HDFS Quick Start
HDFS là Hệ thống tập tin phân tán của Hadoop.
Giới thiệu về HDFS
HDFS là viết tắt của Hadoop Distributed File System, tức là Hệ thống tập tin phân tán của Hadoop.
HDFS là một loại hệ thống tập tin dùng để lưu trữ các tập tin siêu lớn với mô hình truy cập dữ liệu dạng stream, nó hoạt động trên cụm máy tính giá rẻ.
Mục tiêu thiết kế của HDFS là quản lý hàng ngàn máy chủ, hàng vạn ổ đĩa, coi tất cả những tài nguyên tính toán quy mô lớn này như một hệ thống lưu trữ duy nhất, cung cấp dung lượng lưu trữ tính bằng PB cho các ứng dụng, cho phép các ứng dụng lưu trữ dữ liệu tập tin quy mô lớn giống như sử dụng hệ thống tập tin thông thường.
HDFS hoạt động trên một cụm máy chủ phân tán quy mô lớn, chia dữ liệu thành các phần sau đó đọc và ghi song song cũng như lưu trữ dự phòng. Bởi vì HDFS có thể triển khai trên một cụm máy chủ lớn, tất cả ổ đĩa của tất cả máy chủ trong cụm đều có thể sử dụng cho HDFS, vì vậy không gian lưu trữ toàn bộ của HDFS có thể đạt đến dung lượng cấp PB.
Ưu điểm của HDFS
- Tính chịu lỗi cao - Dữ liệu có nhiều bản sao, tự động khôi phục khi mất bản sao
- Tính sẵn sàng cao - NameNode HA, chế độ an toàn
- Tính mở rộng cao - Có thể xử lý quy mô 10K nút; xử lý dữ liệu đạt đến GB, TB, thậm chí PB; có thể xử lý số lượng tập tin lên đến hàng triệu, số lượng rất lớn.
- Xử lý hàng loạt - Truy cập dữ liệu dạng stream; vị trí dữ liệu được tiết lộ cho khung tính toán
- Xây dựng trên máy tính thương mại giá rẻ - Cung cấp cơ chế chịu lỗi và phục hồi
Nhược điểm của HDFS
- Không phù hợp cho truy cập dữ liệu độ trễ thấp - Phù hợp với các tình huống có tốc độ thông qua cao, tức là ghi lượng lớn dữ liệu trong một khoảng thời gian nhất định. Nhưng nó không hoạt động trong trường hợp độ trễ thấp, như đọc dữ liệu trong vòng một mili giây, nó khó có thể triển khai.
- Không phù hợp cho lưu trữ nhiều tập tin nhỏ
- Nếu lưu trữ nhiều tập tin nhỏ (ở đây, tập tin nhỏ là tập tin nhỏ hơn kích thước Block của hệ thống HDFS (mặc định 64M)), nó sẽ chiếm nhiều bộ nhớ của NameNode để lưu trữ thông tin về tập tin, thư mục và khối. Điều này không phải là điều mong muốn, bởi vì bộ nhớ của NameNode luôn có hạn.
- Thời gian tìm kiếm trên đĩa vượt quá thời gian đọc
- Không hỗ trợ ghi đồng thời - Một tập tin cùng lúc chỉ có một người ghi
- Không hỗ trợ chỉnh sửa tập tin ngẫu nhiên - Chỉ hỗ trợ ghi tiếp
Kiến trúc HDFS
HDFS sử dụng kiến trúc master-slave, bao gồm một NameNode (NN) duy nhất và nhiều DataNode (DN).
Mỗi Datanode trong cụm thường tương ứng với một nút, chịu trách nhiệm quản lý lưu trữ trên nút của nó. HDFS tiết lộ Namespace của hệ thống tệp, người dùng có thể lưu trữ dữ liệu dưới dạng tệp trên đó. Nhìn từ bên trong, một tệp thực sự được chia thành một hoặc nhiều khối dữ liệu, những khối này được lưu trữ trên một nhóm Datanode. Namenode triển khai các hoạt động Namespace của hệ thống tệp, như mở, đóng, đổi tên tệp hoặc thư mục. Nó cũng chịu trách nhiệm xác định ánh xạ từ khối dữ liệu đến nút Datanode cụ thể.
