Tổng hợp các câu hỏi phỏng vấn hệ điều hành phổ biến (Phần 1)
Bài viết này tóm tắt một số khái niệm quan trọng về hệ điều hành, như chế độ người dùng và chế độ kernel, gọi hệ thống, quy trình và luồng, tình trạng chết khóa, quản lý bộ nhớ, bộ nhớ ảo, hệ thống tệp, v.v.
Bài viết này chỉ là một cái nhìn tổng quan về một số khái niệm quan trọng về hệ điều hành.
Cơ bản về Hệ điều hành

Hệ điều hành là gì?
Có thể tóm tắt hệ điều hành như sau qua bốn điểm sau:
- Hệ điều hành (Operating System, viết tắt là OS) là một chương trình quản lý tài nguyên phần cứng và phần mềm của máy tính, là nền tảng của máy tính.
- Hệ điều hành về bản chất là một chương trình phần mềm chạy trên máy tính, chủ yếu được sử dụng để quản lý tài nguyên phần cứng và phần mềm của máy tính. Ví dụ: Tất cả các ứng dụng chạy trên máy tính của bạn đều thông qua hệ điều hành để gọi tài nguyên như bộ nhớ hệ thống và ổ cứng.
- Hệ điều hành giúp che giấu sự phức tạp của phần cứng. Hệ điều hành giống như một người quản lý sử dụng phần cứng, tổ chức các vấn đề liên quan.
- Nhân (Kernel) của hệ điều hành là phần cốt lõi của hệ điều hành, nó chịu trách nhiệm quản lý bộ nhớ hệ thống, quản lý thiết bị phần cứng, quản lý hệ thống tệp và quản lý ứng dụng. Nhân là cây cầu kết nối giữa ứng dụng và phần cứng, quyết định hiệu suất và tính ổn định của hệ thống.
Nhiều người dễ nhầm lẫn giữa kernel (Kernel) và bộ xử lý trung tâm (CPU, Central Processing Unit). Bạn có thể phân biệt đơn giản qua hai điểm sau:
- kernel thuộc về hệ điều hành, trong khi CPU thuộc về phần cứng.
- CPU chủ yếu cung cấp khả năng tính toán và xử lý các lệnh khác nhau. kernel chủ yếu quản lý hệ thống như quản lý bộ nhớ, nó che giấu các hoạt động liên quan đến phần cứng.
Hình ảnh dưới đây rõ ràng mô tả mối quan hệ giữa ứng dụng, kernel và CPU.
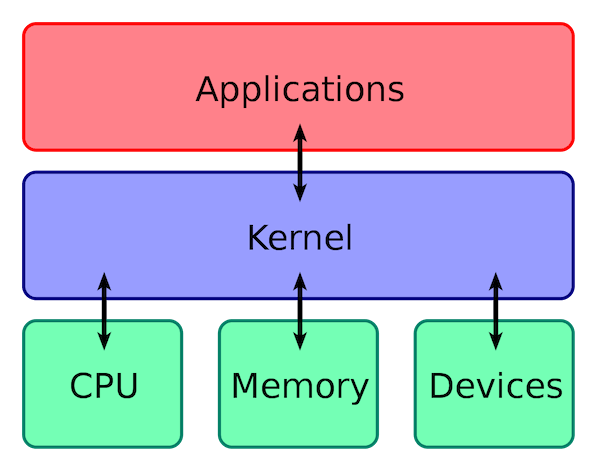
Hệ điều hành có những chức năng chính nào?
Từ góc độ quản lý tài nguyên, hệ điều hành có 6 chức năng chính:
- Quản lý tiến trình và luồng: Tạo, hủy, chặn, đánh thức tiến trình, giao tiếp giữa các tiến trình, v.v.
- Quản lý bộ nhớ: Phân bổ và quản lý bộ nhớ, phân bổ và quản lý bộ nhớ ngoại vi (đĩa, v.v.).
- Quản lý tệp: Đọc, ghi, tạo và xóa tệp.
- Quản lý thiết bị: Xử lý yêu cầu hoặc giải phóng thiết bị (thiết bị nhập xuất và thiết bị lưu trữ ngoại vi), khởi động thiết bị, v.v.
- Quản lý mạng: Hệ điều hành quản lý việc sử dụng mạng máy tính. Mạng là cách kết nối các máy tính khác nhau trong hệ thống máy tính, hệ điều hành cần quản lý cấu hình, kết nối, truyền thông và bảo mật mạng để cung cấp dịch vụ mạng hiệu quả và đáng tin cậy.
- Quản lý bảo mật: Xác thực người dùng, kiểm soát truy cập, mã hóa tệp, v.v., để ngăn chặn người dùng trái phép truy cập và thao tác trên tài nguyên hệ thống.
Các hệ điều hành phổ biến
Windows
Windows là hệ điều hành cá nhân trên máy tính được sử dụng rộng rãi hiện nay, không cần giới thiệu nhiều, mọi người đều biết. Giao diện đơn giản dễ sử dụng, hệ sinh thái phần mềm rất tốt.
Unix
Là hệ điều hành đa người dùng, đa nhiệm đầu tiên. Linux, một hệ điều hành phổ biến, đã tham khảo nhiều khía cạnh từ Unix.
Hiện nay, hệ điều hành này đã dần rời khỏi sân khấu hệ điều hành.
Linux
Linux là một hệ điều hành mã nguồn mở, miễn phí, dựa trên Unix. Linux có nhiều phiên bản phân phối khác nhau, nhưng tất cả đều sử dụng nhân Linux.
Nói chính xác hơn, từ “Linux” chỉ đề cập đến nhân Linux. Trong hệ thống GNU/Linux, Linux thực tế chỉ là nhân Linux, phần còn lại của hệ thống chủ yếu được viết và cung cấp bởi dự án GNU. Nhân Linux đơn lẻ không thể trở thành một hệ điều hành hoạt động bình thường.
Nhiều người thích sử dụng thuật ngữ “GNU/Linux” để diễn đạt điều mọi người thường nói đến là “Linux”.
Mac OS
Hệ điều hành của Apple, trải nghiệm lập trình tương đương với Linux, nhưng giao diện, hệ sinh thái phần mềm và trải nghiệm người dùng đều tốt hơn so với hệ điều hành Linux.
Chế độ người dùng và chế độ kernel
Chế độ người dùng và chế độ kernel là gì?
Dựa trên tính chất của quyền truy cập tài nguyên của quá trình, chúng ta có thể chia quá trình chạy trên hệ thống thành hai cấp độ:
- Chế độ người dùng (User Mode): Quá trình chạy ở chế độ người dùng có thể truy cập trực tiếp vào dữ liệu của chương trình người dùng và có quyền hạn thấp hơn. Khi ứng dụng cần thực hiện một số hoạt động đòi hỏi quyền đặc biệt, chẳng hạn như đọc/ghi vào đĩa, giao tiếp mạng, nó cần gửi yêu cầu hệ thống để thực hiện một cuộc gọi hệ thống và chuyển sang chế độ kernel.
