Phỏng vấn về Cơ sở dữ liệu quan hệ
Chỉ mục và Ràng buộc
Chỉ mục là gì?
Chỉ mục (Index) là một cấu trúc được sắp xếp của một hoặc nhiều cột trong bảng cơ sở dữ liệu, được sử dụng để tìm kiếm dữ liệu một cách hiệu quả.
Ưu điểm và nhược điểm của chỉ mục
✔ Ưu điểm của chỉ mục:
- Chỉ mục giúp giảm lượng dữ liệu mà máy chủ cần quét, từ đó tăng tốc độ truy vấn dữ liệu.
- Trong các cơ sở dữ liệu hỗ trợ khóa hàng (như InnoDB), khi truy cập vào hàng, khóa hàng sẽ được áp dụng. Sử dụng chỉ mục có thể giảm số lượng hàng truy cập, từ đó giảm sự cạnh tranh khóa và tăng khả năng đồng thời.
- Chỉ mục có thể giúp máy chủ tránh sắp xếp và bảng tạm thời.
- Chỉ mục có thể biến I/O ngẫu nhiên thành I/O tuần tự.
- Chỉ mục duy nhất đảm bảo tính duy nhất của mỗi hàng dữ liệu. Bằng cách sử dụng chỉ mục, bạn có thể sử dụng trình tối ưu hóa truy vấn để tăng hiệu suất hệ thống.
❌ Nhược điểm của chỉ mục:
- Tạo và duy trì chỉ mục mất thời gian, và thời gian này tăng lên khi dữ liệu tăng.
- Chỉ mục chiếm không gian lưu trữ bổ sung, ngoài không gian dữ liệu của bảng. Nếu tạo chỉ mục kết hợp, không gian cần thiết sẽ lớn hơn.
- Các hoạt động ghi (
INSERT/UPDATE/DELETE) có thể cần cập nhật chỉ mục, làm giảm hiệu suất ghi của cơ sở dữ liệu.
Khi nào sử dụng chỉ mục
Chỉ mục có thể cải thiện hiệu suất truy vấn một cách đáng kể.
✔ Khi nào thì nên sử dụng chỉ mục:
- Bảng thường xuyên thực hiện các truy vấn
SELECT. - Dữ liệu trong bảng lớn.
- Các cột thường xuyên xuất hiện trong điều kiện
WHEREhoặc điều kiện kết nối (JOIN).
❌ Khi nào không nên sử dụng chỉ mục:
- Hoạt động ghi thường xuyên (
INSERT/UPDATE/DELETE) - cần cập nhật không gian chỉ mục. - Bảng rất nhỏ - trong hầu hết các trường hợp, quét toàn bộ bảng đơn giản hơn.
- Cột không xuất hiện thường xuyên trong điều kiện
WHEREhoặc điều kiện kết nối (JOIN) - chỉ mục sẽ không được sử dụng và tạo thêm chi phí không gian.
Các loại chỉ mục
Các hệ thống cơ sở dữ liệu phổ biến thường hỗ trợ các loại chỉ mục sau:
Dựa trên loại logic (thường được đặt khi tạo bảng):
- Chỉ mục duy nhất (
UNIQUE) - giá trị của cột chỉ mục phải là duy nhất, nhưng có thể chứa giá trị NULL. Nếu là chỉ mục kết hợp, sự kết hợp của các giá trị cột phải là duy nhất. - Chỉ mục chính (
PRIMARY) - một loại đặc biệt của chỉ mục duy nhất, một bảng chỉ có thể có một chỉ mục chính và không cho phép giá trị NULL. Thường được tạo cùng với việc tạo bảng. - Chỉ mục thông thường (
INDEX) - chỉ mục cơ bản nhất, không có ràng buộc đặc biệt. - Chỉ mục kết hợp - chỉ mục được tạo trên nhiều cột, chỉ khi điều kiện truy vấn sử dụng cột đầu tiên trong chỉ mục, chỉ mục mới được sử dụng. Sử dụng nguyên tắc tập con trái nhất.
Dựa trên cấu trúc lưu trữ:
- Chỉ mục gom cụm (
Clustered) - các hàng dữ liệu và các giá trị khóa được lưu trữ theo cùng một thứ tự vật lý, mỗi bảng chỉ có thể có một chỉ mục gom cụm. - Chỉ mục không gom cụm (
Non-clustered) - chỉ mục chỉ định thứ tự logic của các giá trị khóa, dữ liệu được lưu trữ ở một vị trí và chỉ mục được lưu trữ ở một vị trí khác, chỉ mục chứa con trỏ đến vị trí lưu trữ dữ liệu. Có thể có nhiều chỉ mục không gom cụm, nhưng số lượng có giới hạn (thường nhỏ hơn 249).
Cấu trúc dữ liệu của chỉ mục
Các cơ sở dữ liệu phổ biến thường sử dụng cấu trúc dữ liệu B-Tree hoặc B+Tree cho chỉ mục.
B-Tree
B-Tree bậc M là cây có các thuộc tính sau:
- Mỗi nút có tối đa M con.
- Ngoại trừ nút gốc và nút lá, mỗi nút có ít nhất M/2 con.
- Nút gốc có ít nhất hai con (trừ khi cây chỉ chứa một nút).
- Tất cả các nút lá nằm ở cùng một mức, không chứa bất kỳ thông tin khóa nào.
- Nút không phải lá chứa ít nhất M/2-1 và tối đa M-1 khóa.
- Các khóa bên trong mỗi nút được sắp xếp theo thứ tự tăng dần.
- Đối với mỗi nút, có một mảng khóa
Key[]và một mảng con trỏ (trỏ đến các con)Son[].
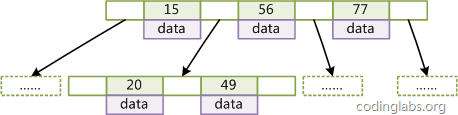
Trong cây B-Tree, quá trình tìm kiếm diễn ra như sau:
- Tìm kiếm trong mảng khóa
Key[]bằng phương pháp tìm kiếm tuần tự (khi độ dài mảng nhỏ) hoặc tìm kiếm nhị phân (khi độ dài mảng lớn), nếu tìm thấy khóa K, trả về địa chỉ của nút và vị trí của K trongKey[]. - Nếu không tìm thấy, có thể xác định K nằm giữa Key[i] và Key[i+1] của một nút, tiếp tục tìm kiếm từ con trỏ Son[i] trỏ đến con trỏ con, cho đến khi tìm thấy nút chứa thành công.
- Hoặc tìm kiếm không thành công khi tìm thấy một nút lá và tìm kiếm trong nút lá không thành công.
B+Tree
B+Tree là biến thể của cây B-Tree:
- Số lượng con của mỗi nút giới hạn là 2d thay vì 2d+1 (d là bậc ra của nút).
- Nút không phải lá không chứa dữ liệu, chỉ chứa khóa.
- Nút lá không chứa con trỏ.
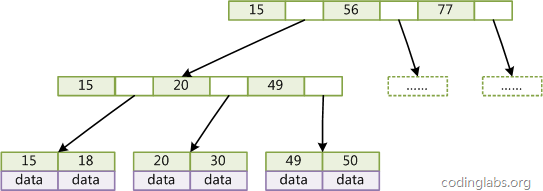
Trong B+Tree, nút lá và nút không phải lá có kích thước khác nhau. Điều này khác với cây B-Tree, trong đó các nút khác nhau chứa cùng số lượng khóa và con trỏ.
Cây B+Tree với con trỏ truy cập tuần tự
Nói chung, cấu trúc B+Tree được sử dụng trong hệ thống cơ sở dữ liệu hoặc hệ thống tệp đã được tối ưu hóa trên cơ sở B+Tree cổ điển bằng việc thêm các con trỏ truy cập tuần tự.
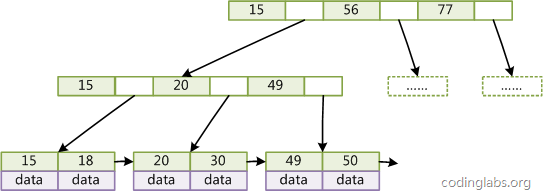
Trong B+Tree với con trỏ truy cập tuần tự, mỗi nút lá được thêm một con trỏ trỏ đến nút lá kế tiếp, tạo thành một chuỗi con trỏ.
Tối ưu hóa này nhằm mục đích cải thiện hiệu suất truy vấn phạm vi, ví dụ: nếu muốn truy vấn tất cả các bản ghi có giá trị khóa từ 18 đến 49, sau khi tìm thấy 18, chỉ cần duyệt theo thứ tự nút và con trỏ để truy cập tất cả các bản ghi, tăng đáng kể hiệu suất truy vấn phạm vi.
B-Tree vs B+Tree
- B+Tree phù hợp hơn cho lưu trữ bên ngoài (thường là lưu trữ đĩa), vì các nút không phải lá không chứa dữ liệu, vì vậy mỗi nút có thể chứa nhiều nút hơn, mỗi nút có thể chứa nhiều giá trị hơn. Điều này có nghĩa là mỗi lần I/O đĩa, lượng thông tin được truy cập bằng chỉ mục B+Tree lớn hơn, tăng hiệu suất I/O.
- MySQL là hệ thống cơ sở dữ liệu quan hệ (RDBMS), thường sẽ truy vấn theo phạm vi trên cột chỉ mục, B+Tree có các nút lá được sắp xếp theo thứ tự, giúp tối ưu hóa truy vấn phạm vi trên cột chỉ mục. Còn B-Tree không thể thực hiện truy vấn phạm vi trên cột chỉ mục.
Hash
Hash chỉ có hiệu lực đối với các truy vấn khớp chính xác tất cả các cột trong chỉ mục.
Đối với mỗi hàng dữ liệu, tính toán một hashcode cho tất cả các cột chỉ mục. Chỉ mục hash lưu trữ tất cả các hashcode trong chỉ mục và sử dụng bảng băm để lưu trữ con trỏ đến hàng dữ liệu.
Lợi ích của chỉ mục băm:
- Vì cấu trúc dữ liệu chỉ mục rất gọn nhẹ, nên tốc độ truy vấn rất nhanh.
- Một số hệ thống cơ sở dữ liệu (như MyISAM) chỉ lưu trữ chỉ mục trong bộ nhớ, trong khi dữ liệu phụ thuộc vào hệ điều hành để lưu trữ. Do đó, chỉ truy cập chỉ mục không sử dụng cuộc gọi hệ thống (thường tốn thời gian).
Nhược điểm của chỉ mục băm:
- Dữ liệu không được lưu trữ theo thứ tự chỉ mục, do đó không thể sử dụng để sắp xếp.
- Chỉ mục băm không hỗ trợ truy vấn phạm vi. Chỉ có thể sử dụng cho truy vấn khớp chính xác.
- Chỉ mục băm không hỗ trợ truy vấn phần của chỉ mục. Ví dụ: nếu chỉ mục băm được tạo trên cột (A, B), và truy vấn chỉ có cột A, thì không thể sử dụng chỉ mục này.
- Chỉ mục băm chỉ hỗ trợ truy vấn so sánh bằng, không hỗ trợ truy vấn phạm vi. Ví dụ:
WHERE price > 100không thể sử dụng chỉ mục băm. - Chỉ mục băm có thể gặp xung đột băm, khi đó phải duyệt qua tất cả các con trỏ hàng trong danh sách liên kết, so sánh từng hàng để tìm hàng phù hợp.
