🔖 Index
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure
Index là một cấu trúc dữ liệu đặc biệt riêng biệt được sử dụng để lưu trữ các giá trị địa chỉ của dữ liệu. Bằng cách sử dụng index, chúng ta có thể nhanh chóng tìm thấy dữ liệu mong muốn.
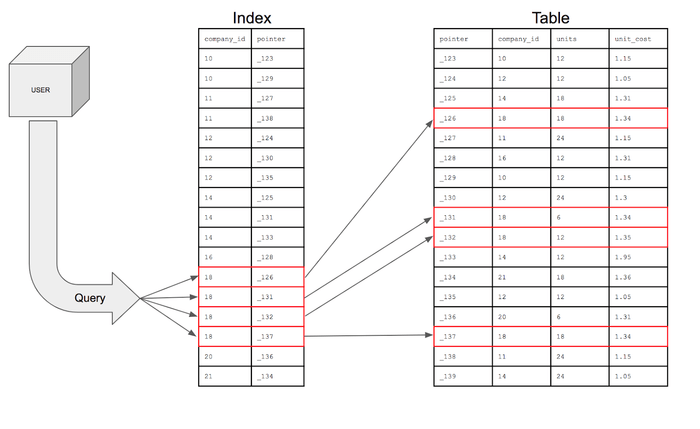
✔️ Point 1 : Tại sao cần có index cho DB table?
🧐 Điều gì xảy ra nếu bạn không đánh index cho table?
SELECT *
FROM customer
WHERE first_name = "Hung";Khi muốn tìm dữ liệu, bạn phải thực hiện quét toàn bộ bảng (full scan).
Nói cách khác, nếu không đánh index cho first_name, tất cả dữ liệu phải được kiểm tra từng cái một để tìm “Hung”.
full scan(=table scan): kiểm tra từng row một
Time Complexity: O(N)
Bởi vì full scan mất nhiều thời gian, nó ảnh hưởng xấu đến service.
🤔 Nếu index được sử dụng?
Time Complexity: O(LogN) (B-tree based index)
Chúng ta sẽ xem xét chi tiết cấu trúc dữ liệu của index sau.
💡 Lý do sử dụng index
- Để truy vấn nhanh chóng các bản ghi (hoặc tập hợp các bản ghi) thỏa mãn điều kiện!
- Để sắp xếp (
order by) hoặc nhóm (group by) nhanh chóng!
Cài đặt index: MySQL
1. Nếu bảng và dữ liệu đã tồn tại
Giả sử chúng ta có một bảng như thế này:
CREATE TABLE PLAYER (
id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
team_id INT NOT NULL,
back_number INT NOT NULL
);Và có hai truy vấn:
SELECT * FROM player WHERE name = "Hung";
SELECT * FROM player WHERE team_id = 111 and back_number = 1;Trong trường hợp này, bạn có thể tạo một index như thế này.
Index của câu lệnh truy vấn thứ hai được tạo dưới dạng UNIQUE INDEX vì mỗi dữ liệu trong bảng player có thể được xác định duy nhất.
-- single column index
CREATE INDEX player_name_idx ON player (name);
-- multi column index
CREATE UNIQUE INDEX team_id_back_number_idx ON player (team_id, back_number);2. Tạo index khi tạo bảng
CREATE TABLE PLAYER (
id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
team_id INT NOT NULL,
back_number INT NOT NULL,
INDEX player_name_idx (name),
UNIQUE INDEX team_id_back_number_idx (team_id, back_number)
);Lưu ý: Hầu hết các hệ quản trị cơ sở dữ liệu quan hệ (RDBMS) tự động đánh index cho khóa chính (primary key).
Multi Column Index
1) Cân nhắc
Trong ví dụ trên, chúng tôi đã tạo một chỉ mục nhiều cột.
-- multi column index
CREATE UNIQUE INDEX team_id_back_number_idx ON player (team_id, back_number);🧐 Trong trường hợp nào bạn nên cân nhắc tạo chỉ mục nhiều cột?
