Redis Basic Data Types
Redis cung cấp nhiều loại dữ liệu, mỗi loại dữ liệu đều có các lệnh hỗ trợ phong phú.
Khi sử dụng Redis, không chỉ cần hiểu các đặc điểm của các loại dữ liệu, mà còn cần linh hoạt và hiệu quả trong việc sử dụng các loại dữ liệu này để xây dựng mô hình dữ liệu phù hợp với kịch bản nghiệp vụ.
Các loại dữ liệu cơ bản mà Redis hỗ trợ:
- STRING: Chuỗi
- HASH: Bảng băm
- LIST: List
- SET: Tập hợp
- ZSET: Tập hợp có thứ tự
Các loại dữ liệu nâng cao mà Redis hỗ trợ:
- BitMap: Bản đồ bit
- HyperLogLog: Đếm dữ liệu khổng lồ
- GEO: Dữ liệu vị trí địa lý
- Stream: Dữ liệu luồng
Sử dụng Redis, không chỉ cần hiểu các đặc tính của các loại dữ liệu mà còn cần linh hoạt và hiệu quả trong việc sử dụng các loại dữ liệu này để xây dựng mô hình theo từng tình huống cụ thể của nghiệp vụ.

Các kiểu dữ liệu cơ bản của Redis
| Kiểu dữ liệu | Giá trị có thể lưu trữ | Các hoạt động |
|---|---|---|
| STRING | Chuỗi, số nguyên hoặc số thực | Thực hiện các hoạt động trên toàn bộ chuỗi hoặc một phần của chuỗi Thực hiện tăng hoặc giảm giá trị số nguyên hoặc số thực |
| LIST | List | Thêm hoặc lấy ra phần tử từ hai đầu Đọc một hoặc nhiều phần tử Thực hiện cắt tỉa, chỉ giữ lại một phạm vi phần tử |
| SET | Tập hợp không thứ tự | Thêm, lấy và xóa một phần tử Kiểm tra xem một phần tử có tồn tại trong tập hợp hay không Tính toán giao, hợp, hiệu Lấy ngẫu nhiên một phần tử từ tập hợp |
| HASH | Bảng băm không thứ tự | Thêm, lấy và xóa một cặp khóa-giá trị Lấy tất cả các cặp khóa-giá trị Kiểm tra xem một khóa có tồn tại trong bảng hay không |
| ZSET | Tập hợp có thứ tự | Thêm, lấy và xóa phần tử Lấy phần tử dựa trên phạm vi hoặc thành viên Tính hạng của một khóa |
STRING
Giới thiệu về String
Kiểu dữ liệu String là một cấu trúc dạng cặp khóa-giá trị.
String là loại dữ liệu an toàn nhị phân. An toàn nhị phân có nghĩa là kiểu dữ liệu String không chỉ có thể lưu trữ dữ liệu văn bản mà còn có thể lưu trữ bất kỳ định dạng dữ liệu nhị phân nào, chẳng hạn như: hình ảnh, âm thanh, video, tệp nén, v.v.
Theo mặc định, giá trị của kiểu dữ liệu String có thể lên đến 512 MB.
Cách triển khai String
Cấu trúc dữ liệu cơ bản của kiểu String chủ yếu là int và SDS (Simple Dynamic String - Chuỗi động đơn giản).
SDS khác với chuỗi C mà chúng ta thường biết. Lý do không sử dụng chuỗi C vì SDS so với chuỗi gốc của C có những ưu điểm sau:
- SDS không chỉ lưu trữ dữ liệu văn bản mà còn lưu trữ dữ liệu nhị phân. SDS sử dụng thuộc tính
lenđể xác định độ dài chuỗi thay vì sử dụng ký tự kết thúc null, và tất cả các API của SDS đều xử lý dữ liệu trong mảngbuf[]như là dữ liệu nhị phân. Do đó, SDS không chỉ có thể lưu trữ dữ liệu văn bản mà còn có thể lưu trữ dữ liệu nhị phân như hình ảnh, âm thanh, video, tệp nén. - Thời gian phức tạp để lấy độ dài chuỗi của SDS là O(1). Vì chuỗi C không ghi lại độ dài của chính nó, nên thời gian phức tạp để lấy độ dài là O(n); trong khi cấu trúc SDS sử dụng thuộc tính
lenđể ghi lại độ dài chuỗi, do đó thời gian phức tạp làO(1). - API của SDS trong Redis là an toàn, việc nối chuỗi sẽ không gây ra tràn bộ đệm. SDS kiểm tra không gian trước khi nối chuỗi, nếu không đủ không gian sẽ tự động mở rộng, do đó sẽ không gây ra vấn đề tràn bộ đệm.
Mã hóa của đối tượng chuỗi có thể là int, raw hoặc embstr.
Các phương pháp mã hóa giá trị của đối tượng chuỗi:
| Giá trị | Mã hóa |
|---|---|
Số nguyên có thể được lưu bằng kiểu long. | int |
Số thực có thể được lưu bằng kiểu long double. | embstr hoặc raw |
Giá trị chuỗi hoặc số nguyên quá lớn không thể biểu diễn bằng long. | embstr hoặc raw |
Nếu một đối tượng chuỗi lưu trữ giá trị số nguyên và giá trị này có thể biểu diễn bằng kiểu long, thì đối tượng chuỗi sẽ lưu trữ giá trị số nguyên trong thuộc tính ptr của cấu trúc đối tượng chuỗi (chuyển void* thành long), và sẽ đặt mã hóa của đối tượng chuỗi thành int.
Ví dụ
> SET number 10086
OK
> OBJECT ENCODING number
"int"Nếu đối tượng chuỗi lưu trữ một giá trị chuỗi và độ dài của chuỗi này lớn hơn 39 byte, thì đối tượng chuỗi sẽ sử dụng một chuỗi động đơn giản (SDS) để lưu trữ giá trị chuỗi này và mã hóa đối tượng sẽ được đặt là raw.
> SET story "Long, long, long ago there lived a king ..."
OK
> STRLEN story
(integer) 43
> OBJECT ENCODING story
"raw"Nếu đối tượng chuỗi lưu trữ một giá trị chuỗi và độ dài của chuỗi này nhỏ hơn hoặc bằng 39 byte, thì đối tượng chuỗi sẽ sử dụng mã hóa embstr để lưu trữ giá trị chuỗi này. Mã hóa embstr là một cách mã hóa tối ưu được thiết kế đặc biệt để lưu trữ các chuỗi ngắn.
Ví dụ
> SET msg "hello"
OK
> OBJECT ENCODING msg
"embstr"Lệnh String
| Lệnh | Mô tả |
|---|---|
SET | Lưu trữ một giá trị chuỗi |
SETNX | Lưu trữ giá trị chuỗi chỉ khi khóa không tồn tại |
GET | Lấy giá trị của khóa cụ thể |
MGET | Lấy giá trị của một hoặc nhiều khóa cụ thể |
INCRBY | Tăng giá trị số lưu trữ trong khóa lên một giá trị nhất định |
DECRBY | Giảm giá trị số lưu trữ trong khóa xuống một giá trị nhất định |
Tham khảo thêm các lệnh khác tại: Tài liệu chính thức về lệnh String của Redis
Ví dụ về các thao tác SET, GET, và DEL
# Lưu giá trị 'hung' cho khóa 'name'
> set name hung
OK
# Lấy giá trị của khóa 'name'
> get name
"hung"
# Lưu giá trị 'unknown' cho khóa 'name' (ghi đè giá trị cũ)
> set name unknown
OK
> get name
"unknown"
# Kiểm tra xem khóa 'name' có tồn tại hay không
> exists name
(integer) 1
# Xóa khóa 'name'
> del name
(integer) 1
# Kiểm tra xem khóa 'name' có tồn tại hay không
> exists name
(integer) 0
# Lấy giá trị của khóa 'name'
> get name
(nil)Ví dụ về thao tác SETNX
# Kiểm tra xem khóa 'lock' có tồn tại hay không
> exists lock
(integer) 0
# Lưu giá trị '1' cho khóa 'lock', lưu thành công
> setnx lock 1
(integer) 1
# Cố gắng lưu giá trị '2' cho khóa 'lock', lưu thất bại do khóa đã tồn tại
> setnx lock 2
(integer) 0
# Lấy giá trị của khóa 'lock'
> get lock
"1"Ví dụ về thao tác MSET, MGET
# Lưu trữ hàng loạt giá trị cho các khóa 'one', 'two', 'three'
> mset one 1 two 2 three 3
OK
# Lấy giá trị của các khóa 'one', 'two', 'three'
> mget one two three
1) "1"
2) "2"
3) "3"Ví dụ về các thao tác INCR, DECR, INCRBY, DECRBY
# Lưu giá trị '0' cho khóa 'counter'
> set counter 0
OK
# Tăng giá trị của khóa 'counter' lên 1
> incr counter
(integer) 1
# Tăng giá trị của khóa 'counter' lên 9
> incrby counter 9
(integer) 10
# Giảm giá trị của khóa 'counter' xuống 1
> decr counter
(integer) 9
# Giảm giá trị của khóa 'counter' xuống 9
> decrby counter 9
(integer) 0Ứng dụng String
Các kịch bản phù hợp: Cache, Bộ đếm, Chia sẻ Session
Cache đối tượng
Có hai cách sử dụng String để cache đối tượng:
- Cache giá trị JSON của đối tượng
> set user:1 {"name":"hung","sex":"man"}- Chia key thành dạng
user:ID:attribute, sử dụng MSET để lưu trữ, dùng MGET để lấy giá trị các thuộc tính
> mset user:1:name hung user:1:sex man
OK
> mget user:1:name user:1:sex
1) "hung"
2) "man"Bộ đếm
Kịch bản yêu cầu
Thống kê số lượt truy cập, lượt yêu thích, lượt thích, v.v. của nội dung trên trang web.
Giải pháp
Sử dụng kiểu String của Redis để lưu trữ một bộ đếm.
Các thao tác phổ biến để duy trì bộ đếm:
- Tăng giá trị thống kê - sử dụng lệnh
INCR,INCRBY - Giảm giá trị thống kê - sử dụng lệnh
DECR,DECRBY
Ví dụ mã
# Khởi tạo số lượt truy cập của bài viết ID là 1024 là 0
> set blog:view:1024 0
OK
# Tăng số lượt truy cập của bài viết ID là 1024 lên 1
> incr blog:view:1024
(integer) 1
# Tăng số lượt truy cập của bài viết ID là 1024 lên 1
> incr blog:view:1024
(integer) 2
# Xem số lượt truy cập của bài viết ID là 1024
> get blog:view:1024
"2"Khóa phân tán
- Yêu cầu khóa
Lệnh SET có tham số NX có thể thực hiện "chỉ chèn khi key không tồn tại", có thể dùng nó để thực hiện khóa phân tán:
- Nếu key không tồn tại, chèn thành công, có thể coi là khóa thành công.
- Nếu key đã tồn tại, chèn thất bại, có thể coi là khóa thất bại.
Thông thường, khóa phân tán cũng sẽ được thiết lập thời gian hết hạn, lệnh khóa phân tán như sau:
SET key value NX PX 30000- key - là từ khóa của khóa phân tán.
- value - là giá trị duy nhất được tạo bởi client.
- NX - chỉ thực hiện SET nếu key không tồn tại. (Nếu Redis đã có key này, thiết lập thất bại và trả về
nil) - PX 30000 - chỉ định key sẽ bị xóa sau 30 giây (nghĩa là khóa sẽ được giải phóng). Thiết lập thời gian hết hạn để tránh khóa không được giải phóng do các tình huống bất ngờ.