Chiến lược lập chỉ mục
Nguyên tắc cơ bản của chỉ mục
- Không phải càng nhiều chỉ mục càng tốt, không nên tạo chỉ mục cho tất cả các cột.
- Tránh sự trùng lặp và chỉ mục không cần thiết.
- Xóa các chỉ mục không được sử dụng.
- Mở rộng các chỉ mục hiện có thay vì tạo mới.
- Cân nhắc thêm chỉ mục cho các cột được sử dụng thường xuyên trong điều kiện lọc
WHERE.
Cột độc lập
Nếu cột trong câu truy vấn không phải là cột độc lập, cơ sở dữ liệu sẽ không sử dụng chỉ mục.
”Cột độc lập” có nghĩa là cột chỉ mục không được tạo thành từ một phần của biểu thức hoặc là đối số của một hàm.
Ví dụ sai:
SELECT actor_id FROM actor WHERE actor_id + 1 = 5;
SELECT ... WHERE TO_DAYS(current_date) - TO_DAYS(date_col) <= 10;Chỉ mục tiền tố và tính chọn lọc của chỉ mục
Đôi khi cần tạo chỉ mục cho các cột có độ dài lớn, điều này làm cho chỉ mục trở nên lớn và chậm.
Giải pháp là: chỉ cần tạo chỉ mục cho một phần đầu của chuỗi, điều này giúp tiết kiệm không gian chỉ mục và tăng hiệu suất chỉ mục. Tuy nhiên, điều này cũng làm giảm tính chọn lọc của chỉ mục.
Tính chọn lọc của chỉ mục là tỷ lệ giữa số giá trị chỉ mục không trùng lặp và tổng số bản ghi trong bảng. Giá trị tối đa là 1, khi mỗi bản ghi có một chỉ mục duy nhất. Tính chọn lọc càng cao, hiệu suất truy vấn càng cao.
Đối với các cột kiểu BLOB/TEXT/VARCHAR, phải sử dụng chỉ mục tiền tố vì cơ sở dữ liệu thường không cho phép chỉ mục đầy đủ cho các cột này.
Cần chọn tiền tố đủ dài để đảm bảo tính chọn lọc cao, đồng thời không quá dài (tiết kiệm không gian).
Ví dụ không hiệu quả:
SELECT COUNT(*) AS cnt, city FROM sakila.city_demo
GROUP BY city ORDER BY cnt DESC LIMIT 10;Ví dụ hiệu quả:
SELECT COUNT(*) AS cnt, LEFT(city, 3) AS pref FROM sakila.city_demo
GROUP BY city ORDER BY cnt DESC LIMIT 10;Chỉ mục đa cột
Không nên tạo chỉ mục riêng cho từng cột.
Ưu tiên đặt các cột có tính chọn lọc cao hoặc số lượng giá trị duy nhất lớn ở đầu chỉ mục đa cột. Tuy nhiên, đôi khi cũng cần xem xét các yếu tố khác như sắp xếp, nhóm và điều kiện phạm vi trong mệnh đề WHERE, vì những yếu tố này cũng ảnh hưởng đáng kể đến hiệu suất truy vấn.
Ví dụ:
Giả sử có bảng user với các cột name, sex, age. Nếu tạo chỉ mục đa cột cho ba cột này, thì thứ tự tốt nhất là: name > age > sex.
Chỉ mục gom nhóm
Chỉ mục gom nhóm không phải là một loại chỉ mục độc lập, mà là một cách lưu trữ dữ liệu. Chi tiết cụ thể phụ thuộc vào cách triển khai. Ví dụ, chỉ mục gom nhóm của InnoDB thực tế là lưu trữ cùng một cấu trúc B-tree của chỉ mục và dòng dữ liệu.
Chỉ mục gom nhóm đại diện cho việc lưu trữ dòng dữ liệu và các giá trị khóa liền kề, do đó truy cập nhanh. Vì không thể lưu trữ dòng dữ liệu trong hai vị trí khác nhau cùng một lúc, nên một bảng chỉ có thể có một chỉ mục gom nhóm.
Nếu không xác định khóa chính, InnoDB sẽ tự động xác định một khóa chính để sử dụng làm chỉ mục gom nhóm.
Chỉ mục che phủ
Chỉ mục chứa tất cả các giá trị cần truy vấn.
Có các lợi ích sau:
- Vì các mục chỉ mục thường nhỏ hơn nhiều so với kích thước dòng dữ liệu, nên chỉ đọc chỉ mục có thể giảm lượng truy cập dữ liệu.
- Một số cơ sở dữ liệu (ví dụ: MyISAM) chỉ lưu trữ chỉ mục trong bộ nhớ, trong khi dữ liệu phụ thuộc vào hệ điều hành để lưu trữ. Do đó, chỉ đọc chỉ mục có thể tránh sử dụng cuộc gọi hệ thống (thường tốn thời gian).
- Đối với cơ sở dữ liệu InnoDB, nếu chỉ mục phụ có thể che phủ truy vấn, không cần truy cập chỉ mục chính.
Sử dụng quét chỉ mục để sắp xếp
MySQL có hai cách để tạo kết quả sắp xếp: thông qua hoạt động sắp xếp; hoặc quét chỉ mục theo thứ tự.
Chỉ mục tốt là chỉ mục có thể được sử dụng để sắp xếp kết quả. Điều này cho phép sử dụng chỉ mục để sắp xếp thay vì sắp xếp trực tiếp.
Nguyên tắc phù hợp nhất bên trái
MySQL sẽ tiếp tục khớp về bên phải cho đến khi gặp các truy vấn phạm vi (>, <, BETWEEN, LIKE).
- Chỉ mục có thể đơn giản như một cột (a), hoặc phức tạp như nhiều cột (a, b, c, d), được gọi là chỉ mục kết hợp.
- Nếu là chỉ mục kết hợp, thì khóa cũng bao gồm nhiều cột. Đồng thời, chỉ có thể sử dụng chỉ mục để kiểm tra xem khóa có tồn tại hay không (tương đương với bằng nhau), và không thể khớp với các truy vấn phạm vi (>, <, between, like).
- Do đó, thứ tự cột quyết định số lượng cột chỉ mục có thể khớp.
Ví dụ:
- Nếu có chỉ mục (a, b, c, d) và điều kiện truy vấn là a = 1 và b = 2 và c > 3 và d = 4, thì chỉ có thể khớp với a, b, c và không thể khớp với d. (Đơn giản: chỉ có thể khớp với các trường hợp bằng nhau, không thể khớp với phạm vi)
Ràng buộc
Có những ràng buộc nào trong cơ sở dữ liệu:
NOT NULL- Được sử dụng để đảm bảo rằng nội dung của trường không thể là giá trị rỗng (NULL).UNIQUE- Nội dung của trường không được lặp lại, một bảng có thể có nhiều ràng buộcUNIQUE.PRIMARY KEY- Kết hợp các cột hoặc thuộc tính trong bảng dữ liệu để định danh duy nhất và hoàn chỉnh cho các đối tượng dữ liệu. Một bảng chỉ được phép có một khóa chính. Giá trị của khóa chính không thể là giá trị rỗng (NULL).FOREIGN KEY- Khóa ngoại trong một bảng là khóa chính của một bảng khác. Nó được sử dụng để ngăn chặn các hành động phá vỡ kết nối giữa các bảng và ngăn chặn việc chèn dữ liệu không hợp lệ vào cột khóa ngoại, vì nó phải là một trong các giá trị trong bảng được chỉ định.CHECK- Sử dụng để kiểm soát phạm vi giá trị của trường.
Kiểm soát đồng thời
Khóa lạc quan và khóa bi quan
- Khóa lạc quan và khóa bi quan trong cơ sở dữ liệu là gì?
- Làm thế nào để thực hiện khóa lạc quan và khóa bi quan trong cơ sở dữ liệu?
Để đảm bảo không xảy ra xung đột khi nhiều giao dịch truy cập cùng một dữ liệu trong cơ sở dữ liệu và đảm bảo tính nhất quán của giao dịch, khóa lạc quan và khóa bi quan là các kỹ thuật chính được sử dụng trong kiểm soát đồng thời.
- Khóa bi quan - Giả định rằng xung đột sẽ xảy ra và ngăn chặn mọi hoạt động có thể vi phạm tính toàn vẹn dữ liệu.
- Khóa ghi trước khi truy vấn dữ liệu và giữ khóa cho đến khi giao dịch được ghi (COMMIT).
- Cách thực hiện: Sử dụng cơ chế khóa trong cơ sở dữ liệu.
- Khóa lạc quan - Giả định rằng không có xung đột và chỉ kiểm tra tính toàn vẹn dữ liệu khi thực hiện thao tác ghi.
- Khóa khi thay đổi dữ liệu và kiểm tra xem có vi phạm tính toàn vẹn dữ liệu khi ghi (COMMIT).
- Cách thực hiện: Sử dụng phiên bản hoặc dấu thời gian.
Khóa hàng và khóa bảng
- Khóa hàng và khóa bảng là gì?
- Khi nào sử dụng khóa hàng? Khi nào sử dụng khóa bảng?
Từ quan điểm về mức độ chi tiết của khóa, MySQL cung cấp hai cấp độ khóa: khóa hàng và khóa bảng.
- Khóa bảng (table lock) - Khóa toàn bộ bảng. Trước khi người dùng thực hiện thao tác ghi trên bảng, họ phải lấy khóa ghi trước, điều này sẽ chặn tất cả các hoạt động đọc và ghi của người dùng khác trên bảng đó. Chỉ khi không có khóa ghi, người dùng khác mới có thể lấy khóa đọc, các khóa đọc không tương tác lẫn nhau.
- Khóa hàng (row lock) - Chỉ khóa các bản ghi hàng cụ thể, điều này cho phép các quá trình khác vẫn có thể thao tác trên các bản ghi khác trong cùng một bảng.
Hai yếu tố cần cân nhắc:
- Lượng dữ liệu bị khóa càng nhỏ, tần suất cạnh tranh khóa càng ít và mức độ đồng thời của hệ thống càng cao.
- Độ chi tiết của khóa càng nhỏ thì chi phí hoạt động của hệ thống càng lớn .
Trong InnoDB, khóa hàng được thực hiện bằng cách khóa các mục chỉ mục trên chỉ mục. Nếu không có chỉ mục, InnoDB sẽ khóa bản ghi thông qua chỉ mục gom nhóm ẩn.
Khóa đọc và khóa ghi
- Khóa đọc và khóa ghi là gì?
- Khóa ghi (Exclusive Lock), viết tắt là X Lock, còn được gọi là khóa viết. Cách sử dụng:
SELECT … FOR UPDATE; - Khóa đọc (Shared Lock), viết tắt là S Lock, còn được gọi là khóa đọc. Cách sử dụng:
SELECT … LOCK IN SHARE MODE;
Mối quan hệ giữa khóa ghi và khóa đọc, nói một cách đơn giản: Khi có khóa ghi, các giao dịch khác không thể thực hiện bất kỳ hoạt động nào.
Trong InnoDB, khóa hàng, khóa khoảng trống và khóa next-key đều thuộc loại khóa ghi.
