Redis Data Structures
SDS
Giới thiệu về SDS
SDS là viết tắt của Simple Dynamic String, tức là Chuỗi Động Đơn Giản. Redis đã tối ưu SDS để thay thế chuỗi C trong việc biểu diễn nội dung chuỗi. Ngoài ra, SDS còn được Redis sử dụng như là vùng đệm (buffer), chẳng hạn như vùng đệm AOF trong mô đun AOF và vùng đệm đầu vào trong trạng thái của khách hàng.
So với chuỗi C, SDS có những ưu điểm sau:
| Chuỗi C | SDS |
|---|---|
| Độ phức tạp để lấy độ dài chuỗi là O(N). | Độ phức tạp để lấy độ dài chuỗi là O(1). |
| API không an toàn, có thể gây tràn bộ đệm. | API an toàn, không gây tràn bộ đệm. |
Đổi độ dài chuỗi N lần sẽ cần phải cấp phát lại N lần bộ nhớ. | Đổi độ dài chuỗi N lần tối đa chỉ cần cấp phát lại N lần bộ nhớ. |
| Chỉ có thể lưu trữ dữ liệu văn bản. | Có thể lưu trữ cả dữ liệu văn bản và dữ liệu nhị phân. |
Có thể sử dụng tất cả các hàm trong thư viện <string.h>. | Chỉ có thể sử dụng một phần hàm trong thư viện <string.h>. |
Triển khai SDS
Mỗi cấu trúc sds.h/sdshdr đại diện cho một giá trị SDS:
struct sdshdr {
// Ghi lại số lượng byte đã sử dụng trong mảng buf
// Bằng với độ dài của chuỗi được lưu bởi SDS
int len;
// Ghi lại số lượng byte chưa sử dụng trong mảng buf
int free;
// Mảng byte được sử dụng để lưu trữ chuỗi
char buf[];
};SDS tuân thủ quy ước chuỗi C với ký tự null kết thúc, trong đó không tính 1 byte được cấp phát cho ký tự null trong thuộc tính len của SDS. Ngoài ra, các thao tác như cấp phát thêm 1 byte cho ký tự null ở cuối chuỗi được xử lý tự động bởi các hàm SDS, làm cho ký tự null này hoàn toàn trong suốt đối với người dùng SDS.
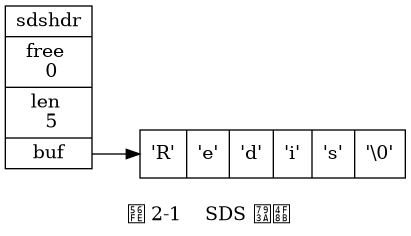
Tính năng của SDS
SDS so với chuỗi C, có những tối ưu hóa sau đây:
Lấy độ dài chuỗi với độ phức tạp hằng số
- Chuỗi C: Vì chuỗi C không ghi nhận thông tin độ dài của chính nó, để lấy độ dài của một chuỗi C, chương trình phải duyệt qua toàn bộ chuỗi, đếm từng ký tự cho đến khi gặp ký tự null đánh dấu kết thúc chuỗi. Độ phức tạp của thao tác này là
O(N). - SDS: SDS ghi nhận độ dài của chính nó trong thuộc tính
len, do đó để lấy độ dài của SDS chỉ mất độ phức tạpO(1). Công việc thiết lập và cập nhật độ dài SDS được thực hiện tự động bởi API của SDS khi thực thi, không cần phải chỉnh sửa độ dài bằng tay.
Ngăn chặn tràn bộ đệm
- Chuỗi C: Vì chuỗi C không ghi nhận độ dài của chính nó, điều này dễ dẫn đến vấn đề tràn bộ đệm (buffer overflow).
- SDS: Khi API của SDS cần thay đổi SDS, nó trước tiên kiểm tra xem không gian SDS có đáp ứng yêu cầu thay đổi hay không. Nếu không đủ, API sẽ tự động mở rộng không gian SDS đến kích thước cần thiết trước khi thực hiện thay đổi thực tế. Do đó, việc sử dụng SDS không cần phải điều chỉnh kích thước không gian SDS thủ công và không gặp vấn đề tràn bộ đệm như chuỗi C.
Giảm số lần phân bổ lại bộ nhớ khi thay đổi độ dài chuỗi
- Chuỗi C: Với một chuỗi C có
Nký tự, triển khai dưới cơ sở dữ liệu của chuỗi C luôn có mảng dàiN+1ký tự (bao gồm một ký tự thêm để lưu ký tự null). Bởi vì có sự tương quan giữa độ dài chuỗi và độ dài của mảng cơ sở, mỗi lần tăng hoặc giảm độ dài của một chuỗi C đều yêu cầu một phép phân bổ lại bộ nhớ cho mảng lưu trữ chuỗi này.- Khi tăng độ dài chuỗi mà không phân bổ lại bộ nhớ, có nguy cơ tràn bộ đệm.
- Khi giảm độ dài chuỗi mà không phân bổ lại bộ nhớ, có nguy cơ rò rỉ bộ nhớ.
- SDS: Bằng cách sử dụng không gian chưa sử dụng, SDS loại bỏ sự phụ thuộc giữa độ dài chuỗi và độ dài của mảng cơ sở: độ dài mảng
buftrong SDS không nhất thiết phải bằng số lượng ký tự cộng một. Thay vào đó, mảng này có thể chứa các byte chưa sử dụng, và số lượng byte này được ghi nhận bởi thuộc tínhfreecủa SDS. SDS thực hiện hai chiến lược tối ưu hóa sau:- Dự trữ không gian - Dự trữ không gian được sử dụng để tối ưu hóa việc mở rộng chuỗi SDS. Khi API của SDS sửa đổi một SDS và cần mở rộng không gian, chương trình không chỉ cấp phát không gian cần thiết cho sửa đổi, mà còn cấp phát không gian chưa sử dụng thêm. Bằng cách này, SDS giảm số lần phân bổ lại bộ nhớ cần thiết khi chuỗi tăng dần liên tục
Nlần từ bắt buộc xuống tối đaNlần. - Giải phóng không gian một cách lười biếng - Chiến lược giải phóng không gian một cách lười biếng được sử dụng để tối ưu hóa việc rút ngắn chuỗi SDS. Khi API của SDS cần rút ngắn chuỗi SDS, chương trình không sử dụng ngay lập tức phân bổ lại bộ nhớ để thu hồi các byte dư thừa sau khi rút ngắn. Thay vào đó, nó sử dụng thuộc tính
freeđể ghi nhận số lượng byte này và chờ đợi sử dụng trong tương lai. Bằng cách này, SDS tránh phải thực hiện phân bổ lại bộ nhớ khi rút ngắn chuỗi và tối ưu hóa cho các thao tác tăng dần có thể xảy ra trong tương lai.
- Dự trữ không gian - Dự trữ không gian được sử dụng để tối ưu hóa việc mở rộng chuỗi SDS. Khi API của SDS sửa đổi một SDS và cần mở rộng không gian, chương trình không chỉ cấp phát không gian cần thiết cho sửa đổi, mà còn cấp phát không gian chưa sử dụng thêm. Bằng cách này, SDS giảm số lần phân bổ lại bộ nhớ cần thiết khi chuỗi tăng dần liên tục
An toàn cho dữ liệu nhị phân
- Chuỗi C: Ký tự trong chuỗi C phải tuân thủ một mã hóa nhất định (ví dụ: ASCII), và ngoài ký tự null ở cuối chuỗi, chuỗi không thể chứa ký tự null. Nếu có, ký tự null đầu tiên được chương trình đọc sẽ bị hiểu lầm là kết thúc chuỗi — những hạn chế này khiến chuỗi C chỉ có thể lưu trữ dữ liệu văn bản và không thể lưu trữ các dạng dữ liệu nhị phân như hình ảnh, âm thanh, video, tệp nén.
