Tổng hợp các câu hỏi phỏng vấn hệ điều hành phổ biến (Phần 2)
Quản lý bộ nhớ
Quản lý bộ nhớ chủ yếu làm gì?
Quản lý bộ nhớ trong hệ điều hành có vai trò quan trọng, chủ yếu thực hiện các nhiệm vụ sau:
- Cấp phát và thu hồi bộ nhớ: Cấp phát và thu hồi bộ nhớ cần thiết cho tiến trình, ví dụ như hàm malloc: yêu cầu bộ nhớ, hàm free: giải phóng bộ nhớ.
- Chuyển đổi địa chỉ: Chuyển đổi địa chỉ ảo trong chương trình thành địa chỉ vật lý trong bộ nhớ.
- Mở rộng bộ nhớ: Khi hệ thống không có đủ bộ nhớ, sử dụng kỹ thuật bộ nhớ ảo hoặc kỹ thuật ghi đè tự động để mở rộng bộ nhớ logic.
- Ánh xạ bộ nhớ: Ánh xạ trực tiếp một tệp vào không gian tiến trình của tiến trình, điều này cho phép truy cập nội dung tệp thông qua con trỏ bộ nhớ, tăng tốc độ truy cập.
- Tối ưu hóa bộ nhớ: Tối ưu hóa việc sử dụng bộ nhớ bằng cách điều chỉnh chiến lược cấp phát và thu hồi bộ nhớ.
- Bảo mật bộ nhớ: Đảm bảo rằng các tiến trình không can thiệp vào bộ nhớ của nhau, tránh các chương trình độc hại thay đổi bộ nhớ và đảm bảo an ninh của hệ thống.
- ……
Phân phân mảnh bộ nhớ là gì?
Phân phân mảnh bộ nhớ là kết quả của việc cấp phát và thu hồi bộ nhớ, thông thường có hai loại:
- Phân phân mảnh bộ nhớ nội (Internal Memory Fragmentation): Là bộ nhớ đã được cấp phát cho tiến trình sử dụng nhưng không được sử dụng hết. Nguyên nhân chính gây ra phân mảnh bộ nhớ nội là khi sử dụng cấp phát bộ nhớ theo trang (page) có độ lớn cố định như
2^n, bộ nhớ được cấp phát cho tiến trình có thể lớn hơn thực tế cần. Ví dụ, một tiến trình chỉ cần 65 byte bộ nhớ, nhưng được cấp phát 128 (2^7) byte bộ nhớ, 63 byte bộ nhớ trở thành phân mảnh bộ nhớ nội. - Phân phân mảnh bộ nhớ ngoại (External Memory Fragmentation): Là những phần bộ nhớ không được cấp phát cho tiến trình nhưng không thể sử dụng do kích thước không đủ lớn để cấp phát cho yêu cầu bộ nhớ của bất kỳ tiến trình nào. Nói cách khác, phân mảnh bộ nhớ ngoại đề cập đến những phần không liên tục nhỏ của không gian bộ nhớ không được sử dụng. Cơ chế phân đoạn (segment) sẽ dẫn đến phân mảnh bộ nhớ ngoại.
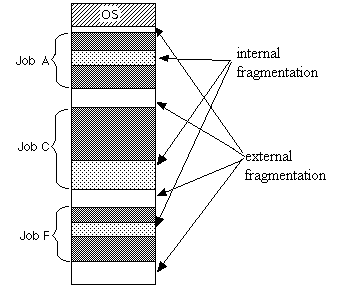
Phân phân mảnh bộ nhớ gây ra sự lãng phí tài nguyên bộ nhớ, làm giảm hiệu suất sử dụng bộ nhớ. Cách giảm thiểu phân mảnh bộ nhớ là một trong những vấn đề quan trọng trong quản lý bộ nhớ.
Các phương pháp quản lý bộ nhớ phổ biến là gì?
Có thể chia các phương pháp quản lý bộ nhớ thành hai loại:
- Quản lý bộ nhớ liên tục: Phân bổ một không gian bộ nhớ liên tục cho một chương trình người dùng, tỷ lệ sử dụng bộ nhớ thường không cao.
- Quản lý bộ nhớ không liên tục: Cho phép một chương trình sử dụng bộ nhớ phân tán hoặc không liên tục, linh hoạt hơn so với quản lý bộ nhớ liên tục.
Quản lý bộ nhớ liên tục
Quản lý theo khối là một phương pháp quản lý bộ nhớ liên tục trong các hệ điều hành máy tính cổ điển, nhưng gặp vấn đề phân phân mảnh bộ nhớ nghiêm trọng. Quản lý theo khối chia bộ nhớ thành một số khối cố định, mỗi khối chỉ chứa một tiến trình. Nếu chương trình cần bộ nhớ, hệ điều hành sẽ cấp phát cho nó một khối, nếu chương trình chỉ cần một phần nhỏ không gian, phần lớn khối bộ nhớ được cấp phát sẽ bị lãng phí. Phần không gian trống trong mỗi khối được gọi là phân mảnh bộ nhớ nội bộ. Ngoài ra, do hai khối bộ nhớ có thể có phân mảnh bộ nhớ ngoại vi không liên tục, những phân mảnh bộ nhớ ngoại vi không liên tục này quá nhỏ để phân bổ lại.
Trong hệ điều hành Linux, quản lý bộ nhớ liên tục sử dụng thuật toán Buddy System để giải quyết vấn đề phân mảnh bộ nhớ ngoại. Đây là một thuật toán phân bổ bộ nhớ liên tục kinh điển, giúp giải quyết vấn đề phân mảnh bộ nhớ ngoại một cách hiệu quả. Ý tưởng chính của Buddy System là chia bộ nhớ thành các khối có kích thước là lũy thừa của 2 (ví dụ: 2^6 = 64 KB), và ghép các khối bộ nhớ liền kề thành cặp đối tác (lưu ý: phải là liền kề mới là đối tác).
Khi phân bổ bộ nhớ, Buddy System sẽ cố gắng tìm khối bộ nhớ phù hợp nhất. Nếu khối bộ nhớ tìm thấy quá lớn, nó sẽ chia nó thành hai khối đối tác có kích thước bằng nhau. Nếu vẫn quá lớn, nó sẽ tiếp tục chia nhỏ cho đến khi đạt đến kích thước phù hợp.
Giả sử hai khối bộ nhớ liền kề được giải phóng, hệ thống sẽ kết hợp hai khối bộ nhớ này để tạo thành một khối bộ nhớ lớn hơn, để phục vụ việc phân bổ bộ nhớ sau này. Điều này giúp giảm thiểu vấn đề phân mảnh bộ nhớ và tăng cường tỷ lệ sử dụng bộ nhớ.
Mặc dù giải quyết vấn đề mảnh bộ nhớ ngoại, hệ thống bạn đồng vẫn tồn tại vấn đề tỷ lệ sử dụng bộ nhớ không cao (phân mảnh bộ nhớ nội bộ). Điều này chủ yếu là do Buddy System chỉ có thể phân phối các khối bộ nhớ có kích thước là 2^n, do đó, khi cần phân bổ bộ nhớ không phải là bội số của 2^n, sẽ lãng phí một phần không gian bộ nhớ. Ví dụ: Nếu cần phân bổ một khối bộ nhớ có kích thước 65, vẫn cần phân bổ một khối bộ nhớ có kích thước 2^7 = 128.
