Hướng dẫn Redis
1. Giới thiệu về Redis
Redis là một cơ sở dữ liệu key-value nhanh chóng và không phụ thuộc vào quan hệ (NoSQL) được lưu trữ trong bộ nhớ, có thể ánh xạ giữa các khóa và năm loại giá trị khác nhau.
Loại khóa chỉ có thể là chuỗi, các loại giá trị được hỗ trợ bao gồm: chuỗi, danh sách, tập hợp, tập hợp có thứ tự và bảng băm.
Các trường hợp sử dụng Redis
- Bộ nhớ đệm - Đặt dữ liệu hot vào bộ nhớ, đặt giới hạn sử dụng bộ nhớ tối đa và chiến lược loại bỏ hết hạn để đảm bảo tỷ lệ trúng đích của bộ nhớ đệm.
- Bộ đếm - Cơ sở dữ liệu bộ nhớ này hỗ trợ các hoạt động đọc và ghi bộ đếm thường xuyên.
- Giới hạn ứng dụng - Hạn chế lưu lượng truy cập vào một trang web.
- Hàng đợi tin nhắn - Sử dụng kiểu dữ liệu danh sách, đó là danh sách liên kết hai chiều.
- Bảng tìm kiếm - Sử dụng kiểu dữ liệu HASH.
- Phép giao của tập hợp - Sử dụng kiểu dữ liệu SET, ví dụ như tìm những người bạn chung của hai người dùng.
- Bảng xếp hạng - Sử dụng kiểu dữ liệu ZSET.
- Phiên phân tán - Lưu trữ phiên của nhiều máy chủ ứng dụng vào Redis để đảm bảo tính nhất quán của phiên.
- Khóa phân tán - Ngoài việc sử dụng SETNX để triển khai khóa phân tán, bạn cũng có thể sử dụng khóa phân tán RedLock do chính thức cung cấp.
Ưu điểm của Redis
- Hiệu suất cao - Redis có thể đọc với tốc độ 110.000 lần / giây và ghi với tốc độ 81.000 lần / giây.
- Loại dữ liệu phong phú - Hỗ trợ chuỗi, danh sách, tập hợp, tập hợp có thứ tự và bảng băm.
- Tính nguyên tử - Tất cả các hoạt động của Redis đều có tính nguyên tử. Một hoạt động đơn lẻ là nguyên tử. Nhiều hoạt động cũng hỗ trợ giao dịch, tức là nguyên tử, bằng cách bao gồm các chỉ thị MULTI và EXEC.
- Dữ liệu bền vững - Redis hỗ trợ việc lưu trữ dữ liệu. Có thể lưu trữ dữ liệu trong bộ nhớ và khôi phục lại khi khởi động lại.
- Sao lưu - Redis hỗ trợ sao lưu dữ liệu, tức là sao lưu dữ liệu theo chế độ master-slave.
- Tính năng phong phú - Redis cũng hỗ trợ xuất bản / đăng ký, thông báo, hết hạn khóa, v.v.
Redis và Memcached
Redis và Memcached thường được so sánh vì cả hai đều có thể được sử dụng làm bộ nhớ đệm, nhưng chúng có một số khác biệt chính như sau:
Loại dữ liệu
- Memcached chỉ hỗ trợ kiểu dữ liệu chuỗi;
- Trong khi đó, Redis hỗ trợ năm loại dữ liệu khác nhau, giúp nó giải quyết vấn đề một cách linh hoạt hơn.
Dữ liệu bền vững
- Memcached không hỗ trợ tính năng bền vững;
- Redis hỗ trợ hai chính sách bền vững: RDB Snapshot và AOF Log.
Phân tán
- Memcached không hỗ trợ phân tán, chỉ có thể triển khai lưu trữ phân tán bằng cách sử dụng thuật toán phân tán như băm nhất quán trên máy khách, điều này yêu cầu tính toán vị trí dữ liệu trên máy khách khi lưu trữ và truy vấn.
- Redis Cluster hỗ trợ phân tán.
Quản lý bộ nhớ
- Memcached chia bộ nhớ thành các khối có độ dài cố định để lưu trữ dữ liệu, giải quyết hoàn toàn vấn đề mảnh vụn bộ nhớ, nhưng phương pháp này làm giảm hiệu suất sử dụng bộ nhớ, ví dụ: nếu kích thước khối là 128 byte và chỉ lưu trữ 100 byte dữ liệu, thì 28 byte còn lại sẽ bị lãng phí.