Khóa ý chí
- Khóa ý chí là gì?
- Khóa ý chí được sử dụng để làm gì?
Khóa ý chí (Intention Lock) được sử dụng để hỗ trợ việc khóa hàng và khóa bảng đồng thời khi cần thiết. Sử dụng khóa ý chí (Intention Lock) giúp dễ dàng hơn trong việc hỗ trợ nhiều cấp độ khóa.
Khóa ý chí được InnoDB tự động thêm vào, không cần sự can thiệp của người dùng.
MVCC
MVCC là gì?
MVCC được sử dụng để làm gì? Giải quyết vấn đề gì?
Nguyên tắc của MVCC là gì?
Kiểm soát đồng thời nhiều phiên bản (Multi-Version Concurrency Control, MVCC) là một cách cụ thể mà InnoDB sử dụng để thực hiện các cấp độ cô lập, bao gồm đọc đã xác nhận và đọc lặp lại. Đồng thời, nó giải quyết vấn đề đọc bẩn và đọc không lặp lại.
Nguyên tắc của MVCC là:
- Lưu trữ bản chụp của dữ liệu tại một thời điểm nhất định. Các hoạt động ghi (DELETE, INSERT, UPDATE) cập nhật bản chụp phiên bản mới nhất, trong khi các hoạt động đọc lấy bản chụp phiên bản cũ, không có sự tương tác. Điều này tương tự như cơ chế CopyOnWrite.
- Đọc bẩn và đọc không lặp lại là do giao dịch đọc dữ liệu chưa được xác nhận từ các giao dịch khác. Để giải quyết vấn đề này, MVCC quy định chỉ có thể đọc các bản chụp đã xác nhận. Một giao dịch có thể đọc bản chụp chưa xác nhận của chính nó, điều này không được coi là đọc bẩn.
Khóa Next-key
Khóa Next-key (Next-Key Lock) là một cách thức khóa được sử dụng bởi InnoDB trong việc triển khai khóa.
MVCC không thể giải quyết vấn đề đọc không đồng nhất, khóa Next-key được sử dụng để giải quyết vấn đề đọc không đồng nhất. Trong cấp độ cô lập đọc lặp lại (REPEATABLE READ), sử dụng MVCC + Next-Key Lock có thể giải quyết vấn đề đọc không đồng nhất.
Ngoài ra, dựa trên điều kiện truy vấn SQL khác nhau, cũng có ba trường hợp khóa cần chú ý.
- Khóa bản ghi (
Record Lock) - Khóa các mục chỉ mục trên bản ghi, nếu không có chỉ mục, sử dụng khóa bảng. - Khóa khoảng trống (
Gap Lock) - Khóa khoảng trống giữa các mục chỉ mục. Khóa các khoảng trống giữa các mục chỉ mục, nhưng không bao gồm mục chỉ mục chính nó. Ví dụ, khi một giao dịch thực hiện câu lệnh sau, các giao dịch khác không thể chèn giá trị 15 vào cột c trong bảng t.SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE; - Khóa Next-key (
Next-Key Lock) - Kết hợp giữaRecord LockvàGap Lock, khóa kết hợp giữa khóa bản ghi trên một khoảng trống. Nó khóa một khoảng trống mở phía trước và đóng phía sau.
Chỉ mục được chia thành hai loại: chỉ mục khóa chính (primary key index) và chỉ mục không phải khóa chính (non-primary key index). Nếu một câu lệnh SQL thao tác trên chỉ mục khóa chính, MySQL sẽ khóa chỉ mục khóa chính đó. Nếu một câu lệnh thao tác trên chỉ mục không phải khóa chính, MySQL sẽ khóa chỉ mục không phải khóa chính đó trước, sau đó khóa chỉ mục khóa chính liên quan. Trong các hoạt động UPDATE và DELETE, MySQL không chỉ khóa tất cả các bản ghi chỉ mục được quét bởi điều kiện WHERE, mà còn khóa các giá trị khóa liền kề, còn được gọi là khóa kế tiếp (next-key lock).
Khi hai giao dịch được thực hiện cùng một lúc, một giao dịch khóa chỉ mục khóa chính và đợi các chỉ mục liên quan. Giao dịch khác khóa chỉ mục không phải khóa chính và đợi chỉ mục khóa chính. Điều này dẫn đến tình trạng xảy ra deadlock. Sau khi xảy ra deadlock, InnoDB thường có thể phát hiện và giải phóng khóa của một giao dịch để quay trở lại trạng thái ban đầu, cho phép giao dịch khác lấy khóa và hoàn thành giao dịch.
Giao dịch
Giao dịch đơn giản là tất cả các hoạt động được thực hiện trong một phiên làm việc (session) phải cùng thành công hoặc cùng thất bại. Cụ thể, giao dịch là một tập hợp các hoạt động thỏa mãn các đặc điểm ACID, có thể được gửi đi bằng cách sử dụng
Commitđể xác nhận giao dịch hoặc sử dụngRollbackđể hoàn tác.
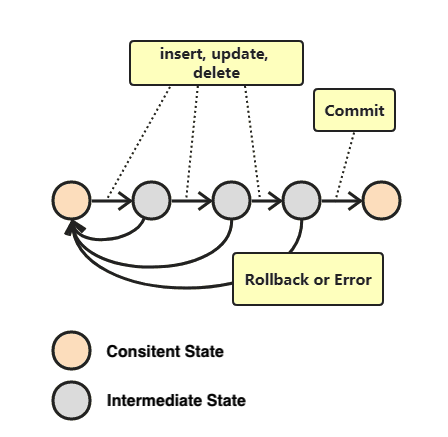
ACID
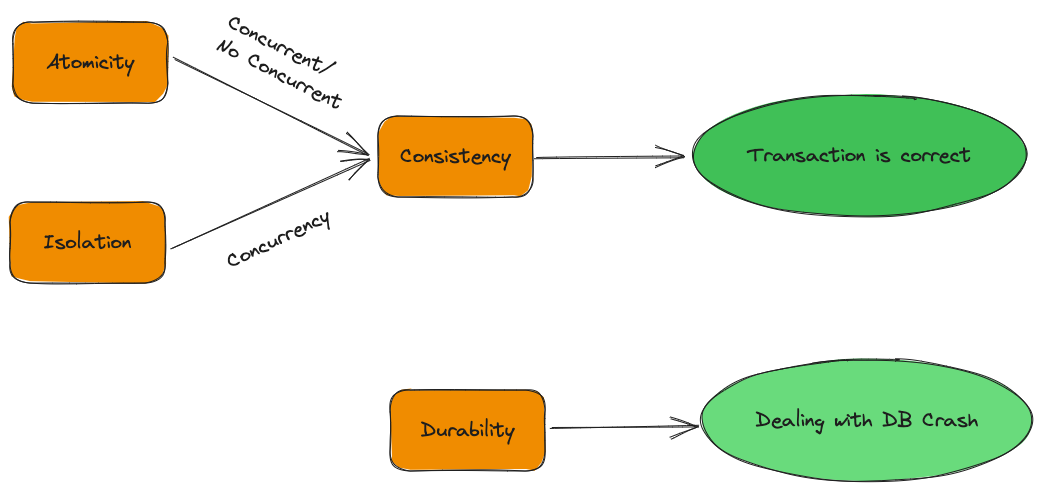
ACID - Bốn yếu tố cơ bản để thực hiện giao dịch cơ sở dữ liệu một cách chính xác:
- Tính nguyên tử (Atomicity)
- Tính nhất quán (Consistency)
- Tính cô lập (Isolation)
- Tính bền vững (Durability)
Hệ thống cơ sở dữ liệu hỗ trợ giao dịch phải có bốn tính chất này, nếu không, không thể đảm bảo tính chính xác của dữ liệu trong quá trình giao dịch.
Vấn đề nhất quán trong môi trường đồng thời
Trong môi trường đồng thời, rất khó để đảm bảo tính cô lập của giao dịch, do đó có nhiều vấn đề về nhất quán trong môi trường đồng thời.
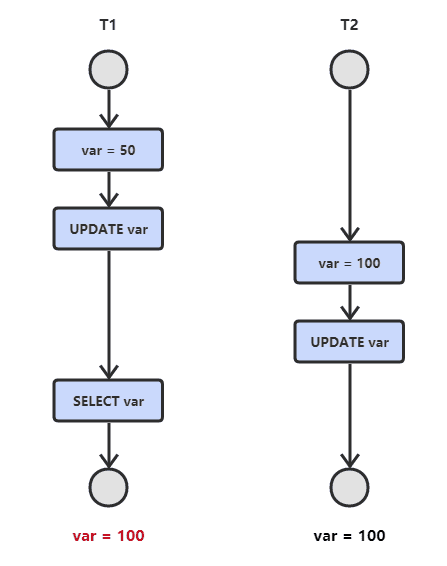
- Mất mát thay đổi
Hai giao dịch T1 và T2 cùng sửa đổi một dữ liệu, T1 sửa đổi trước, T2 sửa đổi sau, sửa đổi của T2 ghi đè lên sửa đổi của T1.
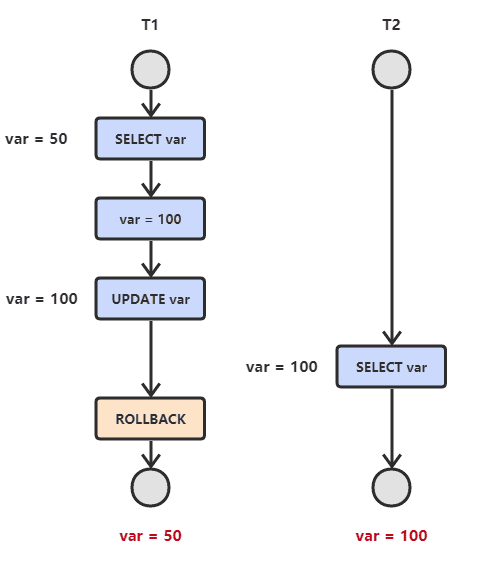
- Đọc dữ liệu bẩn (dirty read)
T1 sửa đổi một dữ liệu, T2 đọc dữ liệu này sau đó. Nếu T1 hủy bỏ sửa đổi này, dữ liệu mà T2 đọc là dữ liệu bẩn.
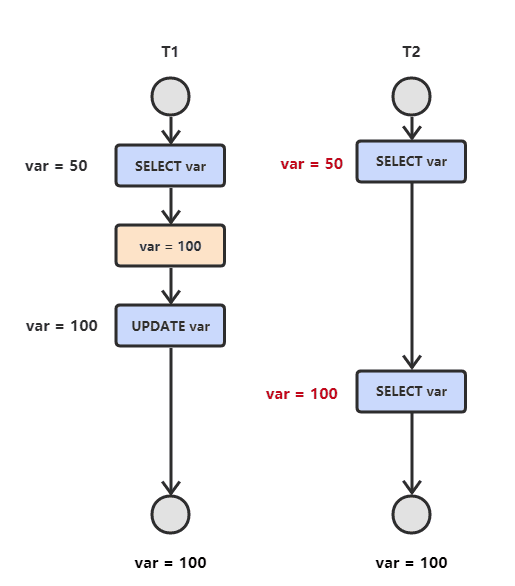
- Đọc không nhất quán (un-repeatable read)
T2 đọc một dữ liệu, T1 sửa đổi dữ liệu này. Nếu T2 đọc lại dữ liệu này, kết quả đọc sẽ khác với lần đọc trước.
