Collection Overview
Collections Overview
Hãy xem biểu đồ này để hình dung về Java Collection
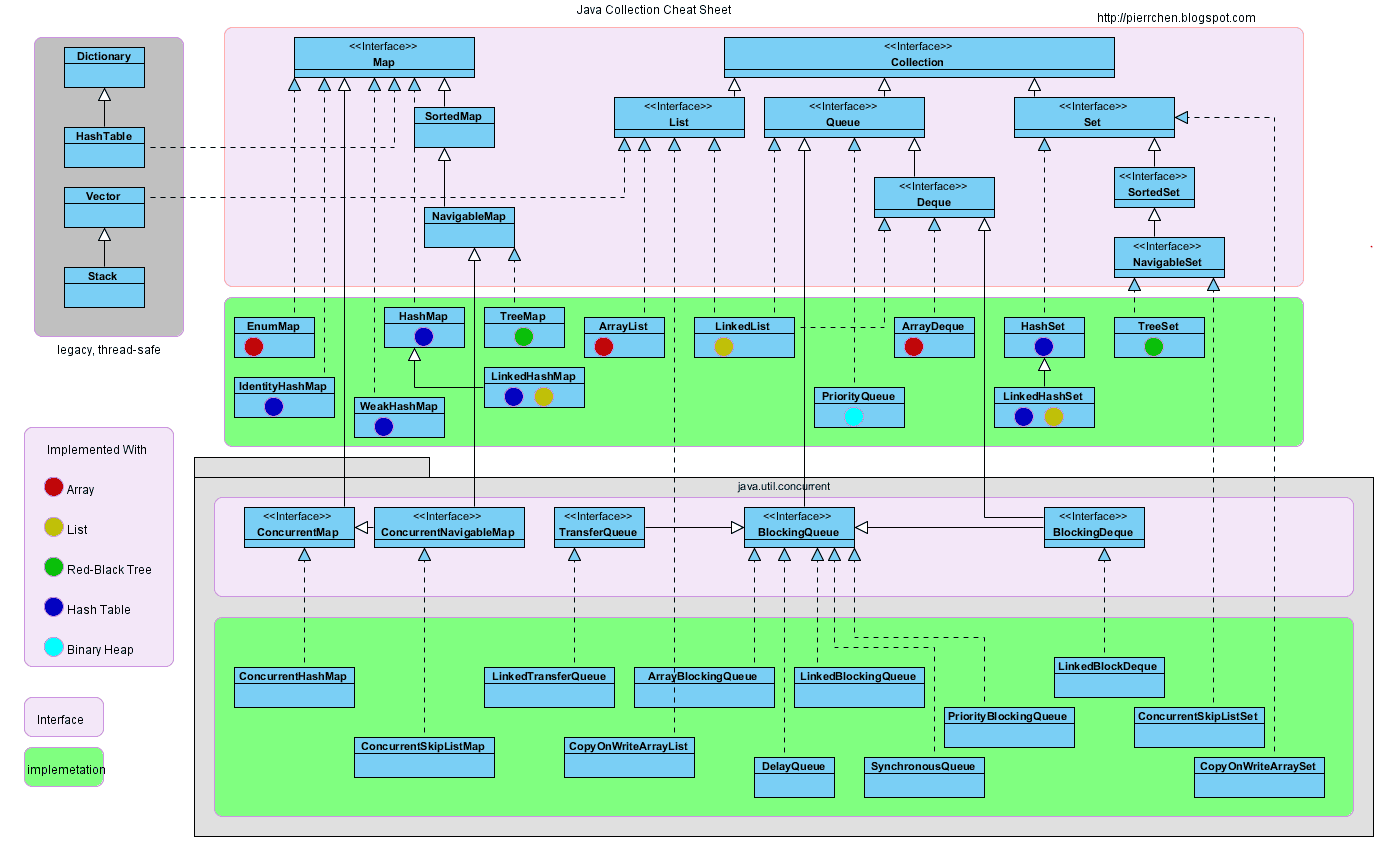
Java Collection có thể chia thành hai nhánh lớn:
① Collection, chủ yếu gồm List, Set và Queue:
- List đại diện cho tập hợp có thứ tự, có thể trùng lặp, đại diện điển hình là ArrayList được bao bọc bởi mảng động và LinkedList được bao bọc bởi danh sách liên kết.
