Phần này sẽ giới thiệu nguyên lý thực hiện của hash trong ngôn ngữ Go. Hash Table (bảng băm) là cấu trúc dữ liệu phổ biến nhất trừ mảng. Hầu như tất cả các ngôn ngữ đều có hai phần tử tập hợp, mảng và bảng băm, một số ngôn ngữ triển khai mảng dưới dạng danh sách và một số ngôn ngữ gọi các hàm băm là dictionary (python) hoặc map (c++). Bất kể nó được đặt tên như thế nào hoặc nó được triển khai như thế nào, mảng và bảng băm là hai ý tưởng để thiết kế các phần tử bộ sưu tập. Mảng được sử dụng để biểu thị trình tự các phần tử, trong khi hàm băm biểu thị mối quan hệ ánh xạ giữa các cặp key-value.
Hash Tablelà một cấu trúc dữ liệu cổ xưa, vào năm 1953, ai đó đã triển khai bảng băm bằng phương pháp separate chaining, có thể trực tiếp lấy giá trị tương ứng với khóa thông qua khóa.
1. Nguyên tắc thiết kế
Bảng băm là một trong những cấu trúc dữ liệu quan trọng nhất trong khoa học máy tính, không chỉ vì O(1) hiệu suất đọc và ghi của, cũng bởi vì nó cung cấp ánh xạ giữa các key-value. Để triển khai bảng băm với hiệu suất tuyệt vời, bạn cần chú ý đến hai điểm chính - hàm băm (hash function) và phương pháp giải quyết xung đột (collision handling).
Hàm Băm
Điểm mấu chốt để nhận ra bảng băm là lựa chọn hàm băm, có thể xác định hiệu suất đọc và ghi của bảng băm ở mức độ lớn. Lý tưởng nhất là hàm băm có thể ánh xạ các khóa khác nhau tới các chỉ mục khác nhau, điều này yêu cầu phạm vi đầu ra của hàm băm lớn hơn phạm vi đầu vào. Nhưng vì số lượng khóa sẽ lớn hơn nhiều so với phạm vi ánh xạ, trong sử dụng thực tế, hiệu ứng lý tưởng này là không thể đạt được.
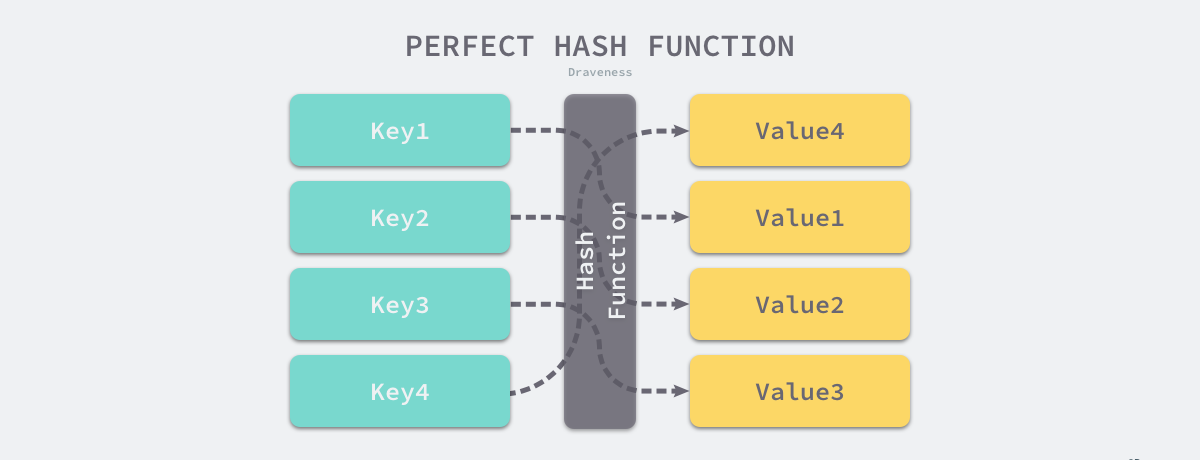
Một cách thực tế hơn là làm cho kết quả của hàm băm được phân bổ đều nhất có thể, sau đó giải quyết vấn đề xung đột hàm băm thông qua các giải pháp kỹ thuật. Kết quả của ánh xạ hàm băm phải càng đồng đều càng tốt. Một hàm băm có kết quả không đồng đều sẽ mang lại nhiều xung đột băm hơn và hiệu suất đọc và ghi kém hơn.
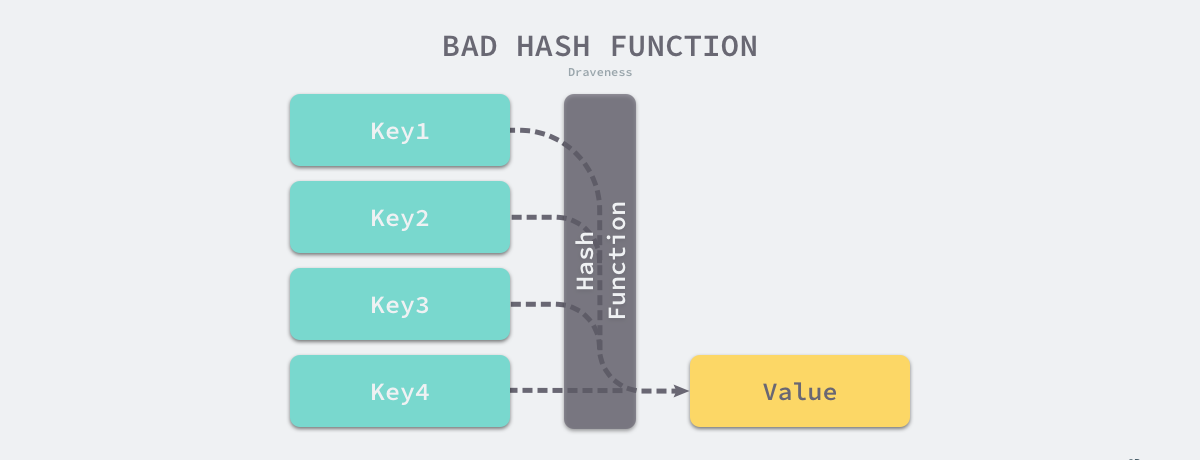
Nếu một hàm băm có phân phối kết quả tương đối đồng đều được sử dụng, thì độ phức tạp về thời gian của việc thêm, xóa, sửa đổi và kiểm tra hàm băm là O(1). Nhưng nếu kết quả của hàm băm được phân phối không đều, độ phức tạp về thời gian của tất cả các hoạt động có thể đạt tới O(n). Từ quan điểm này, điều quan trọng là sử dụng một hàm băm tốt.
Giải quyết xung đột
Như chúng tôi đã đề cập trước đây, trong các trường hợp bình thường, phạm vi đầu vào của hàm băm phải lớn hơn nhiều so với phạm vi đầu ra, vì vậy khi sử dụng bảng băm sẽ xảy ra xung đột, ngay cả khi chúng ta sử dụng hàm băm hoàn hảo, xung đột cũng có thể xảy ra khi nhập đủ key. Tuy nhiên, hầu hết các hàm băm không hoàn hảo, do đó vẫn có khả năng xảy ra xung đột băm, lúc này cần một số phương pháp để giải quyết vấn đề xung đột băm, các phương pháp phổ biến là phương pháp open addressing và phương pháp separate chaining.
Cần lưu ý rằng xung đột băm được đề cập ở đây không phải là nhiều key các giá trị băm tương ứng bằng nhau, mà nhiều giá trị băm có thể có một phần bằng nhau, ví dụ: bốn byte đầu tiên của giá trị băm tương ứng với hai key là giống nhau.
