Java Memory Model
Mô hình bộ nhớ của Java (JMM)
Mô hình bộ nhớ Java (Java Memory Model - JMM) định nghĩa các quy tắc về cách các biến, luồng trong chương trình Java tương tác với bộ nhớ chính và bộ nhớ làm việc. Nó chủ yếu liên quan đến vấn đề về tính khả kiến của các biến dùng chung trong môi trường đa luồng và việc sắp xếp lại lệnh, là một khái niệm quan trọng trong lập trình đa luồng.
Trong lập trình đa luồng, có hai vấn đề chính:
- Các luồng giao tiếp với nhau như thế nào? Tức là: các luồng trao đổi thông tin với nhau bằng cơ chế nào?
- Các luồng đồng bộ với nhau ra sao? Tức là: các luồng kiểm soát thứ tự các thao tác của nhau bằng cơ chế nào?
Có hai mô hình xử lý vấn đề này:
- Mô hình truyền tin nhắn
- Mô hình bộ nhớ dùng chung
| Làm thế nào để giao tiếp | Cách đồng bộ hóa | |
|---|---|---|
| Mô hình truyền tin nhắn đồng thời | Không có trạng thái chung giữa các luồng và giao tiếp giữa các luồng phải được truyền đạt rõ ràng bằng cách gửi tin nhắn. | Việc gửi tin nhắn được đồng bộ hóa một cách tự nhiên, vì việc gửi tin nhắn luôn đi trước việc nhận tin nhắn nên việc đồng bộ hóa là ngầm định. |
| Mô hình bộ nhớ dùng chung | Trạng thái chung của chương trình được chia sẻ giữa các luồng và giao tiếp ngầm được thực hiện bằng cách ghi và đọc trạng thái chung trong bộ nhớ. | Bạn phải xác định rõ ràng rằng một đoạn mã nhất định cần được thực thi riêng giữa các luồng và việc đồng bộ hóa là rõ ràng. |
Java sử dụng mô hình bộ nhớ dùng chung.
Mô hình bộ nhớ của Java
Biến dùng chung là gì?
Trước tiên, hãy xem lại Runtime Data Aera. Đây là điều mà mọi người đều đã quen thuộc:
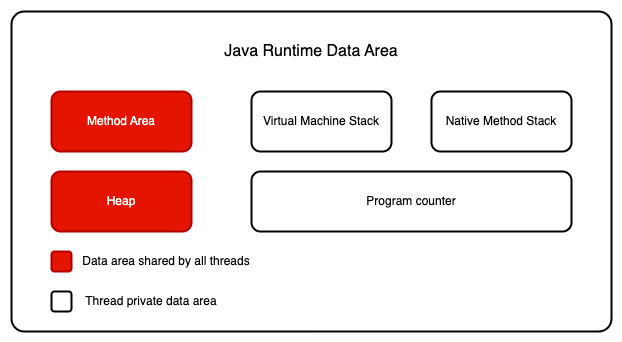
Đối với mỗi luồng, stack là riêng, trong khi vùng heap là dùng chung.
Nói cách khác, các biến trong stack (biến cục bộ, tham số của phương thức, tham số xử lý ngoại lệ) không được chia sẻ giữa các luồng, do đó không có vấn đề về tính khả kiến của bộ nhớ, và không bị ảnh hưởng bởi mô hình bộ nhớ. Ngược lại, các biến trong vùng heap được chia sẻ và thường được gọi là biến dùng chung.
Do đó, tính khả kiến của bộ nhớ áp dụng cho các biến dùng chung trong vùng heap.
Vấn đề về tính khả kiến của bộ nhớ xảy ra như thế nào?
Có thể sẽ có người hỏi: "Nếu vùng heap là dùng chung, tại sao lại xảy ra vấn đề về tính khả kiến của bộ nhớ?"
Điều này là do máy tính hiện đại thường lưu trữ các biến dùng chung trong bộ đệm (cache) tốc độ cao, bởi vì việc CPU truy cập vào bộ đệm nhanh hơn nhiều so với việc truy cập vào bộ nhớ chính (main memory - RAM).
Các biến dùng chung giữa các luồng nằm trong bộ nhớ chính. Mỗi luồng có một bộ nhớ cục bộ riêng, lưu trữ các bản sao của các biến dùng chung mà nó đọc hoặc ghi. Bộ nhớ cục bộ là một khái niệm trừu tượng của mô hình bộ nhớ Java, không thực sự tồn tại. Nó bao gồm bộ đệm, bộ nhớ ghi, thanh ghi,...
Sự giao tiếp giữa các luồng trong Java được kiểm soát bởi mô hình bộ nhớ Java (JMM). Từ góc nhìn trừu tượng, JMM định nghĩa mối quan hệ giữa các luồng và bộ nhớ chính. Sơ đồ trừu tượng của JMM như sau:
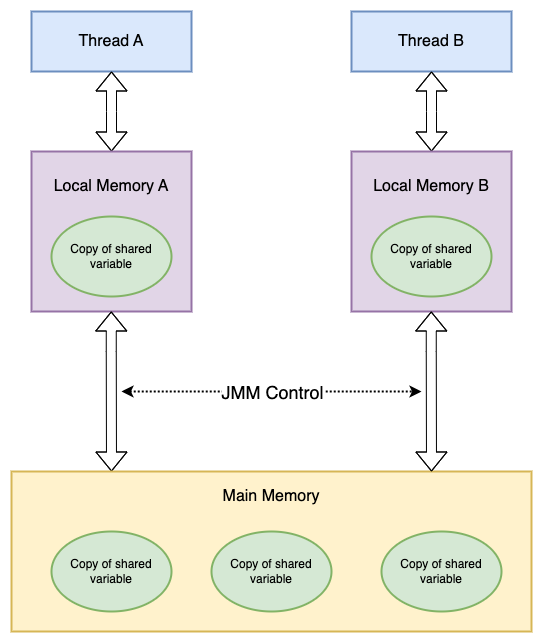
Từ sơ đồ có thể thấy:
- Tất cả các biến dùng chung đều nằm trong bộ nhớ chính.
- Mỗi luồng lưu trữ một bản sao các biến dùng chung mà luồng đó sử dụng.
- Nếu luồng A và luồng B cần giao tiếp với nhau, chúng phải trải qua 2 bước sau:
- Luồng A cập nhật các biến dùng chung từ bộ nhớ cục bộ của nó vào bộ nhớ chính.
- Luồng B đọc các biến dùng chung đã được luồng A cập nhật từ bộ nhớ chính.
Do đó, luồng A không thể trực tiếp truy cập vào bộ nhớ làm việc của luồng B. Việc giao tiếp giữa các luồng phải thông qua bộ nhớ chính.
Lưu ý rằng, theo quy định của JMM, mọi thao tác của luồng đối với biến dùng chung đều phải thực hiện trong bộ nhớ cục bộ của nó, không thể đọc trực tiếp từ bộ nhớ chính.
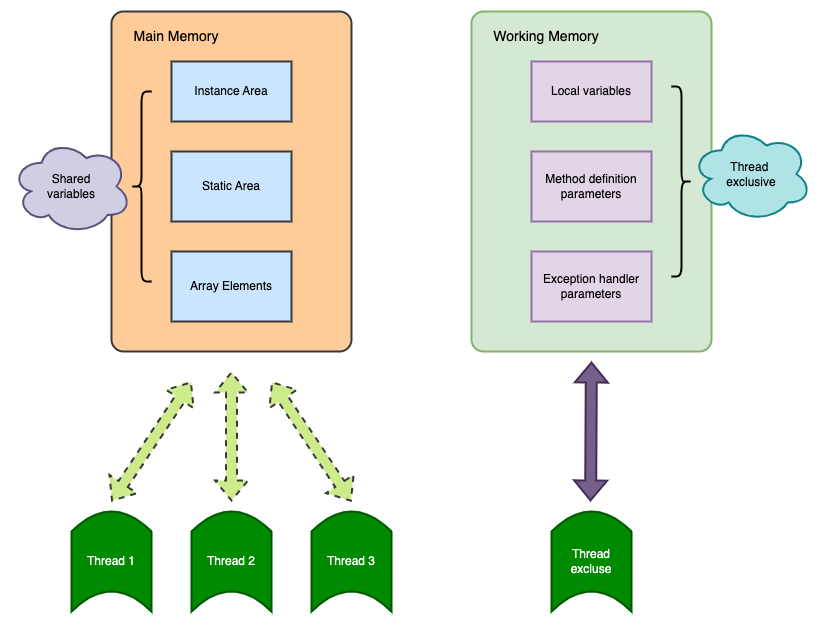
- Bộ nhớ chính: Phần dữ liệu của đối tượng trong vùng heap, tương ứng với bộ nhớ vật lý.
- Bộ nhớ làm việc: Một phần của stack Java, ưu tiên lưu trữ trong thanh ghi và bộ đệm tốc độ cao.
Vì vậy, luồng B không trực tiếp đọc giá trị của biến dùng chung từ bộ nhớ chính mà trước tiên tìm kiếm biến này trong bộ nhớ cục bộ của luồng B. Khi phát hiện biến đã được cập nhật, luồng B đọc giá trị mới từ bộ nhớ chính và sao chép nó vào bộ nhớ cục bộ của mình, sau đó mới tiếp tục sử dụng giá trị mới này.
Làm thế nào để đảm bảo tính khả biến của bộ nhớ?
Vậy làm sao để biết biến dùng chung đã được các luồng khác cập nhật? Đây chính là vai trò của JMM. JMM đảm bảo tính khả kiến của bộ nhớ bằng cách điều khiển tương tác giữa bộ nhớ chính và bộ nhớ cục bộ của mỗi luồng.
Trong Java, từ khóa volatile có thể đảm bảo tính khả kiến của biến dùng chung khi được truy cập bởi nhiều luồng, và cũng ngăn chặn việc sắp xếp lại lệnh. Từ khóa synchronized không chỉ đảm bảo tính khả kiến mà còn đảm bảo tính nguyên tử (tính đồng bộ).
Ở cấp độ thấp hơn, JMM sử dụng rào chắn bộ nhớ để thực hiện tính khả kiến của bộ nhớ và ngăn chặn việc sắp xếp lại lệnh. Để giúp lập trình viên dễ hiểu hơn, JMM đưa ra khái niệm happens-before, một khái niệm đơn giản dễ hiểu hơn, giúp tránh việc lập trình viên phải học những quy tắc sắp xếp lại phức tạp và cách thực hiện chúng.
Sự khác biệt giữa JMM và Runtime Data Area của Java
Như đã đề cập trước đó, JMM và sự phân chia Runtime Data Area của Java có sự khác biệt nhưng cũng có liên hệ nhất định:
Sự khác biệt
Đây là hai khái niệm khác nhau. JMM là một khái niệm trừu tượng, mô tả một tập hợp các quy tắc điều khiển cách truy cập các biến, xoay quanh tính nguyên tử, tính tuần tự và tính khả kiến. Trong khi đó, sự phân chia Runtime Data Area của Java là cụ thể, là sự phân chia bộ nhớ cần thiết khi JVM thực thi chương trình Java.Liên hệ
Cả hai đều có vùng dữ liệu riêng tư và vùng dữ liệu chia sẻ. Nói chung, bộ nhớ chính trong JMM thuộc vùng dữ liệu chia sẻ, bao gồm heap và Method Area; tương tự, bộ nhớ cục bộ trong JMM thuộc vùng dữ liệu riêng tư, bao gồm Program Counter, Native Method Stack và ngăn xếp của máy ảo.
Tóm lại:
Runtime Data Area của Java mô tả cách bộ nhớ được chia thành các vùng khác nhau khi JVM thực thi và cơ chế hoạt động của mỗi vùng. Các vùng chính bao gồm:
- Method Area: Lưu trữ thông tin cấu trúc của mỗi lớp như hằng số thời gian chạy, dữ liệu trường và phương thức, mã byte của các phương thức.
- Heap: Gần như tất cả các đối tượng và mảng đều được cấp phát bộ nhớ ở đây. Đây là vùng quản lý bộ nhớ chính của Java.
- Stack: Mỗi luồng có một ngăn xếp riêng, và mỗi lần gọi phương thức sẽ tạo ra một khung ngăn xếp mới để lưu trữ biến cục bộ, toán tử, liên kết động và điểm thoát của phương thức.
- Native Method Stack: Tương tự như stack, nhưng dành riêng cho các phương thức gốc được JVM sử dụng.
- Program Counter: Mỗi luồng có một Program Counter riêng, dùng để chỉ vị trí dòng mã bytecode mà luồng hiện tại đang thực thi.
Java Memory Model (JMM) chủ yếu nhắm vào cách thực thi an toàn các thao tác giữa bộ nhớ chính và bộ nhớ làm việc trong môi trường đa luồng.
JMM bao gồm các chủ đề như tính khả kiến của biến, sắp xếp lại lệnh và thao tác nguyên tử, nhằm giải quyết các vấn đề phát sinh từ lập trình đa luồng.
- Tính khả kiến: Khi một luồng thay đổi giá trị của biến chia sẻ, giá trị mới này sẽ ngay lập tức được các luồng khác nhận biết.
- Tính nguyên tử: Một hoặc nhiều thao tác không thể bị gián đoạn bởi các luồng hoặc thao tác khác, hoặc tất cả các thao tác đều thực hiện, hoặc không có thao tác nào thực hiện.
- Tính tuần tự: Thứ tự thực thi chương trình phải tuân theo thứ tự mã được viết.
Sự liên quan giữa JMM và happens-before
Một mặt, chúng ta là nhà phát triển cần JMM cung cấp một mô hình bộ nhớ mạnh mẽ để viết mã. Mặt khác, trình biên dịch và bộ xử lý lại mong muốn JMM càng ít ràng buộc càng tốt để tối ưu hóa hiệu suất nhiều nhất có thể, với hy vọng có một mô hình bộ nhớ yếu hơn.
JMM đã cân nhắc cả hai yêu cầu này và tìm ra điểm cân bằng: miễn là không thay đổi kết quả thực thi của chương trình (cho chương trình đơn luồng và chương trình đa luồng đã được đồng bộ hóa đúng cách), thì trình biên dịch và bộ xử lý có thể tối ưu hóa theo bất kỳ cách nào.
Đối với nhà phát triển, JMM cung cấp quy tắc happens-before (theo đặc tả JSR-133), đáp ứng nhu cầu của chúng ta—dễ hiểu và cung cấp đủ khả năng đảm bảo về tính khả kiến của bộ nhớ. Nói cách khác, nếu chúng ta tuân theo quy tắc happens-before, chương trình sẽ có khả năng đảm bảo tính khả kiến của bộ nhớ trong JMM.
JMM sử dụng khái niệm happens-before để xác định thứ tự thực thi giữa hai thao tác. Hai thao tác này có thể nằm trong cùng một luồng hoặc trong các luồng khác nhau.
Định nghĩa mối quan hệ happens-before như sau:
- Nếu một thao tác xảy ra trước (happens-before) một thao tác khác, kết quả của thao tác đầu tiên sẽ có thể thấy được đối với thao tác thứ hai, và thứ tự thực thi của thao tác đầu tiên sẽ xảy ra trước thao tác thứ hai.
- Tồn tại mối quan hệ happens-before giữa hai thao tác không có nghĩa là Java phải thực thi theo đúng thứ tự đó. Nếu kết quả sau khi sắp xếp lại không thay đổi kết quả của chương trình, thì JMM cũng cho phép việc sắp xếp lại.
Mối quan hệ happens-before về bản chất tương tự như ngữ nghĩa "as-if-serial".
Ngữ nghĩa "as-if-serial" đảm bảo rằng kết quả thực thi sau khi sắp xếp lại trong một luồng đơn sẽ giống như kết quả của mã gốc. Còn mối quan hệ happens-before đảm bảo kết quả thực thi của chương trình đa luồng được đồng bộ hóa đúng cách sẽ không bị thay đổi do sắp xếp lại lệnh.
Tóm lại, nếu thao tác A xảy ra trước thao tác B, thì các thay đổi của A trong bộ nhớ sẽ có thể thấy được đối với B, bất kể chúng có thuộc cùng một luồng hay không.
Các mối quan hệ happens-before trong Java
Trong Java, có các mối quan hệ happens-before mặc định sau đây:
- Quy tắc thứ tự chương trình: Mỗi thao tác trong một luồng xảy ra trước bất kỳ thao tác nào tiếp theo trong cùng luồng.
- Quy tắc khóa giám sát: Giải phóng một khóa xảy ra trước bất kỳ lần khóa tiếp theo nào của cùng khóa đó.
- Quy tắc biến volatile: Ghi vào một biến volatile xảy ra trước bất kỳ lần đọc nào sau đó của cùng biến volatile.
- Tính chất bắc cầu: Nếu A xảy ra trước B và B xảy ra trước C, thì A xảy ra trước C.
- Quy tắc start: Nếu luồng A thực thi
ThreadB.start()để khởi động luồng B, thì thao tácThreadB.start()trong luồng A xảy ra trước bất kỳ thao tác nào trong luồng B. - Quy tắc join: Nếu luồng A thực thi
ThreadB.join()và thành công, thì mọi thao tác trong luồng B sẽ xảy ra trước khi luồng A quay lại từThreadB.join().
Ví dụ:
int a = 1; // Thao tác A
int b = 2; // Thao tác B
int sum = a + b; // Thao tác C
System.out.println(sum);Dựa trên quy tắc happens-before, giả sử chỉ có một luồng, ta có thể suy ra:
1> A xảy ra trước B
2> B xảy ra trước C
3> A xảy ra trước CLưu ý rằng khi thực hiện các lệnh, JVM có thể sắp xếp lại thao tác A & B vì dù thực hiện A trước hay B trước, kết quả cũng không thay đổi và chúng vẫn nhìn thấy nhau.
Nếu có sắp xếp lại, điều này có thể làm sai lệch về mặt thị giác quy tắc happens-before, nhưng JMM cho phép điều đó.
Vì vậy, chúng ta chỉ cần quan tâm đến quy tắc happens-before, không cần quan tâm JVM thực thi ra sao. Chỉ cần xác định rằng thao tác A xảy ra trước B là đủ.
Sắp xếp lại có hai loại và JMM có các chiến lược khác nhau cho hai loại này:
- Sắp xếp lại thay đổi kết quả thực thi của chương trình, như A -> C, thì JMM yêu cầu trình biên dịch và bộ xử lý cấm việc sắp xếp lại này.
- Sắp xếp lại không thay đổi kết quả thực thi của chương trình, như A -> B, thì JMM không có yêu cầu và cho phép sắp xếp lại này.
Tóm tắt
- Mô hình bộ nhớ Java (JMM) định nghĩa các quy tắc tương tác giữa biến, luồng, bộ nhớ chính và bộ nhớ làm việc trong chương trình Java, đặc biệt là trong môi trường đa luồng.
- JMM chủ yếu liên quan đến cách thực thi an toàn các thao tác giữa bộ nhớ chính và bộ nhớ làm việc trong môi trường đa luồng.
- Vùng nhớ thời gian chạy của Java mô tả cách bộ nhớ được phân chia khi JVM hoạt động, bao gồm method area, heap, stack, Native Method Stack và program counter.
- Sắp xếp lại lệnh nhằm cải thiện hiệu suất CPU nhưng có thể dẫn đến các vấn đề về tính khả biến trong môi trường đa luồng.
- Quy tắc happens-before cung cấp đảm bảo mạnh mẽ về tính khả kiến của bộ nhớ trong JMM. Chỉ cần tuân thủ quy tắc happens-before, chương trình sẽ đảm bảo tính khả biến trong JMM.