Elasticsearch: Quick Start
Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu phân tán, theo phong cách RESTful, có khả năng giải quyết nhiều tình huống khác nhau đang liên tục xuất hiện. Là trung tâm của Elastic Stack, nó lưu trữ dữ liệu của bạn một cách tập trung, giúp bạn khám phá những điều dự kiến và không dự kiến.
Elasticsearch được phát triển dựa trên thư viện tìm kiếm Lucene. Elasticsearch ẩn đi sự phức tạp của Lucene và cung cấp interface API REST / Java dễ sử dụng (cũng như các interface API bằng ngôn ngữ khác).
Dưới đây sẽ gọi tắt là ES.
Giới thiệu Elasticsearch
Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu phân tán, theo phong cách RESTful, có khả năng giải quyết nhiều tình huống khác nhau đang liên tục xuất hiện. Là trung tâm của Elastic Stack, nó lưu trữ dữ liệu của bạn một cách tập trung, giúp bạn khám phá những điều dự kiến và không dự kiến.
Elasticsearch được phát triển dựa trên thư viện tìm kiếm Lucene. Elasticsearch ẩn đi sự phức tạp của Lucene và cung cấp interface API REST / Java dễ sử dụng (cũng như các interface API bằng ngôn ngữ khác).
Elasticsearch có thể coi là một kho lưu trữ tài liệu, nó chuẩn hóa cấu trúc dữ liệu phức tạp thành JSON để lưu trữ.
Elasticsearch là một công cụ tìm kiếm toàn văn gần như thời gian thực, điều này có nghĩa là:
- Từ khi ghi dữ liệu cho đến khi dữ liệu có thể được tìm kiếm, có một độ trễ nhỏ (khoảng 1 giây)
- Thực hiện tìm kiếm và phân tích dựa trên ES có thể đạt đến mức giây.
Khái niệm cốt lõi
index -> type -> mapping -> document -> field
Cluster
Một cluster bao gồm nhiều node, mỗi node thuộc về cluster nào được quyết định thông qua một cấu hình. Đối với các ứng dụng vừa và nhỏ, ban đầu một cluster chỉ có một node là bình thường.
Node
Node là một node trong cluster, mỗi node cũng có một tên, mặc định là được phân bổ ngẫu nhiên. Mặc định, node sẽ tham gia vào một cluster có tên là elasticsearch. Nếu bạn khởi động một loạt node trực tiếp, chúng sẽ tự động hình thành một cluster elasticsearch, tất nhiên một node cũng có thể hình thành một cluster elasticsearch.
Index
Có thể coi là tập hợp tối ưu của các tài liệu (document).
ES sẽ xây dựng chỉ mục cho tất cả các trường, sau khi xử lý, nó sẽ được ghi vào một chỉ mục đảo ngược (Inverted Index). Khi tìm kiếm dữ liệu, chỉ cần tìm kiếm chỉ mục này.
Vì vậy, đơn vị quản lý dữ liệu hàng đầu của ES được gọi là Index (chỉ mục). Nó tương đương với một cơ sở dữ liệu đơn lẻ. Mỗi Index (hay cơ sở dữ liệu) phải có tên viết thường.
Type
Mỗi chỉ mục có thể chứa một hoặc nhiều loại (type). Type là một phân loại logic của index.
Các Type khác nhau nên có cấu trúc (schema) tương tự, ví dụ, trường id không thể là chuỗi trong một nhóm này, trong khi là giá trị số trong một nhóm khác. Đây là một khác biệt so với bảng của cơ sở dữ liệu quan hệ. Dữ liệu có tính chất hoàn toàn khác nhau (như productsvà logs) nên được lưu trữ dưới dạng hai Index, chứ không phải là hai Type trong một Index (mặc dù có thể làm được).
Chú ý: Theo kế hoạch, phiên bản Elastic 6.x chỉ cho phép mỗi Index chứa một Type, phiên bản 7.x sẽ hoàn toàn loại bỏ Type.