- SDS: Các API của SDS đều an toàn cho dữ liệu nhị phân (binary-safe): Tất cả các API của SDS xử lý dữ liệu trong mảng
buftheo cách xử lý dữ liệu nhị phân, chương trình không giới hạn, lọc, hoặc giả định về dữ liệu trong đó — dữ liệu được viết vào là gì, thì khi đọc ra sẽ vẫn là như vậy. Bằng cách sử dụng SDS an toàn cho dữ liệu nhị phân, Redis không chỉ có thể lưu trữ dữ liệu văn bản, mà còn có thể lưu trữ bất kỳ định dạng dữ liệu nhị phân nào.
Tương thích với một số hàm chuỗi C
Mặc dù các API của SDS an toàn cho dữ liệu nhị phân, SDS vẫn tuân thủ quy ước chuỗi C bằng cách thiết lập ký tự null ở cuối dữ liệu được lưu trữ và luôn cấp phát thêm một byte cho mảng buf để chứa ký tự null này — điều này giúp các SDS lưu trữ dữ liệu văn bản có thể sử dụng lại một phần các hàm được định nghĩa trong thư viện <string.h> của C. Do đó, SDS có thể tương thích với một số hàm chuỗi C.
Danh sách liên kết
Giới thiệu về Danh sách liên kết
Danh sách liên kết được sử dụng rộng rãi trong Redis để thực hiện nhiều chức năng như các khóa Danh sách (List), đăng ký và phát hành (publish-subscribe), truy vấn chậm, trình giám sát và nhiều chức năng khác. Ngoài ra, Redis còn sử dụng danh sách liên kết để lưu trữ thông tin trạng thái của nhiều khách hàng và xây dựng bộ đệm đầu ra (output buffer) cho khách hàng.
Bởi vì ngôn ngữ lập trình C không tích hợp sẵn danh sách liên kết, Redis đã tự triển khai một danh sách liên kết của riêng mình: Danh sách liên kết trong Redis thực tế là một danh sách liên kết hai chiều.
- Mỗi danh sách liên kết được biểu diễn bằng một cấu trúc
list, cấu trúc này bao gồm con trỏ đến nút đầu danh sách, con trỏ đến nút cuối danh sách và thông tin về độ dài của danh sách. - Vì nút trước nút đầu danh sách và nút sau nút cuối danh sách đều trỏ đến
NULL, do đó, cài đặt danh sách liên kết trong Redis là danh sách liên kết không có vòng lặp. - Bằng cách thiết lập các hàm đặc thù cho từng loại, danh sách liên kết trong Redis có thể được sử dụng để lưu trữ các giá trị khác nhau.
Danh sách liên kết trong Redis cung cấp các tính năng chèn, xóa và tìm kiếm hiệu quả, làm cho nó rất hữu ích và linh hoạt trong việc triển khai nhiều cấu trúc dữ liệu và chức năng khác nhau trong Redis.
Triển khai của Danh sách liên kết
Mỗi nút trong danh sách liên kết được biểu diễn bằng cấu trúc adlist.h/listNode. Mỗi nút này có một con trỏ trỏ đến nút phía trước và nút phía sau, do đó, danh sách liên kết trong Redis được triển khai như là một danh sách liên kết hai chiều.
typedef struct listNode {
// Con trỏ đến nút phía trước
struct listNode *prev;
// Con trỏ đến nút phía sau
struct listNode *next;
// Giá trị của nút
void *value;
} listNode;Nhiều listNode có thể được sắp xếp lại với nhau bằng cách sử dụng các con trỏ prev và next, hình thành một danh sách liên kết hai chiều.

Mặc dù chỉ cần sử dụng nhiều cấu trúc listNode là có thể tạo thành danh sách liên kết, nhưng việc sử dụng adlist.h/list để lưu giữ danh sách liên kết sẽ làm cho việc thao tác dễ dàng hơn:
typedef struct list {
// Con trỏ đến nút đầu danh sách
listNode *head;
// Con trỏ đến nút cuối danh sách
listNode *tail;
// Số lượng nút trong danh sách
unsigned long len;
// Hàm sao chép giá trị của nút
void *(*dup)(void *ptr);
// Hàm giải phóng giá trị của nút
void (*free)(void *ptr);
// Hàm so sánh giá trị của nút
int (*match)(void *ptr, void *key);
} list;Cấu trúc list cung cấp con trỏ head (đầu danh sách), tail (cuối danh sách) và len (độ dài danh sách). Các thành viên dup, free và match được sử dụng để triển khai các hàm đặc thù cho từng loại dữ liệu của danh sách:
- Hàm
dup- dùng để sao chép giá trị của nút trong danh sách. - Hàm
free- dùng để giải phóng giá trị của nút trong danh sách. - Hàm
match- dùng để so sánh giá trị của nút với một giá trị khác.
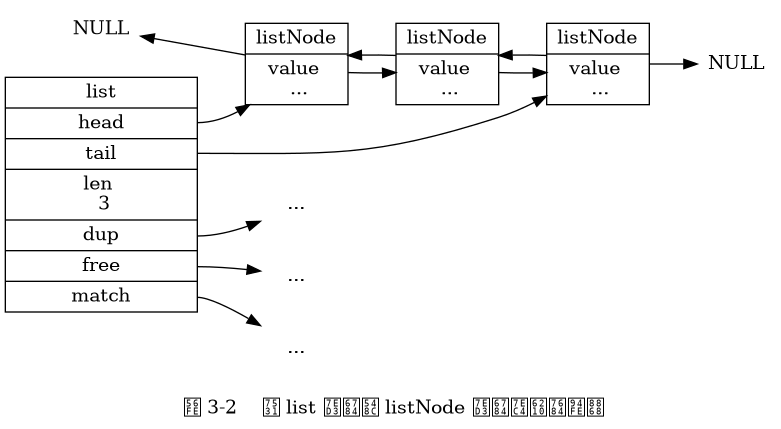
Từ điển
Giới thiệu về Từ điển
Từ điển (Dictionary) là một cấu trúc dữ liệu trừu tượng được sử dụng để lưu trữ các cặp khóa-giá trị (key-value pairs). Mỗi khóa trong từ điển là duy nhất, cho phép chương trình tìm kiếm, cập nhật hoặc xóa giá trị liên quan dựa trên khóa, cùng với các thao tác khác.
Redis đã tự triển khai một cấu trúc từ điển do ngôn ngữ lập trình C không hỗ trợ cấu trúc từ điển sẵn có.
Từ điển được sử dụng rộng rãi trong Redis để triển khai các chức năng khác nhau, bao gồm cả cơ sở dữ liệu và các khóa băm (Hash Keys).
Triển khai của Từ điển
Redis sử dụng bảng băm (hash table) làm cấu trúc dữ liệu cơ sở cho từ điển, trong đó mỗi bảng băm có thể chứa nhiều nút bảng băm, và mỗi nút này lưu trữ một cặp khóa-giá trị trong từ điển.
Cấu trúc dictht trong Redis được định nghĩa như sau:
typedef struct dictht {
// Mảng của bảng băm
dictEntry **table;
// Kích thước của bảng băm
unsigned long size;
// Mặt nạ kích thước của bảng băm, dùng để tính chỉ số
// Luôn luôn bằng size - 1
unsigned long sizemask;
// Số lượng nút hiện có trong bảng băm
unsigned long used;
} dictht;- Thuộc tính
tablelà một mảng các con trỏ tới cấu trúcdictEntry, mỗidictEntrylưu trữ một cặp khóa-giá trị. - Thuộc tính
sizelà kích thước của bảng băm, tức là kích thước của mảngtable. - Thuộc tính
sizemasklà mặt nạ kích thước của bảng băm, được sử dụng để tính chỉ số của khóa. - Thuộc tính
usedlà số lượng nút (cặp khóa-giá trị) đã được thêm vào bảng băm.