- Trong Redis, không phải tất cả dữ liệu đều được lưu trữ trong bộ nhớ, một số giá trị không được sử dụng trong thời gian dài có thể được trao đổi sang đĩa. Dữ liệu của Memcached sẽ luôn nằm trong bộ nhớ.
Tại sao Redis nhanh
Redis có thể đạt được QPS đơn lẻ lên đến 100.000.
Redis sử dụng mô hình đơn luồng (Redis 6.0 đã hỗ trợ mô hình đa luồng), tại sao nó vẫn có thể đạt được đồng thời cao như vậy?
- Redis hoàn toàn dựa trên hoạt động bộ nhớ.
- Cấu trúc dữ liệu của Redis đơn giản.
- Sử dụng mô hình đơn luồng để tránh việc chuyển đổi ngữ cảnh và cạnh tranh giữa các luồng.
- Sử dụng mô hình I/O multiplexing (I/O không chặn).
I/O multiplexing
Mô hình I/O multiplexing là khả năng theo dõi cùng một lúc nhiều luồng I/O sự kiện của select, poll, epoll. Khi không hoạt động, nó sẽ chặn luồng hiện tại và khi một hoặc nhiều luồng có sự kiện I/O, nó sẽ được đánh thức từ trạng thái chặn và sau đó chương trình sẽ kiểm tra tất cả các luồng I/O (epoll chỉ kiểm tra các luồng thực sự gửi sự kiện), và chỉ xử lý từng luồng sẵn sàng, điều này tránh các hoạt động không hữu ích lớn.
2. Các kiểu dữ liệu trong Redis
Redis có các kiểu dữ liệu cơ bản: STRING, HASH, LIST, SET, ZSET
Redis cũng có các kiểu dữ liệu nâng cao: BitMap, HyperLogLog, GEO
💡 Để biết thêm thông tin chi tiết về các tính năng và nguyên lý, vui lòng tham khảo: [[Redis Data Types and Applications]]
3. Xóa dữ liệu không sử dụng trong Redis
Điểm chính về xóa dữ liệu trong bộ nhớ
- Bộ nhớ tối đa - Redis cho phép đặt giá trị tối đa của bộ nhớ thông qua tham số
maxmemory. - Thời gian hết hạn - Là cơ chế quan trọng để xóa dữ liệu vô hiệu, trong các lệnh Redis cung cấp,
EXPIRE,EXPIREAT,PEXPIRE,PEXPIREAT,SETEXvàPSETEXđược sử dụng để đặt thời gian hết hạn cho một cặp khóa-giá trị. Khi một cặp khóa-giá trị được liên kết với thời gian hết hạn, nó sẽ tự động bị xóa sau khi hết hạn (hoặc nói cách khác, trở thành không thể truy cập). - Chiến lược xóa - Khi lưu trữ dữ liệu vào Redis, khi không gian bộ nhớ còn lại không đủ để lưu trữ dữ liệu mới, Redis sẽ thực hiện chiến lược xóa dữ liệu để giải phóng một phần nội dung và đảm bảo dữ liệu mới có thể được lưu trữ trong bộ nhớ. Cơ chế xóa dữ liệu trong bộ nhớ nhằm tối ưu hóa việc sử dụng bộ nhớ, bằng cách đổi lấy một số lần không trúng đích để sử dụng bộ nhớ, đảm bảo rằng dữ liệu được lưu trữ trong bộ nhớ Redis là dữ liệu nóng.
- LRU không chính xác - Trên thực tế, Redis không triển khai LRU đáng tin cậy, có nghĩa là việc xóa khóa không nhất thiết là khóa không được sử dụng lâu nhất.
Thời gian hết hạn của khóa chính
Redis có thể đặt thời gian hết hạn cho mỗi khóa, khi khóa hết hạn, nó sẽ tự động bị xóa.
Đối với các cấu trúc dữ liệu như bảng băm, chỉ có thể đặt thời gian hết hạn cho toàn bộ khóa (toàn bộ bảng băm), không thể đặt thời gian hết hạn cho từng phần tử trong khóa.
Có thể sử dụng EXPIRE hoặc EXPIREAT để đặt thời gian hết hạn cho khóa.
🔔 Lưu ý: Nếu thời gian
EXPIREđược đặt là số âm, thời gian dấu thời gianEXPIREATlà thời gian hết hạn, khóa sẽ bị xóa trực tiếp.