Document
Trong mỗi Index, mỗi bản ghi được gọi là Document. Nhiều Document tạo nên một Index.
Mỗi tài liệu (document) là một tập hợp các trường (field).
Document sử dụng định dạng JSON, dưới đây là một ví dụ.
{
"user": "Hung Nguyen",
"title": "Engineer",
"desc": "Database management"
}Các Document trong cùng một Index không yêu cầu có cấu trúc (scheme) giống nhau, nhưng tốt nhất nên giữ giống nhau, điều này có lợi cho việc cải thiện hiệu suất tìm kiếm.
Field
Trường (field) là cặp khóa-giá trị chứa dữ liệu.
Theo mặc định, Elasticsearch xây dựng chỉ mục cho tất cả dữ liệu trong mỗi trường, và mỗi trường chỉ mục có cấu trúc dữ liệu tối ưu riêng.
Shard
Khi một máy duy nhất không đủ để lưu trữ lượng dữ liệu lớn, Elasticsearch có thể chia dữ liệu trong một chỉ mục thành nhiều shard. Shard được lưu trữ trên nhiều máy chủ. Với shard, bạn có thể mở rộng theo chiều ngang, lưu trữ nhiều dữ liệu hơn, cho phép các hoạt động tìm kiếm và phân tích được phân phối trên nhiều máy chủ, cải thiện throughput và hiệu suất. Mỗi shard đều là một chỉ mục lucene.
Replica
Bất kỳ máy chủ nào cũng có thể gặp sự cố hoặc ngừng hoạt động bất cứ lúc nào, lúc này shard có thể bị mất, do đó, bạn có thể tạo nhiều bản sao (replica) cho mỗi shard. Bản sao có thể cung cấp dịch vụ dự phòng khi shard gặp sự cố, đảm bảo dữ liệu không bị mất, nhiều bản sao còn có thể cải thiện throughput và hiệu suất của hoạt động tìm kiếm. Shard chính (được thiết lập một lần khi tạo chỉ mục, không thể sửa đổi, mặc định là 5), shard bản sao (số lượng có thể được sửa đổi bất cứ lúc nào, mặc định là 1), mặc định mỗi chỉ mục có 10 shard, 5 shard chính, 5 shard bản sao, cấu hình cao có sẵn tối thiểu, là 2 máy chủ.
ES - Khái niệm cốt lõi vs. DB - Khái niệm cốt lõi
| ES | DB |
|---|---|
| index | Cơ sở dữ liệu |
| type | Bảng dữ liệu |
| document | Một dòng dữ liệu |
Nguyên lý cơ bản của ElasticSearch
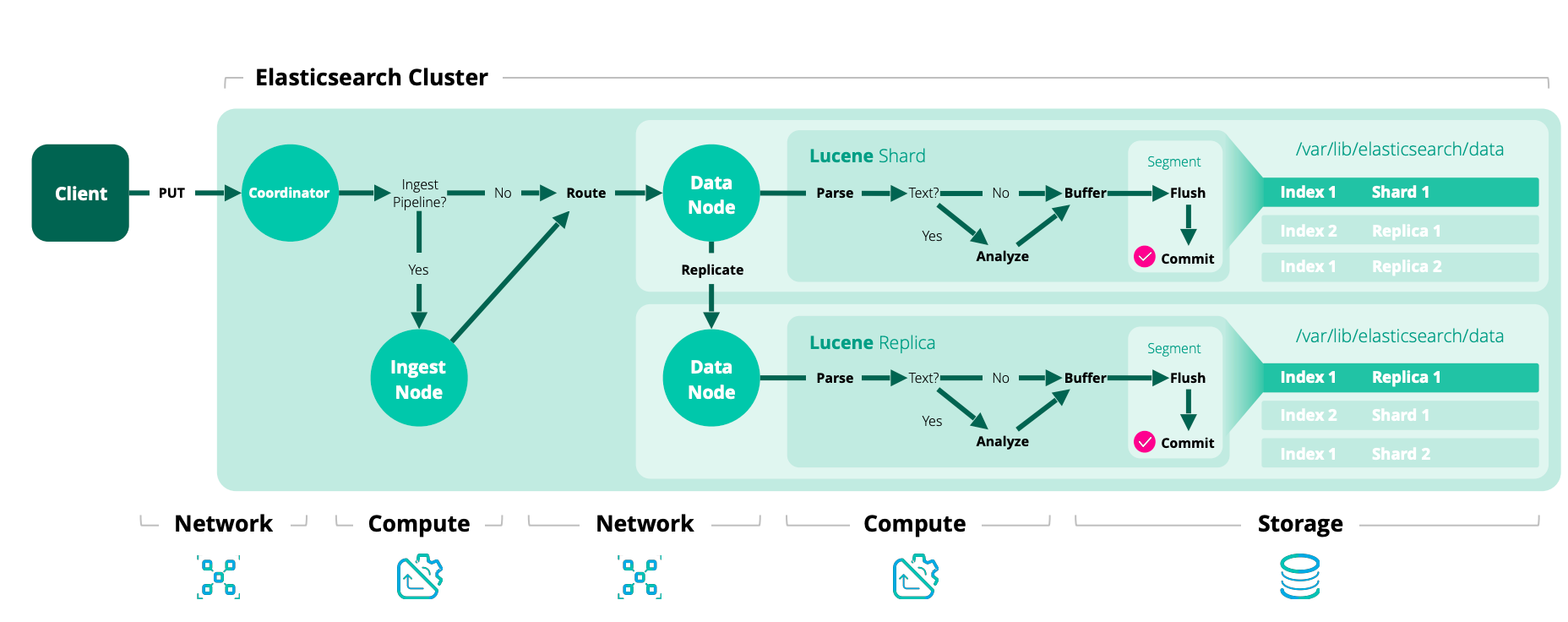