- Set đại diện cho tập hợp không có thứ tự, không trùng lặp, đại diện điển hình là HashSet và TreeSet.
- Queue đại diện cho hàng đợi, đại diện điển hình là hàng đợi hai đầu ArrayDeque và hàng đợi ưu tiên PriorityQueue.
② Map, đại diện cho tập hợp các cặp khóa-giá trị, đại diện điển hình là HashMap.
Dưới đây là đoạn văn bản đã được dịch từ tiếng Trung sang tiếng Việt:
01. List
Đặc điểm của List là lưu trữ có thứ tự, có thể chứa các phần tử trùng lặp, và có thể thao tác trên các phần tử bằng chỉ số.
1) ArrayList
Trước tiên, hãy xem một đoạn mã về thao tác thêm, xóa, sửa, và truy vấn với ArrayList, học cách sử dụng.
// Tạo một danh sách
ArrayList<String> list = new ArrayList<String>();
// Thêm phần tử
list.add("a");
list.add("b");
list.add("c");
// Duyệt danh sách bằng vòng lặp for
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
// Duyệt danh sách bằng for each
for (String s : list) {
System.out.println(s);
}
// Xóa phần tử
list.remove(1);
// Duyệt danh sách
for (String s : list) {
System.out.println(s);
}
// Sửa phần tử
list.set(1, "d");
// Duyệt danh sách
for (String s : list) {
System.out.println(s);
}Giới thiệu đơn giản về đặc điểm của ArrayList, sau này sẽ giải thích chi tiết hơn.
- ArrayList được triển khai bằng mảng, hỗ trợ truy cập ngẫu nhiên, tức là có thể truy cập các phần tử trực tiếp bằng chỉ số.
- Thêm và xóa phần tử từ cuối sẽ nhanh chóng, thêm và xóa phần tử từ giữa sẽ kém hiệu quả vì liên quan đến việc sao chép và di chuyển các phần tử mảng.
- Nếu dung lượng của mảng bên trong không đủ, nó sẽ tự động mở rộng, do đó khi số lượng phần tử rất lớn, hiệu suất sẽ giảm.
2) LinkedList
Cũng tương tự, hãy xem một đoạn mã về thao tác thêm, xóa, sửa, và truy vấn với LinkedList, gần như không có gì khác biệt so với ArrayList.
// Tạo một danh sách
LinkedList<String> list = new LinkedList<String>();
// Thêm phần tử
list.add("A");
list.add("D");
list.add("B");
// Duyệt danh sách bằng vòng lặp for
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
// Duyệt danh sách bằng for each
for (String s : list) {
System.out.println(s);
}
// Xóa phần tử
list.remove(1);
// Duyệt danh sách
for (String s : list) {
System.out.println(s);
}
// Sửa phần tử
list.set(1, "A狗");
// Duyệt danh sách
for (String s : list) {
System.out.println(s);
}Tuy nhiên, LinkedList và ArrayList vẫn có những điểm khác biệt lớn, sau này sẽ giải thích chi tiết hơn.
- LinkedList được triển khai bằng danh sách liên kết đôi, không hỗ trợ truy cập ngẫu nhiên, chỉ có thể duyệt từ một đầu đến khi tìm thấy phần tử cần thiết.
- Thêm và xóa phần tử ở bất kỳ vị trí nào cũng rất thuận tiện vì chỉ cần thay đổi tham chiếu của nút trước và nút sau, không giống như ArrayList phải sao chép và di chuyển các phần tử mảng.
- Vì mỗi phần tử đều lưu trữ tham chiếu đến nút trước và nút sau nên tốn nhiều không gian bộ nhớ hơn so với ArrayList.
