MySQL Storage Engine
Các storage engine trong MySQL
Trong hệ thống tệp, MySQL lưu mỗi cơ sở dữ liệu (cũng có thể gọi là schema) dưới dạng một thư mục con trong thư mục dữ liệu. Khi tạo bảng, MySQL sẽ tạo một tệp .frm cùng tên với bảng trong thư mục cơ sở dữ liệu để lưu định nghĩa của bảng. Vì MySQL sử dụng các thư mục và tệp hệ thống tệp để lưu định nghĩa cơ sở dữ liệu và bảng, tính nhạy cảm chữ hoa chữ thường phụ thuộc vào nền tảng cụ thể. Trong Windows, tính nhạy cảm chữ hoa chữ thường không được áp dụng; trong các hệ thống tương tự Unix, tính nhạy cảm chữ hoa chữ thường được áp dụng. Các storage engine khác nhau lưu trữ dữ liệu và chỉ mục theo cách khác nhau, nhưng định nghĩa bảng thì được xử lý thống nhất ở tầng dịch vụ của MySQL.
MySQL sử dụng các storage engine dưới dạng plugin, mỗi storage engine nhắm đến một môi trường ứng dụng cơ sở dữ liệu cụ thể. Đồng thời, MySQL mã nguồn mở còn cho phép các nhà phát triển thiết lập các storage engine riêng của họ. Dưới đây là một số storage engine phổ biến:
- storage engine InnoDB: Đây là storage engine mặc định từ phiên bản MySQL 5.5 trở đi, với đặc điểm lớn nhất là hỗ trợ giao dịch, khóa cấp hàng, và ràng buộc khóa ngoại.
- storage engine MyISAM: Là storage engine mặc định trước phiên bản MySQL 5.5, không hỗ trợ giao dịch, cũng không hỗ trợ khóa ngoại, nhưng có đặc điểm lớn nhất là tốc độ nhanh và chiếm ít tài nguyên.
- storage engine Memory: Sử dụng bộ nhớ hệ thống làm phương tiện lưu trữ để có được tốc độ phản hồi nhanh hơn. Tuy nhiên, nếu quá trình mysqld bị sập, tất cả dữ liệu sẽ bị mất, do đó chỉ nên sử dụng storage engine Memory khi dữ liệu là tạm thời.
- storage engine NDB: Còn được gọi là storage engine NDB Cluster, chủ yếu được sử dụng cho môi trường cụm phân tán MySQL Cluster, tương tự như cụm RAC của Oracle.
- storage engine Archive: Có cơ chế nén tốt, dùng để lưu trữ tệp. Khi yêu cầu ghi dữ liệu, sẽ thực hiện nén, do đó thường được dùng để làm kho lưu trữ.
Các thao tác liên quan đến storage engine
Lệnh show storage engine
# Xem các storage engine được hỗ trợ
SHOW ENGINES;
# Xem storage engine mặc định
SHOW VARIABLES LIKE 'storage_engine';
# Xem storage engine của một bảng cụ thể
SHOW CREATE TABLE `table_name`;
# Xem storage engine của một bảng cụ thể trong một cơ sở dữ liệu
SHOW TABLE STATUS LIKE 'table_name';
SHOW TABLE STATUS FROM `database_name` WHERE `name` = "table_name";Các lệnh thiết lập storage engine
Lệnh tạo và thay đổi storage engine
# Chỉ định storage engine khi tạo bảng, nếu không chỉ định rõ, mặc định là INNODB
CREATE TABLE t1 (i INT) ENGINE = INNODB;
CREATE TABLE t2 (i INT) ENGINE = CSV;
CREATE TABLE t3 (i INT) ENGINE = MEMORY;
# Thay đổi storage engine
ALTER TABLE t ENGINE = InnoDB;
# Thay đổi storage engine mặc định, cũng có thể thay đổi trong tệp cấu hình my.cnf
SET default_storage_engine=NDBCLUSTER;Mặc định, mỗi khi CREATE TABLE hoặc ALTER TABLE không thể sử dụng storage engine mặc định, sẽ tạo ra một cảnh báo. Để ngăn chặn hành vi gây nhầm lẫn khi storage engine yêu cầu không khả dụng, có thể kích hoạt chế độ NO_ENGINE_SUBSTITUTION SQL. Nếu bộ máy yêu cầu không khả dụng, thiết lập này sẽ tạo ra lỗi thay vì cảnh báo và sẽ không tạo hoặc thay đổi bảng.
Giới thiệu về các storage engine MySQL
Các storage engine tích hợp trong MySQL
- InnoDB - InnoDB là storage engine mặc định từ phiên bản MySQL 5.5 trở đi. Nó cung cấp khóa cấp hàng và ràng buộc khóa ngoại. Hiệu suất tốt và hỗ trợ tự động phục hồi sau khi gặp sự cố.
- MyISAM - Trước phiên bản MySQL 5.5, MyISAM là storage engine mặc định. Nó có nhiều tính năng nhưng không hỗ trợ giao dịch, không hỗ trợ khóa cấp hàng và khóa ngoại, và không có khả năng phục hồi sau sự cố.
- CSV - Có thể xử lý tệp CSV như bảng MySQL, nhưng bảng này không hỗ trợ chỉ mục.
- Memory - Lưu trữ dữ liệu trong bộ nhớ để có tốc độ phản hồi nhanh hơn. Tuy nhiên, nếu quá trình mysqld gặp sự cố, tất cả dữ liệu sẽ bị mất.
- NDB - Còn gọi là storage engine NDB Cluster, chủ yếu dùng cho môi trường cụm phân tán MySQL Cluster, tương tự như cụm RAC của Oracle.
- Archive - storage engine Archive rất phù hợp để lưu trữ dữ liệu.
- storage engine Archive chỉ hỗ trợ thao tác
INSERTvàSELECT. - storage engine Archive sử dụng thuật toán nén zlib, với tỷ lệ nén có thể đạt 1:10.
- storage engine Archive chỉ hỗ trợ thao tác
Cách chọn storage engine phù hợp
Phần lớn trường hợp, InnoDB là lựa chọn đúng đắn, trừ khi cần các tính năng mà InnoDB không có.
Nếu ứng dụng cần chọn storage engine khác InnoDB, có thể xem xét các yếu tố sau:
- Giao dịch: Nếu kịch bản kinh doanh là OLTP, thì InnoDB là storage engine được ưu tiên. Nếu không cần hỗ trợ giao dịch và chủ yếu là các thao tác SELECT và INSERT, MyISAM là lựa chọn tốt. Vì vậy, nếu MySQL được triển khai theo mô hình chủ - phụ và tách biệt đọc/ghi, có thể làm như sau: nút chính chỉ hỗ trợ ghi, bộ máy mặc định là InnoDB; nút phụ chỉ hỗ trợ đọc, bộ máy mặc định là MyISAM.
- Đồng thời: MyISAM chỉ hỗ trợ khóa cấp bảng, trong khi InnoDB hỗ trợ khóa cấp hàng. Do đó, InnoDB có hiệu suất đồng thời cao hơn.
- Khóa ngoại: InnoDB hỗ trợ khóa ngoại.
- Sao lưu: InnoDB hỗ trợ sao lưu nóng trực tuyến.
- Phục hồi sau sự cố: Khả năng hư hỏng sau sự cố của MyISAM cao hơn nhiều so với InnoDB, và tốc độ phục hồi cũng chậm hơn.
- Tính năng khác: MyISAM hỗ trợ bảng nén và chỉ mục dữ liệu không gian.
Giới thiệu về InnoDB
InnoDB là storage engine mặc định từ phiên bản MySQL 5.5 trở đi. Chỉ nên sử dụng storage engine khác khi cần các tính năng mà InnoDB không hỗ trợ.
InnoDB cũng sử dụng cây B+ (B+Tree) làm cấu trúc chỉ mục, nhưng cách thực hiện cụ thể rất khác so với MyISAM. Trong MyISAM, tệp chỉ mục và tệp dữ liệu là tách biệt, tệp chỉ mục chỉ lưu trữ địa chỉ của bản ghi dữ liệu. Trong InnoDB, tệp dữ liệu của bảng chính là một cấu trúc chỉ mục B+Tree. Các nút lá (leaf node) của cây này chứa toàn bộ bản ghi dữ liệu. Chỉ mục này sử dụng khóa chính của bảng làm khóa, do đó, tệp dữ liệu của bảng InnoDB chính là chỉ mục chính.
