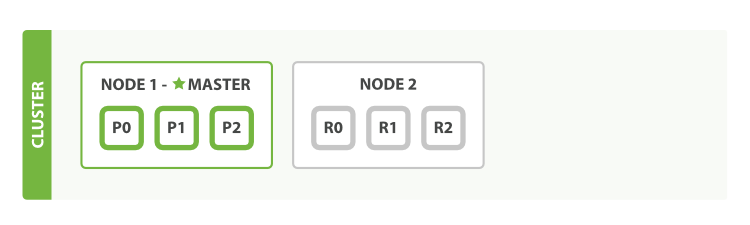
Nếu chúng ta khởi động một nút đơn lẻ không chứa bất kỳ dữ liệu hay chỉ mục nào, cluster của chúng ta sẽ trông như một cluster với một nút nội dung trống.
Hình 1. Cluster với nút nội dung trống
Hình 1: Cluster chỉ có một nút trống
Một thực thể Elasticsearch đang chạy được gọi là một nút, và một cluster bao gồm một hoặc nhiều nút với cấu hình cluster.name giống nhau. Chúng cùng nhau chịu áp lực của dữ liệu và tải. Khi các nút được thêm vào hoặc loại bỏ khỏi cluster, cluster sẽ phân phối lại tất cả dữ liệu một cách đều.
Khi một nút được bầu làm nút chính, nó chịu trách nhiệm quản lý tất cả các thay đổi trong phạm vi cluster, chẳng hạn như thêm hoặc xóa chỉ mục, hoặc thêm hoặc xóa các nút, v.v. Nút chính không cần tham gia vào các thay đổi cấp độ tài liệu và tìm kiếm, vì vậy ngay cả khi lưu lượng tăng lên, nó sẽ không trở thành một nút cổ chai khi cluster chỉ có một nút chính. Bất kỳ nút nào cũng có thể trở thành nút chính. Cluster mẫu của chúng ta chỉ có một nút, vì vậy nó cũng trở thành nút chính.
Là người dùng, chúng ta có thể gửi yêu cầu đến bất kỳ nút nào trong cluster, bao gồm cả nút chính. Mỗi nút đều biết vị trí của bất kỳ tài liệu nào và có thể chuyển tiếp yêu cầu của chúng ta trực tiếp đến nút lưu trữ tài liệu mà chúng ta cần. Không quan trọng chúng ta gửi yêu cầu đến nút nào, nút đó có thể chịu trách nhiệm thu thập dữ liệu từ tất cả các nút chứa tài liệu mà chúng ta cần và trả kết quả cuối cùng cho máy khách. Elasticsearch quản lý tất cả mọi thứ này một cách trong suốt.
Cluster Health
Thông tin giám sát cluster của Elasticsearch chứa nhiều dữ liệu thống kê, trong đó quan trọng nhất là sức khỏe của cluster, được hiển thị là green, yellow, hoặc red trong trường status.
GET /_cluster/health
Trong một cluster trống không chứa bất kỳ chỉ mục nào, nó sẽ có nội dung trả về tương tự như sau:
Trường status chỉ ra liệu cluster hiện tại có hoạt động bình thường tổng thể hay không. Ba màu của nó có ý nghĩa như sau:
green: Tất cả các shard chính và shard phụ đều hoạt động bình thường.
yellow: Tất cả các shard chính đều hoạt động bình thường, nhưng không phải tất cả các shard phụ đều hoạt động bình thường.
red: Có shard chính không hoạt động bình thường.
Thêm chỉ mục
Khi chúng ta thêm dữ liệu vào Elasticsearch, chúng ta cần sử dụng chỉ mục - nơi lưu trữ dữ liệu liên quan. Chỉ mục thực ra là không gian tên logic trỏ đến một hoặc nhiều shard vật lý.
Một shard là một đơn vị công việc cơ bản, nó chỉ lưu trữ một phần của tất cả dữ liệu. Bây giờ chúng ta chỉ cần biết một shard là một thể hiện của Lucene, và nó chính là một công cụ tìm kiếm hoàn chỉnh. Tài liệu của chúng ta được lưu trữ và chỉ mục trong shard, nhưng ứng dụng thực hiện tương tác trực tiếp với chỉ mục chứ không phải với shard.
Elasticsearch sử dụng shard để phân phối dữ liệu đến các nơi khác nhau trong cluster. shard là bộ chứa dữ liệu, tài liệu được lưu trữ trong shard, và shard được phân bổ đến các nút khác nhau trong cluster. Khi kích thước của cluster của bạn mở rộng hoặc thu hẹp, Elasticsearch sẽ tự động di chuyển shard giữa các nút, để dữ liệu vẫn được phân phối đều trong cluster.
Một shard có thể là shard chính hoặc shard sao lưu. Bất kỳ tài liệu nào trong chỉ mục đều thuộc về một shard chính, vì vậy số lượng shard chính quyết định lượng dữ liệu tối đa mà chỉ mục có thể lưu trữ.
Kỹ thuật, một shard chính có thể lưu trữ tối đa Integer.MAX_VALUE - 128 tài liệu, nhưng giá trị tối đa thực tế còn phụ thuộc vào tình huống sử dụng của bạn: bao gồm phần cứng bạn sử dụng, kích thước và độ phức tạp của tài liệu, cách chỉ mục và truy vấn tài liệu cũng như thời gian phản hồi mong đợi của bạn.
Một shard sao lưu chỉ là một bản sao của shard chính. shard sao lưu đóng vai trò là bản sao dự phòng dư thừa để bảo vệ dữ liệu không bị mất khi xảy ra lỗi phần cứng, và cung cấp dịch vụ cho các hoạt động đọc như tìm kiếm và trả về tài liệu.
Số shard chính đã được xác định khi tạo chỉ mục, nhưng số shard sao lưu có thể được thay đổi bất cứ lúc nào.