Ví dụ:
redis> SET mykey "Hello"
"OK"
redis> EXPIRE mykey 10
(integer) 1
redis> TTL mykey
(integer) 10
redis> SET mykey "Hello World"
"OK"
redis> TTL mykey
(integer) -1
redis>Chiến lược xóa dữ liệu
Xóa dữ liệu trong bộ nhớ chỉ là một tính năng mà Redis cung cấp, để triển khai tốt hơn tính năng này, cần cung cấp các chiến lược khác nhau cho các tình huống ứng dụng khác nhau, vấn đề cần giải quyết bao gồm cách chọn không gian khóa để xóa? Làm thế nào để chọn khóa để xóa trong không gian khóa?
Redis cung cấp các chiến lược xóa dữ liệu sau để người dùng lựa chọn:
noeviction- Khi sử dụng bộ nhớ đạt đến ngưỡng, tất cả các lệnh yêu cầu cấp phát bộ nhớ sẽ báo lỗi. Đây là chiến lược mặc định của Redis.allkeys-lru- Trong không gian khóa chính, ưu tiên xóa khóa không được sử dụng gần đây nhất.allkeys-random- Trong không gian khóa chính, xóa ngẫu nhiên một khóa.volatile-lru- Trong không gian khóa có thời gian hết hạn, ưu tiên xóa khóa không được sử dụng gần đây nhất.volatile-random- Trong không gian khóa có thời gian hết hạn, xóa ngẫu nhiên một khóa.volatile-ttl- Trong không gian khóa có thời gian hết hạn, ưu tiên xóa khóa có thời gian hết hạn sớm hơn.
Lựa chọn chiến lược xóa dữ liệu
- Nếu dữ liệu phân bố theo phân phối mũ (có dữ liệu nóng, một số dữ liệu truy cập thường xuyên, một số dữ liệu truy cập ít), hãy sử dụng
allkeys-lru. - Nếu dữ liệu phân bố đồng đều (tần suất truy cập dữ liệu tương đương), hãy sử dụng
allkeys-random. - Nếu muốn sử dụng các giá trị TTL khác nhau để gợi ý cho Redis những khóa nào nên bị xóa, hãy sử dụng
volatile-ttl. volatile-lruvàvolatile-randomphù hợp cho các tình huống vừa sử dụng bộ nhớ cache vừa sử dụng lưu trữ bền vững, tuy nhiên, chúng ta cũng có thể đạt được cùng hiệu quả bằng cách sử dụng hai phiên bản Redis.- Đặt thời gian hết hạn cho khóa thực tế sẽ tiêu tốn nhiều bộ nhớ hơn, do đó, khuyến nghị sử dụng chiến lược
allkeys-lruđể sử dụng bộ nhớ hiệu quả hơn.
Triển khai nội bộ
Có hai cách chính để Redis xóa khóa không hợp lệ:
- Phương pháp tiêu cực (passive way), khi khóa được truy cập và phát hiện rằng nó không hợp lệ, nó sẽ bị xóa.
- Phương pháp tích cực (active way), định kỳ lựa chọn một số khóa không hợp lệ từ không gian khóa có thời gian hết hạn và xóa chúng.
- Xóa tích cực: Khi bộ nhớ đã sử dụng vượt quá giới hạn
maxmemory, kích hoạt chiến lược xóa tích cực, chiến lược này được cấu hình bằng tham số khởi động để xác định thời gian hết hạn chính xác của khóa được duy trì trong từ điểnexpires.
4. Lưu trữ dữ liệu trong Redis
Redis là một cơ sở dữ liệu lưu trữ trong bộ nhớ, để đảm bảo dữ liệu không bị mất sau khi máy chủ gặp sự cố, cần lưu trữ dữ liệu từ bộ nhớ xuống đĩa cứng.
Redis hỗ trợ hai phương pháp lưu trữ dữ liệu: RDB và AOF.
- RDB (Redis Database) là phương pháp chụp nhanh, nó lưu trữ tất cả dữ liệu Redis tại một thời điểm cụ thể vào một tập tin nhị phân được nén (tập tin RDB).
- AOF (Append Only File) là một tập tin nhật ký văn bản, nó ghi lại tất cả các lệnh ghi vào cuối tập tin AOF để ghi lại sự thay đổi dữ liệu. Khi máy chủ khởi động lại, nó sẽ tải và thực thi các lệnh này để khôi phục dữ liệu gốc. AOF thích hợp để sử dụng làm bản sao lưu nóng.