3) Vector và Stack
Một lớp triển khai khác của List là Vector, là một lớp "lão làng" xuất hiện sớm hơn ArrayList. ArrayList và Vector rất giống nhau, chỉ khác là Vector an toàn trong môi trường đa luồng, các phương thức như get, set, add đều thêm từ khóa synchronized, dẫn đến hiệu suất thực thi sẽ thấp hơn, vì vậy hiện nay nó ít được sử dụng.
Tôi sẽ không viết quá nhiều mã, chỉ cần xem mã nguồn của phương thức add là sẽ hiểu.
public synchronized boolean add(E e) {
elementData[elementCount++] = e;
return true;
}Những lớp được thêm phương thức đồng bộ như thế này chắc chắn sẽ bị đào thải, giống như StringBuilder thay thế StringBuffer vậy. Mã nguồn của JDK cũng đã nói rõ:
Nếu không cần an toàn trong môi trường đa luồng, nên sử dụng ArrayList thay cho Vector.
Stack là một lớp con của Vector, bản chất cũng được triển khai bằng mảng động, chỉ khác là nó còn thực hiện chức năng LIFO (Last In, First Out - vào sau ra trước) (dựa trên các phương thức get, set, add và bổ sung thêm các phương thức pop "trả về và xóa phần tử đầu ngăn xếp" và peek "chỉ trả về phần tử đầu ngăn xếp"), nên gọi là ngăn xếp.
Dưới đây là mã nguồn của hai phương thức này, tôi sẽ không viết mã thêm, xóa, sửa, truy vấn vì nó gần như giống với ArrayList và LinkedList.
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}Tuy nhiên, do hiệu suất thực thi của Stack khá thấp (các phương thức cũng thêm từ khóa synchronized), nên nó đã bị thay thế bởi hàng đợi hai đầu ArrayDeque (sẽ được giới thiệu sau).
02. Set
Set là một tập hợp trong Java có các đặc điểm sau: không có thứ tự, không chứa các phần tử trùng lặp, và không thể truy cập các phần tử bằng chỉ số.
1) HashSet
HashSet thực chất là sử dụng HashMap để thực hiện, với giá trị được gắn với một đối tượng Object cố định, và các khóa (key) được sử dụng để thực hiện các thao tác. Dưới đây là mã nguồn cơ bản của HashSet:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
// Giá trị giả để gắn với một đối tượng trong Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
}Trong thực tế, HashSet không phổ biến lắm. Ví dụ, nếu chúng ta cần lưu trữ một tập hợp các phần tử theo thứ tự, thì ArrayList hoặc LinkedList có thể phù hợp hơn; nếu cần lưu trữ các cặp key-value và tìm kiếm dựa trên key, thì HashMap có thể là lựa chọn tốt hơn.
Dưới đây là một ví dụ về cách sử dụng HashSet để thực hiện các thao tác thêm, xoá, sửa và truy vấn:
// Tạo một HashSet mới
HashSet<String> set = new HashSet<>();
// Thêm các phần tử
set.add("a");
set.add("b");
set.add("c");
// In ra số lượng phần tử trong HashSet
System.out.println("HashSet size: " + set.size()); // output: 3
// Kiểm tra xem phần tử có tồn tại trong HashSet hay không
boolean containsA = set.contains("a");
System.out.println("Does set contain 'a'? " + containsA); // output: true
// Xoá phần tử
boolean removeA = set.remove("a");
System.out.println("Removed 'a'? " + removeA); // output: true
// Sửa đổi phần tử, cần xoá và thêm lại
boolean removeC = set.remove("c");
boolean addC = set.add("c");
System.out.println("Modified set? " + (removeChenmo && addBuChenmo)); // output: true
// In ra HashSet sau khi đã sửa đổi
System.out.println("HashSet after modification: " + set); // output: [b, c]HashSet thường được sử dụng để loại bỏ các phần tử trùng lặp, ví dụ như khi ta cần đếm số lượng từ duy nhất trong một đoạn văn, ta có thể sử dụng HashSet để làm điều này:
// Tạo một đối tượng HashSet
HashSet<String> set = new HashSet<>();
// Thêm các phần tử
set.add("a");
set.add("b");
set.add("c");
set.add("a");
// In ra số lượng phần tử trong HashSet
System.out.println("HashSet size: " + set.size()); // output: 3
// Duyệt qua HashSet
for (String s : set) {
System.out.println(s);
}Từ ví dụ trên, có thể thấy HashSet tự động loại bỏ các phần tử trùng lặp. Điều này là bởi vì HashSet sử dụng HashMap để triển khai, trong đó các khóa (keys) là duy nhất và các giá trị trùng lặp sẽ bị ghi đè, do đó lần thứ hai set.add("a") ghi đè lên lần đầu tiên set.add("a").
