Raft Algorithm with golang
Raft Algorithm with golang
1. Giới thiệu
Bài viết này mô tả thuật toán đồng thuận phân tán Raft và cách thực hiện hoàn chỉnh của nó trong Go.
Raft là một thuật toán tương đối mới (2014), nhưng nó đã được sử dụng nhiều trong ngành. Nổi tiếng nhất là K8s , dựa trên Raft thông qua kho lưu trữ khóa-giá trị phân tán etcd.
Mục tiêu của loạt bài này là mô tả một triển khai Raft đầy đủ chức năng và đã được kiểm thử nghiêm ngặt, đồng thời giải thích cách thức hoạt động của Raft. Chúng tôi giả định rằng độc giả đã có kiến thức cơ bản về Raft thông qua các tài liệu liên quan trước đó.
Đừng kỳ vọng có thể nắm bắt hoàn toàn Raft trong một ngày. Mặc dù thiết kế của Raft dễ hiểu hơn so với Paxos, nhưng nó vẫn khá phức tạp. Bản chất của vấn đề mà Raft giải quyết - đồng thuận phân tán - là một thách thức lớn, và độ phức tạp của giải pháp có một giới hạn tối thiểu.
1.1. Sao chép trạng thái máy
Thuật toán đồng thuận phân tán có thể được xem như giải pháp cho vấn đề sao chép một máy trạng thái xác định trên nhiều máy chủ. Thuật ngữ “máy trạng thái” dùng để chỉ bất kỳ dịch vụ nào; vì trong khoa học máy tính, máy trạng thái là một trong những nền tảng cơ bản, và mọi thứ đều có thể được biểu diễn bằng nó. Các dịch vụ như cơ sở dữ liệu, máy chủ tệp, hay máy chủ khóa đều có thể được coi là các máy trạng thái phức tạp.
Hãy xem xét một số dịch vụ được biểu diễn dưới dạng máy trạng thái. Nhiều máy khách (client) có thể kết nối với dịch vụ này, gửi yêu cầu và mong nhận được phản hồi:

Chừng nào máy chủ thực thi máy trạng thái còn hoạt động ổn định, hệ thống sẽ hoạt động bình thường. Tuy nhiên, nếu máy chủ gặp sự cố, dịch vụ sẽ không thể sử dụng được, điều này có thể không chấp nhận được. Trong hầu hết các trường hợp, độ tin cậy của hệ thống phụ thuộc vào máy chủ duy nhất vận hành nó.
Một cách phổ biến để tăng độ tin cậy của dịch vụ là sao chép (replication). Chúng ta có thể chạy nhiều phiên bản của dịch vụ trên các máy chủ khác nhau. Điều này tạo ra một cụm máy (cluster), trong đó các máy chủ phối hợp với nhau để cung cấp dịch vụ. Việc một máy chủ gặp sự cố không nên dẫn đến việc gián đoạn dịch vụ. Đồng thời, cách ly các máy chủ khỏi các lỗi chung có thể ảnh hưởng đến nhiều máy chủ sẽ tiếp tục cải thiện độ tin cậy.
Thay vì gửi yêu cầu tới một máy chủ duy nhất, máy khách sẽ gửi yêu cầu tới toàn bộ cụm máy. Ngoài ra, các bản sao của dịch vụ trong cụm phải giao tiếp với nhau để sao chép trạng thái một cách chính xác:
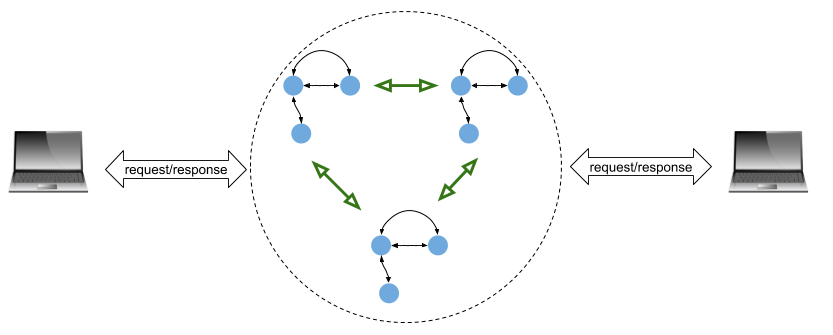
Trong hình, mỗi máy trạng thái là một bản sao của dịch vụ. Ý tưởng là tất cả các máy trạng thái đều thực thi đồng bộ, nhận cùng đầu vào từ các yêu cầu của máy khách và thực hiện các chuyển đổi trạng thái giống nhau. Điều này đảm bảo rằng, ngay cả khi một số máy chủ gặp sự cố, chúng vẫn có thể trả lại cùng một kết quả cho máy khách. Raft chính là thuật toán được thiết kế để đạt được mục tiêu này.
Giải thích một số thuật ngữ liên quan:
- Dịch vụ: Nhiệm vụ logic của hệ thống phân tán mà chúng ta đang triển khai, chẳng hạn như cơ sở dữ liệu khóa-giá trị.
- Máy chủ hoặc bản sao: Một phiên bản dịch vụ hỗ trợ Raft, chạy trên một máy độc lập có kết nối mạng với các bản sao và máy khách khác.
- Cụm (Cluster): Một tập hợp các máy chủ Raft phối hợp với nhau để thực hiện dịch vụ phân tán. Kích thước cụm thông thường là 3 hoặc 5 máy.
1.2. Module đồng thuận và nhật ký Raft
Là một thuật toán tổng quát, Raft không quy định cụ thể cách sử dụng máy trạng thái để triển khai dịch vụ. Mục tiêu của Raft là ghi lại và tái hiện chính xác chuỗi đầu vào của máy trạng thái (còn gọi là lệnh trong Raft) một cách đáng tin cậy và xác định. Với trạng thái ban đầu và tất cả các đầu vào đã biết, máy trạng thái có thể được tái hiện hoàn toàn chính xác.
Một cách suy nghĩ khác: nếu chúng ta có hai bản sao của cùng một máy trạng thái, xuất phát từ cùng trạng thái ban đầu và nhận cùng một chuỗi đầu vào, thì chúng sẽ kết thúc với cùng một trạng thái và tạo ra cùng kết quả đầu ra.