💡 Để biết thêm thông tin chi tiết về các tính năng và nguyên lý, vui lòng tham khảo: [[Redis Persistence]]
5. Sự kiện trong Redis
Redis là một máy chủ sự kiện, nó xử lý hai loại sự kiện:
Sự kiện tập tin (file event) - Redis giao tiếp với khách hàng hoặc các máy chủ khác thông qua socket, sự kiện tập tin là một trừu tượng hóa của hoạt động trên socket. Giao tiếp giữa máy chủ và khách hàng (hoặc các máy chủ khác) tạo ra các sự kiện tập tin, và máy chủ xử lý và xử lý các sự kiện này bằng cách lắng nghe và xử lý chúng.
Sự kiện thời gian (time event) - Redis cần thực hiện một số hoạt động vào một thời điểm nhất định, sự kiện thời gian là một trừu tượng của các hoạt động định thời này.
Sự kiện tập tin
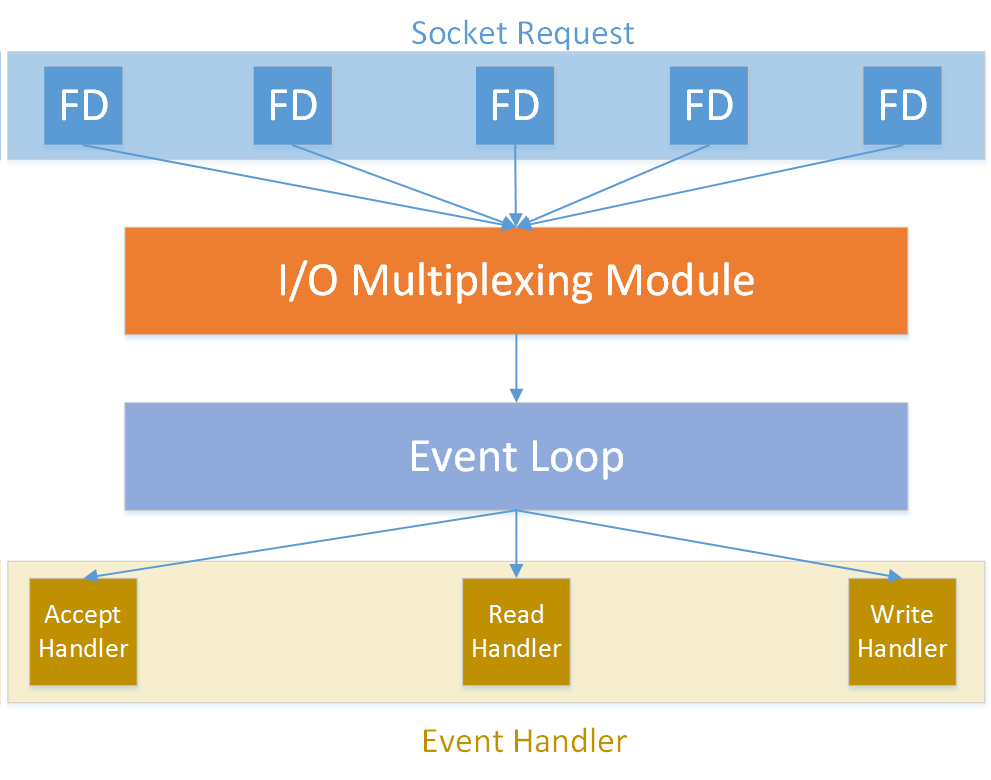
Redis đã phát triển trình xử lý sự kiện mạng của riêng mình dựa trên mô hình Reactor.
- Trình xử lý sự kiện tập tin của Redis sử dụng trình điều khiển I/O đa kênh để lắng nghe đồng thời nhiều socket và liên kết các trình xử lý sự kiện khác nhau với các socket tương ứng dựa trên nhiệm vụ hiện tại của socket.
- Khi socket được lắng nghe đã sẵn sàng để thực hiện kết nối, đọc, ghi hoặc đóng, sự kiện tập tin tương ứng sẽ xảy ra và trình xử lý sự kiện tập tin sẽ gọi trình xử lý sự kiện đã được liên kết trước đó với socket để xử lý các sự kiện này.
Mặc dù trình xử lý sự kiện tập tin chạy dưới dạng một luồng đơn, nhưng bằng cách sử dụng trình điều khiển I/O đa kênh để lắng nghe nhiều socket, trình xử lý sự kiện tập tin đã triển khai mô hình giao tiếp mạng hiệu suất cao.
Trình xử lý sự kiện tập tin bao gồm bốn thành phần: socket, trình điều khiển I/O đa kênh (I/O Multiplexing), bộ phân phối sự kiện tập tin và trình xử lý sự kiện.