2) LinkedHashSet
LinkedHashSet là một lớp con của HashSet và được triển khai bằng cách sử dụng LinkedHashMap. Điểm khác biệt chính của LinkedHashSet so với HashSet là nó duy trì thứ tự của các phần tử dựa trên thời gian chèn vào.
Cấu trúc và cách thức hoạt động
LinkedHashSet được khởi tạo với ba tham số trong constructor mặc định của nó, như sau:
public LinkedHashSet() {
super(16, 0.75f, true);
}Trong đó:
super(16, 0.75f, true);gọi đến constructor của HashSet với ba tham số:initialCapacity(kích thước ban đầu của HashMap),loadFactor(hệ số tải của HashMap), vàtrue(để bật chế độ duy trì thứ tự dựa trên thời gian chèn).
Ví dụ sử dụng LinkedHashSet
Dưới đây là một ví dụ về cách sử dụng LinkedHashSet để thực hiện các thao tác thêm, xoá, sửa và truy vấn:
LinkedHashSet<String> set = new LinkedHashSet<>();
// Thêm các phần tử
set.add("a");
set.add("b");
set.add("c");
// Xoá phần tử
set.remove("b");
// Sửa đổi phần tử
set.remove("a");
set.add("abc");
// Kiểm tra xem phần tử có tồn tại trong set hay không
boolean hasABC = set.contains("abc");
System.out.println("set chứa 'abc'? " + hasABC); // Kết quả: trueLinkedHashSet là một lựa chọn tốt khi bạn cần duy trì thứ tự của các phần tử mà bạn thêm vào, trong khi vẫn có các lợi ích của việc sử dụng HashSet cho các thao tác nhanh chóng với thời gian xác định.
3) TreeSet
TreeSet được triển khai bởi TreeMap (sẽ được giới thiệu sau), chỉ khác là chỗ giữa các phần tử, giá trị được điền vào là một đối tượng cố định.
Giống như TreeMap, TreeSet là một tập hợp có thứ tự được triển khai bằng cây đỏ-đen, nó triển khai interface SortedSet và có thể tự động sắp xếp các phần tử trong tập hợp theo thứ tự tự nhiên của khóa hoặc theo thứ tự của bộ so sánh đã chỉ định.
// Tạo một đối tượng TreeSet
TreeSet<String> set = new TreeSet<>();
// Thêm các phần tử
set.add("a");
set.add("b");
set.add("c");
System.out.println(set); // In ra [a, b, c]
// Xóa phần tử
set.remove("b");
System.out.println(set); // In ra [a, c]
// Sửa đổi phần tử: các phần tử trong TreeSet không hỗ trợ sửa trực tiếp, cần xóa trước rồi thêm lại
set.remove("a");
set.add("d");
System.out.println(set); // In ra [c, d]
// Tìm kiếm phần tử
System.out.println(set.contains("c")); // In ra true
System.out.println(set.contains("a")); // In ra falseCần lưu ý rằng, TreeSet không cho phép chèn phần tử null, nếu chèn null sẽ ném ra ngoại lệ NullPointerException.
03. Hàng đợi (Queue)
Queue, hay còn gọi là hàng đợi, thường tuân theo nguyên tắc "First In First Out" (FIFO), nghĩa là phần tử mới được thêm vào hàng đợi vào cuối cùng và phần tử được truy cập là phần tử ở đầu hàng đợi.
