Giới thiệu về Elasticsearch
Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu dựa trên Lucene, cung cấp một dịch vụ phân tán. Elasticsearch là một sản phẩm mã nguồn mở tuân thủ các điều khoản mã nguồn mở của Apache và hiện là công cụ tìm kiếm cấp doanh nghiệp phổ biến hiện nay.
Nó được sử dụng cho tìm kiếm toàn văn bản, tìm kiếm có cấu trúc, phân tích, và kết hợp ba yếu tố này:
- Wikipedia sử dụng Elasticsearch để cung cấp tìm kiếm toàn văn bản với đánh dấu từ khóa, cũng như các tính năng đề xuất tìm kiếm như tìm kiếm thời gian thực (search-as-you-type) và sửa lỗi tìm kiếm (did-you-mean).
- The Guardian sử dụng Elasticsearch để cung cấp phản hồi thời gian thực cho biên tập viên của họ bằng cách kết hợp dữ liệu nhật ký người dùng và dữ liệu mạng xã hội, giúp họ hiểu rõ phản ứng của công chúng đối với các bài viết mới xuất bản.
- StackOverflow kết hợp tìm kiếm toàn văn bản với truy vấn vị trí địa lý và tính năng more-like-this để tìm các câu hỏi và câu trả lời liên quan.
- Github sử dụng Elasticsearch để tìm kiếm 130 tỷ dòng code. (số liệu có thể thay đổi hàng giờ nên có thể sai lệch tại thời điểm viết)
Đặc điểm của Elasticsearch
- Lưu trữ tệp thời gian thực phân tán, với mỗi trường được lập chỉ mục và có thể tìm kiếm.
- Công cụ tìm kiếm phân tích thời gian thực phân tán.
- Có thể mở rộng linh hoạt lên đến hàng trăm máy chủ, xử lý dữ liệu có cấu trúc hoặc không có cấu trúc ở cấp petabyte.
- Sẵn sàng sử dụng ngay sau khi cài đặt, nó cung cấp nhiều giá trị mặc định hợp lý và ẩn đi lý thuyết công cụ tìm kiếm phức tạp đối với người mới học. Nó có thể được sử dụng trong môi trường product với yêu cầu học tập tối thiểu.
Lịch sử phát triển của Elasticsearch
- Ngày 8 tháng 2 năm 2010, phiên bản công khai đầu tiên của Elasticsearch đã được phát hành.
- Ngày 14 tháng 5 năm 2010, phiên bản ban đầu mang tính bước ngoặt 0.7.0 được phát hành, với các tính năng:
- Mô-đun Zen Discovery tự động phát hiện;
- Hỗ trợ cho Groovy Client;
- Cơ chế quản lý plugin đơn giản;
- Hỗ trợ tốt hơn cho bộ tách từ icu;
- Nhiều API quản lý hơn.
- Mô-đun Zen Discovery tự động phát hiện;
- Đầu năm 2013, GitHub từ bỏ Solr và chọn Elasticsearch để thực hiện tìm kiếm cấp PB của mình.
- Ngày 14 tháng 2 năm 2014, phiên bản 1.0.0 được phát hành, thêm các tính năng quan trọng sau:
- Hỗ trợ cho Snapshot/Restore API backup recovery API;
- Hỗ trợ cho Aggregations;
- Hỗ trợ cho cat API;
- Hỗ trợ cho circuit breakers;
- Giới thiệu Doc values.
- Hỗ trợ cho Snapshot/Restore API backup recovery API;
- Ngày 28 tháng 10 năm 2015, phiên bản 2.0.0 được phát hành, với các tính năng quan trọng sau:
- Thêm Pipleline Aggregations;
- Query/filter query merging, tất cả được hợp nhất vào query, thực hiện các truy vấn khác nhau theo các ngữ cảnh khác nhau;
- Cấu hình lưu trữ nén;
- Mô-đun Rivers đã bị loại bỏ;
- Tính năng Multicast đã bị loại bỏ, trở thành một plugin, và một địa chỉ unicast phải được cấu hình trong môi trường sản xuất.