💁♂️💡 Đối với các cột thường được truy vấn cùng nhau bởi toán tử AND trong mệnh đề WHERE
WHERE team_id = 111 and back_number = 1- Nếu chỉ có index được áp dụng cho cột “team_id”, việc tìm kiếm “back_number” trong các dữ liệu với “team_id” là 111 sẽ là quét toàn bộ dữ liệu (
full scan) vì không có chỉ mục hỗ trợ cho cột “back_number”. Trong trường hợp này, ta nên xem xét thiết lập chỉ mục để cải thiện hiệu suất truy vấn.
🧐 Nó sẽ được sắp xếp như thế nào ?
💁♂️💡 Khi tạo chỉ mục sẽ sắp xếp theo thứ tự các cột.
Trong ví dụ trên, chỉ mục được đặt theo thứ tự INDEX (team_id, back_number).
🧐 Nếu có điều kiện WHERE back_number=1, hiệu suất sẽ như thế nào?
💁♂️💡 Với multi column index, dữ liệu được sắp xếp trước theo team_id. Do đó, hiệu suất có thể tương đương hoặc không tốt hơn so với full scan.
- Trong trường hợp này, có thể tạo single column index cho back_number hoặc thực hiện truy vấn mà không sử dụng chỉ mục. Điều này giúp cải thiện hiệu suất truy vấn.
- Vì vậy, khi tạo chỉ mục đa cột, cần xem xét thứ tự các cột để đảm bảo hiệu suất tốt nhất và phù hợp với yêu cầu phát triển.
2) Ưu điểm: Covering Index
Trong trường hợp như ví dụ trên, khi chỉ mục INDEX(team_id, back_number) được áp dụng. Khi một truy vấn như sau được thực hiện:
SELECT team_id, back_number FROM player WHERE team_id = 5;Chỉ có hai thông tin là team_id và back_number được trả về, không phải tất cả các thuộc tính.
Khi đó, không cần đọc các khối dữ liệu vật lý sau khi tìm kiếm trong chỉ mục.
Nói ngắn gọn:
- Khi index bao phủ (cover) tất cả các thuộc tính được truy vấn
- Hiệu suất truy vấn sẽ nhanh hơn.
Có thể cải thiện tốc độ truy vấn bằng cách thiết lập chỉ mục như vậy. Tuy nhiên, việc thiết lập chỉ mục không đảm bảo tăng tốc độ truy vấn trong mọi trường hợp.
Khi chỉ mục được thiết lập phù hợp theo truy vấn được sử dụng, truy vấn có thể được xử lý nhanh chóng.
Vì vậy, để thiết lập chỉ mục một cách hợp lý, việc hiểu cấu trúc và cách hoạt động của chỉ mục là rất quan trọng cho developer.
✔️ Cấu trúc Index
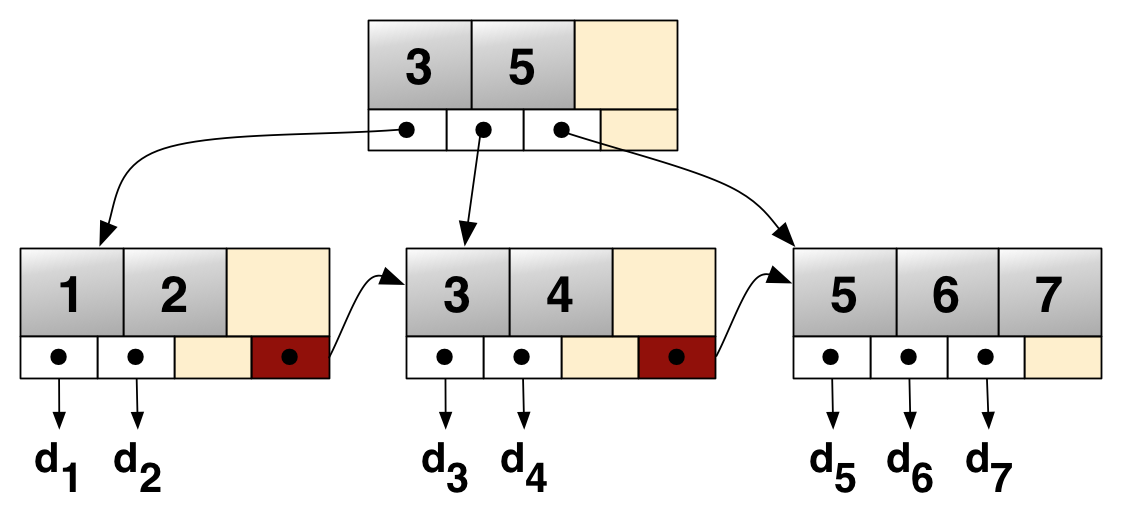
Single-Level Ordered Indexes
- Mỗi index entry bao gồm
<khóa tìm kiếm, con trỏ đến bản ghi> - Các entry được sắp xếp theo thứ tự tăng dần của giá trị khóa tìm kiếm.