- Chế độ kernel (Kernel Mode): Quá trình chạy ở chế độ kernel gần như có thể truy cập vào bất kỳ tài nguyên nào trên máy tính bao gồm không gian bộ nhớ hệ thống, thiết bị, trình điều khiển, v.v. Nó không bị hạn chế và có quyền hạn cao. Khi hệ điều hành nhận được yêu cầu cuộc gọi hệ thống từ tiến trình, nó sẽ chuyển từ chế độ người dùng sang chế độ kernel, thực hiện cuộc gọi hệ thống tương ứng và trả kết quả cho tiến trình, sau đó chuyển lại chế độ người dùng.
Chế độ kernel có đặc quyền cao hơn chế độ người dùng, do đó có thể thực hiện các hoạt động cấp thấp và nhạy cảm hơn. Tuy nhiên, việc chuyển đổi sang chế độ kernel có chi phí cao (bao gồm một loạt các chuyển đổi ngữ cảnh và kiểm tra quyền hạn), do đó nên giảm thiểu số lần chuyển đổi sang chế độ kernel để cải thiện hiệu suất và ổn định của hệ thống.
Tại sao cần có chế độ người dùng và chế độ kernel? Tại sao không chỉ có một chế độ kernel?
- Trong tất cả các chỉ thị của CPU, có một số chỉ thị rất nguy hiểm như phân bổ bộ nhớ, thiết lập đồng hồ, xử lý IO, v.v. Nếu tất cả các chương trình đều có thể sử dụng các chỉ thị này, sẽ gây ra những tác động nghiêm trọng đến hoạt động bình thường của hệ thống. Do đó, chúng ta cần hạn chế các chỉ thị nguy hiểm này chỉ chạy ở chế độ kernel. Những chỉ thị chỉ có thể được thực hiện bởi chế độ kernel được gọi là chỉ thị đặc quyền.
- Nếu chỉ có một chế độ kernel trong hệ thống máy tính, tất cả các chương trình hoặc tiến trình sẽ phải chia sẻ tài nguyên hệ thống như bộ nhớ, CPU, ổ cứng, v.v. Điều này sẽ dẫn đến cạnh tranh và xung đột tài nguyên hệ thống, ảnh hưởng đến hiệu suất và hiệu quả của hệ thống. Ngoài ra, điều này cũng làm giảm tính bảo mật của hệ thống, vì tất cả các chương trình hoặc tiến trình đều có cùng một cấp độ đặc quyền và quyền truy cập.
Do đó, việc có cùng một lúc chế độ người dùng và chế độ kernel chủ yếu nhằm đảm bảo tính bảo mật, ổn định và hiệu suất của hệ thống máy tính.
Làm thế nào để chuyển đổi giữa chế độ người dùng và chế độ kernel?
Có 3 cách để một tiến trình ở chế độ người dùng chuyển sang chế độ kernel:
-
System Call (Trap): Đây là một cách chủ động mà một tiến trình ở chế độ người dùng yêu cầu chuyển sang chế độ kernel. Điều này chủ yếu được sử dụng để thực hiện các nhiệm vụ yêu cầu chế độ kernel, như truy cập tài nguyên đĩa. Cơ chế của một system call dựa trên việc sử dụng một ngắt mà hệ điều hành đặc biệt mở cho người dùng.
-
Ngắt (Interrupt): Khi một thiết bị ngoại vi hoàn thành một yêu cầu của người dùng, nó gửi một tín hiệu ngắt tới CPU. CPU tạm dừng việc thực thi lệnh tiếp theo và chuyển sang chương trình xử lý ngắt tương ứng. Nếu lệnh đã thực thi trước đó ở chế độ người dùng, quá trình chuyển đổi từ chế độ người dùng sang chế độ kernel sẽ xảy ra. Ví dụ, khi một hoạt động I/O đĩa hoàn thành, hệ thống chuyển sang chương trình xử lý ngắt I/O đĩa để thực hiện các hoạt động tiếp theo.
-
Ngoại lệ (Exception): Khi CPU đang thực thi một chương trình ở chế độ người dùng, nếu xảy ra một ngoại lệ không thể dự đoán được, tiến trình đang chạy hiện tại sẽ chuyển sang chương trình kernel liên quan để xử lý ngoại lệ này. Điều này dẫn đến việc chuyển đổi từ chế độ người dùng sang chế độ kernel. Ví dụ, xảy ra ngoại lệ trang không tồn tại.
Trong việc xử lý hệ thống, ngắt và ngoại lệ tương tự nhau. Cả hai đều sử dụng bảng vector ngắt để tìm chương trình xử lý tương ứng. Sự khác biệt là ngắt đến từ bên ngoài bộ xử lý, không phải do bất kỳ lệnh cụ thể nào, trong khi ngoại lệ là kết quả của việc thực thi lệnh hiện tại.
System Call
System Call là gì?
Các chương trình chúng ta chạy thường chạy ở chế độ người dùng (user mode), nhưng nếu chúng ta muốn gọi các chức năng cấp độ hệ điều hành ở chế độ nhân (kernel mode) thì phải sử dụng System Call!
Nghĩa là trong các chương trình người dùng chúng ta chạy, mọi hoạt động liên quan đến tài nguyên cấp độ hệ điều hành (như quản lý tệp tin, quản lý tiến trình, quản lý bộ nhớ, v.v.) phải thông qua việc gửi yêu cầu dịch vụ qua System Call, và được hệ điều hành thực hiện.
Các System Call này có thể được phân loại chức năng chính như sau:
- Quản lý thiết bị: thực hiện yêu cầu hoặc giải phóng thiết bị (thiết bị nhập/xuất và thiết bị lưu trữ ngoại vi), cũng như khởi động thiết bị.
- Quản lý tệp tin: thực hiện chức năng đọc, ghi, tạo và xóa tệp tin.
- Quản lý tiến trình: tạo, hủy, chặn, kích hoạt tiến trình, giao tiếp giữa các tiến trình, v.v.
- Quản lý bộ nhớ: cấp phát, thu hồi bộ nhớ và lấy kích thước và địa chỉ của vùng nhớ được sử dụng bởi công việc.
System Call và cuộc gọi hàm thư viện thông thường rất giống nhau, chỉ khác là System Call được cung cấp bởi nhân hệ điều hành chạy ở chế độ nhân (kernel mode), trong khi cuộc gọi hàm thư viện thông thường được cung cấp bởi thư viện hoặc người dùng và chạy ở chế độ người dùng (user mode).
Tóm lại, System Call là một cách để ứng dụng tương tác với hệ điều hành. Thông qua System Call, ứng dụng có thể truy cập các tài nguyên cấp thấp của hệ điều hành như tệp tin, thiết bị, mạng, v.v.
Bạn hiểu quá trình System Call như thế nào?