InnoDB sử dụng MVCC (Multi-Version Concurrency Control) để hỗ trợ khả năng xử lý đồng thời cao, và thực hiện bốn mức độ cô lập tiêu chuẩn. Mức độ mặc định là đọc lặp lại (REPEATABLE READ) và sử dụng khóa khoảng (next-key locking) để ngăn chặn hiện tượng đọc ảo.
InnoDB được xây dựng dựa trên chỉ mục nhóm (clustered index), khác biệt lớn so với các storage engine khác. Dữ liệu được lưu trong chỉ mục, giúp tránh việc đọc từ đĩa trực tiếp, do đó cải thiện hiệu suất truy vấn.
InnoDB đã thực hiện nhiều tối ưu nội bộ, bao gồm đọc dữ liệu từ đĩa theo dự đoán, chỉ mục băm thích ứng tự động tạo để tăng tốc độ đọc, và vùng đệm chèn giúp tăng tốc độ chèn dữ liệu.
InnoDB hỗ trợ sao lưu nóng trực tuyến thực sự. Các storage engine khác không hỗ trợ sao lưu nóng trực tuyến; để có được chế độ xem nhất quán, cần phải dừng tất cả các thao tác ghi vào bảng, và trong môi trường đọc ghi hỗn hợp, việc dừng ghi cũng có thể đồng nghĩa với việc dừng đọc.
Cấu trúc tệp vật lý của InnoDB:
- Tệp
.frm: Chứa thông tin siêu dữ liệu liên quan đến bảng, bao gồm thông tin định nghĩa cấu trúc bảng. - Tệp
.ibdhoặc.ibdata: Chứa dữ liệu của InnoDB. Có hai cách lưu trữ dữ liệu InnoDB có thể được cấu hình:- Không gian bảng riêng lẻ (file-per-table): Sử dụng tệp
.ibd, mỗi bảng có một tệp.ibd. - Không gian bảng chia sẻ (shared-tablespace): Sử dụng tệp
.ibdata, tất cả các bảng dùng chung một tệp.ibdata(hoặc nhiều tệp, có thể cấu hình).
- Không gian bảng riêng lẻ (file-per-table): Sử dụng tệp
Kiến trúc lưu trữ InnoDB
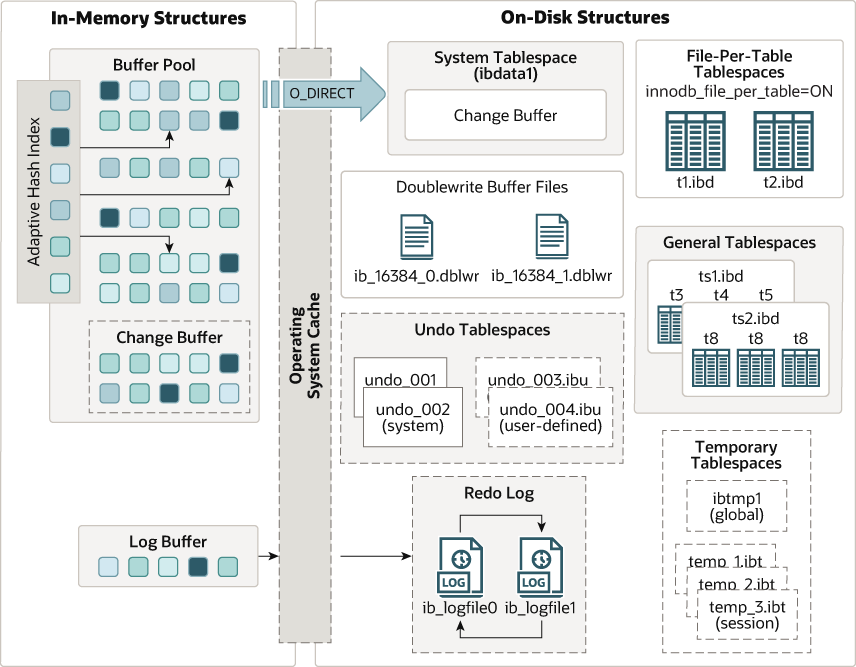
Kiến trúc lưu trữ của InnoDB được chia thành cấu trúc bộ nhớ và cấu trúc đĩa.
Cấu trúc bộ nhớ của InnoDB:
- Buffer Pool: Vùng đệm chính lưu trữ dữ liệu và chỉ mục được đọc từ đĩa.