Open Addressing
Open Addressinglà phương pháp giải quyết xung đột băm trong bảng băm. Ý tưởng cốt lõi của phương pháp này là lần lượt phát hiện và so sánh các phần tử trong mảng để xác định xem cặp key-value mục tiêu có tồn tại trong bảng băm hay không. Chúng ta sử dụng phương pháp open addressing để thực hiện bảng băm, khi đó cấu trúc dữ liệu cơ bản của bảng băm là một mảng, nhưng do độ dài của mảng bị hạn chế nên khi ghi cặp key-value (author, draven) vào bảng băm bảng, nó sẽ duyệt chỉ mục như sau:
index := hash("author") % array.lenKhi chúng ta ghi dữ liệu mới vào bảng băm hiện tại, nếu xung đột xảy ra, cặp key-value sẽ được ghi vào vị trí mà chỉ mục tiếp theo không trống:
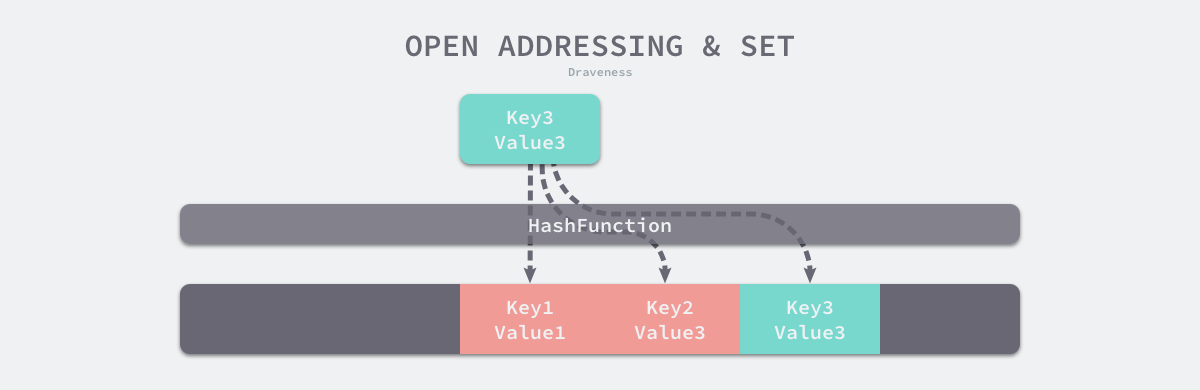
Như minh họa trong hình trên, khi Key3 xung đột với hai cặp key-value Key1 và Key2 đã được lưu trong bảng băm, Key3 sẽ được ghi vào vị trí trống phía sau Key2. Khi chúng ta đi đọc giá trị tương ứng với Key3, trước tiên chúng ta sẽ lấy hàm băm của key và lấy mod, điều này sẽ giúp chúng ta tìm thấy Key1 trước, sau khi tìm thấy Key1, chúng ta thấy rằng nó không bằng Key3, vì vậy chúng ta sẽ tiếp tục tìm kiếm các phần tử sau cho đến khi bộ nhớ trống hoặc phần tử đích được tìm thấy.
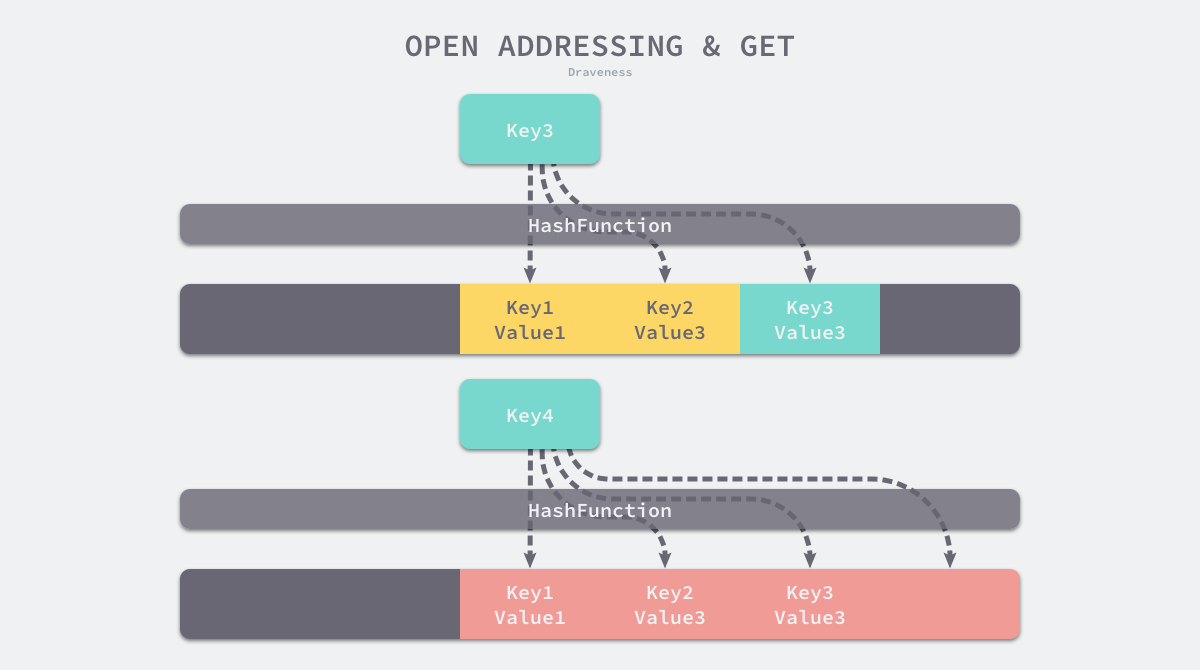
Khi cần tìm giá trị tương ứng với một key nào đó, mảng sẽ được dò tuyến tính từ vị trí index, tìm được cặp key-value đích hoặc bộ nhớ trống đồng nghĩa với việc kết thúc thao tác truy vấn này.
Tác động lớn nhất đến hiệu suất trong open addressing là hệ số tải , là tỷ lệ giữa số phần tử trong mảng với kích thước của mảng. Khi hệ số tải tăng lên, thời gian trung bình dành cho phát hiện tuyến tính sẽ tăng dần, điều này sẽ ảnh hưởng đến hiệu suất đọc và ghi của bảng băm. Khi tốc độ tải vượt quá 70%, hiệu suất của bảng băm sẽ giảm mạnh và khi tốc độ tải đạt 100%, toàn bộ bảng băm sẽ hoàn toàn không hợp lệ, lúc này, độ phức tạp của thời gian tìm kiếm và chèn bất kỳ phần tử nào là O(n). Đúng vậy, lúc này cần phải duyệt qua tất cả các phần tử trong mảng nên chúng ta phải chú ý đến sự thay đổi của hệ số tải khi thực hiện bảng băm.
Separate chaining
So với phương pháp open addressing, phương pháp separate chaining là phương pháp được áp dụng phổ biến nhất của bảng băm, hầu hết các ngôn ngữ lập trình đều sử dụng phương pháp này để triển khai bảng băm. Việc triển khai của nó phức tạp hơn một chút so với phương pháp open addressing, nhưng độ dài tìm kiếm trung bình cũng tương đối ngắn, bộ nhớ được sử dụng cho mỗi nút lưu trữ được áp dụng động, có thể tiết kiệm rất nhiều dung lượng lưu trữ.