- Thêm Pipleline Aggregations;
- Ngày 26 tháng 10 năm 2016, phiên bản 5.0.0 được phát hành, với các thay đổi tính năng lớn sau:
- Hỗ trợ cho Lucene 6.x, giảm một nửa không gian đĩa; giảm một nửa thời gian lập chỉ mục; tăng 25% hiệu suất truy vấn; hỗ trợ cho IPV6;
- Khóa đua được sử dụng để tránh cập nhật đồng thời của cùng một tài liệu đã được loại bỏ ở cấp Internal Engine, dẫn đến cải thiện hiệu suất 15%-20%;
- Shrink API, có thể thu nhỏ số lượng shard thành các yếu tố của nó, ví dụ như nếu trước đây bạn có 15 shard, bạn có thể thu nhỏ thành 5 hoặc 3 hoặc 1, vì vậy chúng ta có thể tưởng tượng một tình huống như thế này, trong giai đoạn thu thập mà áp lực ghi là rất lớn, đặt đủ chỉ mục, tận dụng tối đa khả năng ghi song song của shard, sau khi chỉ mục được viết, thu nhỏ thành ít shard hơn, cải thiện hiệu suất truy vấn;
- Cung cấp SDK client REST gốc Java đầu tiên;
- IngestNode, trước đây nếu bạn cần xử lý dữ liệu, nó được xử lý trước khi lập chỉ mục, ví dụ như logstash có thể cấu trúc và chuyển đổi nhật ký, bây giờ nó có thể được xử lý trực tiếp trong es;
- Cung cấp script Painless, thay thế cho script Groovy;
- Loại bỏ site plugins, có nghĩa là head, bigdesk không thể được cài đặt trực tiếp trong es nữa, nhưng có thể triển khai các trang độc lập (dù sao đó cũng là các tệp tĩnh) hoặc phát triển plugin kibana;
- Thêm loại Sliced Scroll, bây giờ giao diện Scroll có thể được sử dụng để duyệt dữ liệu đồng thời. Mỗi yêu cầu Scroll có thể được chia thành nhiều yêu cầu Slice, có thể được hiểu là các lát, mỗi Slice là độc lập và song song, sử dụng Scroll để xây dựng lại hoặc duyệt sẽ nhanh hơn nhiều lần;
- Thêm Profile API;
- Thêm Rollover API;
- Thêm Reindex;
- Giới thiệu các loại trường mới Text/Keyword để thay thế String;
- Giới hạn kích thước yêu cầu chỉ mục để tránh một số lượng lớn yêu cầu đồng thời làm quá tải ES;
- Giới hạn số lượng shard trong một yêu cầu duy nhất, mặc định 1000.
- Ngày 31 tháng 8 năm 2017, phiên bản 6.0.0 được phát hành, với các tính năng quan trọng sau:
- Hỗ trợ cho Doc Values thưa thớt;
- Index Sorting, tức là sắp xếp ở giai đoạn lập chỉ mục;
- Hỗ trợ cho số thứ tự, mỗi hoạt động es có một số thứ tự (tương tự như thiết kế tăng dần);
- Nâng cấp cuộn mượt mà;
- Bắt đầu từ 6.0, không hỗ trợ nhiều loại trong một index;
- Index-template inheritance, kế thừa phiên bản index, hiện tại các mẫu index đều được khớp và hợp nhất, điều này có thể gây ra một số vấn đề xung đột mẫu index, 6.0 sẽ chỉ khớp một, và index sẽ được xác minh khi tạo;
- Load aware shard routing, định tuyến yêu cầu dựa trên tải, các yêu cầu tìm kiếm hiện tại là toàn nút polling, vì vậy nút hoạt động chậm nhất thường gây ra tăng độ trễ tổng thể, cách thực hiện mới sẽ tự động điều chỉnh độ dài hàng đợi dựa trên thời gian tiêu thụ của hàng đợi, độ dài hàng đợi của nút tải cao sẽ giảm, cho phép các nút khác chia sẻ áp lực nhiều hơn, tìm kiếm và chỉ mục sẽ dựa trên cơ chế này;
- Các chỉ mục đã đóng cũng sẽ hỗ trợ xử lý tự động của bản sao để đảm bảo độ tin cậy của dữ liệu.