1)ArrayDeque
Từ tên có thể thấy, ArrayDeque là một hàng đợi hai đầu được cài đặt dựa trên mảng, để đáp ứng được yêu cầu thêm và xóa phần tử từ hai đầu của mảng, mảng phải là mảng vòng, nghĩa là bất kỳ điểm nào của mảng cũng có thể được xem là điểm bắt đầu hoặc kết thúc.
Đây là một ví dụ về một ArrayDeque chứa 4 phần tử và một ArrayDeque chứa 5 phần tử.

head trỏ vào phần tử đầu tiên hợp lệ của hàng đầu, tail trỏ vào vị trí trống đầu tiên ở cuối hàng đợi để thêm phần tử. Bởi vì mảng là mảng vòng, head không nhất thiết phải bắt đầu từ 0 và tail cũng không nhất thiết phải lớn hơn head.
Hãy xem một đoạn mã về việc thêm, xóa, sửa đổi và tìm kiếm trong ArrayDeque.
// Tạo một ArrayDeque
ArrayDeque<String> deque = new ArrayDeque<>();
// Thêm phần tử
deque.add("a");
deque.add("b");
deque.add("c");
// Xóa phần tử
deque.remove("b");
// Sửa đổi phần tử
deque.remove("a");
deque.add("abc");
// Tìm kiếm phần tử
boolean hasABC = deque.contains("abc");
System.out.println("deque chứa 'abc' không? " + hasABC);2)LinkedList
LinkedList thường được phân loại trong List, nhưng nó cũng triển khai interface Deque và có thể sử dụng như một hàng đợi. Nói cách khác, LinkedList cũng triển khai đầy đủ chức năng của Stack, Queue và PriorityQueue.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{}Nói một cách khác, LinkedList và ArrayDeque đều là hàng đợi hai chiều (deque) trong khung Collection của Java, cho phép thêm và xóa phần tử từ cả hai đầu của hàng đợi. Tuy nhiên, LinkedList và ArrayDeque có một số khác biệt trong việc triển khai:
- Phương thức triển khai cơ sở khác nhau: LinkedList dựa trên danh sách liên kết, trong khi ArrayDeque dựa trên mảng.
- Hiệu suất truy cập ngẫu nhiên khác nhau: Do khác biệt trong triển khai, LinkedList có hiệu suất truy cập ngẫu nhiên thấp hơn, có độ phức tạp thời gian là O(n), trong khi ArrayDeque có thể truy cập phần tử ngẫu nhiên thông qua chỉ số với độ phức tạp thời gian là O(1).
- Hiệu suất của Iterator khác nhau: LinkedList có hiệu suất của Iterator thấp hơn vì nó cần đi qua toàn bộ danh sách liên kết, với độ phức tạp thời gian là O(n), trong khi Iterator của ArrayDeque có hiệu suất cao hơn với độ phức tạp thời gian là O(1) vì nó có thể truy cập trực tiếp vào các phần tử trong mảng.
- Khả năng chiếm dụng bộ nhớ khác nhau: Bởi vì LinkedList dựa trên danh sách liên kết, nó cần thêm không gian bộ nhớ để lưu trữ nút của danh sách liên kết, do đó chiếm dụng bộ nhớ tương đối cao hơn so với ArrayDeque, mà là dựa trên mảng.
Vì vậy, khi chọn giữa sử dụng LinkedList và ArrayDeque, cần dựa trên các tình huống và yêu cầu cụ thể của dự án. Nếu cần thao tác thêm/xóa phần tử thường xuyên từ cả hai đầu của hàng đợi và cần truy cập phần tử ngẫu nhiên, có thể xem xét sử dụng ArrayDeque; nếu cần thao tác thêm/xóa phần tử thường xuyên từ giữa hàng đợi, có thể xem xét sử dụng LinkedList.
Dưới đây là một đoạn mã minh họa LinkedList được sử dụng như một hàng đợi, chú ý sự khác biệt so với khi sử dụng nó như một List.