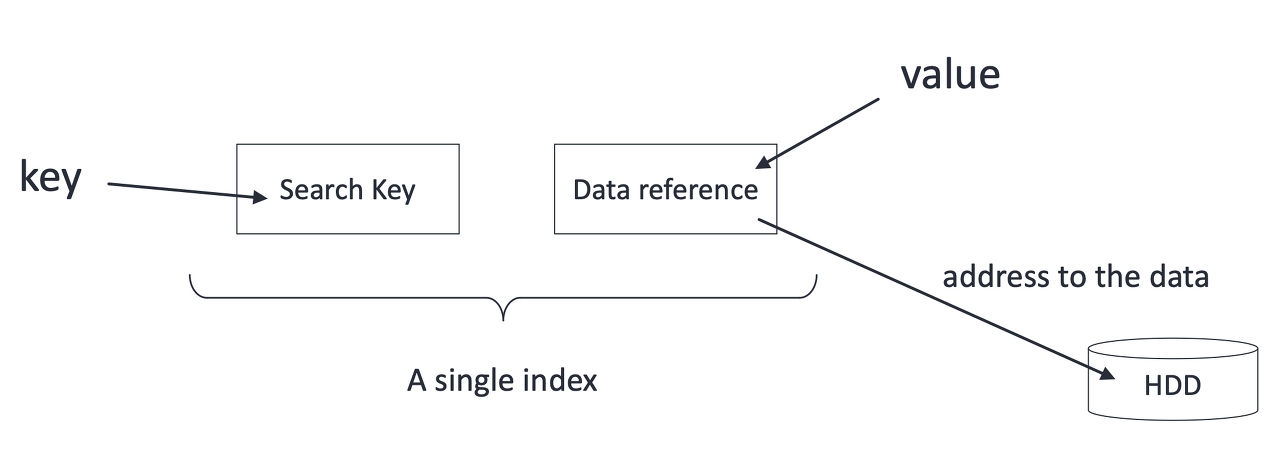
Dense index: Cung cấp index entry cho tất cả các giá trị khóa, tức là tạo chỉ mục cho tất cả các bản ghi.
Sparse index: Chỉ tạo entry cho một số giá trị. Thông thường, sparse index được sử dụng mặc định. Primary index cũng là sparse index.
1) Primary index | sparse index
- Được định nghĩa cho tệp dữ liệu được sắp xếp theo giá trị khóa tìm kiếm.
- Chỉ mục cho khóa tìm kiếm là khóa chính (primary key) của bảng.
2) Clustering index | sparse index
- Được định nghĩa cho tệp dữ liệu được sắp xếp theo giá trị khóa tìm kiếm.
- Có thể sử dụng khi nhiều bản ghi có cùng giá trị trường sắp xếp (ordering field)
3) Secondary index | dense index
- Là chỉ mục hỗ trợ cho các chỉ mục khác và chỉ cho biết vị trí của bản ghi.
- Sử dụng khóa phụ thay vì khóa chính để lấy giá trị mong muốn bằng cách sử dụng phương pháp bổ sung.
Multi-level Indexes
- Khi chỉ mục trở nên lớn, thời gian tìm kiếm chỉ mục cũng có thể tốn nhiều thời gian.
- Để giảm thời gian tìm kiếm mục nhập chỉ mục, chúng ta có thể xem xét lại Single-Level Ordered Indexes như một tệp sắp xếp duy nhất trên đĩa và định nghĩa lại chỉ mục cho nó.
- Chỉ mục cấp cao nhất được gọi là chỉ mục chính (master index).
- Hầu hết sử dụng B+ Tree.
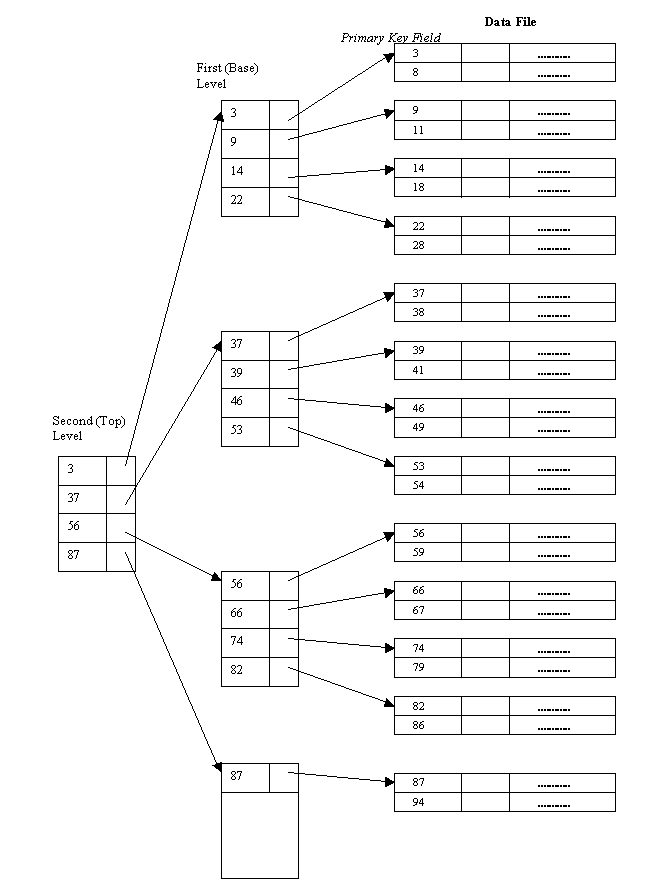
✔️ Point 2 : Cách hoạt động (Cấu trúc dữ liệu)
Vậy chỉ mục sử dụng cấu trúc dữ liệu nào để tìm kiếm nhanh? Và liệu việc tìm kiếm luôn luôn nhanh chóng không? Hãy xem xét cấu trúc dữ liệu để giải quyết những thắc mắc này.
Cấu trúc dữ liệu phổ biến được sử dụng trong chỉ mục cơ sở dữ liệu là B-Tree, B+Tree và Hash Table.
B-Tree
Time Complexity: O(logN)
- B-Tree là một cây có ít nhất 2 nút con.
- Được gọi là cây cân bằng (Balanced Tree), khoảng cách từ nút gốc đến các nút lá là như nhau.