Việc triển khai phương thức separate chaining thường sử dụng một mảng cộng với danh sách được liên kết, nhưng một số ngôn ngữ lập trình đưa cây đỏ đen vào hàm băm của phương pháp separate chaining để tối ưu hóa hiệu suất. Phương pháp separate chaining sử dụng một mảng danh sách được liên kết như cấu trúc dữ liệu cơ bản của hàm băm. Chúng ta có thể thấy nó trong một mảng hai chiều có thể mở rộng:
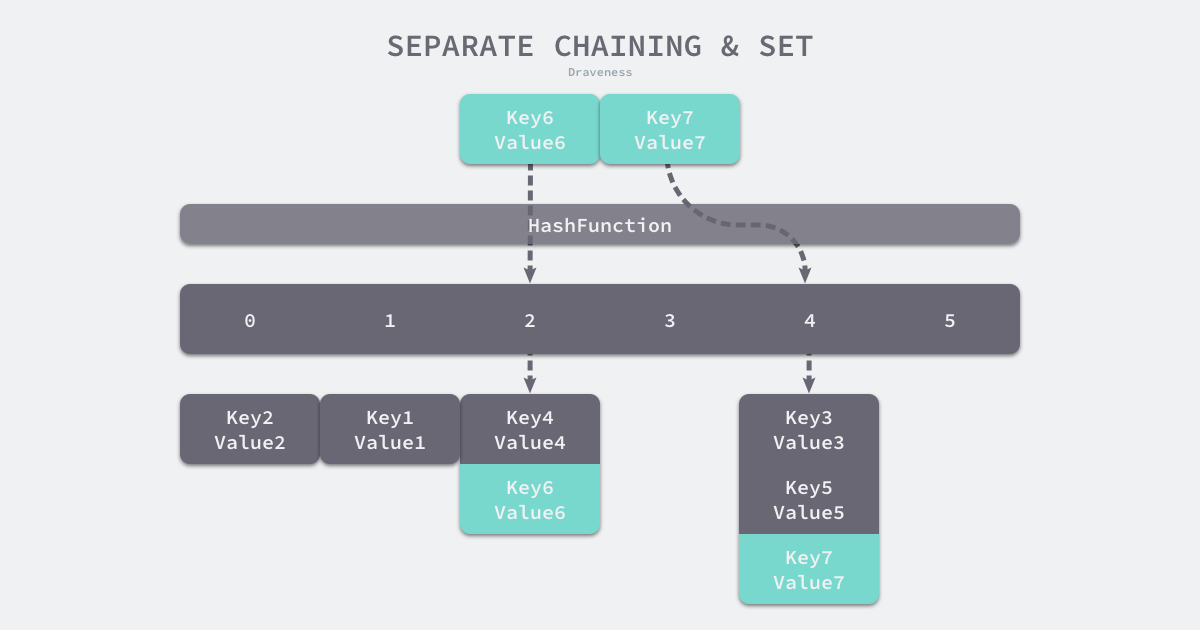
Như thể hiện trong hình trên, khi chúng ta cần ghi một cặp key-value (Key6, Value6) vào bảng băm, key Key6 trong cặp key-value trước tiên sẽ đi qua một hàm băm, giá trị băm được trả về bởi hàm băm sẽ giúp chúng ta chọn một thùng băm. Giống như phương thức open addressing, cách chọn thùng băm là trực tiếp lấy modulo của kết quả được hàm băm trả về:
index := hash("Key6") % array.lenSau khi chọn thùng chứa số 2, bạn có thể duyệt danh sách liên kết trong vùng chứa hiện tại, trong quá trình duyệt danh sách liên kết, bạn sẽ gặp 2 trường hợp sau:
- Tìm cặp key-value có cùng khóa — cập nhật giá trị tương ứng với khóa;
- Không tìm thấy cặp key-value nào có cùng khóa — nối thêm một cặp key-value mới vào cuối danh sách được liên kết;
Nếu bạn muốn lấy giá trị tương ứng với một khóa trong bảng băm, bạn sẽ thực hiện quy trình sau:
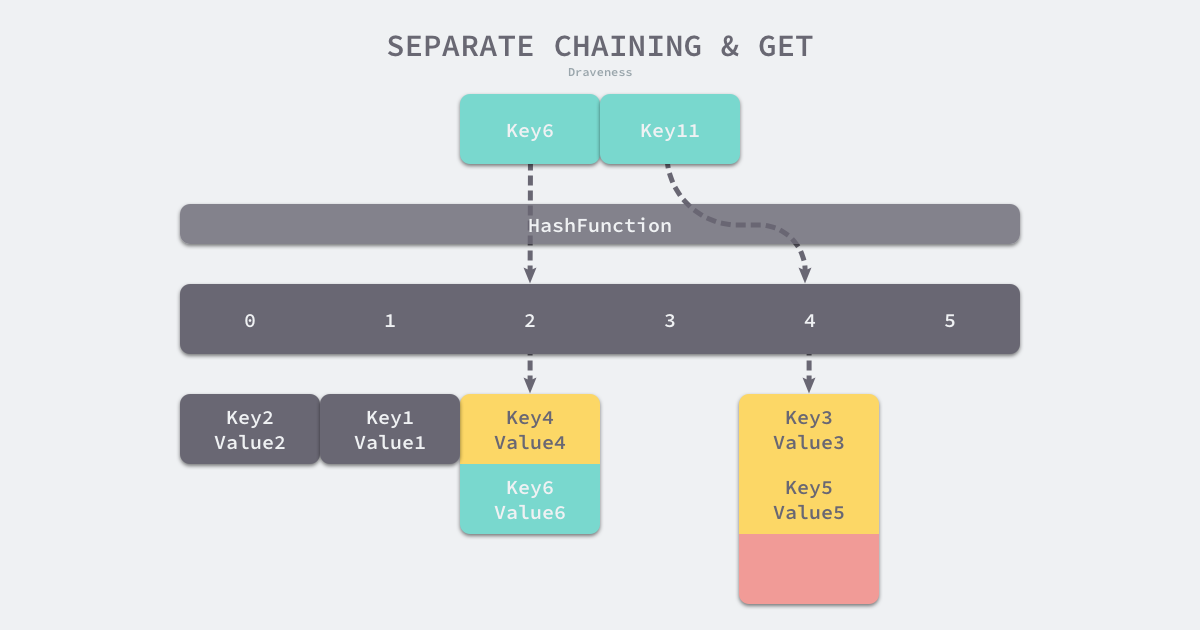
Key11 hiển thị một ví dụ trong đó khóa không tồn tại trong bảng băm. Khi bảng băm phát hiện ra rằng nó chạm vào thùng chứa số 4, nó sẽ lần lượt duyệt qua danh sách được liên kết trong thùng chứa. Tuy nhiên, khóa dự kiến không được tìm thấy sau đó duyệt đến cuối danh sách được liên kết, do đó, không có giá trị cho khóa đó trong bảng băm.
Trong một bảng băm tốt, nên có 01 phần tử trong mỗi nhóm, đôi khi là 23 và hiếm khi nhiều hơn con số này. Ba quá trình tính toán hàm băm, định vị thùng chứa và duyệt qua danh sách được liên kết là các chi phí chính của hoạt động đọc và ghi của bảng băm. Hàm băm được triển khai bằng phương pháp separate chaining cũng có khái niệm về hệ số tải:
Hệ số tải: = số phần tử / số thùng
Giống như phương pháp open addressing, hệ số tải của phương pháp separate chaining càng lớn thì hiệu suất đọc và ghi của hàm băm càng kém. Trong các trường hợp bình thường, hệ số tải của bảng băm sử dụng phương pháp separate chaining sẽ không vượt quá 1. Khi hệ số tải của bảng băm lớn, việc mở rộng hàm băm sẽ được kích hoạt và nhiều thùng hơn sẽ được tạo để lưu trữ các phần tử trong hàm băm. Sẽ không có sự suy giảm nghiêm trọng về hiệu suất. Nếu một bảng băm có 1000 thùng chứa lưu trữ 10000 cặp key-value, thì hiệu suất của nó chỉ bằng 1/10 so với việc lưu trữ 1000 cặp key-value, nhưng nó vẫn tốt hơn 1000 lần so với việc đọc và ghi trực tiếp trong danh sách được liên kết.
2. Cấu trúc dữ liệu
Runtime ngôn ngữ Go sử dụng kết hợp nhiều cấu trúc dữ liệu để biểu thị một bảng băm, trong đó runtime.hmap là cấu trúc cốt lõi. Trước tiên, hãy tìm hiểu các trường bên trong của cấu trúc này:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}count: Cho biết số phần tử trong bảng băm hiện tại;B: Cho biết sốbuckets, nhưng vì số thùng trong bảng băm là bội số của 2, nên trường này sẽ lưu trữ logarit, nghĩa làlen(buckets) == 2^B;hash0: Nó là hạt nhân của hàm băm, có thể tạo ra tính ngẫu nhiên cho kết quả của hàm băm. Giá trị này được xác định khi bảng băm được tạo và được truyền vào dưới dạng tham số khi hàm băm được gọi;oldbuckets: Là thùng băm được sử dụng để lưu trườngbucketstrước khi mở rộng, và kích thước của nó bằng một nửa so vớibucketshiện tại;
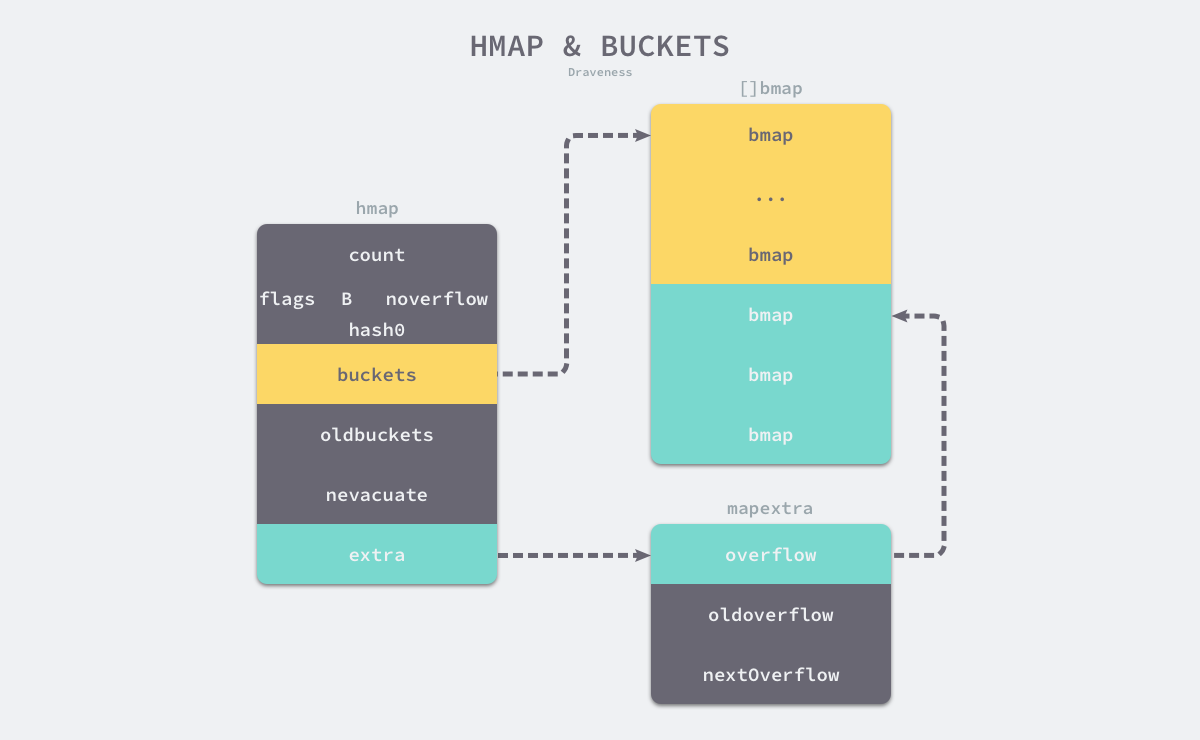
Như thể hiện trong hình trên, các thùng của bảng băm runtime.hmap là các runtime.bmap. Mỗi runtime.bmapcó thể lưu trữ 8 cặp key-value. Khi dữ liệu được lưu trữ trong bảng băm quá nhiều và một thùng đã đầy, thùng ở extra.nextOverflow sẽ được sử dụng để lưu trữ dữ liệu tràn.