Quá trình System Call có thể chia thành các bước sau đây:
- Chương trình ở chế độ người dùng khởi tạo System Call. Vì System Call liên quan đến các lệnh đặc quyền (chỉ có thể được thực thi bởi chế độ nhân), quyền của chương trình ở chế độ người dùng không đủ, do đó nó sẽ bị ngắt (Trap - một dạng ngắt - ngắt mềm).
- Sau khi xảy ra ngắt, chương trình đang chạy trên CPU sẽ bị ngắt và nhảy đến chương trình xử lý ngắt. Chương trình kernel bắt đầu thực thi, tức là bắt đầu xử lý System Call.
- Sau khi xử lý xong, chương trình kernel kích hoạt Trap một lần nữa, điều này sẽ gây ra một lần ngắt khác, chuyển đổi trở lại chế độ người dùng để tiếp tục công việc.
Tiến trình và Luồng
Tiến trình và Luồng là gì?
- Tiến trình (Process) là một phiên bản của chương trình đang chạy trên máy tính. Ví dụ: Ứng dụng Messenger mà bạn mở là một tiến trình.
- Luồng (Thread) còn được gọi là tiến trình nhẹ và nhẹ hơn. Nhiều luồng có thể được thực thi cùng một lúc trong cùng một tiến trình và chia sẻ các tài nguyên của tiến trình như không gian bộ nhớ, bộ xử lý tệp, kết nối mạng, v.v. Ví dụ: Trong ứng dụng Messenger mà bạn mở, có một luồng riêng để lấy tin nhắn mới nhất mà người khác gửi cho bạn.
Sự khác biệt giữa tiến trình và luồng là gì?
- Luồng là một đơn vị thực thi nhỏ hơn của tiến trình, một tiến trình có thể tạo ra nhiều luồng.
- Luồng và tiến trình khác nhau chủ yếu ở chỗ mỗi tiến trình đều độc lập, trong khi các luồng trong cùng một tiến trình có thể ảnh hưởng lẫn nhau.
- Chi phí chuyển đổi giữa các tiến trình là rất lớn, trong khi chi phí chuyển đổi giữa các luồng thấp hơn.
- Luồng nhẹ hơn và một tiến trình có thể tạo ra nhiều luồng.
- Nhiều luồng có thể xử lý đồng thời các nhiệm vụ khác nhau, tận dụng hiệu quả hơn các máy tính đa xử lý và đa nhân. Trong khi đó, một tiến trình chỉ có thể làm một việc trong một thời điểm, nếu gặp vấn đề chặn như chặn IO trong quá trình thực thi, nó sẽ bị treo đến khi kết quả trả về.
- Các luồng trong cùng một tiến trình chia sẻ bộ nhớ và tệp, do đó, chúng không cần gọi kernel để giao tiếp.
Tại sao nên sử dụng đa luồng?
Đầu tiên, nói về tổng quan:
- Từ góc độ của máy tính:
- Luồng có thể coi là tiến trình nhẹ, là đơn vị thực thi nhỏ nhất của chương trình. Chi phí chuyển đổi và lập lịch giữa các luồng thấp hơn so với tiến trình. Ngoài ra, trong thời đại CPU đa nhân, nhiều luồng có thể chạy đồng thời, giảm thiểu chi phí chuyển đổi giữa các luồng.
- Từ xu hướng phát triển Internet hiện đại:
- Hệ thống hiện nay yêu cầu hàng triệu hoặc thậm chí hàng chục triệu lượt truy cập đồng thời. Lập trình đa luồng là cơ sở để phát triển hệ thống đa nhiệm cao, tận dụng tốt cơ chế đa luồng có thể cải thiện khả năng đa nhiệm và hiệu suất tổng thể của hệ thống.
Tiếp theo, đi sâu vào máy tính:
- Thời đại CPU đơn nhân: Trong thời đại CPU đơn nhân, đa luồng chủ yếu để tăng hiệu suất sử dụng CPU và hệ thống IO của một tiến trình. Giả sử chỉ có một tiến trình Java đang chạy, khi chúng ta yêu cầu IO, nếu tiến trình Java chỉ có một luồng, luồng này bị chặn bởi IO và toàn bộ quá trình bị chặn. Chỉ có một CPU và thiết bị IO đang hoạt động, có thể đơn giản nói hiệu suất tổng thể của hệ thống chỉ là 50%. Khi sử dụng đa luồng, một luồng bị chặn bởi IO, các luồng khác vẫn có thể tiếp tục sử dụng CPU. Điều này cải thiện hiệu suất sử dụng tài nguyên hệ thống của tiến trình Java.
- Thời đại CPU đa nhân: Trong thời đại CPU đa nhân, đa luồng chủ yếu để tăng khả năng sử dụng nhiều lõi CPU của tiến trình. Ví dụ: Giả sử chúng ta cần tính toán một nhiệm vụ phức tạp, nếu chỉ sử dụng một luồng, bất kể hệ thống có bao nhiêu lõi CPU, chỉ có một lõi CPU được sử dụng. Tuy nhiên, khi tạo nhiều luồng, các luồng này có thể được ánh xạ vào nhiều CPU cơ bản khác nhau để thực thi. Trong trường hợp các luồng trong nhiệm vụ không cạnh tranh tài nguyên, hiệu suất thực thi nhiệm vụ sẽ được cải thiện đáng kể, xấp xỉ (thời gian thực thi đơn nhân / số lõi CPU).
Các phương pháp đồng bộ hóa luồng là gì?
Đồng bộ hóa luồng là quá trình đảm bảo sự thực thi đồng bộ và an toàn của các luồng đang chia sẻ tài nguyên quan trọng. Dưới đây là một số phương pháp đồng bộ hóa luồng phổ biến:
- Khóa Mutex (Mutual Exculsion): Sử dụng cơ chế đối tượng khóa, chỉ có luồng sở hữu khóa mới có quyền truy cập vào tài nguyên chia sẻ. Vì chỉ có một khóa, nên đảm bảo rằng tài nguyên chia sẻ không bị truy cập đồng thời bởi nhiều luồng. Ví dụ: Trong Java, từ khóa
synchronizedvà các lớpLockkhác đều sử dụng cơ chế này. - Khóa đọc/ghi (Read-Write Lock): Cho phép nhiều luồng đọc tài nguyên chia sẻ cùng một lúc, nhưng chỉ có một luồng có thể thực hiện ghi vào tài nguyên.
- Semaphore: Cho phép nhiều luồng truy cập vào tài nguyên chia sẻ cùng một lúc, nhưng kiểm soát số lượng luồng có thể truy cập vào tài nguyên trong cùng một thời điểm.
- Rào cản (Barrier): Là một nguyên tắc đồng bộ hóa, được sử dụng để đợi cho đến khi tất cả các luồng đạt đến một điểm nhất định trước khi tiếp tục thực thi cùng nhau. Khi một luồng đến rào cản, nó sẽ dừng thực thi và chờ đợi các luồng khác đến rào cản trước khi tiếp tục. Ví dụ: Trong Java, lớp
CyclicBarriersử dụng cơ chế này. - Sự kiện (Event): Sử dụng cơ chế thông báo để duy trì đồng bộ giữa các luồng. Nó cũng cho phép so sánh mức độ ưu tiên giữa các luồng một cách dễ dàng.