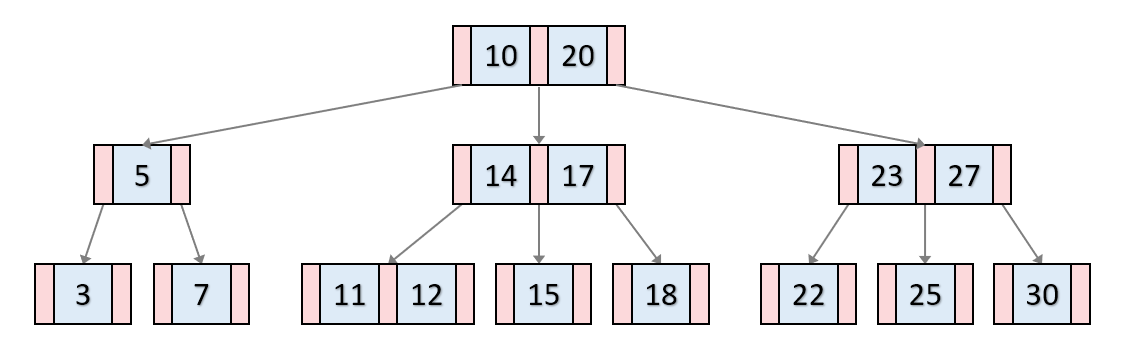
⭐️ B+Tree
- B+Tree là một cấu trúc dữ liệu mở rộng và cải tiến từ B-Tree.
- Có các nút không phải lá (non-leaf) riêng biệt hoạt động như chỉ mục để truy cập nhanh vào dữ liệu đã được phân tách.
- Đây là cấu trúc dữ liệu được sử dụng phổ biến nhất trong cơ sở dữ liệu quan hệ.
Hash Table
Time Complexity: O(1)
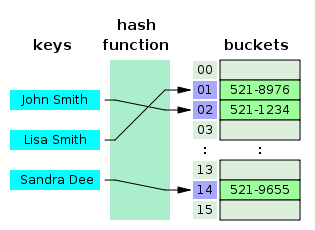
Nó có thể tìm ra kết quả nhanh hơn so với B-Tree đã đề cập ở trên. Nhưng tại sao lại sử dụng B-Tree?
Nhược điểm
- Bảng băm (Hash Table) chỉ tập trung vào phép so sánh bằng (=) nên không phù hợp cho việc tìm kiếm trong cơ sở dữ liệu sử dụng các phép so sánh không bằng (>, <) thường xuyên.
- Nghĩa là chỉ hỗ trợ so sánh bằng (
equality) và không hỗ trợ so sánh phạm vi (range).
- Nghĩa là chỉ hỗ trợ so sánh bằng (
- Trong trường hợp multi column index, chỉ có thể tìm kiếm dựa trên tất cả các thuộc tính (attributes).
- Ví dụ, trong chỉ mục dựa trên B-Tree như đã đề cập ở trên, INDEX(team_id, back_number) có thể tìm kiếm chỉ dựa trên cột team_id trong một số tình huống.
- Tuy nhiên, hash index phải tìm kiếm bằng cả hai cột.
✔️ Tại sao họ B tree được dùng làm index?
Secondary storage (SSD or HDD)
Phần này nhắc lại kiến thức trong Memory Hierachy
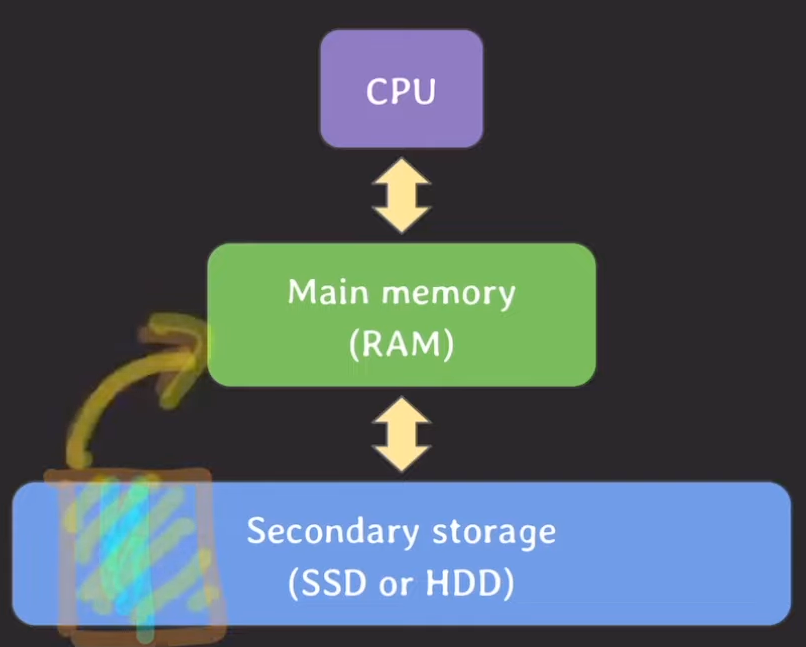
- Tốc độ xử lý dữ liệu là chậm nhất.