Hai thùng khác nhau ở trên được lưu trữ liên tục trong bộ nhớ, ở đây chúng ta gọi chúng là thùng bình thường và thùng tràn tương ứng. runtime.bmap màu vàng trong hình trên là thùng chứa bình thường và runtime.bmap màu xanh lục là thùng chứa tràn. Thùng tràn là một thiết kế được sử dụng khi Go cũng được triển khai trong C, bởi vì nó có thể làm giảm tần số mở rộng, nó đã được sử dụng cho đến bây giờ.
Định nghĩa về cấu trúc thùng chứa runtime.bmap trong mã nguồn ngôn ngữ Go chỉ chứa một trường tophash đơn giản, tophash lưu trữ 8 bit cao của giá trị băm của khóa. Bằng cách so sánh 8 bit cao của giá trị băm của các khóa khác nhau, số lượng khóa truy cập các cặp giá trị có thể được giảm bớt để cải thiện hiệu suất:
type bmap struct {
tophash [bucketCnt]uint8
}Trong runtime, struct runtime.bmap thực sự chứa nhiều hơn trường tophash. Vì các loại cặp key-value khác nhau có thể được lưu trữ trong bảng băm và Và ngôn ngữ Go không hỗ trợ generic, do đó, chỉ có thể suy ra không gian bộ nhớ do các cặp key-value chiếm giữ tại thời điểm biên dịch. Các trường khác trong runtime.bmap cũng được truy cập bằng cách tính toán địa chỉ bộ nhớ trong runtime, vì vậy, nó không bao gồm các trường này trong định nghĩa của nó, nhưng chúng ta có thể xây dựng lại cấu trúc của nó theo hàm cmd/compile/internal/gc.bmap trong quá trình biên dịch:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}Khi dữ liệu được lưu trữ trong bảng băm tăng dần, chúng tôi sẽ mở rộng bảng băm hoặc sử dụng các thùng chứa bổ sung để lưu trữ dữ liệu tràn, để dữ liệu trong một thùng chứa sẽ không vượt quá 8, nhưng thùng chứa tràn chỉ là giải pháp tạm thời. Quá nhiều thùng tràn cuối cùng sẽ dẫn đến việc mở rộng hàm băm.
Từ định nghĩa của hàm băm trong ngôn ngữ Go, có thể thấy rằng các phần tử được cải tiến phức tạp hơn nhiều so với array và slice. Cấu trúc của nó không chỉ chứa một số lượng lớn các trường mà còn sử dụng các cấu trúc lồng nhau phức tạp, các phần sau sẽ giới thiệu các chức năng của các lĩnh vực khác nhau một cách chi tiết.
3. Khởi tạo
Bây giờ các nguyên tắc cơ bản và phương pháp triển khai của bảng băm đã được giới thiệu, chúng ta có thể bắt đầu phân tích việc triển khai bảng băm trong ngôn ngữ Go. Điều đầu tiên cần phân tích là hai phương pháp khởi tạo bảng băm trong ngôn ngữ Go— thông qua Literal và Runtime.
Literal
Các ngôn ngữ lập trình hiện đại hiện nay về cơ bản hỗ trợ việc sử dụng các ký tự để khởi tạo các giá trị băm và thường sử dụng key: value để biểu thị các cặp key-value và ngôn ngữ Go cũng không ngoại lệ:
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}Chúng ta cần khai báo kiểu của cặp key-value khi khởi tạo hàm băm, phương pháp sử dụng khởi tạo theo literal này cuối cùng sẽ khởi tạo thông qua cmd/compile/internal/gc.maplit. Hãy cùng phân tích quá trình khởi tạo bảng băm với hàm này:
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
entries := n.List.Slice()
if len(entries) > 25 {
...
return
}
// Build list of var[c] = expr.
// Use temporaries so that mapassign1 can have addressable key, elem.
...
}Khi số phần tử trong bảng băm nhỏ hơn hoặc bằng 25, trình biên dịch sẽ chuyển đổi cấu trúc khởi tạo bằng chữ thành mã sau, thêm tất cả các cặp key-value vào bảng băm cùng một lúc:
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6Phương thức khởi tạo này gần giống với phương thức khởi tạo của array và slice, vì vậy có vẻ như việc khởi tạo các loại tập hợp có logic xử lý giống nhau trong ngôn ngữ Go.
Khi số lượng phần tử trong bảng băm vượt quá 25, trình biên dịch sẽ tạo hai mảng để lưu trữ key và value tương ứng, và các cặp key-value này sẽ được thêm vào bảng băm thông qua vòng lặp for như hình bên dưới:
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}Hai slice vstatk và vstatv được mở rộng tại đây sẽ được trình soạn thảo mở rộng thêm, về cách mở rộng cụ thể các bạn có thể đọc phần trước để hiểu cách khởi tạo slice trong Golang Slice, nhưng dù sử dụng phương pháp nào thì quá trình khởi tạo theo literal cũng sẽ sử dụng từ khóa make để tạo bảng băm mới và nối các phần tử vào bảng băm thông qua cú pháp [] nguyên thủy nhất .
Runtime
Khi bảng băm đã tạo được cấp phát trong stack và dung lượng của nó nhỏ hơn BUCKETSIZE = 8 , ngôn ngữ Go sẽ sử dụng phương thức sau để nhanh chóng khởi tạo bảng băm trong giai đoạn biên dịch, phương pháp này cũng được trình biên dịch tối ưu hóa cho các hàm băm dung lượng nhỏ:
var h *hmap
var hv hmap
var bv bmap
h := &hv
b := &bv
h.buckets = b
h.hash0 = fashtrand0()Ngoài các tối ưu hóa cụ thể ở trên, bất kể make ở đâu, miễn là chúng ta sử dụng để maketạo bảng băm, trình biên dịch ngôn ngữ Go sẽ chuyển đổi chúng trong quá trình kiểm tra kiểu (Golang Type Check). Sử dụng Literal để khởi tạo hàm băm chỉ là một công cụ phụ trợ được cung cấp bởi ngôn ngữ, hàm cuối được gọi là runtime.makemap
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}Hàm này sẽ thực hiện các bước sau:
- Tính toán xem bộ nhớ bị chiếm bởi bảng băm có tràn hoặc vượt quá giá trị tối đa có thể được phân bổ hay không;
- Gọi
runtime.fastrandđể lấyhash0ngẫu nhiên; - Tính toán số thùng tối thiểu cần thiết theo lượng đến
hint; - Tạo một mảng để giữ các thùng bằng cách sử dụng
runtime.makeBucketArray;
runtime.makeBucketArray sẽ tính toán B và phân bổ một không gian liên tục trong bộ nhớ để lưu trữ dữ liệu:
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
if b >= 4 {
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
buckets = newarray(t.bucket, int(nbuckets))
if base != nbuckets {
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}- Khi số lượng thùng nhỏ hơn
2^4, do lượng dữ liệu nhỏ và khả năng sử dụng thùng chứa tràn thấp, quá trình tạo sẽ được bỏ qua để giảm chi phí bổ sung; - Khi số lượng thùng nhiều hơn
2^4, bổ sung thêm2^(B-4)thùng
Theo đoạn mã trên, chúng tôi có thể xác nhận rằng trong các trường hợp bình thường, không gian lưu trữ của thùng thông thường và thùng tràn trong bộ nhớ là liên tục, nhưng chúng được tham chiếu bởi các trường khác nhau trong runtime.hmap. Khi số lượng thùng chứa tràn lớn, một thùng chứa tràn mới sẽ được tạo thông qua runtime.newobject.