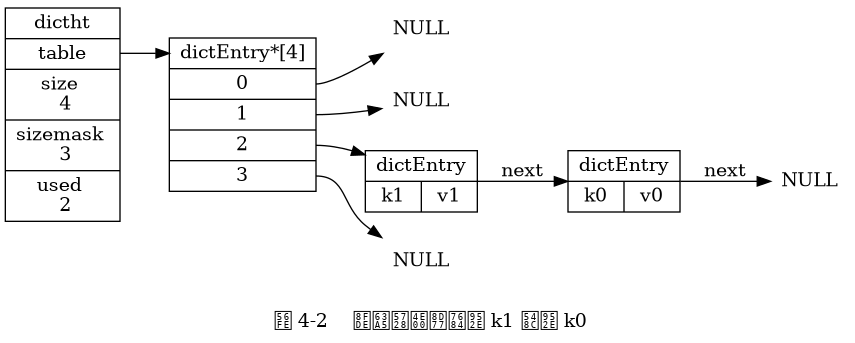
Cấu trúc dictEntry đại diện cho một nút trong bảng băm, lưu trữ một cặp khóa-giá trị như sau:
typedef struct dictEntry {
// Khóa
void *key;
// Giá trị
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// Con trỏ đến nút bảng băm tiếp theo, tạo thành danh sách liên kết
struct dictEntry *next;
} dictEntry;- Thuộc tính
keylưu trữ khóa của cặp khóa-giá trị. - Thuộc tính
vlưu trữ giá trị tương ứng với khóa. Giá trị có thể là một con trỏ, hoặc một số nguyênuint64_thoặcint64_t. - Thuộc tính
nextlà con trỏ đến nút bảng băm kế tiếp trong trường hợp xảy ra va chạm (collision), để tạo thành một danh sách liên kết.
Cấu trúc dict trong Redis đại diện cho từ điển:
typedef struct dict {
// Hàm đặc thù cho từng loại
dictType *type;
// Dữ liệu riêng tư
void *privdata;
// Bảng băm
dictht ht[2];
// Chỉ số tái băm
// Nếu không tái băm thì giá trị là -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
} dict;- Thuộc tính
typevàprivdatađược sử dụng cho các hàm đặc thù của từng loại, cho phép Redis triển khai từ điển đa hình. - Thuộc tính
htlà một mảng có 2 phần tử, mỗi phần tử là một cấu trúcdicthtbảng băm. Thông thường, từ điển chỉ sử dụnght[0],ht[1]được sử dụng chỉ khi tái băm (rehashing). - Thuộc tính
rehashidxlà chỉ số tái băm, ghi nhận tiến độ tái băm hiện tại. Nếu không có tái băm nào đang diễn ra, giá trị sẽ là-1.
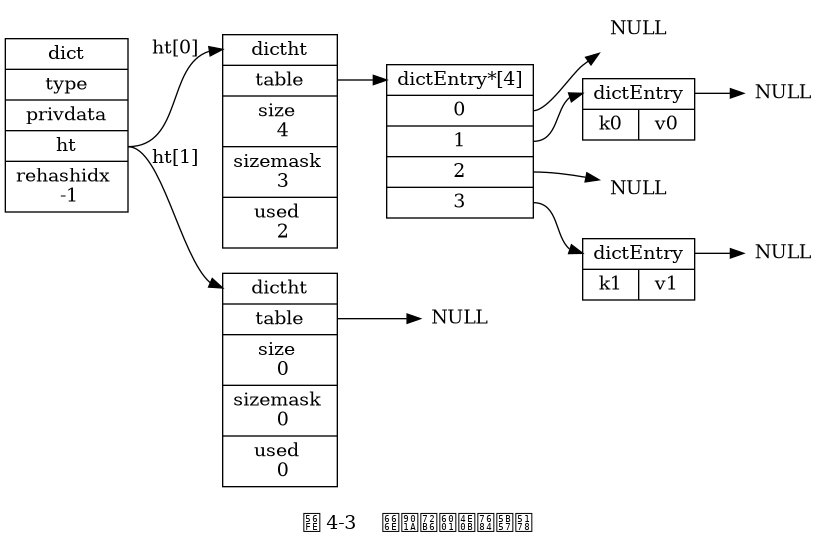
Thuật toán băm
Khi từ điển được sử dụng làm cài đặt cơ sở dữ liệu hoặc cài đặt cơ sở dữ liệu của các khóa băm, Redis sử dụng thuật toán MurmurHash2 để tính toán giá trị băm của khóa.
Redis tính toán giá trị băm và chỉ mục như sau:
// Sử dụng hàm băm được thiết lập cho từ điển, tính toán giá trị băm của khóa key
hash = dict->type->hashFunction(key);
// Sử dụng thuộc tính sizemask của bảng băm và giá trị băm để tính chỉ mục
// Tùy vào hoàn cảnh, ht[x] có thể là ht[0] hoặc ht[1]
index = hash & dict->ht[x].sizemask;Xử lý va chạm
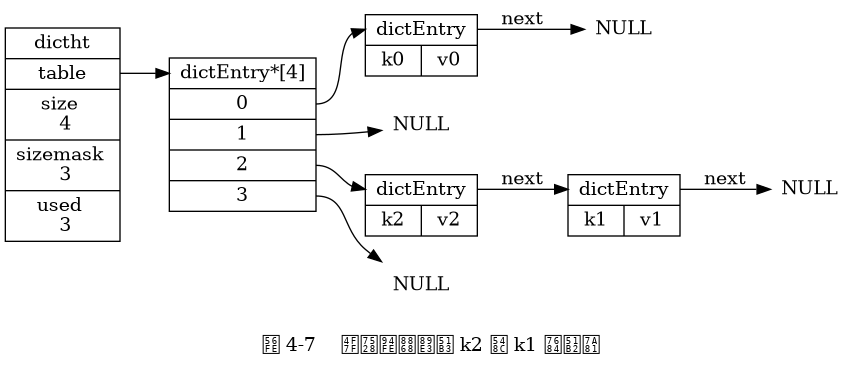
Khi hai hoặc nhiều hơn hai khóa được gán vào cùng một chỉ mục của mảng bảng băm, chúng ta gọi là xảy ra va chạm (collision).
Redis sử dụng phương pháp xử lý va chạm dùng chuỗi riêng (separate chaining) để giải quyết các va chạm: Mỗi nút bảng băm có một con trỏ next, nhiều nút bảng băm có thể được kết nối với nhau để tạo thành một danh sách liên kết đơn hướng, các nút này được gán vào cùng một chỉ mục sẽ được kết nối với nhau qua danh sách liên kết này, từ đó giải quyết được vấn đề của va chạm.
