Các hoạt động tổng hợp trong MongoDB
Các hoạt động tổng hợp trong MongoDB xử lý các bản ghi dữ liệu và trả về kết quả tính toán. Các hoạt động tổng hợp nhóm các giá trị từ nhiều tài liệu và có thể thực hiện các thao tác khác nhau trên dữ liệu nhóm để trả về một kết quả duy nhất. MongoDB cung cấp ba cách thực hiện hoạt động tổng hợp: Pipeline, Map-Reduce và các phương pháp tổng hợp đơn lẻ.
Pipeline
Giới thiệu về Pipeline
Khung tổng hợp của MongoDB được xây dựng dựa trên khái niệm của Pipeline xử lý dữ liệu.
MongoDB hỗ trợ hoạt động tổng hợp thông qua phương thức db.collection.aggregate(). Ngoài ra, MongoDB cung cấp lệnh aggregate để thực hiện pipeline.
Pipeline của MongoDB bao gồm nhiều giai đoạn (stages). Mỗi giai đoạn sẽ chuyển đổi các tài liệu khi chúng đi qua pipeline. Một giai đoạn không cần tạo ra một tài liệu đầu ra cho mỗi tài liệu đầu vào. Ví dụ, một số giai đoạn có thể tạo ra các tài liệu mới hoặc lọc các tài liệu.
Cùng một giai đoạn có thể xuất hiện nhiều lần trong pipeline, trừ các giai đoạn $out, $merge, và $geoNear. Tất cả các giai đoạn pipeline có sẵn có thể được tham khảo tại: Aggregation Pipeline Stages.

- Giai đoạn đầu tiên: Giai đoạn
$matchlọc các tài liệu theo trường trạng thái và chuyển các tài liệu có trạng thái là “A” sang giai đoạn tiếp theo. - Giai đoạn thứ hai: Giai đoạn
$groupnhóm các tài liệu theo trường cust_id để tính tổng số tiền cho mỗi cust_id duy nhất.
Các giai đoạn pipeline cơ bản cung cấp bộ lọc, tương tự như truy vấn, và chuyển đổi tài liệu đầu ra (thay đổi hình thức tài liệu đầu ra).
Các hoạt động pipeline khác cung cấp các công cụ để nhóm và sắp xếp các tài liệu theo trường cụ thể, cũng như tổng hợp nội dung của mảng (bao gồm cả mảng tài liệu). Ngoài ra, các giai đoạn pipeline có thể sử dụng các toán tử để thực hiện các nhiệm vụ như tính trung bình hoặc kết hợp chuỗi.
Pipeline tổng hợp cũng có thể hoạt động trên tập hợp phân đoạn.
Tối ưu hóa Pipeline
Tối ưu hóa Projection
Pipeline có thể xác định xem chỉ cần các trường bắt buộc trong tài liệu để có được kết quả.
Tối ưu hóa tuần tự Pipeline
Tối ưu hóa tuần tự ($project, $unset, $addFields, $set) + $match
Đối với Pipeline có chứa các giai đoạn chiếu (project](https://docs.mongodb.com/manual/reference/operator/aggregation/project/#pipe._S_project) hoặc [unset hoặc addFields](https://docs.mongodb.com/manual/reference/operator/aggregation/addFields/#pipe._S_addFields) hoặc [set) và theo sau là giai đoạn match](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match), MongoDB sẽ di chuyển bộ lọc của tất cả các giai đoạn [match không cần thiết tính toán các giá trị trong giai đoạn chiếu, thành một giai đoạn $match mới trước giai đoạn chiếu.
Nếu Pipeline chứa nhiều giai đoạn chiếu và/hoặc giai đoạn match](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match), MongoDB sẽ thực hiện tối ưu hóa này cho mỗi giai đoạn [match, di chuyển bộ lọc $match vào trước tất cả các giai đoạn chiếu không phụ thuộc vào nó.