- Giải phóng khóa
Giải phóng khóa bằng cách xóa key, nhưng thông thường có thể sử dụng script lua để xóa, so sánh giá trị trước khi xóa, đảm bảo rằng chỉ client nào tạo ra khóa mới có thể xóa khóa đó. Để đảm bảo tính nguyên tử, có thể sử dụng script lua:
-- Xóa khóa nếu giá trị của key trùng khớp với giá trị truyền vào
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
endChia sẻ thông tin Session
Trong môi trường phân tán, nếu một Session của người dùng chỉ được lưu trên một máy chủ, khi bộ cân bằng tải chuyển yêu cầu tiếp theo của người dùng tới máy chủ khác, máy chủ này không có Session của người dùng, có thể dẫn đến việc người dùng phải đăng nhập lại.
Các chiến lược để thực hiện Session phân tán:
- Session dính
- Sao chép và chia sẻ session giữa các máy chủ ứng dụng
- Chia sẻ session dựa trên cache ✅
Thực hiện chia sẻ session dựa trên cache
Sử dụng một máy chủ lưu trữ riêng biệt để lưu trữ dữ liệu Session, có thể là MySQL, Redis hoặc Memcached.
Nhược điểm: Cần triển khai mã để truy xuất Session.
HASH
Giới thiệu về Hash
Hash là một tập hợp các cặp khóa-giá trị (key-value), trong đó giá trị có dạng: value=[{field1, value1}, ...{fieldN, valueN}]. Hash đặc biệt phù hợp để lưu trữ các đối tượng.
Cấu trúc Hash
Mã hóa của đối tượng Hash có thể là ziplist hoặc hashtable.
ziplist: Mã hóa đối tượng Hash bằng List nén làm cấu trúc nền tảng. Mỗi khi có một cặp khóa-giá trị mới được thêm vào đối tượng Hash, chương trình sẽ đẩy nút chứa khóa vào cuối List nén, sau đó đẩy nút chứa giá trị vào cuối List nén.hashtable: Mã hóa đối tượng Hash bằng bảng băm làm cấu trúc nền tảng. Mỗi cặp khóa-giá trị trong đối tượng Hash đều được lưu trữ dưới dạng một cặp khóa-giá trị của bảng băm.
Đối tượng Hash sẽ sử dụng mã hóa ziplist khi đồng thời thỏa mãn hai điều kiện sau; ngược lại, sẽ sử dụng mã hóa hashtable:
- Độ dài của tất cả các khóa và giá trị của các cặp khóa-giá trị trong đối tượng Hash đều nhỏ hơn
64byte (có thể được cấu hình bằnghash-max-ziplist-value). - Số lượng cặp khóa-giá trị trong đối tượng Hash nhỏ hơn
512(có thể được cấu hình bằnghash-max-ziplist-entries).
Lưu ý: Giá trị giới hạn của hai điều kiện này có thể được thay đổi, cụ thể hãy xem phần mô tả trong tệp cấu hình về tùy chọn
hash-max-ziplist-valuevàhash-max-ziplist-entries.
Các lệnh của Hash
| Lệnh | Mô tả |
|---|---|
HSET | Thiết lập giá trị của trường đã chỉ định |
HGET | Lấy giá trị của trường đã chỉ định |
HGETALL | Lấy tất cả các cặp khóa-giá trị |
HMSET | Thiết lập nhiều cặp khóa-giá trị |
HMGET | Lấy giá trị của nhiều trường đã chỉ định |
HDEL | Xóa trường đã chỉ định |
HINCRBY | Tăng giá trị số nguyên của trường đã chỉ định |
HKEYS | Lấy tất cả các trường |
Xem thêm các lệnh tại Tài liệu chính thức về các lệnh của Redis Hash
Ví dụ về các lệnh Hash:
# Lưu trữ một giá trị của bảng băm
HSET key field value
# Lấy giá trị của trường trong bảng băm
HGET key field
# Lưu trữ nhiều cặp khóa-giá trị trong bảng băm
HMSET key field value [field value...]
# Lấy giá trị của nhiều trường trong bảng băm
HMGET key field [field ...]
# Xóa trường trong bảng băm
HDEL key field [field ...]
# Trả về số lượng trường trong bảng băm
HLEN key
# Trả về tất cả các cặp khóa-giá trị trong bảng băm
HGETALL key
# Tăng giá trị của trường trong bảng băm lên n
HINCRBY key field nỨng dụng của Hash
Hash phù hợp để lưu trữ dữ liệu có cấu trúc.
Cache đối tượng
Cấu trúc (key, field, value) của Hash giống với cấu trúc (id đối tượng, thuộc tính, giá trị) của đối tượng, nên cũng có thể dùng để lưu trữ đối tượng.
Ví dụ, với thông tin người dùng trong cơ sở dữ liệu quan hệ:
Chúng ta có thể sử dụng các lệnh sau để lưu trữ thông tin đối tượng người dùng vào Hash:
# Lưu trữ một bảng băm với id người dùng là 1
> HMSET uid:1 name Tom age 15
2
# Lưu trữ một bảng băm với id người dùng là 2
> HMSET uid:2 name Jerry age 13
2
# Lấy tất cả các cặp khóa-giá trị của người dùng có id là 1
> HGETALL uid:1
1) "name"
2) "Tom"
3) "age"
4) "15"Cấu trúc lưu trữ Hash của Redis:
Trong các kịch bản ứng dụng của kiểu String đã được giới thiệu trước đó, việc sử dụng String + JSON cũng là một cách để lưu trữ đối tượng. Vậy khi lưu trữ đối tượng, nên dùng String + JSON hay Hash?
Thông thường, đối tượng được lưu trữ bằng String + JSON. Đối với những thuộc tính thay đổi thường xuyên của đối tượng, có thể tách ra và lưu trữ bằng Hash.
Giỏ hàng
Kịch bản yêu cầu
Người dùng duyệt trang web thương mại điện tử, thêm sản phẩm vào giỏ hàng và hỗ trợ xem giỏ hàng. Cần xem xét trường hợp chưa đăng nhập.
Giải pháp
Có thể sử dụng kiểu HASH để thực hiện chức năng giỏ hàng.
Sử dụng session của người dùng làm khóa, lưu trữ ánh xạ giữa ID sản phẩm và số lượng sản phẩm. Trong đó, ID sản phẩm là trường, số lượng sản phẩm là giá trị.
Tại sao không sử dụng ID người dùng?
Vì trong nhiều trường hợp, cần hỗ trợ người dùng sử dụng giỏ hàng mà không cần đăng nhập, do đó không biết ID người dùng. Trong trường hợp này, việc sử dụng session của người dùng phù hợp hơn. Ngoài ra, khi xóa session, có thể tiện lợi xóa luôn cache giỏ hàng.
Các thao tác phổ biến để duy trì giỏ hàng:
- Thêm sản phẩm -
HSET cart:{session} {productID} 1 - Thêm số lượng -
HINCRBY cart:{session} {productID} 1 - Tổng số sản phẩm -
HLEN cart:{session} - Xóa sản phẩm -
HDEL cart:{session} {productID} - Lấy tất cả sản phẩm trong giỏ hàng -
HGETALL cart:{session}
Hiện tại, chỉ lưu trữ ID sản phẩm vào Redis, khi hiển thị thông tin chi tiết của sản phẩm, cần truy vấn thêm cơ sở dữ liệu để lấy thông tin đầy đủ của sản phẩm.
LIST
Loại List trong Redis là một danh sách có thứ tự.
Giới thiệu về List
List là một danh sách các chuỗi đơn giản, được sắp xếp theo thứ tự chèn vào, có thể thêm phần tử vào List từ đầu hoặc cuối.
List có độ dài tối đa là 2^32 - 1, tức là mỗi List hỗ trợ hơn 4 tỷ phần tử.
Cách triển khai List
Mã hóa đối tượng List có thể là ziplist hoặc linkedlist.
List mã hóa bằng ziplist sử dụng List nén làm cơ sở, mỗi nút trong List nén (entry) lưu trữ một phần tử trong List.

List mã hóa bằng linkedlist sử dụng List liên kết đôi làm cơ sở.
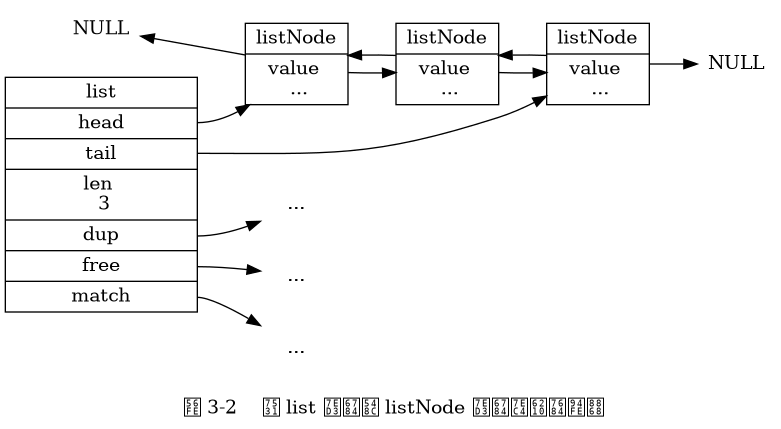
Khi đối tượng List thỏa mãn đồng thời hai điều kiện sau, đối tượng List sử dụng mã hóa ziplist; ngược lại, sử dụng mã hóa linkedlist:
- Độ dài của tất cả các chuỗi trong List nhỏ hơn
64byte. - Số lượng phần tử trong List nhỏ hơn
512.
Lưu ý:
Hai giá trị giới hạn trên của hai điều kiện này có thể được thay đổi, chi tiết xem trong file cấu hình về các tùy chọn
list-max-ziplist-valuevàlist-max-ziplist-entries.
Lệnh List
| Lệnh | Hành vi |
|---|---|
LPUSH | Thêm giá trị vào đầu List. |
RPUSH | Thêm giá trị vào cuối List. |
LPOP | Xóa và trả về giá trị đầu tiên của List. |
RPOP | Xóa và trả về giá trị cuối cùng của List. |
LRANGE | Lấy tất cả các giá trị trong khoảng cho trước. |
LINDEX | Lấy giá trị tại vị trí cho trước trong List. |
LREM | Xóa giá trị đầu tiên trong List. |
LTRIM | Chỉ giữ lại các phần tử trong khoảng cho trước, xóa các phần tử khác. |
Tham khảo thêm các lệnh tại: Tài liệu chính thức về lệnh List của Redis
# Thêm một hoặc nhiều giá trị vào đầu List key
LPUSH key value [value ...]
# Thêm một hoặc nhiều giá trị vào cuối List key
RPUSH key value [value ...]
# Xóa và trả về giá trị đầu tiên của List key
LPOP key
# Xóa và trả về giá trị cuối cùng của List key
RPOP key
# Trả về các phần tử trong List key trong khoảng start và stop, bắt đầu từ 0
LRANGE key start stop
# Xóa phần tử đầu tiên trong List key, nếu không có phần tử nào thì chờ timeout giây, nếu timeout=0 thì chờ mãi mãi
BLPOP key [key ...] timeout
# Xóa phần tử cuối cùng trong List key, nếu không có phần tử nào thì chờ timeout giây, nếu timeout=0 thì chờ mãi mãi
BRPOP key [key ...] timeoutỨng dụng List
Hàng đợi tin nhắn
Hàng đợi tin nhắn cần thỏa mãn ba yêu cầu khi lưu trữ và truy xuất tin nhắn: duy trì thứ tự tin nhắn, xử lý tin nhắn lặp lại và đảm bảo độ tin cậy của tin nhắn.