Đối với vấn đề mảnh bộ nhớ nội bộ, Linux sử dụng SLAB để giải quyết. Tuy nhiên, vì đây không phải là nội dung chính của bài viết này, nên không được giải thích chi tiết ở đây.
Quản lý bộ nhớ không liên tục
- Quản lý theo đoạn (segment): Quản lý/phân bổ bộ nhớ vật lý theo đoạn (các đoạn bộ nhớ liên tục). Không gian địa chỉ ảo của chương trình được chia thành các đoạn không đều, mỗi đoạn định nghĩa một tập hợp thông tin logic, ví dụ: đoạn chương trình chính MAIN, đoạn chương trình con X, đoạn dữ liệu D và đoạn ngăn xếp S.
- Quản lý theo trang (page): Chia bộ nhớ vật lý thành các trang liên tục có độ dài bằng nhau, không gian địa chỉ ảo của chương trình cũng được chia thành các trang ảo liên tục có độ dài bằng nhau. Đây là một phương pháp quản lý bộ nhớ rất phổ biến trong các hệ điều hành hiện đại.
- Cơ chế quản lý đoạn và trang: Kết hợp quản lý theo đoạn và quản lý theo trang, bộ nhớ vật lý được chia thành các đoạn trước, mỗi đoạn được chia thành các trang có cùng kích thước.
Bộ nhớ ảo
Bộ nhớ ảo là gì? Nó có tác dụng gì?
Bộ nhớ ảo (Virtual Memory) là một công nghệ quản lý bộ nhớ quan trọng trong hệ thống máy tính. Về bản chất, nó chỉ tồn tại trong logic và là một không gian bộ nhớ tưởng tượng, chủ yếu được sử dụng như một cầu nối giữa quá trình truy cập vào bộ nhớ chính (bộ nhớ vật lý) và để đơn giản hóa quản lý bộ nhớ.
Tóm tắt, bộ nhớ ảo cung cấp các khả năng sau:
- Cô lập tiến trình: Bộ nhớ vật lý được truy cập thông qua không gian địa chỉ ảo, không gian địa chỉ ảo tương ứng với từng tiến trình. Mỗi tiến trình cho rằng nó sở hữu toàn bộ bộ nhớ vật lý, các tiến trình được cô lập lẫn nhau, mã của một tiến trình không thể thay đổi bộ nhớ vật lý đang được sử dụng bởi một tiến trình khác hoặc hệ điều hành.
- Tăng cường tận dụng bộ nhớ vật lý: Với không gian địa chỉ ảo, hệ điều hành chỉ cần tải một phần dữ liệu hoặc chỉ thị đang được sử dụng bởi tiến trình vào bộ nhớ vật lý.
- Đơn giản hóa quản lý bộ nhớ: Mỗi tiến trình có không gian địa chỉ ảo riêng biệt và đồng nhất, các nhà phát triển không cần làm việc trực tiếp với bộ nhớ vật lý mà thay vào đó sử dụng không gian địa chỉ ảo để truy cập bộ nhớ, từ đó đơn giản hóa quản lý bộ nhớ.
- Chia sẻ bộ nhớ vật lý giữa nhiều tiến trình: Trong quá trình chạy, các tiến trình sẽ tải các thư viện động của hệ điều hành. Các thư viện này là chung cho mỗi tiến trình và thực tế chỉ có một bản sao trong bộ nhớ, phần này được gọi là bộ nhớ chia sẻ.
- Nâng cao bảo mật sử dụng bộ nhớ: Kiểm soát quyền truy cập của tiến trình vào bộ nhớ vật lý, cô lập tiến trình và tăng cường an ninh của hệ thống.
- Cung cấp không gian bộ nhớ sử dụng lớn hơn: Cho phép chương trình sử dụng không gian bộ nhớ lớn hơn kích thước bộ nhớ vật lý của hệ thống. Khi bộ nhớ vật lý không đủ, dữ liệu hoặc trang mã có thể được lưu trữ trên đĩa cứng, và các trang dữ liệu hoặc trang mã sẽ được di chuyển giữa bộ nhớ vật lý và đĩa cứng theo nhu cầu.
Vấn đề khi không có bộ nhớ ảo là gì?
Nếu không có bộ nhớ ảo, chương trình truy cập và điều khiển trực tiếp bộ nhớ vật lý, dường như thiếu một lớp trung gian, nhưng lại gây ra nhiều vấn đề.
Cụ thể vấn đề là gì? Đây là một số ví dụ để giải thích vấn đề này (dựa trên khả năng mà bộ nhớ ảo cung cấp):
- Chương trình người dùng có thể truy cập vào bất kỳ bộ nhớ vật lý nào, có thể vô tình thay đổi bộ nhớ hệ thống đang sử dụng và gây ra sự cố hệ điều hành, ảnh hưởng nghiêm trọng đến an ninh hệ thống.
- Chạy nhiều chương trình cùng một lúc dễ gây ra sự cố. Ví dụ, bạn muốn chạy cùng một lúc một ứng dụng Messenger và một ứng dụng nghe nhạc Spotify. Khi Messenger gán giá trị cho địa chỉ bộ nhớ 1xxx trong quá trình chạy, Spotify cũng gán giá trị cho địa chỉ bộ nhớ 1xxx, điều này sẽ làm ghi đè giá trị được gán bởi Messenger trước đó và có thể gây ra sự cố cho Messenger.
- Tất cả dữ liệu hoặc chỉ thị mà chương trình sử dụng trong quá trình chạy đều phải được tải vào bộ nhớ vật lý, theo nguyên lý cục bộ, một phần lớn dữ liệu có thể không được sử dụng, chiếm dụng tài nguyên bộ nhớ vật lý quý giá.
4…….
Địa chỉ ảo và địa chỉ vật lý là gì?
Địa chỉ vật lý (Physical Address) là địa chỉ thực tế trong bộ nhớ vật lý, cụ thể hơn là địa chỉ trong thanh ghi địa chỉ bộ nhớ. Trong quá trình lập trình, chúng ta truy cập vào địa chỉ bộ nhớ không phải là địa chỉ vật lý, mà là địa chỉ ảo (Virtual Address).
Nghĩa là, khi phát triển và lập trình, chúng ta thực tế đang làm việc với địa chỉ ảo. Ví dụ, trong ngôn ngữ lập trình C, giá trị trong con trỏ có thể hiểu là một địa chỉ trong bộ nhớ, đây chính là địa chỉ ảo.
Hệ điều hành thường sử dụng một thành phần quan trọng trong bộ vi xử lý gọi là MMU (Memory Management Unit, Đơn vị Quản lý Bộ nhớ) để chuyển đổi địa chỉ ảo thành địa chỉ vật lý, quá trình này được gọi là dịch địa chỉ/ chuyển đổi địa chỉ (Address Translation).
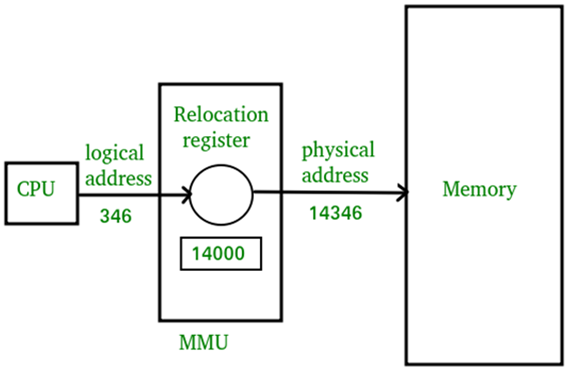
Sau khi MMU chuyển đổi địa chỉ ảo thành địa chỉ vật lý, nó sẽ được truyền qua bus đến thiết bị bộ nhớ vật lý, từ đó thực hiện yêu cầu đọc/ghi bộ nhớ vật lý tương ứng.
MMU sử dụng các cơ chế chính để chuyển đổi địa chỉ ảo thành địa chỉ vật lý:
- Cơ chế phân đoạn (Segmentation)
- Cơ chế phân trang (Paging)
- Cơ chế phân đoạn và phân trang (Segmentation and Paging)
Trong đó, cơ chế phân trang được sử dụng rộng rãi trong các hệ điều hành hiện đại, đó là điểm cần chú ý!
Cơ chế phân đoạn
Cơ chế phân đoạn (Segmentation) quản lý/phân bổ bộ nhớ vật lý theo các đoạn (segment) liên tục. Không gian địa chỉ ảo của chương trình được chia thành các đoạn không đều, mỗi đoạn định nghĩa một tập hợp thông tin logic, ví dụ: đoạn chương trình chính MAIN, đoạn chương trình con X, đoạn dữ liệu D và đoạn ngăn xếp S, v.v.
Bảng đoạn (Segment Table) có tác dụng gì? Quá trình dịch địa chỉ như thế nào?
Phân đoạn sử dụng bảng đoạn (Segment Table) để ánh xạ địa chỉ ảo và địa chỉ vật lý.
Địa chỉ ảo trong cơ chế phân đoạn bao gồm hai phần:
- Số đoạn (Segment Number): Xác định địa chỉ ảo thuộc về đoạn nào trong không gian địa chỉ ảo.
- Độ lệch trong đoạn (Segment Offset): Độ lệch so với địa chỉ bắt đầu của đoạn đó.
Quá trình dịch địa chỉ cụ thể như sau:
- MMU đầu tiên giải mã số đoạn từ địa chỉ ảo.
- Sử dụng số đoạn, MMU truy cập vào bảng đoạn của quá trình để lấy thông tin về đoạn tương ứng (lấy đoạn bảng mục tương ứng).
- Từ thông tin đoạn, MMU lấy địa chỉ vật lý của đoạn đó và cộng với độ lệch trong đoạn để tạo ra địa chỉ vật lý cuối cùng.
Bảng đoạn cũng chứa thông tin khác như độ dài đoạn (có thể được sử dụng để kiểm tra xem địa chỉ ảo có vượt quá phạm vi hợp lệ không) và loại đoạn (loại của đoạn, ví dụ: đoạn mã, đoạn dữ liệu, v.v.).
Có phải luôn phải tìm thấy mục bảng đoạn tương ứng với số đoạn không? Có chắc rằng địa chỉ vật lý tương ứng luôn tồn tại không?
Không nhất thiết. Có thể không tìm thấy mục bảng đoạn:
- Mục bảng đoạn đã bị xóa: Lỗi phần mềm, hành vi độc hại của phần mềm, v.v. có thể dẫn đến việc xóa mục bảng đoạn.
- Mục bảng đoạn chưa được tạo: Nếu không đủ bộ nhớ hệ thống hoặc không thể cấp phát một khối bộ nhớ vật lý liên tục, mục bảng đoạn không thể được tạo.
Tại sao cơ chế phân đoạn dẫn đến tình trạng phân mảnh bộ nhớ ngoại?
Cơ chế phân đoạn dễ dẫn đến tình trạng phân mảnh bộ nhớ bên ngoài, nghĩa là để lại không gian phân mảnh giữa các đoạn (không đủ để ánh xạ cho các đoạn trong không gian địa chỉ ảo).
Ví dụ, giả sử hệ thống có 5G bộ nhớ vật lý và sử dụng cơ chế phân đoạn để phân bổ bộ nhớ. Hiện có 4 tiến trình, mỗi tiến trình sử dụng bộ nhớ như sau:
- Tiến trình 1: 0~1G (Đoạn 1)
- Tiến trình 2: 1~3G (Đoạn 2)
- Tiến trình 3: 3~4.5G (Đoạn 3)
- Tiến trình 4: 4.5~5G (Đoạn 4)
Giả sử chúng ta tắt tiến trình 1 và tiến trình 4, đoạn 1 và đoạn 4 sẽ được giải phóng, bộ nhớ vật lý còn trống 1.5G. Tuy nhiên, vì 1.5G bộ nhớ vật lý không liên tục, không thể phân bổ cho một tiến trình cần sử dụng 1.5G bộ nhớ vật lý.
Cơ chế phân trang
Cơ chế phân trang (Paging) chia bộ nhớ chính (bộ nhớ vật lý) thành các trang vật lý liên tiếp và không đổi, và không gian địa chỉ ảo của chương trình ứng dụng cũng được chia thành các trang ảo liên tiếp và không đổi. Hệ điều hành hiện đại rộng rãi sử dụng cơ chế phân trang.
Lưu ý: Các trang ở đây là liên tiếp và có độ dài bằng nhau, khác với cơ chế phân đoạn với các đoạn có độ dài khác nhau.
Trong cơ chế phân trang, việc ánh xạ địa chỉ ảo và địa chỉ vật lý được thực hiện thông qua bảng trang (Page Table).
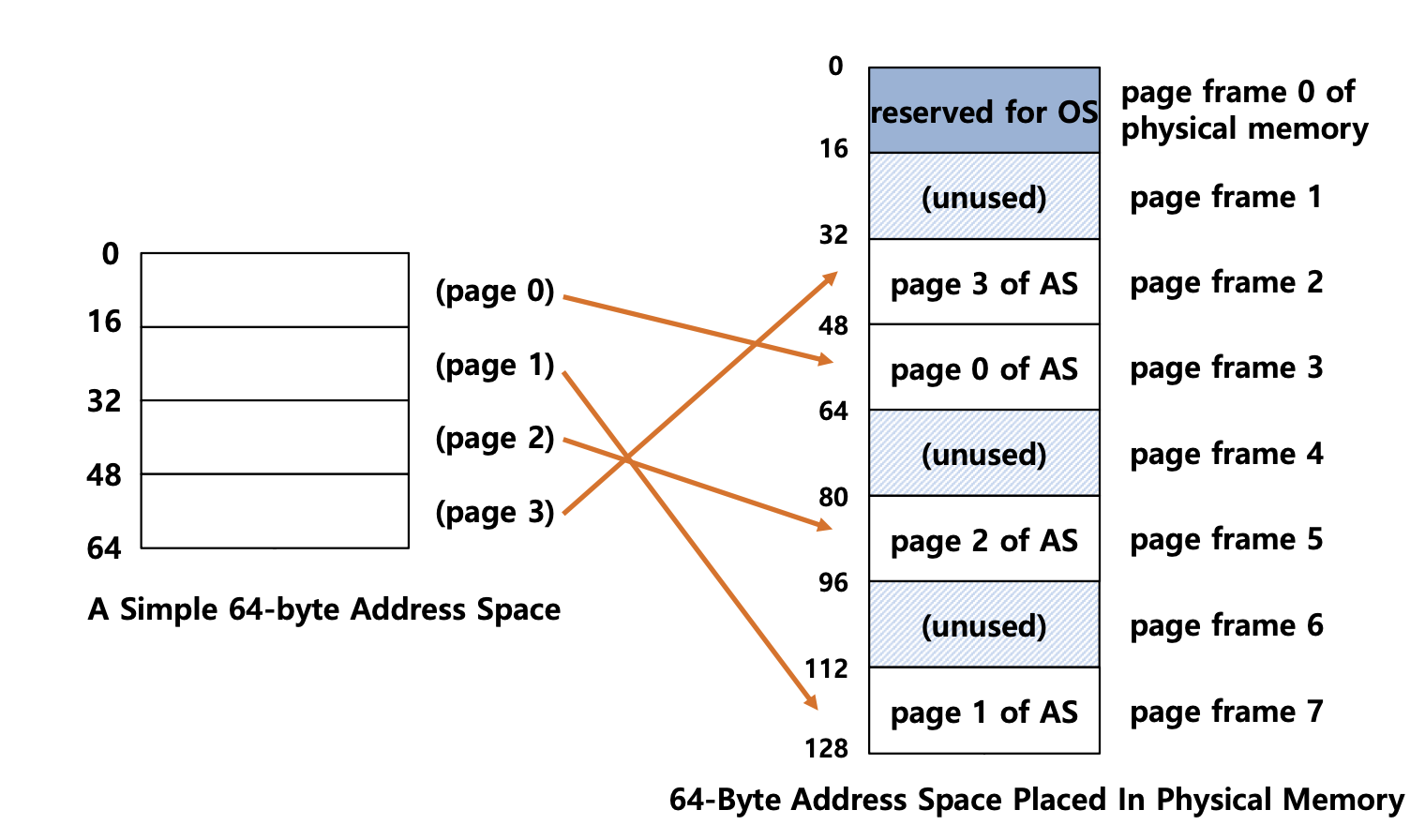
Trong cơ chế phân trang, địa chỉ ảo được chia thành hai phần:
- Số trang (Page Number): Số trang ảo được sử dụng để lấy số trang vật lý tương ứng từ bảng trang của chương trình ứng dụng.
- Độ lệch trang (Page Offset): Địa chỉ vật lý bằng địa chỉ bắt đầu của trang vật lý cộng với độ lệch trang.
Quá trình dịch địa chỉ cụ thể như sau:
- MMU (Memory Management Unit) trích xuất số trang ảo từ địa chỉ ảo.
- Sử dụng số trang ảo để lấy số trang vật lý tương ứng từ bảng trang của chương trình ứng dụng (tìm mục tương ứng trong bảng trang).
- Sử dụng số trang vật lý tương ứng để tính địa chỉ vật lý bằng cộng địa chỉ bắt đầu của trang vật lý với độ lệch trang trong địa chỉ ảo.
Bảng trang cũng chứa thông tin như các cờ truy cập (xác định xem trang đã được truy cập hay chưa), cờ dữ liệu bẩn, v.v.
Có chắc rằng phải tìm số trang vật lý tương ứng với số trang ảo không? Khi đã tìm được số trang vật lý, trang vật lý tương ứng với địa chỉ vật lý đã tìm được sẽ tồn tại chứ?
Không chắc chắn! Có thể xảy ra trường hợp lỗi trang. Điều này có nghĩa là không có trang vật lý tương ứng trong bộ nhớ vật lý hoặc có trang vật lý tương ứng trong bộ nhớ vật lý nhưng không có ánh xạ giữa trang ảo và trang vật lý (mục bảng trang tương ứng không tồn tại). Chi tiết về lỗi trang sẽ được giải thích chi tiết sau.
Có vấn đề gì với bảng trang đơn cấp? Tại sao chúng ta cần bảng trang đa cấp?
Ví dụ với môi trường 32 bit, không gian địa chỉ ảo có tổng cộng 2^32 (4G). Giả sử kích thước của một trang là 2^12 (4KB), bảng trang sẽ có tổng cộng 2^20 mục. Mỗi mục trong bảng trang chiếm 4 byte, 2^20 * 2^2 / 1024 * 1024 = 4MB. Điều này có nghĩa là kích thước của bảng trang cho một chương trình chỉ cần chạy mà không làm gì cũng là 4MB.
Nếu có nhiều chương trình đang chạy trên hệ thống, kích thước của bảng trang sẽ rất lớn. Tuy nhiên, hầu hết các chương trình có thể chỉ sử dụng một số mục trong bảng trang, các mục khác sẽ bị lãng phí.
Để giải quyết vấn đề này, hệ điều hành đã giới thiệu bảng trang đa cấp, trong đó mỗi bảng trang liên kết với bảng trang trước đó. Hệ thống 32 bit thường sử dụng bảng trang hai cấp, trong khi hệ thống 64 bit thường sử dụng bảng trang bốn cấp.
Ở đây, chúng ta sẽ lấy ví dụ về bảng trang hai cấp để giải thích: Bảng trang hai cấp bao gồm bảng trang cấp 1 và bảng trang cấp 2. Bảng trang cấp 1 có tổng cộng 1024 mục, bảng trang cấp 2 cũng có tổng cộng 1024 mục. Mục trong bảng trang cấp 2 là một mối quan hệ một-nhiều với mục trong bảng trang cấp 1. Bảng trang cấp 2 chỉ được tải khi cần thiết (chỉ cần sử dụng một số ít mục trong bảng trang cấp 2), do đó tiết kiệm không gian.
Giả sử chỉ cần 2 bảng trang cấp 2, kích thước của hai bảng trang sẽ là: 4KB (kích thước của bảng trang cấp 1) + 4KB * 2 (kích thước của hai bảng trang cấp 2) = 12KB.
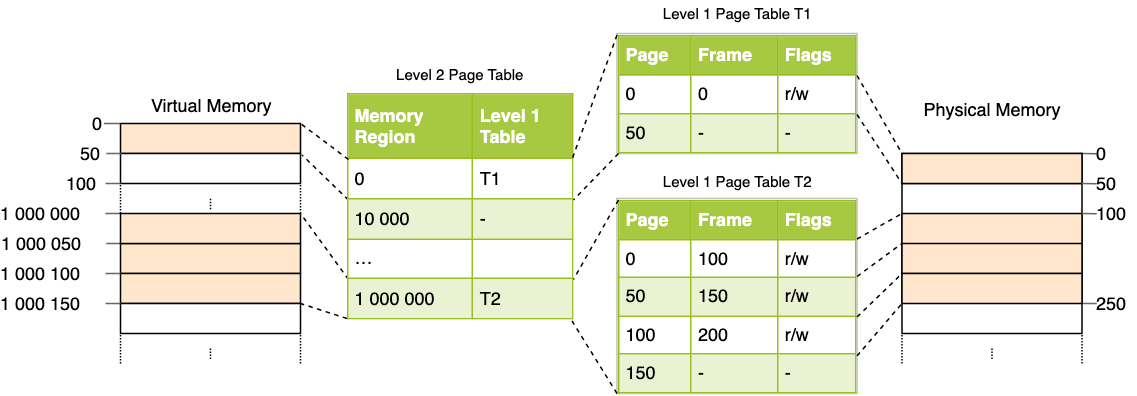
Bảng trang nhiều cấp là một ví dụ về trao đổi thời gian và không gian, tận dụng việc tăng số lần truy vấn bảng trang để giảm không gian chiếm dụng của bảng trang.
TLB có tác dụng gì? Quá trình dịch địa chỉ sau khi sử dụng TLB như thế nào?
Để tăng tốc độ chuyển đổi địa chỉ ảo thành địa chỉ vật lý, hệ điều hành đã giới thiệu bộ đệm dịch địa chỉ (Translation Lookaside Buffer, TLB).
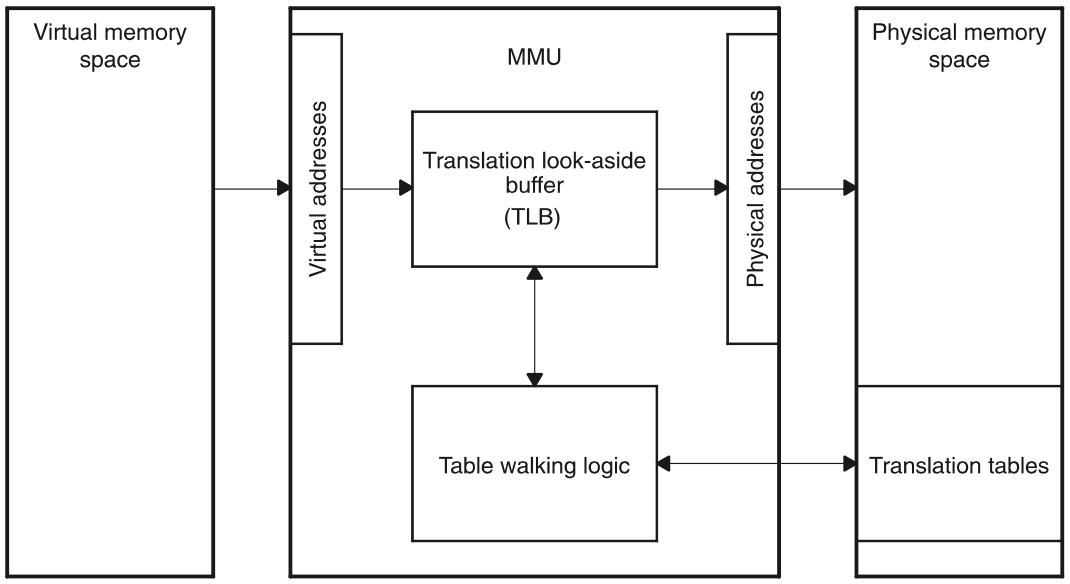
Trong kiến trúc AArch64 và x86-64 phổ biến, TLB là một thành phần nằm trong đơn vị quản lý bộ nhớ (Memory Management Unit, MMU), thực chất là một bộ nhớ cache (Cache), lưu trữ các ánh xạ giữa số trang ảo và số trang vật lý. Bạn có thể xem nó đơn giản như một bảng băm (hash table) lưu trữ các cặp khóa (số trang ảo) và giá trị (số trang vật lý).
Quá trình dịch địa chỉ sau khi sử dụng TLB như sau:
- Sử dụng số trang ảo trong địa chỉ ảo làm khóa để truy vấn TLB.
- Nếu tìm thấy số trang vật lý tương ứng, không cần truy vấn bảng trang nữa, trường hợp này được gọi là TLB hit.
- Nếu không tìm thấy số trang vật lý tương ứng, vẫn cần truy vấn bảng trang trong bộ nhớ chính và thêm mục tương ứng từ bảng trang vào TLB, trường hợp này được gọi là TLB miss.
- Khi TLB đã đầy, và cần thêm một số trang mới, một trang trong TLB sẽ bị loại bỏ theo một chiến lược loại bỏ nhất định.
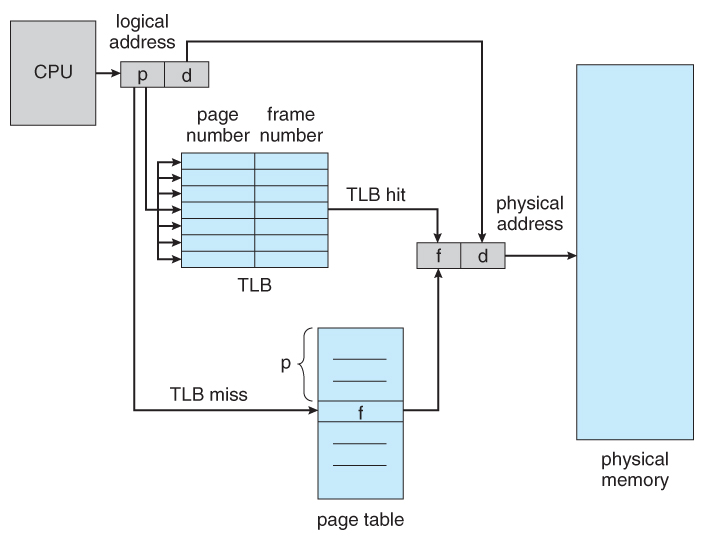
Vì bảng trang cũng nằm trong bộ nhớ chính, nên trước đây, mỗi lần đọc/ghi dữ liệu từ bộ nhớ, CPU phải truy cập hai lần vào bộ nhớ. Nhưng khi có TLB, chỉ cần truy cập một lần vào bộ nhớ cho dữ liệu tồn tại trong TLB.
TLB được thiết kế đơn giản, nhưng tỷ lệ trúng rất cao và hiệu quả. Điều này bởi vì một số trang được truy cập thường xuyên sẽ chiếm một phần nhỏ trong số đó.
Sau khi đọc xong, bạn sẽ nhận thấy rằng TLB và bộ nhớ cache (như Redis) mà chúng ta thường sử dụng trong phát triển hệ thống hàng ngày rất giống nhau. Trên thực tế, rất nhiều ý tưởng và thuật toán kinh điển trong hệ điều hành có thể được tìm thấy trong các công cụ hoặc framework mà chúng ta sử dụng hàng ngày trong phát triển.
Mục đích của cơ chế thay thế trang là gì?
Ý tưởng của cơ chế trang trang là khi bộ nhớ vật lý không đủ, hệ điều hành chọn đưa nội dung của một số trang vật lý vào đĩa cứng, và khi cần sử dụng chúng, nó sẽ đọc chúng vào bộ nhớ vật lý. Điều này có nghĩa là cơ chế trang trang sử dụng thiết bị lưu trữ giá rẻ hơn để mở rộng bộ nhớ vật lý.
Điều này cũng giải thích vì sao trong hệ điều hành, các tiến trình có thể hoạt động bình thường ngay cả khi tổng bộ nhớ vật lý cần thiết cho tất cả các tiến trình lớn hơn bộ nhớ vật lý thực tế, chỉ là tốc độ hoạt động sẽ chậm đi.
Đây cũng là một chiến lược trao đổi thời gian và không gian, bạn sử dụng thời gian tính toán của CPU, thời gian đọc và ghi trang để đổi lấy một không gian bộ nhớ vật lý ảo lớn hơn để hỗ trợ việc chạy chương trình.
Lỗi trang là gì?
Theo Wikipedia:
Lỗi trang (Page Fault), còn được gọi là lỗi cứng, ngắt cứng, lỗi phân trang, trang không tìm thấy, ngắt lỗi trang, lỗi trang không hợp lệ, là một ngắt do MMU phát ra khi phần mềm cố gắng truy cập vào một trang đã được ánh xạ trong không gian địa chỉ ảo nhưng chưa được tải vào bộ nhớ vật lý.
Có hai loại lỗi trang phổ biến:
- Lỗi trang cứng (Hard Page Fault): Không có trang vật lý tương ứng trong bộ nhớ. Do đó, Trình xử lý lỗi trang sẽ chỉ thị CPU đọc nội dung tương ứng từ tệp đĩa đã mở và sau đó MMU xây dựng một ánh xạ giữa trang ảo và trang vật lý tương ứng.
- Lỗi trang mềm (Soft Page Fault): Có trang vật lý tương ứng trong bộ nhớ, nhưng trang ảo và trang vật lý chưa được ánh xạ. Do đó, Trình xử lý lỗi trang sẽ chỉ thị MMU xây dựng ánh xạ giữa trang ảo và trang vật lý tương ứng.
Khi xảy ra lỗi trang, chương trình ứng dụng truy cập vào bộ nhớ vật lý hợp lệ, chỉ là có sự thiếu hụt trang vật lý hoặc ánh xạ giữa trang ảo và trang vật lý chưa được thiết lập. Nếu chương trình ứng dụng truy cập vào bộ nhớ vật lý không hợp lệ, sẽ xảy ra lỗi trang không hợp lệ (Invalid Page Fault).
Các thuật toán thay thế trang phổ biến là gì?
Khi xảy ra lỗi trang cứng, nếu không có trang vật lý trống nào khả dụng trong bộ nhớ vật lý, hệ điều hành phải loại bỏ một trang vật lý khỏi bộ nhớ để tạo không gian để tải trang mới.
Quy tắc được sử dụng để chọn trang vật lý nào để loại bỏ được gọi là thuật toán thay thế trang, chúng ta có thể coi thuật toán thay thế trang là quy tắc loại bỏ trang vật lý.
Việc xảy ra lỗi trang quá thường xuyên sẽ ảnh hưởng đáng kể đến hiệu suất, một thuật toán thay thế trang tốt nên giảm số lần xảy ra lỗi trang.
Có 5 thuật toán thay thế trang phổ biến (có nhiều thuật toán thay thế trang khác dựa trên các thuật toán này):
- Thuật toán thay thế trang tốt nhất (OPT, Optimal): Ưu tiên chọn trang để loại bỏ là trang sẽ không bao giờ được sử dụng trong tương lai hoặc không được truy cập trong thời gian dài nhất. Điều này đảm bảo đạt được tỷ lệ lỗi trang thấp nhất. Tuy nhiên, vì người ta không thể dự đoán được trang nào trong số các trang của quá trình trong bộ nhớ sẽ không được sử dụng trong tương lai dài, nên thuật toán này không thể thực hiện được, chỉ là thuật toán thay thế trang lý thuyết tốt nhất, có thể được sử dụng làm tiêu chuẩn để đo lường hiệu suất của các thuật toán thay thế khác.
- Thuật toán thay thế trang theo thứ tự vào trước ra trước (FIFO, First In First Out): Đây là thuật toán thay thế trang đơn giản nhất, luôn loại bỏ trang đã vào bộ nhớ lâu nhất, tức là chọn trang đã tồn tại trong bộ nhớ lâu nhất để loại bỏ. Thuật toán này dễ triển khai và hiểu, thường chỉ cần sử dụng một hàng đợi FIFO. Tuy nhiên, hiệu suất của nó không tốt.
- Thuật toán thay thế trang gần đây nhất ít được sử dụng (LRU, Least Recently Used): Thuật toán LRU gán mỗi trang một trường truy cập để ghi lại thời gian T mà trang đã trải qua kể từ lần truy cập cuối cùng. Khi cần loại bỏ một trang, chọn trang có giá trị T lớn nhất trong các trang hiện có, tức là trang đã không được sử dụng gần đây nhất. Thuật toán LRU dễ triển khai vì nó dựa trên lịch sử truy cập của các trang. Trong khi đó, thuật toán OPT dựa trên dự đoán truy cập tương lai của các trang, nên không thể triển khai được.
- Thuật toán thay thế trang ít được sử dụng nhất (LFU, Least Frequently Used): Tương tự như thuật toán LRU, nhưng thuật toán này chọn trang đã được sử dụng ít nhất trong một khoảng thời gian trước đó làm trang loại bỏ.
- Thuật toán thay thế trang đồng hồ (Clock): Có thể coi là một thuật toán chưa được sử dụng gần đây nhất, tức là các trang bị loại bỏ đều là các trang không được sử dụng gần đây nhất.
Tại sao thuật toán thay thế trang FIFO không hiệu quả?
Có hai nguyên nhân chính:
- Các trang thường xuyên truy cập hoặc cần tồn tại trong thời gian dài sẽ bị loại bỏ và tải lại nhiều lần: Các trang được tải vào sớm nhất thường là các trang thường xuyên truy cập hoặc cần tồn tại trong thời gian dài, những trang này sẽ bị loại bỏ và tải lại nhiều lần.
- Hiện tượng Belady: Các trang bị loại bỏ không phải là các trang mà quá trình không truy cập, đôi khi có thể xảy ra tình trạng số lượng trang tăng lên nhưng tỷ lệ lỗi trang tăng lên. Nguyên nhân của hiện tượng này là thuật toán FIFO chỉ xem xét thứ tự trang vào bộ nhớ mà không xem xét tần suất và tính cấp thiết của việc truy cập trang.
Thuật toán thay thế trang nào được sử dụng nhiều nhất trong thực tế?
Thuật toán LRU được sử dụng nhiều trong thực tế và được coi là thuật toán thay thế trang gần nhất với OPT.
Tuy nhiên, cần lưu ý rằng trong thực tế, các thuật toán này thường được cải tiến, ví dụ như InnoDB Buffer Pool (cơ chế quản lý trang cache trong cơ sở dữ liệu MySQL) đã cải tiến thuật toán LRU truyền thống và sử dụng một thuật toán gọi là “Adaptive LRU” (kết hợp cả ý tưởng của thuật toán LRU và LFU).
Điểm chung và khác biệt giữa cơ chế phân trang và cơ chế phân đoạn?
Điểm chung:
- Cả hai đều là các phương pháp quản lý bộ nhớ không liên tục.
- Cả hai đều sử dụng phương pháp ánh xạ địa chỉ để ánh xạ địa chỉ ảo sang địa chỉ vật lý, nhằm quản lý và bảo vệ bộ nhớ.
Khác biệt:
- Cơ chế phân trang quản lý bộ nhớ theo trang, trong khi cơ chế phân đoạn quản lý bộ nhớ theo đoạn. Kích thước của một trang là cố định và do hệ điều hành quyết định, thường là một lũy thừa của 2. Trong khi đó, kích thước của một đoạn không cố định và phụ thuộc vào cấu trúc logic của chương trình đang chạy.
- Trang là đơn vị vật lý, tức là hệ điều hành chia bộ nhớ vật lý thành các trang có kích thước cố định và liên tiếp, trong khi đoạn là đơn vị logic, được thiết kế để đáp ứng yêu cầu logic của chương trình. Trong cơ chế phân trang, các trang vật lý có thể được ánh xạ vào bất kỳ trang ảo nào, trong khi trong cơ chế phân đoạn, các đoạn vật lý phải được ánh xạ vào các đoạn ảo tương ứng.
- Cơ chế phân đoạn dễ gây ra tình trạng phân mảnh ngoại, tức là để lại khoảng trống giữa các đoạn (không đủ để ánh xạ cho các đoạn trong không gian địa chỉ ảo). Cơ chế phân trang giải quyết vấn đề phân mảnh ngoại, nhưng vẫn có thể gây ra tình trạng phân mảnh nội.
- Cơ chế phân trang sử dụng bảng trang để ánh xạ địa chỉ ảo sang địa chỉ vật lý, bảng trang được thực hiện thông qua bảng trang cấp 1 và bảng trang cấp 2. Trong khi đó, cơ chế phân đoạn sử dụng bảng đoạn để ánh xạ địa chỉ ảo sang địa chỉ vật lý, mỗi mục trong bảng đoạn ghi lại địa chỉ bắt đầu và độ dài của đoạn tương ứng.
- Cơ chế phân trang không đòi hỏi bất kỳ yêu cầu nào đối với chương trình, chương trình chỉ cần truy cập theo địa chỉ ảo. Trong khi đó, cơ chế phân đoạn yêu cầu lập trình viên chia chương trình thành các đoạn và sử dụng thanh ghi đoạn để truy cập các đoạn khác nhau.
Cơ chế đoạn-trang
Cơ chế quản lý bộ nhớ kết hợp giữa quản lý theo đoạn và quản lý theo trang, trong đó bộ nhớ vật lý được chia thành các đoạn và mỗi đoạn lại được chia thành các trang có kích thước bằng nhau.
Trong cơ chế đoạn-trang, quá trình dịch địa chỉ được thực hiện qua hai bước:
- Ánh xạ địa chỉ theo đoạn.
- Ánh xạ địa chỉ theo trang.
Nguyên lý cục bộ
Để hiểu tốt hơn về công nghệ bộ nhớ ảo, cần phải biết về nguyên lý quan trọng trong máy tính được gọi là nguyên lý cục bộ (Locality Principle). Nguyên lý cục bộ áp dụng không chỉ cho cấu trúc chương trình mà còn cho cấu trúc dữ liệu, đó là một khái niệm rất quan trọng.
Nguyên lý cục bộ đề cập đến sự tồn tại của tính chất cục bộ về không gian và thời gian trong quá trình truy cập dữ liệu và chỉ thị trong quá trình thực thi chương trình. Thời gian cục bộ đề cập đến tính chất một mục dữ liệu hoặc chỉ thị được sử dụng lặp lại trong một khoảng thời gian, trong khi không gian cục bộ đề cập đến tính chất một mục dữ liệu hoặc chỉ thị kề cận được sử dụng lặp lại trong một khoảng thời gian.
Trong cơ chế trang, bảng trang được sử dụng để chuyển đổi địa chỉ ảo thành địa chỉ vật lý, từ đó thực hiện truy cập bộ nhớ. Trong quá trình này, nguyên lý cục bộ được áp dụng vào hai khía cạnh:
- Thời gian cục bộ: Do chương trình thường có các vòng lặp hoặc các hoạt động lặp lại, nên sẽ có việc truy cập lại cùng một trang hoặc một số trang cụ thể, điều này thể hiện tính chất thời gian cục bộ. Để tận dụng tính chất thời gian cục bộ, cơ chế trang thường sử dụng cơ chế bộ nhớ đệm để tăng tỷ lệ trúng trang, tức là đưa một số trang đã truy cập gần đây vào bộ nhớ đệm. Nếu trang tiếp theo được truy cập đã có trong bộ nhớ đệm, không cần truy cập bộ nhớ nữa, mà có thể đọc trực tiếp từ bộ nhớ đệm.
- Không gian cục bộ: Do dữ liệu và chỉ thị trong chương trình thường có tính liên tục về không gian, nên khi truy cập một trang nào đó, thường sẽ truy cập các trang liền kề. Để tận dụng tính chất không gian cục bộ, cơ chế trang thường sử dụng kỹ thuật tiên đoán để trước đọc một số trang liền kề vào bộ nhớ đệm, để khi truy cập trong tương lai, có thể sử dụng trực tiếp từ bộ nhớ đệm, từ đó tăng tốc độ truy cập.
Tóm lại, nguyên lý cục bộ là một trong những nguyên tắc quan trọng trong thiết kế kiến trúc máy tính và là cơ sở cho nhiều thuật toán tối ưu. Trong cơ chế phân trang, việc sử dụng tính chất thời gian cục bộ và không gian cục bộ, kết hợp với bộ nhớ đệm và kỹ thuật tiên đoán, có thể tăng tỷ lệ trúng trang và tăng hiệu suất truy cập bộ nhớ.
Hệ thống tệp
Chức năng chính của hệ thống tệp là gì?
Hệ thống tệp chịu trách nhiệm quản lý và tổ chức các tệp và thư mục trên thiết bị lưu trữ của máy tính. Các chức năng chính của hệ thống tệp bao gồm:
- Quản lý lưu trữ: Lưu trữ dữ liệu tệp vào phương tiện lưu trữ vật lý và quản lý phân bổ không gian, đảm bảo rằng mỗi tệp có đủ không gian để lưu trữ và tránh xung đột giữa các tệp.
- Quản lý tệp: Tạo, xóa, di chuyển, đổi tên, nén, mã hóa, chia sẻ và thực hiện các hoạt động khác liên quan đến tệp.
- Quản lý thư mục: Tạo, xóa, di chuyển, đổi tên và thực hiện các hoạt động khác liên quan đến thư mục.
- Kiểm soát truy cập tệp: Quản lý quyền truy cập của người dùng hoặc quy trình khác nhau đối với các tệp, đảm bảo rằng người dùng chỉ có thể truy cập vào các tệp mà họ được phép truy cập, đảm bảo tính bảo mật và bí mật của tệp.
Sự khác biệt giữa liên kết cứng và liên kết mềm là gì?
Trên hệ thống Linux/Unix tương tự, liên kết tệp (File Link) là một loại tệp đặc biệt có thể trỏ đến một tệp khác trong hệ thống tệp. Có hai loại liên kết tệp phổ biến:
1. Liên kết cứng (Hard Link)
- Trong hệ thống tệp Linux/Unix, mỗi tệp và thư mục có một số inode duy nhất để xác định tệp hoặc thư mục đó. Liên kết cứng được tạo bằng cách sử dụng số inode để tạo liên kết, liên kết cứng và tệp gốc có cùng số inode (có thể coi là hai liên kết cứng cùng trỏ đến cùng một tệp), việc xóa bất kỳ liên kết nào không ảnh hưởng đến tệp gốc.