PCB là gì? Bao gồm những thông tin gì?
PCB (Process Control Block), hay còn gọi là Bảng Điều Khiển Tiến Trình, là một cấu trúc dữ liệu trong hệ điều hành được sử dụng để quản lý và theo dõi các tiến trình. Mỗi tiến trình sẽ có một PCB tương ứng. PCB có thể được coi như “bộ não” của tiến trình.
Khi hệ điều hành tạo ra một tiến trình mới, nó sẽ cấp phát một ID tiến trình duy nhất và tạo một PCB tương ứng cho tiến trình đó. Khi tiến trình được thực thi, thông tin trong PCB sẽ thay đổi theo thời gian và hệ điều hành sẽ sử dụng thông tin này để quản lý và lập lịch tiến trình.
PCB chứa các thông tin sau:
- Thông tin mô tả tiến trình, bao gồm tên tiến trình, định danh và các thông tin khác.
- Thông tin lập lịch tiến trình, bao gồm lý do tiến trình bị chặn, trạng thái tiến trình (sẵn sàng, đang chạy, bị chặn, v.v.), mức độ ưu tiên tiến trình (đánh dấu mức độ quan trọng của tiến trình).
- Thông tin về yêu cầu tài nguyên của tiến trình, bao gồm thời gian CPU, không gian bộ nhớ, thiết bị I/O, v.v.
- Thông tin về các tệp mở của tiến trình, bao gồm mô tả tệp, loại tệp, chế độ mở, v.v.
- Thông tin về trạng thái của bộ xử lý (được tạo thành từ nội dung của các thanh ghi của bộ xử lý), bao gồm thanh ghi thông thường, bộ đếm lệnh, từ điển trạng thái chương trình (PSW), con trỏ ngăn xếp người dùng, v.v.
- ……
PCB là một thành phần quan trọng trong việc quản lý tiến trình và đảm bảo sự chính xác và an toàn trong thực thi các tiến trình.
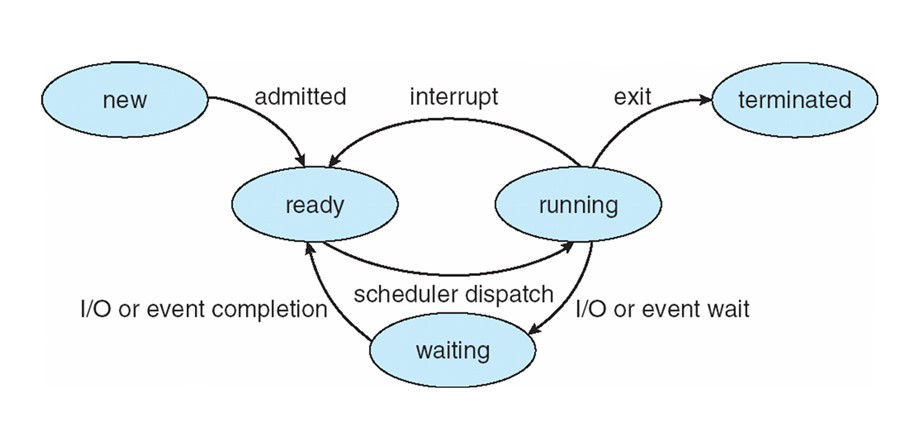
Các trạng thái của tiến trình là gì?
Chúng ta thường chia tiến trình thành khoảng 5 trạng thái chính, tương tự như luồng:
- Trạng thái Tạo mới (New): Tiến trình đang được tạo mới và chưa vào trạng thái sẵn sàng.
- Trạng thái Sẵn sàng (Ready): Tiến trình đã sẵn sàng để thực thi, có nghĩa là tiến trình đã có tất cả các tài nguyên cần thiết ngoại trừ bộ xử lý. Khi được cấp phát bộ xử lý (time slice), tiến trình sẽ chuyển sang trạng thái Chạy.
- Trạng thái Chạy (Running): Tiến trình đang chạy trên bộ xử lý (trong trường hợp CPU đơn nhân, chỉ có một tiến trình chạy tại một thời điểm).
- Trạng thái Bị chặn (Waiting): Còn được gọi là trạng thái Chờ đợi, tiến trình đang chờ đợi một sự kiện nào đó và tạm dừng thực thi, ví dụ như chờ tài nguyên sẵn có hoặc chờ hoàn thành thao tác IO. Ngay cả khi bộ xử lý trống, tiến trình này cũng không thể chạy.
- Trạng thái Kết thúc (Terminated): Tiến trình đang thoát khỏi hệ thống. Có thể là do tiến trình kết thúc bình thường hoặc bị gián đoạn và thoát khỏi thực thi.
Các phương pháp giao tiếp giữa các tiến trình là gì?
Tóm tắt:
- Ống/Ống vô danh (Pipe): Được sử dụng để giao tiếp giữa các tiến trình có quan hệ họ hàng, ví dụ như giữa tiến trình cha và tiến trình con hoặc giữa các tiến trình anh em.
- Ống có tên (Named Pipe): Ống vô danh chỉ có thể được sử dụng cho giao tiếp giữa các tiến trình có quan hệ họ hàng. Để khắc phục nhược điểm này, ống có tên được đề xuất. Ống có tên tuân thủ nguyên tắc First In First Out (FIFO). Ống có tên tồn tại dưới dạng tệp trên đĩa và cho phép giao tiếp giữa hai tiến trình bất kỳ trên cùng một máy.
- Tín hiệu (Signal): Tín hiệu là một phương pháp giao tiếp phức tạp hơn, được sử dụng để thông báo cho tiến trình nhận biết rằng một sự kiện nào đó đã xảy ra.
- Hàng đợi tin nhắn (Message Queue): Hàng đợi tin nhắn là một danh sách liên kết các tin nhắn, có định dạng cụ thể và được lưu trữ trong bộ nhớ và được định danh bằng một số nhận dạng hàng đợi tin nhắn. Dữ liệu giao tiếp qua ống và hàng đợi tin nhắn đều tuân thủ nguyên tắc FIFO. Tuy nhiên, khác với ống (ống vô danh: chỉ tồn tại trong bộ nhớ; ống có tên: tồn tại trên thiết bị lưu trữ thực tế hoặc hệ thống tệp), hàng đợi tin nhắn được lưu trữ trong kernel và chỉ bị xóa thực sự khi kernel khởi động lại (tức là hệ điều hành khởi động lại) hoặc được xóa một cách rõ ràng.