Loại List và Stream trong Redis có thể thỏa mãn ba yêu cầu này. Trước tiên, chúng ta sẽ tìm hiểu về cách thực hiện hàng đợi tin nhắn dựa trên List, sau đó sẽ tìm hiểu về Stream.
1. Làm thế nào để duy trì thứ tự tin nhắn?
List tự thân là List lưu trữ dữ liệu theo nguyên tắc vào trước ra trước (FIFO), do đó, nếu sử dụng List làm hàng đợi tin nhắn, sẽ tự nhiên thỏa mãn yêu cầu này.
List có thể sử dụng lệnh LPUSH + RPOP (hoặc ngược lại, RPUSH+LPOP) để thực hiện hàng đợi tin nhắn.
Nhà sản xuất sử dụng lệnh
LPUSH key value[value...]để chèn tin nhắn vào đầu List, nếu key không tồn tại, nó sẽ tạo một List trống trước khi chèn tin nhắn.Người tiêu thụ sử dụng lệnh
RPOP keyđể lần lượt đọc tin nhắn từ List, theo thứ tự vào trước ra trước.
Tuy nhiên, khi người tiêu thụ đọc dữ liệu, có một nguy cơ tiềm ẩn về hiệu suất.
Khi nhà sản xuất chèn dữ liệu vào List, List sẽ không tự động thông báo cho người tiêu thụ rằng có tin nhắn mới, nếu người tiêu thụ muốn xử lý tin nhắn kịp thời, họ cần phải liên tục gọi lệnh RPOP (ví dụ sử dụng vòng lặp while(1)). Nếu có tin nhắn mới, lệnh RPOP sẽ trả về kết quả, ngược lại, lệnh RPOP sẽ trả về giá trị trống và tiếp tục vòng lặp.
Vì vậy, ngay cả khi không có tin nhắn mới chèn vào List, người tiêu thụ cũng phải liên tục gọi lệnh RPOP, dẫn đến việc tiêu thụ CPU không cần thiết.
Để giải quyết vấn đề này, Redis cung cấp lệnh BRPOP. Lệnh BRPOP còn gọi là đọc chặn, khi không đọc được dữ liệu từ List, khách hàng sẽ tự động chặn, đợi đến khi có dữ liệu mới chèn vào List, sau đó mới bắt đầu đọc dữ liệu. So với việc chương trình người tiêu thụ tự mình liên tục gọi lệnh RPOP, cách này giúp tiết kiệm tài nguyên CPU.
2. Làm thế nào để xử lý tin nhắn lặp lại?
Người tiêu thụ cần thực hiện xác định tin nhắn lặp lại từ hai khía cạnh:
- Mỗi tin nhắn cần có một ID duy nhất toàn cục.
- Người tiêu thụ cần ghi lại các ID tin nhắn đã được xử lý. Khi nhận được một tin nhắn, chương trình người tiêu thụ có thể so sánh ID tin nhắn nhận được với ID tin nhắn đã được xử lý để xác định liệu tin nhắn hiện tại đã được xử lý chưa. Nếu đã được xử lý, chương trình người tiêu thụ sẽ không xử lý lại.
Nhưng List không tự động tạo ID cho mỗi tin nhắn, vì vậy chúng ta cần tự tạo một ID duy nhất toàn cục cho mỗi tin nhắn, sau đó khi sử dụng lệnh LPUSH để chèn tin nhắn vào List, chúng ta cần bao gồm ID duy nhất này trong tin nhắn.
Ví dụ, chúng ta có thể thực hiện lệnh sau để chèn một tin nhắn với ID duy nhất toàn cục là 111000102 và số lượng kho là 99 vào hàng đợi tin nhắn:
> LPUSH mq "111000102:stock:99"
(integer) 13. Làm thế nào để đảm bảo độ tin cậy của tin nhắn?
Khi chương trình người tiêu thụ đọc một tin nhắn từ List, tin nhắn sẽ không còn lưu trữ trong List. Vì vậy, nếu chương trình người tiêu thụ gặp sự cố hoặc tắt máy trong quá trình xử lý tin nhắn, tin nhắn sẽ không được xử lý xong và chương trình người tiêu thụ khởi động lại sẽ không thể đọc lại tin nhắn từ List.
Để lưu trữ tin nhắn, List cung cấp lệnh BRPOPLPUSH. Lệnh này cho phép chương trình người tiêu thụ đọc tin nhắn từ một List, đồng thời Redis sẽ chèn tin nhắn đó vào một List khác (có thể gọi là List sao lưu) để lưu trữ.
Nhờ vậy, nếu chương trình người tiêu thụ đọc tin nhắn nhưng không xử lý thành công, khi khởi động lại, nó có thể đọc lại tin nhắn từ List sao lưu và tiếp tục xử lý.
Như vậy, chúng ta có thể thấy rằng dựa trên List, hàng đợi tin nhắn có thể đáp ứng ba yêu cầu chính (duy trì thứ tự tin nhắn, xử lý tin nhắn lặp lại và đảm bảo độ tin cậy của tin nhắn).
- Duy trì thứ tự tin nhắn: sử dụng LPUSH + RPOP.
- Chặn đọc: sử dụng BRPOP.
- Xử lý tin nhắn trùng lặp: nhà sản xuất tự triển khai một ID duy nhất trên toàn cầu.
- Độ tin cậy của tin nhắn: Sử dụng BRPOPLPUSH
Hạn chế của List dưới dạng hàng đợi tin nhắn là gì?
List không hỗ trợ nhiều người tiêu thụ sử dụng cùng một tin nhắn** , vì khi một người tiêu thụ lấy một tin nhắn, tin nhắn sẽ bị xóa khỏi Danh sách và những người tiêu thụ khác không thể sử dụng lại.
Để nhận ra rằng một tin nhắn có thể được sử dụng bởi nhiều người tiêu thụ, nhiều người tiêu thụ phải được hợp thành một nhóm người tiêu thụ để nhiều người tiêu thụ có thể sử dụng cùng một thông báo. Tuy nhiên, loại List không hỗ trợ việc triển khai các nhóm người tiêu thụ.
Đây là về kiểu dữ liệu Stream do Redis cung cấp bắt đầu từ phiên bản 5.0. Stream cũng có thể đáp ứng ba yêu cầu chính của hàng đợi tin nhắn và nó cũng hỗ trợ đọc tin nhắn dưới dạng "nhóm người tiêu thụ".
Tự động nhập dữ liệu
【Kịch bản nhu cầu】
Dựa vào thông tin nhập từ người dùng, tự động hoàn thành thông tin, như: danh sách liên lạc, tên hàng hóa,...
- Tình huống điển hình 1 - Backend website mạng xã hội ghi lại 100 người bạn mà người dùng đã liên hệ gần đây. Khi người dùng tìm kiếm bạn bè, tên sẽ tự động được điền dựa trên từ khóa đã nhập.
- Tình huống điển hình 2 - Phần backend của website thương mại điện tử ghi lại 10 sản phẩm mà người dùng đã xem gần đây. Khi người dùng tìm kiếm một sản phẩm, tên sản phẩm sẽ tự động được điền dựa trên từ khóa đã nhập.
【Giải pháp】
Sử dụng kiểu List của Redis để lưu trữ danh sách thông tin gần đây, sau đó tại thời điểm cần tự động hoàn thành thông tin, hiển thị số lượng dữ liệu tương ứng.
Các thao tác phổ biến để duy trì danh sách các tin nhắn gần đây như sau:
- Nếu tin nhắn được chỉ định đã tồn tại trong danh sách tin nhắn gần đây thì nó sẽ bị xóa khỏi danh sách. Sử dụng
LREMlệnh. - Thêm tin nhắn được chỉ định vào đầu danh sách tin nhắn gần đây. Sử dụng
LPUSHlệnh. - Sau khi thao tác thêm hoàn tất, nếu số trong danh sách thông tin gần đây vượt quá giới hạn trên N thì thao tác cắt bớt sẽ được thực hiện. Sử dụng
LTRIMlệnh.
SET
Loại Set trong Redis là một tập hợp không có thứ tự và loại bỏ trùng lặp.
Giới thiệu về Set
Set trong Redis là một tập hợp các cặp key - value không có thứ tự và các giá trị là duy nhất, tức là mỗi giá trị trong Set là duy nhất và không thứ tự về thời gian.
Một Set có thể lưu trữ tối đa 2^32-1 phần tử. Set trong Redis giống như tập hợp trong toán học, cho phép thực hiện các phép toán như giao, hợp, hiệu, và các hoạt động khác trên các tập hợp. Vì vậy, Set không chỉ hỗ trợ thêm, xóa, sửa và truy vấn các phần tử trong tập hợp mà còn hỗ trợ các phép toán với nhiều tập hợp như giao, hợp, hiệu.
Sự khác biệt giữa Set và List trong Redis như sau:
- List có thể lưu trữ các phần tử trùng lặp, trong khi Set chỉ có thể lưu trữ các phần tử duy nhất.
- List lưu trữ các phần tử theo thứ tự chèn, trong khi Set lưu trữ các phần tử mà không có thứ tự nhất định.
Set trong Redis là một cấu trúc dữ liệu mạnh mẽ để lưu trữ và xử lý các tập hợp các phần tử độc lập một cách hiệu quả.
Triển khai Set
Các đối tượng Set trong Redis có thể được mã hóa dưới hai dạng: intset hoặc hashtable.
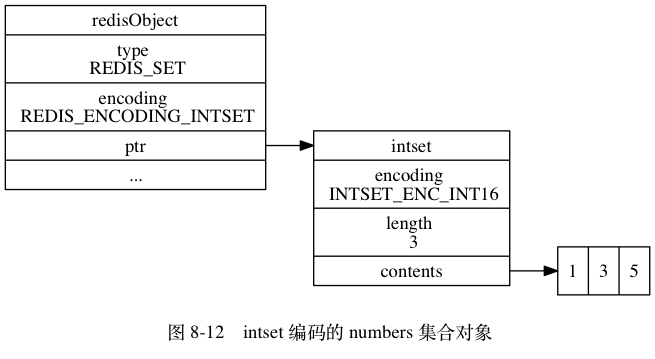
Mã hóa intset
Set được mã hóa bằng intset sử dụng một tập hợp số nguyên làm cấu trúc dữ liệu cơ sở. Tất cả các phần tử trong Set được lưu trữ trong tập hợp số nguyên này.
Mã hóa hashtable
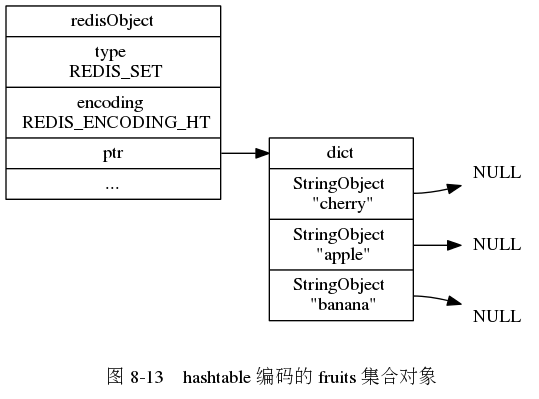
Set được mã hóa bằng hashtable sử dụng một từ điển làm cấu trúc dữ liệu cơ sở. Mỗi khóa của từ điển là một đối tượng chuỗi, mỗi đối tượng chuỗi này chứa một phần tử của Set và các giá trị của từ điển được đặt là NULL.
Điều kiện sử dụng intset hoặc hashtable
Set sẽ sử dụng mã hóa intset khi đáp ứng cùng lúc hai điều kiện sau; nếu không, nó sẽ sử dụng mã hóa hashtable:
- Tất cả các phần tử trong Set là giá trị số nguyên.
- Số lượng phần tử trong Set không vượt quá
512.
Lưu ý: Giá trị trần của điều kiện thứ hai có thể được thay đổi. Xem thêm thông tin trong tài liệu cấu hình về tùy chọn
set-max-intset-entries.
Mã hóa intset và hashtable cung cấp cho Redis sự linh hoạt trong việc lưu trữ và quản lý các tập hợp dữ liệu, tối ưu hóa hiệu suất dựa trên các đặc tính của dữ liệu trong Set.
Các lệnh Set
Redis Set hỗ trợ nhiều lệnh để thao tác và thực hiện các phép toán trên tập hợp. Dưới đây là một số lệnh phổ biến:
| Lệnh | Hành vi |
|---|---|
SADD | Thêm một hoặc nhiều thành viên vào tập hợp. |
SMEMBERS | Trả về tất cả các thành viên của tập hợp. |
SISMEMBER | Kiểm tra xem một thành viên có tồn tại trong tập hợp hay không. |
SREM | Xoá một hoặc nhiều thành viên khỏi tập hợp. |
SCARD | Lấy số lượng thành viên trong tập hợp. |
SRANDMEMBER | Lấy một hoặc nhiều thành viên ngẫu nhiên từ tập hợp. |
SPOP | Xoá và trả về một hoặc nhiều thành viên ngẫu nhiên từ tập hợp. |
| Lệnh | Hành vi |
|---|---|
SINTER | Tính giao của nhiều tập hợp. |
SINTERSTORE | Tính giao của nhiều tập hợp và lưu kết quả vào một tập hợp mới. |
SUNION | Tính hợp của nhiều tập hợp. |
SUNIONSTORE | Tính hợp của nhiều tập hợp và lưu kết quả vào một tập hợp mới. |
SDIFF | Tính hiệu của hai tập hợp. |
SDIFFSTORE | Tính hiệu của hai tập hợp và lưu kết quả vào một tập hợp mới. |
Để biết thêm chi tiết và các lệnh khác, bạn có thể tham khảo tài liệu lệnh Set của Redis.
Các Thao Tác Phổ Biến trên Set:
Thêm và Xoá Thành Viên:
# Thêm các thành viên vào một tập hợp
SADD key member [member ...]
# Xoá các thành viên khỏi một tập hợp
SREM key member [member ...]Lấy Thành Viên:
# Lấy tất cả các thành viên của một tập hợp
SMEMBERS key
# Kiểm tra xem một thành viên có tồn tại trong tập hợp hay không
SISMEMBER key memberĐếm Số Lượng Thành Viên:
# Lấy số lượng thành viên trong một tập hợp
SCARD keyThao Tác Ngẫu Nhiên trên Tập Hợp:
# Lấy một hoặc nhiều thành viên ngẫu nhiên từ tập hợp (không xoá chúng)
SRANDMEMBER key [count]
# Xoá và lấy một hoặc nhiều thành viên ngẫu nhiên từ tập hợp
SPOP key [count]Các Phép Toán trên Tập Hợp (Giao, Hợp, Hiệu):
# Tính giao của nhiều tập hợp
SINTER key [key ...]
# Tính giao của nhiều tập hợp và lưu kết quả vào một tập hợp mới
SINTERSTORE destination key [key ...]
# Tính hợp của nhiều tập hợp
SUNION key [key ...]
# Tính hợp của nhiều tập hợp và lưu kết quả vào một tập hợp mới
SUNIONSTORE destination key [key ...]
# Tính hiệu của hai tập hợp
SDIFF key [key ...]
# Tính hiệu của hai tập hợp và lưu kết quả vào một tập hợp mới
SDIFFSTORE destination key [key ...]Ứng dụng Set
Set trong Redis có các đặc tính chính là không có thứ tự, duy nhất và hỗ trợ các phép toán như giao, hợp, hiệu, ...
Do đó, Set rất phù hợp để loại bỏ dữ liệu trùng lặp và đảm bảo tính duy nhất của dữ liệu. Ngoài ra, nó cũng có thể được sử dụng để thống kê các phép giao, hợp và hiệu của nhiều tập hợp. Khi lưu trữ dữ liệu không có thứ tự và cần loại bỏ các giá trị trùng lặp, Set là lựa chọn lý tưởng.
Tuy nhiên, tôi muốn nhắc bạn rằng có một nguy cơ tiềm ẩn ở đây. Việc tính toán các phép hiệu, giao và hợp của Set có độ phức tạp cao. Trong trường hợp dữ liệu lớn, việc thực hiện các phép toán này trực tiếp có thể dẫn đến Redis bị chặn.
Trong một cụm sao lưu chính, để tránh việc máy chủ chính bị chặn do thực hiện các phép toán tổng hợp (giao, hiệu, hợp) trên Set, chúng ta có thể chọn một máy chủ sao lưu để hoàn thành các thống kê tổng hợp, hoặc trả dữ liệu về cho khách hàng để họ thực hiện các thống kê tổng hợp.
Lượt thích (Đánh giá tích cực)
Set trong Redis cho phép đảm bảo rằng mỗi người dùng chỉ có thể thực hiện một lần đánh giá tích cực cho một mục, ví dụ như một bài viết. Trong ví dụ sau, key là id của bài viết và value là id của người dùng.
Ba người dùng uid:1, uid:2, uid:3 đã thực hiện đánh giá tích cực cho bài viết article:1.
# Người dùng uid:1 đánh giá tích cực cho bài viết article:1
> SADD article:1 uid:1
(integer) 1
# Người dùng uid:2 đánh giá tích cực cho bài viết article:1
> SADD article:1 uid:2
(integer) 1
# Người dùng uid:3 đánh giá tích cực cho bài viết article:1
> SADD article:1 uid:3
(integer) 1Người dùng uid:1 hủy đánh giá tích cực cho bài viết article:1.
> SREM article:1 uid:1
(integer) 1Lấy danh sách tất cả người dùng đã đánh giá tích cực cho bài viết article:1:
> SMEMBERS article:1
1) "uid:3"
2) "uid:2"Lấy số lượng người dùng đã đánh giá tích cực cho bài viết article:1:
> SCARD article:1
(integer) 2Kiểm tra xem người dùng uid:1 đã đánh giá tích cực cho bài viết article:1 hay chưa:
> SISMEMBER article:1 uid:1
(integer) 0 # Trả về 0 có nghĩa là chưa đánh giá tích cực, trả về 1 có nghĩa là đã đánh giá tích cựcChia sẻ lựa chọn
Set trong Redis hỗ trợ phép toán giao của nó, vì vậy nó có thể được sử dụng để tính toán những gì mà nhiều người dùng cùng quan tâm như bạn bè chung, các tài khoản công cộng và nhiều hơn nữa.
Key có thể là ID người dùng, giá trị là ID của tài khoản công cộng mà họ đã theo dõi.
Người dùng uid:1 theo dõi tài khoản công cộng với ID là 5, 6, 7, 8, 9; người dùng uid:2 theo dõi tài khoản công cộng với ID là 7, 8, 9, 10, 11.
# Người dùng uid:1 theo dõi các tài khoản công cộng với ID là 5, 6, 7, 8, 9
> SADD uid:1 5 6 7 8 9
(integer) 5
# Người dùng uid:2 theo dõi các tài khoản công cộng với ID là 7, 8, 9, 10, 11
> SADD uid:2 7 8 9 10 11
(integer) 5Các tài khoản công cộng mà uid:1 và uid:2 cùng theo dõi:
# Lấy giao của chung
> SINTER uid:1 uid:2
1) "7"
2) "8"
3) "9"Gợi ý cho uid:2 các tài khoản công cộng mà uid:1 đã theo dõi:
> SDIFF uid:1 uid:2
1) "5"
2) "6"Xác minh xem một tài khoản công cộng cụ thể có được theo dõi bởi uid:1 hoặc uid:2 hay không:
> SISMEMBER uid:1 5
(integer) 1 # Trả về 1, tức là đã theo dõi
> SISMEMBER uid:2 5
(integer) 0 # Trả về 0, tức là chưa theo dõiHoạt động rút thăm may mắn
Set trong Redis rất hữu ích để lưu trữ tên người dùng đã trúng thưởng trong một hoạt động rút thăm may mắn, với tính năng loại bỏ các giá trị trùng lặp, đảm bảo rằng mỗi người dùng chỉ có thể trúng thưởng một lần.
Key là tên của hoạt động rút thăm, value là tên của nhân viên. Đưa tất cả tên nhân viên vào hộp rút thăm:
>SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
(integer) 7Nếu cho phép trúng thưởng lặp lại, bạn có thể sử dụng lệnh SRANDMEMBER.
# Rút 1 giải nhất:
> SRANDMEMBER lucky 1
1) "Tom"
# Rút 2 giải nhì:
> SRANDMEMBER lucky 2
1) "Mark"
2) "Jerry"
# Rút 3 giải ba:
> SRANDMEMBER lucky 3
1) "Sary"
2) "Tom"
3) "Jerry"Nếu không cho phép trùng lặp, bạn có thể sử dụng lệnh SPOP.
# Rút 1 giải nhất:
> SPOP lucky 1
1) "Sary"
# Rút 2 giải nhì:
> SPOP lucky 2
1) "Jerry"
2) "Mark"
# Rút 3 giải ba:
> SPOP lucky 3
1) "John"
2) "Sean"
3) "Lindy"Đây là cách sử dụng Set trong Redis để thực hiện hoạt động rút thăm may mắn, đảm bảo tính duy nhất của các giải thưởng và người dùng chỉ có thể trúng thưởng một lần.
ZSET (Sorted Set)
Loại Zset trong Redis là một tập hợp được sắp xếp và loại bỏ trùng lặp.
Giới thiệu về Zset
Zset (tập hợp có thứ tự) là một loại dữ liệu đặc biệt trong Redis, so với loại Set, nó có thêm một thuộc tính sắp xếp gọi là điểm (score). Đối với tập hợp có thứ tự Zset, mỗi phần tử lưu trữ bao gồm hai giá trị: một là giá trị thành viên của tập hợp và hai là giá trị sắp xếp (score).
Tập hợp có thứ tự giữ nguyên tính chất thành viên không thể trùng lặp như Set, nhưng khác biệt ở chỗ các thành viên trong tập hợp có thứ tự có thể được sắp xếp theo thứ tự.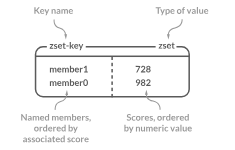
Triển khai Zset
Loại dữ liệu tập hợp có thứ tự (Zset) có thể được mã hóa bằng ziplist hoặc skiplist.
Đối tượng Zset mã hóa bằng ziplist sử dụng danh sách nén làm cơ chế lưu trữ cơ sở. Mỗi phần tử của tập hợp được lưu trữ bằng hai nút danh sách nén kề nhau. Nút đầu tiên lưu trữ thành viên của phần tử (member), trong khi nút thứ hai lưu trữ giá trị điểm (score) của phần tử. Các phần tử trong danh sách nén được sắp xếp theo thứ tự từ điểm thấp đến cao, tức là các phần tử có điểm thấp hơn được đặt gần đầu danh sách, và các phần tử có điểm cao hơn được đặt gần cuối danh sách.