4. Thao tác đọc ghi
Là một cấu trúc dữ liệu, bảng băm phải phân tích các hoạt động phổ biến của nó, trước hết là nguyên tắc hoạt động đọc và ghi. Truy cập bảng băm thường được thực hiện bằng cách đăng ký hoặc duyệt qua:
_ = hash[key]
for k, v := range hash {
// k, v
}Mặc dù hai phương pháp này có thể đọc dữ liệu của bảng băm, nhưng các chức năng và nguyên tắc cơ bản được sử dụng là hoàn toàn khác nhau. Cách đầu cần biết khóa của bảng băm và chỉ có thể nhận giá trị tương ứng với một khóa duy nhất tại một thời điểm. Trong khi cách sau có thể duyệt qua tất cả các cặp key-value trong bảng băm và không cần biết khóa trước khi truy cập dữ liệu. Ở đây chúng tôi sẽ giới thiệu phương thức truy cập đầu và phương thức truy cập thứ hai sẽ được phân tích chi tiết trong phần range.
Việc viết cấu trúc dữ liệu thường đề cập đến việc thêm, xóa và sửa đổi. Các câu lệnh lập chỉ mục và gán được sử dụng để thêm và sửa đổi các trường và các từ khóa delete được yêu cầu để xóa dữ liệu trong từ điển:
hash[key] = value
hash[key] = newValue
delete(hash, key)Ngoài các hoạt động này, chúng tôi cũng sẽ phân tích quá trình mở rộng của bảng băm, điều này có thể giúp chúng tôi hiểu sâu sắc cách bảng băm lưu trữ dữ liệu.
Truy cập
Trong quá trình kiểm tra kiểu trong biên dịch, hash[key] và các thao tác tương tự sẽ được chuyển thành các thao tác OINDEXMAP và giai đoạn tạo mã trung gian sẽ chuyển các thao tác OINDEXMAP thành mã sau trong hàm cmd/compile/internal/gc.walkexpr:
v := hash[key] // => v := *mapaccess1(maptype, hash, &key)
v, ok := hash[key] // => v, ok := mapaccess2(maptype, hash, &key)Số lượng tham số được chấp nhận ở phía bên trái của câu lệnh gán xác định phương thức runtime được sử dụng:
- Khi một tham số được chấp nhận, nó sẽ được sử dụng
runtime.mapaccess1và hàm sẽ chỉ trả về một con trỏ tới giá trị đích; - Khi chấp nhận hai tham số, nó sẽ được sử dụng
runtime.mapaccess2, ngoài việc trả về giá trị đích, nó cũng sẽ trả về một giá trịboolđể báo lỗi:
Trước tiên, runtime.mapaccess1 sẽ lấy giá trị băm tương ứng với khóa hiện tại thông qua hàm băm và hạt nhân (hash0) trong bảng băm, sau đó lấy số thùng chứa và 8 bit cao của cặp key-value thông qua runtime.add và runtime.bucketMask .
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
return v
}
}
}
return unsafe.Pointer(&zeroVal[0])
}Trong vòng lặp bucketloop, hàm băm sẽ lần lượt duyệt qua dữ liệu trong vùng chứa bình thường và vùng chứa tràn. Đầu tiên, nó sẽ so sánh 8 bit cao của giá trị băm với tophash được lưu trữ trong thùng băm, sau đó so sánh giá trị đến với giá trị trong bucket để tăng tốc độ đọc và ghi dữ liệu. Các bit thấp của giá trị băm được sử dụng để chọn số thùng, 8 bit cao của hàm băm được sử dụng để tăng tốc độ truy cập. Thiết kế này có thể giảm khả năng có một số lượng lớn tophash bằng nhau trong cùng một thùng ảnh hưởng đến hiệu suất.
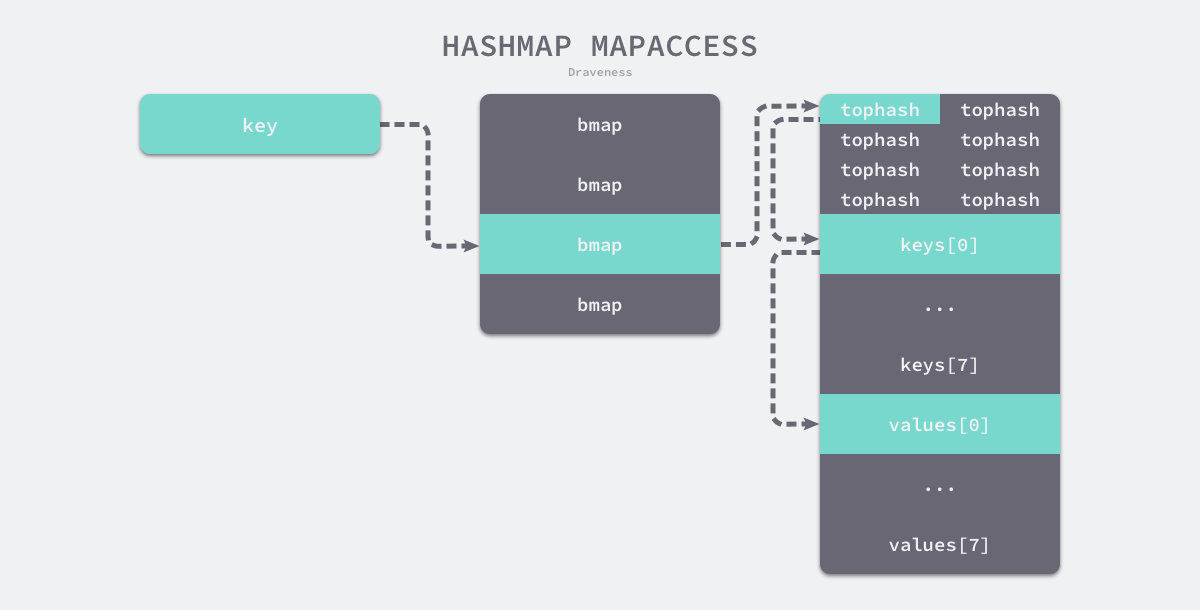
Như trong hình trên, mỗi thùng là một phần không gian bộ nhớ, khi tìm thấy tophash trong thùng khớp với tophash của khóa đến, chúng ta sẽ lấy khóa keys[0] được lưu trong bảng băm thông qua con trỏ và offset rồi so sánh nó với key. Nếu cả hai giống nhau, một con trỏ values[0] tới giá trị đích sẽ được lấy và trả về.
runtime.mapaccess2 cũng được sử dụng để truy cập dữ liệu trong bảng băm chỉ khác runtime.mapaccess1là trả về thêm một giá trị bool biểu thị có lỗi hay không:
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
...
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
return v, true
}
}
}
return unsafe.Pointer(&zeroVal[0]), false
}Khi truy cập các phần tử trong bảng băm ở dạng v, ok := hash[k], chúng ta có thể sử dụng giá trị Boolean này để biết chính xác hơn khi v == nil, ý nghĩa là phần tử v không được lưu trong bảng băm hay phần tử tương ứng với khóa không tồn tại. Vì vậy khi truy cập vào bảng băm, nên sử dụng phương pháp này để xác định xem một phần tử có tồn tại hay không.
Quá trình trên là hiệu suất truy cập các phần tử trong bảng băm trong điều kiện bình thường, tuy nhiên cũng giống như mảng, bảng băm có thể bị mở rộng khi hệ số tải quá cao hoặc có quá nhiều thùng chứa tràn. không phải là một quá trình nguyên tử. Việc đảm bảo truy cập bảng băm trong quá trình mở rộng dung lượng là một chủ đề thú vị hơn. Chúng tôi cũng bỏ qua mã liên quan ở đây, mã này sẽ được giới thiệu trong các phần sau.
Ghi
Khi một biểu thức hash[k] có xuất hiện ở bên trái ký hiệu gán thì biểu thức đó cũng sẽ được chuyển thành lời gọi hàm runtime.mapassign trong quá trình biên dịch, hàm này cũng tương tự như runtime.mapaccess1, chúng ta sẽ chia thành nhiều phần và phân tích theo trình tự. Đầu tiên, hàm sẽ tính giá trị băm và thùng tương ứng theo khóa được truyền vào:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
h.flags ^= hashWriting
again:
bucket := hash & bucketMask(h.B)
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)Sau đó, bằng cách duyệt qua và so sánh các giá trị băm của và tophash, nếu tìm thấy kết quả tương tự, thì địa chỉ của vị trí đích sẽ được trả về. Trong số đó, inserti đại diện cho chỉ mục của phần tử đích trong thùng, insertk và val tương ứng đại diện cho địa chỉ của cặp key-value. Sau khi lấy được địa chỉ đích, cặp key-value k và val sẽ được lấy thông qua tính toán địa chỉ:
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if !alg.equal(key, k) {
continue
}
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}Vòng lặp for ở trên sẽ tuần tự duyệt dữ liệu được lưu trữ trong thùng bình thường và thùng tràn. Toàn bộ quá trình sẽ đánh giá xem tophash bằng nhau hay không, key có bằng nhau hay không và sẽ nhảy ra khỏi vòng lặp sau khi duyệt xong.