- Change Buffer: Vùng đệm thay đổi lưu trữ các thay đổi đối với chỉ mục không duy nhất.
- Adaptive Hash Index: Chỉ mục băm thích ứng tự động tạo để tăng tốc độ truy vấn.
- Log Buffer: Vùng đệm ghi lại các thay đổi trước khi được ghi vào tệp nhật ký.
Cấu trúc đĩa của InnoDB:
- Tablespace: Không gian lưu trữ các tệp dữ liệu và chỉ mục.
- Doublewrite Buffer: Vùng đệm ghi đôi để đảm bảo tính toàn vẹn dữ liệu.
- Redo log: Nhật ký ghi lại các thay đổi để phục hồi sau sự cố.
- Undo log: Nhật ký hoàn tác giúp hỗ trợ giao dịch và khôi phục trạng thái trước đó của dữ liệu.
InnoDB mang lại nhiều lợi ích về hiệu suất và độ tin cậy nhờ các tính năng và cấu trúc lưu trữ tiên tiến.
Không gian bảng InnoDB
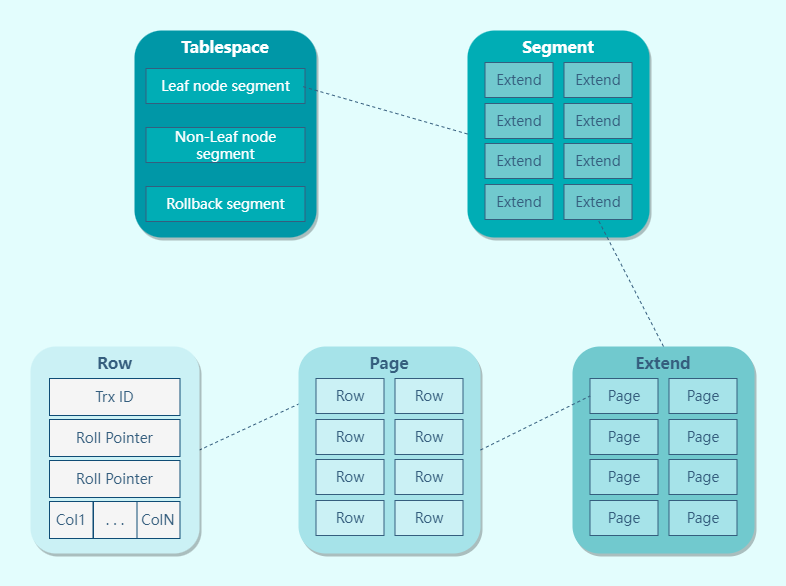
Dòng (Row)
Các bản ghi trong bảng cơ sở dữ liệu được lưu trữ theo dòng (row), mỗi dòng bản ghi có cấu trúc lưu trữ khác nhau tùy thuộc vào định dạng dòng. Sau này chúng ta sẽ giới thiệu chi tiết về định dạng dòng của InnoDB, đây cũng là nội dung chính của bài viết này.
Trang (Page)
Bản ghi được lưu trữ theo dòng, nhưng việc đọc cơ sở dữ liệu không phải theo "dòng", vì nếu vậy mỗi lần đọc (một lần thao tác I/O) chỉ xử lý một dòng dữ liệu, hiệu quả sẽ rất thấp. Do đó, dữ liệu của InnoDB được đọc và ghi theo đơn vị "trang". Điều này có nghĩa là khi cần đọc một bản ghi, không phải đọc chỉ một dòng từ đĩa, mà là đọc cả một trang vào bộ nhớ.
Mặc định mỗi trang có kích thước 16KB, có nghĩa là đảm bảo không gian lưu trữ liên tục tối đa 16KB. Trang là đơn vị quản lý nhỏ nhất của đĩa trong storage engine InnoDB, nghĩa là mỗi lần cơ sở dữ liệu đọc ghi ít nhất là 16KB, đọc từ đĩa vào bộ nhớ ít nhất là 16K, và ghi từ bộ nhớ ra đĩa ít nhất là 16K.
Có nhiều loại trang, phổ biến nhất là trang dữ liệu, trang nhật ký undo, trang tràn, v.v. Các bản ghi trong bảng được quản lý bởi "trang dữ liệu", cấu trúc của trang dữ liệu không được đề cập chi tiết ở đây. Bạn có thể tham khảo bài viết này để biết thêm chi tiết: Thay đổi góc nhìn về cây B+.