- Hỗ trợ cho Doc Values thưa thớt;
- Ngày 10 tháng 4 năm 2019, phiên bản 7.0.0 được phát hành, với các tính năng quan trọng sau:
- Thay đổi kết nối cụm: TransportClient đã bị loại bỏ, mã java của es7 chỉ có thể sử dụng restclient; đối với lập trình java, nên sử dụng High-level-rest-client để vận hành cụm ES;
- Gói chương trình ES mặc định đóng gói jdk: phiên bản gói chương trình 7.x trở thành 300MB+, so với 6.x, gói lớn hơn 200MB+, đây chính là kích thước của JDK;
- Sử dụng Lucene 9.0;
- Chính thức loại bỏ hỗ trợ cho nhiều Type dưới một chỉ mục duy nhất, thời gian es6, chính thức đã nói rằng es7 sẽ xóa type, và thời gian es6, đã quy định rằng mỗi chỉ mục chỉ có thể có một loại. Trong es7, sử dụng _doc mặc định như là loại, chính thức nói trong phiên bản 8.x sẽ hoàn toàn loại bỏ loại. Phương thức yêu cầu API cũng gửi thay đổi, chẳng hạn như lấy một tài liệu của một ID cụ thể của một chỉ mục: GET index/_doc/id nơi chỉ mục và id là các giá trị cụ thể;
- Giới thiệu một bộ cắt mạch bộ nhớ thực sự, có thể phát hiện chính xác hơn các yêu cầu không thể xử lý và ngăn chúng làm cho một nút duy nhất không ổn định;
- Zen2 là lớp điều phối cụm hoàn toàn mới của Elasticsearch, cải thiện độ tin cậy, hiệu suất, và trải nghiệm người dùng, trở nên nhanh hơn, an toàn hơn, và dễ sử dụng hơn.
- Thay đổi kết nối cụm: TransportClient đã bị loại bỏ, mã java của es7 chỉ có thể sử dụng restclient; đối với lập trình java, nên sử dụng High-level-rest-client để vận hành cụm ES;
Các khái niệm về Elasticsearch
Dưới đây là một số khái niệm cốt lõi của Elasticsearch. Hiểu rõ những khái niệm này từ đầu sẽ giúp bạn đơn giản hóa quá trình học Elasticsearch.
Gần thời gian thực (NRT)
Elasticsearch là một nền tảng tìm kiếm gần thời gian thực. Điều này có nghĩa là có một khoảng trễ nhỏ (thường là một giây) từ lúc lập chỉ mục cho một tài liệu cho đến khi tài liệu đó có thể được tìm kiếm.
Chỉ mục (Index)
Trong các ngữ cảnh khác nhau, "chỉ mục" có những ý nghĩa khác nhau:
- Chỉ mục (danh từ): Một chỉ mục tương tự như một cơ sở dữ liệutrong cơ sở dữ liệu quan hệ truyền thống, là một nơi chứa các tài liệu dạng quan hệ. Chỉ mục thực chất là một không gian tên logic trỏ đến một hoặc nhiều phân đoạn vật lý.
- Chỉ mục (động từ): Chỉ mục một tài liệu có nghĩa là lưu trữ một tài liệu vào một chỉ mục (danh từ) để có thể được tìm kiếm và truy vấn. Điều này rất giống với từ khóa
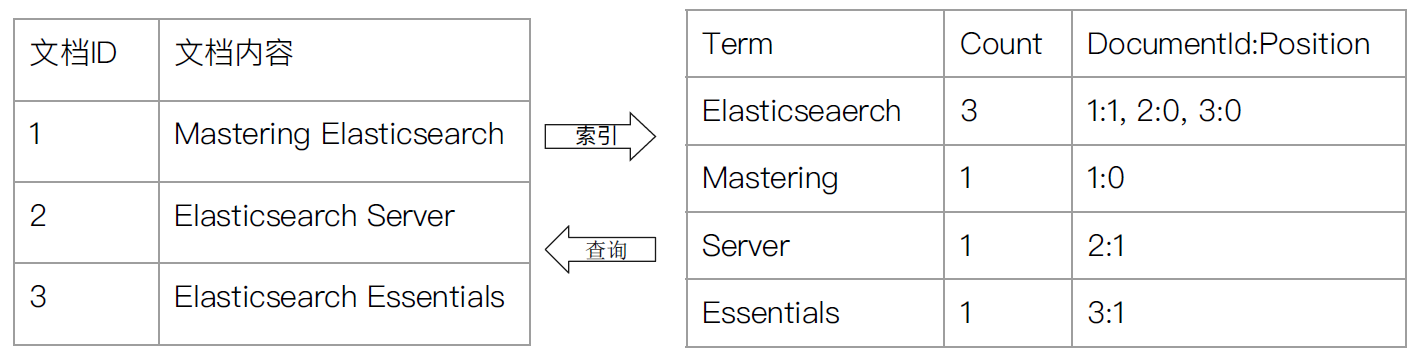
INSERTtrong SQL, ngoại trừ khi tài liệu đã tồn tại, tài liệu mới sẽ thay thế tài liệu cũ. - Chỉ mục đảo ngược : Cơ sở dữ liệu quan hệ tăng tốc độ truy vấn dữ liệu bằng cách thêm một chỉ mục, chẳng hạn như một chỉ mục cây B, vào các cột được chỉ định. Elasticsearch và Lucene sử dụng một cấu trúc gọi là chỉ mục đảo ngược để đạt được mục đích tương tự.
Chỉ mục của Mapping và Setting
Mappingxác định kiểu của các trường tài liệuSettingxác định phân phối dữ liệu khác nhau
Ví dụ:
{
"settings": { ... any settings ... },
"mappings": {
"type_one": { ... any mappings ... },
"type_two": { ... any mappings ... },
...
}
}Chỉ mục đảo ngược
index template
index template (mẫu chỉ mục) giúp người dùng đặt Mapping và Setting, và tự động khớp chúng với chỉ mục mới được tạo theo một quy tắc nhất định.
- Mẫu chỉ có hiệu lực khi một chỉ mục được tạo. Việc sửa đổi mẫu sẽ không ảnh hưởng đến các chỉ mục đã tạo.
- Bạn có thể đặt nhiều mẫu chỉ mục, các thiết lập này sẽ được kết hợp lại với nhau.
- Bạn có thể chỉ định giá trị order để kiểm soát quá trình kết hợp.
Khi tạo mới một chỉ mục:
- Áp dụng Mapping và Setting mặc định của ES
- Áp dụng các thiết lập trong mẫu chỉ mục có giá trị order thấp
- Áp dụng các thiết lập trong mẫu chỉ mục có giá trị order cao, các thiết lập trước đó sẽ bị ghi đè
- Áp dụng Mapping và Setting được chỉ định bởi người dùng khi tạo chỉ mục, và ghi đè các thiết lập trong mẫu trước đó.
Ví dụ: Tạo mẫu chỉ mục mặc định
PUT _template/template_default
{
"index_patterns": ["*"],
"order": 0,
"version": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
PUT /_template/template_test
{
"index_patterns": ["test*"],
"order": 1,
"settings": {
"number_of_shards": 1,
"number_of_replicas": 2
},
"mappings": {
"date_detection": false,
"numeric_detection": true
}
}
# Kiểm tra mẫu chỉ mục
GET /_template/template_default
GET /_template/temp*
# Ghi dữ liệu mới, chỉ mục bắt đầu bằng test
PUT testtemplate/_doc/1
{
"someNumber": "1",
"someDate": "2019/01/01"
}
GET testtemplate/_mapping
GET testtemplate/_settings
PUT testmy
{
"settings":{
"number_of_replicas":5
}
}
PUT testmy/_doc/1
{
"key": "value"
}
GET testmy/_settings
DELETE testmy
DELETE /_template/template_default
DELETE /_template/template_testdynamic template
- Dựa vào kiểu dữ liệu được ES nhận biết, kết hợp với tên trường, để đặt động kiểu trường:
- Tất cả các kiểu chuỗi đều được đặt thành Keyword, hoặc tắt trường keyword.
- Các trường bắt đầu bằng "is" đều được đặt thành boolean.
- Các trường bắt đầu bằng "long_" đều được đặt thành kiểu long.
- Mẫu động được định nghĩa trong Mapping của một chỉ mục.
- Mẫu có một tên.
- Quy tắc khớp là một mảng.
- Đặt Mapping cho các trường khớp.
Ví dụ:
#Dynaminc Mapping dựa trên kiểu và tên trường
DELETE my_index
PUT my_index/_doc/1
{
"firstName": "Ruan",
"isVIP": "true"
}
GET my_index/_mapping
DELETE my_index
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match": "is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
GET my_index/_mapping
DELETE my_index
#Kết hợp với đường dẫn
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"full_name": {
"path_match": "name.*",
"path_unmatch": "*.middle",
"mapping": {
"type": "text",
"copy_to": "full_name"
}
}
}
]
}
}
GET my_index/_mapping
PUT my_index/_doc/1
{
"name": {
"first": "John",
"middle": "Winston",
"last": "Lennon"
}
}
GET my_index/_search?q=full_name:John
DELETE my_indexKiểu (Type)
Kiểu là một phân loại hay phân vùng theo ý nghĩa logic, cho phép tạo nhiều loại trong cùng một chỉ mục. Bản chất, nó tương đương với một điều kiện lọc, các phiên bản cao hơn sẽ loại bỏ khái niệm loại.
Từ phiên bản 6.0.0 trở đi, loại đã bị loại bỏ
Tài liệu (Document)
Elasticsearch là hướng tới tài liệu, tài liệu là đơn vị nhỏ nhất của tất cả dữ liệu có thể tìm kiếm.
Elasticsearch sử dụng JSON làm định dạng tuần tự hóa cho tài liệu.
Trong chỉ mục/loại, bạn có thể lưu trữ bất kỳ số lượng tài liệu nào theo nhu cầu.
Mỗi tài liệu đều có một ID duy nhất
- Người dùng có thể tự chỉ định
- Hoặc được Elasticsearch tự động tạo
Metadata của tài liệu
Một tài liệu không chỉ chứa dữ liệu của nó, mà còn chứa metadata - thông tin về tài liệu.
_index: Tài liệu được lưu trữ ở đâu_type: Loại đối tượng mà tài liệu đại diện_id: Định danh duy nhất của tài liệu_source: Dữ liệu Json gốc của tài liệu_all: Tích hợp tất cả nội dung của các trường vào trường này, đã bị loại bỏ_version: Thông tin phiên bản của tài liệu_score: Điểm liên quan
Ví dụ:
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": ["sports", "music"]
}
}Nút (Node)
Giới thiệu về nút
Một thực thể Elasticsearch đang chạy được gọi là một nút.
Thực thể Elasticsearch về cơ bản là một tiến trình Java. Một máy có thể chạy nhiều tiến trình Elasticsearch, nhưng môi trường product nên chạy một tiến trình Elasticsearch trên một máy.
Mỗi nút đều có tên, được cấu hình thông qua tệp cấu hình, hoặc chỉ định khi khởi động thông qua -E node.name=node1.
Sau khi mỗi nút khởi động, nó sẽ được gán một UID, được lưu trong thư mục data.
Loại nút
- Nút chính (master node): Mỗi nút đều lưu trữ trạng thái của cụm, chỉ có nút chính mới có thể sửa đổi thông tin trạng thái của cụm (đảm bảo tính nhất quán của dữ liệu). Trạng thái cụm duy trì thông tin sau:
- Thông tin về tất cả các nút
- Tất cả các chỉ mục và thông tin liên quan đến mapping và setting
- Thông tin định tuyến phân đoạn
- Nút ứng cử (master eligible node): Nút ứng cử có thể tham gia vào quá trình bầu chọn chính. Nút khởi động đầu tiên sẽ tự bầu làm nút chính.
- Sau khi mỗi nút khởi động, mặc định là nút ứng cử, có thể bị cấm thông qua cấu hình
node.master: false
- Sau khi mỗi nút khởi động, mặc định là nút ứng cử, có thể bị cấm thông qua cấu hình
- Nút dữ liệu (data node): Chịu trách nhiệm lưu trữ dữ liệu phân đoạn.
- Nút điều phối (coordinating node): Chịu trách nhiệm nhận yêu cầu từ khách hàng, phân phối yêu cầu đến nút thích hợp, cuối cùng tổng hợp kết quả lại với nhau. Mỗi nút Elasticsearch mặc định đều là nút điều phối (coordinating node).
- Nút lạnh/nóng (warm/hot node): Dành cho các nút dữ liệu (data node) với cấu hình phần cứng khác nhau, để thực hiện kiến trúc Hot & Warm, giảm chi phí triển khai cụm.
- Nút học máy (machine learning node): Chịu trách nhiệm thực hiện công việc học máy, được sử dụng để phát hiện bất thường.
Cấu hình nút
| Tham số cấu hình | Giá trị mặc định | Giải thích |
|---|---|---|
| node.master | true | Có phải là nút chính không |
| node.data | true | Có phải là nút dữ liệu không |
| node.ingest | true | |
| node.ml | true | Có phải là nút học máy không (cần bật x-pack) |
Khuyến nghị
Trong môi trường development, một nút có thể đảm nhận nhiều vai trò. Tuy nhiên, trong môi trường product, nút nên được đặt làm một vai trò duy nhất.
Cụm (Cluster)
Giới thiệu về cụm
Các nút Elasticsearch có cùng cấu hình cluster.name tạo thành một cụm. cluster.name mặc định là elasticsearch, có thể được sửa đổi thông qua tệp cấu hình, hoặc chỉ định khi khởi động thông qua -E cluster.name=xxx.
Khi có nút được thêm vào cụm hoặc loại bỏ khỏi cụm, cụm sẽ phân phối lại tất cả dữ liệu một cách đều đặn.
Khi một nút được bầu làm nút chính, nó sẽ chịu trách nhiệm quản lý tất cả các thay đổi trong phạm vi cụm, chẳng hạn như thêm, xóa chỉ mục, hoặc thêm, xóa nút, v.v. Tuy nhiên, nút chính không cần tham gia vào các thay đổi ở cấp độ tài liệu và các hoạt động tìm kiếm, vì vậy ngay cả khi cụm chỉ có một nút chính, nó cũng không sẽ trở thành nút hẹp khi lưu lượng tăng lên. Bất kỳ nút nào cũng có thể trở thành nút chính.
Đối với người dùng, chúng ta có thể gửi yêu cầu đến bất kỳ nút nào trong cụm, bao gồm cả nút chính. Mỗi nút đều biết vị trí của bất kỳ tài liệu nào và có thể chuyển yêu cầu của chúng ta trực tiếp đến nút lưu trữ tài liệu mà chúng ta cần. Bất kể chúng ta gửi yêu cầu đến nút nào, nó đều có thể chịu trách nhiệm thu thập dữ liệu từ tất cả các nút chứa tài liệu mà chúng ta cần, và trả kết quả cuối cùng về cho khách hàng. Elasticsearch quản lý tất cả những điều này một cách minh bạch.
Sức khỏe của cụm
Thông tin giám sát cụm của Elasticsearch chứa nhiều dữ liệu thống kê, trong đó một mục quan trọng nhất là sức khỏe cụm, nó được hiển thị trong trường status như green, yellow hoặc red.
Trong một cụm rỗng không chứa bất kỳ chỉ mục nào, nó sẽ có một nội dung trả về tương tự như sau:
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 5,
"active_shards" : 5,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}Trường status chỉ ra liệu cụm hiện tại có hoạt động bình thường trên phạm vi tổng thể hay không. Ba màu của nó có ý nghĩa như sau:
green: Tất cả các phân đoạn chính và phân đoạn sao chép đều hoạt động bình thường.yellow: Tất cả các phân đoạn chính đều hoạt động bình thường, nhưng không phải tất cả các phân đoạn sao chép đều hoạt động bình thường.red: Có phân đoạn chính không hoạt động bình thường.
Phân đoạn (Shards)
Giới thiệu về phân đoạn
Chỉ mục thực chất là một không gian tên logic trỏ đến một hoặc nhiều phân đoạn vật lý.