Sự kiện thời gian
Sự kiện thời gian được chia thành hai loại:
- Sự kiện định thời: là việc cho phép một đoạn chương trình được thực thi một lần trong khoảng thời gian đã chỉ định;
- Sự kiện định kỳ: là sự kiện cho phép một đoạn chương trình thực thi mỗi khoảng thời gian cụ thể.
Redis lưu trữ tất cả các sự kiện thời gian trong một danh sách liên kết không tuần tự. Khi trình thực thi sự kiện thời gian chạy, nó sẽ duyệt qua toàn bộ danh sách liên kết để tìm các sự kiện thời gian đã đến và gọi trình xử lý sự kiện tương ứng.
Lập lịch và thực thi sự kiện
Để nhận được các sự kiện tập tin chờ xử lý, máy chủ cần lắng nghe liên tục các socket, nhưng không thể lắng nghe mãi mãi, nếu không sự kiện thời gian sẽ không thể được thực hiện trong thời gian quy định. Do đó, thời gian lắng nghe phải được xác định dựa trên sự kiện thời gian gần nhất.
Lập lịch và thực thi sự kiện được thực hiện bởi hàm aeProcessEvents, mã giả như sau:
def aeProcessEvents():
## Tìm sự kiện thời gian gần nhất đã đến
time_event = aeSearchNearestTimer()
## Tính toán thời gian còn lại đến sự kiện thời gian gần nhất
remaind_ms = time_event.when - unix_ts_now()
## Nếu sự kiện đã đến, giá trị remaind_ms có thể là số âm, đặt nó thành 0
if remaind_ms < 0:
remaind_ms = 0
## Tạo timeval dựa trên remaind_ms
timeval = create_timeval_with_ms(remaind_ms)
## Chờ và chặn để chờ sự kiện tập tin xảy ra, thời gian chặn tối đa được xác định bởi timeval được truyền vào
aeApiPoll(timeval)
## Xử lý tất cả các sự kiện tập tin đã xảy ra
processFileEvents()
## Xử lý tất cả các sự kiện thời gian đã đến
processTimeEvents()Đặt hàm aeProcessEvents trong một vòng lặp, kèm theo các hàm khởi tạo và dọn dẹp, sẽ tạo thành hàm chính của máy chủ Redis, mã giả như sau:
def main():
## Khởi tạo máy chủ
init_server()
## Xử lý sự kiện liên tục cho đến khi máy chủ tắt
while server_is_not_shutdown():
aeProcessEvents()
## Máy chủ tắt, thực hiện dọn dẹp
clean_server()6. Giao dịch trong Redis
Redis không cung cấp giao dịch nghiêm ngặt, Redis chỉ đảm bảo thực hiện các lệnh theo thứ tự và đảm bảo thực hiện tất cả các lệnh, nhưng khi một lệnh thực hiện không thành công, nó sẽ tiếp tục thực hiện các lệnh tiếp theo mà không có quá trình rollback.
MULTI, EXEC, DISCARD và WATCH là các lệnh liên quan đến giao dịch trong Redis.
Giao dịch cho phép thực hiện nhiều lệnh cùng một lúc và có hai cam kết quan trọng sau:
- Giao dịch là một hoạt động cô lập độc lập: Tất cả các lệnh trong giao dịch sẽ được thực hiện theo thứ tự và tuần tự. Trong quá trình thực hiện giao dịch, nó sẽ không bị gián đoạn bởi các yêu cầu lệnh từ khách hàng khác.
- Giao dịch là một hoạt động nguyên tử: Tất cả các lệnh trong giao dịch sẽ được thực hiện hoặc không được thực hiện.
MULTI
Lệnh MULTI được sử dụng để bắt đầu một giao dịch, nó luôn trả về OK.
Sau khi thực hiện MULTI, khách hàng có thể tiếp tục gửi bất kỳ số lượng lệnh nào đến máy chủ, các lệnh này sẽ không được thực hiện ngay lập tức mà sẽ được đặt vào một hàng đợi. Khi lệnh EXEC được gọi, tất cả các lệnh trong hàng đợi sẽ được thực hiện.
Dưới đây là một ví dụ về giao dịch, nó tăng giá trị của hai khóa foo và bar một cách nguyên tử:
> MULTI
OK
> INCR foo
QUEUED
> INCR bar
QUEUED
> EXEC
1) (integer) 1
2) (integer) 1EXEC
Lệnh EXEC được sử dụng để kích hoạt và thực hiện tất cả các lệnh trong giao dịch.