- Đọc dữ liệu ảo (phantom read)
T1 đọc một phạm vi dữ liệu, T2 chèn dữ liệu mới vào phạm vi này, T1 đọc lại phạm vi dữ liệu này, kết quả đọc sẽ khác với lần đọc trước.
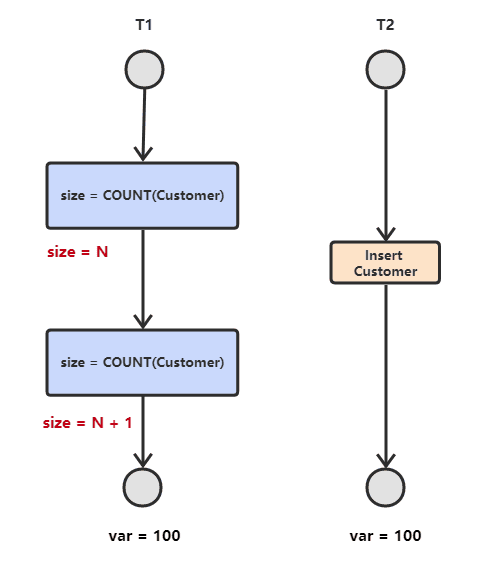
Giải pháp cho vấn đề nhất quán trong môi trường đồng thời:
Vấn đề nhất quán trong môi trường đồng thời chủ yếu xuất phát từ việc vi phạm tính cô lập của giao dịch. Giải pháp là sử dụng kiểm soát đồng thời để đảm bảo tính cô lập.
Kiểm soát đồng thời có thể được thực hiện bằng cách sử dụng khóa, nhưng thao tác khóa phức tạp và phụ thuộc vào người dùng tự điều khiển. Hệ quản trị cơ sở dữ liệu cung cấp các cấp độ cô lập giao dịch để người dùng xử lý vấn đề nhất quán trong môi trường đồng thời một cách dễ dàng hơn.
Mức độ cộ lâp (Isolation Level)
Cấp độ cô lập cơ sở dữ liệu:
Đọc chưa cam kết(READ UNCOMMITTED) - Các sửa đổi trong giao dịch, ngay cả khi chưa được xác nhận, cũng có thể nhìn thấy bởi các giao dịch khác.Đọc đã cam kết(READ COMMITTED) - Một giao dịch chỉ có thể đọc các sửa đổi đã được xác nhận của các giao dịch khác. Nghĩa là các sửa đổi của một giao dịch trong quá trình thực hiện chưa được nhìn thấy bởi các giao dịch khác.Đọc lặp lại(REPEATABLE READ) - Đảm bảo kết quả đọc của cùng một dữ liệu trong một giao dịch là như nhau.Tuần tự hoá(SERIALIZABLE) - Buộc các giao dịch thực hiện tuần tự.
Cấp độ cô lập giải quyết các vấn đề nhất quán:
| Cấp độ cô lập | Đọc bẩn | Đọc không nhất quán | Đọc dữ liệu ảo |
|---|---|---|---|
| Đọc chưa cam kết | ❌ | ❌ | ❌ |
| Đã đã cam kết | ✔️ | ❌ | ❌ |
| Đọc lặp lại | ✔️ | ✔️ | ❌ |
| Tuần tự hoá | ✔️ | ✔️ | ✔️ |
Giao dịch phân tán
Trong một nút dữ liệu duy nhất, giao dịch chỉ giới hạn trong việc kiểm soát truy cập vào tài nguyên cơ sở dữ liệu duy nhất, được gọi là giao dịch cục bộ. Hầu hết các hệ quản trị cơ sở dữ liệu quan hệ đã được phát triển cung cấp hỗ trợ gốc cho giao dịch cục bộ.
Giao dịch phân tán là khi các bên tham gia giao dịch, máy chủ hỗ trợ giao dịch, máy chủ tài nguyên và trình quản lý giao dịch nằm trên các nút khác nhau của hệ thống phân tán.
Cam kết hai giai đoạn
Cam kết hai giai đoạn (XA) có ích cho các giao dịch phân tán. Lợi thế lớn nhất của nó là không ảnh hưởng đến người dùng, người dùng có thể sử dụng giao dịch phân tán dựa trên giao thức XA như sử dụng giao dịch cục bộ. Giao thức XA đảm bảo tính ACID của giao dịch.
Đảm bảo tính ACID của giao dịch là một con dao hai lưỡi. Trong quá trình thực hiện giao dịch, tất cả các tài nguyên cần được khóa, điều này phù hợp với giao dịch ngắn thời gian xác định. Đối với giao dịch dài, việc chiếm giữ tài nguyên trong suốt quá trình giao dịch sẽ làm giảm hiệu suất đáng kể đối với hệ thống kinh doanh phụ thuộc vào dữ liệu tập trung. Do đó, trong các tình huống nơi hiệu suất đồng thời là quan trọng nhất, giao dịch phân tán dựa trên giao thức XA không phải là lựa chọn tốt nhất.
Giao dịch mềm
Nếu giao dịch thỏa mãn các yếu tố ACID, nó được gọi là giao dịch cứng. Nếu giao dịch dựa trên yếu tố BASE, nó được gọi là giao dịch mềm. BASE là viết tắt của Basic Availability, Soft state và Eventual consistency.
- Basic Availability đảm bảo các bên tham gia giao dịch không cần phải cùng online.
- Soft state cho phép cập nhật trạng thái của hệ thống có một độ trễ nhất định, độ trễ này có thể không thể nhận thấy được bởi khách hàng.
- Eventual consistency thường được đảm bảo bằng cách truyền tin nhắn để đảm bảo tính nhất quán của hệ thống.
Giao dịch mềm dựa trên yếu tố BASE không phải là giải pháp tối ưu cho tất cả các tình huống. Chỉ khi nó phù hợp nhất với tình huống cụ thể, giao dịch cứng dựa trên yếu tố ACID và giao dịch mềm dựa trên yếu tố BASE mới có thể phát huy tối đa ưu điểm của chúng. Bảng dưới đây so sánh chi tiết giữa các giải pháp giao dịch.
So sánh các giải pháp giao dịch
| Giao dịch cục bộ | Hai giai đoạn giao dịch | Giao dịch mềm | |
|---|---|---|---|
| Sửa đổi | Không hỗ trợ | Hỗ trợ | Hỗ trợ |
| Cô lập | Không hỗ trợ | Hỗ trợ | Do bên tham gia đảm bảo |
| Hiệu suất | Không ảnh hưởng | Giảm nghiêm trọng | Giảm nhẹ |
| Phù hợp | Không phù hợp | Giao dịch ngắn & ít đồng thời | Giao dịch dài & nhiều đồng thời |
Phân chia cơ sở dữ liệu và bảng
Khái niệm
Phân chia cơ sở dữ liệu và bảng là gì? Phân chia dọc là gì? Phân chia ngang là gì? Sharding là gì?
Phân chia cơ sở dữ liệu và bảng được thực hiện để giải quyết vấn đề gì?
Phân chia cơ sở dữ liệu và bảng có những ưu điểm gì?
Phân chia cơ sở dữ liệu và bảng có những chiến lược nào?
Phân chia cơ sở dữ liệu và bảng là ý tưởng cơ bản là chia nhỏ dữ liệu ban đầu thành nhiều phần và lưu trữ trên các cơ sở dữ liệu hoặc bảng khác nhau.
Phân vùng và phân bảng luôn nhằm hỗ trợ hai vấn đề chính: đồng thời xử lý nhiều yêu cầu và xử lý lượng dữ liệu lớn.
Phân chia theo chiều dọc
Phân chia theo chiều dọc, là việc phân tách một bảng có nhiều cột thành nhiều bảng hoặc trên nhiều cơ sở dữ liệu. Thông thường, ta sẽ đặt các cột ít hơn và được truy cập thường xuyên vào một bảng riêng, sau đó đặt các cột nhiều hơn và được truy cập ít thường xuyên vào một bảng khác. Bởi vì cơ sở dữ liệu có bộ nhớ cache, khi số lượng các hàng có tần suất truy cập cao ít đi, ta có thể lưu trong cache được nhiều hàng hơn, từ đó hiệu suất tốt hơn. Điều này thường được áp dụng ở mức độ của các bảng.
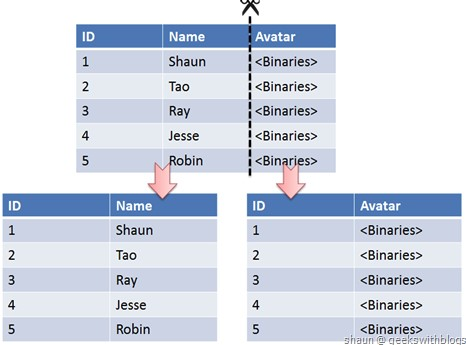
Thông thường, khi đạt đến các điều kiện sau, bạn có thể xem xét việc mở rộng:
- Mysql vượt quá 50 triệu bản ghi, Oracle vượt quá 100 triệu bản ghi, cơ sở dữ liệu sẽ gặp áp lực lớn.
- Khi có hơn 2000 yêu cầu mỗi giây vào cơ sở dữ liệu, cơ sở dữ liệu nên duy trì ở mức khoảng 1000 yêu cầu mỗi giây.
Phân chia dọc cơ sở dữ liệu được thực hiện ở mức bảng trong cơ sở dữ liệu bằng cách đặt các bảng có mật độ cao vào các cơ sở dữ liệu khác nhau. Ví dụ, cơ sở dữ liệu ban đầu của cửa hàng điện tử có thể được phân chia dọc thành cơ sở dữ liệu sản phẩm, cơ sở dữ liệu người dùng, v.v.
Phân chia theo chiều ngang
Phân chia ngang, còn được gọi là Sharding, là quá trình chia các bản ghi trong cùng một bảng thành nhiều bảng có cấu trúc giống nhau. Khi dữ liệu của một bảng quá lớn, nó sẽ ảnh hưởng đến hiệu suất thực thi SQL. Phân chia bảng là việc phân phối dữ liệu từ một bảng ban đầu vào các node khác nhau trong cụm cơ sở dữ liệu, từ đó giải tỏa áp lực cho điểm duy nhất.
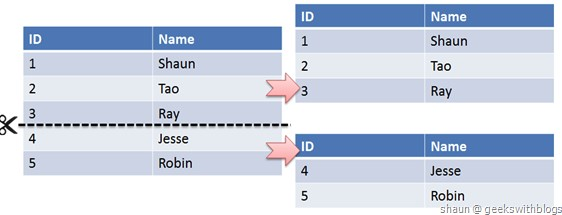
Thông thường, khi một bảng có 2 triệu bản ghi, hiệu suất sẽ giảm đáng kể, và cần xem xét phân chia bảng. Tuy nhiên, điều này cũng phụ thuộc vào tình huống cụ thể, có thể là 1 triệu bản ghi hoặc 5 triệu bản ghi, số lượng bản ghi càng ít thì hiệu suất càng tốt.