Đối tượng Zset mã hóa bằng skiplist sử dụng cấu trúc zset như là cơ chế lưu trữ cơ sở. Mỗi zset bao gồm đồng thời một từ điển (dictionary) và một bảng bỏ qua (skiplist).
typedef struct zset {
zskiplist *zsl;
dict *dict;
} zset;zskiplist: Skiplist sắp xếp từ điểm thấp đến cao các phần tử của tập hợp. Mỗi nút skiplist lưu trữ một phần tử của tập hợp: thuộc tính
objectcủa nút skiplist lưu trữ thành viên của phần tử, trong khi thuộc tínhscorecủa nút skiplist lưu trữ điểm của phần tử. Bằng cách này, Redis có thể thực hiện các phép toán phạm vi trên tập hợp có thứ tự như ZRANK, ZRANGE dựa trên API của skiplist.dict: Từ điển tạo một ánh xạ từ thành viên đến điểm của tập hợp có thứ tự. Mỗi cặp khóa-giá trị trong từ điển lưu trữ một phần tử của tập hợp: khóa của từ điển lưu trữ thành viên của phần tử, trong khi giá trị của từ điển lưu trữ điểm của phần tử. Redis có thể truy vấn điểm của một thành viên cụ thể với độ phức tạp O(1) bằng lệnh ZSCORE, và nhiều lệnh khác của tập hợp có thứ tự dựa trên tính năng này.
Mỗi thành viên của tập hợp có thứ tự là một đối tượng chuỗi, và mỗi điểm của thành viên là một số thực loại double. Đáng chú ý là, mặc dù zset sử dụng cả skiplist và từ điển để lưu trữ các phần tử của tập hợp có thứ tự, nhưng cả hai cấu trúc dữ liệu này sẽ chia sẻ cùng một con trỏ cho các thành viên và điểm tương tự nhau. Do đó, việc sử dụng đồng thời skiplist và từ điển để lưu trữ các phần tử của tập hợp có thứ tự không tạo ra bất kỳ thành viên hoặc điểm lặp lại nào và cũng không lãng phí bộ nhớ thừa.
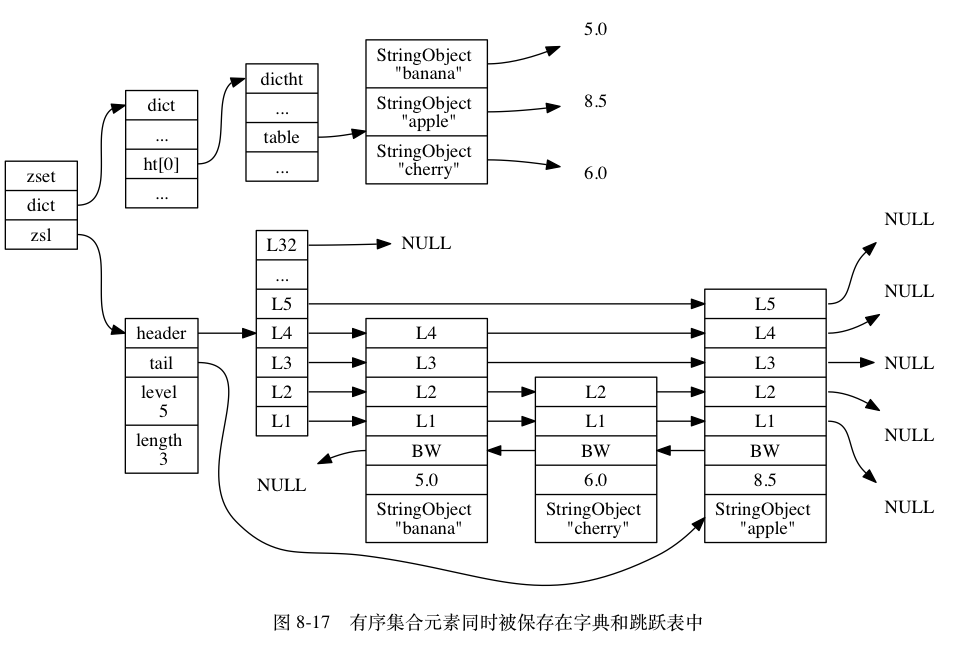
Khi đối tượng tập hợp có thứ tự có thể đáp ứng đồng thời hai điều kiện sau đây, nó sẽ sử dụng mã hóa ziplist; ngược lại, nó sẽ sử dụng mã hóa skiplist:
- Số lượng phần tử của tập hợp có thứ tự nhỏ hơn
128. - Độ dài của tất cả các thành viên của tập hợp có thứ tự nhỏ hơn
64byte.
Lưu ý: Các giới hạn trên đều có thể được điều chỉnh, vui lòng xem trong tài liệu cấu hình về các tùy chọn
zset-max-ziplist-entriesvàzset-max-ziplist-valueđể biết thêm chi tiết.
Trong Redis 7.0, cấu trúc dữ liệu ziplist đã bị loại bỏ và được triển khai bằng cấu trúc dữ liệu listpack.
Zset Commands
| Command | Behavior |
|---|---|
ZADD | Thêm một thành viên với điểm xếp hạng đã cho vào tập hợp có thứ tự |
ZRANGE | Sắp xếp theo thứ tự và trả về các thành viên trong khoảng xếp hạng chỉ định |
ZREVRANGE | Sắp xếp theo thứ tự ngược và trả về các thành viên trong khoảng xếp hạng chỉ định |
ZRANGEBYSCORE | Sắp xếp theo thứ tự và trả về các thành viên trong khoảng xếp hạng chỉ định cùng với điểm xếp hạng |
ZREVRANGEBYSCORE | Sắp xếp theo thứ tự ngược và trả về các thành viên trong khoảng xếp hạng chỉ định cùng với điểm xếp hạng |
ZREM | Xóa các thành viên được chỉ định khỏi tập hợp có thứ tự |
ZSCORE | Lấy điểm xếp hạng của một thành viên được chỉ định |
ZCARD | Lấy số lượng thành viên trong tập hợp có thứ tự |
Các hoạt động phổ biến của Zset:
# Thêm thành viên với điểm xếp hạng vào tập hợp có thứ tự
ZADD key score member [[score member]...]
# Xóa thành viên từ tập hợp có thứ tự
ZREM key member [member...]
# Lấy điểm xếp hạng của thành viên
ZSCORE key member
# Lấy số lượng thành viên trong tập hợp
ZCARD key
# Tăng điểm xếp hạng của thành viên trong tập hợp có thứ tự
ZINCRBY key increment member
# Lấy các thành viên theo thứ tự từ vị trí start đến stop
ZRANGE key start stop [WITHSCORES]
# Lấy các thành viên theo thứ tự ngược từ vị trí start đến stop
ZREVRANGE key start stop [WITHSCORES]
# Lấy các thành viên trong khoảng điểm xếp hạng từ min đến max, sắp xếp theo thứ tự
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
# Lấy các thành viên trong khoảng từ min đến max theo thứ tự từ điển, với điểm xếp hạng giống nhau
ZRANGEBYLEX key min max [LIMIT offset count]
# Lấy các thành viên trong khoảng từ max đến min theo thứ tự từ điển, với điểm xếp hạng giống nhau
ZREVRANGEBYLEX key max min [LIMIT offset count]Các phép toán Zset (so với loại Set, loại Zset không hỗ trợ phép toán hiệu):
# Phép toán hợp nhất (tổng hợp điểm xếp hạng cho các thành viên giống nhau), numberkeys là số lượng key, WEIGHTS là tích điểm xếp hạng cho từng key
ZUNIONSTORE destkey numberkeys key [key...]
# Phép toán giao nhau (tổng hợp điểm xếp hạng cho các thành viên giống nhau), numberkeys là số lượng key, WEIGHTS là tích điểm xếp hạng cho từng key
ZINTERSTORE destkey numberkeys key [key...]Ứng dụng của Zset
Loại dữ liệu Zset (Sorted Set - Tập hợp có thứ tự) trong Redis cho phép sắp xếp các phần tử dựa trên trọng số của chúng, mà ta có thể tự định nghĩa. Ví dụ, chúng ta có thể sử dụng thời gian chèn các phần tử vào Sorted Set để xác định giá trị trọng số, các phần tử chèn trước sẽ có giá trị trọng số nhỏ hơn và các phần tử chèn sau sẽ có giá trị trọng số lớn hơn.
Trong các tình huống cần hiển thị danh sách mới nhất, bảng xếp hạng và các ứng dụng cần cập nhật dữ liệu thường xuyên hoặc cần hiển thị theo trang, thì sử dụng Sorted Set là lựa chọn hàng đầu.
Bảng xếp hạng
[Các tình huống cần thiết]
Các loại bảng xếp hạng khác nhau như: bảng xếp hạng lượt xem/đánh giá/bình luận của nội dung (video, bài hát, bài viết) trên các nền tảng nội dung; bảng xếp hạng doanh số bán hàng của các sản phẩm trên các trang thương mại điện tử.
[Giải pháp]
Sorted Set (Tập hợp có thứ tự) là một trong những giải pháp phổ biến cho các bảng xếp hạng. Ví dụ như bảng xếp hạng điểm số học sinh, bảng xếp hạng điểm trong game, bảng xếp hạng video phát sóng, bảng xếp hạng doanh số sản phẩm trên hệ thống thương mại điện tử.
Chúng ta lấy ví dụ về bảng xếp hạng các bài viết được thích của người dùng có tên là Xiaolin, Xiaolin đã đăng năm bài viết và có số lượng lượt thích là 200, 40, 100, 50 và 150 lượt lần lượt.
# Bài viết arcticle:1 có 200 lượt thích
> ZADD user:xiaolin:ranking 200 arcticle:1
(integer) 1
# Bài viết arcticle:2 có 40 lượt thích
> ZADD user:xiaolin:ranking 40 arcticle:2
(integer) 1
# Bài viết arcticle:3 có 100 lượt thích
> ZADD user:xiaolin:ranking 100 arcticle:3
(integer) 1
# Bài viết arcticle:4 có 50 lượt thích
> ZADD user:xiaolin:ranking 50 arcticle:4
(integer) 1
# Bài viết arcticle:5 có 150 lượt thích
> ZADD user:xiaolin:ranking 150 arcticle:5
(integer) 1Nếu bài viết arcticle:4 có thêm một lượt thích mới, ta có thể sử dụng lệnh ZINCRBY (tăng giá trị điểm số cho thành viên trong Sorted Set):
> ZINCRBY user:xiaolin:ranking 1 arcticle:4
"51"Để xem số lượt thích của một bài viết cụ thể, ta có thể sử dụng lệnh ZSCORE (trả về giá trị điểm số của thành viên trong Sorted Set):
> ZSCORE user:xiaolin:ranking arcticle:4
"50"Để lấy danh sách 3 bài viết của Xiaolin có số lượt thích cao nhất, ta sử dụng lệnh ZREVRANGE (lấy danh sách các thành viên từ cao đến thấp trong Sorted Set):
# WITHSCORES cho biết cả điểm số
> ZREVRANGE user:xiaolin:ranking 0 2 WITHSCORES
1) "arcticle:1"
2) "200"
3) "arcticle:5"
4) "150"
5) "arcticle:3"
6) "100"Để lấy danh sách các bài viết của Xiaolin có từ 100 đến 200 lượt thích, ta sử dụng lệnh ZRANGEBYSCORE (lấy danh sách các thành viên trong một khoảng điểm số từ thấp đến cao trong Sorted Set):
> ZRANGEBYSCORE user:xiaolin:ranking 100 200 WITHSCORES
1) "arcticle:3"
2) "100"
3) "arcticle:5"
4) "150"
5) "arcticle:1"
6) "200"Sắp xếp theo tiền tố
Sử dụng các lệnh ZRANGEBYLEX hoặc ZREVRANGEBYLEX trên tập hợp có thứ tự (Sorted Set) cho phép chúng ta sắp xếp số điện thoại hoặc tên theo thứ tự. Chúng ta sẽ lấy ví dụ về lệnh ZRANGEBYLEX (trả về các thành viên trong một khoảng nhất định theo thứ tự từ điển).