【Ví dụ】Ví dụ tối ưu hóa tuần tự Pipeline
Trước tối ưu hóa:
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: {
name: "Joe Schmoe",
maxTime: { $lt: 20 },
minTime: { $gt: 5 },
avgTime: { $gt: 7 }
} }Sau tối ưu hóa:
{ $match: { name: "Joe Schmoe" } },
{ $addFields: {
maxTime: { $max: "$times" },
minTime: { $min: "$times" }
} },
{ $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } },
{ $project: {
_id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
avgTime: { $avg: ["$maxTime", "$minTime"] }
} },
{ $match: { avgTime: { $gt: 7 } } }Giải thích:
{ name: "Joe Schmoe" } không cần tính toán bất kỳ giá trị nào trong giai đoạn chiếu, vì vậy nó có thể đặt ở đầu tiên.
{ avgTime: { $gt: 7 } } phụ thuộc vào trường avgTime của giai đoạn $project, nên không thể di chuyển.
Trường maxTime và minTime được phụ thuộc vào giai đoạn undefinedmatch mới được tạo ra và đặt trước giai đoạn $project.
Tối ưu hóa song song Pipeline
Nếu có thể, giai đoạn tối ưu hóa sẽ kết hợp các giai đoạn Pipeline vào giai đoạn trước đó. Thông thường, việc kết hợp xảy ra sau tối ưu hóa lại thứ tự của bất kỳ chuỗi nào.
$sort + $limit
Khi sort](https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort) đứng trước [limit và không có giai đoạn trung gian nào thay đổi số lượng tài liệu (ví dụ: unwind](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind), [group), trình tối ưu hóa có thể kết hợp limit](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) vào [sort. Nếu có giai đoạn trung gian thay đổi số lượng tài liệu giữa sort](https://docs.mongodb.com/manual/reference/operator/aggregation/sort/#pipe._S_sort) và [limit, MongoDB sẽ không kết hợp limit](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) vào [sort.
【Ví dụ】$sort + $limit
Trước tối ưu hóa:
{ $sort : { age : -1 } },
{ $project : { age : 1, status : 1, name : 1 } },
{ $limit: 5 }Sau tối ưu hóa:
{
"$sort" : {
"sortKey" : {
"age" : -1
},
"limit" : NumberLong(5)
}
},
{ "$project" : {
"age" : 1,
"status" : 1,
"name" : 1
}
}$limit + $limit
Nếu một limit](https://docs.mongodb.com/manual/reference/operator/aggregation/limit/#pipe._S_limit) ngay sau một [limit khác, chúng có thể được kết hợp thành một.
Trước tối ưu hóa:
{ $limit: 100 },
{ $limit: 10 }Sau tối ưu hóa:
{
$limit: 10
}$skip + $skip
Nếu một skip](https://docs.mongodb.com/manual/reference/operator/aggregation/skip/#pipe._S_skip) ngay sau một [skip khác, chúng có thể được kết hợp thành một.
Trước tối ưu hóa:
{ $skip: 5 },
{ $skip: 2 }Sau tối ưu hóa:
{
$skip: 7
}$match + $match
Nếu một match](https://docs.mongodb.com/manual/reference/operator/aggregation/match/#pipe._S_match) ngay sau một [match khác, chúng có thể được kết hợp thành một bằng $and.
Trước tối ưu hóa:
{ $match: { year: 2014 } },
{ $match: { status: "A" } }Sau tối ưu hóa:
{
$match: {
$and: [{ year: 2014 }, { status: 'A' }]
}
}$lookup + $unwind
Nếu một unwind](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind) ngay sau một [lookup và unwind](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind) được thực hiện trên trường as của [lookup, trình tối ưu hóa có thể kết hợp unwind](https://docs.mongodb.com/manual/reference/operator/aggregation/unwind/#pipe._S_unwind) vào [lookup để tránh tạo ra các tài liệu trung gian lớn hơn.
