1. Hướng dẫn nhanh về Elastic
Giấy phép mã nguồn mở: Apache 2.0
1. Giới thiệu
1.1. Elastic Stack là gì
Elastic Stack còn được gọi là ELK Stack.
ELK là viết tắt của ba sản phẩm của công ty Elastic: ElasticSearch, Logstash, và Kibana.
- Elasticsearch là một công cụ tìm kiếm và phân tích.
- Logstash là một pipeline xử lý dữ liệu phía máy chủ, có khả năng thu thập dữ liệu từ nhiều nguồn cùng một lúc, chuyển đổi dữ liệu, sau đó gửi dữ liệu đến các "kho lưu trữ" như Elasticsearch.
- Kibana cho phép người dùng trực quan hóa dữ liệu trong Elasticsearch bằng các biểu đồ và biểu đồ.
Elastic Stack là phiên bản cập nhật của ELK Stack, sản phẩm mới nhất đã giới thiệu các bộ thu thập dữ liệu chức năng đơn lẻ nhẹ và đặt tên cho chúng là Beats.
1.2. Tại sao sử dụng Elastic Stack
Đối với các công ty có quy mô nhất định, thường sẽ có nhiều ứng dụng và được triển khai trên một số lượng lớn máy chủ. Nhân viên vận hành và phát triển thường cần xem nhật ký để xác định vấn đề. Nếu ứng dụng được triển khai theo cụm, hãy tưởng tượng nếu bạn đăng nhập vào từng máy chủ để xem nhật ký, điều này sẽ tốn nhiều thời gian và công sức.
Với giải pháp ELK, bạn có thể thu thập, tìm kiếm và phân tích nhật ký cùng một lúc.
1.3. Kiến trúc Elastic Stack
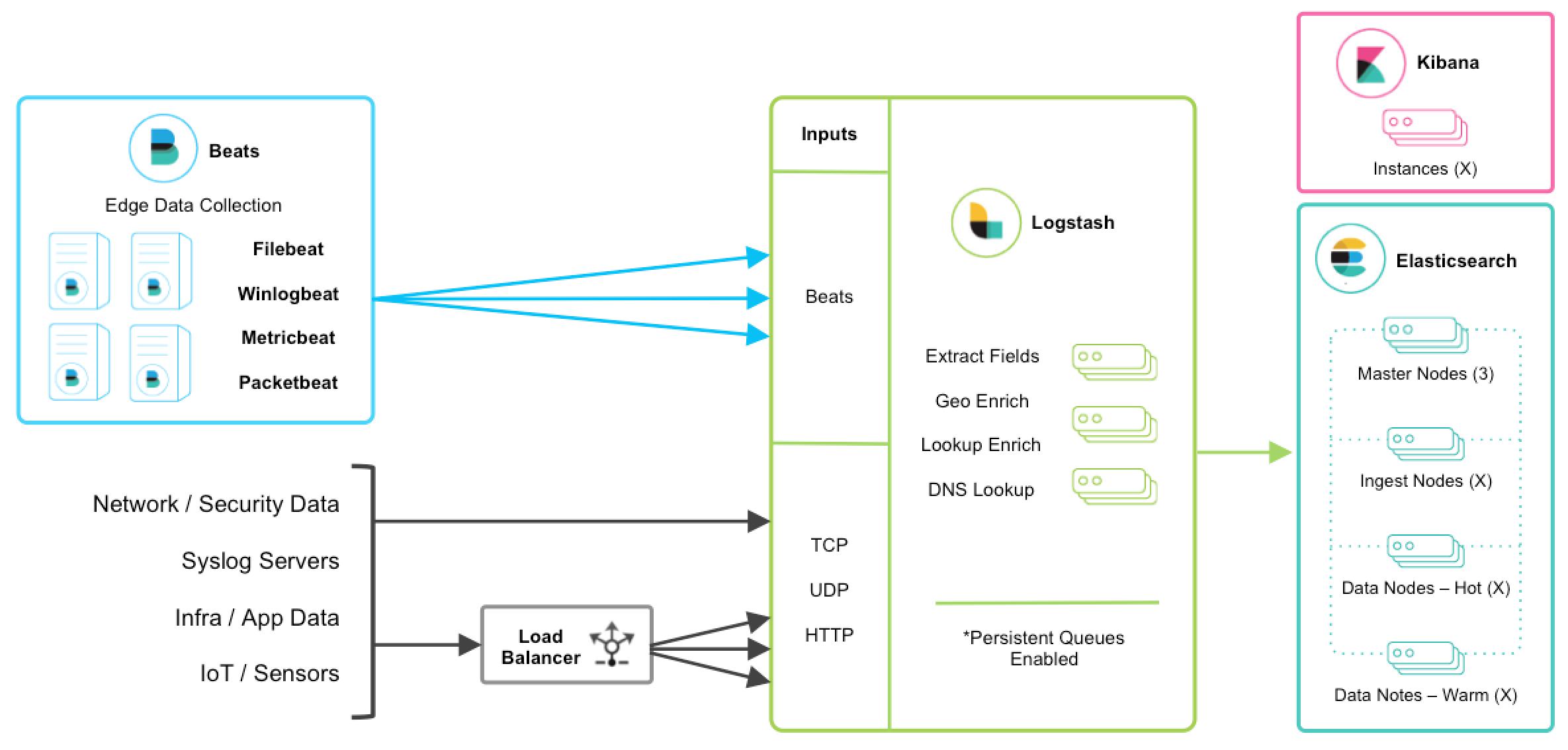
Giải thích
Đây là một sơ đồ kiến trúc của Elastic Stack. Từ hình trên, bạn có thể rõ ràng thấy hướng dòng dữ liệu.
- Beats là một nền tảng truyền dữ liệu đơn chức năng, nó có thể gửi dữ liệu từ nhiều máy chủ đến Logstash hoặc ElasticSearch. Tuy nhiên, Beats không phải là một phần không thể thiếu, vì vậy bài viết này sẽ không giới thiệu.
- Logstash là một pipeline thu thập dữ liệu động. Hỗ trợ thu thập dữ liệu theo nhiều cách như TCP/UDP/HTTP (cũng có thể nhận dữ liệu được Beats truyền đến), và xử lý dữ liệu để làm giàu hoặc trích xuất trường.
- ElasticSearch là một công cụ tìm kiếm và phân tích phân tán dựa trên JSON. Là trung tâm của ELK, nó lưu trữ dữ liệu tập trung.
- Kibana là giao diện người dùng của ELK. Nó trực quan hóa dữ liệu đã thu thập (các báo cáo, dữ liệu hình học) và cung cấp giao diện để cấu hình, quản lý ELK.
2. ElasticSearch
Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu phong cách RESTful, phân tán, có thể giải quyết nhiều trường hợp sử dụng xuất hiện liên tục. Là trung tâm của Elastic Stack, nó lưu trữ dữ liệu của bạn, giúp bạn khám phá các tình huống dự kiến và không dự kiến.
2.1. Giới thiệu về ElasticSearch
Elasticsearch được phát triển dựa trên thư viện tìm kiếm Lucene. Elasticsearch giấu đi sự phức tạp của Lucene, cung cấp giao diện API REST / Java dễ sử dụng (cũng như các giao diện API bằng ngôn ngữ khác).
Elasticsearch có thể được xem như một kho lưu trữ tài liệu, nơi nó chuyển đổi các cấu trúc dữ liệu phức tạp thành JSON để lưu trữ.
ElasticSearch là một công cụ tìm kiếm toàn văn gần như thời gian thực, điều này có nghĩa là:
- Từ khi ghi dữ liệu đến khi dữ liệu có thể được tìm kiếm, có một độ trễ nhỏ (khoảng 1s)
- Các hoạt động tìm kiếm và phân tích dựa trên ES có thể đạt được mức độ giây
2.1.1. Khái niệm cốt lõi
Indexcó thể được coi là một tập hợp tối ưu của các tài liệu (document).- Mỗi
documentlà một tập hợp các trường (field). Fieldlà một cặp giá trị key-value chứa dữ liệu.- Theo mặc định, Elasticsearch xây dựng chỉ mục cho tất cả dữ liệu trong mỗi trường và mỗi trường chỉ mục đều có cấu trúc dữ liệu tối ưu hóa riêng.
- Mỗi chỉ mục có thể có một hoặc nhiều loại (type).
Typelà một phân loại logic của chỉ mục, - Khi một máy không đủ để lưu trữ dữ liệu lớn, Elasticsearch có thể chia dữ liệu trong một chỉ mục thành nhiều
shard.Shardđược lưu trữ trên nhiều máy chủ. Với shard, bạn có thể mở rộng theo chiều ngang, lưu trữ nhiều dữ liệu hơn, cho phép các hoạt động tìm kiếm và phân tích được phân phối trên nhiều máy chủ, tăng cường throughput và hiệu suất. Mỗi shard đều là một chỉ mục lucene. - Bất kỳ máy chủ nào cũng có thể gặp sự cố hoặc bị tắt bất cứ lúc nào, lúc này shard có thể bị mất, do đó, bạn có thể tạo nhiều
replicacho mỗi shard. Replica có thể cung cấp dịch vụ dự phòng khi shard gặp sự cố, đảm bảo dữ liệu không bị mất, nhiều replica cũng có thể tăng cường throughput và hiệu suất của hoạt động tìm kiếm. Primary shard (được thiết lập khi tạo chỉ mục, không thể sửa đổi, mặc định là 5), replica shard (có thể thay đổi số lượng bất cứ lúc nào, mặc định là 1), mặc định mỗi chỉ mục có 10 shard, 5 primary shard, 5 replica shard, cấu hình có sẵn tối thiểu, là 2 máy chủ.
2.2. Nguyên lý ElasticSearch
2.2.1. Quá trình ghi dữ liệu ES
- Máy khách chọn một node và gửi yêu cầu đến, node này được gọi là
coordinating node(nút điều phối). Coordinating nodethực hiện định tuyến cho document và chuyển tiếp yêu cầu đến node tương ứng (có primary shard).Primary shardtrên node thực tế xử lý yêu cầu, sau đó đồng bộ hóa dữ liệu vớireplica node.- Nếu
coordinating nodephát hiệnprimary nodevà tất cảreplica nodeđều đã hoàn thành, nó sẽ trả lại kết quả phản hồi cho máy khách.
2.2.2. Quá trình đọc dữ liệu es
Bạn có thể tìm kiếm theo doc id, sẽ dựa trên doc id để thực hiện hash, xác định xem lúc đó doc id đã được phân bổ vào shard nào, từ shard đó để tìm kiếm.
- Máy khách gửi yêu cầu đến bất kỳ một node, trở thành
coordinate node. Coordinate nodeđịnh tuyếndoc idtheo hash, chuyển yêu cầu đến node tương ứng, lúc này sẽ sử dụng thuật toán round-robin ngẫu nhiên, chọn ngẫu nhiên một trong sốprimary shardvà tất cả các replica của nó, để cân bằng tải yêu cầu đọc.- Node nhận yêu cầu trả về document cho
coordinate node. Coordinate nodetrả về document cho máy khách.
2.2.3. Nguyên lý cơ bản của việc ghi dữ liệu
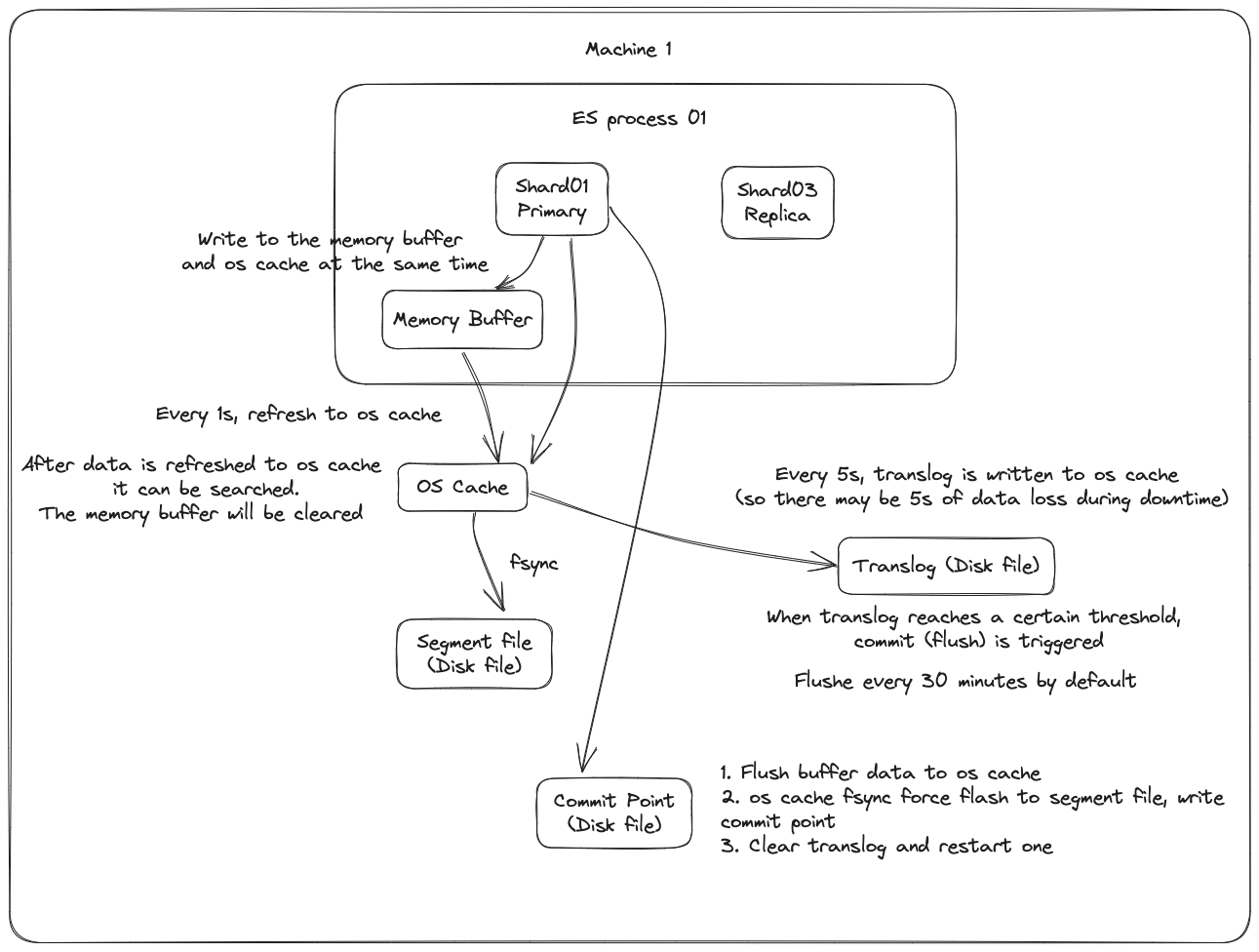
Đầu tiên, dữ liệu sẽ được ghi vào bộ đệm trong bộ nhớ (buffer), trong quá trình này dữ liệu không thể được tìm kiếm; đồng thời dữ liệu cũng được ghi vào tệp nhật ký translog.
Nếu bộ đệm gần như đầy, hoặc sau một khoảng thời gian nhất định, dữ liệu trong bộ đệm sẽ được refresh vào một segment file mới, nhưng lúc này dữ liệu không được ghi trực tiếp vào tệp segment file trên đĩa, mà phải đi vào os cache trước. Quá trình này được gọi là refresh.
Mỗi giây, ES sẽ ghi dữ liệu trong bộ đệm vào một segment file mới, mỗi giây sẽ tạo ra một tệp đĩa segment file mới, tệp segment file này sẽ lưu trữ dữ liệu được ghi vào bộ đệm trong 1 giây gần đây.
Tuy nhiên, nếu không có dữ liệu trong bộ đệm, thì tất nhiên không có quá trình refresh nào được thực hiện, nếu có dữ liệu trong bộ đệm, mặc định sẽ thực hiện một lần refresh mỗi giây, đẩy dữ liệu vào một segment file mới.
Trên hệ điều hành, tệp đĩa thực tế đều có một thứ gọi là os cache, tức là trước khi dữ liệu được ghi vào tệp đĩa, nó sẽ được đưa vào os cache trước, đầu tiên vào bộ nhớ cache cấp hệ điều hành. Chỉ cần dữ liệu trong bộ đệm được chuyển vào os cache thông qua hoạt động refresh, dữ liệu này có thể được tìm kiếm.
Tại sao nói rằng ES là gần như thời gian thực? NRT, tên đầy đủ là near real-time. Mặc định là refresh mỗi giây một lần, vì vậy ES là gần như thời gian thực, vì dữ liệu được ghi vào sau 1 giây mới có thể được tìm thấy. Bạn có thể sử dụng restful api của es hoặc java api để thực hiện một hoạt động refresh thủ công, tức là thủ công đưa dữ liệu trong bộ đệm vào os cache, để dữ liệu có thể được tìm kiếm ngay lập tức. Miễn là dữ liệu được đưa vào os cache, bộ đệm sẽ được làm sạch, vì không cần giữ bộ đệm nữa, dữ liệu đã được lưu trữ trong tệp nhật ký translog một lần.
Lặp lại các bước trên, dữ liệu mới liên tục vào bộ đệm và translog, liên tục ghi dữ liệu buffer vào một segment file mới sau mỗi lần refresh, sau mỗi lần refresh bộ đệm sẽ được làm sạch, translog sẽ được giữ lại. Khi quá trình này tiếp diễn, translog sẽ ngày càng lớn. Khi translog đạt đến một độ dài nhất định, nó sẽ kích hoạt hoạt động commit.
Bước đầu tiên của hoạt động commit là ghi dữ liệu hiện có trong bộ đệm vào os cache, sau đó làm sạch bộ đệm. Sau đó, ghi một commit point vào tệp đĩa, trong đó đánh dấu tất cả các segment file tương ứng với commit point này, đồng thời buộc os cache chứa tất cả dữ liệu hiện tại để được fsync vào tệp đĩa. Cuối cùng, xóa tệp nhật ký translog hiện tại, khởi động lại một translog, lúc này hoạt động commit đã hoàn thành.
Hoạt động commit này được gọi là flush. Mặc định là mỗi 30 phút tự động thực hiện một lần flush, nhưng nếu translog quá lớn, cũng sẽ kích hoạt flush. Hoạt động flush tương ứng với toàn bộ quá trình commit, chúng ta có thể thông qua api của es, thực hiện thủ công hoạt động flush, thủ công fsync dữ liệu trong os cache vào đĩa.
Tệp nhật ký translog có vai trò gì? Trước khi bạn thực hiện hoạt động commit, dữ liệu có thể đang nằm trong bộ đệm hoặc nằm trong os cache. Dù là bộ đệm hay os cache đều là bộ nhớ, nếu máy này bị hỏng, dữ liệu trong bộ nhớ sẽ mất hết. Vì vậy, cần ghi các hoạt động tương ứng của dữ liệu vào một tệp nhật ký đặc biệt là translog, nếu máy bị hỏng lúc này, khi khởi động lại, es sẽ tự động đọc dữ liệu từ tệp nhật ký translog và phục hồi vào bộ nhớ buffer và os cache.
Thực tế, translog cũng được ghi vào os cache trước, mặc định là mỗi 5 giây sẽ đẩy vào đĩa một lần, vì vậy mặc định, có thể có 5 giây dữ liệu chỉ nằm trong bộ đệm hoặc os cache hoặc tệp translog, không nằm trên đĩa, nếu máy này bị hỏng lúc này, sẽ mất 5 giây dữ liệu. Nhưng hiệu suất như vậy tốt hơn, mất tối đa 5 giây dữ liệu. Bạn cũng có thể đặt translog để mỗi lần ghi phải fsync trực tiếp vào đĩa, nhưng hiệu suất sẽ kém hơn nhiều.
Thực tế, nếu bạn ở đây, nếu người phỏng vấn không hỏi bạn về vấn đề mất dữ liệu của es, bạn có thể tự hào với người phỏng vấn ở đây, bạn nói, thực tế es trước tiên là gần như thời gian thực, dữ liệu được ghi vào sau 1 giây mới có thể được tìm thấy; có thể mất dữ liệu. Có 5 giây dữ liệu, nằm trong bộ đệm, os cache của translog, os cache của segment file, không nằm trên đĩa, nếu máy này bị hỏng lúc này, sẽ dẫn đến mất 5 giây dữ liệu.
Tóm lại, dữ liệu được ghi vào bộ đệm trước, sau đó mỗi giây, dữ liệu sẽ được refresh vào os cache, khi dữ liệu đến os cache, dữ liệu có thể được tìm kiếm (đó là lý do tại sao chúng ta nói rằng từ khi dữ liệu được ghi vào cho đến khi có thể tìm kiếm, có độ trễ 1s). Mỗi 5 giây, dữ liệu sẽ được ghi vào tệp translog (do đó, nếu máy bị hỏng, tất cả dữ liệu trong bộ nhớ sẽ mất, tối đa sẽ mất 5s dữ liệu), khi translog lớn đến một mức độ nhất định, hoặc mặc định mỗi 30 phút, một hoạt động commit sẽ được kích hoạt, đẩy tất cả dữ liệu trong bộ đệm vào tệp segment filetrên đĩa.
Sau khi dữ liệu được ghi vào
segment file, chỉ mục đảo ngược cũng sẽ được tạo ngay lập tức.
2.2.4. Nguyên lý cơ bản khi xóa/cập nhật dữ liệu
Nếu là hoạt động xóa, khi commit sẽ tạo ra một tệp .del, trong đó đánh dấu một doc nhất định là trạng thái deleted, vì vậy khi tìm kiếm, dựa vào tệp .del, bạn sẽ biết liệu doc có bị xóa hay không.
Nếu là hoạt động cập nhật, nó sẽ đánh dấu doc gốc là trạng thái deleted và sau đó ghi một dữ liệu mới.
Mỗi khi bộ đệm được refresh, một segment file sẽ được tạo ra, vì vậy mặc định là một segment file mỗi giây, vì vậy segment file sẽ ngày càng nhiều, lúc này sẽ thường xuyên thực hiện merge. Mỗi lần merge, nhiều segment file sẽ được hợp nhất thành một, đồng thời ở đây, doc được đánh dấu là deleted sẽ được xóa vật lý, sau đó ghi segment file mới vào đĩa, ở đây sẽ ghi một commit point, đánh dấu tất cả segment file mới, sau đó mở segment file để tìm kiếm, và sau đó xóa segment file cũ.
2.2.5. Lớp cơ bản Lucene
Đơn giản, Lucene chỉ là một thư viện jar, bên trong nó chứa các mã thuật toán đã được đóng gói để tạo chỉ mục đảo ngược. Khi chúng ta phát triển bằng Java, chúng ta chỉ cần import thư viện jar Lucene, sau đó phát triển dựa trên API của Lucene.
Thông qua Lucene, chúng ta có thể tạo chỉ mục cho dữ liệu hiện có, Lucene sẽ tổ chức cấu trúc dữ liệu chỉ mục trên ổ đĩa cục bộ cho chúng ta.
2.2.5. Chỉ mục đảo ngược
Trong công cụ tìm kiếm, mỗi tài liệu đều có một ID tài liệu tương ứng, nội dung tài liệu được biểu diễn dưới dạng một tập hợp các từ khóa. Ví dụ, sau khi phân loại, tài liệu 1 đã trích xuất 20 từ khóa, mỗi từ khóa đều ghi lại số lần xuất hiện và vị trí xuất hiện của nó trong tài liệu.
Vậy, chỉ mục đảo ngược là ánh xạ từ từ khóa đến ID tài liệu, mỗi từ khóa đều tương ứng với một loạt tài liệu, trong đó tất cả các tài liệu đều xuất hiện từ khóa.
Ví dụ.
Có các tài liệu sau:
| DocId | Doc |
|---|---|
| 1 | Cha của Google Maps chuyển sang Facebook |
| 2 | Cha của Google Maps gia nhập Facebook |
| 3 | Người sáng lập Google Maps, Lars rời Google để gia nhập Facebook |
| 4 | Cha của Google Maps chuyển sang Facebook có liên quan đến việc hủy dự án Wave |
| 5 | Cha của Google Maps, Lars gia nhập trang web xã hội Facebook |
Sau khi phân loại tài liệu, chúng ta nhận được chỉ mục đảo ngược sau.
| WordId | Word | DocIds |
|---|---|---|
| 1 | 1,2,3,4,5 | |
| 2 | Maps | 1,2,3,4,5 |
| 3 | Cha | 1,2,4,5 |
| 4 | Chuyển sang | 1,4 |
| 5 | 1,2,3,4,5 | |
| 6 | Gia nhập | 2,3,5 |
| 7 | Người sáng lập | 3 |
| 8 | Lars | 3,5 |
| 9 | Rời | 3 |
| 10 | Và | 4 |
| .. | .. | .. |
Ngoài ra, chỉ mục đảo ngược hữu ích còn có thể ghi lại nhiều thông tin hơn, chẳng hạn như thông tin tần suất tài liệu, cho biết có bao nhiêu tài liệu chứa một từ nhất định trong tập hợp tài liệu.
Vì vậy, với chỉ mục đảo ngược, công cụ tìm kiếm có thể dễ dàng phản hồi truy vấn của người dùng. Ví dụ, người dùng nhập truy vấn Facebook, hệ thống tìm kiếm tra cứu chỉ mục đảo ngược, đọc từ đó các tài liệu chứa từ này, các tài liệu này là kết quả tìm kiếm được cung cấp cho người dùng.
Cần chú ý đến hai chi tiết quan trọng của chỉ mục đảo ngược:
- Tất cả các mục từ trong chỉ mục đảo ngược tương ứng với một hoặc nhiều tài liệu;
- Các mục từ trong chỉ mục đảo ngược được sắp xếp theo thứ tự từ điển tăng dần.
Trên chỉ là một ví dụ đơn giản, không được sắp xếp theo thứ tự từ điển tăng dần một cách nghiêm ngặt.
3. Logstash
Logstash là một pipeline xử lý dữ liệu phía máy chủ mã nguồn mở, có khả năng thu thập dữ liệu từ nhiều nguồn cùng một lúc, chuyển đổi dữ liệu, sau đó gửi dữ liệu đến "kho lưu trữ" mà bạn thích.
3.1. Giới thiệu về Logstash
Logstash có thể truyền và xử lý nhật ký, giao dịch hoặc dữ liệu khác của bạn.
Logstash là pipeline dữ liệu tốt nhất của Elasticsearch.
Logstash sử dụng mô hình quản lý dạng plugin, có thể sử dụng plugin để tùy chỉnh trong quá trình nhập, lọc, xuất cũng như mã hóa. Cộng đồng Logstash có hơn 200 plugin có sẵn.
3.2. Nguyên lý hoạt động của Logstash
Logstash có hai yếu tố cần thiết: input và output, và một yếu tố tùy chọn: filter.
Ba yếu tố này, tương ứng với ba giai đoạn xử lý sự kiện của Logstash: nhập > bộ lọc > xuất.
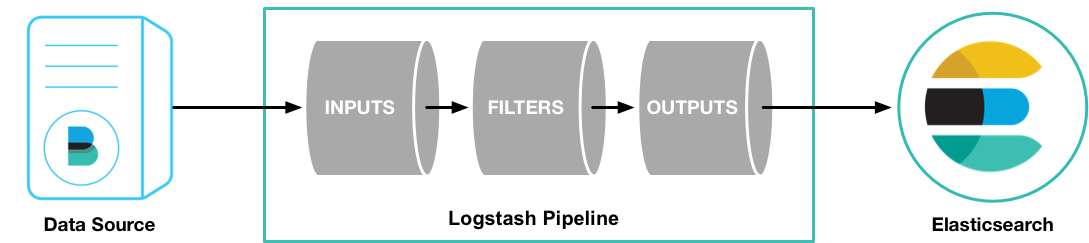
input- chịu trách nhiệm thu thập dữ liệu từ nguồn dữ liệu.filter- chỉnh sửa dữ liệu theo định dạng hoặc nội dung bạn chỉ định.output- chuyển dữ liệu đến điểm đến.
Trong các tình huống ứng dụng thực tế, thường có nhiều hơn một đầu vào, đầu ra, bộ lọc. Logstash sử dụng cách quản lý dạng plugin cho ba yếu tố này, người dùng có thể lựa chọn linh hoạt các plugin cần thiết ở mỗi giai đoạn và kết hợp chúng để sử dụng.
4. Beats
Beats là đại lý chuyển tiếp dữ liệu được cài đặt trên máy chủ.
Beats có thể truyền dữ liệu trực tiếp đến Elasticsearch hoặc truyền đến Logstash.
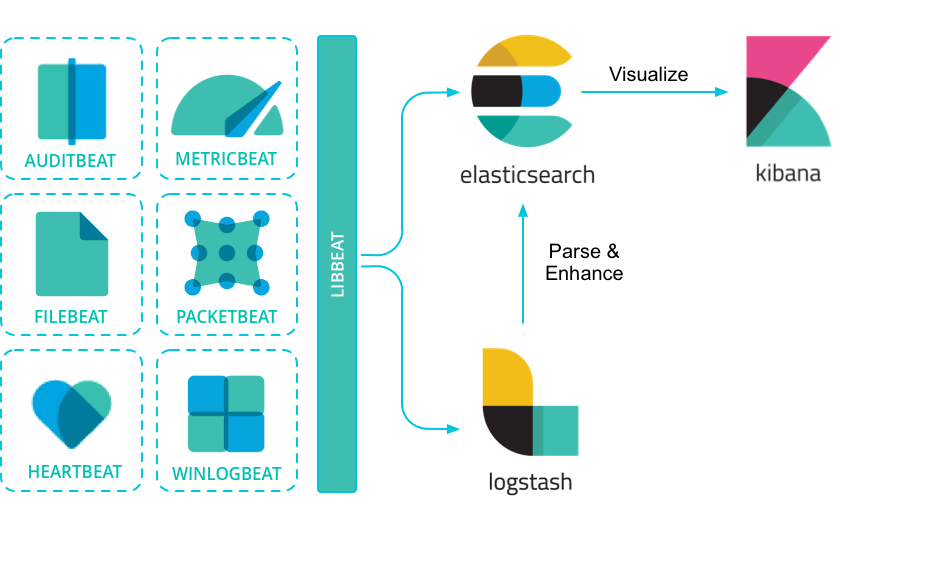
Beats có nhiều loại, bạn có thể chọn loại phù hợp dựa trên nhu cầu ứng dụng thực tế.
Các loại phổ biến bao gồm:
- Packetbeat: Phân tích gói dữ liệu mạng, cung cấp thông tin về các giao dịch trao đổi giữa các máy chủ ứng dụng của bạn.
- Filebeat: Gửi tệp nhật ký từ máy chủ của bạn.
- Metricbeat: Là một đại lý giám sát máy chủ, thu thập chỉ số từ hệ điều hành và dịch vụ chạy trên máy chủ định kỳ.
- Winlogbeat: Cung cấp nhật ký sự kiện Windows.
4.1. Giới thiệu về Filebeat
Vì tôi chỉ tiếp xúc với Filebeat, nên bài viết này chỉ giới thiệu về Filebeat trong các thành phần của Beats.
So với Logstash, FileBeat nhẹ nhàng hơn.
Trong bất kỳ môi trường nào, ứng dụng đều có khả năng ngừng hoạt động. Filebeat đọc và chuyển tiếp các dòng nhật ký, nếu bị gián đoạn, nó sẽ ghi nhớ vị trí của tất cả các sự kiện khi trạng thái trực tuyến được khôi phục.
Filebeat đi kèm với các mô-đun nội bộ (auditd, Apache, Nginx, System và MySQL), có thể đơn giản hóa việc thu thập, phân tích và trực quan hóa định dạng nhật ký thông thường thông qua một lệnh chỉ định.
FileBeat sẽ không làm cho pipeline của bạn quá tải. Nếu FileBeat truyền dữ liệu đến Logstash, khi Logstash bận xử lý dữ liệu, nó sẽ thông báo cho FileBeat làm chậm tốc độ đọc. Một khi tắc nghẽn được giải quyết, FileBeat sẽ trở lại tốc độ ban đầu và tiếp tục truyền.
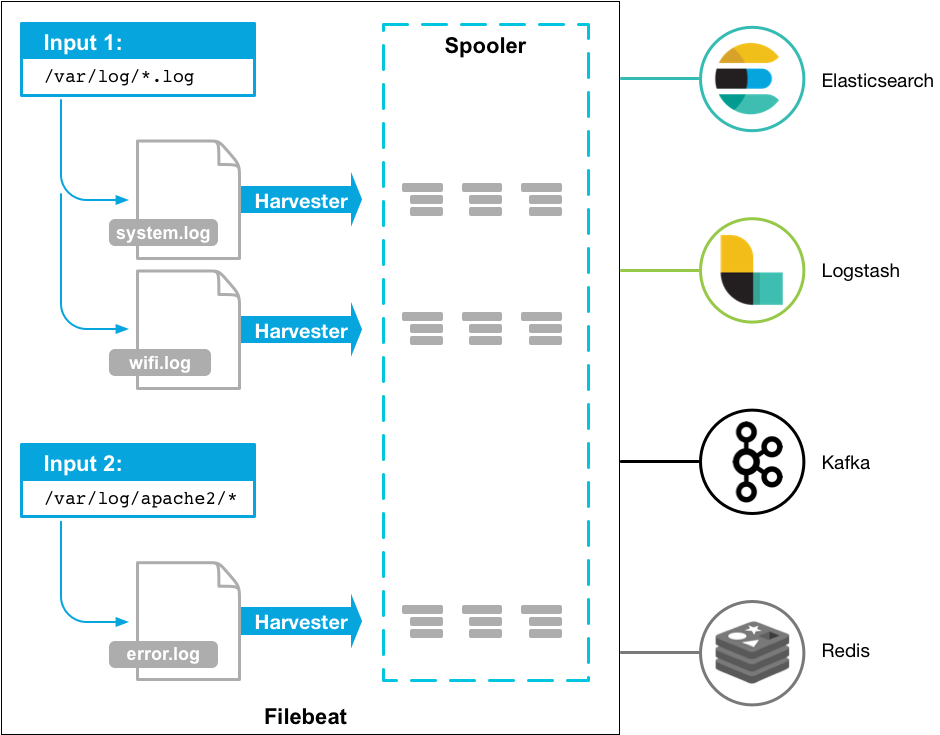
4.2. Nguyên lý hoạt động của Filebeat
Filebeat có hai thành phần chính:
harvester: chịu trách nhiệm đọc nội dung của một tệp. Nó sẽ đọc từng dòng nội dung của tệp và gửi nội dung đến điểm đến xuất.prospector: chịu trách nhiệm quản lý harvester và tìm tất cả các nguồn tệp cần đọc. Ví dụ, nếu loại là nhật ký, prospector sẽ duyệt qua tất cả các tệp phù hợp với yêu cầu trong đường dẫn đã chỉ định.
filebeat.prospectors:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.logFilebeat duy trì trạng thái của mỗi tệp và thường xuyên làm mới trạng thái đĩa trong tệp đăng ký. Trạng thái được sử dụng để ghi nhớ vị trí độ lệch cuối cùng mà harvester đang đọc và đảm bảo tất cả các dòng nhật ký được gửi.
Filebeat lưu trạng thái gửi của mỗi sự kiện trong tệp đăng ký. Vì vậy, nó có thể đảm bảo rằng sự kiện được gửi ít nhất một lần đến xuất được cấu hình, không có dữ liệu bị mất.
5. Vận hành
- [[Elasticsearch Operations|Vận hành ElasticSearch]]
- [[Logstash Operation|Vận hành Logstash]]
- [[Kibana Operation|Vận hành Kibana]]
- [[Filebeat Operation]]
6. Tài liệu tham khảo
- Nguồn chính thức
- Bài viết