Quá trình ghi dữ liệu vào ES
- Máy khách chọn một node và gửi yêu cầu đến, node này được gọi là
coordinating node(nút điều phối). Coordinating nodethực hiện định tuyến cho document và chuyển tiếp yêu cầu đến node tương ứng (có primary shard).Primary shardtrên node thực tế xử lý yêu cầu, sau đó đồng bộ hóa dữ liệu vớireplica node.- Nếu
coordinating nodephát hiệnprimary nodevà tất cảreplica nodeđều đã hoàn thành, nó sẽ trả lại kết quả phản hồi cho máy khách.
Quá trình đọc dữ liệu từ ES
Bạn có thể truy vấn thông qua doc id, sẽ dựa vào doc id để thực hiện hash, xác định xem lúc đó doc id đã được phân bổ vào shard nào, và truy vấn từ shard đó.
- Máy khách gửi yêu cầu đến bất kỳ node nào, trở thành
coordinating node. Coordinating nodethực hiện định tuyến hash chodoc id, chuyển yêu cầu đến node tương ứng, lúc này nó sẽ sử dụng thuật toánround-robinvòng quay để chọn ngẫu nhiên một trong sốprimary shardvà tất cả các replica, để cân bằng tải yêu cầu đọc.- Node nhận yêu cầu trả lại document cho
coordinating node. Coordinating nodetrả lại document cho máy khách.
Quá trình tìm kiếm dữ liệu trong ES
Điểm mạnh nhất của ES là thực hiện tìm kiếm toàn văn, ví dụ, bạn có ba dữ liệu:
Java is interesting
Java is so difficult to learn
J2EE is greatBạn tìm kiếm theo từ khóa java, nó sẽ tìm kiếm các document chứa java. ES sẽ trả về cho bạn: Java is interesting, Java is so difficult to learn
- Máy khách gửi yêu cầu đến một
coordinating node. - Nút điều phối chuyển yêu cầu tìm kiếm đến tất cả
primary shardhoặcreplica shardtương ứng. - Giai đoạn truy vấn (query phase): mỗi shard sẽ trả lại kết quả tìm kiếm của mình (thực tế chỉ là một số
doc id) cho nút điều phối, nút điều phối thực hiện các hoạt động như hợp nhất dữ liệu, sắp xếp, phân trang, etc., để tạo ra kết quả cuối cùng. - Giai đoạn lấy (fetch phase): sau đó, nút điều phối sẽ lấy dữ liệu
documentthực tế từ các node dựa trêndoc id, và cuối cùng trả lại cho máy khách.