- Nếu có nhiều disk I/O (đặc biệt là I/O ngẫu nhiên), thì tốc độ sẽ chậm hơn.
- Dung lượng lưu trữ dữ liệu là lớn nhất.
- Dữ liệu được đọc và ghi theo đơn vị block.
Trong trường hợp này, cơ sở dữ liệu được lưu trữ trên bộ nhớ phụ (secondary storage).
Xem xét các đặc điểm trên, việc truy cập bộ nhớ thứ cấp càng ít càng tốt để đạt được hiệu suất khi truy xuất dữ liệu từ cơ sở dữ liệu.
(Quá trình I/O trong cơ sở dữ liệu liên quan đến hoạt động vật lý thông qua đĩa)
Hơn nữa, vì dữ liệu được đọc và ghi theo đơn vị block, việc lưu trữ dữ liệu liên quan lại cùng nhau sẽ giúp đọc và ghi hiệu quả hơn.
Kết luận
💡 Tóm lại, càng ít truy cập vào secondary storage càng tốt.
🧐 Nhưng tại sao không sử dụng Binary Tree hoặc Red-Black Tree mà lại sử dụng B-Tree và các biến thể của nó?
💡 Bằng cách sử dụng họ B-Tree, chúng ta có thể nhanh chóng thu hẹp phạm vi tìm kiếm khi tìm kiếm dữ liệu hơn so với các cây khác (Binary Tree, Red-Black Tree).
💡 Ngoài ra, nút của B-Tree có thể lưu trữ nhiều dữ liệu. (= Có thể có nhiều nút con.)
Vậy là chúng ta đã tìm hiểu được các cấu trúc dữ liệu mà có thể dùng cho index.
(Chi tiết hơn sẽ được tổ chức và tóm tắt trong phần cấu trúc dữ liệu. ∑ Data Structure)
Tuy nhiên, chỉ việc tạo chỉ mục không đảm bảo tăng hiệu suất truy vấn trong mọi trường hợp.
Vì vậy, hãy xem xét những gì cần được xem xét khi thiết lập chỉ mục.
✔️ Point 3 : Những yếu tố cần xem xét khi đánh Index
Hiệu suất giảm
- Khi thực hiện các hoạt động ghi (INSERT, DELETE, UPDATE) trên bảng, index cũng phải được cập nhật theo, đòi hỏi các thao tác bổ sung.
- Chiếm thêm không gian lưu trữ.
Vì vậy, nên tránh tạo chỉ mục không cần thiết.
Trường hợp full scan tốt hơn index
DB Optimizer quyết định xem có thực hiện full scan hay không.
1) Khi bảng có ít dữ liệu
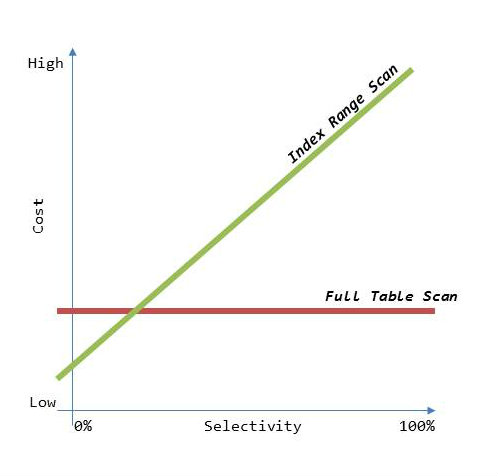
2) Khi dữ liệu cần truy vấn chiếm phần lớn bảng
Chỉ mục được sử dụng trong trường hợp truy vấn một lượng nhỏ dữ liệu từ bảng. Trong hệ thống xử lý giao dịch trực tuyến (OLTP), truy vấn dữ liệu nhỏ là chủ yếu, vì vậy tinh chỉnh chỉ mục là rất quan trọng.