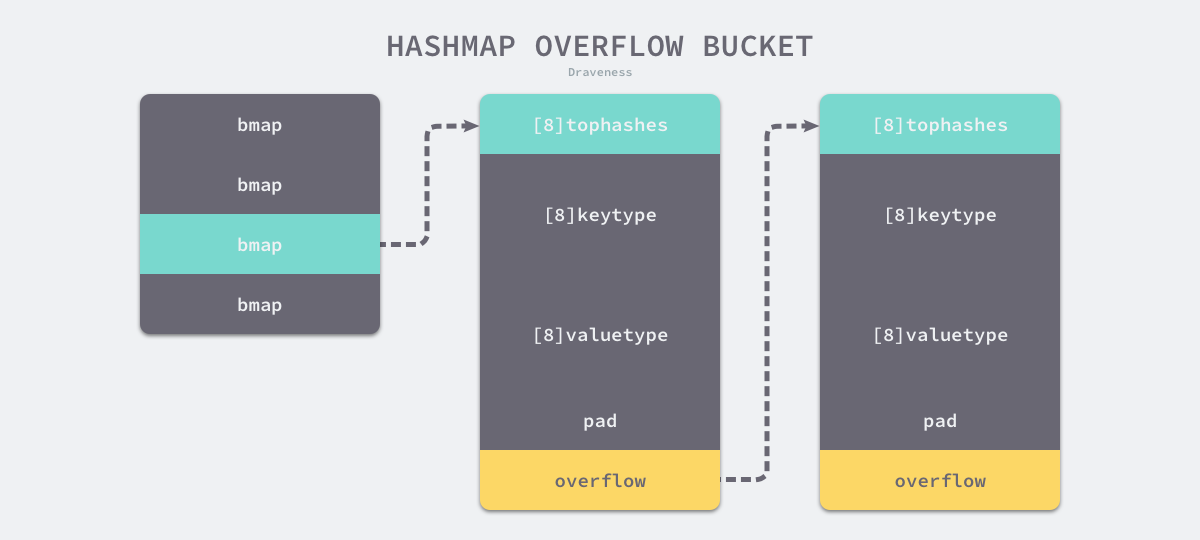
Nếu thùng chứa hiện tại đã đầy, bảng băm sẽ gọi runtime.hmap.newoverflow để tạo một thùng chứa mới hoặc sử dụng một thùng chứa runtime.hmap đã tạo trước để lưu dữ liệu. Thùng chứa mới được tạo sẽ không chỉ được thêm vào cuối thùng chứa hiện có mà còn tăng bộ đếm noverflow của thùng chứa bảng băm.
if inserti == nil {
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
typedmemmove(t.key, insertk, key)
*inserti = top
h.count++
done:
return val
}Nếu cặp key-value hiện tại không tồn tại trong hàm băm, bảng băm sẽ lập kế hoạch địa chỉ bộ nhớ lưu trữ cho cặp key-value mới bằng cách di chuyển khoá đến không gian bộ nhớ tương ứng thông quaruntime.typedmemmove và trả về địa chỉ của giá trị tương ứng với khóa là val . Nếu cặp key-value hiện tại tồn tại trong hàm băm, nó sẽ trực tiếp trả về địa chỉ bộ nhớ của vùng đích. Bảng băm sẽ không sao chép giá trị vào thùng chứa trong hàm runtime runtime.mapassign. Hàm chỉ trả về địa chỉ bộ nhớ, phép gán thực tế được chèn vào trong quá trình biên dịch:
00018 (+5) CALL runtime.mapassign_fast64(SB)
00020 (5) MOVQ 24(SP), DI ;; DI = &value
00026 (5) LEAQ go.string."88"(SB), AX ;; AX = &"88"
00027 (5) MOVQ AX, (DI) ;; *DI = AXruntime.mapassign_fast64tương tự như logic của runtime.mapassign, điều chúng ta cần chú ý là 3 dòng code sau, 24(SP) là địa chỉ của giá trị mà hàm trả về, chúng ta lưu địa chỉ của chuỗi vào thanh ghi AX thông qua lệnh LEAQ, lệnh MOVQ lưu trữ "88" chuỗi trong địa chỉ đích để hoàn thành ghi bảng băm.
Mở rộng
Trong phần giới thiệu trước về quá trình ghi của hàm băm, thao tác mở rộng thực sự đã bị bỏ qua, với việc các phần tử trong bảng băm tăng dần, hiệu suất của hàm băm sẽ dần kém đi, vì vậy chúng tôi cần nhiều thùng hơn và bộ nhớ lớn hơn để đảm bảo hiệu suất đọc và ghi băm:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
...
}Hàm runtime.mapassignnày sẽ kích hoạt việc mở rộng hàm băm khi xảy ra hai tình huống sau:
- Hệ số tải đã vượt quá 6,5;
- Bảng băm sử dụng quá nhiều thùng tràn;
Tuy nhiên, vì việc mở rộng hàm băm ngôn ngữ Go không phải là một quy trình nguyên tử, runtime.mapassigncũng cần phải đánh giá xem hàm băm hiện tại đã ở trạng thái mở rộng hay chưa, để tránh nhầm lẫn do mở rộng thứ cấp.
Theo các điều kiện kích hoạt khác nhau, có hai cách để mở rộng dung lượng. Nếu việc mở rộng này là do quá nhiều thùng chứa bị tràn, thì việc mở rộng này là mở rộng tương đương sameSizeGrow. sameSizeGrow là một sự mở rộng xảy ra trong các trường hợp đặc biệt. Khi chúng ta tiếp tục chèn dữ liệu vào bảng băm và xóa tất cả, nếu lượng dữ liệu trong bảng băm không vượt quá ngưỡng, nó sẽ tiếp tục tích tụ các thùng tràn gây rò rỉ bộ nhớ chậm. runtime: limit the number of map overflow buckets sameSizeGrow được giới thiệu để giải quyết vấn đề này bằng cách sử dụng lại cơ chế mở rộng hàm băm hiện có. Khi có quá nhiều thùng chứa tràn trong bảng băm, nó sẽ tạo một thùng chứa mới để lưu dữ liệu và garbage collection sẽ dọn sạch các thùng tràn cũ và giải phóng bộ nhớ.