Yêu cầu ghi được ghi vào primary shard, sau đó đồng bộ hóa với tất cả các replica shard; yêu cầu đọc có thể được đọc từ primary shard hoặc replica shard, sử dụng thuật toán round-robin.
Nguyên lý cơ bản khi ghi dữ liệu
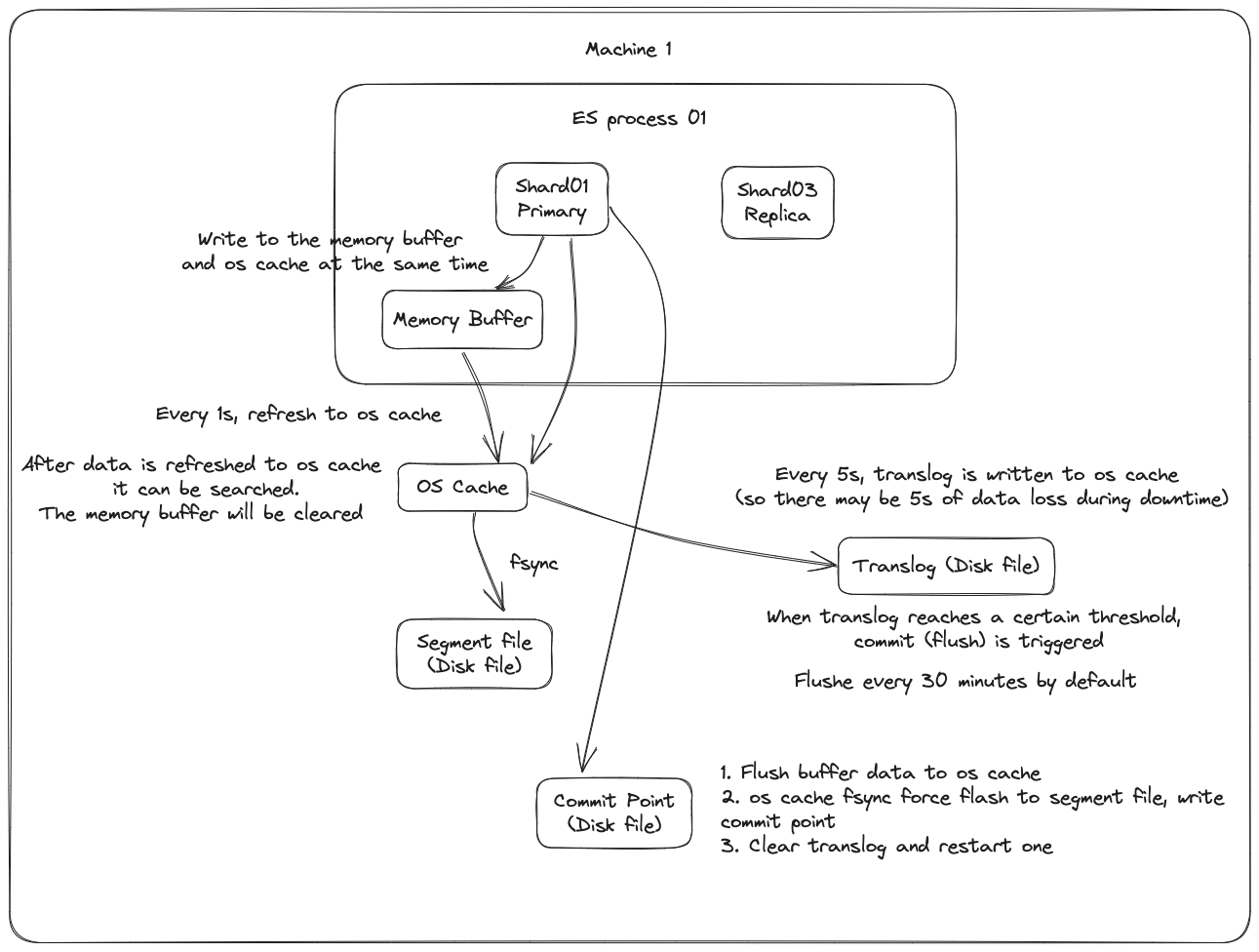
Đầu tiên, dữ liệu sẽ được ghi vào bộ đệm trong bộ nhớ (buffer), trong quá trình này dữ liệu không thể được tìm kiếm; đồng thời dữ liệu cũng được ghi vào tệp nhật ký translog.
Nếu bộ đệm gần như đầy, hoặc sau một khoảng thời gian nhất định, dữ liệu trong bộ đệm sẽ được refresh vào một segment file mới, nhưng lúc này dữ liệu không được ghi trực tiếp vào tệp segment file trên đĩa, mà phải đi vào os cache trước. Quá trình này được gọi là refresh.
Mỗi giây, ES sẽ ghi dữ liệu trong bộ đệm vào một segment file mới, mỗi giây sẽ tạo ra một tệp đĩa segment file mới, tệp segment file này sẽ lưu trữ dữ liệu được ghi vào bộ đệm trong 1 giây gần đây.
Tuy nhiên, nếu không có dữ liệu trong bộ đệm, thì tất nhiên không có quá trình refresh nào được thực hiện, nếu có dữ liệu trong bộ đệm, mặc định sẽ thực hiện một lần refresh mỗi giây, đẩy dữ liệu vào một segment file mới.
Trên hệ điều hành, tệp đĩa thực tế đều có một thứ gọi là os cache, tức là trước khi dữ liệu được ghi vào tệp đĩa, nó sẽ được đưa vào os cache trước, đầu tiên vào bộ nhớ cache cấp hệ điều hành. Chỉ cần dữ liệu trong bộ đệm được chuyển vào os cache thông qua hoạt động refresh, dữ liệu này có thể được tìm kiếm.
Tại sao nói rằng ES là gần như thời gian thực? NRT, tên đầy đủ là near real-time. Mặc định là refresh mỗi giây một lần, vì vậy ES là gần như thời gian thực, vì dữ liệu được ghi vào sau 1 giây mới có thể được tìm thấy. Bạn có thể sử dụng restful api của es hoặc java api để thực hiện một hoạt động refresh thủ công, tức là thủ công đưa dữ liệu trong bộ đệm vào os cache, để dữ liệu có thể được tìm kiếm ngay lập tức. Miễn là dữ liệu được đưa vào os cache, bộ đệm sẽ được làm sạch, vì không cần giữ bộ đệm nữa, dữ liệu đã được lưu trữ trong tệp nhật ký translog một lần.
Lặp lại các bước trên, dữ liệu mới liên tục vào bộ đệm và translog, liên tục ghi dữ liệu buffer vào một segment file mới sau mỗi lần refresh, sau mỗi lần refresh bộ đệm sẽ được làm sạch, translog sẽ được giữ lại. Khi quá trình này tiếp diễn, translog sẽ ngày càng lớn. Khi translog đạt đến một độ dài nhất định, nó sẽ kích hoạt hoạt động commit.
Bước đầu tiên của hoạt động commit là ghi dữ liệu hiện có trong bộ đệm vào os cache, sau đó làm sạch bộ đệm. Sau đó, ghi một commit point vào tệp đĩa, trong đó đánh dấu tất cả các segment file tương ứng với commit point này, đồng thời buộc os cache chứa tất cả dữ liệu hiện tại để được fsync vào tệp đĩa. Cuối cùng, xóa tệp nhật ký translog hiện tại, khởi động lại một translog, lúc này hoạt động commit đã hoàn thành.