Ưu điểm của phân chia cơ sở dữ liệu và bảng
| # | Trước khi phân chia | Sau khi phân chia |
|---|---|---|
| Xử lý đồng thời | Không thể xử lý tải cao | Từ một máy chủ đến nhiều máy chủ, có thể xử lý tải cao hơn nhiều lần |
| Sử dụng đĩa cứng | Đĩa cứng trên một máy chủ gần như đầy | Phân chia thành nhiều cơ sở dữ liệu, tăng hiệu suất sử dụng đĩa cứng của máy chủ cơ sở dữ liệu |
| Hiệu suất thực thi SQL | Dữ liệu của một bảng quá lớn, thực thi SQL chậm | Dữ liệu của một bảng giảm, hiệu suất thực thi SQL cải thiện đáng kể |
Chiến lược phân chia cơ sở dữ liệu và bảng
- Phân chia dựa trên hàm băm:
hash(key) % Nhoặcid % N- Ưu điểm: Cân bằng tải cho mỗi cơ sở dữ liệu và giảm áp lực yêu cầu (cân bằng tải).
- Nhược điểm: Phức tạp khi mở rộng, cần di chuyển dữ liệu.
- Phân chia dựa trên phạm vi: phân chia dựa trên ID hoặc thời gian.
- Ưu điểm: Mở rộng đơn giản.
- Nhược điểm: Chiến lược này dễ gây ra vấn đề điểm nóng (hotspot).
- Bảng ánh xạ: sử dụng một cơ sở dữ liệu riêng để lưu trữ các mối quan hệ ánh xạ.
- Nhược điểm: Cơ sở dữ liệu lưu trữ mối quan hệ ánh xạ cũng có thể trở thành hạn chế hiệu suất và nếu cơ sở dữ liệu này gặp sự cố, cơ sở dữ liệu phân chia cơ sở dữ liệu và bảng sẽ không hoạt động. Do đó, không khuyến nghị sử dụng chiến lược này.
- Ưu điểm: Mở rộng đơn giản, có thể giải quyết vấn đề ID phân tán.
Phần mềm trung gian phân chia cơ sở dữ liệu và bảng
❓ Các phần mềm trung gian phân chia cơ sở dữ liệu và bảng phổ biến là gì? Hãy giới thiệu một cách đơn giản.
❓ Các phần mềm trung gian phân chia cơ sở dữ liệu và bảng có các đặc điểm và ưu nhược điểm gì?
❓ Làm thế nào để chọn công nghệ phân chia cơ sở dữ liệu và bảng?
Các phần mềm trung gian phân chia cơ sở dữ liệu và bảng phổ biến
- Cobar - Được phát triển và phát hành bởi nhóm Alibaba B2B, là một giải pháp tầng proxy, nằm giữa máy chủ ứng dụng và máy chủ cơ sở dữ liệu. Ứng dụng truy cập vào cụm cobar thông qua trình điều khiển JDBC, cobar sẽ phân giải SQL và phân phối nó đến các cơ sở dữ liệu MySQL khác nhau trong cụm để thực thi. Tuy nhiên, cobar không hỗ trợ đọc / ghi phân tán, lưu trữ thủ tục, liên kết cơ sở dữ liệu và phân trang.
- TDDL - Được phát triển bởi nhóm Taobao, là một giải pháp tầng khách hàng. TDDL hỗ trợ các cú pháp CRUD cơ bản và đọc / ghi phân tán, nhưng không hỗ trợ liên kết, truy vấn đa bảng và một số cú pháp khác. Hiện tại, không có nhiều người sử dụng TDDL, vì nó vẫn phụ thuộc vào hệ thống quản lý cấu hình diamond của Taobao.
- Atlas - Được phát triển bởi 360, là một giải pháp tầng proxy. Trước đây, một số công ty đã sử dụng Atlas, nhưng phiên bản mới nhất của cộng đồng đã không được bảo trì trong 5 năm. Hiện nay, ít công ty sử dụng Atlas.
- sharding-jdbc - Được phát triển bởi Dangdang, là một giải pháp tầng khách hàng. sharding-jdbc hỗ trợ phân chia cơ sở dữ liệu và bảng, đọc / ghi phân tán, sinh ID phân tán, giao dịch linh hoạt (giao dịch tối đa nỗ lực, giao dịch TCC). Hiện nay, sharding-jdbc vẫn được sử dụng khá nhiều và đã phát triển đến phiên bản 2.0, hỗ trợ phân chia cơ sở dữ liệu và bảng, đọc / ghi phân tán, sinh ID phân tán, giao dịch linh hoạt (giao dịch tối đa nỗ lực, giao dịch TCC). Cộng đồng vẫn tiếp tục phát triển và bảo trì, và có nhiều công ty đang sử dụng sharding-jdbc.
- Mycat - Là một phiên bản được cải tiến từ cobar, là một giải pháp tầng proxy. Mycat hỗ trợ đầy đủ các chức năng và hiện đang trở thành một giải pháp trung gian cơ sở dữ liệu phổ biến và ngày càng được sử dụng. Cộng đồng rất sôi nổi và một số công ty đã bắt đầu sử dụng Mycat. Tuy nhiên, so với sharding-jdbc, Mycat còn trẻ hơn một chút và ít kinh nghiệm hơn.
Lựa chọn công nghệ phân chia cơ sở dữ liệu và bảng
Nên sử dụng sharding-jdbc và Mycat.
- sharding-jdbc là một giải pháp tầng khách hàng nhẹ nhàng, có chi phí vận hành thấp, không cần triển khai, không cần chuyển tiếp yêu cầu lần thứ hai qua tầng proxy, hiệu suất cao. Tuy nhiên, nếu gặp vấn đề nâng cấp, bạn cần phải nâng cấp phiên bản của tất cả các hệ thống và phát hành lại, và tất cả các hệ thống đều phải phụ thuộc vào sharding-jdbc.
- Mycat là một giải pháp tầng proxy, có chi phí vận hành cao, tự quản lý một hệ thống trung gian. Tuy nhiên, lợi ích của Mycat là đối với các dự án khác nhau, nó là透明的, nghĩa là không cần sửa đổi mã nguồn ứng dụng, chỉ cần cấu hình Mycat, và nhiều dự án sẽ sử dụng trực tiếp.
Thường thì, các giải pháp này đều có thể chọn, nhưng cá nhân tôi khuyến nghị các công ty vừa và nhỏ nên sử dụng sharding-jdbc, một giải pháp tầng khách hàng nhẹ nhàng, chi phí vận hành thấp, không cần triển khai, không cần chuyển tiếp yêu cầu lần thứ hai qua tầng proxy, hiệu suất cao. Tuy nhiên, các công ty lớn nên sử dụng Mycat, một giải pháp tầng proxy, vì có thể có nhiều hệ thống và dự án, đội ngũ lớn, nên tốt nhất là có một người chuyên nghiệp để nghiên cứu và bảo trì Mycat, và nhiều dự án sẽ sử dụng trực tiếp.
Các vấn đề phổ biến của phân chia cơ sở dữ liệu và bảng
Các vấn đề phổ biến của việc chia cơ sở dữ liệu và bảng là gì?
Bạn đã giải quyết vấn đề chia cơ sở dữ liệu và bảng như thế nào?
Dưới đây, tôi sẽ trình bày từng vấn đề thông thường của việc chia cơ sở dữ liệu và bảng cùng với các giải pháp.
Giao dịch phân tán
Giải pháp 1: Sử dụng giao dịch cơ sở dữ liệu
- Ưu điểm: Được quản lý bởi cơ sở dữ liệu, đơn giản và hiệu quả
- Nhược điểm: Tốn kém về hiệu suất, đặc biệt là khi số shard ngày càng nhiều
Giải pháp 2: Điều khiển chung bởi ứng dụng và cơ sở dữ liệu
- Nguyên tắc: Chia một giao dịch phân tán qua nhiều cơ sở dữ liệu thành nhiều giao dịch nhỏ chỉ nằm trên một cơ sở dữ liệu duy nhất và sử dụng ứng dụng để kiểm soát các giao dịch nhỏ này.
- Ưu điểm: Có lợi về hiệu suất
- Nhược điểm: Yêu cầu thiết kế linh hoạt trong việc kiểm soát giao dịch trên ứng dụng. Nếu sử dụng quản lý giao dịch của Spring, việc thay đổi sẽ gặp khó khăn.
Liên kết giữa các shard
Dù có cách thiết kế và phân vùng tốt, vấn đề liên kết giữa các shard vẫn không thể tránh khỏi. Tuy nhiên, thiết kế và phân vùng tốt có thể giảm thiểu tình huống này. Giải pháp cho vấn đề này là thực hiện truy vấn hai lần. Trong lần truy vấn đầu tiên, lấy ra danh sách id của các dữ liệu liên quan từ kết quả truy vấn và sau đó thực hiện truy vấn thứ hai để lấy dữ liệu liên quan.
Tính toán trên các shard, bao gồm count, order by, group by và các hàm tổng hợp
Đây là một nhóm vấn đề, vì tất cả đều yêu cầu tính toán dựa trên tập dữ liệu toàn bộ. Hầu hết các proxy không tự động xử lý việc kết hợp này.
Giải pháp: Tương tự như việc giải quyết vấn đề liên kết giữa các shard, thực hiện truy vấn trên từng shard riêng lẻ và sau đó kết hợp kết quả trên ứng dụng. Khác biệt là các truy vấn trên từng shard có thể được thực hiện song song, do đó thường nhanh hơn so với truy vấn trên một bảng lớn duy nhất. Tuy nhiên, nếu kết quả truy vấn lớn, nó sẽ tốn nhiều bộ nhớ của ứng dụng.
Giải pháp từ góc nhìn kinh doanh:
- Nếu cung cấp phân trang trong ứng dụng frontend, hạn chế người dùng chỉ có thể xem n trang đầu tiên, điều này cũng hợp lý về mặt kinh doanh, thông thường không có ý nghĩa lớn khi xem các trang sau (nếu người dùng vẫn muốn xem, có thể yêu cầu họ giới hạn phạm vi và thực hiện truy vấn lại).
- Nếu đó là một tác vụ xử lý hàng loạt phía sau, yêu cầu lấy dữ liệu theo từng phần, bạn có thể tăng kích thước trang, ví dụ: lấy 5000 bản ghi mỗi lần để giảm số lượng trang (tất nhiên, truy cập ngoại tuyến thường đi qua cơ sở dữ liệu sao lưu để tránh ảnh hưởng đến cơ sở dữ liệu chính).
ID phân tán
Một khi cơ sở dữ liệu đã được phân vùng thành nhiều shard, chúng ta không thể phụ thuộc vào cơ chế sinh ID chính của cơ sở dữ liệu nữa. Một phần vì ID được tạo ra bởi mỗi shard riêng biệt không đảm bảo duy nhất trên toàn cầu; một phần khác là ứng dụng cần có ID trước khi chèn dữ liệu để thực hiện định tuyến SQL.
Một số chiến lược phổ biến để tạo ID:
- Sử dụng ID toàn cầu duy nhất: GUID.
- Gán một phạm vi ID cho mỗi shard.
- Sử dụng các công cụ tạo ID phân tán (như thuật toán Snowflake của Twitter).
Di chuyển dữ liệu, lập kế hoạch dung lượng, mở rộng và các vấn đề khác
Đây là các vấn đề liên quan đến việc di chuyển dữ liệu giữa các shard, lập kế hoạch dung lượng, mở rộng và có nhiều giới hạn. Các giải pháp hiện tại không hoàn hảo và đôi khi có một số nhược điểm. Điều này cũng phản ánh khó khăn trong việc mở rộng phân vùng.