- Nếu khách hàng mở một giao dịch bằng cách sử dụng
MULTInhưng không thực hiện thành côngEXEC, tất cả các lệnh trong giao dịch sẽ không được thực hiện. - Trên một khía cạnh khác, nếu khách hàng thực hiện thành công
EXECsau khi mở giao dịch, tất cả các lệnh trong giao dịch sẽ được thực hiện.
DISCARD
Khi thực hiện lệnh DISCARD, giao dịch sẽ bị hủy bỏ, hàng đợi giao dịch sẽ được xóa và khách hàng sẽ thoát khỏi trạng thái giao dịch.
Ví dụ:
> SET foo 1
OK
> MULTI
OK
> INCR foo
QUEUED
> DISCARD
OK
> GET foo
"1"WATCH
Lệnh WATCH trong Redis cung cấp hành vi check-and-set (CAS) cho giao dịch.
Các khóa được theo dõi bởi WATCH sẽ được giám sát và phát hiện xem chúng có bị thay đổi không. Nếu ít nhất một khóa được theo dõi đã được thay đổi trước khi EXEC được thực thi, toàn bộ giao dịch sẽ bị hủy bỏ và EXEC sẽ trả về nil-reply để chỉ ra giao dịch đã thất bại.
WATCH mykey
val = GET mykey
val = val + 1
MULTI
SET mykey $val
EXECSử dụng mã trên, nếu giá trị của mykey được thay đổi bởi một khách hàng khác sau khi WATCH được thực thi và trước khi EXEC được thực thi, giao dịch của khách hàng hiện tại sẽ thất bại. Chương trình cần làm là lặp lại thao tác này cho đến khi không có xung đột xảy ra.
Hình thức khóa này được gọi là khóa lạc quan (optimistic lock), đây là một cơ chế khóa rất mạnh mẽ. Và vì hầu hết các khách hàng thường truy cập vào các khóa khác nhau, xung đột xảy ra rất ít, nên thường không cần phải thử lại.
WATCH yêu cầu EXEC chỉ được thực thi khi tất cả các khóa được giám sát không bị thay đổi. Nếu điều kiện này không được đáp ứng, giao dịch sẽ không được thực thi.
Lệnh WATCH có thể được gọi nhiều lần. Giám sát các khóa bắt đầu có hiệu lực sau khi WATCH được thực thi và kết thúc khi EXEC được gọi.
Người dùng cũng có thể giám sát nhiều khóa trong một lệnh WATCH, ví dụ:
redis> WATCH key1 key2 key3
OKCác tình huống hủy WATCH
Khi EXEC được gọi, giám sát cho tất cả các khóa sẽ bị hủy bỏ, bất kể giao dịch có được thực thi thành công hay không.
Ngoài ra, khi khách hàng ngắt kết nối, giám sát của khách hàng đối với các khóa cũng sẽ bị hủy bỏ.
Sử dụng lệnh UNWATCH không có tham số có thể hủy bỏ giám sát cho tất cả các khóa. Đối với một số giao dịch yêu cầu thay đổi nhiều khóa, đôi khi chương trình cần khóa đồng thời nhiều khóa và kiểm tra xem giá trị hiện tại của các khóa đó có đáp ứng yêu cầu của chương trình hay không. Khi giá trị không đáp ứng yêu cầu, có thể sử dụng lệnh UNWATCH để hủy bỏ giám sát hiện tại, từ bỏ giao dịch này và chờ đợi lần thử giao dịch tiếp theo.
Sử dụng WATCH để tạo thao tác nguyên tử
WATCH có thể được sử dụng để tạo ra các thao tác nguyên tử không được tích hợp sẵn trong Redis.
Ví dụ, đoạn mã sau triển khai lệnh ZPOP tự tạo, nó có thể lấy ra phần tử có điểm số nhỏ nhất trong tập hợp có thứ tự:
WATCH zset
element = ZRANGE zset 0 0
MULTI
ZREM zset element
EXECRollback
Redis không hỗ trợ rollback. Lý do Redis không hỗ trợ rollback:
- Lệnh Redis chỉ thất bại do cú pháp sai hoặc lệnh được sử dụng trên loại khóa sai.
- Vì không cần hỗ trợ rollback, nên Redis có thể giữ cho nội bộ đơn giản và nhanh chóng.
7. Redis Pipeline
Redis là một dịch vụ TCP dựa trên mô hình C/S và giao thức yêu cầu/phản hồi. Redis hỗ trợ công nghệ Pipeline. Công nghệ Pipeline cho phép gửi yêu cầu theo cách bất đồng bộ, tức là cho phép gửi yêu cầu mới trong khi đáp ứng của yêu cầu cũ vẫn chưa trả về. Phương pháp này có thể cải thiện đáng kể hiệu suất truyền tải.