Hoạt động commit này được gọi là flush. Mặc định là mỗi 30 phút tự động thực hiện một lần flush, nhưng nếu translog quá lớn, cũng sẽ kích hoạt flush. Hoạt động flush tương ứng với toàn bộ quá trình commit, chúng ta có thể thông qua api của es, thực hiện thủ công hoạt động flush, thủ công fsync dữ liệu trong os cache vào đĩa.
Tệp nhật ký translog có vai trò gì? Trước khi bạn thực hiện hoạt động commit, dữ liệu có thể đang nằm trong bộ đệm hoặc nằm trong os cache. Dù là bộ đệm hay os cache đều là bộ nhớ, nếu máy này bị hỏng, dữ liệu trong bộ nhớ sẽ mất hết. Vì vậy, cần ghi các hoạt động tương ứng của dữ liệu vào một tệp nhật ký đặc biệt là translog, nếu máy bị hỏng lúc này, khi khởi động lại, es sẽ tự động đọc dữ liệu từ tệp nhật ký translog và phục hồi vào bộ nhớ buffer và os cache.
Thực tế, translog cũng được ghi vào os cache trước, mặc định là mỗi 5 giây sẽ đẩy vào đĩa một lần, vì vậy mặc định, có thể có 5 giây dữ liệu chỉ nằm trong bộ đệm hoặc os cache hoặc tệp translog, không nằm trên đĩa, nếu máy này bị hỏng lúc này, sẽ mất 5 giây dữ liệu. Nhưng hiệu suất như vậy tốt hơn, mất tối đa 5 giây dữ liệu. Bạn cũng có thể đặt translog để mỗi lần ghi phải fsync trực tiếp vào đĩa, nhưng hiệu suất sẽ kém hơn nhiều.
Thực tế, nếu bạn ở đây, nếu người phỏng vấn không hỏi bạn về vấn đề mất dữ liệu của es, bạn có thể tự hào với người phỏng vấn ở đây, bạn nói, thực tế es trước tiên là gần như thời gian thực, dữ liệu được ghi vào sau 1 giây mới có thể được tìm thấy; có thể mất dữ liệu. Có 5 giây dữ liệu, nằm trong bộ đệm, os cache của translog, os cache của segment file, không nằm trên đĩa, nếu máy này bị hỏng lúc này, sẽ dẫn đến mất 5 giây dữ liệu.
Tóm lại, dữ liệu được ghi vào bộ đệm trước, sau đó mỗi giây, dữ liệu sẽ được refresh vào os cache, khi dữ liệu đến os cache, dữ liệu có thể được tìm kiếm (đó là lý do tại sao chúng ta nói rằng từ khi dữ liệu được ghi vào cho đến khi có thể tìm kiếm, có độ trễ 1s). Mỗi 5 giây, dữ liệu sẽ được ghi vào tệp translog (do đó, nếu máy bị hỏng, tất cả dữ liệu trong bộ nhớ sẽ mất, tối đa sẽ mất 5s dữ liệu), khi translog lớn đến một mức độ nhất định, hoặc mặc định mỗi 30 phút, một hoạt động commit sẽ được kích hoạt, đẩy tất cả dữ liệu trong bộ đệm vào tệp segment filetrên đĩa.
Sau khi dữ liệu được ghi vào
segment file, chỉ mục đảo ngược cũng sẽ được tạo ngay lập tức.
Nguyên lý cơ bản khi xóa/cập nhật dữ liệu
Nếu là hoạt động xóa, khi commit sẽ tạo ra một tệp .del, trong đó đánh dấu một doc nhất định là trạng thái deleted, vì vậy khi tìm kiếm, dựa vào tệp .del, bạn sẽ biết liệu doc có bị xóa hay không.
Nếu là hoạt động cập nhật, nó sẽ đánh dấu doc gốc là trạng thái deleted và sau đó ghi một dữ liệu mới.