Thường thì chỉ khi dữ liệu được lọc ra khoảng 5-10% tổng số dữ liệu, việc sử dụng chỉ mục sẽ mang lại hiệu quả tốt.
Trong trường hợp dữ liệu cần truy vấn chiếm hơn 20% tổng số dữ liệu, thì việc thực hiện full scan có thể nhanh hơn.
SELECT * FROM customer WHERE mobile_carrier = "Viettel";- Điểm cân đối ưu điểm của chỉ mục
Table Full Scan: Truy cập tuần tự (sequential access), I/O đa khốiIndex Range Scan: Truy cập ngẫu nhiên (random access), I/O đơn khối
Tinh chỉnh chỉ mục là việc giảm số lần truy cập vào bảng. Truy cập bảng dựa trên địa chỉ bản ghi từ chỉ mục là một hoạt động chi phí cao.
Vì vậy, khi lượng dữ liệu cần đọc vượt quá một mức nhất định, việc quét toàn bộ bảng sẽ trở nên chậm hơn.
Điều này xảy ra vì khi lượng dữ liệu cần đọc tăng lên, lượng chỉ mục quét cũng tăng lên và truy cập ngẫu nhiên vào bảng cũng tăng lên.
Điểm mà index và full scan có hiệu suất tương đương nhau được gọi là điểm cân đối ưu điểm của chỉ mục.
Random access
Truy cập ngẫu nhiên là việc sử dụng chỉ mục để xem địa chỉ dữ liệu và di chuyển đến vị trí đó để lấy dữ liệu.
Khi cần truy xuất ít dữ liệu, chỉ cần di chuyển đến các vị trí cần thiết trong disk, do đó rất hiệu quả.
Tuy nhiên, nếu phải đi qua nhiều vị trí, thì thời gian di chuyển lên xuống trong disk sẽ tốn thời gian.
Sequential access
Truy cập tuần tự là việc truy cập theo từng khối dữ liệu trong disk. Thời gian di chuyển giảm, giảm chi phí truy cập.
Tiêu chí đánh Index
Vậy chúng ta nên thiết lập chỉ mục dựa trên những tiêu chí nào?
1) Số lượng giá trị duy nhất (Cardinality)
- Cardinality càng cao thì cột đó càng phù hợp để thiết lập chỉ mục. Điều này có nghĩa là cột đó có ít giá trị trùng lặp.
- Tức là chỉ mục có thể lọc ra phần lớn dữ liệu không cần thiết.
- Như đã đề cập trước đó, nếu dữ liệu được lọc bằng WHERE chiếm phần lớn dữ liệu gốc, thì hiệu suất có thể giảm.
2) Tính chọn lọc (Selectivity)
- Selectivity càng thấp thì cột đó càng phù hợp để thiết lập chỉ mục. (Thường là khoảng 5-10%)
- Selectivity thấp có nghĩa là một cột chỉ tìm thấy một số lượng nhỏ bản ghi dựa trên một giá trị duy nhất
Cách tính Selectivity (Tỷ lệ bản ghi được chọn theo điều kiện so với tổng số bản ghi)
Số row chứa giá trị cụ thể của cột / Tổng số row trong table * 100
Ví dụ:
Trong 100 học sinh, có 20 học sinh cùng tuổi (age)
Selectivity = (20/100) * 100 = 20%
3) Tính hữu dụng (Utility)
Mức độ sử dụng càng cao, cột đó càng phù hợp để thiết lập chỉ mục.
4) Tần suất sửa đổi
- Tần suất sửa đổi càng thấp thì cột đó càng phù hợp để thiết lập chỉ mục.
- Nếu cột đã được thiết lập chỉ mục và giá trị của nó thay đổi, chỉ mục cũng phải được cập nhật.