Trước tối ưu hóa:
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y"
}
},
{ $unwind: "$resultingArray"}Sau tối ưu hóa:
{
$lookup: {
from: "otherCollection",
as: "resultingArray",
localField: "x",
foreignField: "y",
unwinding: { preserveNullAndEmptyArrays: false }
}
}Giới hạn của Pipeline
Mỗi tài liệu trong tập kết quả bị giới hạn bởi kích thước tài liệu BSON (hiện tại là 16 MB).
Giới hạn bộ nhớ của Pipeline là 100 MB.
Map-Reduce
Pipeline tổng hợp cung cấp hiệu suất tốt hơn và giao diện nhất quán hơn so với map-reduce.
Map-reduce là một mô hình xử lý dữ liệu được sử dụng để tổng hợp một lượng lớn dữ liệu thành kết quả tổng hợp hữu ích. Để thực hiện thao tác map-reduce, MongoDB cung cấp lệnh cơ sở dữ liệu mapReduce.
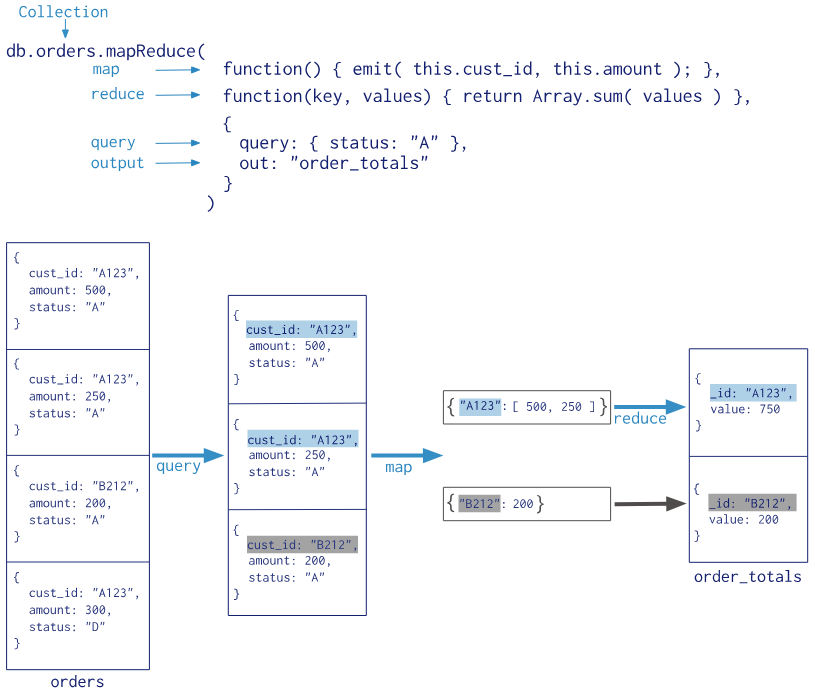
Trong quá trình trên, MongoDB áp dụng giai đoạn map cho mỗi tài liệu đầu vào (tức là tài liệu trong bộ sưu tập khớp với điều kiện truy vấn). Hàm map phân phối nhiều cặp khóa-giá trị. Đối với các khóa có nhiều giá trị, MongoDB áp dụng giai đoạn reduce, giai đoạn này thu thập và tổng hợp dữ liệu tổng hợp. Sau đó, MongoDB lưu kết quả vào bộ sưu tập. Tùy chọn, đầu ra của hàm reduce có thể được tổng hợp thêm bằng hàm finalize.
Tất cả các hàm map-reduce trong MongoDB đều là JavaScript và chạy trong quá trình mongod. Thao tác map-reduce nhận đầu vào là tài liệu của một bộ sưu tập và có thể thực hiện bất kỳ sắp xếp và giới hạn nào trước giai đoạn map. mapReduce có thể trả về kết quả của thao tác map-reduce dưới dạng tài liệu hoặc ghi kết quả vào bộ sưu tập.