Hãy tạo một chỉ mục có tên blogs trong một cluster với một nút trống. Theo mặc định, chỉ mục sẽ được phân bổ 5 shard chính, nhưng vì mục đích minh họa, chúng tôi sẽ phân bổ 3 shard chính và một bản sao (mỗi shard chính có một shard sao lưu):
Số lượng shard sao lưu không được phân bổ cho bất kỳ nút nào
Sức khỏe của cluster ở trạng thái yellow có nghĩa là tất cả các shard chính đều hoạt động bình thường (cluster có thể phục vụ tất cả các yêu cầu), nhưng không phải tất cả các shard sao lưu đều ở trạng thái bình thường. Thực tế, tất cả 3 shard sao lưu đều là unassigned - chúng không được phân bổ cho bất kỳ nút nào. Việc lưu trữ dữ liệu gốc và bản sao trên cùng một nút không có ý nghĩa, bởi vì một khi chúng ta mất nút đó, chúng ta cũng sẽ mất tất cả dữ liệu bản sao trên nút đó.
Hiện tại, cluster của chúng ta đang hoạt động bình thường, nhưng có nguy cơ mất dữ liệu khi xảy ra lỗi phần cứng.
Thêm khả năng chuyển đổi khi gặp sự cố
Khi chỉ có một nút đang hoạt động trong cluster, điều này có nghĩa là sẽ có một vấn đề về điểm lỗi đơn - không có sự dự phòng. May mắn thay, chúng ta chỉ cần khởi động thêm một nút nữa để ngăn chặn mất dữ liệu.
Để kiểm tra tình hình sau khi khởi động nút thứ hai, bạn có thể khởi động một nút mới trong cùng một thư mục, hoàn toàn tuân theo cách khởi động nút đầu tiên (xem Cài đặt và chạy Elasticsearch). Nhiều nút có thể chia sẻ cùng một thư mục.
Khi bạn khởi động nút thứ hai trên cùng một máy, miễn là nó có cấu hình cluster.name giống với nút đầu tiên, nó sẽ tự động phát hiện cluster và tham gia vào đó. Tuy nhiên, khi khởi động nút trên các máy khác nhau, để tham gia vào cùng một cluster, bạn cần cấu hình danh sách host unicast có thể kết nối.
Nếu chúng ta khởi động một nút thứ hai, cluster của chúng ta sẽ trở thành một cluster với hai nút - tất cả các shard chính và shard sao lưu đều đã được phân bổ.
Hình 3. Cluster với hai nút - tất cả các shard chính và shard sao lưu đều đã được phân bổ
Khi nút thứ hai tham gia vào cluster, 3 shard sao lưu sẽ được phân bổ cho nút này - mỗi shard chính có một shard sao lưu tương ứng. Điều này có nghĩa là khi bất kỳ nút nào trong cluster gặp sự cố, dữ liệu của chúng ta vẫn còn nguyên vẹn.
Tất cả các tài liệu mới được chỉ mục sẽ được lưu trữ trong shard chính, sau đó được sao chép song song đến shard sao lưu tương ứng. Điều này đảm bảo rằng chúng ta có thể lấy tài liệu từ shard chính cũng như từ shard sao lưu.
cluster-health hiện tại hiển thị trạng thái là green, điều này cho thấy tất cả 6 shard (bao gồm 3 shard chính và 3 shard sao lưu) đều đang hoạt động bình thường.
Cluster của chúng ta hiện tại không chỉ đang hoạt động bình thường, mà còn ở trạng thái luôn sẵn sàng.
Mở rộng ngang
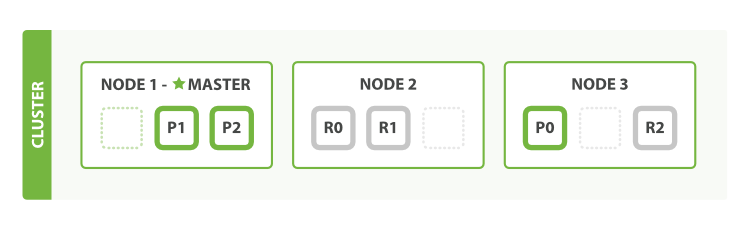
Làm thế nào để chúng ta mở rộng theo nhu cầu cho ứng dụng đang phát triển của chúng ta? Khi khởi động một nút thứ ba, cluster của chúng ta sẽ trở thành một cluster với ba nút - phân phối lại các shard để phân tán tải.
Hình 4. Cluster với ba nút - phân phối lại các shard để phân tán tải
Một shard từ Node 1 và Node 2 đã được di chuyển đến nút mới Node 3, bây giờ mỗi nút đều có 2 shard, thay vì 3 như trước. Điều này có nghĩa là tài nguyên phần cứng (CPU, RAM, I/O) của mỗi nút sẽ được chia sẻ cho ít shard hơn, hiệu suất của mỗi shard sẽ được cải thiện.
Một shard là một công cụ tìm kiếm hoàn chỉnh, nó có khả năng sử dụng tất cả các tài nguyên trên một nút. Chỉ mục của chúng ta có 6 shard (3 shard chính và 3 shard sao lưu) có thể mở rộng tối đa lên đến 6 nút, mỗi nút có một shard, và mỗi shard có toàn bộ tài nguyên của nút nơi nó đặt.
Shard
Tại sao tìm kiếm là gần thời gian thực?
Tại sao các hoạt động CRUD (Tạo - Đọc - Cập nhật - Xóa) trên tài liệu là thời gian thực?
Elasticsearch làm thế nào để đảm bảo các cập nhật được lưu trữ một cách bền vững mà không mất dữ liệu khi mất điện?
Tại sao việc xóa tài liệu không giải phóng không gian ngay lập tức?
API refresh, flush, và optimize làm gì và khi nào bạn nên sử dụng chúng?
Làm cho văn bản có thể tìm kiếm
Thách thức đầu tiên cần giải quyết là làm thế nào để làm cho văn bản có thể tìm kiếm. Các cơ sở dữ liệu truyền thống lưu trữ một giá trị duy nhất cho mỗi trường, nhưng điều này không đủ cho tìm kiếm toàn văn. Mỗi từ trong trường văn bản cần được tìm kiếm, điều này đối với cơ sở dữ liệu có nghĩa là cần có khả năng lập chỉ mục nhiều giá trị (ở đây là từ) cho một trường duy nhất.