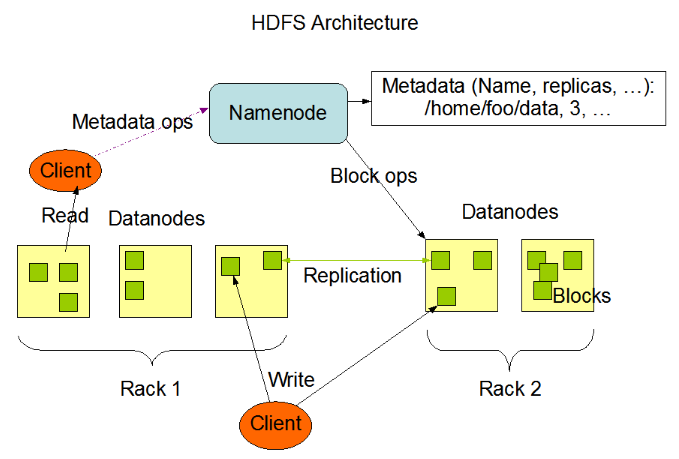
NameNode
NameNode chịu trách nhiệm quản lý Namespace của hệ thống tệp và truy cập tệp của client. Trách nhiệm của NameNode:
- Quản lý Namespace
- Quản lý dữ liệu metdata: vị trí tệp, chủ sở hữu, quyền, khối dữ liệu, v.v.
- Quản lý chiến lược sao lưu Block: mặc định là 3 bản sao
- Xử lý yêu cầu đọc / ghi của client, phân công công việc cho DataNode
DataNode
DataNode chịu trách nhiệm lưu trữ dữ liệu tệp và hoạt động đọc / ghi, HDFS chia dữ liệu tệp thành một số khối dữ liệu (Block), mỗi DataNode lưu trữ một phần khối dữ liệu, do đó tệp được lưu trữ phân tán trong toàn bộ cụm máy chủ HDFS.
- Lưu trữ Block và checksum dữ liệu
- triển khai các hoạt động đọc / ghi được gửi bởi client
- Thông qua cơ chế heartbeat, báo cáo trạng thái hoạt động và thông tin danh sách Block cho NameNode định kỳ (mặc định là 3 giây)
- Khi cụm khởi động, DataNode cung cấp thông tin danh sách Block cho NameNode
Namespace
Không gian tên hệ thống tệp của HDFS có cấu trúc phân cấp giống như hầu hết các hệ thống tệp khác (như Linux), hỗ trợ việc tạo, di chuyển, xóa và đổi tên thư mục và tệp, hỗ trợ cấu hình người dùng và quyền truy cập, nhưng không hỗ trợ liên kết cứng và liên kết mềm. NameNode chịu trách nhiệm duy trì Namespace hệ thống tệp, ghi lại bất kỳ thay đổi nào đối với Namespace hoặc thuộc tính của nó.
Khối dữ liệu Block
- Đơn vị lưu trữ nhỏ nhất của HDFS
- Tệp được ghi vào HDFS sẽ được chia thành một số Block
- Kích thước Block cố định, mặc định là 128MB, có thể tùy chỉnh
- Nếu kích thước của một Block nhỏ hơn giá trị đã đặt, nó sẽ không chiếm toàn bộ không gian khối
- Theo mặc định, mỗi Block có 3 bản sao
Client
- Chia tệp thành khối dữ liệu Block
- Tương tác với NameNode, nhận dữ liệu metada của tệp
- Tương tác với DataNode, đọc hoặc ghi dữ liệu
- Quản lý HDFS
Luồng dữ liệu trong HDFS
Đọc tệp từ HDFS
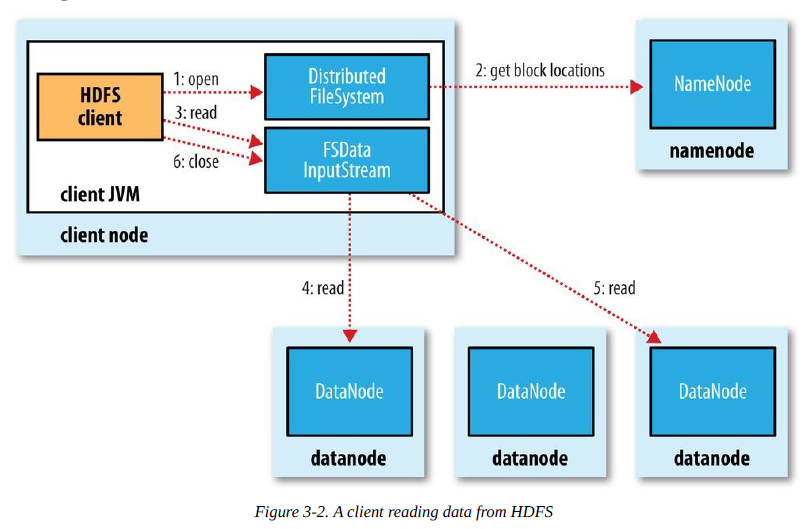
- Client gọi phương thức open() của đối tượng FileSystem để mở tệp cần đọc trong hệ thống tệp phân tán.
- Hệ thống tệp phân tán sử dụng RPC (Remote Procedure Call) để gọi namenode, xác định vị trí khối đầu tiên của tệp.
- Lớp DistributedFileSystem của hệ thống tệp phân tán trả về một đối tượng stream FSDataInputStream hỗ trợ định vị tệp, đối tượng FSDataInputStream sau đó đóng gói một đối tượng DFSInputStream (chứa địa chỉ datanode của một số khối đầu tiên của tệp), Client gọi phương thức read() trên stream này.
- DFSInputStream kết nối với datanode gần nhất, bằng cách gọi phương thức read nhiều lần, dữ liệu được truyền từ datanode đến Client.
- Khi đến cuối khối, DFSInputStream đóng kết nối với datanode đó, tìm datanode tốt nhất cho khối tiếp theo.
- Client hoàn thành việc đọc, gọi phương thức close() trên FSDataInputStream để đóng kết nối.
Ghi tệp vào HDFS
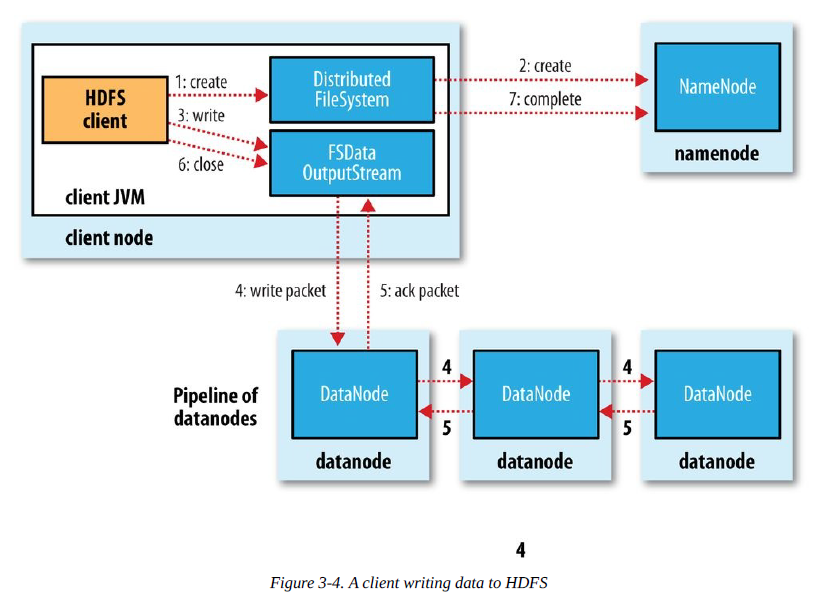
- Client tạo một tệp mới bằng cách gọi phương thức create() trên đối tượng DistributedFileSystem.
- Hệ thống tệp phân tán gọi namenod thông qua một cuộc gọi RPC, tạo một tệp mới trong không gian tên của hệ thống tệp.
- Sau khi namenode kiểm tra tệp mới không có lỗi, hệ thống tệp phân tán trả về cho Client một đối tượng FSDataOutputStream, đối tượng FSDataOutputStream đóng gói một đối tượng DFSoutPutstream, phụ trách việc xử lý giao tiếp giữa namenode và datanode, Client bắt đầu ghi dữ liệu.
- FSDataOutputStream chia dữ liệu thành một số gói dữ liệu, ghi vào hàng đợi nội bộ “hàng đợi dữ liệu”, DataStreamer chịu trách nhiệm truyền dữ liệu từng gói dữ liệu một cách tuần tự vào pipeline gồm một nhóm namenode.
- DFSOutputStream duy trì hàng đợi xác nhận chờ đợi datanode nhận xác nhận, khi nhận được xác nhận từ tất cả datanode trong pipeline, gói dữ liệu được xóa khỏi hàng đợi xác nhận.
- Client hoàn thành việc ghi dữ liệu, gọi phương thức close() trên dòng dữ liệu.
- Namenode xác nhận hoàn tất.
Sao chép dữ liệu HDFS
Do Hadoop được thiết kế để hoạt động trên máy tính giá rẻ, điều này có nghĩa là phần cứng không đáng tin cậy, để đảm bảo khả năng chịu lỗi, HDFS cung cấp cơ chế sao lưu dữ liệu. HDFS lưu trữ mỗi tệp dưới dạng một chuỗi khối, mỗi khối được đảm bảo chịu lỗi bằng nhiều bản sao, kích thước khối và yếu tố sao chép có thể được cấu hình (theo mặc định, kích thước khối là 128M, yếu tố sao chép mặc định là 3).
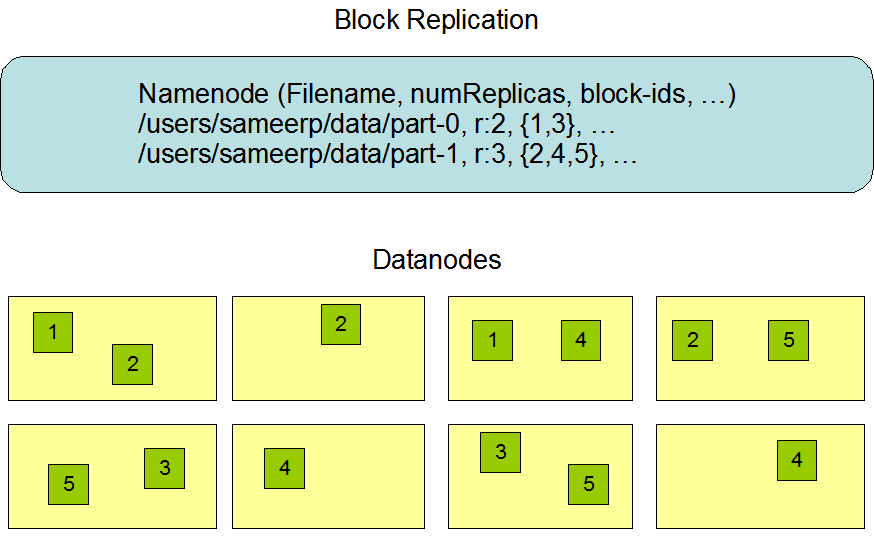
Namenode quản lý toàn bộ việc sao chép khối dữ liệu, nó nhận tín hiệu heartbeat và báo cáo trạng thái khối (Blockreport) theo chu kỳ từ mỗi Datanode trong cụm. Việc nhận tín hiệu heartbeat có nghĩa là nút Datanode đó đang hoạt động bình thường. Báo cáo trạng thái khối chứa danh sách tất cả khối dữ liệu trên Datanode đó.