Điểm bắt đầu để mở rộng là runtime.hashGrow:
func hashGrow(t *maptype, h *hmap) {
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
h.extra.nextOverflow = nextOverflow
}Trong quá trình mở rộng, bảng băm sẽ tạo một tập hợp các thùng mới và các thùng tràn được tạo trước thông qua runtime.makeBucketArray. Sau đó đặt mảng thùng ban đầu thành oldbuckets và đặt các nhóm trống mới thành buckets. Đồng thời các thùng tràn cũng được cập nhật bằng logic tương tự, như hình dưới đây hiển thị hàm băm sau khi mở rộng được kích hoạt:
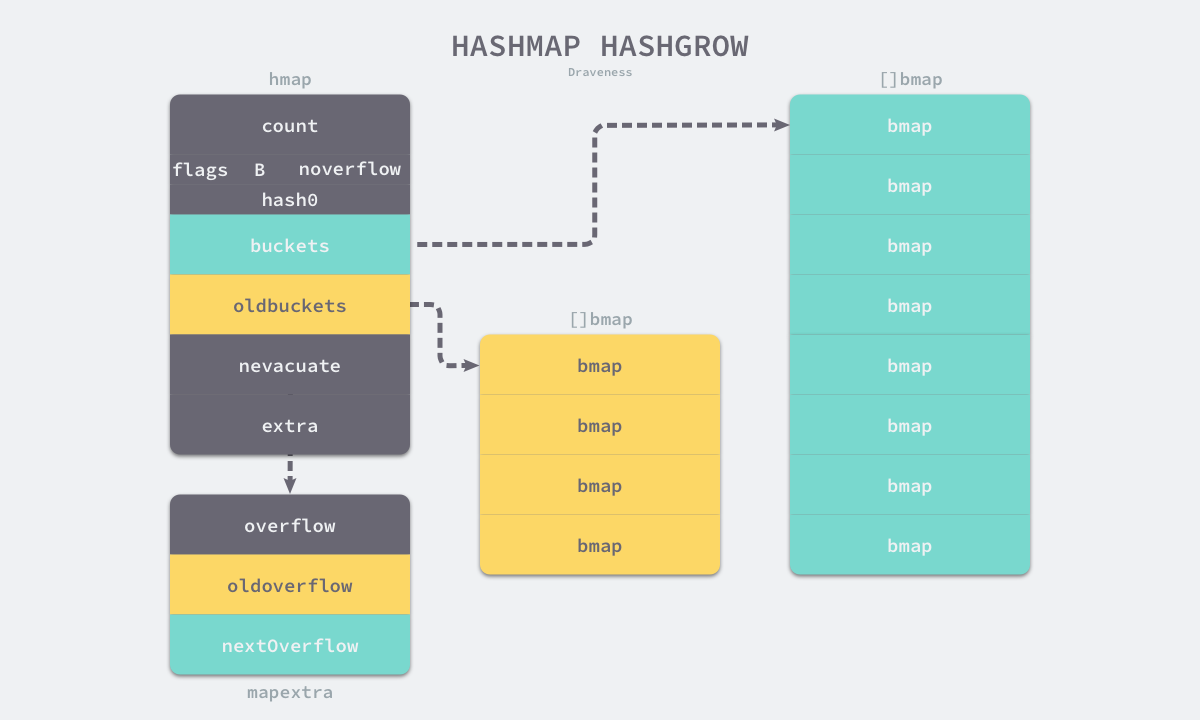
Chúng ta không thấy quá nhiều sự khác biệt giữa mở rộng bằng nhau và mở rộng gấp đôi trong runtime.hashGrow. Số lượng thùng mới được tạo bởi mở rộng bằng nhau chỉ bằng số lượng của các nhóm cũ. Hàm này chỉ tạo nhóm mới, không sao chép và lưu trữ dữ liệu. Quá trình di chuyển dữ liệu của bảng băm được hoàn tất trong runtime.evacuate, quá trình này sẽ phân phối lại các phần tử trong thùng chứa sắp tới.
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
newbit := h.noldbuckets()
if !evacuated(b) {
var xy [2]evacDst
x := &xy[0]
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.v = add(x.k, bucketCnt*uintptr(t.keysize))
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.v = add(y.k, bucketCnt*uintptr(t.keysize))runtime.evacuatesẽ chia dữ liệu trong một thùng cũ sẽ thành hai thùng mới. do đó, nó sẽ tạo ra hai struct runtime.evacDst và hai struct này trỏ đến một thùng mới tương ứng:
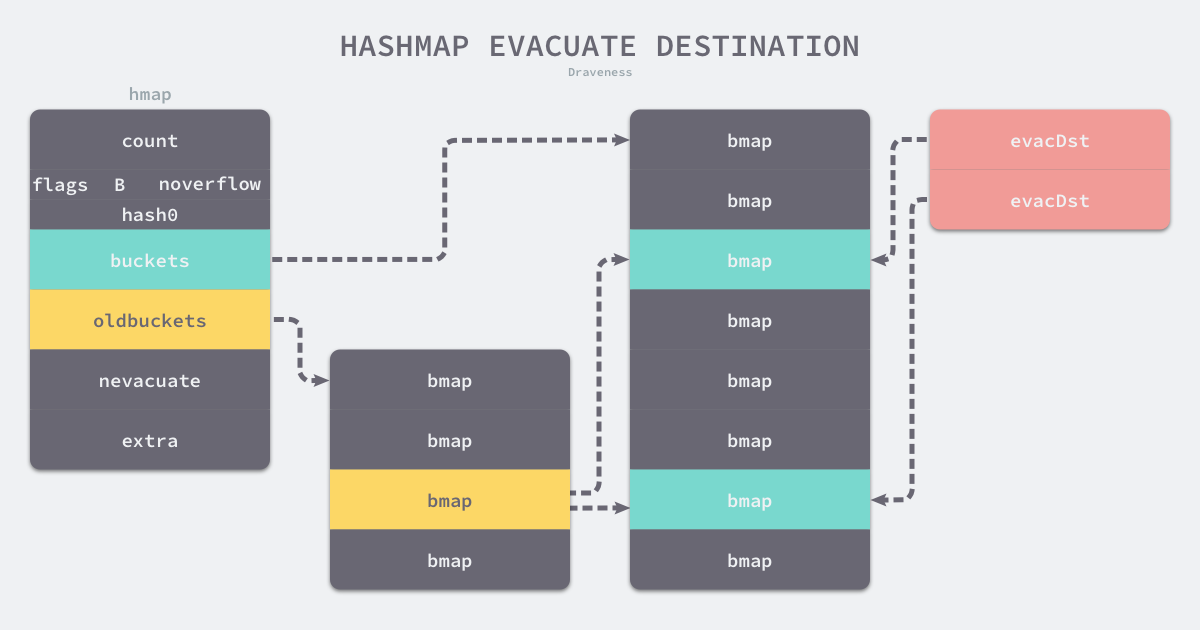
Nếu đây là sự mở rộng bằng nhau, thì có mối quan hệ một đối một giữa thùng cũ và thùng mới, vì vậy chỉ một trong hai runtime.evacDstđược khởi tạo. Khi dung lượng của bảng băm tăng gấp đôi, các phần tử của mỗi nhóm cũ sẽ được chia thành hai nhóm mới. Dưới đây là phân tích kỹ lưỡng về logic của việc phân chia các phần tử:
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
top := b.tophash[i]
k2 := k
var useY uint8
hash := t.key.alg.hash(k2, uintptr(h.hash0))
if hash&newbit != 0 {
useY = 1
}
b.tophash[i] = evacuatedX + useY
dst := &xy[useY]
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.v = add(dst.k, bucketCnt*uintptr(t.keysize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.key, dst.k, k)
typedmemmove(t.elem, dst.v, v)
dst.i++
dst.k = add(dst.k, uintptr(t.keysize))
dst.v = add(dst.v, uintptr(t.valuesize))
}
}
...
}Chỉ sử dụng hàm băm thì không thể định vị một nhóm cụ thể. Hàm băm sẽ chỉ trả về một giá trị băm rất dài, ví dụ: b72bfae3f3285244c4732ce457cca823bc189e0b, chúng ta vẫn cần một số phương pháp để ánh xạ hàm băm vào một thùng cụ thể. Chúng tôi thường sử dụng các phép toán modulo hoặc bit để lấy số lượng thùng. Nếu bảng băm hiện tại chứa 4 thùng, thì mặt nạ thùng của nó là 0b11 (3), và phép toán bit sẽ nhận được 3 và chúng ta sẽ ở trong thùng 3. Dữ liệu là được lưu trữ trong nhóm số:
0xb72bfae3f3285244c4732ce457cca823bc189e0b & 0b11 #=> 0Nếu bảng băm mới có 8 thùng, trong hầu hết các trường hợp, thùng 3 cũ sau khi đi qua mặt nạ thùng 0b11 sẽ được chuyển sang thùng số 3 và số 7 mới vì mặt nạ nhóm được tăng thêm một bit và trở thành 0b111. Tất cả dữ liệu cũng sẽ được sao chép vào thùng chứa đích bằng runtime.typedmemmove:
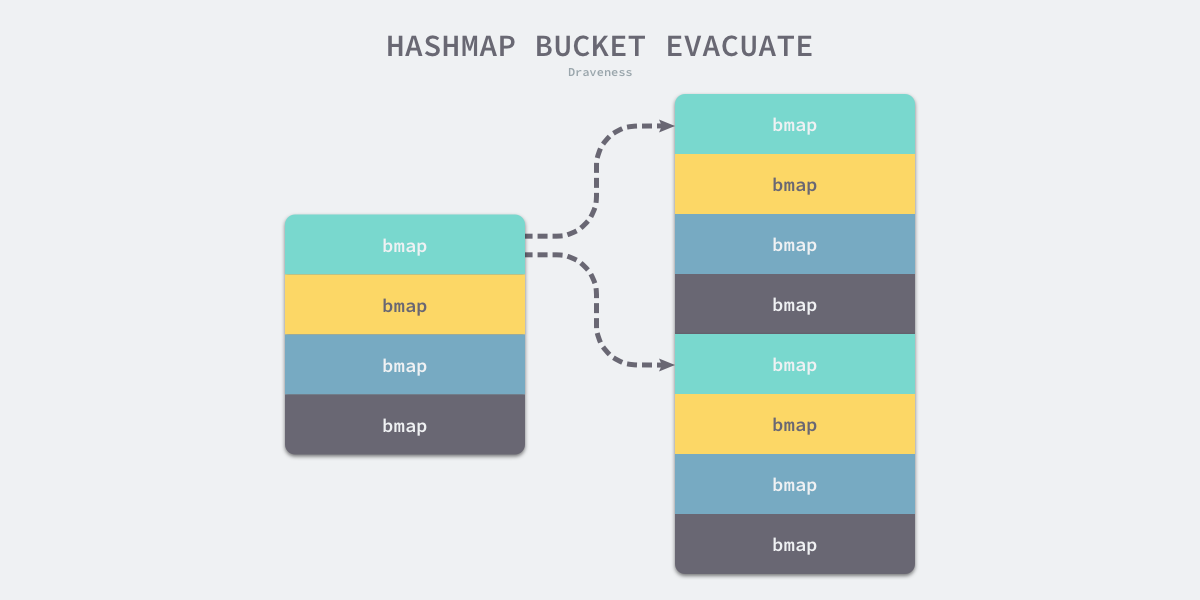
runtime.evacuate cuối cùng sẽ gọi runtime.advanceEvacuationMarkđể tăng bộ đếm được băm nevacuate và xoá oldbuckets và oldoverflow của bảng băm sau khi tất cả các thùng cũ được chuyển:
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit == # of oldbuckets
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}Trong phân tích trước về hàm truy cập bảng băm runtime.mapaccess1, logic lấy các cặp key-value trong quá trình mở rộng đã thực sự bị bỏ qua. Khi bảng băm tồn tại oldbuckets, trước tiên, nó sẽ định vị thùng cũ và lấy cặp key-value từ đó khi thùng không bị chuyển.
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
bucketloop:
...
}Vì các phần tử trong thùng cũ chưa được shunt bởi hàm runtime.evacuate và dữ liệu chúng ta cần sử dụng vẫn được lưu trữ trong nó, thùng cũ sẽ thay thế thùng trống mới tạo để cung cấp dữ liệu.
Chúng tôi cũng đã bỏ qua một đoạn logic trong hàm runtime.mapassign, khi bảng băm ở trạng thái mở rộng, mỗi khi một giá trị được ghi vào bảng băm, nó sẽ kích hoạt runtime.growWorkmột bản sao gia tăng nội dung của bảng băm:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
...
}Tất nhiên, ngoài thao tác ghi, thao tác xóa cũng sẽ được kích hoạt trong quá trình mở rộng bảng băm runtime.growWork, phương thức kích hoạt và mã gần giống với logic ở đây, đó là tính toán nhóm chứa giá trị hiện tại định vị, sau đó sao chép các phần tử trong nhóm.
Hãy tóm tắt ngắn gọn thiết kế và nguyên tắc mở rộng bảng băm. Băm sẽ kích hoạt hoạt động mở rộng khi có quá nhiều phần tử lưu trữ, mỗi lần tăng gấp đôi số lượng thùng. Quá trình mở rộng không phải là nguyên tử mà được kích hoạt theo runtime.growWorksố gia. được sử dụng khi truy cập bảng băm trong quá trình mở rộng và việc chuyển đổi các phần tử thùng chứa cũ sẽ được kích hoạt khi dữ liệu được ghi vào bảng băm. Ngoài việc mở rộng bình thường này, để giải quyết vấn đề rò rỉ bộ nhớ do số lượng lớn ghi và xóa, Hash giới thiệu cơ chế sameSizeGrownày khi có nhiều thùng tràn, bộ nhớ băm sẽ được sắp xếp để giảm chiếm dụng không gian.
xóa #
Nếu muốn xóa một phần tử trong bảng băm, bạn cần sử dụng deletetừ khóa , chức năng duy nhất của từ khóa này là xóa phần tử tương ứng với một khóa nào đó khỏi bảng băm, bất kể giá trị đó có tương ứng với khóa có tồn tại hay không. , các hàm tích hợp không trả về bất kỳ kết quả nào.
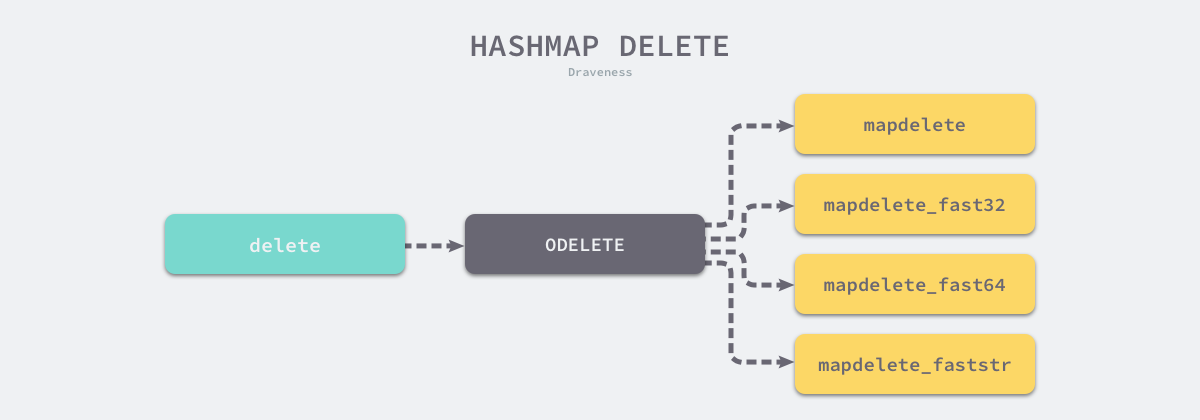
Hình 3-18 Thao tác xóa bảng băm
Trong quá trình biên dịch, các từ khóa được chuyển deleteđổi thành các nút hoạt động ODELETEtrên và nútcmd/compile/internal/gc.walkexpr được chuyển đổi thành một trong các nhóm chức năng, bao gồm , và :ODELETEruntime.mapdeleteruntime.mapdeletemapdelete_faststr``mapdelete_fast32``mapdelete_fast64
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
case ODELETE:
init.AppendNodes(&n.Ninit)
map_ := n.List.First()
key := n.List.Second()
map_ = walkexpr(map_, init)
key = walkexpr(key, init)
t := map_.Type
fast := mapfast(t)
if fast == mapslow {
key = nod(OADDR, key, nil)
}
n = mkcall1(mapfndel(mapdelete[fast], t), nil, init, typename(t), map_, key)
}
}Việc triển khai các chức năng này thực sự tương tự nhau, hãy chọn một trong số chúng runtime.mapdeletevà phân tích nó . Logic xóa của bảng băm rất giống với logic ghi, ngoại trừ các từ khóa là cần thiết để kích hoạt việc xóa hàm băm. Nếu gặp phải sự mở rộng của bảng băm trong quá trình xóa, các phần tử trong nhóm sẽ bị chuyển hướng, và thùng sẽ được tìm thấy sau khi quá trình chuyển đổi hoàn tất. Phần tử đích trong hoàn tất việc xóa các cặp key-value.
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
if h.growing() {
growWork(t, h, bucket)
}
...
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if !alg.equal(key, k2) {
continue
}
*(*unsafe.Pointer)(k) = nil
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
*(*unsafe.Pointer)(v) = nil
b.tophash[i] = emptyOne
...
}
}
}Thực ra chúng ta chỉ cần biết deletetừ khóa được chuyển đổi thành thành viên của cụm hàm sau quá trình kiểm tra kiểu và sinh mã trung gian trong quá trình biên dịch, hàm dùng để xử lý logic xóa gần giống như hàm băm nên chúng ta không cần để ý đến nó.runtime.mapdeleteruntime.mapassign
5 Tóm tắt
Ngôn ngữ Go sử dụng phương thức zip để giải quyết vấn đề xung đột hàm băm và triển khai bảng băm. Các hoạt động của ngôn ngữ này như truy cập, ghi và xóa được chuyển đổi thành các hàm hoặc phương thức runtime trong quá trình biên dịch. Hàm băm lưu trữ 8 chữ số đầu tiên của khóa tương ứng với hàm băm trong mỗi nhóm. Khi hoạt động trên hàm băm, những chữ số này tophashsẽ trở thành đệm có thể giúp hàm băm duyệt nhanh các phần tử trong nhóm.
Mỗi nhóm của bảng băm chỉ có thể lưu trữ 8 cặp key-value. Khi một nhóm của hàm băm hiện tại vượt quá 8, các cặp key-value mới sẽ được lưu trữ trong nhóm tràn của hàm băm. Khi số lượng cặp key-value tăng lên, số lượng nhóm tràn và hệ số tải của hàm băm sẽ tăng dần. Nếu vượt quá một phạm vi nhất định, quá trình mở rộng sẽ được kích hoạt và việc mở rộng sẽ tăng gấp đôi số lượng nhóm. phân phối lại các phần tử còn được gọi là Thao tác ghi được thực hiện tăng dần, điều này sẽ không gây ra hiện tượng rung pha hiệu suất tức thời lớn.