Nói chung, bạn chỉ cần biết các bản ghi trong bảng được lưu trữ trong "trang dữ liệu".
Vùng (Extent)
Chúng ta biết rằng storage engine InnoDB tổ chức dữ liệu bằng cây B+ (B+Tree). Trong cây B+, mỗi tầng được kết nối bằng danh sách liên kết hai chiều. Nếu phân bổ không gian lưu trữ theo đơn vị trang, vị trí vật lý của hai trang liền kề trong danh sách liên kết có thể không liên tiếp, có thể rất xa nhau, điều này dẫn đến nhiều thao tác I/O ngẫu nhiên, rất chậm.
Giải pháp rất đơn giản, làm cho vị trí vật lý của các trang liền kề trong danh sách liên kết cũng liền kề, như vậy có thể sử dụng I/O tuần tự. Điều này cải thiện hiệu suất khi thực hiện các truy vấn phạm vi (quét các nút lá).
Cách cụ thể để giải quyết vấn đề này là gì?
Khi lượng dữ liệu trong bảng lớn, việc phân bổ không gian cho một chỉ mục không còn theo đơn vị trang, mà theo đơn vị vùng (extent). Mỗi vùng có kích thước 1MB, đối với trang 16KB, 64 trang liên tiếp sẽ tạo thành một vùng. Điều này làm cho vị trí vật lý của các trang liền kề trong danh sách liên kết cũng liền kề, và có thể sử dụng I/O tuần tự.
Đoạn (Segment)
Không gian bảng được tạo thành từ các đoạn (segment), mỗi đoạn gồm nhiều vùng (extent). Các đoạn thường được chia thành đoạn dữ liệu, đoạn chỉ mục và đoạn hoàn tác.
- Đoạn chỉ mục: Chứa các vùng của các nút không phải lá của cây B+.
- Đoạn dữ liệu: Chứa các vùng của các nút lá của cây B+.
- Đoạn hoàn tác: Chứa các vùng của dữ liệu hoàn tác.
Vậy là chúng ta đã hoàn thành việc mô tả cấu trúc của không gian bảng. Tiếp theo, chúng ta sẽ nói chi tiết về định dạng dòng của InnoDB.
Việc giới thiệu vòng quanh này nhằm giúp bạn hiểu dòng bản ghi được lưu trữ ở tệp nào và khu vực nào trong không gian bảng này, từ góc nhìn từ trên xuống. Điều này giúp bạn hiểu rõ hơn và không thấy mơ hồ.
Cấu trúc bộ nhớ InnoDB
Bộ đệm (Buffer Pool)
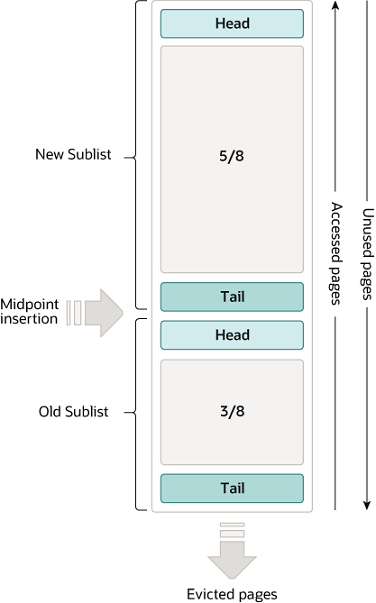
Bộ đệm dùng để tăng tốc độ truy cập và chỉnh sửa dữ liệu bằng cách lưu trữ dữ liệu nóng trong bộ nhớ, giảm thiểu tối đa I/O từ đĩa và tăng tốc độ đọc và ghi dữ liệu nóng.
Dữ liệu trong Buffer Pool được lưu trữ theo đơn vị trang và được quản lý bằng cấu trúc danh sách liên kết đơn theo đơn vị trang. Do giới hạn của bộ nhớ, Buffer Pool chỉ có thể chứa được dữ liệu nóng nhất. Buffer Pool sử dụng thuật toán LRU (Least Recently Used) để loại bỏ dữ liệu không nóng.
Dựa trên nguyên lý cục bộ thời gian và không gian, Buffer Pool lưu trữ các trang dữ liệu hoạt động hiện tại bằng cách sử dụng cơ chế đọc trước (Read-ahead) để lưu trữ các trang dữ liệu gần dữ liệu mục tiêu.
Cơ chế đọc trước dẫn đến vấn đề đọc trước thất bại. InnoDB sử dụng cơ chế phân chia thế hệ để giải quyết vấn đề này: chia Buffer Pool thành hai phần là New SubList và Old SubList, đặt các trang dữ liệu mới đọc vào đầu Old SubList, các trang dữ liệu trong Old SubList được truy cập lại sẽ được đặt vào đầu New SubList; các trang dữ liệu lạnh thất bại trong việc đọc trước sẽ nhanh chóng bị loại bỏ khỏi Old SubList mà không ảnh hưởng đến dữ liệu nóng trong New SubList.
InnoDB sử dụng cơ chế cửa sổ thời gian (Time Window) để giải quyết vấn đề ô nhiễm bộ đệm: đối với các trang dữ liệu trong Old SubList, chúng phải ở lại Old SubList trong một khoảng thời gian nhất định rồi mới được chuyển vào New SubList nếu được truy cập lại. Cửa sổ mặc định là 1 giây.
Đối với truy vấn dữ liệu trong Buffer Pool, InnoDB sẽ đọc và trả về trực tiếp; đối với sửa đổi dữ liệu trong Buffer Pool, InnoDB sẽ sửa trực tiếp trong Buffer Pool và ghi sửa đổi vào redo Log. Khi trang dữ liệu bị thuật toán LRU loại bỏ, nó sẽ được ghi vào đĩa, nếu hệ thống gặp sự cố trước khi được ghi vào đĩa, sẽ sử dụng redo Log để khôi phục khi khởi động lại.
Bộ đệm thay đổi (Change Buffer)

Change Buffer dùng để tăng tốc độ ghi vào chỉ mục thứ cấp của dữ liệu không nóng. Do tính không liên tục của dữ liệu chỉ mục thứ cấp, việc sửa đổi chỉ mục thứ cấp yêu cầu I/O đĩa thường xuyên, tiêu tốn nhiều hiệu năng. Change Buffer lưu trữ các thao tác sửa đổi chỉ mục thứ cấp và ghi vào redo log. Khi Change Buffer đạt đến một lượng nhất định hoặc hệ thống ít bận rộn, nó sẽ thực hiện thao tác ibuf merge để ghi sửa đổi vào đĩa. Change Buffer có vùng lưu trữ bền bỉ trong không gian bảng hệ thống.
Kích thước Change Buffer mặc định chiếm 25% Buffer Pool, được khởi tạo khi khởi động máy chủ. Cấu trúc vật lý của nó là một cây B-Tree gọi là ibuf. Điều kiện sử dụng Change Buffer là:
- InnoDB bật
innodb_change_bufferingvà bảng hiện tại không có thao tácflush. - Chỉ sửa đổi các nút lá của cây chỉ mục thứ cấp và trang chỉ mục không nằm trong Buffer Pool.
- Đối với chỉ mục thứ cấp duy nhất, chỉ có thao tác xóa có thể được lưu vào bộ đệm.
Thời điểm thực hiện ibuf merge:
- Khi người dùng sử dụng chỉ mục thứ cấp để truy vấn.
- Khi dự đoán rằng không gian trang sẽ không đủ khi lưu trữ thao tác chèn, có thể dẫn đến phân chia trang chỉ mục.
- Khi thao tác lưu trữ lần này dẫn đến phân chia trang cây ibuf và kích thước Change Buffer vượt quá giới hạn sau khi phân loại.
- Khi luồng master thực hiện lệnh
merge. - Khi người dùng thực hiện thao tác
flushtrên bảng.
Chỉ mục băm thích nghi (Adaptive Hash Index)
Chỉ mục băm thích nghi (Adaptive Hash Index, AHI) dùng để tăng tốc độ truy vấn cho các trang dữ liệu nóng. Khi sử dụng chỉ mục cụm (clustered index) để định vị trang dữ liệu, cần đi từ nút gốc đến nút lá của cây chỉ mục, thường mất 3-4 lần truy vấn. InnoDB phân tích việc sử dụng chỉ mục và các trường chỉ mục để tạo hoặc xóa chỉ mục băm một cách tự động.
AHI áp dụng cho các trang dữ liệu và chỉ mục được truy vấn thường xuyên. Vì trang dữ liệu là một phần của chỉ mục cụm, AHI được xây dựng trên chỉ mục. Đối với chỉ mục thứ cấp, nếu trúng AHI, sẽ lấy trực tiếp con trỏ bản ghi từ chỉ mục thứ cấp trong AHI và sau đó theo khóa chính tìm dữ liệu dọc theo chỉ mục cụm; nếu truy vấn chỉ mục cụm cũng trúng AHI, sẽ trả về trực tiếp con trỏ bản ghi của trang dữ liệu mục tiêu, từ đó có thể định vị trang dữ liệu trực tiếp theo con trỏ bản ghi.
Kích thước AHI là 1/64 của Buffer Pool. Từ MySQL 5.7 trở đi, AHI hỗ trợ phân vùng để giảm cạnh tranh trên khóa AHI toàn cục, mặc định là 8 phân vùng.
Bộ đệm nhật ký (Log Buffer)
Bộ đệm nhật ký (Log Buffer) được dùng để lưu trữ tạm thời các dữ liệu nhật ký cần ghi vào đĩa. Tất cả các thao tác sửa đổi của InnoDB sẽ được ghi vào các tệp nhật ký như redo log, undo log. Nếu mỗi lần sửa đổi đều được ghi trực tiếp vào đĩa, sẽ gây ra rất nhiều I/O. Log Buffer tối ưu vấn đề này bằng cách lưu trữ các thao tác sửa đổi trong vùng nhớ này trước, sau đó định kỳ ghi hàng loạt vào đĩa.
Kích thước của bộ đệm nhật ký có thể được điều chỉnh bằng cấu hình innodb_log_buffer_size, mặc định là 16MB.
MyISAM
MyISAM là hệ thống lưu trữ mặc định của MySQL trước phiên bản 5.5.
MyISAM được thiết kế đơn giản với dữ liệu được lưu trữ theo định dạng nén. MyISAM thích hợp cho dữ liệu chỉ đọc, hoặc bảng nhỏ có thể chấp nhận các thao tác sửa chữa.
MyISAM sử dụng cấu trúc B+Tree cho chỉ mục, trong đó nút lá của trường dữ liệu lưu trữ địa chỉ của các bản ghi dữ liệu.
MyISAM cung cấp nhiều tính năng như: chỉ mục toàn văn, bảng nén, và các hàm không gian. Tuy nhiên, MyISAM không hỗ trợ giao dịch và khóa cấp hàng. MyISAM cũng không hỗ trợ khôi phục an toàn sau khi hệ thống gặp sự cố.
Cấu trúc tệp vật lý của MyISAM:
- Tệp
.frm: lưu trữ thông tin siêu dữ liệu liên quan đến bảng, bao gồm định nghĩa cấu trúc bảng. - Tệp
.MYD(MYData): dành riêng cho MyISAM để lưu trữ dữ liệu của bảng MyISAM. - Tệp
.MYI(MYIndex): dành riêng cho MyISAM để lưu trữ thông tin liên quan đến chỉ mục của bảng MyISAM.
So sánh InnoDB và MyISAM
Bảng so sánh giữa InnoDB và MyISAM:
| Đối chiếu | MyISAM | InnoDB |
|---|---|---|
| Khóa ngoại | Không hỗ trợ | Hỗ trợ |
| Giao dịch | Không hỗ trợ | Hỗ trợ |
| Khóa | Hỗ trợ khóa cấp bảng | Hỗ trợ khóa cấp bảng và khóa cấp hàng |
| Chỉ mục | Sử dụng chỉ mục không phân cụm | Chỉ mục chính sử dụng chỉ mục phân cụm để cải thiện hiệu suất IO |
| Không gian bảng | Nhỏ | Lớn |
| Điểm tập trung | Hiệu suất | Giao dịch |
| Bộ đếm | Duy trì bộ đếm, hiệu suất SELECT COUNT(*) là O(1) | Không duy trì bộ đếm, cần quét toàn bộ bảng |
InnoDB thường được chọn khi cần hỗ trợ giao dịch, khóa cấp hàng và khả năng khôi phục sau sự cố, trong khi MyISAM có thể được sử dụng cho các bảng chỉ đọc hoặc bảng nhỏ nơi hiệu suất và không gian lưu trữ là ưu tiên chính.