Một phân đoạn là một đơn vị công việc cơ bản, nó chỉ lưu trữ một phần của toàn bộ dữ liệu. Một phân đoạn có thể được coi là một thực thể Lucene, và nó chính là một máy tìm kiếm đầy đủ. Tài liệu của chúng ta được lưu trữ và chỉ mục trong các phân đoạn, nhưng ứng dụng tương tác trực tiếp với chỉ mục chứ không phải với phân đoạn.
Elasticsearch sử dụng phân đoạn để phân phối dữ liệu đến các nơi khác nhau trong cụm. phân đoạn là bộ chứa dữ liệu, tài liệu được lưu trữ trong phân đoạn, và phân đoạn sau đó được phân phối đến các nút khác nhau trong cụm. Khi quy mô cụm của bạn mở rộng hoặc thu hẹp, Elasticsearch sẽ tự động di chuyển phân đoạn giữa các nút, để dữ liệu vẫn được phân phối đều trong cụm.
phân đoạn chính và phân đoạn sao chép
phân đoạn được chia thành phân đoạn chính (Primary Shard) và phân đoạn sao chép (Replica Shard).
phân đoạn chính: được sử dụng để giải quyết vấn đề mở rộng theo chiều ngang của dữ liệu. Thông qua phân đoạn chính, dữ liệu có thể được phân phối đến các nút khác nhau trong cụm.
- Bất kỳ tài liệu nào trong chỉ mục đều thuộc về một phân đoạn chính.
- Số lượng phân đoạn chính được chỉ định khi tạo chỉ mục và không được phép sửa đổi sau đó, trừ khi Reindex.
phân đoạn sao chép (Replica Shard): được sử dụng để giải quyết vấn đề khả dụng cao của dữ liệu. phân đoạn sao chép là bản sao của phân đoạn chính. phân đoạn sao chép hoạt động như một bản sao dự phòng dự phòng khi có sự cố phần cứng để bảo vệ dữ liệu không bị mất, và cung cấp dịch vụ cho các hoạt động đọc như tìm kiếm và trả về tài liệu.
- Số lượng phân đoạn sao chép có thể được điều chỉnh động.
- Tăng số lượng bản sao cũng có thể cải thiện khả năng sẵn sàng của dịch vụ (thông qua việc tăng lưu lượng đọc) đến một mức độ nhất định.
Đối với cài đặt phân đoạn trong môi trường sản xuất, cần lập kế hoạch dung lượng từ trước.
Số lượng phân đoạn quá nhỏ:
- Không thể mở rộng theo chiều ngang.
- Số lượng phân đoạn đơn lẻ quá lớn, dẫn đến việc phân phối lại dữ liệu tốn thời gian.
Số lượng phân đoạn quá lớn:
- Ảnh hưởng đến việc tính điểm liên quan của kết quả tìm kiếm, ảnh hưởng đến độ chính xác của kết quả thống kê.
- Quá nhiều phân đoạn trên một nút sẽ gây lãng phí tài nguyên và ảnh hưởng đến hiệu suất.
Bản sao (Replicas)
Bản sao chủ yếu là việc sao chép các phân đoạn chính (Shards) trong Elasticsearch, mỗi phân đoạn chính có thể có 0 hoặc nhiều bản sao.
Mục đích chính của phân đoạn sao chép là để chuyển đổi khi có sự cố.
phân đoạn sao chép rất quan trọng, chủ yếu vì hai lý do:
- Nó cung cấp khả năng sẵn sàng cao khi có sự cố với phân đoạn hoặc nút. Do đó, phân đoạn sao chép sẽ không bao giờ nằm trên cùng một nút với phân đoạn chính mà nó sao chép;
- phân đoạn sao chép cũng có thể nhận yêu cầu tìm kiếm, cho phép tìm kiếm song song, từ đó tăng cường lưu lượng hệ thống.
Mỗi phân đoạn Elasticsearch đều là một chỉ mục Lucene. Một chỉ mục Lucene đơn lẻ có thể chứa số lượng tài liệu tối đa. Đến LUCENE-5843, giới hạn là 2,147,483,519 (=
Integer.MAX_VALUE- 128) tài liệu. Bạn có thể sử dụng API _cat/shards để giám sát kích thước phân đoạn.