1. Sắp xếp số điện thoại
Chúng ta có thể lưu trữ các số điện thoại trong Sorted Set và lấy các số điện thoại trong một dãy cụ thể:
> ZADD phone 0 13100111100 0 13110114300 0 13132110901
(integer) 3
> ZADD phone 0 13200111100 0 13210414300 0 13252110901
(integer) 3
> ZADD phone 0 13300111100 0 13310414300 0 13352110901
(integer) 3Lấy tất cả các số điện thoại:
> ZRANGEBYLEX phone - +
1) "13100111100"
2) "13110114300"
3) "13132110901"
4) "13200111100"
5) "13210414300"
6) "13252110901"
7) "13300111100"
8) "13310414300"
9) "13352110901"Lấy các số điện thoại trong dãy 132:
> ZRANGEBYLEX phone [132 (133
1) "13200111100"
2) "13210414300"
3) "13252110901"Lấy các số điện thoại trong dãy 132 và 133:
> ZRANGEBYLEX phone [132 (134
1) "13200111100"
2) "13210414300"
3) "13252110901"
4) "13300111100"
5) "13310414300"
6) "13352110901"2. Sắp xếp theo tên
> zadd names 0 Toumas 0 Jake 0 Bluetuo 0 Gaodeng 0 Aimini 0 Aidehua
(integer) 6Lấy tất cả các tên:
> ZRANGEBYLEX names - +
1) "Aidehua"
2) "Aimini"
3) "Bluetuo"
4) "Gaodeng"
5) "Jake"
6) "Toumas"Lấy các tên bắt đầu bằng chữ cái A:
> ZRANGEBYLEX names [A (B
1) "Aidehua"
2) "Aimini"Lấy các tên từ chữ cái C đến Z:
> ZRANGEBYLEX names [C [Z
1) "Gaodeng"
2) "Jake"
3) "Toumas"Đó là các ví dụ về cách sử dụng ZRANGEBYLEX để sắp xếp các thành viên trong Sorted Set theo thứ tự từ điển.
Ứng dụng thực tê
Case study - Bài viết phổ biến nhất
Để chọn ra các bài viết phổ biến nhất, cần hỗ trợ việc đánh giá bài viết.
Bình chọn cho bài viết
(1) Lưu trữ bài viết bằng HASH
Sử dụng kiểu dữ liệu HASH để lưu trữ thông tin của bài viết. Trong đó: key là ID của bài viết; field là khóa thuộc tính của bài viết; value là giá trị tương ứng của thuộc tính.

Các thao tác:
- Lưu trữ thông tin bài viết - Sử dụng lệnh HSET hoặc HMSET
- Truy vấn thông tin bài viết - Sử dụng lệnh HGETALL
- Thêm phiếu bình chọn - Sử dụng lệnh HINCRBY
(2) Sử dụng ZSET để sắp xếp tập hợp bài viết theo các tiêu chí khác nhau
Sử dụng kiểu dữ liệu ZSET để lưu trữ tập hợp các ID bài viết được sắp xếp theo thời gian và điểm số.
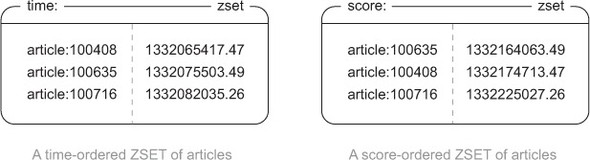
Các thao tác:
- Thêm bản ghi - Sử dụng lệnh ZADD
- Thêm điểm - Sử dụng lệnh ZINCRBY
- Lấy ra nhiều bài viết - Sử dụng lệnh ZREVRANGE
(3) Để tránh việc bình chọn trùng lặp, sử dụng kiểu dữ liệu SET để ghi lại tập hợp các bài viết đã được bình chọn.

Các thao tác:
- Thêm người bình chọn - Sử dụng lệnh SADD
- Đặt thời gian hiệu lực - Sử dụng lệnh EXPIRE
(4) Giả sử user:115423 bình chọn cho article:100408, cần cập nhật cả tập hợp sắp xếp theo điểm số và tập hợp bình chọn.

Khi cần bình chọn cho một bài viết, chương trình cần sử dụng lệnh ZSCORE để kiểm tra tập hợp sắp xếp theo thời gian đăng bài viết và xác định xem thời gian đăng bài viết có vượt quá thời gian hiệu lực của bình chọn (ví dụ: một tuần) hay không.
public void articleVote(Jedis conn, String user, String article) {
// Tính toán thời gian kết thúc bình chọn của bài viết.
long cutoff = (System.currentTimeMillis() / 1000) - ONE_WEEK_IN_SECONDS;
// Kiểm tra xem có thể bình chọn cho bài viết hay không
// (Mặc dù có thể lấy thời gian đăng bài viết từ HASH,
// nhưng tập hợp sắp xếp trả về thời gian đăng bài viết dưới dạng số thực,
// nên có thể sử dụng trực tiếp mà không cần chuyển đổi).
if (conn.zscore("time:", article) < cutoff) {
return;
}
// Lấy ID của bài viết từ định danh article:id.
String articleId = article.substring(article.indexOf(':') + 1);
// Nếu người dùng chưa bình chọn cho bài viết này, tăng số lượng bình chọn và điểm số của bài viết.
if (conn.sadd("voted:" + articleId, user) == 1) {
conn.zincrby("score:", VOTE_SCORE, article);
conn.hincrBy(article, "votes", 1);
}
}Đăng và lấy bài viết
Đăng bài viết:
- Thêm bài viết - Sử dụng lệnh
INCRđể tính toán ID mới cho bài viết, điền thông tin bài viết và sử dụng lệnhHSEThoặcHMSETđể ghi vào cấu trúcHASH. - Thêm ID tác giả vào List bình chọn - Sử dụng lệnh
SADDđể thêm vào cấu trúcSETđại diện cho List bình chọn. - Đặt thời gian hiệu lực của bình chọn - Sử dụng lệnh
EXPIREđể đặt thời gian hiệu lực của bình chọn.
public String postArticle(Jedis conn, String user, String title, String link) {
// Tạo một ID mới cho bài viết.
String articleId = String.valueOf(conn.incr("article:"));
String voted = "voted:" + articleId;
// Thêm người dùng đăng bài vào List đã bình chọn của bài viết,
conn.sadd(voted, user);
// Đặt thời gian tồn tại của List này là một tuần (Chương 3 sẽ giải thích chi tiết hơn về thời gian tồn tại).
conn.expire(voted, ONE_WEEK_IN_SECONDS);
long now = System.currentTimeMillis() / 1000;
String article = "article:" + articleId;
// Lưu thông tin bài viết vào một hash.
HashMap<String, String> articleData = new HashMap<String, String>();
articleData.put("title", title);
articleData.put("link", link);
articleData.put("user", user);
articleData.put("now", String.valueOf(now));
articleData.put("votes", "1");
conn.hmset(article, articleData);
// Thêm bài viết vào tập hợp sắp xếp theo thời gian đăng và tập hợp sắp xếp theo điểm số.
conn.zadd("score:", now + VOTE_SCORE, article);
conn.zadd("time:", now, article);
return articleId;
}Truy vấn phân trang cho các bài viết phổ biến:
Sử dụng lệnh ZINTERSTORE để truy vấn List ID bài viết theo trang, số bài viết trên mỗi trang và số thứ tự sắp xếp theo điểm số từ cao xuống thấp.
public List<Map<String, String>> getArticles(Jedis conn, int page, String order) {
// Đặt chỉ mục bắt đầu và kết thúc để lấy bài viết.
int start = (page - 1) * ARTICLES_PER_PAGE;
int end = start + ARTICLES_PER_PAGE - 1;
// Lấy List ID bài viết.
Set<String> ids = conn.zrevrange(order, start, end);
List<Map<String, String>> articles = new ArrayList<>();
// Lấy thông tin chi tiết của bài viết dựa trên ID bài viết.
for (String id : ids) {
Map<String, String> articleData = conn.hgetAll(id);
articleData.put("id", id);
articles.add(articleData);
}
return articles;
}Phân nhóm bài viết
Nếu bài viết cần được phân nhóm, chức năng sẽ được chia thành hai phần:
- Ghi nhận bài viết thuộc nhóm nào
- Trích xuất các bài viết trong nhóm
Thêm và xóa nhóm cho bài viết:
public void addRemoveGroups(Jedis conn, String articleId, String[] toAdd, String[] toRemove) {
// Xây dựng tên khóa để lưu thông tin bài viết.
String article = "article:" + articleId;
// Thêm bài viết vào các nhóm mà nó thuộc về.
for (String group : toAdd) {
conn.sadd("group:" + group, article);
}
// Xóa bài viết khỏi các nhóm.
for (String group : toRemove) {
conn.srem("group:" + group, article);
}
}Trích xuất các bài viết trong nhóm:
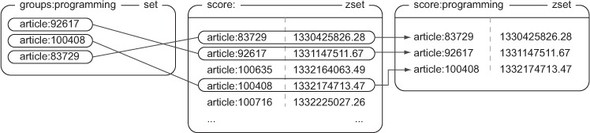
- Bằng cách thực hiện lệnh
ZINTERSTOREtrên tập hợp các bài viết trong nhóm và tập hợp sắp xếp theo điểm số của bài viết, chúng ta có thể nhận được các bài viết trong nhóm được sắp xếp theo điểm số. - Bằng cách thực hiện lệnh
ZINTERSTOREtrên tập hợp các bài viết trong nhóm và tập hợp sắp xếp theo thời gian đăng bài viết, chúng ta có thể nhận được các bài viết trong nhóm được sắp xếp theo thời gian đăng.
public List<Map<String, String>> getGroupArticles(Jedis conn, String group, int page, String order) {
// Tạo một khóa cho mỗi thứ tự sắp xếp của mỗi nhóm.
String key = order + group;
// Kiểm tra xem có kết quả sắp xếp đã được lưu trữ trong bộ nhớ cache chưa, nếu chưa thì tiến hành sắp xếp.
if (!conn.exists(key)) {
// Sắp xếp các bài viết trong nhóm theo điểm số hoặc thời gian đăng bài viết.
ZParams params = new ZParams().aggregate(ZParams.Aggregate.MAX);
conn.zinterstore(key, params, "group:" + group, order);
// Đặt thời gian tồn tại của tập hợp sắp xếp này là 60 giây.
conn.expire(key, 60);
}
// Gọi hàm getArticles đã được định nghĩa trước đó để phân trang và lấy dữ liệu bài viết.
return getArticles(conn, page, key);
}Case study - Quản lý token
Trang web thường lưu trữ thông tin xác thực người dùng dưới dạng Cookie, Session, Token và các thông tin tương tự.
Có thể lưu trữ mappinng giữa Cookie/Session/Token và người dùng trong cấu trúc HASH.
Dưới đây là ví dụ với Token.
Kiểm tra Token
public String checkToken(Jedis conn, String token) {
// Thử lấy và trả về người dùng tương ứng với token.
return conn.hget("login:", token);
}Cập nhật Token
- Mỗi lần người dùng truy cập trang, có thể ghi lại mapping giữa token và timestamp hiện tại, lưu vào một cấu trúc ZSET để phân tích xem người dùng có hoạt động hay không, sau đó có thể định kỳ xóa các token cũ nhất, thống kê số người dùng đang trực tuyến, v.v.