Cấu trúc dữ liệu phù hợp nhất để hỗ trợ yêu cầu nhiều giá trị cho một trường là chỉ mục đảo ngược mà chúng ta đã giới thiệu trong chương Chỉ mục đảo ngược. Chỉ mục đảo ngược bao gồm một danh sách đã sắp xếp, chứa tất cả các cá thể không trùng lặp xuất hiện trong tài liệu, hoặc được gọi là cụm từ, và cho mỗi cụm từ, chứa danh sách tất cả các tài liệu mà nó đã xuất hiện.
Term | Doc 1 | Doc 2 | Doc 3 | ...
------------------------------------
brown | X | | X | ...
fox | X | X | X | ...
quick | X | X | | ...
the | X | | X | ...
Khi thảo luận về chỉ mục đảo ngược, chúng ta sẽ nói về tài liệu được lập chỉ mục, bởi vì lịch sử, chỉ mục đảo ngược đã được sử dụng để lập chỉ mục cho toàn bộ tài liệu văn bản không cấu trúc. Trong Elasticsearch, một tài liệu là một tài liệu JSON có cấu trúc với trường và giá trị. Thực tế, trong tài liệu JSON, mỗi trường được lập chỉ mục đều có chỉ mục đảo ngược riêng của mình.
Chỉ mục đảo ngược này so với danh sách tài liệu mà một cụm từ cụ thể đã xuất hiện, sẽ chứa thông tin khác nhiều hơn. Nó sẽ lưu tổng số tài liệu mà mỗi cụm từ đã xuất hiện, tổng số lần một cụm từ cụ thể xuất hiện trong tài liệu, thứ tự của cụm từ trong tài liệu, độ dài của mỗi tài liệu, độ dài trung bình của tất cả các tài liệu, v.v. Thông tin thống kê này cho phép Elasticsearch quyết định từ nào quan trọng hơn từ khác, tài liệu nào quan trọng hơn tài liệu khác, những nội dung này được mô tả trong Độ liên quan là gì?.
Để có thể thực hiện như mong đợi, chỉ mục đảo ngược cần biết tất cả các tài liệu trong tập hợp, đây là vấn đề quan trọng cần nhận biết.
Tìm kiếm toàn văn ban đầu sẽ tạo một chỉ mục đảo ngược lớn cho toàn bộ tập hợp tài liệu và ghi nó vào đĩa. Một khi chỉ mục mới đã sẵn sàng, nó sẽ thay thế chỉ mục cũ, do đó, các thay đổi gần đây có thể được tìm kiếm.
Bất biến
Chỉ mục đảo ngược sau khi được ghi vào đĩa là bất biến: nó sẽ không bao giờ được sửa đổi. Sự bất biến có giá trị quan trọng:
Không cần khóa. Nếu bạn không bao giờ cập nhật chỉ mục, bạn không cần phải lo lắng về vấn đề nhiều quy trình cùng lúc sửa đổi dữ liệu.
Một khi chỉ mục được đọc vào bộ nhớ đệm hệ thống tệp tin của hạt nhân, nó sẽ ở đó, do tính bất biến của nó. Miễn là bộ nhớ đệm hệ thống tệp tin còn đủ không gian, hầu hết các yêu cầu đọc sẽ trực tiếp yêu cầu bộ nhớ, không phải đĩa. Điều này mang lại một cải tiến lớn về hiệu suất.
Bộ nhớ đệm khác (như bộ nhớ đệm bộ lọc) luôn hợp lệ trong suốt vòng đời của chỉ mục. Chúng không cần được xây dựng lại mỗi khi dữ liệu thay đổi, bởi vì dữ liệu không thay đổi.
Viết một chỉ mục đảo ngược lớn duy nhất cho phép dữ liệu được nén, giảm I/O đĩa và số lượng chỉ mục cần được lưu vào bộ nhớ đệm.
Tất nhiên, một chỉ mục không thay đổi cũng có nhược điểm. Điểm chính là nó không thể thay đổi! Bạn không thể sửa đổi nó. Nếu bạn cần để một tài liệu mới có thể tìm kiếm, bạn cần xây dựng lại toàn bộ chỉ mục. Điều này hoặc đặt giới hạn lớn về số lượng dữ liệu mà một chỉ mục có thể chứa, hoặc đặt giới hạn về tần suất mà chỉ mục có thể được cập nhật.
Cập nhật chỉ mục động
Vấn đề tiếp theo cần giải quyết là làm thế nào để cập nhật chỉ mục đảo ngược trong khi vẫn giữ tính bất biến? Câu trả lời là: sử dụng nhiều chỉ mục hơn.
Thay vì ghi đè toàn bộ chỉ mục đảo ngược, ta thêm các chỉ mục bổ sung mới để phản ánh các thay đổi gần đây. Mỗi chỉ mục đảo ngược sẽ được truy vấn theo lượt - bắt đầu từ cái cũ nhất - và sau đó kết quả sẽ được hợp nhất.
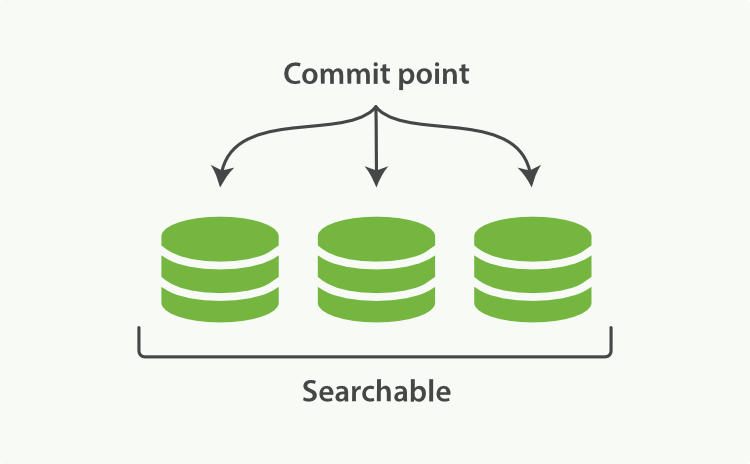
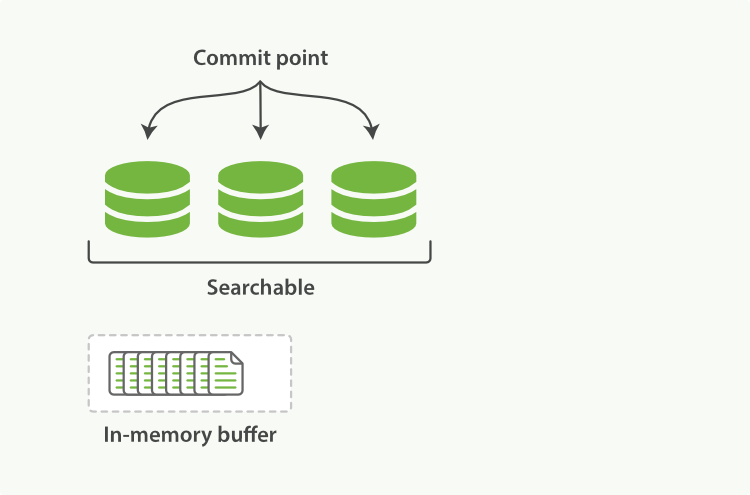
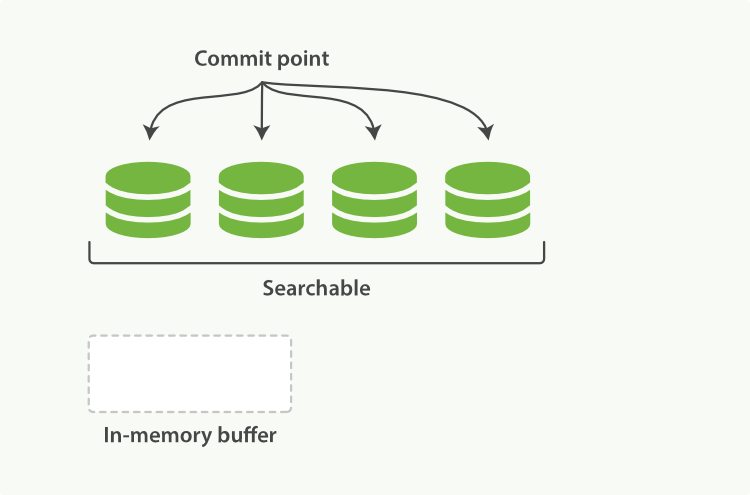
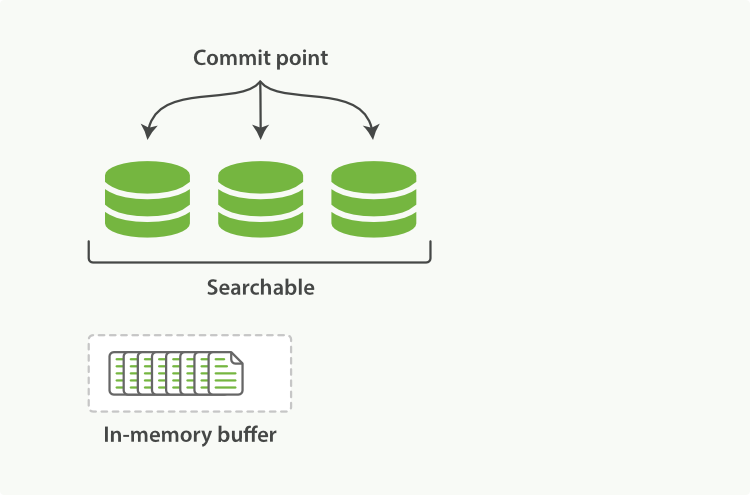
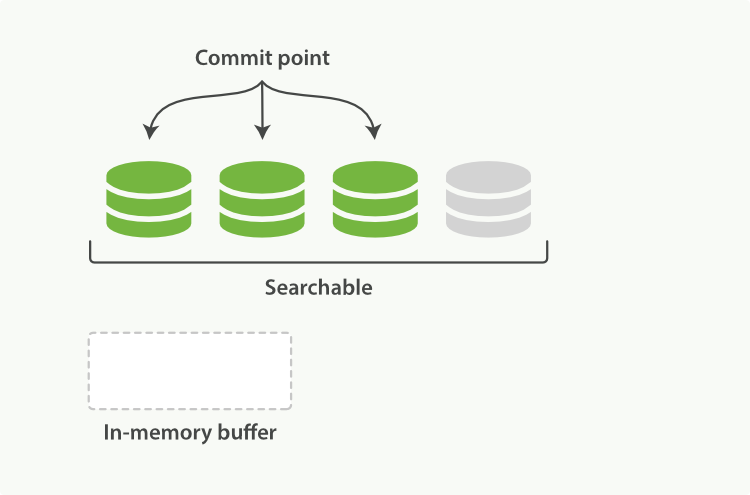
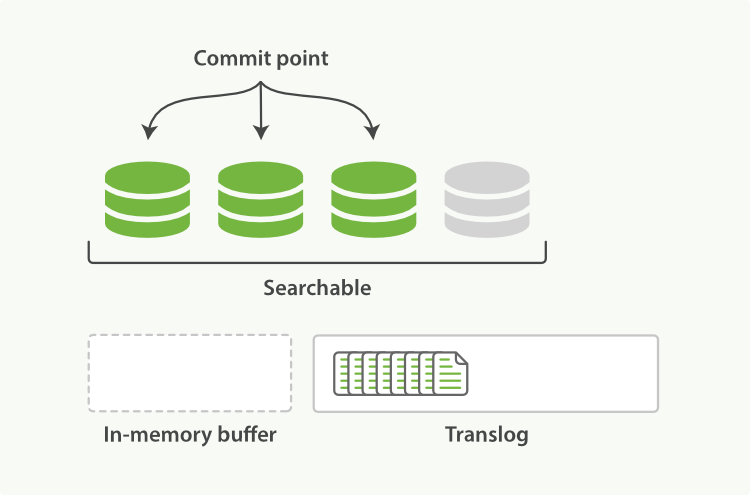
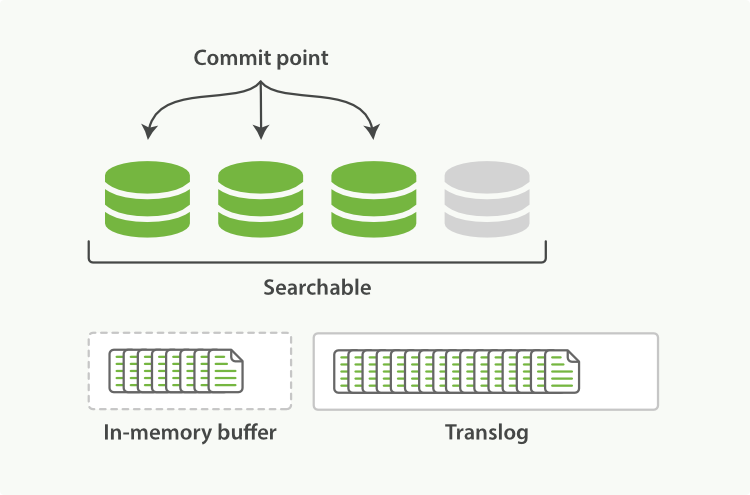
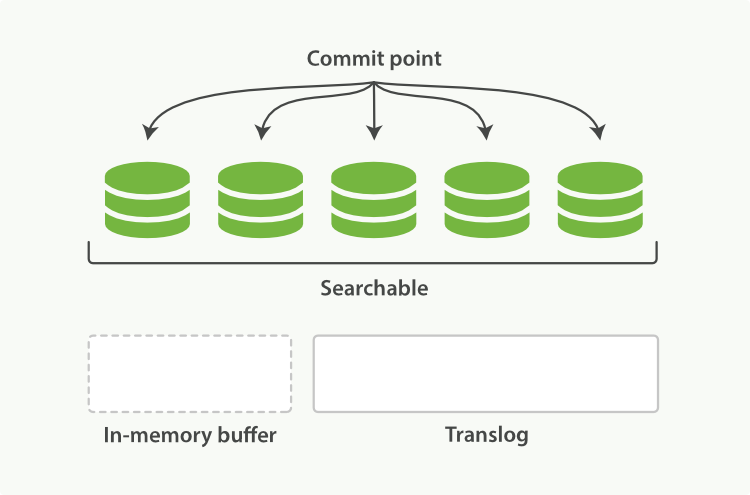
Elasticsearch dựa trên Lucene, thư viện Java này đã giới thiệu khái niệm tìm kiếm theo shard. Mỗi shard là một chỉ mục đảo ngược, nhưng chỉ mục trong Lucene ngoài việc là tập hợp của tất cả các shard, còn thêm khái niệm điểm commit - một tệp liệt kê tất cả các shard đã biết, giống như trong Hình 16, “Một chỉ mục Lucene bao gồm một điểm commit và ba shard”. Như Hình 17, “Một chỉ mục Lucene trong bộ đệm bộ nhớ chứa các tài liệu mới” cho thấy, tài liệu mới đầu tiên được thêm vào bộ đệm chỉ mục trong bộ nhớ, sau đó được ghi vào một shard dựa trên đĩa, như Hình 18, “Sau một lần commit, một shard mới được thêm vào điểm commit và bộ đệm được xóa sạch.”.
Hình 16. Một chỉ mục Lucene bao gồm một điểm commit và ba shard
Khái niệm gây nhầm lẫn là một chỉ mục Lucene mà chúng ta gọi là shard trong Elasticsearch. Một chỉ mục Elasticsearch là một tập hợp các shard. Khi Elasticsearch tìm kiếm trong một chỉ mục, nó gửi truy vấn đến mỗi shard thuộc về chỉ mục (chỉ mục Lucene), sau đó hợp nhất kết quả từ mỗi shard thành một tập kết quả toàn cầu, như đã mô tả trong Thực hiện tìm kiếm phân tán.
Tìm kiếm theo shard sẽ hoạt động theo quy trình sau:
Tài liệu mới được thu thập vào bộ đệm chỉ mục trong bộ nhớ, xem Hình 17, “Một chỉ mục Lucene trong bộ đệm bộ nhớ chứa các tài liệu mới”.
Thỉnh thoảng, bộ đệm được commit:
Một shard mới - một chỉ mục đảo ngược bổ sung - được ghi vào đĩa.
Một điểm commit mới chứa tên shard mới được ghi vào đĩa.
Đĩa được đồng bộ hóa - tất cả các ghi chờ trong bộ đệm hệ thống tệp tin được đẩy xuống đĩa để đảm bảo rằng chúng được ghi vào tệp vật lý.
shard mới được mở, làm cho tài liệu bên trong có thể tìm kiếm.
Bộ đệm trong bộ nhớ được xóa sạch, sẵn sàng để nhận tài liệu mới.
Hình 17. Một chỉ mục Lucene trong bộ đệm bộ nhớ chứa các tài liệu mới
Hình 18. Sau một lần commit, một shard mới được thêm vào chỉ mục và bộ đệm được xóa sạch.
Khi một truy vấn được kích hoạt, tất cả các shard đã biết sẽ được truy vấn theo thứ tự. Thống kê từ sẽ được tổng hợp từ kết quả của tất cả các shard, để đảm bảo rằng mỗi từ và mỗi tài liệu được tính toán chính xác. Cách này cho phép thêm tài liệu mới vào chỉ mục với chi phí tương đối thấp.
Xóa và cập nhật
shard là bất biến, vì vậy không thể xóa tài liệu từ shard cũ, cũng không thể sửa đổi shard cũ để phản ánh việc cập nhật tài liệu. Thay vào đó, mỗi điểm commit sẽ chứa một tệp .del, liệt kê các shard của tài liệu đã bị xóa.
Khi một tài liệu bị “xóa”, thực tế là nó chỉ được đánh dấu xóa trong tệp .del. Một tài liệu đã bị đánh dấu xóa vẫn có thể khớp với một truy vấn, nhưng nó sẽ bị xóa khỏi tập kết quả trước khi kết quả cuối cùng được trả về.
Cập nhật tài liệu cũng hoạt động theo cách tương tự: khi một tài liệu được cập nhật, phiên bản cũ của tài liệu được đánh dấu xóa, và phiên bản mới của tài liệu được lập chỉ mục vào một shard mới. Cả hai phiên bản của tài liệu có thể khớp với một truy vấn, nhưng phiên bản đã bị xóa sẽ bị loại bỏ khỏi kết quả trước khi kết quả cuối cùng được trả về.
Trong Hợp nhất shard, chúng tôi thảo luận về cách một tài liệu đã bị xóa được loại bỏ khỏi hệ thống tệp.
Tìm kiếm gần thời gian thực
Với sự phát triển của tìm kiếm theo shard, độ trễ từ khi một tài liệu mới được lập chỉ mục đến khi nó có thể tìm kiếm đã giảm đáng kể. Tài liệu mới có thể được tìm kiếm trong vòng vài phút, nhưng điều này vẫn chưa đủ nhanh.
Đĩa ở đây trở thành nút thắt. Để commit một shard mới vào đĩa, cần một lệnh fsync để đảm bảo rằng shard được ghi vào đĩa vật lý, do đó dữ liệu sẽ không bị mất khi mất điện. Nhưng lệnh fsync tốn kém; nếu thực hiện mỗi lần lập chỉ mục một tài liệu sẽ gây ra vấn đề về hiệu suất.
Chúng ta cần một cách nhẹ nhàng hơn để làm cho một tài liệu có thể tìm kiếm, điều này có nghĩa là fsync cần được loại bỏ khỏi toàn bộ quy trình.
Hình 19. Một chỉ mục Lucene trong bộ đệm bộ nhớ chứa các tài liệu mới
Lucene cho phép shard mới được ghi và mở - làm cho tài liệu bên trong có thể tìm kiếm mà không cần một lần commit đầy đủ. Cách này tốn ít chi phí hơn rất nhiều so với việc commit và có thể thực hiện thường xuyên mà không ảnh hưởng đến hiệu suất.
Hình 20. Nội dung bộ đệm đã được ghi vào một shard, có thể tìm kiếm, nhưng chưa được commit
refresh API
Trong Elasticsearch, quy trình nhẹ để viết và mở một shard mới được gọi là refresh. Mặc định, mỗi shard sẽ tự động làm mới mỗi giây. Đây là lý do tại sao chúng ta nói Elasticsearch là gần thời gian thực: thay đổi tài liệu không ngay lập tức có thể tìm kiếm, nhưng sẽ có thể tìm kiếm trong vòng một giây.
Hành vi này có thể gây nhầm lẫn cho người dùng mới: họ lập chỉ mục cho một tài liệu và sau đó cố gắng tìm kiếm nó, nhưng không tìm thấy. Cách giải quyết vấn đề này là sử dụng API refresh để thực hiện một lần làm mới thủ công:
POST /_refreshPOST /blogs/_refresh
Làm mới tất cả các chỉ mục
Chỉ làm mới chỉ mục blogs
Mặc dù việc làm mới là một thao tác nhẹ hơn rất nhiều so với việc commit, nó vẫn gây ra chi phí hiệu suất. Khi viết các bài kiểm tra, việc làm mới thủ công rất hữu ích, nhưng không nên trong môi trường sản xuất mỗi lần lập chỉ mục cho một tài liệu đều thực hiện làm mới thủ công. Thay vào đó, ứng dụng của bạn cần nhận biết tính chất gần thời gian thực của Elasticsearch và chấp nhận những hạn chế của nó.
Không phải tất cả các trường hợp đều cần làm mới mỗi giây. Có thể bạn đang sử dụng Elasticsearch để lập chỉ mục cho một lượng lớn tệp nhật ký, bạn có thể muốn tối ưu hóa tốc độ lập chỉ mục hơn là tìm kiếm gần thời gian thực, bạn có thể giảm tần suất làm mới cho mỗi chỉ mục bằng cách đặt refresh_interval:
PUT /my_logs{ "settings": { "refresh_interval": "30s" }}
Làm mới chỉ mục my_logs mỗi 30 giây.
refresh_interval có thể được cập nhật động trên các chỉ mục hiện có. Trong môi trường sản xuất, khi bạn đang xây dựng một chỉ mục mới lớn, bạn có thể tắt làm mới tự động trước, sau đó bật lại khi bắt đầu sử dụng chỉ mục đó:
PUT /my_logs/_settings
{ "refresh_interval": -1 }
PUT /my_logs/_settings
{ "refresh_interval": "1s" }
Tắt làm mới tự động.
Tự động làm mới mỗi giây.
refresh_interval cần một giá trị khoảng thời gian, ví dụ 1s (1 giây) hoặc 2m (2 phút). Một giá trị tuyệt đối 1 biểu thị 1 millisecond - chắc chắn sẽ làm cho cụm của bạn trở nên tê liệt.
Lưu trữ thay đổi
Nếu không sử dụng fsync để đẩy dữ liệu từ bộ đệm hệ thống tệp lên ổ đĩa, chúng ta không thể đảm bảo dữ liệu sẽ vẫn còn sau khi mất điện hoặc thậm chí là khi chương trình thoát bình thường. Để đảm bảo tính đáng tin cậy của Elasticsearch, chúng ta cần đảm bảo rằng thay đổi dữ liệu được lưu trữ trên ổ đĩa.
Trong Cập nhật chỉ mục động, chúng ta đã nói rằng một lần commit hoàn chỉnh sẽ đẩy shard lên ổ đĩa và viết một điểm commit chứa danh sách tất cả các shard. Elasticsearch sử dụng điểm commit này khi khởi động hoặc mở lại một chỉ mục để xác định shard nào thuộc về shard hiện tại.
Mặc dù đã thực hiện tìm kiếm gần thời gian thực thông qua làm mới mỗi giây, chúng ta vẫn cần thực hiện commit hoàn chỉnh thường xuyên để đảm bảo có thể phục hồi từ lỗi. Nhưng về những tài liệu đã thay đổi giữa hai lần commit thì sao? Chúng ta cũng không muốn mất những dữ liệu này.
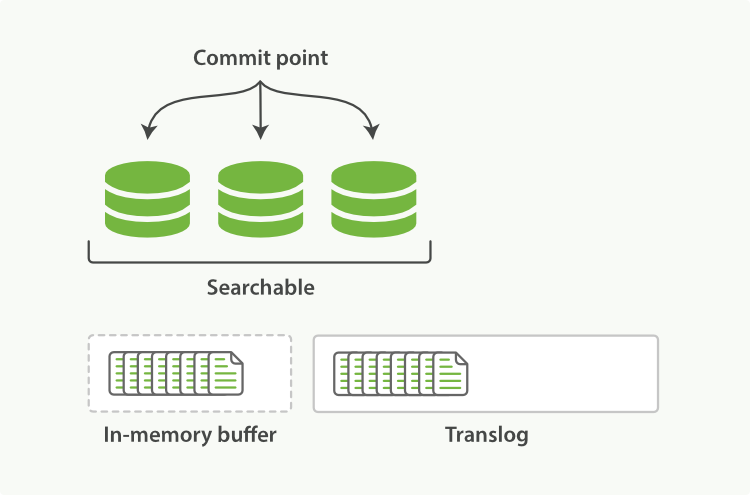
Elasticsearch đã thêm một translog, hoặc gọi là nhật ký giao dịch, ghi lại mọi thao tác được thực hiện trên Elasticsearch. Với translog, toàn bộ quá trình như sau:
Tất cả tài liệu trong bộ đệm được viết vào một shard mới.
Bộ đệm được xóa sạch.
Một điểm commit được viết vào ổ đĩa.
Bộ đệm hệ thống tệp được làm mới (flush) thông qua fsync.
Nhật ký giao dịch cũ được xóa.
Translog cung cấp một bản ghi vĩnh viễn cho tất cả các thao tác chưa được đẩy lên ổ đĩa. Khi Elasticsearch khởi động, nó sẽ sử dụng điểm commit cuối cùng từ ổ đĩa để khôi phục các shard đã biết và sẽ chơi lại tất cả các thao tác thay đổi trong translog sau lần commit cuối cùng.
Translog cũng được sử dụng để cung cấp CRUD thời gian thực. Khi bạn cố gắng truy vấn, cập nhật, xóa một tài liệu theo ID, nó sẽ kiểm tra bất kỳ thay đổi gần đây nào trong translog trước khi cố gắng lấy từ các shard tương ứng. Điều này có nghĩa là nó luôn có thể lấy được phiên bản mới nhất của tài liệu một cách thời gian thực.
Hình 24. Sau khi làm mới, shard được commit hoàn chỉnh và nhật ký giao dịch được xóa sạch
flush API
Hành động thực hiện một commit và cắt translog tại Elasticsearch được gọi là một flush. Mỗi 30 phút, một shard sẽ được tự động flush, hoặc khi translog trở nên quá lớn. Hãy xem tài liệu translog để thiết lập, nó có thể được sử dụng để kiểm soát các ngưỡng này:
flush API có thể được sử dụng để thực hiện một flush thủ công:
POST /blogs/_flush
POST /_flush?wait_for_ongoing
Flush chỉ mục blogs.
Flush tất cả các chỉ mục và chờ tất cả các flush hoàn thành trước khi trả về.
Bạn ít khi cần thực hiện flush thủ công; thường thì flush tự động là đủ.
Tuy nhiên, thực hiện flush trước khi khởi động lại nút hoặc đóng chỉ mục có lợi cho chỉ mục của bạn. Khi Elasticsearch cố gắng khôi phục hoặc mở lại một chỉ mục, nó cần phải chơi lại tất cả các hoạt động trong translog, vì vậy nếu log càng ngắn, thì khôi phục càng nhanh.
Mục đích của translog là đảm bảo không có hoạt động nào bị mất. Điều này đặt ra câu hỏi: Translog an toàn đến mức nào?
Các tệp được ghi trước khi được fsync lên ổ đĩa sẽ bị mất sau khi khởi động lại. Mặc định, translog được fsync lên ổ cứng mỗi 5 giây, hoặc sau mỗi yêu cầu ghi hoàn tất (ví dụ: index, delete, update, bulk). Quá trình này xảy ra trên cả shard chính và shard sao chép. Cuối cùng, cơ bản là, trước khi yêu cầu hoàn toàn được fsync lên translog của shard chính và sao chép, client của bạn sẽ không nhận được phản hồi 200 OK.
Việc thực hiện một fsync sau mỗi yêu cầu sẽ dẫn đến một số mất mát hiệu suất, mặc dù thực tế cho thấy mất mát này tương đối nhỏ (đặc biệt là khi nhập bulk, nơi mà chi phí của một lượng lớn tài liệu được phân phối trong một yêu cầu).
Tuy nhiên, đối với một số cụm có dung lượng lớn, việc mất đi một số dữ liệu trong vài giây cũng không quá nghiêm trọng, việc sử dụng fsync không đồng bộ có thể rất hữu ích. Ví dụ, dữ liệu được ghi được lưu trữ trong bộ nhớ cache, sau đó fsync mỗi 5 giây.
