Hadoop YARN
Giới thiệu về hadoop yarn
Apache YARN (Yet Another Resource Negotiator) là hệ thống quản lý tài nguyên cụm được giới thiệu trong hadoop 2.0. Người dùng có thể triển khai các khung dịch vụ khác nhau trên YARN, và YARN sẽ quản lý và phân bổ tài nguyên một cách tổng thể.
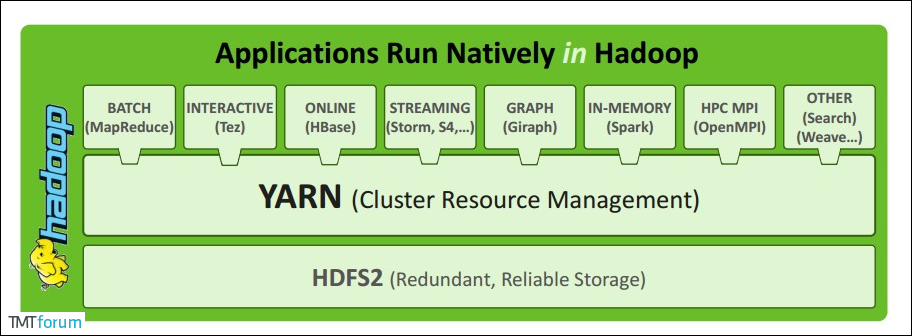
Kiến trúc YARN
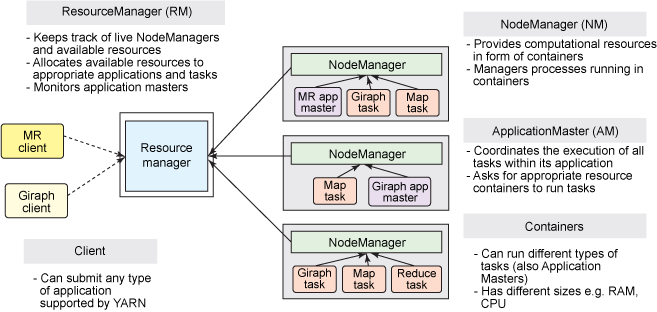
1. ResourceManager
ResourceManager thường chạy dưới dạng tiến trình nền trên một máy riêng biệt, nó là người phối hợp và quản lý tài nguyên chính của toàn bộ cụm. ResourceManager phân bổ tài nguyên cho tất cả các ứng dụng người dùng gửi, nó đưa ra quyết định dựa trên ưu tiên của ứng dụng, dung lượng hàng đợi, ACLs, vị trí dữ liệu, v.v., sau đó xác định chiến lược phân bổ dưới dạng chia sẻ, an toàn, đa thuê ký.
2. NodeManager
NodeManager là người quản lý của mỗi nút cụ thể trong cụm YARN. Chủ yếu chịu trách nhiệm quản lý vòng đời tất cả các container trong nút này, giám sát tài nguyên và theo dõi sức khỏe nút. Cụ thể như sau:
- Đăng ký với
ResourceManagerkhi khởi động và gửi thông điệp heartbeat theo định kỳ, chờ chỉ thị từResourceManager; - Duy trì vòng đời của
Container, giám sát việc sử dụng tài nguyên củaContainer; - Quản lý các phụ thuộc liên quan đến chạy nhiệm vụ, sao chép chương trình cần thiết và phụ thuộc của nó đến cục bộ trước khi khởi động
Containertheo yêu cầu củaApplicationMaster.
3. ApplicationMaster
Khi người dùng gửi một ứng dụng, YARN sẽ khởi động một tiến trình nhẹ ApplicationMaster. ApplicationMaster chịu trách nhiệm phối hợp tài nguyên từ ResourceManager và giám sát việc sử dụng tài nguyên trong container thông qua NodeManager, đồng thời còn chịu trách nhiệm giám sát nhiệm vụ và khả năng chịu lỗi. Cụ thể như sau:
- Quyết định nhu cầu tài nguyên tính toán động dựa trên trạng thái chạy của ứng dụng;
- Yêu cầu tài nguyên từ
ResourceManager, giám sát việc sử dụng tài nguyên đã yêu cầu; - Theo dõi trạng thái và tiến trình của nhiệm vụ, báo cáo việc sử dụng tài nguyên và thông tin tiến trình của ứng dụng;
- Chịu trách nhiệm khả năng chịu lỗi của nhiệm vụ.
4. Container
Container là trừu tượng hóa tài nguyên trong YARN, nó đóng gói tài nguyên đa chiều trên một nút nhất định, chẳng hạn như bộ nhớ, CPU, đĩa, mạng, v.v. Khi AM yêu cầu tài nguyên từ RM, RM sẽ trả lại tài nguyên cho AM dưới dạng Container. YARN sẽ cấp một Container cho mỗi nhiệm vụ, nhiệm vụ chỉ có thể sử dụng tài nguyên được mô tả trong Container đó. ApplicationMaster có thể chạy bất kỳ loại nhiệm vụ nào trong Container. Ví dụ, MapReduce ApplicationMaster yêu cầu một container để khởi động nhiệm vụ map hoặc reduce, trong khi Giraph ApplicationMaster yêu cầu một container để chạy nhiệm vụ Giraph.
Mô tả ngắn gọn về cách làm việc của YARN
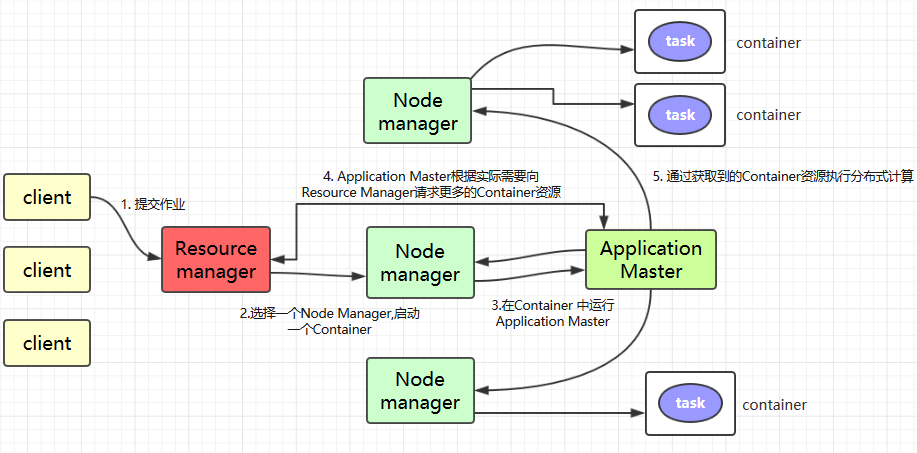
Clientgửi công việc đến YARN;Resource Managerchọn mộtNode Manager, khởi động mộtContainervà chạy một thể hiện củaApplication Master;Application Masteryêu cầu thêm tài nguyênContainertừResource Managerdựa trên nhu cầu thực tế (nếu công việc rất nhỏ, trình quản lý ứng dụng sẽ chọn chạy tác vụ trong JVM của chính nó);Application Masterthực hiện tính toán phân tán thông qua tài nguyênContainerđã nhận được.
Chi tiết về cách hoạt động của YARN
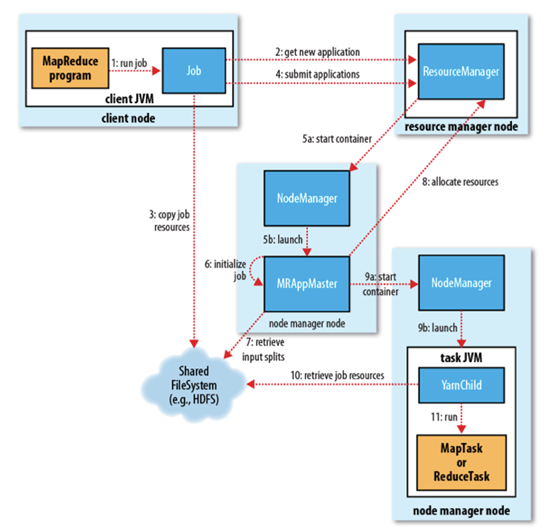
1. Gửi công việc
Client gọi phương thức job.waitForCompletion để gửi công việc MapReduce đến cụm toàn bộ (bước 1). ID công việc mới (ID ứng dụng) được ResourceManager phân bổ (bước 2). Client của công việc kiểm tra đầu ra của công việc, tính toán input split, sao chép tài nguyên công việc (bao gồm gói Jar, tệp cấu hình, thông tin split) cho HDFS (bước 3). Cuối cùng, gửi công việc bằng cách gọi phương thức submitApplication() của ResourceManager (bước 4).