Cụm
Chủ đề này sẽ phụ thuộc vào cơ sở dữ liệu mà bạn quen, nhưng các cơ sở dữ liệu phổ biến và đã được thử nghiệm đều có một số chức năng cơ bản, chỉ khác nhau về cách triển khai và chiến lược. Vì tôi quen thuộc với Mysql hơn, dưới đây tôi sẽ giới thiệu chủ yếu về các vấn đề kiến trúc hệ thống của Mysql.
Cơ chế sao chép
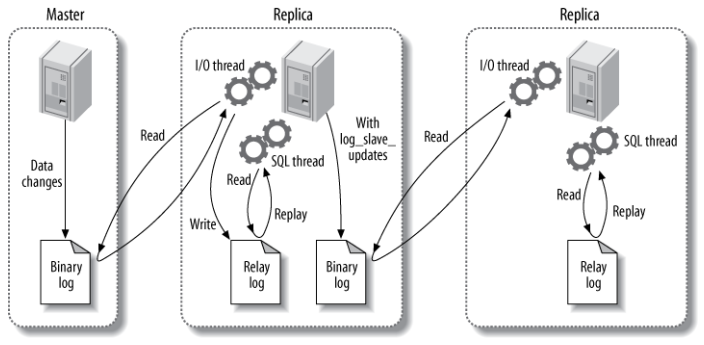
MySQL hỗ trợ hai cơ chế sao chép: sao chép dựa trên hàng và sao chép dựa trên câu lệnh.
Cả hai cơ chế này đều ghi lại nhật ký nhị phân (binlog) trên máy chủ chính, sau đó cập nhật các bản ghi nhật ký trên máy chủ phụ theo cách không đồng bộ. Điều này có nghĩa là quá trình sao chép có thời gian trễ, trong khoảng thời gian này, dữ liệu trên máy chủ chính và máy chủ phụ có thể không đồng nhất (tức là có tính nhất quán cuối cùng).
Có ba luồng chính liên quan: luồng binlog, luồng I/O và luồng SQL.
- Luồng binlog: Đảm nhiệm việc ghi dữ liệu thay đổi từ máy chủ chính vào tệp nhị phân (binlog).
- Luồng I/O: Đảm nhiệm việc đọc tệp nhị phân nhật ký từ máy chủ chính và ghi vào nhật ký của máy chủ phụ.
- Luồng SQL: Đảm nhiệm việc đọc nhật ký và thực thi các câu lệnh SQL để cập nhật dữ liệu.
Phân tách đọc và ghi
Máy chủ chính được sử dụng để xử lý các hoạt động ghi và các hoạt động đọc có yêu cầu thời gian thực cao, trong khi máy chủ phụ được sử dụng để xử lý các hoạt động đọc.
Phân tách đọc và ghi thường được thực hiện bằng cách sử dụng cách thức ủy quyền, trong đó máy chủ ủy quyền nhận các yêu cầu đọc và ghi từ tầng ứng dụng, sau đó quyết định chuyển tiếp yêu cầu đến máy chủ nào.
Phân tách đọc và ghi trong MySQL có thể cải thiện hiệu suất vì:
- Máy chủ chính và máy chủ phụ chịu trách nhiệm cho việc đọc và ghi riêng biệt, giảm đáng kể sự cạnh tranh khóa;
- Máy chủ phụ có thể được cấu hình với MyISAM Engine, cải thiện hiệu suất truy vấn và tiết kiệm tài nguyên hệ thống;
- Tăng cường tính dự phòng, nâng cao khả năng sẵn có.
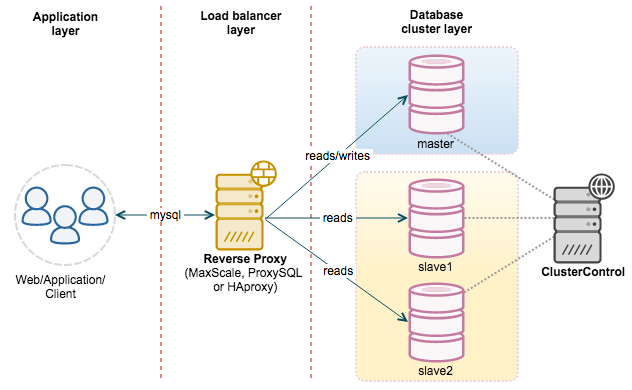
Cân bằng tải
Cân bằng tải trong MySQL là quá trình phân phối công việc và tải của các yêu cầu từ ứng dụng đến nhiều máy chủ MySQL. Mục tiêu của cân bằng tải là đảm bảo rằng mỗi máy chủ nhận được một lượng công việc hợp lý và không bị quá tải.
Có nhiều phương pháp cân bằng tải trong MySQL, bao gồm:
- Cân bằng tải dựa trên phần vùng: Dữ liệu được chia thành các phần vùng và mỗi máy chủ chịu trách nhiệm cho một phần vùng cụ thể.
- Cân bằng tải dựa trên người dùng: Các yêu cầu từ người dùng được phân phối đều cho các máy chủ khác nhau.
- Cân bằng tải dựa trên trạng thái: Các yêu cầu được phân phối dựa trên trạng thái hiện tại của máy chủ, như tải CPU, bộ nhớ, hoặc số lượng kết nối.
Cân bằng tải giúp tăng hiệu suất và đảm bảo tính sẵn sàng của hệ thống MySQL.
Tối ưu cơ sở dữ liệu
Hướng tối ưu cơ sở dữ liệu thường bao gồm: tối ưu SQL, tối ưu cấu trúc, tối ưu cấu hình và tối ưu phần cứng. Hai hướng đầu tiên thường được xem xét bởi các nhà phát triển thông thường, trong khi hai hướng sau thường được xem xét bởi các DBA.
Tối ưu SQL
Tối ưu SQL là biện pháp tối ưu cơ sở dữ liệu phổ biến và cơ bản nhất.
Trong quá trình thực thi câu lệnh SQL, thứ tự các trường trong câu lệnh, chiến lược truy vấn, v.v. có thể ảnh hưởng đến hiệu suất thực thi SQL.
Kế hoạch thực thi
Làm thế nào để kiểm tra xem SQL đã được tối ưu sau khi thay đổi? Điều này đòi hỏi sử dụng kế hoạch thực hiện (EXPLAIN).
Sử dụng EXPLAIN để phân tích hiệu suất truy vấn SELECT, các nhà phát triển có thể tối ưu hóa câu lệnh truy vấn bằng cách phân tích kết quả EXPLAIN.
Các trường quan trọng bao gồm:
select_type- Loại truy vấn, bao gồm truy vấn đơn giản, truy vấn kết hợp, truy vấn con, v.v.key- Chỉ mục được sử dụngrows- Số hàng được quét
Xem thêm: Using EXPLAIN in Mysql to analyze and improve query performance
Tối ưu truy cập dữ liệu
Giảm lượng dữ liệu được yêu cầu:
- Chỉ trả về các cột cần thiết : Tránh truy vấn các cột không cần thiết, hạn chế sử dụng câu lệnh
SELECT *. - Chỉ trả về các hàng cần thiết : Sử dụng câu lệnh
WHEREđể lọc dữ liệu truy vấn, đôi khi cần sử dụng câu lệnhLIMITđể giới hạn dữ liệu trả về. - Lưu trữ dữ liệu truy vấn lặp lại trong bộ nhớ cache : Sử dụng bộ nhớ cache để tránh truy vấn trong cơ sở dữ liệu, đặc biệt là với các dữ liệu được truy vấn lặp lại, việc sử dụng cache có thể cải thiện đáng kể hiệu suất truy vấn.
Giảm số hàng được quét bởi máy chủ:
- Cách hiệu quả nhất là sử dụng chỉ mục để truy vấn (tức là trường truy vấn sau
WHEREnên là trường chỉ mục).
Tái cấu trúc cách truy vấn
Chia nhỏ truy vấn
Nếu một truy vấn lớn được thực hiện một lần, nó có thể khóa nhiều dữ liệu, làm đầy nhật ký giao dịch, tiêu tốn tài nguyên hệ thống và chặn nhiều truy vấn nhỏ nhưng quan trọng.
DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0Phân tách truy vấn liên kết
Phân tách một truy vấn liên kết lớn thành các truy vấn đơn bảng, sau đó kết hợp kết quả trong ứng dụng, có thể mang lại các lợi ích sau:
- Cache hiệu quả hơn. Đối với truy vấn liên kết, nếu một trong các bảng thay đổi, bộ nhớ cache của truy vấn toàn bộ sẽ không thể sử dụng. Nhưng sau khi phân tách thành các truy vấn riêng lẻ, ngay cả khi một trong các bảng thay đổi, bộ nhớ cache của các truy vấn khác vẫn có thể sử dụng.
- Phân tách thành nhiều truy vấn đơn bảng, kết quả của các truy vấn đơn bảng có thể được sử dụng bởi các truy vấn khác, từ đó giảm thiểu việc truy vấn các bản ghi trùng lặp.
- Giảm thiểu cạnh tranh khóa.
- Dễ dàng kết hợp cơ sở dữ liệu trong ứng dụng, dễ dàng mở rộng hiệu suất và khả năng mở rộng.
- Có thể cải thiện hiệu suất của truy vấn. Ví dụ, trong ví dụ dưới đây, việc sử dụng
IN()thay thế cho truy vấn liên kết có thể cho phép MySQL thực hiện truy vấn theo thứ tự ID, điều này có thể hiệu quả hơn việc truy vấn liên kết ngẫu nhiên.
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);Chi tiết câu lệnh SQL
Chọn thứ tự bảng hiệu quả nhất
Cơ sở dữ liệu xử lý các bảng trong mệnh đề FROM của câu lệnh SQL theo thứ tự từ phải sang trái.
- Nếu các bảng không có mối quan hệ, hãy đặt bảng có ít bản ghi và cột nhất ở cuối cùng.
- Nếu có 3 bảng trở lên trong truy vấn, hãy đặt bảng được tham chiếu nhiều nhất ở cuối cùng.
Ví dụ: Truy vấn số nhân viên, tên, lương, cấp lương và tên phòng ban.
Bảng emp được tham chiếu nhiều nhất và có nhiều bản ghi nhất, nên đặt ở cuối trong mệnh đề FROM
select emp.empno,emp.ename,emp.sal,salgrade.grade,dept.dname
from salgrade,dept,emp
where (emp.deptno = dept.deptno) and (emp.sal between salgrade.losal and salgrade.hisal)Thứ tự kết nối trong mệnh đề WHERE
Cơ sở dữ liệu xử lý mệnh đề WHERE theo thứ tự từ phải sang trái.
Do đó, kết nối giữa các bảng phải được viết bên trái của các điều kiện WHERE khác, và các điều kiện có thể lọc ra số lượng bản ghi lớn nhất phải được viết bên phải của mệnh đề WHERE.
emp.sal có thể lọc ra nhiều bản ghi, nên được viết bên phải của mệnh đề WHERE
select emp.empno,emp.ename,emp.sal,dept.dname
from dept,emp
where (emp.deptno = dept.deptno) and (emp.sal > 1500)Tránh sử dụng * trong mệnh đề SELECT
Khi viết câu lệnh SQL, khuyến nghị sử dụng tên cột cụ thể thay vì sử dụng *, vì:
- Sử dụng
*sẽ tốn thời gian để truy vấn từ điển dữ liệu. - Câu lệnh SQL sử dụng
*không rõ ràng và không dễ hiểu.