Hành vi này có thể được kích hoạt bằng cách đặt tham số durability thành async:
PUT /my_index/_settings{ "index.translog.durability": "async", "index.translog.sync_interval": "5s"}
Tùy chọn này có thể được đặt riêng lẻ cho mỗi chỉ mục và có thể được thay đổi một cách động. Nếu bạn quyết định sử dụng translog không đồng bộ, bạn cần đảm bảo rằng, trong trường hợp xảy ra lỗi, việc mất dữ liệu trong khoảng thời gian sync_interval là không quan trọng. Hãy hiểu rõ tính năng này trước khi quyết định.
Nếu bạn không chắc chắn về hậu quả của hành vi này, tốt nhất là sử dụng tham số mặc định ("index.translog.durability": "request") để tránh mất dữ liệu.
shard hợp nhất
Do quá trình làm mới tự động tạo ra một shard mới mỗi giây, số lượng shard trong một khoảng thời gian ngắn có thể tăng lên rất nhanh. Tuy nhiên, nếu có quá nhiều shard, điều này có thể gây ra rắc rối. Mỗi shard sẽ tiêu tốn cơ sở dữ liệu tệp, bộ nhớ và chu kỳ CPU. Điều quan trọng hơn là mỗi yêu cầu tìm kiếm phải kiểm tra từng shard; vì vậy, càng nhiều shard, tìm kiếm càng chậm.
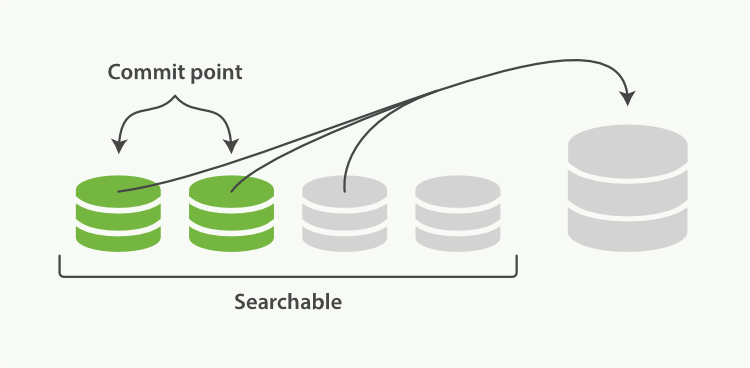
Elasticsearch giải quyết vấn đề này bằng cách thực hiện shard hợp nhất ở phía sau. Các shard nhỏ được hợp nhất thành các shard lớn hơn, sau đó các shard lớn hơn này lại được hợp nhất thành các shard còn lớn hơn.
Trong quá trình hợp nhất shard, những tài liệu đã xóa cũ (hoặc các phiên bản cũ của tài liệu đã được cập nhật) sẽ được loại bỏ khỏi hệ thống tệp. Các tài liệu đã bị xóa (hoặc các phiên bản cũ của tài liệu đã được cập nhật) sẽ không được sao chép vào shard lớn mới.
Khi đang chỉ mục, quá trình làm mới sẽ tạo ra shard mới và mở shard để tìm kiếm.
Quá trình hợp nhất chọn một số lượng nhỏ các shard có kích thước tương tự và hợp nhất chúng thành một shard lớn hơn ở phía sau. Điều này không làm gián đoạn việc chỉ mục và tìm kiếm.
Hình 25. Hai shard đã commit và một shard chưa commit đang được hợp nhất thành một shard lớn hơn
shard mới được làm mới (flush) lên ổ đĩa. ** Viết một điểm commit mới chứa shard mới và loại bỏ các shard cũ và nhỏ hơn.
shard mới được mở để tìm kiếm.
Các shard cũ bị xóa.
Hợp nhất shard lớn cần tiêu tốn rất nhiều tài nguyên I/O và CPU, nếu để mặc sẽ ảnh hưởng đến hiệu suất tìm kiếm. Elasticsearch mặc định sẽ hạn chế tài nguyên cho quá trình hợp nhất, vì vậy tìm kiếm vẫn có đủ tài nguyên để thực hiện tốt.
optimize API
optimize API có thể coi là hợp nhất cưỡng bức API. Nó sẽ hợp nhất một shard thành số lượng shard mà tham số max_num_segments chỉ định. Mục đích là giảm số lượng shard (thường giảm xuống còn một) để cải thiện hiệu suất tìm kiếm.
optimize API không nên được sử dụng trên một chỉ mục đang hoạt động - một chỉ mục đang được cập nhật một cách tích cực. Quá trình hợp nhất nền tảng đã làm việc rất tốt. Optimize sẽ cản trở quá trình này. Đừng can thiệp vào nó!
Trong một số trường hợp cụ thể, việc sử dụng optimize API rất hữu ích. Ví dụ, trong trường hợp nhật ký, các nhật ký hàng ngày, hàng tuần, hàng tháng được lưu trữ trong một chỉ mục. Các chỉ mục cũ về cơ bản là chỉ đọc; chúng không có khả năng thay đổi nhiều.
Trong trường hợp này, việc sử dụng optimize để tối ưu các chỉ mục cũ, hợp nhất mỗi shard thành một shard đơn lẻ rất hữu ích; điều này không chỉ tiết kiệm tài nguyên mà còn làm cho việc tìm kiếm nhanh hơn:
POST /logstash-2014-10/_optimize?max_num_segments=1
Hợp nhất mỗi shard trong chỉ mục thành một shard đơn lẻ
Xin lưu ý, việc kích hoạt hợp nhất shard bằng optimize API sẽ không bị giới hạn bởi bất kỳ tài nguyên nào. Điều này có thể tiêu thụ toàn bộ tài nguyên I/O của nút của bạn, không còn đủ nguồn lực để xử lý các yêu cầu tìm kiếm, do đó có thể khiến cụm không phản hồi. Nếu bạn muốn optimize một chỉ mục, bạn cần di chuyển chỉ mục đến một nút an toàn trước bằng cách sử dụng phân phối shard (xem Di chuyển chỉ mục cũ), sau đó thực hiện.