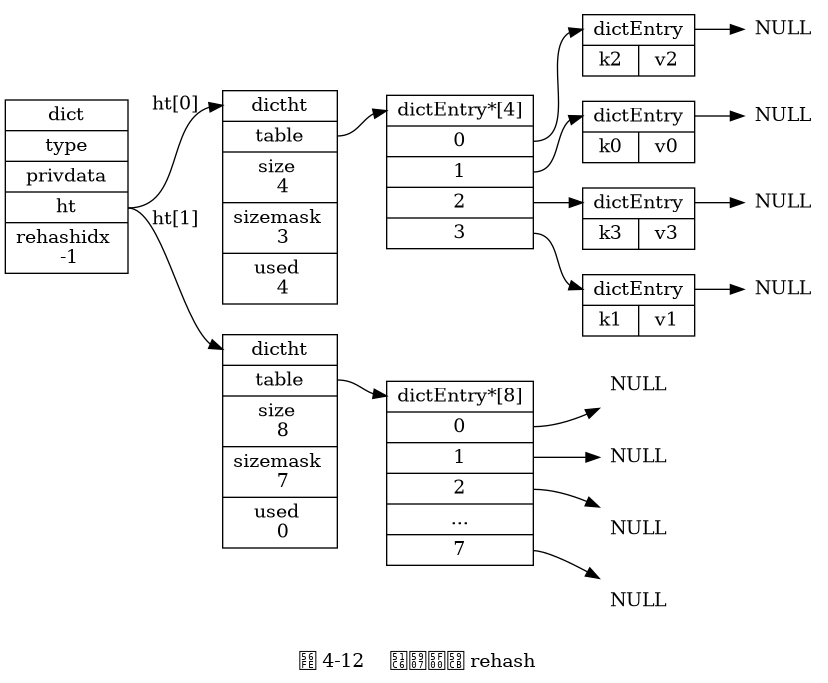
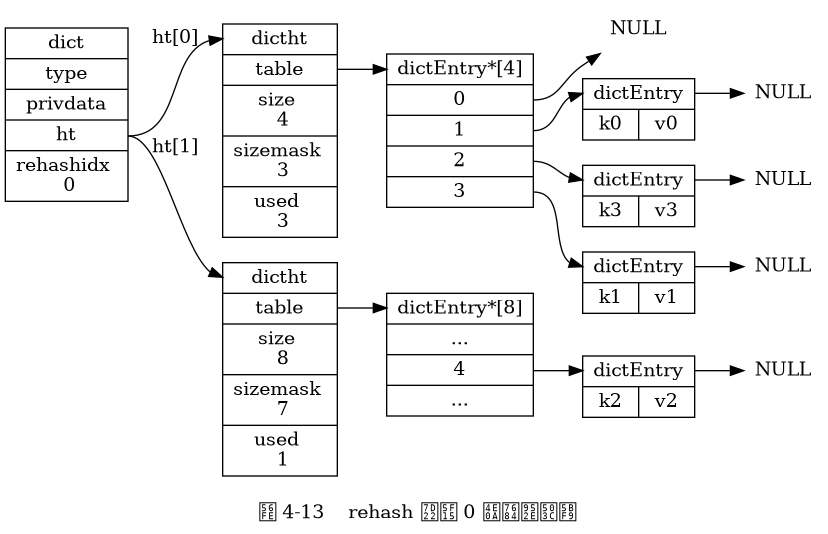
rehash
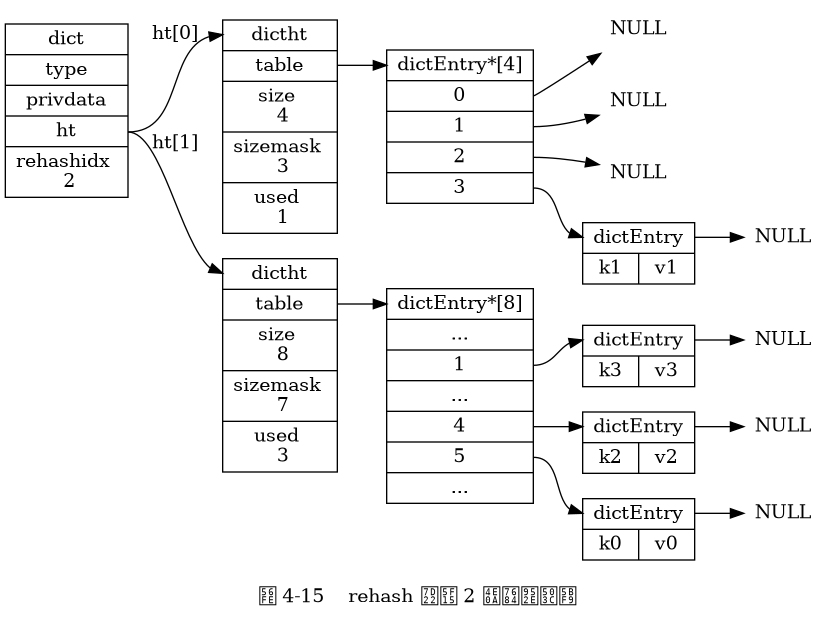
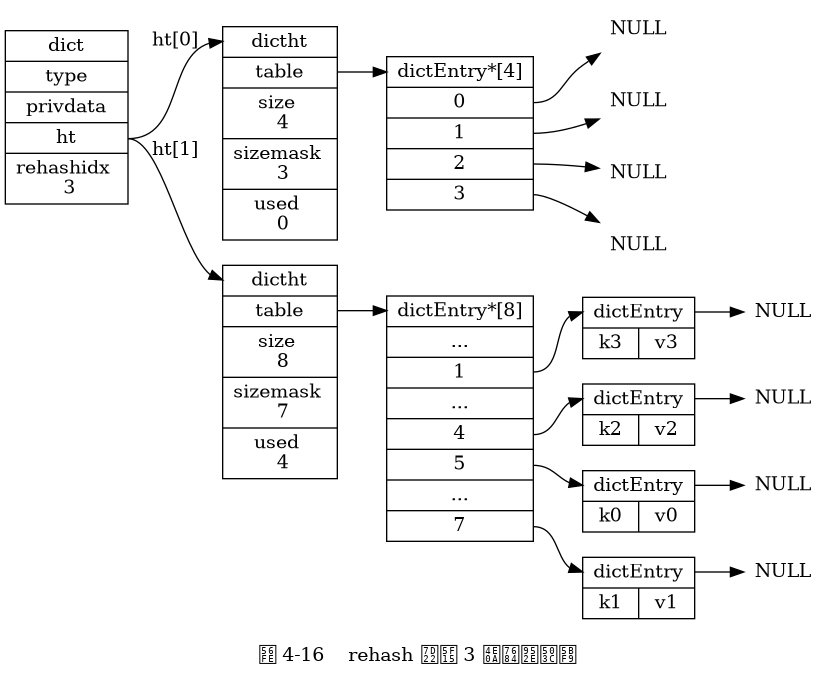
Các bước của rehash
Phân bổ không gian cho
ht[1]:- Tạo không gian cho bảng băm
ht[1]của từ điển, kích thước của bảng này phụ thuộc vào hoạt động cụ thể và số lượng cặp khóa-giá trị hiện có tronght[0](được biểu diễn bởi thuộc tínhht[0].used).
- Tạo không gian cho bảng băm
Di chuyển tất cả các cặp khóa-giá trị từ
ht[0]sanght[1]:- Rehashing đề cập đến việc tính toán lại giá trị băm của khóa và chỉ mục của nó, sau đó đặt cặp khóa-giá trị vào vị trí xác định trong bảng băm
ht[1].
- Rehashing đề cập đến việc tính toán lại giá trị băm của khóa và chỉ mục của nó, sau đó đặt cặp khóa-giá trị vào vị trí xác định trong bảng băm
Khi tất cả các cặp khóa-giá trị từ
ht[0]đã được di chuyển sanght[1]:ht[0]sẽ trở thành bảng rỗng, được giải phóng, vàht[1]sẽ được thiết lập làht[0].- Một bảng băm mới trống sẽ được tạo cho
ht[1], chuẩn bị cho lần rehash tiếp theo.

Các điều kiện để thực hiện rehash
Khi một trong những điều kiện sau được đáp ứng, Redis sẽ tự động bắt đầu mở rộng bảng băm:
- Server hiện không thực thi lệnh BGSAVE hoặc BGREWRITEAOF và hệ số tải của bảng băm (
load factor) lớn hơn hoặc bằng1. - Server đang thực thi lệnh BGSAVE hoặc BGREWRITEAOF và hệ số tải của bảng băm lớn hơn hoặc bằng
5.