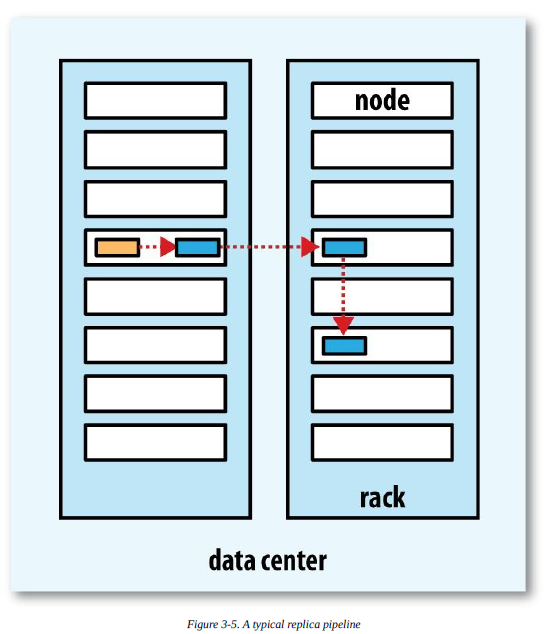
Các phiên bản HDFS lớn thường được phân tán trên nhiều máy chủ trên nhiều rack, hai máy chủ trên các rack khác nhau giao tiếp với nhau qua switch. Trong hầu hết các trường hợp, băng thông mạng giữa các máy chủ trên cùng một rack lớn hơn băng thông mạng giữa các máy chủ trên các rack khác nhau. Do đó, HDFS áp dụng chiến lược đặt bản sao nhận biết rack, đối với trường hợp thường gặp, khi yếu tố sao chép là 3, chiến lược đặt của HDFS là:
- Bản sao 1: Đặt trên nút mà Client đang ở
- Đối với Client từ xa, hệ thống sẽ chọn nút ngẫu nhiên
- Bản sao 2: Đặt trên nút thuộc rack khác
- Bản sao 3: Đặt trên một nút khác thuộc cùng rack với bản sao thứ hai
- Bản sao N: Chọn ngẫu nhiên
- Lựa chọn nút: Trong điều kiện ngang nhau, ưu tiên chọn nút rảnh
Để giảm thiểu tiêu thụ băng thông và độ trễ đọc tối đa, khi HDFS triển khai yêu cầu đọc, nó ưu tiên đọc bản sao gần đọc nhất. Nếu có bản sao trên cùng một rack với nút đọc, ưu tiên chọn bản sao đó. Nếu cụm HDFS trải qua nhiều trung tâm dữ liệu, ưu tiên chọn bản sao trên trung tâm dữ liệu cục bộ.
HDFS sẵn sàng cao
Chịu trách nhiệm về lỗi lưu trữ dữ liệu
Do các yếu tố môi trường hoặc thời gian, đĩa có thể bị hỏng trong quá trình lưu trữ. Phản ứng của HDFS là tính toán và lưu trữ checksums cho các khối dữ liệu được lưu trữ trên DataNode. Khi đọc dữ liệu, tính toán lại checksum của dữ liệu đã đọc. Nếu checksum không chính xác, một ngoại lệ sẽ được ném ra. Ứng dụng nắm bắt ngoại lệ và sau đó đọc dữ liệu sao lưu từ DataNodes khác.
