JVM Questions
Phỏng vấn JVM cấp tốc
Bạn có thể giải thích JVM là gì không? Nó hoạt động như thế nào?
Chúng ta đều biết rằng trong hệ thống Windows, một gói cài đặt phần mềm là tệp exe, đúng không? Nhưng trong MacOS, tệp exe không thể cài đặt được, chỉ có thể cài đặt các gói có đuôi dmg. Tương tự như vậy, gói cài đặt trong hệ thống Mac không thể cài đặt trên Windows.
Vậy tại sao phần mềm không thể sử dụng chung giữa các hệ điều hành khác nhau? Điều này là do cách triển khai cơ bản của hệ điều hành là khác nhau, và machine code được tạo ra không thể sử dụng chung. Tuy nhiên, những ai đã học Java đều biết rằng sau khi đóng gói thành tệp Jar, không quan trọng là ở Windows, MacOS hay Linux, Java vẫn có thể chạy được, đúng không?
Vậy Java làm cách nào để thực hiện điều này? "Anh hùng" đứng sau đó chính là JVM của chúng ta. Khác với các ngôn ngữ khác, mã Java sau khi biên dịch không phải là machine code trực tiếp, mà là bytecode chỉ JVM mới có thể nhận diện. Không quan trọng Java chạy trên môi trường nào, chỉ cần JVM có thể cài đặt, chương trình Java có thể chạy trực tiếp.
JVM đóng vai trò như một trình thông dịch, biên dịch động mã Java thành machine code mà hệ điều hành có thể nhận diện. Điều này giúp Java thực hiện được tầm nhìn "Write Once, Run Anywhere" (Viết một lần, chạy ở mọi nơi).
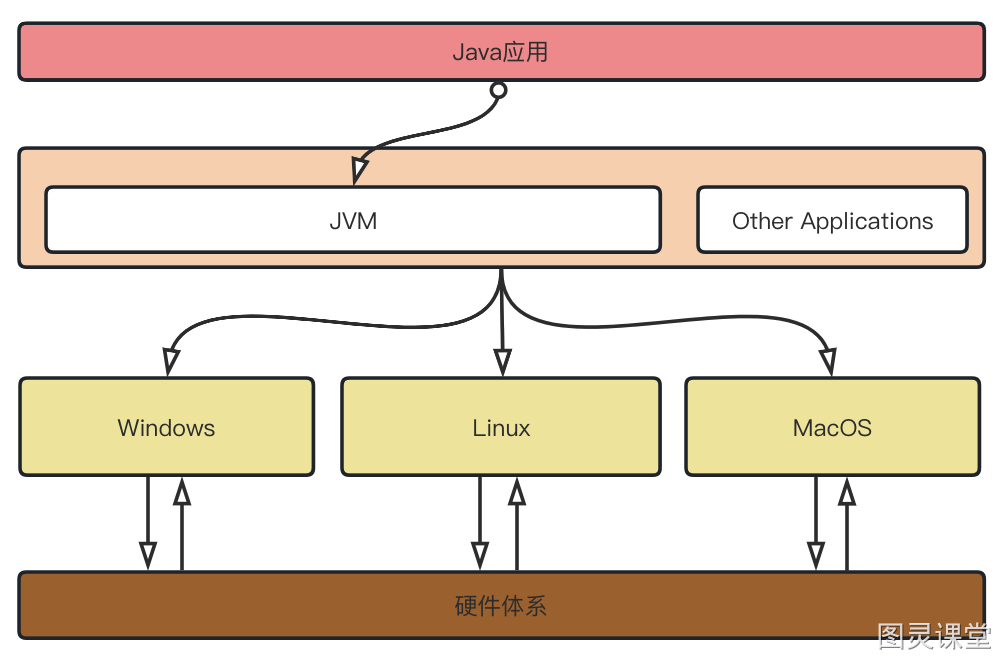
Viết một lần, chạy ở mọi nơi ("Write Once, Run Anywhere")
Nhiều bạn có thể thắc mắc, cũng giống như ngôn ngữ C trước đây hay ngôn ngữ Go hiện nay, việc đóng gói phần mềm cho các nền tảng khác nhau không phải là một việc quá khó khăn. Không lẽ chỉ vì tính năng này mà chúng ta phải chuyển sang dùng Java? Thực ra câu nói này chỉ là một khẩu hiệu, cho đến bây giờ, khi chạy Java trên các nền tảng khác nhau vẫn gặp một số vấn đề. Java nổi lên thực sự nhờ nhiều yếu tố khác nhau, như cú pháp đơn giản dễ học, hệ sinh thái mở, khả năng mở rộng của ngôn ngữ, tính ổn định và một phần là do may mắn. Việc chạy trên nhiều nền tảng chỉ là một phần nhỏ trong những yếu tố đó.
Nhiều người mới bắt đầu học Java cũng có một hiểu lầm rằng chỉ có ngôn ngữ Java mới có thể chạy trên JVM. Nhưng thực tế là JVM chạy bytecode, không phụ thuộc vào ngôn ngữ cụ thể. Nói cách khác, nếu bạn viết mã JavaScript và biên dịch thành bytecode, JVM vẫn có thể chạy được. Thực tế hiện nay JVM đã có thể chạy mã JavaScript. Mặc dù tên gọi là Java Virtual Machine, nhưng nó không có sự ràng buộc đặc biệt với ngôn ngữ Java, mà chỉ đơn giản là đọc và thực thi các tệp Class theo đúng tiêu chuẩn JVM.
Nếu bạn hiểu sâu về JVM, bạn hoàn toàn có thể tự viết một ngôn ngữ riêng, miễn là ngôn ngữ đó có thể biên dịch thành bytecode chuẩn thì nó có thể chạy trên JVM. Có rất nhiều ngôn ngữ đã làm điều này, như Scala, Kotlin, đều theo cùng một hướng đi.
Chúng ta sẽ dừng lại phần giới thiệu về JVM tại đây. Tập tiếp theo, tôi sẽ dẫn các bạn khám phá sâu hơn về thế giới của JVM!
Bạn có thể nói về các thành phần chính của JVM không?
Sự khác biệt giữa JDK và JRE là điều mà bất kỳ lập trình viên Java nào cũng biết. Nhưng nhiều người không biết rằng JRE chính là triển khai của Java Virtual Machine (JVM). Nó có thể phân tích bytecode, thông dịch mã và sau đó thực thi nó. Với tư cách là lập trình viên, việc hiểu về cấu trúc của JVM là rất quan trọng. Nó giúp chúng ta viết mã tối ưu hơn và phân tích các vấn đề về hiệu suất. Tiếp theo, chúng ta sẽ tìm hiểu về cấu trúc và các thành phần của JVM.
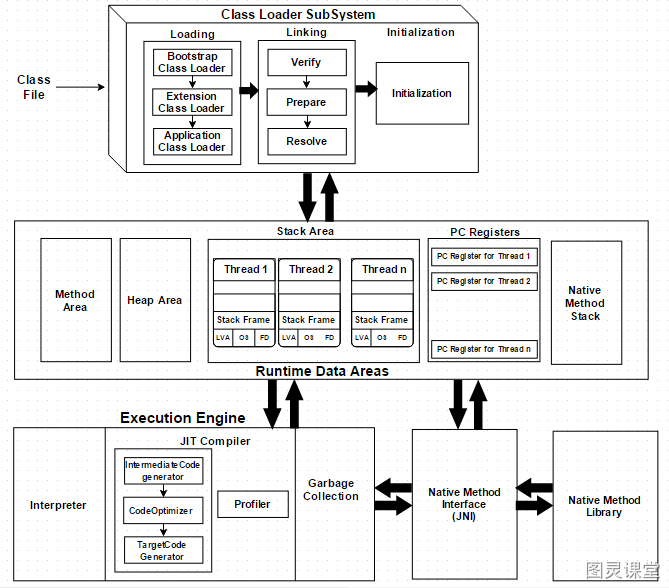
Nhìn vào biểu đồ trên, mặc dù có rất nhiều thành phần trông khá phức tạp, nhưng trước hết chúng ta sẽ không đi sâu vào chi tiết mà chỉ tập trung vào ba phần chính bên ngoài:
- ClassLoader SubSystem
- Runtime Data Area
- Execution Engine
Trình tải lớp (ClassLoader)
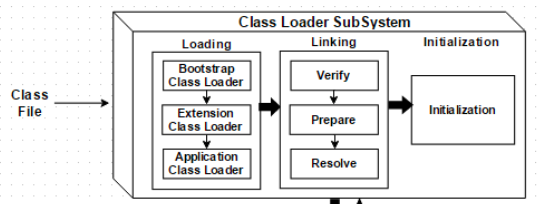
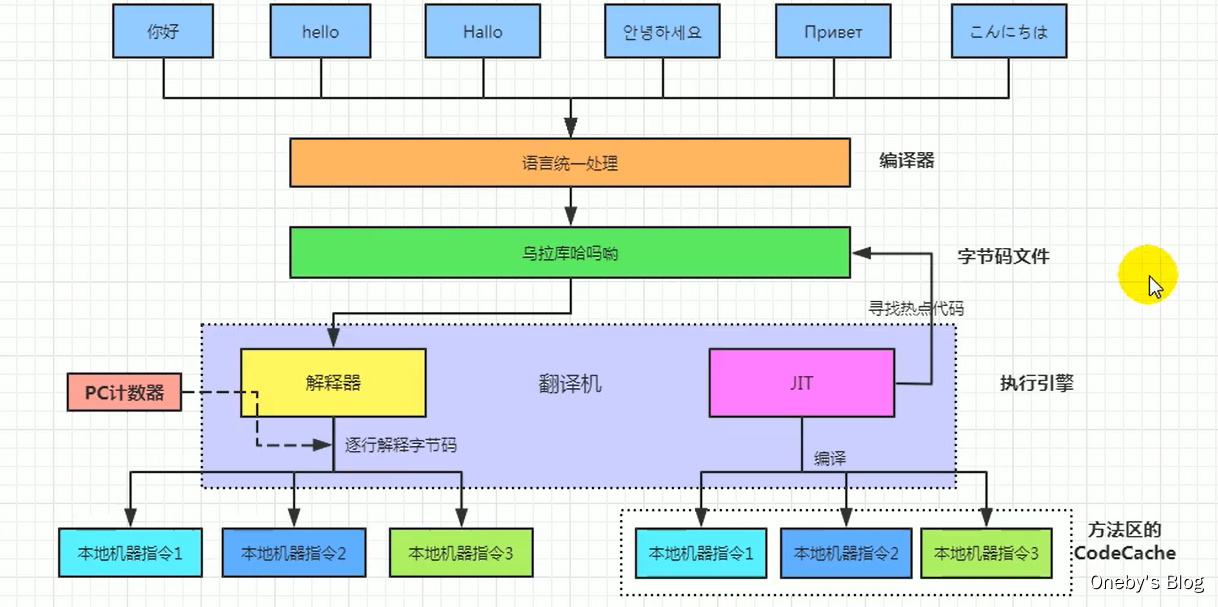
Sau khi Java Virtual Machine biên dịch mã nguồn Java thành bytecode, nó có thể đọc bytecode này vào bộ nhớ để phân tích cú pháp và thực thi. Quá trình này được gọi là "cơ chế tải lớp" (classloader) của Java Virtual Machine. Việc thực thi bytecode của JVM có thể được chia thành bảy giai đoạn: Tải (Loading), xác minh (Verify), chuẩn bị (Prepare), phân tích (Resolve), khởi tạo (Initialization), sử dụng (Use) và hủy (Unload).
Runtime Data Area
Runtime Data Area còn được gọi là "JVM Memory Model (JMM - Java Memory Model)". Nó chỉ ra rằng JVM chia bộ nhớ mà nó quản lý thành các vùng dữ liệu khác nhau khi chương trình đang chạy. Có năm phần chính: Method Area, Heap, JVM Stack, Program Counter, và Native Method Stack.
JVM Stack và Program Counter là các khu vực riêng của từng luồng, trong khi Heap và Method Area là các khu vực được chia sẻ giữa các luồng.
Execution Engine
Mã cuối cùng cần được chạy, và công việc này được thực hiện bởi Execution Engine. Nó sẽ đọc bytecode và từng đoạn bytecode sẽ được thực thi bởi Execution Engine.
Java là một ngôn ngữ vừa thông dịch vừa biên dịch, vì vậy Execution Engine được chia thành trình thông dịch (Interpreter) và trình biên dịch JIT (Just-In-Time Compiler). Trình thông dịch sẽ dịch từng dòng bytecode thành machine code để thực thi, trong khi JIT sẽ biên dịch trực tiếp mã nguồn thành machine code.
Bạn có thể giải thích về vai trò của trình nạp lớp (ClassLoader) trong JVM không?
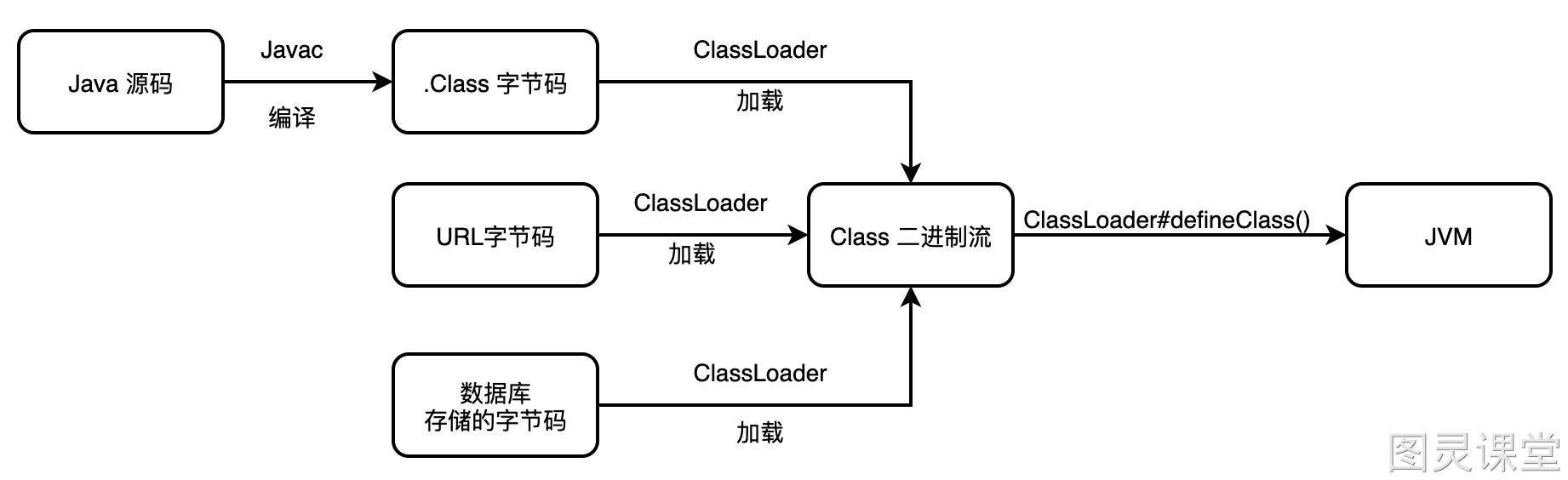
Trước đây, chúng ta đã nói qua về trình nạp lớp. Nó là một thành phần đọc bytecode và chuyển đổi thành một đối tượng của lớp java.lang.Class. Thông qua phương thức newInstance() có thể tạo ra một thể hiện của lớp. Nói thì có vẻ đơn giản, nhưng thực tế có thể phức tạp hơn nhiều, chẳng hạn như bytecode của Java có thể được tạo động thông qua các công cụ, hoặc được tải xuống qua mạng. Trong phần này, chúng ta sẽ thảo luận chi tiết về trình nạp lớp ~
Trong ngôn ngữ Java, việc nạp, liên kết và khởi tạo các loại (type) đều được thực hiện trong Runtime. Chiến lược này tuy có thể làm tăng nhẹ chi phí hiệu suất khi nạp lớp, nhưng mang lại cho ứng dụng Java tính linh hoạt cao. Đặc tính mở rộng động của Java dựa trên việc nạp động (dynamic loading) và liên kết động (dynamic linking) trong Runtime.
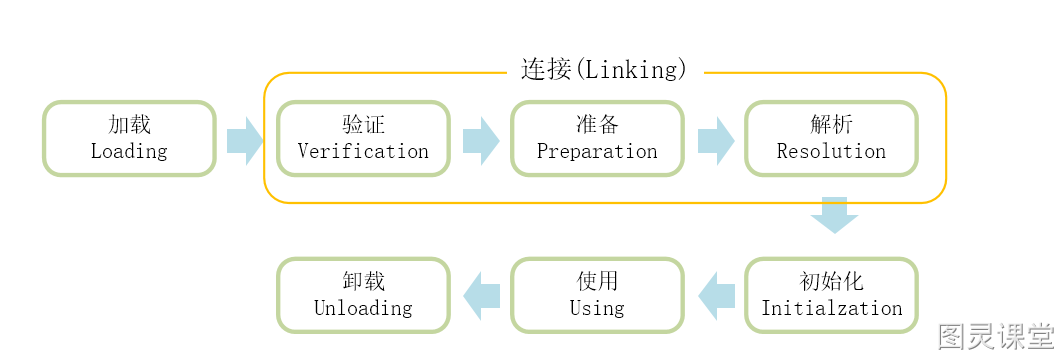
Hình trên là vòng đời của một lớp. Từ hình có thể thấy, vòng đời của một lớp từ khi được nạp vào bộ nhớ của máy ảo đến khi được dỡ bỏ, bao gồm 7 giai đoạn: Nạp (Loading), Xác minh (Verification), Chuẩn bị (Preparation), phân tích (Resolution), Khởi tạo (Initialization), Sử dụng (Using), Dỡ bỏ (Unloading). Trong đó, ba phần xác minh, chuẩn bị và phân tích được gọi chung là liên kết. Năm giai đoạn nạp, xác minh, chuẩn bị, khởi tạo và dỡ bỏ có thứ tự xác định và phải tuân theo tuần tự. Giai đoạn phân tích có thể diễn ra sau giai đoạn khởi tạo để hỗ trợ đặc tính liên kết muộn của Java (dynamic binding hoặc late binding).
Nạp
Giai đoạn “Nạp” (Loading) là một phần của quá trình “Nạp lớp” (Class Loading). Trong giai đoạn này, JVM cần thực hiện ba việc sau:
- Nhận bytecode của lớp từ tên đầy đủ của nó.
- Chuyển đổi cấu trúc lưu trữ bytecode thành cấu trúc dữ liệu tại Runtime trong Method Area.
- Tạo ra một đối tượng
java.lang.Classtrong bộ nhớ, đại diện cho lớp và làm cổng truy cập các dữ liệu của lớp trong Method Area.
Tiêu chuẩn của Java Virtual Machine Specification không quy định quá chi tiết về ba yêu cầu này, để lại sự linh hoạt cho JVM và ứng dụng Java. Ví dụ: “Nhận bytecode từ tên đầy đủ của lớp” không chỉ ra rằng bytecode phải đến từ tệp Class, hay từ đâu và cách lấy bytecode.
Chính sự linh hoạt này đã tạo điều kiện cho các lập trình viên sáng tạo nhiều phương pháp nạp lớp khác nhau, xây dựng nền tảng cho nhiều công nghệ Java quan trọng, chẳng hạn như:
- Lấy bytecode từ tệp ZIP, điều này rất phổ biến và sau này trở thành cơ sở cho định dạng JAR, EAR, WAR.
- Tải từ mạng, ứng dụng phổ biến nhất là Web Applet.
- Tạo bytecode động, thường thấy trong kỹ thuật proxy động, như trong
java.lang.reflect.Proxy, nơi sử dụngProxyGenerator.generateProxyClass()để tạo lớp proxy. - Lấy từ tệp mã hóa, đây là một biện pháp bảo vệ chống lại việc bị giải mã tệp Class.
So với các giai đoạn khác của quá trình nạp lớp, giai đoạn nạp là giai đoạn có tính linh hoạt cao nhất, đặc biệt là trong việc lấy bytecode. Giai đoạn nạp có thể được thực hiện bằng trình nạp lớp tích hợp sẵn hoặc bằng các trình nạp lớp tùy chỉnh. Lập trình viên có thể kiểm soát cách lấy bytecode bằng cách ghi đè phương thức findClass() hoặc loadClass().
Khi hoàn tất giai đoạn nạp, bytecode bên ngoài sẽ được lưu trữ theo định dạng mà JVM yêu cầu trong Method Area, và một đối tượng java.lang.Class sẽ được tạo trong bộ nhớ heap để truy cập dữ liệu này.
Xác minh
Xác minh là bước đầu tiên trong quá trình liên kết. Mục tiêu của giai đoạn này là đảm bảo rằng bytecode của Class tuân theo yêu cầu của JVM và không gây nguy hiểm cho hệ thống. Giai đoạn xác minh bao gồm bốn bước:
- Xác minh định dạng tệp: Kiểm tra bytecode có tuân thủ tiêu chuẩn Class file không, ví dụ như bytecode có bắt đầu bằng 0xCAFEBABE không.
- Xác minh siêu dữ liệu: Phân tích cú pháp bytecode để đảm bảo thông tin mô tả phù hợp với tiêu chuẩn ngôn ngữ Java.
- Xác minh bytecode: Phân tích dòng dữ liệu và dòng điều khiển để đảm bảo tính hợp pháp của bytecode.
- Xác minh tham chiếu ký hiệu: Đảm bảo quá trình phân tích các tham chiếu có thể thực thi thành công.
Giai đoạn xác minh rất quan trọng nhưng không bắt buộc. Để rút ngắn thời gian nạp lớp, bạn có thể sử dụng tham số -Xverifynone để tắt hầu hết các bước xác minh.
Chuẩn bị
Giai đoạn chuẩn bị là nơi phân bổ bộ nhớ cho các biến tĩnh và gán giá trị mặc định cho chúng trong Method Area.
Một số điểm cần lưu ý:
- Giai đoạn này chỉ phân bổ bộ nhớ cho các biến tĩnh (static), không bao gồm các biến thực thể (instance).
- Các biến tĩnh được gán giá trị mặc định (0, null, false...) chứ không phải giá trị được gán trong mã Java.
Ví dụ: public static int value = 3;
Sau giai đoạn chuẩn bị, value sẽ được gán giá trị mặc định là 0. Việc gán value bằng 3 sẽ diễn ra trong giai đoạn khởi tạo.
Phân tích
Giai đoạn phân tích chuyển đổi các tham chiếu ký hiệu thành tham chiếu trực tiếp, như địa chỉ bộ nhớ thực tế hoặc con trỏ.
Khởi tạo
Giai đoạn khởi tạo thực hiện việc gán giá trị khởi tạo cho các biến tĩnh và thực thi các khối mã tĩnh.
JVM sẽ khởi tạo lớp theo các bước sau:
- Nếu lớp chưa được nạp và liên kết, nó sẽ được thực hiện.
- Nếu lớp cha chưa được khởi tạo, nó sẽ được khởi tạo trước.
- Thực thi các câu lệnh khởi tạo trong lớp.
Sử dụng
Sau khi khởi tạo xong, JVM sẽ chạy mã của chương trình.
Dỡ bỏ
Khi chương trình kết thúc, JVM bắt đầu huỷ đối tượng Class đã khởi tạo và cuối cùng JVM xoá lớp khỏi bộ nhớ.
Bạn có biết các bộ tải lớp của JVM là gì không? Cơ chế ủy quyền của cha mẹ là gì?
Các nhà thiết kế JVM đã đưa hành động "sử dụng 'tên đầy đủ của lớp' để lấy luồng byte nhị phân định nghĩa lớp này" vào giai đoạn tải lớp ra bên ngoài JVM (JVM), để cho phép ứng dụng tự quyết định cách lấy các lớp cần thiết. Mô-đun mã thực hiện hành động này được gọi là "bộ tải lớp".
Lớp và bộ tải lớp
Đối với bất kỳ lớp nào, tính duy nhất của lớp đó trong JVM phải được xác lập bởi bộ tải lớp và chính lớp đó. Nói cách khác, hai lớp đến từ cùng một tệp Class và được nạp bởi cùng một bộ tải lớp thì mới được coi là bằng nhau.
Mô hình ủy quyền của cha mẹ
Từ góc độ của máy ảo, chỉ có hai loại bộ tải lớp khác nhau: Một là bộ tải lớp khởi động (Bootstrap ClassLoader), bộ tải lớp này được triển khai bằng ngôn ngữ C++ và là một phần của chính máy ảo. Còn lại là tất cả các bộ tải lớp khác, những bộ tải này được triển khai bằng ngôn ngữ Java, độc lập với JVM và đều kế thừa từ lớp trừu tượng java.lang.ClassLoader.
Từ góc độ của nhà phát triển Java, hầu hết các chương trình Java thường sử dụng ba bộ tải lớp được cung cấp bởi hệ thống:
- Bộ tải lớp khởi động (Bootstrap ClassLoader): Chịu trách nhiệm tải các thư viện trong thư mục
JAVA_HOME\libmà có thể được JVM nhận diện vào bộ nhớ JVM. Nếu tên thư viện không khớp, ngay cả khi nó nằm trong thư mụclibthì cũng sẽ không được tải. Bộ tải lớp này không thể được chương trình Java tham chiếu trực tiếp. - Bộ tải lớp mở rộng (Extension ClassLoader): Bộ tải này chủ yếu chịu trách nhiệm tải thư mục
JAVA_HOME\lib\và có thể được nhà phát triển sử dụng trực tiếp. - Bộ tải lớp ứng dụng (Application ClassLoader): Bộ tải này còn được gọi là bộ tải lớp hệ thống, chịu trách nhiệm tải các thư viện được chỉ định trên đường dẫn lớp của người dùng (Classpath). Nhà phát triển có thể sử dụng trực tiếp bộ tải lớp này. Nếu ứng dụng không tự định nghĩa bộ tải lớp riêng, thông thường đây sẽ là bộ tải lớp mặc định của chương trình.
Các ứng dụng của chúng ta đều được tải bởi sự kết hợp của ba bộ tải lớp này, và chúng ta cũng có thể thêm bộ tải lớp tự định nghĩa của mình. Mối quan hệ giữa các bộ tải lớp này được hiển thị trong hình sau:
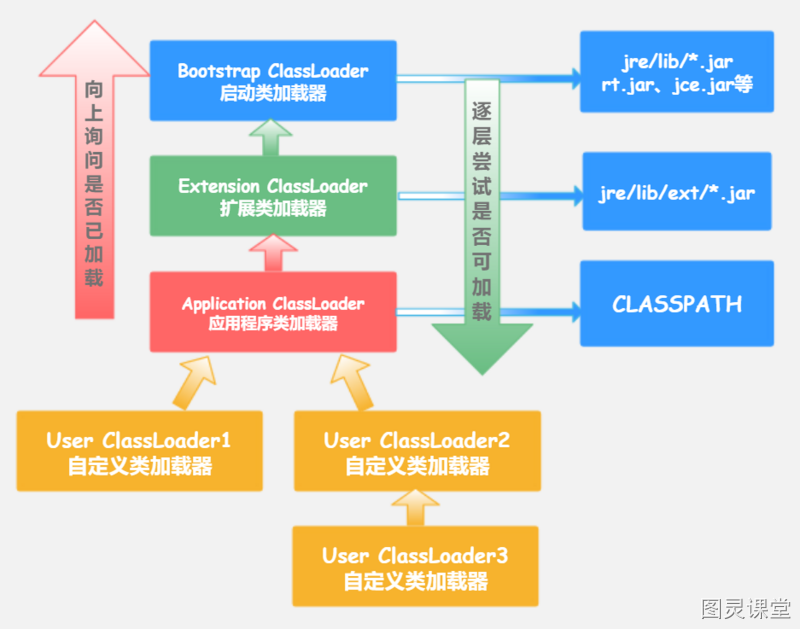
Quan hệ phân cấp giữa các bộ tải lớp như trên được gọi là mô hình ủy quyền của cha mẹ (Parent Delegation Model). Mô hình này yêu cầu ngoài bộ tải lớp khởi động ở cấp cao nhất, tất cả các bộ tải lớp khác đều phải có bộ tải lớp cha của riêng mình. Mối quan hệ giữa bộ tải lớp con và bộ tải lớp cha không được triển khai bằng cách kế thừa mà thông qua quan hệ tổ hợp để tái sử dụng mã của bộ tải lớp cha.
Quy trình làm việc của mô hình ủy quyền cha mẹ là: Nếu một bộ tải lớp nhận được yêu cầu tải lớp, nó sẽ không tự mình cố gắng tải lớp đó ngay, mà sẽ chuyển yêu cầu này cho bộ tải lớp cha để thực hiện. Mỗi cấp bộ tải lớp đều như vậy, do đó tất cả các yêu cầu tải lớp đều sẽ được chuyển đến bộ tải lớp khởi động ở cấp cao nhất. Chỉ khi bộ tải lớp cha phản hồi rằng không thể hoàn thành yêu cầu tải (không tìm thấy lớp tương ứng trong phạm vi tìm kiếm của bộ tải lớp đó), bộ tải lớp con mới cố gắng tự mình tải lớp.
Việc sử dụng mô hình này để tổ chức mối quan hệ giữa các bộ tải lớp có lợi ích là các lớp Java cùng với bộ tải lớp của nó tạo thành một hệ thống phân cấp có ưu tiên. Ví dụ, lớp java.lang.Object, dù bất kỳ bộ tải lớp nào cố gắng tải lớp này, cuối cùng vẫn sẽ do bộ tải lớp khởi động tải, do đó lớp Object trong môi trường của các bộ tải lớp khác nhau vẫn là cùng một lớp.
Nếu không sử dụng mô hình này, nếu người dùng tự định nghĩa một lớp java.lang.Object và đặt nó trong classpath, thì sẽ xuất hiện nhiều lớp Object trong hệ thống và ứng dụng sẽ trở nên hỗn loạn. Nếu chúng ta tự định nghĩa một lớp Java trùng tên với một lớp đã có trong tệp rt.jar, ta sẽ thấy JVM có thể biên dịch bình thường, nhưng lớp đó sẽ không bao giờ được tải và chạy. Trong lớp java.lang.ClassLoader của gói rt.jar, chúng ta có thể xem mã nguồn của quy trình triển khai tải lớp, cụ thể mã như sau:
protected synchronized Class loadClass(String name, boolean resolve)
throws ClassNotFoundException {
// Đầu tiên kiểm tra xem lớp được chỉ định bởi name đã được tải chưa
Class c = findLoadedClass(name);
if (c == null) {
try {
if (parent != null) {
// Nếu parent không null, gọi parent.loadClass để tải lớp
c = parent.loadClass(name, false);
} else {
// Nếu parent null, gọi BootstrapClassLoader để tải lớp
c = findBootstrapClass0(name);
}
} catch (ClassNotFoundException e) {
// Nếu vẫn không tải được, gọi findClass của chính nó để tải
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}Qua đoạn mã trên, có thể thấy mô hình ủy quyền cha mẹ được triển khai thông qua phương thức loadClass(). Dựa trên mã và chú thích trong mã, ta có thể dễ dàng hiểu quy trình này thực ra rất đơn giản:
Đầu tiên kiểm tra xem lớp đã được tải chưa, nếu chưa thì gọi phương thức loadClass() của bộ tải lớp cha, nếu bộ tải lớp cha là null thì mặc định sử dụng bộ tải lớp khởi động làm bộ tải cha.
Nếu bộ tải lớp cha thất bại trong việc tải, thì sẽ ném ra ngoại lệ ClassNotFoundException, sau đó mới gọi phương thức findClass() của chính nó để tải.
Mô hình ủy quyền cha mẹ của bộ tải lớp được giới thiệu từ JDK1.2 và chỉ là một mô hình khuyến nghị, không phải yêu cầu bắt buộc, vì vậy có một số ngoại lệ không tuân theo mô hình này: (tìm hiểu thêm)
- Trước JDK1.2, các bộ tải lớp tự định nghĩa đều phải ghi đè phương thức
loadClassđể thực hiện chức năng tải lớp. Sau khi mô hình ủy quyền cha mẹ được giới thiệu, phương thứcloadClassđược sử dụng để ủy quyền cho bộ tải lớp cha thực hiện tải lớp. Chỉ khi bộ tải lớp cha không thể hoàn thành yêu cầu tải, phương thứcfindClasscủa chính nó mới được gọi để tải lớp. Do đó, trong các bộ tải lớp trước JDK1.2, phương thứcloadClasskhông tuân theo mô hình ủy quyền cha mẹ, và sau JDK1.2, bộ tải lớp tự định nghĩa không nên ghi đè phương thứcloadClassnữa, mà chỉ cần ghi đè phương thứcfindClass. - Mô hình ủy quyền cha mẹ giải quyết tốt vấn đề thống nhất lớp cơ bản của các bộ tải lớp, các lớp càng cơ bản càng được tải bởi các bộ tải lớp ở cấp cao hơn. Tuy nhiên, vấn đề phát sinh khi các lớp cơ bản muốn gọi ngược lại mã người dùng ở cấp thấp hơn thì không thể ủy quyền cho bộ tải lớp con để thực hiện. Để giải quyết vấn đề này, JDK đã giới thiệu ngữ cảnh của luồng ThreadContext thông qua phương thức
setContextClassLoaderđể đặt bộ tải lớp ngữ cảnh của luồng. JavaEE chỉ là một đặc tả, Sun chỉ đưa ra giao diện chuẩn và việc triển khai cụ thể là do các nhà sản xuất thực hiện. Do đó, các thư viện JNDI, JDBC, JAXB… có thể được các thư viện của JDK gọi đến. Bộ tải lớp ngữ cảnh của luồng cũng không tuân theo mô hình ủy quyền cha mẹ. - Trong những năm gần đây, các ứng dụng yêu cầu thay đổi mã nóng (hot code swapping), triển khai module nóng (module hot deployment) mà không cần khởi động lại JVM đã thúc đẩy công nghệ OSGi. Trong OSGi, hệ thống bộ tải lớp đã phát triển thành cấu trúc dạng lưới và không hoàn toàn tuân theo mô hình ủy quyền cha mẹ.
Bộ tải lớp tự định nghĩa
Đọc thêm, không mở rộng quá nhiều.
Bạn hiểu gì về JVM Memory Model?
Tôi tin rằng mọi người đã rất rõ về cách một tệp nguồn Java biến thành tệp bytecode, cũng như ý nghĩa của bytecode đó. Tiếp theo, Java Virtual Machine (JVM) sẽ chạy tệp bytecode, để đưa ra kết quả cuối cùng mà chúng ta mong muốn. Trong quá trình này, JVM sẽ tải bytecode vào bộ nhớ, sau đó thực hiện một loạt các bước khởi tạo và cuối cùng là chạy chương trình để đưa ra kết quả.
Vậy dữ liệu bytecode được lưu trữ trong bộ nhớ JVM như thế nào? JVM phân bổ bộ nhớ cho các biến thành viên hoặc đối tượng như thế nào? Để trả lời những câu hỏi này, trước tiên chúng ta cần hiểu về JVM Memory Model.
Thực tế, JVM Memory Model không phải là cách gọi chính thức. Trong "Java Virtual Machine Specification", thuật ngữ được sử dụng là "Runtime Data Area". Tuy nhiên, nhiều lúc thuật ngữ này không thực sự trực quan, và theo thói quen tích lũy lâu ngày, chúng ta thường gọi nó là JVM Memory Model.
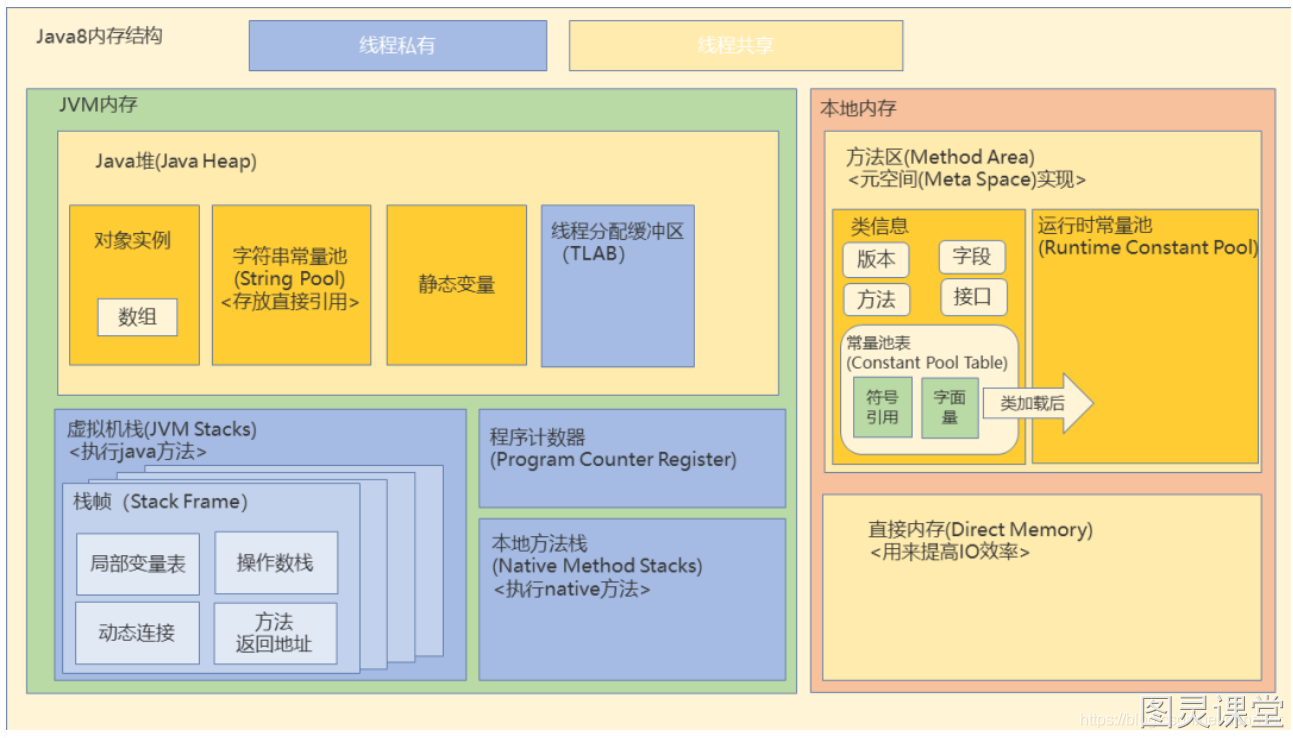
Theo "Java Virtual Machine Specification," bộ nhớ của JVM có thể chia thành hai phần: chung và riêng. Phần chung được chia sẻ bởi tất cả các luồng, bao gồm Heap, Method Area, và Constant Pool. Phần riêng chỉ dành riêng cho từng luồng, bao gồm: PC Register, JVM Stack, và Native Method Stack.
Phần bộ nhớ chia sẻ: Java Heap, Method Area, và Constant Pool
Trong JVM, phần chia sẻ bộ nhớ bao gồm Java Heap, Method Area và Constant Pool.
Java Heap là một vùng bộ nhớ được JVM cắt ra để phân bổ cho các đối tượng Java. Gần như tất cả các đối tượng được tạo ra đều được phân bổ ở đây. Tại sao lại nói "gần như"? Vì có một số trường hợp ngoại lệ, chẳng hạn như khi các đối tượng nhỏ có thể được phân bổ trực tiếp trên Stack, hiện tượng này gọi là "phân bổ trên Stack". Chúng ta sẽ không đi sâu vào vấn đề này ở đây, mà sẽ giới thiệu sau.
Method Area là vùng chứa các dữ liệu bytecode của các lớp Java, bao gồm thông tin về cấu trúc của lớp như runtime constant pool, dữ liệu về các field và method, và cả các constructor. Có thể thấy Constant Pool thực ra được lưu trữ trong Method Area, nhưng "Java Virtual Machine Specification" đặt Constant Pool và Method Area ngang hàng, điều này chúng ta chỉ cần biết là được.
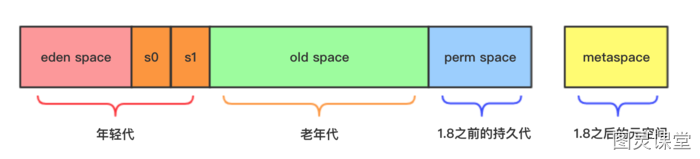
Tùy vào từng phiên bản JVM, Method Area có thể có tên khác nhau. Chẳng hạn, trong HotSpot JVM phiên bản 1.7, nó được gọi là Permanent Space, còn trong JDK 1.8 thì được gọi là MetaSpace.
Sau khi hiểu rõ chức năng chính của các phần này, chúng ta sẽ đi sâu hơn vào Java Heap.
Java Heap được chia thành hai khu vực dựa trên tuổi thọ của đối tượng: Young Generation và Old Generation. Young Generation còn được chia thành ba phần: Eden, From Survivor 0, và To Survivor 1.
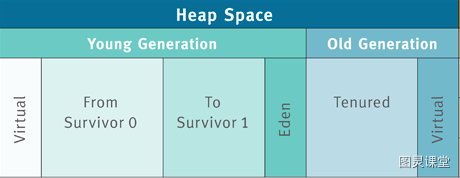
Khi có đối tượng cần phân bổ, nó luôn được phân bổ trong Eden của Young Generation. Khi bộ nhớ của Eden không đủ, JVM sẽ kích hoạt quá trình thu gom rác (GC).
Lúc này, bộ nhớ của các đối tượng không còn tham chiếu trong Eden sẽ bị thu gom, trong khi các đối tượng có tuổi thọ lâu hơn sẽ được chuyển vào Old Generation.
Trong JVM, tham số -XX:MaxTenuringThreshold dùng để thiết lập số lần GC cần trải qua trước khi đối tượng được chuyển từ Young Generation sang Old Generation. Khi đối tượng trong Young Generation vượt qua số lần GC này, nó sẽ chuyển sang Old Generation trong lần GC tiếp theo.
Hãy suy nghĩ một chút: Tại sao Java Heap lại được chia khu vực như vậy?
Dựa trên kinh nghiệm của chúng ta, các đối tượng trong JVM thường có tuổi thọ khác nhau, từ ngắn đến dài. Nếu chúng ta trộn chúng lại với nhau, các đối tượng có tuổi thọ ngắn sẽ dẫn đến việc thu gom rác thường xuyên hơn. Trong quá trình thu gom rác, JVM phải quét qua toàn bộ bộ nhớ, nhưng việc quét qua những đối tượng có tuổi thọ cao là một sự lãng phí thời gian. Vì vậy, việc phân khu vực là để tăng hiệu suất thu gom rác.
Một câu hỏi khác là: Tại sao cấu hình mặc định của JVM lại là eden:from:to = 8:1:1?
Thực ra, đây là kết quả nghiên cứu của IBM dựa trên các thống kê. Theo IBM, 80% các đối tượng có tuổi thọ rất ngắn. Vì vậy, họ đã đặt Eden là 80% của Young Generation, để giảm thiểu lãng phí bộ nhớ và tăng hiệu suất sử dụng bộ nhớ.
Phần bộ nhớ riêng: PC Register, JVM Stack, và Native Method Stack
Java Heap và Method Area là dữ liệu được chia sẻ, nhưng có một số phần là riêng tư cho từng luồng. Những phần riêng tư này bao gồm: PC Register, JVM Stack, và Native Method Stack.
PC Register: là thanh ghi Program Counter, lưu địa chỉ của phương thức hiện tại mà luồng đang thực thi.
Nếu phương thức này không phải là native, PC Register sẽ lưu địa chỉ của lệnh bytecode mà JVM đang thực thi. Nếu là native, giá trị của PC Register là undefined.
Tại bất kỳ thời điểm nào, một luồng JVM chỉ thực thi một phương thức, và phương thức này được gọi là "phương thức hiện tại", địa chỉ của nó được lưu trong PC Register.
JVM Stack: được tạo ra cùng với luồng, dùng để lưu trữ các stack frame, là nơi lưu trữ biến cục bộ và các kết quả tạm thời. Dữ liệu trong stack frame bao gồm: bảng biến cục bộ và operator stack.
Native Method Stack: khi JVM sử dụng ngôn ngữ khác (như C) để thực thi các lệnh, nó sẽ sử dụng Native Method Stack. Nếu JVM không hỗ trợ phương thức native và không phụ thuộc vào stack truyền thống, Native Method Stack không cần được hỗ trợ.
JVM Memory Model là một phần cần phải nắm vững khi học về JVM, đặc biệt là Java Heap, vì rất nhiều vấn đề trực tuyến phát sinh từ đây. Do đó, việc hiểu rõ phân chia bộ nhớ trong Java Heap và cách điều chỉnh các tham số thông dụng là rất quan trọng.
Ngoài sáu phần trên, trong Java còn có Direct Memory, các Stack Frame, nhưng vì các cấu trúc này ít được sử dụng, nên chúng ta không nhắc đến ở đây để tránh làm cho người mới bắt đầu bị rối.
Đến đây, một tệp Java đã được tải vào bộ nhớ, thông tin về lớp Java được lưu trong Method Area. Nếu tạo đối tượng, dữ liệu đối tượng sẽ được lưu trong Java Heap. Nếu gọi phương thức, sẽ sử dụng PC Register, JVM Stack, và Native Method Stack.
Nói về những thuật toán thu gom rác của JVM mà bạn biết?
Khi nói đến JVM Memory Model (JMM), chúng ta đã đề cập rằng phần này thực tế được chỉ định bởi "Java Virtual Machine Specification", và mỗi JVM có thể có các cách triển khai khác nhau. Thực tế, khi liên quan đến bộ nhớ của JVM, chúng ta không thể không nhắc đến cơ chế thu gom rác của nó. Vì bộ nhớ luôn có giới hạn, chúng ta cần một cơ chế để liên tục thu gom những bộ nhớ không còn sử dụng, nhằm tái sử dụng lại bộ nhớ và giúp chương trình có thể tiếp tục hoạt động bình thường.
So với JVM Memory Model có quy định cụ thể trong "Java Virtual Machine Specification", cơ chế thu gom rác không có quy định rõ ràng nào. Vì vậy, nhiều JVM khác nhau sẽ có những cách triển khai khác nhau. Phần dưới đây chúng ta sẽ thảo luận về các thuật toán thu gom rác dựa trên JVM HotSpot.
Thế nào được xem là rác?
Để thực hiện thu gom rác, câu hỏi quan trọng nhất là: Làm sao để xác định đâu là rác?
Giống như trong cuộc sống hằng ngày, nếu một thứ không còn được sử dụng thường xuyên, thì nó có thể được xem là rác. Trong Java cũng tương tự, nếu một đối tượng không còn có khả năng được tham chiếu, thì đối tượng đó được xem là rác và cần được thu gom.
Dựa trên ý tưởng này, chúng ta có thể dễ dàng nghĩ đến phương pháp đếm tham chiếu để xác định rác. Khi một đối tượng được tham chiếu, đếm tham chiếu của nó tăng lên một đơn vị, và khi tham chiếu bị loại bỏ, đếm tham chiếu giảm đi. Bằng cách này, chúng ta có thể xác định một đối tượng là rác nếu đếm tham chiếu của nó bằng không. Phương pháp này thường được gọi là phương pháp đếm tham chiếu.
Mặc dù phương pháp này rất đơn giản, nhưng nó có một vấn đề chết người, đó là tham chiếu vòng. Ví dụ, đối tượng A tham chiếu đối tượng B, đối tượng B tham chiếu đối tượng C, và đối tượng C tham chiếu lại đối tượng A. Mỗi đối tượng đều có một tham chiếu đếm là 1, nhưng không có đối tượng nào trong số này được tham chiếu từ bên ngoài. Theo khái niệm về rác, cả ba đối tượng này đều không còn được sử dụng và cần phải bị thu gom, nhưng do đếm tham chiếu của chúng không bằng 0, vấn đề vòng tham chiếu sẽ xuất hiện.
Hiện nay, cách mà JVM sử dụng để xác định đối tượng rác là thuật toán truy vết GC Root (GC Root Tracing). Quy trình của nó như sau: Bắt đầu từ GC Root, tất cả các đối tượng có thể tiếp cận được đều là đối tượng còn sống, và các đối tượng không thể tiếp cận được là rác.
Điều quan trọng nhất ở đây là tập hợp GC Root, thực chất là một nhóm các tham chiếu hoạt động. Tuy nhiên, nhóm này khác với các tập hợp đối tượng thông thường, vì nó đã được chọn lọc cẩn thận, thường bao gồm:
- Tất cả các lớp Java hiện đang được tải
- Các biến tĩnh kiểu tham chiếu của lớp Java
- Các hằng số kiểu tham chiếu trong Constant Pool của lớp Java
- Các cấu trúc dữ liệu tĩnh trong máy ảo trỏ đến các đối tượng trong heap của GC
- ...
Nói đơn giản, GC Root là một tập hợp các tham chiếu hoạt động đã được chọn lọc kỹ lưỡng, và các đối tượng có thể tiếp cận được từ những tham chiếu này cũng sẽ được xem là còn sống.
Làm thế nào để thu gom rác?
Đến đây, chúng ta đã hiểu rác là gì và cách JVM xác định các đối tượng rác. Vậy sau khi đã xác định được các đối tượng rác, JVM sẽ tiến hành thu gom chúng như thế nào? Đây là nội dung mà chúng ta sẽ thảo luận tiếp theo: Thu gom rác được thực hiện như thế nào?
Có ba thuật toán thu gom rác đơn giản: Thuật toán đánh dấu và dọn dẹp (Mark-Sweep), Thuật toán sao chép (Mark-Copy), và Thuật toán đánh dấu và nén (Mark-Compact).
Thuật toán đánh dấu và dọn dẹp: Được chia làm hai giai đoạn: Giai đoạn đánh dấu và giai đoạn dọn dẹp. Một cách thực hiện khả thi là, trong giai đoạn đánh dấu, JVM đánh dấu tất cả các đối tượng có thể tiếp cận được từ GC Root. Sau đó, tất cả các đối tượng không được đánh dấu sẽ bị xem là rác và bị thu gom trong giai đoạn dọn dẹp. Vấn đề lớn nhất của thuật toán này là vấn đề phân mảnh bộ nhớ. Nếu có quá nhiều phân mảnh, bộ nhớ sẽ trở nên không liên tục và việc cấp phát cho các đối tượng lớn sẽ kém hiệu quả hơn so với bộ nhớ liên tục.
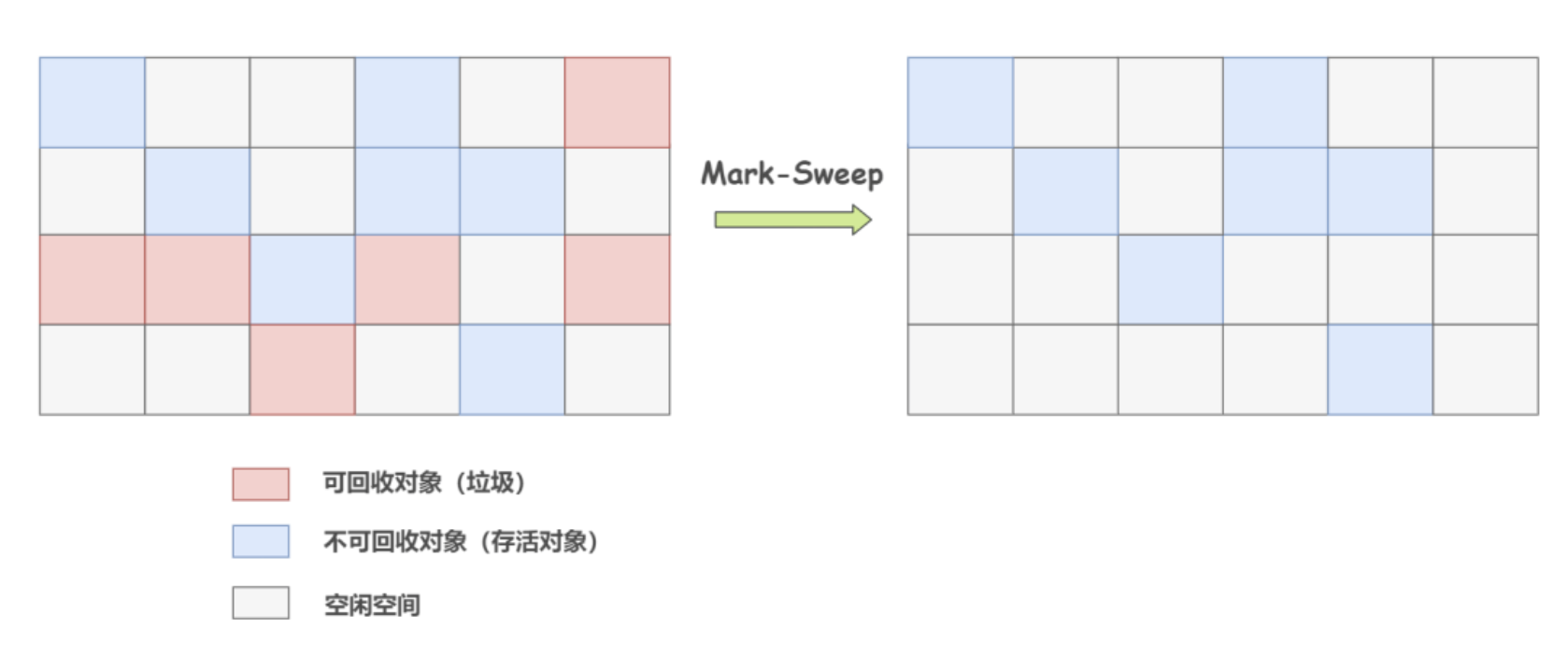
image.png Thuật toán sao chép: Ý tưởng cốt lõi của thuật toán này là chia bộ nhớ thành hai phần, chỉ sử dụng một phần tại một thời điểm. Khi thực hiện thu gom rác, các đối tượng còn sống trong vùng nhớ đang sử dụng sẽ được sao chép sang phần còn lại chưa sử dụng. Sau đó, tất cả các đối tượng trong vùng nhớ đang sử dụng sẽ bị dọn dẹp, và hai vùng nhớ sẽ hoán đổi vai trò cho nhau để hoàn tất thu gom rác. Nhược điểm của thuật toán này là phải chia đôi bộ nhớ, gây lãng phí không gian.
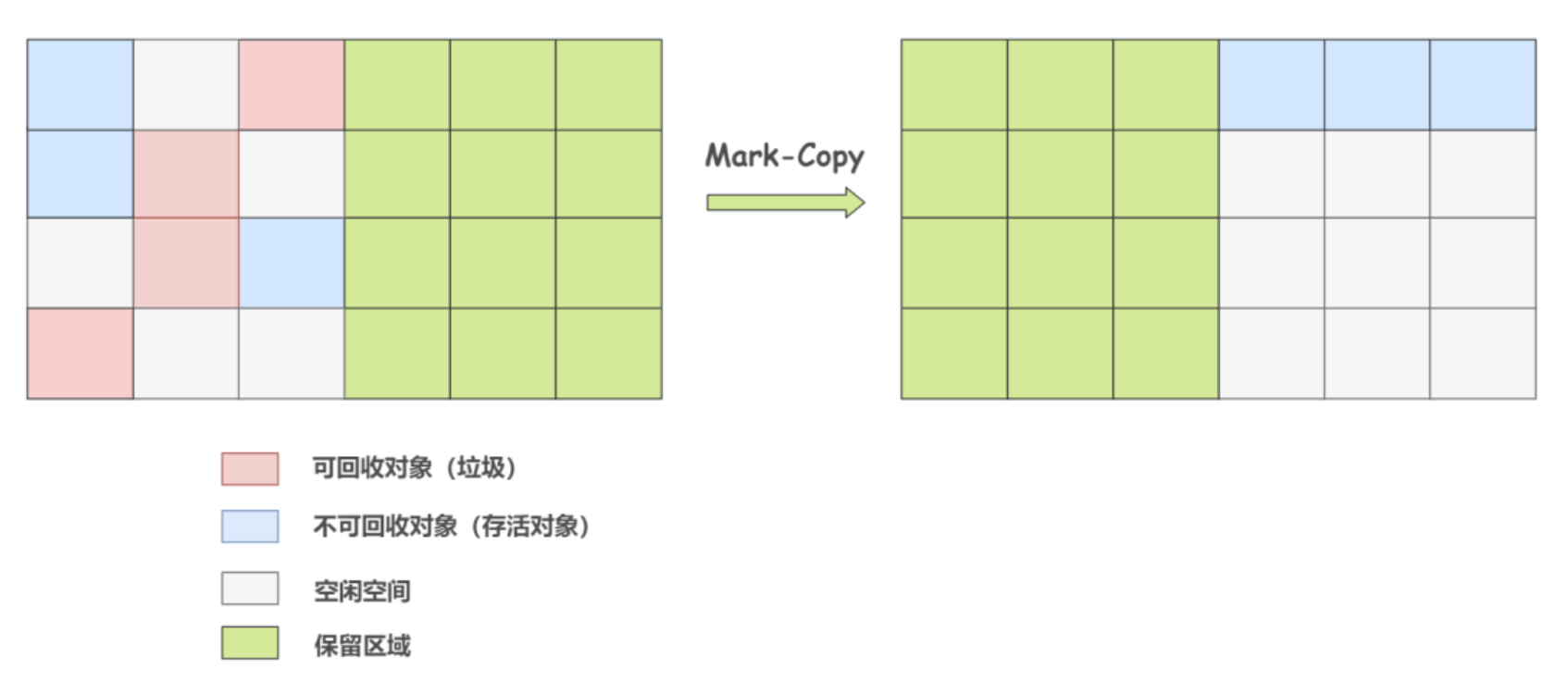
image.png Thuật toán đánh dấu và nén: Đây là phiên bản cải tiến của thuật toán đánh dấu và dọn dẹp. Thuật toán này cũng trải qua hai giai đoạn: giai đoạn đánh dấu và giai đoạn nén. Trong giai đoạn đánh dấu, tất cả các đối tượng có thể tiếp cận từ tập hợp GC Root sẽ được đánh dấu. Trong giai đoạn nén, các đối tượng còn sống sẽ được nén về một phía của bộ nhớ, và không gian bên ngoài sẽ được dọn dẹp.
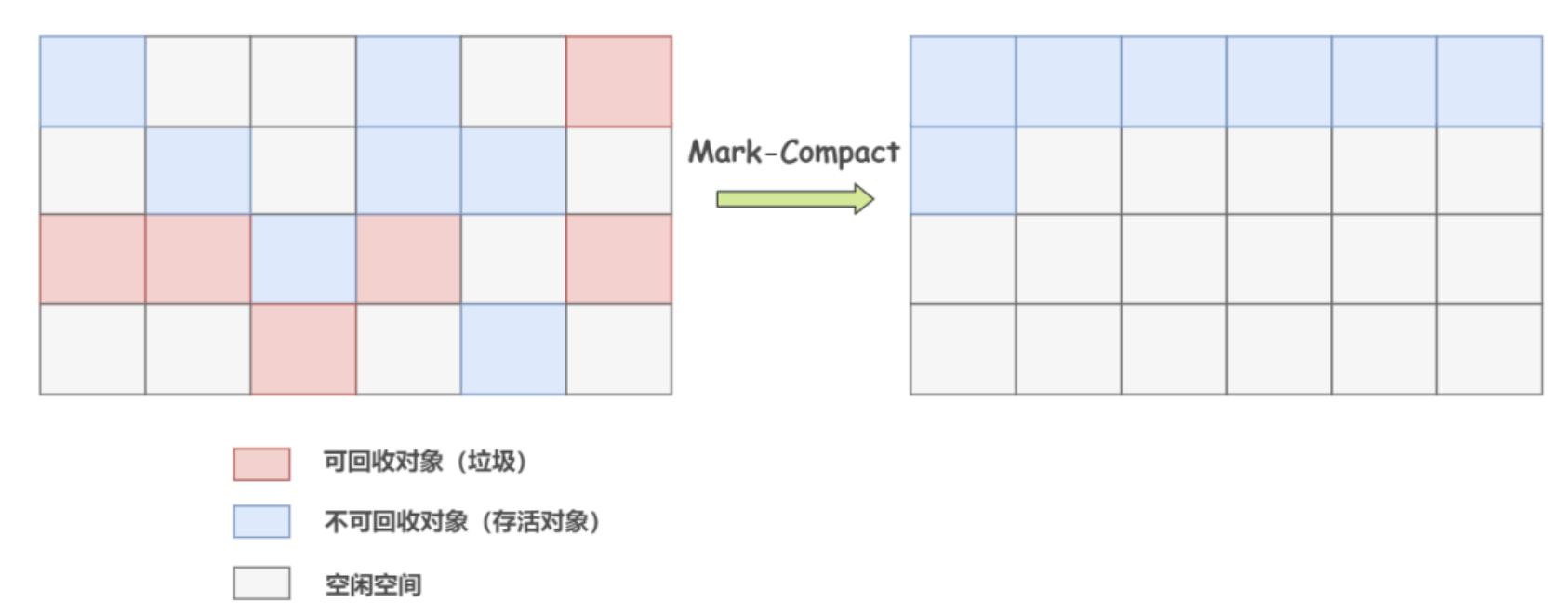
image.png
So sánh ba thuật toán trên, chúng ta thấy rằng mỗi thuật toán đều có ưu và nhược điểm riêng. Thuật toán đánh dấu và dọn dẹp tạo ra phân mảnh bộ nhớ nhưng không cần di chuyển quá nhiều đối tượng, phù hợp với tình huống có nhiều đối tượng còn sống. Thuật toán sao chép tuy lãng phí không gian và yêu cầu di chuyển đối tượng còn sống, nhưng không tạo ra phân mảnh bộ nhớ, phù hợp với trường hợp có ít đối tượng còn sống. Thuật toán đánh dấu và nén là phiên bản tối ưu của thuật toán đánh dấu và dọn dẹp, giảm thiểu phân mảnh bộ nhớ.
Tư tưởng phân thế hệ
Hãy tưởng tượng nếu chúng ta chỉ áp dụng một loại thuật toán nào đó thì hiệu quả thu gom rác cuối cùng sẽ không được cao. Trên thực tế, những người xây dựng máy ảo JVM cũng nghĩ như vậy, do đó trong các thuật toán thu gom rác thực tế, họ đã áp dụng tư tưởng phân thế hệ.
Phân thế hệ nghĩa là tùy theo khu vực bộ nhớ khác nhau trong JVM, áp dụng các thuật toán thu gom rác khác nhau. Ví dụ, đối với khu vực Young Generation, nơi có ít đối tượng sống sót, thích hợp sử dụng thuật toán sao chép. Như vậy, chỉ cần sao chép một lượng nhỏ đối tượng là có thể hoàn thành việc thu gom rác và không gây ra phân mảnh bộ nhớ. Còn đối với khu vực Old Generation, nơi có nhiều đối tượng sống sót, thích hợp sử dụng thuật toán đánh dấu nén hoặc đánh dấu xóa, giúp không phải di chuyển quá nhiều đối tượng trong bộ nhớ.
Hãy tưởng tượng nếu không áp dụng tư tưởng phân thế hệ mà sử dụng thuật toán sao chép trong khu vực Old Generation. Trong trường hợp cực đoan, tỷ lệ sống sót của các đối tượng trong khu vực Old Generation có thể đạt 100%, khi đó chúng ta cần sao chép toàn bộ số đối tượng này sang một vùng nhớ khác, khối lượng công việc này là rất lớn.
Tại đây, chúng ta sẽ thảo luận sâu hơn về thuật toán thu gom rác áp dụng trong Young Generation. Như đã đề cập ở trên, đặc điểm của Young Generation là số lượng đối tượng sống sót ít, thích hợp sử dụng thuật toán sao chép. Cách thực hiện đơn giản nhất của thuật toán sao chép là sử dụng một nửa bộ nhớ và giữ lại nửa còn lại để dự phòng. Nhưng thực tế chúng ta biết rằng, trong JVM thực tế, khu vực Young Generation không được chia thành hai vùng nhớ bằng nhau. Thay vào đó, nó được chia thành ba khu vực: vùng Eden, vùng from supervisor, và vùng to supervisor. Vậy tại sao JVM lại sử dụng cách này thay vì chia đôi bộ nhớ thành hai phần bằng nhau?
Để trả lời câu hỏi này, chúng ta cần tìm hiểu sâu hơn về đặc điểm của các đối tượng trong Young Generation. Theo nghiên cứu của IBM, 98% đối tượng trong Young Generation chỉ tồn tại trong thời gian ngắn, vì vậy không cần chia bộ nhớ theo tỷ lệ 1:1. Trong JVM của HotSpot, bộ nhớ được chia thành một vùng Eden lớn và hai vùng Survivor nhỏ, với tỷ lệ kích thước là 8:1:1. Khi thu gom rác, các đối tượng sống sót trong Eden và Survivor sẽ được sao chép sang vùng Survivor còn lại, sau đó dọn dẹp vùng Eden và vùng Survivor vừa sử dụng.
Bằng cách này, hiệu suất sử dụng bộ nhớ đạt đến 90%, chỉ có 10% bộ nhớ bị lãng phí. Trong khi đó, nếu chia đều bộ nhớ thành hai phần, hiệu suất sử dụng chỉ đạt 50%, sự chênh lệch giữa hai cách tiếp cận là gần gấp đôi.
Tư tưởng phân vùng
Tư tưởng phân thế hệ chia các đối tượng dựa trên vòng đời của chúng thành hai phần (Young Generation và Old Generation), nhưng trong JVM còn có một tư tưởng phân vùng, tức là chia toàn bộ không gian heap thành các vùng liên tiếp nhỏ.
Mỗi vùng nhỏ này được sử dụng và thu gom độc lập, ưu điểm của thuật toán này là có thể kiểm soát số lượng vùng được thu gom trong mỗi lần, từ đó kiểm soát tốt hơn thời gian của GC.
Đến đây, chúng ta cơ bản đã giải thích đầy đủ về quá trình thu gom rác của JVM, từ việc xác định thế nào là rác, cách JVM nhận diện đối tượng rác, cách thu gom rác, cho đến hai tư tưởng quan trọng trong thu gom rác: tư tưởng phân thế hệ và phân vùng. Qua đó, chúng ta đã có cái nhìn tổng quan về toàn bộ quá trình thu gom rác.
Bạn có biết có những bộ thu gom rác nào trong JVM không?
Chúng ta đã giới thiệu về JMM và cơ chế thu gom rác của JVM, vậy trong bài viết này, chúng ta sẽ nói về các bộ thu gom rác cụ thể thực hiện việc thu gom rác.
Nhìn chung, bộ thu gom rác trong JVM có thể chia thành bốn loại lớn: Bộ thu gom rác tuần tự, bộ thu gom rác song song, bộ thu gom rác CMS, và bộ thu gom rác G1.
Bộ thu gom rác tuần tự
Bộ thu gom rác tuần tự là bộ thu gom sử dụng một luồng duy nhất để thực hiện thu gom rác. Vì mỗi lần thu gom chỉ có một luồng hoạt động, nên trên các máy tính có khả năng xử lý đồng thời yếu, đặc điểm tập trung và độc quyền của nó thường mang lại hiệu suất tốt hơn.
Bộ thu gom rác tuần tự có thể được sử dụng cho cả Young Generation và Old Generation, tùy thuộc vào khu vực heap mà nó hoạt động. Dựa trên đó, có bộ thu gom rác tuần tự cho Young Generation và bộ thu gom rác tuần tự cho Old Generation.
Bộ thu gom rác tuần tự cho Young Generation
Bộ thu gom tuần tự là một trong những bộ thu gom rác lâu đời nhất và cơ bản nhất trong JDK.
Trong bộ thu gom rác tuần tự cho Young Generation, thuật toán sử dụng là thuật toán sao chép. Khi bộ thu gom rác tuần tự thực hiện thu gom rác, hiện tượng Stop-The-World (dừng toàn bộ các luồng khác) sẽ xảy ra, tức là các luồng khác sẽ bị tạm dừng để chờ cho việc thu gom rác hoàn thành. Do đó, trong một số trường hợp, nó có thể gây ra trải nghiệm người dùng kém.
Sử dụng tham số -XX:+UseSerialGC có thể chỉ định sử dụng cả bộ thu gom rác tuần tự cho Young Generation và Old Generation. Khi máy ảo chạy ở chế độ Client, nó mặc định sử dụng bộ thu gom rác này.
Bộ thu gom rác tuần tự cho Old Generation
Trong bộ thu gom rác tuần tự cho Old Generation, thuật toán được sử dụng là thuật toán đánh dấu nén. Cũng giống như bộ thu gom rác tuần tự cho Young Generation, nó chỉ thu gom rác theo kiểu tuần tự và độc quyền, vì vậy thời gian dừng Stop-The-World thường sẽ kéo dài.
Tuy nhiên, một lợi thế của bộ thu gom rác tuần tự cho Old Generation là nó có thể kết hợp với nhiều bộ thu gom rác khác dành cho Young Generation. Để kích hoạt bộ thu gom rác tuần tự cho Old Generation, bạn có thể thử các tham số sau:
-XX:+UseSerialGC: Sử dụng bộ thu gom rác tuần tự cho cả Young Generation và Old Generation.-XX:+UseParNewGC: Young Generation sử dụng bộ thu gom ParNew, Old Generation sử dụng bộ thu gom tuần tự.-XX:+UseParallelGC: Young Generation sử dụng bộ thu gom ParallelGC, Old Generation sử dụng bộ thu gom tuần tự.
Bộ thu gom rác song song
Bộ thu gom rác song song được cải tiến từ bộ thu gom tuần tự, sử dụng nhiều luồng để thực hiện thu gom rác. Đối với các máy tính có khả năng xử lý đồng thời mạnh, nó có thể rút ngắn thời gian thu gom rác hiệu quả.
Dựa trên khu vực bộ nhớ mà nó tác động, bộ thu gom rác song song cũng có ba loại: bộ thu gom ParNew cho Young Generation, bộ thu gom ParallelGC cho Young Generation, và bộ thu gom ParallelGC cho Old Generation.
Bộ thu gom ParNew cho Young Generation
Bộ thu gom ParNew cho Young Generation hoạt động trong khu vực Young Generation và thực chất chỉ là một phiên bản đa luồng của bộ thu gom tuần tự. Chiến lược thu gom, thuật toán và tham số của nó giống với bộ thu gom tuần tự cho Young Generation.
Bộ thu gom ParNew cho Young Generation cũng sử dụng thuật toán sao chép và khi thu gom rác, nó cũng gây ra hiện tượng Stop-The-World. Tuy nhiên, vì sử dụng nhiều luồng để thực hiện thu gom rác, trên các CPU có khả năng xử lý đồng thời mạnh, thời gian dừng sẽ ngắn hơn so với bộ thu gom tuần tự.
Tuy nhiên, trên các hệ thống có khả năng xử lý yếu, hiệu suất của bộ thu gom song song có thể kém hơn do phải chuyển đổi giữa các luồng. Để kích hoạt bộ thu gom ParNew cho Young Generation, bạn có thể sử dụng các tham số sau:
-XX:+UseParNewGC: Young Generation sử dụng bộ thu gom ParNew, Old Generation sử dụng bộ thu gom tuần tự.-XX:+UseConcMarkSweepGC: Young Generation sử dụng bộ thu gom ParNew, Old Generation sử dụng CMS.-XX:ParallelGCThreads: Chỉ định số lượng luồng làm việc cho bộ thu gom ParNew.
Bộ thu gom ParallelGC cho Young Generation
Bộ thu gom ParallelGC cho Young Generation rất giống với ParNew, cũng sử dụng thuật toán sao chép và là bộ thu gom đa luồng. Nó cũng gây ra hiện tượng Stop-The-World. Tuy nhiên, điểm khác biệt lớn của nó là rất chú trọng đến hiệu suất thông lượng của hệ thống.
Lý do bộ thu gom ParallelGC chú trọng đến hiệu suất thông lượng là vì nó có một cơ chế điều chỉnh GC tự động. Bạn có thể sử dụng tham số -XX:+UseAdaptiveSizePolicy để kích hoạt cơ chế này. Khi chế độ này được bật, kích thước của Young Generation, tỷ lệ giữa Eden và Survivor, và độ tuổi của các đối tượng thăng cấp lên Old Generation sẽ được tự động điều chỉnh để đạt được sự cân bằng giữa kích thước heap, thông lượng, và thời gian dừng.
Bộ thu gom ParallelGC cung cấp hai tham số quan trọng để điều chỉnh hiệu suất thông lượng của hệ thống:
-XX:MaxGCPauseMillis: Thiết lập thời gian dừng tối đa cho thu gom rác. Khi bộ thu gom ParallelGC hoạt động, nó sẽ tự động điều chỉnh các tham số để giữ thời gian dừng trong phạm vi đã thiết lập. Để đạt được mục tiêu này, có thể kích thước heap sẽ bị giảm đi, dẫn đến việc GC xảy ra thường xuyên hơn.-XX:GCTimeRatio: Thiết lập tỷ lệ thông lượng, là một số nguyên từ 0 đến 100. Nếu giá trị của GCTimeRatio là n, hệ thống sẽ không tiêu tốn quá 1/(1+n) thời gian để thu gom rác. Ví dụ, nếu GCTimeRatio có giá trị là 19, thời gian dành cho việc thu gom rác sẽ không vượt quá 1/(1+19) = 5%. Mặc định, giá trị này là 99, nghĩa là không quá 1% thời gian được sử dụng để thu gom rác.
Để kích hoạt bộ thu gom ParallelGC cho Young Generation, bạn có thể sử dụng các tham số sau:
-XX:+UseParallelGC: Young Generation sử dụng bộ thu gom Parallel, Old Generation sử dụng bộ thu gom tuần tự.-XX:+UseParallelOldGC: Young Generation sử dụng bộ thu gom ParallelGC, Old Generation sử dụng bộ thu gom ParallelOldGC.
Bộ Thu Gom Rác ParallelOldGC cho Old Generation
Bộ thu gom rác ParallelOldGC cho Old Generation cũng là một bộ thu gom rác đa luồng, tương tự như bộ thu gom rác ParallelGC cho Young Generation, nhưng tập trung vào việc tối ưu hóa hiệu suất.
Bộ thu gom ParallelOldGC sử dụng thuật toán đánh dấu và nén, và chỉ có thể sử dụng trong JDK 1.6. Chúng ta có thể sử dụng tham số
-XX:UseParallelOldGC để kích hoạt bộ thu gom ParallelGC cho Young Generation và bộ thu gom ParallelOldGC cho Old Generation.
Tham số -XX:ParallelGCThreads cũng có thể được sử dụng để thiết lập số lượng luồng khi thu gom rác.
Bộ Thu Gom Rác CMS
Khác với ParallelGC và ParallelOldGC, bộ thu gom rác CMS chủ yếu tập trung vào thời gian ngừng hệ thống. CMS (Concurrent Mark Sweep) là thuật toán thu gom rác sử dụng nhiều luồng song song.
Các Bước Làm Việc
Các bước chính của CMS bao gồm: đánh dấu ban đầu, đánh dấu đồng thời, tiền làm sạch, đánh dấu lại, làm sạch đồng thời và nén đồng thời. Trong đó, đánh dấu ban đầu và đánh dấu lại sẽ chiếm dụng tài nguyên hệ thống, còn các giai đoạn khác có thể thực thi song song với các luồng người dùng.
Trong suốt quá trình thu gom rác của CMS, theo mặc định sẽ có hoạt động tiền làm sạch. Chúng ta có thể tắt chức năng này bằng cách sử dụng tham số -XX:-CMSPrecleaningEnabled. Do đánh dấu lại chiếm dụng CPU, nếu một GC Young Generation xảy ra ngay sau đó, thời gian ngừng sẽ rất dài. Để tránh tình huống này, trong quá trình tiền làm sạch, CMS sẽ chờ một lần GC Young Generation xảy ra trước khi tiến hành làm sạch.
Các Tham Số Chính
Để khởi động bộ thu gom rác CMS, chúng ta cần sử dụng tham số: -XX:+UseConcMarkSweepGC. Số lượng luồng đồng thời có thể được thiết lập thông qua các tham số -XX:ConcGCThreads hoặc -XX:ParallelCMSThreads.
Ngoài ra, chúng ta cũng có thể thiết lập tham số -XX:CMSInitiatingOccupancyFraction để chỉ định ngưỡng sử dụng không gian Old Generation. Khi tỷ lệ sử dụng không gian Old Generation đạt ngưỡng này, một lần thu gom CMS sẽ được thực hiện, thay vì chờ đến khi bộ nhớ không đủ.
Như đã đề cập trước đó, nhược điểm của thuật toán đánh dấu và làm sạch là gây ra phân mảnh bộ nhớ, do đó, bộ thu gom CMS có thể tạo ra nhiều phân mảnh bộ nhớ. Chúng ta có thể sử dụng tham số -XX:+UseCMSCompactAtFullCollection để yêu cầu CMS thực hiện nén bộ nhớ sau khi hoàn tất thu gom rác. Tham số -XX:CMSFullGCsBeforeCompaction sẽ được sử dụng để chỉ định số lần thu gom CMS trước khi thực hiện nén bộ nhớ.
Nếu muốn sử dụng CMS để thu gom vùng Perm, chúng ta có thể bật tham số -XX:+CMSClassUnloadingEnabled. Khi mở tham số này, nếu điều kiện cho phép, hệ thống sẽ sử dụng cơ chế của CMS để thu gom dữ liệu Class trong vùng Perm.
Bộ Thu Gom Rác G1
Bộ thu gom rác G1 là bộ thu gom rác hoàn toàn mới được sử dụng trong JDK 1.7, với mục tiêu dài hạn là thay thế bộ thu gom CMS.
Bộ thu gom G1 sở hữu một chiến lược thu gom rác độc đáo, khác biệt với các bộ thu gom rác trước đó. Về mặt phân tầng, G1 vẫn thuộc loại thu gom rác phân tầng, nhưng thay đổi lớn nhất của nó là sử dụng thuật toán phân vùng, cho phép các khối bộ nhớ như khu vực Eden, From/To Survivor và Old Generation không cần phải liên tục.
Trước bộ thu gom G1, tất cả các bộ thu gom rác đều yêu cầu phân bổ bộ nhớ liên tục.
Tuy nhiên, trong bộ thu gom G1, một khối lớn bộ nhớ được chia thành nhiều khối nhỏ, không yêu cầu bộ nhớ phải liên tục.
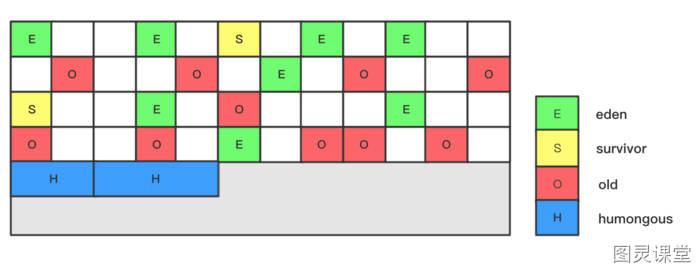
Mỗi Region được đánh dấu là E, S, O và H, cho thấy mỗi Region có vai trò khác nhau trong quá trình hoạt động. Tất cả các Region được đánh dấu là E thuộc về khu vực Eden và không cần phải liên tục. Tương tự, khu vực Survivor và Old Generation cũng vậy.
Ngoài ra, H đại diện cho Humongous, cho biết những Region này lưu trữ các đối tượng humongous (humongous object). Khi kích thước đối tượng mới lớn hơn một nửa kích thước của Region, nó sẽ được phân bổ trực tiếp trong một hoặc nhiều Region liên tục và được đánh dấu là H.
Kích thước của một Region trong bộ nhớ heap có thể được chỉ định thông qua tham số -XX:G1HeapRegionSize, với các kích thước chỉ có thể là 1M, 2M, 4M, 8M, 16M và 32M.
Các Bước Làm Việc
Quá trình thu gom của bộ thu gom G1 chủ yếu có bốn giai đoạn:
- GC Young Generation
- Chu kỳ đánh dấu đồng thời
- Thu gom hỗn hợp
- Nếu cần, có thể thực hiện Full GC
GC Young Generation tương tự như các bộ thu gom khác, là làm sạch khu vực Eden và di chuyển các đối tượng còn sống sang khu vực Survivor, một số đối tượng đạt tuổi sẽ được di chuyển sang Old Generation.
Chu kỳ đánh dấu đồng thời được chia thành các giai đoạn: đánh dấu ban đầu, quét khu vực gốc, đánh dấu đồng thời, đánh dấu lại, làm sạch độc quyền và làm sạch đồng thời. Trong đó, đánh dấu ban đầu, đánh dấu lại và làm sạch độc quyền là độc quyền và gây ra sự ngừng lại. Đồng thời, đánh dấu ban đầu sẽ kích hoạt một lần GC Young Generation.
Giai đoạn thu gom hỗn hợp sẽ ưu tiên thu gom bộ nhớ trong Collection Set, vì tỷ lệ rác trong đó cao hơn. Tên G1 (Garbage First) chính là ý nghĩa này, nghĩa là xử lý rác trước tiên. Trong giai đoạn thu gom hỗn hợp, cũng sẽ thực hiện nhiều lần GC Young Generation và GC hỗn hợp để tiến hành thu gom bộ nhớ.
Khi cần thiết, bộ thu gom G1 sẽ thực hiện Full GC. Khi gặp tình huống bộ nhớ không đủ trong giai đoạn thu gom, G1 sẽ ngừng thu gom rác và thực hiện một Full GC để giải phóng thêm không gian.
Tham Số Liên Quan
Để mở bộ thu gom G1, chúng ta có thể sử dụng tham số: -XX:+UseG1GC.
Để thiết lập thời gian ngừng tối đa, có thể sử dụng tham số: -XX:MaxGCPauseMillis.
Để thiết lập số lượng luồng làm việc của GC, có thể sử dụng tham số: -XX:ParallelGCThreads.
Để thiết lập tỷ lệ sử dụng heap kích hoạt chu kỳ đánh dấu đồng thời, có thể sử dụng tham số: -XX:InitiatingHeapOccupancyPercent.
Từ bộ thu gom rác đơn luồng ban đầu, đến bộ thu gom rác đa luồng, bộ thu gom rác CMS và cuối cùng là bộ thu gom rác G1, các bộ thu gom rác không ngừng được cải tiến, nâng cao hiệu quả thu gom rác. Đặc biệt, sau khi tư tưởng phân vùng ra đời, việc kiểm soát thời gian ngừng của thu gom rác trở nên tinh tế hơn, giúp ứng dụng có kiểm soát độ trễ tốt hơn, từ đó mang lại trải nghiệm người dùng tốt hơn.
Một Số Loại Thu Gom Rác
Chúng ta thường nghe nhiều thuật ngữ liên quan đến thu gom rác, chẳng hạn như: Minor GC, Major GC, Young GC, Old GC, Full GC, Stop-The-World, v.v. Nhưng những thuật ngữ GC này thực sự có ý nghĩa gì và sự khác biệt giữa chúng là gì? Hôm nay chúng ta sẽ cùng tìm hiểu chi tiết.
Minor GC
Việc thu gom rác từ không gian Young Generation được gọi là Minor GC, đôi khi cũng được gọi là Young GC. Một số điểm bạn cần biết về Minor GC:
- Khi JVM không thể phân bổ không gian cho một đối tượng mới, Minor GC sẽ được kích hoạt, chẳng hạn khi khu vực Eden đã đầy. Do đó, khu vực Eden càng nhỏ, Minor GC sẽ càng được thực hiện thường xuyên.
- Khi khu vực Eden trong Young Generation được phân bổ đầy, một số đối tượng trong Young Generation sẽ được nâng cấp lên Old Generation, vì vậy sau Minor GC, lượng bộ nhớ sử dụng trong Old Generation thường sẽ tăng lên.
- Chất vấn nhận thức thông thường, tất cả các Minor GC đều sẽ kích hoạt Stop-The-World, tạm dừng các luồng của ứng dụng. Đối với hầu hết các ứng dụng, độ trễ do tạm dừng gây ra là có thể bỏ qua, vì phần lớn các đối tượng trong khu vực Eden có thể được coi là rác và sẽ không bao giờ được sao chép sang khu vực Survivor hoặc không gian Old Generation. Nếu ngược lại, tức là phần lớn các đối tượng mới trong khu vực Eden không đủ điều kiện để thu gom rác (tức là chúng không bị bộ thu gom rác thu gom), thời gian tạm dừng khi thực hiện Minor GC sẽ lâu hơn nhiều (bởi vì JVM phải sao chép chúng sang khu vực Survivor hoặc Old Generation).
Major GC
Việc thu gom rác từ không gian Old Generation được gọi là Major GC, đôi khi cũng được gọi là Old GC.
Nhiều Major GC được kích hoạt bởi Minor GC, vì vậy trong nhiều trường hợp, việc tách biệt hai loại GC này là không khả thi.
Minor GC tác động lên Young Generation, trong khi Major GC tác động lên Old Generation. Khi phân bổ bộ nhớ cho đối tượng mà phát hiện bộ nhớ không đủ, Minor GC sẽ được kích hoạt. Minor GC sẽ di chuyển các đối tượng vào Old Generation; nếu lúc này không gian trong Old Generation không đủ, Major GC sẽ được kích hoạt. Vì lý do đó, nhiều Major GC là do Minor GC gây ra.
Full GC
Full GC là quá trình làm sạch toàn bộ không gian heap — bao gồm Young Generation, Old Generation và PermGen (nếu có). Do đó, có thể nói Full GC là sự kết hợp của Minor GC và Major GC.
Khi chuẩn bị kích hoạt một Minor GC, nếu phát hiện không gian còn lại trong Young Generation nhỏ hơn không gian đã nâng cấp trước đó, thì sẽ không kích hoạt Minor GC mà sẽ chuyển sang kích hoạt Full GC. Vì lúc này JVM cho rằng: khi không gian đủ lớn, đã có đối tượng được nâng cấp, và bây giờ không gian còn lại nhỏ hơn, thì rất có khả năng sẽ có đối tượng nâng cấp. Vì vậy, JVM sẽ trực tiếp thực hiện một Full GC để sắp xếp lại không gian trong Old Generation và Young Generation.
Ngoài ra, nếu không gian phân bổ trong PermGen không đủ, Full GC cũng sẽ được kích hoạt.
Stop-The-World
Stop-The-World, thường được dịch sang tiếng Việt là "tất cả dừng lại", chỉ việc trong quá trình thu gom rác, vì nhu cầu đánh dấu hoặc làm sạch, tất cả các luồng thực thi nhiệm vụ phải dừng lại để cho phép luồng thu gom rác thu gom rác trong khoảng thời gian đó.
Trong thời gian Stop-The-World, tất cả các luồng không thực hiện thu gom rác đều không thể hoạt động và đều bị tạm dừng. Chỉ khi luồng thu gom rác hoàn thành công việc của mình thì các luồng khác mới có thể tiếp tục làm việc. Có thể thấy, độ dài thời gian Stop-The-World sẽ liên quan đến thời gian phản hồi của ứng dụng, vì vậy thời gian Stop-The-World trong quá trình GC là một chỉ số rất quan trọng.
Bạn đã từng tối ưu hóa JVM chưa, hãy chia sẻ ý tưởng tối ưu của bạn?
Tại sao cần tối ưu hóa
- Ngăn ngừa xuất hiện lỗi OOM (Out of Memory)
- Giải quyết lỗi OOM
- Giảm tần suất xuất hiện của Full GC
Trước đây, chúng ta đã đề cập đến nhiều kiến thức cơ bản về JVM, và bây giờ chúng ta đã đến với chủ đề tối ưu hóa JVM. Tối ưu hóa JVM là một phương tiện, nhưng không phải tất cả các vấn đề đều có thể được giải quyết thông qua việc tối ưu hóa JVM. Vì vậy, khi thực hiện tối ưu hóa JVM, chúng ta cần tuân thủ một số nguyên tắc:
- Hầu hết các ứng dụng Java không cần tối ưu hóa JVM;
- Hầu hết nguyên nhân gây ra vấn đề GC là do vấn đề ở mã nguồn (mã nguồn);
Trước khi đưa vào sản xuất, nên cân nhắc thiết lập các tham số JVM của máy đến mức tối ưu;- Giảm số lượng đối tượng được tạo ra (mã nguồn);
- Giảm việc sử dụng biến toàn cục và đối tượng lớn (mã nguồn);
- Ưu tiên tối ưu hóa kiến trúc và mã nguồn, tối ưu hóa JVM là phương tiện cuối cùng (mã nguồn, kiến trúc);
- Phân tích tình hình GC để tối ưu hóa mã nguồn tốt hơn so với tối ưu hóa tham số JVM (mã nguồn);
Thông qua các nguyên tắc trên, chúng ta nhận thấy rằng phương pháp tối ưu hóa hiệu quả nhất thực sự là tối ưu hóa ở cấp độ kiến trúc và mã nguồn, trong khi tối ưu hóa JVM là phương pháp cuối cùng, có thể nói là sự “vắt kiệt” cuối cùng của cấu hình máy chủ. Tiếp theo, chúng ta sẽ xem cách thực hiện tối ưu hóa JVM. Tối ưu hóa không phải là hành động mù quáng; mỗi khi chúng ta thay đổi một tham số JVM, đều có lý do và dữ liệu hỗ trợ đứng sau. Dưới đây là các bước tối ưu hóa JVM khá chung ⬇️
Các bước tối ưu hóa JVM chung là:
- Bước 1: Phân tích nhật ký GC và các tệp dump, xác định xem có cần tối ưu hóa hay không, xác định điểm nghẽn vấn đề;
- Bước 2: Xác định mục tiêu định lượng tối ưu hóa JVM;
- Bước 3: Xác định các tham số tối ưu hóa JVM (dựa trên các tham số JVM lịch sử để điều chỉnh);
- Bước 4: Tối ưu hóa một máy chủ, so sánh và quan sát sự khác biệt trước và sau khi tối ưu hóa;
- Bước 5: Phân tích và điều chỉnh liên tục cho đến khi tìm được cấu hình tham số JVM phù hợp;
- Bước 6: Tìm tham số phù hợp nhất, áp dụng những tham số này cho tất cả các máy chủ và tiến hành theo dõi sau đó.
Phân tích nhật ký GC và các tệp dump, xác định xem có cần tối ưu hóa hay không, xác định điểm nghẽn vấn đề
Như đã đề cập trước đó, mỗi thay đổi tham số đều có dữ liệu hỗ trợ đứng sau. Vậy dữ liệu đến từ đâu? Đó chính là từ việc phân tích nhật ký GC và các tệp dump. Trong phần này, chúng ta sẽ cùng thảo luận chi tiết về các công cụ để xem nhật ký GC và tệp dump, cũng như cách phân tích chúng để tìm ra nguyên nhân vấn đề.
Phân tích nhật ký GC
Trước tiên, chúng ta hãy xem xét phân tích nhật ký GC. Có thể nhiều bạn chưa từng thấy nhật ký GC, nhưng nhật ký này ghi lại tình trạng hoạt động của bộ thu gom rác (garbage collector), bao gồm lý do thu gom rác, thời gian, luồng thực thi, không gian bộ nhớ được thu hồi, và nhiều thông tin khác. Nó chủ yếu được sử dụng để phân tích hiệu suất của bộ thu gom rác và tối ưu hóa. Ở đây, chúng ta sẽ tìm hiểu cách mà dự án của chúng ta có thể lấy được nhật ký GC, sau đó sẽ thảo luận về các công cụ và phương pháp phân tích. Chúng ta sẽ đề cập đến các chương trình Java, dự án Tomcat, và dự án Spring Boot.
Chương trình Java
Chương trình Java có thể kích hoạt việc ghi nhật ký GC bằng cách thêm các tham số thích hợp vào tham số khởi động. Cụ thể, bạn có thể sử dụng các tham số sau:
- -XX:+PrintGC: Bật ghi nhật ký GC;
- -XX:+PrintGCDetails: Xuất thông tin chi tiết trong nhật ký GC;
- -XX:+PrintGCDateStamps: Xuất dấu thời gian trong nhật ký GC;
- -Xlog:gc+heap=trace: Xuất thông tin chi tiết về heap trước và sau khi GC;
- -Xlog:gc:<tên_tệp>: Ghi nhật ký GC vào tệp chỉ định.
Dựa trên phiên bản Java 17:
Ví dụ, bạn có thể sử dụng lệnh sau để khởi động chương trình Java và xuất nhật ký GC vào tệp gc.log:
-Xms5M -Xmx5M -Xlog:gc:/Users/a123/IdeaProjects/java-example/logs/gc.log -XX:+PrintGC -Xlog:gc+heap=traceTrong quá trình chạy chương trình, nhật ký GC sẽ được ghi vào tệp chỉ định, và bạn có thể phân tích nhật ký để hiểu tình trạng thu gom rác, từ đó tiến hành tối ưu hóa.
Tomcat
Đối với dự án Tomcat, bạn có thể thêm các tham số tương ứng vào biến JAVA_OPTS trong tập lệnh khởi động Tomcat để bật ghi nhật ký GC. Cụ thể, bạn có thể chỉnh sửa tệp catalina.sh hoặc catalina.bat (trên Windows) và thêm các tham số sau:
JAVA_OPTS="-Xloggc:/path/to/gc.log -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC"Trong đó, /path/to/gc.log là đường dẫn đến tệp nhật ký xuất.
Spring Boot
Đối với dự án Spring Boot, bạn có thể thêm các tham số sau vào tệp cấu hình application.properties hoặc application.yml:
logging.file=gc.log
logging.level.gc=infoTrong đó, logging.file chỉ định tên tệp nhật ký, logging.level.gc chỉ định mức độ ghi nhật ký, ở đây đặt là info để xuất nhật ký GC.
Cần lưu ý rằng, các phiên bản khác nhau của Tomcat và Spring Boot có thể có sự khác biệt, do đó cách thêm tham số cụ thể có thể khác nhau. Trong quá trình sử dụng, bạn nên tham khảo tài liệu hoặc hướng dẫn của phiên bản tương ứng để biết cách đúng nhất để kích hoạt ghi nhật ký GC.
Chúng ta cùng xem một ví dụ về nhật ký GC:
[2023-02-14T22:13:12.554+0800] -XX:+PrintGC is deprecated. Will use -Xlog:gc instead.
[2023-02-14T22:13:12.557+0800] Using G1
[2023-02-14T22:13:12.593+0800] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 3M->3M(8M) 1.720ms
[2023-02-14T22:13:12.596+0800] GC(1) Pause Young (Concurrent Start) (G1 Preventive Collection) 4M->3M(8M) 1.533ms
[2023-02-14T22:13:12.596+0800] GC(2) Concurrent Mark Cycle
[2023-02-14T22:13:12.598+0800] GC(3) Pause Young (Normal) (G1 Preventive Collection) 4M->4M(8M) 1.069ms
[2023-02-14T22:13:12.601+0800] GC(4) To-space exhausted
[2023-02-14T22:13:12.601+0800] GC(4) Pause Young (Normal) (G1 Preventive Collection) 5M->5M(8M) 2.454ms
[2023-02-14T22:13:12.606+0800] GC(5) To-space exhausted
[2023-02-14T22:13:12.606+0800] GC(5) Pause Young (Normal) (G1 Evacuation Pause) 6M->6M(8M) 4.494ms
[2023-02-14T22:13:12.617+0800] GC(6) Pause Full (G1 Compaction Pause) 6M->6M(8M) 10.797ms
[2023-02-14T22:13:12.627+0800] GC(7) Pause Full (G1 Compaction Pause) 6M->6M(8M) 10.258ms
[2023-02-14T22:13:12.627+0800] GC(2) Concurrent Mark Cycle 31.610ms
[2023-02-14T22:13:12.628+0800] GC(8) Pause Young (Normal) (G1 Evacuation Pause) 6M->6M(8M) 0.243ms
[2023-02-14T22:13:12.636+0800] GC(9) Pause Full (G1 Compaction Pause) 6M->6M(8M) 8.079ms
[2023-02-14T22:13:12.646+0800] GC(10) Pause Full (G1 Compaction Pause) 6M->6M(8M) 10.570ms
[2023-02-14T22:13:12.647+0800] GC(11) Pause Young (Concurrent Start) (G1 Evacuation Pause) 6M->6M(8M) 0.307ms
[2023-02-14T22:13:12.647+0800] GC(13) Concurrent Mark Cycle
[2023-02-14T22:13:12.648+0800] GC(12) Pause Full (G1 Compaction Pause) 6M->1M(8M) 1.330ms
[2023-02-14T22:13:12.648+0800] GC(13) Concurrent Mark Cycle 1.388msNhật ký có thể nhìn không trực quan và hơi khó khăn để phân tích. Thực tế, có nhiều công cụ trực quan hóa để phân tích nhật ký GC, dưới đây là một số công cụ tiêu biểu:
- GCViewer: Chức năng đơn giản, dễ sử dụng, phù hợp cho người mới bắt đầu.
- GCEasy: Tự động phát hiện nhật ký GC và cung cấp một loạt báo cáo và gợi ý, phù hợp để nhanh chóng xác định và giải quyết các vấn đề về GC.
- HPROF: Công cụ phân tích bộ nhớ heap đi kèm với Java, có thể kết hợp với các công cụ như GCViewer để cung cấp phân tích toàn diện hơn.
- Java Mission Control: Công cụ giám sát hiệu suất đi kèm với JDK, cung cấp nhiều chỉ số giám sát, bao gồm GC, và có thể tích hợp với VisualVM.
- VisualVM: Chức năng toàn diện, nhiều plugin, hỗ trợ nhiều chỉ số giám sát và phương pháp phân tích, phù hợp cho người dùng nâng cao và chuyên gia.
- GClogAnalyzer: Cung cấp nhiều biểu đồ và công cụ phân tích, có khả năng phân tích sâu về nhiều khía cạnh của nhật ký GC.
- YourKit Java Profiler: Chức năng phong phú, dễ sử dụng, cung cấp phân tích GC, CPU, bộ nhớ, và nhiều chức năng khác, phù hợp cho chuyên gia.
- JProfiler: Cung cấp nhiều công cụ phân tích hiệu suất và gỡ lỗi, bao gồm phân tích GC, CPU, bộ nhớ, phù hợp cho chuyên gia.
Bạn có thể chọn công cụ theo sở thích và thói quen của mình. Đồng thời, JDK cũng cung cấp nhiều bộ công cụ tối ưu hóa JVM, có thể tìm thấy trong thư mục bin của gói cài đặt. Dưới đây là ví dụ trên máy tính của tôi:
/Library/Java/JavaVirtualMachines/jdk-17.0.5.jdk/Contents/Home/bin
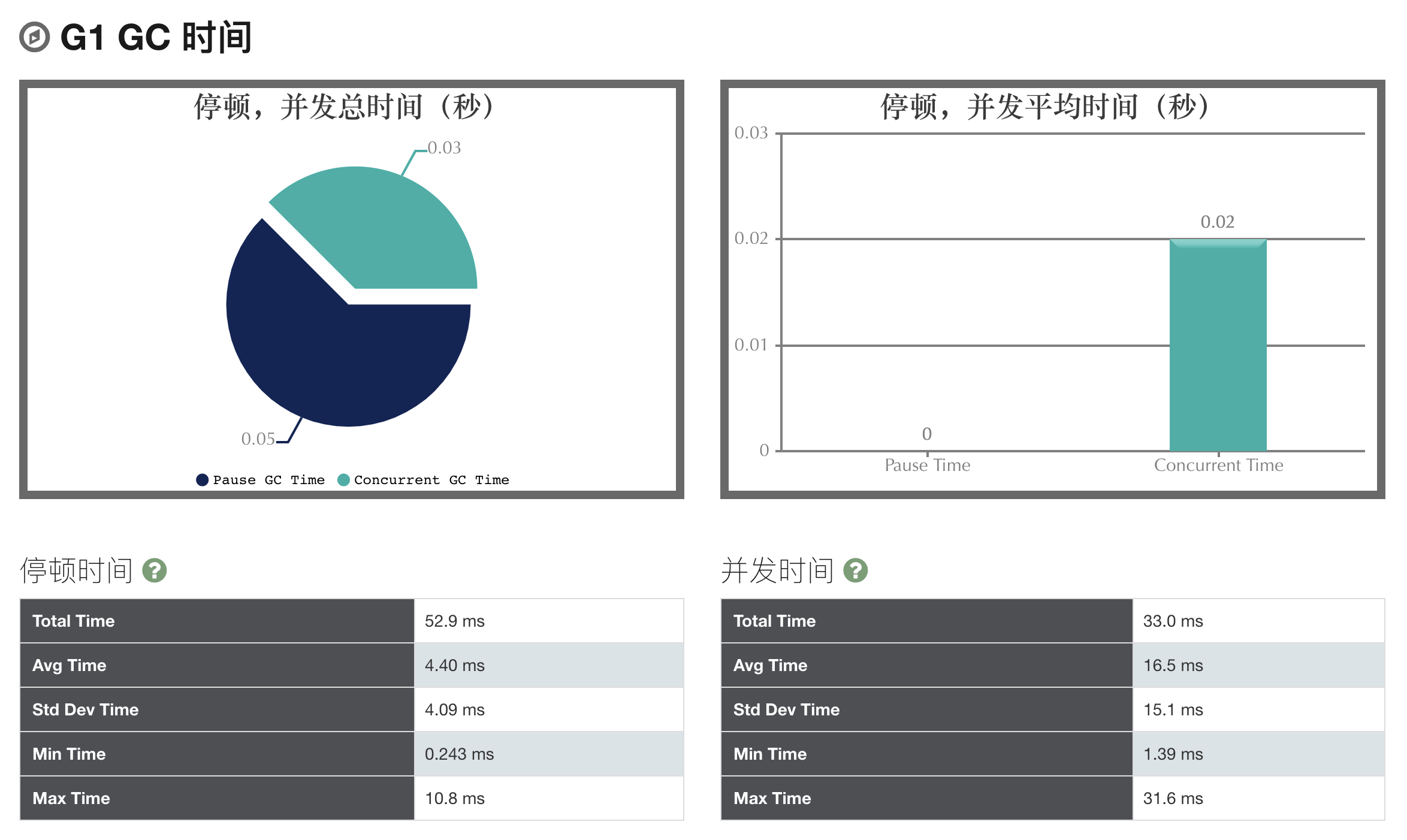
Phân tích nhật ký GC
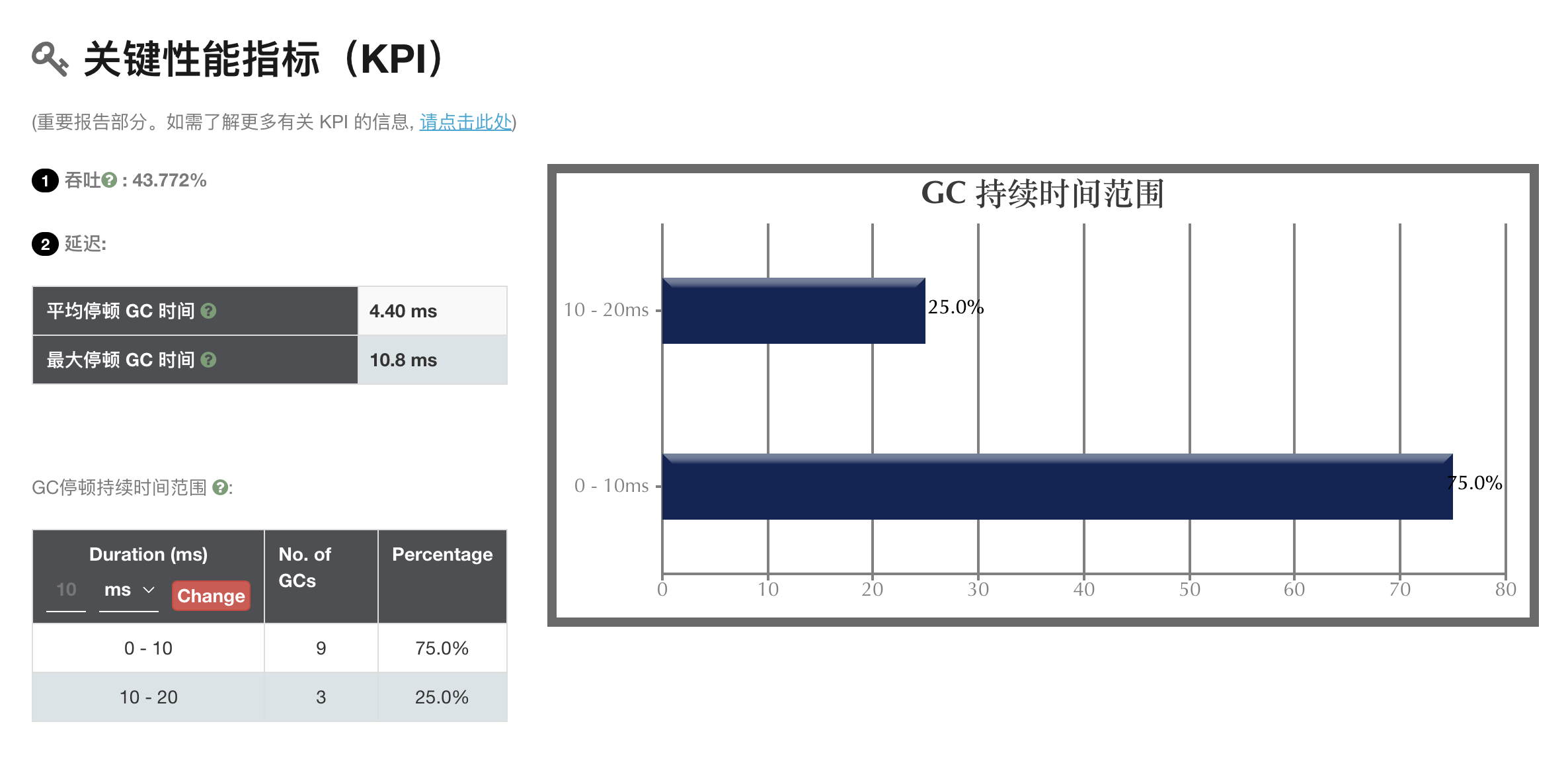
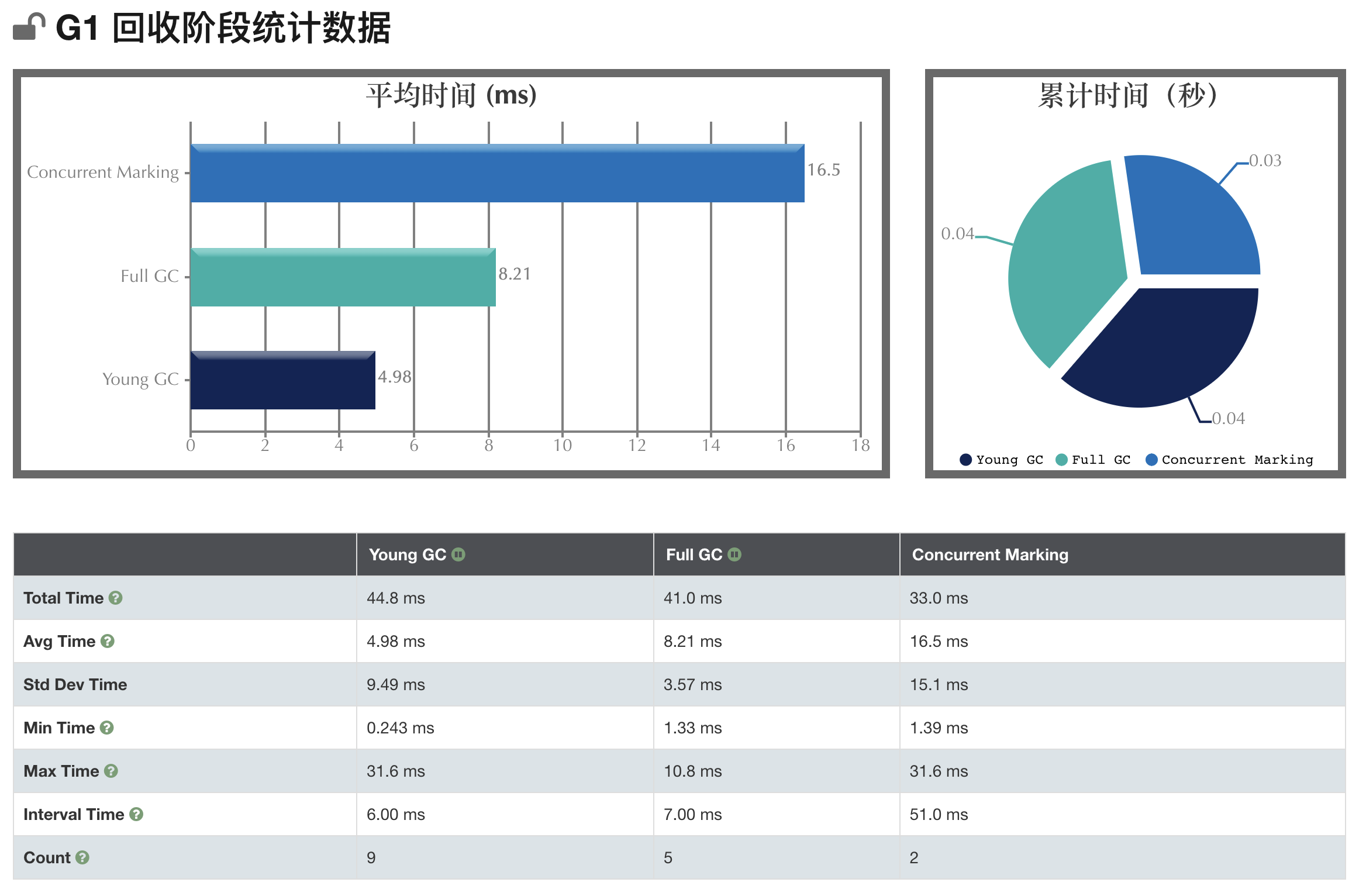
Cách tốt nhất để phân tích nhật ký GC là sử dụng các công cụ phân tích đã đề cập ở trên. Chúng có thể giúp bạn trực quan hóa, hiển thị và cung cấp nhiều thông tin chi tiết cần thiết cho việc tối ưu hóa hiệu suất. Một số thông số quan trọng mà bạn có thể quan tâm bao gồm:
- Time: Thời gian tiêu tốn cho từng loại GC;
- Pause: Thời gian tạm dừng của các luồng trong quá trình GC;
- Heap usage: Sử dụng bộ nhớ heap trước và sau khi GC;
- GC Frequency: Tần suất gọi GC;
- Survivor Space: Thông tin về bộ nhớ survivor.
Cùng với việc phân tích nhật ký GC, bạn cũng có thể theo dõi chỉ số hiệu suất khác nhau trong mã nguồn hoặc trong quá trình sản xuất để tối ưu hóa ứng dụng và cải thiện hiệu suất. Dưới đây là một số hướng dẫn tối ưu hóa mà bạn có thể tham khảo:
Tối ưu hóa sử dụng bộ nhớ: Thay vì tạo đối tượng mới, cố gắng sử dụng lại đối tượng có sẵn. Điều này sẽ giảm thiểu việc thu gom rác và tăng hiệu suất.
Giảm thiểu việc tạo các đối tượng lớn: Cố gắng chia nhỏ các đối tượng lớn thành nhiều đối tượng nhỏ, giúp việc thu gom rác hiệu quả hơn.
Chọn GC hợp lý: Dựa trên đặc điểm ứng dụng, lựa chọn bộ thu gom rác thích hợp, ví dụ G1 cho ứng dụng yêu cầu độ trễ thấp.
Theo dõi và điều chỉnh kích thước heap: Theo dõi việc sử dụng bộ nhớ và điều chỉnh kích thước heap phù hợp để tránh tình trạng đầy bộ nhớ.
Xem xét các lựa chọn bộ nhớ cho Spring Boot: Khi sử dụng Spring Boot, cần xem xét cấu hình bộ nhớ của Spring để tối ưu hóa hiệu suất.
Cuối cùng, việc tối ưu hóa hiệu suất không chỉ dựa vào việc điều chỉnh GC mà còn cần xem xét tổng thể về cách thức mã nguồn và cấu hình phần mềm hoạt động cùng nhau để đạt được kết quả tốt nhất.