Cấu trúc của dịch vụ tổng quát sử dụng Raft như sau:
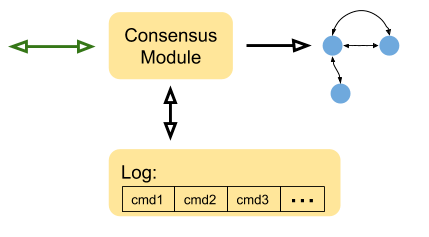
Chi tiết về các thành phần:
- Máy trạng thái: Tương tự như đã đề cập trước đó, biểu diễn bất kỳ dịch vụ nào. Trong quá trình giới thiệu Raft, kho lưu trữ khóa-giá trị là một ví dụ phổ biến.
- Nhật ký: Lưu trữ tất cả các lệnh (đầu vào) từ phía máy khách. Các lệnh không được áp dụng trực tiếp lên máy trạng thái mà chỉ được áp dụng khi đã sao chép thành công tới phần lớn máy chủ trong cụm. Nhật ký được lưu trữ bền bỉ (persistent) trên bộ lưu trữ ổn định, giúp phục hồi sau sự cố và tái hiện trạng thái máy.
- Mô-đun đồng thuận: Là cốt lõi của thuật toán Raft. Nó tiếp nhận lệnh từ máy khách, đảm bảo lệnh được lưu vào nhật ký và sao chép tới các bản sao Raft khác trong cụm. Khi xác nhận lệnh an toàn, nó sẽ gửi lệnh đến máy trạng thái để thực thi và thông báo thay đổi thực tế tới máy khách.
1.3. Lãnh đạo và người theo dõi
Raft sử dụng mô hình lãnh đạo mạnh mẽ, trong đó một bản sao trong cụm đóng vai trò lãnh đạo (leader) và các bản sao còn lại đóng vai trò người theo dõi (follower). Lãnh đạo chịu trách nhiệm xử lý yêu cầu từ khách hàng, sao chép lệnh tới các người theo dõi, và trả lời kết quả cho khách hàng.
Trong quá trình hoạt động bình thường, nhiệm vụ của người theo dõi là sao chép nhật ký của lãnh đạo. Nếu lãnh đạo gặp sự cố hoặc bị phân đoạn mạng, một người theo dõi có thể đảm nhận vai trò lãnh đạo để đảm bảo dịch vụ vẫn khả dụng.
Mô hình này có ưu và nhược điểm:
- Ưu điểm quan trọng là tính đơn giản. Dữ liệu luôn chảy từ lãnh đạo tới người theo dõi, và chỉ lãnh đạo mới phản hồi yêu cầu từ khách hàng. Điều này làm cho cụm Raft dễ phân tích, kiểm thử và gỡ lỗi hơn.
- Nhược điểm là hiệu năng: vì chỉ có một máy chủ trong cụm giao tiếp với khách hàng, nó có thể trở thành nút thắt cổ chai khi lượng yêu cầu tăng cao. Vì vậy, Raft không phù hợp cho các dịch vụ có lưu lượng cao. Thay vào đó, Raft thích hợp hơn với các dịch vụ lưu lượng thấp nhưng yêu cầu tính nhất quán cao, dù phải hy sinh một phần tính sẵn sàng.
1.4. Tương tác với khách hàng
Như đã đề cập trước đó, máy khách giao tiếp với toàn bộ cụm thay vì với một máy chủ đơn lẻ để thực hiện dịch vụ. Nhưng làm thế nào để máy khách giao tiếp với cả cụm?
Câu trả lời khá đơn giản:
- Máy khách biết địa chỉ mạng của các bản sao trong cụm Raft.
- Ban đầu, máy khách gửi yêu cầu đến một bản sao bất kỳ. Nếu bản sao đó là lãnh đạo, nó sẽ ngay lập tức chấp nhận yêu cầu và máy khách sẽ chờ phản hồi đầy đủ. Từ đó, máy khách ghi nhớ bản sao đó là lãnh đạo để không cần tìm kiếm lại (trừ khi có sự cố, ví dụ như lãnh đạo gặp lỗi).
- Nếu bản sao không phải là lãnh đạo, máy khách sẽ thử gửi yêu cầu tới một bản sao khác. Một tối ưu hóa khả thi là bản sao theo dõi có thể chỉ cho máy khách biết bản sao nào là lãnh đạo. Do các bản sao liên tục trao đổi thông tin, chúng thường biết chính xác lãnh đạo hiện tại. Điều này giúp tiết kiệm thời gian dò tìm cho máy khách. Trong trường hợp khác, máy khách có thể phát hiện bản sao không phải là lãnh đạo nếu yêu cầu của nó không được xử lý trong thời gian chờ nhất định. Điều này có thể do bản sao đó bị cách ly khỏi các máy chủ Raft khác. Khi hết thời gian chờ, máy khách sẽ tìm kiếm một lãnh đạo khác.
Trong hầu hết trường hợp, tối ưu hóa ở bước 3 là không cần thiết. Trong Raft, việc phân biệt giữa hoạt động bình thường và sự cố rất hữu ích. Thông thường, dịch vụ sẽ dành 99,9% thời gian ở trạng thái hoạt động bình thường, khi máy khách biết chính xác lãnh đạo là ai từ lần tương tác đầu tiên.
Các tình huống lỗi (fault scenarios), mà chúng tôi sẽ trình bày chi tiết ở phần sau, chắc chắn sẽ gây ra gián đoạn, nhưng chỉ trong thời gian ngắn. Như sẽ được giải thích trong các bài viết tiếp theo, cụm Raft thường khôi phục nhanh chóng từ sự cố tạm thời của máy chủ hoặc phân đoạn mạng — trong hầu hết các trường hợp, chỉ mất khoảng một giây. Khi một lãnh đạo mới đảm nhận vai trò và máy khách nhận biết lãnh đạo mới, cụm sẽ nhanh chóng trở lại trạng thái hoạt động bình thường.
1.5. Raft và khả năng chịu lỗi cùng nguyên tắc CAP**
Hãy xem lại sơ đồ minh họa ba bản sao Raft không kết nối với khách hàng:
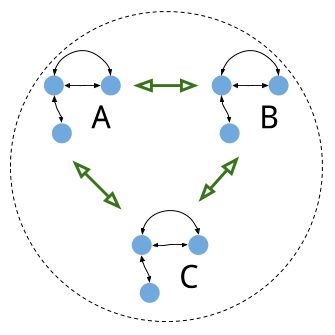
Trong một cụm, chúng ta có thể dự đoán những lỗi nào?
Trong các hệ thống máy tính hiện đại, mọi thành phần đều có thể gặp sự cố. Tuy nhiên, để đơn giản hóa thảo luận, chúng ta coi các máy chủ chạy các bản sao Raft là một đơn vị nguyên tử. Điều này dẫn đến hai loại lỗi chính:
Máy chủ gặp sự cố: Một máy chủ ngừng phản hồi toàn bộ lưu lượng mạng trong một khoảng thời gian. Máy chủ gặp sự cố thường có thể khởi động lại và hoạt động trở lại sau một gián đoạn ngắn.
Phân vùng mạng: Một hoặc nhiều máy chủ bị mất kết nối với các máy chủ và/hoặc khách hàng khác do sự cố với thiết bị mạng hoặc phương tiện truyền thông.
Từ góc nhìn của máy chủ A khi giao tiếp với máy chủ B, lỗi do B gặp sự cố không thể phân biệt được với một phân vùng mạng giữa A và B. Cả hai đều biểu hiện giống nhau — A ngừng nhận bất kỳ tin nhắn hoặc phản hồi nào từ B. Ở cấp độ hệ thống, phân vùng mạng phức tạp hơn nhiều vì chúng có thể ảnh hưởng đồng thời đến nhiều máy chủ. Trong phần tiếp theo, chúng ta sẽ đề cập đến một số trường hợp khó khăn do phân vùng mạng gây ra.
Để xử lý một cách ưu việt bất kỳ phân vùng mạng hoặc lỗi máy chủ nào, Raft yêu cầu đa số các máy chủ trong cụm phải hoạt động, và tại bất kỳ thời điểm nào, lãnh đạo có thể sử dụng đa số này để tiếp tục tiến trình.
- Với 3 máy chủ, Raft có thể chịu được lỗi của một máy.
- Với 5 máy chủ, Raft có thể chịu được lỗi của hai máy.
- Với 2N+1 máy chủ, Raft có thể chịu được lỗi của N máy.
Điều này dẫn đến định lý CAP, với kết quả thực tế là trong trường hợp có phân vùng mạng, chúng ta phải đánh đổi giữa tính khả dụng (Availability) và tính nhất quán (Consistency).
Trong sự đánh đổi này, Raft nghiêng về phía tính nhất quán. Các bất biến của nó được thiết kế để ngăn chặn cụm đạt đến trạng thái không nhất quán, nơi các khách hàng khác nhau có thể nhận được các câu trả lời khác nhau. Để đạt được điều này, Raft hy sinh tính khả dụng.
Như đã đề cập trước đó, Raft không được thiết kế cho các dịch vụ có thông lượng cao và độ chi tiết mịn. Mỗi yêu cầu từ khách hàng kích hoạt một lượng công việc lớn — bao gồm giao tiếp giữa các bản sao Raft để sao chép và ghi nhận vào đa số các bản sao trước khi phản hồi khách hàng.
Ví dụ, chúng ta sẽ không thiết kế một cơ sở dữ liệu mà mọi yêu cầu của khách hàng đều phải được sao chép qua Raft. Điều này sẽ quá chậm. Thay vào đó, Raft phù hợp hơn cho các nguyên thủy phân tán thô — như thực hiện máy chủ khóa (lock server), bầu chọn lãnh đạo cho giao thức cấp cao, hoặc sao chép dữ liệu cấu hình quan trọng trong các hệ thống phân tán.
1.6. Vì sao chọn Go
Trong loạt bài này, việc triển khai Raft được viết bằng Go. Từ góc nhìn của tác giả, Go có ba ưu điểm lớn khiến nó trở thành một ngôn ngữ đầy triển vọng cho loạt bài này và các dịch vụ mạng nói chung:
Tính đồng thời: Các thuật toán như Raft vốn có tính đồng thời sâu sắc. Mỗi bản sao thực thi các hoạt động đang diễn ra, chạy bộ hẹn giờ cho các sự kiện định kỳ, và phải xử lý các yêu cầu không đồng bộ từ các bản sao khác cũng như từ khách hàng.
Thư viện chuẩn: Go có một thư viện chuẩn mạnh mẽ, giúp việc xây dựng các máy chủ mạng phức tạp trở nên dễ dàng mà không cần nhập hoặc học thêm bất kỳ thư viện bên thứ ba nào. Đặc biệt, trong trường hợp Raft, câu hỏi đầu tiên cần trả lời là “Làm thế nào để gửi tin nhắn giữa các bản sao?”. Nhiều người bị sa lầy vào việc thiết kế giao thức và các chi tiết tuần tự hóa, hoặc sử dụng các thư viện bên thứ ba nặng nề. Go có net/rpc, một giải pháp đủ tốt cho nhiệm vụ này, được xây dựng nhanh chóng và không yêu cầu nhập thêm gì.
Đơn giản: Ngay cả trước khi xem xét ngôn ngữ lập trình, việc triển khai đồng thuận phân tán đã đủ phức tạp. Bạn có thể viết mã rõ ràng, đơn giản với bất kỳ ngôn ngữ nào, nhưng trong Go, đây là thói quen mặc định. Ngôn ngữ này phản đối sự phức tạp ở mọi cấp độ.
2. Bầu cử
2.1 Cấu trúc mã
Thông tin liên quan đến cách tổ chức triển khai Raft, áp dụng cho tất cả các phần trong loạt bài.
Thông thường, Raft được triển khai dưới dạng một đối tượng được đưa vào một số dịch vụ. Tuy nhiên, vì chúng ta không phát triển dịch vụ ở đây mà chỉ tập trung vào Raft, tôi đã tạo một kiểu đơn giản gọi là Server. Kiểu này bao bọc ConsensusModule (mô-đun đồng thuận) để cô lập các phần mã mà chúng ta quan tâm nhất:
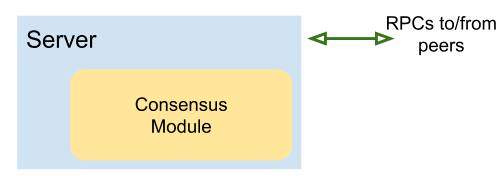
ConsensusModule (CM) là phần lõi triển khai thuật toán Raft và được đặt trong tệp raft.go. Nó hoàn toàn được trừu tượng hóa khỏi các chi tiết mạng và kết nối với các bản sao khác trong cụm. Trong ConsensusModule, các trường liên quan đến mạng duy nhất là:
// ID của máy chủ trong CM
id int
// Danh sách ID của các nút trong cụm
peerIds []int
// Máy chủ chứa CM, xử lý giao tiếp RPC giữa các nút
server *ServerTrong triển khai này, mỗi bản sao Raft gọi các bản sao khác trong cụm là “endpoint” (điểm cuối). Mỗi điểm cuối trong cụm có một ID số duy nhất, cùng với danh sách tất cả ID của các điểm cuối. Trường server là một con trỏ đến máy chủ chứa nó (được triển khai trong server.go), cho phép ConsensusModule gửi tin nhắn đến các điểm cuối khác. Cách thức thực hiện điều này sẽ được trình bày sau.
Thiết kế này nhằm loại bỏ toàn bộ chi tiết về mạng, để tập trung vào thuật toán Raft. Thông thường, để ánh xạ tài liệu Raft sang triển khai này, bạn chỉ cần quan tâm đến kiểu ConsensusModule và các phương thức của nó. Phần mã máy chủ chỉ là một khung mạng Go đơn giản, với một số phức tạp nhỏ để hỗ trợ kiểm thử nghiêm ngặt. Chúng ta sẽ không tập trung vào phần này trong loạt bài, nhưng nếu có điều gì không rõ, bạn có thể để lại câu hỏi.
2.2. Trạng thái của máy chủ Raft
Về tổng quan, ConsensusModule (CM) là một máy trạng thái với ba trạng thái:
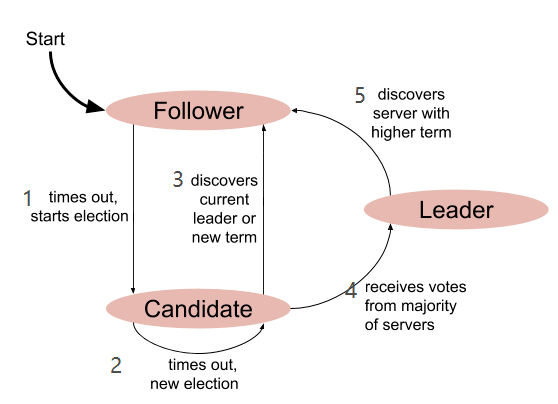
- Hết thời gian chờ, bắt đầu bầu cử
- Hết thời gian chờ, khởi tạo bầu cử mới
- Phát hiện lãnh đạo hiện tại hoặc nhiệm kỳ mới
- Nhận đủ phiếu bầu từ đa số máy chủ
- Phát hiện một nhiệm kỳ cao hơn
- Khái niệm này có thể gây nhầm lẫn, vì phần trước đã dành nhiều thời gian để giải thích cách Raft giúp thực thi máy trạng thái. Thông thường, thuật ngữ trạng thái ở đây bị “quá tải” ý nghĩa. Raft là một thuật toán dùng để triển khai máy trạng thái nhân bản bất kỳ, nhưng bản thân nó cũng có một máy trạng thái nhỏ bên trong. Trong bối cảnh này, trạng thái nào được đề cập sẽ rõ ràng từ ngữ cảnh; nếu không, chúng tôi sẽ làm rõ.
Trong một kịch bản ổn định điển hình, một máy chủ trong cụm là lãnh đạo, còn tất cả các máy chủ khác là người theo dõi. Mặc dù chúng ta không muốn xảy ra sự cố, nhưng mục tiêu của Raft là khả năng chịu lỗi, vì vậy chúng ta sẽ dành phần lớn thời gian để thảo luận các tình huống không điển hình, chẳng hạn như lỗi, sự cố máy chủ, hoặc một số máy chủ bị mất kết nối.
Như đã đề cập trước đó, Raft sử dụng một mô hình lãnh đạo mạnh mẽ. Lãnh đạo phản hồi các yêu cầu từ khách hàng, thêm các mục mới vào nhật ký, và sao chép chúng đến các máy theo dõi. Trong trường hợp lãnh đạo gặp sự cố hoặc ngừng phản hồi, mỗi người theo dõi luôn sẵn sàng đảm nhận vai trò lãnh đạo. Điều này được minh họa bằng chuyển đổi từ trạng thái “người theo dõi” sang “ứng cử viên” khi “hết thời gian chờ, bắt đầu bầu cử”.
2.3. Nhiệm kỳ
Cũng giống như trong các cuộc bầu cử thông thường, Raft cũng có khái niệm nhiệm kỳ. Nhiệm kỳ là khoảng thời gian một máy chủ giữ vai trò lãnh đạo. Một cuộc bầu cử mới sẽ kích hoạt một nhiệm kỳ mới, và thuật toán Raft đảm bảo rằng trong một nhiệm kỳ nhất định, chỉ có một lãnh đạo duy nhất.
Tuy nhiên, việc so sánh này có chút không chính xác, vì bầu cử trong Raft khác biệt khá nhiều so với các cuộc bầu cử thực tế. Trong Raft, bầu cử mang tính hợp tác hơn; mục tiêu của ứng cử viên không phải là chiến thắng mà là đảm bảo có một ứng cử viên phù hợp giành chiến thắng trong mỗi nhiệm kỳ. Sau này, chúng ta sẽ phân tích chi tiết ý nghĩa của "phù hợp".
2.4. Bộ đếm thời gian bầu cử
Một trong những thành phần quan trọng của thuật toán Raft là bộ đếm thời gian bầu cử. Đây là một bộ đếm thời gian hoạt động liên tục trên mỗi máy chủ giữ vai trò follower (người theo dõi). Mỗi lần nhận được thông điệp từ lãnh đạo hiện tại, bộ đếm thời gian sẽ được đặt lại.
Lãnh đạo sẽ gửi các heartbeat (nhịp tim) định kỳ, và khi follower không nhận được heartbeat, nó sẽ coi như lãnh đạo đã gặp sự cố hoặc bị ngắt kết nối và bắt đầu bầu cử (chuyển sang trạng thái ứng cử viên).
Hỏi: Không phải tất cả các follower đều sẽ đồng thời trở thành ứng cử viên sao?
Đáp: Bộ đếm thời gian bầu cử được đặt ngẫu nhiên, và đây là một trong những yếu tố quan trọng giúp Raft đơn giản hóa quá trình này. Phương pháp ngẫu nhiên này giảm khả năng nhiều follower cùng lúc tổ chức bầu cử.
Tuy nhiên, ngay cả khi xảy ra tình huống này, trong một nhiệm kỳ cụ thể, chỉ một ứng cử viên sẽ được bầu làm lãnh đạo. Trong những trường hợp hiếm hoi, nếu phiếu bầu bị chia đều và không ứng cử viên nào chiến thắng, sẽ có một cuộc bầu cử mới (với nhiệm kỳ mới).
Về lý thuyết, việc liên tục tổ chức lại các cuộc bầu cử là có thể, nhưng xác suất xảy ra việc này trong mỗi vòng bầu cử giảm đáng kể.
Hỏi: Nếu follower bị ngắt kết nối với cụm (phân vùng mạng) thì sao? Nó sẽ không bắt đầu bầu cử vì không nhận được thông báo từ lãnh đạo sao?
Đáp: Đây là một trong những vấn đề phức tạp của phân vùng mạng. Follower không thể phân biệt được ai đang bị phân vùng. Đúng là nó sẽ bắt đầu bầu cử, nhưng nếu follower này bị ngắt kết nối, cuộc bầu cử sẽ vô ích - vì nó không thể liên lạc với các endpoint khác và sẽ không nhận được phiếu bầu nào.
Follower đó có thể vẫn giữ trạng thái ứng cử viên (và định kỳ tổ chức lại bầu cử), cho đến khi nó được kết nối lại với cụm. Chúng ta sẽ tìm hiểu chi tiết hơn về tình huống này sau.
2.5 Giao thức RPC giữa các endpoint
Raft sử dụng hai loại giao thức RPC để trao đổi giữa các endpoint. Chi tiết các tham số và quy tắc của chúng được thể hiện trong . Dưới đây là mục tiêu chính:
RequestVotes (RV):
- Chỉ sử dụng trong trạng thái ứng cử viên.
- Ứng cử viên sử dụng giao thức này để yêu cầu các endpoint khác bỏ phiếu trong cuộc bầu cử.
- Phản hồi sẽ bao gồm chỉ dẫn về việc chấp thuận hoặc từ chối phiếu bầu.
AppendEntries (AE):
- Chỉ sử dụng trong trạng thái lãnh đạo.
- Lãnh đạo sử dụng giao thức này để sao chép các mục nhật ký đến các follower và gửi heartbeat.
- Ngay cả khi không có mục nhật ký mới để sao chép, giao thức này vẫn được gửi định kỳ đến từng follower.
Từ nội dung trên, ta có thể suy ra rằng follower không gửi bất kỳ RPC nào. Điều này hoàn toàn đúng; follower không khởi tạo bất kỳ RPC nào với các endpoint khác, nhưng chúng chạy bộ đếm thời gian bầu cử ở chế độ nền. Nếu không nhận được thông báo từ lãnh đạo trong khoảng thời gian này, follower sẽ chuyển sang trạng thái ứng cử viên và bắt đầu gửi RPC loại RV.
2.6 Triển khai bộ đếm thời gian bầu cử
Hãy đi sâu vào mã nguồn. Tệp mã sẽ được cung cấp ở cuối bài viết. Danh sách đầy đủ các trường của ConsensusModule có thể được tham khảo trong mã nguồn.
func (cm *ConsensusModule) runElectionTimer() {
timeoutDuration := cm.electionTimeout()
cm.mu.Lock()
termStarted := cm.currentTerm
cm.mu.Unlock()
cm.dlog("election timer started (%v), term=%d", timeoutDuration, termStarted)
// This loops until either:
// - we discover the election timer is no longer needed, or
// - the election timer expires and this CM becomes a candidate
// In a follower, this typically keeps running in the background for the
// duration of the CM's lifetime.
ticker := time.NewTicker(10 * time.Millisecond)
defer ticker.Stop()
for {
<-ticker.C
cm.mu.Lock()
if cm.state != Candidate && cm.state != Follower {
cm.dlog("in election timer state=%s, bailing out", cm.state)
cm.mu.Unlock()
return
}
if termStarted != cm.currentTerm {
cm.dlog("in election timer term changed from %d to %d, bailing out", termStarted, cm.currentTerm)
cm.mu.Unlock()
return
}
// Start an election if we haven't heard from a leader or haven't voted for
// someone for the duration of the timeout.
if elapsed := time.Since(cm.electionResetEvent); elapsed >= timeoutDuration {
cm.startElection()
cm.mu.Unlock()
return
}
cm.mu.Unlock()
}
}Trong ConsensusModule (CM), bộ đếm thời gian bầu cử được triển khai thông qua một goroutine, chạy một hàm như sau:
- Chọn thời gian chờ ngẫu nhiên: Hàm bắt đầu bằng việc gọi
cm.electionTimeoutđể chọn một giá trị ngẫu nhiên làm thời gian chờ bầu cử, với phạm vi được khuyến nghị trong tài liệu là 150 đến 300ms. - Đồng bộ hóa truy cập dữ liệu: Hầu hết các phương thức của
ConsensusModule, bao gồmrunElectionTimer, đều khóa cấu trúc khi truy cập các trường dữ liệu. Điều này cần thiết để đảm bảo tính đồng bộ, tận dụng ưu điểm của Go trong việc xử lý mã tuần tự. Điều này giúp mã chạy theo thứ tự và không bị phân mảnh thành nhiều trình xử lý sự kiện. Tuy nhiên, vì các RPC diễn ra đồng thời, việc bảo vệ các cấu trúc dữ liệu chia sẻ là rất quan trọng. - Chu kỳ kiểm tra: Vòng lặp chính của phương thức chạy với chu kỳ 10ms. Dù có các cách hiệu quả hơn để chờ sự kiện, cách tiếp cận này đơn giản và phù hợp cho việc gỡ lỗi/log. Mỗi lần lặp, nó kiểm tra trạng thái hệ thống và nhiệm kỳ hiện tại. Nếu trạng thái không như dự kiến hoặc nhiệm kỳ thay đổi, vòng lặp sẽ dừng.
- Kích hoạt bầu cử: Nếu đủ thời gian kể từ sự kiện "đặt lại bầu cử" (ví dụ: nhận được heartbeat hợp lệ hoặc bỏ phiếu cho ứng viên khác), CM sẽ bắt đầu bầu cử và trở thành ứng cử viên.
2.7. Trở thành ứng cử viên
Khi một follower không nhận được thông báo từ lãnh đạo hoặc ứng cử viên khác trong thời gian đủ dài, nó sẽ bắt đầu bầu cử. Trước khi đi sâu vào mã, hãy xem những gì cần thiết cho quá trình này:
- Chuyển trạng thái và tăng nhiệm kỳ: Follower chuyển sang trạng thái ứng cử viên, tăng nhiệm kỳ hiện tại lên 1 (theo quy định của thuật toán Raft).
- Gửi RequestVotes RPC: Gửi yêu cầu bỏ phiếu (RequestVotes) tới tất cả endpoint.
- Chờ phản hồi và kiểm tra phiếu: Đếm số phiếu bầu. Nếu đủ đa số, trở thành lãnh đạo.
Trong Go, tất cả các logic này có thể được thực hiện trong một hàm duy nhất:
func (cm *ConsensusModule) startElection() {
cm.state = Candidate
cm.currentTerm += 1
savedCurrentTerm := cm.currentTerm
cm.electionResetEvent = time.Now()
cm.votedFor = cm.id
cm.dlog("becomes Candidate (currentTerm=%d); log=%v", savedCurrentTerm, cm.log)
var votesReceived int32 = 1
// Send RequestVote RPCs to all other servers concurrently.
for _, peerId := range cm.peerIds {
go func(peerId int) {
args := RequestVoteArgs{
Term: savedCurrentTerm,
CandidateId: cm.id,
}
var reply RequestVoteReply
cm.dlog("sending RequestVote to %d: %+v", peerId, args)
if err := cm.server.Call(peerId, "ConsensusModule.RequestVote", args, &reply); err == nil {
cm.mu.Lock()
defer cm.mu.Unlock()
cm.dlog("received RequestVoteReply %+v", reply)
if cm.state != Candidate {
cm.dlog("while waiting for reply, state = %v", cm.state)
return
}
if reply.Term > savedCurrentTerm {
cm.dlog("term out of date in RequestVoteReply")
cm.becomeFollower(reply.Term)
return
} else if reply.Term == savedCurrentTerm {
if reply.VoteGranted {
votes := int(atomic.AddInt32(&votesReceived, 1))
if votes*2 > len(cm.peerIds)+1 {
// Won the election!
cm.dlog("wins election with %d votes", votes)
cm.startLeader()
return
}
}
}
}
}(peerId)
}
// Run another election timer, in case this election is not successful.
go cm.runElectionTimer()
}- Tự bỏ phiếu cho mình: Ứng cử viên đầu tiên tự bỏ phiếu bằng cách gán
votesReceived = 1và đặtcm.votedFor = cm.id. - Gửi RPC đồng thời: RPC được gửi tới tất cả endpoint trong các goroutine riêng biệt, bởi vì các cuộc gọi RPC của hệ thống là đồng bộ (chờ phản hồi).
Ví dụ RPC:
cm.server.Call(peer, "ConsensusModule.RequestVote", args, &reply)Hàm này sử dụng con trỏ Server từ trường ConsensusModule.server để thực hiện cuộc gọi từ xa, trong đó "ConsensusModule.RequestVote" là tên phương thức từ xa được gọi.
Kiểm tra trạng thái sau khi RPC hoàn tất: Khi RPC trả về (sau một khoảng thời gian), ứng cử viên cần kiểm tra trạng thái hiện tại. Nếu trạng thái không còn là ứng cử viên (do đã thắng bầu cử hoặc bị giáng xuống follower bởi nhiệm kỳ cao hơn), vòng lặp sẽ dừng.
So sánh nhiệm kỳ: Nếu phản hồi từ RPC có nhiệm kỳ cao hơn, ứng cử viên chuyển về trạng thái follower (có thể xảy ra khi một ứng cử viên khác đã thắng cử trong khi CM thu thập phiếu). Nếu nhiệm kỳ khớp với nhiệm kỳ ban đầu, CM kiểm tra xem đã nhận được phiếu bầu hay chưa.
Kiểm tra số phiếu bầu: Một biến đếm phiếu được quản lý an toàn để thu thập phiếu từ nhiều goroutine. Nếu CM nhận được đa số phiếu (bao gồm cả phiếu của chính nó), nó sẽ trở thành lãnh đạo.
Lưu ý:
Phương thức startElection không chặn luồng chính. Nó cập nhật trạng thái, khởi tạo nhiều goroutine, rồi trả về ngay. Đồng thời, nó khởi chạy bộ đếm thời gian bầu cử mới để đảm bảo rằng nếu lần bầu cử này không thành công, một cuộc bầu cử mới sẽ được kích hoạt sau khi hết thời gian chờ.
Điều này giải thích tại sao runElectionTimer cần kiểm tra trạng thái: Nếu CM đã trở thành lãnh đạo, vòng lặp chạy đồng thời trong runElectionTimer sẽ tự dừng khi nhận thấy trạng thái không phù hợp.
2.8 Trở thành lãnh đạo
Khi hồ sơ bỏ phiếu cho thấy nút này đã chiến thắng, chúng ta có thể thấy phương thức startLeader được gọi trong startElection.
func (cm *ConsensusModule) startLeader() {
cm.state = Leader
cm.dlog("becomes Leader; term=%d, log=%v", cm.currentTerm, cm.log)
go func() {
ticker := time.NewTicker(50 * time.Millisecond)
defer ticker.Stop()
// Send periodic heartbeats, as long as still leader.
for {
cm.leaderSendHeartbeats()
<-ticker.C
cm.mu.Lock()
if cm.state != Leader {
cm.mu.Unlock()
return
}
cm.mu.Unlock()
}
}()
}Phương thức này thực sự rất đơn giản: tất cả các hoạt động đều xoay quanh việc khởi chạy một bộ đếm thời gian heartbeat - một goroutine sẽ gọi leaderSendHeartbeats mỗi 50ms, miễn là ConsensusModule (CM) vẫn là lãnh đạo.
Gửi heartbeat
func (cm *ConsensusModule) leaderSendHeartbeats() {
cm.mu.Lock()
savedCurrentTerm := cm.currentTerm
cm.mu.Unlock()
for _, peerId := range cm.peerIds {
args := AppendEntriesArgs{
Term: savedCurrentTerm,
LeaderId: cm.id,
}
go func(peerId int) {
cm.dlog("sending AppendEntries to %v: ni=%d, args=%+v", peerId, 0, args)
var reply AppendEntriesReply
if err := cm.server.Call(peerId, "ConsensusModule.AppendEntries", args, &reply); err == nil {
cm.mu.Lock()
defer cm.mu.Unlock()
if reply.Term > savedCurrentTerm {
cm.dlog("term out of date in heartbeat reply")
cm.becomeFollower(reply.Term)
return
}
}
}(peerId)
}
}Tương tự như trong startElection, phương thức này tạo một goroutine cho mỗi đối tác (peer) để gửi RPC. Tuy nhiên, lần này, RPC là AppendEntries không có nội dung nhật ký. Trong Raft, các RPC này hoạt động như heartbeat, giúp lãnh đạo giữ liên lạc với các follower.
Xử lý phản hồi RPC
Giống như khi xử lý phản hồi RequestVote, nếu một phản hồi RPC trả về nhiệm kỳ (term) lớn hơn nhiệm kỳ hiện tại, CM sẽ chuyển trạng thái từ leader thành follower:
func (cm *ConsensusModule) becomeFollower(term int) {
cm.dlog("becomes Follower with term=%d; log=%v", term, cm.log)
cm.state = Follower
cm.currentTerm = term
cm.votedFor = -1
cm.electionResetEvent = time.Now()
go cm.runElectionTimer()
}Phương thức này sẽ:
- Thiết lập trạng thái CM là follower.
- Cập nhật nhiệm kỳ và thiết lập lại các trường trạng thái quan trọng.
- Bắt đầu một bộ đếm thời gian bầu cử mới.
2.9. Phản hồi RPC
Cho đến thời điểm này, chúng ta đã triển khai các phần hoạt động: khởi tạo RPC, bộ đếm thời gian và chuyển đổi trạng thái. Tuy nhiên, để hoàn thiện, cần xem xét các phương thức của server. Hãy bắt đầu với RequestVote:
Xử lý RequestVote
func (cm *ConsensusModule) RequestVote(args RequestVoteArgs, reply *RequestVoteReply) error {
cm.mu.Lock()
defer cm.mu.Unlock()
if cm.state == Dead {
return nil
}
cm.dlog("RequestVote: %+v [currentTerm=%d, votedFor=%d]", args, cm.currentTerm, cm.votedFor)
if args.Term > cm.currentTerm {
cm.dlog("... term out of date in RequestVote")
cm.becomeFollower(args.Term)
}
if cm.currentTerm == args.Term &&
(cm.votedFor == -1 || cm.votedFor == args.CandidateId) {
reply.VoteGranted = true
cm.votedFor = args.CandidateId
cm.electionResetEvent = time.Now()
} else {
reply.VoteGranted = false
}
reply.Term = cm.currentTerm
cm.dlog("... RequestVote reply: %+v", reply)
return nil
}Phân tích logic:
- Kiểm tra trạng thái “chết”: Nếu CM đã ở trạng thái Dead, phương thức sẽ ngay lập tức thoát ra mà không làm gì.
- Cập nhật nhiệm kỳ: Nếu nhiệm kỳ của yêu cầu lớn hơn nhiệm kỳ hiện tại, CM trở thành follower với nhiệm kỳ mới.
- Xử lý phiếu bầu:
- Nếu nhiệm kỳ phù hợp và CM chưa bỏ phiếu cho ứng viên khác, CM sẽ bỏ phiếu cho ứng viên hiện tại.
- CM không bỏ phiếu cho các yêu cầu RPC cũ.
- Phản hồi: Trả về nhiệm kỳ hiện tại và thông báo về việc có cấp quyền bỏ phiếu hay không.
Xử lý AppendEntries
func (cm *ConsensusModule) AppendEntries(args AppendEntriesArgs, reply *AppendEntriesReply) error {
cm.mu.Lock()
defer cm.mu.Unlock()
// Kiểm tra trạng thái "chết"
if cm.state == Dead {
return nil
}
cm.dlog("AppendEntries: %+v", args)
// Nếu nhiệm kỳ mới lớn hơn nhiệm kỳ hiện tại, trở thành follower
if args.Term > cm.currentTerm {
cm.dlog("... term out of date in AppendEntries")
cm.becomeFollower(args.Term)
}
reply.Success = false
// Nếu nhiệm kỳ khớp nhưng trạng thái không phải follower, trở thành follower
if args.Term == cm.currentTerm {
if cm.state != Follower {
cm.becomeFollower(args.Term)
}
cm.electionResetEvent = time.Now()
reply.Success = true
}
reply.Term = cm.currentTerm
cm.dlog("AppendEntries reply: %+v", *reply)
return nil
}Phân tích logic:
- Kiểm tra trạng thái “chết”: Tương tự như
RequestVote, nếu CM đã “chết”, không thực hiện thêm thao tác nào. - Cập nhật nhiệm kỳ:
- Nếu nhiệm kỳ của yêu cầu lớn hơn nhiệm kỳ hiện tại, CM chuyển sang trạng thái follower.
- Nếu nhiệm kỳ khớp nhưng CM không ở trạng thái follower, CM sẽ chuyển sang follower.
- Cập nhật bộ đếm thời gian bầu cử: Đặt lại sự kiện bầu cử để duy trì trạng thái hiện tại.
- Phản hồi: Trả về kết quả (thành công hay không) và nhiệm kỳ hiện tại.
Tình huống đặc biệt:
if cm.state != Follower {
cm.becomeFollower(args.Term)
}Câu hỏi: Nếu nút này là lãnh đạo, tại sao nó lại trở thành follower của một lãnh đạo khác?
Trả lời: Raft đảm bảo rằng trong một nhiệm kỳ cụ thể, chỉ có một lãnh đạo duy nhất.
- Logic trong
RequestVotevàstartElectionđảm bảo không thể tồn tại hai lãnh đạo với cùng nhiệm kỳ trong cùng một cụm. - Khi một ứng viên nhận thấy một nút khác đã chiến thắng bầu cử, nó sẽ trở thành follower, tuân thủ quy tắc này.
2.10. Trạng thái và goroutine
Xem lại tất cả các trạng thái mà CM có thể ở và các goroutine khác nhau chạy trong đó:
- Follower (Người theo dõi): CM được khởi tạo thành người theo dõi và mỗi khi gọi
beginFollower, một goroutine mới sẽ bắt đầu chạyrunElectionTimer. Lưu ý rằng trong một khoảng thời gian ngắn, có thể có nhiều goroutine chạy cùng lúc. Giả sử người theo dõi nhận được một yêu cầu RV từ người lãnh đạo trong một nhiệm kỳ cao hơn, một cuộc gọibeginFollowerkhác sẽ được kích hoạt và một goroutine hẹn giờ mới sẽ bắt đầu. Tuy nhiên, goroutine cũ sẽ không làm gì và sẽ thoát ngay khi nhận thấy nhiệm kỳ đã thay đổi.
2.11. Máy chủ mất kiểm soát và tăng nhiệm kỳ
Tóm tắt các phần trên, chúng ta nghiên cứu một tình huống đặc biệt có thể xảy ra và cách Raft xử lý. Ví dụ này rất thú vị và mang tính gợi mở. Ở đây, tôi cố gắng trình bày nó như một câu chuyện, nhưng bạn có thể muốn sử dụng một tờ giấy để theo dõi trạng thái của các máy chủ khác nhau. Nếu bạn không thể theo kịp ví dụ này, vui lòng gửi email cho tôi, chúng tôi rất vui khi sửa nó để làm cho nó rõ ràng hơn.
Hãy tưởng tượng một cụm với ba máy chủ: A, B và C. Giả sử A là người lãnh đạo, nhiệm kỳ bắt đầu từ 1 và cụm chạy bình thường. A gửi một yêu cầu heartbeat AE đến B và C mỗi 50 ms và nhận phản hồi nhanh chóng trong vài mili giây; mỗi yêu cầu AE này sẽ làm lại eletementResetEvent của B và C, do đó chúng vẫn là những người theo dõi.
Vào một thời điểm nào đó, do sự cố với bộ định tuyến mạng, máy chủ B bị phân tách khỏi A và C. A vẫn gửi yêu cầu AE mỗi 50 ms, nhưng các yêu cầu AE này hoặc lỗi ngay lập tức hoặc bị lỗi do hết thời gian trong RPC engine. A không thể làm gì, nhưng điều này không có gì nghiêm trọng. Chúng ta chưa thảo luận về sao chép nhật ký, nhưng vì hai trong số ba máy chủ vẫn đang hoạt động, cụm vẫn có thể cam kết các lệnh từ khách hàng.
Vậy B thì sao? Giả sử khi bị ngắt kết nối, thời gian chờ của cuộc bầu cử của nó là 200 ms. Khoảng 200 ms sau khi bị ngắt kết nối, goroutine runElectionTimer của B nhận ra rằng nó không nhận được tin nhắn timeout từ người lãnh đạo. B không thể phân biệt ai đang tồn tại, vì vậy nó sẽ trở thành ứng cử viên và bắt đầu một cuộc bầu cử mới.
Do đó, nhiệm kỳ của B sẽ trở thành 2 (trong khi A và C vẫn có nhiệm kỳ là 1). B sẽ gửi yêu cầu RV RPC đến A và C yêu cầu họ bỏ phiếu. Tất nhiên, các yêu cầu RPC này đã bị mất trong mạng của B. startElection của B sẽ khởi động một goroutine runElectionTimer khác và nó sẽ đợi trong 250 ms (thời gian hết hạn dao động từ 150-300 ms là ngẫu nhiên) để xem liệu có điều gì quan trọng xảy ra do cuộc bầu cử trước đó không. B không làm gì cả vì nó vẫn hoàn toàn bị cô lập. Vì vậy, runElectionTimer sẽ bắt đầu một cuộc bầu cử mới và nhiệm kỳ sẽ được tăng lên 3.
Rất lâu sau, bộ định tuyến của B cần vài giây để thiết lập lại và phục hồi trạng thái trực tuyến. Trong khi đó, B thỉnh thoảng sẽ tiến hành bầu cử lại và nhiệm kỳ của nó đã lên tới 8.
Vào lúc này, phân vùng mạng phục hồi và B kết nối lại với A và C.
Sau đó, yêu cầu AE từ A sẽ đến. Nhớ lại rằng A luôn gửi yêu cầu mỗi 50 ms mặc dù B tạm thời không phản hồi.
Bây giờ AppendEntries của B được thực thi và phản hồi với term = 8.
A nhận được phản hồi này trong LeaderSendHeartbeats, kiểm tra nhiệm kỳ trong phản hồi và nhận thấy nhiệm kỳ này lớn hơn nhiệm kỳ của chính nó. Nó sẽ cập nhật nhiệm kỳ của mình thành 8 và trở thành người theo dõi. Cụm tạm thời mất người lãnh đạo.
Vài tình huống có thể xảy ra tiếp theo. B là ứng cử viên, nhưng có thể nó đã gửi RV trước khi mạng phục hồi. C là người theo dõi, nhưng trong khoảng thời gian hết hạn bầu cử của chính nó, nó sẽ trở thành ứng cử viên vì không còn nhận được các yêu cầu AE định kỳ từ A. A trở thành người theo dõi và cũng sẽ trở thành ứng cử viên trong thời gian hết hạn bầu cử của mình.
Do đó, bất kỳ máy chủ nào trong ba máy chủ này đều có thể chiến thắng trong cuộc bầu cử tiếp theo. Điều này chỉ xảy ra vì chúng ta thực sự không sao chép nhật ký ở đây. Như chúng ta sẽ thấy trong phần tiếp theo, trong thực tế, A và C có thể đã thêm một số lệnh khách hàng mới trong khi B không có mặt, vì vậy nhật ký của chúng sẽ là mới nhất. Do đó, B không thể trở thành người lãnh đạo mới - một cuộc bầu cử mới sẽ diễn ra và A hoặc C sẽ chiến thắng; chúng ta sẽ thảo luận về tình huống này một lần nữa trong phần tiếp theo.
Giả sử kể từ khi B bị ngắt kết nối, không có lệnh mới nào được thêm vào, thì việc thay đổi người lãnh đạo do kết nối lại cũng hoàn toàn có thể xảy ra.
Điều này có vẻ không hiệu quả lắm. Vì việc thay đổi người lãnh đạo không thực sự cần thiết, vì A vẫn rất khỏe mạnh trong toàn bộ tình huống này. Tuy nhiên, trong một số trường hợp, việc giữ nguyên các bất biến mà không làm giảm hiệu suất là một trong những lựa chọn thiết kế của Raft. Trong hầu hết các trường hợp (không có sự gián đoạn), hiệu suất mới là yếu tố quan trọng, vì 99,9% thời gian, cụm hoạt động bình thường.
Ứng cử viên: Cũng có một bộ hẹn giờ goroutine bầu cử, ngoài ra còn có nhiều goroutine gửi RPC. Có các biện pháp bảo vệ giống như người theo dõi, có thể dừng "chương trình bầu cử cũ" khi các goroutine mới dừng. Lưu ý rằng các goroutine RPC có thể mất thời gian lâu để hoàn thành, vì vậy nếu chúng nhận thấy cuộc gọi RPC đã lỗi thời khi trả về, chúng phải rời đi một cách im lặng, điều này rất quan trọng.
Lãnh đạo: Lãnh đạo không có goroutine bầu cử, nhưng có một goroutine heartbeats thực thi mỗi 50 ms.
Trong mã còn có một trạng thái phụ - trạng thái chết (Dead). Trạng thái này giúp đóng CM một cách có trật tự. Khi gọi Stop, trạng thái sẽ được đặt thành Dead và tất cả các goroutine sẽ thoát ngay sau khi nhận thấy trạng thái này.
Việc làm cho tất cả các goroutine này chạy có thể làm bạn lo lắng - nếu một số trong số chúng vẫn chạy trong nền thì sao? Hoặc tệ hơn, chúng liên tục rò rỉ và số lượng của chúng tăng trưởng vô tận? Đây chính là mục đích của việc kiểm tra rò rỉ, và một số kiểm tra đã kích hoạt tính năng này.