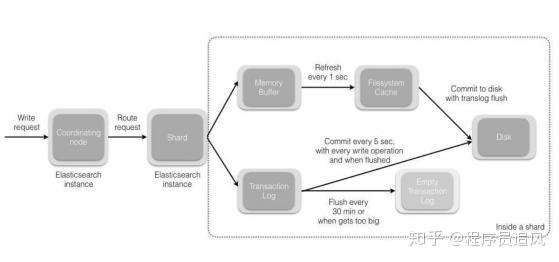
shard = hash(document_id) % (num_of_primary_shards)(1) Khi nút chứa phân đoạn nhận được yêu cầu từ nút điều phối, nó sẽ ghi yêu cầu vào MemoryBuffer, sau đó định kỳ (mặc định là mỗi giây) ghi vào Filesystem Cache, quá trình từ MomeryBuffer sang Filesystem Cache này được gọi là refresh.
(2) Tất nhiên, trong một số trường hợp, dữ liệu tồn tại trong Momery Buffer và Filesystem Cache có thể bị mất, ES sử dụng cơ chế translog để đảm bảo tính đáng tin cậy của dữ liệu. Cơ chế thực hiện là sau khi nhận được yêu cầu, cũng sẽ ghi vào translog, khi dữ liệu trong Filesystem cache được ghi vào đĩa, mới được xóa, quá trình này được gọi là flush.
(3) Trong quá trình flush, bộ đệm trong bộ nhớ sẽ được xóa, nội dung được ghi vào một phân đoạn mới, fsync của phân đoạn sẽ tạo một điểm commit mới và làm mới nội dung vào đĩa, translog cũ sẽ bị xóa và bắt đầu một translog mới.
(4) Thời điểm kích hoạt flush là định kỳ (mặc định 30 phút) hoặc khi translog trở nên quá lớn (mặc định là 512M).
Bổ sung: Về Segement của Lucene:
(1) Chỉ mục Lucene được tạo thành từ nhiều phân đoạn, mỗi phân đoạn là một chỉ mục nghịch đảo đầy đủ chức năng.
(2) Phân đoạn là bất biến, cho phép Lucene thêm tài liệu mới vào chỉ mục một cách tăng dần mà không cần xây dựng lại chỉ mục từ đầu.
(3) Đối với mỗi yêu cầu tìm kiếm, tất cả các phân đoạn trong chỉ mục sẽ được tìm kiếm, và mỗi phân đoạn sẽ tiêu thụ chu kỳ đồng hồ CPU, tay cầm tệp và bộ nhớ. Điều này có nghĩa là càng nhiều phân đoạn, hiệu suất tìm kiếm sẽ càng thấp.
(4) Để giải quyết vấn đề này, Elasticsearch sẽ hợp nhất các phân đoạn nhỏ vào một phân đoạn lớn hơn, gửi phân đoạn hợp nhất mới đến đĩa, và xóa các phân đoạn nhỏ cũ.
Mô tả chi tiết quá trình Elasticsearch cập nhật và xóa tài liệu.
(1) Xóa và cập nhật đều là các thao tác ghi, nhưng tài liệu trong Elasticsearch là bất biến, do đó không thể bị xóa hoặc thay đổi để thể hiện sự thay đổi của nó;
(2) Mỗi phân đoạn trên đĩa đều có một tệp .del tương ứng. Khi yêu cầu xóa được gửi, tài liệu không bị xóa thật sự, mà chỉ được đánh dấu là đã xóa trong tệp .del. Tài liệu vẫn có thể khớp với truy vấn, nhưng sẽ bị lọc ra khỏi kết quả. Khi các phân đoạn được hợp nhất, tài liệu đã được đánh dấu là đã xóa trong tệp .del sẽ không được ghi vào phân đoạn mới.
(3) Khi tạo tài liệu mới, Elasticsearch sẽ gán một số phiên bản cho tài liệu đó, khi thực hiện cập nhật, phiên bản cũ của tài liệu được đánh dấu là đã xóa trong tệp .del, phiên bản mới của tài liệu được lập chỉ mục vào một phân đoạn mới. Phiên bản cũ của tài liệu vẫn có thể khớp với truy vấn, nhưng sẽ bị lọc ra khỏi kết quả.
Mô tả chi tiết quá trình tìm kiếm của Elasticsearch.
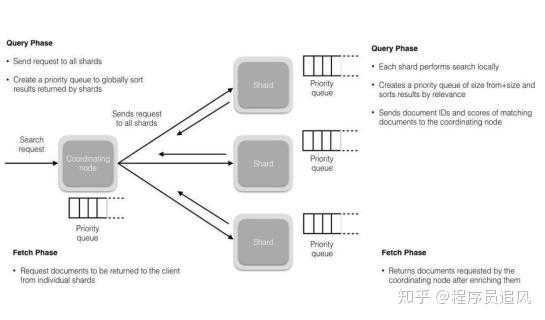
(1) Tìm kiếm được thực hiện theo một quy trình hai giai đoạn, chúng tôi gọi nó là Query Then Fetch;
(2) Trong giai đoạn truy vấn ban đầu, truy vấn sẽ được phát sóng đến mỗi bản sao phân đoạn trong chỉ mục (phân đoạn chính hoặc phân đoạn sao chép). Mỗi phân đoạn thực hiện tìm kiếm cục bộ và xây dựng một hàng đợi ưu tiên có kích thước là from + size cho tài liệu khớp.
Lưu ý: Khi tìm kiếm, nó sẽ truy vấn Filesystem Cache, nhưng một số dữ liệu vẫn còn trong MemoryBuffer, vì vậy tìm kiếm là gần thời gian thực.
(3) Mỗi phân đoạn trả về ID và giá trị sắp xếp của tất cả các tài liệu trong hàng đợi ưu tiên của mình cho nút điều phối, nó hợp nhất các giá trị này vào hàng đợi ưu tiên của mình để tạo ra một danh sách kết quả đã sắp xếp toàn cầu.
(4) Tiếp theo là giai đoạn lấy, nút điều phối xác định những tài liệu nào cần được lấy và gửi nhiều yêu cầu GET đến các phân đoạn liên quan. Mỗi phân đoạn tải và làm giàu tài liệu, nếu cần, sau đó trả lại tài liệu cho nút điều phối. Một khi tất cả các tài liệu đã được lấy, nút điều phối trả kết quả cho khách hàng.
(5) Bổ sung: Loại tìm kiếm Query Then Fetch tham chiếu đến dữ liệu phân đoạn cục bộ khi điểm số liên quan đến tài liệu, điều này có thể không chính xác khi số lượng tài liệu nhỏ, DFS Query Then Fetch thêm một xử lý truy vấn trước, hỏi về Term và Document frequency, điểm số này chính xác hơn, nhưng hiệu suất sẽ giảm.
Trong Elasticsearch, làm thế nào để tìm thấy chỉ mục nghịch đảo tương ứng với một từ?
(1) Quá trình lập chỉ mục của Lucene, là quá trình viết bảng nghịch đảo theo định dạng tệp này theo quy trình cơ bản của tìm kiếm toàn văn.
(2) Quá trình tìm kiếm của Lucene, là quá trình đọc thông tin đã được lập chỉ mục vào tệp này theo định dạng này, sau đó tính điểm (score) cho mỗi tài liệu.
Khi triển khai Elasticsearch, phương pháp tối ưu hóa nào có thể áp dụng cho Linux?
(1) Máy có bộ nhớ 64 GB là lý tưởng nhất, nhưng máy có bộ nhớ 32 GB và 16 GB cũng rất phổ biến. Máy có bộ nhớ dưới 8 GB sẽ không hiệu quả.
(2) Nếu bạn phải lựa chọn giữa CPU nhanh hơn và nhiều nhân hơn, hãy chọn nhiều nhân hơn. Sự song song hóa do nhiều nhân mang lại sẽ vượt trội hơn nhiều so với tốc độ xung nhịp nhanh hơn một chút.
(3) Nếu bạn có thể chi trả cho SSD, nó sẽ vượt trội hơn bất kỳ phương tiện quay nào. Nút dựa trên SSD, cả hiệu suất truy vấn và chỉ mục đều được cải thiện. Nếu bạn có thể chi trả, SSD là một lựa chọn tốt.
(4) Kể cả khi các trung tâm dữ liệu gần nhau, cũng nên tránh triển khai cụm trên nhiều trung tâm dữ liệu. Hãy hoàn toàn tránh cụm trải qua khoảng cách địa lý lớn.
(5) Hãy đảm bảo rằng JVM chạy ứng dụng của bạn và JVM của máy chủ hoàn toàn giống nhau. Elasticsearch sử dụng tuần tự hóa gốc Java ở một số nơi.
(6) Bằng cách thiết lập gateway.recover_after_nodes, gateway.expected_nodes, gateway.recover_after_time, bạn có thể tránh trao đổi quá nhiều phân đoạn khi khởi động lại cụm, điều này có thể giảm thời gian khôi phục dữ liệu từ một vài giờ xuống chỉ vài giây.
(7) Elasticsearch mặc định được cấu hình để sử dụng khám phá unicast để tránh việc các nút không mong muốn tham gia vào cụm. Chỉ có các nút chạy trên cùng một máy mới tự động tạo thành một cụm. Nên sử dụng unicast thay vì multicast.
(8) Đừng thay đổi kích thước của thu gom rác (CMS) và các hồ bơi luồng một cách tùy tiện.
(9) Đưa một nửa (hoặc ít hơn) bộ nhớ của bạn cho Lucene (nhưng không quá 32 GB!), thông qua biến môi trường ES_HEAP_SIZE.
(10) Việc trao đổi bộ nhớ sang đĩa là chết người đối với hiệu suất máy chủ. Nếu bộ nhớ được trao đổi sang đĩa, một hoạt động 100 microsecond có thể trở thành 10 millisecond. Hãy nghĩ về việc cộng dồn độ trễ của nhiều hoạt động 10 microsecond. Không khó để thấy swapping là một nỗi kinh hoàng đối với hiệu suất.
(11) Lucene sử dụng rất nhiều tệp. Đồng thời, Elasticsearch cũng sử dụng rất nhiều socket để giao tiếp giữa các nút và HTTP Client. Tất cả những điều này đều yêu cầu đủ số lượng mô tả tệp. Bạn nên tăng số lượng mô tả tệp của mình, đặt một giá trị lớn, như 64,000.
Bổ sung: Phương pháp tăng cường hiệu suất trong giai đoạn chỉ mục
(1) Sử dụng yêu cầu hàng loạt và điều chỉnh kích thước của nó: Mỗi lô dữ liệu từ 5-15 MB là một điểm bắt đầu tốt.
(2) Lưu trữ: Sử dụng SSD
(3) Phân đoạn và hợp nhất: Elasticsearch mặc định là 20 MB/s, đối với đĩa cơ học, đây có thể là một cài đặt tốt. Nếu bạn sử dụng SSD, bạn có thể cân nhắc tăng lên 100-200 MB/s. Nếu bạn đang thực hiện nhập hàng loạt, hoàn toàn không quan tâm đến tìm kiếm, bạn có thể tắt hoàn toàn giới hạn hợp nhất. Ngoài ra, bạn cũng có thể tăng thiết lập index.translog.flush_threshold_size từ mặc định là 512 MB lên một giá trị lớn hơn, như 1 GB, điều này có thể tạo ra phân đoạn lớn hơn trong nhật ký giao dịch mỗi khi xảy ra xảy ra một lần xả.
(4) Nếu kết quả tìm kiếm của bạn không cần độ chính xác gần thời gian thực, hãy xem xét thay đổi index.refresh_interval của mỗi chỉ mục thành 30s.
(5) Nếu bạn đang thực hiện nhập hàng loạt, hãy xem xét tắt bản sao bằng cách đặt index.number_of_replicas: 0.
Đối với GC, điều gì cần chú ý khi sử dụng Elasticsearch?
(1) Chỉ mục từ nghịch đảo cần phải cố định trong bộ nhớ, không thể GC, cần giám sát xu hướng tăng segmentmemory trên data node.
(2) Các loại bộ nhớ đệm, field cache, filter cache, indexing cache, bulk queue, v.v., nên được đặt kích thước hợp lý, và nên dựa vào trường hợp xấu nhất để xem liệu heap có đủ không, tức là khi tất cả các loại bộ nhớ đệm đều được sử dụng hết, liệu vẫn còn không gian heap để cấp phát cho nhiệm vụ khác không? Tránh việc sử dụng phương pháp như clear cache để giải phóng bộ nhớ.
(3) Tránh tìm kiếm và tổng hợp trả về một lượng lớn kết quả. Trong những tình huống thực sự cần rút lớn dữ liệu, bạn có thể sử dụng scan & scroll api để thực hiện.
(4) Cluster stats được giữ trong bộ nhớ và không thể mở rộng theo chiều ngang, cụm quy mô siêu lớn có thể xem xét chia thành nhiều cụm thông qua tribe node.
(5) Muốn biết heap có đủ không, bạn phải kết hợp với tình huống ứng dụng thực tế, và tiếp tục giám sát việc sử dụng heap của cụm.
(6) Dựa vào dữ liệu giám sát để hiểu nhu cầu về bộ nhớ, cấu hình hợp lý cho các loại circuit breaker, giảm thiểu rủi ro tràn bộ nhớ xuống mức thấp nhất.
18. Elasticsearch làm thế nào để thực hiện tổng hợp số lượng lớn dữ liệu (hàng tỷ)?
Elasticsearch cung cấp một loại tổng hợp gần đúng gọi là cardinality. Nó cung cấp số lượng giá trị duy nhất (distinct hoặc unique) của một trường. Điều này được thực hiện dựa trên thuật toán HyperLogLog (HLL). HLL sẽ đầu tiên thực hiện các phép tính băm trên đầu vào, sau đó dựa vào các bit trong kết quả băm để ước lượng xác suất và thu được số lượng giá trị duy nhất. Những đặc điểm của nó bao gồm:
- Độ chính xác có thể cấu hình, được sử dụng để kiểm soát việc sử dụng bộ nhớ (độ chính xác cao hơn = sử dụng nhiều bộ nhớ hơn).
- Đối với tập dữ liệu nhỏ, độ chính xác rất cao.
- Bạn có thể đặt số lượng bộ nhớ cố định cần thiết cho việc loại bỏ trùng lặp thông qua các tham số cấu hình. Bất kể số lượng giá trị duy nhất là hàng nghìn hay hàng tỷ, lượng bộ nhớ sử dụng chỉ liên quan đến độ chính xác bạn cấu hình.
19. Trong tình huống đồng thời, Elasticsearch làm thế nào để đảm bảo tính nhất quán của đọc và ghi?
(1)Có thể sử dụng kiểm soát đồng thời lạc quan thông qua số phiên bản, để đảm bảo rằng phiên bản mới sẽ không bị phiên bản cũ ghi đè, và để lớp ứng dụng xử lý các xung đột cụ thể.
(2)Ngoài ra, đối với thao tác ghi, mức độ nhất quán hỗ trợ quorum/one/all, mặc định là quorum, tức chỉ cho phép thao tác ghi khi phần lớn các phân đoạn có sẵn. Tuy nhiên, ngay cả khi phần lớn đều có sẵn, cũng có thể xảy ra tình huống do mạng và những nguyên nhân khác dẫn đến việc ghi vào bản sao thất bại, điều này khiến bản sao đó bị coi là lỗi, và phân đoạn sẽ được xây dựng lại trên một nút khác.
(3)Đối với thao tác đọc, bạn có thể đặt replication là sync (mặc định), điều này khiến thao tác chỉ trả về sau khi hoàn thành trên cả phân đoạn chính và phân đoạn sao; nếu đặt replication là async, bạn cũng có thể đặt tham số yêu cầu tìm kiếm _preference là primary để truy vấn phân đoạn chính, đảm bảo rằng tài liệu là phiên bản mới nhất.
20. Làm thế nào để giám sát trạng thái của cụm Elasticsearch?
Marvel cho phép bạn dễ dàng giám sát Elasticsearch thông qua Kibana. Bạn có thể xem trạng thái sức khỏe và hiệu suất của cụm trong thời gian thực, cũng như phân tích các chỉ số cụm, chỉ mục và nút trong quá khứ.
21. Hãy giới thiệu về kiến trúc công nghệ tổng thể của tìm kiếm thương mại điện tử của bạn.
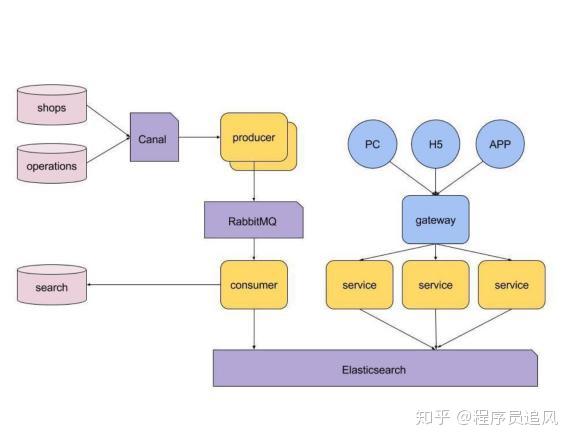
Hãy giới thiệu về giải pháp tìm kiếm cá nhân hóa của bạn?
Thực hiện tìm kiếm cá nhân hóa dựa trên word2vec và Elasticsearch
(1)Dựa trên word2vec, Elasticsearch và plug-in script tùy chỉnh của chúng tôi, chúng tôi đã thực hiện một dịch vụ tìm kiếm cá nhân hóa, so với phiên bản gốc, tỷ lệ nhấp chuột và tỷ lệ chuyển đổi mới đều tăng đáng kể;
(2)Vector sản phẩm dựa trên word2vec cũng có một ứng dụng khác, đó là có thể được sử dụng để thực hiện đề xuất sản phẩm tương tự;
(3)Sử dụng word2vec để thực hiện tìm kiếm cá nhân hóa hoặc đề xuất cá nhân hóa có một số hạn chế, bởi vì nó chỉ có thể xử lý dữ liệu chuỗi thời gian như lịch sử nhấp chuột của người dùng, và không thể xem xét toàn diện sở thích của người dùng, điều này vẫn còn rất nhiều không gian để cải thiện và nâng cao;
Bạn có biết về Trie (cây từ điển) không?
Ý tưởng chính của Trie là sử dụng không gian để tiết kiệm thời gian, sử dụng tiền tố chung của chuỗi để giảm thiểu chi phí truy vấn và tăng hiệu suất. Nó có 3 tính chất cơ bản:
1)Nút gốc không chứa ký tự, ngoại trừ nút gốc, mỗi nút chỉ chứa một ký tự.
2)Từ nút gốc đến một nút nào đó, các ký tự trên đường đi nối lại với nhau, tạo thành chuỗi tương ứng với nút đó.
3)Tất cả các nút con của mỗi nút đều chứa các ký tự không giống nhau.
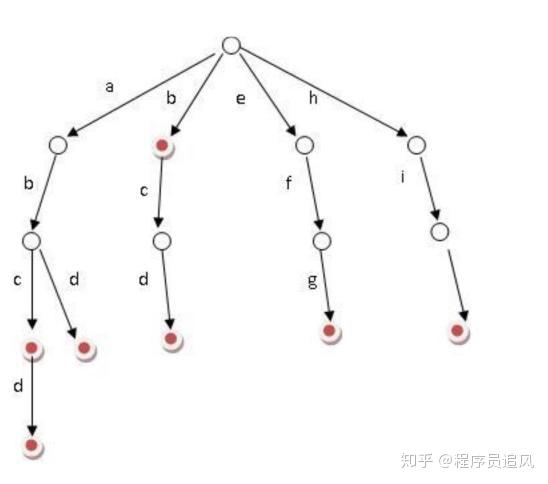
(1)Bạn có thể thấy rằng, số lượng nút ở mỗi cấp của cây Trie là ở cấp độ . Vì vậy, để tiết kiệm không gian, chúng ta có thể sử dụng danh sách liên kết động, hoặc mô phỏng động bằng mảng. Và việc sử dụng không gian, sẽ không vượt quá số lượng từ × độ dài từ.
(2)Cài đặt: Mở một mảng kích thước bộ chữ cái cho mỗi nút, mỗi nút treo một danh sách liên kết, sử dụng phương pháp biểu diễn con trái người anh em phải để ghi lại cây này;
Làm thế nào để thực hiện sửa lỗi chính tả?
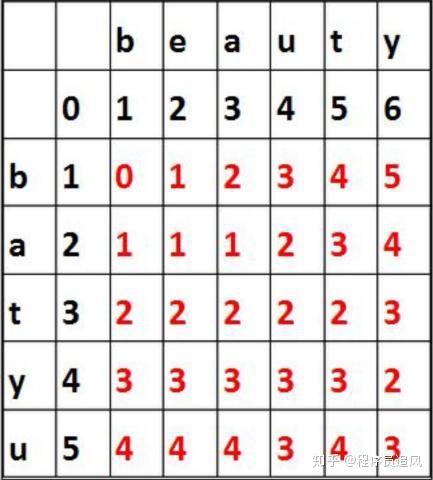
(1)Sửa lỗi chính tả được thực hiện dựa trên khoảng cách chỉnh sửa; khoảng cách chỉnh sửa là một phương pháp tiêu chuẩn, nó được sử dụng để biểu thị số lượng tối thiểu các hoạt động chèn, xóa và thay thế từ một chuỗi chuyển đổi sang một chuỗi khác;
(2)Quá trình tính toán khoảng cách chỉnh sửa: ví dụ, để tính khoảng cách chỉnh sửa giữa batyu và beauty, trước tiên tạo một bảng 7×8 (độ dài của batyu là 5, độ dài của coffee là 6, cộng thêm 2), sau đó, điền số đen vào các vị trí sau. Quá trình tính toán của ô khác là lấy giá trị nhỏ nhất trong ba giá trị sau:
Nếu ký tự ở trên cùng bằng ký tự ở bên trái, thì nó là số ở góc trên bên trái. Nếu không, nó là số ở góc trên bên trái +1. (Đối với 3,3, nó là 0)
Số bên trái +1 (đối với ô 3,3, nó là 2)
Số ở trên +1 (đối với ô 3,3, nó là 2)
Cuối cùng, lấy giá trị ở góc dưới bên phải là giá trị khoảng cách chỉnh sửa 3.