- Đếm đồng bộ (Semaphore): Semaphore là một bộ đếm, được sử dụng để đồng bộ hóa truy cập dữ liệu chia sẻ của nhiều tiến trình. Mục đích của semaphore là đồng bộ hóa giữa các tiến trình. Phương pháp giao tiếp này chủ yếu được sử dụng để giải quyết các vấn đề liên quan đến đồng bộ và tránh các điều kiện cạnh tranh.
- Bộ nhớ chia sẻ (Shared Memory): Cho phép nhiều tiến trình truy cập vào cùng một vùng bộ nhớ, cho phép các tiến trình khác nhau nhìn thấy các cập nhật dữ liệu trong bộ nhớ chia sẻ. Phương pháp này yêu cầu sự đồng bộ hóa bằng cách sử dụng các phép toán như khóa mutex và semaphore. Nó có thể coi là phương pháp giao tiếp giữa các tiến trình hiệu quả nhất.
- Socket: Phương pháp này chủ yếu được sử dụng để giao tiếp qua mạng giữa máy khách và máy chủ. Socket là đơn vị cơ bản để giao tiếp mạng hỗ trợ TCP/IP, có thể coi là điểm kết nối hai chiều giữa các tiến trình trên các máy chủ khác nhau, được thực hiện bằng cách sử dụng các hàm liên quan đến socket.
Các thuật toán lập lịch tiến trình là gì?
Đây là một khái niệm quan trọng! Để xác định tiến trình nào được thực thi trước và tiến trình nào được thực thi cuối cùng để đạt được tối đa hiệu suất sử dụng CPU, các nhà khoa học máy tính đã định nghĩa một số thuật toán, bao gồm:
- First Come, First Served (FCFS): Chọn tiến trình đầu tiên đến hàng đợi sẵn sàng để phân bổ tài nguyên cho nó, cho phép nó chạy ngay lập tức và tiếp tục chạy cho đến khi hoàn thành hoặc bị chặn bởi một sự kiện nào đó và cần phải được lập lịch lại.
- Shortest Job First (SJF): Chọn tiến trình có thời gian thực thi ước tính ngắn nhất từ hàng đợi sẵn sàng để phân bổ tài nguyên cho nó, cho phép nó chạy ngay lập tức và tiếp tục chạy cho đến khi hoàn thành hoặc bị chặn bởi một sự kiện nào đó và cần phải được lập lịch lại.
- Round-Robin (RR): Thuật toán Round-Robin là một trong những thuật toán lập lịch cổ điển nhất, đơn giản nhất, công bằng nhất và phổ biến nhất. Mỗi tiến trình được cấp một khoảng thời gian, gọi là time slice, tức là thời gian tiến trình được phép chạy.
- Multi-level Feedback Queue (MFQ): Các thuật toán lập lịch tiến trình trước đây có một số hạn chế. Ví dụ: thuật toán SJF chỉ quan tâm đến tiến trình ngắn mà bỏ qua tiến trình dài. Thuật toán MFQ không chỉ đáp ứng các công việc ưu tiên cao mà còn giúp tiến trình ngắn (tiến trình) hoàn thành nhanh chóng. Do đó, nó được coi là một trong những thuật toán lập lịch tiến trình tốt nhất hiện nay và được sử dụng rộng rãi trong hệ điều hành UNIX.
- Ưu tiên (Priority): Mỗi tiến trình được gán một mức ưu tiên và tiến trình có mức ưu tiên cao nhất được thực thi trước, và tiếp tục như vậy. Các tiến trình có cùng mức ưu tiên sẽ được thực thi theo thứ tự FCFS. Ưu tiên có thể được xác định dựa trên yêu cầu bộ nhớ, yêu cầu thời gian hoặc bất kỳ yêu cầu tài nguyên nào khác.
Định nghĩa tiến trình zombie và tiến trình mồ côi là gì?
Trong hệ thống Unix/Linux, tiến trình con thường được tạo ra bằng cách sử dụng cuộc gọi hệ thống fork(), cuộc gọi này sẽ tạo ra một tiến trình mới, là một bản sao của tiến trình gốc. Tiến trình con và tiến trình cha chạy độc lập với nhau, mỗi tiến trình đều có một bảng điều khiển quá trình (PCB) riêng, ngay cả khi tiến trình cha kết thúc, tiến trình con vẫn có thể tiếp tục chạy.
Khi một tiến trình gọi cuộc gọi hệ thống exit() để kết thúc cuộc sống của nó, hạt nhân sẽ giải phóng tất cả các tài nguyên của tiến trình đó, bao gồm các tệp mở, bộ nhớ đã sử dụng, nhưng PCB tương ứng vẫn tồn tại trong hệ thống. Thông tin này chỉ được giải phóng khi tiến trình cha gọi cuộc gọi hệ thống wait() hoặc waitpid() để lấy thông tin trạng thái của tiến trình con.
Thiết kế này cho phép tiến trình cha nhận thông tin trạng thái của tiến trình con khi nó kết thúc và ngăn chặn tiến trình zombie (tiến trình con kết thúc nhưng PCB vẫn tồn tại nhưng tiến trình cha không thể lấy thông tin trạng thái).
- Tiến trình zombie: Tiến trình con đã kết thúc, nhưng tiến trình cha vẫn đang chạy và không gọi cuộc gọi hệ thống wait() hoặc waitpid() để lấy thông tin trạng thái của tiến trình con, giải phóng tài nguyên mà tiến trình con đã sử dụng. Trong trường hợp này, tiến trình con được gọi là “tiến trình zombie”. Để tránh tiến trình zombie, tiến trình cha cần gọi cuộc gọi hệ thống wait() hoặc waitpid() kịp thời để thu hồi tiến trình con.
- Tiến trình mồ côi: Một tiến trình mồ côi là một tiến trình mà tiến trình cha của nó đã kết thúc hoặc không tồn tại, nhưng tiến trình đó vẫn đang chạy. Trong trường hợp này, tiến trình được gọi là “tiến trình mồ côi”. Tiến trình mồ côi thường xảy ra khi tiến trình cha kết thúc mà không gọi cuộc gọi hệ thống wait() hoặc waitpid() để thu hồi tiến trình con. Để tránh tiến trình mồ côi tiêu tốn tài nguyên hệ thống, hệ điều hành sẽ đặt tiến trình mồ côi có tiến trình cha là quá trình init (với số tiến trình là 1), tiến trình init sẽ thu hồi tài nguyên của tiến trình mồ côi.
Deadlock (Bế tắc)
Định nghĩa deadlock là gì?
Deadlock (Bế tắc) mô tả một tình huống trong đó nhiều tiến trình/luồng bị chặn đứng, một hoặc tất cả chúng đang chờ đợi một tài nguyên nào đó được giải phóng. Vì các tiến trình/luồng bị chặn vô thời hạn, chương trình không thể kết thúc một cách bình thường.
Bạn có thể đưa ra một ví dụ về deadlock trong hệ điều hành không?
