Redis Interview
Giới thiệu về Redis
Redis là gì
【Câu hỏi】
- Redis là gì?
- Redis có những tính năng và đặc điểm gì?
【Trả lời】
Redis là gì:
Redis là một cơ sở dữ liệu "in-memory" mã nguồn mở. Vì Redis triển khai các thao tác đọc ghi hoàn toàn trong bộ nhớ, do đó, tốc độ đọc ghi của nó rất nhanh.
- Hiệu suất cao - Do các thao tác đọc ghi của Redis đều triển khai trong bộ nhớ, nên hiệu suất rất cao.
- Khả năng xử lý song song cao - Redis đơn lẻ có thể đạt QPS (số yêu cầu mỗi giây) lên đến 10.0000+, gần gấp 10 lần so với MySQL.
Redis thường được sử dụng trong các trường hợp như bộ nhớ đệm, hàng đợi tin nhắn, khóa phân tán, v.v..
Tính năng và đặc điểm của Redis:
- Redis hỗ trợ nhiều kiểu dữ liệu. Như: String (chuỗi), Hash (băm), List (danh sách), Set (tập hợp), Zset (tập hợp có thứ tự), Bitmaps (bản đồ bit), HyperLogLog (thống kê cardinal), GEO (không gian địa lý), Stream (dòng).
- Redis sử dụng mô hình "đơn luồng" để đọc ghi, do đó, các thao tác của nó có tính nguyên tử.
- Redis hỗ trợ hai chiến lược lưu trữ: RDB và AOF.
- Redis có nhiều giải pháp khả dụng cao: chế độ sao chép Master-Slave, chế độ sentinel, chế độ cụm.
- Redis hỗ trợ nhiều tính năng phong phú như: giao dịch, kịch bản Lua, xuất bản/đăng ký, xóa dữ liệu hết hạn, loại bỏ bộ nhớ, v.v.
Các trường hợp ứng dụng của Redis
【Câu hỏi】
- Redis có những trường hợp ứng dụng nào?
【Trả lời】
- Bộ nhớ đệm - Đặt dữ liệu nóng vào bộ nhớ, thiết lập giới hạn sử dụng bộ nhớ tối đa và chiến lược loại bỏ hết hạn để đảm bảo tỷ lệ truy xuất bộ nhớ đệm.
- Bộ đếm - Redis là cơ sở dữ liệu trong bộ nhớ có thể hỗ trợ các thao tác đọc ghi thường xuyên của bộ đếm.
- Giới hạn truy cập ứng dụng - Giới hạn lưu lượng truy cập vào một trang web.
- Hàng đợi tin nhắn - Sử dụng kiểu dữ liệu List, là một danh sách liên kết hai chiều.
- Bảng tra cứu - Sử dụng kiểu dữ liệu HASH.
- Tính toán tập hợp - Sử dụng kiểu dữ liệu SET, ví dụ như để tìm bạn chung của hai người dùng.
- Bảng xếp hạng - Sử dụng kiểu dữ liệu ZSET.
- Session phân tán - Session của nhiều máy chủ ứng dụng đều được lưu trữ trong Redis để đảm bảo tính nhất quán của Session.
- Khóa phân tán - Ngoài việc sử dụng SETNX để triển khai khóa phân tán, bạn còn có thể sử dụng RedLock - khóa phân tán chính thức do Redis cung cấp.
Redis vs. Memcached
【Câu hỏi】
- Redis và Memcached có những điểm giống nhau nào?
- Redis và Memcached có những khác biệt nào?
- Khi lựa chọn công nghệ bộ nhớ đệm phân tán, nên chọn Redis hay Memcached, tại sao?
【Trả lời】
Điểm giống nhau giữa Redis và Memcached:
- Cả hai đều là cơ sở dữ liệu trong bộ nhớ, do đó hiệu suất đều rất cao.
- Cả hai đều có chiến lược hết hạn.
Vì hai điểm trên, chúng thường được sử dụng làm bộ nhớ đệm.
Điểm khác nhau giữa Redis và Memcached:
| Redis | Memcached | |
|---|---|---|
| kiểu dữ liệu | Hỗ trợ nhiều kiểu dữ liệu: String, Hash, List, Set, ZSet, v.v. | Chỉ hỗ trợ kiểu dữ liệu String |
| Lưu trữ lâu dài | Hỗ trợ hai chiến lược lưu trữ lâu dài: RDB và AOF | Không hỗ trợ lưu trữ lâu dài, dữ liệu sẽ bị mất khi khởi động lại hoặc gặp sự cố |
| Phân tán | Hỗ trợ phân tán | Không hỗ trợ phân tán một cách tự nhiên, chỉ có thể triển khai phân tán bằng cách sử dụng thuật toán phân tán như hash nhất quán trên phía client, điều này đòi hỏi phải tính toán vị trí dữ liệu trên các nút trong quá trình lưu trữ và truy xuất dữ liệu |
| Mô hình luồng | Sử dụng mô hình đơn luồng + IO đa kênh, hiệu suất cao hơn khi lưu trữ dữ liệu nhỏ | Sử dụng mô hình đa luồng + IO đa kênh, hiệu suất cao hơn Redis khi xử lý dữ liệu lớn hơn 100k |
| Chức năng khác | Hỗ trợ mô hình pub/sub, Lua Script, giao dịch, v.v. | Không hỗ trợ |
Lựa chọn công nghệ bộ nhớ đệm phân tán:
Qua phân tích trên, có thể thấy Redis có nhiều ưu điểm hơn trong nhiều khía cạnh. Do đó, trong hầu hết các trường hợp, Redis nên được ưu tiên làm bộ nhớ đệm phân tán.
Redis tại sao lại nhanh
【Câu hỏi】
- Redis nhanh đến mức nào?
- Tại sao Redis lại nhanh như vậy?
【Trả lời】
Theo tài liệu Redis Official Benchmark, QPS của Redis đơn lẻ có thể đạt đến 10w+.
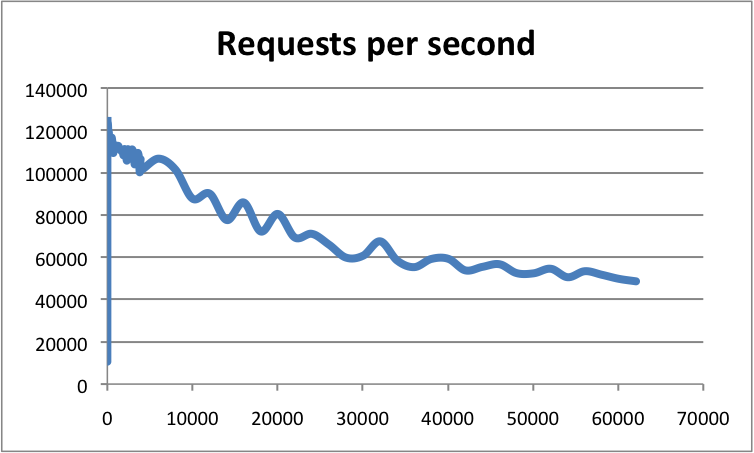
Redis sử dụng mô hình đơn luồng (Redis 6.0 đã hỗ trợ mô hình đa luồng), tại sao vẫn có thể đạt được độ đồng thời cao như vậy?
- Redis đọc/ghi dựa trên bộ nhớ
- IO đa luồng + Mô hình đơn luồng đọc/ghi
- IO đa luồng tận dụng khả năng của select, poll, epoll để theo dõi đồng thời nhiều sự kiện I/O trên nhiều luồng khác nhau. Khi rỗi, nó sẽ chặn luồng hiện tại và khi có một hoặc nhiều luồng có sự kiện I/O, nó sẽ đánh thức luồng này khỏi trạng thái chặn. Chương trình sau đó sẽ lặp qua tất cả các luồng (epoll chỉ lặp qua các luồng thực sự phát sinh sự kiện) và chỉ xử lý lần lượt các luồng đã sẵn sàng, điều này giúp tránh nhiều thao tác không cần thiết.
- Mô hình đơn luồng tránh được các chi phí phát sinh từ việc chuyển đổi luồng, cạnh tranh khóa do độ đồng thời.
