MySQL Q&A
60 Câu Hỏi Phỏng Vấn Cơ Sở Dữ Liệu Được Chọn Lọc: Phải Xem:
Hình ảnh và giải thích chi tiết 60 câu hỏi phỏng vấn MySQL thường gặp, lần này tôi sẽ dễ dàng vượt qua phỏng vấn viên (tay chó). Tổng hợp: Trầm Mặc Vương Nhị, nhấn vào liên kết bài viết để xem sơ đồ tư duy chi tiết; Tác giả: Herongwei, nhấn vào liên kết gốc.
Kiến Thức Cơ Bản
1. Sự khác biệt giữa cơ sở dữ liệu quan hệ và phi quan hệ?
Ưu điểm của cơ sở dữ liệu quan hệ:
- Dễ hiểu vì nó sử dụng mô hình quan hệ để tổ chức dữ liệu.
- Có thể duy trì tính nhất quán của dữ liệu.
- Chi phí cập nhật dữ liệu tương đối thấp.
- Hỗ trợ các truy vấn phức tạp (truy vấn với mệnh đề where).
Ưu điểm của cơ sở dữ liệu phi quan hệ (NoSQL):
- Không cần phân tích qua lớp SQL, hiệu suất đọc/ghi cao.
- Dựa trên cặp khóa-giá trị, hiệu suất đọc/ghi cao, dễ mở rộng.
- Có thể hỗ trợ nhiều loại dữ liệu như hình ảnh, tài liệu, v.v.
- Mở rộng (có thể chia thành cơ sở dữ liệu trong bộ nhớ và cơ sở dữ liệu tài liệu, như Redis, MongoDB, HBase, v.v., phù hợp với các kịch bản: hệ thống nhật ký có khả năng chịu tải cao/dữ liệu địa lý).
2. Mô tả chi tiết các bước thực hiện một câu lệnh MySQL
Các bước thực hiện SQL của lớp Server theo thứ tự như sau:
- Yêu cầu từ khách hàng -> Bộ kết nối (xác minh danh tính người dùng, cấp quyền)
- Bộ nhớ đệm truy vấn (nếu tồn tại bộ nhớ đệm thì trả về trực tiếp, nếu không thì thực hiện các bước tiếp theo)
- Bộ phân tích (thực hiện phân tích từ vựng và phân tích cú pháp cho SQL)
- Bộ tối ưu hóa (tối ưu hóa SQL để chọn phương pháp thực hiện tối ưu nhất)
- Bộ thực thi (kiểm tra xem người dùng có quyền thực thi hay không, nếu có thì sử dụng giao diện do công cụ cung cấp) -> Lấy dữ liệu từ lớp công cụ và trả về (nếu mở bộ nhớ đệm truy vấn thì sẽ lưu kết quả truy vấn).
Liên Quan Đến Chỉ Mục
3. Lý do MySQL sử dụng chỉ mục?
Nguyên nhân cơ bản:
- Sự xuất hiện của chỉ mục nhằm nâng cao hiệu suất truy vấn dữ liệu, giống như mục lục của một cuốn sách.
- Đối với bảng của cơ sở dữ liệu, chỉ mục thực chất là "mục lục" của nó.
Mở rộng:
- Tạo chỉ mục duy nhất có thể đảm bảo tính duy nhất của mỗi hàng dữ liệu trong bảng cơ sở dữ liệu.
- Giúp lớp động cơ tránh sắp xếp và tạo bảng tạm thời.
- Biến IO ngẫu nhiên thành IO tuần tự, tăng tốc kết nối giữa các bảng.
4. Ba cấu trúc dữ liệu cơ bản của chỉ mục và ưu nhược điểm của chúng
Ba cấu trúc dữ liệu cơ bản của chỉ mục: Bảng băm, mảng có thứ tự và cây tìm kiếm.
- Bảng băm: Phù hợp với các tình huống truy vấn bằng giá trị, ví dụ như memcached và một số động cơ NoSQL khác, không phù hợp với truy vấn phạm vi.
- Mảng có thứ tự: Chỉ phù hợp với động cơ lưu trữ tĩnh, hiệu suất tốt trong truy vấn giá trị và phạm vi nhưng chi phí cập nhật dữ liệu cao.
- Cây N-ary: Do ưu điểm về hiệu suất đọc/ghi và phù hợp với mô hình truy cập đĩa, được sử dụng rộng rãi trong các động cơ cơ sở dữ liệu.
Mở rộng (ví dụ với chỉ mục của một trường số nguyên trong InnoDB, số N xấp xỉ là 1200. Khi cây có chiều cao là 4, nó có thể chứa giá trị tương đương 1200 mũ 3, tức là 1,7 tỷ. Cân nhắc rằng khối dữ liệu của gốc cây luôn nằm trong bộ nhớ, một chỉ mục của một trường số nguyên trên bảng 1 tỷ hàng, tìm một giá trị chỉ cần truy cập đĩa 3 lần. Thực tế, tầng thứ hai của cây cũng có khả năng lớn nằm trong bộ nhớ, vì vậy số lần truy cập đĩa trung bình sẽ ít hơn nữa.)
5. Các loại chỉ mục thông thường và chúng hoạt động như thế nào?
Dựa trên nội dung của các nút lá, chỉ mục được chia thành chỉ mục khóa chính và chỉ mục không khóa chính.
- Nút lá của chỉ mục khóa chính chứa toàn bộ dữ liệu hàng, trong InnoDB cũng được gọi là chỉ mục cụm.
- Nút lá của chỉ mục không khóa chính chứa giá trị của khóa chính, trong InnoDB cũng được gọi là chỉ mục thứ cấp.
6. Sự khác biệt giữa cách thực hiện chỉ mục B-tree của MyISAM và InnoDB là gì?
- Động cơ lưu trữ InnoDB: Nút lá của chỉ mục B+ tree lưu trữ dữ liệu thực tế, tệp dữ liệu thực chất là tệp chỉ mục.
- Động cơ lưu trữ MyISAM: Nút lá của chỉ mục B+ tree lưu trữ địa chỉ vật lý của dữ liệu, vùng dữ liệu của nút lá lưu trữ địa chỉ của bản ghi dữ liệu, tệp chỉ mục và tệp dữ liệu được tách biệt.
7. Tại sao InnoDB thiết kế chỉ mục B+ tree?
Hai yếu tố cân nhắc:
- Các tình huống và chức năng mà InnoDB cần thực hiện yêu cầu có hiệu suất mạnh mẽ trong các truy vấn cụ thể.
- CPU mất nhiều thời gian để tải dữ liệu từ đĩa vào bộ nhớ.
Tại sao chọn B+ tree:
Chỉ mục băm tuy có thể cung cấp truy vấn phức tạp O(1), nhưng không hỗ trợ tốt truy vấn phạm vi và sắp xếp, cuối cùng sẽ dẫn đến quét toàn bộ bảng.
Cây B có thể lưu trữ dữ liệu ở các nút không phải là lá, nhưng điều này có thể dẫn đến nhiều IO ngẫu nhiên hơn khi truy vấn dữ liệu liên tục.
Các nút lá của cây B+ có thể kết nối với nhau bằng con trỏ, giảm IO ngẫu nhiên do duyệt tuần tự.
Chỉ mục duy nhất hay không duy nhất?
Vì chỉ mục duy nhất không thể sử dụng cơ chế tối ưu hóa của bộ đệm thay đổi, do đó nếu nghiệp vụ có thể chấp nhận, từ góc độ hiệu suất, nên ưu tiên chỉ mục không duy nhất.
8. Chỉ mục bao phủ và chỉ mục đẩy là gì?
Chỉ mục bao phủ:
- Trong một truy vấn, chỉ mục k đã "bao phủ" nhu cầu truy vấn của chúng ta, được gọi là chỉ mục bao phủ.
- Chỉ mục bao phủ có thể giảm số lần tìm kiếm trên cây, tăng đáng kể hiệu suất truy vấn, vì vậy sử dụng chỉ mục bao phủ là một phương pháp tối ưu hiệu suất phổ biến.
Chỉ mục đẩy:
- MySQL 5.6 giới thiệu tối ưu hóa chỉ mục đẩy (index condition pushdown), có thể trong quá trình duyệt chỉ mục, trước tiên thực hiện phán đoán trên các trường chứa trong chỉ mục, lọc trực tiếp các bản ghi không thỏa mãn điều kiện, giảm số lần quay lại bảng.
9. Những thao tác nào khiến chỉ mục không còn hiệu lực?
- Sử dụng khớp mẫu bên trái hoặc khớp mẫu trái phải, tức là like %xx hoặc like %xx%, đều gây chỉ mục không còn hiệu lực. Nguyên nhân là kết quả truy vấn có thể là nhiều, không biết so sánh từ giá trị chỉ mục nào, vì vậy chỉ có thể quét toàn bộ bảng.
- Thực hiện chức năng trên chỉ mục hoặc tính toán biểu thức trên chỉ mục, vì chỉ mục giữ giá trị gốc của trường chỉ mục, không phải là giá trị sau khi tính toán bởi chức năng, do đó không thể sử dụng chỉ mục.
- Thực hiện chuyển đổi ngầm trên chỉ mục tương đương với việc sử dụng chức năng mới.
- Trong câu lệnh WHERE có câu lệnh OR, chỉ cần có một điều kiện không phải là trường chỉ mục, sẽ thực hiện quét toàn bộ bảng.
10. Thêm chỉ mục cho chuỗi ký tự
- Tạo chỉ mục đầy đủ trực tiếp, có thể tốn nhiều không gian.
- Tạo chỉ mục tiền tố, tiết kiệm không gian, nhưng tăng số lần quét truy vấn và không thể sử dụng chỉ mục bao phủ.
- Lưu trữ ngược rồi tạo chỉ mục tiền tố để tránh vấn đề không đủ độ phân biệt của tiền tố chuỗi.
- Tạo chỉ mục trường băm, hiệu suất truy vấn ổn định, có thêm chi phí lưu trữ và tính toán, giống như cách thứ ba, đều không hỗ trợ quét phạm vi.
Liên Quan Đến Nhật Ký
11. Change Buffer của MySQL là gì?
- Khi cần cập nhật một trang dữ liệu, nếu trang dữ liệu đó đã nằm trong bộ nhớ thì sẽ cập nhật trực tiếp; còn nếu trang dữ liệu đó chưa nằm trong bộ nhớ, InnoDB sẽ lưu các thao tác cập nhật này vào change buffer mà không ảnh hưởng đến tính nhất quán của dữ liệu.
- Bằng cách này, không cần phải đọc trang dữ liệu này từ đĩa vào bộ nhớ. Khi có truy vấn cần truy cập trang dữ liệu này, trang dữ liệu sẽ được đọc vào bộ nhớ, sau đó thực hiện các thao tác liên quan trong change buffer. Qua đó, có thể đảm bảo tính chính xác của dữ liệu.
- Lưu ý rằng việc cập nhật chỉ mục duy nhất không thể sử dụng change buffer, thực tế chỉ có chỉ mục thông thường mới có thể sử dụng.
- Ứng dụng:
- Đối với các nghiệp vụ ghi nhiều đọc ít, khả năng trang dữ liệu được truy cập ngay sau khi ghi xong là khá thấp, lúc này việc sử dụng change buffer sẽ hiệu quả nhất. Mô hình nghiệp vụ này thường thấy trong các hệ thống quản lý hóa đơn, nhật ký.
- Ngược lại, nếu một nghiệp vụ có mô hình cập nhật là ghi xong sẽ truy vấn ngay lập tức, mặc dù có thể ghi change buffer trước nhưng ngay sau đó sẽ truy cập trang dữ liệu này, quá trình merge sẽ được kích hoạt ngay. Do đó, số lần truy cập IO ngẫu nhiên sẽ không giảm, thậm chí tăng thêm chi phí bảo trì change buffer.
12. MySQL làm thế nào để đánh giá số lượng hàng cần quét?
- Trước khi thực sự bắt đầu thực hiện câu lệnh, MySQL không thể biết chính xác có bao nhiêu bản ghi thỏa mãn điều kiện này.
- MySQL chỉ có thể ước lượng số lượng bản ghi dựa trên thông tin thống kê, thông tin này chính là độ phân biệt của chỉ mục.
13. Sự khác biệt giữa redo log và binlog của MySQL?
14. Tại sao cần redo log?
- Redo log chủ yếu dùng để khôi phục dữ liệu khi MySQL khởi động lại sau khi gặp sự cố, đảm bảo tính nhất quán của dữ liệu.
- Thực tế, redo log hỗ trợ cơ chế WAL của MySQL. Vì MySQL thực hiện cập nhật, để có thể phản hồi nhanh chóng, nên sử dụng kỹ thuật ghi không đồng bộ vào đĩa, ghi vào bộ nhớ xong là trả lời. Nhưng điều này gây ra nguy cơ mất dữ liệu trong bộ nhớ sau khi crash, và redo log có khả năng đảm bảo an toàn khi crash.
15. Tại sao redo log có khả năng crash-safe, mà binlog không thể thay thế được?
Điểm đầu tiên: Redo log có thể đảm bảo InnoDB xác định dữ liệu nào đã được ghi vào đĩa, dữ liệu nào chưa.
- Redo log và binlog có một sự khác biệt lớn là, một cái ghi tuần hoàn, một cái ghi thêm. Redo log chỉ ghi lại các nhật ký chưa được ghi vào đĩa, còn các dữ liệu đã được ghi vào đĩa sẽ được xóa khỏi file nhật ký có kích thước giới hạn này. Binlog là nhật ký ghi thêm, lưu trữ toàn bộ nhật ký.
- Khi cơ sở dữ liệu gặp sự cố, muốn khôi phục dữ liệu chưa được ghi vào đĩa nhưng đã ghi vào redo log và binlog vào bộ nhớ, binlog không thể khôi phục được. Mặc dù binlog có toàn bộ nhật ký, nhưng không có dấu hiệu nào cho phép InnoDB xác định dữ liệu nào đã được ghi vào đĩa, dữ liệu nào chưa.
- Nhưng redo log thì khác, dữ liệu nào đã được ghi vào đĩa sẽ được xóa khỏi redo log vì nó là ghi tuần hoàn. Sau khi khởi động lại cơ sở dữ liệu, chỉ cần khôi phục các dữ liệu trong redo log vào bộ nhớ.
Điểm thứ hai: Nếu ghi redo log thất bại, điều này có nghĩa là thao tác đó thất bại, và giao dịch cũng không thể được cam kết.
- Sau mỗi thao tác cập nhật, redo log sẽ được ghi vào nhật ký. Nếu ghi thất bại, điều đó có nghĩa là thao tác này thất bại, và giao dịch cũng không thể được cam kết.
- Cấu trúc bên trong của redo log dựa trên trang, ghi lại sự thay đổi của các giá trị trường trên trang đó, chỉ cần đọc redo log và thực hiện lại sau khi crash là có thể khôi phục dữ liệu.
- Đó là lý do tại sao redo log có khả năng crash-safe, trong khi binlog thì không.
16. Khi cơ sở dữ liệu gặp sự cố, làm thế nào để khôi phục dữ liệu chưa được ghi vào đĩa vào bộ nhớ?
Dựa trên cơ chế cam kết hai giai đoạn của redo log và binlog, dữ liệu chưa được lưu trữ bao gồm các trường hợp sau:
- Change buffer đã được ghi, redo log đã fsync nhưng chưa cam kết, binlog chưa fsync vào đĩa, dữ liệu này bị mất.
- Change buffer đã được ghi, redo log fsync nhưng chưa cam kết, binlog đã fsync vào đĩa, khôi phục redo log từ binlog, sau đó khôi phục change buffer từ redo log.
- Change buffer đã được ghi, redo log và binlog đều đã fsync, khôi phục trực tiếp từ redo log.
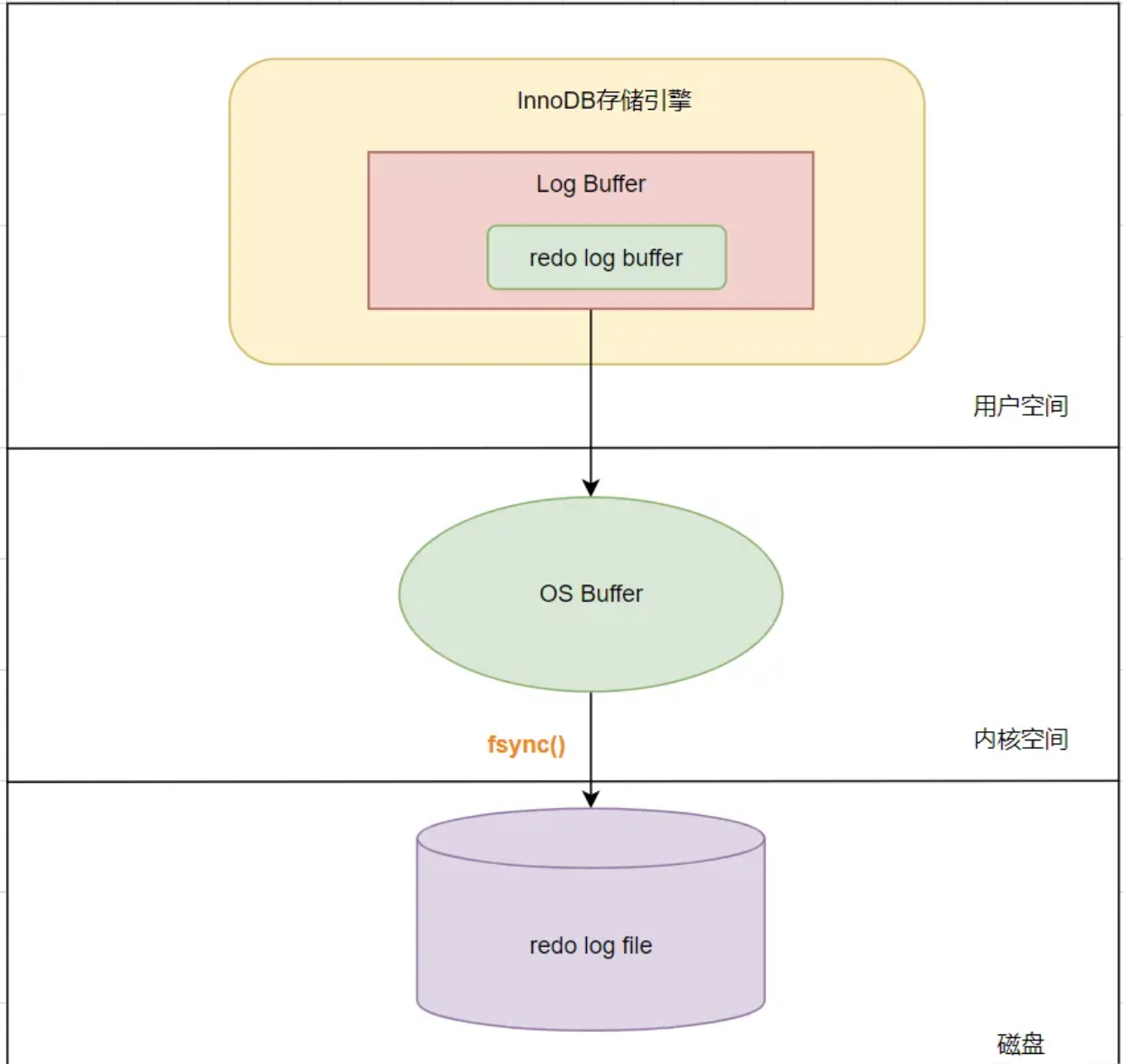
17. Cách ghi redo log?
Redo log bao gồm hai phần: bộ đệm nhật ký (redo log buffer) trong bộ nhớ và tệp nhật ký (redo log file) trên đĩa.
MySQL thực hiện mỗi câu lệnh DML, trước tiên sẽ ghi lại vào redo log buffer (không gian người dùng), sau đó lưu vào bộ đệm của hệ điều hành OS-buffer, và sau đó vào một thời điểm nào đó sẽ ghi lại nhiều thao tác vào redo log file (ghi vào đĩa). Kỹ thuật này gọi là WAL.
Có thể thấy, redo log buffer được ghi vào redo log file thông qua OS buffer. Thực tế, có thể cấu hình thông qua tham số innodb_flush_log_at_trx_commit, với các giá trị sau:
0: gọi là ghi trễ, khi cam kết giao dịch sẽ không ghi nhật ký trong redo log buffer vào OS buffer, mà sẽ ghi vào OS buffer mỗi giây và sau đó gọi ghi vào redo log file.1: gọi là ghi thời gian thực, khi cam kết giao dịch sẽ ghi nhật ký trong redo log buffer vào OS buffer và lưu vào redo log file mỗi lần.2: gọi là ghi thời gian thực, ghi trễ vào đĩa, khi cam kết giao dịch sẽ ghi vào OS buffer, sau đó mỗi giây sẽ ghi nhật ký vào redo log file.
18. Quy trình thực hiện của redo log?
Chúng ta cùng xem quy trình thực hiện của redo log, giả sử câu lệnh SQL như sau:
update T set a = 1 where id = 666- MySQL client gửi câu lệnh
update T set a = 1 where id = 666tới lớp MySQL Server. - Lớp MySQL Server nhận câu lệnh SQL, phân tích, tối ưu hóa và thực hiện các công việc liên quan, sau đó gửi kế hoạch thực hiện SQL tới lớp InnoDB Storage Engine để thực hiện.
- Lớp InnoDB Storage Engine ghi nhận thao tác a được sửa thành 1 vào bộ nhớ.
- Sau khi ghi vào bộ nhớ, sẽ cập nhật ghi chép trong redo log, thêm một dòng ghi chép với nội dung thực hiện thay đổi gì trên trang dữ liệu nào.
- Sau đó, đặt trạng thái của giao dịch thành
prepare, cho biết đã sẵn sàng cam kết giao dịch. - Khi lớp MySQL Server xử lý xong giao dịch, sẽ đặt trạng thái của giao dịch thành
commit, tức là cam kết giao dịch. - Sau khi nhận yêu cầu cam kết giao dịch, redo log sẽ ghi các thao tác đã ghi vào bộ nhớ vào đĩa, hoàn thành quá trình ghi nhật ký.
19. Binlog là gì, chức năng của nó là gì, và nó có đảm bảo an toàn khi gặp sự cố không?
- Binlog là nhật ký lưu trữ, thuộc về lớp MySQL Server. Nó có hai chức năng chính là sao chép chính-phụ và khôi phục dữ liệu.
- Khi cần khôi phục dữ liệu, có thể trích xuất binlog trong khoảng thời gian cụ thể để phát lại và khôi phục.
- Tuy nhiên, binlog không đảm bảo an toàn khi gặp sự cố vì trước khi sự cố xảy ra, binlog có thể chưa được ghi hoàn toàn vào MySQL. Do đó, cần phải kết hợp với redo log để đảm bảo an toàn khi gặp sự cố.
20. Giao dịch hai giai đoạn là gì?
MySQL chia quá trình ghi redo log thành hai bước: prepare và commit, xen giữa là quá trình ghi binlog, đó là "giao dịch hai giai đoạn".
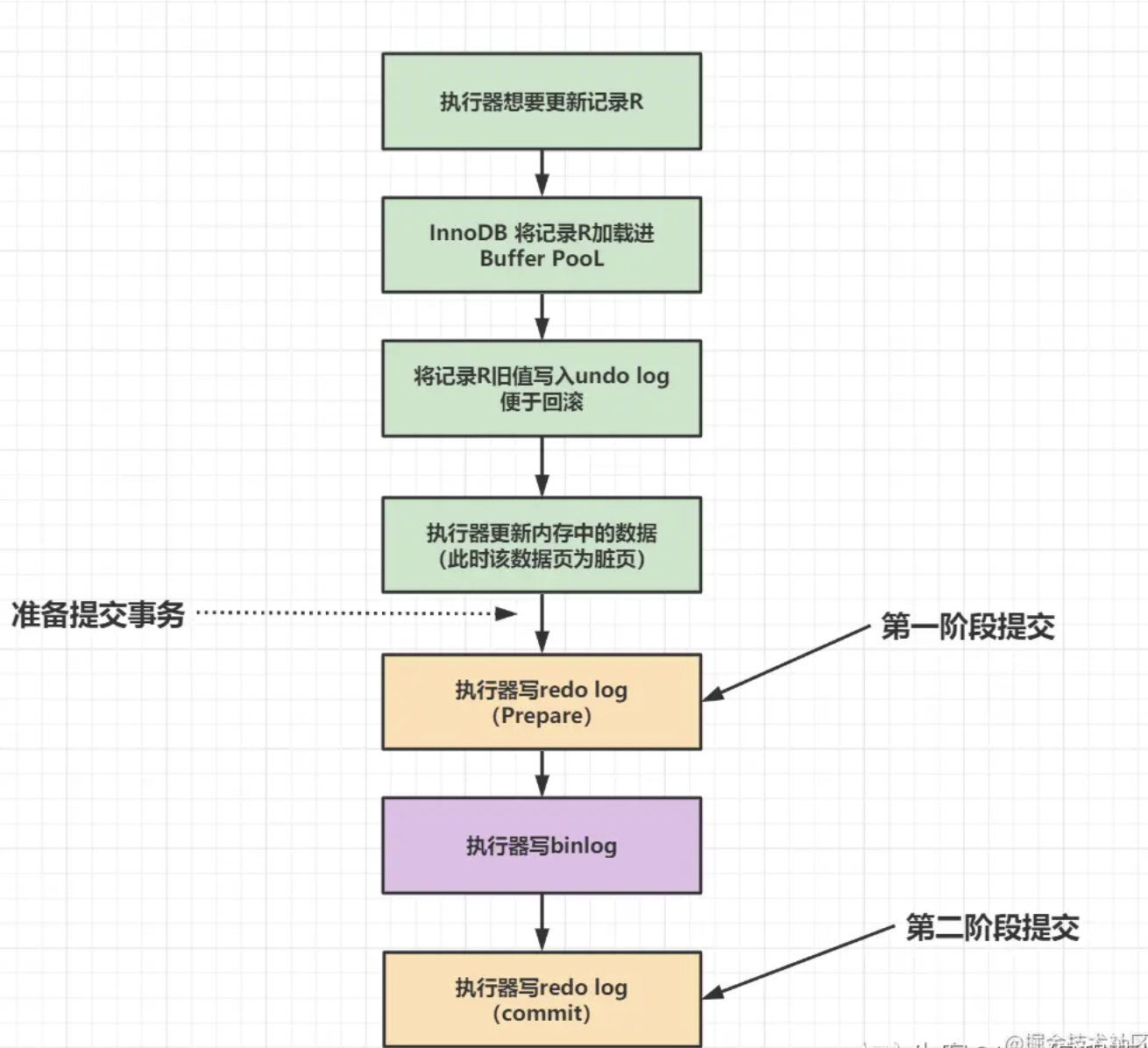
Giao dịch hai giai đoạn giúp đảm bảo hai trạng thái này duy trì tính nhất quán logic. Redo log dùng để khôi phục dữ liệu chưa cập nhật khi máy chủ gặp sự cố, binlog dùng cho sao lưu. Vì cả hai là hai thực thể độc lập, để giữ cho chúng nhất quán, cần sử dụng giải pháp giao dịch phân tán.
Tại sao cần giao dịch hai giai đoạn?
- Nếu không dùng giao dịch hai giai đoạn, có thể xảy ra các tình huống sau:
- Ghi redo log trước, sau đó gặp sự cố, quá trình sao lưu binlog sẽ thiếu một lần cập nhật, không nhất quán với dữ liệu hiện tại.
- Ghi binlog trước, sau đó gặp sự cố, do redo log chưa được ghi, giao dịch không hợp lệ, vì vậy khi sao lưu binlog, dữ liệu sẽ không nhất quán.
- Giao dịch hai giai đoạn đảm bảo sự nhất quán an toàn của dữ liệu giữa redo log và binlog. Chỉ khi hai tệp nhật ký này nhất quán logic, bạn mới có thể yên tâm sử dụng.
Khi khôi phục dữ liệu, nếu trạng thái của redo log là commit thì binlog cũng thành công, khôi phục dữ liệu trực tiếp; nếu redo log ở trạng thái prepare, cần kiểm tra xem giao dịch tương ứng trong binlog có thành công hay không để quyết định rollback hoặc tiếp tục thực hiện.
21. MySQL làm thế nào để biết binlog là hoàn chỉnh?
Binlog của một giao dịch có định dạng hoàn chỉnh:
- Đối với định dạng statement, binlog cuối cùng sẽ có COMMIT;
- Đối với định dạng row, binlog cuối cùng sẽ có một sự kiện XID.
22. WAL là gì và ưu điểm của nó là gì?
WAL, viết tắt của Write-Ahead Logging, có nghĩa là ghi nhật ký trước khi ghi vào đĩa. Sau khi MySQL thực hiện thao tác cập nhật, trước khi thực sự ghi dữ liệu vào đĩa, trước tiên sẽ ghi nhật ký.
Ưu điểm là không cần ghi dữ liệu vào đĩa ngay lập tức cho mỗi thao tác, ngay cả khi gặp sự cố, có thể khôi phục dữ liệu thông qua redo log, do đó có thể phản hồi nhanh chóng các câu lệnh SQL.
23. Các định dạng nhật ký binlog
Binlog có ba định dạng:
- Statement: Sao chép dựa trên câu lệnh (statement-based replication, SBR)
- Row: Sao chép dựa trên hàng (row-based replication, RBR)
- Mixed: Sao chép ở chế độ hỗn hợp (mixed-based replication, MBR)
Định dạng Statement
Mỗi câu lệnh SQL thay đổi dữ liệu đều được ghi lại trong binlog.
- Ưu điểm: Không cần ghi lại từng thay đổi của mỗi hàng, giảm lượng nhật ký binlog, tiết kiệm IO, cải thiện hiệu suất.
- Nhược điểm: Vì chỉ ghi lại câu lệnh thực hiện, để các câu lệnh này có thể chạy đúng trên máy chủ phụ, cần ghi lại một số thông tin liên quan khi thực hiện mỗi câu lệnh để đảm bảo tất cả các câu lệnh trên máy chủ phụ có kết quả giống như khi thực hiện trên máy chủ chính.
Định dạng Row
Không ghi lại thông tin liên quan đến câu lệnh SQL, chỉ lưu trữ hàng nào bị thay đổi.
- Ưu điểm: Binlog không cần ghi lại thông tin liên quan đến ngữ cảnh của câu lệnh SQL, chỉ cần ghi lại hàng nào bị thay đổi và thay đổi thành gì. Do đó, nội dung nhật ký row-level sẽ ghi chi tiết các thay đổi của từng hàng dữ liệu. Không gặp vấn đề về sao chép đúng trong một số tình huống nhất định như các thủ tục lưu trữ, hàm, hoặc trigger.
- Nhược điểm: Có thể tạo ra lượng lớn nội dung nhật ký.
Định dạng Mixed
Thực chất là sự kết hợp giữa Statement và Row. Các câu lệnh thay đổi thông thường sử dụng định dạng statement để lưu trữ binlog, như các hàm mà statement không thể thực hiện sao chép chính-phụ thì sử dụng định dạng row để lưu trữ binlog. MySQL sẽ dựa trên từng câu lệnh SQL cụ thể để quyết định định dạng nhật ký nào.
24. Định dạng nhật ký redo log
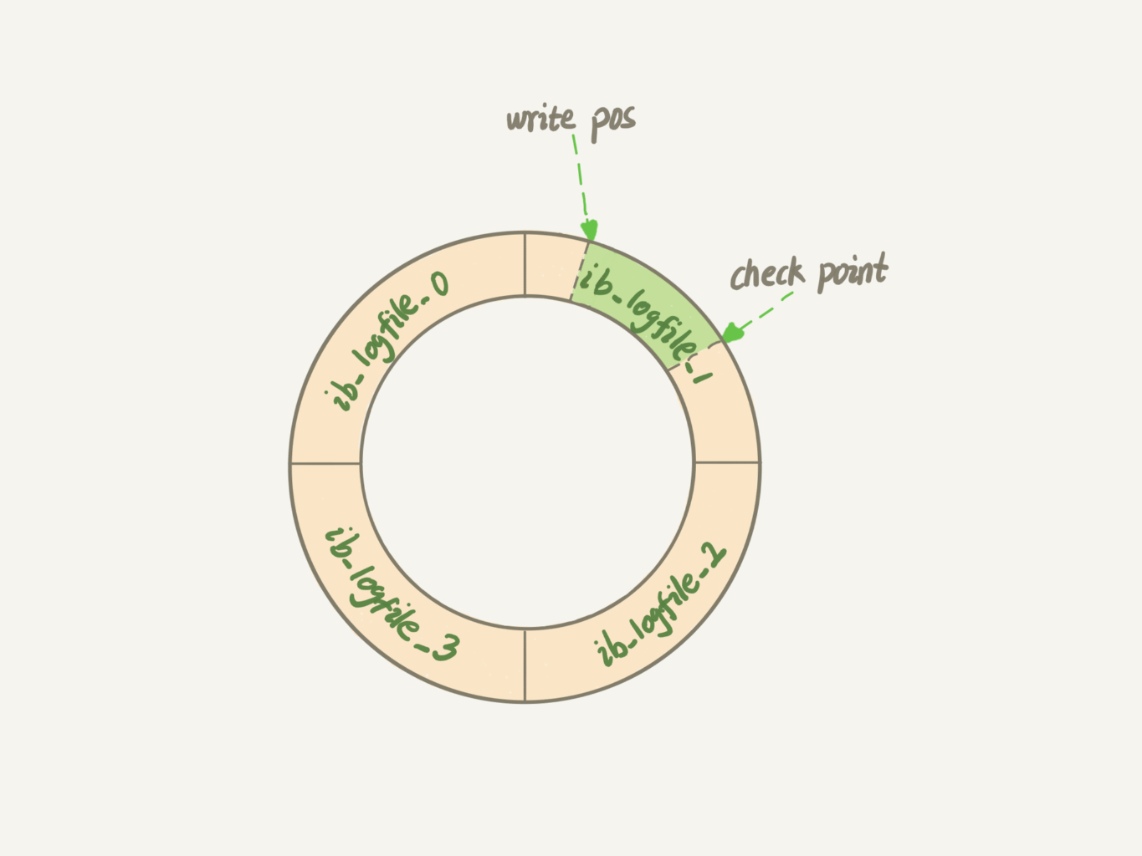
Redo log buffer (trong bộ nhớ) được tạo thành từ bốn tệp nối tiếp nhau, bao gồm: ib_logfile_1, ib_logfile_2, ib_logfile_3, ib_logfile_4.
- Write pos là vị trí hiện tại ghi nhật ký, khi ghi xong sẽ di chuyển về phía sau. Khi ghi đến cuối tệp thứ ba thì quay lại đầu tệp 0.
- Checkpoint là vị trí hiện tại cần xóa, cũng di chuyển về phía sau và lặp lại. Trước khi xóa nhật ký cần cập nhật nhật ký vào tệp dữ liệu.
- Khoảng trống giữa write pos và checkpoint là phần chưa được sử dụng, có thể ghi nhật ký mới.
- Nếu write pos đuổi kịp checkpoint, nghĩa là nhật ký đã đầy, không thể thực hiện các cập nhật mới mà phải dừng lại để xóa một số nhật ký, đẩy checkpoint về phía trước.
- Với redo log, khi cơ sở dữ liệu gặp sự cố và khởi động lại, có thể khôi phục dữ liệu chưa được ghi vào đĩa (dữ liệu sau checkpoint) từ redo log, đảm bảo các bản ghi giao dịch đã được hoàn thành không bị mất, khả năng này được gọi là crash-safe.
25. Những nguyên nhân gì khiến câu lệnh SQL đáng lẽ thực thi rất nhanh nhưng lại chạy chậm hơn dự kiến? Làm thế nào để giải quyết?
Nguyên nhân: Từ lớn đến nhỏ có thể chia thành bốn tình huống:
- MySQL bị tắc nghẽn, chẳng hạn như: tài nguyên hệ thống hoặc mạng không đủ.
- Câu lệnh SQL bị tắc nghẽn, chẳng hạn như: khóa bảng, khóa hàng, làm cho bộ máy lưu trữ không thực hiện câu lệnh SQL tương ứng.
- Do sử dụng chỉ mục không đúng, không sử dụng chỉ mục.
- Đặc điểm của dữ liệu trong bảng dẫn đến, mặc dù có chỉ mục nhưng số lần quay lại bảng rất lớn.
Giải pháp:
- Xem xét sử dụng force index để ép buộc chọn một chỉ mục.
- Xem xét sửa đổi câu lệnh, hướng dẫn MySQL sử dụng chỉ mục mà bạn mong muốn. Ví dụ, thay đổi "order by b limit 1" thành "order by b, a limit 1", logic ngữ nghĩa là tương đương.
- Phương pháp thứ ba là, trong một số tình huống, có thể tạo một chỉ mục phù hợp hơn để cung cấp cho bộ tối ưu hóa để lựa chọn, hoặc xóa chỉ mục bị sử dụng sai.
- Nếu xác định chỉ mục không cần thiết, có thể xem xét xóa chỉ mục.
26. Cấu trúc trang dữ liệu của InnoDB
Một trang dữ liệu được chia thành bảy phần:
- File Header: Biểu thị thông tin chung của trang, chiếm 38 byte cố định.
- Page Header: Biểu thị thông tin riêng của trang dữ liệu, chiếm 56 byte cố định.
- Minimum + Supermum: Hai bản ghi giả lập, lần lượt biểu thị bản ghi nhỏ nhất và lớn nhất trong trang, chiếm 26 byte cố định.
- User Records: Thực sự lưu trữ dữ liệu chúng ta chèn vào, kích thước không cố định.
- Free Space: Phần chưa được sử dụng trong trang, kích thước không cố định.
- Page Directory: Vị trí tương đối của một số bản ghi trong trang, nghĩa là địa chỉ của mỗi bản ghi trong trang.
- File Trailer: Dùng để kiểm tra trang có hoàn chỉnh không, chiếm 8 byte cố định.
Các khái niệm liên quan đến dữ liệu
27. MySQL đảm bảo dữ liệu không bị mất như thế nào?
- Chỉ cần
redologvàbinlogđảm bảo được ghi vào đĩa thì có thể đảm bảo dữ liệu của MySQL có thể được khôi phục sau khi khởi động lại do lỗi. - Khi khôi phục dữ liệu, nếu trạng thái
redologlàcommitthì có nghĩa làbinlogcũng đã thành công, dữ liệu được khôi phục trực tiếp; nếu trạng tháiredologlàprepare, cần kiểm tra giao dịchbinlogtương ứng có thành công hay không để quyết định khôi phục hoặc rollback.
28. Làm gì khi dữ liệu bị xóa nhầm?
Công việc cốt lõi của DBA là đảm bảo tính toàn vẹn của dữ liệu. Trước tiên, cần thực hiện các biện pháp phòng ngừa thông qua các điểm sau:
- Kiểm soát và phân quyền (quyền hạn của cơ sở dữ liệu và máy chủ)
- Thiết lập quy trình thao tác
- Đào tạo định kỳ cho các nhà phát triển
- Xây dựng bản sao lưu trễ
- Thực hiện kiểm tra SQL, tất cả các câu lệnh thay đổi dữ liệu trên môi trường trực tuyến (DML và DDL) cần được kiểm tra kỹ lưỡng
- Thực hiện sao lưu. Có hai phương pháp sao lưu:
- Nếu dữ liệu lớn, sử dụng sao lưu vật lý
xtrabackup. Thực hiện sao lưu toàn bộ định kỳ và có thể sao lưu gia tăng. - Nếu dữ liệu nhỏ, sử dụng
mysqldumphoặcmysqldumper. Sau đó khôi phục bằngbinloghoặc xây dựng cấu hình master-slave để khôi phục dữ liệu. Định kỳ sao lưu tệpbinlogcũng rất cần thiết.
- Nếu dữ liệu lớn, sử dụng sao lưu vật lý
- Khi xảy ra thao tác xóa dữ liệu, có thể khôi phục theo các phương pháp sau:
- Nếu thao tác DML gây mất hoặc không hoàn chỉnh dữ liệu, có thể sử dụng
flashbackhoặc công cụmyflashcủa Meituan. Cả hai đều phân tích sự kiệnbinlogvà thực hiện đảo ngược các thao tác nhưdeletethànhinsert,insertthànhdelete, hoán đổi ảnh trước và sau củaupdate. Điều này đòi hỏibinlog_formatphải làrowvàbinlog_row_imagelàfull. Khôi phục dữ liệu trước tiên nên thực hiện trên instance tạm thời, sau đó khôi phục lên master. - Nếu thao tác DDL như
truncatehoặcdropxảy ra, do DDL không ghi hình ảnh (image) trongbinlog, nên khôi phục sẽ phức tạp hơn, cần sử dụng phương pháp sao lưu toàn bộ và áp dụngbinlog. Khi dữ liệu lớn, thời gian khôi phục sẽ rất lâu. - Khi lệnh
rmxóa dữ liệu, sử dụng sao lưu lưu trữ ở trung tâm dữ liệu khác hoặc tốt nhất là ở thành phố khác.
- Nếu thao tác DML gây mất hoặc không hoàn chỉnh dữ liệu, có thể sử dụng
29. Sự khác biệt giữa drop, truncate và delete
- Lệnh
DELETExóa từng dòng trong bảng và ghi lại thao tác xóa vào nhật ký để có thể rollback. - Lệnh
TRUNCATE TABLExóa tất cả dữ liệu trong bảng mà không ghi lại từng thao tác xóa vào nhật ký, nên không thể khôi phục. Quá trình xóa không kích hoạt trigger liên quan và thực thi nhanh chóng. - Lệnh
dropgiải phóng toàn bộ không gian bảng. - Về tốc độ,
drop>truncate>delete. - Nếu muốn xóa một phần dữ liệu, sử dụng
deletevới điều kiệnwherevà đảm bảo vùng rollback đủ lớn. - Nếu muốn xóa bảng, sử dụng
drop; nếu muốn giữ bảng nhưng xóa tất cả dữ liệu, sử dụngtruncatenếu không liên quan đến giao dịch. - Nếu liên quan đến giao dịch hoặc cần trigger, sử dụng
delete. Nếu cần sắp xếp lại các đoạn trống trong bảng, sử dụngtruncatevớireuse storage, sau đó nhập lại dữ liệu.
30. Có hai lệnh kill trong MySQL
kill query + id luồng, chấm dứt câu lệnh đang chạy trong luồng đó.kill connection + id luồng(hoặckill + id luồng), ngắt kết nối của luồng đó.
Lý do lệnh kill không hoạt động:
- Lệnh
killbị chặn và chưa đến nơi. - Lệnh
killđã đến nơi nhưng chưa được kích hoạt ngay lập tức. - Lệnh
killđã được kích hoạt nhưng cần thời gian để hoàn tất.
31. Hiểu như thế nào về việc đọc và gửi dữ liệu đồng thời trong MySQL
- Nếu khách hàng nhận dữ liệu chậm, MySQL sẽ gặp khó khăn trong việc gửi kết quả, làm kéo dài thời gian thực thi giao dịch.
- Máy chủ không cần lưu trữ toàn bộ tập kết quả, quá trình lấy và gửi dữ liệu được thực hiện thông qua
next_buffer. - Các trang dữ liệu trong bộ nhớ được quản lý trong
Buffer_Pool. - InnoDB quản lý
Buffer_Poolbằng thuật toán LRU cải tiến, sử dụng danh sách liên kết và chia tỷ lệ 5:3 thành các khu vựcyoungvàold.
32. Tại sao truy vấn bảng lớn trong MySQL không làm đầy bộ nhớ?
- MySQL gửi dữ liệu đồng thời khi đọc, nên không cần lưu trữ toàn bộ tập kết quả trên máy chủ. Nếu khách hàng nhận dữ liệu chậm, quá trình truy vấn MySQL sẽ bị chặn nhưng không làm đầy bộ nhớ.
- Nội bộ InnoDB có chiến lược loại bỏ, quản lý
Buffer_Poolbằng thuật toán LRU cải tiến. InnoDB chia danh sách liên kết LRU theo tỷ lệ 5:3 thành các khu vựcyoungvàold. Việc quét toàn bộ dữ liệu lạnh cũng có thể được kiểm soát.
33. Cách sử dụng và đặc tính của bảng tạm thời trong MySQL
- Chỉ hiển thị cho session hiện tại.
- Có thể trùng tên với bảng thường.
- Sử dụng để thêm, xóa, sửa, truy vấn dữ liệu tạm thời.
show tableskhông hiển thị bảng tạm thời.- Trong ứng dụng thực tế, bảng tạm thời thường dùng để xử lý các logic tính toán phức tạp.
- Vì bảng tạm thời chỉ hiển thị cho từng luồng riêng lẻ, không cần lo lắng về việc trùng tên khi nhiều luồng thực thi cùng một xử lý. Bảng tạm thời sẽ tự động xóa khi luồng kết thúc.
34. Giới thiệu các bộ máy lưu trữ MySQL (InnoDB, MyISAM, MEMORY)
- InnoDB là bộ máy lưu trữ chính cho cơ sở dữ liệu giao dịch, hỗ trợ bảng an toàn giao dịch (ACID), khóa dòng và khóa ngoại. Từ MySQL 5.5.5 trở đi, InnoDB là bộ máy lưu trữ mặc định.
- MyISAM dựa trên ISAM và mở rộng thêm. Đây là bộ máy lưu trữ phổ biến trong các ứng dụng web, lưu trữ dữ liệu và các môi trường khác. MyISAM có tốc độ chèn và truy vấn cao nhưng không hỗ trợ giao dịch. Trước phiên bản MySQL 5.5.5, MyISAM là bộ máy lưu trữ mặc định.
- MEMORY lưu trữ dữ liệu trong bộ nhớ, cung cấp truy cập nhanh cho các truy vấn và tham chiếu dữ liệu từ bảng khác.
35. InnoDB tốt, nhưng có nên sử dụng bộ máy MEMORY không?
- Bảng bộ nhớ là bảng được tạo bằng bộ máy MEMORY.
- Tôi không khuyến khích sử dụng bảng bộ nhớ trong môi trường sản xuất vì các lý do chính sau: vấn đề khóa hạt mịn và vấn đề lưu trữ dữ liệu.
- Do dữ liệu bị mất khi khởi động lại, nếu một máy sao lưu khởi động lại, nó sẽ dừng đồng bộ hóa từ máy chủ chính. Nếu cấu hình master-master, dữ liệu bảng bộ nhớ trên máy chủ chính cũng có thể bị xóa.
36. Làm thế nào để khôi phục dữ liệu khi thao tác nhầm trên cơ sở dữ liệu?
Khi xảy ra thao tác nhầm, tìm đến binlog gần nhất với thời điểm thao tác nhầm, phát lại trên cơ sở dữ liệu tạm thời, sau đó chọn dữ liệu bị xóa nhầm và khôi phục lại trên cơ sở dữ liệu chính.
Liên quan đến sao lưu chính phụ
37. MySQL đảm bảo đồng bộ chính phụ như thế nào?
Thiết lập quan hệ chính phụ:
- Ban đầu, khi thiết lập quan hệ chính phụ, là do phụ định trước, ví dụ dựa trên quan hệ chính phụ theo điểm vị trí, phụ sẽ nói "Tôi muốn đồng bộ từ vị trí P của tệp binlog A", và chính sẽ bắt đầu gửi từ vị trí đó.
- Sau khi thiết lập quan hệ chính phụ, chính quyết định gửi dữ liệu nào cho phụ, do đó, khi chính có nhật ký mới sẽ gửi cho phụ.
Quy trình chuyển đổi chính phụ trong MySQL:
- Khách hàng đọc và ghi đều trực tiếp truy cập vào A, trong khi B là phụ, chỉ cần đồng bộ hóa các cập nhật của A đến B để đảm bảo dữ liệu là giống nhau.
- Khi cần chuyển đổi, chỉ cần đổi vị trí, tức là B trở thành chính và A trở thành phụ.
Quá trình đồng bộ hóa một giao dịch hoàn chỉnh:
- Phụ B và chính A thiết lập một kết nối dài, trong A có một luồng chuyên dụng để duy trì kết nối dài này.
- Trên phụ B, sử dụng lệnh
changemasterđể thiết lập địa chỉ IP, cổng, tên người dùng và mật khẩu của chính A cũng như bắt đầu yêu cầu binlog từ vị trí nào, bao gồm tên tệp và độ lệch nhật ký. - Trên phụ B, thực hiện lệnh
start-slave, phụ sẽ khởi động hai luồng:io_threadvàsql_threadđể thiết lập kết nối và đọc, phân tích và thực thi nhật ký trung gian. - Phụ đọc tệp binlog mà chính đã gửi và ghi lại vào nhật ký trung gian.
- Sau này, do giới thiệu của phương pháp sao chép đa luồng,
sql_threadđã phát triển thành nhiều luồng.
38. Độ trễ chính phụ là gì?
Độ trễ giữa chính và phụ khi thực hiện cùng một giao dịch xảy ra do:
- Trong một số điều kiện triển khai, hiệu suất của máy phụ kém hơn so với chính.
- Áp lực lớn trên phụ.
- Giao dịch lớn, nếu một câu lệnh trên chính mất 10 phút để thực hiện, thì giao dịch này có thể gây ra độ trễ 10 phút trên phụ.
39. Tại sao cần có chiến lược sao chép đa luồng?
- Vì khả năng sao chép đơn luồng hoàn toàn thấp hơn so với sao chép đa luồng, đối với chính có áp lực cập nhật lớn, phụ có thể không bao giờ theo kịp chính, dẫn đến giá trị
seconds_behind_mastertrên phụ ngày càng lớn. - Trong ứng dụng thực tế, nên sử dụng chiến lược ưu tiên độ tin cậy để giảm độ trễ chính phụ, tăng tính khả dụng của hệ thống và giảm thiểu thao tác giao dịch lớn, chia nhỏ giao dịch lớn thành giao dịch nhỏ.
40. Các chiến lược song song của MySQL là gì?
- Chiến lược phân phối theo bảng: Nếu hai giao dịch cập nhật các bảng khác nhau, chúng có thể song song. Do dữ liệu được lưu trữ trong bảng, nên phân phối theo bảng có thể đảm bảo hai worker không cập nhật cùng một dòng. Nhược điểm: Nếu gặp bảng nóng, tức là tất cả các giao dịch cập nhật đều liên quan đến một bảng, thì tất cả các giao dịch sẽ được phân bổ vào một worker, trở thành sao chép đơn luồng.
- Chiến lược phân phối theo dòng: Nếu hai giao dịch không cập nhật cùng một dòng, chúng có thể song song trên phụ. Rõ ràng, chế độ này yêu cầu định dạng binlog phải là
row. Nhược điểm: So với chiến lược phân phối song song theo bảng, chiến lược phân phối song song theo dòng cần tốn nhiều tài nguyên tính toán hơn khi quyết định phân phối luồng.
41. Sự khác biệt giữa một chính một phụ và một chính nhiều phụ trong MySQL là gì?
Trong cấu trúc một chính một phụ của mô hình M kép, chuyển đổi chính phụ chỉ cần chuyển lưu lượng khách hàng sang phụ; trong khi trong cấu trúc một chính nhiều phụ, chuyển đổi chính phụ không chỉ cần chuyển lưu lượng khách hàng sang phụ mà còn cần kết nối các phụ với chính mới.
42. Làm thế nào để giải quyết vấn đề khi chính gặp sự cố?
- Chuyển đổi chính phụ dựa trên điểm vị trí: Có vấn đề tìm điểm đồng bộ hóa.
- Phiên bản MySQL 5.6 đã giới thiệu GTID, giải quyết triệt để vấn đề này. GTID là gì và làm thế nào để giải quyết vấn đề tìm điểm đồng bộ hóa?
- GTID (Global Transaction ID): ID giao dịch toàn cầu, được tạo ra khi giao dịch được cam kết, là định danh duy nhất của giao dịch này; nó bao gồm hai phần, định dạng là: GTID=server_uuid:gno.
- Mỗi phiên bản MySQL duy trì một tập hợp GTID để tương ứng với "tất cả các giao dịch mà phiên bản này đã thực hiện".
- Trong quan hệ chính phụ dựa trên GTID, hệ thống cho rằng chỉ cần thiết lập quan hệ chính phụ thì phải đảm bảo rằng nhật ký mà chính gửi cho phụ là đầy đủ. Do đó, nếu phụ B yêu cầu nhật ký không còn tồn tại, A' sẽ từ chối gửi nhật ký cho B.
43. Các giải pháp cho vấn đề đọc quá hạn liên quan đến phân tách đọc ghi trong MySQL là gì?
- Giải pháp bắt buộc truy cập chính.
- Giải pháp sử dụng
sleep. - Giải pháp xác định không có độ trễ chính phụ.
- Giải pháp kết hợp semi-sync.
- Giải pháp chờ điểm vị trí của chính.
- Giải pháp GTID.
- Trong sản xuất thực tế, đầu tiên phân loại yêu cầu của khách hàng, phân biệt yêu cầu nào có thể chấp nhận đọc quá hạn và yêu cầu nào không thể chấp nhận đọc quá hạn; sau đó, đối với các câu lệnh không thể chấp nhận đọc quá hạn, sử dụng giải pháp chờ GTID hoặc chờ điểm vị trí.
44. Sự khác biệt giữa kết nối đồng thời và truy vấn đồng thời trong MySQL là gì?
- Trong kết quả của lệnh
show processlist, nhìn thấy hàng ngàn kết nối, đó là kết nối đồng thời. Còn các câu lệnh "đang thực hiện" mới là truy vấn đồng thời. - Số lượng kết nối đồng thời lớn ảnh hưởng đến bộ nhớ, số lượng truy vấn đồng thời cao ảnh hưởng đến CPU. Một máy tính có số lượng lõi CPU hạn chế, nếu tất cả các luồng cùng thực hiện, chi phí chuyển đổi ngữ cảnh sẽ quá cao.
- Do đó, cần thiết lập tham số
innodb_thread_concurrencyđể giới hạn số lượng luồng. Khi số lượng luồng đạt đến tham số này, InnoDB sẽ coi như số lượng luồng đã dùng hết và sẽ ngăn chặn các câu lệnh khác vào động cơ thực thi.
Liên quan đến hiệu suất
45. Cách nâng cao hiệu suất MySQL trong thời gian ngắn
- Phương pháp thứ nhất: Xử lý các kết nối đang chiếm giữ nhưng không hoạt động. Hoặc cân nhắc ngắt kết nối trong giao dịch đã rảnh rỗi quá lâu.
kill connection + id. - Phương pháp thứ hai: Giảm thiểu chi phí của quá trình kết nối: Vấn đề hiệu suất truy vấn chậm trong MySQL có thể gây ra các vấn đề về hiệu suất, có ba khả năng chính: Thiết kế chỉ mục không tốt; Câu lệnh SQL viết không tốt; MySQL chọn sai chỉ mục (dùng
force index).
46. Tại sao ID khóa chính tự tăng của MySQL không liên tục?
Xung đột khóa duy nhất.
Giao dịch bị quay lui.
Yêu cầu tăng số lượng khóa chính tự tăng.
Nguyên nhân sâu xa là MySQL không kiểm tra sự tồn tại của khóa chính tự tăng, nhằm giảm phạm vi và mức độ khóa, do đó có thể duy trì hiệu suất cao hơn, đảm bảo khóa chính tự tăng không thể quay lui, vì vậy khóa chính tự tăng không liên tục.
Làm thế nào để khóa chính tự tăng đạt được tính duy nhất? Giá trị tự tăng thêm 1 và kiểm soát đồng thời thông qua khóa tự tăng.
47. Tại sao InnoDB sử dụng ID tự tăng làm khóa chính?
Chế độ chèn khóa chính tự tăng phù hợp với chèn tăng dần, mỗi lần đều là thao tác bổ sung, không liên quan đến di chuyển bản ghi, cũng không kích hoạt phân chia nút lá.
Mỗi lần chèn bản ghi mới sẽ được thêm tuần tự vào vị trí tiếp theo của nút chỉ mục hiện tại, khi một trang được viết đầy, sẽ tự động mở ra một trang mới.
Trong khi các trường có logic nghiệp vụ làm khóa chính, không dễ đảm bảo chèn theo thứ tự, do mỗi lần chèn giá trị khóa chính gần như ngẫu nhiên.
Do đó, mỗi bản ghi mới đều phải được chèn vào một vị trí nào đó giữa các trang chỉ mục hiện có, việc di chuyển và phân trang thường xuyên gây ra nhiều mảnh vụn, dẫn đến cấu trúc chỉ mục không đủ chặt chẽ, chi phí ghi dữ liệu cao.
48. Cách sao chép một bảng nhanh nhất?
- Để tránh khóa đọc trên bảng nguồn, phương pháp an toàn hơn là viết dữ liệu ra tệp văn bản bên ngoài, sau đó ghi lại vào bảng đích.
- Một cách là sử dụng lệnh
mysqldumpđể xuất dữ liệu thành một tập hợp các câu lệnhINSERT. - Cách khác là xuất trực tiếp kết quả thành tệp
.csv. MySQL cung cấp cú pháp để xuất kết quả truy vấn ra thư mục cục bộ của máy chủ:select * from db1.t where a>900 into outfile '/server_tmp/t.csv'; sau khi có tệp xuất.csv, bạn có thể sử dụng lệnhload datasau đây để nhập dữ liệu vào bảng đíchdb2.t:load data infile '/server_tmp/t.csv' into table db2.t;. - Sao chép vật lý: Phiên bản MySQL 5.6 đã giới thiệu phương pháp không gian bảng có thể truyền tải (transportable tablespace), có thể thực hiện sao chép vật lý bảng thông qua xuất và nhập không gian bảng.
49. Lệnh grant và flush privileges
- Lệnh
grantsẽ đồng thời sửa đổi bảng dữ liệu và bộ nhớ, việc xác định quyền sử dụng dữ liệu trong bộ nhớ, do đó, sử dụng đúng cách không cần thêm lệnhflush privileges. - Lệnh
flush privilegessẽ xây dựng lại dữ liệu quyền bộ nhớ từ dữ liệu bảng, do đó, chỉ sử dụng khi dữ liệu quyền có thể không nhất quán.
50. Có nên sử dụng bảng phân vùng?
- Phân vùng không phải là càng nhỏ càng tốt. Thực tế, bảng đơn hoặc phân vùng đơn có dữ liệu 10 triệu dòng, nếu không có chỉ mục quá lớn, đối với khả năng phần cứng hiện tại, vẫn được coi là bảng nhỏ.
- Cũng không cần dự trữ quá nhiều phân vùng trước, chỉ cần tạo trước khi sử dụng. Ví dụ, nếu phân vùng theo tháng, vào cuối năm có thể tạo trước 12 phân vùng mới cho năm tiếp theo. Đối với các phân vùng lịch sử không có dữ liệu, cần xóa bỏ kịp thời.
51. Cách sử dụng join
- Sử dụng
left join, bảng bên trái không nhất thiết là bảng dẫn. - Nếu cần ngữ nghĩa
left join, không nên đặt các trường của bảng dẫn vào điều kiệnwheređể thực hiện so sánh bằng hoặc không bằng, mà phải viết trongon. - Câu lệnh
group bytiêu chuẩn cần có hàm tổng hợp trong phầnselect, ví dụ:select a, count(*) from t group by a order by null;.
52. MySQL có những ID tự tăng nào? Các trường hợp sử dụng của chúng là gì?
Khi ID tự tăng của bảng đạt giới hạn, việc yêu cầu giá trị sẽ không thay đổi, dẫn đến lỗi xung đột khóa chính khi chèn dữ liệu liên tục.
Khi
row_idđạt giới hạn, sẽ quay về 0 và tăng lại, nếu xuất hiệnrow_idtrùng lặp, dữ liệu ghi sau sẽ ghi đè dữ liệu trước đó.Xidchỉ cần không xuất hiện giá trị trùng lặp trong cùng một tệp binlog là được, lý thuyết có thể xuất hiện giá trị trùng lặp nhưng xác suất cực nhỏ, có thể bỏ qua.Giá trị tăng của
max_trx_idtrong InnoDB sẽ được lưu lại mỗi lần MySQL khởi động lại.Xidđược duy trì bởi lớp server. InnoDB sử dụngXidđể làm liên kết giữa giao dịch InnoDB và server. Tuy nhiên,trx_idcủa InnoDB là do InnoDB tự duy trì.thread_idlà ID tự tăng phổ biến nhất trong quá trình sử dụng và cũng được xử lý tốt nhất, sử dụng thuật toáninsert_unique.
53. Xid trong MySQL được tạo ra như thế nào?
MySQL nội bộ duy trì một biến toàn cục global_query_id, mỗi lần thực hiện câu lệnh (bao gồm cả câu lệnh select) sẽ gán giá trị của nó cho Query_id, sau đó tăng biến này lên 1. Nếu câu lệnh hiện tại là câu lệnh đầu tiên của giao dịch, MySQL cũng sẽ gán giá trị Query_id cho Xid của giao dịch này.
global_query_id là một biến trong bộ nhớ, sẽ được đặt lại về 0 khi khởi động lại. Do đó, trong cùng một phiên bản cơ sở dữ liệu, Xid của các giao dịch khác nhau có thể trùng lặp. Tuy nhiên, MySQL sẽ tạo ra tệp binlog mới khi khởi động lại, đảm bảo rằng trong cùng một tệp binlog, Xid là duy nhất.
Liên quan đến khóa
54. Nói về khóa của MySQL
- MySQL sử dụng nhiều loại khóa ở cả lớp server và lớp lưu trữ.
- Lớp server của MySQL cần nhắc đến hai loại khóa: khóa MDL (metadata lock) và khóa bảng (Table Lock).
- MDL còn được gọi là khóa siêu dữ liệu. Siêu dữ liệu là bất kỳ thông tin nào mô tả cơ sở dữ liệu, chẳng hạn như cấu trúc bảng, cấu trúc cơ sở dữ liệu, v.v. Tại sao cần khóa MDL?
- Chủ yếu giải quyết hai vấn đề: vấn đề cách ly giao dịch và vấn đề sao chép dữ liệu.
- InnoDB có năm loại khóa bảng: IS (ý định đọc), IX (ý định viết), S (đọc), X (viết), AUTO-INC.
- Khi thực hiện các lệnh select/insert/delete/update trên bảng sẽ không thêm khóa bảng.
- IS và IX dùng để xác định xem trong bảng có bản ghi nào đã được khóa hay không.
- Khóa tự tăng (AUTO-INC) đảm bảo giá trị tự tăng của khóa chính, ở cấp độ câu lệnh: khi thêm cột AUTO_INCREMENT vào bảng, mỗi lần chèn bản ghi, giá trị của cột này sẽ tự động tăng lên.
- InnoDB có bốn loại khóa hàng:
- RecordLock: Khóa bản ghi.
- GapLock: Khóa khoảng cách để giải quyết vấn đề đọc ảo; khi một truy vấn trước đó không tìm thấy dữ liệu nhưng truy vấn sau đó lại tìm thấy, điều này xảy ra do có giao dịch B chèn dữ liệu giữa hai lần truy vấn của giao dịch A.
- Next-KeyLock: Khóa bản ghi hiện tại và ngăn chặn giao dịch khác chèn bản ghi mới vào khoảng cách trước bản ghi này.
- InsertIntentionLock: Khóa ý định chèn; nếu nhiều giao dịch chèn vào cùng một khoảng cách mà không cùng vị trí, thì không cần chờ đợi.
- Lựa chọn giữa khóa hàng và khóa bảng:
- Sử dụng khóa hàng khi thực hiện quét toàn bộ bảng.
55. Thế nào là đọc ảo (phantom read)?
- Đọc ảo xảy ra khi trong cùng một giao dịch, có hai lần truy vấn cùng một phạm vi dữ liệu, nhưng lần thứ hai thấy dữ liệu mà lần đầu không thấy.
Các tình huống dẫn đến đọc ảo:
- Mức cách ly của giao dịch là Đọc lặp lại (Repeatable Read), và là đọc hiện tại (Read commited).
- Đọc ảo đề cập đến các hàng mới được chèn.
Vấn đề do đọc ảo gây ra:
- Phá vỡ ngữ nghĩa khóa hàng.
- Phá vỡ tính nhất quán dữ liệu.
Giải pháp:
- Thêm khóa khoảng cách để khóa khoảng cách giữa các hàng, ngăn chặn thao tác chèn mới.
- Vấn đề do đó gây ra: giảm độ đồng thời, có thể dẫn đến deadlock.
Những câu hỏi khác
56. Tại sao MySQL lại thỉnh thoảng chậm lại?
- Các trang bẩn (dirty page) sẽ được flush tự động bởi các luồng nền, hoặc do loại bỏ trang dữ liệu mà gây ra flush. Quá trình flush trang bẩn sử dụng tài nguyên, có thể làm tăng thời gian phản hồi của các lệnh cập nhật và truy vấn.
57. Tại sao sau khi xóa bảng, kích thước tệp bảng vẫn không thay đổi?
- Sau khi xóa dữ liệu, một trang trong InnoDB có thể được đánh dấu là có thể sử dụng lại.
- Lệnh delete xóa toàn bộ dữ liệu trong bảng, kết quả là, tất cả các trang dữ liệu sẽ được đánh dấu là có thể sử dụng lại. Nhưng trên đĩa, kích thước tệp sẽ không thay đổi.
- Các bảng đã trải qua nhiều lần thêm, xóa, sửa đổi có thể có các khoảng trống. Các khoảng trống này cũng chiếm dung lượng, vì vậy, nếu có thể loại bỏ các khoảng trống này, ta có thể giảm kích thước bảng.
- Việc xây dựng lại bảng có thể đạt được mục tiêu này. Có thể sử dụng lệnh
alter table A engine=InnoDBđể xây dựng lại bảng.
58. Cách thực hiện count(*) và so sánh các loại count
- Đối với
count(id chính), InnoDB sẽ duyệt toàn bộ bảng, lấy ra giá trị id của mỗi hàng và trả về cho lớp server. Lớp server sau đó kiểm tra id và cộng dồn. - Đối với
count(1), InnoDB duyệt toàn bộ bảng nhưng không lấy giá trị. Lớp server nhận mỗi hàng và chèn một số “1” vào, kiểm tra không null và cộng dồn. So vớicount(id chính),count(1)nhanh hơn vì không cần lấy và sao chép giá trị trường. - Đối với
count(trường), nếu trường được định nghĩa là not null, mỗi hàng được đọc và kiểm tra không null rồi cộng dồn. Nếu trường có thể null, phải lấy giá trị ra kiểm tra trước khi cộng dồn. count(*)được tối ưu hóa, không lấy giá trị mà chỉ cộng dồn.- Kết luận: hiệu suất từ thấp đến cao là
count(trường) < count(id chính) < count(1) ≈ count(*), do đó, nên sử dụngcount(*)khi có thể.
59. Nguyên lý sắp xếp orderby
- MySQL sẽ cấp phát một bộ nhớ (sort-buffer) cho mỗi luồng để sắp xếp, kích thước là sort_buffer_size.
- Nếu lượng dữ liệu sắp xếp nhỏ hơn sort_buffer_size, việc sắp xếp sẽ hoàn thành trong bộ nhớ.
- Có hai loại sắp xếp nội bộ:
- Sắp xếp toàn bộ trường: tìm id chính thỏa điều kiện trong cây chỉ mục, lấy dữ liệu và đặt vào sort_buffer, sau đó sắp xếp.
- Sắp xếp rowid: kiểm soát độ dài dữ liệu sắp xếp để tối đa hóa số lượng dữ liệu trong sort_buffer.
- Nếu lượng dữ liệu lớn, không đủ bộ nhớ, sẽ sử dụng tệp tạm thời trên đĩa để hỗ trợ sắp xếp, gọi là sắp xếp bên ngoài.
- Sắp xếp bên ngoài: MySQL sẽ chia dữ liệu thành nhiều tệp tạm thời, mỗi tệp sắp xếp riêng rồi hợp nhất thành một tệp lớn.
60. Cách sử dụng MySQL để chọn ngẫu nhiên một cách hiệu quả
- Lấy ngẫu nhiên Y1, Y2, Y3, sau đó tính Ymax, Ymin.
- Sau khi có id, tính toán Y1, Y2, Y3 tương ứng với ba id, cuối cùng
select * from t where id in (id1, id2, id3), số hàng được quét là C + Ymax + 3.
mysql> select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
Ymax = max(Y1,Y2,Y3)
Ymin = min(Y1,Y2,Y3)
select id from t limit Ymin, (Ymax - Ymin)