Giả sử có hai tiến trình A và B, cùng với hai tài nguyên X và Y, phân bổ tài nguyên như sau:
| Tiến trình | Tài nguyên đã sử dụng | Tài nguyên cần |
|---|---|---|
| A | X | Y |
| B | Y | X |
Lúc này, tiến trình A đã sử dụng tài nguyên X và yêu cầu tài nguyên Y, trong khi tiến trình B đã sử dụng tài nguyên Y và yêu cầu tài nguyên X. Cả hai tiến trình đều đang chờ đợi nhau giải phóng tài nguyên, không thể tiếp tục thực thi và rơi vào trạng thái deadlock.
Các điều kiện cần thiết để xảy ra deadlock là gì?
- Loại trừ lẫn nhau (Mutual Exclusion): Tài nguyên phải ở chế độ không thể chia sẻ, có nghĩa là chỉ có một tiến trình có thể sử dụng tài nguyên tại một thời điểm. Nếu một tiến trình khác yêu cầu tài nguyên đó, nó phải chờ đến khi tài nguyên được giải phóng.
- Chiếm giữ và chờ (Hold and Wait): Một tiến trình phải giữ ít nhất một tài nguyên và đang chờ đợi một tài nguyên khác mà bị chiếm giữ bởi một tiến trình khác.
- Không thể giành lại (No Preemption): Tài nguyên không thể bị giành lại từ một tiến trình khi nó đang sử dụng. Tài nguyên chỉ có thể được giải phóng khi tiến trình hoàn thành công việc của nó.
- Vòng lặp chờ đợi (Circular Wait): Có một chuỗi các tiến trình, mỗi tiến trình trong chuỗi đang chờ đợi tài nguyên được giữ bởi tiến trình kế tiếp trong chuỗi. Tiến trình cuối cùng trong chuỗi đang chờ đợi tài nguyên được giữ bởi tiến trình đầu tiên trong chuỗi.
Lưu ý: Đây là các điều kiện cần thiết để xảy ra deadlock, nghĩa là nếu hệ thống gặp phải deadlock, các điều kiện này sẽ tồn tại. Tuy nhiên, nếu một trong các điều kiện trên không được thỏa mãn, deadlock sẽ không xảy ra.
Bạn có thể viết một đoạn mã mô phỏng deadlock không?
Dưới đây là một đoạn mã mô phỏng deadlock dựa trên ví dụ sau:
public class DeadLockDemo {
private static Object resource1 = new Object(); // Tài nguyên 1
private static Object resource2 = new Object(); // Tài nguyên 2
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread().getName() + " đã có resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " đang chờ resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread().getName() + " đã có resource2");
}
}
}, "Thread 1");
Thread thread2 = new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread().getName() + " đã có resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " đang chờ resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread().getName() + " đã có resource1");
}
}
}, "Thread 2");
thread1.start();
thread2.start();
}
}Kết quả:
Thread 1 đã có resource1
Thread 2 đã có resource2
Thread 1 đang chờ resource2
Thread 2 đang chờ resource1Tiến trình A sử dụng synchronized (resource1) để có được khóa giám sát của resource1, sau đó sử dụng Thread.sleep(1000); để cho phép tiến trình B được thực thi và có được khóa giám sát của resource2. Cả tiến trình A và tiến trình B đã kết thúc việc ngủ và bắt đầu yêu cầu tài nguyên của nhau, dẫn đến tình trạng chờ đợi lẫn nhau, tạo thành deadlock.
Phương pháp giải quyết deadlock
Có nhiều phương pháp để giải quyết deadlock, thông thường chúng được chia thành bốn loại: phòng ngừa, tránh, phát hiện và giải phóng.
-
Phòng ngừa (Prevention): Sử dụng các chiến lược để hạn chế yêu cầu tài nguyên đồng thời của các tiến trình để đảm bảo rằng các điều kiện cần thiết để xảy ra deadlock không được đáp ứng trong hệ thống. Phòng ngừa deadlock thường liên quan đến việc phá vỡ một hoặc nhiều trong số bốn điều kiện cần thiết để xảy ra deadlock.
-
Tránh (Avoidance): Hệ thống dự đoán và quản lý việc phân bổ tài nguyên dựa trên thông tin về việc sử dụng tài nguyên của các tiến trình. Bằng cách đánh giá tiềm năng của các yêu cầu tài nguyên, hệ thống có thể tránh phân bổ tài nguyên mà có thể dẫn đến deadlock. Một trong những thuật toán phổ biến để tránh deadlock là thuật toán ngân hàng (banker’s algorithm).
-
Phát hiện (Detection): Hệ thống sử dụng các thuật toán để phát hiện xem deadlock đã xảy ra hay chưa. Các thuật toán phát hiện deadlock quét qua các tiến trình và tài nguyên để tìm kiếm các chu trình chờ đợi tài nguyên. Khi một chu trình chờ đợi tài nguyên được tìm thấy, hệ thống có thể thực hiện các biện pháp như tắt các tiến trình hoặc giải phóng tài nguyên để giải quyết deadlock.
-
Giải phóng (Recovery): Hệ thống thực hiện các biện pháp để giải phóng deadlock. Các biện pháp này có thể bao gồm việc tắt các tiến trình hoặc giải phóng tài nguyên mà các tiến trình đang giữ để phá vỡ chu trình chờ đợi tài nguyên và giải quyết deadlock.
Phòng ngừa tình trạng bế tắc
Các điều kiện cần thiết để xảy ra tình trạng bế tắc đã được liệt kê ở trên, rõ ràng, chỉ cần phá vỡ bất kỳ điều kiện cần thiết nào trong bốn điều kiện đó thì có thể ngăn chặn xảy ra tình trạng bế tắc.
Phá vỡ điều kiện đầu tiên điều kiện độc quyền: làm cho các tài nguyên có thể truy cập đồng thời, đây là một phương pháp đơn giản, có thể quản lý ổ cứng bằng phương pháp này, nhưng chúng ta cần biết rằng có rất nhiều tài nguyên thường không thể truy cập đồng thời, vì vậy phương pháp này không thể áp dụng trong hầu hết các trường hợp.
Phá vỡ điều kiện thứ ba không thể thu hồi: có thể sử dụng giải thuật lập lịch cướp đoạt để phá vỡ điều kiện này, nhưng phương pháp lập lịch cướp đoạt hiện tại thường chỉ áp dụng cho việc phân phối tài nguyên bộ nhớ chính và tài nguyên xử lý, không áp dụng cho tất cả các tài nguyên, dẫn đến giảm hiệu suất sử dụng tài nguyên.
Vì vậy, phương pháp phòng ngừa tình trạng bế tắc thường được sử dụng là bằng cách xem xét việc phá vỡ điều kiện thứ hai và thứ tư.
1. Chiến lược phân phối tĩnh
Chiến lược phân phối tĩnh có thể phá vỡ điều kiện thứ hai của tình trạng bế tắc (sở hữu và chờ đợi). Chiến lược phân phối tĩnh đề cập đến việc một tiến trình phải yêu cầu tất cả các tài nguyên cần thiết trước khi bắt đầu thực thi và chỉ bắt đầu thực thi khi tất cả các tài nguyên mà nó cần đã được đáp ứng. Tiến trình có thể sở hữu tất cả các tài nguyên sau đó bắt đầu thực thi, hoặc không sở hữu tài nguyên nào, không có trường hợp tiến trình sở hữu một số tài nguyên và chờ đợi một số tài nguyên.
Chiến lược phân phối tĩnh có logic đơn giản, dễ triển khai, nhưng phương pháp này giảm nghiêm trọng hiệu suất sử dụng tài nguyên, vì trong tất cả các tài nguyên mà mỗi tiến trình sở hữu, có một số tài nguyên được sử dụng trong thời gian thực sự muộn hơn, thậm chí có một số tài nguyên chỉ được sử dụng trong các trường hợp bổ sung, điều này có thể dẫn đến một tiến trình sở hữu một số tài nguyên gần như không được sử dụng và khiến cho các tiến trình khác cần tài nguyên đó phải chờ đợi.
2. Chiến lược phân phối theo tầng
Chiến lược phân phối theo tầng phá vỡ điều kiện thứ tư của tình trạng bế tắc (chuỗi chờ đợi). Theo chiến lược phân phối theo tầng, tất cả các tài nguyên được chia thành nhiều tầng, một tiến trình chỉ có thể yêu cầu tài nguyên ở một tầng thấp hơn; khi một tiến trình muốn giải phóng một tài nguyên ở một tầng nào đó, nó phải giải phóng tất cả các tài nguyên ở tầng cao hơn mà nó đang sở hữu. Theo cách này, không thể xảy ra chuỗi chờ đợi vòng lặp, vì nếu như vậy, tiến trình đã yêu cầu tài nguyên ở tầng cao hơn và sau đó lại yêu cầu tài nguyên ở tầng thấp hơn, không phù hợp với chiến lược phân phối theo tầng.
Tránh tình trạng bế tắc
Phá vỡ một trong bốn điều kiện cần thiết để xảy ra tình trạng bế tắc đã được đề cập ở trên có thể ngăn chặn xảy ra tình trạng bế tắc trong hệ thống. Tuy nhiên, điều này có thể dẫn đến hiệu suất thấp của quá trình thực thi và sử dụng tài nguyên. Trái lại, tránh tình trạng bế tắc cho phép tồn tại cùng lúc bốn điều kiện cần thiết, miễn là ta có kiểm soát được việc yêu cầu và phân bổ tài nguyên của mỗi tiến trình và đưa ra lựa chọn thông minh và hợp lý. Điều này vẫn có thể tránh được tình trạng bế tắc vì bốn điều kiện chỉ là điều kiện cần để xảy ra tình trạng bế tắc.
Chúng ta chia trạng thái của hệ thống thành trạng thái an toàn và trạng thái không an toàn. Mỗi khi kiểm tra trạng thái hệ thống trước khi phân bổ tài nguyên cho một tiến trình, nếu việc phân bổ tài nguyên cho tiến trình sẽ dẫn đến tình trạng bế tắc, chúng ta sẽ từ chối phân bổ. Ngược lại, nếu hệ thống vẫn ở trạng thái an toàn sau khi phân bổ tài nguyên cho tiến trình, chúng ta sẽ chấp nhận yêu cầu và phân bổ tài nguyên cho tiến trình đó.
Nếu hệ điều hành có thể đảm bảo tất cả các tiến trình sẽ nhận được toàn bộ tài nguyên cần thiết trong một khoảng thời gian hữu hạn, thì hệ thống được coi là ở trạng thái an toàn, ngược lại, hệ thống được coi là không an toàn. Rõ ràng, nếu hệ thống ở trạng thái an toàn, thì không có tình trạng bế tắc xảy ra, và nếu hệ thống ở trạng thái không an toàn, thì có thể xảy ra tình trạng bế tắc.
Vậy làm thế nào để đảm bảo hệ thống luôn ở trạng thái an toàn? Bằng cách sử dụng thuật toán, thuật toán tránh tình trạng bế tắc tiêu biểu là thuật toán ngân hàng của Dijkstra. Thuật toán ngân hàng cho phép tiến trình thử nghiệm yêu cầu tài nguyên trước, sau đó sử dụng thuật toán an toàn để kiểm tra xem hệ thống có ở trong trạng thái an toàn sau khi phân bổ hay không. Nếu không an toàn, yêu cầu thử nghiệm bị hủy bỏ và tiến trình tiếp tục chờ đợi, nếu hệ thống có thể vào trạng thái an toàn, tài nguyên sẽ được phân bổ cho tiến trình thực sự.
Chi tiết về thuật toán Banker có thể được xem tại: Banker’s Algorithm in Operating System - GeeksforGeeks
Phương pháp tránh tình trạng bế tắc (thuật toán ngân hàng) cải thiện vấn đề hiệu suất sử dụng tài nguyên thấp, nhưng nó yêu cầu kiểm tra liên tục việc sử dụng và yêu cầu tài nguyên của mỗi tiến trình, cùng với việc thực hiện kiểm tra an toàn, điều này đòi hỏi nhiều thời gian và công sức.
Kiểm tra tình trạng bế tắc
Giới hạn phân bổ tài nguyên có thể ngăn chặn và tránh tình trạng bế tắc, nhưng đồng thời cũng không tạo điều kiện cho việc chia sẻ tài nguyên một cách tối đa giữa các tiến trình. Một phương pháp khác để giải quyết vấn đề bế tắc là kiểm tra và giải quyết bế tắc (đây gợi nhớ đến khái niệm của khóa lạc quan và khóa bi quan, cảm giác như kiểm tra và giải quyết bế tắc giống như khóa lạc quan, không quan tâm đến việc có xảy ra bế tắc hay không khi phân bổ tài nguyên, chỉ khi thực sự xảy ra bế tắc thì mới giải quyết, trong khi phòng ngừa và tránh bế tắc giống như khóa bi quan, luôn cho rằng bế tắc sẽ xảy ra, vì vậy khi phân bổ tài nguyên rất cẩn thận).
Phương pháp này không giới hạn phân bổ tài nguyên và không áp dụng biện pháp tránh bế tắc, mà thay vào đó, hệ thống chạy định kỳ một chương trình “kiểm tra bế tắc”, kiểm tra xem hệ thống có bị bế tắc hay không. Nếu phát hiện tình trạng bế tắc, các biện pháp sẽ được thực hiện để giải quyết nó.
Đồ thị phân bổ tiến trình-tài nguyên
Mỗi trạng thái của hệ thống tại mỗi thời điểm trong hệ điều hành có thể được biểu diễn bằng đồ thị phân bổ tiến trình-tài nguyên, là một đồ thị có hướng mô tả mối quan hệ giữa tiến trình và yêu cầu và phân bổ tài nguyên. Nó được sử dụng để kiểm tra xem hệ thống có ở trạng thái bế tắc hay không.
Mỗi tài nguyên được biểu diễn bằng một hình vuông, các điểm đen trong hình vuông đại diện cho các tài nguyên cụ thể trong tài nguyên đó. Mỗi tiến trình được biểu diễn bằng một hình tròn, và các cạnh có hướng biểu thị cho yêu cầu và phân bổ tài nguyên của tiến trình.
Hình 2-21 là một ví dụ về đồ thị phân bổ tiến trình-tài nguyên, trong đó có ba lớp tài nguyên và tình trạng sở hữu và yêu cầu tài nguyên của mỗi tiến trình được biểu diễn rõ ràng trong đồ thị. Trong ví dụ này, do có chu trình chờ và sở hữu tài nguyên, một nhóm tiến trình luôn ở trạng thái chờ tài nguyên, dẫn đến tình trạng bế tắc.
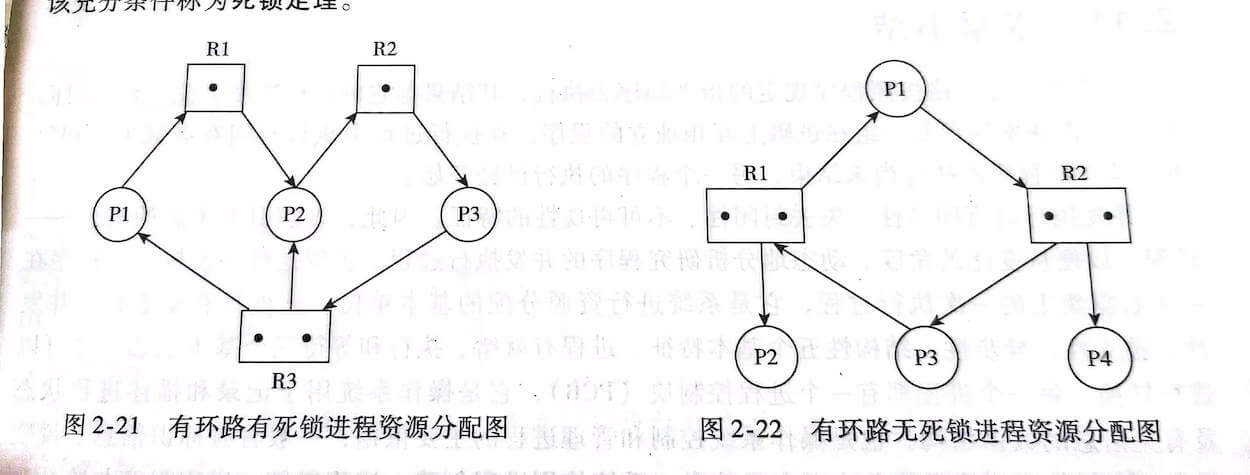
Tuy nhiên, việc có chu trình chờ tài nguyên trong đồ thị phân bổ tiến trình-tài nguyên không nhất thiết là đã xảy ra tình trạng bế tắc. Vì chu trình chờ tài nguyên chỉ là điều kiện cần để xảy ra tình trạng bế tắc, không phải là điều kiện đủ. Hình 2-22 là một ví dụ về một đồ thị có chu trình chờ tài nguyên mà không có tình trạng bế tắc. Mặc dù tiến trình P1 và P3 đều sở hữu một tài nguyên R1 và R2 tương ứng, và tạo ra chu trình chờ tài nguyên bằng cách chờ một tài nguyên R2 và R1 khác, tiến trình P2 và P4 cũng sở hữu một tài nguyên R1 và R2 tương ứng, yêu cầu tài nguyên của họ đã được đáp ứng, và sau một thời gian hạn chế, họ sẽ trả lại tài nguyên, do đó tiến trình P1 hoặc P3 có thể nhận được tài nguyên cần thiết, chu trình sẽ tự động giải quyết và hệ thống không có tình trạng bế tắc.
Bước kiểm tra tình trạng bế tắc
Hiểu được nguyên lý kiểm tra tình trạng bế tắc, chúng ta có thể sử dụng các bước sau để viết một chương trình kiểm tra tình trạng bế tắc, kiểm tra xem hệ thống có bị bế tắc hay không.
- Nếu không có chu trình chờ tài nguyên trong đồ thị phân bổ tiến trình-tài nguyên, thì hệ thống không có tình trạng bế tắc.
- Nếu có chu trình chờ tài nguyên trong đồ thị phân bổ tiến trình-tài nguyên và mỗi lớp tài nguyên chỉ có một tài nguyên, thì hệ thống đã bị bế tắc.
- Nếu có chu trình chờ tài nguyên trong đồ thị phân bổ tiến trình-tài nguyên và liên quan đến nhiều tài nguyên, thì hệ thống không nhất thiết phải bị bế tắc. Nếu có thể tìm ra một tiến trình không bị chặn và không độc lập trong đồ thị phân bổ tiến trình-tài nguyên, tiến trình đó có thể trả lại tài nguyên đã sở hữu trong một khoảng thời gian hạn chế, tức là loại bỏ cạnh, lặp lại quá trình này cho đến khi có thể loại bỏ tất cả các cạnh trong một khoảng thời gian hạn chế, thì không có tình trạng bế tắc xảy ra, ngược lại, sẽ xảy ra tình trạng bế tắc. (Quá trình loại bỏ cạnh tương tự như sắp xếp đồ thị).
Giải quyết tình trạng bế tắc
Khi chương trình kiểm tra tình trạng bế tắc phát hiện ra tình trạng bế tắc, cần phải tìm cách giải quyết nó để hệ thống có thể phục hồi từ trạng thái bế tắc. Có bốn phương pháp thông thường để giải quyết tình trạng bế tắc:
- Kết thúc ngay lập tức tất cả các tiến trình và khởi động lại hệ điều hành: Phương pháp này đơn giản, nhưng công việc đã thực hiện trước đó sẽ bị hủy bỏ, gây thiệt hại lớn.
- Thu hồi tất cả các tiến trình liên quan đến tình trạng bế tắc và tiếp tục chạy sau khi giải quyết tình trạng bế tắc: Phương pháp này có thể hoàn toàn phá vỡ điều kiện chu trình chờ của bế tắc, nhưng sẽ gây ra mất mát lớn, ví dụ như một số tiến trình có thể đã tính toán trong một thời gian dài và các kết quả phần đã được xóa bỏ, khi thực hiện lại, cần tính toán lại từ đầu.
- Thu hồi lần lượt từng tiến trình liên quan đến tình trạng bế tắc và thu hồi tài nguyên cho đến khi tình trạng bế tắc được giải quyết.
- Cướp tài nguyên: Cướp lấy tài nguyên từ một hoặc một số tiến trình liên quan đến tình trạng bế tắc và phân phối lại tài nguyên đã cướp cho các tiến trình liên quan đến tình trạng bế tắc cho đến khi tình trạng bế tắc được giải quyết.