Khi cần thực thi một loạt lệnh Redis, nếu thực thi từng lệnh một, rõ ràng là rất không hiệu quả. Để giảm số lần truyền thông và giảm độ trễ, có thể sử dụng chức năng Pipeline của Redis. Chức năng Pipeline của Redis không cung cấp hỗ trợ dòng lệnh, nhưng nó được triển khai trong các phiên bản khách hàng của nhiều ngôn ngữ.
Lấy ví dụ với Jedis:
Pipeline pipe = conn.pipelined();
pipe.multi();
pipe.hset("login:", token, user);
pipe.zadd("recent:", timestamp, token);
if (item != null) {
pipe.zadd("viewed:" + token, timestamp, item);
pipe.zremrangeByRank("viewed:" + token, 0, -26);
pipe.zincrby("viewed:", -1, item);
}
pipe.exec();🔔 Lưu ý: Khi gửi các lệnh bằng Pipeline, Redis Server sẽ đặt một số yêu cầu vào hàng đợi bộ nhớ cache (chiếm bộ nhớ), và sau khi thực thi xong, gửi kết quả một lần duy nhất. Nếu cần gửi một số lượng lớn lệnh, sẽ chiếm nhiều bộ nhớ, do đó nên xử lý theo số lượng hợp lý và chia thành các lô để xử lý.
8. Redis Publish/Subscribe
Redis cung cấp 5 lệnh Publish/Subscribe:
| Lệnh | Mô tả |
|---|---|
SUBSCRIBE | SUBSCRIBE channel [channel …] — Đăng ký các kênh đã chỉ định. |
UNSUBSCRIBE | UNSUBSCRIBE [channel [channel …]] — Hủy đăng ký các kênh đã chỉ định. |
PUBLISH | PUBLISH channel message — Gửi tin nhắn đến kênh đã chỉ định. |
PSUBSCRIBE | PSUBSCRIBE pattern [pattern …] — Đăng ký các kênh phù hợp với mẫu đã chỉ định. |
PUNSUBSCRIBE | PUNSUBSCRIBE [pattern [pattern …]] — Hủy đăng ký các kênh phù hợp với mẫu đã chỉ định. |
Sau khi người đăng ký đã đăng ký kênh, nhà xuất bản sẽ gửi tin nhắn chuỗi tới kênh và tất cả các người đăng ký sẽ nhận được nó.
Một khách hàng sử dụng SUBSCRIBE để đăng ký một kênh, các khách hàng khác có thể sử dụng PUBLISH để gửi tin nhắn vào kênh này.
Mô hình Publish/Subscribe khác với mô hình Observer:
- Trong mô hình Observer, người quan sát và chủ đề đều biết sự tồn tại của nhau; trong khi đó, trong mô hình Publish/Subscribe, người xuất bản và người đăng ký không biết sự tồn tại của nhau, và họ giao tiếp thông qua kênh.
- Mô hình Observer là đồng bộ, khi sự kiện xảy ra, chủ đề sẽ gọi phương thức của người quan sát; trong khi đó, mô hình Publish/Subscribe là bất đồng bộ.
Dưới đây là các tính năng và chức năng của Redis Cluster
9. Redis Replication
Các cơ sở dữ liệu quan hệ thường sử dụng một máy chủ chính để gửi cập nhật cho nhiều máy chủ phụ và sử dụng các máy chủ phụ để xử lý các yêu cầu đọc, Redis cũng triển khai tính năng sao chép theo cùng một cách.
Sao chép cũ
Tính năng sao chép Redis trước phiên bản 2.8 dựa trên lệnh SYNC.
Tính năng sao chép Redis được chia thành hai hoạt động: đồng bộ hóa (sync) và truyền lệnh (command propagate):
- Đồng bộ hóa (sync) - Được sử dụng để cập nhật trạng thái cơ sở dữ liệu của máy chủ phụ với trạng thái cơ sở dữ liệu hiện tại của máy chủ chính.
- Truyền lệnh (command propagate) - Khi trạng thái cơ sở dữ liệu của máy chủ chính bị thay đổi, dẫn đến sự không đồng nhất giữa trạng thái cơ sở dữ liệu của máy chủ chính và máy chủ phụ, cho phép máy chủ phụ trở lại trạng thái đồng nhất với máy chủ chính.
Phương pháp này có nhược điểm: không xử lý hiệu quả trường hợp sao chép sau khi kết nối lại sau khi mất kết nối.