Sử dụng TRUNCATE thay vì DELETE
Nếu cần xóa tất cả các bản ghi trong bảng, sử dụng TRUNCATE sẽ hiệu quả hơn DELETE:
DELETE xóa từng bản ghi một, trong khi TRUNCATE xóa toàn bộ bảng và chỉ giữ lại cấu trúc bảng
Sử dụng hàm nội bộ để tăng hiệu suất SQL
Ví dụ, việc sử dụng hàm concat() của MySQL sẽ nhanh hơn việc sử dụng toán tử ||, vì hàm concat() đã được tối ưu hóa bởi MySQL.
Sử dụng tên bảng hoặc cột đại diện
Nếu tên bảng hoặc cột quá dài, sử dụng các đại diện ngắn hơn cũng có thể cải thiện hiệu suất SQL một chút. Điều này giảm số lượng ký tự cần quét.
Sử dụng chữ hoa cho từ khóa SQL
Khi viết SQL, nên sử dụng chữ hoa cho từ khóa SQL, ví dụ: SELECT, FROM, WHERE, v.v. Vì máy chủ Oracle luôn chuyển đổi chữ thường thành chữ hoa trước khi thực thi.
Sử dụng >= thay vì >
❌ Không hiệu quả:
-- Đầu tiên, định vị các bản ghi với DEPTNO=3 và quét đến bản ghi DEPT đầu tiên lớn hơn 3
SELECT * FROM EMP WHERE DEPTNO > 3✔ Hiệu quả hơn:
-- Trực tiếp đến bản ghi DEPT đầu tiên bằng 4
SELECT * FROM EMP WHERE DEPTNO >= 4Sử dụng IN thay vì OR
❌ Không hiệu quả:
select * from emp where sal = 1500 or sal = 3000 or sal = 800;✔ Hiệu quả hơn:
select * from emp where sal in (1500,3000,800);Luôn sử dụng cột đầu tiên của chỉ mục
Nếu chỉ mục được xây dựng trên nhiều cột, chỉ khi cột đầu tiên được tham chiếu trong mệnh đề WHERE, trình tối ưu sẽ chọn sử dụng chỉ mục đó. Khi chỉ tham chiếu cột thứ hai của chỉ mục, không tham chiếu cột đầu tiên, trình tối ưu sẽ sử dụng quét toàn bộ bảng thay vì chỉ mục.
create index emp_sal_job_idex
on emp(sal,job);
----------------------------------
select *
from emp
where job != 'SALES';Tối ưu cấu trúc
Tối ưu cấu trúc cơ sở dữ liệu có thể bao gồm các phương pháp sau:
- Tối ưu kiểu dữ liệu
- Tối ưu hóa chuẩn hóa và phi chuẩn hóa
- Tối ưu hóa chỉ mục - xem thêm trong phần chỉ mục và ràng buộc
- Phân tách cơ sở dữ liệu - xem thêm trong phần phân tách cơ sở dữ liệu
Nguyên tắc tối ưu kiểu dữ liệu
- Nhỏ hơn là tốt hơn
- Đơn giản là tốt, ví dụ: kiểu số nguyên tốt hơn kiểu ký tự vì thao tác với số nguyên tốn ít tài nguyên hơn.
- Tránh NULL nếu có thể
Chuẩn hóa và phi chuẩn hóa
Mục tiêu của việc chuẩn hóa là giảm thiểu các cột trùng lặp và tiết kiệm không gian.
- Lợi ích của việc chuẩn hóa là:
- Giảm thiểu cột trùng lặp, giảm số lượng dữ liệu cần phải ghi, cải thiện hiệu suất ghi;
- Giảm số lượng cột dữ liệu cần truy xuất khi thực hiện các thao tác
DISTINCThoặcGROUP BY.
- Nhược điểm của việc chuẩn hóa là: tăng số lượng truy vấn liên kết.
Mục tiêu của việc phi chuẩn hóa là tăng cường hiệu suất truy vấn bằng cách thêm các cột trùng lặp.
- Nhược điểm của việc phi chuẩn hóa là:
- Tăng kích thước dữ liệu, giảm hiệu suất ghi;
- Các hoạt động
DISTINCThoặcGROUP BYtăng lên.
Tối ưu cấu hình
Tối ưu cấu hình chủ yếu là cho máy chủ MySQL, ví dụ:
max_connections,max_heap_table_size,open_files_limit,max_allowed_packet, v.v.Trong các môi trường và tình huống khác nhau, nên sử dụng cấu hình phù hợp. Việc tối ưu này đòi hỏi kinh nghiệm quản trị MySQL, thường ít được lập trình viên tiếp xúc.
Tối ưu phần cứng
Mở rộng cơ sở dữ liệu, sử dụng thiết bị cao cấp hơn, v.v. Tóm lại trong một từ: 💵 Money!
Lý thuyết cơ sở dữ liệu
Phụ thuộc hàm
Ghi nhớ A→B có nghĩa là A xác định B, hoặc có thể nói B phụ thuộc vào A.
Nếu {A1, A2, …, An} là một tập hợp các thuộc tính của một quan hệ, tập hợp này xác định tất cả các thuộc tính khác của quan hệ và là tối thiểu, thì tập hợp này được gọi là khóa.
Đối với A→B, nếu có thể tìm thấy một tập con thực sự A’ của A sao cho A’→B, thì A→B được gọi là phụ thuộc hàm một phần, ngược lại, nó được gọi là phụ thuộc hàm đầy đủ;
Đối với A→B và B→C, thì A→C được gọi là phụ thuộc chuyển tiếp.
Các vấn đề
Quan hệ Student-Course sau đây có phụ thuộc hàm là Sno, Cname → Sname, Sdept, Mname, Grade, và khóa là {Sno, Cname}. Điều này có nghĩa là sau khi xác định Student và Course, chúng ta có thể xác định các thông tin khác.
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | Student-1 | Department-1 | Manager-1 | Course-1 | 90 |
| 2 | Student-2 | Department-2 | Manager-2 | Course-2 | 80 |
| 2 | Student-2 | Department-2 | Manager-2 | Course-1 | 100 |
| 3 | Student-3 | Department-2 | Manager-2 | Course-2 | 95 |
Các quan hệ không tuân theo các hình thức chuẩn hoá sẽ gây ra nhiều vấn đề, chủ yếu bao gồm bốn vấn đề sau:
- Dữ liệu dư thừa: ví dụ như Student-2 xuất hiện hai lần.
- Vấn đề sửa đổi: sửa đổi thông tin trong một bản ghi, nhưng thông tin tương tự trong bản ghi khác không được sửa đổi.
- Vấn đề xóa: xóa một thông tin, cũng sẽ mất thông tin khác. Ví dụ: nếu xóa Course-1, cần xóa hàng đầu tiên và hàng thứ ba, thông tin Student-1 sẽ bị mất.
- Vấn đề chèn: ví dụ muốn chèn thông tin của một Student, nếu Student đó chưa chọn Course, thì không thể chèn.
Hình thức chuẩn hoá
NF: Normal Form
Lý thuyết hình thức chuẩn được tạo ra để giải quyết bốn vấn đề trên.
Hình thức cao hơn phụ thuộc vào hình thức thấp hơn, 1NF là hình thức thấp nhất.

Chuẩn hoá 1NF
Các thuộc tính không thể phân chia.
Chuẩn hoá 2NF
- Mỗi thuộc tính không chính phụ thuộc hoàn toàn vào khóa.
- Có thể đạt được bằng cách phân tách.
Trước khi phân tách
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | Student-1 | Department-1 | Manager-1 | Course-1 | 90 |
| 2 | Student-2 | Department-2 | Manager-2 | Course-2 | 80 |
| 2 | Student-2 | Department-2 | Manager-2 | Course-1 | 100 |
| 3 | Student-3 | Department-2 | Manager-2 | Course-2 | 95 |
Trong quan hệ Student-Course trên, {Sno, Cname} là khóa, có các phụ thuộc hàm sau:
- Sno → Sname, Sdept
- Sdept → Mname
- Sno, Cname→ Grade
Grade phụ thuộc hoàn toàn vào khóa, không có dữ liệu dư thừa, mỗi Student mỗi Course đều có điểm số cụ thể.
Sname, Sdept và Mname đều phụ thuộc một phần vào khóa, khi một Student chọn nhiều Course, dữ liệu này sẽ xuất hiện nhiều lần, gây ra nhiều dữ liệu dư thừa.
Sau khi phân tách
Relation-1
| Sno | Sname | Sdept | Manager |
|---|---|---|---|
| 1 | Student-1 | Department-1 | Manager-1 |
| 2 | Student-2 | Department-2 | Manager-1 |
| 3 | Student-3 | Department-2 | Manager-1 |
Có các phụ thuộc hàm sau:
- Sno → Sname, Sdept
Relation-2
| Sno | Cname | Grade |
|---|---|---|
| 1 | Course-1 | 90 |
| 2 | Course-2 | 80 |
| 2 | Course-1 | 100 |
| 3 | Course-2 | 95 |
Có các phụ thuộc hàm sau:
- Sno, Cname → Grade
Hình thức 3NF
- Thuộc tính không phụ thuộc chuyển tiếp vào khóa.
Trong Relation-1 ở trên, có phụ thuộc chuyển tiếp sau: Sno → Sdept → Mname, có thể phân tách như sau:
Relation-11
| Sno | Sname | Sdept |
|---|---|---|
| 1 | Student-1 | Department-1 |
| 2 | Student-2 | Department-2 |
| 3 | Student-3 | Department-2 |
Relation-12
| Sdept | Mname |
|---|---|
| Department-1 | Manager-1 |
| Department-2 | Manager-2 |
Storage Engine
MySQL có nhiều loại Storage Engine khác nhau, các Engine lưu trữ dữ liệu và chỉ mục theo cách khác nhau, nhưng định nghĩa bảng được xử lý chung trên tầng dịch vụ MySQL.
Dưới đây là một số Engine lưu trữ phổ biến:
- InnoDB - Engine lưu trữ giao dịch mặc định của MySQL, cung cấp khóa hàng và ràng buộc khóa ngoại. Hiệu suất tốt và hỗ trợ khôi phục tự động.
- MyISAM - Engine lưu trữ mặc định cho MySQL trước phiên bản 5.1. Có nhiều tính năng nhưng không hỗ trợ giao dịch, khóa hàng và ràng buộc khóa ngoại, cũng không có khả năng khôi phục.
- CSV - Cho phép xử lý tệp CSV như một bảng trong MySQL, nhưng bảng này không hỗ trợ chỉ mục.
- MEMORY - Dữ liệu được lưu trữ hoàn toàn trong bộ nhớ, tốc độ xử lý dữ liệu nhanh, nhưng không an toàn.
InnoDB vs. MyISAM
InnoDB và MyISAM là hai Engine lưu trữ MySQL phổ biến nhất hiện nay.