Phương pháp tổng hợp đơn mục đích
MongoDB hỗ trợ các phương pháp tổng hợp đơn mục đích sau đây:
db.collection.estimatedDocumentCount(): Đếm ước lượng số lượng tài liệu trong một bộ sưu tập.db.collection.count(): Đếm số lượng tài liệu trong một bộ sưu tập.db.collection.distinct(): Lấy các giá trị duy nhất từ một trường trong một bộ sưu tập.
Tất cả các thao tác này tổng hợp các tài liệu trong một bộ sưu tập duy nhất. Mặc dù các thao tác này cung cấp cách tiếp cận đơn giản cho các quy trình tổng hợp thông thường, nhưng chúng thiếu tính linh hoạt và tính năng phong phú so với pipeline tổng hợp và map-reduce.
So sánh Aggregation trong SQL và MongoDB
Pipeline trong MongoDB cung cấp nhiều phép toán tương đương với các câu lệnh hoặc hàm tổng hợp phổ biến trong SQL.
Bảng dưới đây tóm tắt sự tương ứng giữa các câu lệnh hoặc khái niệm tổng hợp SQL phổ biến và các phép toán tổng hợp MongoDB:
| SQL Terms, Functions, and Concepts | MongoDB Aggregation Operators |
|---|---|
WHERE | $match |
GROUP BY | $group |
HAVING | $match |
SELECT | $project |
ORDER BY | $sort |
LIMIT | $limit |
SUM() | $sum |
COUNT() | $sum$sortByCount |
JOIN | $lookup |
SELECT INTO NEW_TABLE | $out |
MERGE INTO TABLE | $merge (Có sẵn từ MongoDB 4.2 trở đi) |
UNION ALL | $unionWith (Có sẵn từ MongoDB 4.4 trở đi) |
【Ví dụ】
db.orders.insertMany([
{
_id: 1,
cust_id: 'Ant O. Knee',
ord_date: new Date('2020-03-01'),
price: 25,
items: [
{ sku: 'oranges', qty: 5, price: 2.5 },
{ sku: 'apples', qty: 5, price: 2.5 }
],
status: 'A'
},
{
_id: 2,
cust_id: 'Ant O. Knee',
ord_date: new Date('2020-03-08'),
price: 70,
items: [
{ sku: 'oranges', qty: 8, price: 2.5 },
{ sku: 'chocolates', qty: 5, price: 10 }
],
status: 'A'
},
{
_id: 3,
cust_id: 'Busby Bee',
ord_date: new Date('2020-03-08'),
price: 50,
items: [
{ sku: 'oranges', qty: 10, price: 2.5 },
{ sku: 'pears', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 4,
cust_id: 'Busby Bee',
ord_date: new Date('2020-03-18'),
price: 25,
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
status: 'A'
},
{
_id: 5,
cust_id: 'Busby Bee',
ord_date: new Date('2020-03-19'),
price: 50,
items: [{ sku: 'chocolates', qty: 5, price: 10 }],
status: 'A'
},
{
_id: 6,
cust_id: 'Cam Elot',
ord_date: new Date('2020-03-19'),
price: 35,
items: [
{ sku: 'carrots', qty: 10, price: 1.0 },
{ sku: 'apples', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 7,
cust_id: 'Cam Elot',
ord_date: new Date('2020-03-20'),
price: 25,
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
status: 'A'
},
{
_id: 8,
cust_id: 'Don Quis',
ord_date: new Date('2020-03-20'),
price: 75,
items: [
{ sku: 'chocolates', qty: 5, price: 10 },
{ sku: 'apples', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 9,
cust_id: 'Don Quis',
ord_date: new Date('2020-03-20'),
price: 55,
items: [
{ sku: 'carrots', qty: 5, price: 1.0 },
{ sku: 'apples', qty: 10, price: 2.5 },
{ sku: 'oranges', qty: 10, price: 2.5 }
],
status: 'A'
},
{
_id: 10,
cust_id: 'Don Quis',
ord_date: new Date('2020-03-23'),
price: 25,
items: [{ sku: 'oranges', qty: 10, price: 2.5 }],
status: 'A'
}
])So sánh cách tổng hợp trong SQL và MongoDB:
