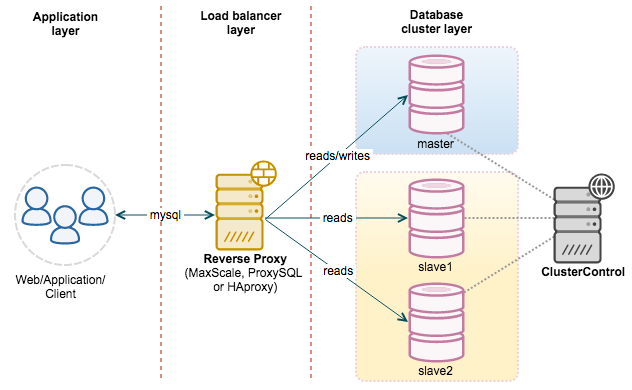
MySQL Replication
Replication
Replication là một phương pháp phổ biến để giải quyết vấn đề có sẵn cao của hệ thống. Ý tưởng cơ bản là: không nên để tất cả trứng vào một giỏ.
Vấn đề cơ bản mà replication giải quyết là đồng bộ hóa dữ liệu của một máy chủ với các máy chủ khác. Dữ liệu từ một máy chủ chính có thể được replication đến nhiều máy chủ dự phòng, và các máy chủ dự phòng có thể được cấu hình thành một máy chủ chính cho một máy chủ khác. Có nhiều cách khác nhau để kết hợp máy chủ chính và máy chủ dự phòng.
MySQL hỗ trợ hai phương pháp replication: replication dựa trên hàng và replication dựa trên câu lệnh. Cả hai phương pháp đều sử dụng cách ghi lại bin log trên máy chủ chính và chạy lại log trên máy chủ dự phòng để thực hiện replication dữ liệu bất đồng bộ. Điều này có nghĩa là quá trình replication có độ trễ và trong khoảng thời gian này, dữ liệu giữa máy chủ chính và máy chủ phụ có thể không đồng nhất.
Cách thức hoạt động của replication
Trong MySQL, quá trình replication được chia thành ba bước, mỗi bước do một luồng hoàn thành:
- Luồng binlog dump - Trên máy chủ chính có một luồng đặc biệt gọi là luồng binlog dump, chịu trách nhiệm ghi các thay đổi dữ liệu từ máy chủ chính vào binlog.
- Luồng I/O - Trên máy chủ dự phòng có một luồng I/O, chịu trách nhiệm đọc binlog từ máy chủ chính và ghi vào log trung gian (relay log) của máy chủ dự phòng.
- Luồng SQL - Trên máy chủ dự phòng có một luồng SQL, chịu trách nhiệm đọc log trung gian (relay log) và thực hiện lại các câu lệnh SQL từ đó.
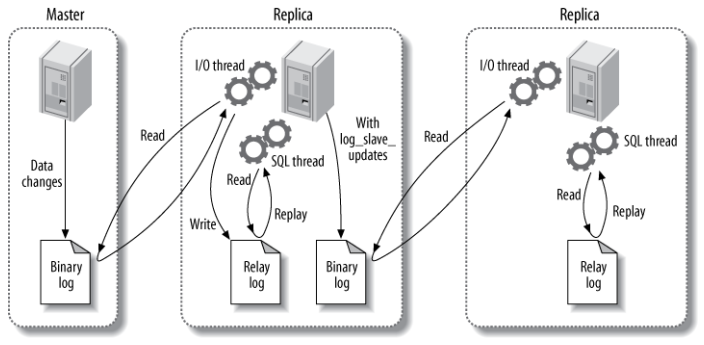
Kiến trúc này giải quyết vấn đề giải phóng dữ liệu và đồng bộ hóa dữ liệu bất đồng bộ. Tuy nhiên, kiến trúc này cũng giới hạn quá trình replication, điểm quan trọng nhất là các truy vấn đang chạy song song trên máy chủ chính phải được thực hiện tuần tự trên máy chủ dự phòng, vì chỉ có một luồng SQL để chạy lại các sự kiện trong relay log.
Cấu hình replication Master-Slave
Giả sử bạn cần cấu hình một cặp nút MySQL Master-Slave với môi trường sau đây:
- Nút Master: 192.168.8.10
- Nút Slave: 192.168.8.11
Các bước trên nút Master
Sửa đổi cấu hình và khởi động lại
Sử dụng lệnh
vi /etc/my.cnf, thêm các cấu hình sau:
[mysqld]
server-id=1
log_bin=/var/lib/mysql/binlogserver-id- ID duy nhất của máy chủ trong kiến trúc Master-Slave.log_bin- Đường dẫn và tên tập tin log để đồng bộ, đảm bảo thư mục này có quyền ghi của MySQL.
Sau khi chỉnh sửa, khởi động lại MySQL để cập nhật cấu hình:
systemctl restart mysql- Tạo người dùng đồng bộ
Truy cập vào MySQL console:
$ mysql -u root -p
Password:Thực thi các lệnh SQL sau:
-- a. Tạo người dùng 'slave' có thể đăng nhập từ bất kỳ địa chỉ IP nào
CREATE USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%';
-- b. Hoặc, tạo người dùng 'slave' có thể đăng nhập từ một địa chỉ IP cụ thể
CREATE USER 'slave'@'192.168.8.11' IDENTIFIED WITH mysql_native_password BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'192.168.8.11';
-- Làm mới lại các quyền
FLUSH PRIVILEGES;Để đảm bảo tương thích với MySQL 8 trở lên, sử dụng mysql_native_password cho phương thức xác thực.
- Khóa đọc
Để đồng bộ dữ liệu giữa Master và Slave, khóa đọc trên Master:
mysql> FLUSH TABLES WITH READ LOCK;- Xem trạng thái của Master
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+---------------------------------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+---------------------------------------------+-------------------+
| mysql-bin.000001 | 4202 | | mysql,information_schema,performance_schema | |
+------------------+----------+--------------+---------------------------------------------+-------------------+
1 row in set (0.00 sec)Ghi lại File và Position này để sử dụng sau này.
- Xuất SQL
mysqldump -u root -p --all-databases --master-data > dbdump.sql- Mở khóa đọc
Sau khi xuất SQL, mở khóa đọc trên Master:
mysql> UNLOCK TABLES;- Chuyển SQL xuống Slave
Sử dụng SCP hoặc phương tiện truyền tải khác để chuyển dbdump.sql xuống Slave:
scp dbdump.sql root@192.168.8.11:/homeThao tác trên máy chủ Slave
- Sửa đổi cấu hình và khởi động lại
Sử dụng lệnh vi /etc/my.cnf để chỉnh sửa cấu hình như sau:
[mysqld]
server-id=2
log_bin=/var/lib/mysql/binlogserver-id- Số ID của máy chủ. Trong kiến trúc master-slave, mỗi máy chủ phải có một ID duy nhất.log_bin- Đường dẫn và tên tập tin nhật ký đồng bộ, đảm bảo thư mục này có quyền ghi cho MySQL.
Sau khi chỉnh sửa, khởi động lại MySQL để áp dụng cấu hình:
systemctl restart mysql- Nhập dữ liệu từ tệp SQL
Sử dụng lệnh sau để nhập dữ liệu từ tệp dbdump.sql vào cơ sở dữ liệu:
mysql -u root -p < /home/dbdump.sql- Thiết lập kết nối từ máy chủ Backup đến máy chủ Master
Đăng nhập vào MySQL console:
$ mysql -u root -p
Password:Thực hiện các lệnh SQL sau:
-- Dừng dịch vụ slave
STOP SLAVE;
-- Chú ý: MASTER_USER và
CHANGE MASTER TO
MASTER_HOST='192.168.8.10',
MASTER_USER='slave',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='binlog.000001',
MASTER_LOG_POS=4202;MASTER_LOG_FILEvàMASTER_LOG_POSphải tương ứng với giá trị củaFilevàPositiontừ lệnhshow master status.MASTER_HOSTlà địa chỉ IP của máy chủ Master.MASTER_USERvàMASTER_PASSWORDlà tên và mật khẩu của người dùng đã đăng ký trên máy chủ Master.
- Khởi động tiến trình slave
mysql> START SLAVE;- Kiểm tra trạng thái đồng bộ giữa Master và Slave
mysql> SHOW SLAVE STATUS\G;Nếu cả hai tham số sau đều là YES, đồng nghĩa với việc cấu hình đúng:
Slave_IO_RunningSlave_SQL_Running
- Thiết lập máy chủ Slave chỉ cho phép đọc
mysql> SET GLOBAL read_only=1;
mysql> SET GLOBAL super_read_only=1;
mysql> SHOW GLOBAL VARIABLES LIKE "%read_only%";
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_read_only | OFF |
| read_only | ON |
| super_read_only | ON |
| transaction_read_only | OFF |
+-----------------------+-------+Lưu ý: Thiết lập máy chủ slave chỉ cho phép đọc không ảnh hưởng đến quá trình đồng bộ với máy chủ Master.
Cơ chế sao chép
Phân tách đọc và ghi
Máy chủ chính được sử dụng để xử lý các hoạt động ghi và các hoạt động đọc có yêu cầu thời gian thực cao, trong khi máy chủ phụ được sử dụng để xử lý các hoạt động đọc.
Phân tách đọc và ghi thường được thực hiện thông qua cách thức ủy quyền, trong đó máy chủ proxy nhận các yêu cầu đọc và ghi từ tầng ứng dụng, sau đó quyết định chuyển tiếp yêu cầu đến máy chủ nào.
MySQL phân tách đọc và ghi có thể cải thiện hiệu suất vì:
- Máy chủ chính và phụ chịu trách nhiệm cho việc ghi và đọc riêng biệt, giảm đáng kể sự cạnh tranh khóa.
- Máy chủ phụ có thể được cấu hình với động cơ MyISAM, cải thiện hiệu suất truy vấn và tiết kiệm tài nguyên hệ thống.
- Tăng cường tính sẵn có bằng cách tạo ra các bản sao dự phòng.