Hệ số tải của bảng băm có thể tính theo công thức sau:
load_factor = ht[0].used / ht[0].size- Server hiện không thực thi lệnh BGSAVE hoặc BGREWRITEAOF và hệ số tải của bảng băm (
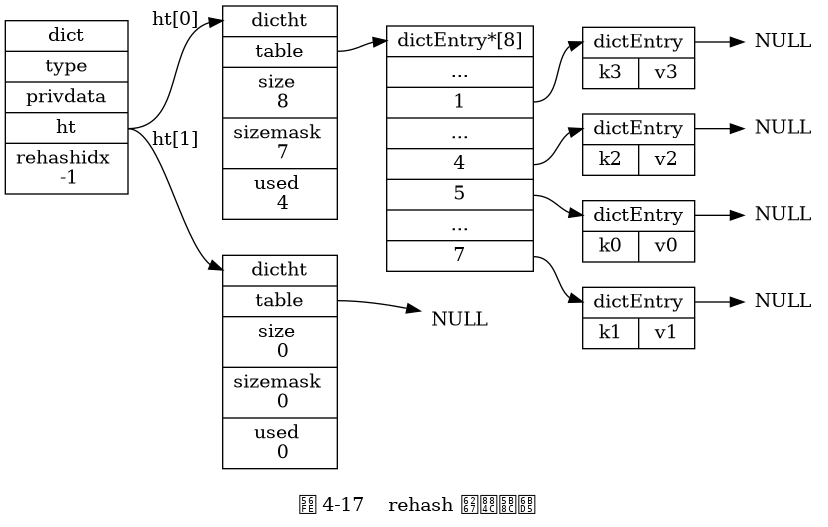
Rehash từng bước (Progressive rehash)
- Bước chi tiết của rehash tiến bộ như sau:
- Phân bổ không gian cho
ht[1], cho phép từ điển giữ cả hai bảng bămht[0]vàht[1]. - Duy trì một biến đếm chỉ mục rehash
rehashidxtrong từ điển và thiết lập nó bằng0để bắt đầu công việc rehash. - Trong suốt quá trình rehash, mỗi lần thực hiện thêm, xóa, tìm kiếm hoặc cập nhật trong từ điển, chương trình sẽ thực hiện rehash tất cả các cặp khóa-giá trị của
ht[0]tại chỉ mụcrehashidxsanght[1]. - Sau khi công việc rehash hoàn tất, giá trị của
rehashidxsẽ tăng lên một. - Khi mọi cặp khóa-giá trị từ
ht[0]đã được rehash sanght[1], Redis sẽ đặt giá trị củarehashidxthành-1, chỉ ra rằng công việc rehash đã hoàn thành.
- Phân bổ không gian cho
Qua việc sử dụng MurmurHash2 và phương pháp xử lý va chạm bằng chuỗi riêng, Redis đảm bảo hiệu quả và hiệu suất của từ điển trong việc lưu trữ và truy xuất các cặp khóa-giá trị một cách hiệu quả.
Skip List
Giới thiệu về Skip List
Skip List (hay còn gọi là skiplist) là một cấu trúc dữ liệu sắp xếp, được xây dựng dựa trên các con trỏ nối đến các nút khác nhau trong mỗi nút để thực hiện việc truy cập nhanh chóng vào các nút. Skip List hỗ trợ việc tìm kiếm các nút với độ phức tạp trung bình là O(log N), trong trường hợp xấu nhất là O(N), và cũng hỗ trợ các thao tác tuần tự để xử lý các nút một cách nhanh chóng.
Trong hầu hết các trường hợp, hiệu suất của Skip List có thể sánh ngang với cây cân bằng và vì cách thức triển khai đơn giản hơn, nên có nhiều chương trình sử dụng Skip List để thay thế cho cây cân bằng.
Redis sử dụng Skip List làm một trong các triển khai cơ sở của các khóa tập hợp có thứ tự: nếu một tập hợp có thứ tự chứa một số lượng phần tử lớn, hoặc các thành viên trong tập hợp có thứ tự là các chuỗi dài, Redis sẽ sử dụng Skip List làm cơ sở dữ liệu của khóa tập hợp có thứ tự.
Bên cạnh đó, Redis cũng sử dụng Skip List trong các nút cụm của mạng lưới.
Triển khai Skip List
Triển khai Skip List trong Redis bao gồm hai cấu trúc: zskiplist và zskiplistNode, trong đó zskiplist được sử dụng để lưu trữ thông tin của Skip List (ví dụ như nút đầu tiên và nút cuối cùng của Skip List, độ dài), và zskiplistNode được sử dụng để đại diện cho từng nút trong Skip List.
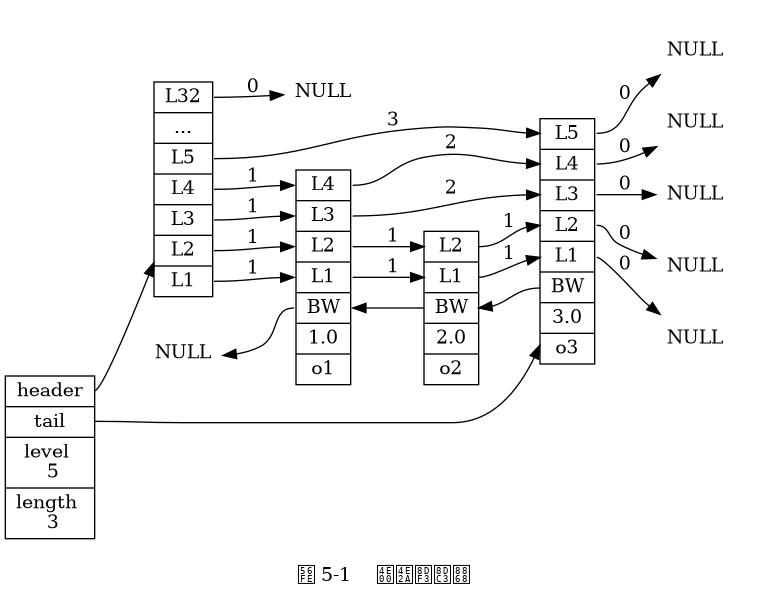
Cấu trúc của zskiplist được định nghĩa như sau:
typedef struct zskiplist {
// Con trỏ đến nút đầu tiên và nút cuối cùng của Skip List
struct zskiplistNode *header, *tail;
// Số lượng nút trong Skip List
unsigned long length;
// Số lớp của nút có số lượng lớn nhất trong Skip List
int level;
} zskiplist;- Con trỏ
headervàtaillần lượt trỏ tới nút đầu tiên và nút cuối cùng của Skip List, cho phép việc xác định nút đầu và nút cuối của Skip List với độ phức tạp O(1). - Thuộc tính
lengthlưu trữ số lượng nút trong Skip List, cho phép trả về độ dài của Skip List với độ phức tạp O(1). - Thuộc tính
levelđược sử dụng để xác định số lớp của nút có số lượng lớn nhất trong Skip List, với mỗi nút trong Skip List có số lớp từ 1 đến 32 được chọn ngẫu nhiên.
Cấu trúc của nút Skip List zskiplistNode được định nghĩa như sau:
typedef struct zskiplistNode {
// Con trỏ lùi
struct zskiplistNode *backward;
// Điểm số
double score;
// Đối tượng thành viên
robj *obj;
// Các lớp
struct zskiplistLevel {
// Con trỏ tiến
struct zskiplistNode *forward;
// Khoảng cách
unsigned int span;
} level[];
} zskiplistNode;- Các cấp (level): Mỗi cấp bao gồm một con trỏ tiến và một khoảng cách. Con trỏ tiến được sử dụng để truy cập các nút khác ở phía cuối của Skip List và khoảng cách ghi lại sự khác biệt giữa nút tiến và nút hiện tại trong Skip List. Trong hình ảnh trên, các mũi tên có số thể hiện con trỏ tiến và số lượng thể hiện khoảng cách. Khi bạn đi qua từ nút đầu đến nút cuối, hành vi duyệt theo cấp sẽ được sử dụng.