- Vì Redis đọc/ghi dựa trên bộ nhớ, hiệu suất rất cao nên CPU không phải là giới hạn hiệu suất của Redis. Phần lớn bị giới hạn bởi kích thước bộ nhớ và I/O mạng, do đó việc sử dụng mô hình đơn luồng cho mạng lõi của Redis không gặp vấn đề gì.
- Cấu trúc dữ liệu hiệu quả
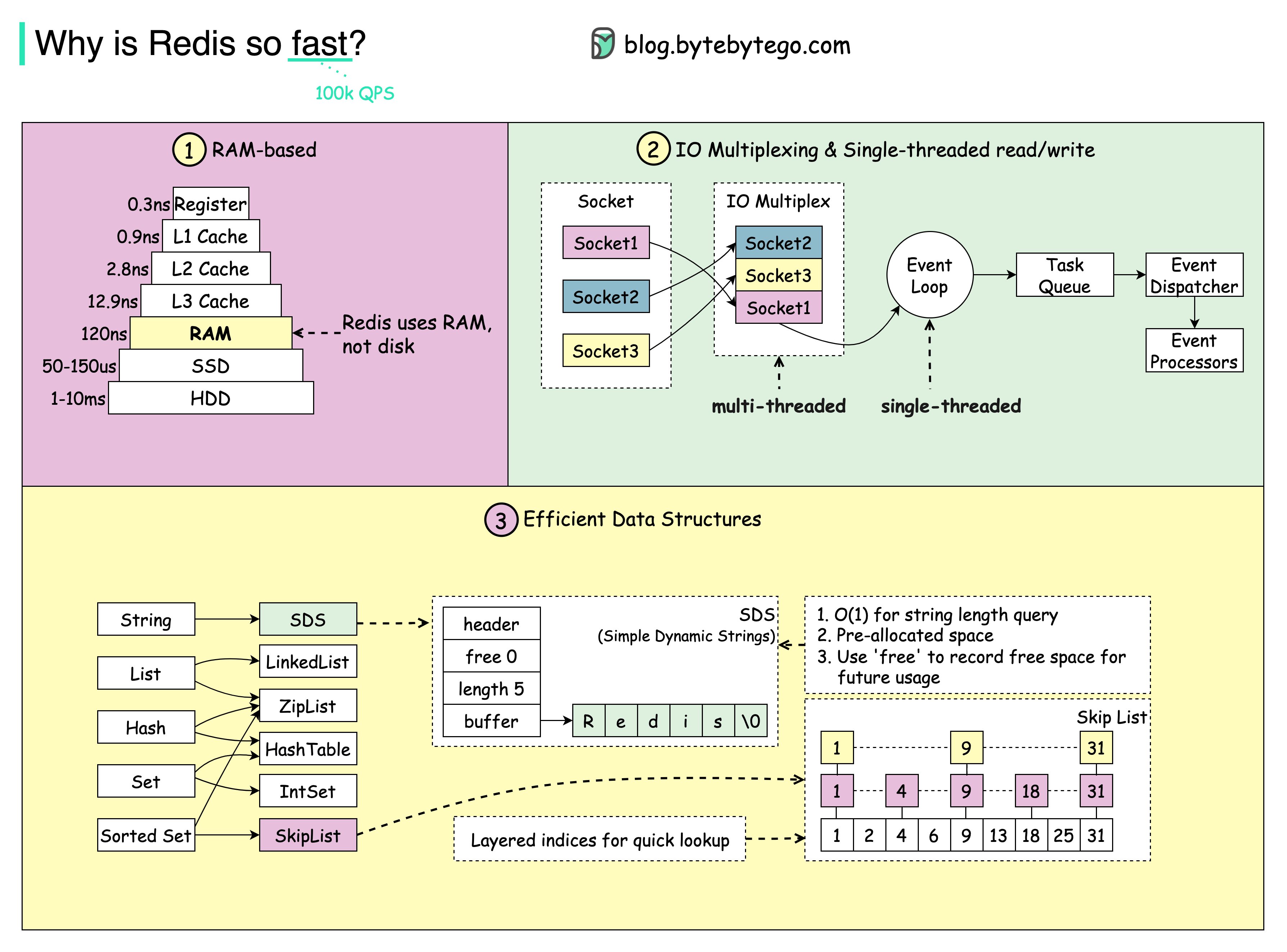
Hình ảnh từ Why is redis so fast?
Các Kiểu Dữ Liệu Redis
Redis Hỗ Trợ Những kiểu dữ Liệu Nào
【Câu hỏi】
- Redis hỗ trợ những kiểu dữ liệu nào?
【Trả lời】
- Redis hỗ trợ năm kiểu dữ liệu cơ bản: String (chuỗi), Hash (băm), List (danh sách), Set (tập hợp), Zset (tập hợp có thứ tự).
- Theo các phiên bản nâng cấp của Redis, còn hỗ trợ thêm các kiểu dữ liệu sau: BitMap (thêm từ phiên bản 2.2), HyperLogLog (thêm từ phiên bản 2.8), GEO (thêm từ phiên bản 3.2), Stream (thêm từ phiên bản 5.0).

Ứng Dụng Các kiểu dữ Liệu Của Redis
【Câu hỏi】
Ứng dụng của các kiểu dữ liệu trong Redis là gì?
【Trả lời】
String (chuỗi) - Dùng cho bộ nhớ đệm đối tượng, Session phân tán, khóa phân tán, bộ đếm, hạn chế lưu lượng, ID phân tán, v.v.
Hash (băm) - Dùng cho bộ nhớ đệm đối tượng, giỏ hàng mua sắm, v.v.
List (danh sách) - Dùng cho hàng đợi tin nhắn.
Set (tập hợp) - Dùng cho tính toán tổng hợp (hợp, giao, hiệu), như yêu thích, theo dõi chung, hoạt động rút thăm, v.v.
Zset (tập hợp có thứ tự) - Dùng cho các kịch bản sắp xếp như bảng xếp hạng, sắp xếp tên và số điện thoại, v.v.
BitMap (thêm từ phiên bản 2.2) - Dùng cho các kịch bản thống kê trạng thái nhị phân, ví dụ như điểm danh, kiểm tra trạng thái đăng nhập của người dùng, tổng số người dùng đăng nhập liên tục, v.v.
HyperLogLog (thêm từ phiên bản 2.8) - Dùng cho các kịch bản thống kê số lượng lớn dữ liệu, ví dụ như đếm UV trang web với quy mô hàng triệu.
GEO (thêm từ phiên bản 3.2) - Dùng cho các kịch bản lưu trữ thông tin vị trí địa lý, ví dụ như gọi xe trên ứng dụng.
Stream (thêm từ phiên bản 5.0) - Dùng cho hàng đợi tin nhắn, so với hàng đợi tin nhắn dựa trên List có các đặc điểm riêng như tạo tự động ID tin nhắn duy nhất, hỗ trợ tiêu thụ dữ liệu dưới dạng nhóm.

Triển khai Cơ Sở Các kiểu dữ Liệu Cơ Bản Trong Redis
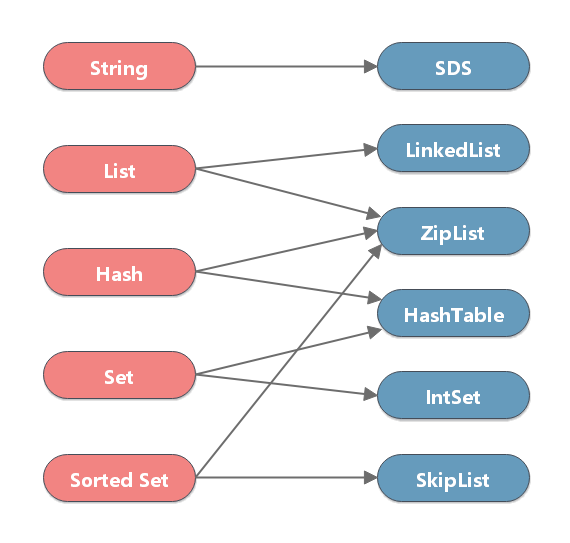
- Loại String - Loại String có cấu trúc dữ liệu cơ bản là SDS. SDS là sự tối ưu hóa cho loại chuỗi của Redis với các đặc điểm:
- Độ phức tạp cố định khi lấy độ dài chuỗi.
- Tránh tràn bộ đệm.
- Giảm số lần phân bổ lại bộ nhớ khi thay đổi độ dài chuỗi.
- Loại List - Mã hóa của đối tượng danh sách có thể là
ziplisthoặclinkedlist. Khi đối tượng danh sách thỏa mãn đồng thời hai điều kiện sau, sẽ sử dụng mã hóaziplist; nếu không sẽ sử dụng mã hóalinkedlist.- Tất cả các chuỗi phần tử của danh sách đều ngắn hơn
64byte. - Số lượng phần tử của danh sách ít hơn
512.
- Tất cả các chuỗi phần tử của danh sách đều ngắn hơn
- Loại Hash - Mã hóa của đối tượng băm có thể là
ziplisthoặchashtable. Khi đối tượng băm thỏa mãn đồng thời hai điều kiện sau, sẽ sử dụng mã hóaziplist; nếu không sẽ sử dụng mã hóahashtable.- Tất cả các khóa và giá trị của cặp khóa-giá trị của đối tượng băm đều ngắn hơn
64byte. - Số lượng cặp khóa-giá trị của đối tượng băm ít hơn
512.
- Tất cả các khóa và giá trị của cặp khóa-giá trị của đối tượng băm đều ngắn hơn
- Loại Set - Mã hóa của đối tượng tập hợp có thể là
intsethoặchashtable. Khi đối tượng tập hợp thỏa mãn đồng thời hai điều kiện sau, sẽ sử dụng mã hóaintset; nếu không sẽ sử dụng mã hóahashtable.- Tất cả các phần tử của tập hợp đều là giá trị nguyên.
- Số lượng phần tử của tập hợp không vượt quá
512.
- Loại Zset - Mã hóa của đối tượng tập hợp có thứ tự có thể là
ziplisthoặcskiplist. Khi đối tượng tập hợp có thứ tự thỏa mãn đồng thời hai điều kiện sau, sẽ sử dụng mã hóaziplist; nếu không sẽ sử dụng mã hóaskiplist.- Số lượng phần tử của tập hợp có thứ tự ít hơn
128. - Tất cả các phần tử thành viên của tập hợp có thứ tự có độ dài ngắn hơn
64byte.
- Số lượng phần tử của tập hợp có thứ tự ít hơn
Redis Quản Lý Hết Hạn và Loại Bỏ Bộ Nhớ
Chiến lược Xóa Hết Hạn Của Redis
【Câu hỏi】
- Chiến lược xóa hết hạn của Redis là gì?
【Trả lời】
Redis sử dụng chiến lược hết hạn là: Xóa định kỳ + Xóa lười biếng.
Xóa định thời - Khi cài đặt thời gian hết hạn cho khóa, Redis tạo ra một bộ đếm thời gian để triển khai xóa khóa ngay khi thời gian hết hạn đến.
- Ưu điểm - Đảm bảo khóa hết hạn được xóa nhanh nhất có thể, giải phóng bộ nhớ.
- Nhược điểm - Nếu có nhiều khóa hết hạn, có thể chiếm một phần lớn CPU, ảnh hưởng đến thông lượng và thời gian phản hồi của máy chủ.
Xóa lười biếng - Bỏ qua khóa hết hạn, nhưng mỗi khi truy cập vào khóa, kiểm tra xem khóa có hết hạn hay không. Nếu hết hạn, xóa khóa; nếu không, trả về khóa.
- Ưu điểm - Chiếm ít CPU nhất. Chương trình chỉ kiểm tra hết hạn khi đọc/ghi khóa hiện tại, không có thêm chi phí CPU.
- Nhược điểm - Khóa hết hạn có thể không được truy cập và không được giải phóng, gây lãng phí bộ nhớ, có nguy cơ rò rỉ bộ nhớ.
Xóa định kỳ - Cứ sau một khoảng thời gian, chương trình kiểm tra cơ sở dữ liệu và xóa các khóa hết hạn. Số lượng khóa cần xóa và số cơ sở dữ liệu cần kiểm tra được quyết định bởi thuật toán. Xóa định kỳ là một giải pháp trung hòa giữa hai chiến lược trước. Thách thức là thời lượng và tần suất triển khai thao tác xóa.
- triển khai quá thường xuyên hoặc thời gian quá dài, sẽ gặp vấn đề như xóa định kỳ.
- triển khai quá ít hoặc thời gian quá ngắn, sẽ gặp vấn đề như xóa lười biếng.
Xử Lý Khóa Hết Hạn Khi Lưu Trữ
RDB lưu trữ
- Giai đoạn tạo file RDB - Khi lưu trữ từ trạng thái bộ nhớ thành file RDB, kiểm tra khóa hết hạn, khóa hết hạn “không” được lưu vào file RDB mới, do đó khóa hết hạn trong Redis không ảnh hưởng đến việc tạo file RDB mới.
- Giai đoạn tải file RDB - Tải file RDB tùy thuộc vào việc máy chủ là chủ hay phụ, với các trường hợp sau:
- Nếu Redis chạy ở chế độ máy chủ chính, khi tải file RDB, chương trình kiểm tra khóa trong file, khóa hết hạn “không” được tải vào cơ sở dữ liệu. Do đó, khóa hết hạn không ảnh hưởng đến máy chủ chính khi tải file RDB.
- Nếu Redis chạy ở chế độ máy chủ phụ, khi tải file RDB, tất cả các khóa, bao gồm cả khóa hết hạn, đều được tải vào cơ sở dữ liệu. Nhưng do quá trình đồng bộ dữ liệu giữa máy chủ chính và phụ, dữ liệu của máy chủ phụ sẽ được xóa. Do đó, khóa hết hạn không ảnh hưởng đến máy chủ phụ khi tải file RDB.
AOF lưu trữ
- Giai đoạn ghi file AOF - Khi Redis lưu trữ bằng chế độ AOF, nếu có khóa hết hạn trong cơ sở dữ liệu mà chưa bị xóa, file AOF sẽ giữ khóa hết hạn đó. Khi khóa hết hạn bị xóa, Redis thêm lệnh DEL vào file AOF để xóa khóa đó.
- Giai đoạn viết lại AOF - Khi viết lại AOF, kiểm tra khóa trong Redis, khóa hết hạn không được lưu vào file AOF mới, do đó không ảnh hưởng đến việc viết lại AOF.
Xử Lý Khóa Hết Hạn Trong Quá Trình Sao Chép
Khi Redis chạy ở chế độ máy chủ chính - phụ, máy chủ phụ không quét khóa hết hạn một cách chủ động. Khóa hết hạn được xử lý phụ thuộc vào máy chủ chính. Khi khóa hết hạn trên máy chủ chính, máy chủ chính thêm lệnh DEL vào file AOF và đồng bộ lệnh này tới tất cả các máy chủ phụ. Máy chủ phụ thực thi lệnh DEL để xóa khóa hết hạn.
Chiến lược Loại Bỏ Bộ Nhớ Của Redis
【Câu hỏi】
- Redis làm gì khi bộ nhớ không đủ?
- Redis có những Chiến lược loại bỏ bộ nhớ nào?
- Làm sao chọn Chiến lược loại bỏ bộ nhớ?
【Trả lời】
(1) Các điểm chính của loại bỏ bộ nhớ Redis
- Thời gian hết hạn - Là một cơ chế xóa dữ liệu không còn hiệu lực quan trọng. Các lệnh như
EXPIRE,EXPIREAT,PEXPIRE,PEXPIREAT,SETEX, vàPSETEXdùng để cài đặt thời gian hết hạn cho khóa. Khóa sẽ tự động bị xóa khi hết hạn. - Bộ nhớ tối đa - Redis cho phép cài đặt bộ nhớ tối đa bằng tham số
maxmemory. Khi bộ nhớ đạt đến ngưỡng, sẽ kích hoạt quá trình loại bỏ bộ nhớ. - Loại bỏ bộ nhớ - Làm sạch một phần bộ nhớ để sử dụng tốt hơn, đảm bảo Redis chứa dữ liệu nóng.
(2) Các Chiến lược loại bỏ bộ nhớ của Redis
Không loại bỏ
noeviction- Khi bộ nhớ đạt ngưỡng, tất cả các lệnh yêu cầu bộ nhớ báo lỗi. Đây là chiến lược mặc định của Redis.
Loại bỏ trong các khóa hết hạn
volatile-random- Ngẫu nhiên xóa một khóa trong không gian khóa có thời gian hết hạn.volatile-ttl- Xóa khóa có thời gian hết hạn gần nhất trong không gian khóa có thời gian hết hạn.volatile-lru- Xóa khóa ít được sử dụng nhất trong không gian khóa có thời gian hết hạn.volatile-lfu(thêm từ Redis 4.0) - Xóa khóa ít được sử dụng nhất trong không gian khóa có thời gian hết hạn.
Loại bỏ trong tất cả các khóa
allkeys-lru- Xóa khóa ít được sử dụng nhất trong toàn bộ không gian khóa.allkeys-random- Ngẫu nhiên xóa một khóa trong toàn bộ không gian khóa.allkeys-lfu(thêm từ Redis 4.0) - Xóa khóa ít được sử dụng nhất trong toàn bộ không gian khóa.
(3) Cách chọn Chiến lược loại bỏ bộ nhớ
- Nếu dữ liệu có phân bố lũy thừa, nghĩa là một phần dữ liệu có tần suất truy cập cao, phần khác có tần suất thấp, dùng
allkeys-lruhoặcallkeys-lfu. - Nếu dữ liệu phân bố đồng đều, nghĩa là tất cả dữ liệu có tần suất truy cập như nhau, dùng
allkeys-random. - Nếu Redis vừa dùng cho bộ nhớ đệm, vừa cho lưu trữ bền vững, dùng
volatile-lru,volatile-lfu,volatile-random. Tuy nhiên, có thể triển khai hai cụm Redis để đạt mục đích tương tự. - Cài đặt thời gian hết hạn cho khóa tiêu thụ nhiều bộ nhớ hơn. Do đó, nếu điều kiện cho phép, nên dùng
allkeys-lruhoặcallkeys-lfuđể sử dụng bộ nhớ hiệu quả hơn.
【Câu hỏi】
- Redis có những chiến lược xóa dữ liệu nào?
- Những chiến lược xóa này phù hợp với những tình huống nào?
- Redis có những phương pháp nào để xóa các key không còn hiệu lực?
- Làm thế nào để đặt thời gian hết hạn cho các key trong Redis?
- Nếu được yêu cầu triển khai thuật toán LRU, bạn sẽ làm như thế nào?
【Trả lời】
(1) Chiến lược xóa dữ liệu trong Redis là: xóa định kỳ + xóa lười.
- Phương pháp tiêu cực (passive way): Khi truy cập vào một key và phát hiện rằng key đã hết hạn, Redis sẽ xóa key đó.
- Phương pháp tích cực (active way): Định kỳ chọn một số key đã đặt thời gian hết hạn và xóa chúng.
(2) Các chiến lược xóa dữ liệu trong Redis:
noeviction: Khi sử dụng hết bộ nhớ, tất cả các lệnh yêu cầu bộ nhớ sẽ bị lỗi. Đây là chiến lược mặc định của Redis.allkeys-lru: Trong không gian key chính, ưu tiên xóa các key không được sử dụng gần đây nhất.allkeys-random: Trong không gian key chính, xóa ngẫu nhiên một key.volatile-lru: Trong không gian key có đặt thời gian hết hạn, ưu tiên xóa các key không được sử dụng gần đây nhất.volatile-random: Trong không gian key có đặt thời gian hết hạn, xóa ngẫu nhiên một key.volatile-ttl: Trong không gian key có đặt thời gian hết hạn, ưu tiên xóa các key có thời gian hết hạn sớm hơn.
(3) Cách chọn chiến lược xóa dữ liệu:
- Nếu dữ liệu phân bố không đồng đều, tức là một số dữ liệu có tần suất truy cập cao, một số dữ liệu có tần suất truy cập thấp, hãy sử dụng
allkeys-lru. - Nếu dữ liệu phân bố đồng đều, tức là tất cả dữ liệu có cùng tần suất truy cập, hãy sử dụng
allkeys-random. - Chiến lược
volatile-lruvàvolatile-randomphù hợp khi ta muốn sử dụng một Redis instance cho cả việc caching và lưu trữ, tuy nhiên ta cũng có thể sử dụng hai Redis instance để đạt được cùng hiệu quả. - Đặt thời gian hết hạn cho key thực tế sẽ tiêu tốn nhiều bộ nhớ hơn, do đó, chúng tôi đề xuất sử dụng chiến lược
allkeys-lruđể tận dụng bộ nhớ hiệu quả hơn.
(4) Cách triển khai thuật toán LRU:
- Bạn có thể kế thừa lớp LinkedHashMap và ghi đè phương thức removeEldestEntry để triển khai một LRUCache đơn giản nhất.
Redis Lưu Trữ Dữ Liệu
Redis Làm Thế Nào Để Đảm Bảo Không Mất Dữ Liệu
【Câu hỏi】
- Redis làm thế nào để đảm bảo không mất dữ liệu?
- Redis có những cách lưu trữ dữ liệu nào?
【Giải đáp】
Để theo đuổi hiệu suất, các thao tác đọc và ghi của Redis đều được triển khai trong bộ nhớ. Một khi khởi động lại, dữ liệu trong bộ nhớ sẽ bị xóa. Để đảm bảo không mất dữ liệu, Redis hỗ trợ cơ chế lưu trữ dữ liệu.
Redis có ba cách lưu trữ dữ liệu:
- Ảnh chụp RDB
- Nhật ký AOF
- Lưu trữ kết hợp
Nguyên lý triển khai của AOF
【Câu hỏi】
- Nguyên lý triển khai của AOF là gì?
- Tại sao lại triển khai lệnh trước rồi mới ghi dữ liệu vào nhật ký?
【Giải đáp】
Yêu cầu lệnh của Redis sẽ được lưu vào bộ đệm AOF, sau đó định kỳ ghi và đồng bộ vào tệp AOF.
Việc triển khai AOF có thể được chia thành ba bước: thêm lệnh (append), ghi tệp, đồng bộ tệp (sync):
- Thêm lệnh - Khi máy chủ Redis bật chức năng AOF, sau khi triển khai xong một lệnh ghi, máy chủ sẽ thêm lệnh đã triển khai vào cuối bộ đệm AOF theo định dạng giao thức lệnh của Redis.
- Ghi tệp và Đồng bộ tệp
- Quá trình của máy chủ Redis là một vòng lặp sự kiện, trong đó các sự kiện tệp chịu trách nhiệm nhận yêu cầu lệnh từ khách hàng và gửi phản hồi lệnh cho khách hàng. Các sự kiện thời gian chịu trách nhiệm triển khai các chức năng chạy định kỳ như
serverCron. - Bởi vì máy chủ có thể triển khai các lệnh ghi trong khi xử lý các sự kiện tệp, các lệnh ghi này sẽ được thêm vào bộ đệm AOF. Máy chủ sẽ quyết định có cần ghi và đồng bộ nội dung trong bộ đệm AOF vào tệp AOF hay không dựa trên tùy chọn
appendfsyncmỗi khi kết thúc vòng lặp sự kiện.
- Quá trình của máy chủ Redis là một vòng lặp sự kiện, trong đó các sự kiện tệp chịu trách nhiệm nhận yêu cầu lệnh từ khách hàng và gửi phản hồi lệnh cho khách hàng. Các sự kiện thời gian chịu trách nhiệm triển khai các chức năng chạy định kỳ như
Việc triển khai lệnh trước rồi mới ghi dữ liệu vào nhật ký có hai lợi ích:
- Tránh chi phí kiểm tra bổ sung
- Không chặn việc triển khai lệnh ghi hiện tại
Tất nhiên, cách làm này cũng có nhược điểm:
- Dữ liệu có thể bị mất:
- Có thể chặn các thao tác khác:
Các Chiến Lược Ghi lại của AOF có Bao Nhiêu Loại
Yêu cầu lệnh của Redis sẽ được lưu vào bộ đệm AOF, sau đó định kỳ ghi và đồng bộ vào tệp AOF.
Tùy chọn khác nhau của appendfsync quyết định hành vi lưu trữ khác nhau:
always- Ghi và đồng bộ tất cả nội dung trong bộ đệm AOF vào tệp AOF. Cách này an toàn nhất về dữ liệu, nhưng hiệu suất kém nhất.no- Ghi tất cả nội dung trong bộ đệm AOF vào tệp AOF, nhưng không đồng bộ tệp AOF, thời điểm đồng bộ do hệ điều hành quyết định. Cách này là không an toàn nhất về dữ liệu, khi gặp sự cố, tất cả dữ liệu chưa kịp đồng bộ sẽ bị mất.everysec- Tùy chọn mặc định củaappendfsync. Ghi tất cả nội dung trong bộ đệm AOF vào tệp AOF, nếu thời gian từ lần đồng bộ AOF cuối cùng đến hiện tại đã quá một giây, thì sẽ triển khai đồng bộ tệp AOF. Hoạt động đồng bộ này được một luồng riêng triển khai. Cách này là phương án trung gian giữa hai cách trên - hiệu suất đủ tốt và ngay cả khi gặp sự cố, chỉ mất dữ liệu trong vòng một giây.
Các giá trị khác nhau của tùy chọn appendfsync ảnh hưởng lớn đến tính an toàn của chức năng lưu trữ AOF và hiệu suất của máy chủ Redis.
Cơ Chế Ghi Lại AOF
【Câu hỏi】
- Khi nhật ký AOF quá lớn, làm thế nào?
- Quá trình ghi lại AOF như thế nào?
- Khi ghi lại AOF, có thể xử lý yêu cầu không?
【Giải đáp】
Khi nhật ký AOF quá lớn, quá trình phục hồi sẽ rất lâu. Để tránh vấn đề này, Redis cung cấp cơ chế ghi lại AOF, tức là khi kích thước nhật ký AOF vượt quá ngưỡng đã đặt, sẽ kích hoạt ghi lại AOF để nén tệp AOF.
Cơ chế ghi lại AOF là đọc tất cả các cặp khóa-giá trị hiện tại trong cơ sở dữ liệu, sau đó ghi lại mỗi cặp khóa-giá trị bằng một lệnh vào nhật ký AOF mới. Khi ghi lại xong, sử dụng nhật ký AOF mới để thay thế nhật ký AOF hiện tại.
Vì đây là một chức năng phụ trợ, rõ ràng Redis không muốn chặn dịch vụ Redis khi ghi lại AOF. Do đó, Redis quyết định tạo một tiến trình con thông qua lệnh BGREWRITEAOF, sau đó tiến trình con chịu trách nhiệm ghi lại tệp AOF, tương tự với nguyên lý của BGSAVE.
- Khi triển khai lệnh
BGREWRITEAOF, máy chủ Redis sẽ duy trì một bộ đệm ghi lại AOF. Khi tiến trình con bắt đầu làm việc, Redis sẽ thêm lệnh triển khai vào cả bộ đệm AOF và bộ đệm ghi lại AOF sau mỗi lệnh ghi. - Do các tiến trình không hoạt động cùng nhau, việc ghi lại AOF không ảnh hưởng đến ghi và đồng bộ AOF. Khi tiến trình con hoàn thành việc tạo tệp AOF mới, máy chủ sẽ thêm tất cả nội dung trong bộ đệm ghi lại vào cuối tệp AOF mới, để đảm bảo tệp AOF mới và cũ lưu trữ trạng thái cơ sở dữ liệu giống nhau.
- Cuối cùng, máy chủ sử dụng tệp AOF mới để thay thế tệp AOF cũ, hoàn thành quá trình ghi lại AOF.
Nguyên Lý triển khai của RDB
【Câu hỏi】
- Nguyên lý triển khai của RDB là gì?
- Khi tạo ảnh chụp RDB, Redis có thể phản hồi yêu cầu không?
【Giải đáp】
Lệnh BGSAVE sẽ “tạo một tiến trình con” (fork), tiến trình con này sẽ chịu trách nhiệm tạo tệp RDB, trong khi tiến trình máy chủ tiếp tục xử lý yêu cầu lệnh, do đó lệnh này “không chặn” máy chủ.
Tại Sao Lại Có Lưu Trữ Kết Hợp?
Ưu điểm của RDB là tốc độ khôi phục dữ liệu nhanh, nhưng tần suất chụp ảnh khó nắm bắt. Nếu tần suất quá thấp, dữ liệu sẽ bị mất nhiều, nếu tần suất quá cao, sẽ ảnh hưởng đến hiệu suất.
Ưu điểm của AOF là mất dữ liệu ít, nhưng tốc độ khôi phục dữ liệu không nhanh.
Để kết hợp ưu điểm của cả hai, Redis 4.0 đã đề xuất sử dụng kết hợp nhật ký AOF và ảnh chụp bộ nhớ, hay còn gọi là lưu trữ kết hợp, vừa đảm bảo tốc độ khởi động nhanh của Redis, vừa giảm nguy cơ mất dữ liệu.
Lưu trữ kết hợp hoạt động trong quá trình ghi lại nhật ký AOF, khi bật lưu trữ kết hợp, trong quá trình ghi lại nhật ký AOF, tiến trình con được tạo ra sẽ trước tiên ghi dữ liệu bộ nhớ chia sẻ với luồng chính dưới dạng RDB vào tệp AOF, sau đó các lệnh thao tác được xử lý bởi luồng chính sẽ được ghi vào bộ đệm ghi lại dưới dạng AOF, sau khi ghi xong, thông báo cho luồng chính thay thế tệp AOF mới chứa cả định dạng RDB và AOF cho tệp AOF cũ.
Nói cách khác, khi sử dụng lưu trữ kết hợp, tệp AOF phần đầu là dữ liệu đầy đủ dưới dạng RDB, phần sau là dữ liệu gia tăng dưới dạng AOF.
Ưu điểm của cách này là, khi khởi động lại Redis để tải dữ liệu, do phần đầu là nội dung RDB, tốc độ tải sẽ rất nhanh.
Sau khi tải xong nội dung RDB, sẽ tải nội dung AOF ở phần sau, đây là những lệnh thao tác của luồng chính trong quá trình ghi lại AOF, điều này giảm nguy cơ mất dữ liệu.
Ưu điểm của lưu trữ kết hợp:
- Lưu trữ kết hợp kết hợp ưu điểm của lưu
trữ RDB và AOF, phần đầu theo định dạng RDB giúp Redis khởi động nhanh hơn, đồng thời kết hợp với ưu điểm của AOF giảm thiểu nguy cơ mất dữ liệu lớn.
Nhược điểm của lưu trữ kết hợp:
- Tệp AOF thêm nội dung theo định dạng RDB làm giảm khả năng đọc của tệp AOF;
- Khả năng tương thích kém, nếu bật lưu trữ kết hợp, tệp AOF lưu trữ kết hợp này không thể sử dụng trên các phiên bản Redis trước 4.0.
Redis Đảm Bảo Tính Sẵn Sàng Cao
【Câu hỏi】
Redis làm thế nào để đảm bảo tính sẵn sàng cao?
Sao Chép Master-Slave của Redis
【Câu hỏi】
- Nguyên lý hoạt động của sao chép Redis? Sao chép phiên bản cũ và mới của Redis khác nhau như thế nào?
- Redis sao chép dữ liệu giữa các nút master và slave như thế nào?
- Tính nhất quán của dữ liệu Redis có phải là tính nhất quán mạnh không?
【Giải đáp】
Phiên bản cũ của sao chép dựa trên lệnh
SYNC. Quá trình này bao gồm hai bước: đồng bộ hóa (sync) và phát tán lệnh (command propagate). Tuy nhiên, cách này có khuyết điểm: không xử lý hiệu quả tình huống sao chép lại sau khi ngắt kết nối.Phiên bản mới của sao chép dựa trên lệnh
PSYNC. Quá trình đồng bộ hóa được chia thành hai phần:- Đồng bộ hóa hoàn toàn (full resychronization): Dùng cho lần sao chép đầu tiên.
- Đồng bộ hóa một phần (partial resychronization): Dùng khi sao chép lại sau khi ngắt kết nối.
- Thiên lệch sao chép (replication offset) của máy chủ.
- Bộ đệm trễ sao chép (replication backlog) của máy chủ chính.
- ID hoạt động của máy chủ.
Quá trình sao chép giữa các nút master và slave trong cụm Redis:
- Bước 1: Cài đặt máy chủ master và slave.
- Bước 2: Thiết lập kết nối TCP giữa máy chủ master và slave.
- Bước 3: Gửi lệnh PING để kiểm tra trạng thái kết nối.
- Bước 4: Xác thực danh tính.
- Bước 5: Gửi thông tin cổng.
- Bước 6: Đồng bộ hóa dữ liệu.
- Bước 7: Phát tán lệnh.
Do quá trình sao chép của Redis là bất đồng bộ, nghĩa là trong giai đoạn phát tán lệnh giữa các máy chủ master và slave, máy chủ chủ sẽ gửi các lệnh ghi mới cho máy chủ tớ. Tuy nhiên, máy chủ chủ không đợi máy chủ tớ thực hiện xong các lệnh này mà sẽ trả kết quả cho khách hàng ngay sau khi máy chủ chủ thực hiện xong các lệnh này. Điều này có nghĩa là nếu máy chủ tớ chưa kịp thực hiện các lệnh đã đồng bộ từ máy chủ chủ, dữ liệu giữa các máy chủ master và slave sẽ không nhất quán. Do đó, không thể đảm bảo tính nhất quán mạnh (dữ liệu giữa master và slave luôn nhất quán), việc mất dữ liệu là khó tránh khỏi.
Redis Sentinel
【Câu hỏi】
- Chức năng của Redis Sentinel?
- Nguyên lý hoạt động của Redis Sentinel?
- Redis Sentinel bầu chọn Leader như thế nào?
- Redis thực hiện chuyển đổi dự phòng như thế nào?
【Giải đáp】
Chế độ sao chép Master-Slave của Redis không thể tự động chuyển đổi dự phòng, nghĩa là khi máy chủ chủ gặp sự cố, cần phải khôi phục thủ công. Để giải quyết vấn đề này, Redis đã thêm chế độ Sentinel (Sentinel mode).
Hệ thống Sentinel bao gồm một hoặc nhiều Sentinel instance có thể giám sát nhiều máy chủ chủ, cũng như tất cả các máy chủ tớ của các máy chủ chủ này. Khi một máy chủ chủ được giám sát rơi vào trạng thái offline, Sentinel sẽ tự động nâng cấp một máy chủ tớ của máy chủ chủ bị offline lên làm máy chủ chủ mới. Máy chủ chủ mới này sẽ tiếp tục xử lý các yêu cầu lệnh thay thế máy chủ chủ đã offline.
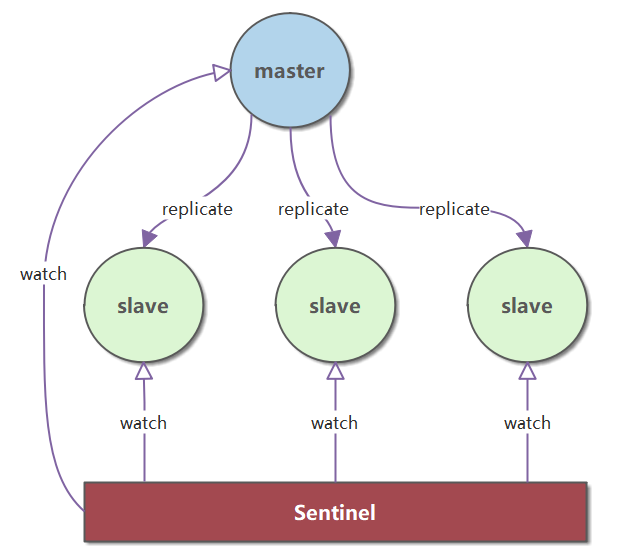
Redis Cluster
Khi lượng dữ liệu của Redis vượt quá giới hạn của một máy chủ đơn, cần phải sử dụng kỹ thuật phân vùng để chia nhỏ và xử lý.
Redis sử dụng chiến lược phân vùng dựa trên các khe băm ảo (virtual hash slots) để ánh xạ các nút và dữ liệu. Trong Redis Cluster, có tổng cộng 16384 khe băm được phân phối cho toàn bộ cụm. Mỗi nút sẽ được phân phối một số khe băm nhất định, quá trình này có thể được thực hiện tự động hoặc thủ công. Nếu bất kỳ khe nào chưa được phân phối, cụm sẽ ở trạng thái offline.
Khi khách hàng gửi yêu cầu đọc/ghi tới máy chủ, đầu tiên cần phải tính toán khe băm của khóa đó (công thức tính toán: CRC16(KEY) mod 16384), sau đó tìm nút chứa khe băm đó. Quá trình này hoàn tất quá trình định vị.
Redis chia rẽ
Split-Brain là gì?
Vấn đề Split-Brain trong hệ thống phân tán là một vấn đề nghiêm trọng về tính nhất quán thường xảy ra khi các nút trong hệ thống phân tán mất kết nối hoặc chỉ có thể giao tiếp một phần với nhau. Thuật ngữ "Split-Brain" bắt nguồn từ phép so sánh với hệ thống phân tán bị chia thành nhiều phần độc lập, mỗi phần hoạt động độc lập mà không có cơ chế điều phối tính nhất quán.
Vấn đề Split-Brain thường xảy ra trong các trường hợp sau:
Mạng bị chia cắt: Khi có sự cố mạng trong hệ thống phân tán làm cho các nút không thể giao tiếp với nhau hoặc chỉ giao tiếp một phần. Nguyên nhân có thể là do sự cố mạng, lỗi phần cứng, cấu hình tường lửa không chính xác và những lý do khác.
Lỗi nút: Khi một nút trong hệ thống phân tán gặp sự cố hoặc bị hỏng, nhưng các nút khác không thể xác định được trạng thái của nút đó, có thể dẫn đến vấn đề Split-Brain.
Kịch bản điển hình của vấn đề Split-Brain xảy ra khi, sau một mạng bị chia cắt hoặc lỗi nút, một số nút trong hệ thống phân tán tin rằng một nhóm nút khác không khả dụng. Do đó, chúng bắt đầu thực hiện các hành động như bầu chọn lãnh đạo mới hoặc chuyển sang chế độ dự phòng. Tuy nhiên, trong một số trường hợp, mạng bị chia cắt có thể tự phục hồi hoặc lỗi nút có thể tự khắc phục, dẫn đến sự tồn tại của nhiều phần hệ thống hoạt động độc lập, mỗi phần tin rằng mình là chính xác.
Trong tình huống như vậy, vấn đề Split-Brain có thể gây ra các vấn đề sau:
Không nhất quán dữ liệu: Các phần hệ thống khác nhau có thể có trạng thái dữ liệu khác nhau, dẫn đến không nhất quán và xung đột dữ liệu.
Xung đột tài nguyên: Nếu các phần hệ thống khác nhau cố gắng truy cập vào cùng một tài nguyên, có thể dẫn đến xung đột tài nguyên và các điều kiện đua nhau.
Vấn đề hiệu suất: Tài nguyên hệ thống có thể được phân bổ nhiều lần, lãng phí tài nguyên và làm giảm hiệu suất.
Để giải quyết vấn đề Split-Brain, hệ thống phân tán thường áp dụng các cơ chế như thuật toán bầu cử, giao thức bầu cử, phát hiện nhịp tim vv., để đảm bảo khi xảy ra mạng bị chia cắt hoặc lỗi nút, hệ thống có thể xác định và xử lý vấn đề một cách chính xác, từ đó duy trì tính nhất quán. Các cơ chế này giúp các nút trong hệ thống hợp tác hiệu quả và tránh vấn đề Split-Brain. Tuy nhiên, quản lý vấn đề Split-Brain vẫn là một thách thức phức tạp trong thiết kế và quản lý hệ thống phân tán, đòi hỏi kế hoạch và kiểm thử cẩn thận để đảm bảo tính đáng tin cậy và ổn định của hệ thống.
Vấn đề split brain trong Redis là gì và làm thế nào nó xảy ra
Trong kiến trúc master-slave của Redis, thường sử dụng mô hình "một chính nhiều phụ" (one master, multiple slaves), trong đó master đảm nhận các thao tác ghi và các slave đảm nhận các thao tác đọc. Khi master đột ngột gặp sự cố mạng và mất kết nối với tất cả các slave, thì trong khi đó kết nối giữa master và khách hàng vẫn bình thường, khách hàng không nhận thức được rằng bên trong Redis đã xảy ra vấn đề. Do đó, khách hàng vẫn tiếp tục gửi yêu cầu ghi dữ liệu đến master bị mất kết nối này (quá trình A). Các dữ liệu này được master cũ lưu vào bộ đệm của mình nhưng vì sự cố kết nối giữa master và slave, các dữ liệu này không thể được đồng bộ hóa với các slave.
Trong trường hợp này, các giám sát (Sentinel) cũng phát hiện master đã mất kết nối và sai lầm rằng master đã bị đổ (mặc dù thực tế master vẫn đang hoạt động, chỉ có vấn đề về mạng). Do đó, các giám sát sẽ bầu ra một người lãnh đạo mới từ các slave làm master mới, dẫn đến việc có hai master trong cụm - đó là hiện tượng phân tách não.
Sau đó, khi mạng bất ngờ khôi phục, giám sát đã bầu ra một master mới. Giám sát sẽ giáng chức master cũ xuống làm slave (A), sau đó slave (A) sẽ yêu cầu đồng bộ dữ liệu từ master mới. Vì lần đồng bộ đầu tiên là đồng bộ toàn bộ dữ liệu, slave (A) sẽ xóa dữ liệu cục bộ của mình trước khi bắt đầu đồng bộ toàn bộ. Do đó, dữ liệu mà khách hàng đã ghi vào trong quá trình A sẽ bị mất đi, đó là vấn đề mà cụm Redis gặp phải khi có hiện tượng phân tách não dẫn đến mất dữ liệu.
Tóm lại, nguyên nhân của vấn đề phân tách não là do sự cố mạng dẫn đến mất kết nối giữa các nút của cụm. Dữ liệu giữa master và các slave không được đồng bộ; quá trình bầu cử lại dẫn đến hai master phục vụ. Khi mạng phục hồi, master cũ sẽ bị giáng chức xuống làm slave, slave (A) thực hiện đồng bộ toàn bộ dữ liệu từ master mới, dẫn đến việc mất dữ liệu mà khách hàng đã ghi vào trong quá trình A.
Cách giải quyết vấn đề split brain trong Redis
Khi master trong Redis phát hiện rằng số lượng slave offline hoặc thời gian chậm trễ vượt quá ngưỡng nhất định, nó sẽ ngừng ghi dữ liệu và trả lỗi trực tiếp cho khách hàng.
Trong tệp cấu hình Redis, chúng ta có hai tham số để thiết lập:
min-slaves-to-write x: Master phải kết nối ít nhất với x slave, nếu ít hơn số này, master sẽ ngừng ghi dữ liệu.min-slaves-max-lag x: Độ trễ cho phép trong quá trình sao chép dữ liệu giữa master và slave không được vượt quá x giây, nếu vượt quá, master sẽ ngừng ghi dữ liệu.
Chúng ta có thể kết hợp cả hai thiết lập này bằng cách đặt ngưỡng N và T.
Yêu cầu kết hợp của hai thiết lập này là master phải có ít nhất N slave kết nối và thời gian trễ ACK trong quá trình sao chép dữ liệu không vượt quá T giây. Nếu không đạt được điều kiện này, master sẽ ngừng nhận yêu cầu ghi từ khách hàng.
Ngay cả khi master gốc bị lỗi giả (false failure), trong thời gian lỗi giả này, nó sẽ không thể phản hồi tin hiệu đập tim của giám sát và không thể sao chép dữ liệu với slave. Điều này dẫn đến việc không thể xác nhận ACK với slave, và do đó yêu cầu kết hợp giữa min-slaves-to-write và min-slaves-max-lag không thể được đáp ứng. Kết quả là master gốc sẽ bị hạn chế nhận yêu cầu ghi từ khách hàng, và khách hàng không thể ghi dữ liệu mới vào master gốc.
Khi master mới trực tuyến, chỉ master mới mới có thể nhận và xử lý yêu cầu từ khách hàng. Lúc này, dữ liệu mới ghi sẽ được lưu trực tiếp vào master mới. Master gốc sẽ được giám sát giảm chức vị xuống làm slave, dù dữ liệu của nó đã bị xóa, nhưng không có dữ liệu mới bị mất.
Ví dụ minh họa:
Giả sử chúng ta đặt min-slaves-to-write là 1, min-slaves-max-lag là 12 giây, và giám sát (sentinel) đặt down-after-milliseconds là 10 giây. Master bị kẹt trong 15 giây vì lý do nào đó, khiến cho giám sát đưa ra kết luận master đã offline và bắt đầu quá trình chuyển đổi từ master sang slave.
Đồng thời, vì master bị kẹt trong 15 giây, không có slave nào có thể sao chép dữ liệu từ master trong 12 giây. Do đó, master cũng không thể nhận yêu cầu ghi từ khách hàng.
Sau khi quá trình chuyển đổi master-slave hoàn tất, chỉ có master mới mới có thể nhận yêu cầu từ khách hàng. Không có hiện tượng split-brain xảy ra và không có vấn đề mất dữ liệu nào xảy ra.
Mô hình luồng của Redis
Redis có phải chỉ có duy nhất một luồng không?
Redis không hoàn toàn chỉ có một luồng.
- Các hoạt động chính của Redis như nhận yêu cầu từ khách hàng, phân tích yêu cầu và thao tác đọc/ghi dữ liệu đều được thực hiện bởi một luồng chính, đây cũng là lý do chính khiến người ta thường nói rằng Redis là một chương trình đơn luồng.
- Bên cạnh luồng chính, Redis còn khởi động thêm các luồng khác để thực hiện các hoạt động như đóng file, đồng bộ ghi AOF và xóa lười biếng.
Mô hình đơn luồng của Redis như thế nào?
Mô hình đơn luồng của Redis ám chỉ rằng mô hình mạng lõi chính của nó được thiết kế để hoạt động dưới một luồng. Mô hình sử dụng đa kênh IO + yêu cầu đọc ghi đơn luồng cho phép Redis xử lý nhiều kết nối máy khách cùng một lúc
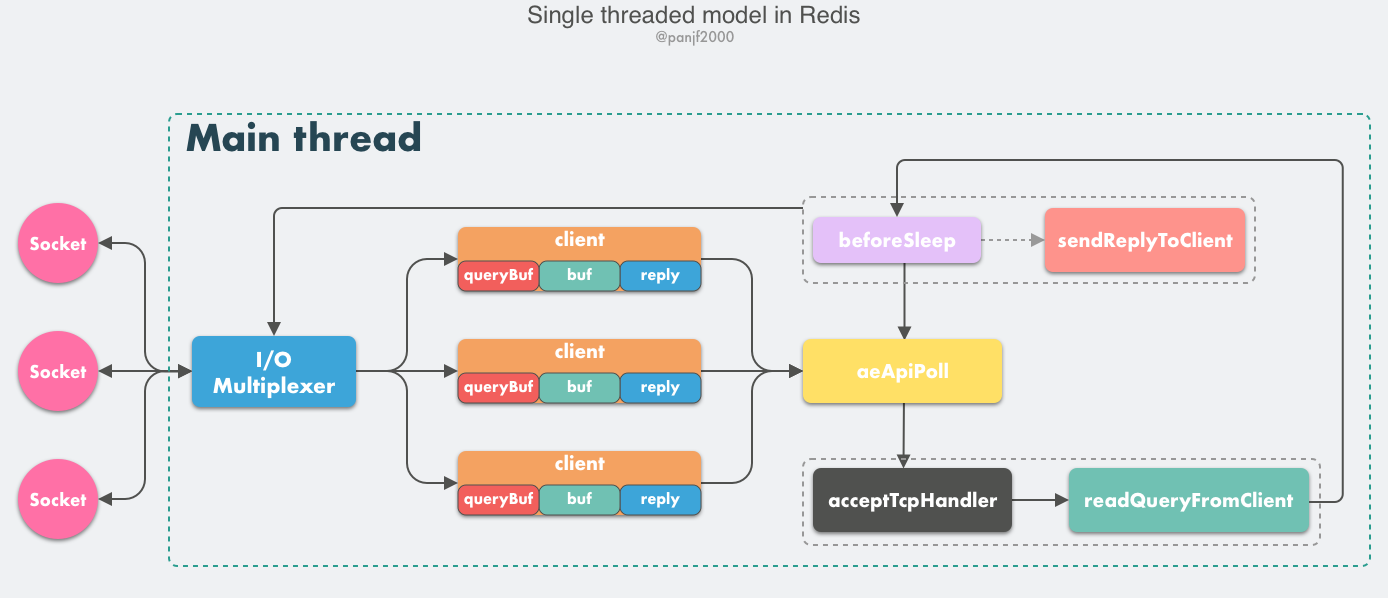
Tại sao mô hình đơn luồng của Redis lại nhanh như vậy?
Mô hình đơn luồng của Redis có hiệu suất cao như vậy chủ yếu nhờ vào những lý do sau:
- Sử dụng đa kênh I/O: Redis sử dụng kỹ thuật đa kênh I/O để đồng thời xử lý nhiều kết nối khách hàng.
- Xử lý đơn luồng các yêu cầu: Điều này cho phép Redis tối ưu hóa hiệu suất với mô hình đơn luồng chạy trên mỗi lõi CPU.
Tại sao Redis 6.0 lại giới thiệu nhiều luồng?
Với sự cải tiến của phần cứng mạng, Redis đã gặp phải các nút thắt cổ chai (botneck) về hiệu suất xử lý I/O mạng, nghĩa là tốc độ xử lý yêu cầu mạng bởi một luồng chính không thể đuổi kịp tốc độ của phần cứng mạng bên dưới.
Để cải thiện tính song song của I/O mạng, Redis 6.0 sử dụng đa luồng để xử lý I/O mạng. Tuy nhiên, Redis vẫn sử dụng một luồng duy nhất để thực thi lệnh.
Redis đã công bố rằng, chức năng đa luồng I/O mà Redis 6.0 giới thiệu đã cải thiện hiệu suất ít nhất gấp đôi.
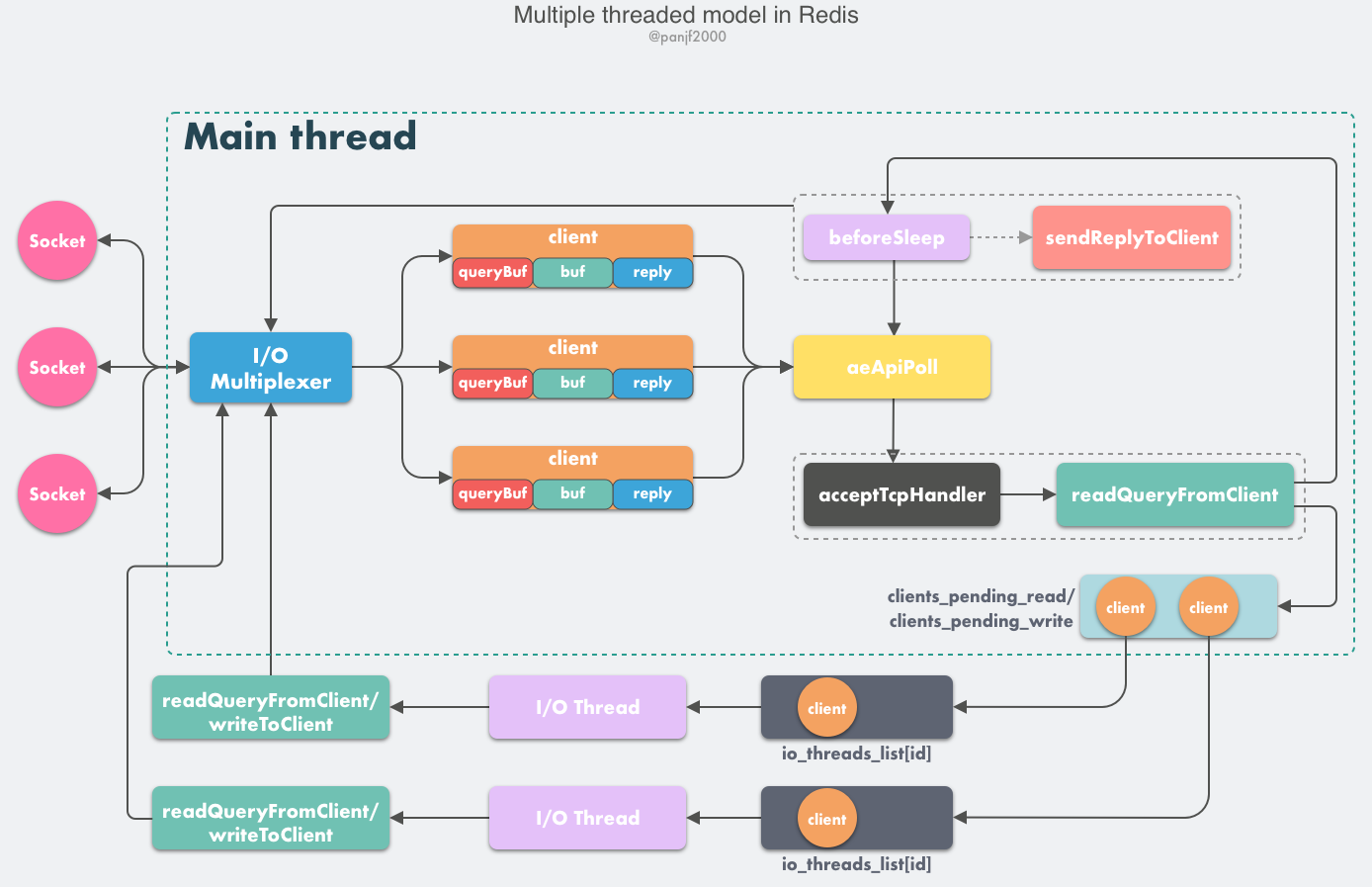
Giao dịch Redis
【Câu hỏi】
- Vấn đề cạnh tranh đồng thời trong Redis là gì? Làm thế nào để giải quyết vấn đề này?
- Redis có hỗ trợ giao dịch không?
- Giao dịch Redis có phải là giao dịch theo nghĩa hẹp không? Tại sao Redis không hỗ trợ rollback.
- Làm thế nào để giao dịch Redis hoạt động?
- Bạn có hiểu về hành vi CAS trong giao dịch Redis không?
【Trả lời】
Tính năng và nguyên lý giao dịch trong Redis
Chi tiết có thể tham khảo: Redis Guide
Redis không cung cấp giao dịch đúng nghĩa, Redis chỉ đảm bảo thực thi tuần tự các lệnh và có thể đảm bảo tất cả các lệnh đều được thực thi, nhưng nếu một lệnh thực thi thất bại, nó sẽ không rollback mà vẫn tiếp tục thực thi các lệnh tiếp theo.
Lý do Redis không hỗ trợ rollback:
- Lệnh Redis chỉ thất bại vì cú pháp sai hoặc lệnh được sử dụng trên khóa sai.
- Vì không cần hỗ trợ rollback, nên Redis có thể giữ cho bên trong đơn giản và nhanh chóng.
MULTI, EXEC, DISCARD và WATCH là các lệnh liên quan đến giao dịch Redis.
Redis có một giải pháp khóa lạc quan CAS tự nhiên để giải quyết vấn đề cạnh tranh đồng thời: trước khi ghi dữ liệu, ta kiểm tra xem timestamp của giá trị hiện tại có mới hơn timestamp của giá trị trong bộ nhớ cache hay không. Nếu là vậy, ta có thể ghi dữ liệu; ngược lại, ta không được ghi đè dữ liệu mới lên dữ liệu cũ.
Redis Pipeline
【Câu hỏi】
- Ngoài giao dịch, có cách nào khác để thực thi hàng loạt các lệnh Redis không?
【Trả lời】
Redis là một dịch vụ TCP dựa trên mô hình C/S (Client/Server) và giao thức yêu cầu/đáp ứng. Redis hỗ trợ kỹ thuật pipeline. Kỹ thuật pipeline cho phép gửi các yêu cầu theo cách không đồng bộ, tức là trong khi phản hồi của yêu cầu cũ chưa được trả về, vẫn có thể gửi các yêu cầu mới. Cách này có thể cải thiện đáng kể hiệu suất truyền tải.
Khi sử dụng pipeline để gửi lệnh, Redis Server sẽ đặt một phần yêu cầu vào hàng đợi bộ nhớ đệm (sử dụng bộ nhớ), sau khi thực thi xong sẽ gửi kết quả một lần. Nếu cần gửi một số lượng lớn các lệnh, sẽ chiếm dụng nhiều bộ nhớ, do đó nên xử lý theo lô với số lượng hợp lý.