Sao chép mới
Tính năng sao chép Redis sau phiên bản 2.8 dựa trên lệnh PSYNC. Lệnh PSYNC có hai chế độ: đồng bộ hoàn toàn (full resynchronization) và đồng bộ một phần (partial resynchronization).
- Đồng bộ hoàn toàn (full resynchronization) - Được sử dụng cho sao chép lần đầu tiên. Các bước thực hiện tương tự như lệnh
SYNC. - Đồng bộ một phần (partial resynchronization) - Được sử dụng cho sao chép sau khi kết nối lại. Nếu điều kiện cho phép, máy chủ chính có thể gửi các lệnh ghi đã thực hiện trong thời gian máy chủ phụ bị mất kết nối và máy chủ phụ chỉ cần nhận và thực hiện các lệnh ghi này để duy trì trạng thái cơ sở dữ liệu giữa máy chủ chính và máy chủ phụ.
Đồng bộ một phần
Đồng bộ một phần bao gồm ba phần:
- Offset sao chép (replication offset) của máy chủ chính và máy chủ phụ
- Bộ đệm chờ sao chép (replication backlog) của máy chủ chính
- ID chạy của máy chủ.
Lệnh PSYNC
Máy chủ phụ gửi lệnh PSYNC <runid> <offset> đến máy chủ chính để sao chép.
- Nếu ID chạy của máy chủ chính và máy chủ phụ giống nhau và offset được chỉ định nằm trong bộ đệm trong bộ nhớ, sao chép sẽ tiếp tục từ điểm bị gián đoạn trước đó.
- Nếu một trong hai điều kiện không được đáp ứng, sao chép sẽ được thực hiện lại hoàn toàn.
Kiểm tra nhịp tim
Máy chủ chính cập nhật trạng thái máy chủ phụ bằng cách truyền lệnh cho máy chủ phụ. Đồng thời, máy chủ phụ gửi lệnh REPLCONF ACK <replication_offset> để kiểm tra nhịp và kiểm tra lệnh bị mất.
💡 Để biết thêm chi tiết về các tính năng và nguyên tắc, vui lòng tham khảo: [[Redis Replication]]
10. Redis Sentinel
Redis Sentinel (hay còn gọi là Sentinel) có thể theo dõi các máy chủ chính và tự động chọn ra máy chủ chính mới khi máy chủ chính bị offline.
💡 Để biết thêm chi tiết về các tính năng và nguyên tắc, vui lòng tham khảo: [[Redis Sentinel]]
11. Redis Cluster
Sharding là phương pháp chia dữ liệu thành nhiều phần và lưu trữ dữ liệu trên nhiều máy chủ, cũng như truy xuất dữ liệu từ nhiều máy chủ, phương pháp này có thể cung cấp hiệu suất tuyến tính trong việc giải quyết một số vấn đề.
Giả sử có 4 phiên bản Redis R0, R1, R2, R3 và nhiều khóa đại diện cho người dùng như user:1, user:2, … và có nhiều cách để chọn một khóa cụ thể để lưu trữ trên máy chủ cụ thể. Cách đơn giản nhất là phân chia theo phạm vi, ví dụ như lưu trữ người dùng có id từ 0 đến 1000 trên phiên bản R0, lưu trữ người dùng có id từ 1001 đến 2000 trên phiên bản R1, và cứ tiếp tục như vậy. Tuy nhiên, điều này đòi hỏi việc duy trì một bảng ánh xạ phạm vi, đòi hỏi công việc duy trì cao. Cách khác là phân chia bằng hàm băm, sử dụng hàm băm CRC32 để chuyển đổi khóa thành một số, sau đó lấy số này chia lấy số dư cho số lượng phiên bản để xác định máy chủ cần lưu trữ.
Có ba phương pháp chia dữ liệu chính:
- Chia dữ liệu trên máy khách: Máy khách sử dụng thuật toán băm nhất quán để xác định khóa được phân phối đến máy chủ nào.
- Chia dữ liệu qua proxy: Gửi yêu cầu từ máy khách đến proxy, proxy sẽ chuyển tiếp yêu cầu đến máy chủ đúng.
- Chia dữ liệu trên máy chủ: Redis Cluster (giải pháp Redis Cluster chính thức từ Redis).
12. Redis Client
Có nhiều loại Redis Client được hỗ trợ trong cộng đồng Redis, bạn có thể tìm kiếm khách hàng phù hợp tại đây: Get started using Redis clients | Redis
Các Redis Client Java được khuyến nghị bởi Redis Official: