Complete Java Interview Questions
Hoành thành tổng hợp câu hỏi phỏng vấn Java
Info
Tổng hợp câu hỏi của toàn bộ, không phải chỉ về JAVA!
Sự khác biệt giữa JDK, JRE và JVM
- JDK (Java SE Development Kit) là bộ công cụ phát triển tiêu chuẩn của Java, cung cấp các công cụ và tài nguyên cần thiết để biên dịch và chạy chương trình Java, bao gồm trình biên dịch Java, môi trường chạy Java, và các thư viện lớp Java thông dụng.
- JRE (Java Runtime Environment) là môi trường chạy Java, được sử dụng để chạy các tệp bytecode của Java. JRE bao gồm JVM và các thư viện cần thiết để JVM hoạt động. Người dùng thông thường chỉ cần cài đặt JRE để chạy chương trình Java, trong khi nhà phát triển cần cài đặt JDK để biên dịch và gỡ lỗi chương trình.
- JVM (Java Virtual Machine) là máy ảo Java, một phần của JRE và là phần quan trọng nhất của Java để hiện thực hóa khả năng đa nền tảng, chịu trách nhiệm chạy các tệp bytecode.
Chúng ta có thể viết mã Java bằng một tệp tin txt, nhưng mã Java sau khi viết cần được biên dịch thành bytecode để có thể chạy được. Để làm điều này, ta cần trình biên dịch, và JDK bao gồm trình biên dịch javac. Sau khi mã Java được biên dịch thành bytecode, JVM (máy ảo Java) sẽ được sử dụng để thực thi bytecode đó.
Nếu chúng ta muốn phát triển chương trình Java, thì cần JDK để biên dịch các tệp nguồn Java. Nếu chỉ muốn chạy các tệp bytecode Java đã được biên dịch sẵn, tức là các tệp *.class, thì chỉ cần JRE. JDK bao gồm JRE, và JRE bao gồm JVM.
Ngoài ra, khi JVM thực thi bytecode Java, nó cần chuyển bytecode thành lệnh máy, mà lệnh máy trên các hệ điều hành khác nhau có thể khác nhau. Do đó, JVM trên các hệ điều hành khác nhau cũng không giống nhau, vì vậy khi cài đặt JDK, ta cần chọn đúng hệ điều hành.
Thêm vào đó, JVM chỉ thực thi bytecode Java, do đó bất kỳ mã nào sau khi biên dịch thành bytecode Java đều có thể chạy trên JVM, chẳng hạn như Apache Groovy, Scala, Kotlin,...
Mối quan hệ giữa hashCode() và equals()
Trong Java, mỗi đối tượng đều có thể gọi phương thức hashCode() của nó để lấy giá trị hash (hashCode), tương tự như dấu vân tay của đối tượng. Thông thường, không có hai dấu vân tay nào giống nhau hoàn toàn, nhưng trong Java, không thể đảm bảo điều này tuyệt đối. Tuy nhiên, ta vẫn có thể sử dụng hashCode để làm một số phán đoán ban đầu, ví dụ:
- Nếu hashCode của hai đối tượng khác nhau, thì chắc chắn chúng là hai đối tượng khác nhau.
- Nếu hashCode của hai đối tượng giống nhau, không đảm bảo rằng chúng là cùng một đối tượng, mà có thể là hai đối tượng khác nhau.
- Nếu hai đối tượng bằng nhau, thì hashCode của chúng chắc chắn giống nhau.
Trong một số lớp Collection của Java, khi so sánh hai đối tượng xem chúng có bằng nhau hay không, sẽ tuân theo nguyên tắc trên. Trước tiên sẽ gọi phương thức hashCode() của đối tượng để so sánh. Nếu hashCode khác nhau, có thể trực tiếp kết luận rằng hai đối tượng này khác nhau. Nếu hashCode giống nhau, sẽ gọi tiếp phương thức equals() để so sánh. Phương thức equals() là để xác định cuối cùng xem hai đối tượng có bằng nhau không. Thường thì phương thức equals() có logic so sánh phức tạp hơn và nặng hơn so với hashCode(), trong khi hashCode() chỉ trả về một giá trị số, nên nhẹ hơn và nhanh hơn.
Do đó, cần lưu ý rằng nếu chúng ta ghi đè phương thức equals(), thì cũng cần đảm bảo rằng phương thức hashCode() tuân thủ các quy tắc trên.
Sự khác biệt giữa String, StringBuffer và StringBuilder
- String là bất biến, nếu cố gắng thay đổi, sẽ tạo ra một đối tượng chuỗi mới. StringBuffer và StringBuilder là có thể thay đổi.
- StringBuffer an toàn trong môi trường đa luồng, trong khi StringBuilder không an toàn, vì vậy StringBuilder sẽ hiệu quả hơn trong môi trường đơn luồng.
Sự khác biệt giữa extends và super trong generic
<? extends T>biểu thị bất kỳ lớp con nào của T, bao gồm cả T.<? super T>biểu thị bất kỳ lớp cha nào của T, bao gồm cả T.
Sự khác biệt giữa == và equals
==: Nếu là kiểu dữ liệu cơ bản, so sánh giá trị; nếu là kiểu đối tượng, so sánh địa chỉ tham chiếu.equals: Tùy thuộc vào cách mỗi lớp ghi đè phương thức equals() sau đó. Ví dụ, với lớp String, mặc dù là kiểu đối tượng, nhưng lớp String đã ghi đè phương thức equals() để so sánh nội dung các ký tự của chuỗi.
Sự khác biệt giữa Overload và Override
- Overload: Trong một lớp, nếu các phương thức cùng tên có danh sách tham số khác nhau (như khác kiểu dữ liệu hoặc số lượng tham số) thì được coi là overload.
- Override: Là khi một lớp con ghi đè lại phương thức của lớp cha với cùng tên phương thức, cùng danh sách tham số và kiểu trả về (có thể là kiểu con của kiểu trả về phương thức trong lớp cha). Phương thức trong lớp con sẽ được sử dụng thay vì phương thức trong lớp cha. Lưu ý rằng quyền truy cập của phương thức trong lớp con không được nhỏ hơn lớp cha.
Sự khác biệt giữa List và Set
- List: Có thứ tự, lưu trữ các đối tượng theo thứ tự chèn vào, có thể trùng lặp, cho phép nhiều phần tử null, có thể sử dụng Iterator để duyệt các phần tử hoặc sử dụng get(int index) để lấy phần tử theo chỉ mục.
- Set: Không có thứ tự, không cho phép phần tử trùng lặp, tối đa chỉ có một phần tử null, chỉ có thể duyệt qua các phần tử bằng Iterator.
Nguyên lý hoạt động của ArrayList
- Khi khởi tạo ArrayList, nếu không chỉ định dung lượng, sẽ tạo một mảng rỗng. Nếu chỉ định dung lượng, sẽ tạo mảng có kích thước tương ứng.
- Khi thêm phần tử, trước tiên sẽ kiểm tra dung lượng của mảng có đủ không, nếu không đủ sẽ mở rộng, theo quy tắc tăng 1.5 lần. Sau khi dung lượng đủ, phần tử sẽ được thêm vào mảng.
- Khi thêm phần tử vào vị trí cụ thể, trước tiên sẽ kiểm tra chỉ mục có vượt quá giới hạn không, sau đó kiểm tra dung lượng, nếu không đủ sẽ mở rộng. Sau đó, phần tử mới sẽ được thêm vào vị trí chỉ định và các phần tử phía sau sẽ được dịch chuyển.
- Khi lấy phần tử tại chỉ mục, sẽ kiểm tra xem chỉ mục có hợp lệ không rồi lấy phần tử tương ứng từ mảng.
Sự khác biệt giữa ArrayList và LinkedList
- Cấu trúc dữ liệu khác nhau, ArrayList dựa trên mảng, LinkedList dựa trên danh sách liên kết.
- Do khác nhau về cấu trúc dữ liệu, ArrayList phù hợp hơn cho việc truy vấn ngẫu nhiên, trong khi LinkedList phù hợp hơn cho việc xóa và thêm phần tử. Độ phức tạp về thời gian của truy vấn, thêm và xóa cũng khác nhau.
- Cả ArrayList và LinkedList đều triển khai interface List, nhưng LinkedList còn triển khai thêm interface Deque, vì vậy nó có thể được sử dụng như một hàng đợi.
Cơ chế mở rộng của ConcurrentHashMap
Phiên bản 1.7
- ConcurrentHashMap 1.7 được triển khai dựa trên phân đoạn (Segment).
- Mỗi Segment tương đương với một HashMap nhỏ.
- Mỗi Segment sẽ tự thực hiện mở rộng, giống với cách HashMap mở rộng.
- Đầu tiên, tạo một mảng mới, sau đó chuyển các phần tử vào mảng mới.
- Mỗi Segment tự xác định khi nào cần mở rộng, bằng cách kiểm tra xem có vượt ngưỡng không.
Phiên bản 1.8
- ConcurrentHashMap 1.8 không còn dựa trên Segment.
- Khi một luồng thực hiện put mà phát hiện ConcurrentHashMap đang mở rộng, luồng đó sẽ tham gia vào việc mở rộng.
- Nếu không có quá trình mở rộng diễn ra, luồng sẽ thêm key-value vào ConcurrentHashMap và kiểm tra xem có vượt ngưỡng không, nếu có sẽ mở rộng.
- ConcurrentHashMap hỗ trợ nhiều luồng mở rộng cùng lúc.
- Trước khi mở rộng, sẽ tạo một mảng mới.
- Khi chuyển các phần tử, sẽ phân chia mảng cũ thành các nhóm và mỗi luồng sẽ chịu trách nhiệm chuyển một hoặc nhiều nhóm phần tử.
Những thay đổi từ JDK1.7 đến JDK1.8 trong HashMap (phần cơ bản)
- Trong JDK1.7, cấu trúc dữ liệu cơ bản là mảng + danh sách liên kết, trong JDK1.8 là mảng + danh sách liên kết + cây đỏ đen. Việc thêm cây đỏ đen nhằm nâng cao hiệu suất chèn và tìm kiếm trong HashMap.
- Trong JDK1.7, danh sách liên kết được chèn bằng cách chèn vào đầu, trong JDK1.8, danh sách liên kết được chèn bằng cách chèn vào đuôi, bởi vì trong JDK1.8, khi chèn cặp khóa và giá trị cần phải kiểm tra số lượng phần tử trong danh sách, do đó chèn vào đuôi là hợp lý.
- Trong JDK1.7, thuật toán băm khá phức tạp, bao gồm nhiều phép dịch phải và XOR, còn trong JDK1.8, thuật toán này đã được đơn giản hóa. Vì mục đích của thuật toán băm phức tạp là cải thiện tính phân tán, nhưng với sự bổ sung của cây đỏ đen trong JDK1.8, việc đơn giản hóa thuật toán này giúp tiết kiệm tài nguyên CPU.
Quy trình phương thức put của HashMap
Quy trình cơ bản của phương thức put trong HashMap:
- Tính chỉ số mảng từ khóa thông qua thuật toán băm.
- Nếu chỉ số đó trong mảng trống, thì đóng gói cặp khóa-giá trị vào đối tượng
Entry(trong JDK1.7 làEntry, trong JDK1.8 làNode) và đặt vào vị trí đó. - Nếu vị trí đó không trống, thì xử lý tùy theo trường hợp:
- Trong JDK1.7, kiểm tra xem có cần mở rộng không, nếu có thì thực hiện mở rộng, nếu không thì tạo đối tượng
Entrymới và thêm vào danh sách liên kết bằng cách chèn vào đầu. - Trong JDK1.8, trước tiên kiểm tra loại nút
Nodehiện tại, có thể là nút của cây đỏ đen hoặc danh sách liên kết.- Nếu là nút cây đỏ đen, đóng gói cặp khóa-giá trị thành một nút cây đỏ đen mới và thêm vào cây. Trong quá trình này, kiểm tra xem cây có chứa khóa hiện tại không, nếu có thì cập nhật giá trị.
- Nếu là nút danh sách liên kết, đóng gói cặp khóa-giá trị thành một nút danh sách liên kết mới và thêm vào đuôi danh sách. Trong quá trình duyệt danh sách, nếu phát hiện có khóa trùng, thì cập nhật giá trị. Nếu sau khi chèn mà danh sách có nhiều hơn 8 phần tử, thì chuyển danh sách liên kết thành cây đỏ đen.
- Sau khi thêm cặp khóa-giá trị vào danh sách liên kết hoặc cây đỏ đen, kiểm tra xem có cần mở rộng không, nếu cần thì mở rộng, nếu không thì kết thúc phương thức
put.
- Trong JDK1.7, kiểm tra xem có cần mở rộng không, nếu có thì thực hiện mở rộng, nếu không thì tạo đối tượng
Sự khác biệt giữa sao chép sâu và sao chép nông
Sao chép sâu và sao chép nông liên quan đến việc sao chép một đối tượng, trong đó có hai loại thuộc tính: kiểu dữ liệu cơ bản và tham chiếu đến đối tượng khác.
- Sao chép nông chỉ sao chép các giá trị của kiểu dữ liệu cơ bản và địa chỉ tham chiếu của đối tượng khác, không sao chép đối tượng mà tham chiếu đó trỏ đến. Kết quả là, các đối tượng sao chép nông có cùng tham chiếu đến một đối tượng chung.
- Sao chép sâu sao chép cả giá trị của kiểu dữ liệu cơ bản và sao chép cả đối tượng mà tham chiếu trỏ đến. Kết quả là, các đối tượng sao chép sâu có tham chiếu đến các đối tượng khác nhau.
Cơ chế mở rộng của HashMap
Phiên bản JDK1.7
- Tạo một mảng mới.
- Duyệt qua từng vị trí của mảng cũ và các phần tử trong danh sách liên kết tại vị trí đó.
- Tính lại chỉ số mảng mới cho từng phần tử dựa trên chiều dài mảng mới.
- Thêm phần tử vào mảng mới.
- Sau khi tất cả phần tử đã được chuyển sang mảng mới, gán mảng mới cho thuộc tính
tablecủa đối tượng HashMap.
Phiên bản JDK1.8
- Tạo một mảng mới.
- Duyệt qua từng vị trí của mảng cũ, bao gồm danh sách liên kết và cây đỏ đen.
- Nếu là danh sách liên kết, tính lại chỉ số và thêm từng phần tử vào mảng mới.
- Nếu là cây đỏ đen:
- Duyệt qua từng phần tử trong cây và tính chỉ số trong mảng mới.
- Nếu số phần tử tại một chỉ số lớn hơn 8, tạo một cây đỏ đen mới và thêm vào vị trí đó.
- Nếu số phần tử nhỏ hơn hoặc bằng 6, tạo danh sách liên kết và thêm vào vị trí đó.
- Sau khi tất cả phần tử đã được chuyển sang mảng mới, gán mảng mới cho thuộc tính
tablecủa HashMap.
Nguyên lý của CopyOnWriteArrayList
- CopyOnWriteArrayList sử dụng mảng bên trong để lưu trữ dữ liệu. Khi thêm một phần tử, nó sẽ sao chép một mảng mới, các thao tác ghi sẽ thực hiện trên mảng mới, còn các thao tác đọc sẽ thực hiện trên mảng cũ.
- Các thao tác ghi được khóa để ngăn ngừa sự cố ghi dữ liệu đồng thời.
- Sau khi kết thúc ghi, mảng cũ sẽ được thay thế bằng mảng mới.
- CopyOnWriteArrayList phù hợp với các tình huống đọc nhiều ghi ít, vì cho phép đọc trong khi đang thực hiện ghi mà không cần khóa đọc.
Bytecode là gì? Lợi ích của việc sử dụng bytecode là gì?
Bộ biên dịch (javac) sẽ biên dịch mã nguồn Java (*.java) thành tệp bytecode (*.class), giúp mã Java có thể biên dịch một lần và chạy ở nhiều nơi. Các tệp class có thể chạy trên nhiều hệ điều hành khác nhau. Tuy nhiên, để thực hiện điều này, các hệ điều hành cần có các phiên bản JDK hoặc JRE khác nhau, vì bytecode cần được chuyển thành mã máy khác nhau trên các hệ điều hành.
Lợi ích của việc sử dụng bytecode là giúp Java có khả năng đa nền tảng và tăng hiệu suất thực thi. Bộ biên dịch có thể tối ưu hóa mã trong quá trình biên dịch, chẳng hạn như loại bỏ khóa, thay thế đại lượng, hoặc nội tuyến phương thức.
Hệ thống xử lý ngoại lệ trong Java
- Tất cả các ngoại lệ trong Java đều bắt nguồn từ lớp cha cao nhất là Throwable.
- Throwable có hai lớp con chính là Exception và Error.
- Error đại diện cho các lỗi nghiêm trọng như
java.lang.StackOverFlowErrorvàJava.lang.OutOfMemoryError, thường những lỗi này không thể được xử lý bởi chương trình. Chúng thường là vấn đề ở cấp độ máy ảo, đĩa hoặc hệ điều hành, do đó, không khuyến nghị xử lý chúng trong mã vì chương trình có thể đã ngừng hoạt động. - Exception đại diện cho các ngoại lệ mà chương trình có thể xử lý, như
NullPointerExceptionhoặcIllegalAccessException. Chúng ta có thể bắt các ngoại lệ này để xử lý đặc biệt. - Các lớp con của Exception có thể chia thành hai loại: RuntimeException và Non-RuntimeException.
- RuntimeException là các ngoại lệ phát sinh khi chương trình đang chạy, là ngoại lệ không cần kiểm tra. Chúng ta có thể chọn bắt hoặc không bắt những ngoại lệ này, thường là do lỗi logic chương trình, ví dụ:
NullPointerException,IndexOutOfBoundsException. - Non-RuntimeException là ngoại lệ cần kiểm tra và bắt buộc phải xử lý, ví dụ:
IOException,SQLExceptionhoặc các ngoại lệ do người dùng tự định nghĩa.
- RuntimeException là các ngoại lệ phát sinh khi chương trình đang chạy, là ngoại lệ không cần kiểm tra. Chúng ta có thể chọn bắt hoặc không bắt những ngoại lệ này, thường là do lỗi logic chương trình, ví dụ:
Trong cơ chế xử lý ngoại lệ của Java, khi nào nên ném ngoại lệ và khi nào nên bắt ngoại lệ?
Ngoại lệ tương đương với một thông báo. Nếu chúng ta ném ngoại lệ, điều đó có nghĩa là phương thức hiện tại không thể xử lý và yêu cầu phương thức ở lớp trên xử lý. Lớp trên cũng cần quyết định xem có thể xử lý hay tiếp tục ném ngoại lệ cho lớp trên tiếp theo.
Khi viết một phương thức, cần cân nhắc liệu phương thức có thể xử lý ngoại lệ một cách hợp lý hay không. Nếu không, thì tiếp tục ném ngoại lệ. Nếu phương thức phát hiện ngoại lệ khi gọi một phương thức khác, và ngoại lệ này nên được xử lý tại đây, thì cần bắt và xử lý ngoại lệ đó.
Generic Erasure trong Java là gì?
Trong JDK 1.5 và các phiên bản trước đó không tồn tại khái niệm về generic. Từ JDK 1.5 trở đi, khái niệm generic đã được giới thiệu để tương thích với các phiên bản JDK trước đó, từ đó khái niệm "generic erasure" (xóa bỏ generic) ra đời.
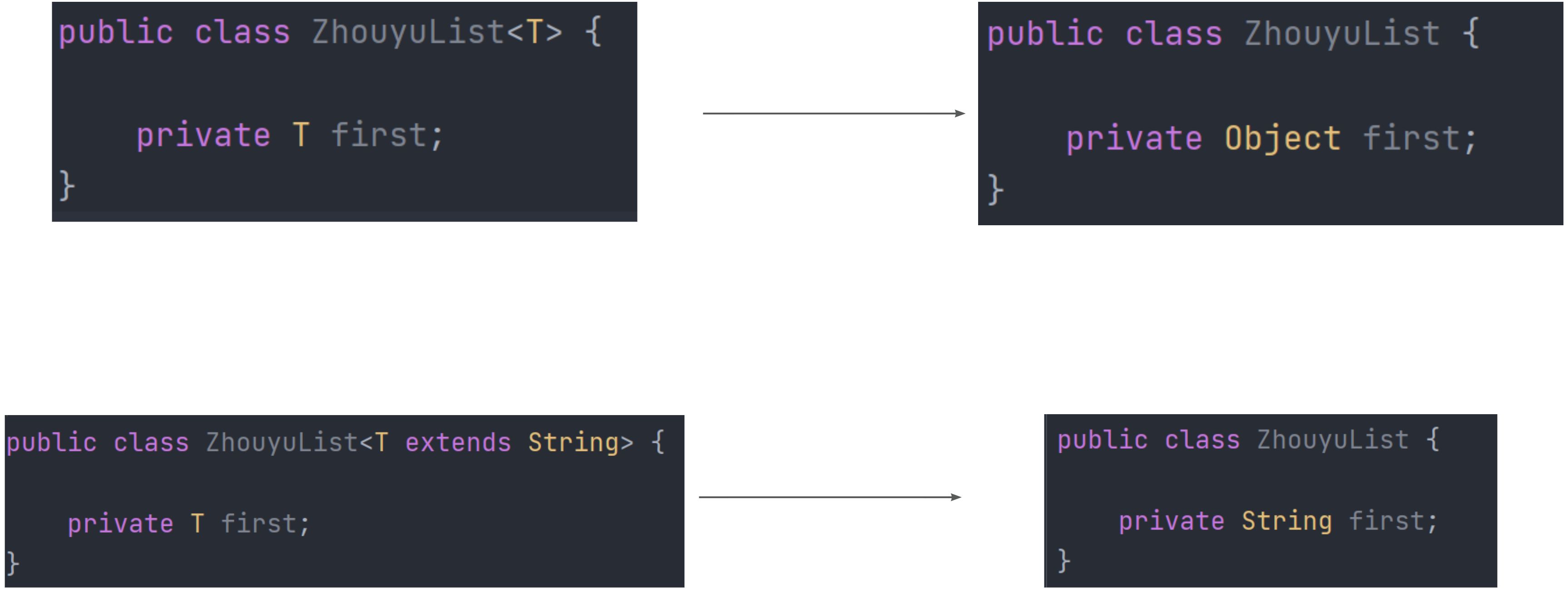
Dưới đây là hai kiểu tương đương, bề ngoài generic đã bị xóa bỏ, tất cả đều là ArrayList:
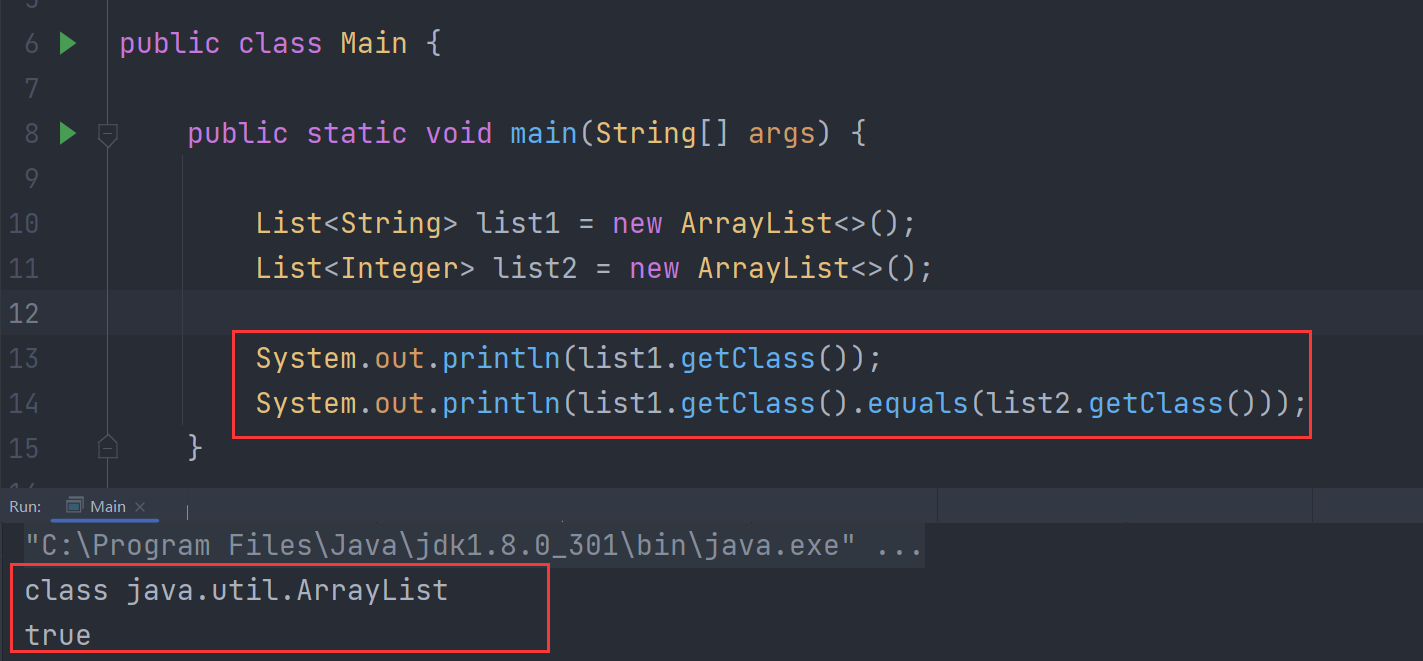
API dưới đây chỉ có thể lấy được số lượng generic, nhưng không thể lấy được loại cụ thể của generic:
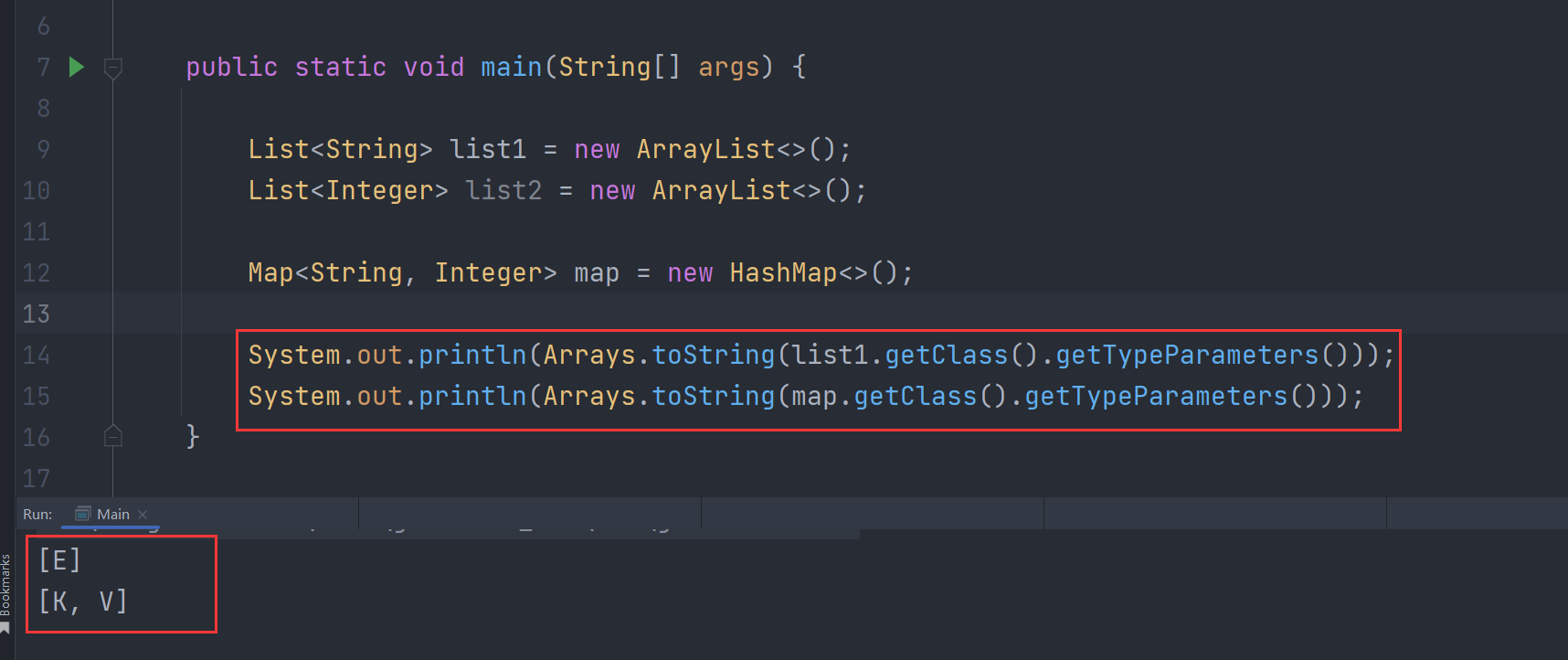
Thông qua phản chiếu (reflection), ta có thể thêm các phần tử thuộc kiểu khác nhau vào danh sách (List), vì kiểu thực sự đã bị xóa bỏ, biến thành Object:
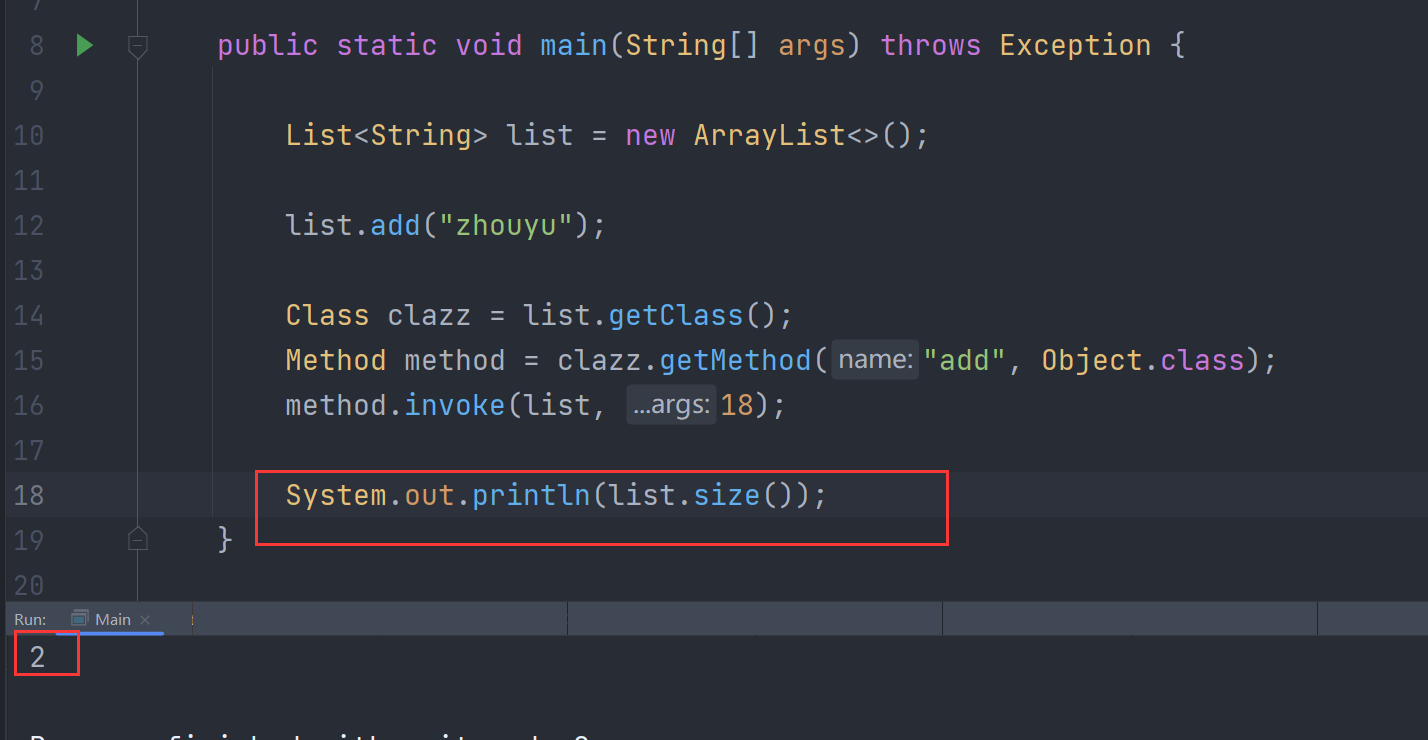
Mặc dù generic đã bị xóa bỏ, nhưng thông tin cụ thể về generic vẫn được lưu trữ trong bytecode:
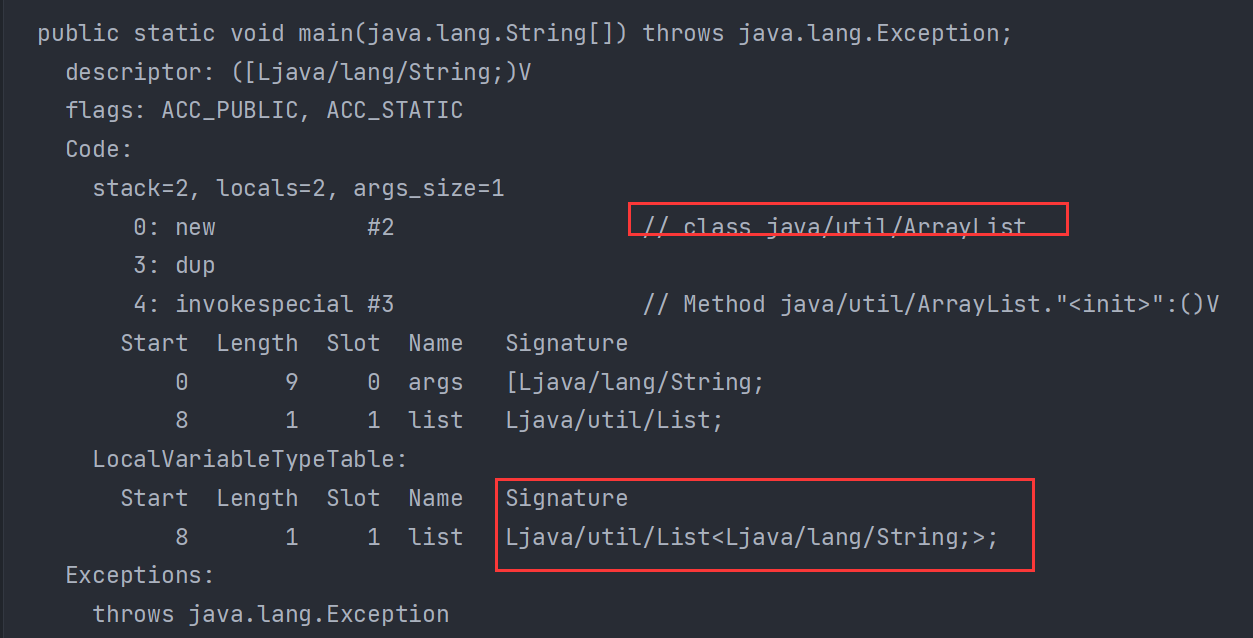
Do đó, vẫn có một số cách dễ dàng để lấy được kiểu thực sự của generic:
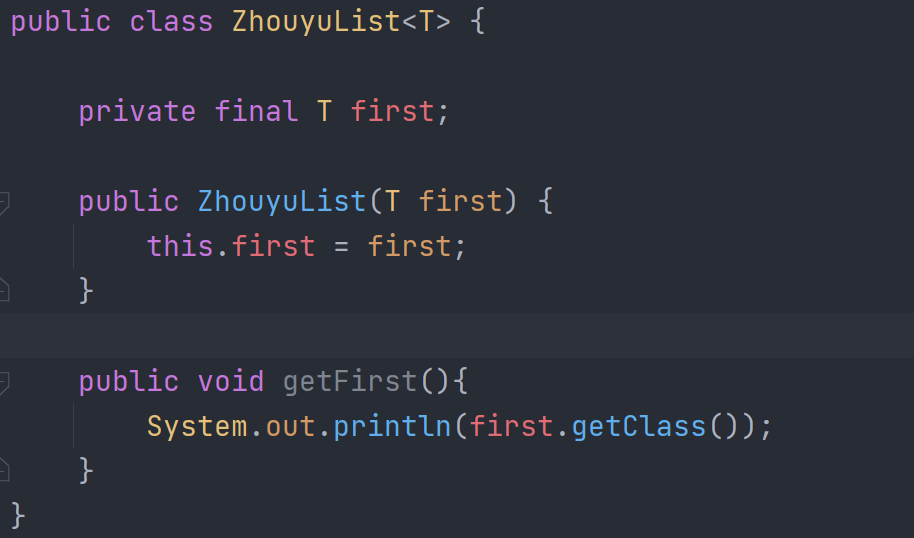
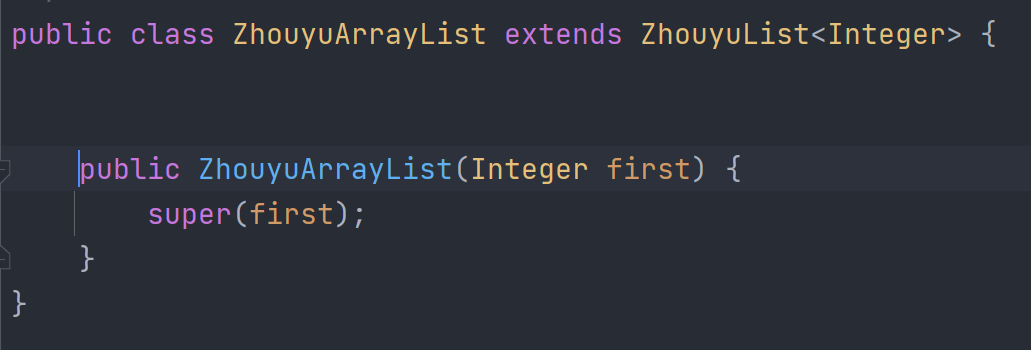
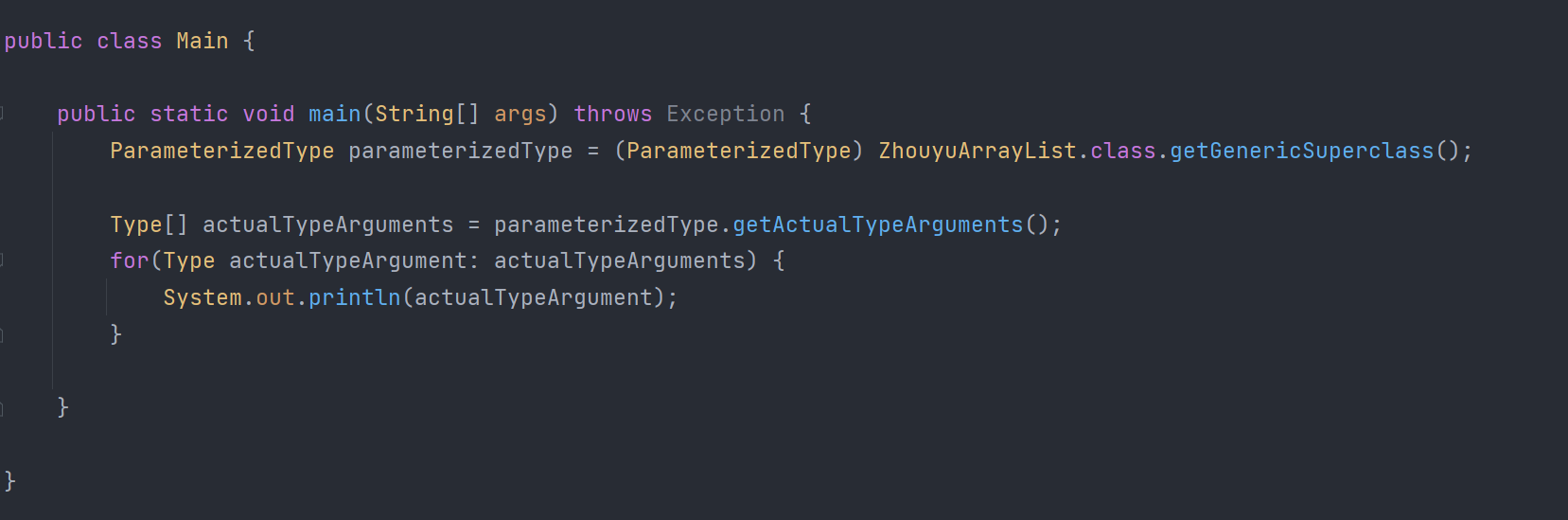
Ngoài ra, đối với JVM, nếu tạo mã mục tiêu cho từng loại generic khác nhau, giả sử có 10 danh sách (List) generic khác nhau, ta sẽ phải tạo ra 10 bytecode riêng, điều này sẽ không chỉ làm mã tăng kích thước mà còn làm một bytecode tương ứng với một đối tượng Class, chiếm rất nhiều bộ nhớ.
Các class loader trong Java
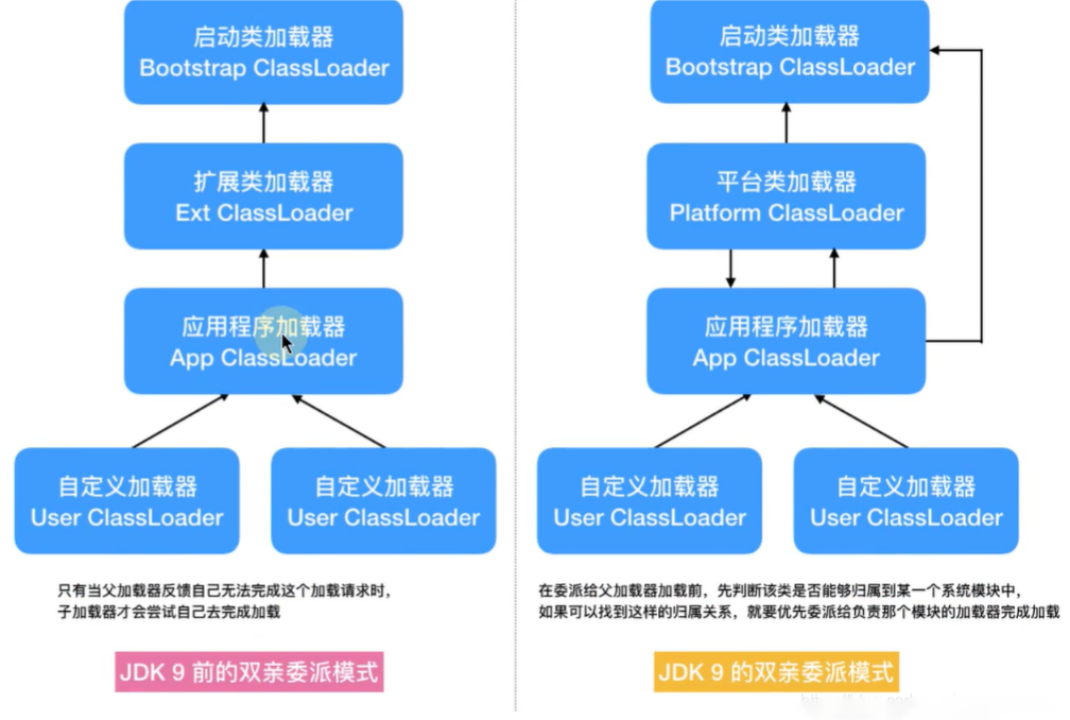
JDK tích hợp sẵn ba class loader:
- Bootstrap ClassLoader: Class loader cha của ExtClassLoader, chịu trách nhiệm tải các file jar và class trong thư mục
%JAVA_HOME%/lib. - ExtClassLoader: Class loader cha của AppClassLoader, chịu trách nhiệm tải các file jar và class trong thư mục
%JAVA_HOME%/lib/ext. - AppClassLoader: Class loader cha của các class loader do người dùng định nghĩa, chịu trách nhiệm tải các file class trong classpath.
Mô hình ủy quyền theo cha mẹ của class loader
Trong JVM có ba class loader mặc định:
- BootstrapClassLoader
- ExtClassLoader
- AppClassLoader
AppClassLoader có ExtClassLoader làm class loader cha, và ExtClassLoader có BootstrapClassLoader làm cha.
Khi JVM tải một lớp, nó sẽ gọi phương thức loadClass của AppClassLoader để tải lớp đó. Trong phương thức này, trước tiên nó sẽ gọi phương thức loadClass của ExtClassLoader để tải lớp. Tương tự, trong ExtClassLoader sẽ gọi phương thức loadClass của BootstrapClassLoader trước. Nếu BootstrapClassLoader tải thành công, quá trình sẽ hoàn tất. Nếu không, ExtClassLoader sẽ tự thử tải lớp, nếu không thành công, AppClassLoader sẽ tải lớp đó.
Vì vậy, mô hình ủy quyền cha mẹ đề cập đến việc JVM ủy quyền cho ExtClassLoader và BootstrapClassLoader tải lớp trước, nếu không thành công thì AppClassLoader mới thực hiện tải lớp đó.
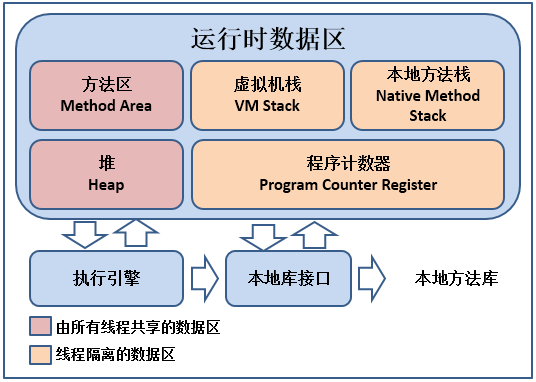
Những khu vực nào của JVM được chia sẻ giữa các luồng?
Vùng Heap và vùng Method là các khu vực được tất cả các luồng (threads) chia sẻ, trong khi Stack, Native Method Stack, và Program Counter là các khu vực riêng biệt của mỗi luồng.
Bạn xử lý các vấn đề JVM trong dự án như thế nào?
Đối với hệ thống vẫn đang chạy bình thường:
- Có thể sử dụng jmap để xem tình trạng sử dụng các vùng bộ nhớ của JVM.
- Dùng jstack để xem tình trạng hoạt động của các luồng, ví dụ như luồng nào bị khóa hoặc có xảy ra deadlock không.
- Dùng lệnh jstat để kiểm tra tình trạng thu gom rác (garbage collection), đặc biệt là full GC. Nếu thấy full GC xảy ra thường xuyên, cần tối ưu hóa.
- Phân tích kết quả của các lệnh hoặc dùng công cụ như jvisualvm để xem xét.
- Đầu tiên, hãy phỏng đoán lý do gây ra full GC thường xuyên. Nếu full GC diễn ra nhiều nhưng không xảy ra lỗi tràn bộ nhớ (OutOfMemoryError), điều đó có nghĩa là GC đang thu gom rất nhiều đối tượng. Cần đảm bảo các đối tượng này được thu gom trong young GC trước khi vào vùng cũ (old generation). Hãy thử tăng kích thước của vùng young generation. Nếu số lần full GC giảm, thì chỉnh sửa đã có hiệu quả.
- Có thể tìm ra luồng chiếm dụng CPU nhiều nhất, sau đó tối ưu hóa phương thức này để xem có thể tránh tạo ra một số đối tượng và tiết kiệm bộ nhớ hay không.
Đối với hệ thống đã xảy ra lỗi OutOfMemoryError (OOM):
- Thường hệ thống sản xuất được cấu hình để tạo file dump khi xảy ra lỗi OOM bằng các tham số: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/base.
- Có thể dùng công cụ như jvisualvm để phân tích file dump.
- Tìm các đối tượng và luồng bất thường (luồng chiếm CPU cao) trong file dump để xác định mã gây ra vấn đề.
- Sau đó tiến hành phân tích và gỡ lỗi chi tiết.
Tóm lại, việc tối ưu hóa không thể thực hiện ngay lập tức mà cần có sự phân tích, suy luận, thử nghiệm, và đúc kết để tìm ra vấn đề chính.
Khi JVM gặp lỗi OOM có làm treo tiến trình không?
Khi một luồng thực thi, có khả năng cần tạo đối tượng mới, và việc tạo đối tượng đòi hỏi phải phân bổ bộ nhớ. Nếu JVM không đủ bộ nhớ, nó sẽ tiến hành thu gom rác (GC). Sau khi GC mà bộ nhớ vẫn không đủ, JVM sẽ ném ra ngoại lệ OutOfMemoryError. Nếu không bắt ngoại lệ này, luồng sẽ dừng lại giống như khi gặp bất kỳ ngoại lệ nào khác. Nếu bắt được OutOfMemoryError, luồng có thể sẽ không bị dừng lại. Tuy nhiên, việc luồng dừng lại hay không không liên quan trực tiếp đến việc tiến trình có bị dừng hay không. Khi tất cả các luồng không phải là daemon trong tiến trình dừng lại, thì tiến trình sẽ dừng. Hoặc nếu tiến trình chiếm quá nhiều bộ nhớ của hệ điều hành, nó có thể bị hệ điều hành đóng.
Quá trình một đối tượng từ khi được tải vào JVM đến khi bị GC xoá bỏ trải qua những giai đoạn gì?
- Đầu tiên, nội dung file bytecode được tải vào Method Area.
- Sau đó, dựa trên thông tin của lớp, đối tượng được tạo ra trong Heap.
- Đối tượng sẽ được phân bổ ở Eden Area của Young Generation trong Heap. Sau một lần Minor GC, nếu đối tượng vẫn tồn tại, nó sẽ được chuyển vào Survivor Area. Sau mỗi lần Minor GC, nếu đối tượng vẫn tồn tại, nó sẽ được sao chép qua lại giữa hai Survivor Area và tăng tuổi của đối tượng lên 1.
- Khi tuổi đối tượng vượt quá 15 và vẫn tồn tại, nó sẽ được chuyển vào Old Generation.
- Nếu sau Full GC, đối tượng bị đánh dấu là rác, nó sẽ bị luồng GC thu gom.
Làm thế nào để xác định một đối tượng có phải là rác hay không?
- Thuật toán đếm tham chiếu: Cách này ghi lại số lượng tham chiếu tới mỗi đối tượng trong Heap. Nếu số lượng tham chiếu bằng 0, đối tượng được coi là rác. Tuy nhiên, thuật toán này không thể giải quyết vấn đề vòng lặp tham chiếu.
- Thuật toán khả năng tiếp cận: Thuật toán này kiểm tra từ các đối tượng gốc (root) trong bộ nhớ và tìm các đối tượng có liên kết. Những đối tượng được tìm thấy không phải là rác, còn những đối tượng không được tìm thấy sẽ bị coi là rác.
Các thuật toán thu gom rác trong JVM?
Thuật toán đánh dấu và xoá (Mark-and-Sweep):
- Giai đoạn đánh dấu: Đánh dấu các vùng bộ nhớ không còn được sử dụng.
- Giai đoạn xoá: Giải phóng bộ nhớ được đánh dấu là rác.
- Nhược điểm của thuật toán này là gây ra phân mảnh bộ nhớ.
Thuật toán sao chép (Copying Algorithm): Chia bộ nhớ thành hai phần bằng nhau và chỉ sử dụng một phần. Khi thu gom rác, các đối tượng còn sống được sao chép sang phần còn lại và giải phóng toàn bộ bộ nhớ của phần đầu tiên. Cách này không gây phân mảnh nhưng lãng phí bộ nhớ.
Thuật toán đánh dấu và nén (Mark-Compact): Sau khi đánh dấu các đối tượng không sử dụng, thay vì giải phóng trực tiếp, thuật toán này di chuyển các đối tượng còn sống đến một đầu của bộ nhớ, sau đó giải phóng phần bộ nhớ không sử dụng.
STW là gì?
STW (Stop-The-World) là trạng thái trong quá trình thu gom rác, khi JVM tạm dừng tất cả các luồng (trừ các luồng GC). Trong trạng thái STW, các phương thức native có thể chạy nhưng không thể tương tác với JVM. Mục tiêu của các thuật toán tối ưu hóa GC là giảm thời gian STW, và đây cũng là trọng tâm của việc tối ưu hóa JVM.
Các tham số của JVM?
Tham số JVM có thể chia thành ba loại:
- Lệnh chuẩn: Bắt đầu bằng dấu "-". Các tham số này được hỗ trợ bởi tất cả các phiên bản HotSpot. Sử dụng lệnh
java -helpđể liệt kê. - Lệnh không chuẩn: Bắt đầu bằng "-X". Thường gắn liền với các phiên bản cụ thể của HotSpot. Sử dụng lệnh
java -Xđể xem. - Tham số không ổn định: Bắt đầu bằng "-XX". Những tham số này thay đổi nhiều giữa các phiên bản HotSpot.
Hiểu biết về an toàn luồng (thread safety)?
An toàn luồng đề cập đến việc khi một đoạn mã được thực thi bởi nhiều luồng đồng thời, không xảy ra tình trạng xung đột và kết quả vẫn chính xác. Ví dụ, khi một biến i được khởi tạo là 0, nếu hai luồng cùng thực thi câu lệnh i++, kết quả của một luồng phải là 1 và của luồng kia phải là 2. Nếu cả hai luồng đều cho kết quả là 1, điều đó cho thấy đoạn mã không an toàn luồng.
Vì vậy, an toàn luồng có nghĩa là một đoạn mã khi được nhiều luồng thực thi đồng thời vẫn đảm bảo cho kết quả đúng.
Hiểu biết về luồng daemon (luồng nền)
Luồng trong Java được chia thành hai loại: luồng người dùng và luồng daemon (luồng nền). Luồng người dùng là các luồng bình thường mà chúng ta tạo ra, còn luồng daemon là các luồng chạy ở chế độ nền của JVM, ví dụ như luồng xử lý rác (garbage collection). Luồng daemon sẽ tự động tắt khi tất cả các luồng người dùng đã kết thúc. Chúng ta có thể thiết lập một luồng trở thành luồng daemon bằng cách gọi thread.setDaemon(true).
Nguyên lý cơ bản của ThreadLocal
- ThreadLocal là một cơ chế lưu trữ dữ liệu riêng cho từng luồng trong Java, nó cho phép một luồng lưu trữ và truy cập dữ liệu tại bất kỳ thời điểm nào trong quá trình thực thi, mà không bị chia sẻ bởi các luồng khác.
- Ở tầng thấp, ThreadLocal được thực hiện thông qua một cấu trúc dữ liệu gọi là ThreadLocalMap. Mỗi đối tượng
Threadcó một bản sao riêng củaThreadLocalMap, trong đókeylà đối tượngThreadLocalvàvaluelà giá trị cần lưu trữ. - Sử dụng ThreadLocal trong các luồng của thread pool có thể gây ra rò rỉ bộ nhớ nếu không xóa các entry sau khi sử dụng. Để khắc phục, sau khi dùng xong
ThreadLocal, ta nên gọi phương thứcremoveđể giải phóng tài nguyên. - Một ví dụ phổ biến của ThreadLocal là trong quản lý kết nối, nơi mỗi luồng giữ một kết nối riêng biệt.
Sự khác biệt giữa đồng thời, song song và tuần tự
- Tuần tự: Các tác vụ được thực thi lần lượt, tác vụ này hoàn thành rồi mới đến tác vụ khác.
- Song song (Parallelism): Hai tác vụ được thực thi cùng lúc, trên hai luồng hoặc CPU khác nhau.
- Đồng thời (Concurrency): Hai tác vụ xuất hiện như đang thực thi cùng lúc, nhưng thực tế CPU chuyển đổi giữa các tác vụ rất nhanh.
Làm sao để tránh deadlock trong Java?
Deadlock xảy ra khi bốn điều kiện sau đều thỏa mãn:
- Tài nguyên chỉ được một luồng sử dụng tại một thời điểm.
- Luồng chờ tài nguyên không nhả các tài nguyên đã chiếm giữ.
- Tài nguyên không thể bị cưỡng chế lấy lại.
- Luồng hình thành mối quan hệ chờ tài nguyên theo chu kỳ.
Để tránh deadlock, chỉ cần vi phạm một trong bốn điều kiện trên, ví dụ:
- Thiết lập một thứ tự khóa cố định giữa các luồng.
- Thiết lập thời gian chờ khi khóa.
- Sử dụng cơ chế kiểm tra deadlock để phát hiện sớm.
Nguyên lý làm việc của thread pool
Thread pool kết hợp giữa hàng đợi và luồng. Khi thêm một tác vụ vào thread pool:
- Nếu số luồng hiện tại ít hơn
corePoolSize, tạo thêm luồng mới để xử lý. - Nếu đã đạt đến
corePoolSize, tác vụ được đưa vào hàng đợi. - Nếu hàng đợi đầy và số luồng ít hơn
maximumPoolSize, tạo thêm luồng mới. - Nếu số luồng đã đạt đến
maximumPoolSize, sử dụng chiến lược đã định để xử lý tác vụ (thường là từ chối tác vụ). - Khi số luồng vượt quá
corePoolSizevà luồng rảnh quá lâu, luồng sẽ bị hủy.
Tại sao thread pool thêm vào hàng đợi trước khi tạo luồng tối đa?
Khi các luồng đang bận, các tác vụ sẽ được đưa vào hàng đợi thay vì tạo thêm luồng ngay lập tức. Nếu hàng đợi đầy, mới bắt đầu tạo thêm luồng. Điều này tương tự như trong công ty: nếu có quá nhiều công việc, thay vì thuê thêm người ngay, công việc sẽ được đưa vào danh sách chờ để nhân viên hiện tại hoàn thành dần.
Sự khác biệt giữa khóa công bằng và thiên vị trong ReentrantLock
Khóa công bằng và thiên vị đều sử dụng AQS để quản lý hàng đợi, sự khác biệt là ở lúc lấy khóa:
- Khóa công bằng: Luồng sẽ kiểm tra hàng đợi, nếu có luồng đang chờ, nó sẽ xếp hàng.
- Khóa thiên vị: Luồng sẽ cố gắng giành khóa ngay mà không kiểm tra hàng đợi.
Dù khóa công bằng hay thiên vị, khi một luồng không giành được khóa, nó đều phải xếp hàng. Khi khóa được giải phóng, luồng ở đầu hàng sẽ được đánh thức.
Sự khác biệt giữa tryLock() và lock() trong ReentrantLock
- tryLock(): Cố gắng lấy khóa, nếu lấy được sẽ trả về
true, nếu không lấy được sẽ trả vềfalsemà không chặn luồng. - lock(): Chặn luồng cho đến khi lấy được khóa.
Sự khác biệt giữa CountDownLatch và Semaphore
- CountDownLatch: Một cơ chế đếm ngược. Một luồng chờ đợi khi giá trị đếm về 0, các luồng khác giảm giá trị đếm xuống. Khi giá trị đạt 0, tất cả các luồng chờ đợi sẽ được đánh thức.
- Semaphore: Một cơ chế quản lý tín hiệu. Cho phép một số lượng luồng nhất định chạy đồng thời. Khi một luồng giải phóng tín hiệu, một luồng khác trong hàng đợi sẽ được đánh thức.
Sychronized: Khóa thiên vị, khóa nhẹ, và khóa nặng
- Khóa thiên vị: Trong phần header của đối tượng khóa sẽ lưu lại ID của luồng hiện tại đang giữ khóa, nếu luồng đó yêu cầu khóa lại, nó có thể lấy khóa trực tiếp.
- Khóa nhẹ: Khi một luồng khác cạnh tranh để lấy khóa trong khi khóa đang ở trạng thái khóa thiên vị, khóa sẽ nâng cấp lên khóa nhẹ. Khóa nhẹ được thực hiện bằng cách quay vòng (spin), do đó không làm chặn luồng.
- Nếu số lần quay vòng quá nhiều mà vẫn không lấy được khóa, nó sẽ nâng cấp lên khóa nặng, khiến luồng bị chặn.
- Khóa quay vòng (spin lock): Khóa này không làm chặn luồng, thay vì đó, luồng sẽ quay vòng liên tục để thử lấy khóa bằng cách sử dụng lệnh CAS (Compare-And-Swap). Nếu khóa không được lấy, luồng tiếp tục quay vòng mà không bị hệ điều hành can thiệp vào việc chặn hoặc đánh thức luồng.
Sự khác biệt giữa Synchronized và ReentrantLock
- Synchronized là một từ khóa, còn ReentrantLock là một lớp.
- Synchronized tự động khóa và mở khóa, còn ReentrantLock yêu cầu lập trình viên phải khóa và mở khóa thủ công.
- Synchronized hoạt động ở mức JVM, còn ReentrantLock hoạt động ở mức API.
- Synchronized là khóa thiên vị, còn ReentrantLock có thể lựa chọn khóa công bằng hoặc thiên vị.
- Synchronized khóa đối tượng, thông tin về khóa được lưu trong phần đầu của đối tượng, trong khi ReentrantLock sử dụng một biến
statekiểuintđể xác định trạng thái khóa. - Synchronized có cơ chế nâng cấp khóa trong tầng thấp.
Hiểu biết về AQS và cách AQS thực hiện khóa tái nhập
- AQS (AbstractQueuedSynchronizer) là một khung đồng bộ hóa luồng trong Java, là phần cốt lõi của nhiều công cụ khóa trong JDK.
- AQS duy trì một biến tín hiệu
statevà một hàng đợi các luồng dưới dạng danh sách liên kết kép. Hàng đợi này dùng để xếp hàng cho các luồng, cònstatenhư một đèn tín hiệu, điều khiển việc luồng có được phép tiếp tục hay không. Tùy vào từng ngữ cảnh,statesẽ mang ý nghĩa khác nhau. - Trong trường hợp khóa tái nhập,
stateđược dùng để biểu thị số lần khóa. Khistatelà 0, nghĩa là không có khóa nào, mỗi lần khóa thành côngstatesẽ tăng lên 1, và khi mở khóa thìstatesẽ giảm đi 1.
Hiểu biết về IoC
Thông thường, chúng ta biết rằng Spring có hai đặc điểm lớn là IoC và AOP. Vậy làm thế nào để hiểu được IoC (Inversion of Control - Đảo ngược quyền kiểm soát)?
Đối với nhiều người mới học, khái niệm IoC thường khiến họ cảm thấy "mình có vẻ hiểu nhưng lại không biết diễn đạt". Vậy IoC thực sự là gì? Đây là một vấn đề lớn, vì vậy chúng ta hãy chia nó thành những phần nhỏ hơn để trả lời. IoC là sự đảo ngược quyền kiểm soát, vậy:
- Điều gì đang được kiểm soát?
- Điều gì bị đảo ngược? Trước khi đảo ngược, ai kiểm soát? Sau khi đảo ngược, ai kiểm soát và kiểm soát bằng cách nào?
- Tại sao cần phải đảo ngược? Trước khi đảo ngược có vấn đề gì? Sau khi đảo ngược mang lại lợi ích gì?
Hãy bắt đầu với câu hỏi đầu tiên: Kiểm soát điều gì?
Khi sử dụng Spring, chúng ta cần làm những gì:
- Tạo một số lớp, ví dụ như
UserService,OrderService. - Sử dụng một số annotation như
@Autowired.
Chúng ta đều biết rằng, khi chương trình chạy, nó sử dụng các đối tượng cụ thể của UserService và OrderService. Những đối tượng này được tạo khi nào? Ai đã tạo ra chúng? Các thuộc tính bên trong đối tượng được gán giá trị khi nào? Ai đã gán giá trị? Tất cả những điều này không phải do lập trình viên làm, mà là do Spring thực hiện. Spring chính là người kiểm soát ngầm ở phía sau.
Kiểm soát bao gồm:
- Kiểm soát việc tạo đối tượng.
- Kiểm soát việc gán giá trị cho các thuộc tính của đối tượng.
Nếu không sử dụng Spring, chúng ta sẽ phải tự thực hiện những việc này. Ngược lại, khi sử dụng Spring, ta chỉ cần định nghĩa lớp và các thuộc tính cần được Spring gán giá trị (ví dụ, sử dụng @Autowired), đây chính là sự đảo ngược quyền kiểm soát.
Tại sao cần phải đảo ngược?
Nếu chúng ta tự tạo đối tượng và tự gán giá trị cho các thuộc tính, điều gì sẽ xảy ra? Ví dụ:
- Lớp A có thuộc tính
C c. - Lớp B cũng có thuộc tính
C c. - Lớp C là một lớp bình thường.
Chúng ta cần tạo đối tượng cho cả ba lớp và gán giá trị cho các thuộc tính:
A a = new A();B b = new B();C c = new C();a.c = c;b.c = c;
Những dòng mã này là những phần mà chúng ta phải viết thêm nếu không dùng Spring. Khi số lượng lớp tăng lên hoặc số thuộc tính trong mỗi lớp nhiều hơn, mã sẽ trở nên phức tạp và rắc rối hơn. Vì vậy, khi chúng ta để Spring kiểm soát, mã nguồn sẽ giảm đi và đơn giản hơn.
Tóm lại, IoC là sự đảo ngược quyền kiểm soát. Nếu sử dụng Spring, Spring sẽ chịu trách nhiệm tạo đối tượng và gán giá trị cho các thuộc tính của đối tượng.
Single Bean và Singleton
Singleton có nghĩa là trong JVM chỉ tồn tại duy nhất một đối tượng của một lớp nào đó.
Còn Single Bean không có nghĩa là trong JVM chỉ có duy nhất một đối tượng Bean của một lớp nào đó.
Cơ chế truyền tải giao dịch trong Spring
Khi nhiều phương thức giao dịch gọi lẫn nhau, giao dịch sẽ được truyền tải như thế nào giữa các phương thức này? Giả sử phương thức A là một phương thức giao dịch và trong quá trình thực thi, phương thức A gọi phương thức B. Khi đó, việc phương thức B có sử dụng giao dịch hay không và yêu cầu của phương thức B về giao dịch sẽ ảnh hưởng đến cách thức giao dịch của phương thức A được thực thi. Đồng thời, giao dịch của phương thức A cũng ảnh hưởng đến cách thức giao dịch của phương thức B. Những ảnh hưởng này được quyết định bởi loại hình truyền tải giao dịch của hai phương thức.
- REQUIRED (mặc định trong Spring): Nếu không có giao dịch hiện tại, tạo mới một giao dịch; nếu đang có giao dịch hiện tại, tham gia vào giao dịch đó.
- SUPPORTS: Nếu có giao dịch hiện tại, tham gia vào giao dịch đó; nếu không có giao dịch hiện tại, thực thi như một phương thức không có giao dịch.
- MANDATORY: Nếu có giao dịch hiện tại, tham gia vào giao dịch đó; nếu không có giao dịch hiện tại, ném ra ngoại lệ.
- REQUIRES_NEW: Tạo mới một giao dịch, nếu đang có giao dịch hiện tại thì tạm ngừng giao dịch đó.
- NOT_SUPPORTED: Thực thi như một phương thức không có giao dịch, nếu có giao dịch hiện tại thì tạm ngừng giao dịch đó.
- NEVER: Không sử dụng giao dịch, nếu có giao dịch hiện tại thì ném ra ngoại lệ.
- NESTED: Nếu có giao dịch hiện tại, thực thi trong một giao dịch lồng nhau; nếu không có giao dịch hiện tại, hoạt động giống như
REQUIRED(tạo mới một giao dịch).
Tám tình huống làm cho giao dịch trong Spring không hiệu quả và nguyên nhân phân tích
- Tự gọi trong phương thức: Giao dịch Spring dựa trên AOP. Khi một phương thức được gọi thông qua đối tượng proxy, giao dịch Spring mới có hiệu lực. Nhưng khi trong một phương thức gọi
this.xxx()để gọi phương thức khác,thiskhông phải là đối tượng proxy, dẫn đến giao dịch không có hiệu lực.- Giải pháp 1: Tách phương thức gọi sang một Bean khác.
- Giải pháp 2: Tự tiêm chính mình.
- Giải pháp 3: Sử dụng
AopContext.currentProxy()cùng với@EnableAspectJAutoProxy(exposeProxy = true).
- Phương thức là private: Giao dịch Spring dựa trên CGLIB để thực hiện AOP. Nếu phương thức trong lớp cha là
private, lớp con không thể ghi đè, và do đó không thể bổ sung logic giao dịch của Spring. - Phương thức là final: Lý do tương tự với phương thức private, vì lớp con không thể ghi đè phương thức final của lớp cha.
- Phương thức được gọi bởi một luồng riêng: Khi MyBatis hoặc JdbcTemplate thực thi SQL, nó lấy đối tượng kết nối cơ sở dữ liệu từ
ThreadLocal. Nếu luồng khởi tạo giao dịch và luồng thực thi SQL không cùng một luồng, kết nối cơ sở dữ liệu sẽ không được lấy đúng, dẫn đến MyBatis hoặc JdbcTemplate sẽ tự tạo kết nối mới, khiến giao dịch không được kiểm soát đúng cách. - Không thêm annotation
@Configuration: Nếu không thêm annotation này trong các cấu hình Spring truyền thống, có thể dẫn đến việc Spring không quản lý đúng các Bean và không lấy được kết nối cơ sở dữ liệu từThreadLocal. - Ngoại lệ bị nuốt mất: Nếu Spring không bắt được ngoại lệ, giao dịch sẽ không bị rollback. Mặc định, Spring sẽ bắt các ngoại lệ loại
RuntimeExceptionvàError. - Lớp không được Spring quản lý.
- Cơ sở dữ liệu không hỗ trợ giao dịch.
Các bước tạo Bean trong Spring
Quá trình tạo một Bean trong Spring gồm các bước sau:
- Suy đoán phương thức khởi tạo.
- Khởi tạo đối tượng.
- Tiêm thuộc tính, hay còn gọi là tiêm phụ thuộc.
- Xử lý các callback của Aware.
- Trước khi khởi tạo, xử lý annotation
@PostConstruct. - Khởi tạo, xử lý interface
InitializingBean. - Sau khi khởi tạo, tiến hành AOP.
Bean trong Spring có an toàn trong môi trường đa luồng không?
Spring không xử lý riêng vấn đề an toàn luồng cho các Bean. Vì vậy:
- Nếu Bean là không có trạng thái, nó sẽ an toàn trong môi trường đa luồng.
- Nếu Bean có trạng thái, nó không an toàn trong môi trường đa luồng.
Vấn đề Bean có an toàn trong môi trường đa luồng hay không không liên quan đến phạm vi của Bean, mà phụ thuộc vào trạng thái của chính Bean đó.
Sự khác biệt giữa ApplicationContext và BeanFactory
BeanFactory là một thành phần cốt lõi trong Spring, đóng vai trò như một nhà máy tạo và quản lý các Bean. ApplicationContext kế thừa BeanFactory, vì vậy nó có tất cả các chức năng của BeanFactory. Ngoài ra, ApplicationContext còn cung cấp các chức năng khác như quản lý biến môi trường hệ thống, quốc tế hóa, và phát sự kiện mà BeanFactory không có.
Spring giao dịch được thực hiện như thế nào
- Giao dịch trong Spring được xây dựng dựa trên giao dịch của cơ sở dữ liệu và cơ chế AOP.
- Đối với các Bean có sử dụng annotation
@Transactional, Spring sẽ tạo một đối tượng proxy cho Bean đó. - Khi gọi phương thức của đối tượng proxy, Spring sẽ kiểm tra xem phương thức đó có annotation
@Transactionalhay không. - Nếu có, Spring sẽ sử dụng bộ quản lý giao dịch để tạo một kết nối cơ sở dữ liệu.
- Đồng thời, thay đổi thuộc tính
autocommitcủa kết nối thànhfalseđể ngăn việc tự động commit. Đây là bước rất quan trọng để thực hiện giao dịch trong Spring. - Sau đó, phương thức hiện tại sẽ được thực thi, bao gồm cả các câu lệnh SQL.
- Sau khi phương thức được thực thi, nếu không xảy ra ngoại lệ, giao dịch sẽ được commit.
- Nếu có ngoại lệ và ngoại lệ này yêu cầu rollback, giao dịch sẽ được rollback. Nếu ngoại lệ không yêu cầu rollback, giao dịch vẫn sẽ được commit.
- Mức độ cách ly của giao dịch Spring tương ứng với mức độ cách ly của cơ sở dữ liệu.
- Cơ chế truyền tải giao dịch là phần phức tạp nhất của Spring và được thực hiện dựa trên các kết nối cơ sở dữ liệu. Mỗi kết nối tương ứng với một giao dịch. Nếu cơ chế truyền tải yêu cầu mở một giao dịch mới, Spring sẽ tạo một kết nối mới và thực thi SQL trên kết nối đó.
Khi nào annotation @Transactional trong Spring không có hiệu lực
Vì giao dịch trong Spring được thực hiện dựa trên các proxy, nên một phương thức có annotation @Transactional chỉ có hiệu lực khi nó được gọi thông qua đối tượng proxy. Nếu phương thức được gọi không thông qua đối tượng proxy, annotation @Transactional sẽ không có hiệu lực.
Ngoài ra, nếu phương thức là private, thì @Transactional cũng sẽ không có hiệu lực. Điều này là do CGLIB, một công cụ tạo proxy của Spring, dựa trên mối quan hệ cha-con. Các phương thức private của lớp cha không thể bị ghi đè bởi lớp con, do đó không thể sử dụng proxy, dẫn đến annotation @Transactional không có hiệu lực.
Quy trình khởi động của Spring
- Khi tạo Spring container (khởi động Spring):
- Trước hết, Spring sẽ quét để tìm tất cả các đối tượng
BeanDefinitionvà lưu trữ chúng trong một Map. - Sau đó, Spring sẽ tạo các Bean đơn nhất (non-lazy) từ các
BeanDefinition. Các Bean có phạm vi nhiều hơn sẽ không được tạo trong quá trình khởi động, mà sẽ được tạo mỗi khi Bean đó được yêu cầu. - Việc tạo Bean từ
BeanDefinitionlà quá trình vòng đời của Bean. Nó bao gồm các bước như hợp nhấtBeanDefinition, suy đoán phương thức khởi tạo, khởi tạo đối tượng, tiêm thuộc tính, trước khi khởi tạo, khởi tạo và sau khi khởi tạo. AOP sẽ xảy ra ở bước sau khi khởi tạo. - Sau khi tạo tất cả các Bean đơn nhất, Spring sẽ phát ra một sự kiện khởi động container.
- Kết thúc quá trình khởi động Spring.
- Trong mã nguồn của Spring, quá trình này phức tạp hơn, bao gồm các phương thức mẫu cho các lớp con thực hiện. Ngoài ra, mã nguồn còn xử lý đăng ký
BeanFactoryPostProcessorvàBeanPostProcessor. Quá trình quét của Spring dựa vàoBeanFactoryPostProcessorvà việc tiêm phụ thuộc dựa vàoBeanPostProcessor. - Trong quá trình khởi động, Spring cũng sẽ xử lý các annotation như
@Import.
Các mẫu thiết kế được sử dụng trong Spring

Các annotation thường dùng trong Spring Boot và cách thức hoạt động
@SpringBootApplication: annotation này đánh dấu một ứng dụng Spring Boot, thực chất là tổ hợp của ba annotation:
- @SpringBootConfiguration: annotation này tương đương với
@Configuration, biểu thị rằng lớp khởi động cũng là một lớp cấu hình. - @EnableAutoConfiguration: Tự động tải các cấu hình được xác định trong
SpringFactoriesdướiClassPathvào Spring container dưới dạng các Bean cấu hình. - @ComponentScan: Xác định đường dẫn để quét các thành phần, mặc định quét đường dẫn của lớp khởi động.
- @SpringBootConfiguration: annotation này tương đương với
@Bean: Dùng để định nghĩa một Bean, tương tự như thẻ
<bean>trong XML. Khi Spring khởi động, nó sẽ phân tích các phương thức có annotation@Bean, sử dụng tên phương thức làm tên Bean và thực thi phương thức để tạo đối tượng Bean.Các annotation như
@Controller,@Service,@ResponseBody,@Autowiredcũng có thể được sử dụng.
Cách Spring Boot khởi động Tomcat
- Trước hết, khi Spring Boot khởi động, nó sẽ tạo một Spring container.
- Trong quá trình tạo Spring container, Spring Boot sẽ kiểm tra xem có tồn tại thư viện Tomcat trong
classpathhay không bằng cách sử dụng kỹ thuật@ConditionalOnClass. Nếu có, Spring Boot sẽ tạo một Bean khởi động Tomcat. - Sau khi Spring container được tạo, Spring Boot sẽ lấy Bean khởi động Tomcat, tạo một đối tượng Tomcat, cấu hình các cổng kết nối, và khởi động Tomcat.
Ưu điểm và nhược điểm của MyBatis
Ưu điểm:
- Dựa trên các câu lệnh SQL, linh hoạt và không gây ảnh hưởng đến thiết kế của ứng dụng hoặc cơ sở dữ liệu. SQL được viết trong XML, giúp tách biệt giữa SQL và mã chương trình, dễ dàng quản lý. Hỗ trợ viết SQL động và có thể tái sử dụng.
- Giảm hơn 50% lượng mã so với JDBC, loại bỏ các mã dư thừa trong JDBC và không cần tự tay mở/đóng kết nối.
- Tương thích tốt với nhiều cơ sở dữ liệu (MyBatis sử dụng JDBC để kết nối cơ sở dữ liệu, nên hỗ trợ mọi cơ sở dữ liệu mà JDBC hỗ trợ).
- Tích hợp tốt với Spring.
- Cung cấp các thẻ ánh xạ hỗ trợ ORM, ánh xạ giữa các trường trong cơ sở dữ liệu và đối tượng.
Nhược điểm:
- Lượng công việc viết SQL lớn, đặc biệt là khi có nhiều trường hoặc bảng liên kết. Yêu cầu lập trình viên có kỹ năng viết SQL tốt.
- SQL phụ thuộc vào cơ sở dữ liệu, gây khó khăn trong việc di chuyển cơ sở dữ liệu.
Sự khác biệt giữa #{} và ${} trong MyBatis
#{}là xử lý trước biên dịch và đóng vai trò như một dấu chỗ.${}là thay thế chuỗi và đóng vai trò như một chuỗi kết nối.
Khi MyBatis xử lý #{}, nó sẽ thay thế giá trị trong SQL bằng dấu ? và sử dụng PreparedStatement để gán giá trị.
Khi MyBatis xử lý ${}, nó sẽ thay thế giá trị bằng chuỗi trực tiếp trong SQL và sử dụng Statement để thực thi.
Sử dụng #{} có thể giúp ngăn ngừa tấn công SQL injection, nâng cao độ bảo mật của hệ thống.
Nguyên lý cơ bản của chỉ mục (Index)
Chỉ mục được sử dụng để tìm kiếm nhanh chóng các bản ghi có giá trị cụ thể. Nếu không có chỉ mục, thông thường khi thực hiện truy vấn sẽ phải duyệt toàn bộ bảng.
Nguyên lý của chỉ mục: Biến dữ liệu không có trật tự thành dữ liệu có trật tự để truy vấn.
- Sắp xếp nội dung của các cột đã tạo chỉ mục.
- Tạo bảng đảo ngược từ kết quả đã sắp xếp.
- Gắn kết địa chỉ dữ liệu vào nội dung của bảng đảo ngược.
- Khi truy vấn, đầu tiên lấy nội dung của bảng đảo ngược, sau đó lấy ra địa chỉ dữ liệu để lấy dữ liệu cụ thể.
Nguyên tắc thiết kế chỉ mục
Chỉ mục cần truy vấn nhanh hơn và chiếm ít không gian hơn.
- Các cột phù hợp để chỉ mục thường là những cột xuất hiện trong mệnh đề WHERE hoặc được chỉ định trong mệnh đề JOIN.
- Các bảng có cơ sở dữ liệu nhỏ sẽ cho hiệu quả chỉ mục kém, không cần thiết phải tạo chỉ mục cho cột này.
- Sử dụng chỉ mục ngắn. Nếu chỉ mục cho các cột chuỗi dài, nên chỉ định một độ dài tiền tố để tiết kiệm không gian chỉ mục. Nếu từ tìm kiếm vượt quá độ dài tiền tố của chỉ mục, sử dụng chỉ mục để loại trừ các dòng không phù hợp, sau đó kiểm tra các dòng còn lại có thể khớp hay không.
- Không nên tạo chỉ mục quá mức. Chỉ mục cần thêm không gian đĩa và làm giảm hiệu suất của các thao tác ghi. Khi sửa đổi nội dung bảng, chỉ mục sẽ được cập nhật hoặc thậm chí tái cấu trúc, thời gian này sẽ kéo dài hơn nếu có nhiều cột chỉ mục. Do đó, chỉ cần giữ lại các chỉ mục cần thiết cho việc truy vấn.
- Các cột dữ liệu được định nghĩa có khóa ngoại nhất định phải tạo chỉ mục.
- Các cột có tần suất cập nhật cao không phù hợp để tạo chỉ mục.
- Các cột không thể phân biệt hiệu quả dữ liệu không phù hợp làm cột chỉ mục (ví dụ như giới tính, có thể chỉ có ba loại: nam, nữ, chưa xác định, độ phân biệt quá thấp).
- Nên mở rộng chỉ mục hiện có thay vì tạo chỉ mục mới. Ví dụ: nếu bảng đã có chỉ mục cho a và giờ cần thêm chỉ mục cho (a, b), chỉ cần chỉnh sửa chỉ mục hiện tại.
- Đối với các cột ít được truy vấn hoặc có nhiều giá trị trùng lặp, không nên tạo chỉ mục.
- Không nên tạo chỉ mục cho các cột có kiểu dữ liệu được định nghĩa là text, image và bit.
Các đặc tính cơ bản của giao dịch và mức độ cách ly
Các đặc tính cơ bản của giao dịch (ACID) bao gồm:
Tính nguyên tử: Trong một giao dịch, các thao tác phải thành công hoàn toàn hoặc thất bại hoàn toàn.
Tính nhất quán: Cơ sở dữ liệu luôn chuyển từ một trạng thái nhất quán sang một trạng thái nhất quán khác. Ví dụ, nếu A chuyển cho B 100 đồng và giả sử A chỉ có 90 đồng, trước khi thanh toán, dữ liệu trong cơ sở dữ liệu phải tuân theo các ràng buộc. Nếu giao dịch thành công, dữ liệu trong cơ sở dữ liệu sẽ vi phạm các ràng buộc, vì vậy giao dịch không thể thành công. Tại đây, chúng ta nói rằng giao dịch cung cấp đảm bảo tính nhất quán.
Tính cách ly: Các thay đổi của một giao dịch không thể nhìn thấy bởi các giao dịch khác trước khi nó được xác nhận.
Tính bền vững: Khi một giao dịch đã được xác nhận, các thay đổi sẽ được lưu trữ vĩnh viễn trong cơ sở dữ liệu.
Tính cách ly có bốn mức độ, bao gồm:
Read uncommitted (Đọc chưa xác nhận): Có thể đọc dữ liệu chưa được xác nhận từ các giao dịch khác, còn gọi là đọc bẩn. Người dùng đáng lẽ phải đọc được tuổi của người dùng với id=1 là 10, nhưng lại đọc được tuổi từ một giao dịch khác chưa được xác nhận, kết quả là tuổi=20, đây là trường hợp đọc bẩn.
Read committed (Đọc đã xác nhận): Hai lần đọc kết quả không nhất quán, gọi là đọc không lặp lại. Đọc đã xác nhận giải quyết vấn đề đọc bẩn, chỉ đọc các giao dịch đã xác nhận. Người dùng mở giao dịch đọc người dùng với id=1, phát hiện tuổi=10, nhưng khi đọc lại thấy kết quả là 20. Trong cùng một giao dịch, cùng một truy vấn đọc được các kết quả khác nhau gọi là đọc không lặp lại.
Repeatable read (Đọc có thể lặp lại): Đây là mức độ mặc định của MySQL, mỗi lần đọc kết quả đều giống nhau, nhưng có thể phát sinh vấn đề đọc ma.
Serializable (Tuần tự): Thường không được sử dụng, vì nó sẽ khóa từng dòng dữ liệu được đọc, dẫn đến nhiều vấn đề về thời gian chờ và cạnh tranh khóa.
MVCC là gì?
MVCC (Multi-Version Concurrency Control - Kiểm soát đồng thời đa phiên bản) đề cập đến quá trình truy cập chuỗi phiên bản của các bản ghi khi thực hiện các thao tác SELECT thông thường trong các giao dịch sử dụng mức độ cách ly READ COMMITTED và REPEATABLE READ. Điều này cho phép các thao tác đọc-ghi và ghi-đọc của các giao dịch khác nhau thực hiện đồng thời, từ đó nâng cao hiệu suất hệ thống. Một điểm khác biệt lớn giữa hai mức độ cách ly READ COMMITTED và REPEATABLE READ là: thời điểm tạo ReadView khác nhau. READ COMMITTED sẽ tạo một ReadView trước mỗi lần thực hiện thao tác SELECT thông thường, trong khi REPEATABLE READ chỉ tạo một ReadView trước lần thực hiện SELECT đầu tiên, và sau đó các thao tác truy vấn sau sẽ tái sử dụng ReadView này.
Tóm tắt sự khác biệt giữa MyISAM và InnoDB
MyISAM:
- Không hỗ trợ giao dịch, nhưng mỗi lần truy vấn đều là nguyên tử.
- Hỗ trợ khóa cấp bảng, tức là mỗi thao tác đều khóa toàn bộ bảng.
- Lưu trữ tổng số hàng của bảng.
- Một bảng MYISAM có ba tệp: tệp chỉ mục, tệp cấu trúc bảng và tệp dữ liệu.
- Sử dụng chỉ mục không tập trung, trong đó miền dữ liệu của tệp chỉ mục lưu trữ các con trỏ chỉ vào tệp dữ liệu. Chỉ mục phụ gần như giống với chỉ mục chính, nhưng chỉ mục phụ không cần đảm bảo tính duy nhất.
InnoDB:
- Hỗ trợ giao dịch ACID, hỗ trợ bốn mức độ cách ly của giao dịch.
- Hỗ trợ khóa cấp hàng và ràng buộc khóa ngoại, do đó có thể hỗ trợ ghi đồng thời.
- Không lưu trữ tổng số hàng.
- Một động cơ InnoDB lưu trữ trong một không gian tệp (không gian bảng chia sẻ, kích thước bảng không bị hệ điều hành kiểm soát, một bảng có thể phân bố trên nhiều tệp), cũng có thể là nhiều không gian (được đặt thành không gian bảng độc lập, kích thước bảng bị giới hạn bởi kích thước tệp của hệ điều hành, thường là 2G), phụ thuộc vào giới hạn kích thước tệp của hệ điều hành.
- Chỉ mục khóa chính sử dụng chỉ mục tập trung (miền dữ liệu của chỉ mục lưu trữ chính tệp dữ liệu), miền dữ liệu của chỉ mục phụ lưu trữ giá trị khóa chính; vì vậy, để tìm dữ liệu qua chỉ mục phụ, cần phải tìm giá trị khóa chính qua chỉ mục phụ trước, rồi truy cập chỉ mục phụ; tốt nhất là sử dụng khóa chính tự tăng để tránh phải điều chỉnh lớn tệp khi chèn dữ liệu, nhằm duy trì cấu trúc B+ cây.
Các trường trong kết quả của câu lệnh Explain đại diện cho điều gì
| Tên cột | Mô tả |
|---|---|
| id | Mỗi khi xuất hiện một từ khóa SELECT trong câu truy vấn, MySQL sẽ gán một giá trị id duy nhất cho nó. Một số truy vấn con có thể được tối ưu thành truy vấn JOIN, do đó id xuất hiện sẽ giống nhau. |
| select_type | Loại truy vấn tương ứng với từ khóa SELECT. |
| table | Tên bảng. |
| partitions | Thông tin về các phân vùng phù hợp. |
| type | Phương thức truy vấn đối với bảng đơn (quét toàn bộ bảng, chỉ mục). |
| possible_keys | Các chỉ mục có thể được sử dụng. |
| key | Chỉ mục thực tế đã sử dụng. |
| key_len | Độ dài của chỉ mục thực tế đã sử dụng. |
| ref | Thông tin về đối tượng được khớp với cột chỉ mục khi sử dụng truy vấn với giá trị bằng. |
| rows | Số lượng bản ghi dự đoán cần đọc. |
| filtered | Tỷ lệ phần trăm số bản ghi còn lại sau khi bảng được lọc qua điều kiện tìm kiếm. |
| Extra | Một số thông tin bổ sung, chẳng hạn như sắp xếp, v.v. |
Phân tích chín tình huống làm mất hiệu lực của chỉ mục trong MySQL
Dữ liệu bảng:
CREATE TABLE `t1` (
a int primary key,
b int,
c int,
d int,
e varchar(20)
) ENGINE=InnoDB;
insert into t1 values(4,3,1,1,'d');
insert into t1 values(1,1,1,1,'a');
insert into t1 values(8,8,8,8,'h');
insert into t1 values(2,2,2,2,'b');
insert into t1 values(5,2,3,5,'e');
insert into t1 values(3,3,2,2,'c');
insert into t1 values(7,4,5,5,'g');
insert into t1 values(6,6,4,4,'f');Tình trạng chỉ mục:

Trường a là khóa chính, tương ứng với chỉ mục khóa chính, ba trường b, c, d tạo thành một chỉ mục kết hợp, và trường e có một chỉ mục.
1. Không tuân thủ nguyên tắc khớp trái nhất

Khi bỏ điều kiện b=1, sẽ không tuân thủ nguyên tắc khớp trái nhất, dẫn đến tất cả đều bị mất hiệu lực.

2. Truy vấn Like không chính xác
Không sử dụng like có thể sử dụng chỉ mục:

Sử dụng like đúng cách:

Sử dụng like không đúng cách:

3. Thực hiện phép tính trên cột chỉ mục hoặc sử dụng hàm


4. Chuyển đổi kiểu trên cột chỉ mục
Trường e có kiểu là varchar, câu SQL dưới đây cần chuyển đổi ký tự trong trường e thành số, điều này sẽ làm mất hiệu lực của chỉ mục.

5. <> không bằng gây mất hiệu lực chỉ mục
b=1 có thể sử dụng chỉ mục, nhưng b<>1 thì không.
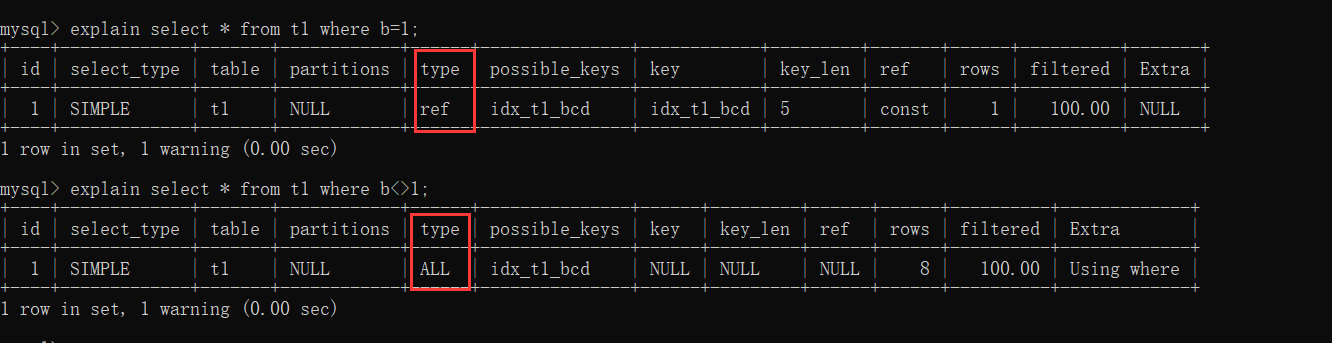
6. order by gây mất hiệu lực chỉ mục
Dù có sử dụng chỉ mục, nhưng do là select * nên cần phải truy vấn lại bảng, và chi phí truy vấn lại khá cao, vì vậy sẽ không sử dụng chỉ mục.

Nếu là select b thì cần phải truy vấn lại bảng, và sẽ chọn sử dụng chỉ mục.

7. Sử dụng or gây mất hiệu lực chỉ mục
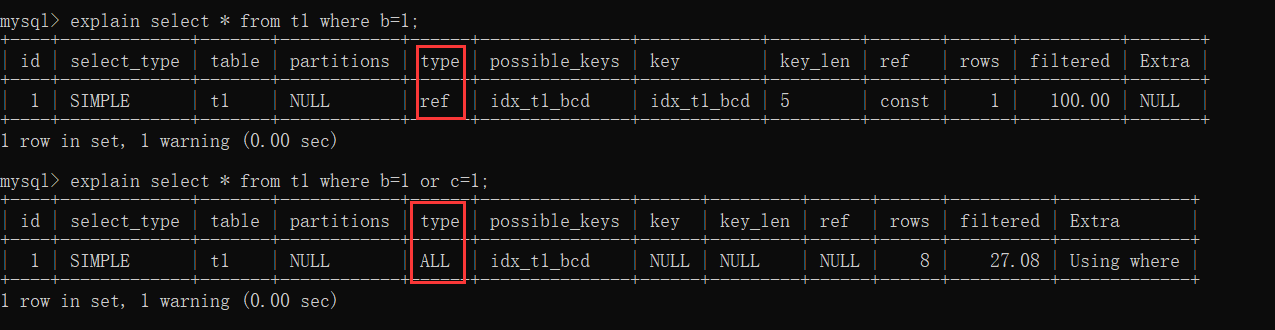
8. select * gây mất hiệu lực chỉ mục
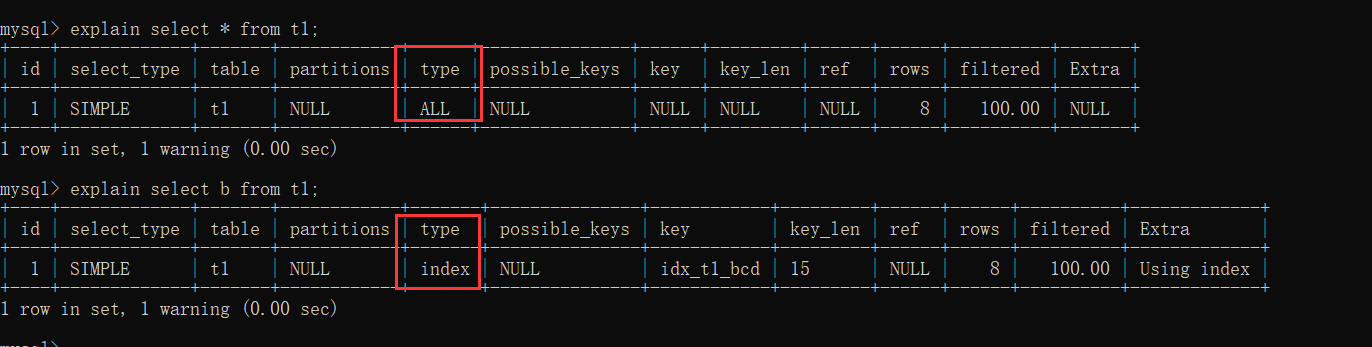
9. Truy vấn phạm vi với khối lượng dữ liệu quá lớn dẫn đến mất hiệu lực chỉ mục
Thêm một số dữ liệu mới:
insert into t1 values(10,3,1,1,'d');
insert into t1 values(20,1,1,1,'a');
insert into t1 values(15,8,8,8,'h');
insert into t1 values(18,2,2,2,'b');
insert into t1 values(14,2,3,5,'e');
insert into t1 values(13,3,2,2,'c');
insert into t1 values(17,4,5,5,'g');
insert into t1 values(22,6,4,4,'f');
Chỉ mục bao phủ là gì?
Chỉ mục bao phủ là khi một câu SQL trong quá trình thực thi có thể sử dụng chỉ mục để tìm kiếm nhanh chóng, và các trường cần truy vấn của câu SQL này đều có trong các trường tương ứng của chỉ mục hiện tại. Điều này có nghĩa là sau khi câu SQL thực hiện xong chỉ mục, nó không cần phải quay lại bảng nữa, vì các trường cần thiết đã có sẵn trên các nút lá của chỉ mục hiện tại và có thể được trả về trực tiếp như kết quả.
Nguyên tắc tiền tố trái nhất là gì?
Khi một câu SQL muốn sử dụng chỉ mục, nó nhất định phải cung cấp trường ở bên trái nhất trong các trường tương ứng của chỉ mục, tức là trường đứng đầu tiên. Ví dụ, nếu một chỉ mục kết hợp được tạo cho các trường a, b, c, thì khi viết một câu SQL, điều kiện cho trường a nhất định phải được cung cấp. Điều này đảm bảo rằng chỉ mục kết hợp được sử dụng, vì khi tạo chỉ mục kết hợp cho các trường a, b, c, cây B+ cơ sở sẽ được sắp xếp theo thứ tự từ trái sang phải dựa trên a, b, c. Do đó, nếu muốn sử dụng cây B+ để tìm kiếm nhanh chóng, phải tuân theo quy tắc này.
Innodb thực hiện giao dịch như thế nào?
Innodb sử dụng Buffer Pool, LogBuffer, Redo Log, và Undo Log để thực hiện giao dịch. Ví dụ với một câu lệnh update:
- Khi Innodb nhận được một câu lệnh update, nó sẽ tìm trang dữ liệu theo điều kiện và lưu trang đó vào Buffer Pool.
- Thực hiện câu lệnh update, sửa đổi dữ liệu trong Buffer Pool, tức là dữ liệu trong bộ nhớ.
- Tạo một đối tượng RedoLog cho câu lệnh update và lưu vào LogBuffer.
- Tạo một bản ghi undolog cho câu lệnh update, dùng để hoàn tác giao dịch.
- Nếu giao dịch được xác nhận, đối tượng RedoLog sẽ được lưu trữ vĩnh viễn; sau đó, còn có các cơ chế khác để lưu các trang dữ liệu đã chỉnh sửa trong Buffer Pool vào đĩa.
- Nếu giao dịch bị hoàn tác, sẽ sử dụng bản ghi undolog để quay lại.
Sự khác biệt giữa B-tree và B+ tree, tại sao MySQL lại sử dụng B+ tree?
Đặc điểm của B-tree:
- Các nút được sắp xếp.
- Một nút có thể chứa nhiều phần tử, và các phần tử đó cũng được sắp xếp.
Đặc điểm của B+ tree:
- Có các đặc điểm của B-tree.
- Các nút lá có liên kết với nhau bằng con trỏ.
- Các phần tử trên nút không phải là nút đều được lưu trữ trên các nút lá, tức là tất cả các phần tử đều được lưu trữ trong các nút lá và được sắp xếp.
MySQL sử dụng B+ tree cho chỉ mục, vì chỉ mục được dùng để tăng tốc độ truy vấn, và B+ tree có thể tăng tốc độ truy vấn bằng cách sắp xếp dữ liệu. Hơn nữa, một nút có thể chứa nhiều phần tử, giúp chiều cao của B+ tree không quá lớn. Trong MySQL, một trang Innodb chính là một nút B+ tree, với kích thước mặc định là 16KB. Do đó, trong trường hợp thông thường, một B+ tree có hai tầng có thể chứa khoảng 20 triệu hàng dữ liệu. Bằng cách sử dụng các nút lá của B+ tree để lưu trữ tất cả dữ liệu và sắp xếp chúng, cũng như có các con trỏ giữa các nút lá, có thể hỗ trợ tốt cho việc quét toàn bộ bảng và các truy vấn tìm kiếm theo phạm vi.
Các loại khóa trong MySQL và cách hiểu
Phân loại theo độ chi tiết của khóa:
- Khóa hàng: Khóa một hàng dữ liệu, có độ chi tiết nhỏ nhất, cho phép đồng thời cao.
- Khóa bảng: Khóa toàn bộ bảng, có độ chi tiết lớn nhất, cho phép đồng thời thấp.
- Khóa khoảng: Khóa một khoảng dữ liệu.
Có thể phân loại thêm:
- Khóa chia sẻ: Còn gọi là khóa đọc, một giao dịch khóa một hàng dữ liệu cho phép các giao dịch khác có thể đọc, nhưng không được ghi.
- Khóa độc quyền: Còn gọi là khóa ghi, một giao dịch khóa một hàng dữ liệu khiến các giao dịch khác không thể đọc hay ghi.
Có thể phân loại thêm:
- Khóa lạc quan: Không thực sự khóa một hàng ghi nào mà thực hiện qua một số phiên bản.
- Khóa bi quan: Các khóa hàng, khóa bảng đã đề cập ở trên đều là khóa bi quan.
Trong việc thực hiện các mức độ cách ly của giao dịch, cần sử dụng khóa để giải quyết vấn đề đọc ma (phantom read).
Làm thế nào để tối ưu hóa truy vấn chậm trong MySQL?
- Kiểm tra xem có sử dụng chỉ mục không; nếu không, tối ưu hóa SQL để sử dụng chỉ mục.
- Kiểm tra chỉ mục đang sử dụng, xem có phải là chỉ mục tối ưu không.
- Kiểm tra xem các trường truy vấn có phải là cần thiết không; có thể đã truy vấn quá nhiều trường, dẫn đến dữ liệu thừa.
- Kiểm tra xem dữ liệu trong bảng có quá nhiều không; có thể cần phân tách cơ sở dữ liệu và bảng.
- Kiểm tra cấu hình hiệu suất của máy chủ nơi có cơ sở dữ liệu, xem có quá thấp không; có thể tăng thêm tài nguyên nếu cần.
Trong MySQL, bảng lớn là bảng có kích thước bao nhiêu?
Chúng ta thường nói rằng bảng quá lớn, một nghĩa khác là dữ liệu quá nhiều, dẫn đến hiệu quả của chỉ mục không còn rõ ràng, chỉ có thể phân tách bảng. Vì vậy, khi thảo luận về bảng lớn là gì, cần phân tích từ góc độ chỉ mục MySQL để xác định khi nào dữ liệu trở thành bảng lớn.
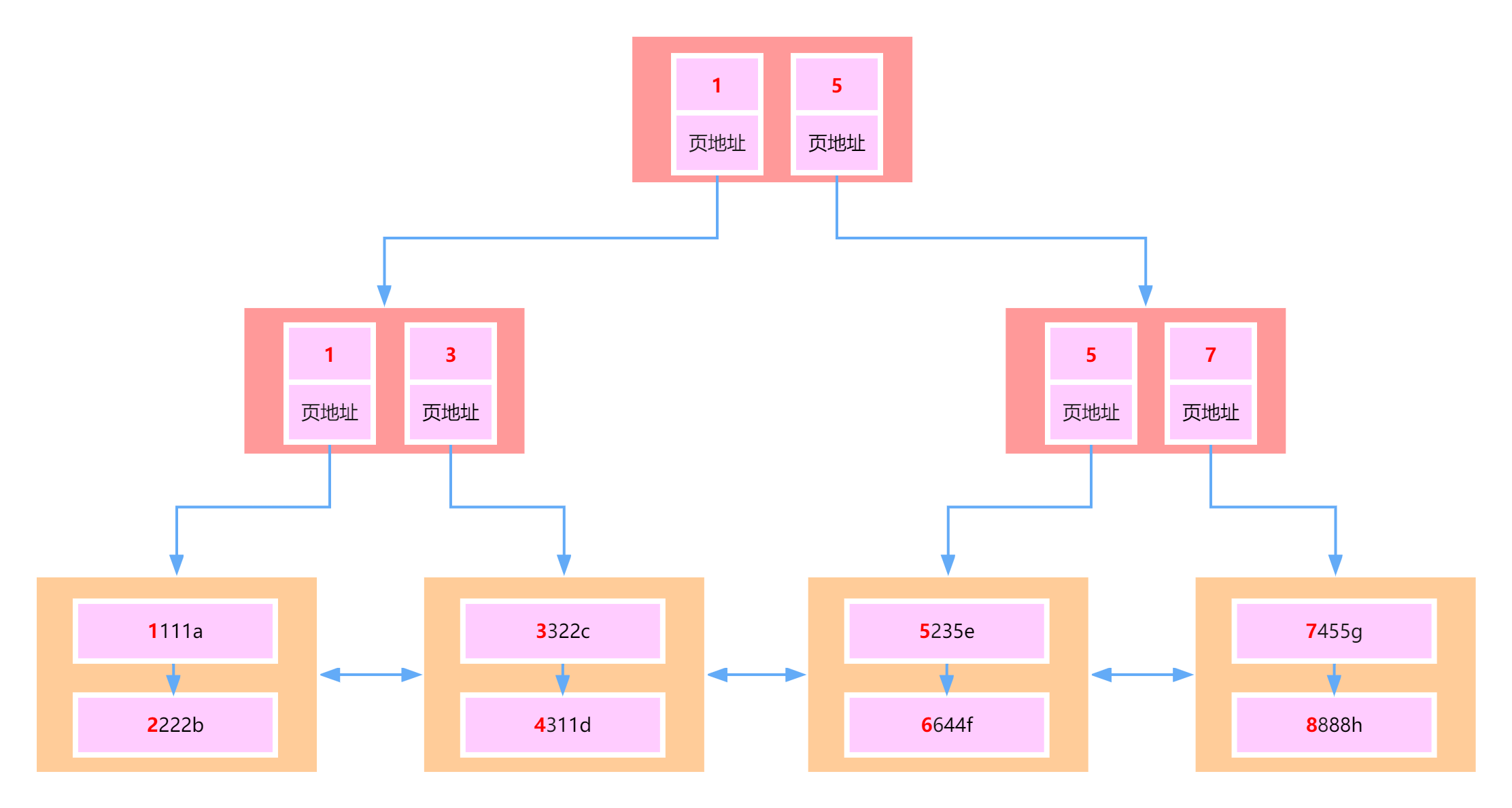
Hình trên là một chỉ mục khóa chính trong Innodb, tức là một cây B+. Mỗi nút trong cây là một trang Innodb, kích thước mặc định là 16KB, và mỗi nút lá chủ yếu lưu trữ dữ liệu, trong khi các nút không phải lá lưu trữ khóa chính và địa chỉ trang.
Vì vậy, chúng ta có thể tính toán xem nếu chiều cao của cây B+ là 2, nó có thể chứa bao nhiêu bản ghi.
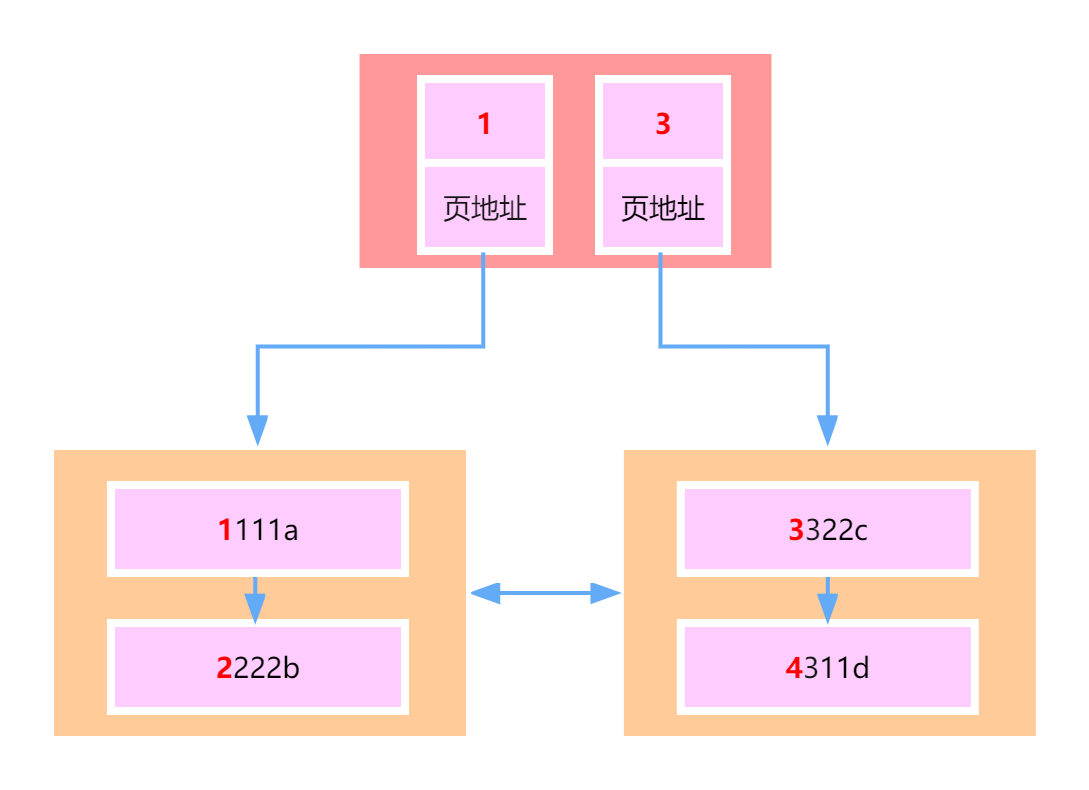
- Giả sử một bản ghi là 1KB.
- Kiểu khóa chính là kiểu int, tức là một khóa chính chiếm 4 byte.
- Trong innodb, một địa chỉ trang cần chiếm 6 byte.
Vì vậy, trong một trang, tức là trong một nút, có thể chứa:
- 16KB / 1KB = 16 bản ghi dữ liệu.
- 16KB / (4B + 6B) = 1638 bản ghi chỉ mục (khóa chính + địa chỉ chỉ mục).
Vì vậy, nếu chiều cao của cây B+ là 2, thì các nút lá sẽ có 1638 nút, do đó số lượng bản ghi dữ liệu có thể lưu trữ là: 1638 * 16 = 26208 bản ghi.
Nếu chiều cao của cây B+ là 3, thì một nút ở tầng đầu tiên, 1638 nút ở tầng thứ hai, 1638 * 1638 nút ở tầng thứ ba, cuối cùng số bản ghi sẽ là: 1638 * 1638 * 16 = 42,928,704.
Tức là khoảng 40 triệu bản ghi.
Nếu kiểu khóa chính là bigint, mỗi khóa chính chiếm 8 byte, vì vậy khi chiều cao là 3, có thể lưu:
- 16KB / (8B + 6B) = 1170.
- 1170 * 1170 * 16 = 21,902,400.
Tức là hơn 20 triệu bản ghi.
Vì vậy, chúng ta có thể sử dụng phương pháp này để xác định xem số lượng dữ liệu trong một bảng có quá nhiều không (chiều cao của cây B+ thường không nên vượt quá ba tầng, vì dữ liệu của B+ tree đều được lưu trên đĩa, cây quá cao sẽ làm tăng số lần IO, và hiệu suất tổng thể sẽ giảm). Mọi người có thể sử dụng phương pháp mà tôi giới thiệu để tính số lượng bản ghi mà một bảng có thể lưu trữ khi chiều cao của B+ tree là 2 hoặc 3. Nếu tổng số bản ghi thực tế trong bảng vượt quá số lượng mà 3 tầng có thể chứa, thì bảng đó được coi là bảng lớn, lúc này hiệu suất của chỉ mục sẽ không cao, và cần phải phân tách bảng.
Sự khác biệt giữa count(*) và count(1)
Trong công việc, thường xuyên cần thực hiện thống kê, chẳng hạn như khi phân trang, cần biết tổng số dòng dữ liệu trong bảng, lúc này sẽ sử dụng count(). Vậy thì nên sử dụng count(*), count(1), hay count(cột nào đó)?
Trên trang web chính thức của MySQL, thực tế đã mô tả count(*), nhấp vào đây để xem.
Trong tài liệu chính thức, count(expr) được mô tả như sau:
Returns a count of the number of non-NULL values of expr in the rows retrieved by a SELECT statement. The result is a BIGINT value.
If there are no matching rows, COUNT() returns 0Dịch sang tiếng Việt có nghĩa là: nó trả về số lượng giá trị không NULL của biểu thức expr trong các dòng được truy vấn bởi câu lệnh SELECT. Nếu không có dòng nào phù hợp, COUNT() sẽ trả về 0.
Ví dụ với SQL dưới đây:
select count(*) from t1Là để thống kê tổng số dòng của kết quả từ câu lệnh SQL:
select * from t1Ngay sau đó, tài liệu cũng mô tả riêng về count(*):
COUNT(*) is somewhat different in that it returns a count of the number of rows retrieved, whether or not they contain NULL values.Điều này có nghĩa là count(*) có một chút khác biệt, vì count() thông thường sẽ không thống kê các giá trị NULL, nhưng count(*) sẽ thống kê cả giá trị NULL.
Chẳng hạn, bây giờ có một bảng với chỉ một cột và ba bản ghi, trong đó có hai giá trị f và một giá trị NULL:
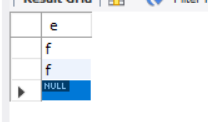
Lúc này, kết quả của count(*) sẽ là 3, kết quả của count(e) sẽ là 2, và kết quả của count(1) sẽ là 3.
Trong MyISAM, sẽ có một vị trí riêng để ghi lại số lượng dòng trong bảng, vì vậy khi thực hiện count(*) trong MyISAM sẽ nhanh hơn, tất nhiên điều kiện là câu lệnh SQL không có điều kiện WHERE, vì MyISAM ghi lại tổng số dòng trong bảng không có điều kiện.
Tuy nhiên, Innodb không có cơ chế này, vì Innodb hỗ trợ giao dịch và các giao dịch có các cấp độ cách ly khác nhau. Đối với cùng một bảng, các giao dịch khác nhau có thể cùng lúc thao tác trên bảng này, và mỗi giao dịch là độc lập. Giao dịch A chèn một dữ liệu, trong khi giao dịch B có thể không cần biết đến điều đó, điều này khiến Innodb không thể ghi lại tổng số dòng giống như MyISAM.
Vậy count() trong Innodb thực hiện như thế nào? Nó sẽ sử dụng chỉ mục.
Ví dụ, khi thực hiện count(*), nó sẽ chọn một chỉ mục nào đó trong bảng, vì chỉ mục B+ tree sẽ ghi lại tất cả các dòng dữ liệu trong bảng (một số trường của mỗi dòng), nên việc sử dụng trang chỉ mục có thể thống kê tổng số dòng nhanh hơn.
Ví dụ bây giờ có một bảng với năm cột a, b, c, d, e, trong đó a là khóa chính, b, c, d là một chỉ mục kết hợp. Lúc này nếu thực hiện:
explain select count(*) from t1Sẽ thấy rằng câu lệnh SQL này sẽ sử dụng chỉ mục kết hợp bcd.

Vì chỉ mục bcd có ít trường hơn, dẫn đến số lượng nút lá trong B+ tree ít hơn, nhưng không ảnh hưởng đến số lượng dòng dữ liệu (mỗi dòng chỉ lưu trữ trường b, c, d, nói chính xác là cũng lưu a, nhưng trường e chắc chắn không có lưu).
Đó là count(*), tương tự như sẽ sử dụng chỉ mục để thống kê tổng số dòng.
Còn count(1) và count(*) thì giống nhau, như tài liệu chính thức đã mô tả:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.Nếu là count(cột nào đó), thì cũng xem cột đó có chỉ mục nào có sẵn không; nếu có thì sử dụng chỉ mục để thống kê, nếu không thì thực hiện quét toàn bộ bảng để thống kê, tất nhiên sẽ loại bỏ giá trị NULL.
Trên đây là quá trình phân tích của tôi kết hợp với tài liệu chính thức và thực nghiệm, tóm tắt như sau:
- Trong MyISAM,
count(*)nhanh hơn vì có thể lấy trực tiếp tổng số dòng do MyISAM giúp thống kê. - Trong Innodb,
count(*)sẽ chọn chỉ mục và sau đó sử dụng chỉ mục để thống kê tổng số dòng. count(1)vàcount(*)là giống nhau, không phân biệt giữa Innodb hay MyISAM.count(cột nào đó)sẽ chọn chỉ mục có sẵn của cột đó để thống kê, nếu không có thì thực hiện quét toàn bộ bảng; bất kể làcount(cột nào đó)đều sẽ loại bỏ giá trị NULL, không phân biệt có sử dụng chỉ mục hay không.
RDB và AOF là gì
RDB: Redis DataBase, là cách lưu trữ dữ liệu trong Redis bằng cách chụp ảnh (snapshot) của tập dữ liệu trong bộ nhớ và ghi vào đĩa trong các khoảng thời gian xác định. Quá trình này thực hiện bằng cách tạo một tiến trình con (fork) để ghi tập dữ liệu vào tệp tạm thời, sau khi ghi thành công, nó sẽ thay thế tệp trước đó bằng tệp đã được nén nhị phân.
Ưu điểm:
- Toàn bộ cơ sở dữ liệu Redis chỉ chứa một tệp
dump.rdb, thuận tiện cho việc lưu trữ lâu dài. - Khả năng phục hồi tốt, dễ dàng sao lưu.
- Tối đa hóa hiệu suất, tiến trình con được sử dụng để thực hiện các thao tác ghi, cho phép tiến trình chính tiếp tục xử lý lệnh, vì vậy I/O được tối đa hóa. Sử dụng tiến trình con riêng để thực hiện lưu trữ lâu dài, tiến trình chính sẽ không thực hiện bất kỳ thao tác I/O nào, đảm bảo hiệu suất cao cho Redis.
- Khi tập dữ liệu lớn, hiệu suất khởi động cao hơn so với AOF.
Nhược điểm:
- An toàn dữ liệu thấp. RDB thực hiện việc lưu trữ theo khoảng thời gian, nếu có sự cố xảy ra trong khoảng thời gian giữa hai lần lưu trữ, dữ liệu có thể bị mất. Phương pháp này phù hợp hơn với những yêu cầu dữ liệu không quá nghiêm ngặt.
- Do RDB sử dụng tiến trình con để hỗ trợ thực hiện công việc lưu trữ dữ liệu, nên khi tập dữ liệu lớn, có thể làm toàn bộ máy chủ ngừng hoạt động từ vài trăm mili giây đến một giây.
AOF: Append Only File, ghi lại mọi thao tác ghi và xóa mà máy chủ xử lý dưới dạng nhật ký. Các thao tác truy vấn sẽ không được ghi lại và được lưu dưới dạng văn bản, có thể mở tệp để xem chi tiết các thao tác đã thực hiện.
Ưu điểm:
- An toàn dữ liệu, Redis cung cấp ba chính sách đồng bộ: đồng bộ mỗi giây, đồng bộ mỗi lần thay đổi và không đồng bộ. Thực tế, đồng bộ mỗi giây cũng được thực hiện không đồng bộ, với hiệu suất cao. Sự khác biệt là nếu hệ thống gặp sự cố, dữ liệu đã thay đổi trong giây đó sẽ bị mất. Trong khi đồng bộ mỗi lần thay đổi, chúng ta có thể coi như lưu trữ đồng bộ, tức là mỗi thay đổi dữ liệu sẽ ngay lập tức được ghi vào đĩa.
- Thông qua chế độ ghi append, ngay cả khi máy chủ gặp sự cố giữa chừng, nội dung đã tồn tại sẽ không bị hỏng, có thể sử dụng công cụ
redis-check-aofđể giải quyết vấn đề nhất quán dữ liệu. - Chế độ ghi lại (rewrite) của cơ chế AOF. Thực hiện ghi lại định kỳ tệp AOF để đạt được mục đích nén.
Nhược điểm:
- Tệp AOF lớn hơn tệp RDB và tốc độ phục hồi chậm hơn.
- Khi tập dữ liệu lớn, hiệu suất khởi động thấp hơn RDB.
- Hiệu suất chạy không cao bằng RDB.
Tệp AOF có tần suất cập nhật cao hơn tệp RDB, ưu tiên sử dụng AOF để khôi phục dữ liệu. AOF an toàn hơn và lớn hơn, trong khi RDB có hiệu suất tốt hơn AOF. Nếu cả hai đều được cấu hình, ưu tiên tải AOF trước.
Chiến lược xóa khóa hết hạn trong Redis
Redis là cơ sở dữ liệu key-value, cho phép chúng ta thiết lập thời gian hết hạn cho các khóa lưu trữ trong Redis. Chiến lược hết hạn của Redis chỉ ra cách Redis xử lý khi một khóa hết hạn.
- Hết hạn lười biếng (Lazy Expiration): Chỉ kiểm tra khóa đã hết hạn khi có truy cập đến khóa đó; nếu hết hạn thì sẽ xóa. Chiến lược này tiết kiệm tối đa tài nguyên CPU nhưng không thân thiện với bộ nhớ. Trong tình huống cực đoan, có thể có nhiều khóa hết hạn không được truy cập lại, dẫn đến việc không bị xóa và chiếm dụng một lượng lớn bộ nhớ.
- Hết hạn định kỳ (Periodic Expiration): Mỗi khoảng thời gian nhất định, sẽ quét một số lượng khóa nhất định trong từ điển
expirescủa cơ sở dữ liệu và xóa các khóa đã hết hạn. Chiến lược này là một phương án thỏa hiệp. Bằng cách điều chỉnh khoảng thời gian quét định kỳ và thời gian quét mỗi lần, có thể tối ưu hóa tài nguyên CPU và bộ nhớ trong các tình huống khác nhau.
(Từ điển expires sẽ lưu trữ tất cả các dữ liệu thời gian hết hạn của khóa đã được thiết lập thời gian hết hạn. Trong đó, khóa là con trỏ đến một khóa trong không gian khóa, giá trị là thời gian hết hạn được biểu diễn bằng dấu thời gian UNIX với độ chính xác mili giây. Không gian khóa là tất cả các khóa được lưu trữ trong cụm Redis.)
Redis sử dụng đồng thời cả hai chiến lược hết hạn lười biếng và hết hạn định kỳ.
Tóm tắt việc thực hiện giao dịch trong Redis
1. Bắt đầu giao dịch
Thực hiện lệnh _MULTI_ đánh dấu bắt đầu một giao dịch. Lệnh _MULTI_ sẽ mở cờ REDIS_MULTI trong thuộc tính flags của trạng thái máy khách.
2. Lệnh được xếp hàng
Khi một máy khách chuyển sang trạng thái giao dịch, máy chủ sẽ thực hiện các thao tác khác nhau dựa trên các lệnh mà máy khách gửi đến. Nếu lệnh được gửi là một trong các lệnh _MULTI_, _EXEC_, _WATCH_, _DISCARD_, máy chủ sẽ thực hiện ngay lệnh đó, nếu không thì lệnh sẽ được đưa vào một hàng đợi giao dịch, sau đó gửi phản hồi QUEUED cho máy khách.
- Nếu lệnh được máy khách gửi là một trong bốn lệnh EXEC, DISCARD, WATCH, MULTI, máy chủ sẽ thực hiện ngay lệnh đó.
- Nếu lệnh được máy khách gửi là các lệnh khác ngoài bốn lệnh trên, máy chủ sẽ không thực hiện ngay lệnh đó. Đầu tiên, kiểm tra định dạng của lệnh có đúng không, nếu không đúng, máy chủ sẽ tắt cờ
REDIS_MULTItrong thuộc tính trạng thái của máy khách (redisClient) và gửi thông tin lỗi cho máy khách. Nếu đúng, lệnh sẽ được đưa vào hàng đợi giao dịch và gửi phản hồiQUEUEDcho máy khách.
Hàng đợi giao dịch sẽ lưu trữ các lệnh theo cách FIFO (first in, first out).
3. Thực thi giao dịch
Khi máy khách gửi lệnh EXEC, máy chủ sẽ thực hiện logic của lệnh EXEC.
- Nếu thuộc tính
flagscủa trạng thái máy khách không chứa cờREDIS_MULTI, hoặc chứa các cờREDIS_DIRTY_CAShoặcREDIS_DIRTY_EXEC, thì giao dịch sẽ bị hủy bỏ. - Nếu không, máy khách đang ở trạng thái giao dịch (có cờ
REDIS_MULTI), máy chủ sẽ duyệt qua hàng đợi giao dịch của máy khách và thực hiện tất cả các lệnh trong hàng đợi, cuối cùng sẽ trả lại tất cả kết quả cho máy khách.
Redis không hỗ trợ cơ chế rollback (hoàn tác) giao dịch, nhưng nó sẽ kiểm tra xem từng lệnh trong giao dịch có bị lỗi hay không.
Giao dịch Redis không hỗ trợ kiểm tra những lỗi logic do lập trình viên tự gây ra. Ví dụ, thực hiện thao tác trên kiểu dữ liệu HashMap đối với một khóa kiểu String!
- Lệnh
WATCHlà một khóa lạc quan, có thể cung cấp hành vi kiểm tra và thiết lập (check-and-set - CAS) cho giao dịch Redis. Nó có thể theo dõi một hoặc nhiều khóa, và một khi bất kỳ khóa nào trong số đó bị thay đổi (hoặc xóa), giao dịch sau đó sẽ không được thực hiện, việc theo dõi sẽ tiếp tục cho đến khi lệnhEXECđược thực hiện. - Lệnh
MULTIđược sử dụng để bắt đầu một giao dịch, nó luôn trả về OK. Sau khi thực hiệnMULTI, máy khách có thể tiếp tục gửi bất kỳ số lượng lệnh nào tới máy chủ, những lệnh này sẽ không được thực hiện ngay lập tức mà sẽ được đưa vào một hàng đợi, và khi lệnhEXECđược gọi, tất cả các lệnh trong hàng đợi mới được thực hiện. - Lệnh
EXEC: thực hiện tất cả các lệnh trong khối giao dịch. Trả về giá trị trả về của tất cả các lệnh trong khối giao dịch, theo thứ tự thực hiện. Khi thao tác bị gián đoạn, trả về giá trị rỗngnil. - Bằng cách gọi lệnh
DISCARD, máy khách có thể làm trống hàng đợi giao dịch và từ bỏ việc thực hiện giao dịch, đồng thời máy khách sẽ thoát khỏi trạng thái giao dịch. - Lệnh
UNWATCHcó thể hủy bỏ việc theo dõi tất cả các khóa.
Nguyên lý cốt lõi của sao chép master-slave trong Redis
Bằng cách thực hiện lệnh slaveof hoặc thiết lập tùy chọn slaveof, cho phép một máy chủ sao chép dữ liệu từ máy chủ khác. Cơ sở dữ liệu chính có thể thực hiện các thao tác đọc và ghi, khi các thao tác ghi gây ra sự thay đổi dữ liệu, dữ liệu sẽ tự động được đồng bộ đến cơ sở dữ liệu từ. Cơ sở dữ liệu từ thường chỉ là đọc, và nhận dữ liệu đồng bộ từ cơ sở dữ liệu chính. Một cơ sở dữ liệu chính có thể có nhiều cơ sở dữ liệu từ, trong khi một cơ sở dữ liệu từ chỉ có thể có một cơ sở dữ liệu chính.
Sao chép toàn bộ:
- Cơ sở dữ liệu chính thông qua lệnh
bgsavetạo một tiến trình con để thực hiện lưu trữ RDB, quá trình này rất tiêu tốn CPU, bộ nhớ (sao chép bảng trang) và I/O ổ cứng. - Cơ sở dữ liệu chính sẽ gửi tệp RDB qua mạng cho cơ sở dữ liệu từ, điều này sẽ tiêu tốn băng thông của cả hai máy chủ.
- Quá trình từ cơ sở dữ liệu từ làm sạch dữ liệu cũ và tải tệp RDB mới là quá trình chặn (blocking), không thể phản hồi các lệnh từ máy khách; nếu cơ sở dữ liệu từ thực hiện
bgrewriteaof, điều này cũng sẽ dẫn đến tiêu tốn thêm tài nguyên.
Sao chép một phần:
- Offset sao chép: Cả hai bên thực hiện sao chép, cơ sở dữ liệu chính và từ, sẽ duy trì một offset sao chép riêng.
- Bộ đệm sao chép: Cơ sở dữ liệu chính nội bộ duy trì một hàng đợi FIFO (first in, first out) có độ dài cố định làm bộ đệm sao chép. Khi độ chênh lệch giữa offset của máy chủ chính và từ vượt quá độ dài của bộ đệm, việc thực hiện sao chép một phần sẽ không khả thi và chỉ có thể thực hiện sao chép toàn bộ.
- ID máy chủ chạy (runid): Mỗi nút Redis đều có ID chạy của nó, ID này được tự động tạo ra khi nút khởi động. Cơ sở dữ liệu chính sẽ gửi ID chạy của mình đến cơ sở dữ liệu từ, cơ sở dữ liệu từ sẽ lưu giữ ID chạy của cơ sở dữ liệu chính. Khi cơ sở dữ liệu từ Redis kết nối lại, nó sẽ dựa vào ID chạy để xác định tiến độ đồng bộ:
- Nếu
runidđược lưu trong cơ sở dữ liệu từ giống vớirunidhiện tại của cơ sở dữ liệu chính, điều này có nghĩa là cơ sở dữ liệu chính và từ đã đồng bộ trước đó, cơ sở dữ liệu chính sẽ tiếp tục cố gắng sử dụng sao chép một phần (có thể thực hiện sao chép một phần hay không còn phụ thuộc vào tình hình offset và bộ đệm sao chép); - Nếu
runidđược lưu trong cơ sở dữ liệu từ khác vớirunidhiện tại của cơ sở dữ liệu chính, điều này có nghĩa là cơ sở dữ liệu từ đã đồng bộ với nút Redis trước đó không phải là cơ sở dữ liệu chính hiện tại, chỉ có thể thực hiện sao chép toàn bộ.
- Nếu
Các cấu trúc dữ liệu trong Redis là gì? Mỗi cấu trúc có những trường hợp ứng dụng điển hình nào?
Cấu trúc dữ liệu của Redis có:
- Chuỗi (String): Có thể được sử dụng để làm dữ liệu đơn giản nhất, có thể lưu trữ một chuỗi đơn giản hoặc một chuỗi định dạng JSON, việc thực hiện khóa phân tán trong Redis sử dụng cấu trúc dữ liệu này, cũng như có thể thực hiện các bộ đếm, chia sẻ phiên (Session), ID phân tán.
- Bảng băm (Hash): Có thể được sử dụng để lưu trữ một số cặp key-value, thích hợp hơn để lưu trữ các đối tượng.
- Danh sách (List): Danh sách trong Redis có thể được sử dụng như ngăn xếp (stack) hoặc hàng đợi (queue) nhờ vào các lệnh kết hợp, có thể dùng để lưu trữ dữ liệu dòng tin nhắn từ các ứng dụng như WeChat, Weibo.
- Tập hợp (Set): Tương tự như danh sách, cũng có thể lưu trữ nhiều phần tử nhưng không được trùng lặp, có thể thực hiện các phép toán giao, hợp và hiệu của tập hợp, từ đó có thể thực hiện các chức năng như: người mà tôi và ai đó cùng theo dõi, tương tác trong vòng bạn bè.
- Tập hợp có thứ tự (Sorted Set): Tập hợp không có thứ tự, nhưng tập hợp có thứ tự có thể thiết lập thứ tự, có thể được sử dụng để thực hiện chức năng bảng xếp hạng.
Cách thức hoạt động của khóa phân tán trong Redis?
- Đầu tiên, sử dụng
setnxđể đảm bảo: nếu khóa không tồn tại thì mới có thể nhận được khóa, nếu khóa tồn tại, không thể nhận được khóa. - Tiếp theo, cần sử dụng Lua Script để đảm bảo tính nguyên tử của nhiều thao tác Redis.
- Đồng thời cần xem xét đến việc khóa hết hạn, vì vậy cần có một tác vụ watchdog định kỳ để theo dõi xem khóa có cần gia hạn hay không.
- Đồng thời cũng cần xem xét tình huống khi nút Redis gặp sự cố, vì vậy cần sử dụng phương pháp Redlock để đồng thời yêu cầu khóa từ N/2+1 nút, chỉ khi tất cả đều nhận được khóa thì mới xác nhận việc nhận khóa thành công. Như vậy, ngay cả khi một trong các nút Redis gặp sự cố, khóa cũng không thể được nhận bởi các máy khách khác.
Nguyên lý cốt lõi của sao chép chính - phụ trong Redis (master-slave replication)
Sao chép chính - phụ trong Redis là một biện pháp hiệu quả để tăng tính đáng tin cậy của Redis. Quy trình sao chép chính - phụ như sau:
- Khi khởi động cụm, hệ thống sẽ thiết lập kết nối giữa cơ sở dữ liệu chính và phụ để chuẩn bị cho việc sao chép toàn bộ dữ liệu.
- Cơ sở dữ liệu chính sẽ đồng bộ tất cả dữ liệu sang cơ sở dữ liệu phụ. Sau khi nhận dữ liệu, cơ sở dữ liệu phụ sẽ tải dữ liệu lên bộ nhớ địa phương, quá trình này phụ thuộc vào snapshot bộ nhớ RDB.
- Trong quá trình đồng bộ dữ liệu từ cơ sở dữ liệu chính sang cơ sở dữ liệu phụ, cơ sở dữ liệu chính sẽ không bị chặn, vẫn có thể xử lý các yêu cầu bình thường. Tuy nhiên, các thao tác ghi trong những yêu cầu này sẽ không được ghi lại vào file RDB mới tạo. Để đảm bảo tính nhất quán của dữ liệu giữa cơ sở dữ liệu chính và phụ, cơ sở dữ liệu chính sẽ sử dụng một replication buffer (bộ nhớ đệm sao chép) trong bộ nhớ để ghi lại tất cả các thao tác ghi xảy ra trong quá trình tạo file RDB.
- Cuối cùng, sau khi hoàn thành việc gửi file RDB, cơ sở dữ liệu chính sẽ gửi các lệnh ghi mới nhận được trong quá trình này từ replication buffer sang cơ sở dữ liệu phụ để cơ sở dữ liệu phụ thực hiện các lệnh này, từ đó đạt được sự đồng bộ.
- Sau đó, cả cơ sở dữ liệu chính và phụ đều có thể xử lý các thao tác đọc của máy khách, nhưng chỉ có cơ sở dữ liệu chính mới xử lý được các thao tác ghi. Cơ sở dữ liệu chính sẽ gửi các thao tác ghi tới cơ sở dữ liệu phụ để thực hiện đồng bộ gia tăng.
Chiến lược Redis cluster
Redis cung cấp ba chiến lược cluster:
Chế độ chính - phụ: Chế độ này khá đơn giản, cơ sở dữ liệu chính có thể đọc và ghi, đồng thời đồng bộ dữ liệu với cơ sở dữ liệu phụ. Tuy nhiên, khi cơ sở dữ liệu chính hoặc phụ bị hỏng, cần phải sửa đổi IP thủ công và chế độ này khó mở rộng. Dữ liệu của toàn bộ cụm bị giới hạn bởi dung lượng bộ nhớ của một máy, do đó không thể hỗ trợ lượng dữ liệu quá lớn.
Chế độ Sentinel: Trên cơ sở chính - phụ, thêm vào các nút Sentinel. Khi cơ sở dữ liệu chính gặp sự cố, Sentinel sẽ phát hiện và chọn một cơ sở dữ liệu phụ trở thành cơ sở dữ liệu chính mới. Sentinel cũng có thể tạo thành cụm để đảm bảo khi một Sentinel gặp sự cố, vẫn còn các Sentinel khác tiếp tục làm việc. Tuy nhiên, chế độ này vẫn không thể giải quyết tốt vấn đề giới hạn dung lượng của Redis.
Chế độ Cluster: Đây là chế độ được sử dụng phổ biến nhất, hỗ trợ nhiều cơ sở dữ liệu chính và phụ. Chế độ này phân chia các slot theo key để phân tán các key khác nhau tới các nút chính khác nhau, giúp cụm hỗ trợ dung lượng dữ liệu lớn hơn. Mỗi nút chính có thể có nhiều nút phụ, và khi nút chính gặp sự cố, một nút phụ sẽ được bầu chọn làm nút chính mới.
Đối với ba chế độ này, nếu lượng dữ liệu Redis cần lưu trữ không lớn, có thể chọn chế độ Sentinel. Nếu dữ liệu lớn và cần mở rộng liên tục, nên chọn chế độ Cluster.
Cache xuyên thấu, cache đâm thủng, và cache sụp đổ là gì?
Trong cache thường lưu trữ các dữ liệu "nóng" nhằm tránh việc phải truy cập trực tiếp vào MySQL. Các vấn đề có thể xảy ra là:
Cache sụp đổ: Khi một lượng lớn dữ liệu "nóng" hết hạn cùng lúc, sẽ dẫn đến lượng lớn các yêu cầu truy cập trực tiếp vào MySQL. Cách giải quyết là thêm một số giá trị ngẫu nhiên vào thời gian hết hạn hoặc xây dựng cụm Redis có tính khả dụng cao.
Cache đâm thủng: Khác với cache sụp đổ là nhiều dữ liệu cùng hết hạn, cache đâm thủng xảy ra khi một key "nóng" đột ngột hết hạn, dẫn đến lượng lớn yêu cầu truy cập trực tiếp vào MySQL. Giải pháp là không đặt thời gian hết hạn cho key "nóng".
Cache xuyên thấu: Nếu vào một thời điểm nào đó có nhiều key không tồn tại trong Redis được truy vấn (ví dụ hacker cố tình tạo các key ngẫu nhiên), sẽ gây áp lực lên cơ sở dữ liệu. Giải pháp là sử dụng Bloom filter để chặn các key không tồn tại trước khi truy cập vào cache.
Làm thế nào để đảm bảo dữ liệu nhất quán giữa Redis và MySQL?
Cập nhật MySQL trước, sau đó cập nhật Redis. Tuy nhiên, nếu cập nhật Redis thất bại, dữ liệu có thể không đồng nhất.
Xóa dữ liệu cache trong Redis trước, sau đó cập nhật MySQL. Khi có truy vấn tiếp theo, dữ liệu mới sẽ được thêm lại vào cache. Cách này giải quyết được vấn đề trong phương pháp 1 nhưng có hiệu suất thấp trong môi trường có độ đồng thời cao, và vẫn có khả năng xảy ra không nhất quán dữ liệu.
Double delete with delay: Xóa dữ liệu trong Redis trước, sau đó cập nhật MySQL, và sau một vài trăm mili giây xóa lại dữ liệu trong Redis. Điều này đảm bảo rằng nếu có thread khác đọc dữ liệu cũ từ MySQL và đưa vào Redis, dữ liệu sẽ bị xóa lần nữa, giữ được tính nhất quán.
Cơ chế lưu trữ dữ liệu của Redis
RDB:
RDB (Redis DataBase) lưu trữ ảnh chụp nhanh của bộ nhớ tại một thời điểm cụ thể dưới dạng nhị phân vào đĩa.
Kích hoạt thủ công:
- Lệnh
save: khiến Redis bị khóa cho đến khi hoàn thành việc lưu trữ RDB, sau đó mới phản hồi các lệnh từ các client khác. Vì vậy, nên sử dụng cẩn thận trong môi trường sản xuất. - Lệnh
bgsave: fork ra một tiến trình con để thực hiện lưu trữ, tiến trình chính chỉ bị khóa trong thời gian ngắn khi fork. Sau khi tiến trình con được tạo, tiến trình chính có thể tiếp tục phản hồi các yêu cầu từ client.
Kích hoạt tự động:
save m n: trong m giây, nếu có n khóa thay đổi, việc lưu trữ sẽ được kích hoạt tự động thông quabgsave. Nếu có nhiều điều kiện, chỉ cần một điều kiện thỏa mãn thì sẽ kích hoạt. Có thể cấu hình trong file cấu hình (có thể vô hiệu hóa).flushall: dùng để xóa toàn bộ dữ liệu trong Redis,flushdbchỉ xóa dữ liệu trong database hiện tại của Redis (mặc định là database số 0). Việc này sẽ xóa file RDB và tạo ra filedump.rdbrỗng.- Đồng bộ hóa master-slave: khi đồng bộ toàn bộ, lệnh
bgsavesẽ được kích hoạt tự động để tạo file RDB và gửi đến node slave.
Ưu điểm:
- Redis chỉ chứa một file
dump.rdb, thuận tiện cho việc lưu trữ. - Khả năng chịu lỗi tốt, dễ dàng sao lưu.
- Hiệu suất tối đa: fork tiến trình con để ghi dữ liệu, tiến trình chính tiếp tục xử lý lệnh, tối ưu IO.
- Khi dataset lớn, RDB khởi động nhanh hơn AOF.
Nhược điểm:
- Độ an toàn dữ liệu thấp. RDB chỉ lưu trữ theo khoảng thời gian, nên nếu Redis gặp sự cố giữa các lần lưu trữ, dữ liệu có thể bị mất.
- Khi dataset lớn, quá trình fork có thể khiến server bị dừng trong vài trăm mili giây, thậm chí 1 giây, tiêu tốn CPU.
AOF:
AOF (Append Only File) lưu trữ các lệnh ghi và xóa theo dạng nhật ký, các lệnh truy vấn không được lưu. Dữ liệu được ghi dưới dạng văn bản, có thể mở file để xem chi tiết các lệnh.
- Mọi lệnh ghi sẽ được thêm vào bộ đệm AOF.
- Bộ đệm AOF sẽ được đồng bộ với đĩa theo chiến lược được cấu hình.
- Khi file AOF ngày càng lớn, cần định kỳ thực hiện viết lại AOF để giảm dung lượng.
- Khi Redis khởi động, có thể tải file AOF để khôi phục dữ liệu.
Chiến lược đồng bộ:
- Đồng bộ mỗi giây: thực hiện không đồng bộ, hiệu suất cao, nhưng nếu hệ thống gặp sự cố, dữ liệu thay đổi trong một giây có thể bị mất.
- Đồng bộ mỗi lần thay đổi: lưu trữ đồng bộ, mỗi khi có thay đổi dữ liệu sẽ được ghi ngay vào đĩa, tối đa chỉ mất một lệnh.
- Không đồng bộ: do hệ điều hành kiểm soát, có thể mất nhiều dữ liệu hơn.
Ưu điểm:
- An toàn dữ liệu.
- Chế độ ghi
appendđảm bảo dữ liệu không bị hỏng nếu server gặp sự cố. - Cơ chế rewrite giúp nén file AOF để tiết kiệm dung lượng.
Nhược điểm:
- File AOF lớn hơn file RDB và tốc độ khôi phục chậm hơn.
- Khi dataset lớn, AOF khởi động chậm hơn RDB.
- Hiệu suất chạy không bằng RDB.
So sánh:
- AOF cập nhật thường xuyên hơn RDB, ưu tiên sử dụng AOF để khôi phục dữ liệu. AOF an toàn hơn nhưng dung lượng lớn hơn.
- RDB có hiệu suất tốt hơn AOF.
- Nếu cả hai được cấu hình, Redis sẽ ưu tiên tải AOF trước.
Redis đơn luồng tại sao lại nhanh
Redis dựa trên mô hình Reactor, phát triển bộ xử lý sự kiện mạng và bộ xử lý sự kiện tệp (file event handler). Redis là đơn luồng, do đó được gọi là mô hình đơn luồng. Nó sử dụng cơ chế IO đa kênh (IO multiplexing) để lắng nghe nhiều Socket cùng lúc. Dựa trên loại sự kiện xảy ra trên Socket, Redis chọn bộ xử lý sự kiện tương ứng để xử lý. Điều này cho phép thực hiện một mô hình giao tiếp mạng hiệu suất cao, đồng thời duy trì tính đơn giản của mô hình luồng nội bộ.
Cấu trúc của bộ xử lý sự kiện tệp gồm 4 phần: nhiều Socket, chương trình IO đa kênh, bộ điều phối sự kiện tệp và các bộ xử lý sự kiện (như bộ xử lý yêu cầu lệnh, bộ xử lý phản hồi lệnh, bộ xử lý kết nối...).
Nhiều Socket có thể tạo ra các sự kiện đồng thời, chương trình IO đa kênh sẽ lắng nghe các Socket, đưa Socket vào hàng đợi. Mỗi lần, chương trình sẽ lấy ra một Socket theo thứ tự từ hàng đợi và giao cho bộ điều phối sự kiện, sau đó bộ điều phối sẽ chuyển Socket đó đến bộ xử lý sự kiện tương ứng.
Khi một Socket được xử lý xong, chương trình IO đa kênh mới tiếp tục lấy Socket tiếp theo từ hàng đợi và giao cho bộ điều phối sự kiện. Bộ điều phối sự kiện sẽ lựa chọn bộ xử lý phù hợp dựa trên sự kiện hiện tại mà Socket tạo ra.
- Khi Redis khởi động, bộ xử lý kết nối được liên kết với sự kiện AE_READABLE.
- Khi một máy khách khởi tạo kết nối, sẽ tạo ra một sự kiện AE_READABLE, và bộ xử lý kết nối sẽ xử lý việc tạo kết nối, đồng thời tạo ra socket cho máy khách. Sau đó, sự kiện AE_READABLE của socket này sẽ được liên kết với bộ xử lý yêu cầu lệnh để máy khách có thể gửi yêu cầu đến Redis.
- Khi máy khách gửi yêu cầu tới Redis (dù là đọc hay ghi), socket của máy khách sẽ tạo ra một sự kiện AE_READABLE, kích hoạt bộ xử lý yêu cầu lệnh. Bộ xử lý này sẽ đọc nội dung yêu cầu và gửi tới chương trình thực thi tương ứng.
- Khi Redis đã sẵn sàng phản hồi dữ liệu cho máy khách, sự kiện AE_WRITABLE của socket sẽ được liên kết với bộ xử lý phản hồi lệnh. Khi máy khách sẵn sàng đọc dữ liệu, socket sẽ tạo ra sự kiện AE_WRITABLE, và bộ xử lý phản hồi sẽ ghi dữ liệu vào socket để máy khách có thể đọc.
- Khi bộ xử lý phản hồi lệnh đã ghi xong dữ liệu vào socket, sự kiện AE_WRITABLE và liên kết của nó với bộ xử lý phản hồi sẽ bị xoá.
Lý do Redis đơn luồng nhanh:
- Các thao tác chỉ diễn ra trên bộ nhớ.
- Cơ chế IO đa kênh không chặn.
- Tránh được vấn đề chuyển đổi ngữ cảnh giữa nhiều luồng.
Mô tả ngắn gọn về việc thực hiện giao dịch trong Redis
- Bắt đầu giao dịch: Khi lệnh MULTI được thực thi, nó đánh dấu sự bắt đầu của một giao dịch. MULTI mở cờ REDIS_MULTI trong thuộc tính flags của trạng thái máy khách.
- Lệnh vào hàng đợi: Sau khi máy khách chuyển sang trạng thái giao dịch, Redis sẽ xếp các lệnh của máy khách vào hàng đợi giao dịch. Nếu máy khách gửi lệnh MULTI, EXEC, WATCH, hoặc DISCARD, Redis sẽ thực thi ngay lập tức, nếu không, lệnh sẽ được đưa vào hàng đợi và trả về thông báo QUEUED.
- Thực thi giao dịch: Khi máy khách gửi lệnh EXEC, Redis sẽ thực thi tất cả các lệnh trong hàng đợi theo thứ tự FIFO. Redis không hỗ trợ hoàn tác (rollback), nhưng sẽ kiểm tra lỗi trong mỗi lệnh.
Redis không kiểm tra lỗi logic của lập trình viên (như việc thực hiện lệnh không hợp lệ trên kiểu dữ liệu không tương ứng).
Lý thuyết CAP là gì?
Lý thuyết CAP là một lý thuyết hướng dẫn rất quan trọng trong lĩnh vực hệ thống phân tán. C (Consistency) biểu thị tính nhất quán mạnh, A (Availability) biểu thị tính khả dụng, và P (Partition Tolerance) biểu thị tính chịu lỗi phân vùng. Lý thuyết CAP chỉ ra rằng trong các điều kiện phần cứng hiện tại, một hệ thống phân tán phải đảm bảo tính chịu lỗi phân vùng. Trên cơ sở đó, hệ thống phân tán hoặc đảm bảo CP (Consistency và Partition Tolerance) hoặc đảm bảo AP (Availability và Partition Tolerance), nhưng không thể đảm bảo đồng thời cả ba yếu tố CAP.
Tính chịu lỗi phân vùng biểu thị rằng dù hệ thống là phân tán nhưng đối với người dùng, hệ thống vẫn phải trông như một tổng thể. Điều này có nghĩa là nếu một nút trong hệ thống bị lỗi hoặc có sự cố về mạng, hệ thống vẫn không được gây ra bất kỳ sự cố nào đối với người dùng.
Tính nhất quán mạnh nghĩa là dữ liệu giữa các nút trong một hệ thống phân tán phải được đồng bộ ngay lập tức, và trong quá trình đồng bộ hóa, hệ thống không được cung cấp dịch vụ cho người dùng vì nếu không sẽ dẫn đến dữ liệu không nhất quán. Do đó, tính nhất quán mạnh và tính khả dụng không thể đảm bảo đồng thời.
Tính khả dụng biểu thị rằng hệ thống phân tán phải đảm bảo có thể cung cấp dịch vụ liên tục cho người dùng.
Lý thuyết BASE là gì?
Do không thể đồng thời đảm bảo được CAP, lý thuyết BASE đã xuất hiện:
- BA: Basically Available - biểu thị tính khả dụng cơ bản, cho phép một số mức độ không khả dụng nhất định, chẳng hạn như yêu cầu xử lý lâu hơn do sự cố hệ thống hoặc các chức năng không quan trọng có thể không khả dụng.
- S: Soft State - biểu thị rằng hệ thống phân tán có thể ở trạng thái trung gian, chẳng hạn như dữ liệu đang được đồng bộ.
- E: Eventually Consistent - biểu thị tính nhất quán cuối cùng, không yêu cầu dữ liệu trong hệ thống phân tán phải đồng bộ ngay lập tức mà chỉ cần sau một khoảng thời gian, hệ thống sẽ đạt được trạng thái nhất quán.
RPC là gì?
RPC là viết tắt của Remote Procedure Call (Gọi thủ tục từ xa), đối với các ngôn ngữ hướng đối tượng như Java, RPC cũng có thể hiểu là gọi phương thức từ xa. RPC khác với HTTP, vì RPC chỉ là cách gọi phương thức từ xa, và có thể được thực hiện thông qua giao thức HTTP hoặc trực tiếp dựa trên giao thức TCP. Trong Java, ta có thể sử dụng đối tượng proxy của một giao diện dịch vụ để thực thi phương thức, và tầng dưới sẽ gửi yêu cầu HTTP để gọi phương thức từ xa. Vì vậy, có thể hiểu RPC như một giao thức cao hơn HTTP.
Các mô hình nhất quán dữ liệu là gì?
Nhất quán mạnh: Khi thao tác cập nhật hoàn tất, bất kỳ tiến trình nào sau đó truy cập sẽ luôn trả về giá trị mới nhất đã cập nhật. Đây là mô hình thân thiện nhất với người dùng, đảm bảo rằng người dùng viết gì lần trước thì lần sau sẽ đọc được đúng như vậy. Theo lý thuyết CAP, mô hình này phải hy sinh tính sẵn sàng.
Nhất quán yếu: Hệ thống sau khi ghi dữ liệu thành công không cam kết sẽ có thể đọc ngay được giá trị mới cập nhật, và cũng không cam kết cụ thể về thời gian bao lâu thì có thể đọc được. Người dùng cần một khoảng thời gian để thao tác cập nhật hệ thống trở nên đồng bộ, gọi là “cửa sổ không nhất quán”.
Nhất quán cuối cùng: Là trường hợp đặc biệt của nhất quán yếu, nhấn mạnh rằng sau một khoảng thời gian đồng bộ, tất cả các bản sao dữ liệu cuối cùng sẽ đạt đến một trạng thái nhất quán. Bản chất của nhất quán cuối cùng là hệ thống đảm bảo dữ liệu cuối cùng sẽ nhất quán, nhưng không cần đảm bảo nhất quán mạnh theo thời gian thực. Thời gian để đạt đến nhất quán cuối cùng chính là thời gian cửa sổ không nhất quán, và khi không có lỗi xảy ra, thời gian này chủ yếu bị ảnh hưởng bởi độ trễ truyền thông, tải hệ thống và số lượng bản sao.
ID phân tán là gì? Các giải pháp nào có thể áp dụng?
Trong phát triển, chúng ta thường cần một ID duy nhất để nhận dạng dữ liệu. Nếu là kiến trúc đơn thể, có thể sử dụng khóa chính của cơ sở dữ liệu hoặc duy trì một số tự tăng trong bộ nhớ để làm ID. Tuy nhiên, trong hệ thống phân tán, có thể xảy ra xung đột ID, do đó có một số giải pháp sau:
- UUID: Giải pháp này có độ phức tạp thấp nhất, nhưng ảnh hưởng đến không gian lưu trữ và hiệu suất.
- MySQL: Sử dụng khóa chính tự tăng của cơ sở dữ liệu đơn lẻ làm bộ tạo ID phân tán. Độ phức tạp vừa phải, ID ngắn hơn UUID, nhưng bị giới hạn bởi hiệu suất của cơ sở dữ liệu đơn và không phải là giải pháp tối ưu khi có nhiều yêu cầu đồng thời.
- Redis, Zookeeper: Sử dụng lệnh tự tăng của Redis hoặc các nút thứ tự trong Zookeeper. So với cơ sở dữ liệu đơn lẻ (MySQL), hiệu suất được cải thiện và có thể sử dụng trong các trường hợp nhất định.
- Thuật toán Snowflake: Đây là giải pháp sử dụng thuật toán để tạo ID phân tán, trong đó mỗi máy sẽ tự tăng một số trong một mili giây cụ thể, đảm bảo ID duy nhất trong hệ thống phân tán. Giải pháp này đảm bảo ID tăng theo xu hướng. Các middleware mã nguồn mở như TinyID, Leaf đã hiện thực thuật toán này.
Các trường hợp sử dụng khóa phân tán là gì? Có những giải pháp nào?
Trong kiến trúc đơn thể, các luồng (thread) thuộc cùng một tiến trình, do đó khi gặp phải tranh chấp tài nguyên trong quá trình thực thi đồng thời, có thể sử dụng các kỹ thuật như ReentrantLock hoặc synchronized để khóa và kiểm soát tài nguyên chia sẻ.
Tuy nhiên, trong kiến trúc phân tán, các luồng có thể thuộc các tiến trình khác nhau, và khi gặp phải tranh chấp tài nguyên, không thể sử dụng ReentrantLock hay synchronized. Do đó, cần khóa phân tán, tức là một bộ tạo khóa phân tán mà các ứng dụng trong hệ thống phân tán có thể sử dụng để đồng bộ.
Hiện nay, có hai giải pháp chính để thực hiện khóa phân tán:
- Zookeeper: Sử dụng các nút tạm thời, nút theo thứ tự và cơ chế theo dõi (watch) của Zookeeper. Đặc điểm của khóa phân tán Zookeeper là tính nhất quán cao, do Zookeeper đảm bảo CP (Consistency và Partition Tolerance), nên khóa này đáng tin cậy và không gây ra tình trạng lộn xộn.
- Redis: Sử dụng lệnh
setnx, script Lua và cơ chế subscribe/publish của Redis. Đặc điểm của khóa phân tán Redis là tính sẵn sàng cao, do Redis đảm bảo AP (Availability và Partition Tolerance). Tuy nhiên, khi dữ liệu trong Redis không nhất quán, có thể xảy ra tình trạng nhiều client cùng giữ khóa.
Giao dịch phân tán là gì? Có những giải pháp nào?
Trong hệ thống phân tán, một quy trình nghiệp vụ có thể cần nhiều ứng dụng để thực hiện. Ví dụ, khi người dùng gửi yêu cầu đặt hàng, nó sẽ liên quan đến hệ thống đặt hàng tạo đơn và hệ thống kho hàng trừ kho. Đối với một đơn đặt hàng, việc tạo đơn và trừ kho phải thành công hoặc thất bại cùng lúc. Tuy nhiên, trong hệ thống phân tán, nếu không xử lý đúng cách, có thể xảy ra tình trạng tạo đơn thành công nhưng trừ kho thất bại. Để giải quyết vấn đề này, cần sử dụng giao dịch phân tán. Các giải pháp phổ biến bao gồm:
Bảng tin nhắn cục bộ: Khi tạo đơn, thêm thông báo trừ kho vào giao dịch cục bộ và cùng lúc lưu vào bảng tin nhắn cục bộ trong cơ sở dữ liệu. Sau đó, gọi hệ thống kho hàng. Nếu gọi thành công, trạng thái tin nhắn trong bảng sẽ được cập nhật thành công. Nếu gọi thất bại, một nhiệm vụ định kỳ sẽ lấy tin nhắn chưa thành công từ bảng và thử lại việc gọi hệ thống kho.
Hàng đợi tin nhắn: Hiện tại, RocketMQ hỗ trợ giao dịch tin nhắn, với nguyên tắc hoạt động như sau:
- Hệ thống đặt hàng trước tiên gửi một tin nhắn "half" (nửa chừng) đến Broker. Tin nhắn này không thể nhìn thấy đối với Consumer.
- Sau đó tạo đơn hàng và gửi lệnh commit hoặc rollback đến Broker tùy thuộc vào việc tạo đơn có thành công hay không.
- Hệ thống đặt hàng cũng có thể cung cấp giao diện gọi lại cho Broker. Nếu Broker phát hiện không nhận được lệnh nào trong một thời gian dài từ tin nhắn "half", nó sẽ chủ động gọi lại giao diện để kiểm tra xem đơn hàng đã được tạo thành công chưa.
- Nếu tin nhắn "half" được commit, hệ thống kho sẽ tiêu thụ tin nhắn. Nếu tiêu thụ thành công, tin nhắn sẽ bị xóa và giao dịch phân tán kết thúc thành công.
- Nếu tiêu thụ thất bại, hệ thống sẽ thử lại theo chiến lược tái thử. Nếu thất bại tiếp, tin nhắn sẽ được đưa vào hàng đợi chết để xử lý thêm.
Seata: Là một khung giao dịch phân tán mã nguồn mở của Alibaba, hỗ trợ nhiều chế độ như AT và TCC, và dựa trên lý thuyết cam kết hai giai đoạn để thực hiện.
Giao thức ZAB là gì?
Giao thức ZAB là giao thức phát sóng nguyên tử nhất quán được sử dụng bởi Zookeeper để đạt được tính nhất quán. Giao thức này mô tả cách Zookeeper thực hiện tính nhất quán, bao gồm ba giai đoạn:
Giai đoạn bầu lãnh đạo: Từ cụm Zookeeper, một nút sẽ được chọn làm Leader. Tất cả các yêu cầu ghi sẽ được xử lý bởi nút Leader.
Giai đoạn đồng bộ dữ liệu: Dữ liệu giữa các nút trong cụm phải nhất quán với Leader. Nếu không nhất quán, dữ liệu sẽ được đồng bộ hóa.
Giai đoạn phát sóng yêu cầu: Khi Leader nhận được yêu cầu ghi, nó sẽ sử dụng cơ chế cam kết hai giai đoạn để phát sóng yêu cầu ghi, đảm bảo rằng các yêu cầu ghi được thực hiện như một giao dịch trên các nút khác, để đạt được tính nhất quán của dữ liệu.
Mặc dù Zookeeper cố gắng đạt được tính nhất quán mạnh, nhưng thực tế, nó vẫn chỉ là tính nhất quán cuối cùng.
Tại sao Zookeeper có thể được sử dụng làm trung tâm đăng ký?
Zookeeper có thể sử dụng các nút tạm thời và cơ chế watch để thực hiện việc đăng ký và khám phá tự động cho trung tâm đăng ký. Ngoài ra, dữ liệu trong Zookeeper được lưu trữ trong bộ nhớ và Zookeeper sử dụng mô hình đa luồng và NIO ở tầng dưới, vì vậy hiệu suất của nó khá cao, thích hợp để làm trung tâm đăng ký. Tuy nhiên, nếu xét về độ khả dụng, Zookeeper có thể không phải là lựa chọn tốt nhất vì nó là hệ thống đảm bảo CP (tính nhất quán và phân vùng chịu lỗi), tập trung vào tính nhất quán. Khi dữ liệu trong cụm không nhất quán, hệ thống sẽ không khả dụng. Do đó, Redis, Eureka hoặc Nacos sẽ phù hợp hơn để làm trung tâm đăng ký.
Quy trình bầu chọn lãnh đạo trong Zookeeper là gì?
Đối với cụm Zookeeper, toàn bộ cụm cần chọn ra một node làm Leader. Quy trình tổng quát như sau:
- Ban đầu, mỗi node trong cụm đều ở trạng thái LOOKING (đang quan sát) và tự bỏ phiếu cho mình vì nghĩ rằng mình phù hợp nhất để làm Leader.
- Sau đó, các node sẽ tương tác với nhau để bỏ phiếu. Mỗi node sẽ nhận được phiếu bầu từ các node khác, và so sánh phiếu, đầu tiên so sánh zxid (Zookeeper Transaction ID), ai có zxid lớn hơn sẽ thắng. Nếu zxid bằng nhau thì so sánh myid (ID của mỗi node), ai có myid lớn hơn sẽ thắng.
- Nếu một node nhận được phiếu bầu từ node khác và sau khi so sánh thấy mình thua, node đó sẽ đổi phiếu, bầu cho node có zxid hoặc myid lớn hơn, và gửi phiếu mới cho các node khác.
- Nếu so sánh bằng nhau, node sẽ giữ phiếu vừa nhận vào hộp phiếu của mình.
- Nếu node thắng so sánh, nó sẽ bỏ qua phiếu bầu nhận được.
- Mỗi node sẽ tính toán số phiếu trong hộp phiếu của mình. Nếu hơn một nửa số node cùng bầu cho một node, thì node đó sẽ được chọn làm Leader.
- Tất cả các node trong cụm sẽ thực hiện cùng quy trình này. Cuối cùng, mỗi node sẽ đồng ý với kết quả và Leader của cụm sẽ được chọn ra.
Dữ liệu giữa các node trong cụm Zookeeper được đồng bộ hóa như thế nào?
- Trước tiên, cụm sẽ bầu chọn Leader, sau đó xác định các node là Follower và Observer.
- Leader sẽ tiến hành đồng bộ dữ liệu với các node khác, thông qua việc gửi snapshot (bản sao chụp) và Diff log (bản ghi sự khác biệt).
- Trong quá trình hoạt động, mọi yêu cầu ghi đều được gửi tới Leader, các node khác chỉ xử lý yêu cầu đọc.
- Khi Leader nhận được một yêu cầu ghi, nó sẽ sử dụng cơ chế hai giai đoạn để xử lý.
- Leader gửi bản ghi tương ứng với yêu cầu ghi tới các Follower và chờ các Follower ghi bản ghi thành công.
- Khi Follower nhận được bản ghi, nó sẽ lưu trữ bản ghi và gửi lại tín hiệu Ack cho Leader nếu thành công.
- Khi Leader nhận được hơn một nửa Ack, nó sẽ cập nhật dữ liệu bộ nhớ của mình và gửi lệnh commit cho các Follower.
- Các Follower sau khi nhận lệnh commit sẽ cập nhật dữ liệu bộ nhớ của mình.
- Đồng thời, Leader cũng gửi trực tiếp yêu cầu ghi tới các Observer, và Observer chỉ thực hiện cập nhật dữ liệu bộ nhớ mà không cần commit.
- Cuối cùng, Leader trả lại phản hồi thành công cho client.
- Cơ chế đồng bộ và cơ chế hai giai đoạn đảm bảo tính nhất quán dữ liệu giữa các node trong cụm.
Dubbo hỗ trợ những chiến lược cân bằng tải nào?
- Ngẫu nhiên: Lựa chọn ngẫu nhiên một dịch vụ từ các nhà cung cấp để xử lý yêu cầu. Khi số lượng gọi tăng lên, các yêu cầu sẽ được phân phối đều hơn, và có thể thiết lập xác suất ngẫu nhiên theo trọng số.
- Vòng lặp: Lựa chọn các nhà cung cấp dịch vụ lần lượt để xử lý yêu cầu, và hỗ trợ cân bằng theo trọng số, sử dụng thuật toán vòng lặp có trọng số mượt mà.
- Số lượng gọi hoạt động ít nhất: Thống kê số lượng yêu cầu mà nhà cung cấp đang xử lý, yêu cầu mới sẽ được gửi tới nhà cung cấp có số lượng hoạt động ít nhất.
- Băm nhất quán: Các yêu cầu với cùng tham số sẽ luôn được gửi tới cùng một nhà cung cấp dịch vụ.
Dubbo thực hiện xuất dịch vụ như thế nào?
- Dubbo sẽ phân tích annotation
@DubboServicehoặc@Serviceđể lấy các tham số dịch vụ mà lập trình viên đã định nghĩa, bao gồm tên dịch vụ, giao diện dịch vụ, thời gian chờ, giao thức dịch vụ, v.v., và tạo ra một ServiceBean. - Sau đó gọi phương thức
exportcủa ServiceBean để thực hiện việc xuất dịch vụ. - Dubbo sẽ đăng ký thông tin dịch vụ vào trung tâm đăng ký. Nếu có nhiều giao thức hoặc nhiều trung tâm đăng ký, dịch vụ sẽ được đăng ký lần lượt theo từng giao thức và từng trung tâm.
- Sau khi đăng ký dịch vụ vào trung tâm, Dubbo sẽ gắn các bộ lắng nghe để theo dõi sự thay đổi từ trung tâm cấu hình động.
- Cuối cùng, dựa trên giao thức dịch vụ, Dubbo sẽ khởi động các máy chủ Web hoặc các framework mạng tương ứng như Tomcat, Netty, v.v.
Dubbo thực hiện nhập dịch vụ như thế nào?
- Khi lập trình viên sử dụng annotation
@Referenceđể nhập dịch vụ, Dubbo sẽ phân tích cú pháp của annotation và thông tin dịch vụ để lấy tên và giao diện dịch vụ. - Dubbo sẽ truy vấn thông tin dịch vụ từ trung tâm đăng ký, lấy thông tin nhà cung cấp dịch vụ và lưu vào danh mục dịch vụ của phía Consumer.
- Dubbo cũng sẽ gắn các bộ lắng nghe để theo dõi sự thay đổi từ trung tâm cấu hình động.
- Cuối cùng, Dubbo sẽ tạo ra một đối tượng proxy cho giao diện dịch vụ dựa trên thông tin nhà cung cấp và đưa vào Spring container như một Bean.
Kiến trúc của Dubbo là gì?
Dubbo có thiết kế kiến trúc rất xuất sắc, được chia thành nhiều tầng và mỗi tầng đều có thể mở rộng. Các tầng gồm:
- Proxy (tầng dịch vụ proxy): Hỗ trợ các cơ chế proxy như JDK dynamic proxy, javassist, v.v.
- Registry (tầng trung tâm đăng ký): Hỗ trợ Zookeeper, Redis, v.v. làm trung tâm đăng ký.
- Protocol (tầng gọi từ xa): Hỗ trợ các giao thức gọi như Dubbo, Http, v.v.
- Transport (tầng truyền tải mạng): Hỗ trợ các framework truyền tải mạng như Netty, Mina, v.v.
- Serialize (tầng tuần tự hóa dữ liệu): Hỗ trợ các cơ chế tuần tự hóa như JSON, Hessian, v.v.
Giải thích các tầng:
- Tầng cấu hình: Đối với giao diện cấu hình, tập trung vào
ServiceConfigvàReferenceConfig, có thể trực tiếp khởi tạo hoặc thông qua Spring để phân tích cú pháp và tạo ra các lớp cấu hình. - Tầng dịch vụ proxy: Cung cấp dịch vụ proxy minh bạch cho các dịch vụ, tạo ra Stub ở phía client và Skeleton ở phía server, với
ServiceProxylà trung tâm vàProxyFactorylà giao diện mở rộng. - Tầng trung tâm đăng ký: Đóng gói việc đăng ký và phát hiện địa chỉ dịch vụ, tập trung vào URL dịch vụ, giao diện mở rộng là
RegistryFactory,Registry, vàRegistryService. - Tầng định tuyến: Đóng gói việc định tuyến và cân bằng tải cho nhiều nhà cung cấp dịch vụ và kết nối với trung tâm đăng ký, với
Invokerlà trung tâm. - Tầng giám sát: Theo dõi số lượng và thời gian của các cuộc gọi RPC, với
Statisticslà trung tâm. - Tầng gọi từ xa: Đóng gói các cuộc gọi RPC, với
Invocation,Resultlà trung tâm. - Tầng trao đổi thông tin: Đóng gói các yêu cầu/đáp ứng, chuyển từ đồng bộ sang bất đồng bộ, với
Request,Responselà trung tâm. - Tầng truyền tải mạng: Trừu tượng hóa Netty và Mina thành một giao diện thống nhất, với
Messagelà trung tâm. - Tầng tuần tự hóa dữ liệu: Các công cụ có thể tái sử dụng, với giao diện mở rộng là
Serialization,ObjectInput, vàObjectOutput.
Giải thích mối quan hệ
- Trong RPC, Protocol là tầng cốt lõi. Chỉ cần Protocol + Invoker + Exporter là có thể thực hiện cuộc gọi RPC không minh bạch. Invoker là điểm chặn chính của quá trình chính.
- Consumer và Provider trong sơ đồ là khái niệm trừu tượng giúp người xem dễ hiểu hơn về phân loại các lớp thuộc phía máy khách và máy chủ. Provider, Consumer, Registry, và Monitor được sử dụng để chia logic các node topo trong nhiều ngữ cảnh khác nhau, giữ khái niệm thống nhất.
- Cluster là khái niệm ngoại vi. Mục đích của Cluster là giả lập nhiều Invoker thành một Invoker để các tầng khác chỉ cần quan tâm đến tầng Invoker của Protocol. Thêm hoặc bớt Cluster sẽ không ảnh hưởng đến các tầng khác vì khi chỉ có một nhà cung cấp, Cluster không cần thiết.
- Tầng Proxy đóng gói proxy minh bạch cho tất cả giao diện, và ở các tầng khác đều tập trung vào Invoker. Khi lộ ra cho người dùng sử dụng, Proxy sẽ chuyển Invoker thành giao diện hoặc chuyển việc thực hiện giao diện thành Invoker. Loại bỏ tầng Proxy, RPC vẫn chạy được, chỉ là không minh bạch và không giống việc gọi dịch vụ cục bộ.
- Remoting là sự thực hiện của giao thức Dubbo. Nếu bạn chọn giao thức RMI, toàn bộ Remoting sẽ không được sử dụng. Remoting được chia thành tầng Transport (truyền tải) và tầng Exchange (trao đổi thông tin). Transport chỉ chịu trách nhiệm truyền tải thông điệp một chiều, trừu tượng hóa Mina, Netty, Grizzly, và có thể mở rộng truyền tải UDP. Exchange đóng gói ngữ nghĩa yêu cầu-đáp ứng trên tầng Transport.
- Registry và Monitor thực chất không phải là một tầng mà là một node độc lập. Chúng được vẽ thành tầng để cung cấp cái nhìn tổng quan.
Các thuật toán cân bằng tải:
- Round Robin (Cân bằng vòng): Yêu cầu được phân phối lần lượt theo thứ tự đến các máy chủ phía sau. Phương pháp này đối xử công bằng với từng máy chủ mà không quan tâm đến số lượng kết nối thực tế hay tải hệ thống hiện tại của các máy chủ.
- Random (Ngẫu nhiên): Sử dụng thuật toán ngẫu nhiên của hệ thống, chọn ngẫu nhiên một máy chủ trong danh sách để truy cập. Theo lý thuyết xác suất, khi số lượng yêu cầu từ phía máy khách tăng lên, kết quả thực tế sẽ tiến gần đến việc phân phối đều các yêu cầu cho tất cả các máy chủ, tương tự như phương pháp vòng lặp.
- Source IP Hash (Băm theo địa chỉ IP nguồn): Dựa trên địa chỉ IP của máy khách, tính toán một giá trị thông qua hàm băm, sau đó sử dụng giá trị này để chia cho kích thước danh sách máy chủ, kết quả sẽ cho ra số thứ tự của máy chủ mà máy khách sẽ truy cập. Khi danh sách máy chủ không thay đổi, cùng một địa chỉ IP sẽ luôn được ánh xạ đến cùng một máy chủ.
- Weighted Round Robin (Cân bằng vòng có trọng số): Các máy chủ phía sau có cấu hình và tải hệ thống khác nhau, do đó khả năng chịu tải cũng không giống nhau. Phương pháp này gán trọng số cao hơn cho các máy chủ có cấu hình mạnh và tải nhẹ, để chúng xử lý nhiều yêu cầu hơn; trong khi các máy chủ có cấu hình yếu và tải nặng được gán trọng số thấp hơn để giảm bớt tải. Phương pháp này giúp phân phối yêu cầu một cách hợp lý theo trọng số.
- Weighted Random (Ngẫu nhiên có trọng số): Tương tự phương pháp vòng lặp có trọng số, nhưng thay vì phân phối yêu cầu theo thứ tự, các yêu cầu được phân phối ngẫu nhiên dựa trên trọng số của máy chủ.
- Least Connections (Ít kết nối nhất): Đây là một thuật toán linh hoạt và thông minh hơn. Nó lựa chọn máy chủ dựa trên số lượng kết nối hiện tại của các máy chủ, chọn máy chủ có số lượng kết nối ít nhất để xử lý yêu cầu. Phương pháp này giúp tăng hiệu suất sử dụng của máy chủ và phân phối tải hợp lý giữa các máy chủ.
Giải pháp chia sẻ Session trong kiến trúc phân tán
Sử dụng dịch vụ không trạng thái, loại bỏ Session.
Lưu vào cookie (có nguy cơ về bảo mật).
Đồng bộ Session giữa các máy chủ. Điều này đảm bảo mỗi máy chủ đều có thông tin Session, nhưng khi số lượng máy chủ lớn, việc đồng bộ sẽ có độ trễ hoặc thậm chí thất bại.
Sử dụng chính sách ràng buộc IP.
- Sử dụng Nginx (hoặc các phần mềm và phần cứng cân bằng tải phức tạp khác) với chính sách ràng buộc IP. Mỗi IP chỉ được truy cập cùng một máy chủ. Tuy nhiên, điều này làm mất ý nghĩa của cân bằng tải và khi một máy chủ bị hỏng, một số lượng lớn người dùng sẽ bị ảnh hưởng, tạo ra rủi ro lớn.
Sử dụng Redis để lưu trữ Session.
Lưu Session vào Redis giúp tăng tính phức tạp của kiến trúc và cần thêm một lần truy cập Redis, nhưng nó mang lại nhiều lợi ích:
- Thực hiện chia sẻ Session.
- Có thể mở rộng ngang (thêm máy chủ Redis).
- Server khởi động lại không làm mất Session (cần chú ý cơ chế làm mới/hết hạn Session trong Redis).
- Không chỉ chia sẻ Session giữa các server, mà còn có thể chia sẻ giữa các nền tảng (ví dụ: giữa trang web và ứng dụng di động).
Cách thực hiện tính idempotency cho API
- ID duy nhất: Mỗi lần thao tác, tạo một ID duy nhất dựa trên thao tác và nội dung. Trước khi thực hiện, kiểm tra xem ID này đã tồn tại chưa. Nếu chưa tồn tại, thực hiện thao tác và lưu vào cơ sở dữ liệu hoặc Redis.
- Token từ server: Máy chủ cung cấp một API để gửi token. Trước khi gọi API xử lý nghiệp vụ, lấy token trước rồi gửi cùng với yêu cầu. Máy chủ sẽ kiểm tra xem token có tồn tại trong Redis hay không. Nếu tồn tại, nghĩa là đây là lần đầu tiên thực hiện yêu cầu, tiếp tục xử lý và xóa token trong Redis sau khi hoàn thành.
- Bảng loại bỏ trùng lặp: Lưu trữ các trường có định danh duy nhất vào một bảng loại bỏ trùng lặp. Nếu bảng này đã có dữ liệu, tức là thao tác đã được xử lý trước đó.
- Kiểm soát phiên bản: Thêm số phiên bản. Chỉ khi số phiên bản hợp lệ thì mới được phép cập nhật dữ liệu.
- Kiểm soát trạng thái: Ví dụ, đơn hàng có các trạng thái như "Đã thanh toán," "Chưa thanh toán," "Đang thanh toán," và "Thanh toán thất bại." Chỉ khi ở trạng thái "Chưa thanh toán" mới được phép chuyển sang "Đang thanh toán" hoặc các trạng thái khác.
Tổng quan về dịch vụ đặt tên, quản lý cấu hình và quản lý cụm trong Zookeeper
Dịch vụ đặt tên: Dịch vụ này cung cấp cách lấy tài nguyên hoặc địa chỉ dịch vụ thông qua một tên cụ thể. Zookeeper có thể tạo ra một đường dẫn duy nhất toàn cầu, đường dẫn này có thể được coi là một tên. Các thực thể được đặt tên có thể là các máy trong cụm, địa chỉ dịch vụ, hoặc đối tượng từ xa. Một số framework phân tán như RPC, RMI sử dụng dịch vụ đặt tên để giúp ứng dụng khách lấy được tài nguyên hoặc thông tin về địa chỉ dịch vụ theo tên.
Quản lý cấu hình: Trong phát triển dự án thực tế, các tệp cấu hình như .properties hoặc .xml thường chứa các thông tin quan trọng như cấu hình kết nối cơ sở dữ liệu, địa chỉ FPS, cổng, v.v. Khi triển khai chương trình theo cách phân tán, nếu lưu các thông tin cấu hình này vào Zookeeper (trong các znode), khi cần thay đổi cấu hình, có thể cập nhật znode. Nhờ cơ chế watcher, các thay đổi sẽ được thông báo đến tất cả các máy khách để cập nhật cấu hình.
Quản lý cụm: Quản lý cụm bao gồm giám sát và kiểm soát cụm, tức là giám sát trạng thái của các máy trong cụm, loại bỏ hoặc thêm máy mới. Zookeeper giúp quản lý cụm một cách hiệu quả bằng cách giám sát sự thay đổi của các znode. Khi phát hiện một máy bị ngắt kết nối, znode tạm thời tương ứng sẽ bị xóa và thông báo được gửi đến tất cả các máy khác. Thêm máy mới vào cụm cũng diễn ra tương tự.
Cơ chế Watch trong Zookeeper
Máy khách có thể thiết lập watch trên các znode để theo dõi sự thay đổi trong thời gian thực.
Watch là một trình kích hoạt một lần. Khi dữ liệu mà watch được thiết lập thay đổi, Zookeeper sẽ gửi thông báo về thay đổi này cho máy khách đã thiết lập watch.
- Việc tạo, sửa đổi, hoặc xóa nút cha sẽ kích hoạt sự kiện Watcher.
- Việc tạo hoặc xóa các nút con cũng sẽ kích hoạt sự kiện Watcher.
Tính một lần: Một khi watch bị kích hoạt, nó sẽ bị xóa. Để theo dõi tiếp tục, phải đăng ký lại watch. Cơ chế này giúp giảm tải hệ thống, vì mỗi thay đổi chỉ cần thông báo một lần cho tất cả các máy khách. Từ phiên bản 3.6.0, Zookeeper hỗ trợ watch đệ quy và có thể kích hoạt nhiều lần.
Tính nhẹ: Watch chỉ thông báo rằng có sự kiện xảy ra mà không gửi kèm thông tin chi tiết, giúp giảm tải cho máy chủ và tiết kiệm băng thông.
Cơ chế Watch gồm ba thành phần chính: luồng của máy khách, WatchManager trên máy khách, và máy chủ Zookeeper.
- Máy khách đăng ký một Watcher với máy chủ Zookeeper.
- Thông tin về Watcher được lưu vào WatchManager của máy khách.
- Khi một znode trong Zookeeper thay đổi, máy chủ sẽ thông báo cho máy khách, và máy khách sẽ gọi phương thức callback trong Watcher tương ứng để xử lý sự kiện.
Sự khác biệt giữa Zookeeper và Eureka
Zookeeper (ZK): Zookeeper được thiết kế dựa trên nguyên tắc CP (Consistency & Partition tolerance - Tính nhất quán và khả năng chịu phân vùng). Mục tiêu của ZK là trở thành hệ thống điều phối phân tán, dùng để quản lý tài nguyên thống nhất. Khi một nút bị crash, cần phải thực hiện bầu chọn leader, trong khoảng thời gian này, dịch vụ ZK sẽ không thể sử dụng.
Eureka: Eureka được thiết kế dựa trên nguyên tắc AP (Availability & Partition tolerance - Tính khả dụng và khả năng chịu phân vùng). Mục tiêu của Eureka là trở thành hệ thống đăng ký và phát hiện dịch vụ, chuyên dùng trong kiến trúc microservices. Các nút trong Eureka đều bình đẳng, việc một vài nút bị hỏng sẽ không ảnh hưởng đến các nút khác. Các nút còn lại vẫn có thể cung cấp dịch vụ đăng ký và truy vấn. Nếu một nút Eureka bị ngắt kết nối, máy khách sẽ tự động chuyển sang nút khác. Miễn là có ít nhất một nút Eureka còn hoạt động, dịch vụ đăng ký vẫn có thể sử dụng, mặc dù thông tin có thể không phải là mới nhất (không đảm bảo tính nhất quán mạnh).
Ngoài ra, khi máy chủ Eureka phát hiện hơn 85% dịch vụ không có tín hiệu heartbeat, nó sẽ cho rằng mạng của mình gặp vấn đề và sẽ không xóa các dịch vụ này khỏi danh sách. Đồng thời, máy khách Eureka cũng sẽ lưu trữ thông tin dịch vụ trong bộ đệm. Điều này giúp Eureka trở thành lựa chọn tốt cho việc phát hiện và đăng ký dịch vụ.
Cách giải quyết vấn đề khóa chính duy nhất sau khi tách bảng
- UUID: Đơn giản, hiệu suất tốt, không có thứ tự, không chứa thông tin nghiệp vụ, có rủi ro rò rỉ địa chỉ MAC.
- Khóa chính từ cơ sở dữ liệu: Dễ thực hiện, tăng dần, có tính đọc hiểu theo nghiệp vụ, phụ thuộc vào cơ sở dữ liệu, có nguy cơ gây nghẽn hiệu suất, có thể làm lộ thông tin nghiệp vụ.
- Redis, MongoDB, Zookeeper: Tăng độ phức tạp và đòi hỏi sự ổn định cao hơn cho hệ thống.
- Thuật toán Snowflake:
Nguyên lý của thuật toán Snowflake
Thuật toán Snowflake tạo ID với cấu trúc sau:
- Bit đầu tiên là bit dấu, cố định là 0.
- 41 bit tiếp theo là thời gian, tính từ mốc thời gian cố định.
- 10 bit là workId (ID của máy).
- 12 bit cuối cùng là số thứ tự tăng dần trong mỗi mili giây.
Ưu điểm: Mỗi mili giây có thể tạo ra nhiều ID, dễ dàng điều chỉnh theo yêu cầu của hệ thống. Hiệu suất tốt và ID tăng dần theo thời gian, có thể tùy chỉnh số lượng bit để linh hoạt theo yêu cầu bố trí cơ sở dữ liệu.
Nhược điểm: Phụ thuộc nhiều vào đồng hồ của máy. Nếu đồng hồ bị lùi thời gian, có thể tạo ra ID trùng lặp, dẫn đến lỗi. Do đó, trong trường hợp đồng hồ lùi, thuật toán sẽ ném ngoại lệ và ngừng tạo ID, có thể làm dịch vụ không thể hoạt động.
Cách giải quyết vấn đề truy vấn không sử dụng khóa phân vùng
- Mapping (Ánh xạ): Ánh xạ trường truy vấn với khóa phân vùng, tạo bảng riêng để lưu trữ (sử dụng chỉ mục bao phủ) hoặc lưu trữ trong bộ đệm.
- Phương pháp Gene (Phân chia theo bit): Sử dụng các bit cuối của khóa phân vùng được lấy từ trường truy vấn sau khi hash, phù hợp khi trường truy vấn không phải khóa phân vùng chỉ có một giá trị duy nhất.
- Redundancy (Dư thừa): Lưu trữ dư thừa trường truy vấn.
Các thành phần phổ biến của Spring Cloud và chức năng
- Eureka: Trung tâm đăng ký dịch vụ.
- Nacos: Trung tâm đăng ký và cấu hình.
- Consul: Trung tâm đăng ký và cấu hình.
- Spring Cloud Config: Trung tâm quản lý cấu hình.
- Feign/OpenFeign: RPC Calling.
- Kong: Gateway.
- Zuul: Gateway.
- Spring Cloud Gateway: Gateway.
- Ribbon: Cân bằng tải.
- Spring Cloud Sleuth: Theo dõi liên kết.
- Zipkin: Theo dõi liên kết.
- Seata: Giao dịch phân tán.
- Dubbo: RPC Calling.
- Sentinel: Ngắt mạch dịch vụ.
- Hystrix: Ngắt mạch dịch vụ.
Cách tránh xuyên thủng bộ nhớ đệm, phá vỡ bộ nhớ đệm, và sụp đổ bộ nhớ đệm
Sụp đổ bộ nhớ đệm là khi một lượng lớn bộ nhớ đệm bị hết hạn cùng một lúc, khiến tất cả các yêu cầu rơi vào cơ sở dữ liệu, tạo ra lượng lớn truy vấn đến cơ sở dữ liệu trong thời gian ngắn, dẫn đến sụp đổ.
Giải pháp:
- Đặt thời gian hết hạn bộ nhớ đệm ngẫu nhiên để tránh việc hết hạn cùng lúc một lượng lớn dữ liệu.
- Thêm dấu hiệu bộ nhớ đệm cho mỗi dữ liệu để kiểm tra xem bộ nhớ đệm có hết hạn hay không, nếu dấu hiệu hết hạn, thì cập nhật bộ nhớ đệm.
- Khóa trước khi làm nóng bộ nhớ đệm.
Xuyên thủng bộ nhớ đệm là khi cả bộ nhớ đệm và cơ sở dữ liệu đều không có dữ liệu, dẫn đến tất cả các yêu cầu đều đi thẳng vào cơ sở dữ liệu, gây quá tải cho cơ sở dữ liệu trong thời gian ngắn.
Giải pháp:
- Thêm xác thực ở tầng API, như xác thực người dùng hoặc kiểm tra cơ bản với ID. Nếu ID <= 0, thì chặn yêu cầu.
- Nếu không tìm thấy dữ liệu trong bộ nhớ đệm và cơ sở dữ liệu, có thể ghi key-value với giá trị key-null. Thời gian hiệu lực của bộ nhớ đệm có thể ngắn, khoảng 30 giây, để tránh việc bị tấn công lặp lại với cùng một ID.
- Sử dụng Bloom Filter để hash tất cả các dữ liệu có thể tồn tại vào một bitmap lớn. Dữ liệu không tồn tại sẽ bị Bloom Filter chặn, tránh áp lực lên hệ thống lưu trữ cơ sở.
Phá vỡ bộ nhớ đệm xảy ra khi dữ liệu không còn trong bộ nhớ đệm nhưng vẫn có trong cơ sở dữ liệu. Nếu số lượng người dùng đồng thời lớn, họ sẽ cùng truy cập vào cơ sở dữ liệu, gây áp lực lên cơ sở dữ liệu. Điều này khác với sụp đổ bộ nhớ đệm ở chỗ phá vỡ xảy ra khi chỉ một dữ liệu cụ thể bị truy vấn đồng thời, trong khi sụp đổ là khi nhiều dữ liệu khác nhau bị hết hạn cùng lúc.
Giải pháp:
- Đặt dữ liệu nóng không bao giờ hết hạn hoặc sử dụng khóa trước khi truy xuất.
Các giải pháp bộ nhớ đệm thường dùng trong hệ thống phân tán
- Bộ nhớ đệm phía máy khách: Bộ nhớ đệm trang và trình duyệt, bộ nhớ đệm ứng dụng, bộ nhớ đệm H5, localStorage và sessionStorage.
- CDN: Bộ nhớ đệm nội dung: dữ liệu; Phân phối nội dung: cân bằng tải.
- Bộ nhớ đệm Nginx: cho tài nguyên tĩnh.
- Bộ nhớ đệm phía máy chủ: Bộ nhớ đệm cục bộ và bộ nhớ đệm ngoài.
- Bộ nhớ đệm cơ sở dữ liệu: Bộ nhớ đệm tầng bền vững (mybatis, hibernate nhiều tầng bộ nhớ đệm), bộ nhớ đệm truy vấn MySQL.
- Bộ nhớ đệm hệ điều hành: PageCache, BufferCache.
Các chiến lược hết hạn bộ nhớ đệm
- Hết hạn định thời: Mỗi key có thời gian hết hạn sẽ tạo ra một bộ hẹn giờ, và khi đến thời gian hết hạn, nó sẽ được xóa ngay lập tức. Chiến lược này giải phóng bộ nhớ tốt, nhưng tiêu tốn nhiều CPU để xử lý các key hết hạn, làm giảm thời gian phản hồi và lưu lượng của bộ nhớ đệm.
- Hết hạn lười biếng: Chỉ khi truy cập một key mới kiểm tra nó có hết hạn hay không. Nếu hết hạn, sẽ xóa. Chiến lược này tiết kiệm CPU, nhưng sẽ giữ lại nhiều dữ liệu đã hết hạn trong bộ nhớ, gây tốn nhiều bộ nhớ.
- Hết hạn định kỳ: Mỗi khoảng thời gian nhất định sẽ quét một số lượng key nhất định và xóa các key đã hết hạn. Chiến lược này cân bằng giữa hết hạn định thời và hết hạn lười biếng.
- Chiến lược phân vùng: Tối ưu hóa việc hết hạn định kỳ bằng cách nhóm các key có thời gian hết hạn gần nhau và quét theo phân vùng thời gian.
Các thuật toán loại bỏ bộ nhớ đệm phổ biến
- FIFO (First In First Out - Vào trước ra trước): Dữ liệu được lưu trữ lâu nhất sẽ bị loại bỏ trước.
- LRU (Least Recently Used - Ít được sử dụng gần đây): Dữ liệu ít được sử dụng nhất sẽ bị loại bỏ.
- LFU (Least Frequently Used - Ít được sử dụng nhất): Dữ liệu ít được truy cập nhất trong khoảng thời gian nhất định sẽ bị loại bỏ.
Nguyên lý và ưu, nhược điểm của Bloom Filter
- Bitmap:
int[10]có 320 bit (10 * 32 bit). Khi thêm dữ liệu, nó sẽ hash dữ liệu và ánh xạ đến các bit trong bitmap, các bit đó sẽ chuyển thành 1. Hash function có thể định nghĩa nhiều hàm khác nhau để giảm xung đột. - Truy vấn: Nếu bất kỳ bit nào trong các bit được hash là 0, dữ liệu không tồn tại; nếu tất cả các bit đều là 1, dữ liệu có thể tồn tại.
Ưu điểm:
- Tiết kiệm bộ nhớ.
- Thời gian thêm và truy vấn dữ liệu là O(K) với K là số lượng hash function, không phụ thuộc vào kích thước dữ liệu.
- Không cần lưu trữ chính dữ liệu, giúp bảo mật.
- Bloom Filter có thể thực hiện các phép giao, hợp và hiệu.
Nhược điểm:
- Có tỷ lệ sai sót (False Positive), không thể xác định chính xác dữ liệu.
- Thông thường không thể xóa dữ liệu khỏi Bloom Filter.
Thuật toán định địa chỉ bộ nhớ đệm phân tán
- Thuật toán hash: Dựa trên kết quả của hàm băm (hash) được tính từ khóa (key), sau đó lấy phần dư của số lượng phân mảnh để xác định phân mảnh. Phù hợp với các kịch bản có số lượng phân mảnh cố định. Khi mở rộng hoặc giảm số lượng phân mảnh, tất cả dữ liệu cần được tính toán lại và lưu trữ vào phân mảnh mới.
- Hash nhất quán: Tổ chức toàn bộ dải giá trị hash thành một vòng tròn kín, tính giá trị hash của mỗi máy chủ và ánh xạ vào vòng tròn. Sử dụng cùng thuật toán băm để tính giá trị hash của dữ liệu, ánh xạ nó vào vòng tròn và tìm kiếm theo chiều kim đồng hồ, máy chủ đầu tiên tìm thấy là nơi lưu trữ dữ liệu. Khi thêm hoặc xóa nút, chỉ các giá trị nằm giữa nút đó và nút gần nhất theo chiều ngược kim đồng hồ mới bị ảnh hưởng. Có thể gặp vấn đề phân bố không đều trên vòng hash, điều này có thể giải quyết bằng cách sử dụng các nút ảo.
- Hash slot: Tách biệt dữ liệu và máy chủ. Dữ liệu được ánh xạ vào các slot, các slot được ánh xạ vào máy chủ. Khi thêm hoặc xóa nút, chỉ cần di chuyển slot là đủ.
Sự khác biệt giữa Spring Cloud và Dubbo?
Spring Cloud là một khung công tác microservices, cung cấp nhiều thành phần chức năng trong lĩnh vực microservice. Dubbo ban đầu là một khung RPC (Remote Procedure Call), trọng tâm là giải quyết vấn đề gọi dịch vụ. Spring Cloud là một khung toàn diện, trong khi Dubbo tập trung hơn vào việc gọi dịch vụ, vì vậy các tính năng của Dubbo không đa dạng như Spring Cloud. Tuy nhiên, hiệu suất gọi dịch vụ của Dubbo cao hơn Spring Cloud. Spring Cloud và Dubbo không đối lập nhau mà có thể kết hợp để sử dụng cùng nhau.
Tuyết lở dịch vụ là gì? Giới hạn lưu lượng dịch vụ là gì?
- Khi dịch vụ A gọi dịch vụ B, dịch vụ B gọi dịch vụ C, lúc này có một lượng lớn yêu cầu đột ngột đến dịch vụ A. Giả sử dịch vụ A có thể chịu được những yêu cầu này, nhưng nếu dịch vụ C không thể chịu nổi, dẫn đến yêu cầu gửi tới dịch vụ C bị dồn ứ, từ đó yêu cầu gửi tới dịch vụ B cũng bị dồn ứ, khiến dịch vụ A không khả dụng. Đây chính là hiện tượng tuyết lở dịch vụ. Giải pháp cho vấn đề này là hạ cấp dịch vụ và ngắt mạch dịch vụ.
- Giới hạn lưu lượng dịch vụ là việc trong các tình huống có nhiều yêu cầu đồng thời, để bảo vệ hệ thống, có thể giới hạn số lượng yêu cầu truy cập vào dịch vụ, từ đó ngăn ngừa hệ thống bị quá tải bởi số lượng yêu cầu lớn. Trong các sự kiện bán hàng "flash sale", giới hạn lưu lượng là vô cùng quan trọng.
Ngắt mạch dịch vụ là gì? Hạ cấp dịch vụ là gì? Sự khác biệt là gì?
- Ngắt mạch dịch vụ là khi dịch vụ A gọi một dịch vụ B mà dịch vụ B không khả dụng. Để bảo vệ chính mình, dịch vụ A ngừng gọi dịch vụ B và trả về kết quả trực tiếp, giảm áp lực cho cả hai dịch vụ cho đến khi B phục hồi.
- Hạ cấp dịch vụ là khi hệ thống quá tải, một số dịch vụ sẽ bị tắt hoặc giới hạn để giảm tải cho hệ thống.
Điểm chung:
- Cả hai đều nhằm ngăn ngừa hệ thống bị sập.
- Cả hai đều khiến người dùng cảm nhận một số tính năng tạm thời không khả dụng.
Điểm khác biệt:
- Ngắt dịch vụ được kích hoạt khi dịch vụ phía dưới gặp sự cố.
- Hạ cấp dịch vụ được thực hiện để giảm tải cho hệ thống.
Mối quan hệ và sự khác biệt giữa SOA, phân tán và microservices là gì?
- Kiến trúc phân tán là việc tách các phần của kiến trúc đơn thể ra và triển khai trên các máy hoặc tiến trình khác nhau. SOA và microservices về cơ bản đều là kiến trúc phân tán.
- SOA là một kiến trúc hướng dịch vụ, trong đó tất cả các dịch vụ của hệ thống được đăng ký trên một bus chung, khi có yêu cầu gọi dịch vụ, hệ thống sẽ tìm kiếm thông tin dịch vụ trên bus và sau đó thực hiện gọi dịch vụ.
- Microservices là một kiến trúc hướng dịch vụ triệt để hơn, tách các chức năng của hệ thống thành các ứng dụng nhỏ, thường giữ một ứng dụng tương ứng với một dịch vụ trong kiến trúc.
Làm thế nào để tách microservices?
Khi tách microservices, để đảm bảo tính ổn định của chúng, cần tuân theo một số nguyên tắc cơ bản:
- Cố gắng không để microservices có sự giao thoa về nghiệp vụ.
- Các microservices chỉ có thể gọi dịch vụ qua API, không được truy cập trực tiếp vào dữ liệu của nhau mà không thông qua api.
- Tạo sự kết hợp nội bộ chặt chẽ (high cohesion) và mức độ phụ thuộc thấp (low coupling).
Làm thế nào để thiết kế microservices có độ kết hợp nội bộ chặt chẽ và mức độ phụ thuộc thấp?
Thiết kế có độ kết hợp nội bộ chặt chẽ và mức độ phụ thuộc thấp là một phương pháp từ trên xuống để hướng dẫn thiết kế microservices. Có hai cách chính để thực hiện điều này: gọi api đồng bộ và sự kiện điều khiển không đồng bộ.
Bạn đã từng nghe về thiết kế DDD (Domain-Driven Design)?
DDD là gì: Được Eric Evans giới thiệu vào năm 2004, DDD là một cách tiếp cận để giải quyết sự phức tạp trong phần mềm. Domain-Driven Design – Tackling Complexity in the Heart of Software.
Monolith: Không phù hợp cho việc tách microservices. Kiến trúc monolith được tách ra vẫn có thể là các dịch vụ lẫn lộn. Khi nghiệp vụ dịch vụ trở nên phức tạp, monolith này có thể mở rộng thành một monolith lớn hơn.
DDD chỉ là một phương pháp luận, không có một khung công nghệ cố định. DDD yêu cầu rằng domain (miền) không phụ thuộc vào công nghệ, lưu trữ hay giao tiếp.
Trung tâm (Middle Platform) là gì?
Trung tâm (middle platform) là việc tách ra các chức năng có thể tái sử dụng từ các tuyến nghiệp vụ khác nhau, bỏ đi các tính năng cá nhân, trích xuất các điểm chung, và tạo ra các thành phần có thể tái sử dụng.
Về cơ bản, trung tâm có thể chia thành ba loại: trung tâm nghiệp vụ, trung tâm dữ liệu và trung tâm kỹ thuật. Vấn đề big data bị thao túng – trung tâm dữ liệu.
Sự kết hợp giữa trung tâm và DDD: DDD sẽ tách hệ thống thành các domain qua giới hạn ngữ cảnh (bounded context), và giới hạn này tự nhiên trở thành rào cản logic giữa các trung tâm.
DDD cung cấp hướng dẫn tốt cho việc xây dựng trung tâm trong cả kỹ thuật và quản lý tài nguyên.
DDD chia làm thiết kế chiến lược và thiết kế chiến thuật. Thiết kế chiến lược ở tầng cao giúp hướng dẫn phân chia trung tâm, trong khi thiết kế chiến thuật ở tầng thấp giúp xây dựng microservices hiệu quả.
Dự án của bạn đảm bảo phát triển agile cho microservices như thế nào?
- Tích hợp phát triển và vận hành.
- Phát triển agile: Mục tiêu là để nâng cao hiệu suất delivery của team, nhanh chóng lặp lại và thử nghiệm nhanh.
- Mỗi tháng phát hành phiên bản mới một cách cố định, lưu trữ dưới dạng nhánh trong kho mã. Nhập công việc nhanh chóng. Bảng nhiệm vụ, cuộc họp đứng. Nhân sự trong đội linh hoạt chuyển đổi, đồng thời hình thành các đại diện chuyên gia.
- Môi trường test - Môi trường product - Môi trường dev và kiểm thử SIT - Môi trường kiểm thử tích hợp - Môi trường kiểm thử tải STR - Môi trường pre-product - Môi trường product PRD.
- Cuộc họp sáng, cuộc họp tuần, cuộc họp tách yêu cầu.
Làm thế nào để chọn lựa hàng đợi tin nhắn?
- Kafka:
- Ưu điểm: Khả năng thông lượng rất lớn, hiệu suất rất tốt, cụm có tính khả dụng cao.
- Nhược điểm: Có thể mất dữ liệu, chức năng khá đơn giản.
- Tình huống sử dụng: Phân tích nhật ký, thu thập dữ liệu lớn.
- RabbitMQ:
- Ưu điểm: Độ tin cậy tin nhắn cao, chức năng toàn diện.
- Nhược điểm: Khả năng thông lượng khá thấp, tích lũy tin nhắn có thể ảnh hưởng nghiêm trọng đến hiệu suất. Ngôn ngữ Erlang khó tùy chỉnh.
- Tình huống sử dụng: Tình huống quy mô nhỏ.
- RocketMQ:
- Ưu điểm: Khả năng thông lượng cao, hiệu suất cao, có tính khả dụng cao, chức năng rất toàn diện.
- Nhược điểm: Phiên bản mã nguồn mở không có chức năng bằng phiên bản thương mại trên đám mây. Tài liệu chính thức và hệ sinh thái xung quanh chưa đủ trưởng thành. Máy khách chỉ hỗ trợ Java.
- Tình huống sử dụng: Gần như trong mọi tình huống.
Tin nhắn giao dịch của RocketMQ được thực hiện như thế nào?
- Hệ thống đặt hàng của Producer trước tiên gửi một tin nhắn "half" đến Broker, tin nhắn "half" là không thể thấy được đối với Consumer.
- Sau đó tạo đơn hàng, dựa vào việc đơn hàng được tạo thành công hay không, gửi yêu cầu commit hoặc rollback đến Broker.
- Hệ thống đặt hàng của Producer cũng có thể cung cấp giao diện gọi lại cho Broker, khi Broker phát hiện tin nhắn "half" không nhận được bất kỳ lệnh thao tác nào trong một khoảng thời gian, nó sẽ chủ động gọi giao diện này để kiểm tra xem đơn hàng đã được tạo thành công hay chưa.
- Một khi tin nhắn "half" được commit, hệ thống tồn kho của Consumer sẽ đến tiêu thụ, nếu tiêu thụ thành công, tin nhắn sẽ bị xóa, giao dịch phân tán sẽ kết thúc thành công.
- Nếu tiêu thụ thất bại, sẽ thử lại theo chính sách thử lại, nếu cuối cùng vẫn thất bại sẽ vào hàng đợi chết, chờ xử lý thêm.
Tại sao RocketMQ không sử dụng Zookeeper làm trung tâm đăng ký?
Theo lý thuyết CAP, một lúc chỉ có thể thỏa mãn tối đa hai yếu tố, trong khi Zookeeper thỏa mãn CP, có nghĩa là Zookeeper không thể đảm bảo tính khả dụng của dịch vụ. Khi Zookeeper thực hiện bầu cử, thời gian bầu cử quá dài, trong thời gian đó, toàn bộ cụm đều không khả dụng, điều này là không thể chấp nhận đối với một trung tâm đăng ký, bởi vì việc phát hiện dịch vụ phải được thiết kế cho tính khả dụng.
Dựa trên cân nhắc về hiệu suất, việc triển khai NameServer rất nhẹ và có thể mở rộng theo chiều ngang bằng cách thêm máy móc, tăng cường khả năng chịu tải của cụm, trong khi việc ghi của Zookeeper là không thể mở rộng. Để giải quyết vấn đề này, Zookeeper phải phân chia lĩnh vực, chia thành nhiều cụm Zookeeper, nhưng điều này đầu tiên là quá phức tạp để vận hành, và thứ hai, vẫn vi phạm thiết kế A trong CAP, dẫn đến việc các dịch vụ không thể kết nối với nhau.
Vấn đề phát sinh từ cơ chế lưu trữ lâu dài, giao thức ZAB của ZooKeeper sẽ giữ một nhật ký giao dịch cho mỗi yêu cầu ghi ở mỗi nút ZooKeeper, đồng thời thường xuyên sao lưu dữ liệu bộ nhớ (Snapshot) vào đĩa để đảm bảo tính nhất quán và tính bền vững của dữ liệu. Tuy nhiên, đối với một tình huống phát hiện dịch vụ đơn giản, thực sự không cần thiết phải phức tạp như vậy. Phương án triển khai này quá nặng nề, và dữ liệu lưu trữ nên được tùy chỉnh cao.
Việc gửi tin nhắn nên phụ thuộc yếu vào trung tâm đăng ký, và triết lý thiết kế của RocketMQ chính là dựa trên điều này. Khi Producer gửi tin nhắn lần đầu tiên, nó sẽ lấy địa chỉ Broker từ NameServer và lưu vào bộ nhớ cache cục bộ. Nếu cụm NameServer không khả dụng, trong thời gian ngắn, sẽ không ảnh hưởng lớn đến Producer và Consumer.
Dưới đây là bản dịch sang tiếng Việt:
Nguyên lý thực hiện của RocketMQ?
RocketMQ bao gồm một cụm trung tâm đăng ký NameServer, cụm Producer, cụm Consumer và một số Broker (RocketMQ Process). Nguyên lý kiến trúc của nó như sau:
Broker khi khởi động sẽ đăng ký với tất cả các NameServer và giữ kết nối dài hạn, mỗi 30 giây sẽ gửi một tín hiệu nhịp.
Khi Producer gửi tin nhắn, họ sẽ lấy địa chỉ máy chủ Broker từ NameServer và chọn một máy chủ để gửi tin nhắn dựa trên thuật toán cân bằng tải.
Consumer khi tiêu thụ tin nhắn cũng lấy địa chỉ Broker từ NameServer, sau đó chủ động kéo tin nhắn để tiêu thụ.
Tại sao RocketMQ lại nhanh?
Bởi vì nó sử dụng lưu trữ tuần tự, Page Cache và ghi đĩa bất đồng bộ. Khi ghi vào commitlog, chúng tôi thực hiện việc ghi theo thứ tự, điều này giúp nâng cao hiệu suất so với ghi ngẫu nhiên. Khi ghi vào commitlog, dữ liệu không được ghi trực tiếp vào đĩa mà được ghi vào PageCache của hệ điều hành trước, sau đó hệ điều hành sẽ ghi dữ liệu từ bộ nhớ cache ra đĩa một cách bất đồng bộ.
Hàng đợi tin nhắn làm thế nào để đảm bảo truyền tải tin nhắn đáng tin cậy?
Truyền tải tin nhắn đáng tin cậy có nghĩa là không được gửi quá nhiều hay quá ít.
- Để đảm bảo không gửi quá nhiều tin nhắn, tức là tin nhắn không được lặp lại, Producer không được sản xuất lại tin nhắn, hoặc Consumer không được tiêu thụ lại tin nhắn.
- Trước tiên cần đảm bảo không phát sinh tin nhắn quá mức, vấn đề này không thường xảy ra và cũng khó kiểm soát, vì nếu có phát sinh quá mức, phần lớn nguyên nhân đến từ chính Producer. Để tránh vấn đề này, cần thực hiện kiểm soát ở phía Consumer.
- Để tránh tiêu thụ lại, cơ chế an toàn nhất là Consumer thực hiện tính idempotence, đảm bảo rằng ngay cả khi tiêu thụ lại cũng không gặp vấn đề. Thông qua tính idempotence, vấn đề Producer gửi lại tin nhắn cũng được giải quyết.
- Tin nhắn không được thiếu, có nghĩa là tin nhắn không được mất. Tin nhắn mà Producer gửi đi phải được Consumer tiêu thụ. Vấn đề này cần xem xét hai khía cạnh:
- Khi Producer gửi tin nhắn, cần xác nhận rằng broker đã nhận và lưu trữ tin nhắn đó. Ví dụ, cơ chế xác nhận của RabbitMQ và cơ chế ack của Kafka đều có thể đảm bảo rằng Producer gửi đúng tin nhắn tới broker.
- Broker cần đợi cho đến khi Consumer xác nhận rằng họ đã tiêu thụ tin nhắn trước khi xóa tin nhắn. Điều này thường liên quan đến cơ chế ack của phía consumer; sau khi Consumer nhận được một tin nhắn và xác nhận không có vấn đề gì, họ có thể gửi một ack cho broker. Chỉ khi broker nhận được ack, nó mới xóa tin nhắn.
Hàng đợi tin nhắn có những tác dụng gì?
- Giảm sự phụ thuộc: Sử dụng hàng đợi tin nhắn như một phương thức giao tiếp giữa hai hệ thống, hai hệ thống không cần phải phụ thuộc lẫn nhau.
- Bất đồng bộ: Sau khi hệ thống A gửi xong tin nhắn tới hàng đợi tin nhắn, nó có thể tiếp tục thực hiện các công việc khác.
- Giảm tải: Nếu sử dụng hàng đợi tin nhắn để gọi một hệ thống nào đó, thì tin nhắn sẽ được xếp hàng trong hàng đợi, Consumer tự kiểm soát tốc độ tiêu thụ.
Hàng đợi chết là gì? Hàng đợi trì hoãn là gì?
- Hàng đợi chết cũng là một hàng đợi tin nhắn, nó dùng để lưu trữ những tin nhắn không được tiêu thụ thành công, thường có thể sử dụng để thử lại tin nhắn.
- Hàng đợi trì hoãn là hàng đợi dùng để lưu trữ các phần tử cần được xử lý trong một thời gian chỉ định, thường có thể dùng để xử lý các nghiệp vụ có tính chất hết hạn, chẳng hạn như hủy đơn hàng nếu không thanh toán trong vòng mười phút.
Làm thế nào để đảm bảo đọc và ghi tin nhắn hiệu quả?
Zero Copy: Kafka và RocketMQ đều sử dụng công nghệ zero copy để tối ưu
hóa việc đọc và ghi file.
Phương pháp sao chép file truyền thống: Cần phải sao chép file trong bộ nhớ bốn lần.
Zero Copy: Có hai phương pháp, mmap và transfile. Java đã bao bọc zero copy; phương pháp mmap được thực hiện thông qua đối tượng MappedByteBuffer, trong khi transfile được thực hiện thông qua FileChannel. Mmap phù hợp cho các file nhỏ, thường kích thước file không vượt quá từ 1.5G đến 2G. Transfile không có giới hạn kích thước file. RocketMQ sử dụng phương pháp mmap để đọc và ghi file của mình.
Trong Kafka, file nhật ký index cũng được đọc và ghi thông qua phương pháp mmap. Trong các file nhật ký khác, không sử dụng phương pháp zero copy. Kafka sử dụng phương pháp transfile để tải dữ liệu từ ổ cứng vào card mạng.
Sự khác nhau giữa epoll và poll
- Mô hình select sử dụng mảng để lưu trữ các mô tả file kết nối Socket, dung lượng là cố định, cần phải kiểm tra tuần tự xem có xảy ra sự kiện IO hay không.
- Mô hình poll sử dụng danh sách liên kết để lưu trữ các mô tả file kết nối Socket, dung lượng không cố định, cũng cần phải kiểm tra tuần tự xem có xảy ra sự kiện IO hay không.
- Mô hình epoll thì hoàn toàn khác với poll; epoll là một mô hình thông báo sự kiện, khi xảy ra sự kiện IO, ứng dụng mới thực hiện thao tác IO, không cần phải như mô hình poll để chủ động kiểm tra.
Bắt tay ba bước và bốn bước kết thúc trong TCP
Giao thức TCP là giao thức tầng truyền tải trong mô hình mạng 7 tầng OSI, chịu trách nhiệm cho việc truyền dữ liệu đáng tin cậy.
Khi thiết lập kết nối TCP, cần thực hiện bắt tay ba bước với các bước như sau:
- Máy khách gửi một gói SYN đến máy chủ
- Máy chủ nhận được SYN và gửi lại một gói SYN_ACK cho Máy khách
- Máy khách nhận được SYN_ACK và gửi một gói ACK đến máy chủ
Khi ngắt kết nối TCP, cần thực hiện bắt tay bốn bước kết thúc với các bước như sau:
- Máy khách gửi gói FIN đến máy chủ
- Máy chủ nhận được gói FIN và gửi lại gói ACK cho máy khách, báo rằng đã nhận được yêu cầu ngắt kết nối, và Máy khách không cần gửi thêm dữ liệu nữa, nhưng máy chủ có thể vẫn đang xử lý dữ liệu.
- Sau khi xử lý xong tất cả dữ liệu, máy chủ gửi gói FIN đến Máy khách, báo rằng máy chủ có thể ngắt kết nối
- Máy khách nhận được gói FIN từ máy chủ và gửi lại gói ACK, báo rằng Máy khách cũng sẽ ngắt kết nối.
Trình duyệt gửi yêu cầu và nhận phản hồi trải qua những bước nào?
- Trình duyệt phân tích URL người dùng nhập vào và tạo ra một yêu cầu định dạng HTTP
- Trước tiên kiểm tra file hosts trên máy tính để xem có IP tương ứng với tên miền không. Nếu không có, trình duyệt sẽ gửi tên miền đến DNS được cấu hình để thực hiện phân giải tên miền và nhận được địa chỉ IP.
- Trình duyệt thông qua hệ điều hành để gửi yêu cầu qua giao thức mạng tầng 4
- Yêu cầu có thể đi qua nhiều bộ định tuyến, switch và cuối cùng đến máy chủ
- Máy chủ nhận được yêu cầu, dựa trên cổng chỉ định trong yêu cầu, sẽ truyền yêu cầu đến ứng dụng đang chiếm cổng đó, ví dụ cổng 8080 được tomcat sử dụng.
- Tomcat nhận dữ liệu yêu cầu, phân tích dữ liệu theo định dạng giao thức HTTP và lấy servlet cần truy cập.
- Servlet xử lý yêu cầu. Nếu là DispatcherServlet trong SpringMVC, servlet sẽ tìm phương thức tương ứng trong Controller và thực hiện phương thức đó để lấy kết quả.
- Tomcat nhận được kết quả phản hồi, đóng gói thành định dạng phản hồi HTTP và gửi lại qua mạng đến máy chủ chứa trình duyệt.
- Máy chủ nhận được kết quả sẽ truyền đến trình duyệt, và trình duyệt chịu trách nhiệm phân tích và hiển thị nội dung.
Yêu cầu cross-origin là gì? Có vấn đề gì? Cách giải quyết?
Cross-origin (yêu cầu từ nguồn khác) nghĩa là khi trình duyệt gửi một yêu cầu mạng, nó sẽ kiểm tra xem giao thức, tên miền, và cổng của yêu cầu có khớp với trang hiện tại hay không. Nếu không khớp, trình duyệt sẽ hạn chế yêu cầu đó. Ví dụ, khi truy cập trang web www.baidu.com, việc sử dụng ajax để truy cập www.jd.com sẽ không được phép. Tuy nhiên, các thẻ như img, iframe, script với thuộc tính src vẫn có thể truy cập. Trình duyệt áp dụng lớp hạn chế này để bảo vệ thông tin người dùng. Tuy nhiên, các nhà phát triển có thể vượt qua hạn chế này bằng cách:
- Thêm header vào response, ví dụ
resp.setHeader("Access-Control-Allow-Origin", "*");cho phép truy cập từ mọi trang web mà không bị giới hạn bởi chính sách nguồn gốc. - Sử dụng phương pháp jsonp, kỹ thuật này dựa trên thẻ script vì thẻ này có thể thực hiện cross-origin.
- Máy chủ tự kiểm soát, trước tiên truy cập giao diện trong cùng tên miền, sau đó sử dụng các công cụ như HTTPClient để gọi giao diện mục tiêu.
- Sử dụng gateway, tương tự cách thứ ba, giao cho dịch vụ backend thực hiện cross-origin.
Zero Copy là gì?
Zero Copy (không sao chép) nghĩa là khi ứng dụng cần chuyển dữ liệu từ một vùng của kernel sang một vùng khác trong kernel, không cần sao chép dữ liệu qua không gian người dùng mà có thể thực hiện việc chuyển trực tiếp.
Trong MySQL có 20 triệu dữ liệu, Redis chỉ lưu 200 nghìn dữ liệu, làm thế nào để đảm bảo dữ liệu trong Redis là dữ liệu "hot"?
Đầu tiên, có thể thấy dung lượng của Redis nhỏ hơn nhiều so với MySQL. Vậy Redis có thể lọc ra dữ liệu "hot" như thế nào? Câu hỏi này liên quan đến chính sách loại bỏ dữ liệu của Redis (không nên nhầm lẫn giữa chính sách loại bỏ dữ liệu và chính sách hết hạn dữ liệu). Sau Redis 4.0, có 8 chính sách loại bỏ dữ liệu được cung cấp, trong khi trước 4.0 chỉ có 6 chính sách. Phiên bản mới thêm vào thuật toán LFU. Thực tế là có 8 chính sách nhưng thực sự chỉ có 5 chính sách quan trọng. Với random, lru, và lfu, có hai phạm vi dữ liệu khác nhau: một dành cho dữ liệu có thời gian hết hạn và một dành cho dữ liệu không có thời gian hết hạn. Năm chính sách cụ thể là:
noeviction: Không loại bỏ dữ liệu. Đây là chính sách mặc định của Redis, khi bộ nhớ đệm đầy, Redis sẽ không cho phép thêm dữ liệu mới và yêu cầu ghi sẽ thất bại.random: Chọn ngẫu nhiên. Có hai loại:volatile, dành cho dữ liệu có thời gian hết hạn, vàallkeys, bao gồm tất cả dữ liệu. Khi bộ nhớ đệm đầy, chính sách này sẽ xóa ngẫu nhiên dữ liệu.volatile-ttl: Chỉ dành cho dữ liệu có thời gian hết hạn, và dữ liệu sẽ bị xóa theo thứ tự hết hạn, dữ liệu hết hạn sớm hơn sẽ bị xóa trước.lru: Tương tự chính sách random, có hai tập dữ liệu để xử lý. Thuật toán LRU (Least Recently Used - ít được sử dụng gần đây nhất) dựa trên nguyên tắc: "Nếu dữ liệu gần đây đã được truy cập, khả năng nó sẽ được truy cập lại trong tương lai là cao."lfu: Chính sách LFU (Least Frequently Used - ít được truy cập thường xuyên) thêm yếu tố số lần truy cập vào LRU, giúp xác định chính xác hơn dữ liệu "hot".
Dựa trên vấn đề đặt ra, rõ ràng chúng ta cần sử dụng chiến lược LFU. Chọn volatile hay allkeys phụ thuộc vào nhu cầu cụ thể của hệ thống.
"Vũ khí hủy diệt" trong JDK19: Virtual Thread là gì?
Virtual Thread trong JDK19 chính là Coroutine trong ngành công nghiệp.
Vì coroutine hoạt động ở tầng người dùng (user space) còn thread là tầng kernel (kernel space) của hệ điều hành, nên coroutine vẫn dựa trên thread. Một thread có thể chứa nhiều coroutine, nhưng nếu tất cả coroutine đều chỉ dựa trên một thread, thì hiệu suất chắc chắn sẽ không cao. Vì vậy, trong JDK19, coroutine sẽ dựa trên ForkJoinPool – một loại thread pool, sử dụng nhiều thread để hỗ trợ việc chạy coroutine và sử dụng ForkJoinPool thay vì ThreadPoolExecutor thông thường để hỗ trợ chia nhỏ các tác vụ lớn.
Coroutine trong JDK19 được xây dựng trên nền tảng ForkJoinPool. Khi chúng ta sử dụng coroutine để thực thi một Runnable, về cơ bản, Runnable đó sẽ được gửi đến ForkJoinPool để thực thi. Chúng ta có thể sử dụng các tham số sau để cấu hình số lượng thread chính và số lượng thread tối đa của ForkJoinPool:
-Djdk.virtualThreadScheduler.parallelism=1-Djdk.virtualThreadScheduler.maxPoolSize=1
Cụ thể:
parallelismmặc định làRuntime.getRuntime().availableProcessors()maxPoolSizemặc định là256
Khi một thread trong ForkJoinPool thực thi tác vụ và bị chặn (ví dụ như sleep, lock, hay hoạt động I/O), thì thread này sẽ chuyển sang thực thi các tác vụ khác trong ForkJoinPool, cho phép một thread có thể thực thi nhiều tác vụ cùng lúc, đạt được hiệu quả chạy song song của coroutine.
Làm thế nào để đảm bảo tính idempotent (bất biến khi thực hiện nhiều lần) của API trong môi trường cao tải?
Trước tiên, hãy tìm hiểu khái niệm về idempotent:
"Trong lập trình, một thao tác idempotent có đặc điểm là dù được thực hiện nhiều lần, kết quả cuối cùng vẫn không thay đổi so với khi thực hiện một lần. Hàm idempotent là hàm có thể thực thi nhiều lần với cùng một tham số và luôn trả về cùng một kết quả."
Trong các tình huống thực tế, idempotent là một khái niệm phổ biến, ví dụ:
- Trong các trang thương mại điện tử, người dùng có thể bấm nhiều lần do sự cố mạng, dẫn đến việc đặt hàng nhiều lần
- Hàng đợi tin nhắn MQ có thể bị tiêu thụ nhiều lần
- Cơ chế retry khi xảy ra timeout trong RPC
- Và nhiều tình huống khác
Vậy chúng ta có thể sử dụng những giải pháp nào để đảm bảo tính idempotent?
- Sử dụng khóa chính duy nhất trong cơ sở dữ liệu để đảm bảo tính idempotent
- Cách thực hiện là sử dụng ID phân tán làm khóa chính thay vì sử dụng khóa tự tăng trong MySQL.
- Sử dụng khóa lạc quan để đảm bảo tính idempotent
- Thêm một cột phiên bản vào bảng dữ liệu, chỉ cập nhật thành công khi phiên bản đồng bộ.
- Sử dụng khóa phân tán
- Đơn giản là sử dụng khóa độc quyền phân tán, nhưng có thể điều chỉnh kích thước khóa để cải thiện hiệu suất chương trình.
- Sử dụng token
- Server cung cấp API lấy Token, trước khi thực hiện yêu cầu, client sẽ gọi API này để lấy Token.
- Token sau đó sẽ được lưu vào cơ sở dữ liệu Redis, sử dụng Token làm key (lưu ý phải đặt thời gian hết hạn).
- Token sẽ được trả về cho client, và trong yêu cầu tiếp theo, client sẽ gửi kèm theo Token.
- Khi server nhận được yêu cầu, nó sẽ kiểm tra trong Redis xem Token có tồn tại không (phải đảm bảo tính nguyên tử).
- Nếu Token tồn tại, server sẽ xóa Token và thực hiện logic nghiệp vụ bình thường. Nếu không, server sẽ ném ra ngoại lệ và trả về thông báo lỗi "gửi lại yêu cầu".
Redis làm thế nào để đảm bảo tính nhất quán kép với cơ sở dữ liệu
Hãy cùng phân tích một câu hỏi phỏng vấn, câu hỏi này thiên về ứng dụng thực tế.
Bộ nhớ đệm có thể cải thiện hiệu suất và giảm tải cho cơ sở dữ liệu, nhưng đồng thời cũng mang lại một số vấn đề mới, trong đó nổi bật là vấn đề nhất quán dữ liệu giữa bộ nhớ đệm và cơ sở dữ liệu.
Chắc hẳn trong công việc, ai đã từng sử dụng bộ nhớ đệm đều đã gặp vấn đề này. Vậy làm thế nào để trả lời câu hỏi này?
Trước tiên, hãy xem xét các mức độ nhất quán:
- Nhất quán mạnh: Bất kỳ lần đọc nào cũng có thể đọc được dữ liệu mới nhất từ lần ghi gần nhất.
- Nhất quán yếu: Sau khi dữ liệu được cập nhật, nếu có thể chấp nhận việc các yêu cầu sau đó chỉ có thể truy cập một phần hoặc không thể truy cập được dữ liệu thì gọi là nhất quán yếu.
Giải pháp đảm bảo tính nhất quán kép:
Xóa kép trì hoãn
- Chiến lược xóa kép trì hoãn là một phương pháp thường được sử dụng để duy trì tính nhất quán giữa cơ sở dữ liệu và bộ nhớ đệm trong hệ thống phân tán, tuy nhiên nó không đảm bảo nhất quán mạnh.
- Ý tưởng: Xóa bộ nhớ đệm trước, sau đó cập nhật cơ sở dữ liệu, cuối cùng sau N giây thực hiện xóa lại bộ nhớ đệm.
- Nhược điểm: Có khả năng gặp tình huống không nhất quán, mức độ phụ thuộc cao.
Xóa thông qua MQ (hàng đợi tin nhắn) để thử lại
- Sau khi cập nhật cơ sở dữ liệu, nếu việc xóa bộ nhớ đệm thất bại, gửi một tin nhắn tới MQ để consumer thực hiện xóa lại liên tục.
Xóa bất đồng bộ qua binlog
- Ý tưởng: Giải pháp có độ phụ thuộc thấp là sử dụng Canal. Canal giả lập thành máy phụ của MySQL, lắng nghe tệp nhị phân của MySQL chủ, khi dữ liệu thay đổi, gửi thông báo tới MQ. Sau đó, tiến hành xóa bộ nhớ đệm.
Phân biệt sự khác nhau giữa Cache Penetration, Cache Breakdown và Cache Avalanche, cũng như cách giải quyết
Phân tích câu hỏi phỏng vấn
Câu hỏi này nhằm đánh giá khả năng tư duy về xử lý lượng truy cập cao của ứng viên, và là một trong những câu hỏi phổ biến trong phỏng vấn.
Cache Penetration (Xuyên phá bộ nhớ đệm)
Cache Penetration có nghĩa là khi không tìm thấy dữ liệu trong bộ nhớ đệm, tất cả các yêu cầu sẽ đổ về cơ sở dữ liệu, khiến cho bộ nhớ đệm mất đi ý nghĩa ban đầu và có khả năng gây quá tải cho cơ sở dữ liệu, dẫn đến dịch vụ không khả dụng.
Giải pháp:
- Lưu trữ thông tin kết quả rỗng trong bộ nhớ đệm
- Bloom Filter (Nếu không tồn tại thì chắc chắn không tồn tại, còn nếu tồn tại thì có thể không tồn tại, được thực hiện qua bitmap)
- Lọc các tham số không hợp lệ phổ biến để chặn phần lớn các yêu cầu không hợp lệ
Cache Breakdown (Sập bộ nhớ đệm)
Cache Breakdown là tình huống dữ liệu tồn tại trong cơ sở dữ liệu nhưng không có trong bộ nhớ đệm. Trường hợp này thường xảy ra khi bộ nhớ đệm hết hạn, trong các trường hợp tải cao có thể gây ra quá tải cơ sở dữ liệu.
Giải pháp:
- Thiết lập bộ nhớ đệm không bao giờ hết hạn cho các API nóng có lượng truy cập lớn
- Nếu không thể thiết lập bộ nhớ đệm vĩnh viễn, có thể áp dụng khóa để tránh tình trạng quá tải cơ sở dữ liệu khi cập nhật bộ nhớ đệm
Cache Avalanche (Sụp đổ bộ nhớ đệm)
Cache Avalanche xảy ra khi một lượng lớn bộ nhớ đệm hết hạn cùng lúc, khiến tất cả các yêu cầu đổ về cơ sở dữ liệu, dẫn đến quá tải cơ sở dữ liệu.
Giải pháp:
- Thiết lập bộ nhớ đệm không bao giờ hết hạn cho các API nóng có lượng truy cập lớn
- Thiết lập thời gian hết hạn của bộ nhớ đệm một cách ngẫu nhiên để tránh tình trạng hết hạn đồng loạt
Tìm hiểu về phát hành theo dạng Canary trong 10 phút
Warning
Phát hành Canary (hay còn gọi là phát hành xám) là một phương thức phát hành có khả năng chuyển tiếp mượt mà giữa hai phiên bản của sản phẩm. Trong phương thức này, bạn có thể tiến hành A/B testing để cho một phần người dùng tiếp tục sử dụng tính năng A, trong khi một phần khác bắt đầu sử dụng tính năng B. Nếu người dùng không phản đối tính năng B, thì dần dần mở rộng phạm vi để tất cả người dùng chuyển sang sử dụng tính năng B. Phát hành Canary giúp đảm bảo sự ổn định của hệ thống và cho phép phát hiện, điều chỉnh các vấn đề từ sớm để hạn chế tác động tiêu cực.
Phát hành toàn bộ
- Chu kỳ quay lại lâu
- Lỗi gây ra sụp đổ cụm dịch vụ
- Tính khả dụng của dịch vụ thấp, ảnh hưởng trải nghiệm người dùng
Phát hành Canary
- Giảm thiểu phạm vi ảnh hưởng, cải thiện trải nghiệm người dùng
- Có thể thực hiện mà không cần tắt dịch vụ
- Thời gian quay lại nhanh
Redis có hỗ trợ ACID không?
Nguyên tử (Atomicity): Tất cả các thao tác trong một giao dịch phải được hoàn thành, hoặc không được thực hiện chút nào.
Tính nhất quán (Consistency): Sau khi giao dịch kết thúc, các ràng buộc toàn vẹn của cơ sở dữ liệu không bị phá vỡ, và trạng thái dữ liệu trước và sau giao dịch đều hợp lệ.
Tính cô lập (Isolation): Các thao tác trong giao dịch phải được cách ly với các giao dịch khác, các giao dịch thực thi song song không được can thiệp lẫn nhau.
Tính bền vững (Durability): Một khi giao dịch đã được cam kết, tất cả các thay đổi sẽ được lưu trữ vĩnh viễn trong cơ sở dữ liệu, ngay cả khi hệ thống bị sập hoặc khởi động lại, dữ liệu cũng sẽ không bị mất.
Chức năng giao dịch trong Redis được thực hiện thông qua bốn lệnh nguyên thủy: MULTI, EXEC, DISCARD và WATCH.
Redis sẽ tuần tự hóa tất cả các lệnh trong một giao dịch và thực thi chúng theo thứ tự.
Các thao tác cô lập riêng lẻ
- Tất cả các lệnh trong giao dịch đều sẽ được tuần tự hóa và thực hiện theo thứ tự. Giao dịch sẽ không bị gián đoạn bởi các lệnh từ các client khác trong quá trình thực thi.
Không có khái niệm mức độ cô lập
- Các lệnh trong hàng đợi sẽ không được thực thi cho đến khi giao dịch được cam kết, và trước khi cam kết, không có lệnh nào thực sự được thực hiện.
Không đảm bảo nguyên tử
- Nếu một lệnh trong giao dịch thất bại, các lệnh tiếp theo vẫn sẽ được thực hiện mà không có tính năng rollback.
Lưu ý: Lệnh DISCARD chỉ kết thúc giao dịch hiện tại, và tác động của các lệnh đã thực hiện thành công sẽ vẫn tồn tại.
MULTI: Dùng để mở một giao dịch, luôn trả về OK. Sau khi thực hiệnMULTI, client có thể tiếp tục gửi bất kỳ lệnh nào, nhưng chúng sẽ không được thực thi ngay lập tức mà được thêm vào hàng đợi. Khi lệnhEXECđược gọi, tất cả các lệnh trong hàng đợi mới được thực hiện.EXEC: Thực thi tất cả các lệnh trong khối giao dịch. Trả về giá trị của các lệnh theo thứ tự thực thi. Nếu giao dịch bị gián đoạn, trả vềnil.DISCARD: Dùng để hủy bỏ hàng đợi giao dịch và thoát khỏi trạng thái giao dịch mà không thực thi các lệnh.WATCH: Cung cấp cơ chế kiểm tra và thiết lập (CAS) cho giao dịch trong Redis. Theo dõi một hoặc nhiều khóa, nếu một trong các khóa đó bị thay đổi (hoặc bị xóa), giao dịch sẽ không được thực thi.
Redis có những phương pháp nào để duy trì dữ liệu, và làm thế nào để cấu hình trên môi trường thực tế?
Redis cung cấp hai phương pháp duy trì dữ liệu: RDB và AOF.
RDB (Snapshot)
RDB (Redis DataBase) tạo ra bản sao dữ liệu hiện tại của quá trình và lưu trữ nó trên đĩa dưới dạng snapshot. Đây là bản sao tại một thời điểm cụ thể, vì vậy giá trị trong snapshot sẽ cũ hơn hoặc bằng giá trị trong bộ nhớ.
Ưu điểm:
- Dung lượng nhỏ sau khi nén.
- Tải tệp RDB để khôi phục rất nhanh.
Nhược điểm:
- Tính tức thì không cao.
- Khi thực hiện
bgsave, Redis phải tạo một tiến trình con (fork), chi phí hiệu suất cao khi thực hiện nhiều lần.
AOF (Append Only File)
Redis ghi lại nhật ký sau khi lệnh đã được thực thi, tức là nó sẽ thực thi lệnh và ghi dữ liệu vào bộ nhớ trước, sau đó mới ghi vào nhật ký. Nhật ký ghi lại từng lệnh Redis nhận được và lưu trữ chúng dưới dạng văn bản.
Ưu điểm:
- AOF có thể đảm bảo mất ít dữ liệu tùy thuộc vào cấu hình.
Nhược điểm:
- Dung lượng tệp lớn hơn RDB.
- Khôi phục dữ liệu chậm hơn trong trường hợp dữ liệu lớn.
Kết hợp RDB và AOF
Redis cũng hỗ trợ kết hợp giữa RDB và AOF bằng cách sử dụng aof-use-rdb-preamble yes để tận dụng ưu điểm của cả hai phương pháp.
Nguyên lý Redisson trong việc thực hiện khóa phân tán
Có nhiều giải pháp kỹ thuật để thực hiện khóa phân tán, ví dụ như Redis hoặc Zookeeper. Bây giờ, chúng ta sẽ tìm hiểu cách Redisson thực hiện khóa phân tán.
Các yếu tố cần xem xét khi thực hiện khóa phân tán:
- Tính tương hỗ (Mutual exclusion): Sử dụng
setnx. - Tránh khóa chết (Deadlock prevention):
- Tính tái nhập (Reentrancy):
- Hiệu suất cao:
Sơ đồ nguyên lý Redisson khóa phân tán:
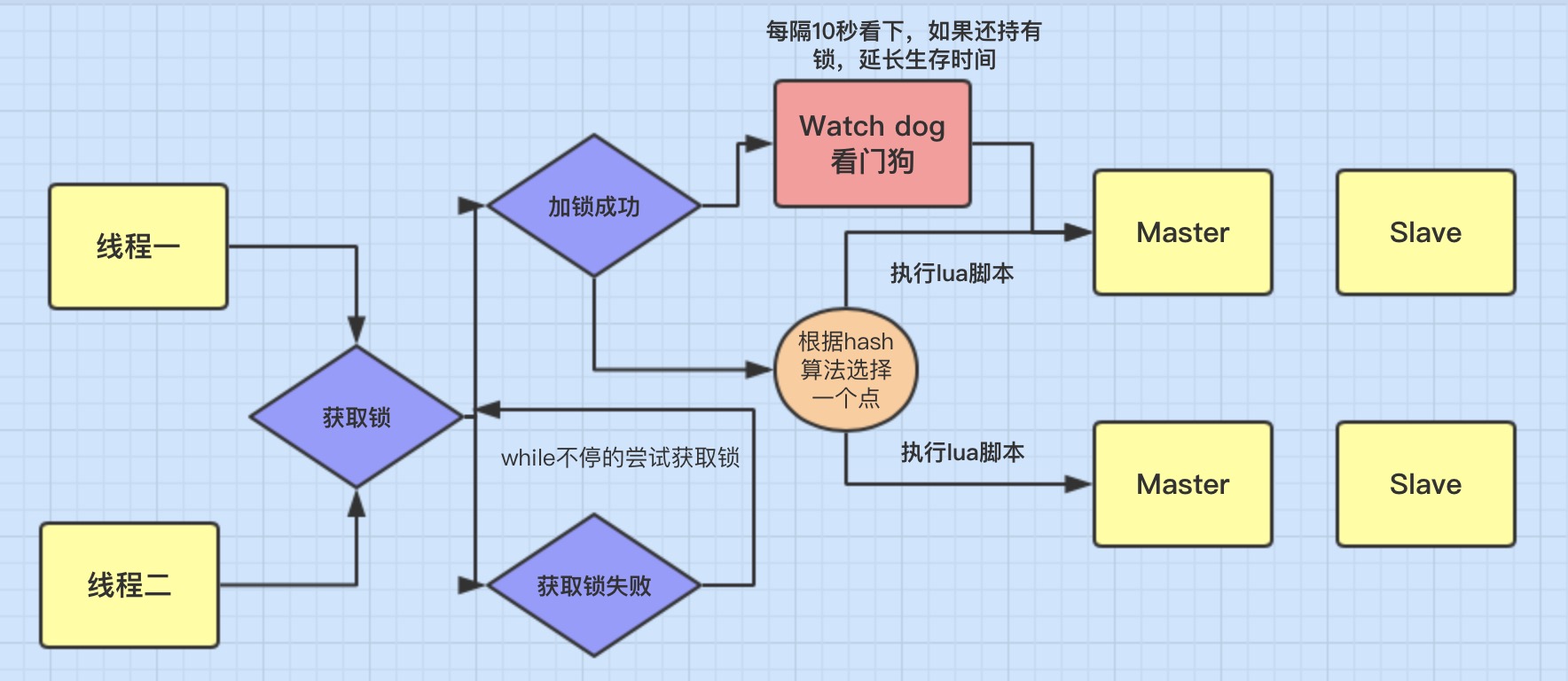
CAP định lý và Lý thuyết BASE là gì?
CAP
Trong khoa học máy tính, mỗi khi chúng ta nói đến hệ thống phân tán, sẽ không thể tránh khỏi việc nhắc đến định lý CAP, một nguyên lý cơ bản trong các hệ thống phân tán. Hãy cùng từng bước khám phá bí ẩn của nó.
CAP bắt nguồn từ một giáo sư của một trường đại học tại Mỹ, người đã đưa ra giả thuyết này tại hội thảo ACM vào năm 2000. Đến năm 2002, hai sinh viên của MIT đã chứng minh giả thuyết này và biến nó thành định lý.

CAP định lý bao gồm ba yếu tố:
- Tính nhất quán (Consistency): Tất cả các nút truy cập cùng một bản sao dữ liệu mới nhất.
- Tính sẵn sàng (Availability): Mỗi yêu cầu đều nhận được phản hồi không bị lỗi — nhưng không đảm bảo rằng dữ liệu nhận được là mới nhất.
- Tính chịu lỗi phân vùng (Partition Tolerance): Về cơ bản, phân vùng là yêu cầu về giới hạn thời gian truyền thông. Hệ thống không thể đạt được tính nhất quán dữ liệu trong khoảng thời gian quy định sẽ coi là xảy ra phân vùng. Lúc này, phải chọn giữa C (nhất quán) và A (sẵn sàng).
Định lý chỉ ra rằng đối với một hệ thống phân tán, không thể cùng lúc thỏa mãn cả ba yếu tố trên. Để dễ hiểu về lý thuyết CAP, hãy tưởng tượng có hai nút nằm ở hai phía của một phân vùng. Nếu cho phép ít nhất một nút cập nhật trạng thái, sẽ dẫn đến dữ liệu không nhất quán, tức là mất tính nhất quán (C). Nếu muốn đảm bảo dữ liệu nhất quán, phải vô hiệu hóa một nút ở phía phân vùng, điều này làm mất tính sẵn sàng (A). Trừ khi hai nút có thể giao tiếp, mới có thể đảm bảo cả tính nhất quán và sẵn sàng, nhưng điều này lại làm mất tính chịu lỗi phân vùng (P).
Vì không thể thỏa mãn đồng thời cả ba yếu tố của CAP, nên khi thiết kế hệ thống, chúng ta cần đưa ra sự cân nhắc và lựa chọn yếu tố nào cần giảm thiểu để hỗ trợ hai yếu tố còn lại.
- Giảm tính nhất quán: Ứng dụng không nhạy cảm với kết quả có thể chấp nhận việc cập nhật thành công sau một khoảng thời gian nhất định, không cần đảm bảo tính nhất quán mạnh mẽ, chỉ cần đảm bảo tính nhất quán cuối cùng. Ví dụ: các trang web tĩnh.
- Giảm tính sẵn sàng: Ứng dụng nhạy cảm với tính nhất quán, như máy ATM của ngân hàng, sẽ dừng dịch vụ khi hệ thống gặp sự cố. Ví dụ: các ứng dụng thanh toán, chuyển khoản. Các thuật toán như Paxos, Raft được thiết kế để đảm bảo tính nhất quán mạnh mẽ.
- Giảm tính chịu lỗi phân vùng: Trong thực tế, xác suất phân vùng mạng là khá nhỏ nhưng không thể tránh khỏi. Trong quá trình thực hành, giao tiếp mạng có thể được cải thiện thông qua các cơ chế như kênh kép để đạt được truyền thông ổn định hơn.
Lý thuyết BASE
Tiếp theo, chúng ta tìm hiểu về lý thuyết BASE (viết tắt của Basically Available - khả dụng cơ bản, Soft state - trạng thái mềm, và Eventually consistent - nhất quán cuối cùng). Lý thuyết BASE là kết quả của việc cân bằng giữa tính nhất quán và tính sẵn sàng trong CAP, dựa trên ý tưởng rằng ngay cả khi hệ thống không thể đạt được tính nhất quán mạnh mẽ, nó vẫn có thể đảm bảo tính nhất quán cuối cùng thông qua các phương pháp phù hợp dựa trên đặc điểm của từng ứng dụng.
- Khả dụng cơ bản: Cho phép mất một phần tính khả dụng khi hệ thống phân tán gặp sự cố. Ví dụ:
- Mất thời gian phản hồi: Thông thường, công cụ tìm kiếm trực tuyến phải trả về kết quả trong vòng 0,5 giây, nhưng khi gặp sự cố, thời gian phản hồi có thể kéo dài đến 1~2 giây.
- Mất chức năng: Cách tiếp cận thông thường là giảm cấp dịch vụ, chẳng hạn như không hiển thị các thành phần có thứ tự trên một trang khi một số thành phần gặp sự cố, chỉ hiển thị danh sách không có thứ tự.
- Trạng thái mềm: Cho phép dữ liệu của hệ thống tồn tại ở trạng thái trung gian mà không ảnh hưởng đến tính khả dụng tổng thể của hệ thống, tức là dữ liệu giữa các bản sao trên các nút khác nhau có thể tồn tại độ trễ trong quá trình đồng bộ hóa.
- Nhất quán cuối cùng: Nhấn mạnh rằng tất cả các bản sao dữ liệu của hệ thống, sau khi đồng bộ hóa trong một khoảng thời gian, cuối cùng sẽ đạt được trạng thái nhất quán. Do đó, bản chất của nhất quán cuối cùng là hệ thống phải đảm bảo dữ liệu cuối cùng nhất quán, nhưng không cần đảm bảo tính nhất quán mạnh mẽ trong mọi thời điểm.
Người phỏng vấn hỏi bạn biết cách viết một đoạn mã Java tạo ra deadlock không?
Câu hỏi này nhằm kiểm tra mức độ hiểu biết của ứng viên về deadlock (sự bế tắc), và cách đặt câu hỏi này cũng khá thú vị.
Trước tiên, để tạo ra một deadlock, cần có bốn điều kiện sau:
- Sử dụng độc quyền: Nghĩa là khi tài nguyên bị một luồng chiếm giữ, các luồng khác không thể sử dụng tài nguyên đó.
- Không thể cưỡng chế thu hồi: Luồng yêu cầu tài nguyên không thể cưỡng ép lấy tài nguyên từ luồng đang chiếm giữ, mà chỉ có luồng chiếm giữ mới có thể tự giải phóng.
- Yêu cầu và duy trì: Khi luồng đang yêu cầu tài nguyên khác, nó vẫn giữ lại tài nguyên ban đầu.
- Chờ đợi vòng tròn: Có một vòng tròn chờ đợi, nghĩa là luồng A cần tài nguyên của luồng B, trong khi luồng B lại cần tài nguyên của luồng A. Điều này tạo ra một vòng tròn chờ đợi.
Vậy, làm thế nào để giải quyết vấn đề deadlock?
- Thiết lập thời gian chờ: Nếu không nhận được khóa trong một khoảng thời gian nhất định, thay vì chờ đợi mãi, chúng ta sẽ làm việc khác, ví dụ như sử dụng phương thức
tryLockcủa giao diệnLocktrong gói JUC, thay vì sử dụngsynchronizedđể chờ đợi vô thời hạn. - Giảm độ phân tán của khóa: Ví dụ, nếu một lớp sử dụng một khóa để bảo vệ, nó có thể dẫn đến hiệu suất kém và tăng nguy cơ deadlock. Nếu có thể, hãy giảm thiểu việc sử dụng khóa, chỉ sử dụng khi thực sự cần thiết để đáp ứng yêu cầu nghiệp vụ.
- Tránh khóa lồng nhau: Ví dụ mà chúng ta đã trình bày trước đó là một trường hợp của khóa lồng nhau. Trong môi trường đa luồng, nếu thứ tự lấy khóa bị đảo ngược, sẽ dẫn đến deadlock.
- Sử dụng khóa chuyên dụng: Không nên sử dụng cùng một khóa cho nhiều chức năng khác nhau, điều này giúp tránh xung đột khóa. Nếu nhiều luồng sử dụng cùng một khóa, rất dễ gây ra deadlock.
- Thuật toán Banker: Đây là một thuật toán nổi tiếng, cốt lõi của nó là trước khi phân bổ tài nguyên, hệ thống sẽ kiểm tra xem liệu có thể thu hồi tài nguyên hay không. Nếu không thu hồi được tài nguyên và có khả năng gây ra deadlock, hệ thống sẽ không phân bổ tài nguyên cho luồng đó. Ngược lại, nếu có thể thu hồi được tài nguyên, hệ thống sẽ phân bổ tài nguyên.
Chỉ mục ẩn trong MySQL 8
MySQL 8 hỗ trợ tính năng Invisible Indexes (chỉ mục ẩn), cho phép một chỉ mục không được sử dụng bởi bộ tối ưu hóa khi tạo kế hoạch truy vấn nhưng vẫn được duy trì khi dữ liệu thay đổi.
-- Đặt chỉ mục làm chỉ mục ẩn
ALTER TABLE xxx ALTER INDEX xxx INVISIBLE;
-- Đặt chỉ mục làm chỉ mục hiện
ALTER TABLE xxx ALTER INDEX xxx VISIBLE;Phương thức được sửa đổi bởi private có thể truy cập thông qua phản chiếu, vậy ý nghĩa của private là gì?
Trong Java, khi chúng ta không muốn người khác truy cập vào một số thuộc tính hoặc phương thức, cách thông thường là sử dụng từ khóa private để sửa đổi. Tuy nhiên, Java được thiết kế cho phép truy cập những phương thức này thông qua cơ chế phản chiếu (reflection), chỉ cần tắt kiểm tra quyền truy cập là được.
import java.lang.reflect.Field;
public class Test {
public static void main(String[] args) {
C c = new C();
try {
Field f = C.class.getDeclaredField("a");
f.setAccessible(true);
Integer i = (Integer) f.get(c);
System.out.println(i);
} catch (Exception e) {}
}
}
class C {
private Integer a = 6;
}Vậy, phải chăng từ khóa private đã mất đi ý nghĩa ban đầu của nó?
Thực ra không phải vậy. Từ khóa private chủ yếu phản ánh khái niệm đóng gói dựa trên tư tưởng OOP (lập trình hướng đối tượng), và nó là một ràng buộc cho người sử dụng, không phải là một cơ chế bảo mật. Ví dụ, khi bạn lái xe trên đường, hệ thống định vị có thể nhắc nhở bạn giới hạn tốc độ, đó là quy định của pháp luật giao thông, nhưng khi xe cứu thương gặp trường hợp khẩn cấp, họ có thể vượt quá tốc độ quy định. Đây chính là sự khác biệt giữa hai vấn đề này.
Khi bạn sử dụng IoC của Spring, bạn biết rằng cần thực hiện “injection” (tiêm), bất kể thuộc tính đó là private, vẫn có thể được tiêm vào, đúng không?
Nếu bạn tuân thủ quy tắc này, thì các nhà phát triển có thể đảm bảo rằng sẽ không gặp vấn đề nào, nhưng nếu không tuân thủ, có thể gây ra hậu quả thảm khốc ở những nơi không ngờ tới.
Tính năng mới của MySQL8 - Chỉ mục sắp xếp theo thứ tự giảm dần
Chỉ mục sắp xếp giảm dần, như tên gọi, chỉ là chỉ mục được sắp xếp theo thứ tự từ lớn đến nhỏ, ngược lại với chỉ mục sắp xếp theo thứ tự tăng dần. Thông thường, các chỉ mục mà chúng ta tạo ra đều là chỉ mục sắp xếp tăng dần.
Khi câu lệnh SQL của chúng ta chỉ chứa một cột, hiệu suất truy vấn giữa chỉ mục sắp xếp tăng dần và giảm dần là như nhau. Tuy nhiên, khi câu lệnh SQL chứa nhiều cột mà mỗi cột có thứ tự sắp xếp khác nhau, chỉ mục sắp xếp giảm dần sẽ phát huy tác dụng quan trọng. Chúng ta sẽ phân tích chi tiết hơn về điều này sau.
Tính năng mới của MySQL8 - Thay đổi bộ ký tự mặc định
Trước phiên bản MySQL 8.0, bộ ký tự mặc định là latin-1, và bộ ký tự UTF8 thực ra lại chỉ trỏ đến utf8mb3. Điều này có thể đã làm khó không ít người, bởi cái tên của nó gây hiểu lầm rất lớn. Khi lưu trữ các ký tự đặc biệt hoặc biểu tượng cảm xúc, hệ thống có thể báo lỗi SQL.
SQLException: Incorrect string value: ‘\xF0\xA1\x8B\xBE\xE5\xA2…’ for column ‘name’utf8mb3 thực ra là viết tắt của "most bytes", nghĩa là số byte tối đa mà một ký tự có thể chiếm. Trong MySQL, độ dài chuỗi được tính bằng số ký tự, không phải số byte. Do đó, với loại dữ liệu char, cần dành đủ không gian cho các ký tự. Khi sử dụng bộ ký tự utf8, giới hạn độ dài tối đa là 3 byte. Nếu muốn có khả năng tương thích tốt hơn, nên sử dụng utf8mb4 thay vì utf8, mặc dù có thể tốn thêm một ít không gian. MySQL khuyến nghị sử dụng VARCHAR thay cho CHAR.
Từ MySQL 8.0 trở đi, bộ mã mặc định đã được thay đổi từ latin1 thành utf8mb4, giúp tránh những vấn đề có thể gặp phải nếu quên thay đổi bộ ký tự, và chúng ta sẽ không cần lo lắng nhiều về bộ ký tự nữa.
Bất ngờ: MySQL8 đã loại bỏ bộ nhớ đệm truy vấn!!!
Ngay cả những tính năng lớn cũng đến lúc phải kết thúc. MySQL 8.0 đã chính thức loại bỏ tính năng Query Cache (bộ nhớ đệm truy vấn). Tính năng này đã bị đánh dấu là không được khuyến khích sử dụng (Deprecated) từ phiên bản 5.7, và mặc định bị tắt.
Vậy tại sao tính năng này lại bị loại bỏ? Mục tiêu ban đầu của nó là gì? Hãy cùng nhau tìm hiểu sâu hơn từng bước để hiểu rõ vấn đề.
Bộ nhớ đệm truy vấn
The query cache stores the text of a SELECT statement together with the corresponding result that was sent to the client. If an identical statement is received later, the server retrieves the results from the query cache rather than parsing and executing the statement again. The query cache is shared among sessions, so a result set generated by one client can be sent in response to the same query issued by another client. The query cache can be useful in an environment where you have tables that do not change very often and for which the server receives many identical queries. This is a typical situation for many Web servers that generate many dynamic pages based on database content. The query cache does not return stale data. When tables are modified, any relevant entries in the query cache are flushed.
Bộ nhớ đệm truy vấn lưu trữ văn bản của câu lệnh SELECT và kết quả tương ứng gửi đến khách hàng. Nếu một câu lệnh tương tự được nhận sau đó, máy chủ sẽ truy xuất kết quả từ bộ nhớ đệm truy vấn thay vì phải phân tích và thực thi câu lệnh lại. Bộ nhớ đệm này chia sẻ giữa các phiên, vì vậy một tập kết quả tạo ra bởi một khách hàng có thể được gửi cho truy vấn tương tự của khách hàng khác.
Bộ nhớ đệm truy vấn rất hữu ích trong môi trường mà các bảng không thay đổi thường xuyên và máy chủ nhận được nhiều truy vấn giống nhau. Đây là tình huống điển hình đối với nhiều máy chủ web tạo ra các trang động dựa trên nội dung cơ sở dữ liệu.
Bộ nhớ đệm truy vấn không trả về dữ liệu lỗi thời. Khi các bảng được sửa đổi, các mục liên quan trong bộ nhớ đệm sẽ bị xóa.
Trích từ tài liệu chính thức của MySQL: https://docs.oracle.com/cd/E17952_01/mysql-5.6-en/query-cache.html
Nguyên lý hoạt động
Trước khi phân tích, MySQL so sánh truy vấn với các truy vấn trong bộ nhớ đệm. Vì vậy, bộ nhớ đệm truy vấn coi hai truy vấn sau là khác nhau:
SELECT * FROM tbl_name
Select * from tbl_nameMặc dù hai câu truy vấn có nghĩa giống nhau, MySQL sẽ tạo ra một giá trị hash cho câu lệnh SQL. Dù chỉ khác nhau ở chữ viết hoa và viết thường, chúng vẫn được coi là hai truy vấn khác nhau.
Sau đó, giá trị hash và kết quả truy vấn sẽ được lưu vào Query Cache. Những truy vấn tiếp theo sẽ so sánh giá trị hash, nếu trùng khớp thì trả về kết quả từ bộ nhớ đệm, nếu không thì sẽ truy vấn lại cơ sở dữ liệu.
Ban đầu, MySQL thiết kế Query Cache để cải thiện hiệu suất truy vấn vì khu vực Query Cache được lưu trong bộ nhớ. Nếu có nhiều truy vấn lặp lại, hệ thống không cần thực hiện lại các bước như phân tích SQL, tối ưu hóa, truy vấn đĩa cứng, từ đó cải thiện hiệu suất đáng kể.
Có vẻ rất tuyệt, vậy tại sao MySQL lại loại bỏ tính năng này?
- Thứ nhất, như đã đề cập, mặc dù hai câu lệnh SQL giống nhau về kết quả nhưng chỉ cần khác biệt nhỏ (chữ hoa, chữ thường) cũng khiến bộ nhớ đệm không được sử dụng. Trong môi trường sản xuất thực tế, nhiều truy vấn tương tự nhau vẫn trả về kết quả giống nhau nhưng do các quy tắc so sánh khắt khe, bộ nhớ đệm không được tận dụng.
- Thứ hai, chính sách hết hạn bộ nhớ đệm cũng rất nghiêm ngặt. Chỉ cần có bất kỳ thay đổi nào trong dữ liệu (thêm, xóa, sửa), hoặc điều chỉnh cấu trúc bảng, bộ nhớ đệm sẽ bị vô hiệu. Điều này chỉ có ý nghĩa trong các môi trường đọc nhiều hơn viết. Đối với các môi trường đọc/ghi cân bằng hoặc viết nhiều hơn đọc, Query Cache không có giá trị nhiều.
- Thứ ba, nếu sử dụng bảng phân vùng, Query Cache sẽ bị vô hiệu và không hoạt động.
- Thứ tư, khi Query Cache được kích hoạt, nếu truy vấn không khớp với bộ nhớ đệm, MySQL sẽ mất thêm tài nguyên để xử lý và ghi vào Query Cache. Trong trường hợp tồi tệ nhất, việc này tiêu tốn khoảng 13% hiệu suất, mặc dù trong các trường hợp thực tế, mức tiêu tốn có thể thấp hơn nhưng vẫn là một sự mất mát không cần thiết.
- Một số hàm cụ thể trong SQL (như
now()) sẽ không sử dụng bộ nhớ đệm.
Tóm lại, MySQL áp đặt nhiều hạn chế với Query Cache, nhưng trong môi trường sản xuất, nhiều truy vấn sẽ không sử dụng được bộ nhớ đệm do các điều kiện giới hạn. Vì vậy, MySQL đã quyết định loại bỏ Query Cache và thay thế bằng các giải pháp khác.
Assuming that scalability could be improved, the limiting factor of the query cache is that since only queries that hit the cache will see improvement; it is unlikely to improve predictability of performance. For user facing systems, reducing the variability of performance is often more important than improving peak throughput:
MySQL đã quyết định loại bỏ hoàn toàn Query Cache trong phiên bản 8.0 và đề xuất sử dụng công cụ thay thế bên thứ ba là ProxySQL để thay thế Query Cache.
Như trong hình dưới đây, MySQL đã so sánh hiệu suất giữa ProxySQL và Query Cache nguyên bản, có thể thấy ProxySQL vượt trội hơn hẳn về hiệu suất truy vấn.