MySQL Architecture
Kiến trúc cơ bản
Nói chung, MySQL có thể được chia thành hai phần: lớp máy chủ và lớp lưu trữ.
Lớp máy chủ bao gồm các thành phần như kết nối, bộ nhớ cache truy vấn, trình phân tích, trình tối ưu hóa, trình thực thi, vv. Nó bao gồm hầu hết các chức năng và dịch vụ cốt lõi của MySQL, cũng như tất cả các hàm tích hợp (như hàm ngày tháng, thời gian, toán học và mã hóa), tất cả các chức năng chung cho tất cả các lưu trữ (như thủ tục lưu trữ, trigger, view, vv).
Lớp lưu trữ chịu trách nhiệm lưu trữ và truy xuất dữ liệu. Kiến trúc của nó là một kiến trúc cắm, hỗ trợ nhiều lưu trữ như InnoDB, MyISAM, Memory, vv. Hiện nay, lưu trữ phổ biến nhất là InnoDB, nó đã trở thành lưu trữ mặc định từ phiên bản MySQL 5.5.5 trở đi.
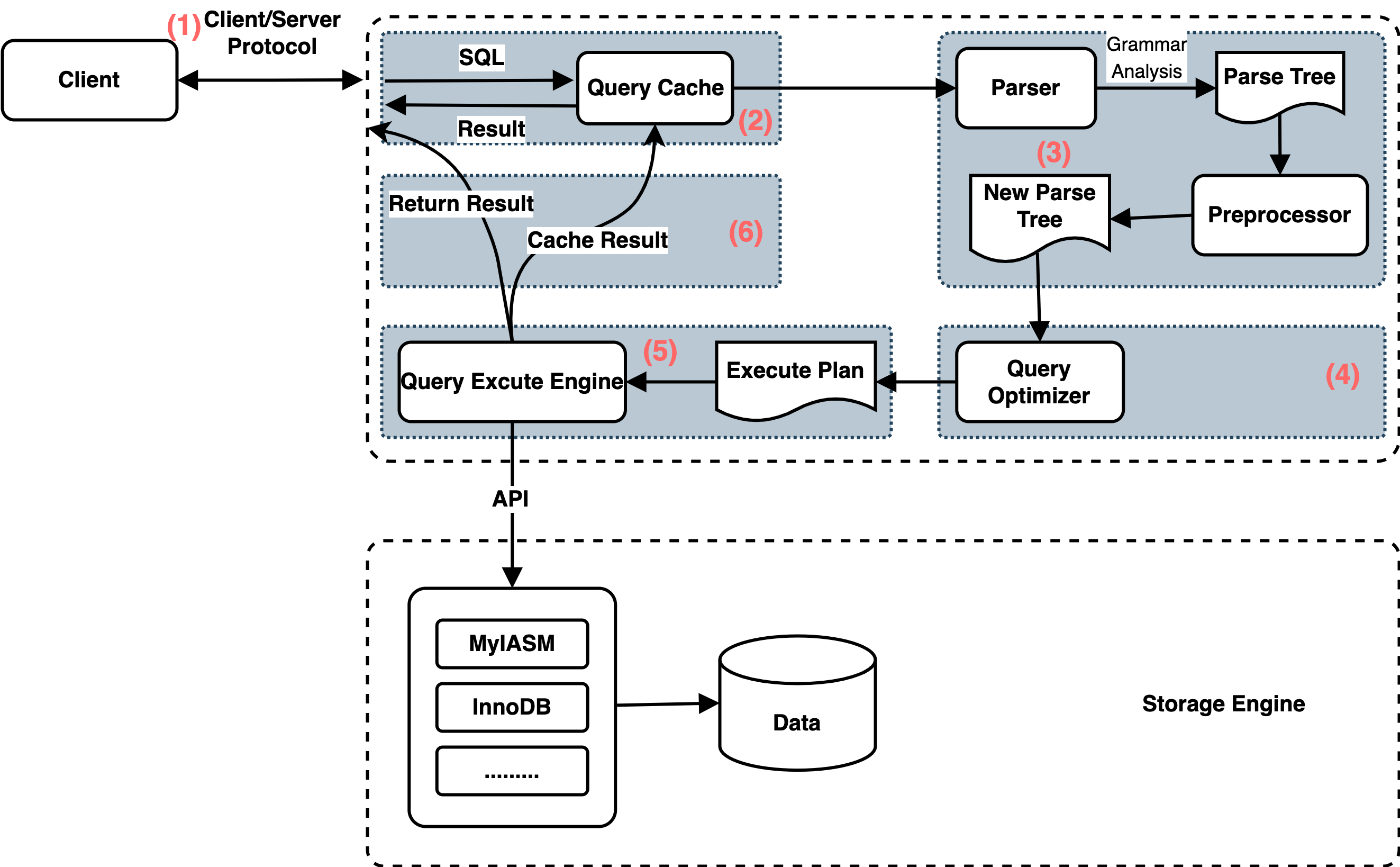
Quá trình truy vấn
Câu lệnh SQL được thực hiện như thế nào trong MySQL?
Quá trình thực hiện truy vấn MySQL tổng cộng có 6 bước, tương ứng với 6 thành phần:
- Kết nối: Kết nối giữa máy khách và máy chủ MySQL; Kết nối chịu trách nhiệm thiết lập kết nối với máy khách, xác định quyền truy cập và duy trì quản lý kết nối.
- MySQL kiểm tra bộ nhớ cache truy vấn trước tiên. Nếu truy vấn được lưu trong bộ nhớ cache, kết quả sẽ được trả về ngay lập tức. Nếu không, chuyển sang bước tiếp theo.
- Máy chủ MySQL thực hiện phân tích SQL: phân tích cú pháp, phân tích từ vựng.
- Máy chủ MySQL sử dụng trình tối ưu hóa để tạo ra kế hoạch thực thi tương ứng.
- Máy chủ MySQL gọi API lưu trữ để thực hiện truy vấn dựa trên kế hoạch thực hiện.
- Máy chủ MySQL trả kết quả cho máy khách, đồng thời lưu kết quả truy vấn vào bộ nhớ cache.
(1) Kết nối
Bước đầu tiên khi sử dụng MySQL là kết nối vào cơ sở dữ liệu. Kết nối chịu trách nhiệm thiết lập kết nối với máy chủ MySQL, xác định quyền truy cập và duy trì quản lý kết nối.
Giao tiếp giữa máy khách và máy chủ MySQL là một chế độ bán song công: vào bất kỳ thời điểm nào, máy chủ có thể gửi dữ liệu cho máy khách hoặc máy khách có thể gửi dữ liệu cho máy chủ. Máy khách gửi một gói dữ liệu duy nhất chứa yêu cầu truy vấn cho máy chủ, vì vậy nếu câu lệnh truy vấn dài, bạn cần thiết lập tham số max_allowed_packet. Tuy nhiên, nếu câu lệnh truy vấn quá lớn, máy chủ sẽ từ chối nhận thêm dữ liệu và ném ra một ngoại lệ.
Lệnh kết nối MySQL của khách hàng: mysql -h<host> -P<port> -u<username> -p<password>. Nếu không chỉ định mật khẩu, bạn sẽ được yêu cầu nhập mật khẩu trước khi truy cập.
Sau khi thiết lập kết nối, nếu không có hoạt động tiếp theo, kết nối sẽ ở trạng thái không hoạt động và bạn có thể thấy nó trong lệnh show processlist. Nếu khách hàng không hoạt động trong thời gian quá lâu, kết nối sẽ tự động bị đóng. Thời gian duy trì kết nối của khách hàng được điều chỉnh bằng tham số wait_timeout, giá trị mặc định là 8 giờ. Nếu kết nối bị đóng và khách hàng gửi yêu cầu truy vấn, bạn sẽ nhận được thông báo lỗi "Lost connection to MySQL server during query". Trong trường hợp này, bạn cần phải kết nối lại và thực hiện yêu cầu truy vấn.
Quá trình thiết lập kết nối thường là phức tạp, do đó, khuyến nghị giảm thiểu số lần thiết lập kết nối trong quá trình sử dụng và sử dụng kết nối dài hơn. Để tăng cường việc tái sử dụng kết nối cơ sở dữ liệu trong chương trình, thường sử dụng bể kết nối cơ sở dữ liệu để quản lý và duy trì.
Tuy nhiên, nếu chỉ sử dụng kết nối dài hơn, bạn có thể nhận thấy rằng MySQL sử dụng bộ nhớ nhanh hơn. Điều này là do MySQL sử dụng bộ nhớ tạm thời trong quá trình thực thi và giữ tài nguyên kết nối. Những tài nguyên này chỉ được giải phóng khi kết nối bị đóng. Do đó, nếu tích lũy kết nối dài hơn, có thể dẫn đến sự sử dụng bộ nhớ quá lớn và bị hệ thống giết (OOM). Khi xảy ra hiện tượng này, MySQL sẽ khởi động lại một cách bất thường.
Làm thế nào để giải quyết vấn đề này? Bạn có thể xem xét hai giải pháp sau đây.
- Đóng kết nối dài hơn định kỳ: Sử dụng một khoảng thời gian hoặc kiểm tra trong chương trình, sau khi thực hiện một hoạt động chiếm nhiều bộ nhớ, đóng kết nối và sau đó thực hiện kết nối lại khi cần truy vấn.
- Nếu bạn đang sử dụng phiên bản MySQL 5.7 trở lên, bạn có thể sử dụng
mysql_reset_connectionđể khởi tạo lại tài nguyên kết nối sau mỗi hoạt động lớn. Quá trình này không cần phải kết nối lại và xác thực quyền, nhưng sẽ khôi phục kết nối về trạng thái ban đầu khi tạo ra.
(2) Bộ nhớ cache truy vấn
Không khuyến nghị sử dụng bộ nhớ cache truy vấn, vì thường có nhiều hại hơn lợi ích.
Trước khi phân tích một câu lệnh truy vấn, nếu bộ nhớ cache truy vấn được bật, MySQL sẽ kiểm tra xem câu lệnh truy vấn này có trúng kết quả trong bộ nhớ cache không. Nếu truy vấn hiện tại trùng khớp với dữ liệu trong bộ nhớ cache, sau khi kiểm tra quyền của người dùng, kết quả sẽ được trả về trực tiếp từ bộ nhớ cache. Trong trường hợp này, truy vấn không được phân tích, không tạo kế hoạch thực hiện, và không thực hiện.
MySQL lưu trữ bộ nhớ cache trong một bảng tham chiếu (đừng hiểu nhầm là table, có thể coi nó là một cấu trúc dữ liệu giống HashMap), được chỉ mục bằng một giá trị băm được tính toán từ các yếu tố có thể ảnh hưởng đến kết quả truy vấn, bao gồm truy vấn hiện tại, cơ sở dữ liệu hiện tại và số phiên bản giao thức khách hàng. Vì vậy, bất kỳ sự khác biệt nào trong các ký tự (ví dụ: khoảng trắng, chú thích) cũng sẽ khiến bộ nhớ cache không trùng khớp.
Nếu truy vấn chứa bất kỳ hàm người dùng, hàm lưu trữ, biến người dùng, bảng tạm thời hoặc bảng hệ thống trong cơ sở dữ liệu mysql, kết quả truy vấn sẽ không được lưu vào bộ nhớ cache. Ví dụ, các hàm NOW() hoặc CURRENT_DATE() sẽ trả về kết quả khác nhau dựa trên thời gian truy vấn, và các truy vấn chứa CURRENT_USER hoặc CONNECTION_ID() sẽ trả về kết quả khác nhau dựa trên người dùng, việc lưu kết quả truy vấn như vậy không có ý nghĩa.
Không khuyến nghị sử dụng bộ nhớ cache truy vấn, vì thường có nhiều hại hơn lợi ích. Tỷ lệ trúng kết quả của bộ nhớ cache truy vấn thường rất thấp, chỉ cần có bất kỳ cập nhật nào trên một bảng, tất cả các bộ nhớ cache truy vấn của bảng đó sẽ bị xóa. Do đó, khả năng trúng kết quả của bộ nhớ cache truy vấn trong cơ sở dữ liệu có áp lực cập nhật lớn sẽ rất thấp. Trừ khi bạn có một bảng tĩnh và chỉ cần cập nhật một lần trong thời gian dài. Ví dụ, một bảng cấu hình hệ thống, trong trường hợp này, truy vấn trên bảng này sẽ phù hợp với việc sử dụng bộ nhớ cache truy vấn.
May mắn thay, MySQL cũng cung cấp cách "sử dụng theo yêu cầu". Bạn có thể đặt tham số query_cache_type thành DEMAND, điều này sẽ không sử dụng bộ nhớ cache truy vấn cho các câu lệnh SQL mặc định. Đối với các câu lệnh SQL mà bạn muốn sử dụng bộ nhớ cache truy vấn, bạn có thể sử dụng SQL_CACHE để chỉ định, giống như câu lệnh dưới đây:
select SQL_CACHE * from T where ID=10;Lưu ý: Phiên bản MySQL 8.0 đã loại bỏ hoàn toàn chức năng bộ nhớ cache truy vấn.
(3) Phân tích cú pháp
Nếu không trúng kết quả bộ nhớ cache truy vấn, quá trình thực thi câu lệnh sẽ bắt đầu. Trước tiên, MySQL cần biết bạn muốn làm gì, vì vậy nó cần phân tích câu lệnh SQL. MySQL sử dụng từ khóa để phân tích câu lệnh SQL và tạo ra một cây phân tích cú pháp tương ứng. Trong quá trình này, trình phân tích sử dụng các quy tắc cú pháp để xác minh và phân tích cây phân tích cú pháp của bạn. Ví dụ, trình phân tích sẽ nhận ra từ khóa "select" bạn nhập và xác định đây là một câu lệnh truy vấn. Nó cũng sẽ nhận ra chuỗi "T" là "tên bảng T" và chuỗi "ID" là "cột ID".
- Trình phân tích đầu tiên thực hiện "phân tích từ vựng". Bạn nhập vào một câu lệnh SQL gồm nhiều chuỗi và dấu cách, MySQL cần xác định các chuỗi đó đại diện cho cái gì. MySQL nhận ra từ khóa "select" từ bạn nhập vào, đó là một câu lệnh truy vấn. Nó cũng nhận ra chuỗi "T" là "tên bảng T" và chuỗi "ID" là "cột ID".
- Tiếp theo, thực hiện "phân tích cú pháp". Dựa trên kết quả phân tích từ vựng, trình phân tích cú pháp sẽ xác định xem câu lệnh SQL bạn nhập có đáp ứng cú pháp của MySQL không. Nếu câu lệnh của bạn không đúng, bạn sẽ nhận được thông báo lỗi "You have an error in your SQL syntax", ví dụ như câu lệnh select bị thiếu chữ cái "s".
(4) Tối ưu hóa truy vấn
Sau khi hoàn thành phân tích và xác định câu lệnh SQL, MySQL sẽ tiến hành tối ưu hóa truy vấn.
Sau khi hoàn thành phân tích và xác định cây phân tích cú pháp, MySQL sẽ chuyển đổi nó thành kế hoạch thực hiện tương ứng. Trong hầu hết các trường hợp, một truy vấn có thể có nhiều cách thực hiện, nhưng kết quả cuối cùng vẫn là cùng một. Nhiệm vụ của trình tối ưu hóa là tìm ra kế hoạch thực hiện tốt nhất trong số đó.
MySQL sử dụng trình tối ưu hóa dựa trên chi phí, nó cố gắng dự đoán chi phí của một truy vấn khi sử dụng một kế hoạch thực hiện cụ thể và chọn kế hoạch có chi phí nhỏ nhất. Trong MySQL, bạn có thể sử dụng giá trị last_query_cost của phiên truy vấn hiện tại để tính toán chi phí truy vấn hiện tại.
mysql> select * from t_message limit 10;
...Omit result set
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 6391.799000 |
+-----------------+-------------+Kết quả trong ví dụ trên cho biết trình tối ưu hóa ước tính rằng truy vấn trên sẽ cần khoảng 6391 trang dữ liệu để tìm kiếm. Kết quả này được tính toán dựa trên một số thông tin thống kê, bao gồm số trang của mỗi bảng hoặc chỉ mục, số lượng trang dữ liệu và chỉ mục, độ dài của hàng dữ liệu và chỉ mục, phân phối chỉ mục, vv.
Có nhiều nguyên nhân có thể dẫn đến việc MySQL chọn kế hoạch thực hiện sai, chẳng hạn như thông tin thống kê không chính xác, không xem xét được chi phí của các hoạt động không được kiểm soát (hàm người dùng, thủ tục lưu trữ), MySQL chọn tối ưu hóa tốt nhất theo quan điểm của nó (chúng ta muốn thời gian thực thi ngắn nhất, nhưng MySQL chọn kế hoạch có chi phí nhỏ nhất, nhưng chi phí nhỏ không có nghĩa là thời gian thực thi ngắn) v.v.
Trình tối ưu hóa truy vấn của MySQL là một thành phần rất phức tạp, nó sử dụng nhiều chiến lược tối ưu hóa để tạo ra kế hoạch thực hiện tốt nhất:
- Định lại thứ tự liên kết bảng (khi có nhiều bảng liên kết, không nhất thiết phải theo thứ tự được chỉ định trong SQL, nhưng có một số kỹ thuật để chỉ định thứ tự liên kết)
- Tối ưu hóa hàm
MIN()vàMAX()(tìm giá trị nhỏ nhất hoặc lớn nhất của một cột, nếu cột có chỉ mục, chỉ cần tìm kiếm chỉ mục B + Tree từ bên trái cùng, ngược lại, chỉ cần tìm kiếm từ bên phải cùng, chi tiết xem bên dưới) - Kết thúc truy vấn sớm (ví dụ: khi sử dụng Limit, sau khi tìm thấy số lượng kết quả đủ, truy vấn sẽ kết thúc ngay lập tức)
- Tối ưu hóa sắp xếp (trong phiên bản cũ MySQL sẽ sử dụng hai lần truyền sắp xếp, tức là đọc con trỏ hàng và cột cần sắp xếp trong bộ nhớ, sau đó đọc hàng dữ liệu dựa trên kết quả sắp xếp, trong khi phiên bản mới sử dụng truyền sắp xếp một lần, tức là đọc tất cả các hàng dữ liệu, sau đó sắp xếp dựa trên cột được chỉ định. Đối với ứng dụng tải I/O nặng, hiệu suất sẽ cao hơn nhiều)
Cùng với sự phát triển không ngừng của MySQL, các chiến lược tối ưu hóa cũng được cải tiến liên tục. Ở đây chỉ giới thiệu một số chiến lược tối ưu hóa phổ biến và dễ hiểu, các chiến lược tối ưu hóa khác, xin vui lòng tìm hiểu thêm.
(5) Thực thi truy vấn
Sau khi hoàn thành phân tích và tối ưu hóa, MySQL sẽ tạo ra kế hoạch thực hiện và truyền nó cho trình thực thi truy vấn.
Trong quá trình thực hiện truy vấn, hầu hết các hoạt động được thực hiện thông qua giao diện của lưu trữ, được gọi là "handler API". Mỗi bảng trong truy vấn được đại diện bởi một thể hiện "handler". Trên thực tế, MySQL đã tạo một thể hiện "handler" cho mỗi bảng trong quá trình tối ưu hóa truy vấn, cho phép tối ưu hóa truy vấn truy cập thông tin bảng liên quan, bao gồm tên cột, thông tin thống kê chỉ mục, v.v.
Giao diện lưu trữ cung cấp nhiều chức năng phong phú, nhưng chỉ có một số giao diện dưới đáy, giao diện này hoạt động như các khối xếp hình lego để hoàn thành hầu hết các hoạt động truy vấn.
(6) Trả kết quả
Bước cuối cùng của quá trình truy vấn là trả kết quả cho máy khách. Ngay cả khi không tìm thấy dữ liệu, MySQL vẫn sẽ trả về thông tin liên quan đến truy vấn, chẳng hạn như số hàng ảnh hưởng và thời gian thực thi.
Nếu bộ nhớ cache truy vấn được bật và truy vấn này có thể được lưu vào bộ nhớ cache, MySQL cũng sẽ lưu kết quả truy vấn vào bộ nhớ cache.
Kết quả truy vấn được trả về cho máy khách là một quá trình tăng dần và liên tục. Có thể rằng MySQL bắt đầu trả về kết quả từ lần đầu tiên tạo ra kết quả đầu tiên. Điều này giúp máy chủ không cần lưu trữ quá nhiều kết quả và tiêu tốn quá nhiều bộ nhớ, cũng như cho phép máy khách nhận kết quả ngay lập tức. Cần lưu ý rằng mỗi hàng trong kết quả sẽ được gửi dưới dạng một gói dữ liệu tuân thủ giao thức được mô tả trong (1), sau đó được truyền qua giao thức TCP. Trong quá trình truyền, có thể lưu trữ gói dữ liệu MySQL trong bộ nhớ cache và sau đó gửi chúng theo lô.
Quá trình cập nhật
Quá trình cập nhật trong MySQL tương tự quá trình truy vấn, nó sẽ đi qua các bước tương tự. Tuy nhiên, quá trình cập nhật còn liên quan đến hai mô-đun nhật ký quan trọng: redo log (nhật ký redo) và binlog (nhật ký lưu trữ).
Redo log
Redo log là một loại nhật ký đặc biệt chỉ có trong InnoDB engine. Redo log là nhật ký vật lý, ghi lại "những thay đổi đã được thực hiện trên một trang dữ liệu cụ thể".
Redo log dựa trên công nghệ WAL (Write-Ahead Logging), điểm quan trọng của WAL là "đầu tiên ghi nhật ký, sau đó ghi vào đĩa". Cụ thể, khi một bản ghi cần được cập nhật, InnoDB engine sẽ trước tiên ghi bản ghi vào redo log và cập nhật bộ nhớ, lúc này quá trình cập nhật được coi là hoàn thành. Đồng thời, InnoDB engine sẽ cập nhật thao tác này vào đĩa vào thời điểm thích hợp, thường là khi hệ thống ít hoạt động.
Redo log của InnoDB có kích thước cố định, ví dụ có thể cấu hình là một nhóm 4 tệp, mỗi tệp có kích thước 1GB, vì vậy "bảng màu" này có thể ghi lại tổng cộng 4GB hoạt động. Khi ghi từ đầu đến cuối, nếu ghi đến cuối cùng thì quay trở lại đầu để ghi tiếp.
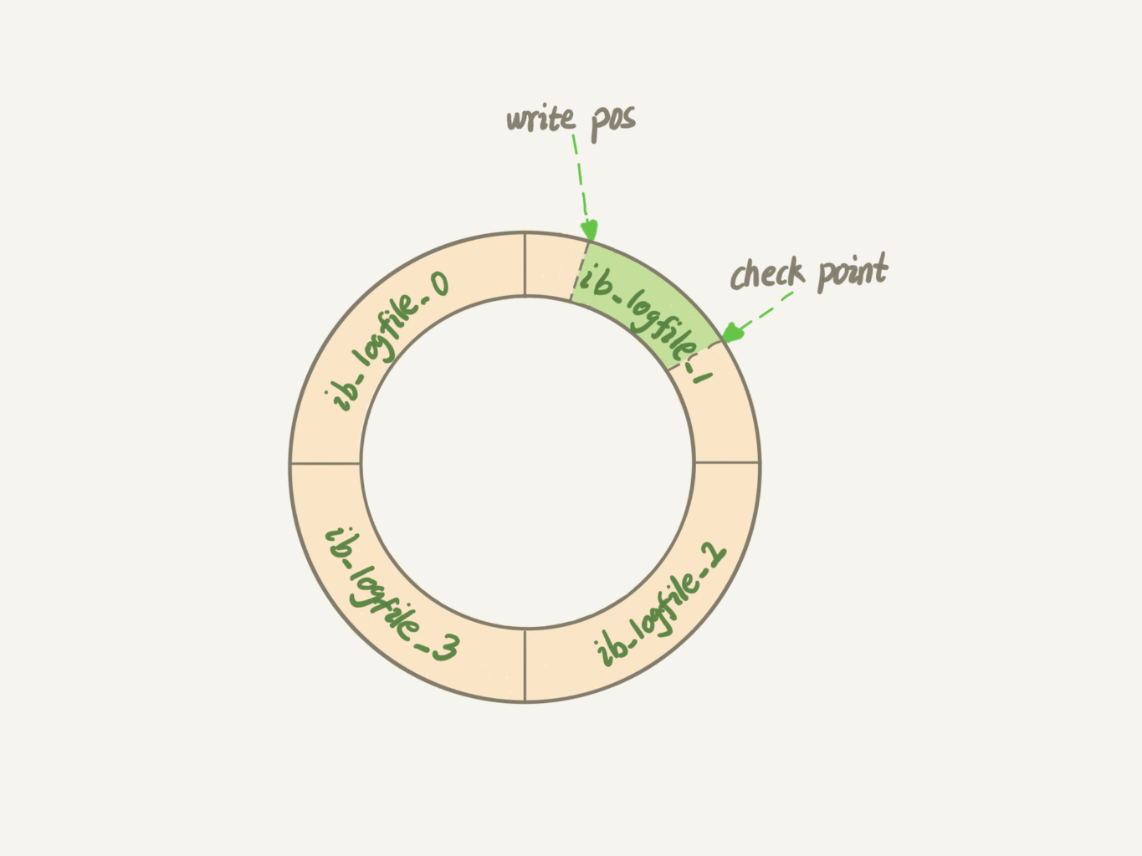
Với redo log, InnoDB có thể đảm bảo rằng ngay cả khi cơ sở dữ liệu bị khởi động lại một cách bất thường, các bản ghi đã được cam kết trước đó sẽ không bị mất, khả năng này được gọi là "crash-safe".
Binlog
Binlog là nhật ký logic, ghi lại các lệnh gốc của câu lệnh đó.
Binlog có thể được ghi thêm, có nghĩa là khi đạt đến kích thước nhất định, nó sẽ chuyển sang tệp tiếp theo mà không ghi đè lên các nhật ký trước đó.
Binlog là một thành phần của MySQL Server, tất cả các engine đều có thể sử dụng.
Khi thiết lập tham số sync_binlog thành 1, mỗi binlog của giao dịch sẽ được lưu trữ trên đĩa. Tôi khuyến nghị bạn nên thiết lập tham số này thành 1 để đảm bảo rằng binlog không bị mất sau khi MySQL khởi động lại một cách bất thường.
Redo log vs. Binlog
Hai loại nhật ký này có ba điểm khác nhau.
- Redo log chỉ có trong InnoDB engine; binlog được triển khai bởi lớp Server của MySQL, tất cả các engine đều có thể sử dụng.
- Redo log là nhật ký vật lý, ghi lại "những thay đổi đã được thực hiện trên một trang dữ liệu cụ thể"; binlog là nhật ký logic, ghi lại logic ban đầu của câu lệnh, ví dụ như "tăng giá trị cột c của hàng có ID=2 lên 1".
- Redo log là ghi tuần hoàn, không gian có kích thước cố định; binlog có thể được ghi thêm. "Ghi thêm" có nghĩa là khi tệp binlog đạt đến kích thước nhất định, nó sẽ chuyển sang tệp tiếp theo mà không ghi đè lên các nhật ký trước đó.
Sau khi hiểu về hai loại nhật ký này, chúng ta hãy xem quá trình nội bộ của trình thực thi và InnoDB engine khi thực hiện câu lệnh update đơn giản này.
- Trình thực thi trước tiên tìm kiếm engine để lấy hàng có ID=2. ID là khóa chính, engine sẽ tìm hàng này trực tiếp bằng cách tìm kiếm cây. Nếu hàng có ID=2 đã tồn tại trong bộ nhớ, nó sẽ được trả về trực tiếp cho trình thực thi; nếu không, trước tiên cần đọc từ đĩa vào bộ nhớ, sau đó trả về.
- Trình thực thi nhận dữ liệu hàng từ engine, tăng giá trị này lên 1, ví dụ từ N thành N+1, nhận được hàng dữ liệu mới và gọi giao diện engine để ghi dữ liệu hàng mới này.
- Engine cập nhật hàng dữ liệu này vào bộ nhớ, đồng thời ghi thao tác cập nhật này vào redo log, lúc này redo log ở trạng thái prepare. Sau đó, thông báo cho trình thực thi rằng đã hoàn thành và có thể gửi giao dịch bất kỳ lúc nào.
- Trình thực thi tạo ra binlog của thao tác này và ghi binlog vào đĩa.
- Trình thực thi gọi giao diện engine để gửi giao dịch, engine chuyển đổi redo log vừa ghi thành trạng thái commit, hoàn tất quá trình cập nhật.
Ở đây tôi cung cấp sơ đồ quá trình thực hiện câu lệnh update này, khung màu nhạt biểu thị các hoạt động được thực hiện trong InnoDB, khung màu đậm biểu thị các hoạt động được thực hiện trong trình thực thi.
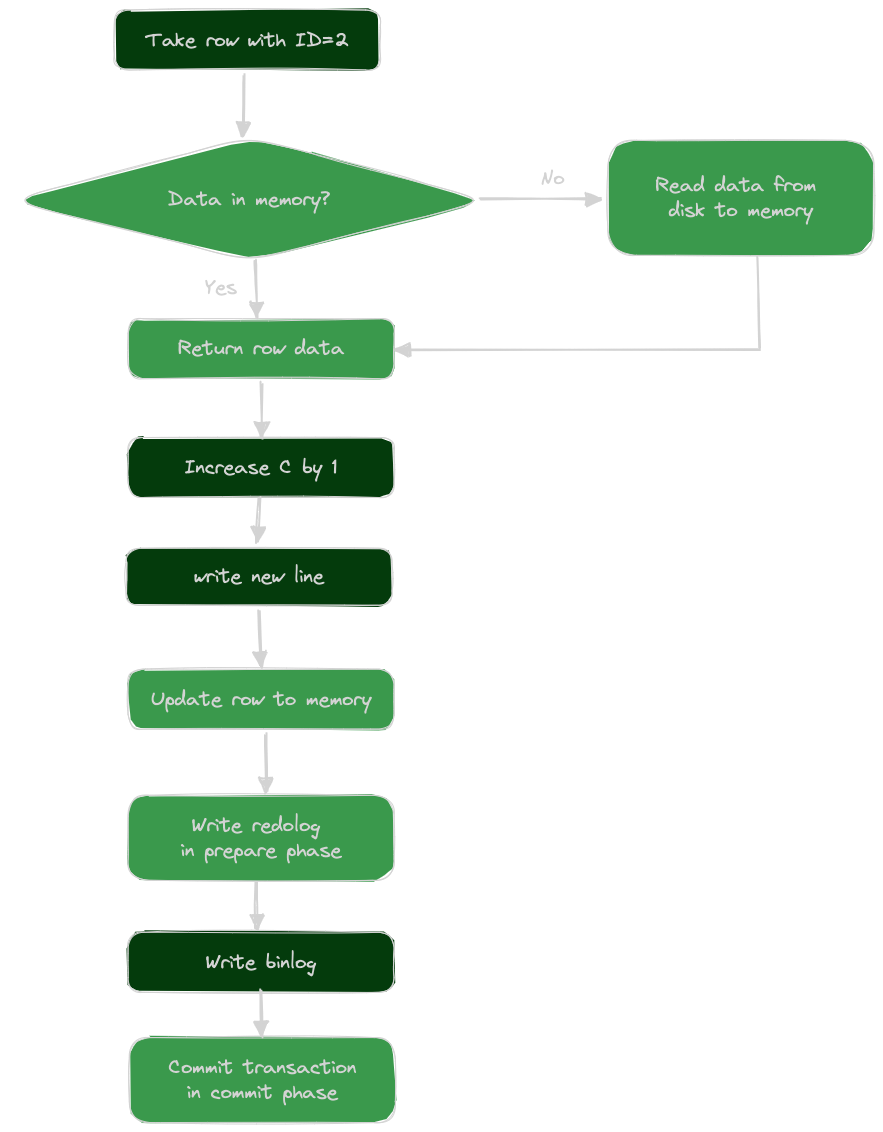
Hai giai đoạn cam kết
Việc ghi redo log được chia thành hai giai đoạn: chuẩn bị (prepare) và cam kết (commit), đây là "hai giai đoạn cam kết". Tại sao nhật ký cần "hai giai đoạn cam kết".
Vì redo log và binlog là hai phần riêng biệt, nếu không sử dụng "hai giai đoạn cam kết", hoặc là viết redo log trước rồi viết binlog sau, hoặc ngược lại. Hãy xem xét những vấn đề mà hai cách này có thể gây ra.
- Viết redo log trước, sau đó viết binlog. Giả sử redo log đã được viết xong, nhưng binlog chưa được viết xong, tiến trình MySQL bị khởi động lại một cách bất thường. Như đã đề cập trước đó, ngay cả khi hệ thống bị sập sau khi hoàn thành việc ghi redo log, dữ liệu vẫn có thể được khôi phục, vì vậy sau khi khôi phục, giá trị c của hàng này sẽ là 1.
Tuy nhiên, vì binlog chưa được viết xong trước khi gặp sự cố, lúc này binlog không ghi lại câu lệnh này. Do đó, khi sao lưu nhật ký sau đó, binlog lưu trữ không chứa câu lệnh này.
Sau đó, bạn sẽ nhận thấy, nếu bạn cần phục hồi cơ sở dữ liệu tạm thời này bằng binlog, do câu lệnh này bị mất trong binlog, cơ sở dữ liệu tạm thời này sẽ thiếu một lần cập nhật, giá trị c của hàng này sẽ là 0, khác với giá trị của cơ sở dữ liệu gốc. - Viết binlog trước, sau đó viết redo log. Nếu tiến trình bị sập sau khi binlog đã được viết xong, nhưng redo log chưa được viết, sau khi khôi phục, giao dịch này sẽ không hợp lệ, vì vậy giá trị c của hàng này sẽ là 0. Tuy nhiên, binlog đã ghi lại câu lệnh "tăng giá trị c từ 0 lên 1". Do đó, khi phục hồi bằng binlog sau đó, sẽ có một giao dịch bổ sung, giá trị c của hàng này sẽ là 1, khác với giá trị của cơ sở dữ liệu gốc.
Có thể thấy, nếu không sử dụng "hai giai đoạn cam kết", trạng thái của cơ sở dữ liệu có thể không khớp với trạng thái của cơ sở dữ liệu được khôi phục bằng nhật ký của nó.