- Con trỏ lùi (backward): Con trỏ lùi chỉ đến nút trước nút hiện tại. Khi duyệt từ cuối đến đầu của Skip List, bạn sử dụng con trỏ lùi.
- Điểm số (score): Trong Skip List, các nút được sắp xếp theo điểm số từ thấp đến cao. Trong cùng một Skip List, nhiều nút có thể chứa cùng một điểm số, nhưng đối tượng thành viên của mỗi nút phải là duy nhất. Các nút trong Skip List được sắp xếp theo điểm số và khi điểm số giống nhau, các nút được sắp xếp theo kích thước của thành viên.
- Đối tượng thành viên (obj): Trong mỗi nút,
o1,o2vào3là các thành viên của nút.
Tập hợp số nguyên
Giới thiệu về tập hợp số nguyên
Tập hợp số nguyên (intset) là một trong những cách thức lưu trữ dữ liệu của Redis cho các tập hợp có các phần tử là số nguyên. Khi một tập hợp chỉ bao gồm các phần tử số nguyên và số lượng phần tử không nhiều, Redis sẽ sử dụng cấu trúc dữ liệu tập hợp số nguyên để làm cơ sở dữ liệu.
Cấu trúc dưới của tập hợp số nguyên là một mảng, mảng này lưu trữ các phần tử của tập hợp theo cách sắp xếp không trùng lặp.
Hoạt động nâng cấp mang lại tính linh hoạt cho tập hợp số nguyên và cũng tiết kiệm bộ nhớ càng nhiều càng tốt.
Tập hợp số nguyên chỉ hỗ trợ hoạt động nâng cấp, không hỗ trợ hoạt động hạ cấp.
Triển khai tập hợp số nguyên
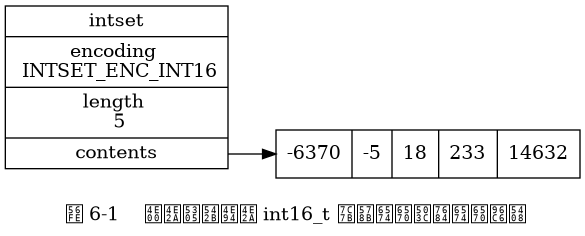
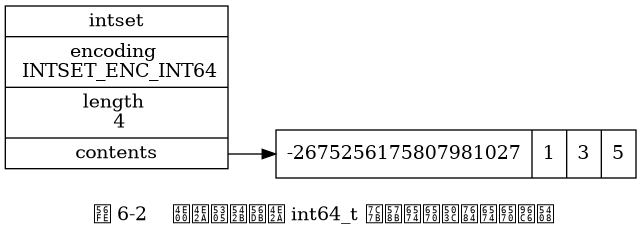
Tập hợp số nguyên là cấu trúc dữ liệu trừu tượng của Redis để lưu trữ các giá trị số nguyên dưới dạng int16_t, int32_t, hoặc int64_t, đảm bảo rằng không có các phần tử trùng lặp trong tập hợp.
Mỗi cấu trúc intset trong intset.h/intset biểu thị một tập hợp số nguyên:
typedef struct intset {
// Phương thức mã hóa
uint32_t encoding;
// Số lượng phần tử trong tập hợp
uint32_t length;
// Mảng lưu trữ các phần tử
int8_t contents[];
} intset;- Mảng
contentslà triển khai cơ sở của tập hợp số nguyên: Mỗi phần tử của tập hợp số nguyên là một phần tử mảng (item) củacontents, các phần tử được sắp xếp theo thứ tự từ bé đến lớn và không chứa bất kỳ phần tử nào làm lặp lại. - Thuộc tính
lengthghi lại số lượng phần tử hiện tại trong tập hợp số nguyên, tức là độ dài của mảngcontents. - Mặc dù cấu trúc
intsetkhai báo thuộc tínhcontentslà một mảng kiểuint8_t, thực tế mảngcontentskhông lưu trữ bất kỳ giá trị kiểuint8_tnào — kiểu thực sự của mảngcontentsphụ thuộc vào giá trị của thuộc tínhencoding:- Nếu thuộc tính
encodingcó giá trị làINTSET_ENC_INT16, thìcontentslà một mảng kiểuint16_tvới mỗi phần tử là một số nguyên kiểuint16_t(giá trị nhỏ nhất là-32,768, lớn nhất là32,767). - Nếu thuộc tính
encodingcó giá trị làINTSET_ENC_INT32, thìcontentslà một mảng kiểuint32_tvới mỗi phần tử là một số nguyên kiểuint32_t(giá trị nhỏ nhất là-2,147,483,648, lớn nhất là2,147,483,647). - Nếu thuộc tính
encodingcó giá trị làINTSET_ENC_INT64, thìcontentslà một mảng kiểuint64_tvới mỗi phần tử là một số nguyên kiểuint64_t(giá trị nhỏ nhất là-9,223,372,036,854,775,808, lớn nhất là9,223,372,036,854,775,807).
- Nếu thuộc tính
Nâng cấp tập hợp số nguyên
Mỗi khi bạn thêm một phần tử mới vào tập hợp số nguyên và kiểu dữ liệu của phần tử mới dài hơn so với tất cả các phần tử hiện có trong tập hợp số nguyên, tập hợp số nguyên sẽ cần phải thực hiện một hoạt động nâng cấp trước khi thêm phần tử mới vào.
Hoạt động nâng cấp và thêm phần tử mới vào tập hợp số nguyên được thực hiện theo ba bước:
- Mở rộng kích thước của mảng cơ sở của tập hợp số nguyên dựa trên kiểu dữ liệu của phần tử mới.
- Chuyển đổi tất cả các phần tử hiện có trong mảng cơ sở sang kiểu dữ liệu giống nhau với phần tử mới và sắp xếp các phần tử đã được chuyển đổi này theo thứ tự.
- Thêm phần tử mới vào mảng cơ sở.
Bởi vì mỗi lần thêm phần tử mới vào tập hợp số nguyên có thể dẫn đến việc nâng cấp, và mỗi lần nâng cấp đều phải chuyển đổi lại tất cả các phần tử hiện có trong mảng cơ sở, do đó thời gian phục vụ thêm phần tử mới vào tập hợp số nguyên là O(N).
Danh sách nén
Định nghĩa về Danh sách nén
Danh sách nén (ziplist) là một cấu trúc dữ liệu tuần tự được thiết kế để tiết kiệm bộ nhớ.
Danh sách nén được sử dụng như một trong các triển khai dưới cùng của khóa danh sách và khóa băm trong Redis.
- Khi một khóa danh sách chỉ chứa một số lượng ít các mục danh sách và mỗi mục danh sách là giá trị số nguyên nhỏ hoặc chuỗi có độ dài ngắn, Redis sẽ sử dụng danh sách nén làm triển khai dưới cùng của khóa danh sách.
- Khi một khóa băm chỉ chứa một số lượng ít các cặp khóa-giá trị và mỗi cặp khóa-giá trị có khóa và giá trị là số nguyên nhỏ hoặc chuỗi có độ dài ngắn, Redis sẽ sử dụng danh sách nén làm triển khai dưới cùng của khóa băm.
Danh sách nén có thể chứa nhiều nút, mỗi nút có thể lưu trữ một mảng byte hoặc giá trị số nguyên.