- Cấu trúc dữ liệu:
- Cả InnoDB và MyISAM đều sử dụng cấu trúc dữ liệu chỉ mục là B+Tree.
- B+ tree của MyISAM lưu trữ giá trị địa chỉ thực tế của dữ liệu. Nghĩa là chỉ mục và dữ liệu thực tế được tách rời nhau, chỉ mục chỉ trỏ đến dữ liệu thực tế. Mô hình chỉ mục này được gọi là chỉ mục không gom nhóm.
- B+ tree của InnoDB lưu trữ dữ liệu thực tế. Chỉ mục này được gọi là chỉ mục gom nhóm.
- Hỗ trợ giao dịch:
- InnoDB hỗ trợ giao dịch và cung cấp khóa hàng và ràng buộc khóa ngoại.
- MyISAM không hỗ trợ giao dịch, khóa hàng và ràng buộc khóa ngoại.
- Khôi phục sau sự cố:
- InnoDB hỗ trợ khôi phục sau sự cố.
- MyISAM không hỗ trợ khôi phục sau sự cố.
So sánh cơ sở dữ liệu
So sánh cơ sở dữ liệu phổ biến
Oracle- Cơ sở dữ liệu thương mại nổi tiếng. Mạnh mẽ, ổn định. Nhược điểm lớn nhất là tiền đâu.Mysql- Trước đây là sự lựa chọn hàng đầu của các công ty Internet, nhưng sau khi Mysql bị Oracle mua lại, có thể không còn thời kỳ tốt đẹp như trước. Nhiều công ty hoặc dự án mã nguồn mở đang tìm kiếm các sản phẩm mã nguồn mở khác để thay thế Mysql.MariaDB- Cơ sở dữ liệu mã nguồn mở. Là phiên bản mã nguồn mở thực sự của Mysql, được tạo ra bởi một số nhân viên cốt lõi của Mysql. Có thể là một sản phẩm thay thế cho Mysql.PostgreSQL- Cơ sở dữ liệu mã nguồn mở. Hoạt động rất giống với Mysql và có sự hỗ trợ tốt từ cộng đồng. Có thể là một sản phẩm thay thế cho Mysql.SQLite- Cơ sở dữ liệu nhỏ gọn mã nguồn mở, thường được sử dụng trên thiết bị di động.H2- Cơ sở dữ liệu trong bộ nhớ, thường được sử dụng trong môi trường phát triển và kiểm thử.SQL Server- Cơ sở dữ liệu của hệ sinh thái Windows của Microsoft.
Oracle vs Mysql
Cho đến nay, Oracle và Mysql vẫn là hai cơ sở dữ liệu quan hệ phổ biến nhất theo DB-Engines Ranking, vì vậy tôi sẽ so sánh chúng.
Khác biệt về đối tượng cơ sở dữ liệu
Trong Mysql, một người dùng có thể tạo nhiều cơ sở dữ liệu.
Trong Oracle, máy chủ Oracle bao gồm hai phần
- Thể hiện cơ sở dữ liệu [được hiểu như một đối tượng, vô hình]
- Cơ sở dữ liệu [được hiểu như một lớp, có thể nhìn thấy]
Một thể hiện cơ sở dữ liệu có thể có nhiều người dùng, một người dùng mặc định có một không gian bảng.
Không gian bảng là nơi lưu trữ bảng cơ sở dữ liệu, không gian bảng có thể chứa nhiều tệp.
Khác biệt về SQL
(1) Tự động tăng
Mysql có thể sử dụng ràng buộc AUTO_INCREMENT để chỉ định khóa chính là một chuỗi tăng tự động.
Oracle cần tạo chuỗi tăng bằng cách sử dụng CREATE SEQUENCE.
(2) Truy vấn phân trang
Mysql sử dụng SELECT … FROM … LIMIT … để thực hiện truy vấn phân trang, đơn giản hơn.
select * from help_category order by parent_category_id limit 10,5;Oracle sử dụng SELECT … FROM (SELECT ROWNUM …) WHERE … để thực hiện truy vấn phân trang, phức tạp hơn.
select * from
(select rownum rr,a.* from (select * from emp order by sal) a )
where rr>5 and rr<=10;Khác biệt về giao dịch
- Auto commit
- Giao dịch Mysql là chế độ auto commit (autocommit);
- Giao dịch Oracle yêu cầu
COMMITthủ công.
- Mức độ cô lập giao dịch
- Mysql mặc định cấp độ cô lập giao dịch là đọc lặp lại (REPEATABLE READ);
- Oracle hỗ trợ hai cấp độ cô lập giao dịch là đọc đã cam kết (READ COMMITTED) và tuần tự hóa (SERIALIZABLE), cấp độ cô lập giao dịch mặc định là đọc đã cam kết (READ COMMITTED).
So sánh kiểu dữ liệu
Mỗi cơ sở dữ liệu có sự hỗ trợ khác nhau cho các kiểu dữ liệu.
Ngay cả khi có cùng một kiểu dữ liệu, cũng có thể tồn tại các vấn đề như tên khác nhau hoặc kích thước khác nhau.
Do đó, chi tiết hỗ trợ kiểu dữ liệu phải tham khảo tài liệu chính thức của từng cơ sở dữ liệu.
Dưới đây là một số so sánh kiểu dữ liệu phổ biến:
| Kiểu dữ liệu | Oracle | MySQL | PostgreSQL |
|---|---|---|---|
boolean | Byte | N/A | Boolean |
integer | Number | Int Integer | Int Integer |
float | Number | Float | Numeric |
currency | N/A | N/A | Money |
string (fixed) | Char | Char | Char |
string (variable) | Varchar Varchar2 | Varchar | Varchar |
binary object | Long Raw | Blob Text | Binary Varbinary |
Bảng so sánh kiểu dữ liệu được trích từ SQL Data Types for MySQL, SQL Server, and MS Access
Câu hỏi thường gặp về SQL
Có sự khác biệt về hiệu suất giữa SELECT COUNT(*), SELECT COUNT(1) và SELECT COUNT(Column) không?
Trong MySQL InnoDB Storage Engine, COUNT(*) và COUNT(1) đều đếm tất cả các kết quả. Do đó, COUNT(*) và COUNT(1) không có sự khác biệt cơ bản, độ phức tạp của chúng đều là O(N), có nghĩa là quét toàn bộ bảng và thực hiện vòng lặp + đếm để thống kê.
Nếu sử dụng MySQL MyISAM Storage Engine, việc đếm số hàng của bảng chỉ mất độ phức tạp O(1), điều này là do mỗi bảng dữ liệu MyISAM có một thông tin meta lưu trữ giá trị row_count, và tính nhất quán được đảm bảo bởi khóa cấp bảng. Vì InnoDB hỗ trợ giao dịch, sử dụng khóa cấp hàng và cơ chế MVCC, nên không thể duy trì chỉ một biến row_count như MyISAM, do đó cần quét toàn bộ bảng và thực hiện vòng lặp + đếm để hoàn thành thống kê.
Cần lưu ý rằng trong thực tế, thời gian thực thi của COUNT(*) và COUNT(1) có thể có một chút khác biệt, tuy nhiên bạn vẫn có thể coi hiệu suất thực thi của chúng là tương đương.
Ngoài ra, trong InnoDB, nếu sử dụng COUNT(*) và COUNT(1) để thống kê số hàng dữ liệu, hãy cố gắng sử dụng chỉ mục cấp hai. Vì COUNT(*) và COUNT(1) không cần tìm kiếm các hàng cụ thể, hệ thống sẽ tự động sử dụng chỉ mục cấp hai chiếm ít không gian hơn để thống kê.
Tuy nhiên, nếu bạn muốn tìm kiếm các hàng cụ thể, thì hiệu suất sử dụng chỉ mục khóa chính sẽ cao hơn. Nếu có nhiều chỉ mục cấp hai, hệ thống sẽ sử dụng chỉ mục cấp hai có key_len nhỏ hơn để quét. Chỉ khi không có chỉ mục cấp hai, hệ thống mới sử dụng chỉ mục khóa chính để thống kê.
Tóm lại:
- Nói chung, hiệu suất thực thi của ba phương thức là
COUNT(*)=COUNT(1)>COUNT(Column). Chúng ta nên sử dụngCOUNT(*)nếu kết quả mong muốn là giống nhau, tuy nhiên nếu bạn muốn thống kê số hàng dữ liệu không rỗng của một trường cụ thể, điều này sẽ khác biệt, bởi vì so sánh hiệu suất thực thi chỉ có ý nghĩa khi kết quả là giống nhau. - Nếu muốn thống kê
COUNT(*), hãy cố gắng tạo chỉ mục cấp hai trên bảng dữ liệu, hệ thống sẽ tự động sử dụng chỉ mục cấp hai cókey_lennhỏ hơn để quét, điều này sẽ cải thiện hiệu suất khi sử dụngSELECT COUNT(*), đôi khi có thể cải thiện một vài lần hoặc nhiều hơn.
ORDER BY có sắp xếp theo nhóm hay sắp xếp theo bản ghi trong nhóm không?
ORDER BY là cách sắp xếp các bản ghi trong một truy vấn. Nếu bạn sử dụng GROUP BY trước ORDER BY, thì đây thực chất là một phương pháp tổ hợp nhóm, đã tổ hợp dữ liệu của một nhóm thành một bản ghi và sau đó tiến hành sắp xếp theo nhóm đã tạo ra.
Các bước thực thi trong một câu lệnh SELECT
Thứ tự thực hiện trong một câu lệnh SELECT hoàn chỉnh như sau:
- Tạo dữ liệu từ mệnh đề FROM (bao gồm kết nối bằng ON).
- Lọc dữ liệu từ mệnh đề WHERE.
- Nhóm dữ liệu từ mệnh đề GROUP BY.
- Tính toán bằng các hàm tổng hợp.
- Lọc dữ liệu từ mệnh đề HAVING.
- Tính toán tất cả các biểu thức.
- Chọn các trường trong mệnh đề SELECT.
- Sắp xếp dữ liệu từ mệnh đề ORDER BY.
- Lọc dữ liệu từ mệnh đề LIMIT.
Khi nào nên sử dụng EXISTS và khi nào nên sử dụng IN?
Điều kiện tiên quyết là phải có chỉ mục. Chỉ cần có chỉ mục, việc lựa chọn thực tế vẫn phụ thuộc vào kích thước của bảng. Bạn có thể hiểu tiêu chuẩn lựa chọn là sử dụng bảng nhỏ để điều khiển bảng lớn. Phương pháp này đạt hiệu suất cao nhất.
Ví dụ:
SELECT * FROM A WHERE cc IN (SELECT cc FROM B)
SELECT * FROM A WHERE EXISTS (SELECT cc FROM B WHERE B.cc=A.cc)Khi A nhỏ hơn B, sử dụng EXISTS. Vì việc thực hiện EXISTS tương đương với vòng lặp bên ngoài, logic thực hiện tương tự như sau:
for i in A
for j in B
if j.cc == i.cc then ...Khi B nhỏ hơn A, sử dụng IN, vì logic thực hiện tương tự như sau:
for i in B
for j in A
if j.cc == i.cc then ...Sử dụng bảng nhỏ để điều khiển bảng lớn, nếu A nhỏ hơn thì sử dụng EXISTS, nếu B nhỏ hơn thì sử dụng IN.