// Tạo một đối tượng LinkedList
LinkedList<String> queue = new LinkedList<>();
// Thêm các phần tử
queue.offer("a");
queue.offer("b");
queue.offer("c");
System.out.println(queue); // In ra [a, b, c]
// Xóa phần tử
queue.poll();
System.out.println(queue); // In ra [b, c]
// Sửa đổi phần tử: Phần tử trong LinkedList không hỗ trợ sửa đổi trực tiếp, cần xóa trước và sau đó thêm mới
String first = queue.poll();
queue.offer("d");
System.out.println(queue); // In ra [c, d]
// Tìm kiếm phần tử: Có thể sử dụng phương thức get() trong LinkedList để tìm kiếm
System.out.println(queue.get(0)); // In ra c
System.out.println(queue.contains("a")); // In ra false
// Tìm kiếm phần tử: Sử dụng Iterator để tìm kiếm phần tử "c"
Iterator<String> iterator = queue.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("c")) {
System.out.println("Đã tìm thấy: " + element);
break;
}
}Khi sử dụng LinkedList như một hàng đợi, có thể sử dụng phương thức offer() để thêm phần tử vào cuối hàng đợi và sử dụng phương thức poll() để xóa phần tử từ đầu hàng đợi. Ngoài ra, vì LinkedList là cấu trúc dữ liệu danh sách liên kết, nó không hỗ trợ truy cập phần tử ngẫu nhiên bằng chỉ số, do đó không thể sử dụng chỉ số để truy cập phần tử mà cần sử dụng Iterator hoặc phương thức poll() để duyệt qua từng phần tử.
3)PriorityQueue
PriorityQueue là một hàng đợi ưu tiên, thứ tự dequeue của nó phụ thuộc vào ưu tiên của các phần tử. Khi thực hiện phương thức remove hoặc poll, phần tử có ưu tiên cao nhất sẽ được trả về.
// Tạo một đối tượng PriorityQueue
PriorityQueue<String> queue = new PriorityQueue<>();
// Thêm các phần tử
queue.offer("a");
queue.offer("b");
queue.offer("c");
System.out.println(queue); // In ra [a, b, c]
// Xóa phần tử
queue.poll();
System.out.println(queue); // In ra [b, c]
// Sửa đổi phần tử: PriorityQueue không hỗ trợ sửa đổi phần tử trực tiếp, cần xóa trước và sau đó thêm mới
String first = queue.poll();
queue.offer("a");
System.out.println(queue); // In ra [a, c]
// Tìm kiếm phần tử: PriorityQueue không hỗ trợ truy cập ngẫu nhiên vào phần tử, chỉ có thể truy cập vào phần tử đầu hàng đợi
System.out.println(queue.peek()); // In ra a
System.out.println(queue.contains("c")); // In ra true
// Tìm kiếm phần tử "c" bằng cách sử dụng vòng lặp for
for (String element : queue) {
if (element.equals("c")) {
System.out.println("Đã tìm thấy: " + element);
break;
}
}Để có thứ tự ưu tiên, các phần tử cần phải triển khai interface Comparable hoặc Comparator (chúng ta sẽ thảo luận về điều này sau).
Đây là hàng ưu tiên được sắp xếp theo độ tuổi và tên gọi bằng cách triển khai interface Comparator.
import java.util.Comparator;
import java.util.PriorityQueue;
class Student {
private String name;
private int englishScore;
private int mathScore;
public Student(String name, int englishScore, int mathScore) {
this.name = name;
this.englishScore = englishScore;
this.mathScore = mathScore;
}
public String getName() {
return name;
}
public int getenglishScore() {
return englishScore;
}
public int getMathScore() {
return mathScore;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", Result=" + (englishScore + mathScore) +
'}';
}
}
class StudentComparator implements Comparator<Student> {
@Override
public int compare(Student s1, Student s2) {
// So sánh tổng điểm
return Integer.compare(s2.getenglishScore() + s2.getMathScore(),
s1.getenglishScore() + s1.getMathScore());
}
}
public class PriorityQueueComparatorExample {
public static void main(String[] args) {
// Tạo hàng đợi ưu tiên được sắp xếp theo tổng điểm
PriorityQueue<Student> queue = new PriorityQueue<>(new StudentComparator());
// Thêm phần tử
queue.offer(new Student("A", 80, 90));
System.out.println(queue);
queue.offer(new Student("B", 95, 95));
System.out.println(queue);
queue.offer(new Student("C", 90, 95));
System.out.println(queue);
queue.offer(new Student("D", 90, 80));
// Xuất các phần tử trong hàng đợi, sắp xếp từ cao xuống thấp theo tổng điểm
while (!queue.isEmpty()) {
System.out.print(queue.poll() + " ");
}
}
}Student à lớp mô tả thông tin của một sinh viên với tên và điểm số môn Toán và Anh.
StudentComparator là một lớp triển khai Comparator để so sánh hai đối tượng Student dựa trên điểm tổng.
PriorityQueueComparatorExample là lớp chính thực hiện các thao tác thêm sinh viên vào PriorityQueue và in ra các sinh viên theo thứ tự từ cao đến thấp dựa trên điểm tổng.
Hãy xem kết quả:
[Student{name='A', Result=170}]
[Student{name='B', Result=190}, Student{name='A', Result=170}]
[Student{name='B', Result=190}, Student{name='A', Result=170}, Student{name='C', Result=185}]
Student{name='B', Result=190} Student{name='C', Result=185} Student{name='D', Result=170} Student{name='A', Result=170}Sử dụng phương thức ưu đãi để thêm các phần tử và cuối cùng sử dụng vòng lặp while để duyệt qua các phần tử (xóa các phần tử thông qua phương thức poll). Như có thể thấy từ kết quả, PriorityQueue Các học sinh được sắp xếp từ cao xuống thấp theo tổng điểm của họ.
04. Map
Map lưu trữ các cặp khoá-giá trị (key-value). Khóa phải là duy nhất và các giá trị có thể lặp lại.
1) HashMap
HashMap triển khai interface Map, cho phép tìm kiếm nhanh chóng giá trị tương ứng với một khóa bằng cách ánh xạ khóa vào vị trí chỉ mục trong bảng băm thông qua hàm băm. Sẽ có thêm chi tiết sau.
Dưới đây là một số đặc điểm cơ bản của HashMap:
- Cả khóa và giá trị trong HashMap đều có thể là null. Nếu khóa là null, thì sẽ được ánh xạ vào vị trí đầu tiên của bảng băm.
- Có thể duyệt qua các cặp khóa-giá trị trong HashMap bằng Iterator hoặc phương thức forEach.
- HashMap có một dung lượng ban đầu và một hệ số tải. Dung lượng ban đầu là kích thước ban đầu của bảng băm, hệ số tải là tỷ lệ số lượng cặp khóa-giá trị có thể lưu trữ trước khi bảng băm được mở rộng. Dung lượng ban đầu mặc định là 16, hệ số tải mặc định là 0.75.
Hãy xem qua ví dụ đơn giản về thêm, xóa, sửa và truy vấn trong HashMap.
// Tạo đối tượng HashMap
HashMap<String, String> hashMap = new HashMap<>();
// Thêm các cặp khóa-giá trị
hashMap.put("a", "1");
hashMap.put("b", "2");
hashMap.put("c", "3");
// Lấy giá trị của một khóa cụ thể
String value1 = hashMap.get("a");
System.out.println("Giá trị tương ứng với 'a' là: " + value1);
// Sửa đổi giá trị của một khóa
hashMap.put("a", "-1");
String value2 = hashMap.get("a");
System.out.println("Giá trị của 'a' sau khi sửa đổi là: " + value2);
// Xóa cặp khóa-giá trị của một khóa cụ thể
hashMap.remove("b");
// Duyệt qua HashMap
for (String key : hashMap.keySet()) {
String value = hashMap.get(key);
System.out.println(key + " tương ứng với giá trị: " + value);
}2) LinkedHashMap
HashMap đã rất mạnh mẽ, nhưng nó không duy trì thứ tự các phần tử. Nếu chúng ta cần một Map có thứ tự, chúng ta có thể sử dụng LinkedHashMap. LinkedHashMap là lớp con của HashMap, nó sử dụng một danh sách liên kết để ghi nhận thứ tự các phần tử được chèn/truy cập.