2. Khởi tạo công việc
Khi ResourceManager nhận được yêu cầu submitApplciation(), nó sẽ gửi yêu cầu này cho scheduler (bộ lập lịch), scheduler phân bổ container, sau đó ResourceManager khởi chạy tiến trình ApplicationMaster trong container đó, được NodeManager giám sát (bước 5).
ApplicationMaster của công việc MapReduce là một ứng dụng Java với lớp chính là MRAppMaster, nó tạo một số đối tượng bookkeeping để giám sát tiến trình công việc, nhận tiến trình và báo cáo hoàn thành nhiệm vụ (bước 6). Sau đó, nó nhận thông tin input split đã được tính toán trước bởi client thông qua hệ thống tệp phân tán (bước 7), sau đó tạo một nhiệm vụ map cho mỗi input split, tạo đối tượng nhiệm vụ reduce dựa trên mapreduce.job.reduces.
3. Phân bổ nhiệm vụ
Nếu công việc nhỏ, ApplicationMaster sẽ chọn chạy nhiệm vụ trong JVM của chính nó.
Nếu không phải là công việc nhỏ, thì ApplicationMaster sẽ yêu cầu ResourceManager cung cấp container để chạy tất cả các nhiệm vụ map và reduce (bước 8). Những yêu cầu này được truyền qua heartbeat, bao gồm vị trí dữ liệu của mỗi nhiệm vụ map, chẳng hạn như tên máy chủ và rack (rack) lưu trữ input split, scheduler sử dụng thông tin này để lập lịch nhiệm vụ, cố gắng phân bổ nhiệm vụ cho các nút lưu trữ dữ liệu, hoặc phân bổ cho các nút trên cùng rack với nút lưu trữ input split.
4. Chạy nhiệm vụ
Khi một nhiệm vụ được phân bổ container bởi scheduler của ResourceManager, ApplicationMaster sẽ liên hệ với NodeManager để khởi chạy container (bước 9). Nhiệm vụ được thực hiện bởi một ứng dụng Java với lớp chính là YarnChild, trước khi chạy nhiệm vụ, nó sẽ đưa tài nguyên cần thiết cho nhiệm vụ về cục bộ, chẳng hạn như cấu hình công việc, tệp JAR, và tất cả các tệp của bộ nhớ cache phân tán (bước 10. Cuối cùng, chạy nhiệm vụ map hoặc reduce (bước 11).
YarnChild chạy trong một JVM riêng biệt, nhưng YARN không hỗ trợ việc tái sử dụng JVM.
5. Cập nhật tiến trình và trạng thái
Nhiệm vụ trong YARN sẽ trả lại tiến trình và trạng thái của nó (bao gồm counter) cho ApplicationMaster, client yêu cầu cập nhật tiến trình từ ApplicationMaster mỗi giây (được thiết lập thông qua mapreduce.client.progressmonitor.pollinterval), hiển thị cho người dùng.
6. Hoàn thành công việc
Ngoài việc yêu cầu cập nhật tiến trình công việc từ ApplicationMaster, client cũng sẽ kiểm tra xem công việc đã hoàn thành chưa mỗi 5 phút bằng cách gọi waitForCompletion(), khoảng thời gian này có thể được thiết lập thông qua mapreduce.client.completion.pollinterval. Sau khi công việc hoàn thành, ApplicationMaster và container sẽ dọn dẹp trạng thái công việc, phương thức dọn dẹp công việc của OutputCommiter cũng sẽ được gọi. Thông tin về công việc sẽ được lưu trữ bởi job history server để người dùng kiểm tra sau này.