Thêm một nút mới vào danh sách nén, hoặc xóa nút từ danh sách nén, có thể gây ra các hoạt động cập nhật chuỗi, nhưng khả năng xảy ra điều này không cao.
Triển khai của Danh sách nén
Các thành phần chi tiết của danh sách nén
| Thuộc tính | Kiểu dữ liệu | Độ dài | Mục đích |
|---|---|---|---|
zlbytes | uint32_t | 4 byte | Ghi lại số byte bộ nhớ chiếm dụng của toàn bộ danh sách nén: được sử dụng trong việc phân bổ lại bộ nhớ của danh sách nén hoặc khi tính vị trí zlend. |
zltail | uint32_t | 4 byte | Ghi lại khoảng cách từ nút đuôi của danh sách nén đến địa chỉ bắt đầu của danh sách nén: thông qua lệnh lệnh này, chương trình không cần duyệt qua toàn bộ danh sách nén mà vẫn có thể xác định vị trí của nút đuôi. |
zllen | uint16_t | 2 byte | Ghi lại số lượng nút có trong danh sách nén: khi giá trị thuộc tính này nhỏ hơn UINT16_MAX (65535), nó biểu thị số lượng nút trong danh sách nén; khi giá trị này bằng UINT16_MAX, số lượng thực sự phải được tính toán bằng cách duyệt qua toàn bộ danh sách nén. |
entryX | Nút danh sách | Không xác định | Các nút đang chứa trong danh sách nén, chiều dài của nút phụ thuộc vào nội dung mà nó lưu trữ. |
zlend | uint8_t | 1 byte | Giá trị đặc biệt 0xFF (255 trong hệ thập phân), được sử dụng để đánh dấu kết thúc của danh sách nén. |
Đối tượng (Object)
Redis không sử dụng các cấu trúc dữ liệu trực tiếp để triển khai cơ sở dữ liệu khóa-giá trị, mà dựa trên các cấu trúc dữ liệu này để tạo ra một hệ thống đối tượng. Hệ thống này bao gồm năm loại đối tượng: chuỗi, danh sách, bảng băm (hash), tập hợp và tập hợp có thứ tự, mỗi loại đều sử dụng ít nhất một trong các cấu trúc dữ liệu mà chúng ta đã giới thiệu trước đó.
Giới thiệu về Đối tượng
Mỗi cặp khóa-giá trị trong cơ sở dữ liệu Redis đều là một đối tượng.
Redis bao gồm năm loại đối tượng: chuỗi (string), danh sách (list), bảng băm (hash), tập hợp (set), và tập hợp có thứ tự (sorted set). Mỗi loại đối tượng này đều có ít nhất hai cách mã hóa khác nhau hoặc nhiều hơn, từ đó tối ưu hóa hiệu suất sử dụng đối tượng trong các tình huống khác nhau.
Trước khi thực hiện một số lệnh nhất định, máy chủ sẽ kiểm tra xem kiểu của khóa cụ thể có thể thực hiện lệnh đó hay không, và việc kiểm tra kiểu của một khóa là kiểm tra kiểu đối tượng của giá trị khóa.
Cơ chế thu hồi bộ nhớ dựa trên đếm tham chiếu - Hệ thống đối tượng của Redis đi kèm với cơ chế tự động thu hồi bộ nhớ dựa trên đếm tham chiếu. Khi một đối tượng không còn được sử dụng nữa, bộ nhớ của đối tượng đó sẽ tự động được giải phóng.
Cơ chế chia sẻ đối tượng dựa trên đếm tham chiếu - Redis chia sẻ các đối tượng chuỗi có giá trị từ 0 đến 9999.
Thời gian chờ rỗng của khóa cơ sở dữ liệu - Đối tượng ghi lại thời gian cuối cùng mà nó được truy cập, thời gian này có thể được sử dụng để tính toán thời gian chờ rỗng của đối tượng.
Kiểu đối tượng trong Redis
Trong Redis, đối tượng được sử dụng để đại diện cho các cặp khóa và giá trị trong cơ sở dữ liệu. Mỗi khi tạo một cặp khóa giá trị mới trong Redis, ít nhất hai đối tượng sẽ được tạo ra: một đối tượng để làm khóa (được gọi là đối tượng khóa), và một đối tượng để làm giá trị (được gọi là đối tượng giá trị).
Mỗi đối tượng trong Redis được biểu diễn bằng một cấu trúc redisObject, trong đó có ba thuộc tính liên quan đến dữ liệu:
typedef struct redisObject {
// Kiểu đối tượng
unsigned type:4;
// Mã hóa
unsigned encoding:4;
// Con trỏ đến cấu trúc dữ liệu thực
void *ptr;
// ...
} robj;Thuộc tính type của đối tượng lưu trữ loại của đối tượng, và Redis có những loại đối tượng sau:
| Đối tượng | Giá trị của type | Kết quả của lệnh TYPE |
|---|---|---|
| Đối tượng chuỗi | REDIS_STRING | "string" |
| Đối tượng danh sách | REDIS_LIST | "list" |
| Đối tượng băm | REDIS_HASH | "hash" |
| Đối tượng tập hợp | REDIS_SET | "set" |
| Đối tượng tập có thứ tự | REDIS_ZSET | "zset" |
Trong Redis, khóa của cặp khóa giá trị luôn là một đối tượng chuỗi, trong khi giá trị có thể là một trong những loại đối tượng như trên: chuỗi, danh sách, băm, tập hợp, hoặc tập có thứ tự.
Ví dụ: Sử dụng lệnh TYPE để xác định loại đối tượng của giá trị cho mỗi khóa trong cơ sở dữ liệu Redis:
# Khóa là đối tượng chuỗi, giá trị là đối tượng chuỗi
> SET msg "Xin chào"
OK
> TYPE msg
string
# Khóa là đối tượng chuỗi, giá trị là đối tượng danh sách
> RPUSH numbers 1 3 5
(integer) 3
> TYPE numbers
list
# Khóa là đối tượng chuỗi, giá trị là đối tượng băm
> HMSET user id 100 name "Nguyen" age 30
OK
> TYPE user
hash
# Khóa là đối tượng chuỗi, giá trị là đối tượng tập hợp
> SADD cities "Hanoi" "Ho Chi Minh" "Danang"
(integer) 3
> TYPE cities
set
# Khóa là đối tượng chuỗi, giá trị là đối tượng tập có thứ tự
> ZADD salary 3000 "Alice" 4000 "Bob" 2500 "Carol"
(integer) 3
> TYPE salary
zsetMã hóa của Đối tượng
Con trỏ ptr của đối tượng trong Redis trỏ đến cấu trúc dữ liệu cụ thể được sử dụng để triển khai đối tượng, và cấu trúc này được quyết định bởi thuộc tính encoding của đối tượng.
Thuộc tính encoding ghi nhận phương thức mã hóa được sử dụng để triển khai đối tượng, tức là đối tượng sử dụng cấu trúc dữ liệu nào làm nền tảng.
Redis hỗ trợ các phương thức mã hóa sau:
| Loại đối tượng | Mã hóa | Đối tượng | Kết quả của lệnh OBJECT ENCODING |
|---|---|---|---|
REDIS_STRING | REDIS_ENCODING_INT | Đối tượng chuỗi được triển khai bằng giá trị số nguyên. | "int" |
REDIS_STRING | REDIS_ENCODING_EMBSTR | Đối tượng chuỗi động đơn giản được triển khai bằng embstr. | "embstr" |
REDIS_STRING | REDIS_ENCODING_RAW | Đối tượng chuỗi động đơn giản được triển khai bằng chuỗi động. | "raw" |
REDIS_LIST | REDIS_ENCODING_ZIPLIST | Đối tượng danh sách được triển khai bằng danh sách nén (ziplist). | "ziplist" |
REDIS_LIST | REDIS_ENCODING_LINKEDLIST | Đối tượng danh sách được triển khai bằng danh sách liên kết (linkedlist). | "linkedlist" |
REDIS_HASH | REDIS_ENCODING_ZIPLIST | Đối tượng bảng băm được triển khai bằng bảng băm nén (ziplist). | "ziplist" |
REDIS_HASH | REDIS_ENCODING_HT | Đối tượng bảng băm được triển khai bằng từ điển (hashtable). | "hashtable" |
REDIS_SET | REDIS_ENCODING_INTSET | Đối tượng tập hợp được triển khai bằng tập hợp số nguyên (intset). | "intset" |
REDIS_SET | REDIS_ENCODING_HT | Đối tượng tập hợp được triển khai bằng từ điển (hashtable). | "hashtable" |
REDIS_ZSET | REDIS_ENCODING_ZIPLIST | Đối tượng tập hợp có thứ tự được triển khai bằng danh sách nén (ziplist). | "ziplist" |
REDIS_ZSET | REDIS_ENCODING_SKIPLIST | Đối tượng tập hợp có thứ tự được triển khai bằng skip list và từ điển (skiplist). | "skiplist" |
Ví dụ
Sử dụng lệnh OBJECT ENCODING để xem mã hóa của đối tượng giá trị của các khóa trong cơ sở dữ liệu Redis:
> SET msg "Xin chào"
OK
> OBJECT ENCODING msg
"embstr"
> SET story "Rất lâu rồi..."
OK
> OBJECT ENCODING story
"raw"
> SADD numbers 1 3 5
(integer) 3
> OBJECT ENCODING numbers
"intset"
> SADD numbers "bảy"
(integer) 1
> OBJECT ENCODING numbers
"hashtable"Kiểm tra loại và đa hình lệnh
Trong Redis, các lệnh có thể được chia thành hai loại chính:
Lệnh đa hình: Các lệnh này có thể thực hiện trên bất kỳ loại khóa nào, chẳng hạn như
DEL,EXPIRE,RENAME,TYPE,OBJECT, vv.Lệnh đặc biệt cho từng loại: Đây là những lệnh chỉ có thể thực hiện trên một loại cụ thể của khóa, như sau:
- Lệnh liên quan đến khóa chuỗi:
SET,GET,APPEND,STRLEN, vv. - Lệnh liên quan đến khóa băm:
HDEL,HSET,HGET,HLEN, vv. - Lệnh liên quan đến khóa danh sách:
RPUSH,LPOP,LINSERT,LLEN, vv. - Lệnh liên quan đến khóa tập hợp:
SADD,SPOP,SINTER,SCARD, vv. - Lệnh liên quan đến khóa tập hợp có thứ tự:
ZADD,ZCARD,ZRANK,ZSCORE, vv.
- Lệnh liên quan đến khóa chuỗi:
Trước khi thực hiện một lệnh đặc biệt cho từng loại, Redis sẽ kiểm tra xem loại đối tượng của khóa đầu vào có phù hợp không, và sau đó quyết định liệu nên thực hiện lệnh cụ thể cho khóa đã cho hay không. Việc kiểm tra loại đối tượng trước khi thực hiện lệnh đặc biệt cho từng loại được thực hiện dựa trên thuộc tính type của cấu trúc redisObject:
- Trước khi thực hiện lệnh đặc biệt cho từng loại, máy chủ sẽ kiểm tra xem đối tượng giá trị của khóa đầu vào có phải là loại cần thiết cho lệnh đó hay không.
- Nếu đúng như vậy, máy chủ sẽ thực hiện lệnh cụ thể cho khóa.
- Nếu không, máy chủ sẽ từ chối thực hiện lệnh và trả về lỗi loại không phù hợp cho khách hàng.
Redis không chỉ dựa vào loại đối tượng để xác định liệu khóa có thể thực hiện lệnh cụ thể cho từng loại hay không, mà còn dựa vào cách mã hóa của đối tượng giá trị để chọn mã lệnh thích hợp để thực hiện lệnh.
Xử lý thu gom rác
Do ngôn ngữ C không hỗ trợ tự động thu gom rác, Redis đã triển khai một cơ chế thu gom rác dựa trên đếm số tham chiếu.
Thông tin đếm tham chiếu của mỗi đối tượng được ghi nhận trong cấu trúc redisObject bằng thuộc tính refcount:
typedef struct redisObject {
// ...
// Số tham chiếu
int refcount;
// ...
} robj;Thông tin đếm tham chiếu của đối tượng sẽ thay đổi theo trạng thái sử dụng của đối tượng:
- Khi tạo một đối tượng mới, giá trị đếm tham chiếu sẽ được khởi tạo là
1. - Khi một đối tượng được sử dụng bởi một chương trình mới, giá trị đếm tham chiếu sẽ được tăng lên.
- Khi một đối tượng không còn được sử dụng bởi bất kỳ chương trình nào nữa, giá trị đếm tham chiếu sẽ giảm đi.
- Khi giá trị đếm tham chiếu của một đối tượng xuống
0, bộ nhớ mà đối tượng đó chiếm dụng sẽ được giải phóng.
Chia sẻ đối tượng
Trong Redis, nhiều khóa có thể chia sẻ cùng một đối tượng giá trị bằng cách thực hiện hai bước sau:
- Chỉ định đến đối tượng hiện tại: Chỉ định con trỏ giá trị của nhiều khóa trong cơ sở dữ liệu đến cùng một đối tượng giá trị hiện tại.
- Tăng số lượng tham chiếu: Tăng số lượng tham chiếu của đối tượng giá trị được chia sẻ lên một.
Cơ chế chia sẻ đối tượng giúp tiết kiệm rất nhiều bộ nhớ. Khi nhiều khóa trong cơ sở dữ liệu lưu trữ cùng một giá trị đối tượng, việc sử dụng cơ chế chia sẻ đối tượng có thể giảm đáng kể lượng bộ nhớ sử dụng.
Redis sẽ tự động chia sẻ các đối tượng chuỗi có giá trị từ 0 đến 9999 khi khởi tạo máy chủ.
Thời gian rảnh của đối tượng
Thuộc tính lru của redisObject ghi lại thời điểm lần cuối cùng mà đối tượng được truy cập bởi các lệnh trong chương trình:
typedef struct redisObject {
// ...
unsigned lru:22;
// ...
} robj;Lệnh OBJECT IDLETIME có thể in ra thời gian rảnh của một khóa đã cho, thời gian rảnh này được tính bằng cách lấy thời gian hiện tại trừ đi thời điểm lru của đối tượng giá trị của khóa:
> SET msg "hello world"
OK
# Chờ một khoảng thời gian ngắn
> OBJECT IDLETIME msg
(integer) 20
# Chờ lâu hơn
> OBJECT IDLETIME msg
(integer) 180
# Truy cập giá trị của khóa msg
> GET msg
"hello world"
# Khóa hiện đang hoạt động, thời gian rảnh là 0
> OBJECT IDLETIME msg
(integer) 0Lưu ý
Lệnh OBJECT IDLETIME có cách triển khai đặc biệt, lệnh này không thay đổi thuộc tính
lrucủa đối tượng giá trị khi truy cập.
Ngoài việc có thể in ra bởi lệnh OBJECT IDLETIME, thời gian rảnh của một khóa cũng có tác dụng khác: nếu máy chủ Redis bật tùy chọn maxmemory và sử dụng thuật toán volatile-lru hoặc allkeys-lru để thu hồi bộ nhớ, khi lượng bộ nhớ máy chủ vượt quá giá trị tối đa được thiết lập bởi maxmemory, các khóa có thời gian rảnh cao sẽ được ưu tiên giải phóng bởi máy chủ để giảm bộ nhớ.