Go: Map Range
Tuyến đường duyệt của map thực sự đơn giản: duyệt qua tất cả các bucket và các overflow bucket được liên kết với nó, sau đó duyệt qua tất cả các cell trong bucket. Mỗi bucket chứa 8 cell, và ta lấy key và value từ cell có key.
Tuy nhiên, thực tế không đơn giản như vậy. Bạn có nhớ quá trình mở rộng không? Quá trình mở rộng không phải là một hoạt động nguyên tử, mỗi lần chỉ di chuyển tối đa 2 bucket, vì vậy nếu quá trình mở rộng được kích hoạt, trong một thời gian dài, trạng thái của map sẽ ở trạng thái trung gian: một số bucket đã di chuyển đến nơi mới, trong khi một số bucket vẫn ở chỗ cũ.
Do đó, nếu việc duyệt xảy ra trong quá trình mở rộng, nó sẽ liên quan đến việc duyệt cả bucket mới và bucket cũ, đây là điểm khó khăn.
Đầu tiên, hãy viết một đoạn mã đơn giản, giả vờ không biết chính xác các hàm được gọi trong quá trình duyệt:
package main
import "fmt"
func main() {
ageMp := make(map[string]int)
ageMp["qcrao"] = 18
for name, age := range ageMp {
fmt.Println(name, age)
}
}Chạy lệnh:
go tool compile -S main.goĐể có mã nguồn gốc. Ở đây, tôi sẽ không giải thích từng dòng mã, bạn có thể xem các bài viết trước để hiểu rõ hơn.
Một số dòng mã quan trọng như sau:
// ......
0x0124 00292 (test16.go:9) CALL runtime.mapiterinit(SB)
// ......
0x01fb 00507 (test16.go:9) CALL runtime.mapiternext(SB)
0x0200 00512 (test16.go:9) MOVQ ""..autotmp_4+160(SP), AX
0x0208 00520 (test16.go:9) TESTQ AX, AX
0x020b 00523 (test16.go:9) JNE 302
// ......Như vậy, quá trình duyệt map được thực hiện bằng cách gọi hàm mapiterinit để khởi tạo bộ lặp, sau đó lặp gọi hàm mapiternext để duyệt map.
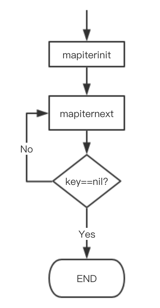
Cấu trúc của bộ lặp:
type hiter struct {
// con trỏ key
key unsafe.Pointer
// con trỏ value
value unsafe.Pointer
// kiểu map, bao gồm kích thước key và các thông tin khác
t *maptype
// header của map
h *hmap
// con trỏ đến buckets
buckets unsafe.Pointer
// bucket hiện tại đang duyệt
bptr *bmap
overflow [2]*[]*bmap
// số thứ tự bucket bắt đầu duyệt
startBucket uintptr
// số thứ tự cell bắt đầu duyệt (mỗi bucket có 8 cell)
offset uint8
// đã duyệt qua từ đầu hay chưa
wrapped bool
// kích thước B
B uint8
// chỉ số cell hiện tại
i uint8
// con trỏ đến bucket hiện tại
bucket uintptr
// bucket cần kiểm tra do mở rộng
checkBucket uintptr
}mapiterinit được sử dụng để khởi tạo các trường trong cấu trúc hiter.
Như đã đề cập trước đó, ngay cả khi duyệt một map cố định, kết quả trả về cũng không có thứ tự. Dưới đây, chúng ta có thể xem xét cài đặt cụ thể của quá trình duyệt map, hy vọng nó sẽ trở nên rõ ràng và dễ hiểu hơn.
// Tạo số ngẫu nhiên r
r := uintptr(fastrand())
if h.B > 31-bucketCntBits {
r += uintptr(fastrand()) << 31
}
// Bắt đầu duyệt từ bucket nào
it.startBucket = r & (uintptr(1)<<h.B - 1)
// Bắt đầu duyệt từ cell nào trong bucket
it.offset = uint8(r >> h.B & (bucketCnt - 1))Ví dụ, nếu B = 2, thì kết quả của uintptr(1)<<h.B - 1 là 3, 8 bit thấp là 0000 0011, và ta sẽ thực hiện phép AND với r để thu được một số thứ tự bucket từ 0 đến 3; bucketCnt - 1 là 7, 8 bit thấp là 0000 0111, sau khi dịch r sang phải 2 bit và thực hiện phép AND với 7, ta sẽ thu được một cell từ 0 đến 7.
Do đó, trong hàm mapiternext, ta sẽ bắt đầu duyệt từ cell có số thứ tự it.offset trong bucket it.startBucket, lấy ra key và value từ đó cho đến khi quay lại bucket ban đầu, hoàn thành quá trình duyệt.
Phần mã nguồn khá dễ hiểu, đặc biệt là sau khi đã hiểu các đoạn mã chú thích ở phần trước, khi đọc phần mã này sẽ không gặp nhiều khó khăn. Vì vậy, tiếp theo, tôi sẽ giải thích quá trình duyệt bằng cách trực quan hóa qua các hình ảnh, hy vọng sẽ giúp bạn hiểu rõ hơn.
Giả sử chúng ta có một map như hình dưới đây, ban đầu B = 1, có hai bucket, sau đó map được mở rộng (đây chỉ là một giả định, không cần quan tâm đến điều kiện mở rộng), B trở thành 2. Và bucket số 1 được chia thành bucket số 1 và bucket số 3; bucket số 0 không được chia. Các bucket cũ được lưu trữ trong con trỏ *oldbuckets, còn bucket mới được lưu trữ trong con trỏ *buckets.
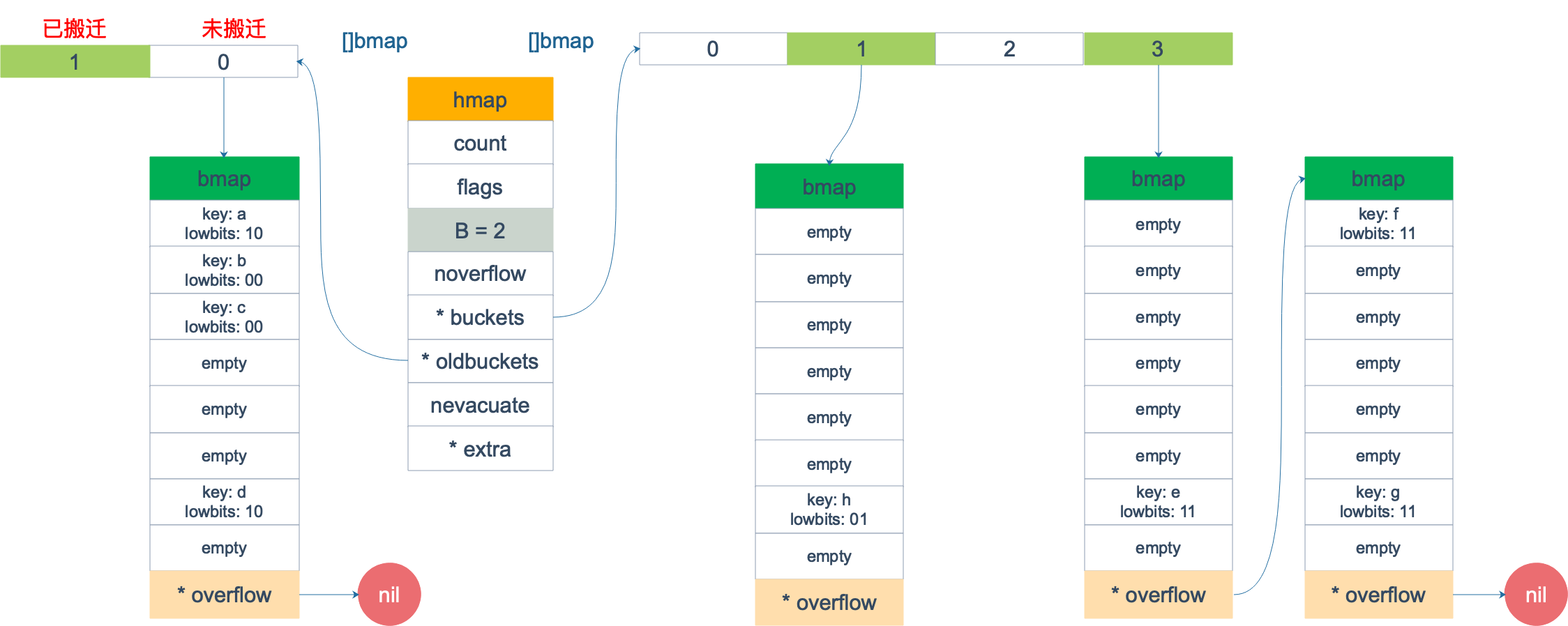
Lúc này, chúng ta muốn duyệt qua map này. Giả sử sau khi khởi tạo, startBucket = 3, offset = 2. Do đó, điểm bắt đầu duyệt sẽ là cell số 2 của bucket số 3, hình dưới đây là trạng thái ban đầu của quá trình duyệt:
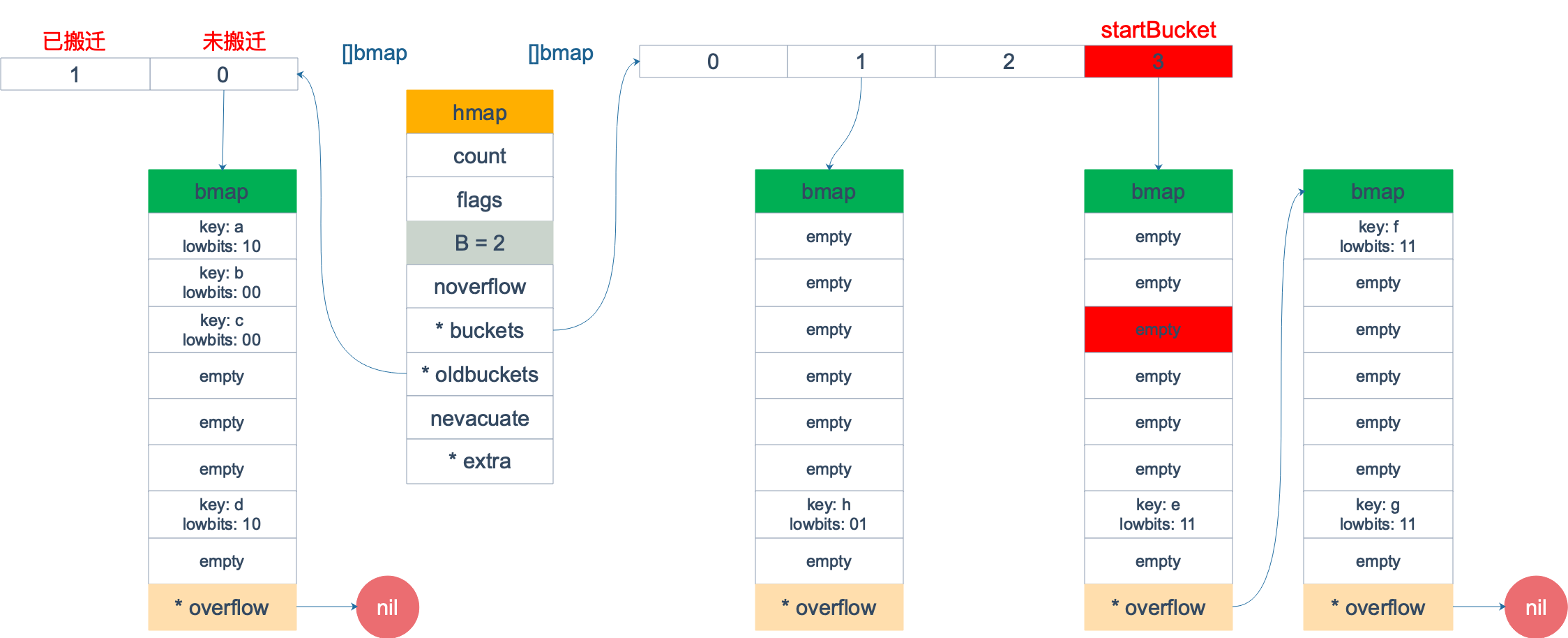
Các vị trí được đánh dấu màu đỏ là điểm bắt đầu, thứ tự duyệt bucket là: 3 → 0 → 1 → 2.
Vì bucket số 3 tương ứng với bucket cũ số 1, nên ta kiểm tra xem bucket cũ số 1 đã được chuyển đi chưa. Phương pháp kiểm tra là:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}Nếu giá trị của b.tophash[0] nằm trong phạm vi giá trị đánh dấu, tức là trong khoảng (0,4), thì có nghĩa là bucket đã được chuyển đi.
empty = 0
evacuatedEmpty = 1
evacuatedX = 2
evacuatedY = 3
minTopHash = 4Trong ví dụ này, bucket cũ số 1 đã được chuyển đi. Vì vậy, giá trị của tophash[0] nằm trong khoảng (0,4), chỉ cần duyệt qua bucket mới số 3.
Tiếp tục duyệt qua các cell của bucket số 3, lúc này ta sẽ tìm thấy key đầu tiên không rỗng: phần tử e. Lúc này, hàm mapiternext trả về và kết quả duyệt chỉ có một phần tử:

Vì key trả về không rỗng, nên sẽ tiếp tục gọi hàm mapiternext.
Tiếp tục duyệt từ vị trí đã duyệt đến trước đó, ta tìm thấy các phần tử f và g trong overflow bucket mới số 3.
Kết quả duyệt cũng được mở rộng:

Sau khi duyệt qua bucket mới số 3, quay lại bucket mới số 0. Bucket mới số 0 tương ứng với bucket cũ số 0, sau khi kiểm tra, ta thấy bucket cũ số 0 chưa được chuyển đi, vì vậy việc duyệt qua bucket mới số 0 sẽ thay đổi thành duyệt qua bucket cũ số 0. Nhưng liệu ta có lấy tất cả các key trong bucket cũ số 0 không?
Không đơn giản như vậy, hãy nhớ rằng sau khi chuyển đi, bucket cũ số 0 đã chia thành 2 bucket mới: bucket mới số 0 và bucket mới số 2. Và lúc này ta chỉ duyệt qua các key trong bucket mới số 0 (lưu ý, việc duyệt là duyệt qua con trỏ *bucket, cũng chính là bucket mới). Vì vậy, ta chỉ lấy các key trong bucket cũ số 0 mà sau khi chia thành 2 bucket mới, nó được phân vào bucket mới số 0.
Do đó, chỉ các key có lowbits == 00 sẽ được lấy ra và thêm vào kết quả duyệt:

Tiếp tục duyệt qua bucket mới số 1, ta thấy bucket cũ số 1 đã được chuyển đi, chỉ cần duyệt qua các phần tử hiện có trong bucket mới số 1 là đủ. Kết quả duyệt trở thành:

Tiếp tục duyệt qua bucket mới số 2, bucket này từ bucket cũ số 0, vì vậy ta chỉ cần lấy các key trong bucket cũ số 0 mà sau khi chia thành 2 bucket mới, nó được phân vào bucket mới số 2, tức là các key có lowbits == 10.
Như vậy, kết quả duyệt trở thành:

Cuối cùng, tiếp tục duyệt qua bucket mới số 3, ta thấy tất cả các bucket đã được duyệt qua, quá trình lặp hoàn tất.
Ngoài ra, nếu gặp phải key là math.NaN() chẳng hạn, cách xử lý cũng tương tự. Quan trọng là xem key đó sẽ rơi vào bucket nào sau khi chia. Chỉ cần xem bit thấp nhất của top hash. Nếu bit thấp nhất là 0, thì nó thuộc phần X; nếu là 1, thì thuộc phần Y. Dựa vào đó, ta quyết định xem có lấy key và thêm vào kết quả duyệt hay không.
Quá trình duyệt map quan trọng là hiểu rõ rằng khi mở rộng lên gấp đôi, bucket cũ sẽ chia thành 2 bucket mới. Và thao tác duyệt sẽ được thực hiện theo thứ tự số thứ tự của bucket mới. Khi gặp trường hợp bucket cũ chưa được chuyển đi, ta sẽ tìm các key sẽ được chuyển đến bucket mới trong tương lai trong bucket cũ.