Đối với việc sửa lỗi chính tả, chúng tôi xem xét việc xây dựng một không gian đo lường (Metric Space), trong đó mọi mối quan hệ trong không gian này đều tuân theo ba điều kiện cơ bản sau:
— Nếu khoảng cách từ x đến y là 0, thì x=y
— Khoảng cách từ x đến y tương đương với khoảng cách từ y đến x
— Bất đẳng thức tam giác
(1)Dựa vào bất đẳng thức tam giác, thì một ký tự B nằm trong phạm vi n từ query, khoảng cách tối đa từ A đến B là d+n, và khoảng cách tối thiểu là d-n.
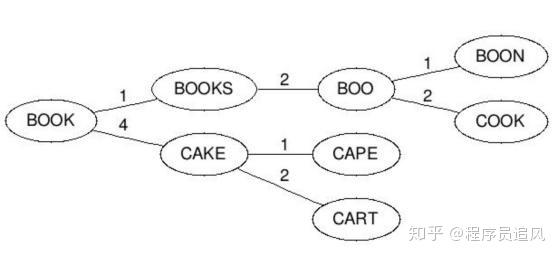
(2)Quá trình xây dựng cây BK như sau: mỗi nút có bất kỳ số lượng nút con, mỗi cạnh có một giá trị biểu thị khoảng cách chỉnh sửa. Tất cả các nút con đến nút cha có giá trị n biểu thị khoảng cách chỉnh sửa chính xác là n. Ví dụ, chúng ta có một cây với nút cha là “book” và hai nút con là “cake” và “books”, cạnh từ “book” đến “books” có giá trị 1, cạnh từ “book” đến “cake” có giá trị 4. Sau khi xây dựng xong cây từ từ điển, bất cứ khi nào bạn muốn chèn một từ mới, bạn tính khoảng cách chỉnh sửa giữa từ mới và nút gốc và tìm cạnh có giá trị d(neweord, root). So sánh đệ quy với mỗi nút con cho đến khi không còn nút con nào, bạn có thể tạo một nút con mới và lưu từ mới tại đó. Ví dụ, chèn “boo” vào cây trong ví dụ trước, chúng ta kiểm tra nút gốc trước, tìm cạnh có giá trị d(“book”, “boo”) = 1, sau đó kiểm tra nút con có giá trị 1 trên cạnh, nhận được từ “books”. Chúng tôi lại tính khoảng cách d(“books”, “boo”)=2, sau đó chèn từ mới sau “books”, và giá trị cạnh là 2.
(3)Quy trình tìm kiếm từ tương tự như sau: Tính khoảng cách chỉnh sửa giữa từ và nút gốc d, sau đó tìm đệ quy mỗi cạnh con có giá trị từ d-n đến d+n (bao gồm). Nếu nút được kiểm tra có khoảng cách d so với từ tìm kiếm nhỏ hơn n, thì trả về nút đó và tiếp tục tìm kiếm. Ví dụ, nhập cape và khoảng cách chịu đựng tối đa là 1, sau đó tính khoảng cách chỉnh sửa với nút gốc d(“book”, “cape”)=4, sau đó tìm kiếm nút con giữa nút gốc và khoảng cách chỉnh sửa từ 3 đến 5, tìm thấy nút cake, tính toán d(“cake”, “cape”)=1, đáp ứng yêu cầu nên trả về cake, sau đó tìm nút con giữa nút cake và khoảng cách chỉnh sửa từ 0 đến 2, tìm thấy nút cape và cart, như vậy, kết quả cape đáp ứng yêu cầu đã được tìm thấy.