Chịu trách nhiệm về lỗi đĩa
Nếu DataNode phát hiện ra rằng một đĩa trên máy của nó bị hỏng, nó sẽ báo cáo tất cả các BlockID được lưu trữ trên đĩa đó cho NameNode. NameNode kiểm tra xem DataNodes nào vẫn còn sao lưu của các khối dữ liệu này và thông báo cho các máy chủ DataNode tương ứng sao chép các khối dữ liệu tương ứng đến các máy chủ khác để đảm bảo rằng số lượng sao lưu khối dữ liệu đáp ứng yêu cầu.
Chịu trách nhiệm về lỗi DataNode
DataNode giữ liên lạc với NameNode thông qua heartbeat. Nếu DataNode không gửi heartbeat trong thời gian chờ, NameNode sẽ coi DataNode này đã thất bại. Nó ngay lập tức kiểm tra xem khối dữ liệu nào được lưu trữ trên DataNode này và khối dữ liệu này được lưu trữ trên máy chủ nào, sau đó thông báo cho các máy chủ này sao chép một bản sao của khối dữ liệu đến các máy chủ khác, đảm bảo rằng số lượng sao lưu khối dữ liệu mà HDFS lưu trữ đáp ứng cài đặt của người dùng. Ngay cả khi một máy chủ thất bại một lần nữa, dữ liệu cũng sẽ không bị mất.
Chịu trách nhiệm về lỗi NameNode
NameNode là trung tâm của toàn bộ HDFS, ghi lại thông tin bảng phân bổ tệp HDFS, tất cả các đường dẫn tệp và thông tin lưu trữ khối dữ liệu được lưu trong NameNode. Nếu NameNode gặp lỗi, toàn bộ cụm hệ thống HDFS không thể sử dụng; nếu dữ liệu được ghi trong NameNode bị mất, tất cả dữ liệu được lưu trữ bởi DataNode của toàn bộ cụm cũng vô ích.
Cơ chế HA của NameNode
NameNode triển khai master-slave thông qua Active NameNode và Standby NameNode.
- Active NameNode - là NameNode đang hoạt động;
- Standby NameNode - là NameNode dự phòng.
Sau khi Active NameNode gặp sự cố, Standby NameNode nhanh chóng nâng cấp thành Active NameNode mới.
Standby NameNode đồng bộ hóa nhật ký chỉnh sửa một cách định kỳ và hợp nhất fsimage và chỉnh sửa vào đĩa cục bộ một cách định kỳ.
Hadoop 3.0 cho phép cấu hình nhiều Standby NameNodes.
Các tệp metada
- edits (tệp nhật ký chỉnh sửa) - Lưu tất cả các hoạt động cập nhật tệp kể từ điểm kiểm tra cuối cùng (Checkpoint).
- fsimage (tệp hình ảnh kiểm tra metada) - Lưu tất cả thông tin thư mục và tệp trong hệ thống tệp, chẳng hạn như: thư mục nào có các thư mục con và tệp nào, và tên tệp, số lượng bản sao tệp, khối nào tệp được tạo thành, v.v.
Có một bản sao của metada mới nhất (= fsimage + edits) trong bộ nhớ của Active NameNode.
Standby NameNode lưu metada trong bộ nhớ vào tệp fsimage một cách định kỳ.
Sử dụng QJM để triển khai metada có sẵn
Dựa trên thuật toán Paxos
Cơ chế QJM (Quorum Journal Manager)
Chỉ cần đảm bảo số lượng hoạt động Quorum (số lượng người đủ điều kiện) thành công, thì đây là một hoạt động thành công cuối cùng
Hệ thống lưu trữ chia sẻ QJM
- Triển khai số lẻ (2N+1) JournalNode
- JournalNode phụ trách lưu trữ nhật ký chỉnh sửa edits
- Khi viết chỉnh sửa, chỉ cần có hơn một nửa (N+1) JournalNode trả về thành công, thì coi như lần ghi này thành công
- Có thể chịu được tối đa N JournalNode gặp sự cố
Sử dụng ZooKeeper để triển khai bầu chọn nút Active.