Gửi công việc để chạy trên YARN
Ở đây, chúng tôi sử dụng chương trình MapReduce tính Pi trong Hadoop Examples làm ví dụ, gói jar liên quan nằm trong thư mục share/hadoop/mapreduce của thư mục cài đặt Hadoop:
# Định dạng gửi: hadoop jar đường dẫn gói jar tên lớp chính tham số lớp chính
# hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3Chiến lược điều phối tài nguyên của YARN
FIFO Scheduler (Bộ lập lịch FIFO)
Chiến lược điều phối
Đặt tất cả các nhiệm vụ vào một hàng đợi, nhiệm vụ nào vào hàng đợi trước sẽ nhận được tài nguyên trước, nhiệm vụ sau chỉ có thể chờ đợi.
Nhược điểm
- Tận dụng tài nguyên thấp, không thể chạy các nhiệm vụ giao nhau.
- Tính linh hoạt kém, ví dụ: nhiệm vụ khẩn cấp không thể chen vào, nhiệm vụ mất thời gian dài sẽ kéo dài thời gian cho nhiệm vụ mất thời gian ngắn.
Capacity Scheduler (Bộ lập lịch theo dung lượng)
Ý tưởng chính - Lập ngân sách trước, chia sẻ tài nguyên cụm dựa trên ngân sách.
Chiến lược điều phối
- Tài nguyên cụm được chia sẻ bởi nhiều hàng đợi
- Mỗi hàng đợi cần thiết lập tỷ lệ phân bổ tài nguyên trước (lập ngân sách trước)
- Tài nguyên rảnh sẽ được ưu tiên phân bổ cho hàng đợi có tỷ lệ “tài nguyên thực tế / tài nguyên ngân sách” thấp nhất
- Bên trong hàng đợi, sử dụng chiến lược lập lịch FIFO
Đặc điểm
- Thiết kế hàng đợi phân cấp: hàng đợi con có thể sử dụng tài nguyên của hàng đợi cha
- Bảo đảm dung lượng: mỗi hàng đợi cần thiết lập tỷ lệ tài nguyên, ngăn chặn việc chiếm đoạt tất cả tài nguyên
- Phân bổ linh hoạt: tài nguyên rảnh có thể được phân bổ cho bất kỳ hàng đợi nào, khi nhiều hàng đợi cạnh tranh, sẽ cân nhắc tỷ lệ
- Hỗ trợ quản lý động: có thể điều chỉnh dung lượng, quyền hạn và các tham số khác của hàng đợi một cách động, cũng có thể tăng hoặc tạm dừng hàng đợi một cách động
- Kiểm soát truy cập: người dùng chỉ có thể gửi nhiệm vụ vào hàng đợi của mình, không thể truy cập vào các hàng đợi khác
- Đa người thuê: nhiều người dùng chia sẻ tài nguyên cụm
Fair Scheduler (Bộ lập lịch công bằng)
Chiến lược điều phối
- Nhiều hàng đợi chia sẻ công bằng tài nguyên cụm
- Phân bổ tài nguyên một cách động thông qua phân chia, không cần thiết lập tỷ lệ phân bổ tài nguyên trước
- Bên trong hàng đợi, có thể cấu hình chiến lược lập lịch: FIFO, Fair (mặc định)
Chiếm dụng tài nguyên
- Kết thúc nhiệm vụ của các hàng đợi khác, buộc chúng phải từ bỏ tài nguyên mà chúng đang chiếm dụng, sau đó phân bổ tài nguyên cho hàng đợi có lượng tài nguyên chiếm dụng ít hơn giới hạn tài nguyên tối thiểu
Trọng số hàng đợi
- Khi có nhiệm vụ đang chờ trong hàng đợi và có tài nguyên rảnh trong cụm, mỗi hàng đợi có thể nhận được tỷ lệ tài nguyên rảnh khác nhau dựa trên trọng số.