LinkedHashMap có thể được coi là sự kết hợp giữa HashMap và LinkedList, nó sử dụng bảng băm để lưu trữ dữ liệu và sử dụng danh sách liên kết hai chiều để duy trì thứ tự.
Dưới đây là một ví dụ đơn giản:
// Tạo một LinkedHashMap, chèn các cặp khóa-giá trị là "a", "b", "c"
LinkedHashMap<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("a", "1");
linkedHashMap.put("b", "2");
linkedHashMap.put("c", "3");
// Duyệt qua LinkedHashMap
for (String key : linkedHashMap.keySet()) {
String value = linkedHashMap.get(key);
System.out.println(key + " tương ứng với giá trị: " + value);
}Kết quả xuất ra như sau:
a tương ứng với giá trị: 1
b tương ứng với giá trị: 2
c tương ứng với giá trị: 3Bạn có thể thấy rằng, LinkedHashMap duy trì thứ tự chèn của các cặp khóa-giá trị. Để so sánh, chúng ta sẽ thử tương tự với HashMap.
// Tạo một HashMap, chèn các cặp khóa-giá trị là "a", "b", "c"
HashMap<String, String> hashMap = new HashMap<>();
hashMap.put("a", "1");
hashMap.put("b", "2");
hashMap.put("c", "3");
// Duyệt qua HashMap
for (String key : hashMap.keySet()) {
String value = hashMap.get(key);
System.out.println(key + " tương ứng với giá trị: " + value);
}Kết quả xuất ra như sau:
a tương ứng với giá trị: 1
c tương ứng với giá trị: 3
b tương ứng với giá trị: 2HashMap không duy trì thứ tự chèn của các cặp khóa-giá trị.
3) TreeMap
TreeMap thực hiện interface SortedMap, tự động sắp xếp các khóa theo thứ tự tự nhiên hoặc theo thứ tự được chỉ định bởi bộ so sánh, đảm bảo sự sắp xếp của các phần tử. Nó sử dụng cây đỏ-đen nội bộ để triển khai việc sắp xếp và tìm kiếm các khóa.
Dưới đây là một ví dụ minh họa về thêm, sửa, xóa và truy vấn trong TreeMap:
// Tạo một đối tượng TreeMap
Map<String, String> treeMap = new TreeMap<>();
// Thêm các cặp khóa-giá trị vào TreeMap
treeMap.put("a", "1");
treeMap.put("b", "2");
treeMap.put("c", "3");
// Tìm kiếm một cặp khóa-giá trị
String name = "a";
if (treeMap.containsKey(name)) {
System.out.println("Tìm thấy " + name + ": " + treeMap.get(name));
} else {
System.out.println("Không tìm thấy " + name);
}
// Sửa đổi một cặp khóa-giá trị
name = "b";
if (treeMap.containsKey(name)) {
System.out.println("Trước khi sửa đổi " + name + ": " + treeMap.get(name));
treeMap.put(name, "-2");
System.out.println("Sau khi sửa đổi " + name + ": " + treeMap.get(name));
} else {
System.out.println("Không tìm thấy " + name);
}
// Xóa một cặp khóa-giá trị
name = "c";
if (treeMap.containsKey(name)) {
System.out.println("Trước khi xóa " + name + ": " + treeMap.get(name));
treeMap.remove(name);
System.out.println("Sau khi xóa " + name + ": " + treeMap.get(name));
} else {
System.out.println("Không tìm thấy " + name);
}
// Duyệt qua TreeMap
for (Map.Entry<String, String> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}Khác với HashMap, TreeMap sẽ sắp xếp các khóa theo thứ tự của chúng:
// Tạo một đối tượng TreeMap
Map<String, String> treeMap = new TreeMap<>();
// Thêm các cặp khóa-giá trị vào TreeMap
treeMap.put("c", "cat");
treeMap.put("a", "apple");
treeMap.put("b", "banana");
// Duyệt qua TreeMap
for (Map.Entry<String, String> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}Kết quả xuất ra sẽ như sau:
a: apple
b: banana
c: catMặc định, TreeMap đã sắp xếp các khóa theo thứ tự tự nhiên của chúng.