- Chỉ khi tất cả các liên kết cứng và tệp gốc đều bị xóa, tệp mới được xóa hoàn toàn.
- Liên kết cứng có một số hạn chế, không thể tạo liên kết cứng cho thư mục hoặc tạo liên kết cứng cho tệp không tồn tại, và liên kết cứng không thể trải qua các hệ thống tệp.
- Lệnh
lnđược sử dụng để tạo liên kết cứng.
2. Liên kết mềm (Symbolic Link hoặc Symlink)
- Liên kết mềm và tệp gốc có số inode khác nhau, thay vào đó, nó trỏ đến một đường dẫn tệp.
- Khi tệp gốc bị xóa, liên kết mềm vẫn tồn tại, nhưng trỏ đến một đường dẫn tệp không hợp lệ.
- Liên kết mềm tương tự như các phím tắt trong hệ điều hành Windows.
- Khác với liên kết cứng, liên kết mềm có thể tạo liên kết mềm cho thư mục hoặc tạo liên kết mềm cho tệp không tồn tại, và liên kết mềm có thể trải qua các hệ thống tệp.
- Lệnh
ln -sđược sử dụng để tạo liên kết mềm.
Tại sao liên kết cứng không thể vượt qua hệ thống tệp?
Trước đó, chúng ta đã đề cập rằng liên kết cứng được tạo bằng cách sử dụng số inode để thiết lập kết nối, và liên kết cứng chia sẻ cùng một số inode với tệp nguồn.
Tuy nhiên, mỗi hệ thống tệp đều có bảng inode riêng của nó và chỉ duy trì các inode trong hệ thống tệp đó. Nếu tạo liên kết cứng giữa các hệ thống tệp khác nhau, có thể gây ra xung đột số inode, có nghĩa là số inode của tệp đích đã được sử dụng trong hệ thống tệp đó.
Tối ưu hóa hiệu suất hệ thống tệp
- Tối ưu phần cứng: Sử dụng các thiết bị phần cứng tốc độ cao (như SSD, NVMe) thay thế cho ổ cứng cơ khí truyền thống, sử dụng các công nghệ RAID (Redundant Array of Inexpensive Disks) để nâng cao hiệu suất đĩa.
- Lựa chọn hệ thống tệp phù hợp: Mỗi hệ thống tệp có các đặc điểm khác nhau, việc lựa chọn hệ thống tệp phù hợp với từng tình huống sẽ giúp cải thiện hiệu suất hệ thống.
- Sử dụng bộ nhớ đệm: Truy cập đĩa cứng có hiệu suất thấp, sử dụng bộ nhớ đệm để giảm số lần truy cập đĩa. Tuy nhiên, cần lưu ý tỷ lệ trúng bộ nhớ đệm, nếu tỷ lệ này quá thấp, hiệu quả sẽ không cao.
- Tránh sử dụng quá tải đĩa: Chú ý đến tỷ lệ sử dụng đĩa, tránh lấp đầy đĩa, để lại một số không gian trống để tránh ảnh hưởng đến hiệu suất hệ thống tệp.
- Phân vùng đĩa một cách hợp lý: Sử dụng phân vùng đĩa một cách hợp lý, cho phép hệ thống tệp lưu trữ các tệp tin ở các vùng khác nhau, từ đó giảm thiểu hiện tượng tệp tin bị phân mảnh, cải thiện hiệu suất đọc/ghi tệp tin.
Các thuật toán lập lịch đĩa phổ biến là gì?
Thuật toán lập lịch đĩa là thuật toán được sử dụng trong hệ điều hành để sắp xếp và điều phối các yêu cầu truy cập đến ổ đĩa, nhằm tăng hiệu suất truy cập đĩa.
Thời gian thực hiện một hoạt động đọc/ghi trên đĩa phụ thuộc vào thời gian tìm kiếm/định vị, thời gian trễ và thời gian truyền dữ liệu. Thuật toán điều phối đĩa có thể giảm thiểu thời gian tìm kiếm và thời gian trễ bằng cách thay đổi thứ tự xử lý các yêu cầu đến đĩa.
Có 6 thuật toán điều phối đĩa phổ biến như sau (có nhiều thuật toán khác được phát triển dựa trên các thuật toán này):
- Thuật toán đến trước phục vụ trước (First-Come First-Served, FCFS): Xử lý các yêu cầu theo thứ tự đến đầu tiên, được phục vụ trước. FCFS dễ triển khai và không có chi phí thuật toán. Tuy nhiên, do không xem xét đường đi và hướng di chuyển của đầu đọc/ghi, thời gian tìm kiếm trung bình dài hơn. Đồng thời, thuật toán này dễ gặp vấn đề đói (starvation), tức là các yêu cầu đến sau có thể phải chờ lâu mới được phục vụ.
- Thuật toán tìm kiếm thời gian ngắn nhất (Shortest Seek Time First, SSTF): Còn được gọi là ưu tiên phục vụ thời gian ngắn nhất (Shortest Service Time First, SSTF), ưu tiên chọn yêu cầu gần nhất với vị trí hiện tại của đầu đọc/ghi để phục vụ. SSTF giúp giảm thiểu thời gian tìm kiếm của đầu đọc/ghi, nhưng dễ gặp vấn đề đói, tức là các yêu cầu xa đầu đọc/ghi có thể chờ lâu mới được phục vụ. Trong thực tế, cần tối ưu hóa cách triển khai thuật toán này để tránh vấn đề đói.
- Thuật toán quét (SCAN): Còn được gọi là thuật toán thang máy (Elevator), hoạt động tương tự như thang máy. Đầu đọc/ghi di chuyển theo một hướng quét trên đĩa, nếu có yêu cầu trên các vòng đĩa đó thì xử lý, cho đến khi đến biên đĩa, sau đó thay đổi hướng di chuyển và tiếp tục quét. Thuật toán SCAN đảm bảo tất cả các yêu cầu được phục vụ, giải quyết vấn đề đói. Tuy nhiên, nếu yêu cầu đến khi đầu đọc/ghi vừa quét xong, yêu cầu đó phải chờ cho đến khi đầu đọc/ghi quét từ phía ngược lại.
- Thuật toán quét vòng (Circular Scan, C-SCAN): Là biến thể của thuật toán SCAN, chỉ quét một phía của đĩa và di chuyển theo một hướng duy nhất, cho đến khi đến biên đĩa, sau đó quay lại điểm bắt đầu và bắt đầu quét lại.
- Thuật toán quét và quan sát (LOOK): Thuật toán LOOK cải tiến thuật toán SCAN bằng cách thay đổi hướng di chuyển ngay khi không còn yêu cầu trên hướng di chuyển hiện tại. Điều này giúp tránh việc di chuyển không cần thiết khi không có yêu cầu trên hướng di chuyển.
- Thuật toán quét vòng cân bằng (C-LOOK): Thuật toán C-LOOK cải tiến thuật toán C-SCAN bằng cách cho phép đầu đọc/ghi quay trở lại vị trí có yêu cầu truy cập đĩa, thay vì quay trở lại điểm bắt đầu.