Mỗi khi bộ đệm được refresh, một segment file sẽ được tạo ra, vì vậy mặc định là một segment file mỗi giây, vì vậy segment file sẽ ngày càng nhiều, lúc này sẽ thường xuyên thực hiện merge. Mỗi lần merge, nhiều segment file sẽ được hợp nhất thành một, đồng thời ở đây, doc được đánh dấu là deleted sẽ được xóa vật lý, sau đó ghi segment file mới vào đĩa, ở đây sẽ ghi một commit point, đánh dấu tất cả segment file mới, sau đó mở segment file để tìm kiếm, và sau đó xóa segment file cũ.
Lớp cơ bản Lucene
Đơn giản, Lucene chỉ là một thư viện jar, bên trong nó chứa các mã thuật toán đã được đóng gói để tạo chỉ mục đảo ngược. Khi chúng ta phát triển bằng Java, chúng ta chỉ cần import thư viện jar Lucene, sau đó phát triển dựa trên API của Lucene.
Thông qua Lucene, chúng ta có thể tạo chỉ mục cho dữ liệu hiện có, Lucene sẽ tổ chức cấu trúc dữ liệu chỉ mục trên ổ đĩa cục bộ cho chúng ta.
Chỉ mục đảo ngược
Trong công cụ tìm kiếm, mỗi tài liệu đều có một ID tài liệu tương ứng, nội dung tài liệu được biểu diễn dưới dạng một tập hợp các từ khóa. Ví dụ, sau khi phân loại, tài liệu 1 đã trích xuất 20 từ khóa, mỗi từ khóa đều ghi lại số lần xuất hiện và vị trí xuất hiện của nó trong tài liệu.
Vậy, chỉ mục đảo ngược là ánh xạ từ từ khóa đến ID tài liệu, mỗi từ khóa đều tương ứng với một loạt tài liệu, trong đó tất cả các tài liệu đều xuất hiện từ khóa.
Ví dụ.
Có các tài liệu sau:
| DocId | Doc |
|---|---|
| 1 | Cha của Google Maps chuyển sang Facebook |
| 2 | Cha của Google Maps gia nhập Facebook |
| 3 | Người sáng lập Google Maps, Lars rời Google để gia nhập Facebook |
| 4 | Cha của Google Maps chuyển sang Facebook có liên quan đến việc hủy dự án Wave |
| 5 | Cha của Google Maps, Lars gia nhập trang web xã hội Facebook |
Sau khi phân loại tài liệu, chúng ta nhận được chỉ mục đảo ngược sau.
| WordId | Word | DocIds |
|---|---|---|
| 1 | 1,2,3,4,5 | |
| 2 | Maps | 1,2,3,4,5 |
| 3 | Cha | 1,2,4,5 |
| 4 | Chuyển sang | 1,4 |
| 5 | 1,2,3,4,5 | |
| 6 | Gia nhập | 2,3,5 |
| 7 | Người sáng lập | 3 |
| 8 | Lars | 3,5 |
| 9 | Rời | 3 |
| 10 | Và | 4 |
| .. | .. | .. |
Ngoài ra, chỉ mục đảo ngược hữu ích còn có thể ghi lại nhiều thông tin hơn, chẳng hạn như thông tin tần suất tài liệu, cho biết có bao nhiêu tài liệu chứa một từ nhất định trong tập hợp tài liệu.
Vì vậy, với chỉ mục đảo ngược, công cụ tìm kiếm có thể dễ dàng phản hồi truy vấn của người dùng. Ví dụ, người dùng nhập truy vấn Facebook, hệ thống tìm kiếm tra cứu chỉ mục đảo ngược, đọc từ đó các tài liệu chứa từ này, các tài liệu này là kết quả tìm kiếm được cung cấp cho người dùng.
Cần chú ý đến hai chi tiết quan trọng của chỉ mục đảo ngược:
- Tất cả các mục từ trong chỉ mục đảo ngược tương ứng với một hoặc nhiều tài liệu;
- Các mục từ trong chỉ mục đảo ngược được sắp xếp theo thứ tự từ điển tăng dần.
Trên chỉ là một ví dụ đơn giản, không được sắp xếp theo thứ tự từ điển tăng dần một cách nghiêm ngặt.