- Nếu người dùng đang xem sản phẩm, có thể ghi lại các sản phẩm đã xem gần đây vào một cấu trúc ZSET (có thể giới hạn số lượng, vượt quá số lượng sẽ bị cắt bỏ), lưu vào một cấu trúc ZSET để phân tích xem người dùng có thể quan tâm đến sản phẩm nào gần đây, từ đó có thể gợi ý sản phẩm.
public void updateToken(Jedis conn, String token, String user, String item) {
// Lấy timestamp hiện tại.
long timestamp = System.currentTimeMillis() / 1000;
// Lưu mapping giữa token và người dùng đã đăng nhập.
conn.hset("login:", token, user);
// Ghi lại thời gian xuất hiện cuối cùng của token.
conn.zadd("recent:", timestamp, token);
if (item != null) {
// Ghi lại các sản phẩm người dùng đã xem.
conn.zadd("viewed:" + token, timestamp, item);
// Xóa các bản ghi cũ, chỉ giữ lại 25 sản phẩm người dùng đã xem gần đây nhất.
conn.zremrangeByRank("viewed:" + token, 0, -26);
conn.zincrby("viewed:", -1, item);
}
}Xóa Token
Như đã đề cập ở phần trước, khi cập nhật token, mapping giữa token và timestamp hiện tại được lưu vào cấu trúc ZSET. Do đó, có thể biết được những token nào là cũ nhất. Nếu không xóa, việc cập nhật token sẽ tiếp tục chiếm dụng bộ nhớ cho đến khi gây ra sự cố.
Ví dụ: Cho phép lưu trữ tối đa 10 triệu thông tin token, kiểm tra định kỳ, nếu số lượng token vượt quá 10 triệu, sắp xếp ZSET từ mới đến cũ và xóa các thông tin vượt quá 10 triệu.
public static class CleanSessionsThread extends Thread {
private Jedis conn;
private int limit;
private volatile boolean quit;
public CleanSessionsThread(int limit) {
this.conn = new Jedis("localhost");
this.conn.select(15);
this.limit = limit;
}
public void quit() {
quit = true;
}
@Override
public void run() {
while (!quit) {
// Lấy số lượng token hiện có.
long size = conn.zcard("recent:");
// Nếu số lượng token không vượt quá giới hạn, ngủ và kiểm tra lại sau.
if (size <= limit) {
try {
sleep(1000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
continue;
}
// Lấy các token cần xóa.
long endIndex = Math.min(size - limit, 100);
Set<String> tokenSet = conn.zrange("recent:", 0, endIndex - 1);
String[] tokens = tokenSet.toArray(new String[tokenSet.size()]);
// Xây dựng các key cho các token sẽ bị xóa.
ArrayList<String> sessionKeys = new ArrayList<String>();
for (String token : tokens) {
sessionKeys.add("viewed:" + token);
}
// Xóa các token cũ nhất.
conn.del(sessionKeys.toArray(new String[sessionKeys.size()]));
conn.hdel("login:", tokens);
conn.zrem("recent:", tokens);
}
}
}Case study - Giỏ hàng
Có thể sử dụng cấu trúc HASH để triển khai chức năng giỏ hàng.
Mỗi giỏ hàng của người dùng lưu trữ ánh xạ giữa ID sản phẩm và số lượng sản phẩm.
Thêm và xóa sản phẩm trong giỏ hàng
public void addToCart(Jedis conn, String session, String item, int count) {
if (count <= 0) {
// Xóa sản phẩm cụ thể khỏi giỏ hàng.
conn.hdel("cart:" + session, item);
} else {
// Thêm sản phẩm cụ thể vào giỏ hàng.
conn.hset("cart:" + session, item, String.valueOf(count));
}
}Xóa toàn bộ giỏ hàng
Dựa trên Xóa Token, khi xóa phiên làm việc, cũng xóa luôn giỏ hàng.
while (!quit) {
long size = conn.zcard("recent:");
if (size <= limit) {
try {
sleep(1000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
continue;
}
long endIndex = Math.min(size - limit, 100);
Set<String> sessionSet = conn.zrange("recent:", 0, endIndex - 1);
String[] sessions = sessionSet.toArray(new String[sessionSet.size()]);
ArrayList<String> sessionKeys = new ArrayList<String>();
for (String sess : sessions) {
sessionKeys.add("viewed:" + sess);
// Dòng code mới được thêm vào để xóa giỏ hàng của người dùng tương ứng với phiên làm việc cũ.
sessionKeys.add("cart:" + sess);
}
conn.del(sessionKeys.toArray(new String[sessionKeys.size()]));
conn.hdel("login:", sessions);
conn.zrem("recent:", sessions);
}Case study - Bộ nhớ cache trang web
Hầu hết nội dung trang web không thay đổi thường xuyên, nhưng khi truy cập, phía máy chủ cần tính toán động, điều này có thể tốn thời gian. Trong trường hợp này, có thể sử dụng cấu trúc STRING để lưu trữ bộ nhớ cache trang web.
public String cacheRequest(Jedis conn, String request, Callback callback) {
// Đối với các yêu cầu không thể được lưu vào bộ nhớ cache, gọi hàm callback trực tiếp.
if (!canCache(conn, request)) {
return callback != null ? callback.call(request) : null;
}
// Chuyển đổi yêu cầu thành một khóa chuỗi đơn giản để dễ dàng tìm kiếm sau này.
String pageKey = "cache:" + hashRequest(request);
// Thử tìm trang web đã được lưu trong bộ nhớ cache.
String content = conn.get(pageKey);
if (content == null && callback != null) {
// Nếu trang web chưa được lưu trong bộ nhớ cache, tạo trang web.
content = callback.call(request);
// Lưu trang web mới tạo vào bộ nhớ cache.
conn.setex(pageKey, 300, content);
}
// Trả về nội dung trang web.
return content;
}Case study - Bộ nhớ cache dòng dữ liệu
Các trang web thương mại điện tử có thể có các hoạt động khuyến mãi, giảm giá, rút thăm may mắn, v.v. Những trang web này chỉ cần tải vài dòng dữ liệu từ cơ sở dữ liệu, chẳng hạn như thông tin người dùng, thông tin sản phẩm.
Có thể sử dụng cấu trúc STRING để lưu trữ bộ nhớ cache cho các dòng dữ liệu này, sử dụng JSON để lưu trữ thông tin có cấu trúc.
Ngoài ra, cần có hai cấu trúc ZSET để ghi lại thời điểm cập nhật bộ nhớ cache:
- Cấu trúc ZSET thứ nhất là tập hợp lịch trình;
- Cấu trúc ZSET thứ hai là tập hợp trễ.
Ghi lại thời điểm cập nhật bộ nhớ cache:
public void scheduleRowCache(Jedis conn, String rowId, int delay) {
// Đặt giá trị trễ cho dòng dữ liệu.
conn.zadd("delay:", delay, rowId);
// Lập lịch cập nhật bộ nhớ cache cho dòng dữ liệu.
conn.zadd("schedule:", System.currentTimeMillis() / 1000, rowId);
}Cập nhật bộ nhớ cache dòng dữ liệu theo định kỳ:
public class CacheRowsThread extends Thread {
private Jedis conn;
private boolean quit;
public CacheRowsThread() {
this.conn = new Jedis("localhost");
this.conn.select(15);
}
public void quit() {
quit = true;
}
@Override
public void run() {
Gson gson = new Gson();
while (!quit) {
// Thử lấy dòng dữ liệu tiếp theo cần được cập nhật và thời điểm lên lịch của nó,
// Lệnh sẽ trả về một List chứa một hoặc không có cặp (tuple).
Set<Tuple> range = conn.zrangeWithScores("schedule:", 0, 0);
Tuple next = range.size() > 0 ? range.iterator().next() : null;
long now = System.currentTimeMillis() / 1000;
if (next == null || next.getScore() > now) {
try {
// Tạm thời không có dòng dữ liệu cần được cập nhật, ngủ 50ms và thử lại.
sleep(50);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
continue;
}
String rowId = next.getElement();
// Lấy thời gian trễ trước lần cập nhật tiếp theo.
double delay = conn.zscore("delay:", rowId);
if (delay <= 0) {
// Không cần cập nhật dòng dữ liệu này nữa, xóa nó khỏi bộ nhớ cache.
conn.zrem("delay:", rowId);
conn.zrem("schedule:", rowId);
conn.del("inv:" + rowId);
continue;
}
// Đọc dòng dữ liệu.
Inventory row = Inventory.get(rowId);
// Cập nhật thời gian lên lịch và đặt giá trị bộ nhớ cache.
conn.zadd("schedule:", now + delay, rowId);
conn.set("inv:" + rowId, gson.toJson(row));
}
}
}Case study - Phân tích trang web
Trang web có thể thu thập hành vi truy cập, tương tác và mua hàng của người dùng, sau đó phân tích thói quen và sở thích của người dùng để đánh giá tình hình thị trường và cơ hội nghiệp vụ tiềm năng.
Vậy làm thế nào để ghi lại các trang sản phẩm mà người dùng đã truy cập trong một khoảng thời gian nhất định?
Tham khảo ví dụ mã code Cập nhật Token, ghi lại số lần truy cập của người dùng vào các trang sản phẩm khác nhau và sắp xếp chúng.
Để xác định xem trang có cần được lưu vào bộ nhớ cache hay không, dựa trên điểm đánh giá để xác định xem trang sản phẩm có phổ biến hay không:
public boolean canCache(Jedis conn, String request) {
try {
URL url = new URL(request);
HashMap<String, String> params = new HashMap<>();
if (url.getQuery() != null) {
for (String param : url.getQuery().split("&")) {
String[] pair = param.split("=", 2);
params.put(pair[0], pair.length == 2 ? pair[1] : null);
}
}
// Thử lấy ID sản phẩm từ trang.
String itemId = extractItemId(params);
// Kiểm tra xem trang này có thể được lưu vào bộ nhớ cache và có phải là trang sản phẩm hay không.
if (itemId == null || isDynamic(params)) {
return false;
}
// Lấy xếp hạng số lần xem của sản phẩm.
Long rank = conn.zrank("viewed:", itemId);
// Dựa trên xếp hạng số lần xem của sản phẩm để xác định xem trang này có cần được lưu vào bộ nhớ cache hay không.
return rank != null && rank < 10000;
} catch (MalformedURLException mue) {
return false;
}
}Case study - Ghi log
Có thể sử dụng cấu trúc LIST để lưu trữ dữ liệu nhật ký (log).
public void logRecent(Jedis conn, String name, String message, String severity) {
String destination = "recent:" + name + ':' + severity;
Pipeline pipe = conn.pipelined();
pipe.lpush(destination, TIMESTAMP.format(new Date()) + ' ' + message);
pipe.ltrim(destination, 0, 99);
pipe.sync();
}Case study - Thống kê dữ liệu
Cập nhật bộ đếm:
public static final int[] PRECISION = new int[] { 1, 5, 60, 300, 3600, 18000, 86400 };
public void updateCounter(Jedis conn, String name, int count, long now) {
Transaction trans = conn.multi();
for (int prec : PRECISION) {
long pnow = (now / prec) * prec;
String hash = String.valueOf(prec) + ':' + name;
trans.zadd("known:", 0, hash);
trans.hincrBy("count:" + hash, String.valueOf(pnow), count);
}
trans.exec();
}Xem dữ liệu bộ đếm:
public List<Pair<Integer>> getCounter(
Jedis conn, String name, int precision) {
String hash = String.valueOf(precision) + ':' + name;
Map<String, String> data = conn.hgetAll("count:" + hash);
List<Pair<Integer>> results = new ArrayList<>();
for (Map.Entry<String, String> entry : data.entrySet()) {
results.add(new Pair<>(
entry.getKey(),
Integer.parseInt(entry.getValue())));
}
Collections.sort(results);
return results;
}Case study - Tìm địa chỉ IP thuộc về đâu
Tìm địa chỉ IP thuộc về đâu bằng cách sử dụng Redis nhanh hơn so với cách thực hiện trên cơ sở dữ liệu quan hệ.
Tải dữ liệu IP
Chuyển đổi địa chỉ IP thành giá trị số nguyên:
public int ipToScore(String ipAddress) {
int score = 0;
for (String v : ipAddress.split("\\.")) {
score = score * 256 + Integer.parseInt(v, 10);
}
return score;
}Tạo ánh xạ giữa địa chỉ IP và ID thành phố:
public void importIpsToRedis(Jedis conn, File file) {
FileReader reader = null;
try {
// Tải dữ liệu từ tệp csv
reader = new FileReader(file);
CSVFormat csvFormat = CSVFormat.DEFAULT.withRecordSeparator("\n");
CSVParser csvParser = csvFormat.parse(reader);
int count = 0;
List<CSVRecord> records = csvParser.getRecords();
for (CSVRecord line : records) {
String startIp = line.get(0);
if (startIp.toLowerCase().indexOf('i') != -1) {
continue;
}
// Chuyển đổi địa chỉ IP thành giá trị số nguyên
int score = 0;
if (startIp.indexOf('.') != -1) {
score = ipToScore(startIp);
} else {
try {
score = Integer.parseInt(startIp, 10);
} catch (NumberFormatException nfe) {
// Bỏ qua dòng đầu tiên của tệp và các mục không đúng định dạng
continue;
}
}
// Xây dựng ID thành phố duy nhất
String cityId = line.get(2) + '_' + count;
// Thêm ID thành phố và giá trị số nguyên tương ứng của địa chỉ IP vào ZSET
conn.zadd("ip2cityid:", score, cityId);
count++;
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
reader.close();
} catch (Exception e) {
// bỏ qua
}
}
}Lưu trữ thông tin thành phố:
public void importCitiesToRedis(Jedis conn, File file) {
Gson gson = new Gson();
FileReader reader = null;
try {
// Tải thông tin từ tệp csv
reader = new FileReader(file);
CSVFormat csvFormat = CSVFormat.DEFAULT.withRecordSeparator("\n");
CSVParser parser = new CSVParser(reader, csvFormat);
// String[] line;
List<CSVRecord> records = parser.getRecords();
for (CSVRecord record : records) {
if (record.size() < 4 || !Character.isDigit(record.get(0).charAt(0))) {
continue;
}
// Chuyển đổi thông tin địa lý thành cấu trúc json và lưu vào HASH
String cityId = record.get(0);
String country = record.get(1);
String region = record.get(2);
String city = record.get(3);
String json = gson.toJson(new String[] { city, region, country });
conn.hset("cityid2city:", cityId, json);
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
reader.close();
} catch (Exception e) {
// bỏ qua
}
}
}Tìm địa chỉ IP thuộc về thành phố nào
Các bước thực hiện:
- Chuyển đổi địa chỉ IP cần tìm thành giá trị số nguyên;
- Tìm tất cả các địa chỉ có điểm số nhỏ hơn hoặc bằng địa chỉ IP cần tìm, lấy ra bản ghi có điểm số lớn nhất;
- Sử dụng ID thành phố tìm thấy để truy vấn thông tin thành phố.
public String[] findCityByIp(Jedis conn, String ipAddress) {
int score = ipToScore(ipAddress);
Set<String> results = conn.zrevrangeByScore("ip2cityid:", score, 0, 0, 1);
if (results.size() == 0) {
return null;
}
String cityId = results.iterator().next();
cityId = cityId.substring(0, cityId.indexOf('_'));
return new Gson().fromJson(conn.hget("cityid2city:", cityId), String[].class);
}Case study - Phát hiện và cấu hình dịch vụ
Case study - Tự động hoàn chỉnh
Yêu cầu: Tự động hoàn chỉnh thông tin dựa trên đầu vào của người dùng, ví dụ: tên liên lạc, tên sản phẩm, v.v.
- Tình huống điển hình 1: Hệ thống mạng xã hội ghi lại 100 người bạn gần đây nhất mà người dùng đã liên lạc, khi người dùng tìm kiếm bạn bè, tự động hoàn chỉnh tên dựa trên từ khóa nhập vào.
- Tình huống điển hình 2: Hệ thống thương mại điện tử ghi lại 10 sản phẩm mà người dùng đã xem gần đây, khi người dùng tìm kiếm sản phẩm, tự động hoàn chỉnh tên sản phẩm dựa trên từ khóa nhập vào.
Mô hình dữ liệu: Sử dụng kiểu dữ liệu LIST của Redis để lưu trữ List liên lạc gần đây.
Xây dựng List hoàn chỉnh tự động thường bao gồm các hoạt động sau:
- Nếu người liên hệ đã được chỉ định tồn tại trong List liên lạc gần đây, hãy loại bỏ nó khỏi List. Tương ứng với lệnh
LREM. - Thêm người liên hệ đã chỉ định vào đầu List liên lạc gần đây. Tương ứng với lệnh
LPUSH. - Sau khi hoạt động thêm đã hoàn thành, nếu số lượng người liên hệ trong List vượt quá 100, thực hiện cắt tỉa. Tương ứng với lệnh
LTRIM.
Case study - Định hướng quảng cáo
Case study - Tìm kiếm vị trí công việc
Yêu cầu: Trên một trang web tuyển dụng, người tìm việc có một List kỹ năng của riêng mình; các công ty tuyển dụng có một List kỹ năng cần thiết cho vị trí công việc. Các công ty tuyển dụng cần tìm kiếm người tìm việc phù hợp với yêu cầu công việc của mình; người tìm việc cần tìm kiếm các vị trí công việc mà mình có thể nộp đơn.
Mô hình dữ liệu quan trọng: Sử dụng kiểu dữ liệu SET để lưu trữ List kỹ năng của người tìm việc và List kỹ năng của vị trí công việc.
Hoạt động quan trọng: Sử dụng lệnh SDIFF để so sánh sự khác biệt giữa hai SET, trả về empty nếu đáp ứng yêu cầu.
Ví dụ sử dụng Redis CLI:
# -----------------------------------------------------------
# Mô hình dữ liệu tìm kiếm vị trí công việc trong Redis
# -----------------------------------------------------------
# (1) Bảng kỹ năng vị trí công việc: Lưu trữ bằng kiểu dữ liệu SET
# Công việc job:001 yêu cầu 4 kỹ năng
SADD job:001 skill:001
SADD job:001 skill:002
SADD job:001 skill:003
SADD job:001 skill:004
# Công việc job:002 yêu cầu 3 kỹ năng
SADD job:002 skill:001
SADD job:002 skill:002
SADD job:002 skill:003
# Công việc job:003 yêu cầu 2 kỹ năng
SADD job:003 skill:001
SADD job:003 skill:003
# Xem List kỹ năng
SMEMBERS job:001
SMEMBERS job:002
SMEMBERS job:003
# (2) Bảng kỹ năng của người tìm việc: Lưu trữ bằng kiểu dữ liệu SET
SADD interviewee:001 skill:001
SADD interviewee:001 skill:003
SADD interviewee:002 skill:001
SADD interviewee:002 skill:002
SADD interviewee:002 skill:003
SADD interviewee:002 skill:004
SADD interviewee:002 skill:005
# Xem List kỹ năng
SMEMBERS interviewee:001
SMEMBERS interviewee:002
# (3) Người tìm việc tìm kiếm các vị trí công việc phù hợp với yêu cầu của mình (trả về empty nếu tất cả các kỹ năng yêu cầu đều được đáp ứng)
# So sánh sự khác biệt giữa List kỹ năng của vị trí công việc và List kỹ năng của người tìm việc
SDIFF job:001 interviewee:001
SDIFF job:002 interviewee:001
SDIFF job:003 interviewee:001
SDIFF job:001 interviewee:002
SDIFF job:002 interviewee:002
SDIFF job:003 interviewee:002
# (4) Công ty tuyển dụng tìm kiếm người tìm việc phù hợp với yêu cầu công việc của mình (trả về empty nếu tất cả các kỹ năng yêu cầu đều được đáp ứng)
# So sánh sự khác biệt giữa List kỹ năng của người tìm việc và List kỹ năng của vị trí công việc
SDIFF interviewee:001 job:001
SDIFF interviewee:002 job:001
SDIFF interviewee:001 job:002
SDIFF interviewee:002 job:002
SDIFF interviewee:001 job:003
SDIFF interviewee:002 job:003Redis có năm loại dữ liệu phổ biến: String (chuỗi), Hash (bảng băm), List (danh sách), Set (tập hợp) và Zset (tập hợp có thứ tự).
Các loại dữ liệu này được triển khai với nhiều cấu trúc dữ liệu khác nhau, chủ yếu là để tối ưu thời gian và không gian lưu trữ. Khi tập dữ liệu nhỏ, việc sử dụng cấu trúc đơn giản hơn có lợi để tiết kiệm bộ nhớ và cải thiện hiệu suất.
Cấu trúc dữ liệu dưới cùng cho các loại dữ liệu Redis có sự khác biệt theo từng phiên bản, ví dụ như:
- Trong phiên bản Redis 3.0, cấu trúc dữ liệu của đối tượng List được triển khai bằng "danh sách liên kết hai chiều" hoặc "ziplist". Tuy nhiên, từ phiên bản 3.2 trở đi, List sử dụng cấu trúc dữ liệu quicklist.
- Trong mã nguồn Redis mới nhất, cấu trúc dữ liệu ziplist đã bị loại bỏ và thay thế bằng listpack.
Ứng dụng của các loại dữ liệu Redis:
- String: Lưu trữ cache, đếm tổng, khóa phân tán, chia sẻ thông tin phiên, v.v.
- List: Hàng đợi tin nhắn (tuy nhiên có hai vấn đề: 1. Nhà sản xuất phải tự triển khai ID duy nhất toàn cầu; 2. Không hỗ trợ việc tiêu thụ dữ liệu theo nhóm).
- Hash: Lưu trữ cache, giỏ hàng mua sắm, v.v.
- Set: Tính toán tổ hợp (hợp, giao, khác), chẳng hạn như thích, theo dõi chung, hoạt động rút thăm, v.v.
- Zset (Sorted Set): Sắp xếp dữ liệu, chẳng hạn như bảng xếp hạng, sắp xếp số điện thoại và tên.
Các loại dữ liệu mới trong Redis và ứng dụng của chúng:
- Bitmap (thêm từ phiên bản 2.2): Thống kê trạng thái nhị phân, chẳng hạn như đánh dấu tham gia, xác định trạng thái đăng nhập của người dùng, tổng số người dùng liên tục đăng ký, v.v.
- HyperLogLog (thêm từ phiên bản 2.8): Thống kê số lượng cơ sở dữ liệu lớn, chẳng hạn như số lượt truy cập trang web hàng triệu.
- GEO (thêm từ phiên bản 3.2): Lưu trữ thông tin vị trí địa lý, chẳng hạn như dịch vụ gọi xe Didi.
- Stream (thêm từ phiên bản 5.0): Hàng đợi tin nhắn, có hai tính năng đặc biệt so với hàng đợi tin nhắn triển khai dựa trên List: tự động tạo ID tin nhắn duy nhất toàn cầu, hỗ trợ tiêu thụ dữ liệu theo nhóm.

Việc sử dụng Redis làm hệ thống hàng đợi tin nhắn phụ thuộc vào tình huống nghiệp vụ của bạn:
- Nếu kịch bản nghiệp vụ của bạn đơn giản, không nhạy cảm với việc mất dữ liệu và khả năng chất đống thông tin ít, Redis có thể được sử dụng như một hàng đợi hoàn toàn.
- Nếu kịch bản nghiệp vụ của bạn có số lượng tin nhắn lớn, tỷ lệ chất đống thông tin cao và không thể chấp nhận mất dữ liệu, hãy sử dụng phần mềm trung gian hàng đợi chuyên nghiệp.